 +
+ +### Model Visual
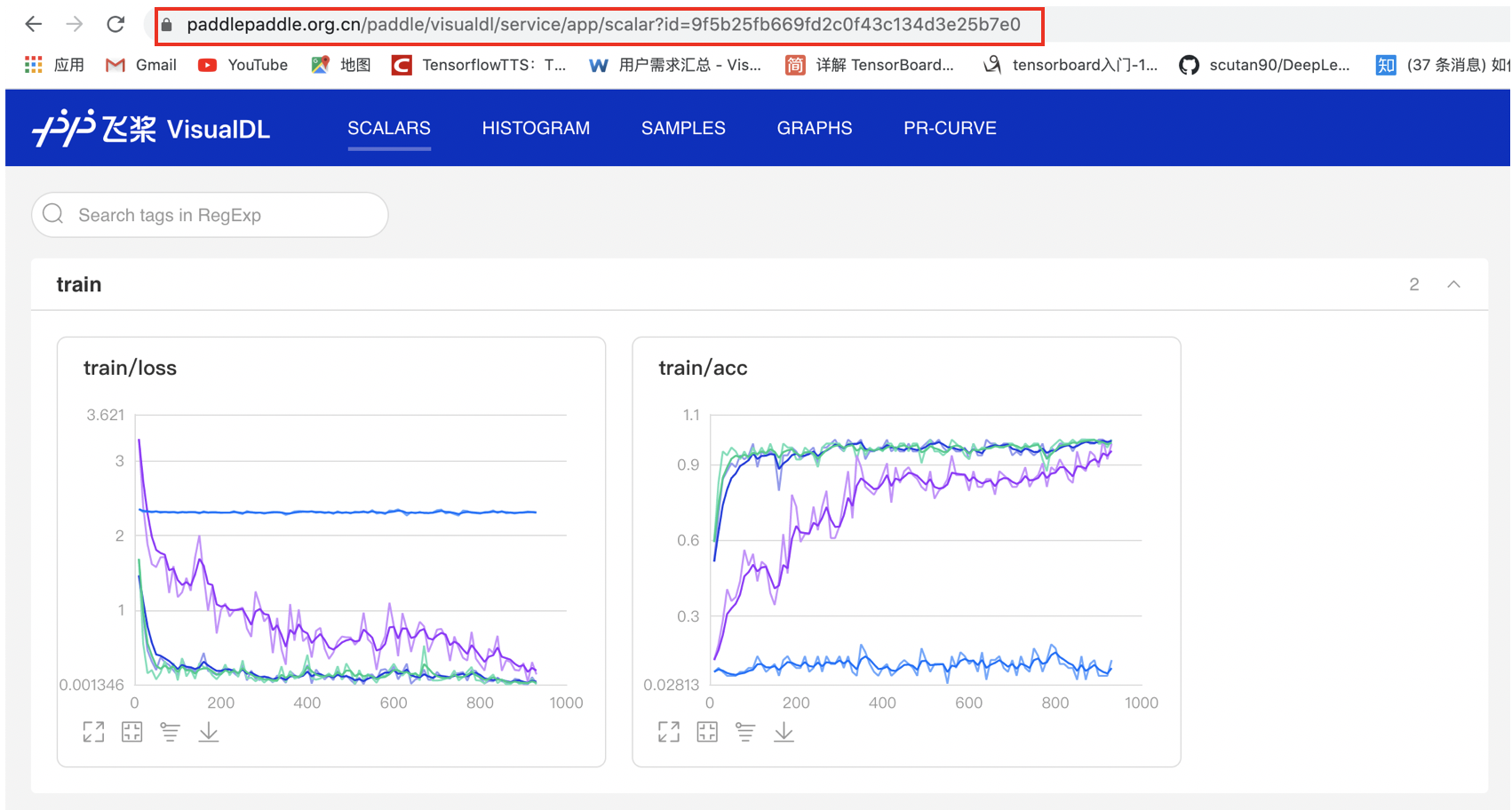
+The data distribution and key statistical information of each layer of the model network are visualized from multiple angles with rich views, which is convenient to quickly understand the rationality of the current model network design and realize the rapid positioning of model anomalies.
+
+
+### Model Visual
+The data distribution and key statistical information of each layer of the model network are visualized from multiple angles with rich views, which is convenient to quickly understand the rationality of the current model network design and realize the rapid positioning of model anomalies.
+
+
+
+
 -
## Frequently Asked Questions
If you are confronted with some problems when using VisualDL, please refer to [our FAQs](./docs/faq.md).
## Contribution
-VisualDL, in which Graph is powered by [Netron](https://github.com/lutzroeder/netron), is an open source project supported by [PaddlePaddle](https://www.paddlepaddle.org/) and [ECharts](https://echarts.apache.org/).
+VisualDL, in which Graph is powered by [Netron](https://github.com/lutzroeder/netron) and [AntV G6](https://github.com/antvis/G6), is an open source project supported by [PaddlePaddle](https://www.paddlepaddle.org/) and [ECharts](https://echarts.apache.org/).
Developers are warmly welcomed to use, comment and contribute.
diff --git a/README_CN.md b/README_CN.md
index f470dbbe1..e16cf4ca1 100644
--- a/README_CN.md
+++ b/README_CN.md
@@ -24,7 +24,7 @@
VisualDL是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布等。可帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型优化。
-VisualDL提供丰富的可视化功能,**支持标量、图结构、数据样本(图像、语音、文本)、超参数可视化、直方图、PR曲线、ROC曲线及高维数据降维呈现等诸多功能**,同时VisualDL提供可视化结果保存服务,通过VDL.service生成链接,保存并分享可视化结果。具体功能使用方式,请参见 [**VisualDL使用指南**](./docs/components/README_CN.md)。如欲体验最新特性,欢迎试用我们的[**在线演示系统**](https://www.paddlepaddle.org.cn/paddle/visualdl/demo)。项目正处于高速迭代中,敬请期待新组件的加入。
+VisualDL提供丰富的可视化功能,**支持标量、图结构、数据样本(图像、语音、文本)、超参数可视化、直方图、PR曲线、ROC曲线及高维数据降维呈现、模型可视化等诸多功能**,同时VisualDL提供可视化结果保存服务,通过VDL.service生成链接,保存并分享可视化结果。具体功能使用方式,请参见 [**VisualDL使用指南**](./docs/components/README_CN.md)。如欲体验最新特性,欢迎试用我们的[**在线演示系统**](https://www.paddlepaddle.org.cn/paddle/visualdl/demo)。项目正处于高速迭代中,敬请期待新组件的加入。
VisualDL支持浏览器:
@@ -412,6 +412,125 @@ value: 3.1297709941864014
+### Model Visual
+
+以丰富的视图多角度低可视化模型网络各层数据的分布和关键统计信息,便于快速了解当前模型网络设计的合理性,实现快速定位模型异常问题。
+
+
-
## Frequently Asked Questions
If you are confronted with some problems when using VisualDL, please refer to [our FAQs](./docs/faq.md).
## Contribution
-VisualDL, in which Graph is powered by [Netron](https://github.com/lutzroeder/netron), is an open source project supported by [PaddlePaddle](https://www.paddlepaddle.org/) and [ECharts](https://echarts.apache.org/).
+VisualDL, in which Graph is powered by [Netron](https://github.com/lutzroeder/netron) and [AntV G6](https://github.com/antvis/G6), is an open source project supported by [PaddlePaddle](https://www.paddlepaddle.org/) and [ECharts](https://echarts.apache.org/).
Developers are warmly welcomed to use, comment and contribute.
diff --git a/README_CN.md b/README_CN.md
index f470dbbe1..e16cf4ca1 100644
--- a/README_CN.md
+++ b/README_CN.md
@@ -24,7 +24,7 @@
VisualDL是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布等。可帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型优化。
-VisualDL提供丰富的可视化功能,**支持标量、图结构、数据样本(图像、语音、文本)、超参数可视化、直方图、PR曲线、ROC曲线及高维数据降维呈现等诸多功能**,同时VisualDL提供可视化结果保存服务,通过VDL.service生成链接,保存并分享可视化结果。具体功能使用方式,请参见 [**VisualDL使用指南**](./docs/components/README_CN.md)。如欲体验最新特性,欢迎试用我们的[**在线演示系统**](https://www.paddlepaddle.org.cn/paddle/visualdl/demo)。项目正处于高速迭代中,敬请期待新组件的加入。
+VisualDL提供丰富的可视化功能,**支持标量、图结构、数据样本(图像、语音、文本)、超参数可视化、直方图、PR曲线、ROC曲线及高维数据降维呈现、模型可视化等诸多功能**,同时VisualDL提供可视化结果保存服务,通过VDL.service生成链接,保存并分享可视化结果。具体功能使用方式,请参见 [**VisualDL使用指南**](./docs/components/README_CN.md)。如欲体验最新特性,欢迎试用我们的[**在线演示系统**](https://www.paddlepaddle.org.cn/paddle/visualdl/demo)。项目正处于高速迭代中,敬请期待新组件的加入。
VisualDL支持浏览器:
@@ -412,6 +412,125 @@ value: 3.1297709941864014
+### Model Visual
+
+以丰富的视图多角度低可视化模型网络各层数据的分布和关键统计信息,便于快速了解当前模型网络设计的合理性,实现快速定位模型异常问题。
+
+
+
+
+### Model Visual
+The data distribution and key statistical information of each layer of the model network are visualized from multiple angles with rich views, which is convenient to quickly understand the rationality of the current model network design and realize the rapid positioning of model anomalies.
+
+
+
+
+### Model Visual
+
+以丰富的视图多角度低可视化模型网络各层数据的分布和关键统计信息,便于快速了解当前模型网络设计的合理性,实现快速定位模型异常问题。
+
+
+
+
 PeterPanZH |  Niandalu |
PeterPanZH | Niandalu |  AuroraHuiyan |
PeterPanZH | Niandalu |
PeterPanZH | Niandalu | AuroraHuiyan |
{t('model-visual:tools.behavior-controller')}
++ {t('model-visual:node-id')}: + {id || t('model-visual:none-data')} +
++ {t('model-visual:node-pos')}: + {(x && y) ? `[${x}, ${y}]` : t('model-visual:none-data')} +
+