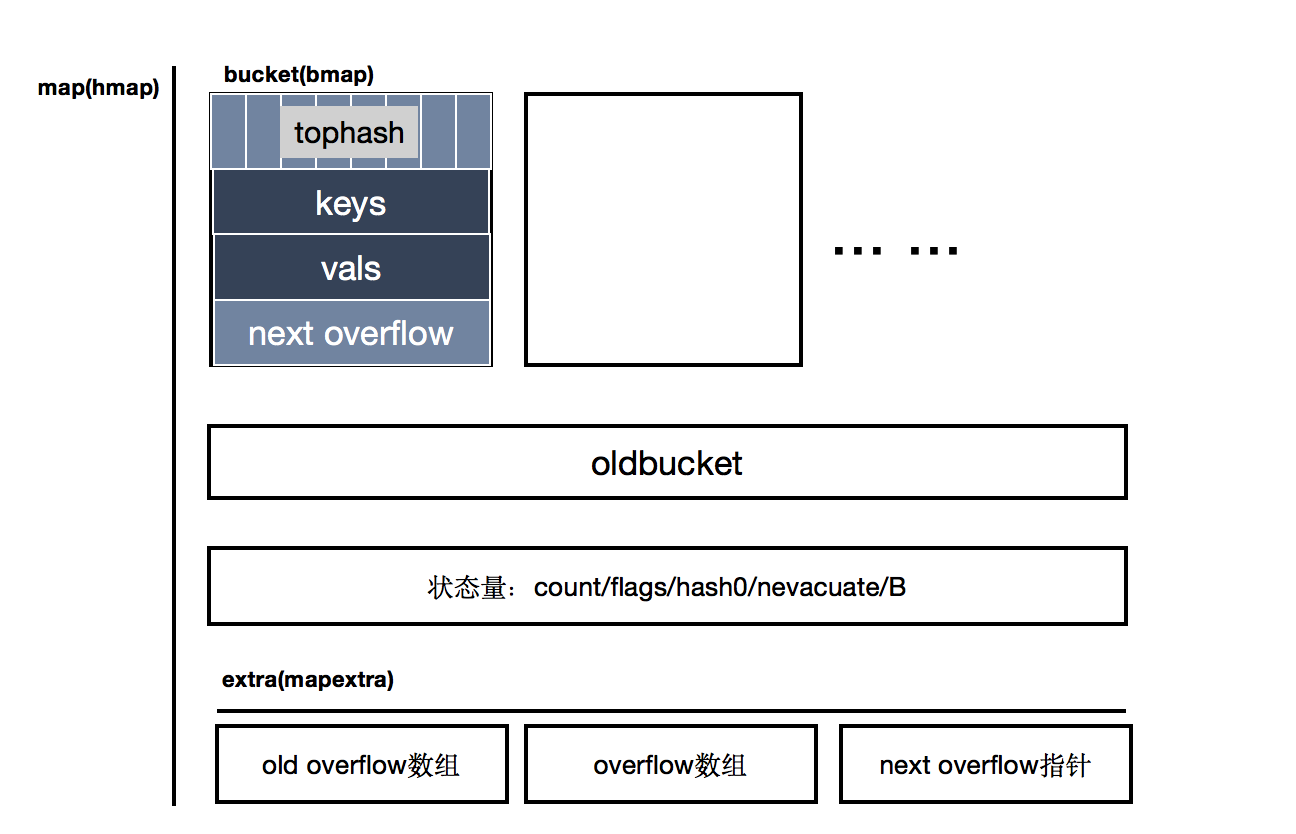
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and value do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and value do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt values.
// NOTE: packing all the keys together and then all the values together makes the
// code a bit more complicated than alternating key/value/key/value/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}###2.算法实现
首先hash值的计算是根据key的类型使用不同的算法计算出来的,返回值为uintptr
// function for hashing objects of this type
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr其次,低位确定所在bucket链(可能已经overflow)
m := bucketMask(h.B) // (1 << h.B) - 1
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) // 这里也限制了B的大小(扩容上限)最后,计算高位hash,遍历bucket链的tophash数组,定位key所在的可能的bmap,最终通过比较原始hash是否相等来判断是否为要查找的key;
// sys.PtrSize: unsafe.Sizeof(uintptr(0)) but an ideal const
// tophash calculates the tophash value for hash.
// 返回hash高8位的值
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}如果key被找到(且在tophash数组的第i个),则可以计算出value的地址为:
// b: 当前bucket(bmap)地址
// dataOffset: bmap结构中tophash和下一个bmap指针的字节大小;
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))如果key没有被找到,返回空值(特殊值):
unsafe.Pointer(&zeroVal[0])首先,计算key的hash以及高低位hash,如果key已经存在则进行更新,否则尝试新增key/val pair
在新增之前,判断是否达到触发(buckets)扩容:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
// 如果触发扩容,需要再进行hash计算和查找
goto again // Growing the table invalidates everything, so try again
}扩容之后,有两种情况,使用现有bucket或者新增overflow,如果需要新增overflow,新增的key默认放在tophash[0];
if inserti == nil {
// all current buckets are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}最后,完成tophash,key的赋值,返回分配给存储val的地址;
首先,依旧是计算hash,查找对应的key,如果存在则进行以下步骤;
清空对应的key/val字段,设置tophash为emptyOne,
// Only clear key if there are pointers in it.
if t.indirectkey() {
*(*unsafe.Pointer)(k) = nil
} else if t.key.kind&kindNoPointers == 0 {
memclrHasPointers(k, t.key.size)
}
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue() {
*(*unsafe.Pointer)(v) = nil
} else if t.elem.kind&kindNoPointers == 0 {
memclrHasPointers(v, t.elem.size)
} else {
memclrNoHeapPointers(v, t.elem.size)
}
b.tophash[i] = emptyOne特殊的,如果当前i之后(包括overflow)的tophash值都为emptyRest,则设置当前tophash值为emptyRest;
减少查找比较次数
1.hash值分段,将key分组,减少查找的比较次数
1.只要map的key/value类型确定,在同一个bucket中定位key/value所在的位置是相当快的
2.动态扩容,增量复制
3.标记删除