Timer.read_us takes 8.5µs, making wait_us unable to wait for less than that on Nucleo F103RB #7397
Comments
|
I applied the patch #7352 , re-compiled using the same settings and the results are the same. |
|
Hi @LaurentLouf [Mirrored to Jira] |
|
I don't think this PR will change something because it modifies the HAL_GetTick() which is only used by HAL_Delay() and not wait_us(). I changed a little bit your example and I did this instead: and the result is: Below 100us delay, the wait_us() is not precise. I don't know what precision we can expect with such low delays ? [Mirrored to Jira] |
|
Investigating a little bit further, the problems seems to come from So it basically comes down to that Since [Mirrored to Jira] |
|
@LaurentLouf What are your timing requirements ? |
|
@0xc0170 the core clock for this target is 72MHz, compared to 84MHz for the F4. I use the standard release profile ( If you check the results from @bcostm , you see that waiting 10µs already yields to an effective 24µs wait. So if I try to use |

@ARMmbed/mbed-os-hal Can you review these requirements? I do not see documented what shall we expect from wait API, only resolution. @LaurentLouf From the requirements your app has, I would use ticker API. In this case, us ticker should be used |
bump :-) Thx [Mirrored to Jira] |
|
@ARMmbed/mbed-os-hal Can you review these requirements? |
|
Software takes time to run, and that includes reading the time. At that clock rate, you're getting <=72 instructions in 1us. Almost any moderate piece of code will take a couple of microseconds. Maybe this platform timer read is a tad slow, but I don't think it's being unreasonable. Code that uses "wait_us(15)" to space things will always wait longer than 15us. The delay is a minimum, and it should normally be absolutely legal to run slow for any protocol that can be done using software-wiggling like this. In this case it seems you do need a maximum pulse. That is an unusual requirement for something using manual pin-wiggling. To achieve that I would suggest a software CPU loop, not a timer loop. I don't think the us_timer can be realistically be guaranteed that sort of precision. And you must be doing it with interrupts disabled. Unfortunately we don't have a There is a local |
|
I believe this is addressed by #10609 - |
|
Thank you for raising this detailed GitHub issue. I am now notifying our internal issue triagers. |
|
Ping @0xc0170 |
Description
Which produces
And more graphically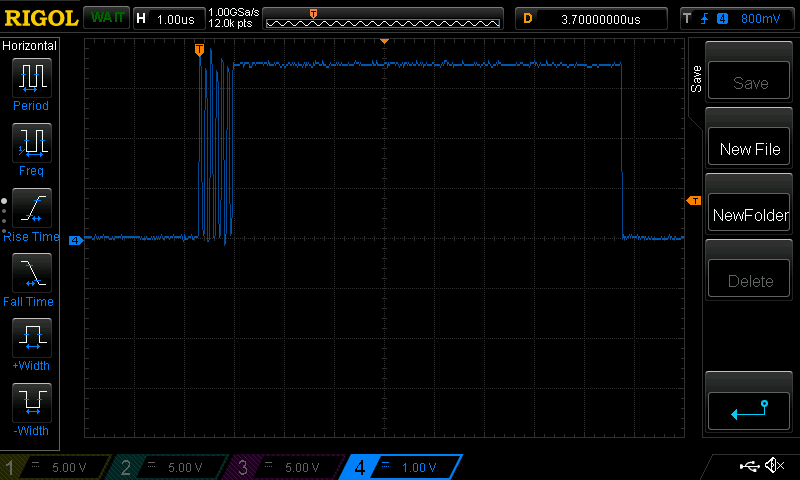
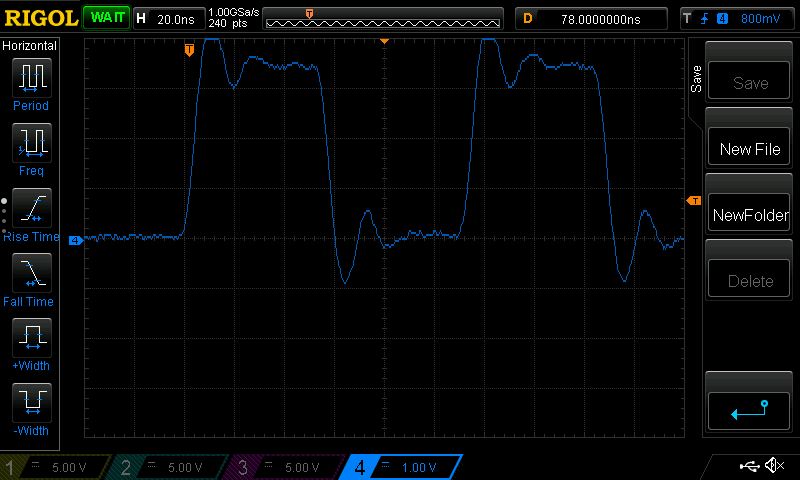
So I was investigating problems with timings, and one thing led to another, I realized that
timer.read_usandwait_usseem to be quite slow on my board. Since they both useticker_read_us, I guess the problem is somewhere there. Thing is, I've Googled and it seems this problem isn't widespread (one thing among others, it breaks OneWire timings, so there should be a few reports on that), so that may come from me, but the example code is pretty straightforward. Any idea ?Issue request type
[ ] Question
[ ] Enhancement
[X] Bug
The text was updated successfully, but these errors were encountered: