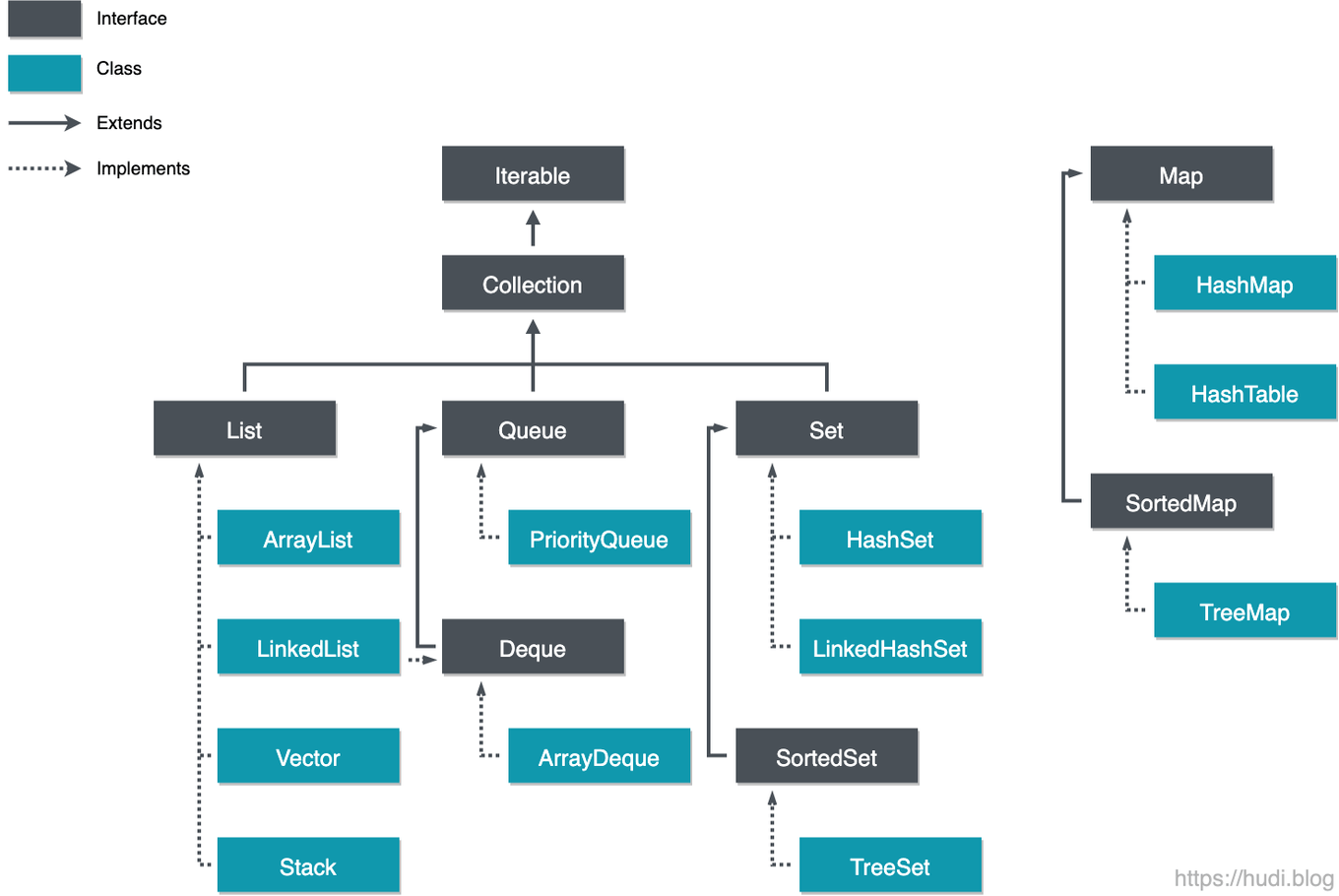
- 컬렉션은 다수의 요소를 하나의 그룹으로 묶어 효율적으로 저장하고, 관리할 수 있는 기능을 제공하는 일종의 컨테이너 이다.
- 가변적인 크기를 갖고, 데이터의 삽입, 탐색, 정렬에 대한 편리한 API를 다수 제공한다.
- JDK 1.2 버전부터 java.util 패키지에서 지원하고 이전에도 Vector, Stack, Hash Table 등이 존재했지만 통일성이 없고 표준화 된 인터페이스가 존재하지 않았다.
- 컬렉션 프레임워크에는 크게 리스트(List), 큐(Queue), 집합(Set), 맵(Map)으로 분류 할 수 있다.
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// 일부 코드 생략
private transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
}- Set과 Map 둘 다 동일하게 HashTable을 사용합니다.
Map은 <Key, Value> 형식으로 Value에 값이 들어가 있는 경우가 많습니다.
Set은 무조건 <Key, NULL> 로 저장합니다. 해시 함수에 대한 HashValue를 키로 사용함으로써, 동일한 키가 존재하면 equals() 메서드를 통해 중복된 값인지 확인합니다.- 사용자가 정의한 Reference type은 Object에 구현되어 있는 동등성 비교(Equals)와 hashcode() 오버라이딩 함으로써 객체가 동일한지 판단할 수 있도록 해줍니다.
- hashCode의 구현부는 JDK에 달려있다고 합니다. 대체적으로 객체의 메모리 주소라고 많이 알려져있는데, 그렇지 않다고 합니다.
- 사용자가 정의한 Reference type은 Object에 구현되어 있는 동등성 비교(Equals)와 hashcode() 오버라이딩 함으로써 객체가 동일한지 판단할 수 있도록 해줍니다.
-
HashMap은 가장 기본적인 Map 자료구조로
<Key, Value>로 구성되어 있습니다. 하지만 iterator를 사용하여 출력 시 순서가 보장되지 않습니다. -
LinkedHashMap은 HashMap에서 순서가 보장되지 않는 단점을 해결하여 순서가 보장되도록 하는 Map 자료구조입니다.
-
TreeMap은 Map에 저장 된 키에 대해서 이진 트리를 기반으로 정렬되어 있는 Map 자료구조를 말합니다.
- HashMap을 사용합니다. Map 자료구조는
<Key, Value>를 통해 찾고자 하는 값을 O(1) 로 찾아낼 수 있다는 장점이 있습니다. Linked 혹은 Tree는 부가적인 기능이 추가된 것이여서, 만약 필요하다면 다른 컬렉션을 사용 할 것 같습니다.- HashMap, LinkedHashMap 같은 경우에는 O(1) 만큼 동일하게 소요되지만, LinkedHashMap 같은 경우에는 Linked-list를 유지하는 비용이 추가로 발생됩니다.
- TreeMap은 RedBlackTree로 구성되어 있고, 트리로 구성되어서 삽입, 탐색하는데 O(logN) 만큼의 시간이 소요됩니다.
- HashMap을 사용합니다. Map 자료구조는
[HashMap]
- HashMap은 **동기화 처리를 하지 않는 자료구조이기에 Thread-safe 하지 않습니다.
- 싱글 쓰레드 환경에서 사용을 해야합니다.
- 동기화 처리를 하지 않아 HashTable과 ConcurrentHashMap에 비해 데이터를 찾는 속도가 빠릅니다.
[HashTable]
- HashTable이 HashMap 보다 먼저 나왔는데, HashTable은 동기화 처리가 되어있습니다.
- HashMap은 key와 value에 null을 허용하는 반면, HashTable은 null을 허용하지 않습니다.
- 인스턴스 메서드에 synchronized 가 걸려있습니다.
public synchronized V put(K key, V value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}[ConcurrentHashMap]
- ConcurrentHashMap은 HashTable의 동기화 성능을 최적화 한 자료구조입니다.
- HashTable은 메서드 자체에 동기화 처리를 하였지만, ConcurrentHashMap은 동기화 블럭을 사용하여 한 Entry에 대해서만 동기화가 이루어집니다.
-
ArrayList는 인덱스를 가지고 있어 인덱스로 조회를 하는 경우에 빠르게 사용 할 수 있다는 장점이 있습니다. 하지만 중간에 값을 추가하거나 삽입하는 과정에서 쉬프트로 인해 많은 비용이 발생하고 데이터가 추가되는 과정에서 GC와 백업에 대한 연산에 있어서도 추가적인 비용이 발생 할 수 있어 정적인 조회가 많은 경우에 사용합니다.
-
LinkedList는 ArrayList와 달리 중간 삽입, 삭제 연산이 빠르지만 탐색 속도가 ArrayList에 비해서 떨어지기때문에 중간 삽입, 삭제 연산이 많다면 LinkedList를 사용합니다.
- ArrayList는 capacity가 초과되면 데이터를 백업하고 메모리 공간을 비웁니다. 이 과정에서 GC가 발생하고, 추가적인 메모리 공간을 늘려 새로운 메모리 공간에 다시 데이터를 적재합니다.
- 자바에서는 해시 충돌에 대해서 Separate Chaning 방식을 택하고 있고, 하나의 해시버킷에 8개의 키-값 쌍이 모이면 RB Tree로 변경됩니다.
-
자바에서는 해시 버킷의 개수의 기본값은 16이고 임계점(loadFactor 0.75)에 도달 할 때마다 버킷 개수의 크기를 두 배씩 증가시킵니다. 버킷의 최대 개수는 2^30 입니다.
-
하지만 이때, 해시 버킷의 개수가 2^a 형태가 되므로 보조 해시 함수의 % M 을 사용할 경우 하위 a개의 비트만 사용하게 되어서 해시 충돌이 쉽게 발생할 수 있다는 문제가 있습니다.
-
자바에서는 해시 충돌을 줄이기 위해 보조 해시 함수를 사용하고 있고, java 7 에서는 다음과 같은 보조 해시 함수를 사용하였습니다.
final int hash(Object k) {
// Java 7부터는 JRE를 실행할 때, 데이터 개수가 일정 이상이면
// String 객체에 대해서 JVM에서 제공하는 별도의 옵션으로
// 해시 함수를 사용하도록 할 수 있다.
// 만약 이 옵션을 사용하지 않으면 hashSeed의 값은 0이다.
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// 해시 버킷의 개수가 2a이기 때문에 해시 값의 a비트 값만을
// 해시 버킷의 인덱스로 사용한다. 따라서 상위 비트의 값이
// 해시 버킷의 인덱스 값을 결정할 때 반영될 수 있도록
// shift 연산과 XOR 연산을 사용하여, 원래의 해시 값이 a비트 내에서
// 최대한 값이 겹치지 않고 구별되게 한다.
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}- java 8 부터는 굉장히 단순해졌는데 해시 값과 해시 값에 대한 시프트 연산으로 >>> 16 만큼 이동한 값과 XOR 연산을 통한 보조 해시 함수를 사용하고 있습니다.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}