##Spark Configuration
oni-ml main component uses Spark and Spark SQL to analyze network events and produce a list of least probable events or most suspicious.
To run oni-ml with its best performance and scalability, it will probably be necessary to configure Yarn, Spark and Spot. Here are our recommended settings.
oni-ml Spark application has been developed and tested on CDH Yarn clusters. Careful tuning of the Yarn cluster may be necessary before analyzing large amounts of data with oni-ml.
For small data sets, under 100 GB parquet files, default Yarn configurations should be enough but if users try to analyze hundreds of gigabytes of data in parquet format it's probable that it don't work; Yarn most likely will start killing containers or will terminate the application with Out Of Memory errors.
For more on how to tune Yarn for general use, we suggest these links:
- Cloudera Tuning Yarn
- Tune Hadoop Cluster to get Maximum Performance
- Best Practices for YARN Resource Management
Users need to keep in mind that to get a Spark application running, especially for big data sets, it might take more than one try before getting any results.
When running Spark on Yarn users can set up a set of properties in order to get the best performance and consume resources in a more effective way. Since not all clusters are the same and not all users are planning to have the same capacity of computation, we have created variables that users need to configure before running oni-ml.
After installing oni-setup users will find the spot.conf file under /etc folder. This file contains all the required configuration to run oni-ml, as explained in INSTALL.md. In this file exist a section for Spark properties, below is the explanation for each of those variables:
SPK_EXEC='' ---> Maximumn number of executors
SPK_EXEC_MEM='' ---> Memory per executor in MB i.e. 30475m
SPK_DRIVER_MEM='' ---> Driver memory in MB i.e. 39485m
SPK_DRIVER_MAX_RESULTS='' ---> Maximumn driver results in MB or GB i.e. 8g
SPK_EXEC_CORES='' ---> Cores per executor i.e. 4
SPK_DRIVER_MEM_OVERHEAD='' ---> Driver memory overhead in MB i.e. 3047. Note that there is no "m" at the end.
SPAK_EXEC_MEM_OVERHEAD='' ---> Executor memory overhead in MB i.e. 3047. Note that there is no "m" at the end.
Besides the variables in duxbay.conf, users can modify the rest of the properties in ml_ops.sh based on their needs.
After Yarn cluster has been tuned the next step is to set Spark properties assigning the right values to duxbay.conf Spark variables.
#####Number of Executors, Executor Memory, Executor Cores and Executor Memory Overhead
The first thing users need to know is how to set the number of executors and the memory per executor as well as the number of cores. To get that number, users should know the available total memory per node after Yarn tuning, this total memory is determined by yarn.nodemanager.resource.memory-mb property and the total number of available cores is given by yarn.nodemanager.resource.cpu-vcores.
Depending on the total physical memory available for Yarn containers, the memory per executor can determine the starting point to set the total amount of executors. To calculate the memory per executor and number of executors we suggest to users follow the next steps:
- Divide the total of physical memory per node by a number between 3 and 5.
- If the result of the division is something equal or bigger than 30 GB then continue to calculate the number of executors.
- If the result of the division is less than 30 GB try smaller number.
- The result of the division will be the memory per executor. Multiply the number used in the first division by the number of nodes.
- The result of step 4 could be the total executors but users need to consider resources for the application driver. Depending on the result of the multiplication, we recommend to subtract 2 or 3 executors.
See example below:
Having a cluster with 9 nodes, each node with 152 GB physical memory available: 152/5 ~ 30 GB. 5 executors x 9 nodes = 45 executors - 2 = 43 executors.
In the previous example, taking off 2 executors ensures enough memory for the application driver.
Users can determine the number of cores per executor having the total of executors and the available vcpus per node:
- Divide the available vcpus by the number of executors.
Example:
Having a total of 432 vcpus, 48 per node: 432/43 ~ 10 cores per executor.
Although it sounds like a good idea to allocate all the available cores, we have seen cases where many cores per executor will cause Spark to assign more task to every executor and that can potentially cause OOM errors. Is recommended to keep a close relation between cores and executor memory.
Lastly, for overhead memory we recommend to use something between 8% and 10% of executor memory.
Following the example, the values for the Spark variables in duxbay.conf would look like this:
SPK_EXEC='43'
SPK_EXEC_MEM='30475m'
SPK_EXEC_CORES='6'
SPAK_EXEC_MEM_OVERHEAD='3047'
#####Driver Memory, Driver Maximum Results and Driver Memory Overhead
oni-ml application executes actions such as .collect, .orderBy, .saveAsTextFile so we recommend to assign a considerable amount of memory for the driver.
The same way, driver maximum results should be enough for the serialized results.
Depending on users data volume these two properties can be small as tens of gigabytes for driver and a couple of gigabytes for driver maximum results or grow up to 50 GB and 8 GB respectively. Users can follow the next steps to determine the amount of memory for driver and maximum results:
- If executor memory is equal or bigger than 30 GB, make driver memory the same as executor memory and driver maximum results a value equal or bigger than 6 GB.
- If executor memory is less than 30 GB but data to be analyzed is equal or bigger than 100 GB make driver something between 30 GB and 50 GB. Driver maximum results should be something equal or bigger than 8 GB.
Following the example in the previous section, with 9 nodes, 43 executors, 30 GB memory each executor, we can set driver memory to 30GB and 8GB driver maximum results.
Memory overhead for driver can be set to something between 8% and 10% of driver memory.
This is how Spark variables look like for driver properties:
SPK_DRIVER_MEM='30475m'
SPK_DRIVER_MAX_RESULTS='8g'
SPK_DRIVER_MEM_OVERHEAD='3047'
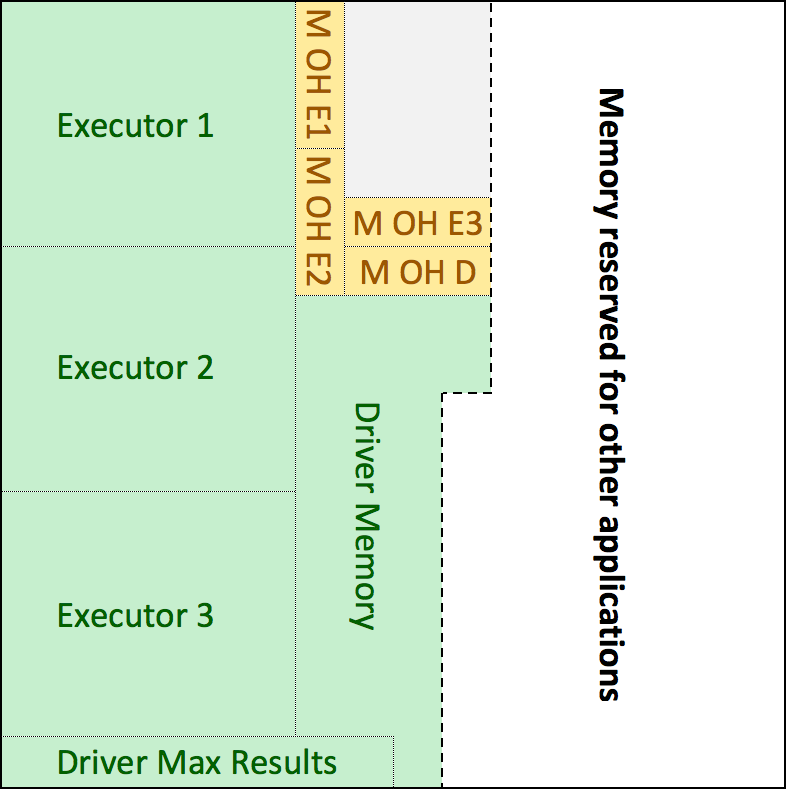
Representation of memory allocation in driver node.
For more information about Spark properties click here.
###Known Spark error messages running oni-ml
####Out Of Memory Error
This issue includes java.lang.OutOfMemoryError: Java heap space and java.lang.OutOfMemoryError : GC overhead limit exceeded. When users get OOME can be for many different issues but we have identified a couple of reasons for this error in oni-ml.
The main reason for this error in oni-ml can be when the ML algorithm returns large results for word probabilities per topic. Since ML algorithm results are broadcast, each executor needs more memory.
Another possible reason for this error is driver is running out of memory, try increasing driver memory.
####Container killed by Yarn for exceeding memory limits. X.Y GB of X GB physical memory used. Consider boosting spark.yarn.executor memoryOverhead
This issue is caused by certain operations, mainly during the join of document probabilities per topic with the rest of the data - scoring stage. If users receive this error they should try with increasing memory overhead up to 10% of executor memory or increase executors memory.
####org.apache.spark.serializer.KryoSerializer
KryoSerializer can cause issues if property spark.kryoserializer.buffer.max is not enough for the data being serialized. Try increasing memory up to 2 GB but keeping in mind the total of the available memory.