Generative Pre-trained Transformer (GPT) is an autoregressive language model that uses deep learning to produce human-like text created by OpenAI. Megatron-LM is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA, It is an ongoing project which is developed based on PyTorch, aiming to achieve efficient, model-parallel (tensor and pipeline), and multi-node pre-training of GPT and BERT using mixed precision.
With SBP (Split, Broadcast, and Partial-value) abstraction, OneFlow supports hybrid of data parallelism and tensor model parallelism easily without extra customized plugins, and naturally supports pipeline parallelism based on the decentralized actor abstraction. OneFlow-GPT scripts in OneFlow-Benchmark repository is the implementation of GPT based on OneFlow.
We compare the performance of both Megatron-LM GPT and OneFlow-GPT in representative configurations under the same hardware conditions. This report is the summary of the other two reports:
All tests were performed on 4 Nodes with 8x Tesla V100-SXM2-16GB GPUs(125 TFLOPS peak performance), and InfiniBand 100 Gb/sec ethernet connection.
In order to compare the performance under the same hardware conditions, a series of tests are designed in this report. The test measurements is throughputs(sequences/sentenses per second), higer throughputs means better performance.
We didn't report GPU Memory Usage in this report because PyTorch uses a caching memory allocator and the unused memory managed by the allocator will still show as if used in nvidia-smi.
4 Groups of test were performed, they are:
- data parallelism test
- tensor model parallelism test
- hybrid parallelism with both data parallelism and tensor model parallelism test
- pipeline model parallelism test
GPT model parameters such as hidden-size, number of layers are varied for each test case. All models use a vocabulary size of 51,200 and a sequence length of 2048.
All test case are named starting with a prefix:
DPstands for Data Parallelism TestMPstands for Tensor Model Parallelism Test2Dstands for Data Parallelism and Tensor Model Parallelism TestPPstands for Pipeline Model Parallelism Test
Following string (e.g. 4x8x1) is the parallel configration for data parallel size (4), tensor model parallel size(8), and number of pipeline stages(1).
Last part is the GPT model parameters: hidden-size x number-of-layers.
Global batch size is between parallel size and GPT model parameters.
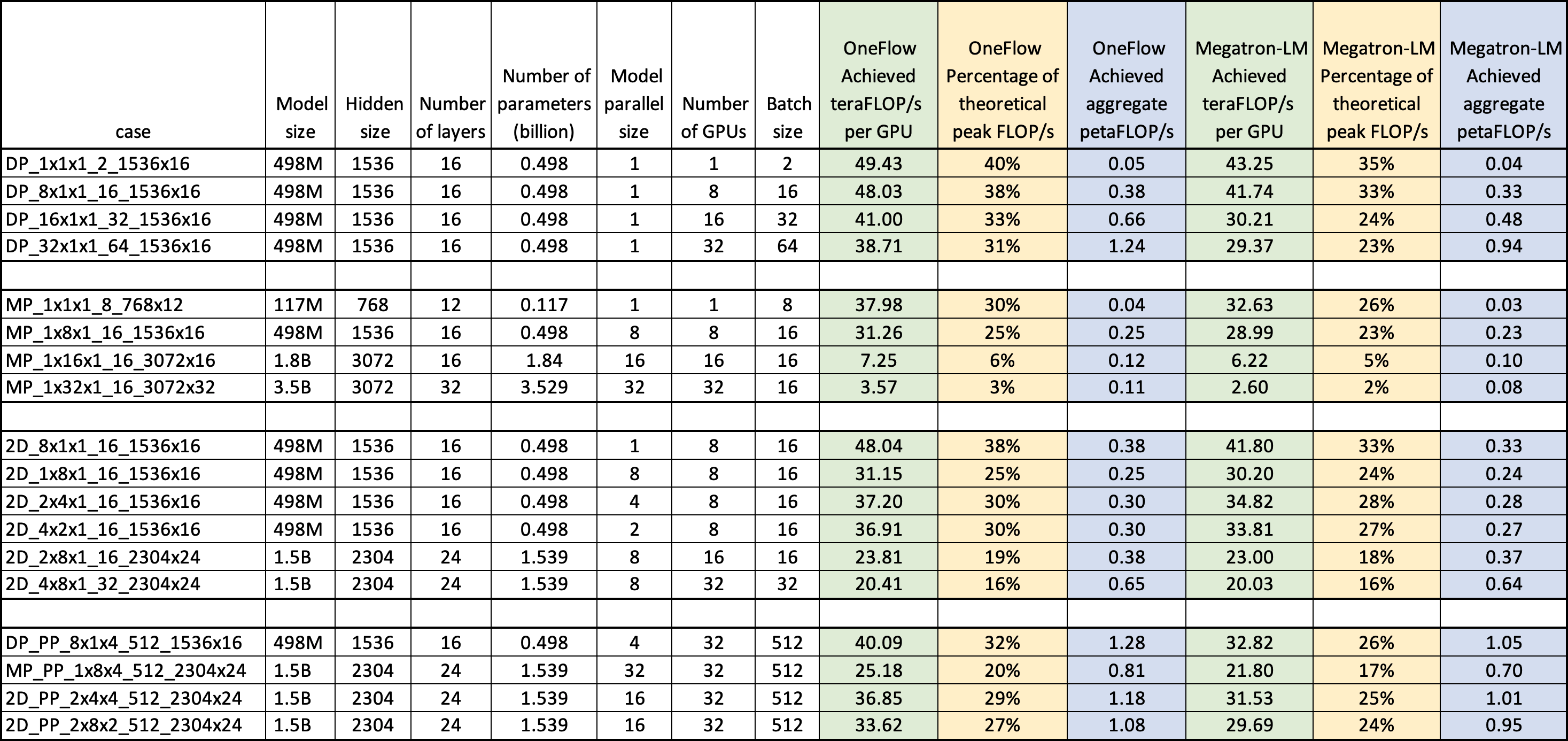
Following table shows the achieved floating-point operations per second for both OneFlow-GPT and Megatron-LM during the test. All results show that OneFlow-GPT has better performance than Megatron-LM under the same environment.
| case | Model size | Hidden size | Number of layers | Number of parameters (billion) | Model-parallel size | Number of GPUs | Batch size | OneFlow Achieved teraFLOP/s per GPU | OneFlow Percentage of theoretical peak FLOP/s | OneFlow Achieved aggregate petaFLOP/s | Megatron-LM Achieved teraFLOP/s per GPU | Megatron-LM Percentage of theoretical peak FLOP/s | Megatron-LM Achieved aggregate petaFLOP/s |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DP_1x1x1_2_1536x16 | 498M | 1536 | 16 | 0.498 | 1 | 1 | 2 | 49.43 | 40% | 0.05 | 43.25 | 35% | 0.04 |
| DP_8x1x1_16_1536x16 | 498M | 1536 | 16 | 0.498 | 1 | 8 | 16 | 48.03 | 38% | 0.38 | 41.74 | 33% | 0.33 |
| DP_16x1x1_32_1536x16 | 498M | 1536 | 16 | 0.498 | 1 | 16 | 32 | 41.00 | 33% | 0.66 | 30.21 | 24% | 0.48 |
| DP_32x1x1_64_1536x16 | 498M | 1536 | 16 | 0.498 | 1 | 32 | 64 | 38.71 | 31% | 1.24 | 29.37 | 23% | 0.94 |
| MP_1x1x1_8_768x12 | 117M | 768 | 12 | 0.117 | 1 | 1 | 8 | 37.98 | 30% | 0.04 | 32.63 | 26% | 0.03 |
| MP_1x8x1_16_1536x16 | 498M | 1536 | 16 | 0.498 | 8 | 8 | 16 | 31.26 | 25% | 0.25 | 28.99 | 23% | 0.23 |
| MP_1x16x1_16_3072x16 | 1.8B | 3072 | 16 | 1.840 | 16 | 16 | 16 | 7.25 | 6% | 0.12 | 6.22 | 5% | 0.10 |
| MP_1x32x1_16_3072x32 | 3.5B | 3072 | 32 | 3.529 | 32 | 32 | 16 | 3.57 | 3% | 0.11 | 2.60 | 2% | 0.08 |
| 2D_8x1x1_16_1536x16 | 498M | 1536 | 16 | 0.498 | 1 | 8 | 16 | 48.04 | 38% | 0.38 | 41.80 | 33% | 0.33 |
| 2D_1x8x1_16_1536x16 | 498M | 1536 | 16 | 0.498 | 8 | 8 | 16 | 31.15 | 25% | 0.25 | 30.20 | 24% | 0.24 |
| 2D_2x4x1_16_1536x16 | 498M | 1536 | 16 | 0.498 | 4 | 8 | 16 | 37.20 | 30% | 0.30 | 34.82 | 28% | 0.28 |
| 2D_4x2x1_16_1536x16 | 498M | 1536 | 16 | 0.498 | 2 | 8 | 16 | 36.91 | 30% | 0.30 | 33.81 | 27% | 0.27 |
| 2D_2x8x1_16_2304x24 | 1.5B | 2304 | 24 | 1.539 | 8 | 16 | 16 | 23.81 | 19% | 0.38 | 23.00 | 18% | 0.37 |
| 2D_4x8x1_32_2304x24 | 1.5B | 2304 | 24 | 1.539 | 8 | 32 | 32 | 20.41 | 16% | 0.65 | 20.03 | 16% | 0.64 |
| DP_PP_8x1x4_512_1536x16 | 498M | 1536 | 16 | 0.498 | 4 | 32 | 512 | 40.09 | 32% | 1.28 | 32.82 | 26% | 1.05 |
| MP_PP_1x8x4_512_2304x24 | 1.5B | 2304 | 24 | 1.539 | 32 | 32 | 512 | 25.18 | 20% | 0.81 | 21.80 | 17% | 0.70 |
| 2D_PP_2x4x4_512_2304x24 | 1.5B | 2304 | 24 | 1.539 | 16 | 32 | 512 | 36.85 | 29% | 1.18 | 31.53 | 25% | 1.01 |
| 2D_PP_2x8x2_512_2304x24 | 1.5B | 2304 | 24 | 1.539 | 16 | 32 | 512 | 33.62 | 27% | 1.08 | 29.69 | 24% | 0.95 |
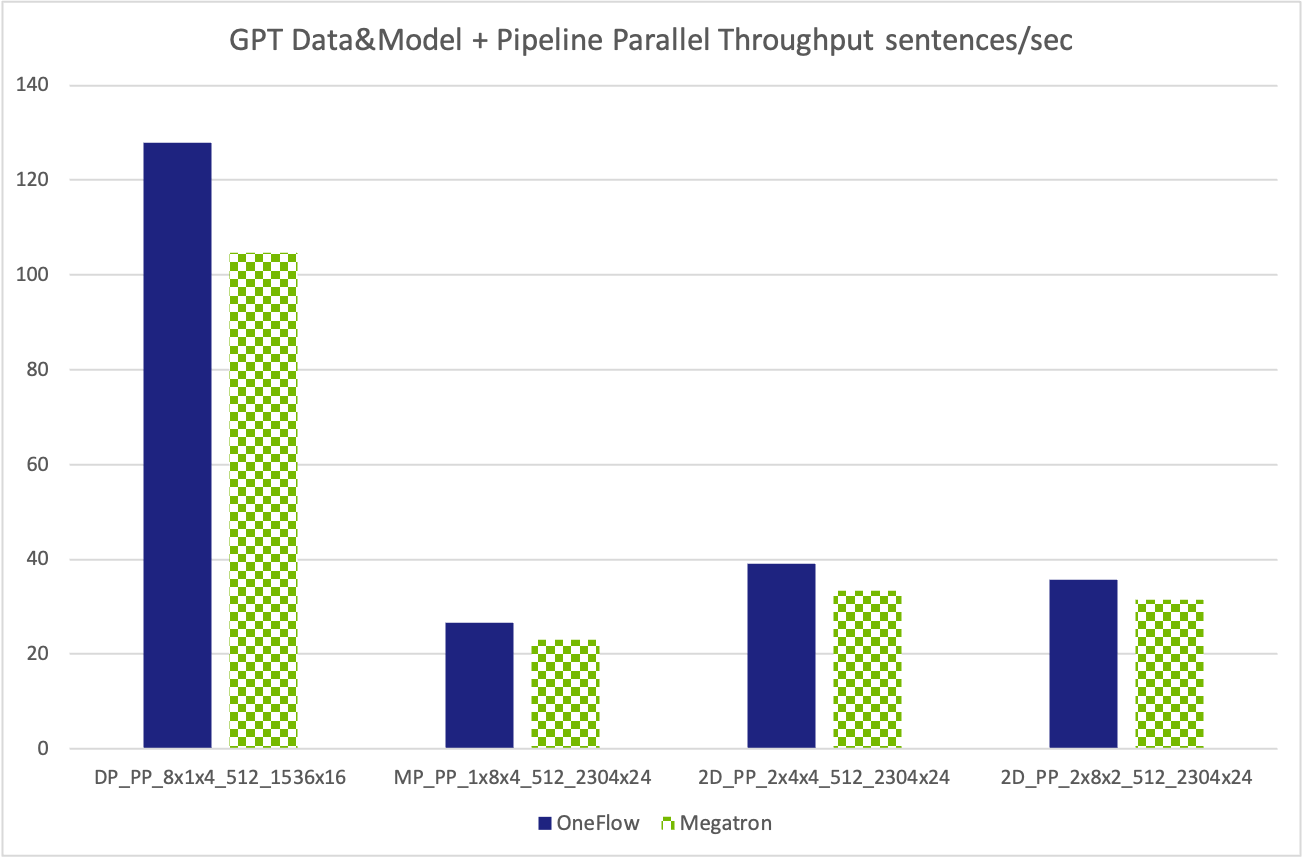
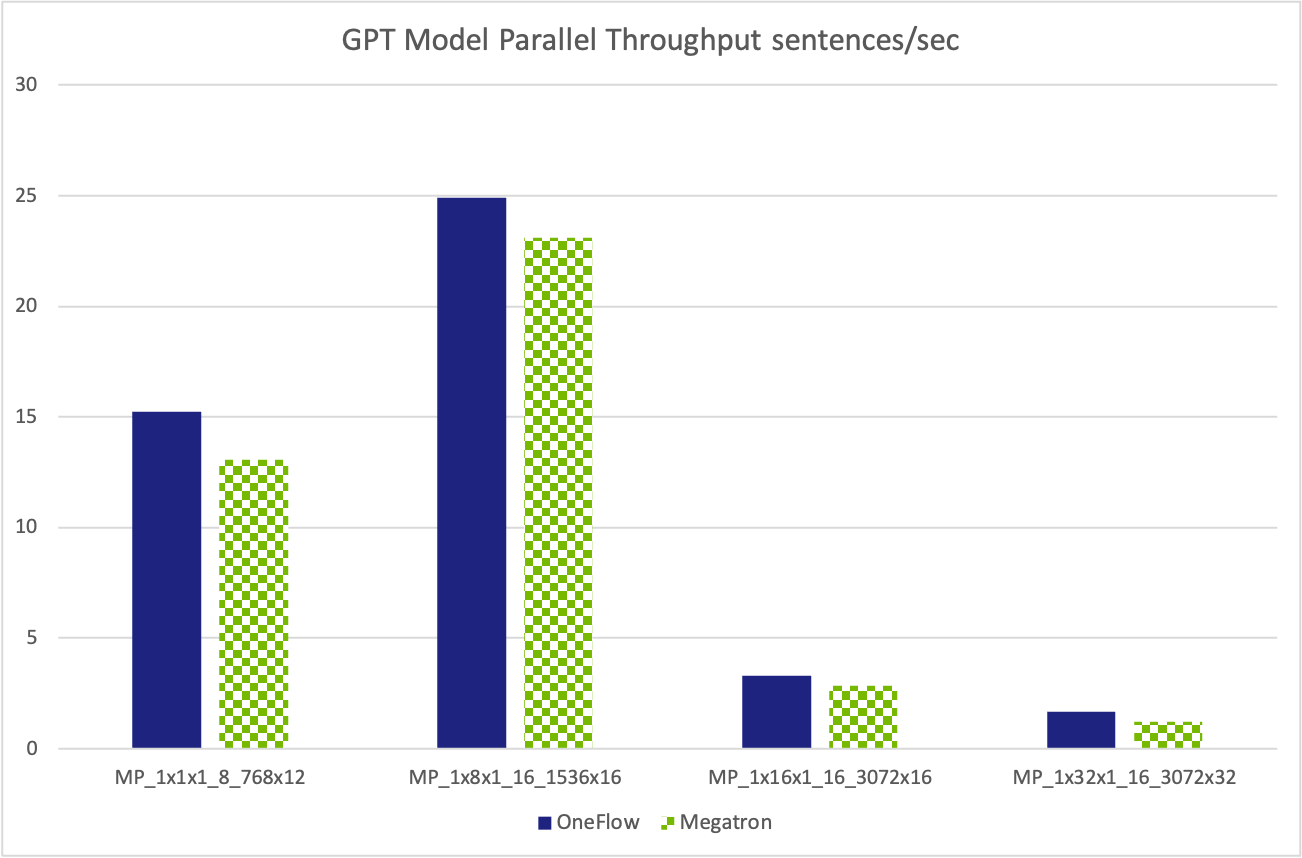
Following figure shows the same value with above table, just for better visualization.
| Test Case | OneFlow sequences/sec |
Megatron-LM sequences/sec |
|---|---|---|
| DP_1x1x1_2_1536x16 | 4.92 | 4.31 |
| DP_8x1x1_16_1536x16 | 38.28 | 33.27 |
| DP_16x1x1_32_1536x16 | 65.35 | 48.16 |
| DP_32x1x1_64_1536x16 | 123.40 | 93.63 |

| Test Case | OneFlow sequences/sec |
Megatron-LM sequences/sec |
|---|---|---|
| MP_1x1x1_8_768x12 | 15.23 | 13.09 |
| MP_1x8x1_16_1536x16 | 24.92 | 23.11 |
| MP_1x16x1_16_3072x16 | 3.32 | 2.85 |
| MP_1x32x1_16_3072x32 | 1.68 | 1.23 |
| Test Case | OneFlow sequences/sec |
Megatron-LM sequences/sec |
|---|---|---|
| 2D_8x1x1_16_1536x16 | 38.29 | 33.32 |
| 2D_1x8x1_16_1536x16 | 24.83 | 24.07 |
| 2D_2x4x1_16_1536x16 | 29.65 | 27.75 |
| 2D_4x2x1_16_1536x16 | 29.42 | 26.95 |
| 2D_2x8x1_16_2304x24 | 12.61 | 12.18 |
| 2D_4x8x1_32_2304x24 | 21.62 | 21.21 |

| Test Case | OneFlow sequences/sec |
Megatron-LM sequences/sec |
|---|---|---|
| DP_PP_8x1x4_512_1536x16 | 127.80 | 104.63 |
| MP_PP_1x8x4_512_2304x24 | 26.67 | 23.10 |
| 2D_PP_2x4x4_512_2304x24 | 39.03 | 33.40 |
| 2D_PP_2x8x2_512_2304x24 | 35.62 | 31.45 |