You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
生成式的模型有高斯模型、贝叶斯网络、朴素贝叶斯、隐马尔可夫模型等,方法关键在于对来自各个种类的样本分布进行假设以及对所假设模型的参数估计。首先通过假设已知样本数据的密度函数 p(x|yi)的形式,比如多项式、高斯分布等。接着可采用迭代算法(如 EM 算法)计算 p(x|yi)的参数,然后根据贝叶斯全概率公式对全部未标签样本数据进行分类。
前言
前阶段时间梳理了机器学习开发实战的系列文章:
1、Python机器学习入门指南(全)
2、Python数据分析指南(全)
3、一文归纳Ai数据增强之法
4、一文归纳Python特征生成方法(全)
5、Python特征选择(全)
6、一文归纳Ai调参炼丹之法
现阶段写作计划会对各类机器学习算法做一系列的原理概述及实践,主要包括无监督聚类、异常检测、半监督算法、强化学习、集成学习等。
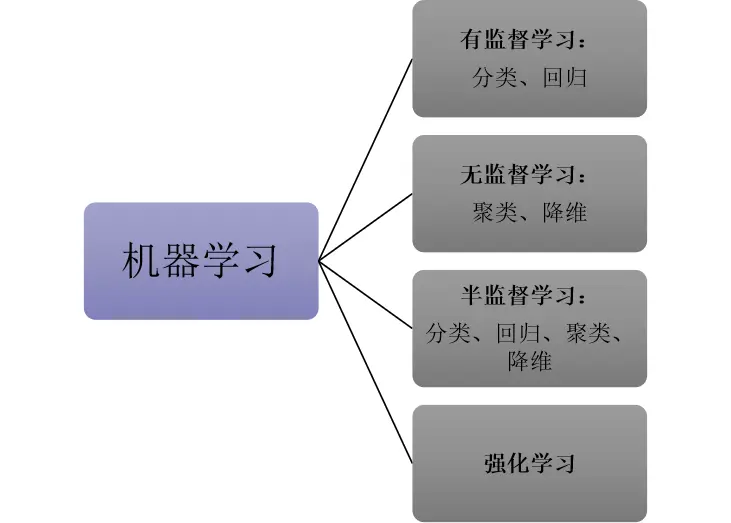
一、机器学习简介
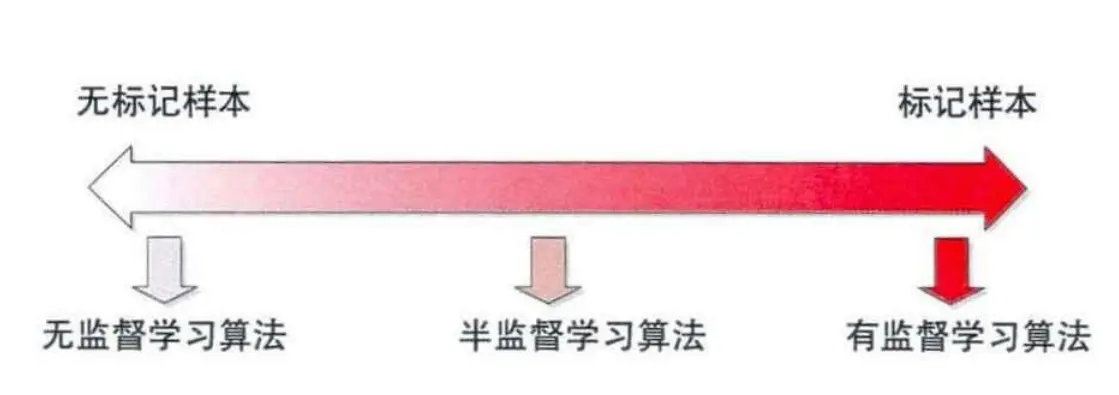
机器学习按照数据的标签情况可以细分为:监督学习,无监督学习,半监督学习以及强化学习。
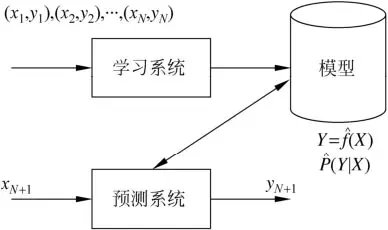
监督学习是利用数据特征及其标签 D ={(x1,y1),…,(xl,yl)}学习输入到输出的映射f:X→Y的方法。
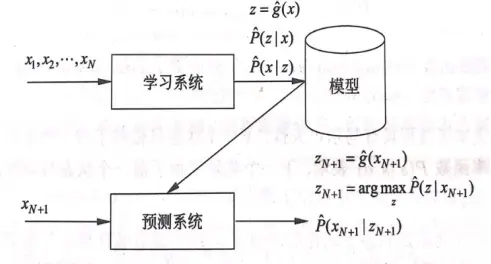
无监督学习是仅利用无类标签的样本数据特征 D={x1,…,xn}学习其对应的簇标签、特征表示等方法。
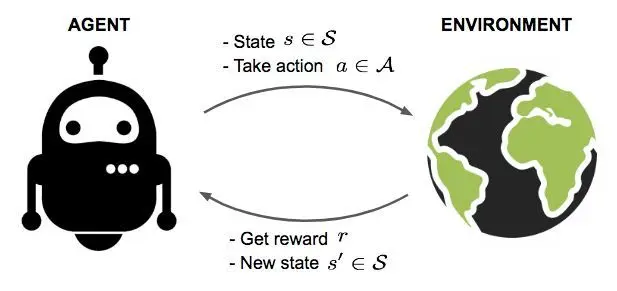
强化学习从某种程度可以看作是有延迟标签信息的监督学习。
半监督学习是介于传统监督学习和无监督学习之间,其思想是在标记样本数量较少的情况下,通过在模型训练中直接引入无标记样本,以充分捕捉数据整体潜在分布,以改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致的学习效果不佳的问题。
二、半监督算法的类别
##2.1 按理论差异划分
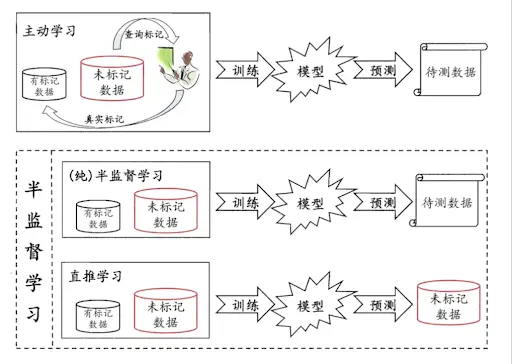
按照统计学习理论差异,半监督学习可以分为:(纯)归纳半监督学习和直推学习。
直推学习只处理样本空间内给定的训练数据,利用训练数据中有类标签的样本和无类标签的样例进行训练,仅预测训练数据中无类标签的样例的类标签,典型如标签传播算法(LPA)。
归纳半监督学习处理整个样本空间中所有给定和未知的样例,不仅预测训练数据中无类标签的样例的类标签,更主要的是预测未知的测试样例的类标签,典型如半监督SVM。
##2.2 按学习场景划分
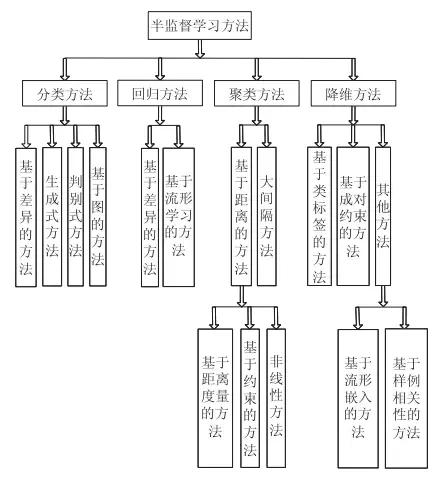
从不同的学习场景看,半监督学习可分为四类:半监督分类(Semi-supervised classification)、半监督回归(Semi-supervised regression)、半监督聚类(Semi-supervised clustering)及半监督降维(Semi-supervised dimensionality reduction)。
半监督分类
半监督分类算法的思想是通过大量的未标记样本帮助学习一个好的分类系统,代表算法可以划分为四类,包括生成式方法、判别式方法、半监督图算法和基于差异的半监督方法(此外还可扩展出半监督深度学习方法,限于篇幅本文没有展开)。
结合现实情况多数为半监督分类场景,下节会针对半监督分类算法原理及实战进行展开。
半监督聚类
半监督聚类算法的思想是如何利用先验信息以更好地指导未标记样本的划分过程。现有的算法多数是在传统聚类算法基础上引入监督信息发展而来,基于不同的聚类算法可以将其扩展成不同的半监督聚类算法。
半监督回归
半监督回归算法的思想是通过引入大量的未标记样本改进监督学习方法的性能,训练得到性能更优的回归器。现有的方法可以归纳为基于协同训练(差异)的半监督回归和基于流形的半监督回归两类。
半监督降维
半监督降维算法的思想在大量的无类标签的样例中引入少量的有类标签的样本,利用监督信息找到高维数据的低维结构表示,同时保持数据的内在固有信息。而利用的监督信息既可以是样例的类标签,也可以是成对约束信息,还可以是其他形式的监督信息。主要的半监督降维方法有基于类标签的方法、基于成对约束等方法。
三、半监督分类算法(Python)
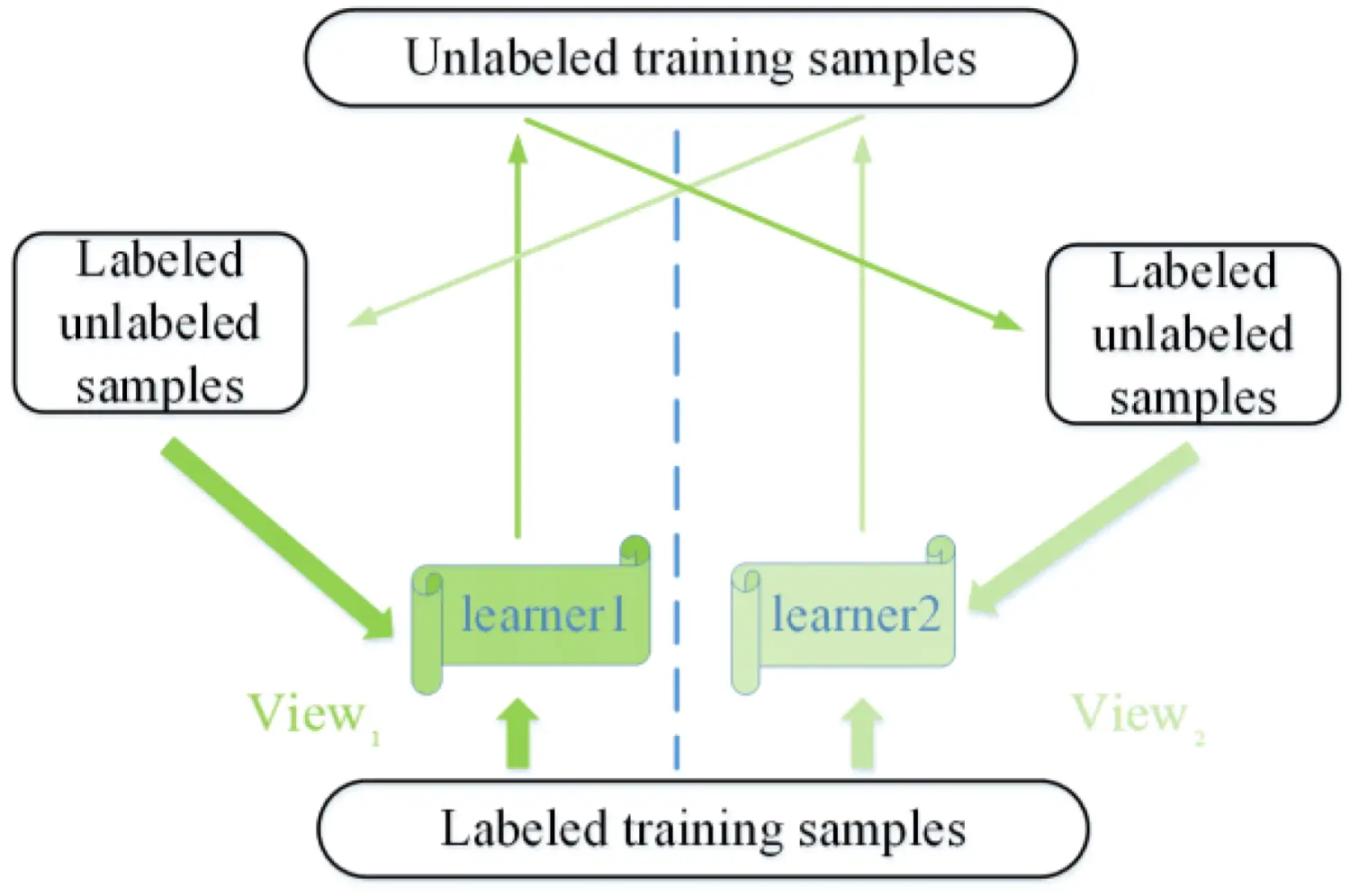
3.1 基于差异的方法
基于差异的半监督学习起源于协同训练算法,其思想是利用多个拟合良好的学习器之间的差异性提高泛化能力。假设每个样本可以从不同的角度(view)训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。
3.2 判别式方法
判别式方法利用最大间隔算法同时训练有类标签的样本和无类标签的样例学习决策边界,使其通过低密度数据区域,并且使学习得到的分类超平面到最近的样例的距离间隔最大。常见的如直推式支持向量机(TSVM)及最近邻(KNN)等。
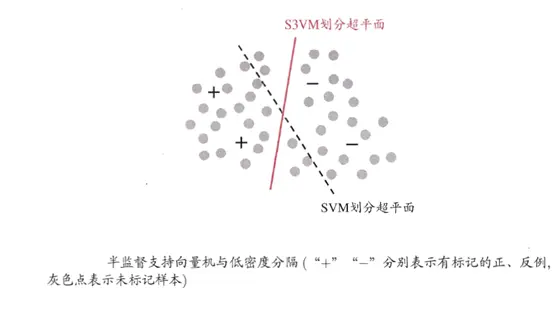
TSVM采用局部搜索的策略来进行迭代求解,即首先使用有标记样本集训练出一个初始SVM,接着使用该学习器对未标记样本进行打标,这样所有样本都有了标记,并基于这些有标记的样本重新训练SVM,之后再寻找易出错样本不断调整。
3.3 生成式方法
生成式的模型有高斯模型、贝叶斯网络、朴素贝叶斯、隐马尔可夫模型等,方法关键在于对来自各个种类的样本分布进行假设以及对所假设模型的参数估计。首先通过假设已知样本数据的密度函数 p(x|yi)的形式,比如多项式、高斯分布等。接着可采用迭代算法(如 EM 算法)计算 p(x|yi)的参数,然后根据贝叶斯全概率公式对全部未标签样本数据进行分类。
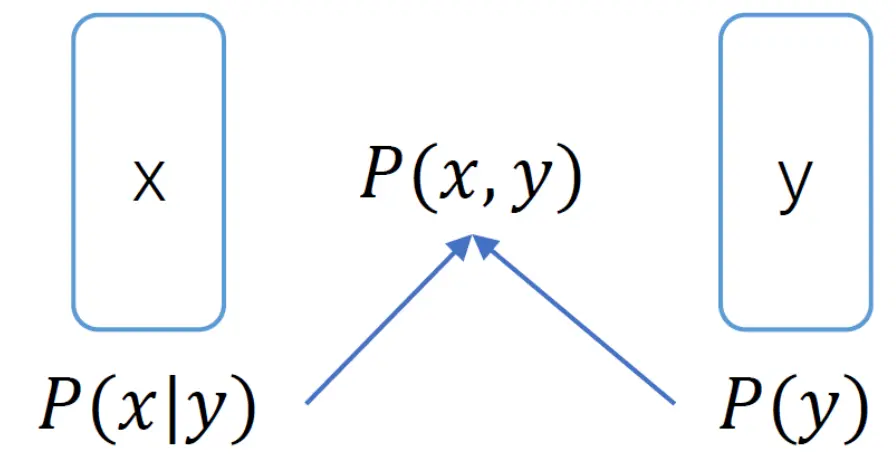
生成式方法可以直接关注半监督学习和决策中的条件概率问题,避免对边缘概率或联合概率的建模以及求解,然而该方法对一些假设条件比较苛刻,一旦假设的 p(x|yi)与样本数据的实际分布情况差距比较大,其分类效果往往不佳。
##3.4 基于图半监督学习方法
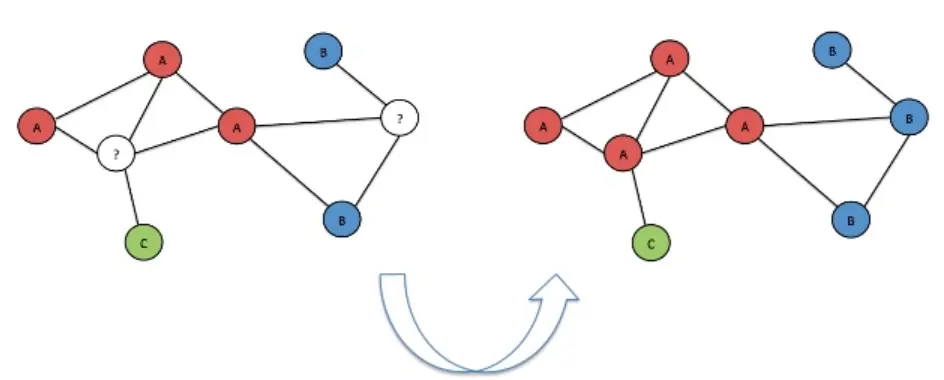
基于图的方法的实质是标签传播,基于流形假设根据样例之间的几何结构构造边(边的权值可以用样本间的相近程度),用图的结点表示样例,利用图上的邻接关系将类标签从有类标签的样本向无类标签的样例传播。基于图的方法通常图计算复杂度较高,且对异常图结构缺乏鲁棒性,主要方法有最小分割方法、标签传播算法(LPA)和流形方法 (manifold method)等。
标签传播算法(LPA)是基于图的半监督学习算法,基本思路是从已标记的节点标签信息来预测未标记的节点标签信息。
1、首先利用样本间的关系(可以是样本客观关系,或者利用相似度函数计算样本间的关系)建立完全图模型。
2、接着向图中加入已标记的标签信息,无标签节点是在用一个唯一的标签初始化。
3、该算法会重复地将一个节点的标签设置为该节点的相邻节点中出现频率最高(有权图需要考虑权重)的标签,重复迭代,直到标签不变算法收敛。
文章首发于算法进阶,公众号阅读原文可访问GitHub源码
The text was updated successfully, but these errors were encountered: