Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[SPARK-23313][DOC] Add a migration guide for ORC
## What changes were proposed in this pull request? This PR adds a migration guide documentation for ORC. 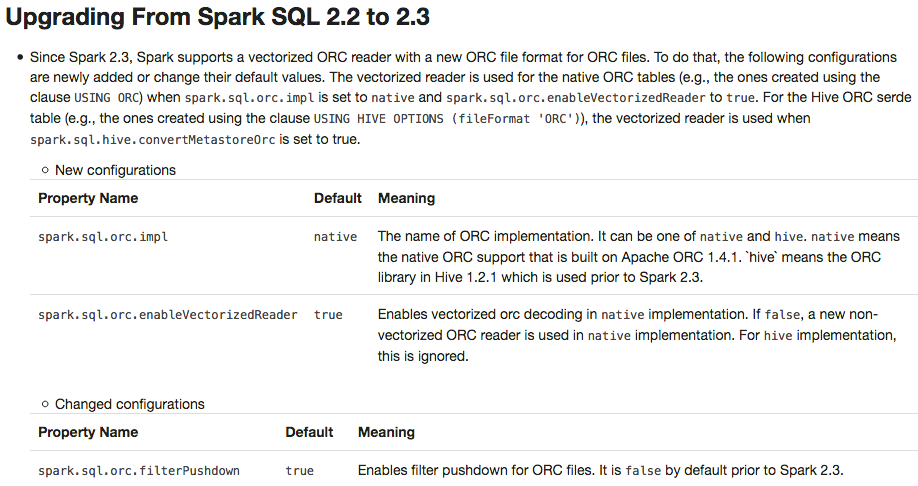 ## How was this patch tested? N/A. Author: Dongjoon Hyun <[email protected]> Closes #20484 from dongjoon-hyun/SPARK-23313.
{kind=link}
- Loading branch information
1 parent
fba01b9
commit 6cb5970