diff --git a/TODO/the-hidden-treasures-of-object-composition.md b/TODO/the-hidden-treasures-of-object-composition.md
index b44d69479c6..85dc6336e7a 100644
--- a/TODO/the-hidden-treasures-of-object-composition.md
+++ b/TODO/the-hidden-treasures-of-object-composition.md
@@ -18,7 +18,7 @@
>
> “优先考虑对象组合而不是类继承。” ~ Gang of Four,[《设计模式:可复用面向对象软件的基础》](https://www.amazon.com/Design-Patterns-Elements-Reusable-Object-Oriented/dp/0201633612//ref=as_li_ss_tl?ie=UTF8&linkCode=ll1&tag=eejs-20&linkId=06ccc4a53e0a9e5ebd65ffeed9755744)
-软件开发中最常见的错误之一就是对于类继承的过度使用。类继承是一个代码复用机制,实例对象和基类构成了 **是一个(is-a)**关系。如果你想要使用 is-a 关系来构建应用程序,你将陷入麻烦,因为在面向对象设计中,类继承是最紧的耦合形式,这种耦合会引起下面这些常见问题:
+软件开发中最常见的错误之一就是对于类继承的过度使用。类继承是一个代码复用机制,实例对象和基类构成了 **is-a** 关系。如果你想要使用 is-a 关系来构建应用程序,你将陷入麻烦,因为在面向对象设计中,类继承是最紧的耦合形式,这种耦合会引起下面这些常见问题:
* 脆弱的基类问题
* 猩猩/香蕉问题
diff --git a/TODO1/11-chrome-apis-that-give-your-web-app-a-native-feel.md b/TODO1/11-chrome-apis-that-give-your-web-app-a-native-feel.md
new file mode 100644
index 00000000000..9b47a6601c3
--- /dev/null
+++ b/TODO1/11-chrome-apis-that-give-your-web-app-a-native-feel.md
@@ -0,0 +1,417 @@
+> * 原文地址:[11 Chrome APIs That Will Give Your Web App a Native Feel](https://blog.bitsrc.io/11-chrome-apis-that-give-your-web-app-a-native-feel-ad35ad648f09)
+> * 原文作者:[Shanika Wickramasinghe](https://medium.com/@shanikanishadhi1992)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/11-chrome-apis-that-give-your-web-app-a-native-feel.md](https://github.com/xitu/gold-miner/blob/master/TODO1/11-chrome-apis-that-give-your-web-app-a-native-feel.md)
+> * 译者:
+> * 校对者:
+
+# 11 Chrome APIs That Will Give Your Web App a Native Feel
+
+
+
+## Why aim for a “native feel” ?
+
+Native apps are more stable, faster and offer many features that web apps are lacking (or at least were lacking up until lately). In short — native apps, generally speaking, offer a better UX than their webby counterpart.
+
+Of course, web apps have their own advantages — they are universal, require minimal effort to get started with, always-up-to-date and most importantly for us as developers, they are cost-effective.
+
+The solution should not be a compromise between the two but the best of both worlds.
+
+## 1. SMS Receiver
+
+](https://cdn-images-1.medium.com/max/2234/0*K3DcqnbwAiKsFJf9)
+
+Mobiles are essentially used for communication and verification of users. For online transactions, mobile phones are verified with a one-time password (OTP ) sent by SMS to their phone numbers. Users copy the OTP and send it over the web browser to the respective agency.
+
+Users need to provide the OTP twice to confirm each process, searching for the SMS, and copying the latest OTP is a tedious and risky task. The SMS receiver app allows you to copy the OTP obtained via the SMS verification message and verifies it.
+
+Once you receive an OTP as SMS, you see a bottom sheet popping up, prompting verification of the phone number. Clicking verify on the SMS receiver app will programmatically transfer the OTP to the browser, and the form will be submitted automatically. Along with SMS Receiver API, it is recommended to use an additional layer of security like form authentication to establish new sessions for users.
+
+#### How the API Works:
+
+1. Feature Detection: Feature detection is enabled for the SMS object.
+
+```JavaScript
+if ('sms' in navigator) {
+ ...
+}
+
+```
+
+2. Process OTP: Once the receiver receives the SMS, a bottom sheet is displayed with the verify button. When the user clicks it, a regular expression is used to extract the OTP and verify the user.
+
+```JavaScript
+const code = sms.content.match(/^[\s\S]*otp=([0-9]{6})[\s\S]*$/m)[1];
+```
+
+3. Submitting the OTP: Once the OTP is retrieved, it will be sent to the server for OTP verification.
+
+](https://cdn-images-1.medium.com/max/2000/0*Gjiw69Zc0oTeQkDG)
+
+Check out this demo:
+[**SMS Receiver API Demo**](https://sms-receiver-demo.glitch.me/)
+
+## 2. Contact Picker
+
+](https://cdn-images-1.medium.com/max/2000/0*IdpUhLkaa07MSVKj)
+
+Picking a contact from your mobile devices contact list is a simple action that most mobile device users take for granted. However, this is not something that is available on web apps, and the only way to enter details of contact was to type it in manually.
+
+Using the contact picker API, you can effortlessly search for a contact from the contact list, select it and add it to a form in a web app. This is an on-demand feature that is available from Chrome 80. The contact picker API allows users to select one or more contacts and then adds limited details in the browser.
+
+You can now have contact information like email, phone number, and name extracted quickly for many purposes. Some use cases are selecting the recipient’s email for web-based client mail, picking the recipient’s phone number to make a voice-over-IP call, and search for a contact on Facebook.
+
+Chrome makes sure to secure all your contact details and data. Review the [Security and Privacy](https://web.dev/contact-picker/#security-considerations) before using this API in applications.
+
+#### How API Works :
+
+This API needs a single call with optional parameters mentioned. First, identify if the feature is available. forWindows, you can use the following code.
+
+```JavaScript
+const supported = ('contacts' in navigator && 'ContactsManager' in window);
+
+```
+
+Next, open the Contact Picker using “navigator.contacts.select()”. then let the user select the contacts they want to share and click **DONE.** The API uses the promise to show the contacts to select and display operations.
+
+```JavaScript
+const props = ['name', 'email', 'tel', 'address', 'icon'];
+const opts = {multiple: true};
+
+try {
+ const contacts = await navigator.contacts.select(props, opts);
+ handleResults(contacts);
+} catch (ex) {
+ // Handle any errors here.
+}
+
+```
+
+Additionally, you need to handle the errors for these API.
+
+Check out this demo:
+[**Contact Picker API Demo**](https://contact-picker.glitch.me/)
+
+## 3. Native File system API
+
+](https://cdn-images-1.medium.com/max/2000/0*Tdc9sdhDmrHaTEa4)
+
+File reading and writing is a common scenario in the digital world. Using the Native File system API, we can now build apps that interact with files on the user’s local device. With the user’s permission, you can allow them to select a file, modify it, and save it back to the device storage.
+
+Files like IDE, editors, and text files can be accessed, changed, and stored on the disk in this manner. Before opening and storing the file, the Web app will be required to request the user for permission.
+
+When writing files to disk, users are allowed to select a different name for them. To modify the existing file on disk, the user needs to grant additional permissions. System files and other important documents are not accessible to ensure the security and stability of the device.
+
+1) The Native file system API can be used to open a directory and enumerate its contents.
+
+2) Permission given by a user to modify existing files or directories can be revoked.
+
+3) Permission persists only until the tab is open.
+
+Once a tab is closed, the web app loses the permissions allowed by the user. Even if the same app is used again, it will be required to prompt for permission each time. The Native File system API is available as an Origin Trial, this allows you to work with the trial version of Native file system API.
+
+Before using this API, please look at its [security and permissions](https://web.dev/native-file-system/#security-considerations).
+
+#### How API Works :
+
+1. First enable the native-file-system-api flag in chrome://flags.
+
+2. Request a token to add it to the page from this [link](https://developers.chrome.com/origintrials/#/view_trial/3868592079911256065).
+
+`<meta http-equiv=”origin-trial” content=”TOKEN_GOES_HERE”>` OR `Origin-Trial: TOKEN_GOES_HERE`.
+
+Once API is running, allow the user to choose the file to be edited using window.chooseFileSystEmentries(). Next, get the file from the system and read it.
+
+```JavaScript
+const file = await fileHandle.getFile();
+const contents = await file.text();
+
+```
+
+Once the file is saved, set the type: `saveFile` to chooseFileSystemEnteries.
+
+```JavaScript
+function getNewFileHandle() {
+ const opts = {
+ type: 'saveFile',
+ accepts: [{
+ description: 'Text file',
+ extensions: ['txt'],
+ mimeTypes: ['text/plain'],
+ }],
+ };
+ const handle = window.chooseFileSystemEntries(opts);
+ return handle;
+}
+
+```
+
+Later save the changes to a file.
+
+```JavaScript
+async function writeFile(fileHandle, contents) {
+ // Create a writer (request permission if necessary).
+ const writer = await fileHandle.createWriter();
+ // Write the full length of the contents
+ await writer.write(0, contents);
+ // Close the file and write the contents to disk
+ await writer.close();
+}
+
+```
+
+apps need permission to write the content to the disk. Once the permission is granted to write, call FileSystemWriter.Writer(). Later use close() method to close the FileSystemSWriter()
+
+Check out this demo:
+
+[**Text Editor**](https://googlechromelabs.github.io/text-editor/)
+
+## 4. Shape Detection API
+
+You can now capture faces in web apps using the shape detection API. The browser-based API and Chrome for Android make it easy to capture images or live videos via the device camera. Integrations with the Android, iOS, and macOS systems at the hardware level allow access to the device camera module without affecting performance.
+
+These implementations are exposed through a set of JavaScript libraries. Supported features include Face Detection, barcode detection, among others. Face detection in web apps will allow you to:
+
+* Annotate people on social media — It will highlight the boundaries of the detected face in the image to facilitate the annotation.
+* Content sites can accurately crop images along with highlighted sites that include specific objects.
+* Overlaying objects on highlighted faces can be easily done.
+
+#### How API Works :
+
+Feature detection: Check the existence of constructors to feature shape detection.
+
+```JavaScript
+const supported = await (async () => 'FaceDetector' in window &&
+ await new FaceDetector().detect(document.createElement('canvas'))
+ .then(_ => true)
+ .catch(e => e.name === 'NotSupportedError' ? false : true))();
+
+```
+
+These detectors work async, so they need some time to detect the face.
+
+## 5. Web Payments API
+
+The Web payments API works along the lines of Web payments web standards. It simplifies online payments and works on various payment systems, browsers, and device types. The Payment Request API is available on multiple browsers, Chrome, Edge, Safari, and Mozilla. It facilitates the payment flow between merchants and users. A merchant can integrate various payment methods with minimal effort.
+
+The Web Payments API works based on three principles:
+
+1. Standard and Open: Provides a universal standard that can be implemented by anyone.
+2. Easy and consistent: Provides a convenient checkout experience for users by restoring the payment details and address that needs to be filled in checkout forms.
+3. Secure and Flexible: Provides industry-leading security with flexibility for many payment flows.
+
+#### How API Works:
+
+To use this API, call hasEnrolledInstrument() method and check for instrument presence.
+
+```JavaScript
+// Checking for payment app availability without checking for instrument presence.
+if (request.hasEnrolledInstrument) {
+ // `canMakePayment()` behavior change corresponds to
+ // `hasEnrolledInstrument()` availability.
+ request.canMakePayment().then(handlePaymentAppAvailable).catch(handleError);
+} else {
+ console.log("Cannot check for payment app availability without checking for instrument presence.");
+}
+
+```
+
+## 6. Wake Lock API
+
+](https://cdn-images-1.medium.com/max/2000/0*zJuBNN-nn9Xx5NwU)
+
+Many types of devices are programmed to sleep when in an idle or unused state. While this is fine when not in use, it can be annoying when users are engaged with the screen, and the device turns off and locks the screen.
+
+There are two types of wake lock APIs — screen and system. While an app is running on the screen, the screen wake lock prevents the device from turning it off, and the system wake lock prevents the device’s CPU from going into standby mode.
+
+Page visibility and fullscreen mode are responsible for activating or releasing the wake lock. Changes in the screen like entering full-screen mode, minimizing the current window, or switching away from a tab will release the wake lock.
+
+#### How API Works :
+
+To avail this feature, get a [token](https://developers.chrome.com/origintrials/#/view_trial/902971725287784449) for your origin. Add that token to your page.
+
+`<meta http-equiv=”origin-trial” content=”TOKEN_GOES_HERE”>` Or `Origin-Trial: TOKEN_GOES_HERE`
+
+Instead of using the token, you can enable it using `#experimental-web-platform-features` flag in chrome://flags.
+
+To request a wake lock, call navigator.wavelock.request() method that returns a WakeLockSentinel object. Excapuslate the call in try…catch block. To release the wake lock, call release() method of wavelocksentinel.
+
+```JavaScript
+// The wake lock sentinel.
+let wakeLock = null;
+// Function that attempts to request a wake lock.
+const requestWakeLock = async () => {
+ try {
+ wakeLock = await navigator.wakeLock.request('screen');
+ wakeLock.addEventListener('release', () => {
+ console.log('Wake Lock was released');
+ });
+ console.log('Wake Lock is active');
+ } catch (err) {
+ console.error(`${err.name}, ${err.message}`);
+ }
+};
+// Request a wake lock…
+await requestWakeLock();
+// …and release it again after 5s.
+window.setTimeout(() => {
+ wakeLock.release();
+ wakeLock = null;
+}, 5000);
+
+```
+
+The Wake lock has a life cycle and is sensitive to page visibility and full-screen mode. Check for these states before requesting a wakelock.
+
+```JavaScript
+const handleVisibilityChange = () => {
+ if (wakeLock !== null && document.visibilityState === 'visible') {
+ requestWakeLock();
+ }
+};
+document.addEventListener('visibilitychange', handleVisibilityChange);
+document.addEventListener('fullscreenchange', handleVisibilityChange);
+
+```
+
+Check out this demo:
+[**Wake Lock Demo**](https://wake-lock-demo.glitch.me/)
+
+## 7. Service workers and the Cache Storage API
+
+The browser’s cache used to be the only way to reload older content of a website, but now you can use service workers and cache storage API to have better control of this process.
+
+A service worker is a JavaScript file that runs to intercept network requests, perform caching, and deliver messages by pushing. They are independent of the main thread and run in the background.
+
+Using the cache storage API, developers can decide and control the contents of the browser cache. It follows a code-driven approach to store cache and is called from a service worker. You can configure the cache storage API with cache-control headers.
+
+The setting Cache-Control needs to be cleared for accessing the versioned and unversioned URL’s. If versioned URLs are added to the cache storage, additional network requests are avoided for these URLs by the browser.
+
+A combination of HTTP cache, service worker, and the cache storage API can allow developers to:
+
+1. Reload cached content in the background.
+2. Impose a cap on the maximum number of assets to be cached.
+3. Add a custom expiration policy.
+4. Compare cached and network responses.
+
+## 8. Asynchronous clipboard API
+
+](https://cdn-images-1.medium.com/max/2000/0*eziEHL8pSojXJ_F_)
+
+The Async clipboard API can be used to copy images and paste them in the browser. The image that needs to be copied is stored as a ‘Blob’. Making a request to a server each time an image needs to be copied is not feasible.
+
+Now, images can be written to a canvas element on a web form by using HTMLCanvasElement.toBlob() directly from the clipboard. While only a single image can be copied at present, a future release will enable copying multiple images simultaneously. To paste an image, the API iterates over it in the clipboard in a promise-based asynchronous manner.
+
+The custom paste handler and custom copy handler allow you to handle paste and copy events for images. A major concern of copying and pasting images on Chrome is accessing image compressed bombs. These are large compressed image files that are too large to be handled on a web form once decompressed. They can also be malicious images that can exploit known vulnerabilities in the operating system.
+
+#### How API Works :
+
+First, we need an image as a blob, that is requested from the server by calling fetch() and set the return type as blob. Then pass an array of clipboarditem to write() method.
+
+```JavaScript
+try {
+ const imgURL = '/images/generic/file.png';
+ const data = await fetch(imgURL);
+ const blob = await data.blob();
+ await navigator.clipboard.write([
+ new ClipboardItem({
+ [blob.type]: blob
+ })
+ ]);
+ console.log('Image copied.');
+} catch(e) {
+ console.error(e, e.message);
+}
+
+```
+
+While pasting the navigator, Clipboard.read() is used to iterate the clipboard objects and read the items.
+
+```JavaScript
+async function getClipboardContents() {
+ try {
+ const clipboardItems = await navigator.clipboard.read();
+ for (const clipboardItem of clipboardItems) {
+ try {
+ for (const type of clipboardItem.types) {
+ const blob = await clipboardItem.getType(type);
+ console.log(URL.createObjectURL(blob));
+ }
+ } catch (e) {
+ console.error(e, e.message);
+ }
+ }
+ } catch (e) {
+ console.error(e, e.message);
+ }
+}
+
+```
+
+Check out this demo:
+[**Image support for the async clipboard API**](https://web.dev/image-support-for-async-clipboard/#demo)
+
+## 9. Web Share Target API
+
+](https://cdn-images-1.medium.com/max/2000/0*6G_C2tZdB3rCYvNY)
+
+Mobile apps make sharing files with other devices and users as easy as a few clicks. The Web share target API allows you to do the same on web apps.
+
+To use this feature, you need to:
+
+1. Register the app as a shared target.
+2. Update the web app manifest with the shared target.
+3. Add the basic information for the target app to accept. Information like data, links, text can be added in the JSON file.
+4. Accept Application changes in the shared target. This will allow data changes in the target app, like creating a bookmark in an app or accepting a file request.
+5. Handle incoming content by processing GET shares and POST shares.
+
+The following code shows how you can create the manifest.json file for accepting basic information.
+
+```JSON
+"share_target": {
+ "action": "/share-target/",
+ "method": "GET",
+ "params": {
+ "title": "title",
+ "text": "text",
+ "url": "url"
+ }
+}
+
+```
+
+## 10. Periodic Background Sync API
+
+Native apps do well in fetching fresh data, even when connectivity is not satisfactory. Time-sensitive things like articles and news are continually being updated. The periodic background sync API offers similar functionality for web apps. It enables the web app to synchronize data periodically.
+
+The API synchronizes data in the background so that the web app does not fetch data while it is launched or relaunched. This reduces page load time and optimizes performance.
+
+Given the high likeliness of this API being used by every developer and it leading to misuse of battery and network resources, Chrome has devised a way of restricting its use. It will not be openly available for every browser tab, but be regulated via a site engagement score, which will ensure that the API will only be active on tabs that are actively being engaged by users.
+
+The following code is an example of periodic background sync to update the article for a news site.
+
+```JavaScript
+async function updateArticles() {
+ const articlesCache = await caches.open('articles');
+ await articlesCache.add('/api/articles');
+}
+
+self.addEventListener('periodicsync', (event) => {
+ if (event.tag === 'update-articles') {
+ event.waitUntil(updateArticles());
+ }
+});
+
+```
+
+## Conclusion
+
+Users expect web applications to have the same capabilities as their native application counterparts. Without similar behavior, users will reject apps or find alternatives. As such, Chrome APIs come as a much-needed benefit for developers.
+
+However, it is important to understand that there are certain restrictions that apply. Developers need to pay attention to these in order to provide a seamless experience. Simply implementing every API will not be worthwhile or useful.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/5-best-practices-to-prevent-git-leaks.md b/TODO1/5-best-practices-to-prevent-git-leaks.md
new file mode 100644
index 00000000000..933e9f236a9
--- /dev/null
+++ b/TODO1/5-best-practices-to-prevent-git-leaks.md
@@ -0,0 +1,132 @@
+> * 原文地址:[5 Best Practices To Prevent Git Leaks](https://levelup.gitconnected.com/5-best-practices-to-prevent-git-leaks-4997b96c1cbe)
+> * 原文作者:[Coder’s Cat](https://medium.com/@coderscat)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/5-best-practices-to-prevent-git-leaks.md](https://github.com/xitu/gold-miner/blob/master/TODO1/5-best-practices-to-prevent-git-leaks.md)
+> * 译者:
+> * 校对者:
+
+# 5 Best Practices To Prevent Git Leaks
+
+
+
+Countless developers are using Git for version control, but many don’t have enough knowledge about how Git works. Some people even use Git and Github as tools for backup files. This leads to information disclosure in Git repositories. [Thousands of new API or cryptographic keys leak via GitHub projects every day.](https://www.zdnet.com/article/over-100000-github-repos-have-leaked-api-or-cryptographic-keys/)
+
+I have been working in the field of information security for three years. About two years ago, our company had a severe security issue triggered by the information leak in a Git repository.
+
+An employee accidentally leaked an AWS key to Github. The attacker used this key to download more sensitive data from our servers. We put a lot of time into fixing this issue, we tried to find out how much data leaked, analyzed the affected systems and related users, and replaced all the leaked keys in systems.
+
+It is a sad story that any company and developer would not want to experience.
+
+I won’t write more details about it. Instead, I hope more people know how to avoid it. Here are my suggestions for you to keep safe from Git leaks.
+
+## Build security awareness
+
+Most junior developers don’t have enough security awareness. Some companies will train new employees, but some companies don’t have systematic training.
+
+As a developer, we need to know which kind of data may introduce security issues. Remember these categories of data can not be checked into Git repository:
+
+1. Any configuration data, including password, API keys, AWS keys, private keys, etc.
+2. [Personally Identifiable Information](https://en.wikipedia.org/wiki/Personal_data) (PII). According to GDPR, if a company leaked the users’ PII, the company needs to notify users, relevant departments and there will be more legal troubles.
+
+If you are working for a company, don’t share any source code or data related to the company without permission.
+
+Attackers can easily find some code with a company copyright on GitHub, which was accidentally leaked to Github by employees.
+
+My advice is, try to distinguish between company affairs and personal stuff strictly.
+
+## Use Git ignore
+
+When we create a new project with Git, we must set a **.gitignore** properly. **gitignore** is a Git configuration file that lists the files or directories that will not be checked into the Git repository.
+
+This project’s [gitignore](https://github.com/github/gitignore) is a collection of useful .gitignore templates, with all kinds of programming language, framework, tool or environment.
+
+We need to know the pattern matching rules of **gitignore** and add our own rules based on the templates.
+
+
+
+## Check commits with Git hooks and CI
+
+No tools could find out all the sensitive data from a Git repository, but a couple of tools and practices can help.
+
+[git-secrets](https://github.com/awslabs/git-secrets) and [talisman](https://github.com/thoughtworks/talisman) are similar tools, they are meant to be installed in local repositories as [pre-commit hooks](https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks). Every change will be checked before committed, pre-commit hooks will reject the commit if they detect a prospective commit may contain sensitive information.
+
+[gitleaks](https://github.com/zricethezav/gitleaks) provides another way to find unencrypted secrets and other unwanted data types in git repositories. We could integrate it into automation workflows such as CICD.
+
+## Code review
+
+Code review is a best practice for team working. All the teammates will learn from each other’s source code. Junior developer’s code should be reviewed by developers with more experience.
+
+Most unintended changes can be found out during the code review stage.
+
+[Enabling branch restrictions](https://help.github.com/en/github/administering-a-repository/enabling-branch-restrictions) can enforce branch restrictions so that only certain users can push to a protected branch in repositories. Gitlab has a similar option.
+
+Setting master to a restricted branch helps us to enforce the code review workflow.
+
+
+
+## Fix it quickly and correctly
+
+With all the above tools and mechanisms, errors still could happen. If we fix it quickly and correctly, the leak may introduce no actual security issue.
+
+If we find some sensitive data leaked in the Git repository, we can not just make another commit to clean up.
+
+
+
+What we need to do is remove all the sensitive data from the entire Git history.
+
+**Remember to backup before any cleanup, and then remove the backup clone after we confirmed everything is OK**.
+
+Use the `--mirror` to clone a bare repository; this is a full copy of the Git database.
+
+```bash
+git clone --mirror git://example.com/need-clean-repo.git
+```
+
+We need **git filter-branch** to remove data from all branches and commit histories. Suppose we want to remove `./config/passwd` from Git:
+
+```bash
+$ git filter-branch --force --index-filter \
+ 'git rm --cached --ignore-unmatch ./config/password' \
+ --prune-empty --tag-name-filter cat -- --all
+```
+
+Remember to add the sensitive file to .gitignore:
+
+```bash
+$ echo "./config/password" >> .gitignore
+$ git add .gitignore
+$ git commit -m "Add password to .gitignore"
+```
+
+Then we push all branches to remote:
+
+```bash
+$ git push --force --all
+$ git push --force --tags
+```
+
+Tell our collaborators to rebase:
+
+```bash
+$ git rebase
+```
+
+[BFG](https://rtyley.github.io/bfg-repo-cleaner/) is a faster and simpler alternative to **git filter-branch** for removing sensitive data. It’s usually 10–720x faster than **git filter-branch**. Except for deleting files, BFG could also be used to replace secrets in files.
+
+BFG will leave the latest commit untouched. It’s designed to protect us from making mistakes. We should explicitly delete the file, commit the deletion, then clean up the history to remove it.
+
+If the leaked Git repository is forked by others, we need to follow the [DMCA Takedown Policy](https://help.github.com/en/github/site-policy/dmca-takedown-policy#c-what-if-i-inadvertently-missed-the-window-to-make-changes) to ask Github to remove the forked repositories.
+
+The whole procedure requires some time to finish, but it’s the only way to remove all the copies.
+
+## Conclusion
+
+Don’t make the same mistake that countless people have made. Try to put some effort to avoid safety accidents.
+
+Use these tools and strategies will help much in avoiding Git leaks.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/5-optimization-tips-for-your-mobile-web-app-for-higher-user-retention.md b/TODO1/5-optimization-tips-for-your-mobile-web-app-for-higher-user-retention.md
new file mode 100644
index 00000000000..ff7e7caff90
--- /dev/null
+++ b/TODO1/5-optimization-tips-for-your-mobile-web-app-for-higher-user-retention.md
@@ -0,0 +1,143 @@
+> * 原文地址:[5 optimization tips for your mobile web app for higher user retention](https://levelup.gitconnected.com/5-optimization-tips-for-your-mobile-web-app-for-higher-user-retention-3d6d158aadb7)
+> * 原文作者:[Axel Wittmann](https://medium.com/@axelcwittmann)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/5-optimization-tips-for-your-mobile-web-app-for-higher-user-retention.md](https://github.com/xitu/gold-miner/blob/master/TODO1/5-optimization-tips-for-your-mobile-web-app-for-higher-user-retention.md)
+> * 译者:
+> * 校对者:
+
+# 5 optimization tips for your mobile web app for higher user retention
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/9310/0*Cj9Dw7l2u-wSTCqK)
+
+> Your mobile website can be more appealing to mobile users by going beyond css style optimization
+
+As of 2020, internet traffic is around half mobile and half desktop. Google looks to your mobile website version to determine at what position to rank your pages when it indexes. A significant share of young users don’t even use desktop devices at all anymore.
+
+These 3 facts show why optimizing your website for mobile usage is more important than ever. And even more importantly: Mobile users are way more picky and subconsciously irritated by UX issues on mobile devices than desktop users. If there are issues in how your website behaves on a mobile device, it’s highly likely your mobile user retention rate is suffering.
+
+Here are a few tips to optimize your mobile website beyond just using different CSS styles for devices below 600px width.
+
+## 1. Remove mobile ghost shadowing click effects
+
+Native apps don’t have them, mobile browsers do. When you click on any button or anything clickable such as an icon, users on browsers such as Safari or Chrome will see a shadow click effect.
+
+The `\<div>`, `\<button>` or other element that is clicked on will have a brief underlying shadow effect. This effect is supposed to give users feedback that something was clicked on and something should happen as a result. Which makes sense for a lot of interactions on websites.
+
+But what if your website actually is responsive enough already and includes effects for loading data? Or you use Angular, React or Vue and a lot of the UX interaction is instantaneous? It is likely, that the shadow click effect gets in the way of your user experience.
+
+You can use the following code in your style-sheet to get rid of this shadow click effect. Don’t worry, it won’t break anything else, even though you need to include it as a global style.
+
+```css
+* {
+ /*prevents tabing highlight issue in mobile */
+ -webkit-tap-highlight-color: rgba(0, 0, 0, 0);
+ -moz-tap-highlight-color: rgba(0, 0, 0, 0);
+}
+```
+
+## 2. Use the user-agent to detect whether the user accesses from a mobile device
+
+I am not talking about abandoning style-sheet specific @media code for devices below 600px width. Quite on the contrary. You should always use your style-sheet to make your website mobile friendly.
+
+However, what if there is an additional effect that you want to show based on whether the user is on a mobile device? And you want to include it in your JavaScript functions — and you don’t want this to change if a user changes its smartphone direction (which increases the width beyond 600px).
+
+For these kind of situations, my advice is to use a globally accessible Helper-function that determines based on the user-agent of the browser if the user device is a mobile device or not.
+
+```js
+$_HelperFunctions_deviceIsMobile: function() {
+ if (/Mobi/i.test(navigator.userAgent)) {
+ return true;
+ } else
+ {return false;
+ }
+}
+```
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/6716/0*qYl5LnaPjGjQqXfp)
+
+## 3. Load mobile versions of larger images
+
+If you use large images and want to make sure that the loading time on mobile is still adequate for your mobile users, always load different versions of images.
+
+You don’t even need JavaScript for it (well, you can also do it with JavaScript too…). For a css version of this strategy, look at the following code.
+
+```html
+<!-- ===== LARGER VERSION OF FILE ========== -->
+<div class="generalcontainer nomobile">
+ <div class="aboutus-picture" id="blend-in-cover" v-bind:style="{ 'background-image': 'url(' + image1 + ')' }"></div>
+</div>
+
+<!-- ===== MOBILE VERSION OF FILE ========== -->
+<div class="generalcontainer mobile-only">
+ <div class="aboutus-picture" id="blend-in-cover" v-bind:style="{ 'background-image': 'url(' + image1-mobile + ')' }"></div>
+</div>
+```
+
+And in your CSS file, define mobile-only and nomobile.
+
+```css
+.mobile-only { display: none; }
+
+@media (max-width: 599px) {
+ ...
+ .nomobile {display: none;}
+ .mobile-only {display: initial;}
+}
+```
+
+## 4. Try out endless scrolling and lazy loaded data
+
+If you have large lists such as users or tasks that run into dozens or hundreds, you should consider lazy loading more users when a user scrolls down instead of showing a `load more` or `show more` button. Native apps typically include such a lazy loaded endless scrolling feature.
+
+It is not hard to do so in a mobile web in Javascript frameworks.
+
+You add a reference ($ref) to an element in your template or simply rely on the absolute scroll position of your window.
+
+The following code shows how to implement this effect in a Vue-app. Similar code can be added in other frameworks such as Angular or React.
+
+```js
+mounted() {
+ this.$nextTick(function() {
+ window.addEventListener('scroll', this.onScroll);
+ this.onScroll(); // needed for initial loading on page
+ });
+},
+beforeDestroy() {
+ window.removeEventListener('scroll', this.onScroll);
+}
+```
+
+The onScroll function loads data if a user scrolls to a certain element or to the bottom of the page:
+
+```js
+onScroll() {
+ var users = this.$refs["users"];
+ if (users) {
+ var marginTopUsers = usersHeading.getBoundingClientRect().top;
+ var innerHeight = window.innerHeight;
+ if ((marginTopUsers - innerHeight) < 0) {
+ this.loadMoreUsersFromAPI();
+ }
+ }
+}
+```
+
+## 5. Make your modals and popups full width or full screen
+
+Mobile screens have limited space. Sometimes developers forget that and use the same type of interface they use on their desktop version. Especially modal windows are a turn off for mobile users if not implemented correctly.
+
+Modal windows are windows you overlay on top of other content on a page. For desktop users, they can work great. Users very often want to click on the background content to get out of the modal window again — typically when a user decides to not perform the action the modal window suggests.
+
+
+
+
+
+Mobile usage of a website and modals represent a different challenge. Due to the limited screen space, large companies with well designed mobile web apps such as Youtube or Instagram make modals full width or full screen with an ‘X’ on the top of the modal to close it.
+
+This is particularly the case for sign-up modals, which in desktop versions are normal modals windows, while full screen on a mobile version.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/5-secret-features-of-json-stringify.md b/TODO1/5-secret-features-of-json-stringify.md
new file mode 100644
index 00000000000..eed742ee70f
--- /dev/null
+++ b/TODO1/5-secret-features-of-json-stringify.md
@@ -0,0 +1,150 @@
+> * 原文地址:[5 Secret features of JSON.stringify()](https://medium.com/javascript-in-plain-english/5-secret-features-of-json-stringify-c699340f9f27)
+> * 原文作者:[Prateek Singh](https://medium.com/@prateeksingh_31398)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/5-secret-features-of-json-stringify.md](https://github.com/xitu/gold-miner/blob/master/TODO1/5-secret-features-of-json-stringify.md)
+> * 译者:[zoomdong](https://github.com/fireairforce)
+> * 校对者:[Long Xiong](https://github.com/xionglong58), [niayyy](https://github.com/niayyy-S)
+
+# JSON.stringify() 的 5 个秘密特性
+
+](https://cdn-images-1.medium.com/max/2000/1*aQy1TrGzC_n_UC0j9hXBbw.jpeg)
+
+> JSON.stringify() 方法能将一个 JavaScript 对象或值转换成一个 JSON 字符串。
+
+作为一名 JavaScript 开发人员,`JSON.stringify()` 是用于调试的最常见函数。但是它的作用是什么呢,难道我们不能使用 `console.log()` 来做同样的事情吗?让我们试一试。
+
+```js
+//初始化一个 user 对象
+const user = {
+ "name" : "Prateek Singh",
+ "age" : 26
+}
+
+console.log(user);
+
+// 结果
+// [object Object]
+```
+
+哦!`console.log()` 没有帮助我们打印出期望的结果。它输出 `**[object Object]**`,**因为从对象到字符串的默认转换是 `[object Object]`**。因此,我们使用 `JSON.stringify()` 首先将对象转换成字符串,然后在控制台中打印,如下所示。
+
+```js
+const user = {
+ "name" : "Prateek Singh",
+ "age" : 26
+}
+
+console.log(JSON.stringify(user));
+
+// 结果
+// "{ "name" : "Prateek Singh", "age" : 26 }"
+```
+
+---
+
+一般来说,开发人员使用 `stringify` 函数的场景较为普遍,就像我们在上面做的那样。但我要告诉你一些隐藏的秘密,这些小秘密会让你开发起来更加轻松。
+
+## 1: 第二个参数(数组)
+
+是的,`stringify` 函数也可以有第二个参数。它是要在控制台中打印的对象的键数组。看起来很简单?让我们更深入一点。我们有一个对象 **product** 并且我们想知道 product 的 name 属性值。当我们将其打印出来:
+ console.log(JSON.stringify(product));
+它会输出下面的结果。
+
+```js
+{"id":"0001","type":"donut","name":"Cake","ppu":0.55,"batters":{"batter":[{"id":"1001","type":"Regular"},{"id":"1002","type":"Chocolate"},{"id":"1003","type":"Blueberry"},{"id":"1004","type":"Devil’s Food"}]},"topping":[{"id":"5001","type":"None"},{"id":"5002","type":"Glazed"},{"id":"5005","type":"Sugar"},{"id":"5007","type":"Powdered Sugar"},{"id":"5006","type":"Chocolate with Sprinkles"},{"id":"5003","type":"Chocolate"},{"id":"5004","type":"Maple"}]}
+```
+
+在日志中很难找到 **name** 键,因为控制台上显示了很多没用的信息。当对象变大时,查找属性的难度增加。
+stringify 函数的第二个参数这时就有用了。让我们重写代码并查看结果。
+
+```js
+console.log(JSON.stringify(product,['name' ]);
+
+// 结果
+{"name" : "Cake"}
+```
+
+问题解决了,与打印整个 JSON 对象不同,我们可以在第二个参数中将所需的键作为数组传递,从而只打印所需的属性。
+
+## 2: 第二个参数(函数)
+
+我们还可以传入函数作为第二个参数。它根据函数中写入的逻辑来计算每个键值对。如果返回 `undefined`,则不会打印键值对。请参考示例以获得更好的理解。
+
+```js
+const user = {
+ "name" : "Prateek Singh",
+ "age" : 26
+}
+```
+
+
+
+```js
+// 结果
+{ "age" : 26 }
+```
+
+只有 `age` 被打印出来,因为函数判断 `typeOf` 为 String 的值返回 `undefined`。
+
+## 3: 第三个参数为数字
+
+第三个参数控制最后一个字符串的间距。如果参数是一个**数字**,则字符串化中的每个级别都将缩进这个数量的空格字符。
+
+```js
+// 注意:为了达到理解的目的,使用 '--' 替代了空格
+
+JSON.stringify(user, null, 2);
+//{
+//--"name": "Prateek Singh",
+//--"age": 26,
+//--"country": "India"
+//}
+```
+
+## 4: 第三个参数为字符串
+
+如果第三个参数是 **string**,那么将使用它来代替上面显示的空格字符。
+
+```js
+JSON.stringify(user, null,'**');
+//{
+//**"name": "Prateek Singh",
+//**"age": 26,
+//**"country": "India"
+//}
+// 这里 * 取代了空格字符
+```
+
+## 5: toJSON 方法
+
+我们有一个叫 `toJSON` 的方法,它可以作为任意对象的属性。`JSON.stringify` 返回这个函数的结果并对其进行序列化,而不是将整个对象转换为字符串。参考下面的例子。
+
+```js
+const user = {
+ firstName : "Prateek",
+ lastName : "Singh",
+ age : 26,
+ toJSON() {
+ return {
+ fullName: `${this.firstName} + ${this.lastName}`
+ };
+ }
+}
+
+console.log(JSON.stringify(user));
+
+// 结果
+// "{ "fullName" : "Prateek Singh"}"
+```
+
+这里我们可以看到,它只打印 `toJSON` 函数的结果,而不是打印整个对象。
+
+我希望你能学到 `stringify()` 的一些基本特征。
+
+如果你觉得这篇文章有用,请点赞,然后跟我读更多类似的精彩文章。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/5-ways-to-create-a-settings-icon.md b/TODO1/5-ways-to-create-a-settings-icon.md
new file mode 100644
index 00000000000..cc2ac295d90
--- /dev/null
+++ b/TODO1/5-ways-to-create-a-settings-icon.md
@@ -0,0 +1,280 @@
+> * 原文地址:[5 Ways to Create a Settings Icon](https://medium.com/@minoraxis/5-ways-to-create-a-settings-icon-fff8dc95e36d)
+> * 原文作者:[Helena Zhang](https://medium.com/@minoraxis)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/5-ways-to-create-a-settings-icon.md](https://github.com/xitu/gold-miner/blob/master/TODO1/5-ways-to-create-a-settings-icon.md)
+> * 译者:
+> * 校对者:
+
+# 5 Ways to Create a Settings Icon
+
+> Learn to use an array of Illustrator features through this exercise
+
+
+
+The gear has become a ubiquitous symbol for **settings** in our digital applications.
+
+
+
+There are many interesting ways you can create this icon. We’ll walk though 5 of them in Adobe Illustrator, to pick up techniques you can take forward to any vector drawing.
+
+(**Keyboard shortcuts** are shown in parentheses.)
+
+## Method 1: Rounded Star
+
+This simple method is effective for a gear with pointed teeth.
+
+
+
+Select the **Star Tool** and **click** anywhere on your canvas.
+
+
+
+Play with the parameters.
+
+
+
+Round the corners—with the **Direct Selection Tool** (**A**) selected, hover over the shape. **Drag** one of the little circular handles to modify all corners. **Double click** a handle to specify a precise corner radius.
+
+
+
+Draw a smaller concentric circle with the **Ellipse Tool** (**L**) to create the eye.
+
+
+
+You can draw the circle free-form or **L** + **click** anywhere on the canvas to specify the exact width and height.
+
+
+
+Use the **Transform** panel to make any adjustments to the dimensions.
+
+
+
+With both shapes selected, clean up the icon by subtracting the smaller circle from the rounded star (**Pathfinder** panel > **Minus Front**).
+
+
+
+Voilà.
+
+
+
+## Method 2: Zig Zag
+
+Let’s try something different to get to a similar effect.
+
+
+
+Draw a circle (**L**) with a fill, no stroke.
+
+
+
+Select the circle and apply a **Zig Zag Effect** (**Effect** > **Distort & Transform** > **Zig Zag**).
+
+
+
+Play with the parameters with Preview toggled on.
+
+
+
+Now we’ll try a smaller eye. Draw a concentric circle.
+
+
+
+Select both shapes. Because we have used an effect, we’ll have to expand the appearance before we merge shapes. Go to **Object** > **Expand Appearance**.
+
+**Why? Effects are dynamic and non-destructive, which means you can go back and change the parameters at any time. Because of this, effects need to be expanded before performing further shape manipulation.**
+
+
+
+Similar to Method 1, we’ll clean up the icon by subtracting the smaller circle from the larger shape (**Pathfinder** panel > **Minus Front**).
+
+
+
+## Method 3: Additive Rotation
+
+Here’s a more complex method that’ll allow us more customization in the gear teeth. We’ll go for a sharper look this time.
+
+
+
+Draw a circle with a fill, no stroke.
+
+
+
+Draw a rectangle with the **Rectangle Tool** (**M**) on top, centered to the circle.
+
+
+
+'Bulge’ the rectangle. There are many ways to do this. You can select the rectangle and use the **Bulge Effect** (**Effect** > **Warp** > **Bulge**).
+
+
+
+My preferred method is to add anchor points and use the **Direct Selection Tool** (**A**) to select specific ones to manipulate.
+
+
+
+To add additional anchor points that are of equal distance from the current ones, select an object and use **Object** > **Path** > **Add Anchor Points**. You can also use the **Pen Tool** (**P**) to manually add points.
+
+
+
+With your shape selected, press **R** for the **Rotate Tool** then **option** + **click** the center of the circle to set that as the reference point. The **Rotate** panel will come up.
+
+
+
+Choose an angle. A 45° angle will create a gear with 8 teeth (360° divided by 8 is 45°).
+
+Here’s the fun part.
+
+Press **Copy** (**not** **OK**). This will copy your shape with the angle and reference point you specified.
+
+
+
+Repeat the action by pressing **Command** + **D** (macOS) or **Ctrl + D** (Windows). Do this twice to complete the circle.
+
+
+
+Alternatively, you can use the **Transform** **Effect** (**Effect** > **Distort & Transform** > **Transform**) to achieve the same rotational copies.
+
+
+
+Effects are non-destructive; whenever you apply one, you can edit it in the **Properties** panel.
+
+
+
+Time to clean up our shapes and add the inner circle.
+
+Combine all shapes with **Pathfinder** panel > **Unite**.
+
+
+
+Draw a smaller concentric circle.
+
+
+
+Use **Pathfinder** panel > **Minus Front** to subtract the smaller circle from the larger shape.
+
+Experiment! Different source shapes yield different end results.
+
+
+
+## Method 4: Subtractive Rotation
+
+Method 4 is similar to Method 3.
+
+
+
+Draw a circle with a fill, no stroke.
+
+
+
+Draw a small circle aligned to the top.
+
+
+
+Select the small circle, press **R** for **Rotate**, then **option** + **click** the center of the circle. Let’s try 6 teeth this time (360°/6). Illustrator will do the calculation for you if you type “360/6” directly.
+
+
+
+Press **Copy**.
+
+
+
+Repeat the action by pressing **Command** + **D** (macOS) or **Ctrl + D** (Windows) 4 times.
+
+
+
+Use **Pathfinder** panel > **Minus Front** to subtract the small circles from the big circle.
+
+Let’s round the corners. With the **Direct Selection Tool** (**A**), **click** + **drag** the little dots to adjust the corner radiuses.
+
+
+
+Draw a smaller concentric circle for the eye and subtract the smaller circle from the larger shape.
+
+
+
+A few more ideas (try different shapes):
+
+
+
+## Method 5: Intersect
+
+For the last method we’ll bring back the **Star Tool**.
+
+
+
+Draw a star.
+
+
+
+Draw a concentric circle on top.
+
+
+
+Select both shapes. **Pathfinder** panel > **Intersect**.
+
+
+
+Draw another concentric circle on top like so:
+
+
+
+**Pathfinder** panel > **Unite**. Now we have a silhouette of a gear.
+
+
+
+You know what to do — draw a third concentric circle and subtract the smaller circle from the larger shape.
+
+
+
+More with this method:
+
+
+
+## Experiment to Find Your Flow
+
+Hope you learned a trick or two from this exercise. Similar methods may be applied in UI-focused vector software like Sketch or Figma, though Illustrator is more precise.
+
+From here, explore different icon styles.
+
+
+
+## Bonus
+
+Some more food for thought…
+
+#### 2 Squares = 1 Star
+
+You can create an 8-pointed star by drawing 2 squares. **Shift** + **drag** with the **Rectangle Tool** (**M**) to create a square, select and **shift** + **drag** with the **Rotate Tool** (**R**) to rotate in 45° increments.
+
+
+
+#### Roundabout Rounding
+
+Once upon a time, I may have hacked rounded corners by adding a stroke — overcomplicated and imprecise. Oof.
+
+
+
+#### Scribble to Shape
+
+If you’re using a tablet or touch interface, you can use the wacky **Shaper Tool** (**shift** + **N**) to non-destructively combine or subtract shapes. Scribble over like so to ‘delete’ the desired areas. The original shapes will be preserved.
+
+
+
+---
+
+🎶 **Written to the sounds of: [Mogwai](https://open.spotify.com/artist/34UhPkLbtFKRq3nmfFgejG?si=QsV-S2PuTlKKJTzlRF1uDw)**
+
+🙏 **Thanks to: Toby Fried, Tate Chow, Christine Lee, Pawel Piekarski, and Monica Chang**
+
+---
+
+More about iconography:
+
+* [7 Principles of Icon Design](https://medium.com/@minoraxis/7-principles-of-icon-design-e7187539e4a2)
+* Icon Grids & Keylines Demystified **(coming soon)**
+* Pixel-Snapping in Icon Design: To Snap or Not to Snap **(coming soon)**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/6-best-javascript-frameworks-in-2020.md b/TODO1/6-best-javascript-frameworks-in-2020.md
new file mode 100644
index 00000000000..be406673ef8
--- /dev/null
+++ b/TODO1/6-best-javascript-frameworks-in-2020.md
@@ -0,0 +1,123 @@
+> * 原文地址:[The Top 6 JavaScript frameworks for 2020](https://medium.com/javascript-in-plain-english/6-best-javascript-frameworks-in-2020-102babf80196)
+> * 原文作者:[Naina Chaturvedi](https://medium.com/@Naina04)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/6-best-javascript-frameworks-in-2020.md](https://github.com/xitu/gold-miner/blob/master/TODO1/6-best-javascript-frameworks-in-2020.md)
+> * 译者:[Roc](https://github.com/QinRoc)
+> * 校对者:[钱俊颖](https://github.com/Baddyo), [niayyy](https://github.com/niayyy-S)
+
+# 2020 年排名前 6 位的 JavaScript 框架
+
+
+
+## 1.Vue.js
+
+
+
+Vue.js 是一个开源框架。它在 Angular 和 React 的基础上发展而来。Vue.js 提供了很多有用的特性,对于很多跨平台应用程序而言,它是一个简单而有效的解决方案。使用 Vue.js 开发的顶尖网站有:
+
+[**Behance**](https://www.behance.net/)
+
+**访问者数量:4929 万**
+
+
+
+Behance —— 平面设计师通过这个网站向全世界展示他们的才华。Behance 的开发团队使用 Vue.js 作为前端编程语言。
+
+#### Gitlab
+
+**访问者数量:2211 万**
+
+
+
+Gitlab 是一个基于 web 的源码版本控制库,它有多个会员选项。它的前端是用 Vue 开发的。
+
+****从这里开始了解 Vue.js**:**
+
+[https://vuejs.org/v2/guide/](https://vuejs.org/v2/guide/)
+
+## 2. Aurelia
+
+Aurelia 是一个 JavaScript 前端框架。它是 ——
+
+1. 最简洁的现代框架之一
+2. 下一代框架,因为它能创建强大、简洁又完美的网站。
+
+
+
+**从这里开始了解 Aurelia:**
+
+[**https://aurelia.io/docs/tutorials/creating-a-todo-app**](https://aurelia.io/docs/tutorials/creating-a-todo-app)
+
+[**Aurelia Projects**](https://github.com/aurelia-project)
+
+## 3. Next.js
+
+Next.js 是一个基于 JavaScript 的开源框架。它 ——
+
+1. 为开发高度可定制的 Web 应用程序而生。
+2. 是 React 应用的零配置、单命令工具链。
+
+
+
+**它的部分最佳特性如下:**
+
+1. 自动化代码切分,基于文件系统的路由,代码热重载,全局渲染
+
+**从这里开始了解 Next.js:**
+
+[**学习 Next.js**](https://nextjs.org/learn/basics/getting-started)
+
+## 4. Riot.js
+
+Riot.js 专注于为用户提供具有 JavaScript 生态中最高效简洁架构的框架。它与 polymer 和 react.js 类似。
+
+
+
+它的部分特性如下:
+
+1. 允许用户在所有页面和 Web 应用程序中应用自定义 HTML 标签。用户可以重用这些标签。
+2. 高度专注于微函数,让用户可以一次分别处理不同的应用程序。
+
+从这里开始了解 Riot.js:
+[**Riot.js 文档**](https://riot.js.org/documentation/)
+
+## 5. WebRx
+>译者注: WebRx 已停止维护。
+
+WebRx 是一个基于浏览器的 model-view-view-model 架构模式的 JavaScript 框架。它带来了 ——
+
+1. 响应式编程和函数式编程并存的特性。
+2. 美观而强大的 UI 环境。
+
+
+
+它的部分最佳特性如下:
+
+1. 一个高效的收集进程,包括过滤映射、分页等功能。
+2. 由不同消息总线支持的强大的组件间通信方式。
+
+ 从这里开始了解 WebRx:
+
+[https://github.com/WebRxJS/WebRx](https://github.com/WebRxJS/WebRx)
+
+**最后但最有前途的是(这个位置总是会引战)……**
+
+## 6. Angular
+
+Angular 是一个成熟的框架,不像 React 那样灵活。它内置了所有东西。它 ——
+
+1. 是一个强大的 JavaScript 框架,能够无缝地组织你的项目。
+2. 具有惊人的速度和多功能性。
+
+ 从这里开始了解 Angular:
+
+[https://github.com/angular/angular](https://github.com/angular/angular)
+
+>译者注:本文是原文作者的一家之言。原文评论区提到的其他框架有 React.js、Svelte、Preact、Nuxt.js、Ember 和 Mithril 等。
+其他可参考资料有 [BestOfJS](https://bestofjs.org/)、[StateOfJS](https://stateofjs.com/) 、[掘金上对 StateofJS 的 2019 年调查结果的说明文章](https://juejin.im/post/5e071b676fb9a016391d5bb8)。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/7-principles-of-icon-design.md b/TODO1/7-principles-of-icon-design.md
new file mode 100644
index 00000000000..1be532ab181
--- /dev/null
+++ b/TODO1/7-principles-of-icon-design.md
@@ -0,0 +1,284 @@
+> * 原文地址:[7 Principles of Icon Design](https://uxdesign.cc/7-principles-of-icon-design-e7187539e4a2)
+> * 原文作者:[Helena Zhang](https://medium.com/@minoraxis)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/7-principles-of-icon-design.md](https://github.com/xitu/gold-miner/blob/master/TODO1/7-principles-of-icon-design.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[Chorer](https://github.com/Chorer),[niayyy-S](https://github.com/niayyy)
+
+# 关于 icon 设计的 7 个准则
+
+> 明确性、可读性、校准、简洁性、一致性、特性、易用性。
+
+
+
+打造出一套高质量的 icon 库需要深思熟虑、专业的眼光、一些迭代和大量的实践。在这篇文章中,我将通过 7 个准则和大量的实际例子来说明 **高质量** icon 库的特征。希望您从中能学习到设计优秀 icon 的技巧。
+
+## 明确性
+
+icon 的主要目的是快速传达一个概念。
+
+)](https://cdn-images-1.medium.com/max/8000/1*gIW6QI70azGalzYXicxj6A@2x.png)
+
+在上面这一系列符号中,哪些您能马上读懂?有经验的驾驶员也许能够了解这些图标的含义。但是的确,某些图标并不直观。您甚至需要一本手册才能明白它们含义。
+
+以下是我对它们大致的感受:
+
+
+
+当 icon 使用了不熟悉的隐喻时,我们很难理解它。安全带提醒灯的 icon(从左数第三个)非常直观,我们马上就能明白它的意思。而电力转向系统警示灯的 icon(最右边)的意思我们就很难读懂。
+
+通常,一个难以理解的 icon 会令人沮丧。并且对于驾驶员来说,误解了警告 icon 将是十分危险的。
+
+下面是一些我们比较熟悉的 icon —— 爱情、警告、音乐以及向上/向前的符号:
+
+ icon 库](https://cdn-images-1.medium.com/max/8000/1*qLfMs1ZZBWVI7QUlkKcLxg@2x.png)
+
+箭头是在指路中使用的强大符号:
+
+)](https://cdn-images-1.medium.com/max/8000/1*Qo1uR98wkC29ZyvLSzbguw@2x.png)
+
+最理想的 icon 不仅对于一群人来说是易于理解的,而且在不同的文化、年龄和背景下都是通用的。站在您的用户角度思考,使用能与用户产生共鸣的隐喻和色彩。
+
+请记住,如果 icon 所表示的意思太抽象,那么单独的 icon 可能不是表达性最好的解决方案。在这种情况下,将 icon 加上文本标签,或者寻找其它的解决方法。
+
+## 可读性
+
+有了可以理解的 icon 后,请确保其可读性。
+
+
+
+上面(第一行)的 **Amtrak** (美国铁路)App 中的车站 icon 就很难辨认出来,因为细节太多了。
+
+**Transit** (美国公交)App 也有类似的问题。因为在板子和夹子之间的间隙太小,所以它们的剪贴板图标看起来像一团墨水:
+
+
+
+稍作调整将带来很大的改进:
+
+
+
+当处理多个形状时,在它们之间留出足够的空间。过细和更多的笔触会使得 icon 更复杂,更难以阅读。
+
+**谷歌地图** 在这一方面就做得很好,他们的交通图标即使在极小的尺寸下也非常易读:
+
+
+
+## 校准
+
+为确保每个图标看起来平衡,需要在视觉上校准元素。
+
+
+
+在这个播放 icon 中,尽管三角形按长度标准放在了圆的中心,我们的眼睛还是认为它不在中心。这是因为三角形较宽的部分看起来比点“重”,使得三角形视觉上向左侧偏移。
+
+这就像排版人员通过视觉错觉来精细调整字体,从而达到平衡的视觉效果。(注意下图中,字母 “i” 和字母 “j” 上偏移中心的点以及[超出准线](https://frerejones.com/blog/typeface-mechanics-001/)的字母 “O”)
+
+
+
+—— icon 设计师会进行类似的调整以平衡图标。要更正上面的示例,请稍微移动元素:
+
+
+
+这看起来就好多了。
+
+这里我们学到的是:不要简单地相信数字;用您的眼睛检查您的工作。
+
+## 简洁性
+
+用简单的几句话完整地表达一个想法,会让人感到高效和优雅。比如下面这句话:
+
+> 教授您所知道的东西可以加强您对这门学科的理解。(Teaching what you know strengthens your own understanding of the subject.)
+
+我们可以更简洁地说(来自 Robert Heinlein):
+
+> 教学相长。(When one teaches, two learn.)
+
+这就十分优雅了。
+
+在将简洁性作为系统中 icon 的设计导向这个方面,**Material** 风格就做得很好。与其使用这种 icon:
+
+)](https://cdn-images-1.medium.com/max/8000/1*MRInntlrUtShOA1q2o5hBA@2x.png)
+
+不如使用简单的:
+
+)](https://cdn-images-1.medium.com/max/8000/1*smf9YlD_yZ59FMx7d1x1AA@2x.png)
+
+简洁性尤其适用于 icon 设计,因为我们经常在小画布上工作。为您的图标使用适当的细节就好,不要增加一些您不需要的。
+
+在用户界面中,简化的风格可以帮助用户抓住重点并为突出内容。比如,**Telegram** 的 icon 就很简洁有趣:
+
+
+
+有时,UI icon 需要具有更强的说明性。**Yelp**(美国商户点评)中这些多色调的 icon 是显示热门食物搜索的一种令人愉快的方式。泰国菜里的虾很精致:
+
+ 的 Yelp icon](https://cdn-images-1.medium.com/max/8000/1*sfStr_fEdvb8IkkvP3DwiQ@2x.png)
+
+对于代表移动、平板和桌面应用的 **App** icon,可以用更多的深度和颜色来增加适当的细节。因为用户清楚自己现在是在设备主屏幕还是屏幕下方的菜单栏(在 iPhone 手机中,指 dock 栏)还是应用商店,所以使用更好地表达品牌和产品的 icon 会比较好。
+
+](https://cdn-images-1.medium.com/max/8000/1*TkO-RQ90wHYlFa2EAigG5w@2x.png)
+
+## 一致性
+
+为了使 icon 库看起来和谐,请始终保持相同的样式规则。
+
+在 iOS 13 之前,**Apple** 的图标展具有各种笔触,填充和大小:
+
+ 的 icon](https://cdn-images-1.medium.com/max/8000/1*Fg6ZRRCMGCEw1oS90ucBhg@2x.png)
+
+瞇着眼睛看这一组 icon。您有感觉到有些图标比其它的看起来更“重”吗?
+
+任何给定的 icon 都有一定的视觉**权重**,这是由填充、笔触厚度、大小和形状等参数决定的。在一系列 icon 中保持这些参数不变就可以建立一致性。
+
+
+
+**Apple** 最近修正了他们 [SF Symbols 的介绍](https://developer.apple.com/videos/play/wwdc2019/206),SF Symbols 是 [San Francisco](https://developer.apple.com/fonts/) 字体的绝佳伴侣。SF Symbols 拥有 9 种权重和 3 种比例的图形 icon 风格(也许有点复杂,绝对详尽)。我们可以发现 icon 之间的过渡 ,填充和轮廓变量变得更加和谐了。
+
+的 icon](https://cdn-images-1.medium.com/max/8000/1*4mYEN31EDW-0sPygspMWdw@2x.png)
+
+要维护一个庞大 icon 库的一致性可不是一件容易的事,特别是当多个作者参与其中时。遵循明确的原则和规则是至关重要的。
+
+**Phosphor** icon 库 —— 由我设计并由[我的另一半](https://github.com/rektdeckard)搭建,通过坚持相同的设计原则和严格测试每个图标来保持 700 多个图标的一致性。虽然每一个都有不同的形状,但它们都有相同的视觉权重,并且很好地结合在一起:
+
+ icon 库中的一个子集](https://cdn-images-1.medium.com/max/8000/1*EjIs1qySoJTw7uq3Hup9Rg@2x.png)
+
+## 特性
+
+每个 icon 集都有自己的风格。是什么让它风格独一无二?它是如何对品牌进行的表达?它会给我们带来怎样的心情?
+
+
+
+**Waze** 的可爱的界面很大程度上依赖于它们的 icon。这些五颜六色、矮胖的图标上仿佛写着:我们不一样!
+
+**Twitter** 的 icon 是比较柔软、轻盈的:
+
+
+
+**Sketch** 的 icon 是比较精致和轻快的:
+
+ 的 icon 来自 [Janik Baumgartner](https://dribbble.com/janik)](https://cdn-images-1.medium.com/max/8000/1*8RUcOyj47DMvDWj32aVzlg@2x.png)
+
+**Freemojis** 的 icon 是比较可爱的:
+
+ 的 icon 来自 [Streamline](https://streamlineicons.com/)](https://cdn-images-1.medium.com/max/8000/1*Pz-DDw-6DhwZTXZKdxXfBg@2x.png)
+
+Android 的 icon 包迎合了主屏幕主题的多种需求,下图分别是抽象、像素、泡沫、和霓虹灯风格:
+
+、[PixBit](https://play.google.com/store/apps/details?id=pixbit.prime)、[Crayon](https://play.google.com/store/apps/details?id=com.jndapp.cartoon.crayon.iconpack)、[Linebit](https://play.google.com/store/apps/details?id=com.edzondm.linebit)](https://cdn-images-1.medium.com/max/8000/1*RMr0OXf8Sx3usFwGL3HGpQ@2x.png)
+
+## 易用性
+
+一个 icon 集被完美地设计出来还不够。它需要进一步的测试和准备,以确保贡献者可以方便地添加新 icon,设计师可以在设计中使用它们(用于屏幕、打印等),工程师可以在开发中使用它们。
+
+一个高质量 icon 集应该是**组织有序的**、 **文档完善的**,并在上下文中进行过**测试**了的。除此之外,它最好还能:支持一些**自定义工具**,如 icon 管理器。
+
+#### 组织有序的
+
+保持 master 分支文件干净,正确命名和存放您的资源文件,这样就很容易可以找到它们,正确命名您的资源文件,把它们放在容易找到的地方。选择一个最适合的分类方法。按字母顺序?按大小?按类型?
+
+ 的 Sketch 文件,按类型组织并分页。](https://cdn-images-1.medium.com/max/8000/1*GRmcLkIwBIiF_x3J-4puYA@2x.png)
+
+#### 文档完善的
+
+表达清楚 icon 库的关键原则:
+
+```
+Phosphor icon 库的原则示例(其实就是对上面介绍的内容):
+
+• 明确性。首先 icon 要清晰明确。使图标易识别和易读。永远不要舍弃 icon 所表达的明确性。
+
+• 简洁性。使用尽可能少的细节。Phosphor 的风格是简化的风格。icon 中的每一笔都要简明扼要,有意识地传达所要表达的本质。
+
+• 特性。可以是独具特色的。适当地添加独特的细节,可能会为原本非常严肃正经的 icon 集增添一丝温暖和乐趣。
+```
+
+列出技术规则:
+
+```
+Phosphor icon 库的技术规则示例:
+
+• 使用 48x48px 的画布
+
+• 使用 1.5px 的中心笔触
+
+• 使用圆角
+
+• 除非断开有助于 icon 的理解,否则请使用连续的笔触。
+
+• 尽可能使用笔直的线段,完美的弧度和 15° 的角度增量
+
+• 必要时调整曲线以遵循设计原则
+
+• 尽可能使用整数、偶数增量进行测量;必要时可以折至 1px 和 .5px
+
+• 使用以下的形状关键线:28x28px 圆形、25x25px 正方形、28x22px 横向矩形、22x28px 纵向矩形
+
+• 保留 6px 的修剪区域
+```
+
+重复上面的这些,如果您愿意,可以像下面一样将文档公开:
+
+* [Material 系统 icon](https://material.io/design/iconography/system-icons.html)
+* IBM 的 [UI icon](https://www.ibm.com/design/language/iconography/ui-icons/design/)、[App icon](https://www.ibm.com/design/language/iconography/app-icons/design/) 以及 [icon 贡献者指南](https://www.carbondesignsystem.com/guidelines/icons/contribute/)
+* [Shopify Polaris 的 icon](https://polaris.shopify.com/design/icons)
+* [Atlassian Iconography(产品)](https://www.atlassian.design/guidelines/product/foundations/iconography)
+
+#### 测试
+
+检查一致性。确保 icon 在上下文中以相应的大小工作。确保它们在更大的视觉系统也能协调工作。
+
+将 icon 放在一起有助于验证我们的原则,这些原则包括明确性、可读性、校准、简洁性、一致性和特性:
+
+ 在质量保证过程中的测试 icon 样单](https://cdn-images-1.medium.com/max/8000/1*cgP99N8laiD4jA6wh43yTA@2x.png)
+
+#### 自定义工具
+
+最后,如果您有足够的资源和能力,请创建能够方便使用图标的工具。
+
+**Material** 通过自定义 icon 资料库我们能够更方便地访问他们的 icon。我们可以搜索需要的 icon,在喜欢的文件格式中下载不同风格(主题)、不同颜色、不同大小的 icon:
+
+](https://cdn-images-1.medium.com/max/8000/1*6xbfiFeRNVYQITy64tYYGg@2x.png)
+
+我们使用的 icon 是有生命的。我们要给予它成功和成长所需要的爱和工具。
+
+---
+
+## 相关资源
+
+#### icon 资料库
+
+一些可选项:
+
+* [Feather](https://feathericons.com/),精美的 icon 集,提供 200 多个可以自由缩放的最小轮廓 icon。
+* [Material system icons](https://material.io/resources/icons/?style=baseline),1 千多个具有 5 种风格的实用 icon。
+* [Nucleo](https://nucleoapp.com/premium-icons),约有 3 万种 icon,提供 3 种样式:轮廓,平面/彩色和字形。
+* [Streamline](https://streamlineicons.com/),精美的 icon 集,提供 3 万多个具有 3 种视觉权重的线性风格 icon。
+
+#### icon 大集合
+
+* [Noun Project](https://thenounproject.com/), 尽管 icon 的质量参差不齐,但这也是从样式和隐喻中寻找灵感的好方法。
+
+#### icon 管理器
+
+* 使用 [Nucleo app](https://nucleoapp.com/application),在您导入 icon 集后,可以查看、导出 icon,还可以将 icon 拖拽到您喜欢的设计软件中。
+
+---
+
+🎶 **文章的音频版:[The Black Dog](https://open.spotify.com/artist/7qdsk0UXx2jCX7jbp6rxeq?si=R2z1R-xpT9K3Cmfp40lcrQ) 和 [Autechre](https://open.spotify.com/artist/6WH1V41LwGDGmlPUhSZLHO?si=9PBpv0i5QSiM66cd1G7mxQ)**
+
+🙏 **感谢:Toby Fried、Monica Chang、Darcy O’Donnell、Sara Thompson、Lonny Huff、Stephany Shigekuni、Clarissa Soto、Tate Chow、Christine Lee、Victor Vasquez、Chris Rodemeyer、David Landa、Pawel Piekarski、Matthew Vargas**
+
+```
+这是我们 icon 系列的第一篇文章。请敬请关注该系列的后续文章:
+
+• 5 步创建一个 Settings icon
+
+• icon 网格 & 关键线大揭秘
+
+• icon 设计中的像素捕捉:捕捉或不捕捉
+```
+
+> 如果发现译文存在错误或其它需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/8-ui-ux-design-trends-for-2020.md b/TODO1/8-ui-ux-design-trends-for-2020.md
new file mode 100644
index 00000000000..242e0147cc5
--- /dev/null
+++ b/TODO1/8-ui-ux-design-trends-for-2020.md
@@ -0,0 +1,170 @@
+> * 原文地址:[8 UI design trends for 2020](https://uxdesign.cc/8-ui-ux-design-trends-for-2020-68e37b0278f6)
+> * 原文作者:[Dawid Tomczyk](https://medium.com/@dawidtomczyk)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/8-ui-ux-design-trends-for-2020.md](https://github.com/xitu/gold-miner/blob/master/TODO1/8-ui-ux-design-trends-for-2020.md)
+> * 译者:
+> * 校对者:
+
+# 8 UI design trends for 2020
+
+
+
+The rapid growth of technology influences design trends every year. As designers we need be aware of the existing and upcoming design trends, constantly learning, improving and expanding our design toolkit in order to be up to date on the current market. Based on my research, experience and observations I’ve selected very carefully 8 UI/UX design trends that you should watch in 2020. Let’s get started then! :)
+
+---
+
+
+
+Illustrations have been in digital product design for a long time. Their evolution in the last years is very impressive. Illustrations as very popular design elements add natural feel and “human touch” to overall UX of our products. Illustrations are also very strong attention grabbers: at the top of that by applying motion to these illustrations we might bring our products to the life and make them stand out— adding extra details and personality.
+
+](https://cdn-images-1.medium.com/max/2000/1*NIpVGu31MRBN5ZOoh2dAjw.gif)
+
+](https://cdn-images-1.medium.com/max/2000/1*nO8JMEHRAeUbhZ5uH1UzBg.gif)
+
+Another benefit of applying motion is capturing users attention and making users engage with your product. Animations are also one of the most effective ways to **tell the story** about your brand, product or services.
+
+---
+
+
+
+Microinteractions exist pretty much in every single app or website. You see them every time when you’re opening your favourite app —for instance Facebook has tons of different microinteractions and I assume that the “Like” feature is just the perfect example. Sometimes we are not even aware of existence, because they are so so obvious, natural and “blended” into user interfaces. Altough, If you remove them from your product you will notice very quickly that something really important is missing.
+
+](https://cdn-images-1.medium.com/max/2000/1*euDrScfMNdCN25w6NVyC-g.gif)
+
+](https://cdn-images-1.medium.com/max/2000/1*W0fsXNGi5V6WYCSb-MqEyA.gif)
+
+Generally speaking, in UI/UX design sometimes even really small and subtle change might make huge impact. Microinteractions are the perfect proof that details and attention to them might greatly improve the overall user experience of your digital products and place them on the next/higher level. Every year, every new device brings new oppurtinitues for creating brand new and innovative microinteractions. 2020 wouldn’t be exception for sure.
+
+---
+
+
+
+3D graphic exist pretty much everywhere — in movies, video games, adverts on the streets. 3D graphic has been introduced few decades ago and since then has improved and evolved dramatically. Mobile and web technology is also growing rapidly fast. New web browser capabilities have opened the door for 3D graphic allowing us as designers to create and implement amazing 3D graphics into modern web and mobile interfaces.
+
+](https://cdn-images-1.medium.com/max/2000/1*qDlbltTzKja0Hx0dCupTCA.gif)
+
+](https://cdn-images-1.medium.com/max/2000/1*zFmiJUB1Z_C3VuwINPycaA.gif)
+
+Creating and then integration of 3D graphic into web and mobile interfaces requires some specific skills and tons of work, but very often the results are very rewarding.
+
+](https://cdn-images-1.medium.com/max/4492/1*4uhVHjD9d6pfYOb2K4TRog.png)
+
+3D graphic renders allows to present the product or services in the a lot more interactive and engaging way: for instance 3D graphic renders could be viewed in 360 degree presentation improving the overall UX of the product.
+
+In 2020 even more brands will use 3D render models to present the product or services in order to emulate the real world (in-store) shopping experience.
+
+---
+
+
+
+2019 has been a big year for VR. In the last years we have seen a lot of progress and excitement in VR headsets — mostly in gaming industry. We need to keep in mind that gaming industry very often brings innovation and new technologies into digital product design. Research proves that VR is no exception as after Oculus Quest in 2019 launch many opportunities have opened for other industries. Facebook CEO Mark Zuckerberg has already tested exciting hand interaction feature and officially announced hand-tracking update for Quest, coming early 2020!
+
+
+
+](https://cdn-images-1.medium.com/max/2000/1*e_CbRfbzCAar13yq8e1YWg.png)
+
+Sony and Microsoft will release their new generation consoles in 2020 holiday season. These would bring a lot opportunities and room to growth for VR technology.
+
+---
+
+
+
+In the last years we have seen a lot of progress, excitement and improvement of AR. The world’s leading tech companies are investing millions into AR development , so we should expect to expand and grow this technology in 2020. Even Apple has introduced their own AR toolkit called [ARKIT 3](https://developer.apple.com/augmented-reality/arkit/) to help designers and developers build AR based products.
+
+](https://cdn-images-1.medium.com/max/5780/1*RRHUec5C2Q0aEdTv-t2aGQ.png)
+
+](https://cdn-images-1.medium.com/max/3200/1*EQ1UOOlsA7ZuXQdkWNMRwA.png)
+
+](https://cdn-images-1.medium.com/max/2000/1*rkl7gOWUrAMWPBvcAMeatQ.gif)
+
+There are endless ****opportunities to innovate and create brand new and exciting experiences in AR space. UI design for AR will be one of the major trends in 2020, so as designers we should be prepared and eager to learn new tools, principles when creating AR experiences.
+
+---
+
+
+
+Generally speaking Skeuomorphic design refers to the design elements that are created in a realistic style/way to match the real life objects. The growth of VR/AR technology and latest design trends shown on the most popular design platforms (Dribbble, Behance etc.) might make skeuomorphic design comeback in 2020 — but this time with a lot modern fashion and slightly modified name: “New skeuomorphism” (also called **Neumorphism**).
+
+ by [Alexander Plyuto](https://dribbble.com/alexplyuto)](https://cdn-images-1.medium.com/max/6400/1*jHc54zFmPjfdCFji2TB3-Q.png)
+
+](https://cdn-images-1.medium.com/max/3200/1*BDEjVxl7yWdb7E5AU9nucQ.png)
+
+](https://cdn-images-1.medium.com/max/3200/1*isXyzOKNJYT66tsQDX3OLA.png)
+
+As you’ve probably noticed: ****Neumorphism represents very detailed and precise design style. Highlight, shadows, glows — attention to details is very impressive and definitely on spot. Neumorphism has already inspired a lot of designers from all over the world and there is big chance that Neumorphism will be the biggest UI design trend in 2020.
+
+---
+
+
+
+In the last years we have noticed huge grown of asymmetrical layouts in digital product design. Traditional / “template” based layouts are definitely going away. 2020 will not be any different as this trend will continue. Proper usage of asymmetrical layouts add a lot of character, dynamic and personality to our designs, so they do not template based anymore.
+
+](https://cdn-images-1.medium.com/max/3200/1*HNXaVNj-XfoIfZjCligjCw.png)
+
+ — [Dawid Tomczyk](https://dribbble.com/shots/5886207-Carine-fashion-store-selection-screen-concept)](https://cdn-images-1.medium.com/max/3200/1*Rnp7xmSbuhHhwvkWxt2H9w.png)
+
+There is a lot of room for creativity as the number of options and opportunities when creating asymmetrical layouts are endless. Although, creating successful asymmetrical layouts requires some practice and time — placing elements randomly on the grid wouldn’t work :) also they should be used and implemented with care — always keeping in mind users needs : we do not want to get them lost when using our digital products — do we? :)
+
+---
+
+
+
+Stories play an very important role in overall UX in the digital product design. You might see them very often on the landing pages as introduction to the brand, product or new service. Storytelling is all about transferring data to the users in the best possible informative and creative way. This could be achieved by copyrighting mixed with strong and balanced visual hierarchy (typography, illustrations, high-quality photos, bold colours, animations and interactive elements).
+
+](https://cdn-images-1.medium.com/max/2712/1*sk8s9LyLmPUWeFMNccWX1A.png)
+
+](https://cdn-images-1.medium.com/max/2000/1*cDpCrm_uTX7jEho18kFQIA.gif)
+
+**Storytelling really helps to create positive emotions and relationships between your brand and users**. Storytelling might also make your brand a lot more memorable and making users feel like they are part of our products or services, so they would like to associate with them. Having said that, storytelling is also great and efficient marketing tool that might greatly increase the sales of your products/services. Storytelling as the very successful tool will continue and expand in 2020.
+
+---
+
+## Summary: 8 UI/UX design trends for 2020
+
+#### #1 Animated Illustrations
+
+By applying motion to illustrations we might really make our designs stand out and bring them to the life — adding extra details and personality.
+
+#### #2 Microinteractions
+
+Microinteractions are the perfect proof that details and attention to them might greatly improve the overall user experience of your digital products and place them on the next/higher level.
+
+#### #3 3D Graphics in web and mobile interfaces
+
+New web browser capabilities have opened the door for 3D graphic allowing us as designers to create and implement amazing 3D graphics into modern web and mobile interfaces.
+
+#### #4 Virtual Reality
+
+Gaming industry very often brings innovation and new technologies into digital product design.
+
+#### #5 Augmented Reality
+
+There are endless ****opportunities to innovate and create brand new and exciting experiences in AR space. UI design for AR will be one of the major trends in 2020, so as designers we should be prepared and eager to learn new tools, principles when creating AR experiences.
+
+#### #6 Neumorphism
+
+The grow of VR/AR technology and latest design trends shown on the most popular design platforms might make skeuomorphic design comeback in 2020 — but this time with a lot modern fashion.
+
+#### #7 Asymmetrical Layouts
+
+There is a lot of room for creativity as the number of options and opportunities when creating asymmetrical layouts are endless. Although, creating successful asymmetrical layouts requires some practice and time.
+
+#### #8 Storytelling
+
+Storytelling is all about transferring data to the users in the best possible informative and creative way. Storytelling is also great and efficient marketing tool that might greatly increase the sales of your products/services.
+
+---
+
+Which of the trends I’ve mentioned has got you the most excited? Is there any other trend that should have been included in the list? Please let me know In the comments section below! :) You might also check my previous articles:
+
+* [**Master the basics of visual: how to become a self-taught UI/UX designer**](https://uxdesign.cc/how-to-become-a-ui-ux-designer-self-taught-8a511170fd7c)
+* [**7 simple & effective methods to get better at Visual/UI Design**](https://uxdesign.cc/7-simple-methods-to-get-better-at-visual-ui-design-21fec0f417b5)
+* [**Top 8 soft skills in UI/UX design**](https://uxdesign.cc/top-8-soft-skills-in-ui-ux-design-e1aedc783ac9)
+
+If you have any questions please feel free to [email me](mailto:dawidtomczykgrafik@gmail.com) — always happy to help. You can also find me at: [Dribbble](https://dribbble.com/dawidtomczyk), [Behance](https://www.behance.net/dawidtomczyk), [Instagram](https://www.instagram.com/daviduxdesigner/), [Uplabs](https://www.uplabs.com/dawidtomczyk), [Facebook](https://www.facebook.com/dawidtomczykuxdesigner), [LinkedIn](https://www.linkedin.com/in/dawid-tomczyk-464b2b91/) or by visiting personal [**portfolio website.**](https://davidux.design/)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/8-useful-tree-data-structures-worth-knowing.md b/TODO1/8-useful-tree-data-structures-worth-knowing.md
new file mode 100644
index 00000000000..eb4249a0ec8
--- /dev/null
+++ b/TODO1/8-useful-tree-data-structures-worth-knowing.md
@@ -0,0 +1,204 @@
+> * 原文地址:[8 Useful Tree Data Structures Worth Knowing](https://towardsdatascience.com/8-useful-tree-data-structures-worth-knowing-8532c7231e8c)
+> * 原文作者:[Vijini Mallawaarachchi](https://medium.com/@vijinimallawaarachchi)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/8-useful-tree-data-structures-worth-knowing.md](https://github.com/xitu/gold-miner/blob/master/TODO1/8-useful-tree-data-structures-worth-knowing.md)
+> * 译者:[Amberlin1970](https://github.com/Amberlin1970)
+> * 校对者:[PingHGao](https://github.com/PingHGao), [Jiangzhiqi4551](https://github.com/Jiangzhiqi4551)
+
+# 8 个值得了解的树形数据结构
+
+对于一棵树你会想到什么呢?树根、分支和树叶?一个有树根、分支和树叶的大橡树可能会在你脑海浮现。相似地,在计算机科学中,树形数据结构有根部、分支和树叶,但它是自上而下的。树是一种层级数据结构,以表达不同节点之间的关系。在这篇文章中,我将会简要地给你介绍 8 种树形数据机构。
+
+#### 树的属性
+
+* 树可以没有节点也可以包含一个特殊的节点**根节点**,该根节点可以包含零或多棵子树。
+* 树的每条边都直接或间接地源于根节点。
+* 每个孩子节点只有一个父节点,但每个父节点可以有很多孩子节点。
+
+
+
+在这篇文章中,我将会简要地解释下面 8 种树形数据结构及它们的用途。
+
+1. 普通树
+2. 二叉树
+3. 二叉搜索树
+4. AVL树
+5. 红黑树
+6. 伸展树
+7. 树堆
+8. B树
+
+## 1. 普通树
+
+**普通树**是一种在层级结构上无限制的树形数据结构。
+
+#### 属性
+
+1. 遵循树的属性。
+2. 一个节点可以有任意数量的孩子。
+
+
+
+#### 用途
+
+1. 用于存储如文件结构类的层级数据。
+
+## 2. 二叉树
+
+**二叉树**是一种有如下属性的树形数据结构。
+
+#### 属性
+
+1. 遵循树的属性。
+2. 一个节点至多有两个孩子。
+3. 这两个孩子分别称为**左孩子**和**右孩子**。
+
+
+
+#### 用途
+
+1. 在编译器中用于构造语法树。
+2. 用于执行表达式解析和表达式求解。
+3. 路由器中用于存储路由器表。
+
+## 3. 二叉搜索树
+
+**二叉搜索树**是二叉树的一种更受限的扩展。
+
+#### 属性
+
+1. 遵循二叉树的属性。
+2. 有一个独特的属性,称作**二叉搜索树属性**。这个属性要求一个给定节点的左孩子的值(或键)应该小于或等于父节点的值,而右孩子的值应该大于或等于父节点的值。
+
+
+
+#### 用途
+
+1. 用于执行简单的排序算法。
+2. 可以用作优先队列。
+3. 适用于数据持续进出的很多搜索应用中。
+
+## 4. AVL树
+
+**平衡二叉树**是一种自我平衡的二叉搜索树。这是介绍的第一种自动平衡高度的树。
+
+#### 属性
+
+1. 遵循二叉搜索树的属性。
+2. 自平衡。
+3. 每一个节点储存了一个值,称为一个**平衡因子**,即为其左子树和右子树的高度差。
+4. 所有的节点都必须有一个平衡因子且只能是 -1、0 或 1。
+
+在进行插入或是删除后,如果有一个节点的平衡因子不是 -1、0 或 1,就必须通过旋转来平衡树(自平衡)。你可以在我前面的文章 [**这里**](https://towardsdatascience.com/self-balancing-binary-search-trees-101-fc4f51199e1d) 阅读到更多的旋转操作。
+
+
+
+#### 用途
+
+1. 用于需要频繁插入的情况。
+2. 在 Linux 内核的内存管理子系统中用于在抢占期间搜索进程的内存区域。
+
+## 5. 红黑树
+
+红黑树是一种自平衡的二叉搜索树,每一个节点都有一种颜色:红或黑。节点的颜色用于确保树在插入和删除时保持大致的平衡。
+
+#### 属性
+
+1. 遵循二叉搜索树的属性。
+2. 自平衡。
+3. 每个节点或是红色或是黑色。
+4. 根节点是黑色(有时省略)。
+5. 所有叶子(标注为 NIL)是黑色。
+6. 如果一个节点是红色,那它的孩子都是黑色。
+7. 从一个给定的节点到其任意的叶子节点的每条路径都必须经过相同数目的黑色节点。
+
+
+
+#### 用途
+
+1. 在计算几何中作为数据结构的基础。
+2. 用于现在的 Linux 内核的**完全公平调度算法**中。
+3. 用于 Linux 内核的 **epoll** 系统中。
+
+## 6. 伸展树
+
+**伸展树**是一种自平衡的二叉搜索树。
+
+#### 属性
+
+1. 遵循二叉搜索树的属性。
+2. 自平衡。
+3. 近期获取过的元素再次获取时速度更快。
+
+在搜索、插入或是删除后,伸展树会执行一个动作,称为**伸展**,在执行伸展动作时,树会被重新排列(使用旋转)将特定元素放置在树的根节点。
+
+
+
+#### 用途
+
+1. 用于实现缓存。
+2. 用在垃圾收集器中。
+3. 用于数据压缩。
+
+## 7. 树堆
+
+**树堆**(名字来源于**树**和**堆**的结合)是一种二叉搜索树。
+
+#### 属性
+
+1. 每个节点有两个值:一个**键**和一个**优先级**。
+2. 键遵循二叉搜索树的属性。
+3. 优先级(随机值)遵循堆的属性。
+
+
+
+#### 用途
+
+1. 用于维护公钥密码系统中的授权证书。
+2. 可以用于执行快速的集合运算。
+
+## 8. B树
+
+B树是一种自平衡的搜索树,而且包含了多个排过序的节点。每个节点有 2 个或多个孩子且包含多个键。
+
+#### 属性
+
+1. 每个节点 x 有如下(属性):
+ * x.n(键的数量)
+ * x.keyᵢ(键以升序存储)
+ * x.leaf(x 是否是一个叶子)
+2. 每个节点 x 有(x.n + 1)孩子。
+3. 键 x.keyᵢ 分割了存储在每个子树中键的范围。
+4. 所有的叶子有相等的深度,即为树的高度。
+5. 节点有存储的键的数量的上界和下界。这里我们考虑一个值 t≥2,称为 B树的**最小度**(或**分支因子**)。
+ * 根节点必须至少有一个键。
+ * 每个其余节点必须有至少(t - 1)个键和至多(2t - 1)个键。因此,每个节点将会有至少 t 个孩子和至多 2t 个孩子。如果一个节点有(2t - 1)个键,我们称这个点是**满的**。
+
+
+
+#### 用途
+
+1. 用于数据库索引以加速搜索。
+2. 在文件系统中用于实现目录。
+
+## 最后的思考
+
+数据结构操作的时间复杂度的备忘录可以在这个[链接](https://www.bigocheatsheet.com/)找到。
+
+我希望这篇文章作为一个对树形结构的简单介绍对你是有用的。我很乐意听你的想法。😇
+
+非常感谢阅读!
+
+祝愉快! 😃
+
+## 参考
+
+ - [1] 算法导论(第三版),作者:Thomas H.Cormen / Charles E.Leiserson / Ronald L.Rivest / Clifford Stein.
+ - [2] [https://en.wikipedia.org/wiki/List_of_data_structures](https://en.wikipedia.org/wiki/List_of_data_structures)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的
+*本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/a-beginners-guide-to-simulating-dynamical-systems-with-python.md b/TODO1/a-beginners-guide-to-simulating-dynamical-systems-with-python.md
new file mode 100644
index 00000000000..cb36373e476
--- /dev/null
+++ b/TODO1/a-beginners-guide-to-simulating-dynamical-systems-with-python.md
@@ -0,0 +1,198 @@
+> * 原文地址:[A Beginner’s Guide to Simulating Dynamical Systems with Python](https://towardsdatascience.com/a-beginners-guide-to-simulating-dynamical-systems-with-python-a29bc27ad9b1)
+> * 原文作者:[Christian Hubbs](https://medium.com/@christiandhubbs)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/a-beginners-guide-to-simulating-dynamical-systems-with-python.md](https://github.com/xitu/gold-miner/blob/master/TODO1/a-beginners-guide-to-simulating-dynamical-systems-with-python.md)
+> * 译者:
+> * 校对者:
+
+# A Beginner’s Guide to Simulating Dynamical Systems with Python
+
+> Numerically Integrate ODEs in Python
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/12000/0*GZYR2gufn9IzhkSu)
+
+Consider the simple pendulum.
+
+
+
+We’ve just got a mass of m hanging from a string with length L that is swinging back and forth.
+
+It’s basically as simple of a system as we can work with. Don’t let this simplicity fool you though, it can create some interesting dynamics. We’ll use this as a starting point to introduce some control theory and compare that to continuous control reinforcement learning. Before we get to that, we need to spend some time understanding the dynamics of the system and how to simulate it!
+
+## TL;DR
+
+We derive the dynamics of the mass and pendulum system, and build two separate simulation models using one of Python’s integration packages and using Euler’s Method. This provides a good stepping stone for more complex systems; many joints and systems in robotic control can even be modeled as pendulums that are linked together.
+
+You can also view the [original post here](https://www.datahubbs.com/simulating-dynamical-systems-with-python/) where the equations are formatted much more nicely than Medium allows.
+
+## Dynamics of Swinging
+
+If we want to simulate this system, we need to understand the dynamics. To start, we’ll draw a free-body diagram (FBD) of the simple pendulum where we show the length, mass, gravity, and force vectors acting on the system.
+
+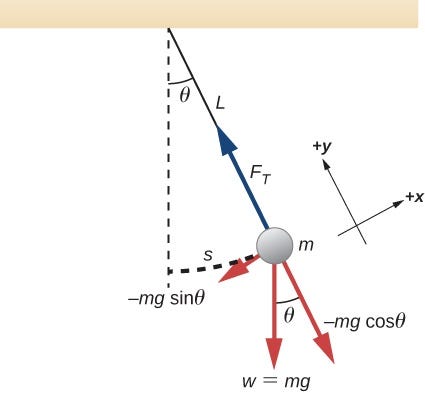
+
+Drawing the FBD helps to make all of the forces explicit to ensure we don’t miss anything. Once we have that, we can use Newton’s 2nd Law of Motion to get the dynamics. You’re probably familiar with the F=ma form, but we’ll modify this slightly for [rotational motion](https://brilliant.org/wiki/rotational-form-of-newtons-second-law/) by writing it as:
+
+
+
+n this case, τ is the torque about the origin, III is the rotational inertia, and α is the angular acceleration. The torque is given by the perpendicular component of force applied to the mass (the moment about the origin), rotational inertia is just I=mL², and the angular acceleration is the second time derivative of θ. We can plug these values into Newton’s 2nd Law above, and we get:
+
+
+
+For completeness, we can also consider friction on the pendulum, which gives us:
+
+
+
+The first thing to notice, we have a second-order ODE (ordinary differential equation) on our hands by virtue of the second derivative (θ¨) in our equation. We want to reduce this to a first-order system to integrate and simulate it. This comes at a cost of complexity because we will break our single, second-order system into two first-order equations. The cost is relatively minor in this case, but for more complicated models (which we’ll get to in future posts) this can become hairy.
+
+To do this, we need to introduce two new variables, we’ll call them θ_1 and θ_2 and define them as:
+
+
+
+This helps because we now can say θ˙_2=θ¨ and reduce the order of our equation.
+
+Now, we have:
+
+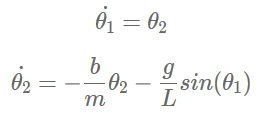
+
+With our equations set up, let’s turn to the code to model this.
+
+## Simulating the Pendulum Dynamics
+
+Start by importing the relevant libraries.
+
+```python
+import numpy as np
+from scipy import integrate
+import matplotlib.pyplot as plt
+```
+
+We need to set some of our values. Let the mass and length be 1 kg and 1 m respectively, and for now at least, we’ll ignore friction by setting b=0. We’ll simulate the pendulum swinging starting from π/2 (raised 90 degrees to the right) and released with no initial velocity. We can simulate this for 10 seconds with a time discretization (Δt) of 0.02 seconds.
+
+```python
+# Input constants
+m = 1 # mass (kg)
+L = 1 # length (m)
+b = 0 # damping value (kg/m^2-s)
+g = 9.81 # gravity (m/s^2)
+delta_t = 0.02 # time step size (seconds)
+t_max = 10 # max sim time (seconds)
+theta1_0 = np.pi/2 # initial angle (radians)
+theta2_0 = 0 # initial angular velocity (rad/s)
+theta_init = (theta1_0, theta2_0)
+# Get timesteps
+t = np.linspace(0, t_max, t_max/delta_t)
+```
+
+We’ll demonstrate two ways to simulate this, first by numerical integration using `scipy`, and then again using Euler’s method.
+
+## Scipy Integration
+
+To integrate using `scipy`, we need to build a function for our model. We’ll call it `int_pendulum_sim` for our integrated simulation. This model will take our initial values for θ_1 and θ_2 (labeled `theta_init` above) and integrate for a single time step. It then returns the resulting theta values. The function itself is just going to be two equations for θ˙_1 and θ˙_2 that we derived above.
+
+```python
+def int_pendulum_sim(theta_init, t, L=1, m=1, b=0, g=9.81):
+ theta_dot_1 = theta_init[1]
+ theta_dot_2 = -b/m*theta_init[1] - g/L*np.sin(theta_init[0])
+ return theta_dot_1, theta_dot_2
+```
+
+We can simulate our system by passing our function as an argument to `scipy.integrate.odeint`. In addition, we need to give our initial values and the time to simulate over.
+
+```python
+theta_vals_int = integrate.odeint(int_pendulum_sim, theta_init, t)
+```
+
+The `odeint` function takes these inputs and integrates our θ˙\dot{\theta}θ˙ values for us, then feeds those results back into the function again as the initial conditions for the next time step. This gets repeated until we’ve integrated over all of the time steps t.
+
+We can plot θ and θ˙ to see how the position and velocity evolve over time.
+
+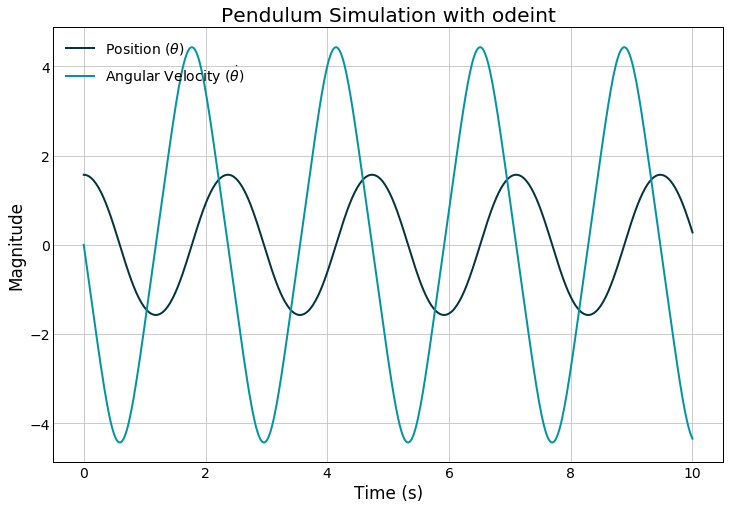
+
+We have no friction or other force in our model, so the pendulum is just going to oscillate back and forth indefinitely between −π/2 and π/2. If you increase the initial velocity, to say, 10 rad/s, you’ll see the position continue to increase as the model shows it circling around again and again.
+
+## Semi-Implicit Euler Method
+
+Solving the model via integration is relatively easy, but integration can be very expensive, particularly for larger models. If we want to see the long-term dynamics of the model, we can use [Euler’s Method](https://en.wikipedia.org/wiki/Semi-implicit_Euler_method) to integrate and simulate the system instead. This is how control problems such as Cart-Pole are solved in OpenAI and allows us to set-up problems for RL control.
+
+To do this, we need to get the [Taylor Series Expansion](https://en.wikipedia.org/wiki/Taylor_series) (TSE) of our ODE’s. The TSE is just a way to approximate a function. You get more accurate the more you expand the series. For our purposes, we’re only going to expand to the first derivative and truncate the higher order terms.
+
+First, note we need a function for θ(t). If we apply the TSE to θ(t) about t-t_0, we get:
+
+
+
+Where O(t²) simply represents our higher order terms, which can be dropped without losing much fidelity. Note that this just follows from the general formula for the TSE. With this equation, we can then refer back to our ODE substitutions above, namely:
+
+
+
+With this, we can link the TSE with our ODE’s such that:
+
+
+
+This gives us a convenient way to update our model at each time step to get the new value for θ_1(t). We can repeat the expansion and substitution for θ˙(t) to get the following:
+
+
+
+As we loop through these in our simulation, we’ll update t0t_0t0 to be the previous time step, so we’ll be incrementally moving the model forward. Also, note that this is the **semi-implicit Euler method**, meaning that in our second equation, we’re using the most recent θ_1(t) that we calculated rather than θ_1(t_0) as a straight application of the Taylor Series Expansion would warrant. We make this subtle substitution because, without it, our model would diverge. Essentially, the approximation we make using TSE has some error in it (remember, we threw away those higher order terms) and this error compounds. In this application, the error introduces new energy into our pendulum — something clearly in violation of the first law of thermodynamics. Making this substitution fixes all of that.
+
+```python
+def euler_pendulum_sim(theta_init, t, L=1, g=9.81):
+ theta1 = [theta_init[0]]
+ theta2 = [theta_init[1]]
+ dt = t[1] - t[0]
+ for i, t_ in enumerate(t[:-1]):
+ next_theta1 = theta1[-1] + theta2[-1] * dt
+ next_theta2 = theta2[-1] - (b/(m*L**2) * theta2[-1] - g/L *
+ np.sin(next_theta1)) * dt
+ theta1.append(next_theta1)
+ theta2.append(next_theta2)
+ return np.stack([theta1, theta2]).T
+```
+
+Now running this new function:
+
+```python
+theta_vals_euler = euler_pendulum_sim(theta_init, t)
+```
+
+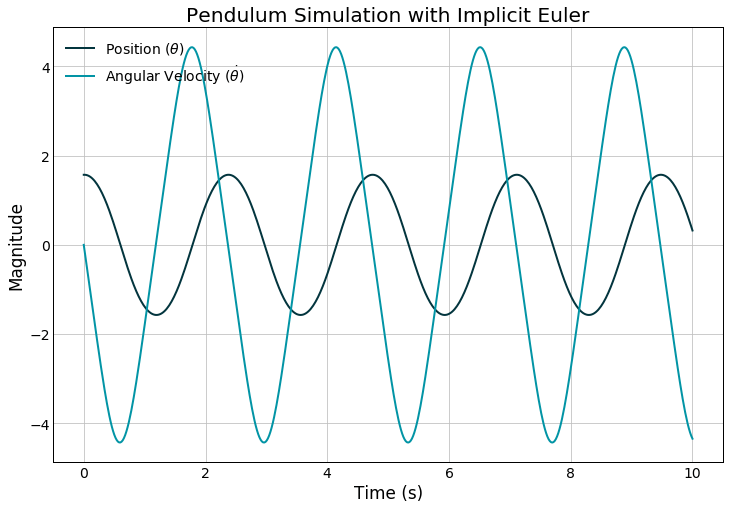
+
+The plot looks good, so let’s see if it matches our previous results.
+
+```python
+mse_pos = np.power(
+ theta_vals_int[:,0] - theta_vals_euler[:,0], 2).mean()
+mse_vel = np.power(
+ theta_vals_int[:,1] - theta_vals_euler[:,1], 2).mean()
+print("MSE Position:\t{:.4f}".format(mse_pos))
+print("MSE Velocity:\t{:.4f}".format(mse_vel))
+
+MSE Position: 0.0009
+MSE Velocity: 0.0000
+```
+
+The mean-squared error between the different methods are incredibly close, meaning we’ve got a pretty good approximation.
+
+We did this using two different methods because I said it’s faster to apply the Euler method than to solve via integration with `odeint`. Rather than take my word for it, let’s test that claim.
+
+```
+%timeit euler_pendulum_sim(theta_init, t)
+
+2.1 ms ± 82.8 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
+
+%timeit integrate.odeint(int_pendulum_sim, theta_init, t)
+
+5.21 ms ± 45.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
+```
+
+And the Euler method comes out on top with a ~2X speed up vs. the integration approach.
+
+With that, we learned how to build and simulate a dynamic model from first principles and apply it to a simple, frictionless pendulum.
+
+Dynamical systems like this are incredibly powerful for understanding nature. I recently wrote a post using these same techniques which show how we can simulate the [spread of a virus outbreak through a population](https://towardsdatascience.com/how-quickly-does-an-influenza-epidemic-grow-7e95786115b3). ODE’s are also great for feedback control and other relevant applications in robotics and engineering, so getting a handle on basic numeric integration is a must!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/a-closer-look-at-the-provider-package.md b/TODO1/a-closer-look-at-the-provider-package.md
index fab3474c522..c75877aef67 100644
--- a/TODO1/a-closer-look-at-the-provider-package.md
+++ b/TODO1/a-closer-look-at-the-provider-package.md
@@ -2,22 +2,22 @@
> * 原文作者:[Martin Rybak](https://medium.com/@martinrybak)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/a-closer-look-at-the-provider-package.md](https://github.com/xitu/gold-miner/blob/master/TODO1/a-closer-look-at-the-provider-package.md)
-> * 译者:
-> * 校对者:
+> * 译者:[EmilyQiRabbit](https://github.com/EmilyQiRabbit)
+> * 校对者:[Baddyo](https://github.com/Baddyo)
-# A Closer Look at the Provider Package
+# 深入解析 Provider 包
-> Plus a Brief History of State Management in Flutter
+> 附加 Flutter 状态管理的简单背景介绍

-[Provider](https://pub.dev/packages/provider) is a state management package written by [Remi Rousselet](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=2ahUKEwjXrMKO8dLjAhWoT98KHUCDB_oQFjAAegQIARAB&url=https%3A%2F%2Ftwitter.com%2Fremi_rousselet&usg=AOvVaw3bEIgT0j4c_5xbq-YWB70q) that has been recently embraced by Google and the Flutter community. But what **is** state management? Heck, what is **state**? Recall that state is simply the data that represents the UI in our app. **State management** is how we create, access, update, and dispose this data. To better understand the Provider package, let’s look at a brief history of state management options in Flutter.
+[Provider](https://pub.dev/packages/provider) 是一个用于状态管理的包,其作者是 [Remi Rousselet](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=2ahUKEwjXrMKO8dLjAhWoT98KHUCDB_oQFjAAegQIARAB&url=https%3A%2F%2Ftwitter.com%2Fremi_rousselet&usg=AOvVaw3bEIgT0j4c_5xbq-YWB70q),最近,这个包在 Google 和 Flutter 社区广受欢迎。那么**什么是**状态管理呢?什么又是**状态**?我们一起来温习一下:状态就是用来表示应用 UI 的数据。**状态管理**则是我们创建、访问以及处理数据的方法。为了能更好地理解 Provider 这个包,我们先来简单回顾一下 Flutter 中的状态管理选项。
-## 1. StatefulWidget
+## 1. 状态组件:StatefulWidget
-A [StatelessWidget](https://api.flutter.dev/flutter/widgets/StatelessWidget-class.html) is a simple UI component that displays only the data it is given. A `StatelessWidget` has no “memory”; it is created and destroyed as needed. Flutter also comes with a [StatefulWidget](https://api.flutter.dev/flutter/widgets/StatefulWidget-class.html) that **does** have a memory thanks to its long-lived companion [State](https://api.flutter.dev/flutter/widgets/State-class.html) object. This class comes with a `setState()` method that, when invoked, triggers the widget to rebuild and display the new state. This is the most basic, out-of-the-box form of state management in Flutter. Here is an example with a button that always shows the last time it was tapped:
+无状态组件 [StatelessWidget](https://api.flutter.dev/flutter/widgets/StatelessWidget-class.html) 很简单,它就是一个展示数据的 UI 组件。`StatelessWidget` 没有记忆功能;并根据需要被创建或者销毁。Flutter 同时也有状态组件 [StatefulWidget](https://api.flutter.dev/flutter/widgets/StatefulWidget-class.html),这个组件是有记忆功能的,此记忆功能来自于它的持久组合状态对象 [State](https://api.flutter.dev/flutter/widgets/State-class.html)。这个类中包含一个 `setState()` 方法,当该方法被调用时,会触发组件重建并渲染出新的状态。这是 Flutter 中最基本的状态管理形式。下面这个例子就是一个展示会展示最近一次被点击的时间的按钮:
-```
+```dart
class _MyWidgetState extends State<MyWidget> {
DateTime _time = DateTime.now();
@@ -33,17 +33,17 @@ class _MyWidgetState extends State<MyWidget> {
}
```
-So what’s the problem with this approach? Let’s say that our app has some global state stored in a root [StatefulWidget](https://api.flutter.dev/flutter/widgets/StatefulWidget-class.html). It contains data that is intended to be used by many different parts of the UI. We share that data by passing it down to every child widget in the form of parameters. And any events that intend to mutate this data are bubbled back up in the form of callbacks. This means a lot of parameters and callbacks being passed through many intermediate widgets, which can get very messy. Even worse, any updates to that root state will trigger a rebuild of the whole widget tree, which is inefficient.
+这种写法的问题是什么呢?假设应用在根 [StatefulWidget](https://api.flutter.dev/flutter/widgets/StatefulWidget-class.html) 组件中保存了一些全局状态。这些数据可能会在 UI 的很多不同部分被用到。我们将数据以参数的方式传送到每个子组件,以此共享数据。任何试图修改数据的事件都要以更新事件的方式冒泡到根组件。这就意味着,很多参数和回调函数都需要传递多层组件,这种方式会让代码非常混乱。更甚至,根状态的任何更新都会触发整个组件树的重构,这是成本非常高的。
-## 2. InheritedWidget
+## 2. 可继承组件:InheritedWidget
-[InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) is a unique component in Flutter that lets a widget access an ancestor widget without having a direct reference. By simply accessing an [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html), a consuming widget is automatically rebuilt whenever the inherited widget requires it. This technique lets us be more efficient when updating our UI. Instead of rebuilding huge parts of our app in response to a small state change, we can surgically choose to rebuild only specific widgets. You’ve already used [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) whenever you’ve used `MediaQuery.of(context)` or `Theme.of(context)`. It’s probably less likely that you’ve ever implemented your own [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) though. That’s because they are [tricky to implement](https://flutterbyexample.com/set-up-inherited-widget-app-state/) correctly.
+[InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) 是 Flutter 中唯一可以不需要直接引用,就可以获取父级组件信息的组件。只需访问 [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html),那么当其子组件需要引用它的时候,该消费组件就可以自动重新构建。这种技术让开发者可以更高效地更新 UI。此时如果想稍微修改某个状态,我们可以只有选择地重新构建 App 中特定的组件,而不必大范围地重新构建了。如果你已经使用了 `MediaQuery.of(context)` 或者 `Theme.of(context)`,那么其实你已经在应用 [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) 了。而由于 [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) [很难正确地实现](https://flutterbyexample.com/set-up-inherited-widget-app-state/),你也不太可能会去实现自己的一个 [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html)。
## 3. ScopedModel
-[ScopedModel](https://pub.dev/packages/scoped_model) is a package created in 2017 by [Brian Egan](https://twitter.com/brianegan) that makes it easier to use an [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) to store app state. First we have to make a state object that inherits from [Model](https://pub.dev/documentation/scoped_model/latest/scoped_model/Model-class.html), and then invoke `notifyListeners()` when its properties change. This is similar to implementing the [PropertyChangeListener](https://docs.oracle.com/javase/7/docs/api/java/beans/PropertyChangeListener.html) interface in Java.
+[ScopedModel](https://pub.dev/packages/scoped_model) 是 [Brian Egan](https://twitter.com/brianegan) 于 2017 年创建的包,它让使用 [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) 存储应用状态变得更加容易了。首先,我们需要创建一个继承了 [Model](https://pub.dev/documentation/scoped_model/latest/scoped_model/Model-class.html) 的状态对象,然后在属性改变的时候调用 `notifyListeners()`。这和 Java 中 [PropertyChangeListener](https://docs.oracle.com/javase/7/docs/api/java/beans/PropertyChangeListener.html) 接口的实现有些类似。
-```
+```dart
class MyModel extends Model {
String _foo;
@@ -56,18 +56,18 @@ class MyModel extends Model {
}
```
-To expose our state object, we wrap our state object instance in a [ScopedModel](https://pub.dev/documentation/scoped_model/latest/scoped_model/ScopedModel-class.html) widget at the root of our app:
+为了暴露出状态对象,我们将其实例包裹在应用根组件的 [ScopedModel](https://pub.dev/documentation/scoped_model/latest/scoped_model/ScopedModel-class.html) 组件中。
-```
+```dart
ScopedModel<MyModel>(
model: MyModel(),
child: MyApp(...)
)
```
-Any descendant widget can now access `MyModel` by using the [ScopedModelDescendant](https://pub.dev/documentation/scoped_model/latest/scoped_model/ScopedModelDescendant-class.html) widget. The model instance is passed into the `builder` parameter:
+这样,任何子组件都可以通过 [ScopedModelDescendant](https://pub.dev/documentation/scoped_model/latest/scoped_model/ScopedModelDescendant-class.html) 组件获取到 `MyModel`。模块实例会作为参数传入 `builder`:
-```
+```dart
class MyWidget extends StatelessWidget {
@override
Widget build(BuildContext context) {
@@ -78,9 +78,9 @@ class MyWidget extends StatelessWidget {
}
```
-Any descendant widget can also **update** the model, and it will automatically trigger a rebuild of any `ScopedModelDescendants` (provided that our model invokes `notifyListeners()` correctly):
+任何子组件也可以**更新**此模块,同时它将自动触发重新构建(前提是我们的模块都正确地调用了 `notifyListeners()`):
-```
+```dart
class OtherWidget extends StatelessWidget {
@override
Widget build(BuildContext context) {
@@ -95,15 +95,15 @@ class OtherWidget extends StatelessWidget {
}
```
-[ScopedModel](https://pub.dev/packages/scoped_model) became a popular form of state management in Flutter, but is limited to exposing state objects that extend the [Model](https://pub.dev/documentation/scoped_model/latest/scoped_model/Model-class.html) class and its change notifier pattern.
+[ScopedModel](https://pub.dev/packages/scoped_model) 是 Flutter 中热门的状态管理结构体,但是它会限制暴露继承自 [Model](https://pub.dev/documentation/scoped_model/latest/scoped_model/Model-class.html) 类的状态以及它自身的变更通知模式。
## 4. BLoC
-At [Google I/O ’18](https://www.youtube.com/watch?v=RS36gBEp8OI), the [Business Logic Component](https://www.freecodecamp.org/news/how-to-handle-state-in-flutter-using-the-bloc-pattern-8ed2f1e49a13/) (BLoC) pattern was introduced as another pattern for moving state out of widgets. BLoC classes are long-lived, non-UI components that hold onto state and expose it in the form of [streams](http://dart stream listen) and [sinks](https://api.dartlang.org/stable/2.4.0/dart-core/Sink-class.html). By moving state and business logic out of the UI, it allows a widget to be implemented as a simple [StatelessWidget](https://api.flutter.dev/flutter/widgets/StatelessWidget-class.html) and use a [StreamBuilder](https://api.flutter.dev/flutter/widgets/StreamBuilder-class.html) to automatically rebuild. This makes the widget “dumber” and easier to test.
+在 [Google 2018 年发者大会上](https://www.youtube.com/watch?v=RS36gBEp8OI),提出了[业务逻辑组件](https://www.freecodecamp.org/news/how-to-handle-state-in-flutter-using-the-bloc-pattern-8ed2f1e49a13/),即 BLoC,作为另一种可以将状态迁移出组件的模式。BLoC 类是一种可持久的、没有 UI 的组件,它会维护自己的状态并将其以 [stream](https://api.dartlang.org/stable/2.6.0/dart-async/Stream/listen.html) 和 [sink](https://api.dartlang.org/stable/2.4.0/dart-core/Sink-class.html) 的形式暴露出来。通过将状态和业务逻辑从 UI 中分离出来,BLoC 模式让组件可以作为[无状态组件(StatelessWidget)](https://api.flutter.dev/flutter/widgets/StatelessWidget-class.html)应用,并可以使用 [StreamBuilder](https://api.flutter.dev/flutter/widgets/StreamBuilder-class.html) 自动重新构建。这让组件比较“傻瓜式”,更易于测试。
-An example of a BLoC class:
+一个 BLoC 类的例子:
-```
+```dart
class MyBloc {
final _controller = StreamController<MyType>();
@@ -121,28 +121,28 @@ class MyBloc {
}
```
-An example of a widget consuming a BLoC:
+一个组件应用 BLoC 模式的例子:
-```
+```dart
@override
Widget build(BuildContext context) {
return StreamBuilder<MyType>(
stream: myBloc.stream,
builder: (context, asyncSnapshot) {
- // YOUR CODE
+ // 其余代码
});
}
```
-The trouble with the BLoC pattern is that it is not obvious how to create and destroy BLoC objects. In the example above, how was the `myBloc` instance created? How do we call `dispose()` on it? [Streams](http://dart stream listen) require the use of a [StreamController](https://api.dartlang.org/stable/2.4.0/dart-async/StreamController-class.html), which must be `closed` when no longer needed in order to prevent memory leaks. (Dart has no notion of a class [destructor](https://en.wikipedia.org/wiki/Destructor_(computer_programming)); only the `StatefulWidget` [State](https://api.flutter.dev/flutter/widgets/State-class.html) class has a `dispose()` method.) Also, it is not clear how to share this BLoC across multiple widgets. So it is often difficult for developers to get started using BLoC. There are some [packages](https://pub.dev/flutter/packages?q=bloc) that attempt to make this easier.
+BLoC 模式的问题是,创建和销毁 BLoC 对象的方法没有那么显而易见。在上面的例子中,`myBloc` 实例是如何创建的?我们如何调用 `dispose()` 来销毁它呢?如果使用了 [stream](https://api.dartlang.org/stable/2.6.0/dart-async/Stream/listen.html),就需要使用 [StreamController 类](https://api.dartlang.org/stable/2.4.0/dart-async/StreamController-class.html),而为了防止内存泄漏,当我们不需要再使用 StreamController 的时候,就必须调用 `closed` 方法销毁它。(Dart 没有类的 [析构函数](https://en.wikipedia.org/wiki/Destructor_(computer_programming)) 的概念;只有 `StatefulWidget` 中的 [State](https://api.flutter.dev/flutter/widgets/State-class.html) 类有一个 `dispose()` 方法)同时,多组件之间共享 BLoC 的方法也不明朗。因此,对于开发者来说,刚开始使用 BLoC 时会觉得很困难。好消息是,有一些[包](https://pub.dev/flutter/packages?q=bloc)可以帮助你度过这一难关。
## 5. Provider
-[Provider](https://pub.dev/packages/provider) is a package written in 2018 by [Remi Rousselet](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=2ahUKEwjXrMKO8dLjAhWoT98KHUCDB_oQFjAAegQIARAB&url=https%3A%2F%2Ftwitter.com%2Fremi_rousselet&usg=AOvVaw3bEIgT0j4c_5xbq-YWB70q) that is similar to [ScopedModel](https://pub.dev/packages/scoped_model) but is not limited to exposing a [Model](https://pub.dev/documentation/scoped_model/latest/scoped_model/Model-class.html) subclass. It too is a wrapper around [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html), but can expose any kind of state object, including BLoC, [streams](http://dart stream listen), [futures](https://api.dartlang.org/stable/dart-async/Future-class.html), and others. Because of its simplicity and flexibility, Google announced at [Google I/O ](https://www.youtube.com/watch?v=d_m5csmrf7I)’19 that [Provider](https://pub.dev/packages/provider) is now its preferred package for state management. Of course, you can still use [others](https://flutter.dev/docs/development/data-and-backend/state-mgmt/options), but if you’re not sure what to use, Google recommends going with [Provider](https://pub.dev/packages/provider).
+[Provider](https://pub.dev/packages/provider) 是 [Remi Rousselet](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=2ahUKEwjXrMKO8dLjAhWoT98KHUCDB_oQFjAAegQIARAB&url=https%3A%2F%2Ftwitter.com%2Fremi_rousselet&usg=AOvVaw3bEIgT0j4c_5xbq-YWB70q) 于 2018 年写得一个代码包,它和 [ScopedModel](https://pub.dev/packages/scoped_model) 类似,但是不限制对 [Model](https://pub.dev/documentation/scoped_model/latest/scoped_model/Model-class.html) 子类的暴露。它同时也是 [可继承组件 InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) 的一个外包,但它允许向外暴露任何状态对象,这其中包括了 BLoC、[stream](https://api.dartlang.org/stable/2.6.0/dart-async/Stream/listen.html)、[futures](https://api.dartlang.org/stable/dart-async/Future-class.html) 等等。由于它简单灵活,Google 在第十九届 [Google 开发者大会](https://www.youtube.com/watch?v=d_m5csmrf7I)上宣布,[Provider](https://pub.dev/packages/provider) 是它的状态管理的首选。当然,你也可以选择使用[其他的管理工具](https://flutter.dev/docs/development/data-and-backend/state-mgmt/options),但是如果你还不确定要用哪个,Google 推荐 [Provider](https://pub.dev/packages/provider)。
-[Provider](https://pub.dev/packages/provider) is built “with widgets, for widgets.” With [Provider](https://pub.dev/packages/provider), we can place any state object into the widget tree and make it accessible from any other (descendant) widget. [Provider](https://pub.dev/packages/provider) also helps manage the lifetime of state objects by initializing them with data and cleaning up after them when they are removed from the widget tree. For this reason, [Provider](https://pub.dev/packages/provider) can even be used to implement BLoC components, or serve as the basis for [other](https://flutter.dev/docs/development/data-and-backend/state-mgmt/options) state management solutions! 😲 Or it can be used simply for [dependency injection](https://en.wikipedia.org/wiki/Dependency_injection) — a fancy term for passing data into widgets in a way that reduces coupling and increases testability. Finally, [Provider](https://pub.dev/packages/provider) comes with a set of specialized classes that make it even more user-friendly. We’ll explore each of these in detail.
+[Provider](https://pub.dev/packages/provider) “由组件构成,为了方便其他组件的应用”。使用 [Provider](https://pub.dev/packages/provider),我们可以将任何状态对象放入组件树中,并在其他任何子组件中访问到这些状态对象。[Provider](https://pub.dev/packages/provider) 可以使用数据初始化状态对象,或者当状态对象从组件树中移除的时候清理它们,以此帮助我们管理状态对象的生命周期。因此,[Provider](https://pub.dev/packages/provider) 甚至可以用来实现 BLoC 组件,或者作为[其他](https://flutter.dev/docs/development/data-and-backend/state-mgmt/options)状态管理方案的基础!😲又或者,它还可以用于[依赖注入](https://en.wikipedia.org/wiki/Dependency_injection) —— 一种将数据注入组件的神奇的形式,这种形式可以降低耦合度并增强可测试性。最后,[Provider](https://pub.dev/packages/provider) 也具有一系列专门的类,这让其变得更加易用。我们下面将会逐个详细讲解:
-* Basic [Provider](https://pub.dev/documentation/provider/latest/provider/Provider-class.html)
+* 基础 [Provider](https://pub.dev/documentation/provider/latest/provider/Provider-class.html)
* [ChangeNotifierProvider](https://pub.dev/documentation/provider/latest/provider/ChangeNotifierProvider-class.html)
* [StreamProvider](https://pub.dev/documentation/provider/latest/provider/StreamProvider-class.html)
* [FutureProvider](https://pub.dev/documentation/provider/latest/provider/FutureProvider-class.html)
@@ -150,36 +150,36 @@ The trouble with the BLoC pattern is that it is not obvious how to create and de
* [MultiProvider](https://pub.dev/documentation/provider/latest/provider/MultiProvider-class.html)
* [ProxyProvider](https://pub.dev/documentation/provider/latest/provider/ProxyProvider-class.html)
-#### Installing
+#### 安装
-First, to use [Provider](https://pub.dev/packages/provider), add the dependency to your pubspec.yaml:
+想要使用 [Provider](https://pub.dev/packages/provider),第一步要做的就是将相关依赖加入 pubspec.yaml 文件:
```
provider: ^3.0.0
```
-Then import the [Provider](https://pub.dev/packages/provider) package where needed:
+然后在需要使用它的地方引入 [Provider](https://pub.dev/packages/provider) 包:
-```
+```dart
import 'package:provider/provider.dart';
```
-#### Basic Provider
+#### 基础 Provider
-Let’s create a basic [Provider](https://pub.dev/packages/provider) at the root of our app containing an instance of our model:
+下面,我们一起来在应用的根节点创建一个基本的 [Provider](https://pub.dev/packages/provider),它将包含应用模型的实例:
-```
+```dart
Provider<MyModel>(
builder: (context) => MyModel(),
child: MyApp(...),
)
```
-> The `builder` parameter creates instance of `MyModel`. If you want to give it an existing instance, use the [Provider.value](https://pub.dev/documentation/provider/latest/provider/Provider/Provider.value.html) constructor instead.
+> 参数 `builder` 创建了 `MyModel` 的实例。如果你想要给它赋值为一个现有的实例,那么请使用 [Provider.value](https://pub.dev/documentation/provider/latest/provider/Provider/Provider.value.html) 构建函数。
-We can then **consume** this model instance anywhere in `MyApp`by using the [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) widget:
+然后你就可以使用 [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) 组件,在 `MyApp` 的任意位置对这个模型实例进行**自定义**。
-```
+```dart
class MyWidget extends StatelessWidget {
@override
Widget build(BuildContext context) {
@@ -190,11 +190,11 @@ class MyWidget extends StatelessWidget {
}
```
-In the example above, the `MyWidget` class obtains the `MyModel` instance using the [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) widget. This widget gives us a `builder` containing our object in the `value` parameter.
+在上面的例子中,`MyWidget` 类包含一个使用了 [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) 组件的 `MyModel` 的实例。这个组件提供了一个 `builder` 方法,该方法的 `value` 参数包含了实例对象。
-Now, what if we want to **update** the data in our model? Let’s say that we have another widget where pushing a button should update the `foo` property:
+那么如果我们想要**更新**模型的数据呢?我们假设有另一个包含按钮的组件,当按钮按下的时候,需要更新 `foo` 属性:
-```
+```dart
class OtherWidget extends StatelessWidget {
@override
Widget build(BuildContext context) {
@@ -209,15 +209,15 @@ class OtherWidget extends StatelessWidget {
}
```
-> Note the different syntax for accessing our `MyModel` instance. This is functionally equivalent to using the [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) widget. The [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) widget is useful if you can’t easily get a [BuildContext](https://api.flutter.dev/flutter/widgets/BuildContext-class.html) reference in your code.
+> 注意访问 `MyModel` 实例时的语法差异。它在功能上和使用 [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) 组件是一致的。而当你无法在代码中获取到 [BuildContext](https://api.flutter.dev/flutter/widgets/BuildContext-class.html) 的时候,[Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) 组件就会派上用场了。
-What do you expect will happen to the original `MyWidget` we created earlier? Do you think it will now display the new value of `bar`? **Unfortunately, no**. It is not possible to listen to changes on plain old Dart objects (at least not without [reflection](https://api.dartlang.org/stable/dart-mirrors/dart-mirrors-library.html), which is not available in Flutter). That means [Provider](https://pub.dev/packages/provider) is not able to “see” that we updated the `foo` property and tell `MyWidget` to update in response.
+你认为这样的操作会对我们之前创建的 `MyWidget` 造成什么影响呢?你是否认为,它将会展示新的 `bar` 值?**但不幸的是你猜错了,这并不会发生**。简单的已创建的旧 Dart 对象并不会监听变化(至少在没有 [reflection](https://api.dartlang.org/stable/dart-mirrors/dart-mirrors-library.html) 的时候不会,而 [reflection](https://api.dartlang.org/stable/dart-mirrors/dart-mirrors-library.html) 目前在 Flutter 中还不可用)。这就意味着,[Provider](https://pub.dev/packages/provider) 无法知道我们更新过了 `foo` 属性,也无法告知 `MyWidget` 响应改变从而作出更新。
#### ChangeNotifierProvider
-However, there is hope! We can make our `MyModel` class implement the [ChangeNotifier](https://api.flutter.dev/flutter/foundation/ChangeNotifier-class.html) mixin. We need to modify our model implementation slightly by invoking a special `notifyListeners()` method whenever one of our properties change. This is similar to how [ScopedModel](https://pub.dev/packages/scoped_model) works, but it’s nice that we don’t need to inherit from a particular model class. We can just implement the [ChangeNotifier](https://api.flutter.dev/flutter/foundation/ChangeNotifier-%E2%80%A6) mixin. Here’s what that looks like:
+但是,我们还是有其他解决问题的希望的!我们可以让 `MyModel` 类实现 [ChangeNotifier](https://api.flutter.dev/flutter/foundation/ChangeNotifier-class.html) mixin。我们只需要稍稍修改模型的实现,即在属性改变的时候调用一个特别的 `notifyListeners()` 方法即可。这和 [ScopedModel](https://pub.dev/packages/scoped_model) 的工作原理类似,但却不需要继承一个特殊的类。只需要实现 [ChangeNotifier](https://api.flutter.dev/flutter/foundation/ChangeNotifier-%E2%80%A6) mixin 即可。代码如下:
-```
+```dart
class MyModel with ChangeNotifier {
String _foo;
@@ -230,38 +230,38 @@ class MyModel with ChangeNotifier {
}
```
-As you can see, we changed our `foo` property into a `getter` and `setter `backed by a private `_foo` variable. This allows us to “intercept” any changes made to the `foo` property and tell our listeners that our object changed.
+正如你所见,我们将 `foo` 属性改成了 `getter` 和 `setter` 函数,它们都会去维护一个私有的 `_foo` 变量。这样做就让我们能“监听”到所有对 `foo` 的修改,并告知监听者:对象发生了变化。
-Now, on the [Provider](https://pub.dev/packages/provider) side, we can change our implementation to use a different class called [ChangeNotifierProvider](https://pub.dev/documentation/provider/latest/provider/ChangeNotifierProvider-class.html):
+现在,在 [Provider](https://pub.dev/packages/provider) 端,我们可以将代码实现改为,使用另一个名为 [ChangeNotifierProvider](https://pub.dev/documentation/provider/latest/provider/ChangeNotifierProvider-class.html) 的类:
-```
+```dart
ChangeNotifierProvider<MyModel>(
builder: (context) => MyModel(),
child: MyApp(...),
)
```
-That’s it! Now when our `OtherWidget` updates the `foo` property on our `MyModel` instance, `MyWidget` will automatically update to reflect that change. Cool huh?
+这样就好了!现在,当 `OtherWidget` 更新了 `MyModel` 实例的 `foo` 属性的时候,`MyWidget` 将会根据改变自动更新。超酷吧?
-One more thing. You may have noticed in the `OtherWidget` button handler that we used the following syntax:
+还有一件事要说。你也许已经注意到了,在 `OtherWidget` 按钮的事件处理函数中,我们使用了下面的语法:
-```
+```dart
final model = Provider.of<MyModel>(context);
```
-**By default, this syntax will automatically cause our `OtherWidget` instance to rebuild whenever `MyModel` changes.** That might not be what we want. After all, `OtherWidget` just contains a button that doesn’t change based on the value of `MyModel` at all. To avoid this, we can use the following syntax to access our model **without** registering for a rebuild:
+**默认情况下,这样写会让 `OtherWidget` 实例在 `MyModel` 变化的时候自动更新**。这也许并不是我们所期望的。毕竟 `OtherWidget` 只包含了一个按钮,并不需要跟随 `MyModel` 的数据变化而变化。为了避免这样的事情发生,我们可以使用如下的语法让模型不再注册重新构建的监听:
-```
+```dart
final model = Provider.of<MyModel>(context, listen: false);
```
-This is another nicety that the [Provider](https://pub.dev/packages/provider) package gives us for free.
+这是 [Provider](https://pub.dev/packages/provider) 包给予我们的另一份免费的便利。
#### StreamProvider
-At first glance, the [StreamProvider](https://pub.dev/documentation/provider/latest/provider/StreamProvider-class.html) seems unnecessary. After all, we can just use a regular [StreamBuilder](https://api.flutter.dev/flutter/widgets/StreamBuilder-class.html) to consume a stream in Flutter. For example, here we listen to the [onAuthStateChanged](https://pub.dev/documentation/firebase_auth/latest/firebase_auth/FirebaseAuth/onAuthStateChanged.html) stream provided by [FirebaseAuth](https://pub.dev/documentation/firebase_auth/latest/firebase_auth/firebase_auth-library.html):
+[StreamProvider](https://pub.dev/documentation/provider/latest/provider/StreamProvider-class.html) 给人的第一印象是:好像并不那么有必要。毕竟在 Flutter 中,我们可以使用常规的 [StreamBuilder](https://api.flutter.dev/flutter/widgets/StreamBuilder-class.html) 来订阅流信息。例如下面这段代码中,我们监听了 [FirebaseAuth](https://pub.dev/documentation/firebase_auth/latest/firebase_auth/firebase_auth-library.html) 提供的 [onAuthStateChanged](https://pub.dev/documentation/firebase_auth/latest/firebase_auth/FirebaseAuth/onAuthStateChanged.html) 流:
-```
+```dart
@override
Widget build(BuildContext context {
return StreamBuilder(
@@ -272,18 +272,18 @@ Widget build(BuildContext context {
}
```
-To do this with [Provider](https://pub.dev/packages/provider) instead, we can expose this stream via a [StreamProvider](https://pub.dev/documentation/provider/latest/provider/StreamProvider-class.html) at the root of our app:
+而如果想使用 [Provider](https://pub.dev/packages/provider) 来完成,我们可以在 App 的根结点,通过 [StreamProvider](https://pub.dev/documentation/provider/latest/provider/StreamProvider-class.html) 暴露出这个流:
-```
+```dart
StreamProvider<FirebaseUser>.value(
stream: FirebaseAuth.instance.onAuthStateChanged,
child: MyApp(...),
}
```
-Then consume it in a child widget like any other [Provider](https://pub.dev/packages/provider):
+然后在子组件中就可以像其他 [Provider](https://pub.dev/packages/provider) 那样使用了:
-```
+```dart
@override
Widget build(BuildContext context) {
return Consumer<FirebaseUser>(
@@ -292,36 +292,36 @@ Widget build(BuildContext context) {
}
```
-Besides making the consuming widget code much cleaner, **it also abstracts away the fact that the data is coming from a stream**. If we ever decide to change the underlying implementation to a [FutureProvider](https://pub.dev/documentation/provider/latest/provider/FutureProvider-class.html), for instance, it will require no changes to our widget code. **In fact, you’ll see that this is the case for all of the different providers below**. 😲
+除了能让组件代码更加清晰,**它也可以抽象并过滤掉数据是否是来自于流的这一信息**。例如,如果我们想要修改 [FutureProvider](https://pub.dev/documentation/provider/latest/provider/FutureProvider-class.html) 的基础实现,此时就无须修改组件的代码。**事实上,你很快就会发现,以下所有不同的 provider 都是这样**。😲
#### FutureProvider
-Similar to the example above, [FutureProvider](https://pub.dev/documentation/provider/latest/provider/FutureProvider-class.html) is an alternative to using the standard [FutureBuilder](https://api.flutter.dev/flutter/widgets/FutureBuilder-class.html) inside our widgets. Here is an example:
+和上面的例子类似,[FutureProvider](https://pub.dev/documentation/provider/latest/provider/FutureProvider-class.html) 是在组件中使用 [FutureBuilder](https://api.flutter.dev/flutter/widgets/FutureBuilder-class.html) 的替换方案。这里是一段代码示例:
-```
+```dart
FutureProvider<FirebaseUser>.value(
value: FirebaseAuth.instance.currentUser(),
child: MyApp(...),
);
```
-To consume this value in a child widget, we use the same [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) implementation used in the [StreamProvider](https://pub.dev/documentation/provider/latest/provider/StreamProvider-class.html) example above.
+我们使用和上文中 [StreamProvider](https://pub.dev/documentation/provider/latest/provider/StreamProvider-class.html) 相关的例子中一样的对 [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) 的应用,来在子元素中获取到这个值。
#### ValueListenableProvider
-[ValueListenable](https://api.flutter.dev/flutter/foundation/ValueListenable-class.html) is a Dart interface implemented by the [ValueNotifier](https://api.flutter.dev/flutter/foundation/ValueNotifier-class.html) class that takes a value and notifies listeners when it changes to another value. We can use it to wrap an integer counter in a simple model class:
+[ValueListenable](https://api.flutter.dev/flutter/foundation/ValueListenable-class.html) 是 [ValueNotifier](https://api.flutter.dev/flutter/foundation/ValueNotifier-class.html) 类实现的 Dart 接口,它可以在自身接收的参数发生变化的时候通知监听者。我们可以在一个简单的模型类中,用它来包裹一个计时器:
-```
+```dart
class MyModel {
final ValueNotifier<int> counter = ValueNotifier(0);
}
```
-> When using complex types, [ValueNotifier](https://api.flutter.dev/flutter/foundation/ValueNotifier-class.html) uses the `**==**` operator of the contained object to determine whether the value has changed.
+> 如果我们使用的是复杂类型的参数,[ValueNotifier](https://api.flutter.dev/flutter/foundation/ValueNotifier-class.html) 将会使用 **`==`** 操作符来确认是否参数值变化了。
-Let’s create a basic [Provider](https://pub.dev/packages/provider) to hold our main model, followed by a [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) and a nested [ValueListenableProvider](https://pub.dev/documentation/provider/latest/provider/ValueListenableProvider-class.html) that listens to the `counter` property:
+让我们来创建一个基础 [Provider](https://pub.dev/packages/provider) 用来容纳主模块,它同时还有一个 [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html),以及一个用于监听 `counter` 属性的嵌套的 [ValueListenableProvider](https://pub.dev/documentation/provider/latest/provider/ValueListenableProvider-class.html):
-```
+```dart
Provider<MyModel>(
builder: (context) => MyModel(),
child: Consumer<MyModel>(builder: (context, value, child) {
@@ -333,11 +333,11 @@ Provider<MyModel>(
}
```
-> Note that the type of the nested provider is `int`. You might have others. If you have multiple Providers registered for the same type, [Provider](https://pub.dev/packages/provider) will return the “closest” one (nearest ancestor).
+> 注意:嵌套的 provider 的类型是 `int`。当然你的代码也会有其他可能的类型。如果有多个 Provider 都注册为同一类型,那么 [Provider](https://pub.dev/packages/provider) 将会返回最“近”的一个(距离最近的父级组件)。
-Here’s how we can listen to the `counter` property from any descendant widget:
+如下代码可以监听任意子组件的 `counter` 属性:
-```
+```dart
class MyWidget extends StatelessWidget {
@override
Widget build(BuildContext context) {
@@ -350,9 +350,9 @@ class MyWidget extends StatelessWidget {
}
```
-And here is how we can **update** the `counter` property from yet another widget. Note that we need to access the original `MyModel` instance.
+如下代码可以**更新**其他组件的 `counter` 属性。注意:我们首先需要获取原始的 `MyModel` 实例。
-```
+```dart
class OtherWidget extends StatelessWidget {
@override
Widget build(BuildContext context) {
@@ -369,9 +369,9 @@ class OtherWidget extends StatelessWidget {
#### MultiProvider
-If we are using many [Provider](https://pub.dev/packages/provider) widgets, we may end up with an ugly nested structure at the root of our app:
+如果我们应用了多个 [Provider](https://pub.dev/packages/provider) 组件,我们可能会在 app 根结点写出这样很丑陋的多层嵌套的结构:
-```
+```dart
Provider<Foo>.value(
value: foo,
child: Provider<Bar>.value(
@@ -384,9 +384,9 @@ Provider<Foo>.value(
)
```
-[MultiProvider](https://pub.dev/documentation/provider/latest/provider/MultiProvider-class.html) lets us declare them all our providers at the same level. This is just [syntactic sugar](https://en.wikipedia.org/wiki/Syntactic_sugar); they are still being nested behind the scenes.
+[MultiProvider](https://pub.dev/documentation/provider/latest/provider/MultiProvider-class.html) 则允许我们在同一层级声明所有的 provider。但这仅仅是一种[语法糖](https://en.wikipedia.org/wiki/Syntactic_sugar);它们实际上还是嵌套的。
-```
+```dart
MultiProvider(
providers: [
Provider<Foo>.value(value: foo),
@@ -399,9 +399,9 @@ MultiProvider(
#### ProxyProvider
-[ProxyProvider](https://pub.dev/documentation/provider/latest/provider/ProxyProvider-class.html) is an interesting class that was added in the v3 release of the [Provider](https://pub.dev/packages/provider) package. This lets us declare Providers that themselves are dependent on up to 6 other Providers. In this example, the `Bar` class depends on an instance of `Foo.` This is useful when establishing a root set of services that themselves have dependencies on one another.
+[ProxyProvider](https://pub.dev/documentation/provider/latest/provider/ProxyProvider-class.html) 是个很有趣的类,它发布于 [Provider](https://pub.dev/packages/provider) 包的 v3 版本。这让我们可以声明依赖于其他 6 种 Provider 的 Provider。在下面这个例子中,`Bar` 类依赖于 `Foo` 的实例。当我们需要建立有赖于其他服务的根服务集时,这就很有用了。
-```
+```dart
MultiProvider (
providers: [
Provider<Foo> (
@@ -415,24 +415,24 @@ MultiProvider (
)
```
-> The first generic type argument is the type your [ProxyProvider](https://pub.dev/documentation/provider/latest/provider/ProxyProvider-class.html) depends on, and the second is the type it returns.
+> 第一个范型参数是 [ProxyProvider](https://pub.dev/documentation/provider/latest/provider/ProxyProvider-class.html) 的类型,第二个是它需要返回的类型。
-#### Listening to Multiple Providers Simultaneously
+#### 同时监听多个 Provider
-What if we want a single widget to list to multiple Providers, and trigger a rebuild whenever any of them change? We can listen to up to 6 Providers at a time using variants of the [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) widget. We will receive the instances as additional parameters in the `builder` method.
+如果我们想要一个组件同时监听多个 Provider,并且当任意一个被监听的 Provider 发生变化时都要重构组件,那我们该怎么做呢?使用 [Consumer](https://pub.dev/documentation/provider/latest/provider/Consumer-class.html) 组件的变量,我们最多可以监听 6 个 Provider。我们将会在 `builder` 方法的附加参数中获取它们的实例。
-```
+```dart
Consumer2<MyModel, int>(
builder: (context, value, value2, child) {
- //value is MyModel
- //value2 is int
+ //value 是 MyModel 类型
+ //value2 是 int 类型
},
);
```
-#### Conclusion
+#### 总结
-By embracing [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html), [Provider](https://pub.dev/packages/provider) gives us a “Fluttery” way of state management. It lets widgets access and listen to state objects in a way that abstracts away the underlying notification mechanism. It helps us manage the lifetimes of state objects by providing hooks to create and dispose them as needed. It can be used for simple dependency injection, or even as the basis for more extensive state management options. Having received Google’s blessing, and with growing support from the Flutter community, it is a safe choice to go with. Give [Provider](https://pub.dev/packages/provider) a try today!
+通过学习 [InheritedWidget](https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html) 和 [Provider](https://pub.dev/packages/provider),我们学会了如何使用 “Flutter 式” 的方法管理状态。组件可以获取并监听状态对象,并同时将内部的通知机制抽象并隔离掉。这种方法通过提供勾子来创建并按需分发状态对象,帮助我们管理了它的生命周期。它可以应用于依赖注入,或者甚至可以作为更复杂的状态管理选择的基础。它已经获取了 Google 的赞许,同时 Flutter 社区也在给予更多的支持,因此选择它肯定是一个风险很小的决策。何不今天就一起来试试看 [Provider](https://pub.dev/packages/provider) 呢!
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/a-new-go-api-for-protocol-buffers.md b/TODO1/a-new-go-api-for-protocol-buffers.md
new file mode 100644
index 00000000000..88c3144333b
--- /dev/null
+++ b/TODO1/a-new-go-api-for-protocol-buffers.md
@@ -0,0 +1,211 @@
+> * 原文地址:[A new Go API for Protocol Buffers](https://blog.golang.org/a-new-go-api-for-protocol-buffers)
+> * 原文作者:Joe Tsai, Damien Neil, and Herbie Ong
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/a-new-go-api-for-protocol-buffers.md](https://github.com/xitu/gold-miner/blob/master/TODO1/a-new-go-api-for-protocol-buffers.md)
+> * 译者:[司徒公子](https://github.com/todaycoder001)
+> * 校对者:[quzhen](https://github.com/quzhen12)、[Chauncey Chen](https://github.com/colorsakura)
+
+# Go 发布新版 Protobuf API
+
+## 介绍
+
+我们很高兴地宣布:发布[protocol buffers](https://developers.google.com/protocol-buffers)的 Go API 主要修订版本 —— Google 独立于编程语言的数据交换接口格式。
+
+## 构建新 API 的动机
+
+第一个用于 Go 的 protocol buffer 版本由 Rob Pike 在 2010 年 3 月发布,Go 的首个正式版在两年后才发布。
+
+在第一个版本发布的数十年间,随着 Go 的发展,package 也在不断发展壮大。用户的需求也在不断的增长。
+
+许多人希望使用 reflection(反射) package 来编写检查 protocol buffer message 的程序,[`reflect`](https://pkg.go.dev/reflect) package 提供了 Go 类型和值的视图,但是忽略了 protocol buffer 类型系统的信息。例如,我们可能希望编写一个函数来遍历日志项,清除所有标注为敏感信息的数据,标注并不是 Go 类型系统的一部分。
+
+另一个常见的需求就是使用 protocol buffer 编译器来生成其他的数据结构,例如动态 message 类型,它能够表示在编译时类型未知的 message。
+
+我们还观察到,时常发生问题的根源在于 [`proto.Message`](https://pkg.go.dev/github.com/golang/protobuf/proto?tab=doc#Message) 接口,该接口标识生成的 message 类型的值,对描述这些类型的行为几乎没有任何帮助。当用户创建实现该接口的类型(时常不经意间将 message 嵌入其他的结构中),并且将这些类型的值传递给期待生成 message 值的函数时,程序发生崩溃或行为难以预料。
+
+这三个问题都有一个共同的原因,而通常的解决方法:`Message` 接口应该完全指定 message 的行为,对 `Message` 值进行操作的函数应该自由的接收任何类型,这些类型的接口都要被正确的实现。
+
+由于不可能在保持 package API 兼容性的同时更改 `Message` 类型的现有定义,所以我们决定是时候开始开发新的、不兼容 protobuf 模块的主要版本了。
+
+今天,我们很高兴地发布这个新模块,希望你们喜欢。
+
+## Reflection(反射)
+
+Reflection(反射)是新实现的旗舰特性。与 `reflect` 包提供 Go 类型和值的视图相似,[`protoreflect`](https://pkg.go.dev/google.golang.org/protobuf/reflect/protoreflect?tab=doc) 包根据 protocol buffer 类型系统提供值的视图。
+
+完整的描述 `protoreflect` package 对于这篇文章来说太长了,但是,我们可以来看看如何编写前面提到的日志清理函数。
+
+首先,我们将编写 `.proto` 文件来定义 [`google.protobuf.FieldOptions`](https://github.com/protocolbuffers/protobuf/blob/b96241b1b716781f5bc4dc25e1ebb0003dfaba6a/src/google/protobuf/descriptor.proto#L509) 类型的扩展名,以便我们可以将注释字段作为标识敏感信息的与否。
+
+```go
+syntax = "proto3";
+import "google/protobuf/descriptor.proto";
+package golang.example.policy;
+extend google.protobuf.FieldOptions {
+ bool non_sensitive = 50000;
+}
+```
+
+我们可以使用此选项来将某些字段标识为非敏感字段。
+
+```go
+message MyMessage {
+ string public_name = 1 [(golang.example.policy.non_sensitive) = true];
+}
+```
+
+接下来,我们将编写一个 Go 函数,它用于接收任意 message 值以及删除所有敏感字段。
+
+```go
+// 清除 pb 中所有的敏感字段
+func Redact(pb proto.Message) {
+ // ...
+}
+```
+
+函数接收 [`proto.Message`](https://pkg.go.dev/google.golang.org/protobuf/proto?tab=doc#Message) 参数,这是由所有已生成的 message 类型实现的接口类型。此类型是 `protoreflect` 包中已定义的别名:
+
+```go
+type ProtoMessage interface{
+ ProtoReflect() Message
+}
+```
+
+为了避免填充生成 message 的命名空间,接口仅包含一个返回 [`protoreflect.Message`](https://pkg.go.dev/google.golang.org/protobuf/reflect/protoreflect?tab=doc#Message) 的方法,此方法提供对 message 内容的访问。
+
+(为什么是别名?由于 `protoreflect.Message` 有返回原始 `proto.Message` 的相应方法,我们需要避免在两个包中循环导入。)
+
+[`protoreflect.Message.Range`](https://pkg.go.dev/google.golang.org/protobuf/reflect/protoreflect?tab=doc#Message.Range) 方法为 message 中的每一个填充字段调用一个函数。
+
+```go
+m := pb.ProtoReflect()
+m.Range(func(fd protoreflect.FieldDescriptor, v protoreflect.Value) bool {
+ // ...
+ return true
+})
+```
+
+使用描述 protocol buffer 类型的 [`protoreflect.FieldDescriptor`](https://pkg.go.dev/google.golang.org/protobuf/reflect/protoreflect?tab=doc#FieldDescriptor) 字段和包含字段值的 [`protoreflect.Value`](https://pkg.go.dev/google.golang.org/protobuf/reflect/protoreflect?tab=doc#Value) 字段来调用 range 函数。
+
+[`protoreflect.FieldDescriptor.Options`](https://pkg.go.dev/google.golang.org/protobuf/reflect/protoreflect?tab=doc#Descriptor.Options) 方法以 `google.protobuf.FieldOptions` message 的形式返回字段选项。
+
+```go
+opts := fd.Options().(*descriptorpb.FieldOptions)
+```
+
+(为什么使用类型断言?由于生成的 `descriptorpb` package 依赖于 `protoreflect`,所以 `protoreflect` package 无法返回正确的选项类型,否则会导致循环导入的问题)
+
+然后,我们可以检查选项以查看扩展为 boolean 类型的值:
+
+```go
+if proto.GetExtension(opts, policypb.E_NonSensitive).(bool) {
+ return true // 不要删减非敏感字段
+}
+```
+
+请注意,我们在这里看到的是字段**描述符**,而不是字段**值**,我们感兴趣的信息在于 protocol buffer 类型系统,而不是 Go 语言。
+
+这也是我们已经简化了 `proto` package API 的一个示例,原来的 [`proto.GetExtension`](https://pkg.go.dev/github.com/golang/protobuf/proto?tab=doc#GetExtension) 返回一个值和错误信息,新的 [`proto.GetExtension`](https://pkg.go.dev/google.golang.org/protobuf/proto?tab=doc#GetExtension) 只返回一个值,如果字段不存在,则返回该字段的默认值。在 `Unmarshal` 的时候报告扩展解码错误。
+
+一旦我们确定了需要修改的字段,将其清除就很简单了:
+
+```go
+m.Clear(fd)
+```
+
+综上所述,我们完整的修改函数如下:
+
+```go
+// 清除 pb 中的所有敏感字段
+func Redact(pb proto.Message) {
+ m := pb.ProtoReflect()
+ m.Range(func(fd protoreflect.FieldDescriptor, v protoreflect.Value) bool {
+ opts := fd.Options().(*descriptorpb.FieldOptions)
+ if proto.GetExtension(opts, policypb.E_NonSensitive).(bool) {
+ return true
+ }
+ m.Clear(fd)
+ return true
+ })
+}
+```
+
+
+一个更加完整的实现应该是以递归的方式深入这些 message 值字段。我们希望这些简单的示例能让你更了解 protocol buffer reflection(反射)以及它的用法。
+
+## 版本
+
+我们将 Go protocol buffer 的原始版本称为 APIv1,新版本称为 APIv2。因为 APIv2 不支持向前兼容 APIv1,所以我们需要为每个模块使用不同的路径。
+
+(这些 API 版本与 protocol buffer 语言的版本:`proto1`、`proto2`、`proto3` 是不同的,APIv1 和 APIv2 是 Go 中的具体实现,他们都支持 `proto2` 和 `proto3` 语言版本。)
+
+ [`github.com/golang/protobuf`](https://pkg.go.dev/github.com/golang/protobuf?tab=overview) 模块是 APIv1。
+
+[`google.golang.org/protobuf`](https://pkg.go.dev/google.golang.org/protobuf?tab=overview) 模块是 APIv2。我们利用需要改变导入路径来切换版本,将其绑定到不同的主机提供商上。(我们考虑了 `google.golang.org/protobuf/v2`,说得更清楚一点,这是 API 的第二个主要版本,但是从长远来看,我们认为更短的路径名是更好的选择。)
+
+我们知道不是所有的用户都以相同的速度迁移到新的 package 版本中,有些会迅速迁移,其他的可能会无限期的停留在老版本上。甚至在一个程序中,也有可能使用不同的 API 版本,这是至关重要的。所以,我们继续支持使用 APIv1 的程序。
+
+* `github.com/golang/protobuf@v1.3.4` 是 APIv1 最新 pre-APIv2 版本。
+* `github.com/golang/protobuf@v1.4.0` 是由 APIv2 实现的 APIv1 的一个版本。API 是相同的,但是底层实现得到了新 API 的支持。该版本包含 APIv1 和 APIv2 之间的转换函数,`proto.Message` 接口来简化两者之间的转换。
+* `google.golang.org/protobuf@v1.20.0` 是 APIv2,该模块取决于 `github.com/golang/protobuf@v1.4.0`,所以任何使用 APIv2 的程序都将会自动选择一个与之对应的集成 APIv1 的版本。
+
+(为什么要从 `v1.20.0` 版本开始?为了清晰的提供服务,我们预计 APIv1 不会达到 `v1.20.0`。因此,版本号就足以区分 APIv1 和 APIv2。)
+
+我们打算长期地保持对 APIv1 的支持。
+
+无论使用哪个 API 版本,该组织都会确保任何给定的程序都仅使用单个 protocol buffer 来实现。它允许程序逐步采用新的 API 或者完全不采用,同时仍然获得新实现的优势。最低版本选择原则意味着程序需要保留原来的实现方法,直到维护者选择更新到新的版本(直接升级或通过更新依赖项)。
+
+## 注意其他的一些特性
+
+[`google.golang.org/protobuf/encoding/protojson`](https://pkg.go.dev/google.golang.org/protobuf/encoding/protojson) package 使用[规范 JSON 映射](https://developers.google.com/protocol-buffers/docs/proto3#json)将 protocol buffer message 转化为 JSON,并修复了旧 `jsonpb` package 的一些问题,这些问题很难在不影响现有用户的情况下进行更改。
+
+ [`google.golang.org/protobuf/types/dynamicpb`](https://pkg.go.dev/google.golang.org/protobuf/types/dynamicpb) package 提供了对 message 中 `proto.Message` 的实现,用于在运行时派生 protocol buffer 类型的 message。
+
+[`google.golang.org/protobuf/testing/protocmp`](https://pkg.go.dev/google.golang.org/protobuf/testing/protocmp) package 提供了使用 [`github.com/google/cmp`](https://pkg.go.dev/github.com/google/go-cmp/cmp) package 来比较 protocol buffer message 的函数。
+
+[`google.golang.org/protobuf/compiler/protogen`](https://pkg.go.dev/google.golang.org/protobuf/compiler/protogen?tab=doc) package 提供了对编写 protocol 编译器插件的支持。
+
+## 结论
+
+`google.golang.org/protobuf` 模块是对 Go protocol buffer 支持的重大改进,为反射(reflection)、自定义 message 实现以及整洁的 API surface 提供优先的支持。我们打算用新的 API 包装的方式来永久维护原来的 API,从而使得用户可以按照自己的节奏逐步采用新的 API。
+
+我们这次更新的目标是在解决旧 API 问题的同时,放大旧 API 的优势。当我们完成每一个新实现的组件时,我们将在 Google 的代码库中投入使用,这种逐步推出的方式使我们对新 API 的可用性、性能以及正确性都充满了信心。我相信已经准备好可以在生产环境使用了。
+
+我们很激动地看到这个版本的发布,并且希望它能在未来十年甚至更长的时间内为 Go 生态系统持续服务。
+
+## 相关文章
+
+* [Working with Errors in Go 1.13](/go1.13-errors)
+* [Debugging what you deploy in Go 1.12](/debugging-what-you-deploy)
+* [HTTP/2 Server Push](/h2push)
+* [Introducing HTTP Tracing](/http-tracing)
+* [Generating code](/generate)
+* [Introducing the Go Race Detector](/race-detector)
+* [Go maps in action](/go-maps-in-action)
+* [go fmt your code](/go-fmt-your-code)
+* [Organizing Go code](/organizing-go-code)
+* [Debugging Go programs with the GNU Debugger](/debugging-go-programs-with-gnu-debugger)
+* [The Go image/draw package](/go-imagedraw-package)
+* [The Go image package](/go-image-package)
+* [The Laws of Reflection](/laws-of-reflection)
+* [Error handling and Go](/error-handling-and-go)
+* ["First Class Functions in Go"](/first-class-functions-in-go-and-new-go)
+* [Profiling Go Programs](/profiling-go-programs)
+* [A GIF decoder: an exercise in Go interfaces](/gif-decoder-exercise-in-go-interfaces)
+* [Introducing Gofix](/introducing-gofix)
+* [Godoc: documenting Go code](/godoc-documenting-go-code)
+* [Gobs of data](/gobs-of-data)
+* [C? Go? Cgo!](/c-go-cgo)
+* [JSON and Go](/json-and-go)
+* [Go Slices: usage and internals](/go-slices-usage-and-internals)
+* [Go Concurrency Patterns: Timing out, moving on](/go-concurrency-patterns-timing-out-and)
+* [Defer, Panic, and Recover](/defer-panic-and-recover)
+* [Share Memory By Communicating](/share-memory-by-communicating)
+* [JSON-RPC: a tale of interfaces](/json-rpc-tale-of-interfaces)
+* [Third-party libraries: goprotobuf and beyond](/third-party-libraries-goprotobuf-and)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
\ No newline at end of file
diff --git a/TODO1/a-realworld-comparison-of-front-end-frameworks-2020.md b/TODO1/a-realworld-comparison-of-front-end-frameworks-2020.md
new file mode 100644
index 00000000000..d6f97821abf
--- /dev/null
+++ b/TODO1/a-realworld-comparison-of-front-end-frameworks-2020.md
@@ -0,0 +1,150 @@
+> - 原文地址:[A RealWorld Comparison of Front-End Frameworks 2020](https://medium.com/dailyjs/a-realworld-comparison-of-front-end-frameworks-2020-4e50655fe4c1)
+> - 原文作者:[Jacek Schae](https://medium.com/@jacekschae)
+> - 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> - 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/a-realworld-comparison-of-front-end-frameworks-2020.md](https://github.com/xitu/gold-miner/blob/master/TODO1/a-realworld-comparison-of-front-end-frameworks-2020.md)
+> - 译者:[snowyYU](https://github.com/snowyYU)
+> - 校对者:[Baddyo](https://github.com/Baddyo)、[IAMSHENSH](https://github.com/IAMSHENSH)
+
+# 2020 年用各大前端框架构建的 RealWorld 应用对比
+
+
+
+来了来了,本篇写于 2020 年,往年的版本请看这里:[2019](https://medium.com/free-code-camp/a-realworld-comparison-of-front-end-frameworks-with-benchmarks-2019-update-4be0d3c78075)、[2018](https://medium.com/free-code-camp/a-real-world-comparison-of-front-end-frameworks-with-benchmarks-2018-update-e5760fb4a962) 和 [2017](https://medium.com/free-code-camp/a-real-world-comparison-of-front-end-frameworks-with-benchmarks-e1cb62fd526c)。
+
+**首先,请务必明白 —— 本篇不是告诉你应该选择哪种作为你未来的前端框架,在此只简短浅显的对比三个方面:各 RealWorld 应用的性能,大小、代码行数。**
+
+请记住哦,好了,让我们开始吧:
+
+**我们对比 RealWorld 应用** —— 相较“to do”类型的应用,它的功能更加强大。通常来说,“to-dos”并不能说明各框架在实际应用中的表现情况。
+
+**项目有一定的规范** —— 一个符合特定规则的项目 —— [相关规范在此](https://github.com/gothinkster/realworld/tree/master/spec)。提供了后端 API,静态 html 模版和样式。
+
+**项目的构建和检查都是由相关技术的大牛完成的** —— 一般来说,相关框架的技术大牛会构建并检查自己 real-world 项目,确保其和别的项目的一致性。
+
+## 我们正在比较哪些库 / 框架?
+
+截至撰写本文时,[RealWorld 仓库](https://github.com/gothinkster/realworld) 中已有 24 个相关实现。也许有受众更多的框架没有出现在这里。但进行对比的前提只有一个 —— 它必须出现在 [RealWorld 仓库](https://github.com/gothinkster/realworld) 页面里。
+
+
+
+## 我们关注什么指标?
+
+**性能** —— 此应用需要多长时间才能显示内容并变得可用。
+
+**大小** —— 应用有多大的体积?我们只会比较编译后的 JavaScript 文件大小。HTML 和 CSS 对所有的 RealWorld 应用都是通用的,并且都可从 CDN 下载。此外,所有技术均可编译或转换为 JavaScript,综上,我们只比较编译后的 JavaScript 文件大小。
+
+**代码行数** —— 开发者需要多少行代码才能根据规范创建 RealWorld 应用?公平来说,有些应用有更多的功能,但这应该没啥大的影响。我们只看 `src/` 文件夹中各文件的代码行数。即使它是自动生成的也可以 —— 你仍需要持续维护它。
+
+---
+
+## 指标 #1:性能
+
+我们使用 Chrome 的拓展插件 [Lighthouse Audit](https://developers.google.com/web/tools/lighthouse/) 来给各个项目的性能评分。Lighthouse 会给出一个范围在 0 到 100 的分数。0 是最低分。想了解更多,请戳 [Lighthouse 评分指南](https://developers.google.com/web/tools/lighthouse/v3/scoring)。
+
+#### 插件相关的配置
+
+
+
+#### 基本原则
+
+渲染的越快,用户就能越早地使用该应用,同样,用户的体验就越好。
+
+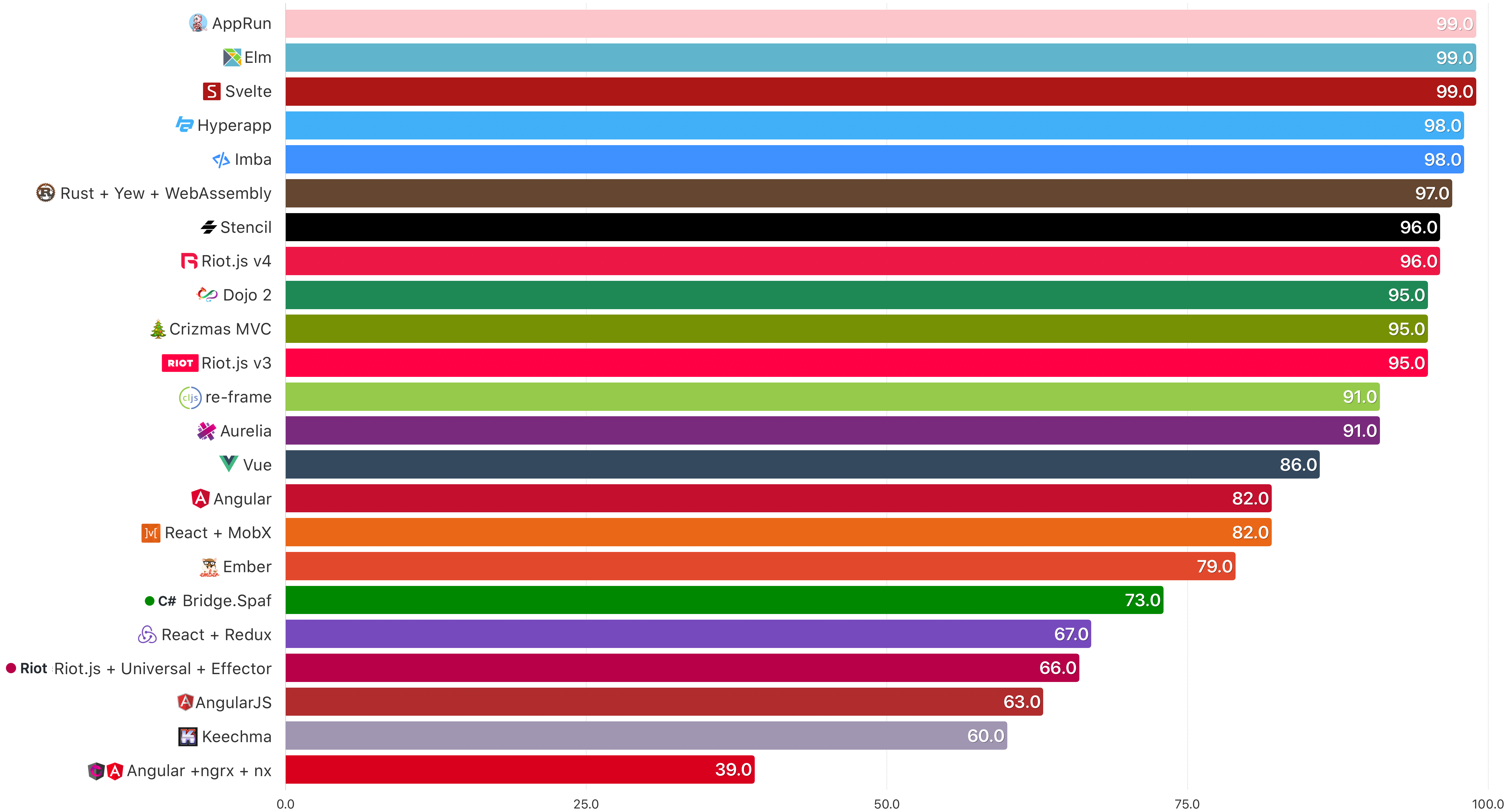
+
+#### 备注
+
+**注意:由于缺少 demo 应用,这里忽略 PureScript。**
+
+#### 总结
+
+Lighthouse Audit 可没闲着。您可以看到未维护/未更新的应用程序跌破了 90 分。得分超过 90 分的应用在性能上差别不大。不得不说,AppRun、Elm 和 Svelte 表现的非常出色。
+
+---
+
+## 指标 #2:大小
+
+需要加载的资源的大小可以从 Chrome 中开发者工具的 Network 标签中得出。服务器提供的 GZIP 响应头和响应主体。
+
+这取决于框架的大小以及所添加的其他依赖包。同样,构建合适的打包工具可以忽略未使用的依赖。
+
+#### 基本原则
+
+文件越小,下载速度越快,并且需要解析的内容越少。
+
+
+
+#### 备注
+
+**注意:由于缺少 demo 应用,这里再次忽略 PureScript。**
+
+**Angular + ngrx + nx 方案的支持者可别打我哟 —— 看一下 Chrome 开发者工具中的 Network 标签里的加载情况,如果我算错了 — 还请告知。**
+
+**Rust + Yew + WebAssembly 方案的大小计算,包括了以 .wasm 结尾的文件。**
+
+#### 总结
+
+Svelte 和 Stencil 社区完成的 RealWorld 应用太棒了,把需要加载的文件控制在了 20KB 以内,可以说是前无古人了。
+
+---
+
+## 指标 #3:代码行数
+
+我们使用 [cloc](https://github.com/AlDanial/cloc) 计算每个库的 src 文件夹中的代码行数。**不包含**空白行和注释。考量这个指标的意义何在呢?
+
+> **如果说调试是消灭 bug 的过程, 那么编码则是产生它的过程 —— Edsger Dijkstra**
+
+#### 基本原则
+
+下面这张图展示了各个库/框架/语言实现的 RealWorld 应用的简洁程度。根据规范,他们各自写了多少行实现了几乎相同的应用程序(其中一些应用具有更多的功能)。
+
+
+
+#### 备注
+
+**由于 [cloc](https://github.com/AlDanial/cloc) 无法统计以 `.svelte` 为后缀的文件,因此 Svelte 在此不做对比。**
+
+**由于 [cloc](https://github.com/AlDanial/cloc) 无法统计以 `.riot` 为后缀文件,因此 riotjs-effector-universal-hot 在此也不做对比。**
+
+**Angular + ngrx: 以`/libs`文件夹为基础完成的代码行数统计仅包括以 `.ts` 和 `.html` 为后缀文件。如果你觉得不应该这样统计, 还望告知正确的代码行数以及你是如何统计它的。**
+
+#### 总结
+
+只有 Imba 和 [ClojureScript + re-frame](https://www.learnreframe.com/) 能在 1000 行代码以内实现 RealWorld 应用。Clojure 以独特的表现力而著称。Imba 第一次出现在这里(去年是因为 cloc 还不能识别以 .imba 为后缀的文件),看起来之后会一直出现在这里。如果你关心自己项目的代码行数,那么你现在知道该怎么做啦。
+
+---
+
+## 最后
+
+请记住,这并不是一个公平、合理的比较。有些在应用的实现上使用了代码拆分,有些则没有。其中有些托管在 GitHub 上,有些托管在 Now 上,有些托管在 Netlify 上。你是否仍然想知道哪一个最好?这我可回答不了。
+
+---
+
+## 常见问题
+
+#### #1 为什么在本篇对比中不包含框架 X,Y 和 Z 呢?
+
+因为以该框架为基础构建的 RealWorld 应用尚未在 [RealWorld 仓库](https://github.com/gothinkster/realworld)上出现或按照规范构建完成。考虑做出你的贡献吧!选择你喜欢的库/框架然后来构建 RealWorld 应用吧,我们下次对比将包括它!
+
+#### #2 为什么你们称其为 real world?
+
+因为它不只是一个 To-Do 应用程序。通过 RealWorld 应用,我们并不是要比较相关技术能拿到的薪水,可维护性,生产力,学习曲线等方面。这有[其他调查](https://insights.stackoverflow.com/survey/2018/)回答了其中一些问题。我们所说的 RealWorld 是指连接到服务器,进行身份验证并允许用户进行 CRUD 操作的应用程序 —— 就像现实世界中的应用程序一样。
+
+#### #3 你为什么不比较我最喜欢的框架?
+
+请参见问题 1,但以防万一,这里还是想强调下:因为以该框架为基础构建的 RealWorld 应用尚未在 [RealWorld 仓库](https://github.com/gothinkster/realworld)上出现或按照规范构建完成。以上所有的 Real World 应用又不是我自己搞出来的-这是整个社区的努力结晶。如果你想在下次对比中看到你喜欢的框架,请考虑为本项目做出贡献吧。
+
+#### #4 包括了哪个版本的库/框架?
+
+所涉及的库/框架在撰写本文时(2020 年 3 月)均可用。该信息来自 [RealWorld 仓库](https://github.com/gothinkster/realworld)。我确定你可以在 [GitHub 仓库](https://github.com/gothinkster/realworld) 中找到相关信息。
+
+#### #5 有比本文中出现的更流行的框架,你怎么忘记比较啦?
+
+同样,请参阅问题 1 和问题 3。以该框架为基础构建的 RealWorld 应用尚未在 [RealWorld 仓库](https://github.com/gothinkster/realworld) 上出现或按照规范构建完成;原因就是这么简单。
+
+> 如果你喜欢这篇文章,请 [在Twitter上关注我](https://twitter.com/JacekSchae)。我只写/推有关编程和技术的文章。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/a-simple-guide-to-a-b-testing-for-data-science.md b/TODO1/a-simple-guide-to-a-b-testing-for-data-science.md
new file mode 100644
index 00000000000..8e77d652743
--- /dev/null
+++ b/TODO1/a-simple-guide-to-a-b-testing-for-data-science.md
@@ -0,0 +1,91 @@
+> * 原文地址:[A Simple Guide to A/B Testing for Data Science](https://towardsdatascience.com/a-simple-guide-to-a-b-testing-for-data-science-73d08bdd0076)
+> * 原文作者:[Terence Shin](https://medium.com/@terenceshin)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/a-simple-guide-to-a-b-testing-for-data-science.md](https://github.com/xitu/gold-miner/blob/master/TODO1/a-simple-guide-to-a-b-testing-for-data-science.md)
+> * 译者:[Amberlin1970](https://github.com/Amberlin1970)
+> * 校对者:[Jiangzhiqi4551](https://github.com/Jiangzhiqi4551),[PingHGao](https://github.com/PingHGao)
+
+# 一份数据科学 A/B 测试的简单指南
+
+> 数据科学家最重要的统计方法之一
+
+
+
+A/B 测试是数据科学和科技界中最重要的概念之一,因为它是确定任意一个假设可能得出的结论最有效的方法之一。理解 A/B 测试并知道它的工作原理十分重要。
+
+## 什么是 A/B 测试?
+
+最简单的说法是,A/B 测试是基于一个给定的标准,判断实验中的两个变量哪一个的表现更好的实验。典型地,两个消费群体面对同一样东西的两个不同版本时,根据谈话、点击率又或是转化率这样的标准判断两个版本之间是否有很大的差异。
+
+以上图为例,我们可以随机地将消费者分成两组,一个控制组和一个变量组。然后,我们可以给变量组展示一个红色的网站横幅,再观察网站的转化率是否会得到大幅提升。必须注意的是,在进行 A/B 测试时,所有其他的变量是保持不变的。
+
+从更专业的角度讲,A/B 测试是一种统计和双样本假设检验的形式。**统计假设检验**是用于一个样本数据集和总体数据进行比较的一种方法。**双样本假设检验**是决定两个样本之间的差异是否具有统计意义的一种方法。
+
+## 为什么一定要了解?
+
+了解 A/B 测试是什么以及它如何工作是很重要的,因为它是量化产品变化或者市场策略变化时最好的方法。而这在由数据驱动的世界里变得日益重要,因为商业决策需要以事实和数字为依据。
+
+## 怎样进行一个标准的 A/B 测试?
+
+#### 1.提出你的假设
+
+在进行一个 A/B 测试之前,你会提出你的零假设和备择假设:
+
+**零假设**是指样本观察的结果完全出自偶然的假设。从 A/B 测试的角度讲,零假设是指控制组和对照组之间**无**差异。
+**备择假设**是指样本观察被一些非随机的因素影响的假设。 从 A/B 测试的角度讲 ,备择假设是指控制组和变量组之间**有**差异。
+
+在提出你的零假设和备择假设时,建议遵循 PICOT 格式。Picot 代表:
+
+- 对象(**P**opulation):参与实验的人群
+- 干预(**I**ntervention):指代研究中的新变量
+- 对照(**C**omparison):指代你计划用于和你的干预进行比较的参考组
+- 结果(**O**utcome):代表你预期的结果
+- 时间(**T**ime):指代整个实验的持续时间(何时开始收集数据及收集数据所花费的时长)
+
+例子:“相较于对照组,干预 A 将会改善临床焦虑水平在 3 个月的癌症患者的焦虑水平(以 HADS 焦虑分量表标准的平均变化来衡量)。”
+
+它(这个例子)符合 PICOT 的标准吗?
+
+* 对象:有临床焦虑的癌症患者
+* 干预:干预 A
+* 对照:对照干预
+* 结果:以 HADS 焦虑分量表标准的平均变化来衡量是改善了焦虑
+* 时间:与对照干预组进行3个月比较
+
+确实如此 —— 因此,这是一个强假设检验的例子。
+
+#### 2.创建你的对照组和测试组
+
+一旦确定了你的零假设和备择假设,下一步就是创建你的对照和测试(变量)组。在这一歩中有两个重要的概念需要考虑,随机采样和样本的大小。
+
+**随机采样**
+随机采样是指对象中的每个样本都有相等的选中概率的一种技术。随机采样在假设检验时很重要,因为它消除了抽样偏差。**消除偏差是很必要的,因为你希望你的 A/B 测试的结果能够代表整个研究对象而不仅是样本自身。**
+
+**样本大小**
+在进行 A/B 测试之前,必须要先设定好你的 A/B 测试的最小样本大小,才能消除由于太少样本而产生的**覆盖偏差**。有大量的[在线计算器](https://www.optimizely.com/sample-size-calculator/) 可以计算给定三个输入时的样本大小,如果你有兴趣了解这背后的数学原理请点击这个[链接]( https://online.stat.psu.edu/stat414/node/306/)!
+
+#### 3.进行测试,对比结果,是否丢弃零假设
+
+
+
+在你进行实验并且收集了你的数据后,你就要确定你的控制组和变量组之间的差异是否是统计显著的。如下几步可用于确定:
+
+* 首先,你需要设定你的 **α** 值,出现 1 类错误的概率。通常 α 的值设定为 5% 或 0.05 。
+* 其次,你需要利用上面的公式计算 t-统计量进而得出概率值(p 值)。
+* 最后,对比 p 值和 α 。如果 p 值大于 α ,不丢弃空假设!
+
+**如果上述内容对你没有意义,我将会花时间从[这里](https://www.khanacademy.org/math/statistics-probability/significance-tests-one-sample/idea-of-significance-tests/v/simple-hypothesis-testing)学习更多假设检验的知识!**
+
+## 谢谢阅读!
+
+如果你喜欢我的文章并且想支持我,请注册我的邮箱列表[这里](https://terenceshin.typeform.com/to/fe0gYe)!
+
+## 参考
+
+[**A/B 测试**](https://en.wikipedia.org/wiki/A/B_testing)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/active-learning-in-machine-learning.md b/TODO1/active-learning-in-machine-learning.md
new file mode 100644
index 00000000000..0dfdc4f3ef1
--- /dev/null
+++ b/TODO1/active-learning-in-machine-learning.md
@@ -0,0 +1,123 @@
+> * 原文地址:[Active Learning in Machine Learning](https://towardsdatascience.com/active-learning-in-machine-learning-525e61be16e5)
+> * 原文作者:[Ana Solaguren-Beascoa, PhD](https://medium.com/@ana.solagurenbeascoa)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/active-learning-in-machine-learning.md](https://github.com/xitu/gold-miner/blob/master/TODO1/active-learning-in-machine-learning.md)
+> * 译者:
+> * 校对者:
+
+# Active Learning in Machine Learning
+
+> A brief introduction to the implementation of active learning
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/11520/0*wvT88RaaNLyiCLt8)
+
+Most supervised machine learning models require large amounts of data to be trained with good results. And even if this statement sounds naive, most companies struggle to provide their data scientists this data, in particular **labelled** data. The latter is key to train any supervised model and can become the main bottleneck for any data team.
+
+In most cases, data scientists are provided with a big, unlabelled data sets and are asked to train well-performing models with them. Generally, the amount of data is too large to manually label it, and it becomes quite challenging for data teams to train good supervised models with that data.
+
+## Active learning: Motivation
+
+Active learning is the name used for the process of prioritising the data which needs to be labelled in order to have the highest impact to training a supervised model. Active learning can be used in situations where the amount of data is too large to be labelled and some priority needs to be made to label the data in a smart way.
+
+**But, why don’t we just chose a random subset of data to manually label them?**
+
+Let’s look at a very simple example to motivate the discussion. Assume we have millions of data points which need to be classified based on two features. The actual solution is shown in the following plot:
+
+
+
+As one can see, both classes (red and purple) can quite nicely be separated by a vertical blue line crossing at 0. The problem is that none of the data points are labelled, so the data is given to us as in the following plot:
+
+
+
+Unfortunately, we don’t have enough time to label all of the data and we randomly chose a subset of the data to label and train a binary classification model on it. The result is not great, as the model prediction deviates quite a lot from the optimal boundary.
+
+
+
+This is where active learning can be used to optimise the data points chosen for labelling and training a model based on them. The following plot shows an example of training a binary classification model after choosing the training of the model based on data points labelled after implementing active learning.
+
+
+
+Making a smart choice of which data points to prioritise when labelling can save data science teams large amounts of time, computation and headaches!
+
+## Active learning strategy
+
+#### Steps for active learning
+
+There are multiple approaches studied in the literature on how to prioritise data points when labelling and how to iterate over the approach. We will nevertheless only present the most common and straightforward methods.
+
+The steps to use active learning on an unlabelled data set are:
+
+1. The first thing which needs to happen is that a very small subsample of this data needs to be manually labelled.
+2. Once there is a small amount of labelled data, the model needs to be trained on it. The model is of course not going to be great but will help us get some insight on which areas of the parameter space need to be labelled first to improve it.
+3. After the model is trained, the model is used to predict the class of each remaining unlabelled data point.
+4. A score is chosen on each unlabelled data point based on the prediction of the model. In the next subsection we will present some of the possible scores most commonly used.
+5. Once the best approach has been chosen to prioritise the labelling, this process can be iteratively repeated: a new model can be trained on a new labelled data set, which has been labelled based on the priority score. Once the new model has been trained on the subset of data, the unlabelled data points can be ran through the model to update the prioritisation scores to continue labelling. In this way, one can keep optimising the labelling strategy as the models become better and better.
+
+#### Prioritisation scores
+
+There are several approaches to assign a priority score to each data point. Below we describe the three basic ones.
+
+**Least confidence:**
+
+This is probably the most simple method. It takes the highest probability for each data point’s prediction, and sorts them from smaller to larger. The actual expression to prioritise using least confidence would be:
+
+
+
+
+
+Let’s use an example to see how this would work. Assume we have the following data with three possible classes:
+
+
+
+In this case, the algorithm would first chose the maximum probability for each data point, hence:
+
+* X1: 0.9
+* X2: 0.87
+* X3:0.5
+* X4:0.99.
+
+The second step is to sort the data based on this maximum probability (from smaller to bigger), hence X3, X2, X1 and X4.
+
+**Margin sampling:**
+
+This method takes into account the difference between the highest probability and the second highest probability. Formally, the expression to prioritise would look like:
+
+
+
+The data points with the lower margin sampling score would be the ones labelled the first; these are the data points the model is least certain about between the most probably and the next-to-most probable class.
+
+Following the example of Table 1, the corresponding scores for each data point are:
+
+* X1: 0.9–0.07 = 0.83
+* X2: 0.87–0.1 = 0.86
+* X3: 0.5–0.3 = 0.2
+* X4: 0.99–0.01 = 0.98
+
+Hence the data points would be shown to label as follows: X3, X1, X2 and X4. As one can see the priority in this case is slightly different to the least confident one.
+
+**Entropy:**
+
+Finally, the last scoring function that we are gonna present here is the entropy score. Entropy is a concept that comes from thermodynamics; in a simple way, it can be understood as a measure of disorder in a system, for instance a gas in a closed box. The higher the entropy the more disorder there is, whereas if the entropy is low, it means that the gas might be mainly in one particular area such as a corner of the box (maybe when the experiment started, before expanding across the box).
+
+This concept can be reused to measure the certainty of a model. If a model is highly certain about a class for a given data point, it will probably have a high certainty for a particular class, whereas all the other classes will have low probability. Isn’t this very similar to having a gas in the corner of a box? In this case we have most of the probability assigned to a particular class. In the case of high entropy it would mean that the model distributes equally the probability for all classes as it is not certain at all which class that data point belongs to, similarly to having the gas distributed equally in all parts of the box. It is therefore straightforward to prioritise data points with higher entropy to the ones with lower entropy.
+
+Formally, we can define the entropy score prioritisation as follows:
+
+
+
+If we apply the entropy score to the example in Table 1:
+
+* X1: **-0.9*log(0.9)-0.07*log(0.07)-0.03*log(0.03)** = 0.386
+* X2: **-0.87*log(0.87)-0.03*log(0.03)-0.1*log(0.1)** = 0.457
+* X3: **-0.2*log(0.2)-0.5*log(0.5)-0.3*log(0.3)** =1.03
+* X4: **-0*log(0)-0.01*log(0.01)-0.99*log(0.99)** = 0.056
+
+**Note that for X4, 0 should be changed for a small epsilon (e.g. 0.00001) for numerical stability.**
+
+In this case the data points should be shown in the following order: X3, X2, X1 and X4, which coincides with the order of the least confident scoring method!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/advanced-tooling-for-web-components.md b/TODO1/advanced-tooling-for-web-components.md
index e3f041934ea..8664a9fa93f 100644
--- a/TODO1/advanced-tooling-for-web-components.md
+++ b/TODO1/advanced-tooling-for-web-components.md
@@ -314,7 +314,7 @@ Web Components 标准不断发展,越来越多的新功能经过讨论并被
2. [编写可以复用的 HTML 模板](https://juejin.im/post/5ca5b858e51d4524a918560f)
3. [从 0 开始创建自定义元素](https://github.com/xitu/gold-miner/blob/master/TODO1/creating-a-custom-element-from-scratch.md)
4. [使用 Shadow DOM 封装样式和结构](https://github.com/xitu/gold-miner/blob/master/TODO1/encapsulating-style-and-structure-with-shadow-dom.md)
-5. [Web Components 的高级工具(**本文**)](https://github.com/xitu/gold-miner/blob/master/TODO1/advanced-tooling-for-web-components/.md)
+5. [Web Components 的高级工具(**本文**)](https://github.com/xitu/gold-miner/blob/master/TODO1/advanced-tooling-for-web-components.md)
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/an-introduction-to-raspberry-pi-4-gpio-and-controlling-it-with-node-js.md b/TODO1/an-introduction-to-raspberry-pi-4-gpio-and-controlling-it-with-node-js.md
new file mode 100644
index 00000000000..0f1b1c71fcf
--- /dev/null
+++ b/TODO1/an-introduction-to-raspberry-pi-4-gpio-and-controlling-it-with-node-js.md
@@ -0,0 +1,311 @@
+> * 原文地址:[An introduction to Raspberry Pi 4 GPIO and controlling it with Node.js](https://itnext.io/an-introduction-to-raspberry-pi-4-gpio-and-controlling-it-with-node-js-10f2ce41af12)
+> * 原文作者:[Uday Hiwarale](https://medium.com/@thatisuday)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/an-introduction-to-raspberry-pi-4-gpio-and-controlling-it-with-node-js.md](https://github.com/xitu/gold-miner/blob/master/TODO1/an-introduction-to-raspberry-pi-4-gpio-and-controlling-it-with-node-js.md)
+> * 译者:
+> * 校对者:
+
+# An introduction to Raspberry Pi 4 GPIO and controlling it with Node.js
+
+> RASPBERRY PI + NODE.JS
+> In this article, we will get familiar with the GPIO of Raspberry Pi and its technical specifications. We will also go through a simple example of Input and Output with a Led and a Switch.
+
+)](https://cdn-images-1.medium.com/max/12000/1*t-dr_5CrKf45RE0Uuww2sg.jpeg)
+
+You might have come across the term “**IoT**”, it is an acronym for the **Internet of Things**. This basically means that a device (**thing**) that can be controlled from the internet. An example of an IoT would be smart bulbs in your house which can be controlled from your smartphone.
+
+Since an IoT can be controlled from the internet, it should always be connected with the internet. There are primarily two ways we can connect a device to the internet, either through an Ethernet cable or through WiFi.
+
+IoT devices can be used for various purposes. For example, you can use an IoT to control the temperature of your house, control lighting or turn on devices before you get home, right from your smartphone.
+
+So what are the technical specifications of an IoT device? Well, in a nutshell, it should have the means to connect to the internet, have some input and output sockets to read/write analog or digital signals to and from a device, and bare minimal hardware to read and execute instructions from a program.
+
+An IoT device has a hardware component that provides an interface for external devices to read digital data or to get electricity. This is called **GPIO** or **General Purpose Input Output**. This hardware component is basically a series of pins that can be connected to external devices.
+
+These GPIO pins can be controlled by a program. For example, based on some conditions, we can turn on a GPIO pin which provides 5V electricity and any device which is connected to this pin will turn on. This program can listen to a message sent from the internet and control this pin. Hence the IoT.
+
+Building such an IoT device from scratch can be tough since it has a lot of components to work with. Luckily, there are pre-built devices that you can purchase and they are extremely cheap. These devices come with GPIO hardware and means to connect to the internet.
+
+#### Arduino Microcontroller
+
+At the moment, if we are looking for simple automation, [**Arduino**](https://en.wikipedia.org/wiki/Arduino) is the best device to go for. It is a **micro-controller** that can be programmed using programming languages like C and C++.
+
+)](https://cdn-images-1.medium.com/max/2000/1*-Tmb_Q7yYmmtFGaUk6iv4A.jpeg)
+
+However, it does not come with the built-in WiFi or Ethernet jack and an external peripheral device (**called as a** shield) has to be connected to connect the Arduino to the internet.
+
+Arduino is meant to be used as a controller for external devices and not a fully-fledged IoT device. Hence, they are extremely cheap. Some of the latest models can go as low as $18.
+
+#### Raspberry Pi Micro-computer
+
+Compared to Arduino, [**Raspberry Pi**](https://en.wikipedia.org/wiki/Raspberry_Pi) is a **beast**. It was created to promote the teaching of basic computer science in schools and in developing countries, but it was picked up by nerds and hobbyists to create new shit. At the moment, it is one of the most popular **single-board computers** in the world.
+
+Raspberry Pi (**latest Model 4B**) comes with an Ethernet connector, WiFi, Bluetooth, HDMI output, USB connectors, a 40-pin GPIO, and other essential features. It is powered by an **ARM** CPU, a **Broadcom** GPU and 1/2/4 GB of **RAM**. You can see these specifications from [**this**](https://en.wikipedia.org/wiki/Raspberry_Pi#Specifications) Wikipedia table.
+
+)](https://cdn-images-1.medium.com/max/2000/1*WE-9WUau6aQlMSHVLjq9KQ.jpeg)
+
+Despite this heavy hardware, the latest model costs between **$40** to **$80**. Don’t forget, this is a fully-fledged computer with a native operating system. This means we do not need to connect with an external computer to program it.
+
+However, unlike our day to day computers, Raspberry Pi provides a GPIO hardware component to control external devices. This makes the Raspberry Pi a device that can do just about anything.
+
+Let’s understand the technical specifications of this GPIO.
+
+---
+
+## Raspberry Pi - GPIO pinout
+
+Raspberry Pi (**model 4B**) has **40 GPIO pins** in total, stacked in `20 x 2` array. As shown in the below diagram, each pin has a specific purpose.
+
+)](https://cdn-images-1.medium.com/max/4128/0*VsaGvGskvJa20hZa.png)
+
+Before we discuss the functionality of each pin, let’s understand some conventions first. Each pin has a specific number attached to it and that’s how we can control these pins from the software.
+
+The numbers you can see in the circle is physical pin numbers on the GPIO hardware. For example, **pin no. 1** provides a constant 3.3V power. This number system is called **Board Pin** or **Physical Pin** numbering system.
+
+We also have another pin numbering system created by [**Broadcom**](https://en.wikipedia.org/wiki/Broadcom_Inc.) since Raspberry Pi 4B uses the [**BCM2711**](https://www.raspberrypi.org/documentation/hardware/raspberrypi/bcm2711/README.md) processor chip. This pin numbering system is called **BCM** or **Broadcom Mode**. The label attached with each pin in the above diagram shows BCM pin numbers. For example, physical **pin no. 7** is **BCM pin no. 7** and labeled as **GPIO 4**.
+
+We can choose to follow either the **Board** or **BCM** numbering system. However, depending on the programming library we use to access the GPIO, we could be stuck with one of them. However, most libraries out there prefer the BCM numbering system since it is referred by the Broadcom CPU chip.
+
+> From here on, if I use **Pin no. x**, it means the **physical pin number** on the board. The BCM pin number will be mentioned with BCM.
+
+#### 💡 Power and Group Pins
+
+Pin no. **1** and **17** provide **3.3V** power while pin no. **2** and **4** provide **5V** power. These pins provide **constant power** when you turn on the Raspberry Pi and these are **not programmable** by any means whatsoever.
+
+Pin no. **6**, **9**, **14**, **20**, **25**, **30**, **34** and **39** provide the ground connection. This is where the **cathode** of a circuit should be attached. We can use a single ground pin for all ground connections in the circuit since they are connected to the same ground rail.
+
+> If you are wondering why so many ground pins, then you can follow [**this thread**](https://www.raspberrypi.org/forums/viewtopic.php?t=132851).
+
+#### 🔌 GPIO Pins
+
+Except for **Power** and **Ground** Pins, rests are general-purpose input and output pins. When a GPIO pin is used in **output mode**, it provides 3.3V constant power when it is turned on.
+
+In the **input mode**, a GPIO pin can also be used to listen for external power. Technically, when a **3.3V** is supplied to a GPIO pin (**when it is in the input mode**), the pin will read as **logical high** or **1**. When the pin is grounded or supplied with **0V**, it will read as **logical low** or **0**.
+
+The output mode is fairly straightforward. In the output mode, we turn on a pin and it sends the 3.3V through the pin. However, in the input of a pin, we need to listen for voltage changes on the pin and when the pin is at the logical high or low, we can do other things like turn on an output GPIO pin.
+
+#### 🧙♀️ SPI, I²C, and UART Protocols
+
+SPI ([**Serial Peripheral Interface**](https://en.wikipedia.org/wiki/Serial_Peripheral_Interface)) is a synchronous serial communication interface used by devices to talk to each other. This interface needs 3 or more data lines to connect a master device to a slave device (**out of one or many**).
+
+I²C ([**Inter-Integrated Circuit**](http://C)) is also similar to SPI but it supports multiple master devices. Also, unlike SPI, it only requires two data lines for unlimited numbers of slaves. However, this makes I²C slower than SPI.
+
+UART ([Universal asynchronous receiver-transmitter](https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter)) is also a serial communication interface but data is sent [**asynchronously**](https://en.wikipedia.org/wiki/Asynchronous_serial_communication).
+
+Raspberry Pi provides a low-level interface to enable these interfaces through GPIO pins just like input and output mode we discussed earlier. However, not all GPIO pins can be configured from these kinds of communications.
+
+In the below diagram, you can see which GPIO pins can be configured from SPI, I²C and UART protocols. You should visit **[pinout.xyz](https://pinout.xyz/).** This web application provides an interactive interface to see what each GPIO pin does.
+
+)](https://cdn-images-1.medium.com/max/2000/1*mpKa3QDHL6G5CmjmMWX3UQ.png)
+
+Besides in a simple input or output mode, a GPIO pin can work in **6 modes** but only one at a time. When you click on a GPIO pin (**in the above website**), you would be able to see its modes on the right side. These are mentioned with ALT0 to ALT5 in the right table.
+
+> You can learn about the specifications of these communication protocols from [**this video**](https://www.youtube.com/watch?v=IyGwvGzrqp8). We won’t be working with these communication protocols in this tutorial, however, I will be covering these topics in the upcoming articles.
+
+#### ⚡ Current Specifications
+
+We have talked about the voltage specifications of the power and GPIO pins. The current specifications are little foggy because they are not mentioned in the Raspberry Pi official documentation.
+
+However, we follow a safety precaution while handling the current. The maximum current that can be drawn from any pin should be less than or equal to **16mA**. Hence, we must adjust our load to meet this requirement.
+
+If we have connected multiple devices to the Raspberry Pi GPIO and other ports like USB, then we must ensure that the maximum current drawn from the circuit is less than **50mA**.
+
+To limit the current, we can add resistors to the circuit so that the maximum current drawn does not cross these limits. When a device needs more power than Raspberry Pi can provide, we should be using relay switches instead.
+
+When it comes to the **input**, these same specifications are used. When a GPIO pin is used as a **drain** (**instead of a** source **of the current**), we should not supply more than **16mA**. Also when multiple GPIO pins are used as input, no more than **50mA** current should be applied in total.
+
+---
+
+## Prerequisites
+
+I believe that you have gone through the setup of the Raspberry Pi. This means you have installed an operating system like [**Raspbian**](https://www.raspberrypi.org/downloads/raspbian/) or your personal favorite and you can access it through SSH or HDMI.
+
+The first thing we need to do is create a project directory. I have created the project directory at `/home/pi/Programs/io-examples` where all our programs will live for these tutorial examples.
+
+Since we want to control the GPIO pins using Node.js, we need to install Node first. You can choose your favorite method but I personally use **[NVM](https://github.com/nvm-sh/nvm)** (**node version manager**). You can follow [**these recommended steps**](https://github.com/nvm-sh/nvm#install--update-script) to install it.
+
+Once you have NVM installed, we can proceed further to install a specific version of Node. I will be using Node v12 since it is the latest stable version. To install Node v12, use the below commands.
+
+```
+$ nvm install 12
+$ nvm use 12
+```
+
+Once Node.js is installed on the Raspberry Pi, we can move ahead with the project creation. Since we want to control the GPIO pins, we need a library that can provide an easy API to do that for us.
+
+One great library to control GPIO on Raspberry Pi is [**onoff**](https://www.npmjs.com/package/onoff). From the project directory, first, create the package.json and then install `onoff` package.
+
+```
+$ cd /home/pi/Programs/io-examples
+$ npm init -y
+$ npm i -S onoff
+```
+
+Now that we have everything we need, we can process with the circuit design and write our first program to test the power of GPIO.
+
+---
+
+## Output example with LED
+
+In this example, we will turn on a Red LED programmatically. Let’s take a look at the below circuit diagram.
+
+
+
+From the above circuit diagram, we have connected **Pin no. 6** (**ground pin**) to the negative (**ground**) rail of the breadboard and **BCM 4** to the one end of a **1k ohm** resistor. The other end of the resistor is connected to the input of a Red LED and the output of the LED drains to the ground.
+
+There is nothing interesting about this circuit except the resistor. The resistor is needed because Red LED operates at **2.4V** and a GPIO pin provides **3.3V** which can damage the LED. Also, the LED draws **20mA** which is above the safe limit of Raspberry Pi, hence resistor will also prevent the excess current.
+
+> We can choose between 330 ohms to 1k ohm resistance. This will impact the current flow but won’t damage the LED.
+
+From the above circuit, the only variable in the circuit is BCM 4 pin output. If the pin is on (**3.3V**), the circuit will close and LED will glow. If the pin is off (**0V**), the circuit is open and LED won’t glow.
+
+Let’s write a program that can programmatically turn on the BCM 4 pin.
+
+```JavaScript
+const { Gpio } = require( 'onoff' );
+
+// set BCM 4 pin as 'output'
+const ledOut = new Gpio( '4', 'out' );
+
+// current LED state
+let isLedOn = false;
+
+// run a infinite interval
+setInterval( () => {
+ ledOut.writeSync( isLedOn ? 0 : 1 ); // provide 1 or 0
+ isLedOn = !isLedOn; // toggle state
+}, 3000 ); // 3s
+```
+
+In the above program, we are importing `onoff` package and extracting `Gpio` constructor. The `Gpio` class configures a GPIO with a certain configuration. In the above example, we have set **BCM 4** in the **output mode**.
+
+> You can follow [**this API documentation**](https://github.com/fivdi/onoff#api) of the `onoff` module to understand various configurations options and API methods.
+
+An instance of `Gpio` class provides high-level API to interact with that pin. The `writeSync` method writes either **1** or **0** to the pin which enables or disables it. When a pin is set to **1**, it turns **on** and outputs the **3.3V** power. When it is set to **0**, it turns **off** and does not provide any power (**0V**).
+
+Using `setInterval`, we are running an endless loop that writes either 0 or 1 to the `ledOut` pin using `ledOut.writeSync(val)` method call. Let’s run this program using Node.js.
+
+```
+$ node rpi-led-out.js
+```
+
+Since this is an endless loop, once we start the program, it will not terminate unless we interrupt it forcefull using `ctrl + c`. During the lifetime of this program, it will toggle the **BCM 4** pin every **3 seconds**.
+
+One interesting thing about the Raspberry Pi GPIO, once a GPIO pin is set to **1** or **0**, it will stay like that until we override the value again or turn off the power supply to the Raspberry Pi. When when you start the program, the LED is off but when you stop it, the LED might remain on.
+
+## Input example with Switch
+
+As we know, when a GPIO is used as an input, we need to supply a voltage close to **3.3V**. We can hook up a switch (**push button**) that supplies a voltage directly from **3.3V** pin as shown in the circuit diagram below.
+
+
+
+We have used a **1K ohm** resistor before the input of the switch to provide some resistance in the circuit. This will prevent too much current drawn from the **3.3V** supply and prevent our switch from getting fried.
+
+We have also attached a **10K ohm** resistor that also draws the current from the output of the button and drains to the ground. These types of resistors (**because of their position in the circuit**) are called **pull-down** resistors since they drain the current (**or atmospheric charge build-up**) to the ground.
+
+> We can alternatively add a **pull-up register** which pulls the current from **3.3V** pin and provides to the input GPIO pin. In this configuration, the input pin always reads **high** or **1**. When the button is pressed, the switch creates a short circuit between the resistor and the ground draining all the current to the ground and no current is passed through the switch to the input pin and it reads **0**. [**Here is a great video**](https://www.youtube.com/watch?v=5vnW4U5Vj0k) demonstrating the pull-up and pull-down resistors.
+
+The output of the switch is connected to the **BCM 17** pin. When the button (**switch**) is pressed, the current will flow through the switch into the BCM 17 pin. However, since the 10K ohm resistor provides a greater obstacle to the current flow, most current flow through the loop represented by the **red dotted line**.
+
+When the button is not pressed, the loop represented by the red dotted line is closed and no current will flow through it. However, the loop represented by the **grey dotted line** is closed, and the BCM 17 pin is grounded (**0V**).
+
+> The main reason to add a 10k ohm resistor is to connect BCM 17 pin to the ground so that it can not read any atmospheric disturbance as input high. By not connecting a input pin to the ground, we keep the input pin in **floating state**. In that state the input pin can read either 0 or 1 due to atmospheric disturbances.
+
+Now that our circuit is ready, let’s write a program to read input value.
+
+```JavaScript
+const { Gpio } = require( 'onoff' );
+
+// set BCM 17 pin as 'input'
+const switchIn = new Gpio( '17', 'in', 'both' );
+
+// listen for pin voltage change
+switchIn.watch( ( err, value ) => {
+ if( err ) {
+ console.log( 'Error', err );
+ }
+
+ // log pin value (0 or 1)
+ console.log( 'Pin value', value );
+} );
+```
+
+In the above program, we have set **BCM 17** pin in the input mode. The third argument of the `Gpio` constructor configures when we want to get notified of the pin input voltage change. This is labeled as the **`edge`** argument since we are reading the value at the edge of voltage rise and drop cycle.
+
+The `edge` argument can have the following values.
+
+When the `rising` value is used, we will get notified when the input voltage to a GPIO pin is **rising from 0V** (**to 3.3V**). At this position, the pin will read **logical high** or **1** because it is getting positive voltage.
+
+When the `falling` value is used, we will get notified when the input voltage is **falling to 0V** (**from 3.3V**). At this position, the pin will read **logical low** or **0** because it is losing voltage.
+
+When `both` value is used, we will get notified of the above two events. When the voltage is rising from 0V (**input high or 1**) or falling from 3.3V (**input low or 0**), we can listen to these events at once.
+
+> The `none` value is not discussed here, read the [**documentation**](https://github.com/fivdi/onoff#gpiogpio-direction--edge--options) to know more.
+
+The `watch` method on a GPIO pin in the input mode watches for the above events. This is an asynchronous method, hence we need to pass a callback function which receives the input high (1) or input low (0) value.
+
+Since we are using `both` value, the `watch` method will execute the callback when the input voltage is rising as well as when the input voltage is falling. Based on the button press, you should get the below values in the console.
+
+```
+Pin value 1 (when button is pressed)
+Pin value 0 (when button is released)
+Pin value 1 (when button is pressed)
+Pin value 1 (repeat value)
+Pin value 0 (when button is pressed)
+```
+
+If you inspect the above output carefully, we sometimes get duplicate values when the button is pressed or released. Since the physical connection between two connectors of the switch mechanism is not always smooth, it can connect and disconnect many times when a switch is not pressed carefully.
+
+To avoid this, we can add capacity in the switch circuit which charges before the actually current flows in the GPIO pin and discharges smoothly when the button is released. You should give this a try since this is fairly simple.
+
+## Combined I/O example
+
+Now that we have a good understanding of how GPIO pin works and how we can configure them, let’s combine our last two examples. The bigger picture is to turn on the LED when the button is pressed and turn it off when the button is released. Let’s first look at the circuit diagram.
+
+
+
+As you can see from the above example, we haven’t changed a thing from the above two examples. Also, both LED and Switch circuits are independent. Which means our earlier program should work just fine with this circuit.
+
+```JavaScript
+const { Gpio } = require( 'onoff' );
+
+// set BCM 4 pin as 'output'
+const ledOut = new Gpio( '4', 'out' );
+
+// set BCM 17 pin as 'input'
+const switchIn = new Gpio( '17', 'in', 'both' );
+
+// listen for pin voltage change
+switchIn.watch( ( err, value ) => {
+ if( err ) {
+ console.log( 'Error', err );
+ }
+
+ // write the input value (0 or 1) 'ledOut' pin
+ ledOut.writeSync( value );
+} );
+```
+
+In the above program, we have GPIO pins configured in the input and output mode individually. Since the value provided by the `watch` method on an input pin is **0** or **1**, we can use the same value to write to an output pin.
+
+Since we are watching `switchIn` input pin in `both` mode, the `watch` will get triggered when the button is pressed sending the `value` **1** and also when the button is released sending the `value` **0**.
+
+We can use this value directly to write to the `ledOut` pin. Hence, when the button is pressed, `value` is `1` and `ledOut.writeSync(1)` will turn on the LED. the reserve will happen when the button is pressed.
+
+---
+
+
+
+Here is the demonstration of the complete input/output circuit we have just created. For your and safety of your Raspberry Pi, I would recommend you to purchase a good case and 40 pin GPIO extension ribbon cable.
+
+I hope you have learned something today. In upcoming tutorials, we will build some complex circuits and learn to connect some fancy devices like character LCD screens and numeric input pad.
+
+---
+
+ / [**Twitter**](https://twitter.com/thatisuday))](https://cdn-images-1.medium.com/max/7898/1*waznApGKL0XENm0UbkCo_A.png)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/btc-history-git.md b/TODO1/btc-history-git.md
new file mode 100644
index 00000000000..7a670985a9b
--- /dev/null
+++ b/TODO1/btc-history-git.md
@@ -0,0 +1,184 @@
+> * 原文地址:[The History of Git: The Road to Domination in Software Version Control](https://www.welcometothejungle.com/en/articles/btc-history-git)
+> * 原文作者:[Andy Favell](https://twitter.com/andy_favell)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/btc-history-git.md](https://github.com/xitu/gold-miner/blob/master/TODO1/btc-history-git.md)
+> * 译者:[fireairforce](https://github.com/fireairforce)
+> * 校对者:[Long Xiong](https://github.com/xionglong58), [司徒公子](http://github.com/todaycoder001)
+
+# Git 的历史: 软件版本控制的统治之路
+
+
+
+**在 2005 年,Linus Torvalds 迫切需要一个新的版本控制系统来维护 Linux 内核的开发。于是他花了一个星期的时间,从头开始编写了一个革命性的新系统,并将其命名为 Git。十五年之后,该平台成为了[这个竞争激烈领域里面当之无愧的领导者](https://en.wikipedia.org/wiki/List_of_version-control_software)。**
+
+在全球范围内,大量的初创企业、集体企业和跨国公司,包括谷歌和微软,使用 Git 来维护它们软件项目的源代码。它们中有些公司拥有自己的 Git 项目,有些公司则通过商业托管公司使用 Git,比如 GitHub(成立于 2007 年),Bitbucket(成立于 2010 年)和 GitLab(成立于 2011 年)。其中最大的 GitHub 拥有 [4000 万注册开发者](https://octoverse.github.com/) 并在 2018 年[被微软](https://news.microsoft.com/2018/06/04/microsoft-to-acquire-github-for-7-5-billion/)以 75 亿美元的天价收购。
+
+Git(及其竞争对手)有时被分类为版本控制系统(VCS),有时是源码管理系统(SCM),还有时是修订控制系统(RCS)。Torvalds 认为生命太短暂而不必去区分这些定义,因此我们不必纠结于此。
+
+Git 的吸引力之一在于它是开源的(就像 Linux 和 Android 那样)。但是,还有其它开源的 VSC,其中包括协作版本系统(CVS)、SVN、Mercurial 和 Monotone,因此单凭这一点并不足以解释它的优点。
+
+关于 Git 市场主导地位的最好体现是 [Stack Overflow 对开发人员的调查](https://insights.stackoverflow.com/survey/)。调查结果显示,2018 年 74289 名受访者中有 88.4% 使用了 Git(高于 2015 年的 69.3%)。最接近的竞争对手是 Subversion,普及率为 16.6%(低于 36.9%);Team Foundation 版本控制,从 2015 年的 12.2% 降为 11.3%;Mercurial 普及率为 3.7%(低于 7.9%)。事实上,Git 的优势如此之大,以至于 Stack Overflow 的数据科学家都懒得在 2019 的调查中提出这个问题。
+
+```
+开源人员使用什么来进行源码控制?
+
+| 2018 | 2015 |
+| ---------------------- | ---------------------- |
+| Git: 88.4% | Git: 69.3% |
+| Subversion: 16.6% | Subversion: 36.9% |
+| Team Foundation: 11.3% | Team Foundation: 12.2% |
+| Mercurial: 3.7% | Mercurial: 7.9% |
+| | CVS: 4.2% |
+| | Perforce: 3.3% |
+
+| 74,298 受访者 | 16,694 受访者 |
+
+数据来源:Stack Overflow 2018/2015 开发者调查报告
+```
+
+## 开始
+
+直到 2005 年 4 月,Torvalds 一直使用 [BitKeeper](http://www.bitkeeper.org/)(BK)管理着一个庞大的 Linux 内核源码,这些源码来自于完全不同的志愿者开发团队,Linux 是一个越来越受欢迎的类 UNIX 开源操作系统。BK 在当时是一个私有的付费工具,但是 Linux 的开发者可以免费使用它,直到 BK 的创始人 Larry McVoy 与一个 Linux 开发人员就不恰当地使用 BK 发生了争执。
+
+从 [Torvalds 的声明](https://marc.info/?l=linux-kernel&m=111280216717070&w=2) 到 Linux 邮件列表,都是关于他计划利用一个工作“假期”来决定如何为 Linux 找到新的 VCS,很明显,他喜欢 BK,并对 Linux 不能再使用它而感到沮丧,而且他对竞争并不敢兴趣。如之前提到的,这次假期诞生了 Git。Torvalds 将它命为 Git 的原因有很多种说法,但实际上他只是喜欢这个词,这是他从披头士的歌曲[《I’m So Tired》](https://genius.com/The-beatles-im-so-tired-lyrics)(第二节)中获得灵感。
+
+**“搞笑的是,我所有的项目都是以我自己的名字命名,而这个项目的名字是‘Git’。Git 在[英国俚语](https://dictionary.cambridge.org/dictionary/english/git)里是‘愚蠢的人’的意思,”** Torvalds 告诉我们。**“它也有一个虚构的首字母缩写 —— Global Information Tracker。但这实际上是一个 ‘backronym’, \[事后\]补上的。”**
+
+那么,Torvalds 对 Git 的巨大成功感到惊讶吗?**“如果我说我能看到它即将成功,那绝对是在撒谎。我当然没有。但是 Git 确实把所有的基础都做对了。有什么事情可以做得更好吗?当然。但总的来说,Git 确实解决了一些与 VCS 有关的真正困难的问题。”** 他说。
+
+## 定义 Git 的目标
+
+传统上,版本控制是客户端服务器,因此代码位于单个存储库中,或者中央服务器的仓库中。协作版本系统(CVS),[Subversion](https://en.wikipedia.org/wiki/Apache_Subversion) 和 Team Foundation 版本控制(TFVC)都是客户端/服务器系统的例子。
+
+客户机-服务器 VCS 在企业环境中运行良好,在企业环境中,开发受到严格控制,由具有良好网络连接的内部开发团队进行。如果有成百上千的开发人员进行协作,自愿、独立、远程地工作,所有人都想要往代码里面添加新的东西,这对 Linux 等开源软件(OSS)项目来说都很常见的,那么这种协作就不太好用了。
+
+BK 首创的分布式 VCS 打破了这种模式。Git、Mercurial 和 Monotone 都遵循这个示例。对于分布式 VCS 来说,最新版本的代码副本在每个开发人员的设备上,从而使开发人员可以更轻松地独立修改代码。**“BK 对使用模式的概念影响很大,确实应该得到所有的赞誉。但由于各种原因,我想让 Git 的实现逻辑与 BK 完全不同,但‘分布式 VCS’ 的概念确实是首要目标,BK 教会了我这一点的重要性,”** Torvalds 说。**“真正的分布式意味着 fork 不是问题,任何人都可以 fork 一个项目并进行自己的开发,然后一个月或一年后回来说,‘看看我做的这件伟大的事情。’”**
+
+客户机-服务器 VCS 的另一个主要缺点,特别是对于开源项目,是在服务器上托管中央存储库的人“掌握”了源代码。然而,在分布式 VCS 中,没有中央存储库,只有许多拷贝复制,因此没有人掌握或控制代码。
+
+**“\[这使得\] 像 GitHub 这样的网站成为可能。当没有包含源代码的中心“主”位置时,你可以突然托管一些东西,而不需要遵循“一个仓库来统治所有人”的策略。”** Torvalds 说。
+
+另一个核心目标是减少将新分支合并到主分支代码或者 “tree”(组成源代码层次结构的目录)的痛苦。关键是为每个对象分配一个加密哈希索引(唯一且安全的数字)。Git 并不是唯一使用哈希的版本控制器,将它提升到了一个新的高度,不仅将它们应用于每个新版本的文件内容,而且还使用它来确定它们之间的关系,包括 tree 和 commit 。这意味着,通过使用 “git diff” 指令,git 可以通过比较哈希的两个索引,非常快速地识别出分支新的/待提交版本与源代码之间的所有更改,甚至是整个 tree。**“Git 索引的真正目的是作为合并的中间步骤,这样你就可以增量地修复冲突,”** Torvalds 说。
+
+在进行完全合并之前,这种中间步骤或暂存区的概念可进行版本之间的比较,并解决主要源代码和附加内容之间的任何问题,这个概念是革命性的。然而,这并没有得到那些习惯于其他 VCS 人的普遍认可。
+
+## 指定一名维护人员
+
+在编写了 Git 之后,Torvalds 将其开放给开源社区进行审查和贡献。在那些参与者中,有一位开发人员特别引人注目:Junio Hamano。因此,仅仅几个月后,Torvalds 就可以[抽出身来](https://marc.info/?l=git&m=112243466603239),专注于Linux,把维护 Git 的责任移交给 Hamano。**“当涉及到代码和功能时,他有明显的、非常重要但难以具体描述的‘好品味’。”**Torvalds 说,**“Junio 确实应该接受所有的荣誉,作为发起人,我理应获得设计 Git 的荣誉。但作为一个项目,Junio 是维护它的人,让它成为一个非常好用的工具。”**
+
+显然,Junio 是一个不错的选择,因为 15 年后,他仍然作为一个[仁慈的独裁者]((http://oss-watch.ac.uk/resources/benevolentdictatorgovernancemodel))来主导并维护 Git,这意味着他控制着 Git 未来发展的方向,对代码的修改拥有最终的决定权,并且他保持着最多提交的记录。
+
+## 扩大 Git 的吸引力
+
+早期支持 Hamano 的一些志愿贡献者到现在仍然在贡献力量,尽管他们现在经常被一些依赖 Git 的公司全职雇用,并希望对其进行维护和改进。
+
+其中一名志愿者是 Jeff King,人们叫他 Peff,他在学生时代就开始参与贡献了。他的第一次代码提交是在 2006 年,在将他的代码仓库从 CVS 迁移到 Git 时发现并修复了 [git-cvsimport](https://git-scm.com/docs/git-cvsimport) 中的一个错误。**“当时我是计算机科学与技术专业的研究生,”**他说,**“所以我花了很多时间在 Git 的邮件列表上,回答问题、修复 bug —— 有时是一些困扰我的问题,有时是对其他人报告的回复。到 2008 年左右,我意外地成为了主要贡献者之一。** King 从 2011 年开始受雇于 Guthub 公司,在工作的同时,也为 Git 贡献自己的一份力量。
+
+King 特别提到了 Git 的两位贡献者的杰出工作,他们都始于 2006 年,并帮助将 Git 的影响扩展到 Linux 社区之外:感谢 Shawn Pearce 为 [JGit](https://gerrit.googlesource.com/jgit/) 所做的工作,为 Java 和 Android 生态系统打开了 Git 的大门;感谢 Johannes Schindelin 为 Git for Windows 所做的工作,向 Windows 社区开放了 Git。他们随后分别在谷歌和微软工作。
+
+**“\[Shawn Pearce\] 是 Git 的早期贡献者并且实现了 [git-gui](https://git-scm.com/docs/git-gui),这是 Git 的第一个图形化界面。但更重要的是他在 JGit 上的工作,JGit 是 Git 的纯 Java 实现”** King 说。**“这使得 Git 用户的整个其他生态系统得以实现,并允许 Eclipse 插件,这是 Android 项目选择 Git 作为其版本控制系统的关键部分。他还写了 [Gerrit](https://www.gerritcodereview.com/) \[在 Google 工作时\],一个基于 Git 的代码审查系统,用于 Android 和许多其它项目。不幸的是,[Shawn 在 2018 年去世](https://sfconservancy.org/blog/2018/jan/30/shawn-pearce/)。”**
+
+Schindelin 现在仍然是 Git for Windows 发行版的维护者。**“由于 Git 是从内核社区中发展而来的,所以对 Windows 支持基本上是后来才想起的,”。**King 说 **“Git 已经被移植到很多平台上,但大多数平台都是类似于 Unix 风格。到目前为止,Windows 是最大的挑战。在 C 代码中不仅存在可移植性问题,而且还存在使用 Bourne shell、Perl 等编写的部分来发布应用程序的挑战。Git for Windows 将所有这些复杂性整合到一个单一的二进制包中,对 Windows 开发人员使用 Git 的增长产生了重大影响。”**
+
+根据 [somsubhra.com](https://www.somsubhra.com/github-release-stats/?username=git-for-windows&repository=git) 统计,Git for Windows 迄今已被下载超过 1800 万次。
+
+## 建立 GitHub
+
+Tom Preston-Werner 是由同事 Dave Fayram 介绍给 Git的,当时他在为一家名为 [Powerset](https://en.wikipedia.org/wiki/Powerset_(company)) 的初创公司做辅助项目。**“\[用 Git \]创建分支、对其进行操作并轻松地将其合并回主分支的能力是革命性的。在这方面 Git 是惊人的。命令行界面需要适应,特别是有一个缓冲区的概念,”** Preston Werner 说。提供基于 Git 的源代码托管服务的机会是显而易见的。**“托管 Git 仓库没有任何好的选择,因此,这对易用性来说是一个大障碍。还缺少一个现代的 web 界面。作为一名 web 开发人员,我认为我可以通过轻松托管 Git 仓库和促进协作来改善这种情况,这是 Git 可以做到的,但并不容易,”**他补充道。
+
+Preston-Werner 与 Chris Wanstrath、Scott Chacon 和 P.J. Hyett 合作,于 2007 年底开始开发 GitHub 项目。GitHub 帮助 Git 成为主流,不仅使它更易于使用,还将其传播到 Linux 社区之外。由于 GitHub 的创始人是 Ruby 开发人员,而且 GitHub 是用 Ruby 编写的,所以这个词很快就在这个社区中传开了,并在被 [Ruby on Rails](https://github.com/rails/rails) 开发框架采用时大获成功。
+
+**“到 2008 年年中,Ruby on Rails 转向了 GitHub,整个 Ruby 社区似乎都很快跟进。我认为,这种背书,加上 Ruby 开发人员愿意接受更新、更好的技术,这些对我们的成功都至关重要。”**Preston-Werner 说。**“其他项目,如 [Node.js](https://github.com/nodejs) 和 [Homebrew](https://github.com/Homebrew),都是从 GitHub 开始的,帮助将 Git 引入了新的社区。”**
+
+Preston-Werner 在 2014 年[辞去了 GitHub CEO 一职](https://github.blog/2014-04-28-follow-up-to-the-investigation-results/),当时有人指控该公司存在欺凌行为和不适当的投诉程序,这些问题或许是该公司发展过快的征兆。
+
+今天,根据 GitHub [自己的数据](https://octoverse.github.com/),GitHub 有超过 4000 万注册开发者。这使得它比竞争对手 —— [Bitbucket 拥有1000万用户](https://bitbucket.org/blog/celebrating-10-million-bitbucket-cloud-registered-users)的规模要大得多,而 GitLab 则表示,它拥有“数百万”用户。
+
+## 被 Android 采用
+
+许多公司使用 [GitHub 企业版](https://github.com/customer-stories?type=enterprise)、[GitLab](https://about.gitlab.com/customers/) 或 Bitbucket 来托管软件项目。但是,最大的 Git 安装往往是内部托管的 —— 因此是在公共视野之外 —— 通常进行定制的修改。
+
+Google 是第一个 Git 的主要采用者(因此也提供了大量的支持),谷歌在 2009 年 3 月决定将 Git 用于 Android 项目,Android 是一个基于 Linux 的手机操作系统。作为开源项目,Android 需要一个允许大量开发人员克隆、使用和贡献代码的平台,并且无需购买特定的工具许可证书。
+
+当时,Git 被认为不足以管理如此庞大的项目,因此团队构建了一个超级仓库,可以委托给子 Git 仓库。然而,谷歌表示:**“超级仓库并不是要取代 Git,只是为了让 Git 更容易使用。**为了帮助查看仓库和管理、审查对源代码的更改,Pearce 领导的团队 —— 创建了 [Gerrit](https://gerrit.googlesource.com/gerrit/)。
+
+## Microsoft 改变态度
+
+考虑到开源社区和微软之间相互仇恨的历史,这个软件巨头肯定是 Git 最不可能的支持者。2001 年,当时的微软首席执行 Steve Ballmer 甚至[称 Linux 为癌症](https://www.theregister.co.uk/2001/06/02/ballmer_linux_is_a_cancer/),微软也有自己的竞争对手 VCS TFVC。
+
+Schindelin 在 Git for Windows 上工作了多年,而微软没有任何人注意到他的努力。但是,到 2015 年,当他在微软工作时,文化发生了巨大的转变。他开玩笑说:**“如果你在 2007 年问我,或者在 2011 年问过我,我是否会拥有一台 Windows 机器,甚至在微软工作,我都会笑死的。**
+
+这一文化转变的第一个证据出现在 2012 年,当时微软开始(实际上)为 Git 开发资源库 [libgit2](https://libgit2.org/)(一个 Git 开发资源库)做出贡献,以帮助加快 Git 应用程序的速度,然后将其嵌入到开发工具中。Edward Thomson,微软团队的一员,仍然是 libgit2 的维护者。
+
+2013 年,微软宣布对其开发工具 Visual Studio(VS)提供 Git 支持,并通过 Azure DevOps(当时称为 Team Foundation Service)的云计算工具和服务套件提供 Git 托管,作为其自身 TFVC 的替代方案,这一消息震惊了科技界。
+
+更值得注意的是,从 2014 年开始,在新的开源友好型 CEO Satya Nadella 的领导下,微软通过 One Engineering System(1ES)计划,在 Git 上逐步实现了内部软件开发的标准化。Azure DevOps 团队在 2015 年开始使用自己的 Git 服务作为自己源码的存储库,这是一个先例。
+
+2017年,微软 Windows 产品套件的整个开发工作转移到了由 Azure 托管的 Git 上,创建了[世界上最大的 Git 存储库](https://devblogs.microsoft.com/bharry/the-largest-git-repo-on-the-planet/)。这包括相当大的调整以帮助 Git 扩展。Git 的[虚拟文件系统](https://vfsforgit.org/)(它是开源的)并没有将整个 300GB 的 Windows 存储库下载到每个客户端设备,而是确保只将适当的文件下载到每个工程师的计算机上。
+
+正如 Schindelin 所指出的:**“当像微软这样历史悠久的大公司决定 Git 可以投入企业级使用时,商业界会非常仔细地倾听。我认为这就是为什么 Git 至少在目前为止是‘赢家’的原因。**
+
+## 收购!
+
+2018 年 6 月,微软[宣布](https://news.microsoft.com/2018/06/04/microsoft-to-acquire-github-for-7-5-billion/)将以 75 亿美元的价格收购 GitHub,这让人大吃一惊。但当你看事实的时候,也许会觉得这次收购并不是那么出乎意料。
+
+微软从 2014 年开始参与 GitHub,当时。.Net 开发者平台是[开源的](https://devblogs.microsoft.com/dotnet/net-core-is-open-source/)。据 [GitHub Octoverse 2019](https://octoverse.github.com/) 调查显示,目前 GitHub 上贡献最多的两个项目都是微软的产品 —— [Visual Studio code](https://github.com/microsoft/vscode) 和 [Microsoft Azure](https://github.com/Azure),而 [OSCI/EPAM 在 2019 年的研究](https://solutionshub.epam.com/OSCI/)显示,微软是 GitHub 上最大的企业贡献者。并且,如前所述,微软已经在 Git 上标准化了内部开发。
+
+```
+开源项目的贡献者数量
+
+| 项目 | 贡献人数 |
+| -------------------------------------- | ------------- |
+| Microsoft/vscode | 19.1k |
+| MicrosoftDocs/azure-docs | 14k |
+| flutter/flutter | 13k |
+| firstcontributions/first-contributions | 11.6k |
+| tensorflow/tensorflow | 9.9k |
+| facebook/react-native | 9.1k |
+| kubernetes/kubernetes | 6.9k |
+| DefinitelyTyped/DefinitelyTyped | 6.9k |
+| ansible/ansible | 6.8k |
+| home-assistant/home-assistant | 6.3k |
+
+来源:GitHub Octoverse 2019
+```
+
+```
+在 GitHub 上的开源项目的公司中活跃的贡献者的数量
+
+| 公司 | 活跃贡献者 |
+| -------------| -------------------- |
+| Microsoft | 4,859 |
+| Google | 4,457 |
+| Red Hat | 2,766 |
+| IBM | 2,108 |
+| Intel | 2,079 |
+| Facebook | 1,114 |
+| Amazon | 850 |
+| Pivotal | 767 |
+| SAP | 732 |
+| GitHub | 663 |
+
+来源: OSCI/EPAM research January 2020
+```
+
+尽管如此,这次收购还是引起了一些 GitHub 用户的担忧,他们还记得在开源社区的眼中刺 Ballmer 领导下的老微软。Bitbucket 和 GitLab 都声称看到了从 GitHub 迁移到他们平台的项目激增。
+
+不过,Torvalds 并不这么认为。**“我对微软的收购没有任何保留意见,部分原因是 Git 的基本分布式特性 —— 它避免了政治问题,另一方面也避免了可怕的‘托管公司控制项目’。我不担心的另一个原因是,我认为微软现在是一家不同的公司...微软根本不是开源的敌人。”**他说,**“在纯粹个人层面上,当我听说微软在 GitHub 上花了很多钱时,我只是说,‘现在我开始的两个项目已经变成了价值数十亿美元的产业’,没有多少人能这么说。我也不只是一个“昙花一现的人”。**
+**“这是‘生活幸福’的一部分。我很高兴我对世界产生了积极而有意义的影响。我个人可能没有直接从 Git 上赚到任何钱,但它给了我能够做我真正的工作和激情,[Linux]。我不再是一个饥肠辘辘的学生了,我作为一个受人尊敬的程序员做得很好。所以其他人在 Git 上获得的成功绝不会让我感到沮丧。”**
+
+**贡献者。感谢:Linus Torvalds,Git 和 Linux 的创始人;Johannes Schindelin,微软软件工程师,Git for Windows 的维护者;Jeff King, GitHub 的 OSS 开发人员;Tom Preston Werner,Chatterbug 的联合创始人,GitHub 的联合创始人;Edward Thomson,GitHub 的产品经理,以及 libgit2 的维护者;Ben Straub,Pro Git 的作者;Evan Phoenix,Rubinius 的创建者;GitLab 高级后端工程师 Christian Couder;GitLab首席营销官 Todd Barr;EPAM 交付管理总监 Patrick Stephens。**
+
+**本文出自 Behind the Code —— 由开发者创建的服务于开发者的媒体平台。通过访问 [Behind the Code](https://www.welcometothejungle.com/collections/behind-the-code),可以发现更多的文章和视频!**
+
+**想要参与贡献?[出版!](https://docs.google.com/forms/d/e/1FAIpQLSeelH8Eh0HohNrrDWnmKJGBRsFijXfMsMw1fPxOSGdMVypCyg/viewform?usp=sf_link)**
+
+**在 [Twitter](https://twitter.com/behind_thecode) 上关注我们吧,保持关注!**
+
+**[Blok](https://fr.creasenso.com/portfolio/blok) 声明**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/build-a-blog-using-nuxt-strapi-and-apollo.md b/TODO1/build-a-blog-using-nuxt-strapi-and-apollo.md
new file mode 100644
index 00000000000..fea0650d307
--- /dev/null
+++ b/TODO1/build-a-blog-using-nuxt-strapi-and-apollo.md
@@ -0,0 +1,727 @@
+> * 原文地址:[Build a blog with Nuxt (Vue.js), Strapi and Apollo](https://strapi.io/blog/build-a-blog-using-nuxt-strapi-and-apollo)
+> * 原文作者:[Maxime Castres](https://slack.strapi.io/)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/build-a-blog-using-nuxt-strapi-and-apollo.md](https://github.com/xitu/gold-miner/blob/master/TODO1/build-a-blog-using-nuxt-strapi-and-apollo.md)
+> * 译者:[vitoxli](https://github.com/vitoxli)
+> * 校对者:[Jessica](https://github.com/cyz980908)
+
+# 使用 Nuxt (Vue.js)、Strapi 和 Apollo 构建博客
+
+## 介绍
+
+几周前,我对自己上网的习惯进行了思考,具体来说,我主要思考了在放松状态下自己喜欢读些什么。通常我是这样做的:先进行搜索,然后去浏览最让我感兴趣的链接。然而最后发现,我总是在阅读有关别人人生经历的文章,而这与我最初搜索的内容相去甚远!
+
+博客非常适合分享经验,想法或感言。而 Strapi 可以帮助你方便地创建博客!所以,你肯定已经猜到这篇文章是关于什么的了。让我们学习如何使用 Strapi 来创建博客吧。
+
+## 目标
+
+如果你关注我们的博客,你应该已经学习了如何使用 [Gatsby](https://strapi.io/blog/building-a-static-website-using-gatsby-and-strapi) 来创建博客。但是,如果改用另一种语言该怎么实现呢?今天我们就是要学习如何使用 Vue.js 来创建博客。
+
+本文的目标是创建一个博客网站,这个网站使用 Strapi 作为后端,使用 Nuxt 作为前端,并使用 Apollo 通过 GraphQL 请求 Strapi API。
+
+可以在 GitHub 中获取源码:[https://github.com/strapi/strapi-tutorials/tree/master/tutorials/nuxt-strapi-apollo-blog/](https://github.com/strapi/strapi-tutorials/tree/master/tutorials/nuxt-strapi-apollo-blog/)
+
+## 准备工作
+
+要学习本教程,你的计算机上需要安装 Strapi 和 Nuxt,但是不用担心,我们来一起安装它们!
+
+**本教程使用 Strapi v3.0.0-beta.17.5。**
+
+**你需要确保安装了 v.12 版的 node。**
+
+## 安装
+
+创建一个名为 blog-strapi 的文件夹并跳转到这个文件夹中!
+
+* `mkdir blog-strapi && cd blog-strapi`
+
+#### 安装后端
+
+这部分很容易,因为在 beta.9 中有了一个很棒的软件包 [create strapi-app]([https://www.npmjs.com/package/create-strapi-app](https://www.npmjs.com/package/create-strapi-app)),你无需全局安装 Strapi 便可在几秒钟内创建一个 Strapi 项目,所以让我们尝试一下。
+
+(在这篇教程中,我们会使用 `yarn` 作为包管理工具)
+
+* `yarn create strapi-app backend --quickstart --no-run`.
+
+这条命令行将创建后端所需的全部内容。记得添加 `--no-run`,因为它会阻止应用自动启动服务,之所以这么做,是因为**剧透:我们需要安装一些很棒的 Strapi 插件。**
+
+既然你已经知道我们需要安装一些插件来增强应用了,那让我们来安装广受欢迎的 `graphql` 插件吧:
+
+* `yarn strapi install graphql`
+
+安装完成后,你可以通过 `strapi dev` 来启动 Strapi 服务并且创建你的第一个管理员账号。这个账号拥有应用的所有权限,所以选择一个合适的密码吧,像(**password123**)这种密码就太不安全了。
+
+
+
+Strapi 运行在 [http://localhost:1337](http://localhost:1337)
+
+**很好!** 现在 Strapi 已经就绪了,我们可以开始创建 Nuxt 应用了。
+
+#### 安装前端
+
+好啦,最简单的部分已经完成了,现在让我们开发我们的博客吧!
+
+**安装 Nuxt**
+
+通过以下命令来创建 Nuxt `前端`服务:
+
+* `yarn create nuxt-app frontend`
+
+**注意:** 终端将提示一些有关项目的详细信息。这些信息与我们的博客关联性不大,因此可以忽略它们。不过,我仍强烈建议你阅读官方文档。让我们继续吧,一直按 Enter 键就好!
+
+同样,安装结束后,可以启动前端应用以确保进展顺利。
+
+```
+cd frontend
+yarn dev
+```
+
+你可能希望有人阅读你的博客或者你想让你的博客“可爱又好看”,我们将使用流行的 CSS 框架 `UiKit` 来设置样式并使用 `Apollo` 通过 **GraphQL** 来查询 Strapi。
+
+**安装依赖**
+
+在运行以下命令前,先确保你在 `frontend` 文件夹中:
+
+**安装 Apollo**
+
+* `yarn add @nuxtjs/apollo graphql`
+
+必须在 `nuxt.config.js` 中进行模块和 Apollo 的设置。
+
+* 在 `nuxt.config.js` 中添加以下模块和 apollo 配置:
+
+`/frontend/nuxt.config.js`
+
+```js
+...
+modules: [
+ '@nuxtjs/apollo',
+],
+apollo: {
+ clientConfigs: {
+ default: {
+ httpEndpoint: process.env.BACKEND_URL || "http://localhost:1337/graphql"
+ }
+ }
+},
+...
+```
+
+(因为我们已经在安装后端时安装了 graphql 插件,所以无需再次安装。这种方式可以让项目更加一致)。
+
+**安装 Uilkit**
+
+UIkit 是一个轻量级的模块化前端框架,用于开发快速而强大的 Web 界面。
+
+* `yarn add uikit`
+
+现在,你需要通过创建一个插件来在 Nuxt 应用中初始化 UIkit 的 Js。
+
+* 创建 `/frontend/plugins/uikit.js` 文件并复制/粘贴下面的代码:
+
+```js
+import Vue from 'vue'
+
+import UIkit from 'uikit/dist/js/uikit-core'
+import Icons from 'uikit/dist/js/uikit-icons'
+
+UIkit.use(Icons)
+UIkit.container = '#__nuxt'
+
+Vue.prototype.$uikit = UIkit
+```
+
+* Add the following part in your `nuxt.config.js` file
+
+```css
+...
+css: [
+ 'uikit/dist/css/uikit.min.css',
+ 'uikit/dist/css/uikit.css',
+ '@assets/css/main.css'
+ ],
+ /*
+ ** Plugins to load before mounting the App
+ */
+ plugins: [
+ { src: '~/plugins/uikit.js', ssr: false }
+ ],
+...
+```
+
+如你所见,我们同时配置了 UIkit 和 `main.css`!现在,我们需要创建 `main.css` 文件。
+
+```css
+a {
+ text-decoration: none;
+}
+
+h1 {
+ font-family: Staatliches;
+ font-size: 120px;
+}
+
+#category {
+ font-family: Staatliches;
+ font-weight: 500;
+}
+
+#title {
+ letter-spacing: .4px;
+ font-size: 22px;
+ font-size: 1.375rem;
+ line-height: 1.13636;
+}
+
+#banner {
+ margin: 20px;
+ height: 800px;
+}
+
+#editor {
+ font-size: 16px;
+ font-size: 1rem;
+ line-height: 1.75;
+}
+
+.uk-navbar-container {
+ background: #fff !important;
+ font-family: Staatliches;
+}
+
+img:hover {
+ opacity: 1;
+ transition: opacity 0.25s cubic-bezier(0.39, 0.575, 0.565, 1);
+}
+```
+
+**注意:** 你无需理解这个文件中的内容。只是一些样式 ;)
+
+让我们为项目添加漂亮的字体(Staatliches)吧!
+
+* 将下面的对象添加到 `nuxt.config.js` 文件中的 `link` 数组中
+
+```js
+link: [
+ { rel: 'stylesheet', href: 'https://fonts.googleapis.com/css?family=Staatliches' }
+ ]
+```
+
+**完美!** 重启服务,并准备好被你应用的前端页面惊艳吧!
+
+
+
+#### 设计数据结构
+
+终于到了这一步!我们将通过创建 `article` 内容类型来构建文章的数据结构:
+
+* 查看你的 strapi 管理面板,然后点击侧边栏中的 `Content Type Builder`
+
+
+
+* 点击 `Add A Content Type` 并命名为 `article`
+
+
+
+现在,你将为你的内容类型创建所有字段:
+
+
+
+* 创建如下字段:
+ * `title`:**String** 类型 (**必填**)
+ * `content`:**Rich Text** 类型 (**必填**)
+ * `image`:**Media** 类型 (**必填**)
+ * `published_at`:**Date** 类型 (**必填**)
+
+**点击保存!** 现在,你的第一个内容类型就创建好了。可能现在你就想创建你的第一篇文章,但是在此之前我们还要做一件事:**开放文章内容类型权限**
+
+* 点击 [Roles & Permission](http://localhost:1337/admin/plugins/users-permissions/roles) 然后选择 `public`。
+* 选中文章的`find` 和 `findone` 选项并保存。
+
+
+
+**棒极了!** 现在你可以创建你的第一篇文章了,并可以在 GraphQL Playground 中获取到它。
+
+* 创建你的第一篇文章还有更多内容!
+
+**例子如下** 
+
+**棒极了!** 现在,你可能想通过 API 真正地获取到文章!
+
+* 访问 [http://localhost:1337/articles](http://localhost:1337/articles)
+
+这是不是很棒!你还可以使用 [GraphQL Playground](http://localhost:1337/graphql) 尝试获取文章
+
+
+
+#### 创建分类
+
+你可能想为文章设置一个分类(新闻、趋势、看法)。你将通过在 strapi 中创建另一种内容类型来做到这一点。
+
+* 创建一个具有如下字段的 `category` 内容类型
+ * `name`:**String** 类型
+
+**点击保存!**
+
+* 在 **Article** 内容类型中创建 **Relation** 的**新字段**,如下图所示,`一个分类下有很多文章`。
+
+
+
+* 点击 [Roles & Permission](http://localhost:1337/admin/plugins/users-permissions/roles) 并点击 `public`。 选择分类的 `find` 和 `findone` 选项并保存。
+
+现在,你可以在右侧的边栏中为文章选择一个类别。
+
+
+
+
+现在我们已经熟悉了 Strapi,让我们开始前端的部分吧!
+
+#### 为应用创建布局
+
+Nuxt 将默认的布局存储在 `layouts/default.vue` 文件中。让我们将其修改为我们自己的!
+
+```html
+<template>
+ <div>
+
+ <nav class="uk-navbar-container" uk-navbar>
+ <div class="uk-navbar-left">
+
+ <ul class="uk-navbar-nav">
+ <li><a href="#modal-full" uk-toggle><span uk-icon="icon: table"></span></a></li>
+ <li>
+ <a href="/">Strapi Blog
+ </a>
+ </li>
+ </ul>
+
+ </div>
+
+ <div class="uk-navbar-right">
+ <ul class="uk-navbar-nav">
+ <!-- <li v-for="category in categories">
+ <router-link :to="{ name: 'categories-id', params: { id: category.id }}" tag="a">{{ category.name }}
+ </router-link>
+ </li> -->
+ </ul>
+ </div>
+ </nav>
+
+ <div id="modal-full" class="uk-modal-full" uk-modal>
+ <div class="uk-modal-dialog">
+ <button class="uk-modal-close-full uk-close-large" type="button" uk-close></button>
+ <div class="uk-grid-collapse uk-child-width-1-2@s uk-flex-middle" uk-grid>
+ <div class="uk-background-cover" style="background-image: url('https://images.unsplash.com/photo-1493612276216-ee3925520721?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=3308&q=80 3308w');" uk-height-viewport></div>
+ <div class="uk-padding-large">
+ <h1 style="font-family: Staatliches;">Strapi blog</h1>
+ <div class="uk-width-1-2@s">
+ <ul class="uk-nav-primary uk-nav-parent-icon" uk-nav>
+ <!-- <li v-for="category in categories">
+ <router-link class="uk-modal-close" :to="{ name: 'categories-id', params: { id: category.id }}" tag="a">{{ category.name }}
+ </router-link>
+ </li> -->
+ </ul>
+ </div>
+ <p class="uk-text-light">Built with strapi</p>
+ </div>
+ </div>
+ </div>
+ </div>
+
+ <nuxt />
+ </div>
+</template>
+
+<script>
+
+export default {
+}
+
+</script>
+```
+
+如你所见,两段代码被注释了。
+
+```html
+ <!-- <li v-for="category in categories">
+ <router-link :to="{ name: 'categories-id', params: { id: category.id }}" tag="a">{{ category.name }}
+ </router-link>
+ </li> -->
+...
+
+ <!-- <li v-for="category in categories">
+ <router-link class="uk-modal-close" :to="{ name: 'categories-id', params: { id: category.id }}" tag="a">{{ category.name }}
+ </router-link>
+ </li> -->
+
+```
+
+实际上,你希望能够列出导航栏中的每个分类。为此,我们需要使用 Apollo 来获取它们,让我们来编写查询!
+
+* 创建 `apollo/queries/category` 文件夹并在其中创建 `categories.gql` 文件,文件内容如下:
+
+```graphql
+query Categories {
+ categories {
+ id
+ name
+ }
+}
+```
+
+* 取消注释并用下面的代码替换 `default.vue` 文件中 `script` 标签中的内容。
+
+```html
+<script>
+import categoriesQuery from '~/apollo/queries/category/categories'
+
+export default {
+ data() {
+ return {
+ categories: [],
+ }
+ },
+ apollo: {
+ categories: {
+ prefetch: true,
+ query: categoriesQuery
+ }
+ }
+}
+
+</script>
+```
+
+**注意**当前代码不适合展示很多分类,所以你可能会遇到一些 UI 的问题。而且本篇文章应该要简短一些,所以你可以通过懒加载等方式来自己改进代码。
+
+目前,链接不起作用,我们将在教程后面部分进行处理 ;)
+
+### 创建文章组件
+
+这个组件将在不同的页面上显示你所有文章,因此通过一个组件列出它们并不是一个坏主意。
+
+* 创建 `components/Articles.vue` 文件并包含如下内容:
+
+```html
+<template>
+ <div>
+
+ <div class="uk-child-width-1-2" uk-grid>
+ <div>
+ <router-link v-for="article in leftArticles" :to="{ name: 'articles-id', params: {id: article.id} }" class="uk-link-reset">
+ <div class="uk-card uk-card-muted">
+ <div v-if="article.image" class="uk-card-media-top">
+ <img :src="'http://localhost:1337' + article.image.url" alt="" height="100">
+ </div>
+ <div class="uk-card-body">
+ <p id="category" v-if="article.category" class="uk-text-uppercase">{{ article.category.name }}</p>
+ <p id="title" class="uk-text-large">{{ article.title }}</p>
+ </div>
+ </div>
+ </router-link>
+
+ </div>
+ <div>
+ <div class="uk-child-width-1-2@m uk-grid-match" uk-grid>
+ <router-link v-for="article in rightArticles" :to="{ name: 'articles-id', params: {id: article.id} }" class="uk-link-reset">
+ <div class="uk-card uk-card-muted">
+ <div v-if="article.image" class="uk-card-media-top">
+ <img :src="'http://localhost:1337/' + article.image.url" alt="" height="100">
+ </div>
+ <div class="uk-card-body">
+ <p id="category" v-if="article.category" class="uk-text-uppercase">{{ article.category.name }}</p>
+ <p id="title" class="uk-text-large">{{ article.title }}</p>
+ </div>
+ </div>
+ </router-link>
+ </div>
+
+ </div>
+ </div>
+
+ </div>
+</template>
+
+<script>
+import articlesQuery from '~/apollo/queries/article/articles'
+
+export default {
+ props: {
+ articles: Array
+ },
+ computed: {
+ leftArticlesCount(){
+ return Math.ceil(this.articles.length / 5)
+ },
+ leftArticles(){
+ return this.articles.slice(0, this.leftArticlesCount)
+ },
+ rightArticles(){
+ return this.articles.slice(this.leftArticlesCount, this.articles.length)
+ }
+ }
+}
+</script>
+```
+
+如你所见,多亏了 GraphQL 查询,你可以获取文章,让我们来编写它!
+
+* 创建一个 `apollo/queries/article/articles.gql` 文件并包含如下内容:
+
+```graphql
+query Articles {
+ articles {
+ id
+ title
+ content
+ image {
+ url
+ }
+ category{
+ name
+ }
+ }
+}
+```
+
+**太棒了!** 现在可以创建你的主页面了。
+
+### 索引页
+
+让我们使用新组件来列出索引页上的每篇文章!
+
+* 更新 `pages/index.vue` 文件中的代码:
+
+```html
+<template>
+ <div>
+
+ <div class="uk-section">
+ <div class="uk-container uk-container-large">
+ <h1>Strapi blog</h1>
+
+ <Articles :articles="articles"></Articles>
+
+ </div>
+ </div>
+
+ </div>
+</template>
+
+<script>
+import articlesQuery from '~/apollo/queries/article/articles'
+import Articles from '~/components/Articles'
+
+export default {
+ data() {
+ return {
+ articles: [],
+ }
+ },
+ components: {
+ Articles
+ },
+ apollo: {
+ articles: {
+ prefetch: true,
+ query: articlesQuery,
+ variables () {
+ return { id: parseInt(this.$route.params.id) }
+ }
+ }
+ }
+}
+</script>
+```
+
+**太棒了!** 现在你可以通过 GraphQL API 真正地获取到文章了!
+
+
+
+### 文章页
+
+如果你点击文章,现在是没有任何东西的。让我们一起来创建文章页吧!
+
+* 创建 `pages/articles` 文件夹并在其中创建 `_id.vue` 文件,文件代码如下:
+
+```html
+<template>
+ <div>
+
+ <div v-if="article.image" id="banner" class="uk-height-small uk-flex uk-flex-center uk-flex-middle uk-background-cover uk-light uk-padding" :data-src="'http://localhost:1337' + article.image.url" uk-img>
+ <h1>{{ article.title }}</h1>
+ </div>
+
+ <div class="uk-section">
+ <div class="uk-container uk-container-small">
+ <div v-if="article.content" id="editor">{{ article.content }}</div>
+ <p v-if="article.published_at">{{ moment(article.published_at).format("MMM Do YY") }}</p>
+ </div>
+ </div>
+
+ </div>
+</template>
+
+<script>
+import articleQuery from '~/apollo/queries/article/article'
+var moment = require('moment')
+
+export default {
+ data() {
+ return {
+ article: {},
+ moment: moment,
+ }
+ },
+ apollo: {
+ article: {
+ prefetch: true,
+ query: articleQuery,
+ variables () {
+ return { id: parseInt(this.$route.params.id) }
+ }
+ }
+ }
+}
+</script>
+```
+
+这里只需要获取一篇文章,让我们编写查询!
+
+* 创建 `apollo/queries/article/article.gql`,包含如下代码:
+
+```graphql
+query Articles($id: ID!) {
+ article(id: $id) {
+ id
+ title
+ content
+ image {
+ url
+ }
+ published_at
+ }
+}
+
+```
+
+
+
+好了,你可能想用 Markdown 语法来展示博客内容?
+
+* 通过 `yarn add @nuxtjs/markdownit` 安装 `markdownit`。
+* 将其添加到 `nuxt.config.js` 文件的模块中,并在下面添加 mardownit 对象的配置:
+
+```js
+...
+modules: [
+ '@nuxtjs/apollo',
+ '@nuxtjs/markdownit'
+],
+markdownit: {
+ preset: 'default',
+ linkify: true,
+ breaks: true,
+ injected: true
+ },
+...
+```
+
+* 通过替换负责显示内容的代码,来显示 `_id.vue` 文件中的内容。
+
+```html
+...
+<div v-if="article.content" id="editor" v-html="$md.render(article.content)"></div>
+...
+```
+
+
+
+### 分类
+
+现在让我们为每个分类创建一个页面!
+
+* 创建 `pages/categories` 文件夹并在其中创建 `_id.vue` 文件,该文件包含如下代码:
+
+```html
+<template>
+ <div>
+
+ <client-only>
+ <div class="uk-section">
+ <div class="uk-container uk-container-large">
+ <h1>{{ category.name }}</h1>
+
+ <Articles :articles="category.articles || []"></Articles>
+
+ </div>
+ </div>
+ </client-only>
+ </div>
+</template>
+
+<script>
+import articlesQuery from '~/apollo/queries/article/articles-categories'
+import Articles from '~/components/Articles'
+
+export default {
+ data() {
+ return {
+ category: []
+ }
+ },
+ components: {
+ Articles
+ },
+ apollo: {
+ category: {
+ prefetch: true,
+ query: articlesQuery,
+ variables () {
+ return { id: parseInt(this.$route.params.id) }
+ }
+ }
+ }
+}
+</script>
+```
+
+别忘记写查询!
+
+* 创建 `apollo/queries/article/articles-categories` 包含以下内容:
+
+```graphql
+query Category($id: ID!){
+ category(id: $id) {
+ name
+ articles {
+ id
+ title
+ content
+ image {
+ url
+ }
+ category {
+ id
+ name
+ }
+ }
+ }
+}
+```
+
+
+
+**太棒了!** 现在可以通过分类来导航了 :)
+
+### 总结
+
+恭喜,你成功地完成了本教程。希望你喜欢它!
+
+
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/combine-getting-started.md b/TODO1/combine-getting-started.md
new file mode 100644
index 00000000000..28eea746de9
--- /dev/null
+++ b/TODO1/combine-getting-started.md
@@ -0,0 +1,473 @@
+> * 原文地址:[Combine: Getting Started](https://www.raywenderlich.com/7864801-combine-getting-started)
+> * 原文作者:[Fabrizio Brancati](https://www.raywenderlich.com/u/fbrancati)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/combine-getting-started.md](https://github.com/xitu/gold-miner/blob/master/TODO1/combine-getting-started.md)
+> * 译者:
+> * 校对者:
+
+# Combine: Getting Started
+
+> Learn how to use Combine’s Publisher and Subscriber to handle event streams, merge multiple publishers and more.
+
+Combine, announced at WWDC 2019, is Apple's new "reactive" framework for handling events over time. You can use Combine to unify and simplify your code for dealing with things like delegates, notifications, timers, completion blocks and callbacks. There have been third-party reactive frameworks available for some time on iOS, but now Apple has made its own.
+
+In this tutorial, you'll learn how to:
+
+- Use `Publisher` and `Subscriber`.
+- Handle event streams.
+- Use `Timer` the Combine way.
+- Identify when to use Combine in your projects.
+
+You'll see these key concepts in action by enhancing FindOrLose, a game that challenges you to quickly identify the one image that's different from the other three.
+
+Ready to explore the magic world of Combine in iOS? Time to dive in!
+
+## Getting Started
+
+Download the project materials using the Download Materials button at the top or bottom of this tutorial.
+
+Open the starter project and check out the project files.
+
+Before you can play the game, you must register at [Unsplash Developers Portal](https://unsplash.com/developers) to get an API key. After registration, you'll need to create an app on their developer's portal. Once complete, you'll see a screen like this:
+
+[](https://koenig-media.raywenderlich.com/uploads/2020/01/FinalUnsplashFindOrLose.jpg)
+
+> Note: Unsplash APIs have a rate limit of 50 calls per hour. Our game is fun, but please avoid playing it too much :]
+
+Open UnsplashAPI.swift and add your Unsplash API key to `UnsplashAPI.accessToken` like this:
+
+
+```swift
+enum UnsplashAPI {
+ static let accessToken = "<your key>"
+ ...
+}
+```
+
+Build and run. The main screen shows you four gray squares. You'll also see a button for starting or stopping the game:
+
+[](https://koenig-media.raywenderlich.com/uploads/2020/01/StartScreen.png)
+
+Tap Play to start the game:
+
+[](https://koenig-media.raywenderlich.com/uploads/2020/01/StartGaming.png)
+
+Right now, this is a fully working game, but take a look at `playGame()` in GameViewController.swift. The method ends like this:
+
+```
+ }
+ }
+ }
+ }
+ }
+ }
+```
+
+That's too many nested closures. Can you work out what's happening, and in what order? What if you wanted to change the order things happen in, or bail out, or add new functionality? Time to get some help from Combine!
+
+## Introduction to Combine
+
+The Combine framework provides a declarative API to process values over time. There are three main components:
+
+1. Publishers: Things that produce values.
+2. Operators: Things that do work with values.
+3. Subscribers: Things that care about values.
+
+Taking each component in turn:
+
+### Publishers
+
+Objects that conform to `Publisher` deliver a sequence of values over time. The protocol has two associated types: `Output`, the type of value it produces, and `Failure`, the type of error it could encounter.
+
+Every publisher can emit multiple events:
+
+- An output value of `Output` type.
+- A successful completion.
+- A failure with an error of `Failure`type.
+
+Several Foundation types have been enhanced to expose their functionality through publishers, including `Timer` and `URLSession`, which you'll use in this tutorial.
+
+### Operators
+
+Operators are special methods that are called on publishers and return the same or a different publisher. An operator describes a behavior for changing values, adding values, removing values or many other operations. You can chain multiple operators together to perform complex processing.
+
+Think of values flowing from the original publisher, through a series of operators. Like a river, values come from the upstream publisher and flow to the downstream publisher.
+
+### Subscribers
+
+Publishers and operators are pointless unless something is listening to the published events. That something is the `Subscriber`.
+
+`Subscriber` is another protocol. Like `Publisher`, it has two associated types: `Input` and `Failure`. These must match the `Output` and `Failure` of the publisher.
+
+A subscriber receives a stream of value, completion or failure events from a publisher.
+
+### Putting it together
+
+A publisher starts delivering values when you call `subscribe(_:)` on it, passing your subscriber. At that point, the publisher sends a subscription to the subscriber. The subscriber can then use this subscription to make a request from the publisher for a definite or indefinite number of values.
+
+After that, the publisher is free to send values to the Subscriber. It might send the full number of requested values, but it might also send fewer. If the publisher is finite, it will eventually return the completion event or possibly an error. This diagram summarizes the process:
+
+[](https://koenig-media.raywenderlich.com/uploads/2020/01/Publisher-Subscriber.png)
+
+## Networking with Combine
+
+That gives you a quick overview of Combine. Time to use it in your own project!
+
+First, you need to create the `GameError` enum to handle all `Publisher` errors. From Xcode's main menu, select File ▸ New ▸ File... and choose the template iOS ▸ Source ▸ Swift File.
+
+Name the new file GameError.swift and add it to the Game folder.
+
+Now add the `GameError` enum:
+
+```swift
+enum GameError: Error {
+ case statusCode
+ case decoding
+ case invalidImage
+ case invalidURL
+ case other(Error)
+
+ static func map(_ error: Error) -> GameError {
+ return (error as? GameError) ?? .other(error)
+ }
+}
+```
+
+This gives you all of the possible errors you can encounter while running the game, plus a handy function to take an error of any type and make sure it's a `GameError`. You'll use this when dealing with your publishers.
+
+With that, you're now ready to handle HTTP status code and decoding errors.
+
+Next, import Combine. Open UnsplashAPI.swift and add the following at the top of the file:
+
+```swift
+import Combine
+```
+
+Then change the signature of `randomImage(completion:)` to the following:
+
+```swift
+static func randomImage() -> AnyPublisher<RandomImageResponse, GameError> {
+```
+
+Now, the method doesn't take a completion closure as a parameter. Instead, it returns a publisher, with an output type of `RandomImageResponse` and a failure type of `GameError`.
+
+`AnyPublisher` is a system type that you can use to wrap "any" publisher, which keeps you from needing to update method signatures if you use operators, or if you want to hide implementation details from callers.
+
+Next, you'll update your code to use `URLSession`'s new Combine functionality. Find the line that begins `session.dataTask(with:`. Replace from that line to the end of the method with the following code:
+
+```swift
+// 1
+return session.dataTaskPublisher(for: urlRequest)
+ // 2
+ .tryMap { response in
+ guard
+ // 3
+ let httpURLResponse = response.response as? HTTPURLResponse,
+ httpURLResponse.statusCode == 200
+ else {
+ // 4
+ throw GameError.statusCode
+ }
+ // 5
+ return response.data
+ }
+ // 6
+ .decode(type: RandomImageResponse.self, decoder: JSONDecoder())
+ // 7
+ .mapError { GameError.map($0) }
+ // 8
+ .eraseToAnyPublisher()
+```
+
+This looks like a lot of code, but it's using a lot of Combine features. Here's the step-by-step:
+
+1. You get a publisher from the URL session for your URL request. This is a `URLSession.DataTaskPublisher`, which has an output type of `(data: Data, response: URLResponse)`. That's not the right output type, so you're going to use a series of operators to get to where you need to be.
+2. Apply the `tryMap` operator. This operator takes the upstream value and attempts to convert it to a different type, with the possibility of throwing an error. There is also a `map` operator for mapping operations that can't throw errors.
+3. Check for `200 OK` HTTP status.
+4. Throw the custom `GameError.statusCode` error if you did not get a `200 OK` HTTP status.
+5. Return the `response.data` if everything is OK. This means the output type of your chain is now `Data`
+6. Apply the `decode` operator, which will attempt to create a `RandomImageResponse` from the upstream value using `JSONDecoder`. Your output type is now correct!
+7. Your failure type still isn't quite right. If there was an error during decoding, it won't be a `GameError`. The `mapError` operator lets you deal with and map any errors to your preferred error type, using the function you added to `GameError`.
+8. If you were to check the return type of `mapError` at this point, you would be greeted with something quite horrific. The `.eraseToAnyPublisher` operator tidies all that mess up so you're returning something more usable.
+
+Now, you could have written almost all of this in a single operator, but that's not really in the spirit of Combine. Think of it like UNIX tools, each step doing one thing and passing the results on.
+
+### Downloading an Image With Combine
+
+Now that you have the networking logic, it's time to download some images.
+
+Open the ImageDownloader.swift file and import Combine at the start of the file with the following code:
+
+```swift
+import Combine
+```
+
+Like `randomImage`, you don't need a closure with Combine. Replace `download(url:, completion:)` with this:
+
+```swift
+// 1
+static func download(url: String) -> AnyPublisher<UIImage, GameError> {
+ guard let url = URL(string: url) else {
+ return Fail(error: GameError.invalidURL)
+ .eraseToAnyPublisher()
+ }
+
+ //2
+ return URLSession.shared.dataTaskPublisher(for: url)
+ //3
+ .tryMap { response -> Data in
+ guard
+ let httpURLResponse = response.response as? HTTPURLResponse,
+ httpURLResponse.statusCode == 200
+ else {
+ throw GameError.statusCode
+ }
+
+ return response.data
+ }
+ //4
+ .tryMap { data in
+ guard let image = UIImage(data: data) else {
+ throw GameError.invalidImage
+ }
+ return image
+ }
+ //5
+ .mapError { GameError.map($0) }
+ //6
+ .eraseToAnyPublisher()
+}
+```
+
+A lot of this code is similar to the previous example. Here's the step-by-step:
+
+1. Like before, change the signature so that the method returns a publisher instead of accepting a completion block.
+2. Get a `dataTaskPublisher` for the image URL.
+3. Use `tryMap` to check the response code and extract the data if everything is OK.
+4. Use another `tryMap` operator to change the upstream `Data` to `UIImage`, throwing an error if this fails.
+5. Map the error to a `GameError`.
+6. `.eraseToAnyPublisher` to return a nice type.
+
+### Using Zip
+
+At this point, you've changed all of your networking methods to use publishers instead of completion blocks. Now you're ready to use them.
+
+Open GameViewController.swift. Import Combine at the start of the file:
+
+```swift
+import Combine
+```
+
+Add the following property at the start of the `GameViewController` class:
+
+```swift
+var subscriptions: Set<AnyCancellable> = []
+```
+
+You'll use this property to store all of your subscriptions. So far you've dealt with publishers and operators, but nothing has subscribed yet.
+
+Now, remove all the code in `playGame()`, right after the call to `startLoaders()`. Replace it with this:
+
+```swift
+// 1
+let firstImage = UnsplashAPI.randomImage()
+ // 2
+ .flatMap { randomImageResponse in
+ ImageDownloader.download(url: randomImageResponse.urls.regular)
+ }
+```
+
+In the code above, you:
+
+1. Get a publisher that will provide you with a random image value.
+2. Apply the `flatMap` operator, which transforms the values from one publisher into a new publisher. In this case you're waiting for the output of the random image call, and then transforming that into a publisher for the image download call.
+
+Next, you'll use the same logic to retrieve the second image. Add this right after `firstImage`:
+
+```swift
+let secondImage = UnsplashAPI.randomImage()
+ .flatMap { randomImageResponse in
+ ImageDownloader.download(url: randomImageResponse.urls.regular)
+ }
+```
+
+At this point, you have downloaded two random images. Now it's time to, pardon the pun, *combine* them. You'll use `zip` to do this. Add the following code right after `secondImage`:
+
+```swift
+// 1
+firstImage.zip(secondImage)
+ // 2
+ .receive(on: DispatchQueue.main)
+ // 3
+ .sink(receiveCompletion: { [unowned self] completion in
+ // 4
+ switch completion {
+ case .finished: break
+ case .failure(let error):
+ print("Error: \(error)")
+ self.gameState = .stop
+ }
+ }, receiveValue: { [unowned self] first, second in
+ // 5
+ self.gameImages = [first, second, second, second].shuffled()
+
+ self.gameScoreLabel.text = "Score: \(self.gameScore)"
+
+ // TODO: Handling game score
+
+ self.stopLoaders()
+ self.setImages()
+ })
+ // 6
+ .store(in: &subscriptions)
+```
+
+Here's the breakdown:
+
+1. `zip` makes a new publisher by combining the outputs of existing ones. It will wait until both publishers have emitted a value, then it will send the combined values downstream.
+2. The `receive(on:)` operator allows you to specify where you want events from the upstream to be processed. Since you're operating on the UI, you'll use the main dispatch queue.
+3. It's your first subscriber! `sink(receiveCompletion:receiveValue:)` creates a subscriber for you which will execute those two closures on completion or receipt of a value.
+4. Your publisher can complete in two ways --- either it finishes or fails. If there's a failure, you stop the game.
+5. When you receive your two random images, add them to an array and shuffle, then update the UI.
+6. Store the subscription in `subscriptions`. Without keeping this reference alive, the subscription will cancel and the publisher will terminate immediately.
+
+Finally, build and run!
+
+[](https://koenig-media.raywenderlich.com/uploads/2020/01/GameWithCombine.png)
+
+Congratulations, your app now successfully uses Combine to handle streams of events!
+
+## Adding a Score
+
+As you may notice, scoring doesn't work any more. Before, your score counted down while you were choosing the correct image, now it just sits there. You're going to rebuild that timer functionality, but with Combine!
+
+First, restore the original timer functionality by replacing `// TODO: Handling game score` in `playGame()` with this code:
+
+```swift
+self.gameTimer = Timer
+ .scheduledTimer(withTimeInterval: 0.1, repeats: true) { [unowned self] timer in
+ self.gameScoreLabel.text = "Score: \(self.gameScore)"
+
+ self.gameScore -= 10
+
+ if self.gameScore <= 0 {
+ self.gameScore = 0
+
+ timer.invalidate()
+ }
+}
+```
+
+In the code above, you schedule `gameTimer` to fire every very `0.1` seconds and decrease the score by `10`. When the score reaches `0`, you invalidate `timer`.
+
+Now, build and run to confirm that the game score decreases as time elapses.
+
+[](https://koenig-media.raywenderlich.com/uploads/2020/01/ScoreDecreases.png)
+
+## Using Timers in Combine
+
+Timer is another Foundation type that has had Combine functionality added to it. You're going to migrate across to the Combine version to see the differences.
+
+At the top of `GameViewController`, change the definition of `gameTimer`:
+
+```swift
+var gameTimer: AnyCancellable?
+```
+
+You're now storing a subscription to the timer, rather than the timer itself. This can be represented with `AnyCancellable` in Combine.
+
+Change the first line of`playGame()` and `stopGame()` with the following code:
+
+```swift
+gameTimer?.cancel()
+```
+
+Now, change the `gameTimer` assignment in `playGame()` with the following code:
+
+```swift
+// 1
+self.gameTimer = Timer.publish(every: 0.1, on: RunLoop.main, in: .common)
+ // 2
+ .autoconnect()
+ // 3
+ .sink { [unowned self] _ in
+ self.gameScoreLabel.text = "Score: \(self.gameScore)"
+ self.gameScore -= 10
+
+ if self.gameScore < 0 {
+ self.gameScore = 0
+
+ self.gameTimer?.cancel()
+ }
+ }
+```
+
+Here's the breakdown:
+
+1. You use the new API for vending publishers from `Timer`. The publisher will repeatedly send the current date at the given interval, on the given run loop.
+2. The publisher is a special type of publisher that needs to be explicitly told to start or stop. The `.autoconnect` operator takes care of this by connecting or disconnecting as soon as subscriptions start or are canceled.
+3. The publisher can't ever fail, so you don't need to deal with a completion. In this case, `sink` makes a subscriber that just processes values using the closure you supply.
+
+Build and run and play with your Combine app!
+
+[](https://koenig-media.raywenderlich.com/uploads/2020/01/FinalGame.png)
+
+## Refining the App
+
+There are just a couple of refinements that are missing. You're continuously adding subscribers with `.store(in: &subscriptions)` without ever removing them. You'll fix that next.
+
+Add the following line at the top of `resetImages()`:
+
+```swift
+subscriptions = []
+```
+
+Here, you assign an empty array that will remove all the references to the unused subscriptions.
+
+Next, add the following line at the top of `stopGame()`:
+
+```swift
+subscriptions.forEach { $0.cancel() }
+```
+
+Here, you iterate over all `subscriptions` and cancel them.
+
+Time to build and run one last time!
+
+[](https://koenig-media.raywenderlich.com/uploads/2020/01/FinalGameGIF-1.gif)
+
+## I want to Combine All The Things Now!
+
+Using Combine may seem like a great choice. It's hot, new, and first party, so why not use it now? Here are some things to think about before you go all-in:
+
+### Older iOS Versions
+
+First of all, you need to think about your users. If you want to continue to support iOS 12, you can't use Combine. (Combine requires iOS 13 or above.)
+
+### Your Team
+
+Reactive programming is quite a change of mindset, and there is going to be a learning curve while your team gets up to speed. Is everyone on your team as keen as you to change the way things are done?
+
+### Other SDKs
+
+Think about the technologies your app already uses before adopting Combine. If you have other callback-based SDKs, like Core Bluetooth, you'll have to build wrappers to use them with Combine.
+
+### Gradual Integration
+
+You can mitigate many of these concerns if you start using Combine gradually. Start from the network calls and then move to the other parts of the app. Also, consider using Combine where you currently have closures.
+
+## Where to Go From Here?
+
+You can download the completed version of the project using the Download Materials button at [original article page](https://www.raywenderlich.com/7864801-combine-getting-started).
+
+In this tutorial, you've learned the basics behind Combine's `Publisher` and `Subscriber`. You also learned about using operators and timers. Congratulations, you're off to a good start with this technology!
+
+To learn even more about using Combine, check out our book [Combine: Asynchronous Programming with Swift](https://store.raywenderlich.com/products/combine-asynchronous-programming-with-swift)!
+
+If you have any questions or comments on this tutorial, please join the forum discussion below!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/composing-software-the-book.md b/TODO1/composing-software-the-book.md
new file mode 100644
index 00000000000..00ad43025fd
--- /dev/null
+++ b/TODO1/composing-software-the-book.md
@@ -0,0 +1,71 @@
+> * 原文地址:[Composing Software: The Book](https://medium.com/javascript-scene/composing-software-the-book-f31c77fc3ddc)
+> * 原文作者:[Eric Elliott](https://medium.com/@_ericelliott)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/composing-software-the-book.md](https://github.com/xitu/gold-miner/blob/master/TODO1/composing-software-the-book.md)
+> * 译者:[zoomdong](https://github.com/fireairforce)
+> * 校对者:[Roc](https://github.com/QinRoc), [niayyy](https://github.com/niayyy-S)
+
+# 组合软件:书
+
+
+
+> **注意:** 这是[**“组合软件”系列丛书**](https://leanpub.com/composingsoftware)的一部分,它最初以一个博客文章系列的形式出现在这里。它从头到尾地包含了 JavaScript(ES6+)中的函数式编程和组合软件技术。[“组合软件”同样也有印刷版本](https://www.amazon.com/Composing-Software-Exploration-Programming-Composition/dp/1661212565/ref=as_li_ss_tl?ie=UTF8&linkCode=ll1&tag=eejs-20&linkId=eee1371063c82dea4c2fc72c097868c6&language=en_US)。
+
+“组合软件”是一个热门的博客文章系列,介绍了 JavaScript 中的函数式编程和软件组合,现在是 [Leanpub 上最畅销的书](https://leanpub.com/composingsoftware)。也有[印刷版本](https://www.amazon.com/Composing-Software-Exploration-Programming-Composition/dp/1661212565/ref=as_li_ss_tl?ie=UTF8&linkCode=ll1&tag=eejs-20&linkId=eee1371063c82dea4c2fc72c097868c6&language=en_US)。
+
+2017 年 2 月 8 日,我开始写一篇关于函数式编程的博客文章。[“跌宕起伏的函数式编程”](https://medium.com/javascript-scene/the-rise-and-fall-and-rise-of-functional-programming-composable-software-c2d91b424c8c) 作为《软件组合》系列的介绍文章。当我开始写作的时候,我并不知道它会吸引超过 10 万的读者,也不知道接下来的文章会有超过 100 万的总阅读量,更不知道它能够[出版](https://leanpub.com/composingsoftware),并在发布的一周内跃升到 Leanpub 畅销书排行榜。
+
+我衷心感谢 JS Cheerleader,她使这本书在很多方面变得更好。如果你觉得这些文章是易于阅读的,那是因为她仔细地校验了每一页,并在每一步都提供了深刻的反馈和鼓励。没有她的帮助,你现在就不会读到这些文章。
+
+感谢博客的读者,他们的热情支持帮助我们把这个小小的博客文章系列变成了一个吸引了数百万读者的现象级文章系列,并为我们提供了把它变成一本书的动力。
+
+感谢计算机科学领域中为我们铺平了道路的传奇人物们。
+
+> “如果说我看得更远,那是因为我站在巨人的肩膀上。” —— 艾萨克·牛顿爵士
+
+组合是所有的软件开发方式:将复杂的问题分解成更小的部分,然后将这些更小的解决方案组合在一起,组成了应用程序。
+
+但是我在面试软件开发工作的面试者时注意到,几乎没有人能描述软件上下文中的组合。当我在面试的时候问 “什么是函数组合?” 或者 “什么是对象组合?”,得到的却是支支吾吾的或者没有任何实质的内容的回答。
+
+怎么会这样呢?99% 的专业开发人员 —— 有些拥有 10 年以上的软件开发经验 —— 怎么可能不知道软件工程中组合的两种最基础形式的定义或例子呢?每个人每天都在构建软件的过程中组合函数和对象,那么怎么会有那么多人不理解这些技术的基本原理呢?
+
+事实上,组合根本不是一门人们关注、教得好、学得好的学科。我突然想到,也许这就是为什么[过度复杂化是软件开发人员每天犯的最大错误](https://medium.com/javascript-scene/the-single-biggest-mistake-programmers-make-every-day-62366b432308)。当你不知道如何把乐高积木拼在一起时,你可能会弄坏胶带和胶水,然后变得烦躁......对于软件开发来说,你也会损害软件、你的队友和用户。
+
+你无法摆脱组合软件 —— 软件就是这样组合在一起的。但如果你不认真组合软件的话,你会做得很差,浪费大量的时间和金钱,造成漏洞,甚至导致严重的人类安全问题。我写了这个系列和这本书来改变这一点。
+
+博客文章的麻烦在于它们从来没有官方索引。欢迎使用“组合软件:博客文章”的官方博客文章索引。
+
+* [简介](https://medium.com/javascript-scene/composing-software-an-introduction-27b72500d6ea)
+* [不变性之道](https://medium.com/javascript-scene/the-dao-of-immutability-9f91a70c88cd)
+* [跌宕起伏的函数式编程](https://medium.com/javascript-scene/the-rise-and-fall-and-rise-of-functional-programming-composable-software-c2d91b424c8c)
+* [为什么用 JavaScript 学习函数式编程?](https://medium.com/javascript-scene/why-learn-functional-programming-in-javascript-composing-software-ea13afc7a257)
+* [纯函数](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-pure-function-d1c076bec976)
+* [什么是函数式编程?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-functional-programming-7f218c68b3a0)
+* [函数式程序员的 JavaScript 简介](https://medium.com/javascript-scene/a-functional-programmers-introduction-to-javascript-composing-software-d670d14ede30)
+* [高阶函数](https://medium.com/javascript-scene/higher-order-functions-composing-software-5365cf2cbe99)
+* [柯里化与函数组合](https://medium.com/javascript-scene/curry-and-function-composition-2c208d774983)
+* [抽象与组合](https://medium.com/javascript-scene/abstraction-composition-cb2849d5bdd6)
+* [Functor 与 Category](https://medium.com/javascript-scene/functors-categories-61e031bac53f)
+* [JavaScript 让 Monad 更简单](https://medium.com/javascript-scene/javascript-monads-made-simple-7856be57bfe8)
+* [被遗忘的面向对象编程史](https://medium.com/javascript-scene/the-forgotten-history-of-oop-88d71b9b2d9f)
+* [对象组合中的宝藏](https://medium.com/javascript-scene/the-hidden-treasures-of-object-composition-60cd89480381)
+* [ES6+ 中的 JavaScript 工厂函数](https://medium.com/javascript-scene/javascript-factory-functions-with-es6-4d224591a8b1)
+* [函数式 Mixin](https://medium.com/javascript-scene/functional-mixins-composing-software-ffb66d5e731c)
+* [为什么类中使用组合很难](https://medium.com/javascript-scene/why-composition-is-harder-with-classes-c3e627dcd0aa)
+* [可自定义数据类型](https://medium.com/javascript-scene/composable-datatypes-with-functions-aec72db3b093)
+* [Lenses:可组合函数式编程的 Getter 和 Setter](https://medium.com/javascript-scene/lenses-b85976cb0534)
+* [Transducers:JavaScript 中高效的数据处理 Pipeline](https://medium.com/javascript-scene/transducers-efficient-data-processing-pipelines-in-javascript-7985330fe73d)
+* [JavaScript 样式元素](https://medium.com/javascript-scene/elements-of-javascript-style-caa8821cb99f)
+* [模拟是一种代码异味](https://medium.com/javascript-scene/mocking-is-a-code-smell-944a70c90a6a)
+
+---
+
+**Eric Elliott** 是一名分布式系统专家,并且是 [《组合软件》](https://leanpub.com/composingsoftware)和[《编写 JavaScript 程序》](https://ericelliottjs.com/product/programming-javascript-applications-ebook/)这两本书的作者。作为 [EricElliottJS.com](https://ericelliottjs.com) 和 [DevAnywhere.io](https://devanywhere.io/) 的联合创始人,他教开发人员远程工作和实现工作以及生活平衡所需的技能。他创建了加密项目的开发团队,并为他们提供建议。他还在软件体验上为 **Adobe 系统、Zumba Fitness、华尔街日报、ESPN、BBC** 以及包括 **Usher、Frank Ocean、Metallica** 等在内的顶级唱片艺术家做出了贡献。
+
+**他和世界上最漂亮的女人一起享受着远程(工作)的生活方式。**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/crafting-reusable-html-templates.md b/TODO1/crafting-reusable-html-templates.md
index b28049c5db6..6e848a8bb5f 100644
--- a/TODO1/crafting-reusable-html-templates.md
+++ b/TODO1/crafting-reusable-html-templates.md
@@ -206,7 +206,7 @@ button.addEventListener('click', event => alert(event));
2. [编写可以复用的 HTML 模板(**本文**)](https://github.com/xitu/gold-miner/blob/master/TODO1/crafting-reusable-html-templates.md)
3. [从 0 开始创建自定义元素](https://github.com/xitu/gold-miner/blob/master/TODO1/creating-a-custom-element-from-scratch.md)
4. [使用 Shadow DOM 封装样式和结构](https://github.com/xitu/gold-miner/blob/master/TODO1/encapsulating-style-and-structure-with-shadow-dom.md)
-5. [Web 组件的高阶工具](https://github.com/xitu/gold-miner/blob/master/TODO1/advanced-tooling-for-web-components/.md)
+5. [Web 组件的高阶工具](https://github.com/xitu/gold-miner/blob/master/TODO1/advanced-tooling-for-web-components.md)
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/create-a-line-chart-in-swiftui-using-paths.md b/TODO1/create-a-line-chart-in-swiftui-using-paths.md
new file mode 100644
index 00000000000..d99d780bc7d
--- /dev/null
+++ b/TODO1/create-a-line-chart-in-swiftui-using-paths.md
@@ -0,0 +1,307 @@
+> * 原文地址:[Create a Line Chart in SwiftUI Using Paths](https://medium.com/better-programming/create-a-line-chart-in-swiftui-using-paths-183d0ddd4578)
+> * 原文作者:[Anupam Chugh](https://medium.com/@anupamchugh)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/create-a-line-chart-in-swiftui-using-paths.md](https://github.com/xitu/gold-miner/blob/master/TODO1/create-a-line-chart-in-swiftui-using-paths.md)
+> * 译者:[chaingangway](https://github.com/chaingangway)
+> * 校对者:[lsvih](https://github.com/lsvih)
+
+# 用 SwiftUI 的 Paths 创建折线图
+
+> 在iOS程序中创建美观的股票图表
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral).](https://cdn-images-1.medium.com/max/8064/0*eZh1HfzXfAjD_9ME)
+
+SwiftUI 框架在 2019 年的 WWDC 大会引入后,广受 iOS 社区欢迎。这种用 Swift 语言编写,易用的、声明式的 API 让开发者可以快速构建 UI 原型。
+
+虽然我们能用 Shapes 协议从头开始构建 [条形图](https://medium.com/better-programming/swiftui-bar-charts-274e9fbc8030),但是构建折线图就不一样了。幸运的是,我们有 `Paths` 这个结构体来帮助我们。
+
+使用 SwiftUI 中的 paths,跟 Core Graphics 框架中的 `CGPaths` 类似,我们可以把直线与曲线结合,来构建美观的标志和形状。
+
+SwiftUI 中的 paths 是一套真正用声明式的方式来构建 UI 的指令集。在下面的几节中,我们将会讨论它的意义。
+
+## 我们的目标
+
+* 探索 SwiftUI 的 Path API,通过它来创建简单的图形。
+* 用 Combine 和 URLSession 来获取历史股票数据。我们将会用 [Alpha Vantage](https://www.alphavantage.co/) 的 API 来取得股票信息。
+* 在 SwiftUI 中创建折线图,来展示随时间变化的股票价格。
+
+读完本文后,你应该能够开发与下面类似的 iOS 程序。
+
+
+
+## 创建一个简单的 Swift Path
+
+下面的例子,是通过在 SwiftUI 中使用 paths 来创建直角三角形:
+
+```Swift
+var body: some View {
+Path { path in
+path.move(to: CGPoint(x: 100, y: 100))
+path.addLine(to: CGPoint(x: 100, y: 300))
+path.addLine(to: CGPoint(x: 300, y: 300))
+}.fill(Color.green)
+}
+```
+
+Path API 有很多函数。`move` 是用来设置路径的起点,`addline` 是用来向指定目标点绘制一条直线。
+
+另外 `addArc`、`addCurve`、`addQuadCurve`、`addRect` 和 `addEllipse` 等方法可以让我们创建圆弧或者贝塞尔曲线。
+
+用 `addPath` 可以添加两条或者多条路径。
+
+下面的插图展示了一个三角形,这个三角形下面有一个圆饼图。
+
+
+
+既然我们已经了解怎样在 SwiftUI 中创建 paths,赶紧来看看 SwiftUI 中的折线图。
+
+## SwiftUI 折线图
+
+下面给出的模型,是用来解析 API 响应返回的 JSON。
+
+```Swift
+struct StockPrice : Codable{
+ let open: String
+ let close: String
+ let high: String
+ let low: String
+
+ private enum CodingKeys: String, CodingKey {
+
+ case open = "1. open"
+ case high = "2. high"
+ case low = "3. low"
+ case close = "4. close"
+ }
+}
+
+struct StocksDaily : Codable {
+ let timeSeriesDaily: [String: StockPrice]?
+
+ private enum CodingKeys: String, CodingKey {
+ case timeSeriesDaily = "Time Series (Daily)"
+ }
+
+ init(from decoder: Decoder) throws {
+ let values = try decoder.container(keyedBy: CodingKeys.self)
+
+ timeSeriesDaily = try (values.decodeIfPresent([String : StockPrice].self, forKey: .timeSeriesDaily))
+ }
+}
+```
+
+创建一个 `ObservableObject` 类。我们用 URLSession 中的 Combine Publisher 来处理 API 请求,然后用 Combine 操作来转换结果。
+
+```Swift
+class Stocks : ObservableObject {
+
+ @Published var prices = [Double]()
+ @Published var currentPrice = "...."
+ var urlBase = "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=NSE:YESBANK&apikey=demo&datatype=json"
+
+ var cancellable : Set<AnyCancellable> = Set()
+
+ init() {
+ fetchStockPrice()
+ }
+
+ func fetchStockPrice(){
+
+ URLSession.shared.dataTaskPublisher(for: URL(string: "\(urlBase)")!)
+ .map{output in
+
+ return output.data
+ }
+ .decode(type: StocksDaily.self, decoder: JSONDecoder())
+ .sink(receiveCompletion: {_ in
+ print("completed")
+ }, receiveValue: { value in
+
+ var stockPrices = [Double]()
+
+ let orderedDates = value.timeSeriesDaily?.sorted{
+ guard let d1 = $0.key.stringDate, let d2 = $1.key.stringDate else { return false }
+ return d1 < d2
+ }
+
+ guard let stockData = orderedDates else {return}
+
+ for (_, stock) in stockData {
+ if let stock = Double(stock.close){
+ if stock > 0.0{
+ stockPrices.append(stock)
+ }
+ }
+ }
+
+ DispatchQueue.main.async{
+ self.prices = stockPrices
+ self.currentPrice = stockData.last?.value.close ?? "..."
+ }
+ })
+ .store(in: &cancellable)
+
+ }
+}
+
+extension String {
+ static let shortDate: DateFormatter = {
+ let formatter = DateFormatter()
+ formatter.dateFormat = "yyyy-MM-dd"
+ return formatter
+ }()
+ var stringDate: Date? {
+ return String.shortDate.date(from: self)
+ }
+}
+```
+
+API 结果中包含用日期作为 key 的内置 JSON。它们在字典中是无序的,需要进行排序。因此,我们声明了一个把字符串转换为日期的扩展,然后在 `sort` 方法中进行比较。
+
+既然已经在 `Published` 属性中获得了价格和股票数据,我们需要将它们传递给 `LineView` — 下面我们将会看到的一个自定义的 SwiftUI 视图:
+
+```Swift
+struct LineView: View {
+ var data: [(Double)]
+ var title: String?
+ var price: String?
+
+ public init(data: [Double],
+ title: String? = nil,
+ price: String? = nil) {
+
+ self.data = data
+ self.title = title
+ self.price = price
+ }
+
+ public var body: some View {
+ GeometryReader{ geometry in
+ VStack(alignment: .leading, spacing: 8) {
+ Group{
+ if (self.title != nil){
+ Text(self.title!)
+ .font(.title)
+ }
+ if (self.price != nil){
+ Text(self.price!)
+ .font(.body)
+ .offset(x: 5, y: 0)
+ }
+ }.offset(x: 0, y: 0)
+ ZStack{
+ GeometryReader{ reader in
+ Line(data: self.data,
+ frame: .constant(CGRect(x: 0, y: 0, width: reader.frame(in: .local).width , height: reader.frame(in: .local).height)),
+ minDataValue: .constant(nil),
+ maxDataValue: .constant(nil)
+ )
+ .offset(x: 0, y: 0)
+ }
+ .frame(width: geometry.frame(in: .local).size.width, height: 200)
+ .offset(x: 0, y: -100)
+
+ }
+ .frame(width: geometry.frame(in: .local).size.width, height: 200)
+
+ }
+ }
+ }
+}
+```
+
+上面的视图从 SwiftUI 中的 ContentView 唤起,传入了名称、价格和历史价格的数组。由于使用了 GeometryReader,我们要向 `Line` 结构中的 frame 传入 reader 的宽和高。我们最后会用 SwiftUI 中的 paths 来连接这些点:
+
+```Swift
+struct Line: View {
+ var data: [(Double)]
+ @Binding var frame: CGRect
+
+ let padding: CGFloat = 30
+
+ var stepWidth: CGFloat {
+ if data.count < 2 {
+ return 0
+ }
+ return frame.size.width / CGFloat(data.count-1)
+ }
+ var stepHeight: CGFloat {
+ var min: Double?
+ var max: Double?
+ let points = self.data
+ if let minPoint = points.min(), let maxPoint = points.max(), minPoint != maxPoint {
+ min = minPoint
+ max = maxPoint
+ }else {
+ return 0
+ }
+ if let min = min, let max = max, min != max {
+ if (min <= 0){
+ return (frame.size.height-padding) / CGFloat(max - min)
+ }else{
+ return (frame.size.height-padding) / CGFloat(max + min)
+ }
+ }
+
+ return 0
+ }
+ var path: Path {
+ let points = self.data
+ return Path.lineChart(points: points, step: CGPoint(x: stepWidth, y: stepHeight))
+ }
+
+ public var body: some View {
+
+ ZStack {
+
+ self.path
+ .stroke(Color.green ,style: StrokeStyle(lineWidth: 3, lineJoin: .round))
+ .rotationEffect(.degrees(180), anchor: .center)
+ .rotation3DEffect(.degrees(180), axis: (x: 0, y: 1, z: 0))
+ .drawingGroup()
+ }
+ }
+}
+```
+
+计算 `stepWidth` 和 `stepHeight` 的目的是在给定 frame 的宽和高的情况下,对图表进行约束。然后,把它们传递给 `Path` 结构体的扩展函数,用来创建折线图:
+
+```Swift
+extension Path {
+
+ static func lineChart(points:[Double], step:CGPoint) -> Path {
+ var path = Path()
+ if (points.count < 2){
+ return path
+ }
+ guard let offset = points.min() else { return path }
+ let p1 = CGPoint(x: 0, y: CGFloat(points[0]-offset)*step.y)
+ path.move(to: p1)
+ for pointIndex in 1..<points.count {
+ let p2 = CGPoint(x: step.x * CGFloat(pointIndex), y: step.y*CGFloat(points[pointIndex]-offset))
+ path.addLine(to: p2)
+ }
+ return path
+ }
+}
+```
+
+最后,展示股票折线图的 SwiftUI 程序就完成了,如下图所示:
+
+
+
+## 总结
+
+本文中,我们再次将 SwiftUI 和 Combine 成功结合 — 这次是抓取股票价格数据,然后在折线图中展示。通过了解 SwiftUI 中 paths 的各种用法,并使用 `path` 方法来构建各种复杂的图形,是一个了解并入门 SwiftUI 的好机会。
+
+你可以使用手势对点和相应的值进行高亮处理,来进一步了解上文中的 SwiftUI 折线图。想知道怎样实现和更多资料,请参照 [这个仓库](https://github.com/AppPear/ChartView)。
+
+上文程序中的全部源码都在这个 [GitHub 仓库](https://github.com/anupamchugh/iowncode/tree/master/SwiftUILineChart).
+
+文章结束了。感谢阅读。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/creating-a-custom-element-from-scratch.md b/TODO1/creating-a-custom-element-from-scratch.md
index 65b31067a47..31429ea15d0 100644
--- a/TODO1/creating-a-custom-element-from-scratch.md
+++ b/TODO1/creating-a-custom-element-from-scratch.md
@@ -295,7 +295,7 @@ class DialogWorkflow extends HTMLElement {
2. [编写可重复使用的 HTML 模板](https://github.com/xitu/gold-miner/blob/master/TODO1/crafting-reusable-html-templates.md)
3. [从 0 开始创建自定义元素(**本文**)](https://github.com/xitu/gold-miner/blob/master/TODO1/creating-a-custom-element-from-scratch.md)
4. [使用 Shadow DOM 封装样式和结构](https://github.com/xitu/gold-miner/blob/master/TODO1/encapsulating-style-and-structure-with-shadow-dom.md)
-5. [Web 组件的高阶工具](https://github.com/xitu/gold-miner/blob/master/TODO1/advanced-tooling-for-web-components/.md)
+5. [Web 组件的高阶工具](https://github.com/xitu/gold-miner/blob/master/TODO1/advanced-tooling-for-web-components.md)
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/creating-website-sitemap.md b/TODO1/creating-website-sitemap.md
new file mode 100644
index 00000000000..a39253eead2
--- /dev/null
+++ b/TODO1/creating-website-sitemap.md
@@ -0,0 +1,206 @@
+> * 原文地址:[5 Easy Steps to Creating a Sitemap For a Website](https://www.quicksprout.com/creating-website-sitemap/)
+> * 原文作者:[quicksprout](https://www.quicksprout.com/)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/creating-website-sitemap.md](https://github.com/xitu/gold-miner/blob/master/TODO1/creating-website-sitemap.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[Chorer](https://github.com/Chorer),[Gavin](https://github.com/redagavin)
+
+# 5 个简单步骤为您的网站创建 Sitemap
+
+## 创建和提交 sitemap 所需的一切
+
+当您想要让您的网站位居搜索引擎的前列时,您需要利用尽可能多的 SEO 技巧。创建 sitemap 绝对是一种可以帮助[提高您 SEO 策略](https://www.quicksprout.com/university/how-to-optimize-your-robots-txt-file/)的技术。
+
+## 什么是 sitemap?
+
+有些人已经对它很熟悉了。但是,在我向您展示如何建立您自己的 sitemap 之前,我会给您一个关于 sitemap 基础知识的速成课程。
+
+简单来说,sitemap,或者说 XML sitemap,是网站上不同页面的列表。XML是“extensible markup language”的缩写,这是在站点上显示信息的一种方式。
+
+我咨询过很多站长,他们之所以被吓到是因为他们认为 sitemap 是 SEO 的技术组成部分。但实际上,创建 sitemap 并不需要您成为一个技术大牛或是有技术背景的人。看完这篇教程之后,您很快就会发现这实际上并不难。
+
+## 为什么你需要 sitemap?
+
+像 Google 这样的搜索引擎,一直致力于向人们展示任何给定的搜索查询中最相关的结果。为了有效地做到这一点,他们使用站点爬虫来读取、组织和索引互联网上的信息。
+
+XML sitemap 使搜索引擎爬虫更容易读取站点上的内容并相应地为页面建立索引。因此,这增加了[提高您的网站 SEO 排名](https://www.quicksprout.com/ways-to-improve-seo-ranking/)的机会。
+
+您的 sitemap 会告诉搜索引擎您的网站上某个页面的位置,它是何时更新的,更新的频率如何,以及这个网页的重要性根据它和您网站上其他页面的关联。如果没有合适的 sitemap,Google 机器人可能会认为您的网站有重复的内容,这实际上会降低您的 SEO 排名。
+
+如果您已经准备好让您的网站更快地被搜索引擎索引,那么只需遵循以下五个简单的步骤来创建 sitemap。
+
+### 第 1 步: 检查页面的结构
+
+您需要做的第一件事是查看您的网站上的现有内容以及所有内容的结构。
+
+看看这个 [sitemap 模板](https://nationalgriefawarenessday.com/48796/website-sitemap-template),并弄明白如何用一张表来表示您的网页。
+
+
+
+这是一个简单易懂的例子。
+
+一切都从主页开始。然后,问问自己主页会链接到哪些页面去。您可能已经根据您网站上的菜单选项找到了答案。
+
+但说到 SEO,并不是所有页面的排名都是一样的。当您处理页面的 SEO 时,您必须记住您网站的深度。要明白一点:离您的网站主页越远的页面排名越靠后。
+
+根据 [搜索引擎日志](https://www.searchenginejournal.com/website-structure-affects-seo/186553/) 这篇文章的说法,您应该致力于创建深度较浅的 sitemap,这意味着只需单击三下即可导航到您网站上的任何页面。对于SEO而言,这会是极好的。
+
+因此,您需要基于页面的重要级别和您希望的它们被索引的方式,来创建一个页面层次结构。按照逻辑层次决定你的内容的优先顺序。如果您不太明白,可以看看这个[例子](https://blog.hubspot.com/marketing/build-sitemap-website)。
+
+
+
+正如您所看到的,ABOUT页面链接到 Our Team 页面以及 Mission & Values 页面。然后,Our Team 页面链接到 Management 页面和 Contact Us 页面。
+
+[“关于”页面是最重要的](https://www.quicksprout.com/how-to-create-about-page/),这就是为什么它位于顶级导航层。将 Management 页面放在与 PRODUCTS 页面、PRICING 页面和 BLOGS 页面同一级别是不合理的,这就是为什么它属于第三级层次。
+
+同样,如果 Basic 页面位于 Compare Packages 页面的上方,则会使逻辑结构被打乱。
+
+所以,请使用这些可视化的 sitemap 模板来确定页面的组织。你们中的有些人可能已经有一个合理的网站结构,只需要进行一些微调即可。
+
+请记住,您应该尽可能实现在三次单击之内就可以到达每个页面。
+
+### 第 2 步:修改您的 URL
+
+现在您已经浏览并确定了每个页面的重要性,也根据重要性安排了网站结构,是时候对这些 URL 进行修改了。
+
+实现这个的方法是使用 XML 标签编排每个 URL 的格式。如果您写过一些 HTML,这对您来说简直是小菜一碟。如前所述,XML 中的 ML 代表”标记语言“(markup language),所以它和 HTML 是类似的。
+
+即使您是第一次接触它,这也并不难。首先打开一个您可以在其中创建 XML 文件的文本编辑器。
+
+就文本编辑器而言,[Sublime Text](https://www.sublimetext.com/) 对您来说会是一个不错的选择。
+
+
+
+接着,为每个 URL 添加相应的代码。
+
+* 网站地址(location)
+* 上一次更新的时间(last changed)
+* 更新频率(changed frequency)
+* 页面的优先级(priority of page)
+
+下面的一些示例展示了代码的大致样子。
+
+* http://www.examplesite.com/page1
+* 2019-1-10
+* weekly
+* 2
+
+慢慢来,一定要把这件事做好。在添加这段代码时,文本编辑器会使您的工作变得更加轻松,但您仍需保持清晰的头脑。
+
+### 第 3 步:验证代码的正确性
+
+任何您手敲代码的过程,都可能发生人为错误。但是,为了让您的 sitemap 正常运行,您的代码不允许有任何错误。
+
+幸运的是,有一些工具可以帮助验证代码以确保语法的正确。网上有一些软件可以帮助你做到这一点。只要在 Google 上搜索“sitemap validation”(不翻墙的话,就百度搜“sitemap 验证”),您就会发现它们。
+
+我喜欢使用 [XML Sitemap 验证工具](https://www.xml-sitemaps.com/validate-xml-sitemap.html)。
+
+
+
+它将挑出代码中的任何错误。
+
+例如,如果您忘记添加结束标记或者类似的东西,这个工具可以很快地发现并进行修复。
+
+### 第 4 步:将 sitemap 添加到站点根目录和 robots.txt
+
+找到网站的根文件夹,并将 sitemap 文件添加到此文件夹中。
+
+这样做实际上也会将页面添加到您的站点,但这并不会有什么问题。事实上,很多网站都有这个页面。你可以输入一个网址,并在后面添加“/sitemap/”,看看会弹出什么。
+
+这是 [Apple](https://www.apple.com/sitemap/) 网站的一个例子。
+
+
+
+注意每个部分的结构和逻辑层次。这与我们在第一步中讨论的内容有关。
+
+现在,我们可以更进一步。您甚至可以通过在 URL 后添加 “/sitemap.xml” 来查看不同网站上的代码。
+
+这是 [HubSpot](https://www.hubspot.com/sitemap.xml) 网站的 sitemap 的样子。
+
+
+
+除了将 sitemap 文件添加到根目录之外,您还需要将其添加到 robots.txt 文件中。您也可以在根文件夹中找到它。
+
+基本上,这可以引导任何索引您网站的爬虫。
+
+robots.txt 文件有两种不同的用法。您可以对其进行设置,以告诉爬虫有哪些 URL 是您不希望他们在搜寻您的网站时进行索引的。
+
+让我们回到 Apple 官网,看看他们的 [robots.txt 页面](https://www.apple.com/robots.txt) 长什么样子。
+
+
+
+如您所见,他们 “disallow” 其网站上的多个页面。因此,爬虫会忽略这些网页。
+
+
+
+同时,Apple 也在这里包含了他们的 sitemap 文件。
+
+事实上,并不是所有人都会建议您将 sitemap 添加到 robots.txt 文件中。因此,您自己决定就好。
+
+话是这样说,但是我是一个遵循成功网站和企业最佳实践的坚定信仰者。所以,如果像 Apple 这样的大公司将 sitemap 写到 robots.txt 页面,这或许对我们来说是一个不错的主意。
+
+### 第 5 步:提交 sitemap
+
+现在您的 sitemap 已经创建好并添加到您的站点文件中了,是时候将它们提交给搜索引擎了。
+
+您需要通过 [Google Search Console](https://search.google.com/search-console/about) 来提交。有些人可能已经使用过它了。就算没有,您也可以快速上手。
+
+进入 Search Console 控制面板后,导航至 Crawl > Sitemaps。
+
+
+
+接着,单击屏幕右上角的 Add/Test Sitemap。
+
+这里可以让您在继续下一步之前再次检验 sitemap 是否有错误。显然,您需要修复所发现的任何错误。一旦您的 sitemap 没有错误,点击提交就可以了。Google 将处理这一切。现在爬虫将很容易地索引您的网站,这将提高您的 SEO 排名。
+
+## 代替方案
+
+虽然这五个步骤非常简单明了,但是可能还是会有些人对手动修改网站上的代码感到不舒服。这完全可以理解。幸运的是,还有许多其它的解决方案可以让您不用自己编辑代码也能创建 sitemap。
+
+我将介绍一些最常用的代替方案供您考虑。
+
+### Yoast 插件
+
+如果您有一个 WordPress 网站,您可以安装 [Yoast 插件](https://kb.yoast.com/kb/enable-xml-sitemaps-in-the-wordpress-seo-plugin/)来为您的网站创建 sitemap。
+
+Yoast 可以让您通过简单的拨动开关来打开和关闭 sitemap。插件安装好后,您可以从 WordPress 的 SEO 标签页中找到所有 XML sitemap 选项。
+
+### Screaming Frog
+
+[Screaming Frog](https://www.screamingfrog.co.uk/xml-sitemap-generator/) 是一款桌面软件,它提供了大量的 SEO 工具。只要网站的页面不超过 500 页,您就可以免费使用和生成 sitemap。对于那些拥有大型网站的用户,您就需要升级付费版本了。
+
+Screaming Frog 支持我们前面讨论过的所有代码的更改,而且不需要您自己实际编写代码。相反,您根据提示操作就行了,这个提示更友好,而且是用通俗易懂的英语写的。然后 sitemap 文件的代码将自动更改。下面的截图就是我要表达的意思。
+
+
+
+只需选择标签页,更改设置,sitemap 文件就会相应地进行调整。
+
+### Slickplan
+
+我非常喜欢 Slickplan,因为它有可视化的 sitemap 构建功能。您将有机会使用 sitemap 模板,类似于我们前面看到的网站结构模板。
+
+在这里,您可以拖放不同的页面到模板来组织您的网站结构。完成后,如果您对可视化的 sitemap 感到满意,就可以将其导出为 XML 文件。
+
+Slickplan 是付费软件,但它们提供免费试用。如果您在犹豫是否购买它,可以去试试。
+
+## 总结
+
+如果您打算提升一下您的 SEO 策略,您需要做的就是为您的站点创建一个 sitemap。
+
+对您而言 sitemap 再也不是难题了。因为正如这篇指南所介绍的,只需五个步骤即可轻松创建 sitemap。
+
+1. 检查页面的结构
+2. 编辑 URL
+3. 验证代码的正确性
+4. 将 sitemap 添加到站点根目录和 robots.txt
+5. 提交 sitemap
+
+这就完事啦!
+
+对于那些仍然对手动更改网站代码束手无策的人,您还可以选择其它代替方案。尽管互联网上有着大量的 sitemap 相关的资源,但是我推荐的 Yoast 插件,Screaming Frog 和 Slickplan 依然都是很不错的入门选择。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/decouple-your-code-with-dependency-injection.md b/TODO1/decouple-your-code-with-dependency-injection.md
new file mode 100644
index 00000000000..05ec9d2f7df
--- /dev/null
+++ b/TODO1/decouple-your-code-with-dependency-injection.md
@@ -0,0 +1,326 @@
+> * 原文地址:[Decouple Your Code With Dependency Injection](https://medium.com/better-programming/decouple-your-code-with-dependency-injection-d893ae9edcf8)
+> * 原文作者:[Ben Weidig](https://medium.com/@benweidig)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/decouple-your-code-with-dependency-injection.md](https://github.com/xitu/gold-miner/blob/master/TODO1/decouple-your-code-with-dependency-injection.md)
+> * 译者:[江不知](https://juejin.im/user/5ae03306f265da0b702592d1)
+> * 校对者:[GJXAIOU](https://github.com/GJXAIOU), [司徒公子](https://github.com/todaycoder001)
+
+# 用依赖注入解耦你的代码
+
+> 无需第三方框架
+
+ 摄于 [Unsplash](https://unsplash.com/s/photos/ingredients?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/12032/1*PfS1KYIt9IIDZTIyIIfMsQ.jpeg)
+
+没有多少组件是能够独立存在而不依赖于其它组件的。除了创建紧密耦合的组件,我们还可以利用**依赖注入**(DI)来改善 [关注点的分离](https://en.wikipedia.org/wiki/Separation_of_concerns)。
+
+这篇文章将会脱离第三方框架向你介绍依赖注入的核心概念。所有的示例代码都将使用 Java,但所介绍的一般原则也适用于其它任何语言。
+
+---
+
+## 示例:数据处理器
+
+为了让如何使用依赖注入更加形象化,我们将从一个简单的类型开始:
+
+```Java
+public class DataProcessor {
+
+ private final DbManager manager = new SqliteDbManager("db.sqlite");
+ private final Calculator calculator = new HighPrecisionCalculator(5);
+
+ public void processData() {
+ this.manager.processData();
+ }
+
+ public BigDecimal calc(BigDecimal input) {
+ return this.calculator.expensiveCalculation(input);
+ }
+}
+```
+
+`DataProcessor` 有两个依赖项:`DbManager` 和 `Calculator`。直接在我们的类型中创建它们有几个明显的缺点:
+
+* 调用构造函数时可能发生崩溃
+* 构造函数签名可能会改变
+* 紧密绑定到显式实现类型
+
+是时候改进它了!
+
+---
+
+## 依赖注入
+
+[**《敏捷开发的艺术》**](https://www.amazon.com/Art-Agile-Development-Pragmatic-Software/dp/0596527675) 的作者 James Shore [很好地指出](https://www.jamesshore.com/Blog/Dependency-Injection-Demystified.html):
+
+> **「依赖注入听起来复杂,实际上它的概念却十分简单。」**
+
+依赖注入的概念实际上非常简单:为组件提供完成其工作所需的一切。
+
+通常,这意味着通过从外部提供组件的依赖关系来解耦组件,而非直接在组件内创建依赖,让组件间过度耦合。
+
+我们可以通过多种方式为实例提供必要的依赖关系:
+
+* 构造函数注入
+* 属性注入
+* 方法注入
+
+#### 构造函数注入
+
+构造函数注入,或称基于初始化器的依赖注入,意味着在实例初始化期间提供所有必需的依赖项,将其作为构造函数的参数:
+
+```Java
+public class DataProcessor {
+
+ private final DbManager manager;
+ private final Calculator calculator;
+
+ public DataProcessor(DbManager manager, Calculator calculator) {
+ this.manager = manager;
+ this.calculator = calculator;
+ }
+
+ // ...
+}
+```
+
+由于这一简单的改变,我们可以弥补大多数最开始的缺点:
+
+* 易于替换:`DbManager` 和 `Calculator` 不再被具体的实现所束缚,现在可以模拟单元测试了。
+* 已经初始化并且「准备就绪」:我们不必担心依赖项所需要的任何子依赖项(例如,数据库文件名、[有效数字(译者注)](https://zh.wikipedia.org/wiki/%E6%9C%89%E6%95%88%E6%95%B0%E5%AD%97)等),也不必担心它们可在初始化期间发生崩溃的可能性。
+* 强制要求:调用方确切地知道创建 `DataProcessor` 的所需内容。
+* 不变性:依赖关系始终如初。
+
+尽管构造函数注入是许多依赖注入框架的首选方法,但它也有明显的缺点。其中最大的缺点是:必须在初始化时提供所有依赖项。
+
+有时,我们无法自己初始化一个组件,或者在某个时刻我们无法提供组件的所有依赖关系。或者我们需要使用另外一个构造函数。一旦设置了依赖项,我们就无法再改变它们了。
+
+但是我们可以使用其它注入类型来缓解这些问题。
+
+#### 属性注入
+
+有时,我们无法访问类型实际的初始化方法,只能访问一个已经初始化的实例。或者在初始化时,所需要的依赖关系并不像之后那样明确。
+
+在这些情况下,我们可以使用**属性注入**而不是依赖于构造函数:
+
+```Java
+public class DataProcessor {
+
+ public DbManager manager = null;
+ public Calculator calculator = null;
+
+ // ...
+
+ public void processData() {
+ // WARNING: Possible NPE
+ this.manager.processData();
+ }
+
+ public BigDecimal calc(BigDecimal input) {
+ // WARNING: Possible NPE
+ return this.calculator.expensiveCalculation(input);
+ }
+}
+```
+
+我们不再需要构造函数了,在初始化后我们可以随时提供依赖项。但这种注入方式也有缺点:**易变性**。
+
+在初始化后,我们不再保证 `DataProcessor` 是「随时可用」的。能够随意更改依赖关系可能会给我们带来更大的灵活性,但同时也会带来运行时检查过多的缺点。
+
+现在,我们必须在访问依赖项时处理出现 `NullPointerException` 的可能性。
+
+#### 方法注入
+
+即使我们将依赖项与构造函数注入与/或属性注入分离,我们也仍然只有一个选择。如果在某些情况下我们需要另一个 `Calculator` 该怎么办呢?
+
+我们不想为第二个 `Calculator` 类添加额外的属性或构造函数参数,因为将来可能会出现第三个这样的类。而且在每次调用 `calc(...)` 前更改属性也不可行,并且很可能因为使用错误的属性而导致 bug。
+
+更好的方法是参数化调用方法本身及其依赖项:
+
+```Java
+public class DataProcessor {
+
+ // ...
+
+ public BigDecimal calc(Calculator calculator, BigDecimal input) {
+ return calculator.expensiveCalculation(input);
+ }
+}
+```
+
+现在,`calc(...)` 的调用者负责提供一个合适的 `Calculator` 实例,并且 `DataProcessor` 类与之完全分离。
+
+通过混合使用不同的注入类型来提供一个默认的 `Calculator`,这样可以获得更大的灵活性:
+
+```Java
+public class DataProcessor {
+
+ // ...
+
+ private final Calculator defaultCalculator;
+
+ public DataProcessor(Calculator calculator) {
+ this.defaultCalculator = calculator;
+ }
+
+ // ...
+
+ public BigDecimal calc(Calculator calculator, BigDecimal input) {
+ return Optional.ofNullable(calculator)
+ .orElse(this.calculator)
+ .expensiveCalculation(input);
+ }
+}
+```
+
+调用者**可以**提供另一种类型的 `Calculator`,但这不是**必须**的。我们仍然有一个解耦的、随时可用的 `DataProcessor`,它能够适应特定的场景。
+
+## 选择哪种注入方式?
+
+每种依赖注入类型都有自己的优点,并没有一种「正确的方法」。具体的选择完全取决于你的实际需求和情况。
+
+#### 构造函数注入
+
+构造函数注入是我的最爱,它也常受依赖注入框架的青睐。
+
+它清楚地告诉我们创建特定组件所需的所有依赖关系,并且这些依赖不是可选的,这些依赖关系在整个组件中应该都是必需的。
+
+#### 属性注入
+
+属性注入更适合可选参数,例如监听或委托。又或是我们无法在初始化时提供依赖关系。
+
+其它编程语言,例如 Swift,大量使用了带属性的 [委托模式](https://en.wikipedia.org/wiki/Delegation_pattern)。因此,使用属性注入将使其它语言的开发人员更熟悉我们的代码。
+
+#### 方法注入
+
+如果在每次调用时依赖项可能不同,那么使用方法注入最好不过了。方法注入进一步解耦组件,它使方法本身持有依赖项,而非整个组件。
+
+请记住,这不是非此即彼。我们可以根据需要自由组合各种注入类型。
+
+## 控制反转容器
+
+这些简单的依赖注入实现可以覆盖很多用例。依赖注入是很好的解耦工具,但事实上我们仍然需要在某些时候创建依赖项。
+
+但随着应用程序和代码库的增长,我们可能还需要一个更完整的解决方案来简化依赖注入的创建和组装过程。
+
+**控制反转**(IoC)是 [控制流](https://en.wikipedia.org/wiki/Control_flow) 的抽象原理。依赖注入是控制反转的具体实现之一。
+
+**控制反转容器**是一种特殊类型的对象,它知道如何实例化和配置其它对象,它也知道如何帮助你执行依赖注入。
+
+有些容器可以通过反射来检测关系,而另一些必须手动配置。有些容器基于运行时,而有些则在编译时生成所需要的所有代码。
+
+比较所有容器的不同之处超出了本文的讨论范围,但是让我通过一个小示例来更好地理解这个概念。
+
+#### 示例: Dagger 2
+
+[Dagger](https://dagger.dev/) 是一个轻量级、编译时进行依赖注入的框架。我们需要创建一个 `Module`,它就知道如何构建我们的依赖项,稍后我们只要添加 `@Inject` 注释就可以注入这个 `Module`。
+
+```Java
+@Module
+public class InjectionModule {
+
+ @Provides
+ @Singleton
+ static DbManager provideManager() {
+ return manager;
+ }
+
+ @Provides
+ @Singleton
+ static Calculator provideCalculator() {
+ return new HighPrecisionCalculator(5);
+ }
+}
+```
+
+`@Singleton` 确保只能创建一个依赖项的实例。
+
+要注入依赖项,我们只需要将 `@Inject` 添加到构造函数、字段或方法中。
+
+```Java
+public class DataProcessor {
+
+ @Inject
+ DbManager manager;
+
+ @Inject
+ Calculator calculator;
+
+ // ...
+}
+```
+
+这些仅仅是一些基础知识,乍一看不可能会给人留下深刻的印象。但是控制反转容器和框架不仅解耦了组件,也让创建依赖关系的灵活性得以最大化。
+
+由于提供了高级特性,创建过程的可配置性变得更强,并且支持了使用依赖项的新方法。
+
+#### 高级特性
+
+这些特性在不同类型的控制反转容器和底层语言之间差异很大,比如:
+
+* [代理模式](https://en.wikipedia.org/wiki/Proxy_pattern) 和延迟加载。
+* 生命周期(例如:单例模式与每个线程一个实例)。
+* 自动绑定。
+* 单一类型的多种实现。
+* 循环依赖。
+
+这些特性是控制反转容器真正的能力。你可能会认为诸如「循环依赖」这样的特性并非好的主意,确实如此。
+
+但是,如果由于遗留代码或是过去不可更改的错误设计而需要这种奇怪的代码构造,那么我们现在有能力可以这样做。
+
+## 总结
+
+我们应该根据抽象(例如接口)而不是具体的实现来设计代码,这样可以帮助我们减少代码耦合。
+
+接口必须提供我们代码所需要的唯一信息,我们不能对实际实现情况做任何假设。
+
+> **「程序应当依赖抽象,而非具体的实现」**
+> —— Robert C. Martin (2000), 《设计原则与设计模式》
+
+依赖注入是通过解耦组件来实现这一点的好办法。它使我们能够编写更简洁明了、更易于维护和重构的代码。
+
+选择三种依赖注入类型中的哪种很大程度上取决于环境和需求,但是我们也可以混合使用三种类型使收益最大化。
+
+控制反转容器有时几乎以一种神奇的方式通过简化组件创建过程来提供另一种便利的布局。
+
+我们应该处处使用它吗?当然不是。
+
+就像其它模式和概念一样,我们应该在适当的时候应用它们,而不是能用则用。
+
+永远不要把自己局限在一种做事的方式上。也许 [工厂模式](https://en.wikipedia.org/wiki/Factory_method_pattern) 甚至是广为厌恶的 [单例模式](https://en.wikipedia.org/wiki/Singleton_pattern) 是能够满足你需求的更好的解决方案。
+
+---
+
+## 资料
+
+* [控制反转容器与依赖注入模式](https://www.martinfowler.com/articles/injection.html) (Martin Fowler)
+* [依赖反转原则](https://en.wikipedia.org/wiki/Dependency_inversion_principle)(维基百科)
+* [控制反转](https://en.wikipedia.org/wiki/Inversion_of_control)(维基百科)
+
+---
+
+## 控制反转容器
+
+#### Java
+
+* [Dagger](https://dagger.dev/)
+* [Spring](https://docs.spring.io/spring-framework/docs/current/spring-framework-reference/core.html#beans-introduction)
+* [Tapestry](https://tapestry.apache.org/ioc.html)
+
+#### Kotlin
+
+* [Koin](https://insert-koin.io/)
+
+#### Swift
+
+* [Dip](https://github.com/AliSoftware/Dip)
+* [Swinject](https://github.com/Swinject/Swinject)
+
+#### C#
+
+* [Autofac](https://autofac.org/)
+* [Castle Windsor](http://www.castleproject.org/projects/windsor/)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/deep-dive-into-react-fiber-internals.md b/TODO1/deep-dive-into-react-fiber-internals.md
new file mode 100644
index 00000000000..791f8d60b8c
--- /dev/null
+++ b/TODO1/deep-dive-into-react-fiber-internals.md
@@ -0,0 +1,432 @@
+> * 原文地址:[A deep dive into React Fiber internals](https://blog.logrocket.com/deep-dive-into-react-fiber-internals/)
+> * 原文作者:[Karthik Kalyanaraman](https://blog.logrocket.com/author/karthikkalyanaraman/)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/deep-dive-into-react-fiber-internals.md](https://github.com/xitu/gold-miner/blob/master/TODO1/deep-dive-into-react-fiber-internals.md)
+> * 译者:
+> * 校对者:
+
+# A deep dive into React Fiber internals
+
+
+
+Ever wondered what happens when you call `ReactDOM.render(<App />, document.getElementById('root'))`?
+
+We know that ReactDOM builds up the DOM tree under the hood and renders the application on the screen. But how does React actually build the DOM tree? And how does it update the tree when the app's state changes?
+
+In this post, I am going to start by explaining how React built the DOM tree until React 15.0.0, the pitfalls of that model, and how the new model from React 16.0.0 solved those problems. This post will cover a wide range of concepts that are purely internal implementation details and are not strictly necessary for actual frontend development using React.
+
+## Stack reconciler
+
+Let's start with our familiar `ReactDOM.render(<App />, document.getElementById('root'))`.
+
+The ReactDOM module will pass the `<App/ >` along to the reconciler. There are two questions here:
+
+1. What does `<App />` refer to?
+2. What is the reconciler?
+
+Let's unpack these two questions.
+
+`<App />` is a React element, and "elements describe the tree."
+
+> "An element is a plain object describing a component instance or DOM node and its desired properties." -- [React Blog](https://reactjs.org/blog/2015/12/18/react-components-elements-and-instances.html#elements-describe-the-tree)
+
+In other words, elements are *not* actual DOM nodes or component instances; they are a way to *describe* to React what kind of elements they are, what properties they hold, and who their children are.
+
+This is where React's real power lies. React abstracts away all the complex pieces of how to build, render, and manage the lifecycle of the actual DOM tree by itself, effectively making the life of the developer easier. To understand what this really means, let's look at a traditional approach using object-oriented concepts.
+
+In the typical object-oriented programming world, the developer needs to instantiate and manage the lifecycle of every DOM element. For instance, if you want to create a simple form and a submit button, the state management even for something as simple as this requires some effort from the developer.
+
+[](https://blog.logrocket.com/deep-dive-into-react-fiber-internals/)
+
+Let's assume the `Button` component has a state variable, `isSubmitted`. The lifecycle of the `Button` component looks something like the flowchart below, where each state needs to be taken care of by the app:
+
+
+
+This size of the flowchart and the number of lines of code grow exponentially as the number of states variables increase.
+
+React has elements precisely to solve this problem. In React, there are two kinds of elements:
+
+- DOM element: When the element's type is a string, e.g., `<button class="okButton"> OK </button>`
+- Component element: When the type is a class or a function, e.g., `<Button className="okButton"> OK </Button>`, where `<Button>` is a either a class or a functional component. These are the typical React components we generally use
+
+It is important to understand that both types are simple objects. They are mere descriptions of what needs to be rendered on the screen and don't actually cause any rendering to happen when you create and instantiate them. This makes it easier for React to parse and traverse them to build the DOM tree. The actual rendering happens later when the traversing is finished.
+
+When React encounters a class or a function component, it will ask that element what element it renders to based on its props. For instance, if the `<App>` component rendered this:
+
+```html
+<Form>
+ <Button>
+ Submit
+ </Button>
+</Form>
+```
+
+Then React will ask the `<Form>` and `<Button>` components what they render to based on their corresponding props. For instance, if the `Form` component is a functional component that looks like this:
+
+```jsx
+const Form = (props) => {
+ return(
+ <div className="form">
+ {props.form}
+ </div>
+ )
+}
+```
+
+React will call `render()` to know what elements it renders and will eventually see that it renders a `<div>` with a child. React will repeat this process until it knows the underlying DOM tag elements for every component on the page.
+
+This exact process of recursively traversing a tree to know the underlying DOM tag elements of a React app's component tree is known as reconciliation. By the end of the reconciliation, React knows the result of the DOM tree, and a renderer like react-dom or react-native applies the minimal set of changes necessary to update the DOM nodes
+
+So this means that when you call `ReactDOM.render()` or `setState()`, React performs a reconciliation. In the case of `setState`, it performs a traversal and figures out what changed in the tree by diffing the new tree with the rendered tree. Then it applies those changes to the current tree, thereby updating the state corresponding to the `setState()` call.
+
+Now that we understand what reconciliation is, let's look at the pitfalls of this model.
+
+Oh, by the way -- why is this called the "stack" reconciler?
+
+This name is derived from the "stack" data structure, which is a last-in, first-out mechanism. And what does stack have anything to do with what we just saw? Well, as it turns out, since we are effectively doing a recursion, it has everything to do with a stack.
+
+## Recursion
+
+To understand why that's the case, let's take a simple example and see what happens in the [call stack](https://developer.mozilla.org/en-US/docs/Glossary/Call_stack).
+
+```js
+function fib(n) {
+ if (n < 2){
+ return n
+ }
+ return fib(n - 1) + fib (n - 2)
+}
+
+fib(10)
+```
+
+
+
+As we can see, the call stack pushes every call to `fib()` into the stack until it pops `fib(1)`, which is the first function call to return. Then it continues pushing the recursive calls and pops again when it reaches the return statement. In this way, it effectively uses the call stack until `fib(3)` returns and becomes the last item to get popped from the stack.
+
+The reconciliation algorithm we just saw is a purely recursive algorithm. An update results in the entire subtree being re-rendered immediately. While this works well, this has some limitations. As [Andrew Clark notes](https://github.com/acdlite/react-fiber-architecture):
+
+- In a UI, it's not necessary for every update to be applied immediately; in fact, doing so can be wasteful, causing frames to drop and degrading the user experience
+- Different types of updates have different priorities --- an animation update needs to complete more quickly than, say, an update from a data store
+
+Now, what do we mean when we refer to dropped frames, and why is this a problem with the recursive approach? In order to grasp this, let me briefly explain what frame rate is and why it's important from a user experience point of view.
+
+Frame rate is the frequency at which consecutive images appear on a display. Everything we see on our computer screens are composed of images or frames played on the screen at a rate that appears instantaneous to the eye.
+
+To understand what this means, think of the computer display as a flip-book, and the pages of the flip-book as frames played at some rate when you flip them. In other words, a computer display is nothing but an automatic flip-book that plays at all times when things are changing on the screen. If this doesn't make sense, watch [this video](https://youtu.be/FV97j-z3B7U).
+
+Typically, for video to feel smooth and instantaneous to the human eye, the video needs to play at a rate of about 30 frames per second (FPS). Anything higher than that will give an even better experience. This is one of the prime reasons why gamers prefer higher frame rate for first-person shooter games, where precision is very important.
+
+Having said that, most devices these days refresh their screens at 60 FPS --- or, in other words, 1/60 = 16.67ms, which means a new frame is displayed every 16ms. This number is very important because if React renderer takes more than 16ms to render something on the screen, the browser will drop that frame.
+
+In reality, however, the browser has housekeeping work to do, so all of your work needs to be completed inside 10ms. When you fail to meet this budget, the frame rate drop, and the content judders on screen. This is often referred to as jank, and it negatively impacts the user's experience.
+
+Of course, this is not a big cause of concern for static and textual content. But in the case of displaying animations, this number is critical. So if the React reconciliation algorithm traverses the entire `App` tree each time there is an update and re-renders it, and if that traversal takes more than 16ms, it will cause dropped frames, and dropped frames are bad.
+
+This is a big reason why it would be nice to have updates categorized by priority and not blindly apply every update passed down to the reconciler. Also, another nice feature to have is the ability to pause and resume work in the next frame. This way, React will have better control over working with the 16ms budget it has for rendering.
+
+This led the React team to rewrite the reconciliation algorithm, and the new algorithm is called Fiber. I hope now it makes sense as to how and why Fiber exists and what significance it holds. Let's look at how Fiber works to solve this problem.
+
+## How Fiber works
+
+Now that we know what motivated the development of Fiber, let's summarize the features that are needed to achieve it.
+
+Again, I am referring to Andrew Clark's notes for this:
+
+- Assign priority to different types of work
+- Pause work and come back to it later
+- Abort work if it's no longer needed
+- Reuse previously completed work
+
+One of the challenges with implementing something like this is how the JavaScript engine works and to a little extent the lack of threads in the language. In order to understand this, let's briefly explore how the JavaScript engine handles execution contexts.
+
+### JavaScript execution stack
+
+Whenever you write a function in JavaScript, the JS engine creates what we call function execution context. Also, each time the JS engine begins, it creates a global execution context that holds the global objects --- for example, the `window` object in the browser and the `global` object in Node.js. Both these contexts are handled in JS using a stack data structure also known as the execution stack.
+
+So, when you write something like this:
+
+```js
+function a() {
+ console.log("i am a")
+ b()
+}
+
+function b() {
+ console.log("i am b")
+}
+
+a()
+```
+
+The JavaScript engine first creates a global execution context and pushes it into the execution stack. Then it creates a function execution context for the function `a()`. Since `b()` is called inside `a()`, it will create another function execution context for `b()` and push it into the stack.
+
+When the function `b()` returns, the engine destroys the context of `b()`, and when we exit function `a()`, the context of `a()` is destroyed. The stack during execution looks like this:
+
+
+
+But what happens when the browser makes an asynchronous event like an [HTTP request](https://blog.logrocket.com/how-to-make-http-requests-like-a-pro-with-axios/)? Does the JS engine stock the execution stack and handle the asynchronous event, or wait until the event completes?
+
+The JS engine does something different here. On top of the execution stack, the JS engine has a queue data structure, also known as the event queue. The event queue handles asynchronous calls like HTTP or network events coming into the browser.
+
+
+
+The way the JS engine handles the stuff in the queue is by waiting for the execution stack to become empty. So each time the execution stack becomes empty, the JS engine checks the event queue, pops items off the queue, and handles that event. It is important to note that the JS engine checks the event queue only when the execution stack is empty or the only item in the execution stack is the global execution context.
+
+Although we call them asynchronous events, there is a subtle distinction here: the events are asynchronous with respect to when they arrive into the queue, but they're not really asynchronous with respect to when they get actually get handled.
+
+Coming back to our stack reconciler, when React traverses the tree, it is doing so in the execution stack. So when updates arrive, they arrive in the event queue (sort of). And only when the execution stack becomes empty, the updates get handled. This is precisely the problem Fiber solves by almost reimplementing the stack with intelligent capabilities --- pausing and resuming, aborting, etc.
+
+Again referencing Andrew Clark's notes here:
+
+> "Fiber is reimplementation of the stack, specialized for React components. You can think of a single fiber as a virtual stack frame.
+>
+> The advantage of reimplementing the stack is that you can keep stack frames in memory and execute them however (and whenever) you want. This is crucial for accomplishing the goals we have for scheduling.
+>
+> Aside from scheduling, manually dealing with stack frames unlocks the potential for features such as concurrency and error boundaries. We will cover these topics in future sections."
+
+In simple terms, a fiber represents a unit of work with its own virtual stack. In the previous implementation of the reconciliation algorithm, React created a tree of objects (React elements) that are immutable and traversed the tree recursively.
+
+In the current implementation, React creates a tree of fiber nodes that can be mutated. The fiber node effectively holds the component's state, props, and the underlying DOM element it renders to.
+
+And since fiber nodes can be mutated, React doesn't need to recreate every node for updates --- it can simply clone and update the node when there is an update. Also, in the case of a fiber tree, React doesn't do a recursive traversal; instead, it creates a singly linked list and does a parent-first, depth-first traversal.
+
+### Singly linked list of fiber nodes
+
+A fiber node represents a stack frame, but it also represents an instance of a React component. A fiber node comprises the following members:
+
+#### Type
+
+`<div>`, `<span>`, etc. for host components (string), and class or function for composite components.
+
+#### Key
+
+Same as the key we pass to the React element.
+
+#### Child
+
+Represents the element returned when we call `render()` on the component. For example:
+
+```jsx
+const Name = (props) => {
+ return(
+ <div className="name">
+ {props.name}
+ </div>
+ )
+}
+```
+
+The child of `<Name>` is `<div>` here as it returns a `<div>` element.
+
+#### Sibling
+
+Represents a case where `render` returns a list of elements.
+
+```jsx
+const Name = (props) => {
+ return([<Customdiv1 />, <Customdiv2 />])
+}
+```
+
+In the above case, `<Customdiv1>` and `<Customdiv2>` are the children of `<Name>`, which is the parent. The two children form a singly linked list.
+
+#### Return
+
+Represents the return back to the stack frame, which is logically a return back to the parent fiber node. Thus, it represents the parent.
+
+#### `pendingProps` and `memoizedProps`
+
+Memoization means storing the values of a function execution's result so you can use it later on, thereby avoiding recomputation. `pendingProps` represents the props passed to the component, and `memoizedProps` gets initialized at the end of the execution stack, storing the props of this node.
+
+When the incoming `pendingProps` are equal to `memoizedProps`, it signals that the fiber's previous output can be reused, preventing unnecessary work.
+
+#### `pendingWorkPriority`
+
+A number indicating the priority of the work represented by the fiber. The [`ReactPriorityLevel`](https://github.com/facebook/react/blob/master/src/renderers/shared/fiber/ReactPriorityLevel.js) module lists the different priority levels and what they represent. With the exception of `NoWork`, which is zero, a larger number indicates a lower priority.
+
+For example, you could use the following function to check if a fiber's priority is at least as high as the given level. The scheduler uses the priority field to search for the next unit of work to perform.
+
+```js
+function matchesPriority(fiber, priority) {
+ return fiber.pendingWorkPriority !== 0 &&
+ fiber.pendingWorkPriority <= priority
+}
+```
+
+#### Alternate
+
+At any time, a component instance has at most two fibers that correspond to it: the current fiber and the in-progress fiber. The alternate of the current fiber is the fiber in progress, and the alternate of the fiber in progress is the current fiber. The current fiber represents what is rendered already, and the in-progress fiber is conceptually the stack frame that has not returned.
+
+#### Output
+
+The leaf nodes of a React application. They are specific to the rendering environment (e.g., in a browser app, they are `div`, `span`, etc.). In JSX, they are denoted using lowercase tag names.
+
+Conceptually, the output of a fiber is the return value of a function. Every fiber eventually has output, but output is created only at the leaf nodes by host components. The output is then transferred up the tree.
+
+The output is eventually given to the renderer so that it can flush the changes to the rendering environment. For example, let's look at how the fiber tree would look for an app whose code looks like this:
+
+```jsx
+const Parent1 = (props) => {
+ return([<Child11 />, <Child12 />])
+}
+
+const Parent2 = (props) => {
+ return(<Child21 />)
+}
+
+class App extends Component {
+ constructor(props) {
+ super(props)
+ }
+ render() {
+ <div>
+ <Parent1 />
+ <Parent2 />
+ </div>
+ }
+}
+
+ReactDOM.render(<App />, document.getElementById('root'))
+```
+
+
+
+We can see that the fiber tree is composed of singly linked lists of child nodes linked to each other (sibling relationship) and a linked list of parent-to-child relationships. This tree can be traversed using a [depth-first search](https://en.wikipedia.org/wiki/Depth-first_search).
+
+### Render phase
+
+In order to understand how React builds this tree and performs the reconciliation algorithm on it, I decided to write a unit test in the React source code and attached a debugger to follow the process.
+
+If you're interested in this process, clone the React source code and navigate to [this directory](https://github.com/facebook/react/tree/769b1f270e1251d9dbdce0fcbd9e92e502d059b8/packages/react-dom/src/__tests__). Add a Jest test and attach a debugger. The test I wrote is a simple one that basically renders a button with text. When you click the button, the app destroys the button and renders a `<div>` with different text, so the text is a state variable here.
+
+```jsx
+'use strict';
+
+let React;
+let ReactDOM;
+
+describe('ReactUnderstanding', () => {
+ beforeEach(() => {
+ React = require('react');
+ ReactDOM = require('react-dom');
+ });
+
+ it('works', () => {
+ let instance;
+
+ class App extends React.Component {
+ constructor(props) {
+ super(props)
+ this.state = {
+ text: "hello"
+ }
+ }
+
+ handleClick = () => {
+ this.props.logger('before-setState', this.state.text);
+ this.setState({ text: "hi" })
+ this.props.logger('after-setState', this.state.text);
+ }
+
+ render() {
+ instance = this;
+ this.props.logger('render', this.state.text);
+ if(this.state.text === "hello") {
+ return (
+ <div>
+ <div>
+ <button onClick={this.handleClick.bind(this)}>
+ {this.state.text}
+ </button>
+ </div>
+ </div>
+ )} else {
+ return (
+ <div>
+ hello
+ </div>
+ )
+ }
+ }
+ }
+ const container = document.createElement('div');
+ const logger = jest.fn();
+ ReactDOM.render(<App logger={logger}/>, container);
+ console.log("clicking");
+ instance.handleClick();
+ console.log("clicked");
+
+ expect(container.innerHTML).toBe(
+ '<div>hello</div>'
+ )
+
+ expect(logger.mock.calls).toEqual(
+ [["render", "hello"],
+ ["before-setState", "hello"],
+ ["render", "hi"],
+ ["after-setState", "hi"]]
+ );
+ })
+
+});
+```
+
+In the initial render, React creates a current tree, which is the tree that gets rendered initially.
+
+`[createFiberFromTypeAndProps()](https://github.com/facebook/react/blob/f6b8d31a76cbbcbbeb2f1d59074dfe72e0c82806/packages/react-reconciler/src/ReactFiber.js#L593)` is the function that creates each React fiber using the data from the specific React element. When we run the test, put a breakpoint at this function, and look at the call stack, it looks something like this:
+
+
+
+As we can see, the call stack tracks back to a `render()` call, which eventually goes down to `createFiberFromTypeAndProps()`. There are a few other functions that are of interest to us here: `workLoopSync()`, `performUnitOfWork()`, and `beginWork()`.
+
+```js
+function workLoopSync() {
+ // Already timed out, so perform work without checking if we need to yield.
+ while (workInProgress !== null) {
+ workInProgress = performUnitOfWork(workInProgress);
+ }
+}
+```
+
+`workLoopSync()` is where React starts building up the tree, starting with the `<App>` node and recursively moving on to `<div>`, `<div>`, and `<button>`, which are the children of `<App>`. The `workInProgress` holds a reference to the next fiber node that has work to do.
+
+`performUnitOfWork()` takes a fiber node as an input argument, gets the alternate of the node, and calls `beginWork()`. This is the equivalent to starting the execution of the function execution contexts in the execution stack.
+
+When React builds the tree, `beginWork()` simply leads up to `createFiberFromTypeAndProps()` and creates the fiber nodes. React recursively performs work and eventually `performUnitOfWork()` returns a null, indicating that it has reached the end of the tree.
+
+Now what happens when we do `instance.handleClick()`, which basically clicks the button and triggers a state update? In this case, React traverses the fiber tree, clones each node, and checks whether it needs to perform any work on each node. When we look at the call stack of this scenario, it looks something like this:
+
+
+
+Although we did not see `completeUnitOfWork()` and `completeWork()` in the first call stack, we can see them here. Just like `performUnitOfWork()` and `beginWork()`, these two functions perform the completion part of the current execution which effectively means returning back to the stack.
+
+As we can see, these four functions together perform the work of executing the unit of work, and also give control over the work being done currently, which is exactly what was missing in the stack reconciler. As we can see from the image below, each fiber node is composed of four phases required to complete that unit of work.
+
+
+
+It's important to note here that each node doesn't move to `completeUnitOfWork()` until its children and siblings return `completeWork()`. For instance, it starts with `performUnitOfWork()` and `beginWork()` for `<App/>`, then moves on to `performUnitOfWork()` and `beginWork()` for Parent1, and so on. It comes back and completes the work on `<App>` once all the children of `<App/>` complete work.
+
+This is when React completes its render phase. The tree that's newly built based on the `click()` update is called the `workInProgress` tree. This is basically the draft tree waiting to be rendered.
+
+## Commit phase
+
+Once the render phase completes, React moves on to the commit phase, where it basically swaps the root pointers of the current tree and `workInProgress` tree, thereby effectively swapping the current tree with the draft tree it built up based on the `click()` update.
+
+
+
+Not just that, React also reuses the old current after swapping the pointer from Root to the `workInProgress` tree. The net effect of this optimized process is a smooth transition from the previous state of the app to the next state, and the next state, and so on.
+
+And what about the 16ms frame time? React effectively runs an internal timer for each unit of work being performed and constantly monitors this time limit while performing the work. The moment the time runs out, React pauses the current unit of work being performed, hands the control back to the main thread, and lets the browser render whatever is finished at that point.
+
+Then, in the next frame, React picks up where it left off and continues building the tree. Then, when it has enough time, it commits the `workInProgress` tree and completes the render.
+
+## Conclusion
+
+I hope you enjoyed reading this post. Please feel free to leave comments or questions if you have any.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/do-you-know-about-the-keyboard-tag-in-html.md b/TODO1/do-you-know-about-the-keyboard-tag-in-html.md
new file mode 100644
index 00000000000..ba5b279f4e9
--- /dev/null
+++ b/TODO1/do-you-know-about-the-keyboard-tag-in-html.md
@@ -0,0 +1,68 @@
+> * 原文地址:[Do You Know About the Keyboard Tag in HTML?](https://medium.com/better-programming/do-you-know-about-the-keyboard-tag-in-html-55bb3986f186)
+> * 原文作者:[Ashay Mandwarya 🖋️💻🍕](https://medium.com/@ashaymurceilago)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/do-you-know-about-the-keyboard-tag-in-html.md](https://github.com/xitu/gold-miner/blob/master/TODO1/do-you-know-about-the-keyboard-tag-in-html.md)
+> * 译者:[IAMSHENSH](https://github.com/IAMSHENSH)
+> * 校对者:[QinRoc](https://github.com/QinRoc)
+
+# 您知道 HTML 的键盘标签吗?
+
+> 使键盘指令有更好的文本格式
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/12000/0*f7nqmMC9F1xGB3im)
+
+HTML5 的 `\<kbd>` 标签用于展示键盘输入。使用此标签包装键盘指令文本,将会在语义上提供更准确的结果,也能让您定位,以便能对其应用一些很棒的样式。而且 `\<kbd>` 标签特别适合用在文档中。
+
+让我们来看看它的实际效果。
+
+## HTML
+
+#### 使用 \<kbd> 标签
+
+```html
+<kbd>Ctrl</kbd>+<kbd>Alt</kbd>+<kbd>Del</kbd>
+```
+
+
+
+#### 不使用 \<kbd> 标签
+
+对比一下,没有使用 `\<kbd>` 标签是这样的:
+
+```html
+<p>Ctrl+Alt+Del</p>
+```
+
+
+
+## CSS
+
+只使用 \<kbd> 标签,看起来差别不大。但通过加上一些样式,可以让它看起来像实际的键盘按钮,具有更逼真的效果。
+
+```css
+kbd {
+border-radius: 5px;
+padding: 5px;
+border: 1px solid teal;
+}
+```
+
+
+
+如果您在控制台中查看该元素,您会发现它除了更改为等宽字体外,没有其他特别之处。
+
+
+
+## 结论
+
+使用 `\<code>` 标签也可以产生同样的效果。那为什么要创建 `\<kbd>` 呢?
+
+答案在于语义上的区别。`\<code>` 用于显示简短的代码片段,而 `\<kbd>` 用于表示键盘输入。
+
+感谢您花时间读完本文!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/edge-detection-in-python.md b/TODO1/edge-detection-in-python.md
new file mode 100644
index 00000000000..56c69203602
--- /dev/null
+++ b/TODO1/edge-detection-in-python.md
@@ -0,0 +1,164 @@
+> * 原文地址:[Edge Detection in Python](https://towardsdatascience.com/edge-detection-in-python-a3c263a13e03)
+> * 原文作者:[Ritvik Kharkar](https://medium.com/@ritvikmathematics)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/edge-detection-in-python.md](https://github.com/xitu/gold-miner/blob/master/TODO1/edge-detection-in-python.md)
+> * 译者:[lsvih](https://github.com/lsvih)
+> * 校对者:[PingHGao](https://github.com/PingHGao), [Amberlin1970](https://github.com/Amberlin1970)
+
+# 使用 Python 进行边缘检测
+
+
+
+上季度,我在学校辅助一门 Python 课程的教学,在此过程中学到了很多图像处理的知识。我希望通过本文分享一些关于边缘检测的知识,包括边缘检测的**理论**以及如何使用 Python **实现**边缘检测。
+
+---
+
+### 为何检测边缘?
+
+我们首先应该了解的问题是:**“为什么要费尽心思去做边缘检测?”**除了它的效果很酷外,为什么边缘检测还是一种实用的技术?为了更好地解答这个问题,请仔细思考并对比下面的风车图片和它的“仅含边缘的图”:
+
+
+
+可以看到,左边的原始图像有着各种各样的色彩、阴影,而右边的“仅含边缘的图”是黑白的。如果有人问,哪一张图片需要更多的存储空间,你肯定会告诉他原始图像会占用更多空间。这就是边缘检测的意义:通过对图片进行边缘检测,丢弃大多数的细节,从而得到“更轻量化”的图片。
+
+因此,在无须保存图像的所有复杂细节,而**“只关心图像的整体形状”**的情况下,边缘检测会非常有用。
+
+---
+
+### 如何进行边缘检测 —— 数学
+
+在讨论代码实现前,让我们先快速浏览一下边缘检测背后的数学原理。作为人类,我们非常擅长识别图像中的“边”,那如何让计算机做到同样的事呢?
+
+首先,假设有一张很简单的图片,在白色背景上有一个黑色的正方形:
+
+
+
+在这个例子中,由于处理的是黑白图片,因此我们可以考虑将图中的每个像素的值都用 **0(黑色)** 或 **1(白色)**来表示。除了黑白图片,同样的理论也完全适用于彩色图像。
+
+现在,我们需要判断上图中绿色高亮的像素是不是这个图像边缘的一部分。作为人类,我们当然可以认出它**是**图像的边缘;但如何让计算机利用相邻的像素来得到同样的结果呢?
+
+我们以绿色高亮的像素为中心,设定一个 3 x 3 像素大小的小框,在图中以红色示意。接着,对这个小方框“应用”一个过滤器(filter):
+
+
+
+上图展示了我们将要“应用”的过滤器。乍一看上去很神秘,让我们仔细研究它做的事情:当我们说**“将过滤器应用于一小块局部像素块”**时,具体是指红色框中的每个像素与过滤器中与之位置对应的像素进行相乘。因此,红色框中左上角像素值为 1,而过滤器中左上角像素值为 -1,它们相乘得到 -1,这也就是结果图中左上角像素显示的值。结果图中的每个像素都是用这种方式得到的。
+
+下一步是对过滤结果中的所有像素值求和,得到 -4。请注意,-4 其实是我们应用这个过滤器可获得的“最小”值(因为原始图片中的像素值只能在 0 到 1 之间)。因此,当获得 -4 这个最小值的时候,我们就能知道,对应的像素点是图像中正方形**顶部竖直方向边缘**的一部分。
+
+为了更好地掌握这种变换,我们可以看看将此过滤器应用于图中正方形底边上的一个像素会发生什么:
+
+
+
+可以看到,我们得到了与前文相似的结果,相加之后得到的结果是 4,这是应用此过滤器能得到的**最大值**。因此,由于我们得到了 4 这一最大值,可以知道这个像素是图像中正方形**底部竖直方向边缘**的一部分。
+
+为了把这些值映射到 0-1 的范围内,我们可以简单地给其加上 4 再除以 8,这样就能把 -4 映射成 0(**黑色**),把 4 映射成 1(**白色**)。因此,我们将这种过滤器称为**纵向 Sobel 过滤器**,可以用它轻松检测图像中垂直方向的边缘。
+
+那如何检测水平方向的边缘呢?只需简单地将**纵向过滤器**进行转置(按照其数值矩阵的对角线进行翻转)就能得到一个新的过滤器,可以用于检测水平方向的边缘。
+
+如果需要同时检测水平方向、垂直方向以及介于两者之间的边缘,我们可以把**纵向过滤器得分和横向过滤器得分进行结合**,这个步骤在后面的代码中将有所体现。
+
+希望上文已经讲清楚了这些理论!下面看一看代码是如何实现的。
+
+---
+
+### 如何进行边缘检测 —— 代码
+
+首先进行一些设置:
+
+```python
+%matplotlib inline
+
+import numpy as np
+import matplotlib.pyplot as plt
+
+# 定义纵向过滤器
+vertical_filter = [[-1,-2,-1], [0,0,0], [1,2,1]]
+
+# 定义横向过滤器
+horizontal_filter = [[-1,0,1], [-2,0,2], [-1,0,1]]
+
+# 读取纸风车的示例图片“pinwheel.jpg”
+img = plt.imread('pinwheel.jpg')
+
+# 得到图片的维数
+n,m,d = img.shape
+
+# 初始化边缘图像
+edges_img = img.copy()
+```
+
+* 你可以把代码中的“pinwheel.jpg”替换成其它你想要找出边缘的图片文件!需要确保此文件和代码在同一工作目录中。
+
+接着编写边缘检测代码本身:
+
+```python
+%matplotlib inline
+
+import numpy as np
+import matplotlib.pyplot as plt
+
+# 定义纵向过滤器
+vertical_filter = [[-1,-2,-1], [0,0,0], [1,2,1]]
+
+# 定义横向过滤器
+horizontal_filter = [[-1,0,1], [-2,0,2], [-1,0,1]]
+
+# 读取纸风车的示例图片“pinwheel.jpg”
+img = plt.imread('pinwheel.jpg')
+
+# 得到图片的维数
+n,m,d = img.shape
+
+# 初始化边缘图像
+edges_img = img.copy()
+
+# 循环遍历图片的全部像素
+for row in range(3, n-2):
+ for col in range(3, m-2):
+
+ # 在当前位置创建一个 3x3 的小方框
+ local_pixels = img[row-1:row+2, col-1:col+2, 0]
+
+ # 应用纵向过滤器
+ vertical_transformed_pixels = vertical_filter*local_pixels
+ # 计算纵向边缘得分
+ vertical_score = vertical_transformed_pixels.sum()/4
+
+ # 应用横向过滤器
+ horizontal_transformed_pixels = horizontal_filter*local_pixels
+ # 计算横向边缘得分
+ horizontal_score = horizontal_transformed_pixels.sum()/4
+
+ # 将纵向得分与横向得分结合,得到此像素总的边缘得分
+ edge_score = (vertical_score**2 + horizontal_score**2)**.5
+
+ # 将边缘得分插入边缘图像中
+ edges_img[row, col] = [edge_score]*3
+
+# 对边缘图像中的得分值归一化,防止得分超出 0-1 的范围
+edges_img = edges_img/edges_img.max()
+```
+
+有几点需要注意:
+
+* 在图片的边界像素上,我们无法创建完整的 3 x 3 小方框,因此在图片的四周会有一个细边框。
+* 既然是同时检测水平方向和垂直方向的边缘,我们可以直接将原始的纵向得分与横向得分分别除以 4(而不像前文描述的分别加 4 再除以 8)。这个改动无伤大雅,反而可以更好地突出图像的边缘。
+* 将纵向得分与横向得分结合起来时,有可能会导致最终的边缘得分超出 0-1 的范围,因此最后还需要重新对最终得分进行标准化。
+
+在更复杂的图片上运行上述代码:
+
+
+
+得到边缘检测的结果:
+
+
+
+---
+
+以上就是本文的全部内容了!希望你了解到了一点新知识,并继续关注更多数据科学方面的文章〜
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/elements-of-javascript-style.md b/TODO1/elements-of-javascript-style.md
new file mode 100644
index 00000000000..258c451b235
--- /dev/null
+++ b/TODO1/elements-of-javascript-style.md
@@ -0,0 +1,474 @@
+> * 原文地址:[Elements of JavaScript Style](https://medium.com/javascript-scene/elements-of-javascript-style-caa8821cb99f)
+> * 原文作者:[Eric Elliott](https://medium.com/@_ericelliott)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/elements-of-javascript-style.md](https://github.com/xitu/gold-miner/blob/master/TODO1/elements-of-javascript-style.md)
+> * 译者:[febrainqu](https://github.com/febrainqu)
+> * 校对者:[Baddyo](https://github.com/Baddyo)、[niayyy-S](https://github.com/niayyy-S)
+
+# JavaScript 风格元素
+
+
+
+> **注意:** 这篇文章现在是[“组合软件”系列丛书](https://leanpub.com/composingsoftware)中的一部分。
+
+1920 年,[William Strunk Jr 的《英文写作指南》](https://www.amazon.com/Elements-Style-Fourth-William-Strunk/dp/020530902X/ref=as_li_ss_tl?ie=UTF8&qid=1493260884&sr=8-1&keywords=the+elements+of+style&linkCode=ll1&tag=eejs-20&linkId=f7eb0eacba0eab243899626551113119)出版了,它为经过了时间考验的英语语言风格制定了指导方针。你可以对你的代码使用类似的标准,以提升你的代码质量。
+
+以下只是参考,不是不可改变的法则。如果其他的方式可以使代码更清晰,那么我们有合理的理由偏离这个方针,但是[要保持警惕和自我意识](https://medium.com/javascript-scene/familiarity-bias-is-holding-you-back-its-time-to-embrace-arrow-functions-3d37e1a9bb75)。这些指导方针能经受住时间考验的理由很充分:它们通常是正确的。只有在有充分理由的情况下才会偏离它们 —— 而不仅仅是一时兴起或个人的风格偏好。
+
+几乎所有**基本组成原则**中的指南都适用于源代码:
+
+* 以段落为单位:每个主题一段。
+* 省略不必要的词。
+* 使用主动语态。
+* 避免连续使用松散的句子。
+* 把相关的单词放在一起。
+* 用肯定句陈述。
+* 在平行概念上使用并列句。
+
+我们可以把基本相同的概念用于代码风格:
+
+1. 以函数为组成单位。每个函数实现一个功能。
+2. 省略不必要的代码。
+3. 使用主动语态。
+4. 避免一连串的松散陈述。
+5. 将相关的代码写在一起。
+6. 把语句和表达式写成肯定的形式。
+7. 对并列概念使用并列代码。
+
+## 1. 以函数为组成单位。每个函数实现一个功能。
+
+> 软件开发的本质是组合。我们通过将模块、函数和数据结构组合在一起来构建软件。
+
+> 理解如何编写和组合函数是软件开发人员的一项基本技能。
+
+模块只是一个或多个函数或数据结构的集合,数据结构是我们表示程序状态的方式,但是在应用函数之前,没有什么有趣的事情发生。
+
+在 JavaScript 中,有以下三种函数:
+
+* 通信函数:执行 I/O 的功能。
+* 过程函数:一组指令的列表。
+* 映射函数:传入一些参数,返回一些相应的结果。
+
+虽然所有可用的程序都会用到 I/O 操作,而且许多程序都遵循一些过程序列,但是你的大多数函数应该是映射函数:传入一些参数,函数将返回一些相应的结果。
+
+**每个函数处理一个功能**:如果你的函数用于 I/O 操作,不要将 I/O 与映射(计算)混合在一起。如果你的函数用于映射,不要将它和 I/O 操作混合在一起。根据定义,过程函数违反了这条准则。过程函数还违反了另一个准则:避免连续的松散声明。
+
+理想函数是一个简单的、确定性的纯函数:
+
+* 给定相同的调用参数,总是返回相同的结果
+* 没有副作用
+
+另见参考,[“什么是纯函数”](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-pure-function-d1c076bec976)
+
+## 2. 省略不必要的代码。
+
+> “有力的写作是简洁的。一个句子不应该包含不必要的单词,一个段落不应该包含不必要的句子,就像一幅画不应该有不必要的线条,一台机器不应该有不必要的零件。这并不要求作者把所有的句子都写得很短,或者避免所有的细节,只处理主题的大纲,而是要求每一个词都能说明问题。” [省略不必要的话]
+~ William Strunk, Jr.,《英文写作指南》
+
+简洁的代码在软件中是至关重要的,因为越多的代码越容易隐藏 bug。**更少的代码 = 更少的地方隐藏 bug = 更少的 bug。**
+
+简洁的代码更容易读懂,因为它有更高的信噪比:读者有必要从较少的干扰中读懂代码的含义。 **更少的代码 = 更少的干扰 = 更强的含义传达。**
+
+借用《英文写作指南》中的一个词:简洁的代码更**有活力。**
+
+```js
+function secret (message) {
+ return function () {
+ return message;
+ }
+};
+```
+
+可以简化为:
+
+```js
+const secret = msg => () => msg;
+```
+
+这对于那些熟悉简洁的箭头函数(在 ES6 中引入的)的人来说更容易理解。它省略了不必要的语法:大括号、`function` 关键字和 `return` 语句。
+
+第一种包括不必要的语法。对于那些熟悉简洁箭头语法的人来说,大括号、`function` 关键字和 `return` 语句毫无用处。它的存在只是为了让那些不熟悉 ES6 的人熟悉代码。
+
+自 2015 年以来,ES6 一直是语言标准。是时候[熟悉它](https://medium.com/javascript-scene/familiarity-bias-is-holding-you-back-its-time-to-embrace-arrow-functions-3d37e1a9bb75)了。
+
+#### 省略不必要的变量
+
+有时我们倾向于给那些不需要命名的东西命名。问题是[人类的大脑在工作记忆方面的资源是有限的](http://www.nature.com/neuro/journal/v17/n3/fig_tab/nn.3655_F2.html),而且每个变量都要存储为一个离散的量子,占用大脑中的一个可用的工作记忆插槽。
+
+因此,有经验的开发人员学会了消除不必要的变量。
+
+例如,在大多数情况下,应该省略仅为了命名返回值而命名的变量。函数的名称应该提供关于函数返回内容的足够信息。请思考下面的代码:
+
+```js
+const getFullName = ({firstName, lastName}) => {
+ const fullName = firstName + ' ' + lastName;
+ return fullName;
+};
+```
+
+对比:
+
+```js
+const getFullName = ({firstName, lastName}) => (
+ firstName + ' ' + lastName
+);
+```
+
+开发人员减少变量的另一种常见方法是使用函数组合和无参风格。
+
+**无参风格** 是一种定义函数而不引用参数的方法。实现无参风格的常见方法包括柯里化和函数组合。
+
+让我们来看一个使用柯里化的例子:
+
+```js
+const add2 = a => b => a + b;
+
+// 现在我们定义一个无参的函数 inc()
+// 任何数加 1。
+const inc = add2(1);
+
+inc(3); // 4
+```
+
+看一下 `inc()` 函数的定义。注意,它没用使用 `function` 关键字,也没有使用 `=>` 语法。没有地方列出参数,因为函数内部没有使用参数。相反,它返回了一个知道如何处理参数的函数。
+
+让我们来看另一个使用函数组合的例子。**函数组合** 是将一个函数用做另一个函数的结果的过程。不管你有没有意识到,你一直都在使用函数组合。例如,每当你使用像 `.map()` 和 `promise.then()` 这样的链式调用的时候都会用到它。它的最基本形式是这样的:`f(g(x))`。在代数中,这种结构通常写为 `f ∘ g` (读为 “f **after** g” 或 “f **composed with** g”)。
+
+当你将两个函数组合在一起时,就不需要创建一个变量来保存两个函数之间的中间值。我们看一下函数组合如何简化代码:
+
+```js
+const g = n => n + 1;
+const f = n => n * 2;
+
+// 使用中间变量:
+const incThenDoublePoints = n => {
+ const incremented = g(n);
+ return f(incremented);
+};
+
+incThenDoublePoints(20); // 42
+
+// compose2 - 取两个函数并返回它们的组合
+const compose2 = (f, g) => x => f(g(x));
+
+// Point-free:
+const incThenDoublePointFree = compose2(f, g);
+
+incThenDoublePointFree(20); // 42
+```
+
+你可以对任何函子做同样的事情。[**函子**](https://medium.com/javascript-scene/functors-categories-61e031bac53f) 是任何你可以映射的东西,例如,数组(`Array.map()`)和 promises (`promise.then()`)。让我们用 map 链写另一个版本的 `compose2`:
+
+```js
+const compose2 = (f, g) => x => [x].map(g).map(f).pop();
+
+const incThenDoublePointFree = compose2(f, g);
+
+incThenDoublePointFree(20); // 42
+```
+
+每当你使用 promise 链时,你都是在做相同的事情。
+
+实际上,每个函数式编程库都至少有两个组合实用程序版本:从右向左应用函数的 `compose()`,从左向右应用函数的 `pipe()`。
+
+Lodash 把它们命名为 `compose()` 和 `flow()`。当我在 Lodash 中使用它们时,我通常这样引入它们:
+
+```js
+import pipe from 'lodash/fp/flow';
+pipe(g, f)(20); // 42
+```
+
+然而,这不是更多的代码,下面的代码也能够实现:
+
+```js
+const pipe = (...fns) => x => fns.reduce((acc, fn) => fn(acc), x);
+pipe(g, f)(20); // 42
+```
+
+如果这个函数组合的东西听起来很陌生,你不知道该如何使用它,仔细想想:
+
+> 软件开发的本质是组合。我们通过将模块、函数和数据结构组合在一起来构建软件。
+
+由此你可以得出结论,理解函数和对象组合的工具就像房屋建筑商了解钻头和钉子枪一样基础。
+
+当你使用命令式代码将函数与中间变量组合在一起时,那就像用胶带和强力胶把它们拼起来。
+
+记住:
+
+* 如果你能用更少的代码做相同的事情,而不改变或混淆意思,那么你应该这么做。
+* 如果你能用更少的变量做相同的事情,而不改变或混淆意思,那么你应该这么做。
+
+## 3. 使用主动语态
+
+> “主动语态通常比被动语态更直接有力。” ~ William Strunk, Jr.,《英文写作指南》
+
+尽可能直接地命名事物。
+
+* `myFunction.wasCalled()` 优于 `myFunction.hasBeenCalled()`
+* `createUser()` 优于 `User.create()`
+* `notify()` 优于 `Notifier.doNotification()`
+
+将谓语和布尔值命名为用“是”或“否”就能回答的问题:
+
+* `isActive(user)` 优于 `getActiveStatus(user)`
+* `isFirstRun = false;` 优于 `firstRun = false;`
+
+使用动词形式命名函数:
+
+* `increment()` 优于 `plusOne()`
+* `unzip()` 优于 `filesFromZip()`
+* `filter(fn, array)` 优于 `matchingItemsFromArray(fn, array)`
+
+**事件处理程序**
+
+事件处理程序和生命周期方法是动词规则的一个例外,因为它们被用作定语;它们表达的不是要做什么,而是什么时候做。它们的名称应该是这样的:“<何时执行>, \<动词>”。
+
+* `element.onClick(handleClick)` 优于 `element.click(handleClick)`
+* component.onDragStart(handleDragStart) 优于 component.startDrag(handleDragStart)
+
+在第二种形式中,看起来我们试图触发事件,而不是响应事件。
+
+#### 生命周期方法
+
+考虑以下组件假设生命周期方法的替代方法,该方法存在于组件更新之前调用处理程序函数:
+
+* componentWillBeUpdated(doSomething)
+* componentWillUpdate(doSomething)
+* `beforeUpdate(doSomething)`
+
+在第一个例子中,我们使用被动语态(将被更新而不是将更新)。它很拗口,而且与其他方式一样不明了。
+
+第二个例子要好得多,但是这个生命周期方法的关键是调用一个处理程序。`componentWillUpdate(handler)` 读起来好像它会更新处理器,但这不是我们的意思。我们的意思是,“在组件更新之前,调用处理程序”。`beforeComponentUpdate()` 更清楚地表达了这种意思。
+
+我们可以进一步简化。因为这些都是方法,所以 subject(组件)是内置的。在方法名中注明它是多余的。考虑一下,如果你把这些方法直接命名为:component.componentWillUpdate(),它应该怎么读。这就好像说,“吉米吉米晚上吃牛排。” 你不需要重复两次听到 subject 的名字。
+
+* component.beforeUpdate(doSomething) 优于 component.beforeComponentUpdate(doSomething)
+
+**函数式 mixins** 是一种向对象添加属性和方法的函数。函数在管道中一个接一个地应用 —— 就像装配线一样。每个函数式 mixin 都将 `instance` 作为输入,并在将其传递给管道中的下一个函数之前附加一些内容。
+
+我倾向用形容词来命名函数式 mixins。你经常能使用 “ing” 或 “able” 后缀找到可用的形容词,例如:
+
+* const duck = composeMixins(flying, quacking);
+* const box = composeMixins(iterable, mappable);
+
+## 4. 避免一系列松散的陈述
+
+> “…一个系列很快就变得单调乏味。”
+~ William Strunk, Jr.,《英文写作指南》
+
+开发人员经常将一个过程中的事件序列串在一起:把一组松散相关的语句,设计成一个接一个地运行。过多的过程就会产生面条式代码。
+
+这类序列经常被许多平行形式重复,每一种形式都微妙地、有时出乎意料地发散。例如,用户界面组件与几乎所有其他用户界面组件共享相同的核心需求。它的关注点可以分为生命周期阶段,并由单独的功能进行管理。
+
+思考以下顺序代码:
+
+```js
+const drawUserProfile = ({ userId }) => {
+ const userData = loadUserData(userId);
+ const dataToDisplay = calculateDisplayData(userData);
+ renderProfileData(dataToDisplay);
+};
+```
+
+这个函数实际上处理三种不同的事情:加载数据、从加载的数据计算视图状态、呈现视图。
+
+在大多数现代前端应用程序体系结构中,这些关注点中的每一个都是单独考虑的。通过分离这些关注点,我们可以轻松地混合和匹配每个关注点的不同功能。
+
+例如,我们可以完全替换渲染器,它不会影响程序的其他部分。React 有丰富的自定义渲染器:ReactNative 用于原生 iOS 和 Android 应用程序,AFrame 用于 WebVR,ReactDOM/Server 用于服务器端渲染,等等。
+
+此函数的另一个问题是,加载数据前,不能简单地计算要显示的数据并生成标记。如果你已经加载了数据呢?你最终要做一些在后续调用中不必要的工作。
+
+分离关注点也使得它们可以独立测试。我喜欢在编写代码时对应用程序进行单元测试,并在每次更改时显示测试结果。但是,如果我们将**呈现代码**绑定到**数据加载代码**,我就不能简单地将一些假数据传递到呈现代码以进行测试。我必须对整个组件进行端到端测试 —— 由于浏览器加载、异步网络 I/O 等原因,这个过程可能会很耗时。
+
+我不能从我的单元测试中得到即时反馈。分离这些函数可以让你独立地进行单元测试。
+
+这个例子中有一些独立的函数,我们可以将这些函数提供给程序中的不同生命周期钩子。当程序装入组件时,会触发加载。计算和渲染可以在响应视图状态更新时发生。
+
+这种结果是产生分工更加明确的代码:每个组件可以重用相同的结构和生命周期挂钩,并且代码性能更好;我们不会重复那些不需要在后续循环中重复的工作。
+
+## 5. 保持相关代码在一起。
+
+许多框架和样板都规定了一种程序组织方法,文件按类型分组。如果你要构建小型计算器或“待办事项”应用程序,这很好,但是对于大型项目,通常把文件按功能分组。
+
+例如,这里有两个可供选择的文件层次结构,分别按类型和功能分类:
+
+**按类型分类**
+
+```
+.
+├── components
+│ ├── todos
+│ └── user
+├── reducers
+│ ├── todos
+│ └── user
+└── tests
+ ├── todos
+ └── user
+```
+
+**按功能分类**
+
+```
+.
+├── todos
+│ ├── component
+│ ├── reducer
+│ └── test
+└── user
+ ├── component
+ ├── reducer
+ └── test
+```
+
+当你将文件按功能分组时,你可以避免在文件列表中上下滚动以查找需要编辑的所有文件,从而使单个功能正常工作。
+
+> 根据特性对文件进行排序。
+
+## 6. 把语句和表达式写成肯定的形式。
+
+> “做出明确的断言。避免使用平淡、无趣、犹豫、不置可否的语言。不要用**不是** 这个词作为否定或对立的手段,永远不要用它作为逃避的手段。”
+~ William Strunk, Jr.,《英文写作指南》
+
+* `isFlying` 优于 `isNotFlying`
+* `late` 优于 `notOnTime`
+
+#### If 语句
+
+```js
+if (err) return reject(err);
+
+// 其它代码...
+```
+
+…优于:
+
+```js
+if (!err) {
+ // ... 其它代码
+} else {
+ return reject(err);
+}
+```
+
+#### 三元运算符
+
+```js
+{
+ [Symbol.iterator]: iterator ? iterator : defaultIterator
+}
+```
+
+…优于:
+
+```js
+{
+ [Symbol.iterator]: (!iterator) ? defaultIterator : iterator
+}
+```
+
+#### 最好使用强否定的变量声明
+
+有时我们只关心一个变量是否存在,因此使用正向名称会迫使我们使用 `!` 运算符对其求反。在这种情况下,请选择强否定形式。单词 “not” 和 `!` 运算符会创建弱表达式。
+
+* `if (missingValue)` 优于 `if (!hasValue)`
+* `if (anonymous)` 优于 `if (!user)`
+* `if (isEmpty(thing))` 优于 `if (notDefined(thing))`
+
+#### 在函数调用中避免 null 和未定义的参数
+
+调用函数时不需要使用 `undefined` 或 `null` 替代可选参数。最好使用命名选项对象:
+
+```js
+const createEvent = ({
+ title = 'Untitled',
+ timeStamp = Date.now(),
+ description = ''
+}) => ({ title, description, timeStamp });
+
+// 后续代码...
+const birthdayParty = createEvent({
+ title: 'Birthday Party',
+ description: 'Best party ever!'
+});
+```
+
+…优于:
+
+```js
+const createEvent = (
+ title = 'Untitled',
+ timeStamp = Date.now(),
+ description = ''
+) => ({ title, description, timeStamp });
+
+// 后续代码...
+const birthdayParty = createEvent(
+ 'Birthday Party',
+ undefined, // 这是可以避免的
+ 'Best party ever!'
+);
+```
+
+## 对并列概念使用并列代码
+
+> “……并行结构要求相似内容和功能的表达式在表面上相似。形式的相似性使读者更容易识别内容和功能的相似性。”
+~ William Strunk, Jr.,《英文写作指南》
+
+程序中很少有问题是在之前的程序中从未出现过的。我们最终会一遍又一遍做同样的事情。发生这种情况时,这就是抽象化的机会。确定相同的部分,并构建一个抽象,你只需完成不同的部分。这正是库和框架为我们所做的。
+
+UI 组件就是一个很好的例子。不到 10 年前,将使用 jQuery 的 UI 更新与应用程序逻辑和网络 I/O 结合在一起是很常见的。然后人们开始意识到我们可以将 MVC 应用于客户端的 web 应用程序,然后人们开始将模型与 UI 更新逻辑分开。
+
+最终,Web 应用程序采用了组件模型方法,这使我们可以使用 JSX 或 HTML 模板等方式对组件进行声明式建模。
+
+我们最终得到的是一种表示 UI 更新逻辑的方法,对于每个组件都是相同的方式,而不是每个组件都使用不同的命令式代码。
+
+对于熟悉组件的人来说,很容易明白每个组件的工作原理:有一些声明性标记表示 UI 元素、用于连接行为的事件处理程序,以及用于附加回调的生命周期钩子,这些回调将在需要时运行。
+
+当我们针对相似的问题重复使用相似的模式时,熟悉该模式的任何人都应该能够快速学习代码的功能。
+
+## 结论:代码应该简洁而不是过分简单
+
+> 简明扼要的写作。句子不应该包含不必要的单词,段落不应该包含不必要的句子,其原因与图纸不应该包含不必要的线条而机器不应该包含不必要的部分相同。**这不要求作者使所有句子简短,也不必避免所有细节而只在轮廓上对待主题,而要使每个单词都说清楚。** [重点补充。]
+~ William Strunk, Jr.,《英文写作指南》
+
+ES6 于 2015 年实现了标准化,但是在 2017 年,ES6 于 2015 年实现了标准化,许多开发人员以编写代码为幌子,拒绝简洁的箭头功能、隐式返回、rest 参数和扩展运算符等功能,因为这样[更为人所熟悉](https://medium.com/javascript-scene/familiarity-bias-is-holding-you-back-its-time-to-embrace-arrow-functions-3d37e1a9bb75)。那是个大错误。熟悉感会随着实践而增加,ES6中的简洁功能显然优于 ES5 替代品:与语法繁重的替代品相比**简洁的代码更纯粹** 。
+
+代码应该简洁而不是过分简单。
+
+简洁的代码带来了:
+
+* 更少的 bug
+* 更简单的 debug
+
+而且这些 bug:
+
+* 修复成本高
+* 带来其它 bug
+* 中断正常的开发流程
+
+简洁的代码也会带来:
+
+* 更简单的书写
+* 更简单的阅读
+* 更简单的维护
+
+为了让开发人员能够快速使用诸如简明语法、柯里化和组合等技术,培训投资是值得的。当我们为了熟悉而没有这样做的时候,我们需要与代码的读者进行沟通,他们才能理解代码,就像一个成年人对一个蹒跚学步的孩子讲话一样。
+
+假设读者对实现一无所知,但是不要假设读者是愚蠢的,或者读者不懂这门语言。
+
+要清楚,但不要简化。把事情简化既浪费又侮辱人。在实践和熟悉度上进行投资,以获得更好的编程词汇和更生动的风格。
+
+> 代码应该简洁而不是过分简单。
+
+---
+
+****Eric Elliott** 是 [“Programming JavaScript Applications”](http://pjabook.com)(O’Reilly)的作者,以及 [DevAnywhere.io] (https://devanywhere.io/)的创始人之一。他为**Adobe 系统**,**Zumba 健身**,**华尔街日报**,**ESPN**,**BBC**以及**Usher**,**Frank Ocean**,**Metallica**,等顶级的唱片艺术家**贡献了软件经验。
+
+**他可以和世界上最漂亮的女人一起工作。**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/encapsulating-style-and-structure-with-shadow-dom.md b/TODO1/encapsulating-style-and-structure-with-shadow-dom.md
index 5497848d31d..05e41314213 100644
--- a/TODO1/encapsulating-style-and-structure-with-shadow-dom.md
+++ b/TODO1/encapsulating-style-and-structure-with-shadow-dom.md
@@ -348,7 +348,7 @@ other-component::part(description) {
2. [编写可以复用的 HTML 模板](https://juejin.im/post/5ca5b858e51d4524a918560f)
3. [从 0 开始创建自定义元素](https://github.com/xitu/gold-miner/blob/master/TODO1/creating-a-custom-element-from-scratch.md)
4. [使用 Shadow DOM 封装样式和结构(**本文**)](https://github.com/xitu/gold-miner/blob/master/TODO1/encapsulating-style-and-structure-with-shadow-dom.md)
-5. [Web Components 的高级工具](https://github.com/xitu/gold-miner/blob/master/TODO1/advanced-tooling-for-web-components/.md)
+5. [Web Components 的高级工具](https://github.com/xitu/gold-miner/blob/master/TODO1/advanced-tooling-for-web-components.md)
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/everything-you-need-to-know-about-javascript-symbols.md b/TODO1/everything-you-need-to-know-about-javascript-symbols.md
new file mode 100644
index 00000000000..081d01e57ab
--- /dev/null
+++ b/TODO1/everything-you-need-to-know-about-javascript-symbols.md
@@ -0,0 +1,186 @@
+> * 原文地址:[Everything you need to know about JavaScript symbols](https://levelup.gitconnected.com/everything-you-need-to-know-about-javascript-symbols-24650a163038)
+> * 原文作者:[Narek Ghevandiani](https://medium.com/@narghev)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/everything-you-need-to-know-about-javascript-symbols.md](https://github.com/xitu/gold-miner/blob/master/TODO1/everything-you-need-to-know-about-javascript-symbols.md)
+> * 译者:
+> * 校对者:
+
+# Everything you need to know about JavaScript symbols
+
+
+
+A **JavaScript Symbol** is a relatively new JavaScript “feature”. It was introduced back in 2015 as part of [ES6](http://es6-features.org). In this article, I am going to cover:
+
+1. What exactly is a JavaScript Symbol
+2. The motivation of adding the data type to the language
+3. Whether the data type was successful in solving the problem it was supposed to
+4. The differences with the symbol data type in other languages, for example Ruby
+5. Well-known JavaScript symbols
+6. Benefiting from the data type
+
+## JavaScript symbol
+
+Symbols were added to the lineup of primitive data types in JavaScript in 2015. It was part of ES6 specification and its sole purpose is to act as a **unique identifier of object properties**, i.e. it can be used as a **key** in objects. You can **think** of symbols as big numbers and every time you create a symbol, a new random number gets generated **(uuid)**. You can use that symbol **(the random big number)** as a key in objects.
+
+A symbol is created by calling the Symbol function which takes an optional argument string which is used only for debugging purposes and acts as a description of the symbol. The Symbol function returns a unique symbol value.
+
+
+
+Note that a Symbol is not a constructor and **cannot** be called with **new**.
+
+
+
+It is also possible to create symbols which will be assigned to the **global symbol registry**. The methods `**Symbol.for()**` and `**Symbol.keyFor()**` help create and read Symbols in the global symbol registry. The `**Symbol.for()**` method looks in the global symbol registry and retrieves or initializes the symbol depending if it is found or not.
+
+
+
+And the `**Symbol.keyFor()**` method looks for the symbol in the global symbol registry and returns its key if found and `undefined` otherwise. Think of the global symbol registry as a global object where the keys are the strings passed to `**Symbol.for()**` and the values are the symbols.
+
+
+
+Symbols registered to the global symbol registry are not only accessible in all scopes, but even accessible across realms.
+
+## Motivations of adding the new data type
+
+One of the reasons of adding the data type was to enable private properties in JavaScript. Before symbols, privacy or immutability were being solved with closures, proxies, and other workarounds. But all of the solutions are too verbose and require a lot of code and logic to achieve their purpose.
+
+So let’s see how the Symbol was supposed to solve the issue. Every symbol value returned from the Symbol function is unique and can be used as an object property identifier. That is the main purpose of the Symbol.
+
+
+
+Since every symbol is unique, and in no way can two symbols be equal to each other, if a symbol is used as a property identifier and is not available in a scope, that property cannot be accessed from that scope.
+
+
+
+
+
+Symbols defined in the global symbol registry can be accessed with **`Symbol.for()`** and will be the same.
+
+
+
+Okay, so symbols are cool. They help us make unique values that can never be repeated and use them to **hide** properties. But do they really solve the privacy problem?
+
+## Do symbols achieve property privacy?
+
+JavaScript symbol does **NOT** achieve property privacy. You cannot rely on symbols to hide something from the user of your library. There is a method defined on the Object class called **Object.getOwnPropertySymbols()** that takes an object as an argument and returns an array of property symbols of the argument object.
+
+
+
+Additionally, if the symbol is assigned to the global symbol registry, nothing can stop accessing the symbol and its property value.
+
+## Symbol in computer programming
+
+If you are familiar with other programming languages, you will know that they have symbols too. And in fact, even if the name of the datatype is the same, there are pretty significant differences between them.
+
+Now let’s talk about symbols in programming in general. The definition of a symbol in [Wikipedia](https://en.wikipedia.org/wiki/Symbol_(programming)) is the following:
+
+> A symbol in computer programming is a primitive data type whose instances have a unique human-readable form.
+
+In JavaScript symbol is a primitive datatype and although the language does not force you to make the instance human-readable, you can provide the symbol with a debugging description property.
+
+Given that, we should know that there are some differences between **JS** symbols and symbols in other languages. Let’s take a look at [**Ruby symbols**](https://ruby-doc.org/core-2.2.0/Symbol.html). In Ruby, Symbol objects are usually used to represent some strings. They are generated using the colon syntax and also by type conversion using the `**to_sym**` method.
+
+
+
+If you noticed, we never assign the “created” symbol to a variable. If we use **(generate)** a symbol in the Ruby program it will always be the same during the entire execution of the program, regardless of its creation context.
+
+
+
+In JavaScript, we can replicate this behavior by creating a symbol in the global symbol registry.
+
+A major difference between symbol in the 2 languages is that in Ruby, symbols can be used instead of string, and in fact in many cases they auto-convert to strings. Methods available on string objects are also available on symbols and as we saw string can be converted to symbols using the `**to_sym**` method.
+
+We already saw the reasons and the motivation of adding symbols to JavaScript, now let’s see what is their purpose in Ruby. In Ruby, we can think of symbols as immutable strings, and that alone results in many advantages of using them. They can be used as object property identifiers, and usually are.
+
+
+
+Symbols also have performance advantages over strings. Every time you use the string notation, a new object gets created in the memory while symbols are always the same.
+
+
+
+Now imagine we use a string as a property identifier and create 100 of that object. Ruby will have to also create 100 different string objects. That can be avoided by using symbols.
+
+Another use-case of symbols is showing status. For example, it is a good practice for functions to return a symbol, indicating the success status like (**:ok**, **:error**) and the result.
+
+In [Rails](https://rubyonrails.org/) **(a famous Ruby web-app framework),** almost all [HTTP status codes can be used with symbols](https://gist.github.com/mlanett/a31c340b132ddefa9cca). You can send status **:ok**, **:internal_server_error** or **:not_found,** and the framework will replace them with correct status code and message.
+
+To conclude, we can say that symbols are not the same and do not share the same purpose in all programming languages and as a person who already was familiar with Ruby symbols, for me JavaScript symbols and their motivation were a bit confusing.
+
+**Note: In some programming languages ([erlang](https://www.erlang.org/), [elixir](https://elixir-lang.org/)), symbol is called an [atom](https://elixir-lang.org/getting-started/basic-types.html#atoms).**
+
+## Well-known JavaScript symbols
+
+JavaScript has some built-in symbols which allow the developer to access some properties which were not exposed before the introduction of symbols to the language.
+
+Here are some of the well-known JavaScript symbols that are used for iteration, Regexp, etc.
+
+#### Symbol.iterator
+
+This symbol gives the developer access to the default iterator for an object. It is used in `**for…of**` and its value should be a generator function.
+
+
+
+
+
+> `function*() {}` is the syntax for defining a **generator function.** A generator function returns a Generator object.
+
+> `yield` is a keyword used to pause and resume generator functions.
+
+> See more on [generator functions](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/function*) and [yield](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/yield).
+
+For async iteration there is **Symbol.asyncIterator** which is used by `**for await…of**` loop.
+
+#### Symbol.match
+
+As we know, functions like **String.prototype.startsWith(), String.prototype.endsWith()** take a string as their first argument.
+
+
+
+Let’s try passing a regexp instead of a string to the function, we get a type error.
+
+
+
+Actually, what happens is that the functions check specifically whether the passed argument is a regexp or not. We can say that an object is not intended to be used as a regexp by setting its `**Symbol.match**` property to **false** or to another falsey value.
+
+
+
+**Note: Honestly, I am not sure why you would want to do this. The code above is an example to demonstrate how to use the `Symbol.match` . It seems like a hack and it will be problematic if used like this because it changes the behavior of functions that are used a lot. I cannot think of any real use-cases for using this one.**
+
+## Benefiting from JavaScript symbols
+
+Although JS Symbol is not being used widely and did not solve the property privacy problem, we still can benefit from it.
+
+We can use the Symbol to define some **metadata** on the object. For example, we want to create a dictionary which we will implement by adding word and definition pairs to the object and for some computational reasons, we want to keep track of the word count in the dictionary. The word count in this case can be considered metadata. It is not really a valuable piece of information for the user and the user may not want to see it when say iterating over the object.
+
+
+
+We can solve this problem by keeping the word count property keyed with a symbol. In this case, we avoid the problem of the user accidentally accessing it.
+
+
+
+And the reason for which symbols will be used the most is probably property name collisions. Sometimes we get and set object properties when iterating over them, or we use a dynamic value to access the property **(with using the** obj[key] **notation)** and as a result of that, accidentally mutate the property we never wanted to. So we can solve this problem by using symbols as property identifiers. In this case, we can never land on that key while iterating over the object or using a dynamic value. Iteration case will not happen because we can never land on them while iterating with `**for…in**`
+
+
+
+The dynamic valued key case cannot happen because there is no other value equal to a symbol except that symbol.
+
+And of course, well-known symbols like `**Symbol.iterator**` or `**Symbol.asyncIterator**` can have interesting use-cases.
+
+
+
+I covered the important concepts and practices needed for grasping the idea of JavaScript Symbol. Of course there is a lot more to cover like other well-known symbols, or use cases of crossing realms with symbols, but I will leave out some useful material that cover those and other parts of JavaScript Symbol.
+
+#### Additional Material
+
+- [JavaScript Symbol MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol)
+- [ES6 Symbol tc39wiki](http://tc39wiki.calculist.org/es6/symbols/)
+- [JS Symbols exploringjs.com](https://exploringjs.com/es6/ch_symbols.html)
+- [JS Realms stackoverflow](https://stackoverflow.com/questions/49832187/how-to-understand-js-realms)
+- [Symbol (programming) wikipedia](https://en.wikipedia.org/wiki/Symbol_(programming))
+- [Ruby Symbols](https://ruby-doc.org/core-2.2.0/Symbol.html)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/expressive-code-for-state-machines-in-cpp.md b/TODO1/expressive-code-for-state-machines-in-cpp.md
index 8617b0d3272..dd8cd07912c 100644
--- a/TODO1/expressive-code-for-state-machines-in-cpp.md
+++ b/TODO1/expressive-code-for-state-machines-in-cpp.md
@@ -2,35 +2,35 @@
> * 原文作者:[Jonathan Boccara](https://www.fluentcpp.com/author/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/expressive-code-for-state-machines-in-cpp.md](https://github.com/xitu/gold-miner/blob/master/TODO1/expressive-code-for-state-machines-in-cpp.md)
-> * 译者:
-> * 校对者:
+> * 译者:[zh1an](https://github.com/zh1an)
+> * 校对者:[todaycoder001](https://github.com/todaycoder001), [PingHGao](https://github.com/PingHGao)
-# Expressive Code for State Machines in C++
+# C++ 中清晰明了的状态机代码
-> This is a guest post from Valentin Tolmer. Valentin is a Software Engineer at Google, where he tries to improve the quality of the code around him. He was bitten by a template when he was young, and now only meta-programs. You can find some of his work on [Github](https://github.com/nitnelave), in particular the [ProtEnc](https://github.com/nitnelave/ProtEnc) library this article is about.
+> 这是 Valentin Tolmer 的特邀文章。 Valetin 是谷歌的一名软件工程师,他试图提高他周围的代码质量。他年轻时就受到模板编程的影响并且现在只致力于元编程。你可以在 [GitHub](https://github.com/nitnelave) 找到他的一些工作内容,特别是本文所涉及的 [ProtEnc](https://github.com/nitnelave/ProtEnc) 库。
-Have you ever run into this kind of comments?
+你曾经遇到过这种注释吗?
```c++
-// IMPORTANT: Do not call this function before calling SetUp()!
+// 重要:在调用 SetUp() 之前请不要调用该函数!
```
-Or checks like these:
+或者做这样的检查:
```c++
-if (my\_field\_.empty()) abort();
+if (my_field_.empty()) abort();
```
-Those are all symptoms of a (often light-weight) protocol that our code must respect. Or sometimes, you have an explicit protocol that you’re following, such as in the implementation of an SSL handshake or other business logic. Or maybe you have an explicit state machine in your code, with the transitions checked each time against a list of possible transitions.
+这些(注释中提出的状态检查要求)都是我们的代码必须遵守的协议的通病。有些时候,你正在遵守的一个明确的协议也会有状态检查的要求,例如在 SSL 握手或者其他业务逻辑实现中。或者可能在你的代码中有一个明确状态转换的状态机,该状态机每次都需要根据可能的转换列表做转换状态检查。
-Let’s have a look at how we can **expressively** handle these cases.
+让我们看看我们如何**清晰明了地**处理这种方案。
-### Example: Building an HTTP Connection
+### 例如:建立一个 HTTP 连接
-Our example today will be building an HTTP connection. To simplify greatly, let’s say that our connection requires at least one header (but can have more), exactly one body, and that the headers must be specified before the body (e.g. because we write into an append-only data structure for performance reasons).
+我们今天的示例是构建一个 HTTP 连接。为了大大简化,我们只说我们的连接请求至少包含一个 header(也许会更多),有且只有一个 body,并且这些 header 必须在 body 之前被指定出来(例如因为性能原因,我们只写入一个追加的数据结构)。
-**Note: this** ****specific**** **problem could be solved with a constructor taking the correct parameters, but I didn’t want to over-complicate the protocol. You’ll see how easily extensible it is.**
+**备注:虽然这个****特定的****问题可以通过给构造函数传递正确的参数来解决,我不想使这个协议过于复杂。你将看到扩展它是多么的容易。**
-Here’s a first implementation:
+这是第一次实现:
```c++
class HttpConnectionBuilder {
@@ -38,12 +38,12 @@ class HttpConnectionBuilder {
void add_header(std::string header) {
headers_.emplace_back(std::move(header);
}
- // IMPORTANT : must be called after at least one add_header
+ // 重要: 至少调用一次 add_header 之后才能被调用
void add_body(std::string body) {
body_ = std::move(body);
}
- // IMPORTANT : must be called after add_body.
- // Consumes the object.
+ // 重要: 只能调用 add_body 之后才能被调用
+ // 消费对象
HttpConnection build() && {
return {std::move(headers_), std::move(body_)};
}
@@ -53,17 +53,17 @@ class HttpConnectionBuilder {
};
```
-Now, this example is quite simple, but already it’s relying on the user not doing things wrong: there’s nothing preventing them from adding another header after the body, if they didn’t read the documentation. Put this into a 1000-line file, and you’ll quickly get bad surprises. Worse, there’s no check that the class is used correctly, so the only way to see that it was misused is through the unwanted side effects! If it causes memory corruption, good luck debugging this.
+直到现在,这个例子相当的简单,但是它依赖于用户不要做错事情:如果他们没有提前阅读过文档,没有什么可以阻止他们在 body 之后添加另外的 header。如果将其放入到一个 1000 行的文件中,你很快就会发现这有多糟糕。更糟糕的是,没有检查类是否被正确的使用,所以,查看类是否被误用的唯一方法是观察是否有意料之外的效果!如果它导致了内存损坏,那么祝您调试顺利。
-We can do better…
+其实我们可以做的更好……
-### Using dynamic enums
+### 使用动态枚举
-As is often the case, this protocol can be represented by a finite state machine: start in the state in which we didn’t add any header (START), in which case the only option is to add a header. Then we’re in the state where we have at least one header (HEADER), from which we can either add another header and stay in this state, or add a body and go to the BODY state. Only from there can we call build, getting us to the final state.
+通常情况下,该协议可以用一个有限状态机来表示:该状态机开始于我们没有添加任何的 header 的状态(START 状态),该状态下只有一个添加 header 的选项。然后进入至少添加一个 header (HEADER 状态),该状态下既可以添加另外的 header 来保持该状态,也可以添加一个 body 而进入到 BODY 状态。只有在 BODY 这个状态下我们可以调用 build,让我们进入到最终状态。

-So, let’s encode that into our class!
+所以,让我们将这些想法写到我们的类中!
```c++
enum BuilderState {
@@ -84,15 +84,15 @@ class HttpConnectionBuilder {
};
```
-And so on for the other functions. That’s already better: we have an explicit state telling us which transitions are possible, and we check it. Of course, you have thorough tests for your code, right? Then you’ll be able to catch any violation at test time, providing you have enough coverage. You might enable those checks in production as well to make sure that you don’t deviate from the protocol (a controlled crash is better than memory corruption), but you’ll have to pay the price of the added checks.
+其他的函数也是这样。这已经很好了:我们有一个确定的状态告诉我们哪种转换是可能的,并且我们检查了它。当然了,你有针对你的代码的周密的测试用例,对吗?如果你的测试对代码有足够的覆盖率,那么你将能够在测试的时候捕获任何违规的操作。你也可以在生产环境中启用这些检查,以确保不会偏离该协议(受控崩溃总比内存损坏要强),但是你必须对增加的检查付出代价。
-### Using typestates
+### 使用类型状态(typestates)
-How can we catch these earlier, and with 100% certainty? Let the compiler do the work! Here I’ll introduce the concept of typestates:
+我们怎么才能更快地、100% 准确地捕获到这些错误呢?那就让编译器来做这些工作!下面我将介绍类型状态(typestates)的概念。
-Roughly speaking, typestates are the idea of encoding the state of an object in its very type. Some languages do this by implementing a separate class for each state (e.g. `HttpBuilderWithoutHeader`, `HttpBuilderWithBody`, …) but that can get fairly verbose in C++: we have to declare the constructors, delete the copy constructors, convert one object into the other… It gets old quickly.
+大致说来,类型状态(typestates)是将对象的状态编码为其本身的类型。有些语言通过为每个状态实现一个单独的类来实现(比如 `HttpBuilderWithoutHeader`、`HttpBuilderWithBody` 等等),但这在 C++ 中将会变得非常的冗长:我们不得不声明构造函数、删除拷贝函数、将一个对象转换成另外一个对象…… 并且它很快就会过期。
-But C++ has another trick up its sleeve: templates! We can encode the state in an enum, and template our builder with this enum. This gives us something like:
+但是 C++ 还有其他的妙招:模板!我们可以在 `enum` 中对状态进行编码,并且使用这个 `enum` 将构造器模板化。这就得到了如下的代码:
```c++
template <BuilderState state>
@@ -108,11 +108,11 @@ class HttpConnectionBuilder {
};
```
-Here we check statically that the object is in the correct state. Invalid code won’t even compile! And we get a pretty clear error message. Every time we create a new object of the type corresponding to the target state, and destroy the object corresponding to the previous state: you call add_header on an object of type `HttpConnectionBuilder<START>`, but you’ll get an `HttpConnectionBuilder<HEADER>` as return value. That’s the core idea of typestates.
+这里我们静态地检查对象是否处于正确的状态,无效代码甚至无法编译!并且我们还可以得到了一个相当清晰的错误信息。每次我们创建与目标状态相对应的新对象时,我们也销毁了与之前状态对应的对象:你在类型为 `HttpConnectionBuilder<START>`的对象上调用 add_header,但是你将得到一个 `HttpConnectionBuilder<HEADER>` 类型的返回值。这就是类型状态(typestates)的核心思想。
-Note that the methods can only be called on r-values (`std::move`, that’s the role of the trailing “`&&`” in the function declaration). Why so? It enforces the destruction of the previous state, so you only get the relevant state. Think about it like a `unique_ptr`: you don’t want to copy the internals and get an invalid state. Just like there should be a single owner for a `unique_ptr`, there should be a single state for a typestate.
+注意:这个方法只能在右值引用(r-values)中调用(`std::move`,就是函数声明行末尾的 `&&` 的作用)。为什么要这样呢?它强制性地破坏了前一个状态,因此只能得到一个相关的状态。可以将其看做 `unique_ptr`:你不想复制一个内部的构件并获得无效的状态。就像 `unique_ptr` 只有一个所有者一样,类型状态(typestates)也必须只有一个状态。
-With this, you can write:
+有了这个,你就可以这样写:
```c++
auto connection = GetConnectionBuilder()
@@ -122,31 +122,31 @@ auto connection = GetConnectionBuilder()
.build();
```
-Any deviation from the protocol will be a compilation failure.
+任何对协议的偏离都会导致编译失败。
-There are however a couple of things to keep in mind:
+这有几个无论如何都要遵守的规则:
-* All your functions must take the object by r-value (i.e. `*this` must be an r-value, the trailing “`&&`”).
-* You probably want to disable copy constructors, unless it makes sense to jump in the middle of the protocol (that’s the reason we have r-values, after all).
-* You need to declare your constructor private, and friend a factory function to make sure that people don’t create the object in a non-start state.
-* You need to friend and implement the move constructor to another state, without which you can transform your object from one state to another.
-* You need to make sure you added checks in every function.
+* 你所有的函数必须使用右值引用的对象(比如 `*this` 必须是一个右值引用,在末尾要要有 `&&`)。
+* 你可能需要禁用拷贝函数,除非跳转到协议中间状态的时候是有意义的(毕竟这就是我们有右值引用的原因)。
+* 你有必要声明你的构造函数为私有,并添加一个工厂(factory)函数来确保人们不会创建一个无开始状态的对象。
+* 你需要将移动构造函数添加为友元并实现到另外一种状态,没有这种状态,你就可以随意地将对象从一个状态转移到另外一种状态。
+* 你需要确定你已经在每个函数中添加了检查。
-All in all, implementing this correctly from scratch is a bit tricky, and you probably don’t want 15 different self-made typestates implementations in the wild. If only there were a framework to easily and safely declare these typestates!
+总而言之,从头开始正确的实现这些是有一点儿棘手的,并且在自然增长中,你很有可能不想要15种不同的自制类型状态(typestates)实现。如果有一个框架可以轻松且安全地声明这些类型状态就好了!
-### The ProtEnc library
+### ProtEnc 库
-Here’s where [ProtEnc](https://github.com/nitnelave/ProtEnc) (short for protocol encoder) comes in. With a scary amount of templates, the library allows for an easy declaration of a class implementing the typestate checks. To use it, you need your (unchecked) implementation of the protocol, the very first class we wrote with all the “IMPORTANT” comments (which we’ll remove).
+这就是 [ProtEnc](https://github.com/nitnelave/ProtEnc)(protocol encoder 的简称)发挥作用的地方。有了数量惊人的模板,该库允许轻松的声明实现 typestate 检查的类。要使用它,需要你的(未检查的)协议实现,这是我们用所有“重要的”注释实现的第一个类。
-We’re going to add a wrapper to that class, presenting the same interface but with typestate checks. The wrapper will contain the information about the possible initial state, transitions and final transitions in its type. Each wrapper function is simply checking if the transition is allowed, then perfect-forwarding the call to the underlying object. All of this without pointer indirection, runtime component or memory footprint, so it’s essentially free!
+我们将给这个类增加一个与其有相同的接口但是增加了类型检查的包装类。该包装类将在它的类型中包含一些诸如可能的初始化状态、转换和最终状态。每个包装类函数只是简单的检查转换是否可行,然后完美的转发调用给下一个对象。所有的这些都不包括指针的间接寻址、运行时组件或者内存分配,所以它完全自由的!
-So, how do we declare this wrapper? First, we have to define the finite state machine. This consists of 3 parts: initial states, transitions, and final states/transitions. The list of initial states is just a list of our enum, like so:
+那么,我们怎么声明这个包装类呢?首先,我们不得不定义一个有限状态机。这包括三个部分:初始状态、转换和最终状态或者转换。初始状态的列表只是我们的枚举类型的列表,就像下边这样的:
```c++
using MyInitialStates = InitialStates<START>;
```
-For the transition, we need the initial state, the final state, and the function that will get us there:
+对于转换,我们需要初始化状态、最终状态和执行状态转换的函数:
```c++
using MyTransitions = Transitions<
@@ -155,22 +155,22 @@ using MyTransitions = Transitions<
Transition<HEADERS, BODY, &HttpConnectionBuilder::add_body>>;
```
-And for the final transitions, we’ll need the state and the function:
+对于最终的转换,我们也需要一个状态和函数:
```c++
using MyFinalTransitions = FinalTransitions<
FinalTransition<BODY, &HttpConnectionBuilder::build>>;
```
-The extra “FinalTransitions” comes from the possibility of having more than one “FinalTransition”.
+这个额外的 "FinalTransitions" 是因为我们可能会定义多个 "FinalTransition"。
-We can now declare our wrapping type. Some of the unavoidable boilerplate had been hidden in a macro, but it’s mostly just constructors and friend declarations with the base class that does the heavy lifting:
+现在我们可以声明我们的包装类的类型了。一些不可避免的模板被宏定义隐藏起来,但它主要是基类的构造或者元的声明。
```c++
PROTENC\_DECLARE\_WRAPPER(HttpConnectionBuilderWrapper, HttpConnectionBuilder, BuilderState, MyInitialStates, MyTransitions, MyFinalTransitions);
```
-That opens a scope (a class) in which we can forward our functions:
+这是展开的一个作用域(一个类),我们可以在其中转发我们的函数:
```c++
PROTENC\_DECLARE\_TRANSITION(add_header);
@@ -178,15 +178,15 @@ PROTENC\_DECLARE\_TRANSITION(add_body);
PROTENC\_DECLARE\_FINAL_TRANSITION(build);
```
-And then close the scope.
+然后是关闭作用域。
```c++
PROTENC\_END\_WRAPPER;
```
-(That one is just a closing brace, but you don’t want mismatching braces, do you?)
+(那只是一个右括号,但你不想要不匹配的括号,是吗?)
-With this simple yet extensible setup, you can use the wrapper just like we used the one from the previous step, and all the operations will be checked 🙂
+通过这个简单但可扩展的设置,你就可以像使用上一步中的包装器一样使用它啦,并且所有的操作都会被检查。🙂
```c++
auto connection = HttpConnectionBuilderWrapper<START>{}
@@ -196,7 +196,7 @@ auto connection = HttpConnectionBuilderWrapper<START>{}
.build();
```
-Trying to call the functions in the wrong order will cause compilation errors. Don’t worry, care was taken to make sure that the first error has a readable error message 😉 For instance, removing the `.add_body("body")` line, you would get:
+试图在错误的顺序下调用函数将导致编译错误。别担心,精心的设计保证了第一个错误信息是可读的😉。例如,移除 `.add_body("body")` 行,你将得到以下错误:
In file included from example/http_connection.cc:6:
@@ -208,13 +208,14 @@ src/protenc.h:257:17: error: static assertion failed: Final transition not
static_assert(!std::is\_same\_v<T, NotFound>, "Final transition not found");
```
-Just make sure that your wrapped class is only constructible from the wrapper, and you’ll have guaranteed enforcement throughout your codebase!
+只要确保包装类只能从包装器构造,就可以保证整个代码库的正确运行!
-If your state machine is encoded in another form (or if it gets too big), it would be trivial to generate code describing it, since all the transitions and initial states are gathered together in an easy-to-read/write format.
+如果您的状态机是以另一种形式编码的(或者如果它变得太大了),那么生成描述它的代码就很简单了,因为所有的转换和初始状态都是以一种容易读/写的格式聚集在一起的。
-The full code of this example can be found in the [repository](https://github.com/nitnelave/ProtEnc). Note that it currently doesn’t work with Clang because of [bug #35655](https://bugs.llvm.org/show_bug.cgi?id=35655).
+完整的代码示例可以在 [GitHub](https://github.com/nitnelave/ProtEnc) 找到。请注意该代码现在不能使用 Clang 因为 [bug #35655](https://bugs.llvm.org/show_bug.cgi?id=35655)。
-### You will also like
+
+### 你将也喜欢
* [TODO_BEFORE(): A Cleaner Codebase for 2019](https://www.fluentcpp.com/2019/01/01/todo_before-clean-codebase-2019/)
* [How to Disable a Warning in C++](https://www.fluentcpp.com/2019/08/30/how-to-disable-a-warning-in-cpp/)
diff --git a/TODO1/eye-tracking-and-the-best-ux-practices-in-the-mobile-world.md b/TODO1/eye-tracking-and-the-best-ux-practices-in-the-mobile-world.md
new file mode 100644
index 00000000000..c9e4dcfd9d6
--- /dev/null
+++ b/TODO1/eye-tracking-and-the-best-ux-practices-in-the-mobile-world.md
@@ -0,0 +1,66 @@
+> * 原文地址:[眼动追踪和移动世界的最佳用户体验实践](https://medium.com/nyc-design/eye-tracking-and-the-best-ux-practices-in-the-mobile-world-a101f67f20dd)
+> * 原文作者:[Naman Sehgal](https://medium.com/@sehgal.naman)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/eye-tracking-and-the-best-ux-practices-in-the-mobile-world.md](https://github.com/xitu/gold-miner/blob/master/TODO1/eye-tracking-and-the-best-ux-practices-in-the-mobile-world.md)
+> * 译者:[Charlo](https://github.com/Charlo-O?tab=repositories)
+> * 校对者:[Long Xiong](https://github.com/xionglong58)、[PingHGao](https://github.com/PingHGao)
+
+# 眼动追踪和移动世界的最佳用户体验实践
+
+
+
+在当今世界,可用性测试对于设计用户友好的界面至关重要。这些测试采用不同的形式和方法来帮助设计师发现可用性问题。这在把握设计期望和用户行为之间的关系时至关重要。诸如眼动追踪一类的以传感器为基础的技术,在深入了解用户如何与技术交互方面具有革命性意义。
+
+眼动追踪是一种可用方法和工具,它可以在给定的界面上显示用户的焦点和访问模式。它能够为设计者提供详尽反馈,界面哪些元素能够吸引用户的眼球。它还可以有效地评估设计/内容层次结构。眼动追踪是一种很有洞察力的研究技术,它决定了用户的关注焦点和用户的注意力。
+
+
+
+## 移动互联网中的眼动追踪
+
+考虑到超过 80% 的人口可以使用移动设备,移动互联网的使用率正在超过传统计算平台。今天的世界是以移动为中心的。因此,关注移动设备的可用性非常重要。
+
+用户体验专家珍妮弗·罗曼诺·伯格斯特伦(Jen Romano Bergstrom)进行了一项研究,利用眼动追踪技术,在多个设备之间比较同一界面的用户体验。结果,她在不同的设备上发现了不同的问题。下面是数据的热点图。红点是主要的焦点,绿色和黄色是用户关注较少的区域。很明显,用户在不同的设备上对相同的界面有不同的关注点。
+
+
+
+## 移动设备的最佳用户体验实践
+
+史蒂夫·克鲁格(Steve Krug)是一名信息架构师和用户体验专家,以著作《点石成金 —— 访客至上的网页设计秘笈法》闻名。他在书中提到,用户在采取行动前会先看。在仔细选择和点击其他链接之前,会先阅读文本。事实上,人们并不是什么都看,他们只是看他们想看的。这是一个重大突破,它强化了可用性工具(如眼动追踪设备)的重要性。
+
+
+
+珍妮弗·罗曼诺·伯格斯特伦(Jen Romano Bergstrom)解释了一些最佳用户体验实践的关键准则,每个用户体验专家都应该遵循。这些准则是在进行了几次眼动跟踪研究后起草的。
+
+**1、跨设备的功能图标**
+
+>图标和图像应该像用户希望的那样,能在不同的设备下被点击,从而产生交互。让主页上的元素可点击将使网页更直观。
+
+**2、清晰而准确的错误信息**
+
+如果出现一个错误消息,它应该解释这个错误消息与什么有关。下面是 Jen 研究中的一个例子。在左侧,弹出一个错误消息。但是,尚不清楚应填写哪个必填字段。右边是用户的注视图。用户试图在整个屏幕上搜索剩下的必填字段。因此,错误消息应该清楚地指出问题所在,便于用户快速进行下一步操作。
+
+
+
+**3、统一页面布局**
+
+请记住,用户可以访问多个设备,一个界面的布局应该在各种移动设备之间保持一致。信息流应该保持不变,因为好的设计可以在所有平台上为用户提供一致的心智模型。
+
+## 结论
+
+尽管眼动追踪是一个耗时且昂贵的过程,但它是一种非常有用的技术,可以让你对特定产品有更深刻的了解。就移动设备中眼球追踪的使用而言,这一领域还有很多值得探索的地方。遵循这些建议的 UX 实践将极大地改善用户体验。
+
+## 参考文献
+
+[http://bit.ly/2AGPlkz](http://bit.ly/2AGPlkz)
+
+[https://www.slideshare.net/JenniferRomanoBergstrom/eye-tracking-the-ux-of-mobile-what-you-need-to-know](https://www.slideshare.net/JenniferRomanoBergstrom/eye-tracking-the-ux-of-mobile-what-you-need-to-know)
+
+[https://www.youtube.com/watch?v=JfzTevZZ-z0&t=326s](https://www.youtube.com/watch?v=JfzTevZZ-z0&t=326s)
+
+Don’t Make Me Think, Steve Krug, 2006
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/fast-pipelines-with-generators-in-typescript.md b/TODO1/fast-pipelines-with-generators-in-typescript.md
new file mode 100644
index 00000000000..513ae294fed
--- /dev/null
+++ b/TODO1/fast-pipelines-with-generators-in-typescript.md
@@ -0,0 +1,166 @@
+> * 原文地址:[Lazy Pipelines with Generators in TypeScript](https://itnext.io/fast-pipelines-with-generators-in-typescript-85d285ae6f51)
+> * 原文作者:[Wim Jongeneel](https://medium.com/@wim.jongeneel1)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/fast-pipelines-with-generators-in-typescript.md](https://github.com/xitu/gold-miner/blob/master/TODO1/fast-pipelines-with-generators-in-typescript.md)
+> * 译者:
+> * 校对者:
+
+# Lazy Pipelines with Generators in TypeScript
+
+ on [Unsplash](https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/9704/1*wEQnHaPoHc_QJo5vxwrCEg.jpeg)
+
+In recent years the JavaScript community has embraced the functional array methods like `map` and `filter`. Writing for-loops has become something that gets associated with 2015 and JQuery. But the array methods in JavaScript are far from ideal when we are talking about performance. Lets look at an example to clarify the issues:
+
+```TypeScript
+const x = [1,2,3,4,5]
+ .map(x => x * 2)
+ .filter(x => x > 5)
+ [0]
+```
+
+This code will execute the following steps:
+
+* create the array with 5 items
+* create a new array with all the numbers doubled
+* create a new array with the numbers filtered
+* take the first item
+
+This involves a lot more stuff happening then is actually needed. The only thing has to happen is that the first item that passes `x > 5` gets processed and returned. In other languages (like Python) iterators are used to solve this issue. Those iterators are a lazy collection and only processes data when it is requested. If JavaScript would use lazy iterators for its array methods the following would happen instead:
+
+* `[0]` requests the first item from `filter`
+* `filter` requests items from `map` until it has found one item that passes the predicate and yields (‘returns’) it
+* `map` has processed an item for each time `filter` requested it
+
+Here we did only `map` and `filter` the first tree items in the array because no more items where requested from the iterator. There where also no additional arrays or iterators constructed because every item goes through the entire pipeline one after the other. This is a concept that **can** result in massive performance gains when processing a lot of data.
+
+## Generators and iterators in JavaScript
+
+Luckily for us JavaScript does actually support the concept of [iterators](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Iterators_and_Generators). They can be created with [generator](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Iterators_and_Generators) functions that yield the items of the collection. A generator function looks as follows:
+
+```TypeScript
+function* iterator() {
+ yield 1
+ yield 2
+ yield 3
+}
+
+for(let x of iterator()) {
+ console.log(x)
+}
+```
+
+Here the for-loop will request an item of the iterator for each loop. The generator function uses the `yield` keyword to return the next item in the collection. As you see we can yield multiple times to create iterators that contain multiple items. There will never be any array constructed in memory. We can make this a bit better to understand when we remove some of the syntax sugar:
+
+```TypeScript
+const itt = iterator()
+let current = itt.next()
+
+while(current.done == false) {
+ console.log(current.value)
+ current = itt.next()
+}
+```
+
+Here you can see that an iterator has a `next` method for requesting the next item. The result of this method has the value and a boolean indicating of we have more results left in the iterator. While this all very interesting, we will need some more things if we want to construct proper data pipelines with iterators:
+
+* conversions from arrays to iterators and back
+* iterators that operate on other iterators, like `map` and `filter` (also called ‘higher-order iterators’)
+* a proper interface to chain all of those together in an elegant and practical way
+
+In the rest of this article I will show how to do those things. At the end I have included a link to a library I created that contains a lot more features. Sadly, this is not a native implementations of lazy iterators. This means that there is overhead and in a lot of cases this library is not worth it. But I still want to show you the concept in action and discuss its pros and cons.
+
+## Iterator constructors
+
+We want to be able to create iterators from multiple data sources. The most oblivious one is arrays. This one is quite easy, we loop over the array and yield all items:
+
+```TypeScript
+function* from_array<a>(a:a[]) {
+ for(const v of a) yield v
+}
+```
+
+Turning an iterator in an array will require us to call `next` until we have gotten all the items. After this we can return our array. Of course you only want to turn an iterator into an array when absolutely needed because this function causes a full iteration.
+
+```TypeScript
+function to_array<a>(a: Iterator<a>) {
+ let result: a[] = []
+ let current = a.next()
+ while(current.done == false) {
+ result.push(current.value)
+ current = a.next()
+ }
+ return result
+}
+```
+
+Another method for reading data from an iterator is `first`. Its implementation is shown bellow. Note that it only request the first item from the iterator! This means that all the following potential values will never be calculated, resulting in less waste of resources in the data pipeline.
+
+```TypeScript
+export function first<a>(a: Iterator<a>) {
+ return a.next().value
+}
+```
+
+In the complete library there are also constructors that create iterators from [functions](https://github.com/WimJongeneel/ts-lazy-collections/blob/master/src/main.ts#L65-L74) or [ranges](https://github.com/WimJongeneel/ts-lazy-collections/blob/master/src/main.ts#L57-L63).
+
+## Higher-order iterators
+
+A higher-order iterator transforms an existing iterator into a new iterator. Those iterators are what makes up the operations in a pipeline. The well-known transform function `map` is shown bellow. It takes an iterator and a function and returns a new iterator where the function is applied to all items in the original iterator. Note that we still yield item-for-item and preserve the lazy nature of the iterators while transforming them. This is very important if we want to actually achieve the higher efficiency I talked about in the intro of this article!
+
+```TypeScript
+function* map<a, b>(a: Iterator<a>, f:(a:a) => b){
+ let value = a.next()
+ while(value.done == false) {
+ yield f(value.value)
+ value = a.next()
+ }
+}
+```
+
+Filter can be implemented in a similar way. When requested for the next item, it will keep requesting items from its inner iterator until it has found one that passed the predicate. This item will be yielded and execution is halted until the request for the next item comes in.
+
+```TypeScript
+function* filter<a>(a: Iterator<a>, p: (a:a) => boolean) {
+ let current = a.next()
+ while(current.done == false) {
+ if(p(current.value)) yield current.value
+ current = a.next()
+ }
+}
+```
+
+Many more higher-order iterators can be constructed in with the same concepts I have show above. The complete library ships with a lot of them, check them out over [here](https://github.com/WimJongeneel/ts-lazy-collections#collection-methods).
+
+## The builder interface
+
+The last part of the library is the public facing API. The library uses the builder pattern to allow you to chain methods like on arrays. This is done by creating a function that takes an iterator and returns an object with the methods on it. Those methods can call the constructor again with an updated iterator for the chaining:
+
+```TypeScript
+const fromIterator = <a>(itt: Iterator<a>) => ({
+ toArray: () => to_array(itt),
+ filter: (p: (a:a) => boolean) => lazyCollection(filter(itt, p)),
+ map: <b>(f:(a:a) => b) => lazyCollection(map(itt, f)),
+ first: () => first(itt)
+})
+```
+
+The example of the start of this article can be written as bellow. In this implementation we don’t create additional arrays and only process the data that is actually used!
+
+```TypeScript
+const x = fromIterator(from_array([1,2,3,4,5]))
+ .map(x => x * 2)
+ .filter(x => x > 5)
+ .first()
+```
+
+## Conclusion
+
+In this article I have shown you how generators and iterators can be used to create a powerful and very efficient library for processing lots of data. Of course iterators are not the golden bullet that will fix everything. The gains in efficiency are down to saving on unnecessary calculations. How much this means in real numbers is completely down to how much calculations there can be optimized out, how heavy those calculations are and how much data you are processing. When there are no calculations to save or the collections are relative small, you will potentially lose performance to the overhead of the library.
+
+The full source code can be found on [Github](https://github.com/WimJongeneel/ts-lazy-collections#collection-methods) and contains more features that fitted in this article. I would love to hear your opinion on this. Do you think it is a pity that JavaScript doesn’t use lazy iteration for the array methods? And do you think that using generators is the way forward for collections in JavaScript? If JavaScript would use lazy iterators by default they should be able to optimize the overhead away (like other languages have done) while still preserving the potential wins with efficiency.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/fixing-memory-leaks-in-web-applications.md b/TODO1/fixing-memory-leaks-in-web-applications.md
new file mode 100644
index 00000000000..b58e1ab628f
--- /dev/null
+++ b/TODO1/fixing-memory-leaks-in-web-applications.md
@@ -0,0 +1,169 @@
+> * 原文地址:[Fixing memory leaks in web applications](https://nolanlawson.com/2020/02/19/fixing-memory-leaks-in-web-applications/)
+> * 原文作者:[Nolan](https://nolanlawson.com/)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/fixing-memory-leaks-in-web-applications.md](https://github.com/xitu/gold-miner/blob/master/TODO1/fixing-memory-leaks-in-web-applications.md)
+> * 译者:[febrainqu](https://github.com/febrainqu)
+> * 校对者:[niayyy-S](https://github.com/niayyy-S)、[QinRoc](https://github.com/QinRoc)、[cyz980908](https://github.com/cyz980908)
+
+## 解决 web 应用程序中的内存泄漏问题
+
+当我们由服务端渲染的应用切换到客户端渲染的单页面应用时,我们要付出的一部分代价是,必须更加注重用户设备上的资源。不要阻塞 UI 进程,不要让笔记本的风扇旋转,不要损耗手机电池等等。我们用在服务端渲染中不存在的一类新问题换来了更好的交互性和更类似 app 的表现。
+
+这类新问题中,其中一个问题就是内存泄漏。一个差的单页面应用会消耗 MB 甚至 GB 的内存,持续地占用越来越多的资源,即使它仅存在于一个背景标签。 因此,页面可能开始变慢,或者浏览器终止这个页面,你会看到 Chrome 熟悉的“喔唷 崩溃啦” 页面。
+
+[](https://nolanwlawson.files.wordpress.com/2020/02/awsnap.png)
+
+(当然,一个服务端渲染的网站也会在服务器端出现内存泄漏。但是在客户端出现内存泄漏的可能性非常小,因为每当我们切换页面时浏览器都会清除内存。)
+
+关于内存泄漏的内容在 web 开发的文章中没有得到很好的覆盖。但是,我确定大多数重要的单页面应用都存在内存泄漏问题,除非他们背后的团队有一个强大的基础架构来捕获和修复内存泄漏。在 JavaScript 中,很容易意外地分配一些内存而忘记清理。
+
+那么,为什么关于内存泄漏的文献如此之少呢?我的猜测:
+
+* **缺乏反馈**:大多数使用者在他们上网时不会认真观察他们的任务管理器。通常,除非泄漏严重到页面崩溃或应用程序运行缓慢,否则你不会得到用户的反馈。
+* **缺乏数据**:Chrome 团队不会提供关于网站通常使用了多少内存的数据。网站通常也不自己测量。
+* **缺乏工具**:使用现有工具识别或修复内存泄漏仍然困难。
+* **缺乏关心**:浏览器非常擅长杀死消耗过多内存的页面。人们会把[这种问题归咎于浏览器](https://www.google.com/search?hl=en&q=chrome%20memory%20hog) 而不是网页。
+
+在这篇文章中,我想分享一些我在解决 Web 应用程序中的内存泄漏方面的经验,并提供一些示例来说明如何有效地跟踪它们。
+
+## 内存泄漏的解析
+
+现代 Web 应用程序框架,例如 React,Vue 和 Svelte 都是基于组件的模型。在此模型中,导致内存泄漏的最常见方法是这样的:
+
+window.addEventListener('message', this.onMessage.bind(this));
+
+就是这样。这样就会导致内存泄漏。如果你在一些全局对象(例如 window, <body> 等)中调用 addEventListener ,然后忘记用 removeEventListener 将它们清理干净。当组件被卸载时,你就创建了一个内存泄漏。
+
+更糟糕的是,你刚刚泄漏了整个组件。因为 this.onMessage 绑定到了 this 上,这个组件就会泄漏。进而它的所有子组件也都会泄漏。因此它的所有子组件也都会泄漏。 而且所有与这些组件相关联的 DOM 节点很可能也都会泄露。这很快就会变得非常糟糕。
+
+解决方法是:
+
+```js
+// 挂载阶段
+this.onMessage = this.onMessage.bind(this);
+window.addEventListener('message', this.onMessage);
+
+// 卸载阶段
+window.removeEventListener('message', this.onMessage);
+```
+
+注意,我们保存了对 `onMessage` 函数的引用。你传递给 `addEventListener` 的参数必须和之前传递给 `removeEventListener` 的参数完全相同,否则它不会生效。
+
+## 内存泄漏情况
+
+根据我的经验,内存泄漏最常见的来源是这样的 API:
+
+1. `addEventListener`。这是最常见的一种。调用 `removeEventListener` 来清理它。
+2. [`setTimeout`](https://developer.mozilla.org/en-US/docs/Web/API/WindowOrWorkerGlobalScope/setTimeout) / [`setInterval`](https://developer.mozilla.org/en-US/docs/Web/API/WindowOrWorkerGlobalScope/setInterval)。如果你创建一个循环计时器(例如,每 30 秒运行一次),那么你就需要用 [`clearTimeout`](https://developer.mozilla.org/en-US/docs/Web/API/WindowOrWorkerGlobalScope/clearTimeout) 或 [`clearInterval`](https://developer.mozilla.org/en-US/docs/Web/API/WindowOrWorkerGlobalScope/clearInterval)来清除它。(如果像 `setInterval` 那样使用 `setTimeout` 会造成内存泄漏 —— 即,在 `setTimeout` 中回调一个新的 `setTimeout`。)
+3. [`IntersectionObserver`](https://developer.mozilla.org/en-US/docs/Web/API/IntersectionObserver),[`ResizeObserver`](https://developer.mozilla.org/en-US/docs/Web/API/ResizeObserver),[`MutationObserver`](https://developer.mozilla.org/en-US/docs/Web/API/MutationObserver) 等。这些新 API 非常方便,但是它们也可能会造成内存泄漏。如果你在组件内部创建了一个观察器,并且将它绑定到一个全局变量上,那么你需要调用 `disconnect()` 来清除它们。(注意,被被垃圾回收的 DOM 节点上绑定的 listener 和 observer 事件也将被垃圾回收。通常,你只需要考虑全局元素,例如 `<body>`,`document`,无处不在的 header 或 footer 元素等等。)
+4. [Promises](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise),[Observables](https://rxjs.dev/guide/observable),[EventEmitters](https://nodejs.org/api/events.html#events_class_eventemitter),等。如果你忘记停止监听,任何用于设置侦听器的编程模型都可能会造成内存泄漏。(如果一个 Promise 从未执行 resolved 或 rejected,那么它可能造成内存泄漏,在这种情况下,任何这个 Promise 对象上的 .then() 回调都会泄漏。)
+5. 全局对象存储。像 [Redux](https://redux.js.org/) 这样的全局对象,如果你不小心,你可以一直为它追加内存,它永远不会被清理。
+6. 无限的新增 DOM。如果你在没有 [virtualization](https://github.com/WICG/virtual-scroller#readme)的情况下,实现无限滚动列表,那么 DOM 节点的数量将无限制地增长。
+
+当然,还有许多其他方法会导致内存泄漏,但这些是我见过的最常见的方式。
+
+## 识别内存泄漏
+
+这是最难的部分。我首先要说的是,我认为现有的工具都不够好。我尝试了 Firefox 的内存工具、Edge 和 IE 的内存工具,甚至 Windows 性能分析器。同类中最好的仍然是 Chrome 开发者工具,但它有很多值得我们去了解的不足。
+
+在 Chrome 开发者工具中,我们选择的主要工具是“Memory”选项卡中的“heap snapshot”工具。Chrome 中有其他内存工具,但我没有发现它们对识别内存泄漏有多大帮助。
+
+[](https://nolanwlawson.files.wordpress.com/2020/02/screenshot-from-2020-02-16-11-03-49.png)
+
+Heap Snapshot 工具允许你对主线程或 web workers 或 iframe 进行内存捕获。
+
+当你单击“take snapshot”按钮时,你已经捕获了该 web 页面上特定 JavaScript VM 中的所有活动对象。这包括 `window` 引用的对象,`setInterval` 回调引用的对象,等等。你可以把它想象成一个代表了那个网页所使用的所有内存的凝固瞬间。
+
+下一步是重现一些你认为可能泄漏的场景 —— 例如,打开和关闭一个模态对话框。一旦对话框关闭,你期望内存恢复到以前的水平。因此,你获取另一张快照,并 **与前一个快照比较**。这个比较功能确实是该工具的杀手级功能。
+
+
+
+然而,你应该意识到这个工具有一些限制:
+
+1. 即使你点击了“collect garbage”按钮,你也可能需要拍几个连续的快照才能真正清理未引用的内存。根据我的经验,三个就足够了。(检查每个快照的总内存大小 —— 它最终应该稳定下来。)
+2. 如果你使用了 web workers、service workers、iframes、shared workers 等,那么这个内存将不会显示在堆快照上,因为它位于另一个 JavaScript VM 中。如果你想的话,你可以捕获这个内存,但是要确保你知道你在测量的是哪一个。
+3. 有时 snapshotter 会卡住或崩溃。在这种情况下,只需关闭浏览器选项卡并重新开始。
+
+此时,如果你的应用程序很简单,那么你可能会在两个快照之间看到**很多**对象泄漏。这是个棘手的问题,因为这些并非都是真正的泄漏。其中很多都是正常的使用 —— 一些对象被释放以满足另一个对象的内存需求,一些对象以某种方式被缓存,以便之后的清理,等等
+
+## 去除干扰
+
+我发现去除干扰的最好方法是重复几次泄漏的场景。例如,不只是打开和关闭一个模态对话框一次,你可以打开和关闭它 7 次。(7 是一个很明显的质数。)然后你可以检查堆快照的差异,以查看是否有任何对象泄漏了 7 次。(或 14 次、21 次。)
+
+[](https://nolanwlawson.files.wordpress.com/2020/02/screenshot-from-2020-02-16-10-56-12-2.png)
+
+一个堆快照差异。请注意,我们正在比较快照 #6 和快照 #3,因为我连续进行了三次捕获,以便进行更多的垃圾回收。还要注意,有几个对象泄漏了 7 次。
+
+(另一种有用的技巧是在记录第一个快照之前遍历一次场景。特别是如果你使用了大量的代码拆分,来实现按需加载,那么你的场景很可能需要一次性的内存开销来加载必要的 JavaScript 模块)
+
+此时,你可能想知道为什么我们应该根据对象的数量而不是总内存来排序。根据直觉,既然我们在试图减少内存泄漏的数量,那么难道我们不应该关注总的内存使用量吗?但是由于一个重要的原因,这个方法不是很有效。
+
+当发生内存泄漏时,([套用乔·阿姆斯特朗的话](https://www.johndcook.com/blog/2011/07/19/you-wanted-banana/)) 由于你紧抓着香蕉不放,你最终得到的是香蕉、抓着香蕉的大猩猩和整个丛林。如果你基于总字节进行度量,那么你是在度量丛林,而不是香蕉。
+
+
+
+通过 [维基共享](https://commons.wikimedia.org/wiki/File:Gorilla_Eating.jpg).
+
+让我们回到上面的 `addEventListener` 事例。内存泄漏的来源是一个事件监听器,它在引用一个函数,这个函数又引用一个组件,这个组件可能还引用大量的东西,比如数组、字符串和对象。
+
+如果你根据总内存对堆快照差异进行排序,那么它将向你显示一堆数组、字符串和对象 —— 其中大多数可能与内存泄漏无关。你真正想要找到的是事件监听器,但是与它所引用的东西相比,它只占用了极小的内存。要修复泄漏,你需要找到的是香蕉,而不是丛林。
+
+因此,如果按泄漏对象的数量排序,你将看到 7 个事件监听器。可能有 7 个组件,14 个子组件,或者类似的东西。“7”这个数字应该很醒目,因为它是一个不寻常的数字。无论你重复该场景多少次,你都应该确切地看到泄漏的对象数量。这就是如何快速找到泄漏源的方法。
+
+## 查找 retainer 树
+
+堆快照差异还将向你展示一个“retainer”链,它显示着保持内存活动的对象间的相互指向。这样你就可以找出内存泄漏对象的分配位置。
+
+[](https://nolanwlawson.files.wordpress.com/2020/02/screenshot-from-2020-02-16-10-56-12-3.png)
+
+retainer 链显示哪个对象正在引用泄漏的对象。阅读它的方法是每个对象都由它下面的对象引用。
+
+在上面的例子中,有一个名为 `someObject` 的变量,它被一个闭包(又名“上下文”)引用,这个闭包又被一个事件监听器引用。 如果你点击源链接,它会跳转到 JavaScript 声明,这种方式相当直接明了:
+
+```js
+class SomeObject () { /* ... */ }
+
+const someObject = new SomeObject();
+const onMessage = () => { /* ... */ };
+window.addEventListener('message', onMessage);
+```
+
+在上面的例子中,“上下文”是 `onMessage` 的闭包,它引用了 `someObject` 变量。(这是一个 [人为的例子](https://github.com/nolanlawson/pinafore/commit/de6ca2d85334ad5f657ddd0f335750b60afab895);真正的内存泄漏可能不那么明显!)
+
+但 heap snapshotting 工具有几个限制:
+
+1. 如果保存并重新加载快照文件,则将丢失对分配对象的位置的所有文件引用。例如,你不会看到 `foo.js` 第 22 行的事件监听器闭包。由于这是非常重要的信息,所以保存和发送堆快照文件几乎毫无用处。
+2. 如果涉及到 [`WeakMap`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/WeakMap),那么 Chrome 将向你显示这些引用,即使它们实际上并不重要 —— 只要清除了其他引用,这些对象就会被释放。所以它们只是干扰。
+3. Chrome 根据原型对这些对象进行分类。因此,使用实际的类/函数越多,使用匿名对象越少,就越容易发现究竟是什么东西在泄漏。例如,想象一下,如果我们的泄漏是由于 `object` 而不是 `EventListener`。由于 `object` 是非常通用的,所以我们不太可能正好看到其中 7 个被泄漏。
+
+这是我识别内存泄漏的基本策略。我曾经成功地使用这种技术发现了许多内存泄漏。
+
+不过,本指南只是一个开始 —— 除此之外,你还必须能够灵活地设置断点、记录日志并测试修复程序,以查看它是否解决了泄漏。不幸的是,这本身就是一个耗时的过程。
+
+## 自动的内存泄漏分析
+
+在此之前,我要说的是,我还没有找到一个自动检测内存泄漏的好方法。Chrome 提供了非标准的 [performance.memory](https://webplatform.github.io/docs/apis/timing/properties/memory/) API,但是由于隐私原因[没有一个非常精确的粒度](https://bugs.webkit.org/show_bug.cgi?id=80444),所以你不能在生产中真正使用它来识别泄漏。[W3C Web 性能工作组](https://github.com/w3c/web-performance) 曾讨论了 [内存](https://docs.google.com/document/d/1tFCEOMOUg4zmqeHNg1Xo11Xpdm7Bmxl5y98_ESLCLgM/edit) [工具](https://github.com/WICG/memory-pressure),但尚未达成新的标准来取代这个API。
+
+在实验环境或综合测试环境中,你可以通过使用 Chrome 标志 [`--enable-precise-memory-info`](https://github.com/paulirish/memory-stats.js/blob/master/README.md)来增加这个 API 的粒度。你还可以通过调用专用的 Chromedriver 命令 [`:takeHeapSnapshot`](https://webdriver.io/docs/api/chromium.html#takeheapsnapshot) 来创建堆快照文件。不过,这也有上面提到的限制 —— 你可能想要连续取三个,并丢弃前两个。
+
+由于事件监听器是最常见的内存泄漏源,所以我使用的另一种技术是对 `addEventListener` 和 `removeEventListener` 的 API 进行功能追加以对引用计数并确保它们归零。这个[例子](https://github.com/nolanlawson/pinafore/blob/2edbd4746dfb5a7c894cb8861cf315c800a16393/tests/spyDomListeners.js)讲述了如何操作。
+
+在 Chrome 开发者工具中,你还可以使用专用的 [`getEventListeners()`](https://developers.google.com/web/tools/chrome-devtools/console/utilities#geteventlisteners) API 来查看绑定到特定元素上的事件监听器。注意,这只能在开发者工具中使用。
+
+**更新:** Mathias Bynens 告诉了我另一个有用的开发者工具的 API:[`queryObjects()`](https://developers.google.com/web/updates/2017/08/devtools-release-notes#query-objects),它可以显示使用特定构造函数创建的所有对象。Christoph Guttandin 也有 [一篇有趣的博客文章](https://media-codings.com/articles/automatically-detect-memory-leaks-with-puppeteer) 关于在 Puppeteer 中使用这个 API 进行自动内存泄漏检测。
+
+## 总结
+
+在 web 应用程序中查找和修复内存泄漏仍然处于初级阶段。在这篇博客文章中,我介绍了一些对我有用的技术,但必须承认,这仍然是一个困难和耗时的过程。
+
+与大多数性能问题一样,预防内存泄漏比发现后再修复重要的多。你可能会发现,在适当的地方进行综合测试比在事后调试内存泄漏更有价值。特别是当一个页面上有几个漏洞时,它可能会变成一个剥洋葱的练习 —— 你修复一个漏洞,然后找到另一个,然后重复(在整个过程中哭泣!)如果你知道要查找什么,代码检查也可以帮助捕获常见的内存泄漏模式。
+
+JavaScript 是一门内存安全的语言,在 web 应用程序中这么容易泄漏内存,实在是有点讽刺。其中一部分是 UI 设计固有的 —— 我们需要监听鼠标事件、滚动事件、键盘事件等等,而这些都是很容易导致内存泄漏的模式。但是,通过尽量降低 web 应用程序的内存使用量,我们可以提高运行时性能,避免崩溃,并尊重用户设备上的资源限制。
+
+**感谢 Jake Archibald 和 Yang Guo 对本文草稿的反馈。感谢 Dinko Bajric 发明了“选择质数”技术,我发现它对内存泄漏分析很有帮助。**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/generator-functions-in-javascript.md b/TODO1/generator-functions-in-javascript.md
new file mode 100644
index 00000000000..a0509840053
--- /dev/null
+++ b/TODO1/generator-functions-in-javascript.md
@@ -0,0 +1,153 @@
+> * 原文地址:[Generator Functions in JavaScript](https://medium.com/better-programming/generator-functions-in-javascript-571ba4cda69e)
+> * 原文作者:[Sachin Thakur](https://medium.com/@thakursachin467)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/generator-functions-in-javascript.md](https://github.com/xitu/gold-miner/blob/master/TODO1/generator-functions-in-javascript.md)
+> * 译者:[niayyy](https://github.com/niayyy-S)
+> * 校对者:[icy](https://github.com/Raoul1996)
+
+# JavaScript 中的 Generator 函数
+
+ on [Unsplash](https://unsplash.com/s/photos/wait?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/10180/1*T-HFCdKSrA6dhlyN66g1uw.jpeg)
+
+在 ES6 中, EcmaScript 发布了一种使用函数的新方法。在本文中,我们将研究这种函数以及研究如何使用和在哪里使用它们
+
+## Generator 函数是什么?
+
+Generator 函数是一种特殊类型的函数,它允许你暂停执行,之后可以随时恢复。
+
+它们还简化了迭代器的创建,稍后我们将介绍。让我们简单地从一些示例中了解它们是什么开始。
+
+创建 generator 函数很简单。这个 `function*` 声明(`function` 关键字后跟一个星号)定义了一个 generator 函数。
+
+```js
+function* generatorFunction() {
+ yield 1;
+}
+```
+
+现在,在 generator 函数中,我们不用使用 `return` 语句,而是使用 `yield` 来指定从迭代器返回的值。现在,在上面的示例中,将会返回 1。
+
+当我们像调用常规的 ES6 函数那样调用 generator 函数时,它不会直接执行函数,而是返回一个 `Generator` 对象。
+
+`Generator` 对象中包含 `next()`、`return` 和 `throw`,可用于和 generator 函数进行交互。它的工作原理类似于 `iterator`,但是你可以有更多的控制权。
+
+让我们看一个示例,了解如何使用 `generatorFunction`。现在,正如我前文所说,我们得到了 `next()` 方法。
+
+这个 `next()` 方法返回一个对象,包含了两个属性,`done` 和 `value`。你也可以向 `next` 方法提供一个参数传递给 generator。让我们看一个示例。
+
+```JavaScript
+function* generatorFunction() {
+ yield 1;
+}
+const iterator = generatorFunction()
+const value=iterator.next().value
+console.log(value)
+```
+
+
+
+现在,正如我前文所说,我们可以通过 `next` 传递一个值给 generator 函数,并且这个值可以在 `generator` 函数内部使用。让我们通过另一个示例看一下它是如何工作的。
+
+```JavaScript
+function* generatorFunction() {
+ let value = yield null
+ yield value + 2;
+ yield 3 + value
+}
+const iterator:Generator = generatorFunction()
+const value=iterator.next(10).value // returns null
+console.log(iterator.next(11).value) //return 13
+```
+
+
+
+当首次获得 generator 对象时,没有一个可以传递值的 `yield` 。因此,首先必须通过调用 generator 上的 `next` 来获取到 `yield`。它将始终返回 `null`。
+
+无论是否传递参数,都无关紧要,它始终返回 `null`。完成这个操作后,就可以使用 `yield` 了,你可以通过 `iterator.next()` 传递一个值,通过 `next` 传递的输入值将高效的替换掉 `yield null`。
+
+然后,当找到另一个 `yield` 时,它将返回给 generator 的使用者,也就是我们的 `iterator`。
+
+现在,让我们谈谈关于 `yield` 关键字。它看起来像 return 一样工作,但是更加的强大,因为 `return` 只是返回当函数调用后,从函数中返回一个值。
+
+在普通函数中,不允许在 `return` 关键字后执行任何操作,但是在 Generator 函数中,`yield` 可以做更多的事情。它会返回一个值,但是当你再次调用时,它会继续执行下一个 `yield` 语句。
+
+`yield` 关键字用于暂停和恢复一个 generator 函数。`yield` 返回一个包含 `value` 和 `done` 的对象。
+
+`value` 是 generator 函数求值后的结果,`done` 表明是否 generator 函数完全地执行完成,,它的值可以为 `true` 或 `false`。
+
+在 generator 函数中也可以使用 `return` 关键字,它会返回相同的对象,但是不会像 `yield` 一样继续执行下去,`return` 之后的代码将永远不会执行,即使后面有许多 `yield` 语句。
+
+所以,需要非常小心的使用 `return`,仅当确定 generator 函数的工作完成后才能使用。
+
+```JavaScript
+function* generatorFunction() {
+ yield 2;
+ return 2;
+ yield 3; // generator 函数永远不会到达这
+}
+const iterator:Generator = generatorFunction()
+```
+
+## Generator 函数的用途
+
+现在,generator 函数可以非常容易的简化迭代器的创建、递归的实现以及更好的异步编程。让我们看一些示例。
+
+```JavaScript
+function* countInfinite(){
+ let i=0;
+ while(true){
+ yield i;
+ i++
+ }
+}
+const iterator= countInfinite()
+console.log(iterator.next().value)
+console.log(iterator.next().value)
+console.log(iterator.next().value)
+```
+
+
+
+在上面示例中,是一个无限循环,但是它只会执行和我们在迭代器上调用 `next` 一样多的次数,它保存着函数继续计数之前的状态。
+
+这只是一个关于如何使用的一个基本的示例,我们在 generator 函数中还可以使用更复杂的逻辑,为我们提供更多的能力。
+
+```JavaScript
+function* fibonacci(num1:number, num2:number) {
+while (true) {
+ yield (() => {
+ num2 = num2 + num1;
+ num1 = num2 - num1;
+ return num2;
+ })();
+ }
+}
+const iterator = fibonacci(0, 1);
+for (let i = 0; i < 10; i++) {
+ console.log(iterator.next().value);
+}
+```
+
+
+
+在上面的示例中,我们实现了无递归的斐波那契数列。 generator 函数功能非常强大,并且只会被你想象力的所限制。
+
+generator 函数另一个优点是它们能高效存储。我们可以在需要的时候再生成值。
+
+在使用、普通函数的情况下,我们生成许多值,但是不知道我们是否会使用。但是,对于 generator 函数而言,我们可以在我们需要使用的时候再进行计算。
+
+在使用 generator 函数前,请记住一些注意事项。你不能再次获取你已经获取过的值。
+
+## 结论
+
+在 JavaScript 中,迭代器函数在做许多事情方面是出色而有效的。使用 generator 函数还有许多其它可能的方向。
+
+例如:使用异步操作会更容易。因为 generator 函数可以在一段时间内生成许多值,所以它也可以被用作一个可观察对象。
+
+我希望本文对你理解 `generator` 函数有所帮助,告诉我你还能使用 `generator` 函数做什么或者正在做什么。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/goodbye-clean-code.md b/TODO1/goodbye-clean-code.md
new file mode 100644
index 00000000000..acf7838290f
--- /dev/null
+++ b/TODO1/goodbye-clean-code.md
@@ -0,0 +1,189 @@
+> * 原文地址:[Goodbye, Clean Code](https://overreacted.io/goodbye-clean-code/)
+> * 原文作者:[Dan Abramov](https://mobile.twitter.com/dan_abramov)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/goodbye-clean-code.md](https://github.com/xitu/gold-miner/blob/master/TODO1/goodbye-clean-code.md)
+> * 译者:[zh1an](https://github.com/zh1an)
+> * 校对者:[ahabhgk](https://github.com/ahabhgk), [febrainqu](https://github.com/febrainqu)
+
+# 再见,整洁的代码
+
+那是一个深夜。
+
+我同事刚刚合并了他们已经写了整整一周的代码。我们在做图形编辑画布,并且他们实现了调整形状大小的方法,比如矩形或者椭圆形在它们的边缘拖拽小按钮。
+
+代码生效了。
+
+但是它单调且重复。每个形状(例如矩形或者椭圆形)都有一组不同按钮,并且往不同的方向拖拽每个按钮都会通过不同的方式来影响着形状的位置和大小。如果用户按住 Shift 按键,我们还应该需要在调整大小时呈现其属性。这也有一大堆数学计算。
+
+代码看起来就像这样:
+
+```jsx
+let Rectangle = {
+ resizeTopLeft(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeTopRight(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeBottomLeft(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeBottomRight(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+};
+
+let Oval = {
+ resizeLeft(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeRight(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeTop(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeBottom(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+};
+
+let Header = {
+ resizeLeft(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeRight(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+}
+
+let TextBlock = {
+ resizeTopLeft(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeTopRight(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeBottomLeft(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+ resizeBottomRight(position, size, preserveAspect, dx, dy) {
+ // 10 行重复的数学计算
+ },
+};
+```
+
+这种重复的数学计算着实让我恼火。
+
+它并不**整洁**。
+
+大多数的重复都在相似的方向之间。例如,`Oval.resizeLeft()` 跟 `Header.resizeLeft()` 相似。这是因为他们两个在左边的拖拽处理基本是类似的。
+
+另外一个相似点就是介于那些相同形状之间的方法之间。例如,`Oval.resizeLeft()` 和另外一个 `Oval` 的方法类似。这是因为他们所有的处理椭圆形的方式类似。在 `Rectangle`、`Header` 和 `TextBlock` 之间有一些也是重复的,因为它们都是矩形。
+
+我有一个想法。
+
+我们可以**移除所有的重复**,把代码组织成这样:
+
+```jsx
+let Directions = {
+ top(...) {
+ // 5 行唯一的数学计算
+ },
+ left(...) {
+ // 5 行唯一的数学计算
+ },
+ bottom(...) {
+ // 5 行唯一的数学计算
+ },
+ right(...) {
+ // 5 行唯一的数学计算
+ },
+};
+
+let Shapes = {
+ Oval(...) {
+ // 5 行唯一的数学计算
+ },
+ Rectangle(...) {
+ // 5 行唯一的数学计算
+ },
+}
+```
+
+然后组合它们的行为:
+
+```jsx
+let {top, bottom, left, right} = Directions;
+
+function createHandle(directions) {
+ // 20 行代码
+}
+
+let fourCorners = [
+ createHandle([top, left]),
+ createHandle([top, right]),
+ createHandle([bottom, left]),
+ createHandle([bottom, right]),
+];
+let fourSides = [
+ createHandle([top]),
+ createHandle([left]),
+ createHandle([right]),
+ createHandle([bottom]),
+];
+let twoSides = [
+ createHandle([left]),
+ createHandle([right]),
+];
+
+function createBox(shape, handles) {
+ // 20 行代码
+}
+
+let Rectangle = createBox(Shapes.Rectangle, fourCorners);
+let Oval = createBox(Shapes.Oval, fourSides);
+let Header = createBox(Shapes.Rectangle, twoSides);
+let TextBox = createBox(Shapes.Rectangle, fourCorners);
+```
+
+这是所有代码的一半,并且那些重复的也消失无踪啦!如此的整洁。如果我们想要改变一个特殊方向或者形状的表现,我们只需要修改一个地方的代码而不是修改所有地方。
+
+当时的确是很晚啦(我忘乎所以了)。我将我重构的代码合并到 `master`,然后就去睡觉了,并且非常骄傲我竟然解开了我同事那杂乱无章的代码。
+
+## [](#the-next-morning)第二天
+
+…… 但事与愿违。
+
+我的上司叫我单独聊,很礼貌地要求我撤回我的更改。我惊呆了。老代码那么乱而我的如此的整洁!
+
+我勉强的服从了,直到多年以后我才知道他们是对的。
+
+## [](#its-a-phase)这是一个阶段
+
+痴迷于“代码的整洁之道”并且移除重复是我们大多数必经的一个阶段。当我们对代码不自信时,很容易将我们的自我价值感和专业自豪感附加到可以衡量的事物上,一组严格的 lint 规则、命名规则、文件结构和没有重复。
+
+你不能使移除重复自动化,但是它**的确**随着练习变得更容易。通常情况下你都可以分辨出在每次更改之后它是更少了还是更多了。结果,移除重复感觉就像是改善代码的一种指标。更糟糕的是,它与人们的认同感交织在一起:“我就是写整洁代码的那个人”。这比任何一种自我欺骗都有效。
+
+一旦我们学习了如何去创建 [abstractions(抽象)](https://www.sandimetz.com/blog/2016/1/20/the-wrong-abstraction),就很容易掌握这种技能,当我们看到重复的代码时,就会从中抽出抽象层。经过几年编码之后,如果我们随处随地看到重复性代码,那么,抽象就是我们新的超能力。如果某个人告诉我们抽象是优点,我们也会认同。并且我们开始判断其他人会不会崇拜这种“整洁”能力。
+
+我现在知道,我的“重构”在两个方面是致命的:
+
+* 第一,我没有跟代码作者讨论。我在没有他们参与的情况下重写了代码并且检出。甚至,假如它“的确”是一种改进(现在我再也不相信了),这种方式也是很可怕的。一个健康的工程师团队不断地**建立信任**。在没有讨论的情况下重写你队友的代码对你在代码库上的有效协作的能力是一个巨大的打击。
+* 第二,天下没有免费的午餐。我的代码通过更改需求来减少重复,然而这并不是个很好的交易。例如,在之后我们需要很多的针对不同的形状的不同的句柄的特殊情况和行为,我们的抽象不得不变得异常的复杂才能负担的起,而对于原始的“杂乱无章的”版本,这样的更改就像蛋糕一样简单。
+
+我要说你应该写“脏”代码吗?不,我建议你对“整洁”或“脏”代码的意思进行深思。你有反抗的感觉吗?或是正直?或是漂亮?或是优雅?对于具体的工程结果来说,你如何准确的命名这些品质?它们有多准确地表达这种代码编写或者[修改](/optimized-for-change/)方式?
+
+我当然没有对这些事情进行过深思熟虑。我对代码的**外观**进行了很多的思考,但并考虑它在压测团队中会如何进化。
+
+编码是一段旅程。考虑从你的第一行代码到你现在的位置有多远。我觉得很高兴看到第一次如何提取一个函数或者重构一个类,它能使错中复杂的代码变得简单。如果你对自己的技术感到自豪,并且很容易做到代码的整洁。那就试试。
+
+但是不要停滞不前,沾沾自喜。不要成为整洁代码的狂热者。整洁代码不是目标。它只是尝试使我们处理的复杂系统获得某种意义。它只是在你还不能确定更改会对代码库有怎样的影响时给出指引,这使一种防御机制。
+
+让整洁代码指引你。**然后,随它去吧。**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/high-speed-inserts-with-mysql.md b/TODO1/high-speed-inserts-with-mysql.md
new file mode 100644
index 00000000000..1084926bcac
--- /dev/null
+++ b/TODO1/high-speed-inserts-with-mysql.md
@@ -0,0 +1,127 @@
+> * 原文地址:[High-speed inserts with MySQL](https://medium.com/@benmorel/high-speed-inserts-with-mysql-9d3dcd76f723)
+> * 原文作者:[Benjamin Morel](https://medium.com/@benmorel)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/high-speed-inserts-with-mysql.md](https://github.com/xitu/gold-miner/blob/master/TODO1/high-speed-inserts-with-mysql.md)
+> * 译者:[司徒公子](https://github.com/todaycoder001)
+> * 校对者:[GJXAIOU](https://github.com/GJXAIOU)、[QinRoc](https://github.com/QinRoc)
+
+# MySQL 最佳实践 —— 高效插入数据
+
+ on [Unsplash](https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/6528/1*9Ihf50zErzTg4KR4JnodzA.jpeg)
+
+当你需要在 MySQL 数据库中批量插入数百万条数据时,你就会意识到,逐条发送 `INSERT` 语句并不是一个可行的方法。
+
+MySQL 文档中有些值得一读的 [INSERT 优化技巧](https://dev.mysql.com/doc/refman/5.7/en/insert-optimization.html)。
+
+在这篇文章里,我将概述高效加载数据到 MySQL 数据库的两大技术。
+
+## LOAD DATA INFILE
+
+如果你正在寻找提高原始性能的方案,这无疑是你的首选方案。`LOAD DATA INFILE` 是一个专门为 MySQL 高度优化的语句,它直接将数据从 CSV / TSV 文件插入到表中。
+
+有两种方法可以使用 `LOAD DATA INFILE`。你可以把数据文件拷贝到服务端数据目录(通常 `/var/lib/mysql-files/`),并且运行:
+
+```sql
+LOAD DATA INFILE '/path/to/products.csv' INTO TABLE products;
+```
+
+这个方法相当麻烦,因为你需要访问服务器的文件系统,为数据文件设置合适的权限等。
+
+好消息是,你也能将数据文件存储**在客户端**,并且使用 `LOCAL` 关键词:
+
+```sql
+LOAD DATA LOCAL INFILE '/path/to/products.csv' INTO TABLE products;
+```
+
+在这种情况下,从客户端文件系统中读取文件,将其透明地拷贝到服务端临时目录,然后从该目录导入。总而言之,**这几乎与直接从服务器文件系统加载文件一样快**,不过,你需要确保服务器启用了此 [选项](https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_local_infile)。
+
+`LOAD DATA INFILE` 有很多可选项,主要与数据文件的结构有关(字段分隔符、附件等)。请浏览 [文档](https://dev.mysql.com/doc/refman/5.7/en/load-data.html) 以查看全部内容。
+
+虽然从性能角度考虑, `LOAD DATA INFILE` 是最佳选项,但是这种方式需要你先将数据以逗号分隔的形式导出到文本文件中。如果你没有这样的文件,你就需要花费额外的资源来创建它们,并且可能会在一定程度上增加应用程序的复杂性。幸运的是,还有一种另外的选择。
+
+## 扩展的插入语句(Extended inserts)
+
+一个典型的 `INSERT` SQL 语句是这样的:
+
+```sql
+INSERT INTO user (id, name) VALUES (1, 'Ben');
+```
+
+extended `INSERT` 将多条插入记录聚合到一个查询语句中:
+
+```sql
+INSERT INTO user (id, name) VALUES (1, 'Ben'), (2, 'Bob');
+```
+
+关键在于找到每条语句中要插入的记录的最佳数量。没有一个放之四海而皆准的数字,因此,你需要对数据样本做基准测试,以找到性能收益的最大值,或者在内存使用和性能方面找到最佳折衷。
+
+为了充分利用 extended insert,我们还建议:
+
+* 使用预处理语句
+* 在事务中运行该语句
+
+## 基准测试
+
+我要插入 120 万条记录,每条记录由 6 个 混合类型数据组成,平均每条数据约 26 个字节大小。我使用了两种常见的配置进行测试:
+
+* 客户端和服务端在同一机器上,通过 UNIX 套接字进行通信
+* 客户端和服务端在不同的机器上,通过延迟非常低(小于 0.1 毫秒)的千兆网络进行通信
+
+作为比较的基础,我使用 `INSERT ... SELECT` 复制了该表,这个操作的性能表现为**每秒插入 313,000 条数据**。
+
+#### LOAD DATA INFILE
+
+令我吃惊的是,测试结果证明 `LOAD DATA INFILE` 比拷贝表**更快**:
+
+* `LOAD DATA INFILE`:每秒 **377,000** 次插入
+* `LOAD DATA LOCAL INFILE` 通过网络:每秒 **322,000** 次插入
+
+这两个数字的差异似乎与从客户端到服务端传输数据的耗时有直接的关系:数据文件的大小为 53 MB,两个基准测试的时间差了 543 ms,这表示传输速度为 780 mbps,接近千兆速度。
+
+这意味着,很有可能,**在完全传输文件之前,MySQL 服务器并没有开始处理该文件**:因此,插入的速度与客户端和服务端之间的带宽直接相关,如果它们不在同一台机器上,考虑这一点则非常重要。
+
+#### Extended inserts
+
+我使用 `BulkInserter` 来测试插入的速度,`BulkInserter` 是我编写的 [开源库](https://github.com/brick/db) PHP 类的一部分,每个查询最多插入 10,000 条记录:
+
+
+
+正如我们所看到的,随着每条查询插入数的增长,插入速度也会迅速提高。与逐条`插入`速度相比,我们在本地主机上性能提升了 6 倍,在网络主机上性能提升了 17 倍:
+
+* 在本地主机上每秒插入数量从 40,000 提升至 247,000
+* 在网络主机上每秒插入数量从 1,2000 提升至 201,000
+
+这两种情况都需要每个查询大约 1,000 个插入来达到最大吞吐量。但是**每条查询 40 个插入就足以在本地主机上达到 90% 的吞吐量**,这可能是一个很好的折衷。还需要注意的是,达到峰值之后,随着每个查询插入数量的增加,性能实际上是会下降。
+
+extended insert 的优势在网络连接的情况下更加明显,因为连续插入的速度取决于你的网络延迟。
+
+```sql
+max sequential inserts per second ~= 1000 / ping in milliseconds
+```
+
+客户端和服务端之间的延迟越高,你从 extended insert 中获益越多。
+
+## 结论
+
+不出所料,**`LOAD DATA INFILE` 是在单个连接上提升性能的首选方案**。它要求你准备格式正确的文件,如果你必须先生成这个文件,并/或将其传输到数据库服务器,那么在测试插入速度时一定要把这个过程的时间消耗考虑进去。
+
+另一方面,extended insert 不需要临时的文本文件,并且可以达到相当于 `LOAD DATA INFILE` 65% 的吞吐量,这是非常合理的插入速度。有意思的是,无论是基于网络还是本地主机,**聚集多条插入到单个查询总是能得到更好的性能**。
+
+如果你决定开始使用 extended insert,一定要先**用生产环境的数据样本**和一些不同的插入数来**测试你的环境**,以找出最佳的数值。。
+
+在增加单个查询的插入数的时候要小心,因此它可能需要:
+
+* 在客户端分配更多的内存
+* 增加 MySQL 服务器的 [max_allowed_packet](https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_max_allowed_packet) 参数配置。
+
+最后,值得一提的是,根据 Percona 的说法,你可以使用并发连接、分区以及多个缓冲池,以获得更好的性能。更多信息请查看 [他们博客的这篇文章](http://www.percona.com/blog/2011/01/07/high-rate-insertion-with-mysql-and-innodb/)。
+
+**基准测试运行在装有 Centos 7 和 MySQL 5.7 的裸服务器上,它的主要硬件配置有 Xeon E3 @3.8 GHz 处理器,32 GB RAM 和 NVMe SSD。MySQL 的基准表使用 InnoBD 存储引擎。**
+
+**基准测试的源代码保存在 [gist](https://gist.github.com/BenMorel/78f742356391d41c91d1d733f47dcb13) 上,结果图保存在 [plot.ly](https://plot.ly/~BenMorel/52) 上。**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/history-of-javascript.md b/TODO1/history-of-javascript.md
new file mode 100644
index 00000000000..c644d59bab7
--- /dev/null
+++ b/TODO1/history-of-javascript.md
@@ -0,0 +1,73 @@
+> * 原文地址:[Brief History of JavaScript](https://roadmap.sh/guides/history-of-javascript)
+> * 原文作者:[Kamran Ahmed](https://twitter.com/kamranahmedse)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/history-of-javascript.md](https://github.com/xitu/gold-miner/blob/master/TODO1/history-of-javascript.md)
+> * 译者:[Pingren](https://github.com/Pingren)
+> * 校对者:[Chorer](https://github.com/Chorer),[PingHGao](https://github.com/PingHGao)
+
+# JavaScript 简史
+
+> JavaScript 的起源以及这些年的发展情况
+
+大约十年前<sup><a name="noteref1" href="#note1">[1]</a></sup>,Jeff Atwood(Stackoverflow 创始人)断言 JavaScript 将会是未来的方向,并创造了 “Atwood 定律”:**任何可以使用 Javascript 编写的程序,最终都会由 Javascript 编写**。十年后的今天,这个断言相比之前更加可信了。JavaScript 的应用范围不断扩大。
+
+### JavaScript 发布
+
+JavaScript 最初由 NetScape 的 [Brendan Eich](https://twitter.com/BrendanEich) 创造,并在 1995 年 Netscape 的闻稿中首次发布。它有着非同寻常的命名历史:首先由创造者命名为 `Mocha`,接着被重命名为 `LiveScript`。1996 年,在发布大约一年之后,NetScape 希望能够蹭蹭 Java 社区的热度(虽然 JavaScript 与 Java 毫无关系),因此决定再将其重命名为 JavaScript,并发布了支持 JavaScript 的 Netscape 2.0 浏览器。
+
+### ES1、ES2 和 ES3
+
+1996 年,Netscape 决定将 JavaScript 提交到 [ECMA 国际](https://en.wikipedia.org/wiki/Ecma_International),期望将其标准化。第 1 版标准规范在 1997 年发布,同时该语言也被标准化了。在首次发布之后,`ECMAScript` 的标准化工作持续进行,不久之后,发布了两个新的版本:1998 年的 ECMAScript 2 和 1999 年的 ECMAScript 3。
+
+### 十年沉寂和 ES4
+
+1999 年发布 ES3 之后,官方标准出现了十年的沉寂,这期间没有任何变化。第 4 版标准起初有一些进展,部分被讨论的特性有类、模块、静态类型、解构等等。它本来定在 2008 年发布,但是由于关于语言复杂度的不同政治意见<sup><a name="noteref2" href="#note2">[2]</a></sup>而被废弃。但是,浏览器厂商不停引入语言的扩展,这让开发者大伤脑筋 —— 他们只能添加 polyfill<sup><a name="noteref3" href="#note3">[3]</a></sup> 来解决不同浏览器之间的兼容性问题。
+
+### 从沉寂到 ES5
+
+Google、Microsoft、Yahoo 和其余 ES4 的争论者最终走到了一起,决定在 ES3 之上创造一个小范围的更新,并暂时命名为 ES3.1。但是整个团队仍旧关于 ES4 该包含什么内容而争论不休。终于,在 2009 年,ES5 发布了,主要修复了兼容性和安全问题等。但是它并没有翻起多大浪花 —— 经过了数年时间后浏览器厂商才完全遵循了相关标准,许多开发者在不知道 “现代” 标准的情况下依旧使用 ES3。
+
+### ES6 —— ECMASript 2015 发布
+
+在 ES5 发布数年之后,事情开始有了转机。TC39(ECMA 国际之下负责 ECMAScript 标准化的委员会)持续进行下一版本的标准化的工作,该版本的 ECMAScript(ES6)起初命名为 ES Harmony<sup><a name="noteref4" href="#note4">[4]</a></sup>,在最终发布时被命名为 ES2015。ES2015 添加了许多重要的特性和语法糖以便于编写复杂的程序。部分 ES6 提供的特性包括了类、模块、箭头函数、加强的对象字面量、模板字符串、解构、默认参数 + Rest 参数 + Spread 操作符、Let 和 Const 语法、异步迭代器 + for..of、生成器、集合 + 映射、Proxy、Symbol、Promise、math + number + string + array + object 的 API [等等](http://es6-features.org/#Constants)<sup><a name="noteref5" href="#note5">[5]</a></sup>。
+
+浏览器对 ES6 的支持依旧十分有限,但是开发者只需要编写 ES6 代码并将其转译至 ES5,就可以使用 ES6 的所有特性。随着第 6 版 ECMAScript 的发布,TC39 决定以每年更新的模式来发布 ECMAScript 的更新,这样新特性就可以在通过时尽快地加入标准,不需要等待完整的规范起草和通过 —— 因此第 6 版 ECMAScript 在 2015 年 6 月发布前,被命名为 ECMAScript 2015 或 ES2015。并且之后的 ECMAScript 版本发布定于每年 6 月。
+
+### ES7 —— ECMASript 2016 发布
+
+在 2016 年 6 月,第 7 版 ECMAScript 发布了。由于 ECMAScript 变成了年更模式,ECMAScript 2016(ES2016)相对来说没有太多新内容。ES2016 只包含了两个新特性:
+
+* 指数运算符 `**`
+* `Array.prototype.includes`
+
+### ES8 —— ECMAScript 2017 发布
+
+第 8 版 ECMAScript 在 2017 年 6 月发布。ES8 主要的亮点在于增加了异步函数,以下是 ES8 新特性的列表:
+
+* `Object.values()` 和 `Object.entries()`
+* 字符串填充 比如 `String.prototype.padEnd()` 和 `String.prototype.padStart()`
+* `Object.getOwnPropertyDescriptors`
+* 在函数参数定义和函数调用中使用尾后逗号
+* 异步函数
+
+### 什么是 ESNext
+
+ESNext 是一个动态的名字,指当前的 ECMAScript 版本。例如,在本文编写的时候,`ES2017` 或 `ES8` 是 `ESNext`。
+
+### 未来会发生什么
+
+自从 ES6 发布后,[TC39](https://github.com/tc39) 极大提高了他们的效率。 现在 TC39 以 Github 组织的形式运行,在上面有许多关于下一版的 ECMAScript 新特性和语法的[提议](https://github.com/tc39/proposals)。任何人都可以[发起提议](https://github.com/tc39/proposals),因此开发者社区可以更多地参与进来。在正式形成规范前,每个提议都会经过[四个发展阶段](https://tc39.github.io/process-document/)。
+
+这差不多就是全部内容了,欢迎在评论区留下你的反馈。以下是原始语言规范的链接:[ES6](https://www.ecma-international.org/ecma-262/6.0/)、[ES7](https://www.ecma-international.org/ecma-262/7.0/) 和 [ES8](https://www.ecma-international.org/ecma-262/8.0/)。
+
+1. 译者注:本文写于 2017 年,所以十年前是 2007 年。<a name="note1" href="#noteref1">↩︎</a>
+2. 译者注:技术层面的分歧以及商业政治都是 ES4 失败的原因,知乎上曾经有过相关的[讨论](https://www.zhihu.com/question/24715618)。<a name="note2" href="#noteref2">↩︎</a>
+3. 译者注:Web 开发中,polyfill 指用于实现浏览器并不支持的原生 API 的代码。<a name="note3" href="#noteref3">↩︎</a>
+4. 译者注:Harmony 有和谐,协调的意思。<a name="note4" href="#noteref4">↩︎</a>
+5. 译者注:如果你感兴趣,可以使用[这个中文教程](https://zh.javascript.info/)学习这些特性。<a name="note5" href="#noteref5">↩︎</a>
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
\ No newline at end of file
diff --git a/TODO1/how-can-cloud-services-help-improve-your-businessess-efficiency.md b/TODO1/how-can-cloud-services-help-improve-your-businessess-efficiency.md
new file mode 100644
index 00000000000..3f3050a8384
--- /dev/null
+++ b/TODO1/how-can-cloud-services-help-improve-your-businessess-efficiency.md
@@ -0,0 +1,92 @@
+> * 原文地址:[How Can Cloud Services Help Improve Your Businesses’s Efficiency?](https://medium.com/better-programming/how-can-cloud-services-help-improve-your-businessess-efficiency-ea3fb038948e)
+> * 原文作者:[SeattleDataGuy](https://medium.com/@SeattleDataGuy)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how-can-cloud-services-help-improve-your-businessess-efficiency.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how-can-cloud-services-help-improve-your-businessess-efficiency.md)
+> * 译者:[Roc](https://github.com/QinRoc)
+> * 校对者:[GPH](https://github.com/PingHGao),[Yinjia](https://github.com/yvonneit)
+
+# 云服务如何帮助你提高业务效率?
+
+ on [Unsplash](https://unsplash.com/s/photos/skyscraper-crane?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/5000/1*qryfe9oN-vJx75kLCWlYDQ.jpeg)
+
+> 了解 IaaS,SaaS,PaaS 和 FaaS
+
+在 20 世纪,企业依靠内部机房里的服务器和计算机开展业务。
+
+这意味着,当需要启用新的服务器时,要耗费数周乃至数月的时间才能把一切准备就绪。从批准预算、下订单、运输服务器,直到安装 —— 这是一个漫长而艰巨的过程。
+
+但是时代已经改变,企业应该在现场配置价值百万美金的服务器的观念已经被云计算服务改变。
+
+简而言之,云计算是一个远程服务,通常能够提供基础设施、软件、存储、平台和许多其他形式的服务。
+
+## 为什么企业会购买 AWS 和 Azure 这样的云计算服务呢?
+
+云计算所提供的多种服务不仅能降低企业的硬件成本,还能降低企业的人力成本。现在 1 到 2 个 开发者就可以完成大部分曾经需要一整个团队的工程师才能完成的工作。
+
+由于种类繁多,要了解所有可能的云服务类型是很困难的 —— 让我们来看看目前有什么可用的云服务类型吧。
+
+## 云计算服务类型
+
+#### IaaS 是什么?
+
+IaaS,是 Infrastructure-as-a-Service(基础设施即服务)的简称。这种服务模式提供大量的虚拟或物理的基础设施,[包括服务器、网络、数据中心、虚拟机管理程序层,甚至虚拟化](https://www.theseattledataguy.com/5-aws-technologies-thatll-make-your-life-easier/)。
+
+通常,这个服务也包括对基础设施和弹性存储的管理。通过 IaaS,企业可以安装操作系统,部署他们的[数据库](https://www.theseattledataguy.com/big-data-bigger-results-data-driven-solutions-for-company/),拥有不断变更存储容量或者运行环境的灵活性。只要你觉得方便,按月、按小时或者按周支付,哪种都可以。
+
+IaaS 是[云计算领域](https://logitanalytics.com/what-are-the-different-kinds-of-cloud-computing-services/)的基础服务提供方式之一。它允许企业通过第三方云计算服务提供商来访问互联网上的存储空间、网络、服务器和其他东西。IaaS 允许组织创建足以满足他们业务需求的 IT 环境。
+
+##### 真实案例
+
+一些最受欢迎的 IaaS 案例包括类似 AWS 的 EC2 或 RDS 的产品。这些服务让你能很简单地就启动一台 Linux 服务器或者一个数据库,并且可以根据你的需要进行扩展。你不再需要获取一台新的服务器,只需要在 AWS 上点击创建按钮就可以了。除此以外,AWS 工作区能够让企业在一个虚拟私有云网络中启动虚拟的台式机,这种方式让安全管理和远程工作更简单了。
+
+##### 不需要买一台计算机
+
+初创企业和小公司特意使用 IaaS 来工作以避免在软硬件上花费过多。他们需要 IaaS 的可扩展性,而 Google 这样的服务提供商很擅长做这个。实际上,你可以通过一个简单的链接来访问一个中央表,然后在上面交换日常文档。
+
+#### SaaS 是什么?
+
+SaaS 是 Software-as-a-Service(软件即服务)的简称。它是一种软件分发模型,可以在线托管应用程序,并且让消费者可以访问。你只需要一个互联网连接和一个浏览器就能使用这些应用程序。
+
+SaaS 最大的好处在于它提供的网页分发模型能彻底终结需要由一个 IT 员工来安装或下载应用到每台计算机上的情况。例如,我经常使用 Google 文档,它提供的在线存储可以在任何地点、任何设备上进行访问,并且拥有自动保存选项,这两点特性很好地帮助了我。
+
+此外,供应商负责处理技术问题,这让 SaaS 用户更方便地使用应用。
+
+##### 真实案例
+
+一些最受欢迎的 SaaS 提供商包括 Google GSuite、Salesforce、Dropbox 和 SAP Concur。SaaS 最好的例子是 Gmail,一个在线邮件服务,它让你从任何设备上都可以访问到 Google 托管的文件和应用。在任何有互联网连接的地方,你都能使用产品,而不需要下载软件或者使用产品密钥。这种能力让员工们在任何地方都有很高的生产力。
+
+#### PaaS 是什么?
+
+PaaS 是 Platform-as-a-Service(平台即服务)的简称。这种云服务模式分发软件和硬件工具,使得消费者能够开发、运行并且测试他们的应用程序。使用 PaaS 的最大优势之一是它可以简单地迁移到混合模型。
+
+PaaS 类似于 SaaS,然而,PaaS 提供一个在线创造软件的平台,而不是像 SaaS 那样通过互联网分发软件。这一点让创建网站和应用更简单。
+
+通常,PaaS 给开发者们提供一个框架,使得他们能够在不需担心基础设施的情况下创建自定义的应用程序。PaaS 专为那些能够在线设计并管理应用程序的开发者服务。这些应用程序往往具有高度的可伸缩性,并且始终可用。
+
+##### 真实案例
+
+一些最受欢迎的 PaaS 服务提供商包括 OpenShift,AWS Beantalk,Google App Engine 和 Windows Azure。以 OpenShift 为例,它包括 Linux 操作系统、网络、注册、监控、授权和容器运行方案,所以消费者可以使用 OpenShift 为自己的企业开发人员搭建基础设施。
+
+#### FaaS 是什么?
+
+FaaS 是 Function-as-a-Service(功能即服务)的简称。这类云服务为开发者提供运行和管理应用的功能的平台,让他们不需要担心基础设施或者应用开发相关的复杂问题。
+
+FaaS 最大的好处是它提供无服务器计算,这点让开发者可以直接把他们的生产代码部署到网络上,而不需要为计算资源的规划、供应或维护发愁。
+
+##### 真实案例
+
+FaaS 最受欢迎的案例有 Amazon Lambda、Microsoft Azure Function、IBM Cloud Functions 和 Google Cloud Functions。以 Lambda 为例,它可以按需执行代码,并且根据需求来自动伸缩每天的请求。因此,将它和 API 网关结合使用,可以很方便地生成一个最佳解决方案。
+
+## 结论
+
+云计算可以帮助一家企业快速扩展他们的 IT 解决方案。它可以提供一个成熟的平台,来管理存储、服务器和虚拟桌面。在诸如 IaaS、PaaS、SaaS 和 FaaS 的云计算服务的帮助下,你的公司可以使用虚拟基础设施来管理其 IT 相关业务。
+
+不仅如此,这种虚拟化技术也让企业更容易降低成本并更好地处理分析业务。
+
+云计算就是要简化技术流程。如果你所在的企业或者部门还没有开始使用云计算相关服务,那么最好就从现在开始吧,不要和当前的市场脱节了。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/how-to-be-a-good-remote-developer.md b/TODO1/how-to-be-a-good-remote-developer.md
new file mode 100644
index 00000000000..9759e097a5f
--- /dev/null
+++ b/TODO1/how-to-be-a-good-remote-developer.md
@@ -0,0 +1,94 @@
+> * 原文地址:[How to Be a Good Remote Developer](https://levelup.gitconnected.com/how-to-be-a-good-remote-developer-e399607d5532)
+> * 原文作者:[John Au-Yeung](https://medium.com/@hohanga)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-be-a-good-remote-developer.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-be-a-good-remote-developer.md)
+> * 译者:
+> * 校对者:
+
+# How to Be a Good Remote Developer
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/12000/0*gcJQWqRaHf8E66Bw)
+
+Being a good remote worker takes a lot of discipline. We have to do everything ourselves without anyone watching.
+
+In this article, we’ll look at some habits we can adopt to become a good remote developer.
+
+## Practice Good Meeting Etiquette
+
+Good meeting etiquette is very important. Since we're starting at our screen for meetings and don’t have to go to a physical meeting room, it’s all on us to be a practice good meeting etiquette.
+
+We should have everyone on separate screens. Our face should be on video if we’re participating.
+
+Also, we have to pay attention and don’t get distracted by random things around us.
+
+If we don’t have anything urgent, then we should do other things.
+
+Being on the computer, it’s easy to take notes, so we should do it.
+
+Also, we should probably wear work attire if we turn on video so that we won’t embarrass ourselves if we stand up and have underwear on.
+
+## Experiment With What Makes Us the Most Productive
+
+Since we aren’t using only office equipment and staying in the office, we can experiment with our home office setup to see what works for us.
+
+We can wear whatever makes us comfortable as long it’s not underwear or any non-business clothing.
+
+Also, we can shift our start and end times a bit as long we don’t miss any meetings.
+
+The type of work that we do during the day can also change according to our schedule since no one is watching and micromanaging what we’re doing.
+
+We can listen to whatever we want and sit anywhere that makes us more comfortable.
+
+Also, we probably don’t have any set lunch hour. That’s nice since that means we can adjust our lunch schedule the way we wish.
+
+## Clear Communication
+
+Since we don’t see each other in person, we can’t read people’s body language to get what they mean when they type a message or talk.
+
+Therefore, we should make sure that everything is clear and that people understand what we want to convey.
+
+Dealing with different time zones and different mediums of communication also makes things harder for us.
+
+Therefore, to make everyone’s lives easier, we should outline our ideas clearly and type out actionable steps.
+
+Meeting notes are more important since we aren’t sitting beside each other to ask questions.
+
+Instead of using a real whiteboard, we have to use a virtual one.
+
+If we have to pair program, we have to talk and share our screens.
+
+Also, no one will know how we feel over the Internet, so we should convey those clearly.
+
+If we need help, we’ve to ask around since not everyone may answer.
+
+Also, we should check our notifications so that we’ll answer people when we see them. People are waiting for our answers and this is more important since no one is around us to answer urgent questions if we need to.
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/15904/0*jlbf4_s4q88Oz-IR)
+
+## Create Boundaries Between Work and Life
+
+If we’re working 9 to 5 at the office, then we got to set similar boundaries even if we’re working at the office.
+
+There’s just no way that we can work 24 hours a day and not burn out and be tired.
+
+Therefore, we should set some boundaries so that we cut off work the same way that we go home at the end of the day.
+
+At the end of the day, turn off work notifications, close all our work stuff and relax. Also, we should take breaks like we do when we’re in the office.
+
+We got to walk around and clear our minds. Also, lunch breaks are equally important, so we should have them.
+
+## Conclusion
+
+Even though we’re working remotely, we got to set our boundaries like we do when we’re working at the office.
+
+The difference is that we have to make sure that we check our notifications more frequently during work hours so that we can answer people’s questions.
+
+Also, we should make sure that we convey everything clearly so that we can be sure that everyone understands us.
+
+Finally, to collaborate, we have to use share screens and use video conference software.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/how-to-build-a-blog-with-nest-js-mongodb-and-vue-js.md b/TODO1/how-to-build-a-blog-with-nest-js-mongodb-and-vue-js.md
new file mode 100644
index 00000000000..bee44c064b8
--- /dev/null
+++ b/TODO1/how-to-build-a-blog-with-nest-js-mongodb-and-vue-js.md
@@ -0,0 +1,1113 @@
+> * 原文地址:[How To Build a Blog with Nest.js, MongoDB, and Vue.js](https://www.digitalocean.com/community/tutorials/how-to-build-a-blog-with-nest-js-mongodb-and-vue-js)
+> * 原文作者:[Oluyemi Olususi](https://www.digitalocean.com/community/users/yemiwebby)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-build-a-blog-with-nest-js-mongodb-and-vue-js.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-build-a-blog-with-nest-js-mongodb-and-vue-js.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[vitoxli](https://github.com/vitoxli),[lihaobhsfer](https://github.com/lihaobhsfer)
+
+# 如何用 Nest.js、MongoDB 和 Vue.js 搭建一个博客
+
+## 概述
+
+[Nest.js](https://nestjs.com/) 是一个可扩展的服务端 JavaScript 框架。它使用 TypeScript 构建,所以它依然与 JavaScript 兼容,这使得它成为构建高效可靠的后端应用的有效工具。它还具有模块化结构,可为 Node.js 开发环境提供一个成熟的结构化的设计模式。
+
+[Vue.js](https://vuejs.org/) 是用于构建用户界面的前端 JavaScript 框架。它不仅有简单但功能强大的 API,还具有出色的性能。Vue.js 能提供任意项目规模的 Web 应用的前端层和逻辑。它可以轻松地将自身与其他库或现有项目集成在一起,这使得它成为大多数现代 Web 应用的理想选择。
+
+在本教程中,我们将通过构建一个 Nest.js 应用,来熟悉它的构建模块以及构建现代 Web 应用的基本原则。我们会将应用划分为两个不同的部分:前端和后端。首先,我们将使用 Nest.js 来构建的 RESTful 后端 API。然后,将使用 Vue.js 来构建前端。其中前后端的应用将在不同的端口上运行,并将作为独立的域运行。
+
+我们将构建的是一个博客应用,用户可以使用该应用创建和保存新文章,在主页上查看保存的文章,以及进行其他操作,例如编辑和删除文章。此外,我们还会连接应用并将应用数据持久化到 [MongoDB](https://www.mongodb.com/) 中,MongoDB 是一种无模式(schema-less)的 NoSQL 数据库,可以接收和存储 JSON 文件。本教程的重点是介绍如何在开发环境中构建应用。如果是在生产环境,我们还应该考虑应用的用户身份验证。
+
+## 前提
+
+要完成本教程,我们需要:
+
+* 在本地安装 [Node.js](https://nodejs.org/en/)(至少 v6 版本)和 [npm](https://www.npmjs.com/)(至少 v5.2 版本)。Node.js 是一个允许您在浏览器之外运行 JavaScript 代码的运行环境。它带有一个名为 `npm` 的预安装的包管理工具,可让您安装和更新软件包。如果要在 macOS 或 Ubuntu 18.04 上安装它们,请遵循文章[如何在 macOS 上安装 Node.js 并创建本地开发环境](https://www.digitalocean.com/community/tutorials/how-to-install-node-js-and-create-a-local-development-environment-on-macos)中的步骤或者文章[如何在 Ubuntu 18.04 上安装 Node.js](https://www.digitalocean.com/community/tutorials/how-to-install-node-js-on-ubuntu-18-04)中的“使用 PPA 进行安装”这一节。
+* 在您的机器上安装 MongoDB 数据库。按照[这里](https://www.mongodb.com/download-center/community)的说明来下载并安装您操作系统所对应的版本。您可以通过在 [Mac](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-os-x/?_ga=2.44532076.918654254.1550698665-2018226388.1550698665#create-the-data-directory) 上使用 [Homebrew](https://brew.sh/) 进行安装,也可以从 [MongoDB 网站](https://www.mongodb.com/download-center/community)下载。
+* 对 TypeScript 和 [JavaScript](https://www.digitalocean.com/community/tutorial_series/how-to-code-in-javascript) 有基本了解。
+* 安装文本编辑器,例如 [Visual Studio Code](https://code.visualstudio.com/)、[Atom](https://atom.io) 或者 [Sublime Text](https://www.sublimetext.com)。
+
+**注意:** 本教程使用 macOS 机器进行开发。如果您正在使用其他的操作系统,可能需要在整个教程中使用 `sudo` 来执行 `npm` 命令。
+
+## 第一步 —— 安装 Nest.js 和其他依赖
+
+在本节中,我们先在本地安装 Nest.js 及其所需依赖。您可以使用 Nest.js 提供的 [CLI](https://docs.nestjs.com/cli/overview) 轻松地安装 Nest.js,也可以从 GitHub 上的入门项目安装。就本教程而言,我们将使用 CLI 来初始化应用。首先,在终端运行以下命令,以便在您的机器上全局安装它:
+
+```sh
+npm i -g @nestjs/cli
+```
+
+您将看到类似于以下内容的输出:
+
+```
+Output@nestjs/cli@5.8.0
+added 220 packages from 163 contributors in 49.104s
+```
+
+要确认已完成 Nest CLI 的安装,请在终端上运行此命令:
+
+```sh
+nest --version
+```
+
+您将看到安装在您计算机上的 Nest 版本:
+
+```
+Output5.8.0
+```
+
+我们将使用 `nest` 命令来管理项目,并使用它来生成相关文件 —— 比如 controller、modules 和 provider。
+
+要开始本教程的项目,请在终端中使用 `nest` 命令运行以下命令行来构建名为 `blog-backend` 的新 Nest.js 项目:
+
+```sh
+nest new blog-backend
+```
+
+在运行该命令之后,`nest` 将立即向您提供一些基本信息,如`描述(description)`、`版本(version)`和`作者(author)`。继续并提供适当的细节。在您回答了每个提示之后,在您的计算机上按`回车`继续。
+
+接下来,我们将选择一个包管理器。就本教程而言,选择 `npm` 并按`回车键`开始安装 Nest.js。
+
+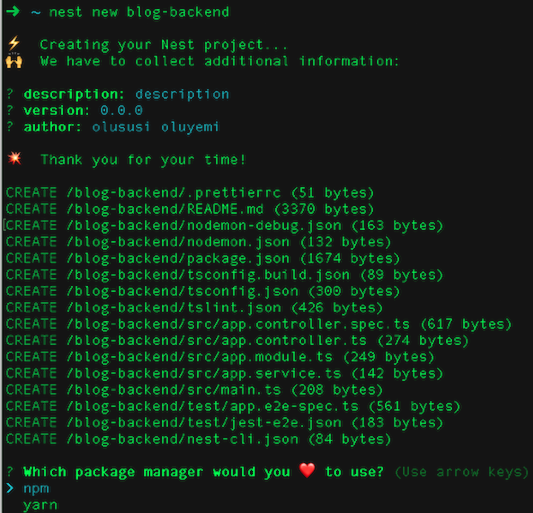
+
+这将在本地开发文件夹中的 `blog-backend` 文件夹中生成一个新的 Nest.js 项目。
+
+接下来,从终端导航到新的项目文件夹:
+
+```sh
+cd blog-backend
+```
+
+运行以下命令以安装其他服务依赖项:
+
+```sh
+npm install --save @nestjs/mongoose mongoose
+```
+
+这时,我们已经安装了 `@nestjs/mongoose` 和 `mongoose`,前者是一个用于 MongoDB 的对象建模工具的 Nest.js 专用软件包,后者是用于操作 Mongoose 的软件包。
+
+现在,使用以下命令启动应用:
+
+```sh
+npm run start
+```
+
+现在,选择您喜欢的浏览器,打开 `http://localhost:3000`,您将看到我们的应用正在运行。
+
+
+
+现在,我们已经在 Nest CLI 命令的帮助下成功地创建了项目。接着,继续运行应用,并在本地机器上的默认端口 `3000` 上访问它。在下一节中,我们将通过设置数据库连接的配置来进一步了解应用。
+
+## 第二步 —— 配置和连接数据库
+
+这一步, 我们将配置 MongoDB 并将其集成到 Nest.js 应用中,用 MongoDB 存储应用的数据。MongoDB 将数据以**字段:值**对的形式存储在 **document** 中。您将使用 [Mongoose](https://mongoosejs.com/) 来访问这些数据结构,Mongoose 是一个对象文档模型(Object Document Modeling,ODM),它能够让我们定义表示 MongoDB 数据库存储的数据类型的 schema 结构。
+
+要启动 MongoDB,首先打开一个单独的终端,使应用可以继续运行,然后执行以下命令:
+
+```sh
+sudo mongod
+```
+
+这将启动 MongoDB 服务并在您机器的后台运行数据库。
+
+在文本编辑器中打开 `blog-backend` 项目,定位到 `./src/app.module.ts` 文件。我们可以通过在根 `ApplicationModule` 中已安装的 `MongooseModule` 来建立到数据库的连接。需要添加以下几行代码来更新 `app.module.ts` 中的内容:
+
+~/blog-backend/src/app.module.ts
+
+```ts
+import { Module } from '@nestjs/common';
+import { AppController } from './app.controller';
+import { AppService } from './app.service';
+import { MongooseModule } from '@nestjs/mongoose';
+
+@Module({
+ imports: [
+ MongooseModule.forRoot('mongodb://localhost/nest-blog', { useNewUrlParser: true }),
+ ],
+ controllers: [AppController],
+ providers: [AppService],
+})
+export class AppModule { }
+```
+
+在这个文件中,我们使用 `forRoot()` 方法来完成与数据库的连接。完成编辑后,保存并关闭文件。
+
+有了这些,我们就可以使用 Mongoose 中对应 MongoDB 的模块来建立数据库连接。在下一节中,我们将使用 Mongoose 库、TypeScript 接口和数据传输对象(DTO)schema 创建一个数据库 schema。
+
+## 第三步 —— 创建数据库 Schema,接口以及 DTO
+
+在这一步, 我们将使用 Mongoose 为数据库创建 **schema**,**接口**和**数据传输对象**。Mongoose 帮助我们管理数据之间的关系,并提供数据类型的 schema 验证。为了更好的定义应用中数据库里数据结构和数据类型,我们将创建文件,以确定以下内容:
+
+* **数据库 schema**: 这是一种数据组织,它是定义数据库需要存储的数据结构和类型的蓝图。
+* **接口**:TypeScript 接口用于类型检查。它可以用来定义在应用中传递的数据的类型。
+* **数据传输对象**: 这个对象定义了数据是以何种形式通过网络发送的以及如何在进程之间进行传输的。
+
+首先, 回到当前应用运行的终端,使用 `CTRL + C` 停止进程,跳转至 `./src/` 文件夹:
+
+```sh
+cd ./src/
+```
+
+然后,创建一个名为 `blog` 的目录,并在其中创建一个 `schemas` 文件夹:
+
+```sh
+mkdir -p blog/schemas
+```
+
+在 `schemas` 文件夹,创建一个名为 `blog.schema.ts` 的新文件。使用文本编辑器打开它。然后,添加以下内容:
+
+~/blog-backend/src/blog/schemas/blog.schema.ts
+
+```ts
+import * as mongoose from 'mongoose';
+
+export const BlogSchema = new mongoose.Schema({
+ title: String,
+ description: String,
+ body: String,
+ author: String,
+ date_posted: String
+})
+```
+
+这里,我们使用 Mongoose 来定义将存储在数据库中的数据类型。我们已经指定所有将存储并且接受的字段只有字符串类型。完成编辑后保存并关闭文件。
+
+现在,确定了数据库 schema 之后,就可以继续创建接口了。
+
+首先,回到 `blog` 文件夹:
+
+```sh
+cd ~/blog-backend/src/blog/
+```
+
+创建一个名为 `interfaces` 的新文件夹,并跳转至文件夹内:
+
+```sh
+mkdir interfaces
+```
+
+在`interfaces` 文件夹,创建一个叫 `post.interface.ts` 的文件,并用文本编辑器打开它。添加以下内容以定义 `Post` 的数据类型:
+
+~/blog-backend/src/blog/interfaces/post.interface.ts
+
+```ts
+import { Document } from 'mongoose';
+
+export interface Post extends Document {
+ readonly title: string;
+ readonly description: string;
+ readonly body: string;
+ readonly author: string;
+ readonly date_posted: string
+}
+```
+
+在这个文件中,我们已经成功地将 `Post` 类型的数据类型定义为字符串值。保存并退出文件。
+
+因为我们的应用将会向数据库发送数据,所以我们将创建一个数据传输对象,它将定义数据会怎样发送到网络。
+
+为此,请在 `./src/blog` 文件夹中创建一个文件夹 `dto`。在新创建的文件夹中,创建一个名为 `create-post.dto.ts` 的文件
+
+定位到 `blog` 文件夹:
+
+```sh
+cd ~/blog-backend/src/blog/
+```
+
+然后创建一个名为 `dto` 的文件夹并跳转到该文件夹:
+
+```sh
+mkdir dto
+```
+
+在 `dto` 文件夹中,创建一个名为 `create-post.dto` 的新文件。使用文本编辑器打开它,添加以下内容:
+
+~/blog-backend/src/blog/dto/create-post.dto.ts
+
+```ts
+export class CreatePostDTO {
+ readonly title: string;
+ readonly description: string;
+ readonly body: string;
+ readonly author: string;
+ readonly date_posted: string
+}
+```
+
+我们已经将 `CreatePostDTO` 类中的每个属性都标记为数据类型为 `string`,并标记为 `readonly`,以避免不必要的数据操作。完成编辑后保存并退出文件。
+
+在这一步中,我们已经为数据库创建了数据库 schema、接口、以及数据库将要存储的数据的数据传输对象。接下来,我们将为博客创建模块、控制器和服务。
+
+## 第四步 —— 为你的博客创建模块(Module)、控制器(Controller)和服务(Service)
+
+在这一步,我们将通过为博客创建一个模块来改进应用的现有结构。这个模块将组织应用中的文件结构。接着,我们将创建一个控制器来处理来自客户端的路由和 HTTP 请求。最后,我们将创建服务来处理应用程序中所有控制器无法处理的复杂业务逻辑。
+
+### 创建模块
+
+与 Angular 等前端框架类似,Nest.js 使用的是模块化语法。Nest.js 应用采用模块化设计;它预装的是单个根模块,这对小型应用来说通常是够用的。但是,当应用业务开始增长时,Nest.js 推荐使用多模块来组织应用,将代码根据相关的功能分解成不同模块。
+
+Nest.js 中的**模块**由 `@Module()` 装饰器标识,并接受有 `controller` 和 `provider` 之类属性的对象。其中每一个属性都会分别采用一组 `controller` 和 `provider`。
+
+我们将为这个博客应用生成一个新模块,使结构更有组织。首先,仍然在 `~/blog-backend` 文件夹中,执行以下命令:
+
+```sh
+nest generate module blog
+```
+
+您将看到类似于以下内容的输出:
+
+```
+OutputCREATE /src/blog/blog.module.ts
+
+UPDATE /src/app.module.ts
+```
+
+该命令生成了一个名为 `blog.module.ts` 的新模块。将新创建的模块导入到应用的根模块中。这将允许 Nest.js 知道根模块之外的另一个模块的存在。
+
+在这个文件中,您将看到以下代码:
+
+~/blog-backend/src/blog/blog.module.ts
+
+```ts
+import { Module } from '@nestjs/common';
+
+@Module({})
+export class BlogModule {}
+```
+
+在本教程的后面,我们将使用所需的属性更新这个 `BlogModule`。现在保存并退出文件。
+
+### 创建服务
+
+**服务**(在 Nest.js 中也称它为 provider)的意义在于从仅应处理 HTTP 请求的控制器中移除业务逻辑,并会将更复杂的任务重定向到其他的服务类。服务是普通的 JavaScript 类,在它们的代码上方会带有 `@Injectable()` 装饰器。要生成新服务,请在该项目目录下终端运行以下命令:
+
+```sh
+nest generate service blog
+```
+
+您将看到类似于以下内容的输出:
+
+```
+Output CREATE /src/blog/blog.service.spec.ts (445 bytes)
+
+CREATE /src/blog/blog.service.ts (88 bytes)
+
+UPDATE /src/blog/blog.module.ts (529 bytes)
+```
+
+这里通过 `nest` 命令创建了一个 `blog.service.spec.ts` 文件,我们可以使用它进行测试。它还创建了一个新的 `blog.service.ts` 文件,它将保存这个应用的所有逻辑,并处理向 MongoDB 数据库的添加和检索 document。此外,它还会自动导入新创建的服务并将其添加到 `blog.module.ts` 中。
+
+服务处理应用中所有的逻辑,负责与数据库交互,并将合适的响应返回给控制器。为此,在文本编辑器中打开`blog.service.ts` 文件,并将内容替换为以下内容:
+
+~/blog-backend/src/blog/blog.service.ts
+
+```ts
+import { Injectable } from '@nestjs/common';
+import { Model } from 'mongoose';
+import { InjectModel } from '@nestjs/mongoose';
+import { Post } from './interfaces/post.interface';
+import { CreatePostDTO } from './dto/create-post.dto';
+
+@Injectable()
+export class BlogService {
+
+ constructor(@InjectModel('Post') private readonly postModel: Model<Post>) { }
+
+ async getPosts(): Promise<Post[]> {
+ const posts = await this.postModel.find().exec();
+ return posts;
+ }
+
+ async getPost(postID): Promise<Post> {
+ const post = await this.postModel
+ .findById(postID)
+ .exec();
+ return post;
+ }
+
+ async addPost(createPostDTO: CreatePostDTO): Promise<Post> {
+ const newPost = await this.postModel(createPostDTO);
+ return newPost.save();
+ }
+
+ async editPost(postID, createPostDTO: CreatePostDTO): Promise<Post> {
+ const editedPost = await this.postModel
+ .findByIdAndUpdate(postID, createPostDTO, { new: true });
+ return editedPost;
+ }
+
+ async deletePost(postID): Promise<any> {
+ const deletedPost = await this.postModel
+ .findByIdAndRemove(postID);
+ return deletedPost;
+ }
+
+}
+```
+
+在这个文件中,我们首先从 `@nestjs/common`、`mongoose` 和 `@nestjs/mongoose` 中导入所需的模块。同时我们还导入了一个名为 `Post` 的接口和一个数据传输对象 `CreatePostDTO`。
+
+在 `constructor` 中,我们使用了 `@InjectModel('Post')`,将 `Post` 模型注入这个 `BlogService` 类中。现在,我们可以使用这个注入的模型来检索所有的文章,获取一篇文章,并执行其他与数据库相关的活动。
+
+接着,我们创建了以下方法:
+
+* `getPosts()`:从数据库中获取所有文章。
+* `getPost()`:从数据库中检索一篇文章。
+* `addPost()`:添加一篇新文章。
+* `editPost()`:更新一篇文章。
+* `deletePost()`:删除特定的文章。
+
+完成后,保存并退出文件。
+
+我们已经完成了几个方法的设置和创建,这些方法将通过后端 API 来与 MongoDB 数据库进行的适当交互。现在,我们将创建用于处理来自前端客户端的 HTTP 调用所需的路由。
+
+### 创建控制器
+
+在 Nest.js 中,**控制器**负责处理来自应用客户端的任何请求并返回适当的响应。与大多数其他 web 框架类似,对于应用而言重要的就是监听请求并响应。
+
+为了满足博客应用的所有 HTTP 请求,我们将利用 `nest` 命令生成一个新的控制器文件。首先确保您仍然在项目目录,`blog-backend`,然后运行以下命令:
+
+```sh
+nest generate controller blog
+```
+
+您将看到类似于以下内容的输出:
+
+```
+OutputCREATE /src/blog/blog.controller.spec.ts (474 bytes)
+
+CREATE /src/blog/blog.controller.ts (97 bytes)
+
+UPDATE /src/blog/blog.module.ts (483 bytes)
+```
+
+这段输出表示该命令在 `src/blog` 目录中创建了两个新文件,`blog.controller.spec.ts` 和 `blog.controller.ts`。前者是一个可以用来为新创建的控制器编写自动测试的文件。后者是控制器文件本身。Nest.js 中的控制器是用 `@Controller` 元数据装饰的 TypeScript 文件。该命令还导入了新创建的控制器并添加它到博客模块。
+
+接下来,用文本编辑器打开 `blog.controller.ts` 文件并用以下内容更新它:
+
+~/blog-backend/src/blog/blog.controller.ts
+
+```ts
+import { Controller, Get, Res, HttpStatus, Param, NotFoundException, Post, Body, Query, Put, Delete } from '@nestjs/common';
+import { BlogService } from './blog.service';
+import { CreatePostDTO } from './dto/create-post.dto';
+import { ValidateObjectId } from '../shared/pipes/validate-object-id.pipes';
+
+
+@Controller('blog')
+export class BlogController {
+
+ constructor(private blogService: BlogService) { }
+
+ @Get('posts')
+ async getPosts(@Res() res) {
+ const posts = await this.blogService.getPosts();
+ return res.status(HttpStatus.OK).json(posts);
+ }
+
+ @Get('post/:postID')
+ async getPost(@Res() res, @Param('postID', new ValidateObjectId()) postID) {
+ const post = await this.blogService.getPost(postID);
+ if (!post) throw new NotFoundException('Post does not exist!');
+ return res.status(HttpStatus.OK).json(post);
+
+ }
+
+ @Post('/post')
+ async addPost(@Res() res, @Body() createPostDTO: CreatePostDTO) {
+ const newPost = await this.blogService.addPost(createPostDTO);
+ return res.status(HttpStatus.OK).json({
+ message: "Post has been submitted successfully!",
+ post: newPost
+ })
+ }
+}
+```
+
+在这个文件中,我们首先引入了来自 `@nestjs/common` 模块的处理 HTTP 请求所需的模块。然后,我们引入了三个新模块:`BlogService`、`CreatePostDTO` 和 `ValidateObjectId`。之后,通过在构造函数中将 `BlogService` 注入到控制器,以使得拥有访问权限来使用 `BlogService` 文件中已经定义好的函数。在 Nest.js 中,这是一种模式,叫作**依赖注入**,有助于提高效率和增强应用的模块化。
+
+最后,我们创建了以下这些异步方法:
+
+* `getPosts()`: 这个方法将执行从客户端接收 HTTP GET 请求时从数据库中获取所有文章,然后返回适当的响应的功能。它用 `@Get('posts')` 装饰。
+* `getPost()`: 这将以 `postID` 作为参数,从数据库中获取一篇文章。除了传递给这个方法的 `postID` 参数之外,还实现了一个名为 `ValidateObjectId()` 的额外方法。这个方法实现了 Nest.js 中的 `PipeTransform` 接口。它是用于验证并确保可以在数据库中找到 `postID` 参数。我们将在下一节中定义这个方法。
+* `addPost()`: 这个方法将处理 HTTP POST 请求,以便向数据库添加新的文章。
+
+为了能够编辑和删除特定的文章,我们需要在 `blog.controller.ts` 文件中添加两个以上的方法。我们需要,在之前添加到 `blog.controller.ts` 的 `addPost()` 方法后,直接加上 `editPost()` 和 `deletePost()` 方法:
+
+~/blog-backend/src/blog/blog.controller.ts
+
+```ts
+...
+@Controller('blog')
+export class BlogController {
+ ...
+ @Put('/edit')
+ async editPost(
+ @Res() res,
+ @Query('postID', new ValidateObjectId()) postID,
+ @Body() createPostDTO: CreatePostDTO
+ ) {
+ const editedPost = await this.blogService.editPost(postID, createPostDTO);
+ if (!editedPost) throw new NotFoundException('Post does not exist!');
+ return res.status(HttpStatus.OK).json({
+ message: 'Post has been successfully updated',
+ post: editedPost
+ })
+ }
+
+
+ @Delete('/delete')
+ async deletePost(@Res() res, @Query('postID', new ValidateObjectId()) postID) {
+ const deletedPost = await this.blogService.deletePost(postID);
+ if (!deletedPost) throw new NotFoundException('Post does not exist!');
+ return res.status(HttpStatus.OK).json({
+ message: 'Post has been deleted!',
+ post: deletedPost
+ })
+ }
+}
+```
+
+这里解释一下我们到底添加了什么:
+
+* `editPost()`: 这个方法接受 `postID` 的查询参数,并执行更新一篇文章的功能。它还利用 `ValidateObjectId` 方法为您需要编辑文章提供适当的认证。
+* `deletePost()`: 这个方法将接受 `postID` 的查询参数,并从数据库中删除特定的文章。
+
+与 `BlogController` 类似,这里定义的每个异步方法都有一个元数据装饰器,并且包含一个 Nest.js 中用于路由机制的前缀。它控制每个控制器接收的请求,以及分别指向应该处理请求和返回的响应方法。
+
+例如,我们在本节中创建的 `BlogController` 具有 `blog` 前缀和一个名为 `getPosts()` 采用 `posts` 前缀的方法。这意味着发送到 `blog/posts`(`http:localhost:3000/blog/posts`)的任何 GET 请求都将由 `getPosts()` 方法处理。其他处理 HTTP 请求的方法与这个示例中的方式类似。
+
+保存并退出文件。
+
+关于应用的完整 `blog.controller.ts` 文件,请访问 [DO Community repository](https://github.com/do-community/nest-vue-project/blob/master/blog-backend/src/blog/blog.controller.ts)。
+
+在这一节中,我们创建了模块,使得应用更便于管理。我们还创建了服务,通过与数据库的交互并返回适当的响应来处理应用程序的业务逻辑。最后,我们创建了控制器并生成了必要的方法来处理来自客户端的 HTTP 请求,例如 `GET`、`POST`、`PUT` 和 `DELETE`。在下一节中,我们将完成后端设置。
+
+## 第五步 —— 为 Mongoose 创建一个额外的认证
+
+我们可以通过唯一的 ID (也称为 `PostID`)来区分博客应用中的每篇文章。这意味着获取文章的话,我们需要将此 ID 作为查询参数传递过去。为了验证这个 `postID` 参数并确保这篇文章在数据库确实存在可用,我们需要创建一个可复用的函数,该函数可以从 `BlogController` 中的任何方法初始化。
+
+要配置它,请定位到 `./src/blog` 文件夹:
+
+```sh
+cd ./src/blog/
+```
+
+然后,创建一个名为 `shared` 的新文件夹:
+
+```sh
+mkdir -p shared/pipes
+```
+
+在 `pipes` 文件夹中,使用文本编辑器创建一个名为 validate-object-id.pipes.ts 的新文件,并打开它。添加以下内容以定义接受的 `postID` 数据:
+
+~/blog-backend/src/blog/shared/pipes/validate-object-id.pipes.ts
+
+```ts
+import { PipeTransform, Injectable, ArgumentMetadata, BadRequestException } from '@nestjs/common';
+import * as mongoose from 'mongoose';
+
+@Injectable()
+export class ValidateObjectId implements PipeTransform<string> {
+ async transform(value: string, metadata: ArgumentMetadata) {
+ const isValid = mongoose.Types.ObjectId.isValid(value);
+ if (!isValid) throw new BadRequestException('Invalid ID!');
+ return value;
+ }
+}
+```
+
+`ValidateObjectId()` 类是由 `@nestjs/common` 模块中的 `PipeTransform` 方法实现的。它有一个名为 `transform()` 的方法,该方法将 value 作为参数 —— 在当前着种情况下为 `postID`。使用这个方法,任何带有无法在数据库中检索到的 `postID` 的应用中的前端 HTTP 请求都会被视为无效。保存并关闭文件。
+
+在创建了服务和控制器之后,我们需要建立基于 `BlogSchema` 的 `Post` 模型。这个配置可以在根 `ApplicationModule` 中设置,但是在这本例中,我们将在 `BlogModule` 中构建模型以维护应用的组织。打开`./src/blog/blog.module.ts` 并用以下内容更新它:
+
+~/blog-backend/src/blog/blog.module.ts
+
+```ts
+import { Module } from '@nestjs/common';
+import { BlogController } from './blog.controller';
+import { BlogService } from './blog.service';
+import { MongooseModule } from '@nestjs/mongoose';
+import { BlogSchema } from './schemas/blog.schema';
+
+@Module({
+ imports: [
+ MongooseModule.forFeature([{ name: 'Post', schema: BlogSchema }])
+ ],
+ controllers: [BlogController],
+ providers: [BlogService]
+})
+export class BlogModule { }
+```
+
+在这里我们使用 `MongooseModule.forFeature()` 方法来定义在模块中应该注册哪些模型。如果没有这个方法,使用 `@injectModel()` 装饰器在 `BlogService` 中注入 `PostModel` 将不起作用。完成添加后,保存并关闭文件。
+
+在这一步中,我们已经用 Nest.js 创建了完整的后端 RESTful API,并将其与 MongoDB 集成。在下一节中,我们将配置服务器以允许来自其他服务器的 HTTP 请求,因为我们的前端应用和后端将运行在不同的端口上。
+
+## 第六步 —— 启用 CORS
+
+跨域的 HTTP 请求通常在默认情况下被阻止,除非服务器指定允许它访问。要使前端应用向后端服务器发出跨域请求,必须启用**跨源资源共享(CORS)**,这是一种允许请求 Web 页面上跨域资源的技术。
+
+在 Nest.js 中启用 CORS,我们需要向 `main.ts` 文件中添加一个方法。用文本编辑器打开位于 `./src/main.ts` 中的文件,并用以下内容更新它:
+
+~/blog-backend/src/main.ts
+
+```ts
+import { NestFactory } from '@nestjs/core';
+import { AppModule } from './app.module';
+
+async function bootstrap() {
+ const app = await NestFactory.create(AppModule);
+ app.enableCors();
+ await app.listen(3000);
+}
+bootstrap();
+```
+
+保存并退出文件。
+
+现在我们已经完成了后端设置,我们将把重点转移到前端,使用 Vue.js 来使用到目前为止构建的 API。
+
+## 第七步 —— 创建 Vue.js 前端
+
+在本节中,我们将使用 Vue.js 创建前端应用。[Vue CLI](https://cli.vuejs.org/) 是一个脚手架,它使我们能够方便简单地快速生成和安装一个新的 Vue.js 项目。
+
+首先,您需要在您的机器上全局安装 Vue CLI 。打开另一个终端,注意路径不是在 `blog-backend` 文件夹,而是在本地项目的 development 文件夹,然后运行:
+
+```sh
+npm install -g @vue/cli
+```
+
+一旦安装过程完成,我们将利用 `vue` 命令创建一个新的 Vue.js 项目:
+
+```sh
+vue create blog-frontend
+```
+
+输入此命令后,我们将看到一个简短的提示。选择 `manually select features` 选项(意思是手动选择特性),然后按下计算机上的`空格`,这时会显示出多个特性来让您来选择此项目所需的特性。我们将选择`Babel`、`Router` 和 `Linter / Formatter`。
+
+
+
+对于下一条指令,输入 `y` 来使用路由的历史模式;这将使历史模式在 router 文件中启用,这个 router 文件将自动为我们的项目生成。此外,仅选择`ESLint with error prevention only` 用于 linter/formatter 的配置。下一步,选择 `Lint on save` 为保留其他的 Lint 功能。然后选择将我们的配置保存到一个 `dedicated config file`(专用配置文件)中,以供将来的项目使用。最后,为我们的这些预置设置输入一个名称,比如 `vueconfig`。
+
+
+
+Vue.js 将开始在一个名为 `blog-frontend` 的目录中创建应用及其所需的所有依赖项。
+
+安装过程完成后,在 Vue.js 应用中定位到:
+
+```sh
+cd blog-frontend
+```
+
+然后,使用以下命令启动服务器:
+
+```sh
+npm run serve
+```
+
+我们的应用将在 `http://localhost:8080` 上运行。
+
+
+
+由于我们将在此应用中执行 HTTP 请求,因此需要安装 axios,这是一种基于 Promise 的浏览器 HTTP 客户端。这里将使用 axios 执行来自应用中不同组件的 HTTP 请求。在您的计算机的终端上按 `CTRL + C` 终止前端应用,然后运行以下命令:
+
+```sh
+npm install axios --save
+```
+
+我们的前端应用将从应用中的不同组件中对特定域上的后端 API 进行 API 调用。为了确保我们应用的路由请求结构是正确的,我们可以创建一个`辅助`文件,在其中定义服务器 `baseURL`。
+
+首先,将仍然位于博客前端的终端中,定位到 `./src/` 文件夹:
+
+```sh
+cd ./src/
+```
+
+创建另一个名为 `utils` 的文件夹:
+
+```sh
+mkdir utils
+```
+
+在 `utils` 文件夹,使用文本编辑器创建一个名为 `helper.js` 的新文件并将其打开。添加以下内容以定义后端 Nest.js 项目的 `baseURL`:
+
+~blog-frontend/src/utils/helper.js
+
+```js
+export const server = {
+
+baseURL: 'http://localhost:3000'
+
+}
+```
+
+定义了 `baseURL` 之后,我们可以从 Vue.js 组件文件中的任何位置调用它。在需要更改 URL 的情况下,更改这个文件中的 baseURL 比在整个应用代码中更新更容易。
+
+在本节中,我们安装了 Vue CLI,这是一个用于创建新的 Vue.js 应用的脚手架工具。我们使用此工具来创建 `blog-frontend` 应用。此外,我们还运行了应用并安装了一个名为 axios 的库,每当应用中出现 HTTP 调用时,我们都使用该库。接下来,我们将为应用创建组件。
+
+## 第八步 —— 创建可复用的组件
+
+现在我们要为我们的应用创建可重用的组件,这是 Vue.js 应用的标准结构。Vue.js 中的组件系统使开发人员能够构建一个单独的、独立的接口单元,该单元具有自己的状态、HTML 和样式。这使得这些组件可以被复用。
+
+每个 Vue.js 组件都包含三个不同的部分:
+
+* `<template>`:包含着 HTML 内容
+* `<script>`:包含所有基本的前端逻辑并定义函数
+* `<style>`:每个组件的单独样式表
+
+首先,我们将创建一个用来创建文章的组件。我们需要在 `./src/components` 文件夹中创建一个名为 `post` 的新文件夹,这个文件夹中存放有关文章的必要的可重用组件。然后使用文本编辑器在新创建的 `post` 文件夹中创建另一个文件并将其命名为 `Create.vue`。打开这个文件并添加以下代码,这段代码告诉了我们提交文章所需的输入字段:
+
+~blog-frontend/src/components/post/Create.vue
+
+```vue
+<template>
+ <div>
+ <div class="col-md-12 form-wrapper">
+ <h2> Create Post </h2>
+ <form id="create-post-form" @submit.prevent="createPost">
+ <div class="form-group col-md-12">
+ <label for="title"> Title </label>
+ <input type="text" id="title" v-model="title" name="title" class="form-control" placeholder="Enter title">
+ </div>
+ <div class="form-group col-md-12">
+ <label for="description"> Description </label>
+ <input type="text" id="description" v-model="description" name="description" class="form-control" placeholder="Enter Description">
+ </div>
+ <div class="form-group col-md-12">
+ <label for="body"> Write Content </label>
+ <textarea id="body" cols="30" rows="5" v-model="body" class="form-control"></textarea>
+ </div>
+ <div class="form-group col-md-12">
+ <label for="author"> Author </label>
+ <input type="text" id="author" v-model="author" name="author" class="form-control">
+ </div>
+
+ <div class="form-group col-md-4 pull-right">
+ <button class="btn btn-success" type="submit"> Create Post </button>
+ </div>
+ </form>
+ </div>
+ </div>
+</template>
+```
+
+这是 `CreatePost` 组件的 `<template>` 部分。它包含创建新文章所需的 HTML 元素 input。每个输入字段都有一个 `v-model` 指令作为输入属性。这是为了使每个表单上的 input 框都有双向数据绑定,以便 Vue.js 更容易获得用户的输入。
+
+接下来,将 `<script>` 部分直接添加到前面的文件中:
+
+~blog-frontend/src/components/post/Create.vue
+
+```js
+...
+<script>
+import axios from "axios";
+import { server } from "../../utils/helper";
+import router from "../../router";
+export default {
+ data() {
+ return {
+ title: "",
+ description: "",
+ body: "",
+ author: "",
+ date_posted: ""
+ };
+ },
+ created() {
+ this.date_posted = new Date().toLocaleDateString();
+ },
+ methods: {
+ createPost() {
+ let postData = {
+ title: this.title,
+ description: this.description,
+ body: this.body,
+ author: this.author,
+ date_posted: this.date_posted
+ };
+ this.__submitToServer(postData);
+ },
+ __submitToServer(data) {
+ axios.post(`${server.baseURL}/blog/post`, data).then(data => {
+ router.push({ name: "home" });
+ });
+ }
+ }
+};
+</script>
+```
+
+这里我们添加了一个名为 `createPost()` 的方法来创建一篇新文章,并使用 axios 将其提交给服务器。一旦用户创建了一篇新文章,应用将重定向回主页,用户可以在那里查看创建的文章的列表。
+
+我们将在本教程的后面配置 vue-router 来实现重定向。
+
+完成编辑后保存并关闭文件。关于应用的完整 `Create.vue` 文件,请访问 [DO Community repository](https://github.com/do-community/nest-vue-project/blob/master/blog-frontend/src/components/post/Create.vue)。
+
+现在,我们需要再创建一个用于编辑特定文章的组件。定位到 `./src/components/post` 文件夹,再创建一个名为 `Edit.vue` 文件。添加以下 `<template>` 部分的代码到文件中:
+
+~blog-frontend/src/components/post/Edit.vue
+
+```vue
+<template>
+<div>
+ <h4 class="text-center mt-20">
+ <small>
+ <button class="btn btn-success" v-on:click="navigate()"> View All Posts </button>
+ </small>
+ </h4>
+ <div class="col-md-12 form-wrapper">
+ <h2> Edit Post </h2>
+ <form id="edit-post-form" @submit.prevent="editPost">
+ <div class="form-group col-md-12">
+ <label for="title"> Title </label>
+ <input type="text" id="title" v-model="post.title" name="title" class="form-control" placeholder="Enter title">
+ </div>
+ <div class="form-group col-md-12">
+ <label for="description"> Description </label>
+ <input type="text" id="description" v-model="post.description" name="description" class="form-control" placeholder="Enter Description">
+ </div>
+ <div class="form-group col-md-12">
+ <label for="body"> Write Content </label>
+ <textarea id="body" cols="30" rows="5" v-model="post.body" class="form-control"></textarea>
+ </div>
+ <div class="form-group col-md-12">
+ <label for="author"> Author </label>
+ <input type="text" id="author" v-model="post.author" name="author" class="form-control">
+ </div>
+
+ <div class="form-group col-md-4 pull-right">
+ <button class="btn btn-success" type="submit"> Edit Post </button>
+ </div>
+ </form>
+ </div>
+ </div>
+</template>
+
+```
+
+这里的 template 部分的内容与 `CreatePost()` 组件类似;唯一的区别是它包含了需要编辑的特定文章的具体内容。
+
+接下来,直接在 `Edit.vue` 中的 `</template>` 部分后面添加 `<script>` 部分:
+
+~blog-frontend/src/components/post/Edit.vue
+
+```js
+...
+<script>
+import { server } from "../../utils/helper";
+import axios from "axios";
+import router from "../../router";
+export default {
+ data() {
+ return {
+ id: 0,
+ post: {}
+ };
+ },
+ created() {
+ this.id = this.$route.params.id;
+ this.getPost();
+ },
+ methods: {
+ editPost() {
+ let postData = {
+ title: this.post.title,
+ description: this.post.description,
+ body: this.post.body,
+ author: this.post.author,
+ date_posted: this.post.date_posted
+ };
+
+ axios
+ .put(`${server.baseURL}/blog/edit?postID=${this.id}`, postData)
+ .then(data => {
+ router.push({ name: "home" });
+ });
+ },
+ getPost() {
+ axios
+ .get(`${server.baseURL}/blog/post/${this.id}`)
+ .then(data => (this.post = data.data));
+ },
+ navigate() {
+ router.go(-1);
+ }
+ }
+};
+</script>
+```
+
+在这里,我们获得了路由参数 `id` 来标识特定文章。然后,我们创建了一个名为 `getPost()` 的方法来从数据库检索这篇文章的详细信息,并使用它更新页面。最后,我们创建了 `editPost()` 方法,用 HTTP PUT 请求将编辑后的文章提交回后端服务器。
+
+完成编辑后保存并关闭文件。关于应用的完整 `Edit.vue` 文件,请访问 [DO Community repository](https://github.com/do-community/nest-vue-project/blob/master/blog-frontend/src/components/post/Edit.vue)。
+
+现在,我们在 `./src/components/post` 文件夹中创建一个名为 `Post.vue` 新组件。这样我们就可以从首页中查看特定文章的详细信息。然后,将以下内容添加到 `Post.vue` 中:
+
+~blog-frontend/src/components/post/Post.vue
+
+```js
+<template>
+ <div class="text-center">
+ <div class="col-sm-12">
+ <h4 style="margin-top: 30px;"><small><button class="btn btn-success" v-on:click="navigate()"> View All Posts </button></small></h4>
+ <hr>
+ <h2>{{ post.title }}</h2>
+ <h5><span class="glyphicon glyphicon-time"></span> Post by {{post.author}}, {{post.date_posted}}.</h5>
+ <p> {{ post.body }} </p>
+
+ </div>
+ </div>
+</template>
+```
+
+这段代码会渲染出文章的详细信息,包括`标题(titile)`、`作者(author)`和文章`正文(body)`。
+
+现在,直接在 `</template>` 之后,添加以下代码:
+
+~blog-frontend/src/components/post/Post.vue
+
+```js
+...
+<script>
+import { server } from "../../utils/helper";
+import axios from "axios";
+import router from "../../router";
+export default {
+ data() {
+ return {
+ id: 0,
+ post: {}
+ };
+ },
+ created() {
+ this.id = this.$route.params.id;
+ this.getPost();
+ },
+ methods: {
+ getPost() {
+ axios
+ .get(`${server.baseURL}/blog/post/${this.id}`)
+ .then(data => (this.post = data.data));
+ },
+ navigate() {
+ router.go(-1);
+ }
+ }
+};
+</script>
+```
+
+这里的 `<script>` 部分的内容与编辑特文章的组件类似,我们从路由中获得了参数 `id` 并使用它来检索特定文章的详细信息。
+
+完成编辑后保存并关闭文件。关于应用的完整 `Post.vue` 文件,请访问 [DO Community repository](https://github.com/do-community/nest-vue-project/blob/master/blog-frontend/src/components/post/Post.vue)。
+
+接下来,要向用户显示所有创建的文章,我们需要创建一个新组件。定位到 `src/views` 中的 `views` 文件夹,您将看到 `Home.vue` 组件 —— 如果此文件不存在,请使用文本编辑器创建它,并添加以下代码:
+
+~blog-frontend/src/views/Home.vue
+
+```vue
+<template>
+ <div>
+
+ <div class="text-center">
+ <h1>Nest Blog Tutorial</h1>
+ <p> This is the description of the blog built with Nest.js, Vue.js and MongoDB</p>
+
+ <div v-if="posts.length === 0">
+ <h2> No post found at the moment </h2>
+ </div>
+ </div>
+
+ <div class="row">
+ <div class="col-md-4" v-for="post in posts" :key="post._id">
+ <div class="card mb-4 shadow-sm">
+ <div class="card-body">
+ <h2 class="card-img-top">{{ post.title }}</h2>
+ <p class="card-text">{{ post.body }}</p>
+ <div class="d-flex justify-content-between align-items-center">
+ <div class="btn-group" style="margin-bottom: 20px;">
+ <router-link :to="{name: 'Post', params: {id: post._id}}" class="btn btn-sm btn-outline-secondary">View Post </router-link>
+ <router-link :to="{name: 'Edit', params: {id: post._id}}" class="btn btn-sm btn-outline-secondary">Edit Post </router-link>
+ <button class="btn btn-sm btn-outline-secondary" v-on:click="deletePost(post._id)">Delete Post</button>
+ </div>
+ </div>
+
+ <div class="card-footer">
+ <small class="text-muted">Posted on: {{ post.date_posted}}</small><br/>
+ <small class="text-muted">by: {{ post.author}}</small>
+ </div>
+
+ </div>
+ </div>
+ </div>
+ </div>
+ </div>
+</template>
+```
+
+这里,在 `<template>` 部分中,通过 `post._id` 参数,我们使用 `<router-link>` 来创建用于编辑文章和查看文章的链接。我们还使用了 `v-if` 指令为用户有选择地呈现文章。如果数据库中没有文章,用户将只看到以下文本:**No post found at the moment(暂时没有发现任何文章)**.
+
+完成编辑后保存并关闭文件。关于应用的完整 `Home.vue` 文件,请访问 [DO Community repository](https://github.com/do-community/nest-vue-project/blob/master/blog-frontend/src/components/post/Home.vue)。
+
+现在,直接在 `Home.vue` 中的 `</template>` 部分之后,添加以下 `</script>` 部分:
+
+~blog-frontend/src/views/Home.vue
+
+```js
+...
+<script>
+// @ 是 /src 的别名
+import { server } from "@/utils/helper";
+import axios from "axios";
+
+export default {
+ data() {
+ return {
+ posts: []
+ };
+ },
+ created() {
+ this.fetchPosts();
+ },
+ methods: {
+ fetchPosts() {
+ axios
+ .get(`${server.baseURL}/blog/posts`)
+ .then(data => (this.posts = data.data));
+ },
+ deletePost(id) {
+ axios.delete(`${server.baseURL}/blog/delete?postID=${id}`).then(data => {
+ console.log(data);
+ window.location.reload();
+ });
+ }
+ }
+};
+</script>
+```
+
+在这个文件的 `<script>` 部分中,我们创建了一个名为 `fetchPosts()` 的方法来从数据库获取所有的文章,并使用服务器返回的数据更新页面。
+
+现在,我们将更新前端应用的 `App` 组件,以便创建到 `Home` 组件和 `Create` 组件的链接。打开 `src/App.vue`,用以下内容更新它:
+
+~blog-frontend/src/App.vue
+
+```vue
+<template>
+ <div id="app">
+ <div id="nav">
+ <router-link to="/">Home</router-link> |
+ <router-link to="/create">Create</router-link>
+ </div>
+ <router-view/>
+ </div>
+</template>
+
+<style>
+#app {
+ font-family: "Avenir", Helvetica, Arial, sans-serif;
+ -webkit-font-smoothing: antialiased;
+ -moz-osx-font-smoothing: grayscale;
+ color: #2c3e50;
+}
+#nav {
+ padding: 30px;
+ text-align: center;
+}
+
+#nav a {
+ font-weight: bold;
+ color: #2c3e50;
+}
+
+#nav a.router-link-exact-active {
+ color: #42b983;
+}
+</style>
+```
+
+上面的代码中,除了包含到 `Home` 和 `Create` 组件的链接之外,还包含了 `<Style>` 部分,它是这个组件的样式表,包含着页面上一些元素的样式定义。保存并退出文件。
+
+在这一节中,我们已经创建了应用所需的所有组件。接下来,我们将配置路由文件。
+
+## 第九步 —— 搭建路由
+
+在创建了所有需要的可复用组件之后,现在我们可以通过更新包含所有组件链接的路由文件,来正确配置路由文件。这将保证前端应用中的所有的路由都会映射到特定的组件,以便采取适当的操作。定位到 `./src/router.js`,并将其内容替换为以下内容:
+
+~blog-frontend/src/router.js
+
+```js
+import Vue from 'vue'
+import Router from 'vue-router'
+import HomeComponent from '@/views/Home';
+import EditComponent from '@/components/post/Edit';
+import CreateComponent from '@/components/post/Create';
+import PostComponent from '@/components/post/Post';
+
+Vue.use(Router)
+
+export default new Router({
+ mode: 'history',
+ routes: [
+ { path: '/', redirect: { name: 'home' } },
+ { path: '/home', name: 'home', component: HomeComponent },
+ { path: '/create', name: 'Create', component: CreateComponent },
+ { path: '/edit/:id', name: 'Edit', component: EditComponent },
+ { path: '/post/:id', name: 'Post', component: PostComponent }
+ ]
+});
+```
+
+我们从 `vue-router` 模块中导入了 `Router`,并通过传递 `mode` 和 `route` 参数实例化了它。`vue-router` 的默认模式是 hash 模式,该模式使用 URL 的 hash 来一个模拟完整的 URL,于是当 URL 更改时页面不会重新加载。如果不需要 hash 模式,我们可以在此处使用 history 模式来实现 URL 的路由而无需重新加载页面。最后,在 `routes` 选项中,我们指定了路由的具体对应组件 —— 应用中调用路由时应该呈现的组件和组件的名称。保存并退出文件。
+
+既然我们已经搭建好了应用的路由,现在就需要引入 Bootstrap 文件来预制应用用户界面的样式。我们需要在文本编辑器中打开 `./public/index.html` 文件,并通过在文件中添加以下内容来包含用于 Bootstrap 的 CDN 文件:
+
+~blog-frontend/public/index.html
+
+```html
+<!DOCTYPE html>
+<html lang="en">
+<head>
+ ...
+ <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css">
+ <title>blog-frontend</title>
+</head>
+<body>
+ ...
+</body>
+</html>
+```
+
+保存并退出文件,然后使用 `npm run serve` 为我们的 `blog-frontend` 项目重新启动应用(如果它当前没有运行的话)。
+
+**注意:** 确保后端服务器和 MongoDB 实例都在运行。如果没有的话,从另一个新的终端定位到 `blog-backend` 项目下并运行 `npm run start`。同样,通过从一个新的终端运行 `sudo mongod` 来启动 MongoDB 服务。
+
+通过 URL 跳转到我们的应用:`http://localhost:8080`。现在您可以通过创建和编辑文章来测试您的博客啦!
+
+
+
+单击应用上的 **Create** 以查看 **Create Post** 视图,该视图与 `CreateComponent` 组件相关并会渲染该组件。在 input 框中输入内容,然后单击 **Create Post** 按钮提交一篇文章。完成后,应用将把您重定向回主页。
+
+应用的主页呈现的是组件 `HomeComponent`。这个组件会调用一个它的方法,会发送一个 HTTP 调用来从数据库获取所有的文章并将它们显示给用户。
+
+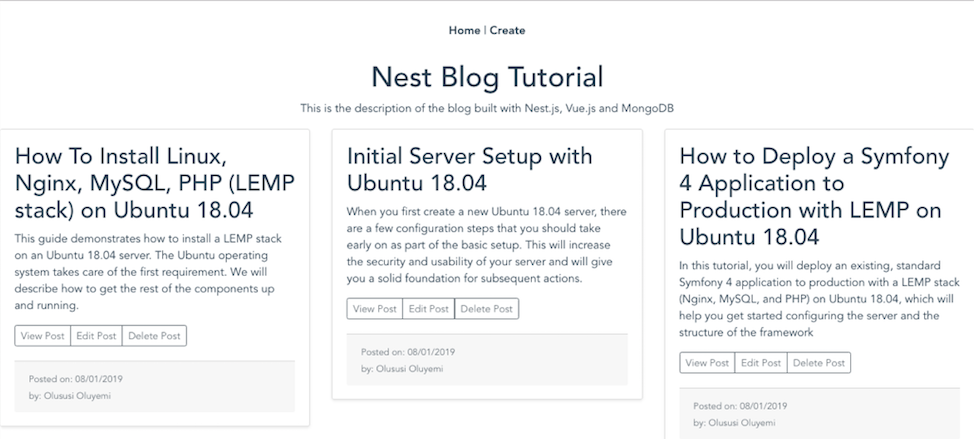
+
+点击某个特定文章的 **Edit Post** 按钮,您会进入一个编辑页面,在那里您可以做任何修改并保存您的文章。
+
+
+
+在本节中,我们配置并搭建了应用的路由。到这里,我们的博客应用就准备好了。
+
+## 总结
+
+在本教程中,您通过使用 Nest.js 来探索了构造 Node.js 应用的新方法。您创建了一个简单的博客应用,使用 Nest.js 构建后端 RESTful API,使用 Vue.js 处理了所有前端逻辑。此外,您还将 MongoDB 数据库集成到 Nest.js 应用中。
+
+想要了解关于如何将身份验证添加到应用中,您可以使用 [Passport.js](http://www.passportjs.org/)。一个流行的 Node.js 认证库。您可以在 [Nest.js 文档](https://docs.nestjs.com/techniques/authentication)中了解关于 Passport.js 的集成。
+
+您可以在[这个项目的 GitHub ](https://github.com/do-community/nest-vue-project)上找到项目的完整源代码。想要获取更多关于 Nest 的信息。您可以访问[官方文档](https://docs.nestjs.com/)。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/how-to-choose-the-right-database.md b/TODO1/how-to-choose-the-right-database.md
new file mode 100644
index 00000000000..4d74f9db7ea
--- /dev/null
+++ b/TODO1/how-to-choose-the-right-database.md
@@ -0,0 +1,171 @@
+> * 原文地址:[How to choose the right database](https://towardsdatascience.com/how-to-choose-the-right-database-afcf95541741)
+> * 原文作者:[Tzoof Avny Brosh](https://medium.com/@tzoof)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-choose-the-right-database.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-choose-the-right-database.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[Ruby](https://github.com/RubyJy),[Starry](https://github.com/Starry316)
+
+# 如何选择合适的数据库
+
+#### 我们将讨论现有数据库的类型以及对于不同项目类型的数据库最佳实践。
+
+无论您是已有工作经验的软件工程师还是正在写大学课设的学生,您总会遇上要为项目选择一个数据库的情形。
+
+如果您曾经使用过数据库,您可能会说“我只会选择 X,那是我所知道并使用过的数据库”,当然如果性能不是系统的重要要求的话,这是完全可以的。否则,当项目规模发展时,错误的数据库可能会成为项目的障碍,并且有时还很难修复。即使您正在负责一个已经使用某个特定的数据库一段时间的成熟项目,了解其局限性并清楚何时应在堆栈中添加另一种类型的数据库(多个数据组合工作是很常见的)也是很重要的。
+
+了解不同数据库及其属性的另一个加分原因是,它是面试中的一个常考题!
+
+在这篇文章中,我们将会讨论两种主要的数据库类型:
+
+* 关系型数据库(基于 SQL)。
+* NoSQL 数据库。
+
+我们将讨论不同类型的 NoSQL 数据库以及何时使用它们。
+最后,我们还会讨论关系型数据库与 NoSQL 数据库的优缺点。
+这篇文章将不会涉及对同类型数据库的不同产品之间的比较(例如 MySQL 和 MS SQL Server)。
+
+文章总结:如果您想要一个快速看完这篇文章的小抄,请跳到文章的最后。
+
+---
+
+
+
+## 关系型数据库(基于 SQL)
+
+关系型数据库由一组连接起来的表(比如 CSV 表)组成。表中的每一行代表一条记录。
+
+为什么叫关系型? 在这种数据库中存在的“关系”是什么?
+假设您有一个学生信息表和一张课程成绩表(课程,成绩,学生证),每个成绩行都与学生信息表的一条记录**相关**。
+参见下图,课程成绩表中 “Student ID” 列的值通过 “ID” 列的值指向 “Students” 表中的行。
+
+所有关系型数据库都使用类似 SQL 的语言进行查询,这些语言很常用,并且自带 JOIN 操作(即连接操作,用于把来自两个或多个表的行结合起来,如上文的学生信息表和课程成绩表)。
+这种数据库支持对列进行索引,使得基于这些列能进行更快的查询。
+
+由于其结构化的特性,关系型数据库的 schema(schema 指数据库中数据的组织和结构)是在插入数据之前确定好的。
+
+**常见的关系型数据库:** MySQL、PostgreSQL、Oracle、MS SQL Server。
+
+---
+
+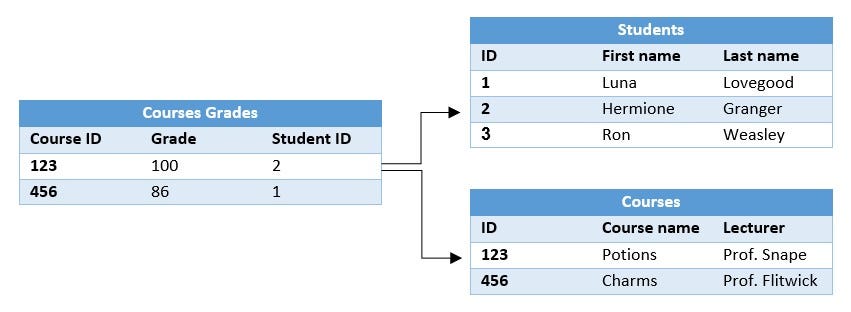
+
+## NoSQL 数据库
+
+虽然在关系型数据库中,所有内容都是按行和列进行结构化好的,但在 NoSQL 数据库中,并没有针对所有记录通用的结构化的 schema。大多数 NoSQL 数据库存储的是 JSON 记录,不同的记录可以包含不同的字段。
+
+---
+
+实际上,应将 NoSQL 数据库称为“不仅仅是 SQL(Not mainly SQL)” —— 因为许多 NoSQL 数据库支持使用 SQL 进行查询,但使用它们并不是最佳实践。
+
+#### NoSQL 数据库主要有 4 种类型:
+
+## 1. 文档存储数据库
+
+文档存储数据库的原子单位是一个文档(document)。
+每个文档都是一个 JSON,不同文档可以有不同的 schema,包含不同的字段。
+文档存储数据库允许对文档中的某些字段建立索引,从而能够基于这些字段进行更快的查询(这将会强制所有文档都具有该字段)。
+
+**应该什么时候选择它?**
+数据分析 —— 由于不同的记录之间并不相互依赖(在逻辑和结构方面),所以**这种数据库支持并行计算**。
+我们可以借助它来轻松地对数据进行大数据分析。
+
+**常见的文档存储数据库:** MongoDB、CouchDB、DocumentDB。
+
+
+
+## 2. 列存储数据库
+
+列存储数据库的原子单位是表中的一列,这意味着数据是按列存储的。它的列存储特点使得基于列的查询非常高效,并且由于每列上的数据几乎拥有相同的结构,因此可以更好地压缩数据。
+
+**应该什么时候选择它?**
+当您倾向于查询数据中的一个列子集时(每次查询的数据不需要都是相同的子集!)。
+列存储数据库执行此类查询的速度非常快,因为它只需要读取这些特定的列(而基于行存储的数据库则必须读取整个数据)。
+
+* 这在数据科学中很常见,其中每一列代表一个特征。作为一名数据科学家,我经常使用特征子集来训练我的模型,并且通常还会检查特征和得分之间的关系(相关性、方差、显著性)。
+* 这在日志中也很常见 —— 我们通常在日志数据库中存储很多字段,但在每个查询中只使用几个字段。
+
+**常见的列存储数据库:** Cassandra。
+
+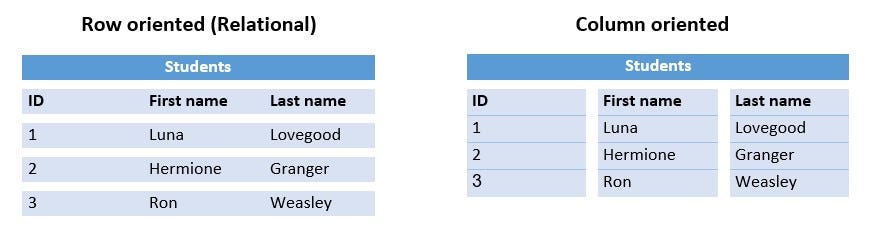
+
+## 3. key-value 存储数据库
+
+查询仅基于键 —— 您请求一个键,拿到对应的值。
+不支持跨不同记录值之间的查询,比如 “select all records where city == New York”。
+这种数据库中一个有用的特性是 TTL 字段(time to live),当记录将要从数据库中删除时,这个字段可以为每个记录和状态设置不同的值。
+
+**优点 ——** 它很快。
+首先是因为使用唯一键,其次是因为大多数 key-value 存储数据库将数据存储在内存(RAM)中,从而可以快速访问。
+**缺点 ——** 您需要定义唯一的键,这些键是很好的标识符,是在查询时根据您所已知的数据创建的。
+通常比其他类型的数据库更加昂贵(因为它是在内存上运行的)。
+
+**应该什么时候选择它?**
+它主要用于缓存,因为它非常快,并且不需要复杂的查询,而且 TTL 特性对缓存非常有用。它还可以用于需要快速查询并满足 key-value 格式的任何其他类型的数据。
+
+
+**常见的 key-value 存储数据库:** Redis、Memcached。
+
+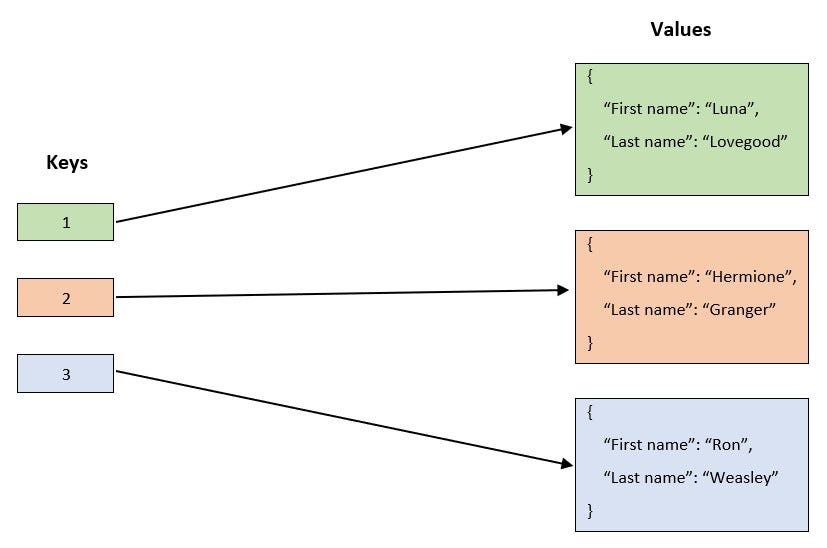
+
+## 4. 图存储数据库
+
+图存储数据库包含代表实体的节点和代表实体之间关系的边。
+
+**应该什么时候选择它?**
+当您的数据是类似于知识图谱和社交网络这种图时。
+
+**常见的图存储数据库:** Neo4j、InfiniteGraph。
+
+---
+
+
+
+## 关系型数据库 vs. 文档存储数据库
+
+您现在可能已经知道了答案了,这个问题没有标准答案,没有一个数据库能够解决所有的问题。
+我们通常使用的是最常见的关系型数据库和文档存储数据库,因此我们将对它们二者进行比较。
+
+#### 关系型数据库的优点
+
+* 它的数据结构简单,可以匹配项目中常见的大多数类型的数据。
+* 它使用 **SQL**。SQL 很常用,并且天生支持连接操作。
+* 允许**数据的快速更新**。所有数据库都保存在一台机器上,记录之间的关系用作指针,这意味着您可以一次更新一条记录,而它的所有相关记录也将立即更新。
+* 关系型数据库也 **支持原子事务**。
+什么是原子事务:假设我想把 X 美元从 Alice 账户转移到 Bob账户。我想执行 3 个操作:减少 Alice 账户 X 刀,增加 Bob 账户 X 刀,最后记录下这个交易事务。我想把这些动作当作一个原子单位 —— 要么所有的动作发生要么一个都不发生。
+
+#### 关系型数据库的缺点
+
+* 由于每个查询都在表上完成 —— **查询执行**时间取决于表的大小。这是一个重要的限制,要求我们保持表相对较小,并在我们的数据库上进行优化以实现可伸缩性。
+* 在关系型数据库的扩展中,可以通过向运行数据库的计算机增加更多的计算能力来进行扩展,这种方法称为“**纵向扩展**”。
+为什么这是一个缺点呢?这是由于计算机能够提供的计算能力有限,而且向计算机扩展资源可能需要一些停机时间。
+* 关系型数据库 **不支持 OOP**,不支持面向对象,即使表示简单的列表也是非常复杂的。
+
+#### 文档存储数据库的优点
+
+* 它使您可以保留具有**不同结构**的对象。
+* 您可以使用可爱的 JSON 表示几乎所有的数据结构,包括**基于对象的 OOP**、列表以及字典。
+* 虽然 NoSQL 本质上是无模式的(指不需要像关系型数据库一样将预定义的结构,即 schema ,向数据库说明),但它通常支持**模式验证**,这意味着您可以使一个数据集合模式化,此模式不会像表那么简单,它是一个带有特定字段的JSON schema。(译者注:这里所说的模式就是 schema)。
+* NoSQL **查询**非常快,每条记录都是独立的,因此查询时间与数据库大小无关,并且**支持并行性**。
+* 在 NoSQL 中,通过添加更多的机器并在它们之间分配数据来扩展数据库,这种方法称为“**水平扩展**”。这允许我们在需要时自动向数据库扩展资源,并且不会导致任何停机。
+
+#### 文档存储数据库的缺点
+
+* 在文档存储数据库中**更新**数据是一个**缓慢**的过程,因为数据会在不同的机器之间进行划分、复制。
+* **原子事务本身不受支持**。您可以通过使用验证和恢复机制将其添加到代码中,但是由于记录是在机器之间划分的,所以它不可能是一个原子过程,并且可能会出现竞争状况。(译者注:MongoDB 4.0 版本已经提供了原生的事务操作)
+
+---
+
+
+
+## 快速小抄:
+
+* 对于**缓存** —— 使用 **key-value 存储数据库**。
+* 对于**类似图形**的数据 —— 使用**图存储数据库**。
+* 如果您倾向于查询**列子集**以及查询特征 —— 使用**列存储数据库**。
+* 对于所有的其他用例 —— 使用**关系型数据库**或者**文档存储数据库**。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/how-to-keep-your-dependencies-secure-and-up-to-date.md b/TODO1/how-to-keep-your-dependencies-secure-and-up-to-date.md
new file mode 100644
index 00000000000..698738b72c3
--- /dev/null
+++ b/TODO1/how-to-keep-your-dependencies-secure-and-up-to-date.md
@@ -0,0 +1,108 @@
+> * 原文地址:[How to Keep Your Dependencies Secure and Up to Date](https://medium.com/better-programming/how-to-keep-your-dependencies-secure-and-up-to-date-92578c7f3c9c)
+> * 原文作者:[Patrick Kalkman](https://medium.com/@pkalkman)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-keep-your-dependencies-secure-and-up-to-date.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-keep-your-dependencies-secure-and-up-to-date.md)
+> * 译者:[chaingangway](https://github.com/chaingangway)
+> * 校对者:[QinRoc](https://github.com/QinRoc)
+
+# 怎样让依赖库保持安全和最新
+
+ on [Unsplash](https://unsplash.com/s/photos/robot?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/4320/1*dJ1mhPOPA1MVEnUfpaCGjA.jpeg)
+
+> 用 Dependabot 自动更新你的依赖
+
+几周前,为了撰写关于[开闭原则](https://medium.com/better-programming/do-you-use-the-most-crucial-principle-of-object-oriented-design-9045dbd1321e)的文章,我在 GitHub 上搜索相关案例作为素材。在浏览 [.NET Core repository](https://github.com/dotnet/core) 的时候,我发现一个没见过的目录。
+
+这个 `.dependabot` 目录下,只包含一个文件 `config.yml`。它是 GitHub 上一个叫做 Dependabot 的新服务的配置文件。
+
+我之前不知道有这个服务。
+
+稍加调研之后,我发现 Dependabot 是一个扫描仓库中依赖的服务。扫描之后,Dependabot 会验证你的外部依赖是否是最新的。
+
+这个服务的真正实用之处在于:
+
+**Dependabot 会自动创建 PR 用来更新依赖。**
+
+我开始在我大多数的仓库中使用 Dependabot。在这篇文章中,我会告诉你怎样使用和配置 Dependabot。
+
+## 使用 Dependabot
+
+如果你在 GitHub 上有公有仓库,你可能见过下图所示的安全警告。GitHub 会自动扫描所有的公有仓库,如果检测到了安全漏洞,它会发出警告。
+
+
+
+如果想要 GitHub 扫描你的私有仓库,你必须手动打开安全通知选项。GitHub 检测漏洞依赖的数据来自于 [GitHub Advisory Database](https://github.com/advisories) 和 [WhiteSource](https://www.whitesourcesoftware.com/whitesource-for-developers/)。
+
+GitHub 发出的警告中还会包含修复方法。
+
+Dependabot 在这个过程中会想得更远,它会自动为你的仓库创建 PR,这个 PR 可以解决你的安全漏洞。
+
+#### 从 Dependabot 开始
+
+要想使用 Dependabot,首先,你需要 [注册](https://app.dependabot.com/auth/sign-up)。GitHub 已经收购了 Dependabot,所以可以免费使用。
+
+注册之后,你必须授予 Dependabot 访问仓库的权限。你可以在 Dependabot 的界面上操作,或者在你的仓库中添加 `config.yml` 文件。
+
+
+
+#### 配置 Dependabot
+
+你可以在仓库根目录下的 `.dependabot` 目录里保存 `config.yml` 文件,用来配置 Dependabot。
+
+#### 必选项
+
+下面的配置文件来自于我的仓库之一。它只包含了必选项。
+
+
+```YAML
+version: 1
+update_configs:
+ - package_manager: "javascript"
+ directory: "/WorkflowEngine"
+ update_schedule: "live"
+ - package_manager: "javascript"
+ directory: "/WorkflowEncoder"
+ update_schedule: "live"
+```
+这个配置文件仅仅使用了必要的 Dependabot 选项。因为在这个仓库里有很多项目,所以我指定了两个更新配置。
+
+* `package_manager` 指定了你所使用的包管理器。Dependabot 支持很多不同的包管理器,比如 JavaScript,[Bundler](https://bundler.io/), [Composer](https://getcomposer.org/), Python, [Maven](https://maven.apache.org/) 等等。完整的列表,请看 [文档](https://dependabot.com/docs/config-file/)。
+* `directory` 指定了包配置的路径。通常,它是你仓库的根目录。如果你在一个仓库中有多个项目,就像我上面的例子一样,你可以指定一个次级目录。
+* 在 `update_schedule` 中,你可以指定 Dependabot 检测更新的频率。Live 意味着尽快。其他的选项是 daily、weekly 和 monthly。
+
+Dependabot **总是** 尽快地创建安全更新。
+
+#### 可选项
+
+Dependabot 有一些额外的选项,可以修改一些东西,比如分支,提交记录,PR 的处理者。下面是完整列表:
+
+* `target_branch `— 创建 PR 的目标分支。
+* `default_reviewers `— 设置 PR 的评审员。
+* `default_assignees` — 设置 PR 的处理者。
+* `default_labels` — 设置 PR 的标签。
+* `default_milestone` — 设置 PR 的里程碑。
+* `allowed_updates` — 设置允许哪次更新。
+* `ignored_updates` — 忽略特定的依赖或者依赖的版本。
+* `automerged_updates` — Dependabot 应该自动合并的更新。
+* `version_requirement_updates` — 怎样更新 App 的版本。
+* `commit_message` — 附加在提交信息上的内容。
+
+#### 验证配置文件
+
+在 Dependabot 网站上有一个[页面](https://dependabot.com/docs/config-file/validator/)可以验证你的配置文件。请确保你的配置文件是正确的。
+
+## 总结
+
+我现在已经使用 Dependabot 几个星期了。最开始,我用的是 “live” 更新计划, 由于 “live” 产生了太多的警告,我又改成了 “weekly”。
+
+我现在每周合并一次 Dependabot 提交的 PR。
+
+你必须让你的依赖保持最新。如果你不更新,你使用的版本和最新版本的差异会增加。这种日益增加的差异会让之后更新依赖更加困难。
+
+感谢阅读。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/how-to-write-a-front-end-developer-resume-that-will-land-you-an-interview.md b/TODO1/how-to-write-a-front-end-developer-resume-that-will-land-you-an-interview.md
new file mode 100644
index 00000000000..5603f3a1334
--- /dev/null
+++ b/TODO1/how-to-write-a-front-end-developer-resume-that-will-land-you-an-interview.md
@@ -0,0 +1,186 @@
+> * 原文地址:[How To Write a Front-End Developer Resume That Will Land You an Interview](https://medium.com/better-programming/how-to-write-a-front-end-developer-resume-that-will-land-you-an-interview-f188ba4fe68b)
+> * 原文作者:[Gareth Cheng](https://medium.com/@garethcheng)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-write-a-front-end-developer-resume-that-will-land-you-an-interview.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-write-a-front-end-developer-resume-that-will-land-you-an-interview.md)
+> * 译者:
+> * 校对者:
+
+# How To Write a Front-End Developer Resume That Will Land You an Interview
+
+> An article for junior to mid-level front-end developers, from the interviewer’s point of view
+
+
+
+As a front-end developer, you build visible stuff, and hopefully, you make it look good. This same kind of mentality should be reflected in your resume. Well-spaced, readable, and breathable.
+
+#### What you’ll learn through this article
+
+1. Basic resume writing tips for software developers.
+2. How to put IT skills and technical abilities on your resume.
+3. A step by step guide on how to present your past experience.
+4. How to build your frontend portfolio.
+5. Using a [resume builder](https://www.cakeresume.com) to write your resume.
+
+## 1. Start With the Basics
+
+
+
+#### Your contact information
+
+Contact information should be located at the top of your resume. Include as much detail as you’re willing to share.
+
+#### Summary statement
+
+Your summary statement should contain a short, compelling professional synopsis of your career accomplishments and future goals.
+
+Keep in mind a few things when you’re writing it:
+
+* Don’t call yourself an Angular[JS]/React developer unless the position explicitly calls for that. Labeling yourself as an X developer tells people that you only want to do X and you may be a rigid person or otherwise not adaptable.
+* Ask yourself, which keywords should I include to ensure the intended audience continues reading the rest of my resume?
+* Read the job description, keeping in mind keywords and key phrases. What are they looking for? What sets you apart from the other applicants?
+
+#### Education
+
+Unless you’re a recent college graduate, there’s no need to list your GPA. Your achievements are more important than your GPA.
+
+## 2. Technical Skills
+
+ on [Unsplash](https://unsplash.com/s/photos/react?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/12000/1*9JIvQ9NwFCmdo0VNGaTu6Q.jpeg)
+
+For a software developer, this part is the most important section to make you stand out. When you list your skills, you should convey a deep understanding of what each skill is, what context it’s used in, and at what level it’s used. Try to be honest and clear here.
+
+#### A few tips getting started
+
+* If you list HTML5, there’s no need to list HTML4. HTML5 implies HTML4 and below. The same goes for CSS3/CSS2.
+* Be specific about your proficiency levels, and be honest. By stating your proficiency levels, the person reading your resume will quickly get a clearer picture of you, and this will save you both time.
+* If a skill isn’t directly related to the position but may be relevant to the industry, include it. This gives you a better chance of being sourced by recruiters.
+
+
+
+#### How not to present your skills
+
+
+
+Don’t do this. That’s an entire IT department.
+
+Try not to present your skills like the example above. If you’ve literally just started learning a new skill, don’t put it on your resume. This will stop recruiters from recommending you for jobs you’re not qualified for.
+
+## 3. Working Experience
+
+
+
+#### Use action words
+
+In this section, you need to present details in a concise manner. Use action words that pop out to impress the intended audience, but avoid hyperbole.
+
+#### Customization
+
+Highlight the relevant information for the position you’re applying for, and keep it short. This will make you stand out from those writing a boilerplate document to send everywhere.
+
+#### Less is more
+
+However, please don’t exaggerate your experience because the interviewer is going to ask about everything you put on your resume. Keep in mind that less is more.
+
+#### Include relevant keywords
+
+The purpose of this is to beat the AOS (Applicant Tracking System) and develop a resume that will actually be findable by headhunters and hiring managers.
+
+You can do this by analyzing the job postings of your desired position, identifying specific words and phrases that best describe it, and then implementing them to your resume.
+
+#### Follow a step by step guide:
+
+```
+// First things first, write down your company name, your title, and the time period you have been working here.
+```
+
+ABC Company, Frontend Developer, 2017-present
+
+```
+// a short intro if your company is not well known
+```
+
+ABC Company is a company that makes the world a better place, we’re trying to solve people’s problems.
+
+```
+// List a few major achievements and put in relevant key words
+```
+
+* Developed a prototype used to visualize transportation routes using React, Antd, and Deck.gl.
+* Built a scheduling tool in the form of a Gantt chart using React and Material-UI.
+* Balanced requirements, UX, and deadlines in order to get most of the business value in a limited timeframe.
+
+```
+// List the technology you used
+```
+
+Technologies: React, Deck.gl, Python, Recharts, Node.js
+
+#### This is how your work experience should be presented:
+
+
+
+## 4. Portfolio — Set Yourself Apart From Your Peers
+
+](https://cdn-images-1.medium.com/max/3836/1*e-lvUJN69OBx3GOhmqM94A.png)
+
+As Coding Bootcamps increase the supply side for front-end developers, a great number of developers are [flooding into the developer job market](https://medium.com/@marceldegas/san-francisco-bootcamp-bubble-cee59e48bf3e).
+
+Adding a little bit about your unique experience or projects would absolutely set you apart from your peers. Also, it’s crucial to building up your own portfolio since the definition of “experience” is different for everyone.
+
+Showcasing your past works and projects quickly proves your web development ability, increasing the chances of landing an interview in the competitive market. You can upload your work on [CodePen](https://codepen.io/) or [CakeResume](https://www.cakeresume.com).
+
+#### Describe the work in your portfolio
+
+Keep in mind, though, that giving a link to your app isn’t building your portfolio. A wireframe or the visual outcome of your app without including your thinking is also a terrible idea.
+
+When you’re building your portfolio, include these things:
+
+* A screenshot or a live demo link.
+* What does your work do?
+* What did you contribute?
+* The language, framework, or pattern you used.
+
+A few examples:
+
+[**ThisIsMe Web App Information Architecture - Jayd Gibbon's Portfolio**](https://www.cakeresume.com/portfolios/thisisme-web-app-information-architecture)
+
+[**Seul Landing Part 1 - Stefan's Portfolio**](https://www.cakeresume.com/portfolios/seul)
+
+#### A few suggestions if you’re starting from scratch
+
+* Imitate the websites you often use.
+* Start writing a tech blog. This could also be part of your portfolio.
+* Go to your first Hackathon and make something.
+* Start to solve your own problem.
+
+## 5. Online Resume Builders
+
+Before we start writing a great resume, try thinking about the kind of format you want your resume to have. Personally, I suggest that software developers write their resumes with an online resume builder, such as [CakeResume](https://www.cakeresume.com/) (free).
+
+Here are some advantages of online [resume builders](https://www.cakeresume.com):
+
+* They help you create your resume with up-to-date designs, which gives a good impression to your future employer.
+* They save you time. Especially for those who don’t know where to start and those who don’t want to mess around with adjusting columns and borders.
+* They help to ensure that you don’t leave out any vital information.
+* They make it easy to update a resume and swap out information. You can slightly tweak a resume to tailor the information for different employers.
+
+## 6. Make Good Use of the Hyperlink
+
+If you decided to build your resume with an online resume builder, you have the advantage of using hyperlinks. Even if you convert your online version to PDF, your links would still work.
+
+#### When to use hyperlinks
+
+* You want to showcase the website you’ve been working on — you could simply provide the URL to the website.
+* You want to mention third-party services or SDKs you used.
+* You want to present the documented solution for a previous problem you tried to solve on your personal blog or Medium.
+
+## Learn More:
+
+* [Cover Letter (cover letter samples, cover letter templates, application letters) — All-in-One Tutorial](https://www.cakeresume.com/resources/cover-letter-all-in-one-tutorial?locale=en)
+* [How To Write an iOS Developer Resume That Will Land You an Interview](https://medium.com/better-programming/how-to-write-an-ios-developer-resume-that-will-land-you-an-interview-43cf66c6d4fa)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/how-to-write-beautiful-and-meaningful-readme-md-for-your-next-project.md b/TODO1/how-to-write-beautiful-and-meaningful-readme-md-for-your-next-project.md
new file mode 100644
index 00000000000..91d5aa5caf3
--- /dev/null
+++ b/TODO1/how-to-write-beautiful-and-meaningful-readme-md-for-your-next-project.md
@@ -0,0 +1,141 @@
+> * 原文地址:[How to Write Beautiful and Meaningful README.md](https://blog.bitsrc.io/how-to-write-beautiful-and-meaningful-readme-md-for-your-next-project-897045e3f991)
+> * 原文作者:[Divyansh Tripathi [SilentLad]](https://medium.com/@silentlad)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-write-beautiful-and-meaningful-readme-md-for-your-next-project.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-write-beautiful-and-meaningful-readme-md-for-your-next-project.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[Vito](https://github.com/vitoxli), [Hsu Zilin](https://github.com/Starry316)
+
+# 如何写出优雅且有意义的 README.md
+
+#### 写出一个超棒的 Readme 文件的小技巧(以及为什么 README 很重要)
+
+作为开发人员,我们对代码以及项目中的所有细节都信手拈来。然而我们中的一些人(包括我在内)就连在网络社区中的软技能都缺乏。
+
+> **一个开发人员会花一个小时来调整一个按钮的 padding 和 margin。却不会抽出 15 分钟的来完善项目的 Readme 文件。**
+
+> 我希望你们大多数人已经知道 README 文件是什么,它是用来做什么的。但是对于萌新来说,我还是会尽可能地来解释它到底是什么。
+
+#### 什么是 Readme.md?
+
+README(顾名思义:“read me“)是启动新项目时应该阅读的第一个文件。它既包含了一系列关于项目的有用信息又是一个项目的手册。它是别人在 Github 或任何 Git 托管网站点,打开你仓库时看到的第一个文件。
+
+
+
+你可以清楚地看到,**Readme.md** 文件位于仓库的根目录中,在 Github 上的项目目录下它会自动显示。
+
+`.md` 这个文件后缀名来自于单词:**markdown**。它是一种用于文本格式化的标记语言。就像 HTML 一样,可以优雅地展示我们的文档。
+
+下面是一个 markdown 文件的例子,以及它在 Github 上会如何渲染。这里,我使用 VSCode 预览,它可以同时显示 markdown 文件渲染后的预览。
+
+
+
+如果你想要深入了解这门语言,这里有一个官方的 **[Github Markdown 备忘录](https://guides.github.com/pdfs/markdown-cheatsheet-online.pdf)**。
+
+## 为什么要在 Readme 上花时间?
+
+现在我们谈正事吧。你花了几个小时在一个项目上,你在 GitHub 上发布了它,并且你希望游客、招聘人员、同事、(或者前任?)看到这个项目。你真的认为他们会进入 `root/src/app/main.js` 来查看你的代码的逻辑吗?真的会吗?
+
+现在你已经意识到这个问题了,让我们看看如何解决这个问题。
+
+## 为你的组件生成文档
+
+除了项目的 Readme 之外,记录组件对于构建易于理解的代码库也很重要。这使得重用组件和维护代码变得更加容易。比如,使用像[**Bit**](https://bit.dev) ([Github](https://github.com/teambit/bit)) 这样的工具,来为在 [bit.dev](https://bit.dev) 上共享的组件自动生成文档。(译者注:这里是作者在打广告)
+
+
+[**团队共享可重用的代码组件 · Bit**](https://bit.dev)
+
+## 描述你的项目!(技巧说白了就是)
+
+为你的项目写一个好的描述。仅出于建议,您可以将描述的格式设置为以下主题:
+
+* 标题(如果可以的话,提供标题图像。如果你不是平面设计师,请在 canva.com 上进行编辑);
+* 描述(用文字和图片来描述);
+* Demo(图片、视频链接、在线演示 Demo 链接);
+* 技术栈;
+* 你项目中需要注意的几个陷阱(你遇到的坑、项目中的独特元素);
+* 项目的技术说明,如:安装、启动、如何贡献;
+
+## 让我们深入探讨技术细节
+
+我将使用我的这个项目作为参考,我认为它是我写过甚至遇到过的的最漂亮的 Readme 文件之一。你可以在这里查看它的 Readme.md 文件的代码: [**silent-lad/VueSolitaire**](https://github.com/silent-lad/VueSolitaire)
+
+使用铅笔图标来显示 markdown 代码:
+
+
+
+## 1. 添加图片!拜托!
+
+你可能对你的项目记忆犹新,但是你的读者可能需要一些项目演示的实际图片。
+
+例如,我制作了一个纸牌项目,并在 Readme 文件中添加了图像作为描述。
+
+
+
+现在你可能想要添加一个视频描述您的项目。就像我项目里那样。但是,Github 不允许在 Readme 文件中添加视频。那…该怎么办呢?
+
+#### …我们可以使用 GIF
+
+
+
+GIF 也是一种图片,Github 支持我们将它放在 Readme 文件中。
+
+## 2. 荣誉勋章
+
+Readme 文件上的徽章会使游客有一定的真实感。您可以从下面的网址,为您的仓库设置自定义或者常规使用的盾牌(徽章):[**https://shields.io**](https://shields.io/)
+
+
+
+你还可以设置个性化的盾牌,如仓库的的星星数量和代码百分比指标。
+
+## 3. 增加一个在线演示 Demo
+
+如果可以的话,请托管你的项目,并开启一个正在运行的演示 demo。之后,**将这个演示链接到 Readme 文件**。你也不知道可能会有多少人来“把玩”你的项目。另外,招聘人员只喜欢可以在线演示的项目。**它表明你的项目不仅仅是放在 Github 上的代码,而是确实跑起来业务。**
+
+
+
+您可以在 Readme 中使用超链接。比如在标题图片下面提供一个在线演示链接。
+
+## 4. 使用代码样式
+
+Markdown 提供了将文本渲染为代码样式的选项。因此,不要以纯文本形式编写代码,应该使用 \`(反单引号)将代码包裹在代码样式中,例如 `var a = 1;`。
+
+Github还提供了**指定代码编写语言**的选项,这样它就可以使用特定的文本高亮来提高代码的可读性。你只需要这样使用:
+
+**\`\`\`{代码语言}\<space>{代码块}\`\`\`**
+
+{ \`\`\` } —— 三个反单引号用于多行代码,同时它还允许你指定代码块的语言。
+
+**使用代码高亮:**
+
+
+
+**不使用代码高亮:**
+
+
+
+## 5. 使用 HTML
+
+是的,你可以在 Readme 里使用 HTML。尽管并不是 HTML 里所有的功能都可以使用,但大部分可以。虽然你最好是只包含 markdown 的语法,但一些功能,如居中图像和居中文本是只能用 HTML 实现的。
+
+
+
+## 6. 有创造性
+
+剩下的就交给你了,每个项目都需要不同的 Readme.md 文件和不同类型的描述。但是请记住,你在 Readme 文件上花费的 15 —— 20 分钟可能会对你 Github 的访问者数量产生**巨大**的影响。
+
+仅供参考,这里有一些带 Readme 的项目:
+
+- [**silent-lad/VueSolitaire**](https://github.com/silent-lad/VueSolitaire)
+- [**silent-lad/Vue2BaremetricsCalendar**](https://github.com/silent-lad/Vue2BaremetricsCalendar)
+
+## 了解更多
+
+- [**如何在项目和应用之间共享 React UI 组件**](https://blog.bitsrc.io/how-to-easily-share-react-components-between-projects-3dd42149c09)
+- [**2020 年的 13 个顶级 React 组件库**](https://blog.bitsrc.io/13-top-react-component-libraries-for-2020-488cc810ca49)
+- [**2020 年的 11 个顶级 React 开发人员工具**](https://blog.bitsrc.io/11-top-react-developer-tools-for-2020-3860f734030b)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/how-to-write-video-chat-app-using-webrtc-and-nodejs.md b/TODO1/how-to-write-video-chat-app-using-webrtc-and-nodejs.md
new file mode 100644
index 00000000000..d4f056c675e
--- /dev/null
+++ b/TODO1/how-to-write-video-chat-app-using-webrtc-and-nodejs.md
@@ -0,0 +1,489 @@
+> * 原文地址:[WebRTC and Node.js: Development of a real-time video chat app](https://tsh.io/blog/how-to-write-video-chat-app-using-webrtc-and-nodejs/)
+> * 原文作者:[Mikołaj Wargowski](https://github.com/Miczeq22)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-write-video-chat-app-using-webrtc-and-nodejs.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-write-video-chat-app-using-webrtc-and-nodejs.md)
+> * 译者:[👊Badd](https://juejin.im/user/5b0f6d4b6fb9a009e405dda1)
+> * 校对者:[RubyJy](https://github.com/RubyJy), [cyz980908](https://github.com/cyz980908)
+
+# WebRTC 联手 Node.js:打造实时视频聊天应用
+
+> **(实时)时间就是金钱,那我就开门见山了。在本文中,我将带你写一个视频聊天应用,支持两个用户之间进行视频和语音通信。没什么难度,也没什么花哨的东西,却是一次 JavaScript —— 严格来说是 WebRTC 和 [Node.js](https://tsh.io/services/web-development/node/) —— 的绝佳试炼。**
+
+## 何为 WebRTC?
+
+**网络实时通信(Web Real-Time Communication,缩写为 WebRTC)是一项 HTML5 规范,它使你能直接用浏览器进行实时通讯,不用依赖第三方插件**。WebRTC 有多种用途(甚至能实现文件共享),但其主要应用为实时点对点音频与视频通讯,本文的重点也是这一点。
+
+WebRTC 的强大之处在于允许访问设备 —— 你可以通过 WebRTC 调用麦克风、摄像头,甚至共享屏幕,而且全部都是实时进行的!因此,WebRTC 用最简单的方式
+
+> **使网页语音视频聊天成为可能。**
+
+## WebRTC JavaScript API
+
+WebRTC 是一个复杂的话题,这其中涉及很多技术。而建立连接、通讯、传输数据是通过一系列 JavaScript API。主要的 API 有:
+
+- **RTCPeerConnection** —— 创建并导航点对点连接,
+- **RTCSessionDescription** —— 描述(潜在的)连接端点及其配置,
+- **navigator.getUserMedia** —— 获取音视频。
+
+## 为何用 Node.js?
+
+若想在两个或多个设备之间建立远程连接,你需要一个服务器。在本例中,你需要的是一个能操控实时通讯的服务器。你知道 Node.js 是支持实时可扩展应用的。要开发能自由交换数据的双向连接应用,你可能会用到 WebSocket,它能在客户端和服务端之间打开一个通讯会话。客户端发出的请求被处理成一个循环 —— 严格讲是事件循环,这使得 Node.js 成为一个不错的选择,因为它使用了“无阻塞”的方法来处理请求,这样就能实现低延迟和高吞吐量。
+
+扩展阅读: [Node.js 新特性将颠覆 AI、物联网等更多惊人领域](https://juejin.im/post/5dbb8d70f265da4d12067a3e)
+
+## 思路演示:我们要做个什么东西?
+
+我们要做一个非常简单的应用,它能向被连接的设备推送音频流和视频流 —— 一个基本的视频聊天应用。我们将会用到:
+
+- Express 库,用以提供用户界面 HTML 文件之类的静态文件,
+- socket.io 库,用 WebSocket 在两个设备间建立一个连接,
+- WebRTC,使媒体设备(摄像头和麦克风)能在连接设备之间推送音频流和视频流。
+
+## 实现视频聊天
+
+第一步,我们要有一个用作应用的用户界面的 HTML 文件。用 `npm init` 初始化一个新的 Node.js 项目。然后,运行 `npm i -D typescript ts-node nodemon @types/express @types/socket.io` 来安装一些开发依赖包,运行 `npm i express socket.io` 来安装生产依赖包。
+
+现在,我们可以在 `package.json` 文件中写一个脚本,来运行项目:
+
+```json
+{
+ "scripts": {
+ "start": "ts-node src/index.ts",
+ "dev": "nodemon --watch 'src/**/*.ts' --exec 'ts-node' src/index.ts"
+ },
+ "devDependencies": {
+ "@types/express": "^4.17.2",
+ "@types/socket.io": "^2.1.4",
+ "nodemon": "^1.19.4",
+ "ts-node": "^8.4.1",
+ "typescript": "^3.7.2"
+ },
+ "dependencies": {
+ "express": "^4.17.1",
+ "socket.io": "^2.3.0"
+ }
+}
+```
+
+我们运行 `npm run dev` 命令后,Nodemon 会监听 src 文件夹中每一个 `.ts` 后缀的文件的变动。现在我们来创建一个 src 文件夹,在 src 中,创建两个 TypeScript 文件:`index.ts` 和 `server.ts`。
+
+在 `server.ts` 里,我们会创建一个 Server 类,并使之配合 Express 和 socket.io:
+
+```ts
+import express, { Application } from "express";
+import socketIO, { Server as SocketIOServer } from "socket.io";
+import { createServer, Server as HTTPServer } from "http";
+
+export class Server {
+ private httpServer: HTTPServer;
+ private app: Application;
+ private io: SocketIOServer;
+
+ private readonly DEFAULT_PORT = 5000;
+
+ constructor() {
+ this.initialize();
+
+ this.handleRoutes();
+ this.handleSocketConnection();
+ }
+
+ private initialize(): void {
+ this.app = express();
+ this.httpServer = createServer(this.app);
+ this.io = socketIO(this.httpServer);
+ }
+
+ private handleRoutes(): void {
+ this.app.get("/", (req, res) => {
+ res.send(`<h1>Hello World</h1>`);
+ });
+ }
+
+ private handleSocketConnection(): void {
+ this.io.on("connection", socket => {
+ console.log("Socket connected.");
+ });
+ }
+
+ public listen(callback: (port: number) => void): void {
+ this.httpServer.listen(this.DEFAULT_PORT, () =>
+ callback(this.DEFAULT_PORT)
+ );
+ }
+}
+```
+
+我们需要在 `index.ts` 文件里新建一个 `Server` 类的实例并调用 `listen` 方法,这样就能启动服务器了:
+
+```ts
+import { Server } from "./server";
+
+const server = new Server();
+
+server.listen(port => {
+ console.log(`Server is listening on http://localhost:${port}`);
+});
+```
+
+现在运行 `npm run dev`,我们将会看到:
+
+
+
+打开浏览器访问 [http://localhost:5000](http://localhost:5000/),我们会看到“Hello World”字样:
+
+
+
+现在,我们要创建一个新的 HTML 文件 `public/index.html`:
+
+```html
+<!DOCTYPE html>
+<html lang="en">
+ <head>
+ <meta charset="UTF-8" />
+ <meta name="viewport" content="width=device-width, initial-scale=1.0" />
+ <meta http-equiv="X-UA-Compatible" content="ie=edge" />
+ <title>Dogeller</title>
+ <link
+ href="https://fonts.googleapis.com/css?family=Montserrat:300,400,500,700&display=swap"
+ rel="stylesheet"
+ />
+ <link rel="stylesheet" href="./styles.css" />
+ <script src="https://cdnjs.cloudflare.com/ajax/libs/socket.io/2.3.0/socket.io.js"></script>
+ </head>
+ <body>
+ <div class="container">
+ <header class="header">
+ <div class="logo-container">
+ <img src="./img/doge.png" alt="doge logo" class="logo-img" />
+ <h1 class="logo-text">
+ Doge<span class="logo-highlight">ller</span>
+ </h1>
+ </div>
+ </header>
+ <div class="content-container">
+ <div class="active-users-panel" id="active-user-container">
+ <h3 class="panel-title">Active Users:</h3>
+ </div>
+ <div class="video-chat-container">
+ <h2 class="talk-info" id="talking-with-info">
+ Select active user on the left menu.
+ </h2>
+ <div class="video-container">
+ <video autoplay class="remote-video" id="remote-video"></video>
+ <video autoplay muted class="local-video" id="local-video"></video>
+ </div>
+ </div>
+ </div>
+ </div>
+ <script src="./scripts/index.js"></script>
+ </body>
+</html>
+```
+
+在这个文件里,我们声明两个视频元素:一个用来呈现远程视频连接,另一个用来呈现本地视频。你可能已经注意到了,我们还引入了本地脚本文件,所以让我们来新建一个文件夹 —— 命名为 `scripts` 并在其中创建 `index.js` 文件。至于样式文件,你可以在 [GitHub 仓库](https://github.com/Miczeq22/simple-chat-app)下载到。
+
+现在就该把 `index.html` 从服务端传给浏览器了。首先你要告诉 Express,你要返回哪个静态文件。这需要我们在 `Server` 类中实现一个新的方法:
+
+```ts
+private configureApp(): void {
+ this.app.use(express.static(path.join(__dirname, "../public")));
+ }
+ ```
+
+别忘了在 `initialize` 方法中调用 `configureApp` 方法:
+
+```ts
+private initialize(): void {
+ this.app = express();
+ this.httpServer = createServer(this.app);
+ this.io = socketIO(this.httpServer);
+
+ this.configureApp();
+ this.handleSocketConnection();
+ }
+```
+
+至此,当打开 [http://localhost:5000](http://localhost:5000/),你会看到 `index.html` 文件已经运行起来了:
+
+
+
+下一步就该访问摄像头和麦克风,并让媒体流展示在 `local-video` 元素中了。打开 `public/scripts/index.js` 文件,添加以下代码:
+
+```js
+navigator.getUserMedia(
+ { video: true, audio: true },
+ stream => {
+ const localVideo = document.getElementById("local-video");
+ if (localVideo) {
+ localVideo.srcObject = stream;
+ }
+ },
+ error => {
+ console.warn(error.message);
+ }
+);
+```
+
+再回到浏览器,你会看到一个请求访问媒体设备的提示框,授权这个请求后,你会看到你的摄像头被唤醒了!
+
+
+
+扩展阅读:[简易指南:Node.js 的并发性及一些坑](https://tsh.io/blog/simple-guide-concurrency-node-js/)
+
+## 如何处理 socket 连接?
+
+现在我们将着重关注如何处理 socket 连接 —— 我们需要连接客户端和服务端,故此要用到 socket.io。在 `public/scripts/index.js` 中添加:
+
+```js
+this.io.on("connection", socket => {
+ const existingSocket = this.activeSockets.find(
+ existingSocket => existingSocket === socket.id
+ );
+
+ if (!existingSocket) {
+ this.activeSockets.push(socket.id);
+
+ socket.emit("update-user-list", {
+ users: this.activeSockets.filter(
+ existingSocket => existingSocket !== socket.id
+ )
+ });
+
+ socket.broadcast.emit("update-user-list", {
+ users: [socket.id]
+ });
+ }
+ }
+```
+
+刷新页面就能看到终端中有一条信息:“Socket connected”。
+
+此时我们再回到 `server.ts` 将 socket 存到内存中,便于保持连接的唯一性。也就是说,在 `Server` 类中增加一个新的私有字段:
+
+```ts
+private activeSockets: string[] = [];
+```
+
+在连接 socket 时检查是否已经有 socket 存在了。如果还没有,那就向内存中添加新的 socket,并将数据发送给连接的用户:
+
+```ts
+this.io.on("connection", socket => {
+ const existingSocket = this.activeSockets.find(
+ existingSocket => existingSocket === socket.id
+ );
+
+ if (!existingSocket) {
+ this.activeSockets.push(socket.id);
+
+ socket.emit("update-user-list", {
+ users: this.activeSockets.filter(
+ existingSocket => existingSocket !== socket.id
+ )
+ });
+
+ socket.broadcast.emit("update-user-list", {
+ users: [socket.id]
+ });
+ }
+ }
+```
+
+还需要在 socket 断开时做出响应,所以要在 socket 里面添加:
+
+```ts
+socket.on("disconnect", () => {
+ this.activeSockets = this.activeSockets.filter(
+ existingSocket => existingSocket !== socket.id
+ );
+ socket.broadcast.emit("remove-user", {
+ socketId: socket.id
+ });
+ });
+```
+
+在客户端(也就是 `public/scripts/index.js`),你需要对这些消息施行对应的操作:
+
+```js
+socket.on("update-user-list", ({ users }) => {
+ updateUserList(users);
+});
+
+socket.on("remove-user", ({ socketId }) => {
+ const elToRemove = document.getElementById(socketId);
+
+ if (elToRemove) {
+ elToRemove.remove();
+ }
+});
+```
+
+这是 `updateUserList` 函数:
+
+```js
+function updateUserList(socketIds) {
+ const activeUserContainer = document.getElementById("active-user-container");
+
+ socketIds.forEach(socketId => {
+ const alreadyExistingUser = document.getElementById(socketId);
+ if (!alreadyExistingUser) {
+ const userContainerEl = createUserItemContainer(socketId);
+ activeUserContainer.appendChild(userContainerEl);
+ }
+ });
+}
+```
+
+还有 `createUserItemContainer` 函数:
+
+```js
+function createUserItemContainer(socketId) {
+ const userContainerEl = document.createElement("div");
+
+ const usernameEl = document.createElement("p");
+
+ userContainerEl.setAttribute("class", "active-user");
+ userContainerEl.setAttribute("id", socketId);
+ usernameEl.setAttribute("class", "username");
+ usernameEl.innerHTML = `Socket: ${socketId}`;
+
+ userContainerEl.appendChild(usernameEl);
+
+ userContainerEl.addEventListener("click", () => {
+ unselectUsersFromList();
+ userContainerEl.setAttribute("class", "active-user active-user--selected");
+ const talkingWithInfo = document.getElementById("talking-with-info");
+ talkingWithInfo.innerHTML = `Talking with: "Socket: ${socketId}"`;
+ callUser(socketId);
+ });
+ return userContainerEl;
+}
+```
+
+请注意,我们在用户容器元素上添加了一个点击事件监听,点击会调用 `callUser` 函数 —— 就目前来说,你可以先写成空函数。现在,当你运行两个浏览器窗口(其中一个作为本地用户窗口),你会发现在应用中有两个连接中的 socket:
+
+
+
+点击列表中的在线用户后,要调用 `callUser` 函数。但在实现该函数前,你需要在 `window` 对象中声明两个类。
+
+```js
+const { RTCPeerConnection, RTCSessionDescription } = window;
+```
+
+我们会在 `callUser` 函数中用到它们:
+
+```js
+async function callUser(socketId) {
+ const offer = await peerConnection.createOffer();
+ await peerConnection.setLocalDescription(new RTCSessionDescription(offer));
+
+ socket.emit("call-user", {
+ offer,
+ to: socketId
+ });
+}
+```
+
+这里,我们创建了一个本地连接请求,并发送给被选中的用户。服务端会监听一个叫做 `call-user` 的事件,拦截本地发出的连接请求,并发送给被选中的用户。在 `server.ts` 中需要这样实现:
+
+```ts
+socket.on("call-user", data => {
+ socket.to(data.to).emit("call-made", {
+ offer: data.offer,
+ socket: socket.id
+ });
+ });
+```
+
+现在在客户端,我们需要对 `call-made` 事件做出响应:
+
+```js
+socket.on("call-made", async data => {
+ await peerConnection.setRemoteDescription(
+ new RTCSessionDescription(data.offer)
+ );
+ const answer = await peerConnection.createAnswer();
+ await peerConnection.setLocalDescription(new RTCSessionDescription(answer));
+
+ socket.emit("make-answer", {
+ answer,
+ to: data.socket
+ });
+});
+```
+
+然后,给这个从服务端收到的连接请求设置一个远程描述,并给该请求创建一个回应。在服务端,你需要把对应的数据传给被选中的用户。在 `server.ts`中,在添加一个事件监听:
+
+```ts
+socket.on("make-answer", data => {
+ socket.to(data.to).emit("answer-made", {
+ socket: socket.id,
+ answer: data.answer
+ });
+ });
+```
+
+相应地,在客户端处理 `answer-made` 事件:
+
+```js
+socket.on("answer-made", async data => {
+ await peerConnection.setRemoteDescription(
+ new RTCSessionDescription(data.answer)
+ );
+
+ if (!isAlreadyCalling) {
+ callUser(data.socket);
+ isAlreadyCalling = true;
+ }
+});
+```
+
+我们使用一个非常有用的标志 —— `isAlreadyCalling` —— 来确保只对该用户呼叫一次。
+
+最后,只需添加本地记录 —— 音频和视频 —— 到连接中即可,这样就能与连接的用户共享音频和视频了。那就需要我们在 `navigator.getMediaDevice` 回调函数中,用 `peerConnection` 对象调用 `addTrack` 函数。
+
+```js
+navigator.getUserMedia(
+ { video: true, audio: true },
+ stream => {
+ const localVideo = document.getElementById("local-video");
+ if (localVideo) {
+ localVideo.srcObject = stream;
+ }
+
+ stream.getTracks().forEach(track => peerConnection.addTrack(track, stream));
+ },
+ error => {
+ console.warn(error.message);
+ }
+);
+```
+
+以及为 `ontrack` 事件添加对应的处理函数:
+
+```js
+peerConnection.ontrack = function({ streams: [stream] }) {
+ const remoteVideo = document.getElementById("remote-video");
+ if (remoteVideo) {
+ remoteVideo.srcObject = stream;
+ }
+};
+```
+
+如你所见,我们从传入的对象中获取到了媒体流,并改写了 `remote-video` 中的 `srcObject`,以便使用接收到的媒体流。所以,现在当你点击了一个在线用户,你就能建立一个音视频连接,如下:
+
+
+
+扩展阅读:[Node.js 和依赖注入 —— 是敌是友?](https://tsh.io/blog/dependency-injection-in-node-js/)
+
+## 现在你已经点亮了开发视频聊天应用的技能啦!
+
+WebRTC 是个庞大的话题 —— 特别是如果你想要知道其深层原理的时候。幸运的是,我们有简单易用的 JavaScript API 可以用,使我们能够做出诸如视频聊天应用等十分简洁的应用!
+
+如果你想深入了解 WebRTC,请看 [WebRTC 官方文档](https://webrtc.org/start/)。个人推荐阅读 [MDN 文档](https://developer.mozilla.org/en-US/docs/Web/API/WebRTC_API)。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/how-we-ditched-redux-for-mobx.md b/TODO1/how-we-ditched-redux-for-mobx.md
index 4b1737b6b5d..1cfbe84ad8e 100644
--- a/TODO1/how-we-ditched-redux-for-mobx.md
+++ b/TODO1/how-we-ditched-redux-for-mobx.md
@@ -2,28 +2,28 @@
> * 原文作者:[Luis Aguilar](https://medium.com/@ldiego08)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how-we-ditched-redux-for-mobx.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how-we-ditched-redux-for-mobx.md)
-> * 译者:
-> * 校对者:
+> * 译者:[lihaobhsfer](https://github.com/lihaobhsfer)
+> * 校对者:[动力小车](https://github.com/Stevens1995)
-# How We Ditched Redux for MobX
+# 我们如何抛弃了 Redux 而选用 MobX
-We at Skillshare embrace change; not because it looks cool in a company’s vision statement, but because it’s **necessary.** That is the premise behind the recent decision to migrate the whole platform to React, leveraging all the goodness it entails. The group tasked with introducing these changes is but a small delta of our lovely engineering team. Making the right decisions early it’s crucial for getting the rest of the team onboard as smoothly and quickly as possible.
+在 Skillshare 我们拥抱改变;不仅因为把它写在公司的前景宣言中很酷,也因为改变确实有必要。这是我们近期将整个平台迁移至 React 并利用其所有优势这一决定背后的前提。执行这个任务的小组仅仅是我们工程师团队的一小部分。尽早做出正确的决定对于让团队其他成员尽可能快而顺畅地切换平台来说至关重要。
-A smooth development experience is everything.
+顺畅的开发体验就是一切。
-**Everything.**
+**一切。**
-And so, along the road of getting React into our codebase, we stumbled upon the most challenging bits of doing frontend development: **state management.**
+然后,在将 React 引入我们的代码库时,我们遇到了前端开发最有挑战的一部分:**状态管理**。
-Oh boy… were we in for some fun.
+唉…接下来就有意思了。
-## Setup
+## 设置
-It all started simple: **“migrate Skillshare’s header to React.”**
+一切都开始于简单的任务:**“将 Skillshare 的页头迁移至 React。”**
-**“Ah, easy as pie,”** we dared saying—it was only the “guest” view which only had a few links and a simple search box. No authentication logic, no session management, nothing magical going on.
+“**小菜一碟**!”我们立下了 flag —— 这个页头只是访客视图,只包含几个链接和一个简单的搜索框。没有授权逻辑,没有 session 管理,没有什么特别神奇的东西。
-Alright, let’s get into some code:
+好的,来敲点代码吧:
```TSX
interface HeaderProps {
@@ -49,34 +49,34 @@ interface SearchBoxProps {
class SearchBox extends Component<SearchBoxProps> {
render() {
- // Render the component ..
+ // 渲染组件…
}
}
```
-Oh yeah, we use TypeScript—it’s the cleanest, most intuitive, and friendly to all devs. How not to love it? We also use [Storybook](https://storybook.js.org/) for UI development, so we’d like to keep components as dumb as possible and do any wiring up at the highest level possible. Since we use [Next](https://nextjs.org/) for server-side rendering, that level would be the page components, which in the end are just plain old components residing in a designated **pages** folder and automatically mapped to URL requests by the runtime. So, if you have a `home.tsx `****file there, it will be automatically mapped to the `/home` route—bye bye goes `renderToString()`.
+没错,我们用 TypeScript —— 它是最简洁、最直观、对所有开发者最友好的语言。怎能不爱它呢?我们还使用 [Storybook](https://storybook.js.org/) 来做 UI 开发,所以我们希望让组件越傻瓜越好,在越高层级将其拼接起来越好。由于我们用 [Next](https://nextjs.org/) 做服务端渲染,那个层级就是页面组件,它们最终就仅仅是广为人知的位于指定 `pages` 目录中的组件,并在运行时自动映射到 URL 请求中。所以,如果你有一个 `home.tsx` 文件,它就会被自动映射到 `/home` 路由 —— 和 `renderToString()` 说再见吧。
-Alright, that’s it for components… but wait! Getting that search box working also involved setting up a state management strategy, and plain local state wouldn’t get us very far.
+好的,组件就讲到这里吧…但等一下!实现搜索框功能还需要制定一个状态管理策略,本地状态不会给我们带来什么长足发展。
-## Confrontation: Redux
+## 对抗:Redux
-In React, when it comes to state management, Redux is the gold standard—it’s got over 40k stars on GitHub, has full TypeScript support, and big guys like Instagram use it.
+在 React 中,提到状态管理时,Redux 就是黄金法则 —— 它在 Github 上有 4w+ Star(截至英文原文发布时。截至本译文发布时已有 5w+ Star。),完全支持 TypeScript,并且像 Instagram 这样的大公司也用它。
-Here’s how it works:
+下图描述了它的原理:
-](https://cdn-images-1.medium.com/max/2400/1*kDO26wU8yMn0Xq7crphztA.png)
+](https://cdn-images-1.medium.com/max/2400/1*kDO26wU8yMn0Xq7crphztA.png)
-Unlike traditional MVW patterns, Redux manages an application-wide state tree. UI events trigger actions, actions pass data to a reducer, the reducer updates the state tree, and ultimately the UI updates.
+不像传统的 MVW 样式,Redux 管理一个覆盖整个应用的状态树。UI 触发 actions,actions 将数据传递给 reducer,reducer 更新状态树,并最终更新 UI。
-Easy, right? Well, let’s do this!
+非常简单,对不?再来敲点代码!
-The entity involved here is called a **“tag.”** Hence, when the user types in the search box, it searches for **tags.**
+这里涉及到的实体是**标签。**因此,当用户在搜索框中输入时,搜索框搜索的是**标签**
```TypeScript
-/* We have three actions here:
- * - Tags search: when the user types and a new search is triggered.
- * - Tags search update: when the search results are ready and have to update.
- * - Tags search error: bad stuff happened.
+/* 这里有三个 action:
+ * - 标签搜索: 当用户进行输入时,触发新的搜索。
+ * - 标签搜索更新: 当搜索结果准备好,必须进行更新。
+ * - 标签搜索报错:发生了不好的事情。
*/
enum TagActions {
@@ -103,7 +103,7 @@ interface TagsSearchErrorAction extends Action {
type TagsSearchActions = TagsSearchAction | TagsSearchUpdateAction | TagsSearchErrorAction;
```
-Well, that was easy. Now we need some helpers to create our actions dynamically based on input parameters:
+还挺简单的。现在我们需要一些帮助函数,基于输入参数来动态创建 actions:
```TypeScript
const search: ActionCreator<TagsSearchAction> =
@@ -126,7 +126,7 @@ const searchError: ActionCreator<TagsSearchErrorAction> =
```
-There! Now the reducer which updates the state depending of the action:
+搞定!接下来是负责基于 action 更新 state 的 reducer:
```TypeScript
interface State {
@@ -171,7 +171,7 @@ const tagSearchReducer: Reducer<State> =
};
```
-Whew, that was quite a chunk of code, but now we’re rolling! Remember all wiring goes on at the highest level, and that’d be our **page** components.
+这段代码还挺长的,但是我们正在取得进展!所有的拼接都在最顶层进行,即我们的**页面**组件。
```TSX
interface HomePageProps {
@@ -215,55 +215,55 @@ const makeStore = (initialState: State) => {
return createStore(reducers, initialState);
}
-// it all comes to this - BEHOLD: THE WIRED-UP HOME PAGE!
+// 所有都汇聚于此 —— 看吧:拼接完成的首页!
export default withRedux(makeStore)(connectedPage);
```
-And we’re done! Time to dust off our hands and grab a beer. We have our UI components, a lovely page, and everything nicely glued together.
+任务完成!掸掸手上的灰来瓶啤酒吧。我们已经有了 UI 组件,一个页面,所有的部分都完好地组接在一起。
-Uhm… wait.
+Emmm…等一下。
-This is just local data.
+这只是本地状态。
-We still have to fetch stuff from the actual API. Redux requires actions to be pure functions; they have to be executable right away. And what doesn’t execute right away? Async operations like fetching data from an API. Hence, Redux has to be paired with other libraries to achieve this. There are plenty of options, like [thunks](https://github.com/reduxjs/redux-thunk), [effects](https://github.com/redux-effects/redux-effects), [loops](https://github.com/redux-loop/redux-loop), [sagas](https://github.com/redux-saga/redux-saga), and each one works differently. That doesn’t only mean additional incline degrees on an already steep learning curve, but even more boilerplate.
+我们仍需要从真正的 API 获取数据。Redux 要求 actions 为纯函数;他们必须立即可执行。什么不会立即执行?像从API获取数据这样的异步操作。因此,Redux 必须与其他库配合来实现此功能。有不少可选用的库,比如 [thunks](https://github.com/reduxjs/redux-thunk)、[effects](https://github.com/redux-effects/redux-effects)、[loops](https://github.com/redux-loop/redux-loop)、[sagas](https://github.com/redux-saga/redux-saga),每一个都有些差别。这不仅仅意味着在原本就陡峭的学习曲线上又增加坡度,并且意味着更多的模板。

-And as we trudged along these muddy waters, the obvious echoed over and over in our heads: **“all this code just for binding a search box?”** And we were sure those would be the exact same words coming from anyone daring enough to venture into our codebase.
+当我们在泥泞中艰难前行中,那个显而易见的问题不停地回响在我们的脑海中:**这么多行代码,就为了绑定一个搜索框**?我们确信,任何一个有勇气查看我们代码库的人都会问同样的问题。
-One can’t diss Redux; it’s the pioneer in its field and a beautiful concept all around. However, we found it’s way too low-level, demanding you to define everything. It is constantly praised for being very opinionated, preventing you from shooting yourself in the foot by enforcing a pattern, but the price of that is an unholy amount of boilerplate and a thick learning barrier.
+我们不能 Diss Redux;它是这个领域的先锋,也是一个优雅的概念。然而,我们发现它过于“低级”,需要你亲自定义一切。它一直由于有非常明确的思想,能避免你在强制一种风格的时候搬起石头砸自己的脚而受到好评,但这些所有都有代价,代价就是大量的模板代码和一个巨大的学习障碍。
-That was the dealbreaker for us.
+这我们就忍不了了。
-How do we tell our team they won’t be seeing their families during the holidays because of boilerplate?
+我们怎么忍心告诉我们的团队,他们假期要来加班,就因为这些模板代码?
-There’s gotta be something else.
+肯定有别的工具。
-Something more **friendly.**
+更加**友好**的工具。
-[**You Might Not Need Redux**](https://medium.com/@dan_abramov/you-might-not-need-redux-be46360cf367)
+[**你并不一定需要 Redux**](https://medium.com/@dan_abramov/you-might-not-need-redux-be46360cf367)
-## Resolution: MobX
+## 解决方案:MobX
-At first, we thought of creating some helpers and decorators to circumvent code repetition. That would mean more code to maintain. Also, when core helpers break, or they need new functionality, it can stall the whole team while making changes. You wouldn’t want to lay fingers on a three-year-old helper used by pretty much the whole app, do you?
+起初,我们想过创建一些帮助函数和装饰器来解决代码重复。而这意味着需要维护更多代码。并且,当核心帮助函数出问题,或者需要新的功能,在修改它们时可能会迫使整个团队停止工作。三年前写的、整个应用都在用的帮助函数代码,你也不想再碰,对不?
-Then some wild thoughts came along…
+然后我们有了一个大胆的想法…
-**“What if we didn’t use redux at all?”**
+**“如果我们根本不用 Redux 呢?”**
-**“What else is there?”**
+**“还有啥别的可以用?”**
-A click on that **“I’m Feeling Lucky”** button yielded the answer: [**MobX**](https://mobx.js.org/)
+点了一下“**我今天感觉很幸运**”按钮,我们的到了答案:[**MobX**](https://mobx.js.org/)
-MobX promises you one thing: to just let you do your work. It applies the principles of reactive programming to React components — yeah, ironically, React is not reactive out of the box. Unlike Redux, you can have multiple stores (i.e. `TagsStore`, `UsersStore`, etc.,) or a root store, and bind them to component props. It is there to help you in managing your state, but how you shape it is entirely up to you.
+MobX 保证了一件事:保证你做你的工作。它将响应式编程的原则应用于 React 组件 —— 没错,讽刺的是,React 并不是开箱即具备响应式特点的。不像 Redux,你可以有很多个 store(比如 `TagsStore`、`UsersStore` 等等),或者一个总的 store,将它们绑定于组件的 props 上。它帮助你管理状态,但是如何构建它,决定权在你手里。
-](https://cdn-images-1.medium.com/max/3200/1*QZ8X8IZfm7IPkZj0iyRC7w.png)
+](https://cdn-images-1.medium.com/max/3200/1*QZ8X8IZfm7IPkZj0iyRC7w.png)
-So we have React integration, full TypeScript support, and minimal-to-no boilerplate.
+所以我们现在整合了 React,完整的 TypeScript 支持,还有极简的模板。
-You know what? I’ll let the code do the talking.
+还是让代码为自己代言吧。
-We start by defining our store:
+我们首先定义 store:
```TypeScript
import { observable, action, extendObservable } from 'mobx';
@@ -288,7 +288,7 @@ export class TagsStore {
@action public loadTags = (query: string) => {
this.query = query;
- // do something here ..
+ // 一些业务代码…
}
}
@@ -297,7 +297,7 @@ export interface StoreMap {
}
```
-Then wire up the page:
+然后拼接一下页面:
```TSX
import React, { Component } from 'react';
@@ -345,17 +345,17 @@ export default () => {
}
```
-And that’s it… you’re done! We got up and running to the same place we were in the Redux example, except in a matter of a few minutes.
+就这样搞定了!我们已经实现了所有在 Redux 例子中有的功能,不过我们这次只用了几分钟。
-So the code is quite self-explanatory, but to clarify, the `inject` helper comes from MobX React integration; it’s the counterpart to Redux’s `connect` helper except that `mapStateToProps` and `mapDispatchToProps` are in a single function. The `Provider` component it’s also MobX, and it takes as many stores as you want which will be later passed on to the `inject` helper. Also, look at those beautiful, **beautiful** decorators—that’s how you configure your store. Any property decorated with `@observable `will notify bound components to re-render on change.
+代码相当清晰了,不过为了说明白,`inject` 帮助函数来自于 MobX React;它与 Redux 的 `connect` 帮助函数对标,只不过它的 `mapStateToProps` 和 `mapDispatchToProps` 在一个函数当中。 `Provider` 组件也来自于 MobX,可以在里面放任意多个 store,它们都会被传递至 `inject` 帮助函数中。并且,快看看那些迷人的,**迷人的**装饰器 —— 就这样配置 store 就对了。所有用 `@observable` 装饰的实体都会通知被绑定的组件在发生改变后重新渲染。
-Now that’s what I call **“intuitive.”**
+这才叫“**直观**”。
-Need I to say more?
+还需多说什么?
-Okay, moving onto API fetching, remember how Redux doesn’t handle async actions out-of -the-box? Remember how you had to use `thunks` (which are hard to test,) or `sagas` (which are hard to understand) if you wanted that? Well, with MobX you have plain old classes, so constructor-inject your fetching library of choice and do it in the actions. Miss sagas and generator functions?
+然后,关于访问 API,是否还记得 Redux 不能直接处理异步操作?是否还记得你为了实现异步操作不得不使用 `thunks`(它们非常不好测试)或者 `sagas`(非常不易理解)?那么,有了 MobX,你可以用普普通通的类,在构造函数里注入你选择的 API 访问库,然后在 action 里执行。还想念 sagas 和 generator 函数吗?
-Behold the `flow` helper!
+请看吧,这就是 `flow` 帮助函数!
```TypeScript
import { action, flow } from 'mobx';
@@ -380,25 +380,25 @@ export class TagsStore {
}
```
-The `flow` helper takes a generator function which yields steps—response data, logging calls, errors, etc. It’s a series of steps which can be executed gradually or paused if needed.
+这个 `flow` 帮助函数用 generator 函数来产出步骤 —— 响应数据,记录调用,报错等等。它是可以渐进执行或在需要时暂停的一系列步骤。
-**A flow!** Get it?
+**一个流程!** 懂了不?
-The times of explaining why **sagas** are named like that are over. Hell, even generator functions seem less scary now.
+那些需要解释为什么**sagas**要这叫这名字的时光结束了。感谢上苍,就连 generator 函数都显得不那么可怕了。
-[**Javascript (ES6) Generators — Part I: Understanding Generators**](https://medium.com/@hidace/javascript-es6-generators-part-i-understanding-generators-93dea22bf1b)
+[**Javascript (ES6) Generators — 第一部分: 了解 Generators**](https://medium.com/@hidace/javascript-es6-generators-part-i-understanding-generators-93dea22bf1b)
-## Aftermath
+## 结果
-Although everything was rainbows and colors so far, an unsettling feeling was still there for some reason—a feeling that going against the current would end up firing back at us. Maybe we needed all that boilerplate to enforce standards. Maybe we needed an opinionated framework. Maybe we needed a well-defined application state tree.
+虽然到目前为止一切都显得那么美好,但不知为何还是有一种令人不安的感觉 —— 总感觉逆流而上总会遭到命运的报复。或许我们仍旧需要那一堆模板代码来强制一些标准。或许我们仍旧需要一个有明确思想的框架。或许我们仍旧需要一个清晰定义的状态树。
-What if we want something like Redux but as convenient as MobX?
+如果我们想要的是一个看上去像 Redux 但是和 MobX 一样方便的工具呢?
-Well, for that there is **[MobX State Tree](https://github.com/mobxjs/mobx-state-tree).**
+如果是这样,来看看 **[MobX State Tree](https://github.com/mobxjs/mobx-state-tree)** 吧。
-With MST, we define the application state tree using a specialized API, and it is immutable, giving you time traveling, serialization and rehydration, and everything else you can expect from an opinionated state management library.
+通过 MST,我们通过一个专门的 API 来定义状态树,并且是不可修改的,允许你回滚,序列化或者再组合,以及所有你希望一个有明确思想的状态管理库所拥有的东西。
-But enough talk, have at you!
+多说无用,来看代码!
```TypeScript
import { flow } from 'mobx';
@@ -434,13 +434,13 @@ export const StoreModel = types
export type Store = typeof StoreModel.Type;
```
-Instead of letting you do whatever you please, MST enforces a pattern by requiring you to define your state tree its way. One might think that this is just MobX but with chained functions instead of classes, but it is way more. The tree is immutable, and each change will create a new **“snapshot”** of it, enabling time travel, serialization and rehydration, and everything else you felt you were missing.
+与其让你在状态管理上为所欲为,MST 通过要求你用它的规定的方式定义状态树。有人可能回想,这就是有了链式函数而不是类的 MobX,但是还有更多。这个状态树无法被修改,并且每一次修改都会创建一个新的“**快照**”,从而允许了回滚,序列化,再组合,以及所有你想念的功能。
-Addressing the elephant in the room, the only low point is that this is a semi-functional approach to MobX, meaning it ditches classes and decorators, meaning [TypeScript support is best effort.](https://github.com/mobxjs/mobx-state-tree#typescript--mst)
+再来看遗留下来的问题,唯一的低分项是,这对 MobX 来讲仅仅是一个部分可用的方法,这意味着它抛弃了类和装饰器,意味着 [TypeScript 支持只能是尽力而为了。](https://github.com/mobxjs/mobx-state-tree#typescript--mst)
-But even so, it’s still pretty great!
+但即便如此,它还是很棒!
-Okay, moving on, let’s wire up the page:
+好的我们继续来构造整个页面。
```TSX
import { Header, HeaderProps } from './header';
@@ -481,15 +481,15 @@ export default () => {
}
```
-See that? Connecting components remains the same, so even the effort of migrating from vanilla MobX to MST is lesser than writing Redux boilerplate.
+看到了吧?连接组件还是通过同样的方式,所以花在从 MobX 迁移到 MST 的精力远小于编写 Redux 模板代码。
-Why didn’t we go all the way to MST?
+那为啥我们没一步到底选 MST 呢?
-Well, MST was overkill for our specific case. We considered it because time travel debugging is a **very** nice to have, but after stumbling upon [**Delorean**](https://github.com/BrascoJS/delorean) that’s no longer a reason to move over. The day when we need something MobX can’t provide might come, but even falling back to Redux doesn’t seem as daunting thanks to how unobtrusive MobX is.
+其实,MST 对于我们的具体例子来说有点杀鸡用牛刀了。我们考虑使用它是因为回滚操作是一个**非常**不错的附加功能,但是当我们发现有 [**Delorean**](https://github.com/BrascoJS/delorean) 这么个东西的时候就觉得没必要再费力气迁移了。以后我们可能会遇到 MobX 对付不了的情况,但是因为 MobX 很谦逊随和,即便返回去重新用上 Redux 也变得不再令人头大。
-All in all, we love you, MobX.
+总之,MobX,我们爱你。
-Stay awesome.
+愿你一直优秀下去。
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/how_to_prep_your_github_for_job_seeking.md b/TODO1/how_to_prep_your_github_for_job_seeking.md
new file mode 100644
index 00000000000..3d324141950
--- /dev/null
+++ b/TODO1/how_to_prep_your_github_for_job_seeking.md
@@ -0,0 +1,181 @@
+> * 原文地址:[How to prep your GitHub for job seeking](https://www.reddit.com/r/webdev/comments/90xmpw/how_to_prep_your_github_for_job_seeking/)
+> * 原文作者:[yopla](https://www.reddit.com/user/yopla/)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/how_to_prep_your_github_for_job_seeking.md](https://github.com/xitu/gold-miner/blob/master/TODO1/how_to_prep_your_github_for_job_seeking.md)
+> * 译者:[nettee](https://github.com/nettee)
+> * 校对者:[PingHGao](https://github.com/PingHGao)、[Chorer](https://github.com/Chorer)
+
+# 如何为求职准备你的 GitHub
+
+不论是否合理,技术招聘方倾向于从你的 GitHub 个人资料中推断出很多关于你的信息。而且现在越来越多的招聘者会要求提供、或者通过简单的 Google 搜索找到你的 GitHub 账号。因此,对于找工作的开发人员而言,有必要将 GitHub 看作简历的扩展。
+
+明白了这一点之后,根据我在过去几周面试过的人的 GitHub 账号中的“错误”,我总结了几点指导方针。
+
+我主要关注的是开发人员,但是很多观点是可以通用的。
+
+> 我迁移到了 GitLab,因为 M\$ 太烂了。(译注:*M\$* 是对 Microsoft 的讽刺写法)
+
+让我们首先快速避开这个误区。
+
+首先,专业的成年人不会(在公开场合)发表这样的言论,所以请你自己保留这个观念,而不要像我曾经看到的一个例子一样,把这句话写在一个置顶仓库的 README.md 里。虽然我们公司现在没有使用任何微软的产品,但不排除未来因为技术或财务上的优点而选择使用微软的某个产品。我们不需要一个不能以开放的态度来评估技术的开发者。
+
+看起来 GitLab 是一个不错的替代品,但由于我自己使用 GitHub,而且我每看 20 个 GitHub 的个人资料才会看一个 GitLab 的,所以我会对 GitHub 的界面更熟悉。当然我不是说你必须使用 GitHub,下面的建议或多或少可以适用于其他的平台。(不过如果你用的是 bitbucket,你显然从来没有投递过我们公司……)
+
+### 整理你的个人资料
+
+首先,让我们看看你的个人资料需要达到的最低要求。
+
+### 添加你的头像、简单的介绍,以及指向你其他相关网站的链接
+
+拥有完整的个人简介会给人一种印象:你在乎你的 GitHub,而且是一个有条理的人。我们已经有你的简历了,也可能有你的 LinkedIn,但如果你的 GitHub 是三者中最差的,会给人留下最长久的印象。
+
+**真实的照片要比卡通、漫画或符号更好。**
+
+如果你在找工作,那仪表整洁很重要。请避免出现那些你一般不会发给雇主的图片,包括裸体、醉酒、忍者、黑客、恐怖分子伪装,或是任何让人觉得你表里不一的图片。
+
+你可能想在 GitHub 个人资料上表现得轻松友好一点,所以避免使用过于正式的照片,但也要保持专业。毫无疑问,这种目标就是“休闲星期五”的风格。
+
+最后,别放你的毕业宽袍照。那不是个好图片,让你看起来没有经验。
+
+**使用 @ 来链接到招聘者应当注意的其他仓库。** 可能是你的公司、组织,或者是其他你正在参与或管理的仓库。
+
+添加你的个人网站的 URL。如果你有个人网站,而且还算看得过去,就应该把它放上去。(提示:如果这个网站看起来像一坨屎,也许你一开始就不应该建这个网站……)
+
+链接到你其他相关的个人资料。如果你在其他网站也很活跃,例如 StackOverflow、CodePen、Behance、Dribble 或其他网站,确保你的个人资料都连接起来。但是不要链接到兽人、御宅或是角色扮演论坛(译注:都是二次元相关),这些和你的专业经历无关。
+
+> **关于意外链接的说明**
+>
+> Google 生成链接的能力很强,所以如果你不想让招聘者发现,最好不要在不同的网站上用一样的昵称。我们在做社交媒体检查的时候就会在 Google 上搜索。
+>
+> 我不知道有多少次搜索一个 GitHub 用户名的时候,从 Google 找到的关联中,发现了他们的另一面,有在 Upwork 上和雇主竞争的,有在 Instagram 上非法养犬并进行投标的。
+
+### 为招聘者选择你的置顶仓库
+
+如果你正在找工作,出现在你的个人资料顶部的置顶仓库不应该是你最常访问的仓库的快捷方式,而应该是展示你最引人注目的仓库的展示处。也许这两者是相同的仓库,但通常情况下不是的。
+
+作为招聘者,我不关心你的 bash_profile,而是想看到你想给招聘者突出显示的仓库。它们应该比较相关、展示你做过的工作,等等。
+
+⚠️ 将你想要让招聘者查看的三个仓库置顶。
+
+### 不要置顶入门教程
+
+请注意,我们会看很多简历。如果你的仓库是教程或者新手训练营,那有可能我已经看过三次或者三十次了。过于简单的项目,或者 80% 来自教程、你只是简单地填了一些空的项目,它们并不能让我了解你的能力,甚至让我觉得你最多只能做这些了。有这些仓库不是问题,只是不要突出显示它们。
+
+如果你只有这些仓库,那么最好不要置顶任何仓库,然后把这些仓库就命名为:教程。不要把它们转化成自己的原创,也不要夸大它们。它们只是新手教程,不会给任何人留下深刻的印象。正如我前面提到过的,我可能已经看过[这个教程](https://github.com/search?q=pig+dom)了。
+
+### 将使用了相关技术的 demo 置顶
+
+**…把它们放在更大型但是技术过时的项目之前。**
+
+例如,如果你在市场上寻求 SPA 开发的职位,则将 Angular/React/Vue 技术的 demo 放在你三年前写的 Laravel + jQuery 的大项目之前。
+
+如果你像大多数人一样,没有一个成功的开源项目,你平时的大部分生产代码都是雇主的资产,你可能会因为没有用来展示的引人注目的项目而难过。不过不用担心,大部分人都是没有的。
+
+最好不要试图展示过于宏大但未完成、几乎废弃的项目(谁还没有一个或者…… 十个呢?),而是在你选择的框架中聚焦于有趣的小型技术 demo。如果你已经在专业领域工作,那肯定有你解决过的问题,可以作为一个有趣 demo 的内容。你只需要快速地重写它,或者让你现在的上司授权给你发布。
+
+**如果你是个初学者**,我建议你制作一些展示你对计算机科学的理解的 demo,即使它只是用 React 或者 Vue 写的冒泡排序或者树遍历的可视化。和你的那些看着 Udemy 教程做出一个 todo 应用的同伴相比,你简直是一个天才。
+
+**一些启发性的项目:**
+
+- <https://www.cs.usfca.edu/~galles/visualization/Algorithms.html>
+- <https://visualgo.net/en>
+
+如果在 CS 以外你还有其他爱好,比如音乐,可以把它们融合起来。例如做一个[小的合成器](https://github.com/JanCVanB/vue-synth/blob/master/src/components/Synth.vue)或者什么。
+
+### 删除无用的 fork
+
+我收到过好多个人资料,里面包含了一大堆 fork 过来的仓库,但没有任何贡献。首先,这会让人看不出你到底真正在做什么;其次,这会让人觉得你不会用 Git(和 GitHub),在把 fork 当书签用。
+
+有些人会用 fork 的项目来“填充”他们的个人资料,似乎这样可以给招聘者或朋友留下深刻的印象。但这并不能让人印象深刻,只会让你看起来像个蠢货。不要这么做。
+
+⚠️ 只有在你真正做贡献的时候才 fork 仓库。其他情况请使用加星或者关注。
+
+### 清理你加星的仓库
+
+这话可能让很多人生气,但事实就是这样:你加星的仓库会让对你感兴趣的访问者改变他们对你技能成熟度的看法,所以你给什么加星会影响别人如何看待你。
+
+⚠️ 你应该检查最新几页的星标内容,删除那些可能让人产生误解的。
+
+#### 初学与高级
+
+粗略地说,寻找高级职位的人应该给那些有复杂项目的仓库加星,而避免给太多初学或教程仓库加星(除非你在为这个仓库做贡献)。
+
+想象一下,你查看一个高级 React 开发者的个人资料,发现她最新感兴趣的两个仓库是 [iliakan/javascript-tutorial-en](https://github.com/iliakan/javascript-tutorial-en) 和 [kay-is/react-from-zero](https://github.com/kay-is/react-from-zero),你可能会怀疑这个候选者是否有她所声称的技能,或者她是否仍然处于入门级别。
+
+另一方面,如果你确实在申请初级职位,或者表明你正在学习这项技术,那么给这两个仓库加星是说得通的。
+
+#### 白帽与黑帽
+
+我喜欢安全方面的东西。从白帽的角度来看,任何开发者关注安全领域都是加分项,但请避免给一长串奇怪的破解工具加星,除非你正在申请安全相关的职位。我曾经看过一个人的资料,有一长串的 wifi 破解和钓鱼工具,然后是一堆共享枚举器,以及密码暴力破解工具。这并不是一种展示自己的好的方式。
+
+等等……
+
+### 整理你所展示的仓库
+
+一旦你选好了几个用于展示的仓库,确保它们是可以访问的。以下是它们应当具备的最低要求:
+
+### 任何项目都应该有一个有趣的 README
+
+无论为了什么,都请你一定、一定给你的项目加上说明。这听起来理所应当,但我不知道有多少次看到了没有任何 readme 的项目,或者是不知道什么框架工具生成的默认 readme。
+
+下面是你的 readme 里应当具备的最低要求:
+
+#### 项目说明
+
+你需要让一个人能在 60 秒内就轻易地理解这个项目究竟是什么,以及为什么能体现你是一个优秀的程序员。
+
+确保你至少回答了以下的问题:
+
+- **它是做什么的?**用一句简短的话概括,列出它的功能。
+- **它是什么?**清楚地指出代码会产出什么。是网页、桌面应用,移动应用,还是库?
+- **使用了什么技术?**列出这个项目使用到的重要的框架和库。对于那些不一定熟悉地球上每一个框架的招聘者来说,这很有用,能让他知道这是 Laravel + Vue,还是 React + Expressjs。
+- **这个项目的目标是什么?**你是仅仅在试驾一项技术,还是准备做出正在或将被使用的技术?
+- **这个项目处在什么阶段?**清楚地指出你正在进行哪一阶段。这个项目是完成了,还是正在进行中?如果是正在进行中,指明已完成和待处理的内容。
+- **是否存在一些已知问题,或没有正确完成的事情?**如果有,列出这些问题,因为比起我自己发现缺点,如果它们是突出列出来的,我会宽容得多。
+
+#### 告诉我该看什么
+
+如果你坚持展示一个大型的项目,那里面很可能会有很多完全没意思的样板代码和辅助内容,因此请毫不犹豫地指出最有趣的部分在哪里。
+
+如果这是一个你正在贡献的 fork 项目,请确定你正在做的部分。如果很难定位到,请不要展示这个项目。
+
+#### 如何运行
+
+你一定需要清晰明确地解释如何运行该项目(或者如果它是一个库,解释如何使用它)。
+
+必须能用一行命令运行项目的演示版本,例如 `npm run`、`graddle serve`、`docker run`…… 或者任何你的框架使用的命令。
+
+在当今时代,无论运行什么东西,都几乎不需要一大堆的手工依赖和先导设置。
+
+**下面这样是你应该争取做到的:**
+
+```bash
+# serve with hot reload at localhost:8080
+npm run dev
+
+# build for production with minification
+npm run build
+
+# build for production and view the bundle analyzer report
+npm run build --report
+
+# regenerate Element component styles in theme/ from element-variables.css
+npm run theme
+
+```
+
+#### 演示
+
+如果你能有即时可访问的演示,直接在说明里放上链接。如果你没有即时演示,可以使用[录屏](https://www.producthunt.com/alternatives/giphy-capture)。如果这些都难以做到,至少要有几张截图。
+
+<https://asciinema.org/> 看起来是一个很酷的控制台录制工具,但我没有用过。
+
+#### 单元测试
+
+已经 2018 年了,如果你的项目没有单元测试的话,你就不应该把它放出来。这是一个反面教材,说明你的习惯很差。没有理由不写单元测试。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/i-built-an-app-that-uses-all-7-new-features-in-javascript-es2020.md b/TODO1/i-built-an-app-that-uses-all-7-new-features-in-javascript-es2020.md
new file mode 100644
index 00000000000..b26ae363e7f
--- /dev/null
+++ b/TODO1/i-built-an-app-that-uses-all-7-new-features-in-javascript-es2020.md
@@ -0,0 +1,416 @@
+> * 原文地址:[I Built an App That Uses All 7 New Features in JavaScript ES2020](https://levelup.gitconnected.com/i-built-an-app-that-uses-all-7-new-features-in-javascript-es2020-647205024984)
+> * 原文作者:[Tyler Hawkins](https://medium.com/@thawkin3)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/i-built-an-app-that-uses-all-7-new-features-in-javascript-es2020.md](https://github.com/xitu/gold-miner/blob/master/TODO1/i-built-an-app-that-uses-all-7-new-features-in-javascript-es2020.md)
+> * 译者:
+> * 校对者:
+
+# I Built an App That Uses All 7 New Features in JavaScript ES2020
+
+
+
+The world of web development moves fast, especially in the JavaScript ecosystem. New features, frameworks, and libraries are constantly emerging, and the minute you stop learning is the minute your skill set starts to become obsolete.
+
+One important part of keeping your JavaScript skills sharp is staying current on the latest features in JavaScript. So, I thought it would be fun to build an app that incorporates all seven of the new features in JavaScript ES2020.
+
+---
+
+I recently did a bit of bulk shopping at Costco to stock up on some food essentials. Like most stores, their price tags display the unit price for each item, so you can assess and compare the quality of each deal. Do you go with the small bag or the large bag? (Who am I kidding? It’s Costco. Go large!)
+
+But what if the unit price wasn’t displayed?
+
+In this article, I’ll build a unit price calculator app using vanilla JavaScript for the front end and [Node.js](https://nodejs.org/en/) with [Express.js](https://expressjs.com/) for the back end. I’ll deploy the app on [Heroku](http://heroku.com/), which is an easy place to [quickly deploy a node.js app](https://devcenter.heroku.com/articles/getting-started-with-nodejs).
+
+## What’s New in JavaScript ES2020?
+
+The JavaScript programming language conforms to a specification known as ECMAScript. Starting with the release of ES2015 (or ES6), a new version of JavaScript has been released each year. As of right now, the latest version is ES2020 (ES11). ES2020 is packed with seven exciting new features that JavaScript developers have been waiting for quite some time to see. The new features are:
+
+1. Promise.allSettled()
+2. Optional Chaining
+3. Nullish Coalescing
+4. globalThis
+5. Dynamic Imports
+6. String.prototype.matchAll()
+7. BigInt
+
+You should note that not all browsers support these features — yet. If you want to start using these features now, make sure you provide appropriate polyfills or use a transpiler like Babel to ensure your code is compatible with older browsers.
+
+## Getting Started
+
+If you want to follow along with your own copy of the code, first create a Heroku account and install the Heroku CLI on your machine. See this [Heroku guide](https://devcenter.heroku.com/articles/getting-started-with-nodejs#set-up) for installation instructions.
+
+Once you’ve done that, you can create and deploy the project easily using the CLI. All of the source code needed to run this example app [is available on GitHub](https://github.com/thawkin3/unit-price-calculator).
+
+Below are step-by-step instructions on how to clone the repo and deploy to Heroku:
+
+```bash
+git clone https://github.com/thawkin3/unit-price-calculator.git
+cd unit-price-calculator
+heroku create
+git push heroku master
+heroku open
+```
+
+## System Overview
+
+My unit price calculator app is fairly simple: it lets you compare various price and weight options for fictional products and then calculates the unit price. When the page loads, it fetches product data from the server by hitting two API endpoints. You can then choose your product, your preferred unit of measurement, and a price/weight combination. The unit price calculation is done once you hit the submit button.
+
+
+
+Now that you’ve seen the app, let’s take a look at how I used all seven of those ES2020 features. For each feature, I’ll discuss exactly what it is, how it’s useful, and how I used it.
+
+## 1. Promise.allSettled()
+
+When a user first visits the calculator app, three API requests are kicked off to fetch product data from the server. We wait for all three requests to finish by using `Promise.allSettled()`:
+
+```JavaScript
+const fetchProductsPromise = fetch('/api/products')
+ .then(response => response.json())
+
+const fetchPricesPromise = fetch('/api/prices')
+ .then(response => response.json())
+
+const fetchDescriptionsPromise = fetch('/api/descriptions')
+ .then(response => response.json())
+
+Promise.allSettled([fetchProductsPromise, fetchPricesPromise, fetchDescriptionsPromise])
+ .then(data => {
+ // handle the response
+ })
+ .catch(err => {
+ // handle any errors
+ })
+```
+
+`Promise.allSettled()` is a new feature that improves upon the existing `Promise.all()` functionality. Both of these methods allow you to provide an array of promises as an argument, and both methods return a promise.
+
+The difference is that `Promise.all()` will short-circuit and reject itself early if any of the promises are rejected. On the other hand, `Promise.allSettled()` waits for **all** of the promises to be settled, regardless of whether they are resolved or rejected, and then resolves itself.
+
+So if you want the results from all your promises, even if some of the promises are rejected, then start using `Promise.allSettled()`.
+
+Let’s look at another example with `Promise.all()`:
+
+```JavaScript
+const fetchProductsPromise = fetch('/api/products')
+ .then(response => response.json())
+
+const fetchPricesPromise = fetch('/api/prices')
+ .then(response => response.json())
+
+const fetchDescriptionsPromise = fetch('/api/descriptions')
+ .then(response => response.json())
+
+Promise.allSettled([fetchProductsPromise, fetchPricesPromise, fetchDescriptionsPromise])
+ .then(data => {
+ // handle the response
+ })
+ .catch(err => {
+ // handle any errors
+ })
+```
+
+And now let’s look at another example with `Promise.allSettled()` to note the difference in behavior when a promise gets rejected:
+
+```JavaScript
+// promises 1-3 all will be resolved
+const promise1 = new Promise((resolve, reject) => setTimeout(() => resolve('promise 1 resolved!'), 100))
+const promise2 = new Promise((resolve, reject) => setTimeout(() => resolve('promise 2 resolved!'), 200))
+const promise3 = new Promise((resolve, reject) => setTimeout(() => resolve('promise 3 resolved!'), 300))
+
+// promise 4 and 6 will be resolved, but promise 5 will be rejected
+const promise4 = new Promise((resolve, reject) => setTimeout(() => resolve('promise 4 resolved!'), 1100))
+const promise5 = new Promise((resolve, reject) => setTimeout(() => reject('promise 5 rejected!'), 1200))
+const promise6 = new Promise((resolve, reject) => setTimeout(() => resolve('promise 6 resolved!'), 1300))
+
+// Promise.allSettled() with no rejections
+Promise.allSettled([promise1, promise2, promise3])
+ .then(data => console.log('all settled! here are the results:', data))
+ .catch(err => console.log('oh no, error! reason:', err))
+// all settled! here are the results: [
+// { status: "fulfilled", value: "promise 1 resolved!" },
+// { status: "fulfilled", value: "promise 2 resolved!" },
+// { status: "fulfilled", value: "promise 3 resolved!" },
+// ]
+
+// Promise.allSettled() with a rejection
+Promise.allSettled([promise4, promise5, promise6])
+ .then(data => console.log('all settled! here are the results:', data))
+ .catch(err => console.log('oh no, error! reason:', err))
+// all settled! here are the results: [
+// { status: "fulfilled", value: "promise 4 resolved!" },
+// { status: "rejected", reason: "promise 5 rejected!" },
+// { status: "fulfilled", value: "promise 6 resolved!" },
+// ]
+```
+
+## 2. Optional Chaining
+
+Once the product data is fetched, we handle the response. The data coming back from the server contains an array of objects with deeply-nested properties. In order to safely access those properties, we use the new optional chaining operator:
+
+```JavaScript
+if (data?.[0]?.status === 'fulfilled' && data?.[1]?.status === 'fulfilled') {
+ const products = data[0].value?.products
+ const prices = data[1].value?.prices
+ const descriptions = data[2].value?.descriptions
+ populateProductDropdown(products, descriptions)
+ saveDataToAppState(products, prices, descriptions)
+ return
+}
+```
+
+Optional chaining is the feature I’m most excited about in ES2020. The optional chaining operator — `?.` — allows you to safely access deeply-nested properties of an object without checking for the existence of each property.
+
+For example, prior to ES2020, you might write code that looks like this in order to access the `street` property of some `user` object:
+
+```JavaScript
+const user = {
+ firstName: 'John',
+ lastName: 'Doe',
+ address: {
+ street: '123 Anywhere Lane',
+ city: 'Some Town',
+ state: 'NY',
+ zip: 12345,
+ },
+}
+
+const street = user && user.address && user.address.street
+// '123 Anywhere Lane'
+
+const badProp = user && user.fakeProp && user.fakePropChild
+// undefined
+```
+
+In order to safely access the `street` property, you first must make sure that the `user` object exists and that the `address` property exists, and then you can try to access the `street` property.
+
+With optional chaining, the code to access the nested property is much shorter:
+
+```JavaScript
+const user = {
+ firstName: 'John',
+ lastName: 'Doe',
+ address: {
+ street: '123 Anywhere Lane',
+ city: 'Some Town',
+ state: 'NY',
+ zip: 12345,
+ },
+}
+
+const street = user?.address?.street
+// '123 Anywhere Lane'
+
+const badProp = user?.fakeProp?.fakePropChild
+// undefined
+```
+
+If at any point in your chain a value does not exist, `undefined` will be returned. Otherwise, the return value will be the value of the property you wanted to access, as expected.
+
+## 3. Nullish Coalescing
+
+When the app loads, we also fetch the user’s preference for their unit of measurement: kilograms or pounds. The preference is stored in local storage, so the preference won’t yet exist for first-time visitors. To handle either using the value from local storage or defaulting to using kilograms, we use the nullish coalescing operator:
+
+```JavaScript
+appState.doesPreferKilograms = JSON.parse(doesPreferKilograms ?? 'true')
+```
+
+The nullish coalescing operator — `??` — is a handy operator for when you specifically want to use a variable's value as long as it is not `undefined` or `null`. You should use this operator rather than a simple OR — `||`— operator if the specified variable is a boolean and you want to use its value even when it's `false`.
+
+For example, say you have a toggle for some feature setting. If the user has specifically set a value for that feature setting, then you want to respect his or her choice. If they haven’t specified a setting, then you want to default to enabling that feature for their account.
+
+Prior to ES2020, you might write something like this:
+
+```JavaScript
+const useCoolFeature1 = true
+const useCoolFeature2 = false
+const useCoolFeature3 = undefined
+const useCoolFeature4 = null
+
+const getUserFeaturePreference = (featurePreference) => {
+ if (featurePreference || featurePreference === false) {
+ return featurePreference
+ }
+ return true
+}
+
+getUserFeaturePreference(useCoolFeature1) // true
+getUserFeaturePreference(useCoolFeature2) // false
+getUserFeaturePreference(useCoolFeature3) // true
+getUserFeaturePreference(useCoolFeature4) // true
+```
+
+With the nullish coalescing operator, your code is much shorter and easier to understand:
+
+```JavaScript
+const useCoolFeature1 = true
+const useCoolFeature2 = false
+const useCoolFeature3 = undefined
+const useCoolFeature4 = null
+
+const getUserFeaturePreference = (featurePreference) => {
+ return featurePreference ?? true
+}
+
+getUserFeaturePreference(useCoolFeature1) // true
+getUserFeaturePreference(useCoolFeature2) // false
+getUserFeaturePreference(useCoolFeature3) // true
+getUserFeaturePreference(useCoolFeature4) // true
+```
+
+## 4. globalThis
+
+As mentioned above, in order to get and set the user’s preference for unit of measurement, we use local storage. For browsers, the local storage object is a property of the `window` object. While you can just call `localStorage` directly, you can also call it with `window.localStorage`. In ES2020, we can also access it through the `globalThis` object (also note the use of optional chaining again to do some feature detection to make sure the browser supports local storage):
+
+```JavaScript
+const doesPreferKilograms = globalThis.localStorage?.getItem?.('prefersKg')
+```
+
+The `globalThis` feature is pretty simple, but it solves many inconsistencies that can sometimes bite you. Simply put, `globalThis` contains a reference to the global object. In the browser, the global object is the `window` object. In a node environment, the global object is literally called `global`. Using `globalThis` ensures that you always have a valid reference to the global object no matter what environment your code is running in. That way, you can write portable JavaScript modules that will run correctly in the main thread of the browser, in a web worker, or in the node environment.
+
+## 5. Dynamic Imports
+
+Once the user has chosen a product, a unit of measurement, and a weight and price combination, he or she can click the submit button to find the unit price. When the button is clicked, a JavaScript module for calculating the unit price is lazy loaded. You can check the network request in the browser’s dev tools to see that the second file isn’t loaded until you click the button:
+
+```JavaScript
+import('./calculate.js')
+ .then(module => {
+ // use a method exported by the module
+ })
+ .catch(err => {
+ // handle any errors loading the module or any subsequent errors
+ })
+```
+
+Prior to ES2020, using an `import` statement in your JavaScript meant that the imported file was automatically included inside the parent file when the parent file was requested.
+
+Bundlers like [webpack](https://webpack.js.org/) have popularized the concept of “code splitting,” which is a feature that allows you to split your JavaScript bundles into multiple files that can be loaded on demand. React has also implemented this feature with its `React.lazy()` method.
+
+Code splitting is incredibly useful for single page applications (SPAs). You can split your code into separate bundles for each page, so only the code needed for the current view is downloaded. This significantly speeds up the initial page load time so that end users don’t have to download the entire app upfront.
+
+Code splitting is also helpful for large portions of rarely-used code. For example, say you have an “Export PDF” button on a page in your app. The PDF download code is large, and including it when the page loads reduces overall load time. However, not every user visiting this page needs or wants to export a PDF. To increase performance, you can make your PDF download code be lazy loaded so that the additional JavaScript bundle is only downloaded when the user clicks the “Export PDF” button.
+
+In ES2020, dynamic imports are baked right into the JavaScript specification!
+
+Let’s look at an example setup for the “Export PDF” functionality without dynamic imports:
+
+```JavaScript
+import { exportPdf } from './pdf-download.js'
+
+const exportPdfButton = document.querySelector('.exportPdfButton')
+exportPdfButton.addEventListener('click', exportPdf)
+
+// this code is short, but the 'pdf-download.js' module is loaded on page load rather than when the button is clicked
+```
+
+And now let’s look at how you could use a dynamic import to lazy load the large PDF download module:
+
+```JavaScript
+const exportPdfButton = document.querySelector('.exportPdfButton')
+
+exportPdfButton.addEventListener('click', () => {
+ import('./pdf-download.js')
+ .then(module => {
+ // call some exported method in the module
+ module.exportPdf()
+ })
+ .catch(err => {
+ // handle the error if the module fails to load
+ })
+})
+
+// the 'pdf-download.js' module is only imported once the user click the "Export PDF" button
+```
+
+## 6. String.prototype.matchAll()
+
+When calling the `calculateUnitPrice` method, we pass the product name and the price/weight combination. The price/weight combination is a string that looks like "$200 for 10 kg". We need to parse that string to get the price, weight, and unit of measurement. (There's certainly a better way to architect this app to avoid parsing a string like this, but I'm setting it up this way for the sake of demonstrating this next feature.) To extract the necessary data, we can use `String.prototype.matchAll()`:
+
+```JavaScript
+const matchResults = [...weightAndPrice.matchAll(/\d+|lb|kg/g)]
+```
+
+There’s a lot going on in that one line of code. We look for matches in our string based on a regular expression that is searching for digits and the strings “lb” or “kg”. It returns an iterator, which we can then spread into an array. This array ends up with three elements in it, one element for each match (200, 10, and “kg”).
+
+This feature is probably the most difficult to understand, particularly if you’re not well-versed in regular expressions. The short and simple explanation of `String.prototype.matchAll()` is that it's an improvement on the functionality found in `String.prototype.match()` and `RegExp.prototype.exec()`. This new method allows you to match a string against a regular expression and returns an iterator of all the matching results, including capture groups.
+
+Did you get all that? Let’s look at another example to help solidify the concept:
+
+```JavaScript
+const regexp = /t(e)(st(\d?))/
+const regexpWithGlobalFlag = /t(e)(st(\d?))/g
+const str = 'test1test2'
+
+// Using `RegExp.prototype.exec()`
+const matchFromExec = regexp.exec(str)
+console.log(matchFromExec)
+// ["test1", "e", "st1", "1", index: 0, input: "test1test2", groups: undefined]
+
+// Using `String.prototype.match()` on a regular expression WITHOUT a global flag returns the capture groups
+const matchFromMatch = str.match(regexp)
+console.log(matchFromMatch)
+// ["test1", "e", "st1", "1", index: 0, input: "test1test2", groups: undefined]
+
+// Using `String.prototype.match()` on a regular expression WITH a global flag does NOT return the capture groups :(
+const matchesFromMatchWithGlobalFlag = str.match(regexpWithGlobalFlag)
+for (const match of matchesFromMatchWithGlobalFlag) {
+ console.log(match)
+}
+// test1
+// test2
+
+// Using `String.prototype.matchAll()` correctly returns even the capture groups when the global flag is used :)
+const matchesFromMatchAll = str.matchAll(regexpWithGlobalFlag)
+for (const match of matchesFromMatchAll) {
+ console.log(match)
+}
+// ["test1", "e", "st1", "1", index: 0, input: "test1test2", groups: undefined]
+// ["test2", "e", "st2", "2", index: 5, input: "test1test2", groups: undefined]
+
+```
+
+## 7. BigInt
+
+Finally, we’ll make the unit price calculation by simply dividing the price by the weight. You can do this with normal numbers, but when working with large numbers, ES2020 introduces the `BigInt` which allows you to do calculations on large integers without losing precision. In the case of our app, using `BigInt` is overkill, but who knows, maybe our API endpoint will change to include some crazy bulk deals!
+
+```JavaScript
+const price = BigInt(matchResults[0][0])
+const priceInPennies = BigInt(matchResults[0][0] * 100)
+const weight = BigInt(matchResults[1][0])
+const unit = matchResults[2][0]
+
+const unitPriceInPennies = Number(priceInPennies / weight)
+const unitPriceInDollars = unitPriceInPennies / 100
+const unitPriceFormatted = unitPriceInDollars.toFixed(2)
+```
+
+If you’ve ever worked with data that contains extremely large numbers, then you know what a pain it can be to ensure the integrity of your numeric data while performing JavaScript math operations. Prior to ES2020, the largest whole number you could safely store was represented by `Number.MAX_SAFE_INTEGER`, which is 2^53 - 1.
+
+If you tried to store a number larger than that value in a variable, sometimes the number wouldn’t be stored correctly:
+
+```JavaScript
+const biggestNumber = Number.MAX_SAFE_INTEGER // 9007199254740991
+
+const incorrectLargerNumber = biggestNumber + 10
+// should be: 9007199254741001
+// actually stored as: 9007199254741000
+```
+
+The new `BigInt` data type helps solve this problem and allows you to work with much larger integers. To make an integer a `BigInt`, you simply append the letter `n` to the end of the integer or call the function `BigInt()` on your integer:
+
+```JavaScript
+const biggestNumber = BigInt(Number.MAX_SAFE_INTEGER) // 9007199254740991n
+
+const correctLargerNumber = biggestNumber + 10n
+// should be: 9007199254741001n
+// actually stored as: 9007199254741001n
+```
+
+## Conclusion
+
+That’s it! Now that you know all about the new ES2020 features, what are you waiting for? Get out there and start writing new JavaScript today!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/i-dont-hate-arrow-functions.md b/TODO1/i-dont-hate-arrow-functions.md
new file mode 100644
index 00000000000..9479e73e02c
--- /dev/null
+++ b/TODO1/i-dont-hate-arrow-functions.md
@@ -0,0 +1,214 @@
+> * 原文地址:[I Don’t Hate Arrow Functions](https://davidwalsh.name/i-dont-hate-arrow-functions)
+> * 原文作者:[Kyle Simpson](https://github.com/getify)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/i-dont-hate-arrow-functions.md](https://github.com/xitu/gold-miner/blob/master/TODO1/i-dont-hate-arrow-functions.md)
+> * 译者:[TiaossuP](https://github.com/tiaossup)
+> * 校对者:[Chorer](https://github.com/Chorer),[scarqin](https://github.com/scarqin)
+
+# 我并不讨厌箭头函数
+
+## 文章篇幅较长,可以直接看下面的总结
+
+箭头函数在某些场景下表现很好,但是在很多情况下,仍然有可能降低代码的可读性,因此要谨慎使用。
+
+尽管箭头函数显然已经在社区中被普遍接受(虽然并非一致支持),但事实证明,对于如何用好 `=>`,大家有各种各样的看法。
+
+可配置的 lint 规则是解决箭头函数的多样性和分歧的最佳解决方案。
+
+我发布了带有一些可配置规则的 [**proper-arrows** ESLint 插件](https://github.com/getify/eslint-plugin-proper-arrows),用于控制代码库中的 `=>` 箭头函数。
+
+## 观点总是见仁见智的
+
+任何关注我(包括推特、书籍、课程等)很久的人,都知道我总是有很多观点。事实上,这是我唯一擅长的事情(这也是我自己的观点),而且从来不会对它们感到困惑。
+
+我不赞同「强观点,弱坚持」*(译注:原文 strong opinions, loosely held 当存在若干现有事实时,要自信而强硬地表达观点;而遇到更强有力的论据时,则要懂得妥协让步)*这种信条。我不会「松散地持有」我的观点,因为没有足够理由支持的观点本来就没有任何意义。我花了很多时间研究、修改、写作、尝试各种想法,然后才形成一个可以公开分享的观点。在这一点上,我的观点是非常坚定的,这是必然的。
+
+更重要的是,我是基于这些观点去教授来自世界各地不同公司的数千名开发人员的 —— 这让我有机会通过无数的讨论和辩论来深入审视我的观点。能身居教学之位我深感荣幸。
+
+这并不意味着我不能或不会改变我的观点。事实上,我曾经最坚定的观点之一 —— 「JS 类型及[强制类型转换](https://developer.mozilla.org/en-US/docs/Glossary/Type_coercion)在 JS 中很有用」最近已经发生了很大程度的变化。我对 JS 类型及类型检测工具为何有用有了更全面和深入的认识。甚至我对 `=>` 箭头函数(本文的主题)的看法也在不断发展和深化。
+
+但是很多人告诉我他们欣赏我的一点是,我不仅陈述观点,还用严密的、深思熟虑的推理来支持这些观点。即使当人们强烈反对我的观点时,他们通常也会称赞我至少拥有那些有理有据的观点。
+
+我试图通过我的演讲、教学和写作来给其他人同样的灵感。我不在乎你是否同意我的观点,我只在乎你能知道自己为什么会在技术上持有这么一个观点,并且可以用你自己的推理来认真地捍卫它。对我来说,这是一种与技术「和谐共处」的方式。
+
+## `=>` 箭头函数 != `function`
+
+我真心觉得 `=>` 箭头函数并不适合替换 JS 代码中所有(或者至少说大多数)的 `function` 函数代码。我发现在大多数情况下,箭头函数并没有让代码更易读。并非只有我这样想,每当我在社交媒体上分享[类似的观点](https://twitter.com/getify/status/1105182569824346112)时,我经常会收到[几十条](https://twitter.com/bence_a_toth/status/1105185760448311296)「我也是!」的回应,只掺杂着几条「你[完全错了](https://twitter.com/fardarter/status/1105347990225649664)」的[回应](https://twitter.com/kostitsyn/status/1105229763369680896)。
+
+但是我并不是想在这里完整地讨论 `=>` 箭头函数。关于它,我已经写了很多篇文章来表达观点,包括我书中的以下部分:
+
+* [“你不知道的 JavaScript(下卷)”,第二章,“箭头函数”](https://github.com/getify/You-Dont-Know-JS/blob/master/es6%20%26%20beyond/ch2.md#arrow-functions)
+* ["Functional-Light JavaScript", Ch2, "Functions Without `function`"](https://github.com/getify/Functional-Light-JS/blob/master/manuscript/ch2.md/#functions-without-function) (and the preceding section on function names).
+
+无论对 `=>` 的偏好如何,把其**仅仅**视为是一个**更好的** `function` 的想法,都有些过于简略了。除了一对一的关系,还有很多细微的差异值得讨论。
+
+关于 `=>` 我还是有一些喜爱的,你可能会很惊讶,因为大多数人认为我讨厌箭头函数。
+
+我并不讨厌它,我认为箭头函数有一些显而易见且重要的优点。
+
+只是我并不完全地把它们视为颠覆式的 `function`,现如今,大多数人都不在意中间派别细微的意见,所以因为我没有站在支持 => 的阵营,我就站在了反对的阵营。**但其实不是这样的**。
+
+我讨厌的是暗示箭头函数普遍更具可读性,或者,客观来说他们在各种情况下都**更好**的这种行为。
+
+我拒绝这一立场的原因是,在许多情况下,**我阅读这些代码都很吃力**。所以那种观点只会让作为开发人员的我感到愚蠢和自卑 ——「这段代码并没有非常易读,肯定是我有什么问题,为什么我这么菜?」而且,我并不是唯一一个被这种绝对观点严重煽动的[冒名顶替者综合症](https://baike.baidu.com/item/冒名顶替综合症)患者。
+
+最扯淡的是,人们告诉你,「你不了解或不喜欢 `=>` 的唯一原因是你没有充分地学习和使用它们」。行吧,谢谢(你屈尊的)提醒,我知道这是因为**我的**无知和经验不足了。但其实我内心只想说呵呵。我已经编写并阅读了成千上万个 `=>` 函数。我对它们足够了解,有资格发表意见。
+
+我没站在支持 `=>` 的阵营中,但我承认有些人确实喜欢它们,这是合理的。有些人从使用 `=>` 的语言转到 JS,所以他们能非常自然地感知和阅读。有些人还喜欢它们与数学符号的相似性。
+
+在我看来,有问题的是,某个阵营中的一些人对不同的意见根本无法做到理解或者产生共鸣,就好像提出异议者一定是**有什么东西做得不对**。
+
+## 好的代码书写体验 != 可读性
+
+我也认为**你们**在讨论代码可读性时其实不知道自己在说什么。总的来说,当你把大多数关于代码可读性的观点分解的时候,它们其实都是基于个人对**书写**简洁代码的偏好的看法。
+
+在关于代码可读性的争论中,当我提出反驳时,有些人只是固执己见,拒绝支持别人的观点。另一些人则会用「可读性只是主观的」来搪塞我的反驳。
+
+这种回答之脆弱令人震惊:两秒钟前,他们还在激烈地宣称 `=>` 箭头**绝对地、客观地**更具有可读性,然后当被追问时,他们承认,「行吧,**我**个人认为它更具有可读性,即使像你这样的无知之人不这么认为。」
+
+你猜怎么着?可读性**是**主观的,**但并不完全如此**。这是一个非常复杂的话题。也有一些人开始正式研究代码可读性的话题,试图找出哪些部分是客观的,哪些部分是主观的。
+
+我读过很多这样的研究,因此我确信这是一个足够复杂的话题,以至于它没法被简化成 T 恤上的 slogan。如果你想了解详情,我建议你自己去谷歌一下。
+
+虽然我无法完整地回答所有关于可读性的问题,但有一件事我可以肯定的是,代码更多的时候是被阅读而不是被写出来的,所以从「写代码更容易/更快」这个论据出发的论点是站不住脚的。需要考虑的不是你节省了多少写代码的时间,而是读者(未来的你或团队中的其他人)能够多清楚地理解。理想情况下,他们能够在不仔细梳理代码的情况下大致理解代码吗?
+
+任何试图证明写代码容易就有利于代码可读性的说法都是站不住脚的,总的来说,这只是在混淆视听。
+
+因此,我坚决反对 `=>` 总是客观地「更具可读性」。
+
+但我还是不讨厌箭头函数。我只是认为如果要有效地利用它们,我们需要更加自律。
+
+## Linter == 准则
+
+您可能(错误地)相信,linter 会告诉您有关代码的客观事实。其实它们**可以**做到这一点,但这不是其主要目的。
+
+能告诉您代码是否有效的最佳工具是编译器(即 JS 引擎)。而最适合告诉您代码是否「正确」(满足需求)的工具是测试集。
+
+但是最适合告诉您代码是否**合适**的工具是 linter。根据那些基于观点制订规则的作者的说法,Linter 就是指导你格式化和组织代码的充满主观观点的规则集合,它可以用于避免可能出现的问题。
+
+这就是规则所做的:**在你的代码中应用这些观点。**
+
+几乎可以肯定的是,这些观点会一次又一次地「冒犯」您。如果您像我们大多数人一样,就会出现「幻想自己做得很好,并且认为您在此代码行上所做的事情是**正确**的。然后 linter 跳出来,说:『不,不要那样做。』」的场景。
+
+如果有时您的直觉告诉你不要同意 linter 提出的意见,那么您就跟我们其余的人一样了!我们从情感上迷恋自己的观点和能力,并且当某种工具指出我们的错误时,我们就会有点狂躁。
+
+我不会对测试集或 JS 引擎感到生气。这些东西都是关于我的代码的**事实**。但是当 linter 的**观点**与我的不同时,我就会非常生气。
+
+我在几周前启用了一个 linter 规则,因为我在重新阅读代码的时候发现有一处让我烦恼的、前后矛盾的地方。但现在,这条 lint 规则每小时会出现两三次,就像 90 年代情景喜剧里典型的老奶奶一样,让我心烦。每一次,我都思考(仅仅是片刻)我是否应该取消这个规则。但最终我让它开着,虽然这令我不爽。
+
+为什么要让我们自己遭受如此痛苦?因为 linter 工具及其观点给我们提供了准则。他们帮助我们更好地与他人协作。
+
+它们最终帮助我们更清晰地表达代码。
+
+我们为什么不让每个开发人员都自己做出决定?因为我们总是倾向于情感依恋。虽然我们写着**自己的代码**,但面对着不合理的压力和期限,我们很可能会以最不值得信赖的心态进行这些判断。
+
+我们应该听从于帮助我们维护准则的工具。
+
+类似于 TDD 倡导的写业务代码前先写测试代码的原则。当我们仔细分析时,会发现我们最看重的是流程的纪律性和全局效果。在代码无法工作、还找不到原因时,我们就只能胡乱挪一挪代码,来看是否能用。在这种情境下,我们是无法建立这样的过程的。
+
+讲道理,我们还是要承认,当我们制定了合理的指导方针,然后遵守它们的准则时,**整体利益**会达到最大化。
+
+## 可配置性为王
+
+如果你有意让自己接受 lint 规则,你(和你的团队,如果有的话)肯定会想要一些发言权 —— 你需要遵守哪些规则。武断和不容置疑的观点是最糟糕的。
+
+还记得 JSLint 么?那里 98% 的规则只是 Crockford 的个人观点,你要么使用这个工具,要么不使用这个工具。他直接在 README 文档中警告你,你会被冒犯,你应该克服它。很有趣,对吧?(有些人可能还在使用 JSLint,但是我认为您应该考虑使用更现代的工具!)
+
+这就是在当代的 linter 工具中,[ESLint 为王](https://eslint.org/)的原因。其基本思想是,让一切都是可配置的。让开发者和团队从自己的准则和利益出发,自行决定要使用什么样的代码规范。
+
+这不意味着每个开发人员都有自己的规则。规则的目的是使代码符合一个合理的折中方案,即「集中式标准」,这是与团队中大多数开发人员进行最清晰沟通的最佳机会。
+
+但是没有任何规则是 100% 完美的。总会有例外情况。所以,使用内联注释来禁用或覆盖规则这一功能不仅仅是一个小特性,还是一个必要功能。
+
+您不希望开发人员通过配置自己本地的 ESLint 规则,来让提交代码时绕过共识规则。您想要的是开发人员要么遵循已建立的规则(首选!),**要么**在破例的地方让这个逃离规则的例外一目了然。
+
+理想情况下,在 code review 期间,可以讨论、审查这些特殊标记。也许这是合理的,也许不是。但至少它是显而易见、可以讨论的。
+
+工具的可配置性指的是让工具为我们服务,而不是我们为工具服务。
+
+有些人更喜欢基于约定,而非基于工具,约定的规则是预先确定的,因此没有讨论或辩论。我知道这对一些开发人员和一些团队是有效的,但是我认为这不是一种可以广泛应用、可持续的方法最终,如果一个工具不能灵活地适应不断变化的项目需求、成为开发人员开发过程中重要的一部分,那么它将会变得模糊,并最终被取代。
+
+## 箭头函数的正当用法
+
+我充分能理解,在这里我使用「正当」这个词会惹怒一些人:「谁有资格说什么是正当的,什么是不正当的?」
+
+记住,我并不是要告诉你什么是正当的。我想让大家接受这样一个观点,即关于 `=>` 箭头函数的各种观点就像它们的语法和用法的所有细微差别一样,最终最正当的是**一些观点**,不管具体是什么,总归会有一些可应用的观点。
+
+虽然我是 ESLint 的狂热粉丝,但是我对 ESLint 的内置规则无法从各个方面支持 `=>` 箭头函数而感到失望,虽然有[很](https://eslint.org/docs/rules/arrow-body-style)少[的](https://eslint.org/docs/rules/arrow-parens)几[个](https://eslint.org/docs/rules/arrow-spacing)内[置](https://eslint.org/docs/rules/implicit-arrow-linebreak)规则,但我很失望,它们似乎主要关注于表面的风格细节,例如空白符。
+
+我认为有许多方面会妨碍 `=>` 箭头函数的可读性,这些问题远远超出了现有 ESLint 规则集所能控制的范围。我在[推特](https://twitter.com/getify/status/1106641030273736704)上问了[很多人](https://twitter.com/getify/status/1106902287010709504),似乎很多人对此都有看法。
+
+顶级的 linter 就应该不仅允许您根据自己的喜好配置规则,还可以在缺少某些内容时构造自己的规则。幸运的是,ESLint 完全支持这一点!
+
+因此,我决定开发一个 ESLint 插件来定义一组围绕 `=>` 箭头函数的附加规则:[**proper-arrows**](https://github.com/getify/eslint-plugin-proper-arrows)。
+
+在解释它之前,我要先指出:它是一组规则,您可以自主决定打开或关闭、配置这些规则。如果你发现哪怕有一个规则的一个细节对您有帮助,使用这个规则/插件都是更好的选择。
+
+我很高兴你对 `=>` 箭头函数有自己的看法。事实上,这才是重点。如果我们都对 `=>` 箭头函数有不同的意见,那么我们应该有工具支持选择和配置这些不同的意见。
+
+这个插件的原理是,对于每个规则,当你打开这个规则时,你会默认打开它的所有报告模式。您可以不打开规则,也可以打开规则,然后根据需要配置它的模式。但我不希望你必须去寻找规则/模式来开启,因为它们的晦涩甚至会阻碍你去考虑它们。所以**每个规则都默认开启**。
+
+唯一的例外是,在默认情况下,所有的规则都忽略了[简单的 `=>` 箭头函数](https://github.com/getify/eslint-plugin-proper-arrows#trivial--arrow-functions),比如 `()=> {}`、`x => x`等。如果您想要检查它们,那么您必须在每个规则的基础上使用 `{ "trivial": true }` 选项打开检查。
+
+### 具体规则
+
+那么具体提供了哪些规则呢?以下是[对项目概述的摘录](https://github.com/getify/eslint-plugin-proper-arrows/blob/master/README.md#overview):
+
+* [`"params"`](https://github.com/getify/eslint-plugin-proper-arrows/blob/master/README.md#rule-params):控制 `=>` 箭头函数参数的定义,例如禁止未使用的参数,禁止短/无语义的参数名称等。
+* [`"name"`](https://github.com/getify/eslint-plugin-proper-arrows/blob/master/README.md#rule-name):要求仅在接收到推断名称的位置使用 `=>` 箭头函数(即分配给变量或属性等),以避免匿名函数表达式的不可读/可调试性。
+* [`"where"`](https://github.com/getify/eslint-plugin-proper-arrows/blob/master/README.md#rule-where):限制可以在程序结构中使用 `=>` 箭头函数的位置:禁止在顶级/全局作用域、对象属性、`export` 语句等地方使用。
+* [`"return"`](https://github.com/getify/eslint-plugin-proper-arrows/blob/master/README.md#rule-return):限制 `=>` 箭头函数的简明返回值类型,例如禁止对象文字简明返回(`x => ({ x })`)、禁止条件/三元表达式的简明返回(`x => x ? y : z`)等。
+* [`"this"`](https://github.com/getify/eslint-plugin-proper-arrows/blob/master/README.md#rule-this):要求/禁止 `=>` 箭头函数在 `=>` 箭头函数自身或嵌套 `=>` 箭头函数中使用 `this` 引用,该规则可以有选择地禁止全局作用域使用带 `this` 的 `=>` 箭头函数。
+
+请记住,每个规则都有不同的模式可供配置,所以这些并非全有或全无的。选择你需要的即可。
+
+为了示意 **proper-arrows** 规则可以检查什么,让我们看看 [`"return"` 规则](https://github.com/getify/eslint-plugin-proper-arrows/blob/master/README.md#rule-return),特别是它的 [`"sequence"` 模式](https://github.com/getify/eslint-plugin-proper-arrows/blob/master/README.md#rule-return-configuration-sequence)。这种模式将 `=>` 箭头函数的简洁返回表达式表示为逗号分隔的序列,如下所示:
+
+```JavaScript
+var myfunc = (x,y) => ( x = 3, y = foo(x + 1), \[x,y\] );
+```
+
+Sequences 通常用于 `=>` 箭头函数的简洁返回结果中,从而将多个(表达式)语句串在一起,而不需要使用完整的 `{ .. }` 分隔函数体和显式的 `return` 语句。
+
+有些人可能喜欢这种风格,这没问题!不过还有很多人更倾向于可读性而不是更简洁的代码,他们更喜欢:
+
+```JavaScript
+var fn2 = (x,y) => { x = 3; y = foo(x + 1); return \[x,y\]; };
+```
+
+请注意,它仍然是一个 `=>` 箭头函数,其实也并没有多出几个字符。但这样可以更清楚的看到,此函数体中包含三个单独的语句。
+
+更好的做法:
+
+```JavaScript
+var fn2 = (x,y) => {
+ x = 3;
+ y = foo(x + 1);
+ return \[x,y\];
+};
+```
+
+需要明确的是, **proper-arrows** 规则不会对琐碎的样式差异进行强制,例如空格/缩进。如果要对这类差异进行统一,可以结合使用其它( ESLint 内置)规则。 **proper-arrows** 规则专注于有关于 `=>` 箭头函数的更实质性的内容。
+
+## 简要总结
+
+针对「什么才能造就**良好、正确**的 `=>` 箭头函数的样式」这件事,您和我一定有不不同的意见。这是一件正常不过的事情。
+
+我有两个目标:
+
+1. 说服您:对这些东西的看法不同是没关系的。
+2. 使您能够使用可配置的工具来制定并推行自己的观点(或团队共识)。
+
+争论基于意见的规则确实没有任何收获。选择您喜欢的,忘记您不喜欢的就够了。
+
+我希望您看一下 [**proper-arrows**](https://github.com/getify/eslint-plugin-proper-arrows),然后看看有没有哪些规则可以为您所用,让您的 `=>` 箭头函数符合您心目中代码的正确形式。
+
+如果这个插件缺少一些有助于定义更多正确箭头的规则,请[提出 issue,咱们一起讨论](https://github.com/getify/eslint-plugin-proper-arrows/issues)!我们完全有可能添加该规则/模式,尽管我个人并不打算开启该规则!
+
+我不讨厌 `=>` 箭头函数,您也不应该。我只是讨厌无知无纪的争辩。让我们拥抱更智能,可配置性更强的工具,然后转向更重要的主题吧!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/image-inpainting-humans-vs-ai.md b/TODO1/image-inpainting-humans-vs-ai.md
new file mode 100644
index 00000000000..f6465bf6771
--- /dev/null
+++ b/TODO1/image-inpainting-humans-vs-ai.md
@@ -0,0 +1,117 @@
+> * 原文地址:[Image Inpainting: Humans vs. AI](https://towardsdatascience.com/image-inpainting-humans-vs-ai-48fc4bca7ecc)
+> * 原文作者:[Mikhail Erofeev](https://medium.com/@mikhail_26901)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/image-inpainting-humans-vs-ai.md](https://github.com/xitu/gold-miner/blob/master/TODO1/image-inpainting-humans-vs-ai.md)
+> * 译者:[Starry](https://github.com/Starry316)
+> * 校对者:[lsvih](https://github.com/lsvih), [Amberlin1970](https://github.com/Amberlin1970)
+
+# 图像修复:人类和 AI 的对决
+
+
+
+在许多任务中,深度学习方法优于相应的传统方法,能够取得与人类专家相近甚至是更好的结果。比如说 GoogleNet 在 ImageNet 基准上的表现超过了人类([Dodge and Karam 2017](https://arxiv.org/abs/1705.02498))。这篇文章中,我们对专业艺术家和计算机算法(包括最近基于深度神经网络的方法,或者叫 DNN)进行比较,看看哪一方能够在图像修复上取得更好的结果。
+
+## 图像修复是什么?
+
+图像修复是对一幅图像丢失部分的重构过程,使得观察者察觉不到这些区域曾被修复。这种技术通常用于移除图像中多余的元素,或者是修复老照片中损坏的部分。下面的图片展示了图像修复结果的例子。
+
+图像修复是一门古老的艺术,最初需要人类艺术家手工作业。但如今,研究人员提出了许多自动修复方法。大多数自动修复方法除了图像本身外,还需要输入一个掩码(mask)来表示需要修复的区域。接下来,我们将对九个自动修复方法和专业艺术家对图像修复的结果进行比较。
+
+)](https://cdn-images-1.medium.com/max/2152/1*EOuFiCNYdNde05bi9UmB8A.jpeg)
+
+)](https://cdn-images-1.medium.com/max/2412/1*_Ldd9jY-9xS2OEE6Z8FTfw.jpeg)
+
+## 数据集
+
+为了创建测试图片数据集,我们从一个私人照片集中截取了 33 个 512x512 像素的图像。然后将一个 180x180 像素的黑色正方形填充到每个图像片的中心。艺术家和自动方法的任务是,通过只改变黑色正方形中的像素,来恢复失真图像的原样。
+
+我们使用一个私有,未公开的照片集来保证参与对比的艺术家们没有接触过原始图片。虽然不规则的掩码是现实世界图像修复的典型特征,但我们只能在图像中心使用正方形的掩码,因为它们是我们对比实验中一些 DNN 方法所唯一允许的掩码类型。
+
+下面是我们数据集中图片的略缩图。
+
+
+
+## 自动修复方法
+
+我们在测试数据集应用了如下六种基于神经网络的图像修复方法:
+
+1. Deep Image Prior ([Ulyanov, Vedaldi, and Lempitsky, 2017](https://arxiv.org/abs/1711.10925))
+2. Globally and Locally Consistent Image Completion ([Iizuka, Simo-Serra, and Ishikawa, 2017](http://hi.cs.waseda.ac.jp/~iizuka/projects/completion/en/))
+3. High-Resolution Image Inpainting ([Yang et al., 2017](https://arxiv.org/abs/1611.09969))
+4. Shift-Net ([Yan et al., 2018](https://arxiv.org/abs/1801.09392))
+5. Generative Image Inpainting With Contextual Attention ([Yu et al., 2018](https://arxiv.org/abs/1801.07892)) — this method appears twice in our results because we tested two versions, each trained on a different data set (ImageNet and Places2)
+6. Image Inpainting for Irregular Holes Using Partial Convolutions ([Liu et al., 2018](https://arxiv.org/abs/1804.07723))
+
+我们测试了三个在人们对深度学习的兴趣爆发前提出的修复方法(非神经网络方法)作为(对比的)基准:
+
+1. Exemplar-Based Image Inpainting ([Criminisi, Pérez, and Toyama, 2004](http://www.irisa.fr/vista/Papers/2004_ip_criminisi.pdf))
+2. Statistics of Patch Offsets for Image Completion ([He and Sun, 2012](http://kaiminghe.com/eccv12/index.html))
+3. Content-Aware Fill in Adobe Photoshop CS5
+
+## 专业艺术家
+
+我们请了三位从事图像后期调整和修复的专业艺术家,让他们修复从我们的数据库中随机选取的三张图片。为了激励他们得到尽可能好的结果。我们跟他们说,如果他或她的作品比竞争对手好,我们会给酬金增加 50% 作为奖励。尽管我们没有给定严格的时间限制,但所有艺术家都在 90 分钟左右的时间内完成了任务。
+
+下面是结果:
+
+
+
+## 人类 vs. 算法
+
+我们使用[Subjectify.us](http://www.subjectify.us)平台将三个专业艺术家和自动图像修复方法的结果与原始、未失真的图像(即真值(ground truth))进行对比。这个平台将结果以两两配对的方式呈现给研究参与者,让他们在每一对图片中选出一个视觉质量更好的。为了保证参与者做出的是思考后的选择,平台还会让他们在真值图片和图像修复范例结果之间进行选择来验证。 如果应答者没有在一个或两个验证问题中选择出正确答案,平台会将他的所有答案抛弃。最终,平台一共收集到了来自 215 名参与者的 6945 个成对判断。
+
+下面是这次比较的总体和每幅图像的主观质量分数:
+
+
+
+ **“Overall”** 图表表明,所有艺术家的表现都比自动方法好上一大截。只有在一个例子下,一个算法击败了一名艺术家: **Statistics of Patch Offsets** (He and Sun, 2012) 对 **“Urban Flowers”** 图片的修复,得分高过了 **Artist #1** 绘制的图片。还有,只有艺术家修复的图片能够媲美甚至比原图更好:**Artist #2** 和 **#3** 修复的 **“Splashing Sea”** 图片得到了比真值更高的质量分数,**Artist #3** 修复的 **“Urban Flowers”** 得分只比真值低一点点。
+
+在自动方法中获得第一名的是深度学习方法 Generative Image Inpainting。但这并不是压倒性的胜利,因为在我们的研究中,这个算法从来没有在任何图片中取得最高分数。对于 **“Urban Flowers”** 和 **“Splashing Sea”** 第一名分别是非神经网络方法的 **Statistics of Patch Offsets** 和 **Exemplar-Based Inpainting**,而 **“Forest Trail”** 的第一名是深度学习方法 **Partial Convolutions**。值得注意的是,根据总体的排行榜来看,其它的深度学习方法都被非神经网络方法超越。
+
+## 一些有趣的例子
+
+一些结果引起了我们的注意。非神经网络的方法 **Statistics of Patch Offsets** (He and Sun, 2012) 生成的图片比起艺术家修复的图片更受到参与比较者的青睐:
+
+
+
+此外,高排名的神经网络方法 **Generative Image Inpainting** 得到的图像,获得了比非神经网络方法 **Statistics of Patch Offsets** 更低的分数:
+
+
+
+另一个令人惊讶的结果是,2018 年提出的神经网络方法 **Generative Image Inpainting**,得分比 14 年前提出的非神经网络方法(**Exemplar-Based Image Inpainting**)还低:
+
+
+
+## 算法之间的比较
+
+为了深入比较神经网络方法和非神经网络方法,我们使用 Subjectify.us 进行了一次额外的主观比较。与第一次比较不同,我们使用完整的 33 张图片数据集对这些方法进行比较。
+
+下面是从 147 名研究参与者给出的 3,969 个成对判断中得到总体主观分数。
+
+
+
+这些结果证实了我们从其他比较中得到的观测结果。第一名(在真值之后)是在 the Places2 数据集上训练的 **Generative Image Inpainting**。没有使用神经网络的 **Content-Aware Fill Tool in Photoshop CS5** 以很小的差别位居第二名。在 ImageNet 上训练的 **Generative Image Inpainting** 获得第三名。值得注意的是,其他所有的非神经网络方法的表现都超过了深度学习方法。
+
+## 结论
+
+我们从自动图像修复方法与专业艺术家的对比研究中得到如下结论:
+
+1. 艺术家的图像修复仍然是取得接近真值质量的唯一方法.
+2. 只有在特定的图像上,自动图像修复方法的结果才能和人类艺术家相媲美。
+3. 尽管在这些自动方法中一个深度学习算法取得了第一名,但非神经网络算法仍然处在一个强有力的位置,并且在众多测试的表现超过了深度学习方法。
+4. 非深度学习方法和专业艺术家(废话)可以修复任意形状的区域,而大部分基于神经网络的却受到掩码形状的严格限制。这个约束使得这些方法在现实世界中的适用性变窄了。我们因此突出强调 **Image Inpainting for Irregular Holes Using Partial Convolutions** 这一深度学习方法上,它的开发人员关注于支持任意形状的掩码。
+
+我们相信未来这一领域的研究,以及 GPU 算力和 RAM 容量的增长,将会使得深度学习算法胜过它们的传统竞争者,得到和人类艺术家相媲美的图像修复结果。然而我们强调,在目前最新的技术下,选择一个传统的图像或视频处理方法,也许会比盲目地只是因为新,而选择一个新的深度学习方法更好。
+
+## 福利
+
+我们已将实验中收集的图片和主观分数进行了分享,因此你可以自己分析这些数据。
+
+* [实验对比中的图像](https://github.com/merofeev/image_inpainting_humans_vs_ai)
+* [主观分数(包含每幅图片的分数)](http://erofeev.pw/image_inpainting_humans_vs_ai/)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/is-no-sql-killing-sql.md b/TODO1/is-no-sql-killing-sql.md
new file mode 100644
index 00000000000..845db71498c
--- /dev/null
+++ b/TODO1/is-no-sql-killing-sql.md
@@ -0,0 +1,79 @@
+> * 原文地址:[Is No-SQL killing SQL?](https://towardsdatascience.com/is-no-sql-killing-sql-3b0daff69ea)
+> * 原文作者:[Tom Waterman](https://medium.com/@tjwaterman99)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/is-no-sql-killing-sql.md](https://github.com/xitu/gold-miner/blob/master/TODO1/is-no-sql-killing-sql.md)
+> * 译者:[江不知](http://jalan.space)
+> * 校对者:[Jessica](https://github.com/cyz980908), [司徒公子](https://github.com/todaycoder001)
+
+# SQL 将死于 No-SQL 之手?
+
+
+
+#### SQL 永生不灭的两个原因
+
+上周,我的一位朋友向我转发了一封来自一位成功创业者的电子邮件,邮件宣称「SQL 已死」。
+
+这位创业者宣称,像 MongoDB、Redis 这样广受欢迎的 No-SQL 数据库会慢慢取代基于 SQL 的数据库,因此,作为数据科学家还需学习 SQL 是一个「历史遗留问题」。
+
+我完全被他的电子邮件震惊了:他怎么得出如此离谱的结论?但是这也使我感到好奇……别人是否也有可能被类似地误导了?这位企业家已经发展了大批追随者,且直言不讳 —— 那么新晋数据科学家是否已经收到了避免学习 SQL 的建议?
+
+因此我觉得我应当公开分享我对该创业者的回应,以防他人认为 SQL 即将走向灭绝。
+
+> 在数据科学的职业生涯中,你**绝对**应当学习 SQL。No-SQL 的存在绝对不会影响学习 SQL 的价值。
+
+基本上有两个原因可以保证 SQL 在未来几十年仍然适用。
+
+**原因 #1:No-SQL 数据库无法取代数据分析型数据库,例如 Presto、Redshift 或 BigQuery**
+
+无论你的应用是使用以 SQL 为后端的数据库,例如 MySQL,或是以 No-SQL 为后端的数据库,例如 MongoDB,这些后端中的数据最终都将被加载到一个专用的数据分析数据库中,例如 Redshift、Snowflake、BigQuery 或 Presto。
+
+
+
+为什么公司要将他们的数据转移到像 Redshift 这样特定的列式存储中?因为和 NoSQL 与 MySQL 这样的行式存储数据库相比,列式存储能**更**快地运行分析查询。事实上,我敢打赌,列式存储和 NoSQL 一样会越来越受欢迎。
+
+因此,无论是 NoSQL 还是其他的应用程序数据库都与数据科学家无关,因为数据科学家不会对应用程序数据库进行操作(尽管有一些例外,这些例外我将在之后讨论)。
+
+**原因 #2:No-SQL 数据库的好处不在于他们不支持 SQL 语言**
+
+事实证明,如果 No-SQL 数据存储支持基于 SQL 的查询引擎是有意义的,那么它们就可以实现该引擎。类似地,SQL 数据库也可以支持 NoSQL 查询语言,但是它们选择不支持。
+
+为什么列式存储**有意选择**提供 SQL 接口呢?
+
+他们之所以作出这样的选择是因为 SQL 是一种表达数据操作指令的强大语言。
+
+让我们来考虑一个简单的查询示例,该查询用于计算来自 NoSQL 数据库 MongoDB 中某集合的文档数量。
+
+> 注意:MongoDB 中的文档类似于行,集合类似于表。
+
+```js
+db.sales.aggregate( [
+ {
+ $group: {
+ _id: null,
+ count: { $sum: 1 }
+ }
+ }
+] )
+```
+
+将其与等价的 SQL 语句进行比较。
+
+```sql
+select count(1) from sales
+```
+
+显然,对于想要提取数据的人来说,SQL 语言是更好的选择。(NoSQL 数据库支持另一种语言,因为对于与数据库连接的应用程序库来说,正确构造 SQL 相对比较困难)。
+
+---
+
+在前面我提到过,应用程序数据库技术与科学家无关的规则是有例外的。例如,在我的第一家公司,我们实际上没有任何像 Redshift 这样的分析型数据库,所以我不得不直接查询该应用程序的数据库。(更准确地说,我是在查询应用程序数据库的只读副本)。
+
+公司的应用也使用了 Redis 这样的 No-SQL 数据库,这样至少有一次,我需要从 Redis 中提取数据,所以我必须学习一些 Redis 的 NoSQL API 的某些组件。
+
+因此,如果在主应用程序环境中完全使用 NoSQL 数据库,那么你学到的任何 SQL 知识都与之无关了。但是这样的环境非常少见,随着公司的发展,他们几乎都会把一个基于 SQL 的列式存储数据库投入使用。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/javascript-native-methods-you-may-not-know.md b/TODO1/javascript-native-methods-you-may-not-know.md
new file mode 100644
index 00000000000..5277b557039
--- /dev/null
+++ b/TODO1/javascript-native-methods-you-may-not-know.md
@@ -0,0 +1,265 @@
+> * 原文地址:[JavaScript Native Methods You May Not Know](https://medium.com/better-programming/javascript-native-methods-you-may-not-know-ccc4b8aa5cfd)
+> * 原文作者:[Moon](https://medium.com/@moonformeli)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/javascript-native-methods-you-may-not-know.md](https://github.com/xitu/gold-miner/blob/master/TODO1/javascript-native-methods-you-may-not-know.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[Baddyo](https://github.com/Baddyo),[Chorer](https://github.com/Chorer)
+
+# 您可能不知道的原生 JavaScript 方法
+
+#### 一些很强大但却经常被忽视的原生 JavaScript 方法
+
+
+
+自从 ES6 发布以来,许多新的、方便的原生方法被添加到 JavaScript 的新标准中。
+
+但是,我还是在 GitHub 的仓库中看到了许多旧代码。当然,这并不是说它们不好,而是说如果使用我下面介绍的这些特性,代码将变得更具可读性、更美观。
+
+---
+
+## Number.isNaN 对比 isNaN
+
+`NaN` 是 number 类型。
+
+```js
+typeof NaN === 'number'
+```
+
+所以您不能直接区分出 `NaN` 和普通数字。
+
+甚至对于 `NaN` 和 普通数字,当调用 Object.prototype.toString.call 方法时都会返回 `[object Number]`。您可能已经知道 `isNaN` 方法可以用于检查参数是否为 `NaN`。但是自从有了 ES6 之后,构造函数 **Number()** 也开始将 isNaN 作为它的方法。那么,这二者有什么不同呢?
+
+* `isNaN` —— 检查值是否不是一个普通数字或者是否不能转换为一个普通数字。
+* `Number.isNaN` —— 检查值是否为 NaN。
+
+这里有一些例子。[Stack Overflow](https://stackoverflow.com/questions/33164725/confusion-between-isnan-and-number-isnan-in-javascript) 上的网友已经讨论过这个话题了。
+
+```js
+Number.isNaN({});
+// <- false,{} 不是 NaN
+Number.isNaN('ponyfoo')
+// <- false,'ponyfoo' 不是 NaN
+Number.isNaN(NaN)
+// <- true,NaN 是 NaN
+Number.isNaN('pony'/'foo')
+// <- true,'pony'/'foo' 是 NaN,NaN 是 NaN
+
+isNaN({});
+// <- true,{} 不是一个普通数字
+isNaN('ponyfoo')
+// <- true,'ponyfoo' 不是一个普通数字
+isNaN(NaN)
+// <- true,NaN 不是一个普通数字
+isNaN('pony'/'foo')
+// <- true,'pony'/'foo' 是 NaN, NaN 不是一个普通数字
+```
+
+---
+
+## Number.isFinite 对比 isFinite
+
+在 JavaScript 中,类似 1/0 这样的计算不会产生错误。相反,它会返回全局对象的一个属性 `Infinity`。
+
+那么,如何检查一个值是否为无穷大呢?抱歉,您做不到。但是,您可以使用 `isFinite` 和 `Number.isFinite` 检查值是否为有限值。
+
+它们的工作原理基本相同,但彼此之间略有不同。
+
+* `isFinite` —— 检查传入的值是否是有限值。如果传入的值的类型不是 `number` 类型,会尝试将这个值转换为 `number` 类型,再判断。
+* `Number.isFinite` —— 检查传入的值是否是有限值。即使传入的值的类型不是 `number` 类型,也不会尝试转换,而是直接判断。
+
+```js
+Number.isFinite(Infinity) // false
+isFinite(Infinity) // false
+
+Number.isFinite(NaN) // false
+isFinite(NaN) // false
+
+Number.isFinite(2e64) // true
+isFinite(2e64) // true
+
+Number.isFinite(undefined) // false
+isFinite(undefined) // false
+
+Number.isFinite(null) // false
+isFinite(null) // true
+
+Number.isFinite('0') // false
+isFinite('0') // true
+```
+
+---
+
+## Math.floor 对比 Math.trunc
+
+在过去,当您需要取出小数点右边的数字时,您可能会使用 `Math.floor` 这个函数。但是从现在开始,如果您真正想要的只是整数部分,可以尝试使用 `Math.trunc` 函数。
+
+* `Math.floor` —— 返回小于等于给定数字的最大整数。
+* `Math.trunc` —— 返回数的整数部分。
+
+基本上,如果给定的数是正数,它们会给出完全相同的结果。但是如果给定的数字是负数,结果就不同了。
+
+```js
+Math.floor(1.23) // 1
+Math.trunc(1.23) // 1
+
+Math.floor(-5.3) // -6
+Math.trunc(-5.3) // -5
+
+Math.floor(-0.1) // -1
+Math.trunc(-0.1) // -0
+```
+
+---
+
+## Array.prototype.indexOf 对比 Array.prototype.includes
+
+当您想在给定数组中查找某个值时,如何查找它?我见过许多开发人员使用 `Array.prototype.indexOf`,如下面的例子所示。
+
+```js
+const arr = [1, 2, 3, 4];
+
+if (arr.indexOf(1) > -1) {
+ ...
+}
+```
+
+* `Array.prototype.indexOf` —— 返回可以在数组中找到给定元素的第一个索引,如果不存在,则返回 `-1`。
+* `Array.prototype.includes` —— 检查给定数组是否包含要查找的特定值,并返回 `true`/`false` 作为结果。
+
+```js
+const students = ['Hong', 'James', 'Mark', 'James'];
+
+students.indexOf('Mark') // 1
+students.includes('James') // true
+
+students.indexOf('Sam') // -1
+students.includes('Sam') // false
+```
+
+要注意,由于 Unicode 编码的差异,所以传入的值是大小写敏感的。
+
+---
+
+## String.prototype.repeat 对比 for 循环
+
+在 ES6 添加此特性之前,生成像 `abcabcabc` 这样的字符串的方法是,根据您的需要将字符串复制多次并连接到一个空字符串后面。
+
+```js
+var str = 'abc';
+var res = '';
+
+var copyTimes = 3;
+
+for (var i = 0; i < copyTimes; i += 1) {
+ for (var j = 0; j < str.length; j += 1) {
+ res += str[j];
+ }
+}
+```
+
+但是这样写实在是又长又乱,有时候可读性也很差。为此,我们可以使用 `String.prototype.repeat` 函数。您所需要做的只是传入一个数字,该数字表示您希望重复字符串的次数。
+
+```js
+'abc'.repeat(3) // "abcabcabc"
+'hi '.repeat(2) // "hi hi "
+
+'empty'.repeat(0) // ""
+'empty'.repeat(null) // ""
+'empty'.repeat(undefined) // ""
+'empty'.repeat(NaN) // ""
+
+'error'.repeat(-1) // RangeError
+'error'.repeat(Infinity) // RangeError
+```
+
+传入的值不能是负数,必须小于无穷大,并且还不能超过字符串的最大长度,不然会造成溢出。
+
+---
+
+## String.prototype.match 对比 String.prototype.includes
+
+要检查字符串中是否包含某些特定字符串,有两种方法 —— `match` 函数和 `includes` 函数。
+
+* `String.prototype.match` —— 接收 RegExp 类型的参数。RegExp 中支持的所有标志都可以使用。
+* `String.prototype.includes` —— 接收两个参数,第一个参数是 `searchString`,第二个参数是 `position`。如果没有传入 `position` 参数,则使用默认值 `0`。
+
+这二者的不同之处在于 `includes` 函数是大小写敏感的,而 `match` 函数可以不是。您可以将标记 `i` 放在 RegExp 中,使其不区分大小写。
+
+```js
+const name = 'jane';
+const nameReg = /jane/i;
+
+const str = 'Jane is a student';
+
+str.includes(name) // false
+str.match(nameReg)
+// ["Jane", index: 0, input: "Jane is a student", groups: undefined]
+```
+
+---
+
+## String.prototype.concat 对比 String.prototype.padStart
+
+当您希望在一个字符串的开头添加一些字符串时,`padStart` 是一个很有用的方法。
+
+同样,`concat` 函数也可以很好地完成这个任务。但是最主要的区别是 `padStart` 函数会从结果字符串的第一位开始重复地将参数中的字符串填充到结果字符串。
+
+我将向您展示如何使用这个函数。
+
+```js
+const rep = 'abc';
+const str = 'xyz';
+```
+
+这里有两个字符串。我想在 `xyz` 前面添加 `rep` —— 但是,不仅是只添加一次,我希望重复添加。
+
+```js
+str.padStart(10, rep);
+```
+
+`padStart` 需要两个参数 —— 新创建的结果字符串的总长度和将要重复的字符串。理解这个函数最简单的方法是用空格代替字母写下来。
+
+```
+// 新建 10 个空格
+1) _ _ _ _ _ _ _ _ _ _
+
+// 在空格中将 'xyz' 填入
+2) _ _ _ _ _ _ _ x y z
+
+// 在剩下的空格中重复 'abc'
+// 直到 'xyz' 的第一个字母出现
+3) a b c a b c a x y z
+
+// 结果最终会是
+4) abcabcaxyz
+```
+
+这个函数对于这个特定场景下非常有用,并且如果用 `concat`( 一个同样用于执行字符串追加的函数)绝对很难做到。
+
+`padEnd` 函数和 `padStart` 函数一样,只不过从位置的末尾开始。
+
+---
+
+## 总结
+
+在 JavaScript 中有许多有趣又有用的方法。虽然它们并不常见,但这并不意味着它们毫无用武之地。如何巧妙地使用它们就取决于您了。
+
+#### 参考资料
+
+* [JavaScript 中 isNaN 函数和 Number.isNaN 函数之间的混淆](https://stackoverflow.com/questions/33164725/confusion-between-isnan-and-number-isnan-in-javascript)
+* [Number.isFinite —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Number/isFinite)
+* [isFinite —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/isFinite)
+* [Math.trunc —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math/trunc)
+* [Math.floor —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math/floor)
+* [Array.prototype.indexOf —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/indexOf)
+* [Array.prototype.includes —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/includes)
+* [String.prototype.repeat —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/repeat)
+* [String.prototype.math —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/match)
+* [String.prototype.includes —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/includes)
+* [String.prototype.padStart —— MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/padStart)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/javascript-top-level-await-in-a-nutshell.md b/TODO1/javascript-top-level-await-in-a-nutshell.md
new file mode 100644
index 00000000000..2b5af197755
--- /dev/null
+++ b/TODO1/javascript-top-level-await-in-a-nutshell.md
@@ -0,0 +1,121 @@
+> * 原文地址:[How the new ‘Top Level Await’ feature works in JavaScript](https://medium.com/javascript-in-plain-english/javascript-top-level-await-in-a-nutshell-4e352b3fc8c8)
+> * 原文作者:[Kesk noren](https://medium.com/@kesk)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/javascript-top-level-await-in-a-nutshell.md](https://github.com/xitu/gold-miner/blob/master/TODO1/javascript-top-level-await-in-a-nutshell.md)
+> * 译者:
+> * 校对者:
+
+# How the new ‘Top Level Await’ feature works in JavaScript
+
+> Short, useful JavaScript lessons — make it easy.
+
+
+
+Previously, in order to use await, code needed to be inside a function marked as async. This meant that you couldn’t use await outside any function notation. Top-level await enables modules to act like async functions.
+
+Modules are asynchronous and have an import and export, and those also expressed at the top-level. The practical implication of this is that if you wanted to provide a module that relied on some asynchronous task in order to do something you had really no good choices.
+
+Top-level await comes to solve this and enables developers to use the await keyword outside async functions. With top-level await, ECMAScript Modules can await resources, causing other modules who import them to wait before they start evaluating their body, or you can use it also as a loading dependency fallback if a module loading fails or to use to load the first resource downloaded.
+
+Notes:
+
+* Top-level await **only works at the top level of modules**. There is no support for classic scripts or non-async functions.
+* ECMAScript stage 3 as of the time of this writing(23/02/2020).
+
+## Use cases
+
+With top-level await, the next code works the way you’d expect within modules
+
+## 1. Using a fallback if module loading fails
+
+The following example attempts to load a JavaScript module from first.com, falling back to if that fails:
+
+```js
+//module.mjs
+
+let module;
+
+try {
+ module= await import('https://first.com/libs.com/module1');
+} catch {
+ module= await import('https://second.com/libs/module1');
+}
+```
+
+## 2. Using whichever resource loads fastest
+
+Here res variable is initialized via whichever download finishes first.
+
+```js
+//module.mjs
+
+const resPromises = [
+ donwloadFromResource1Site,
+ donwloadFromResource2Site
+ ];
+
+const res = await Promise.any(resPromises);
+```
+
+## 3. Resource initialization
+
+The top-level await allows you to await promises in modules as if they were wrapped in an async function. This is useful, for example, to perform app initialization:
+
+```js
+//module.mjs
+
+import { dbConnector} from './dbUtils.js'
+
+//connect() return a promise.
+const connection = await dbConnector.connect();
+
+export default function(){connection.list()}
+```
+
+## 4. Loading modules dynamically
+
+This allows for Modules to use runtime values in order to determine dependencies.
+
+```js
+//module.mjs
+
+const params = new URLSearchParams(window.location.search);
+const lang = params.get('lang');
+const messages = await import(`./messages-${lang}.mjs`);
+```
+
+## 5. Using await outside async functions in DevTools?
+
+Before with async/await, attempting to use an await outside an async function resulted in a: “ SyntaxError: await is only valid in async function” Now, you can use it without it being inside in an async function.
+
+This has been tested in chrome 80 and in firefox 72.0.2 **DevTools**. However, this functionality is non-standard and doesn’t work in nodejs.
+
+```js
+const helloPromise = new Promise((resolve)=>{
+ setTimeout(()=> resolve('Hello world!'), 5000);
+})
+
+const result = await helloPromise;console.log(result);
+
+//5 seconds later...:
+//Hello world!
+```
+
+## Implementations
+
+* V8 with flag: — — harmony-top-level-await
+* Webpack (experimental support in 5.0.0)
+* Parser support has been added to Babel ([babel/plugin-syntax-top-level-await](https://babeljs.io/docs/en/babel-plugin-syntax-top-level-await)).
+
+## References
+
+* [https://github.com/bmeck/top-level-await-talking/](https://github.com/bmeck/top-level-await-talking/)
+* [https://github.com/tc39/proposal-top-level-await#use-cases](https://github.com/tc39/proposal-top-level-await#use-cases)
+
+Thanks for reading me!!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/json-parser-with-javascript.md b/TODO1/json-parser-with-javascript.md
new file mode 100644
index 00000000000..c004caab168
--- /dev/null
+++ b/TODO1/json-parser-with-javascript.md
@@ -0,0 +1,479 @@
+> * 原文地址:[JSON Parser with JavaScript](https://lihautan.com/json-parser-with-javascript/)
+> * 原文作者:[Tan Li Hau](https://lihautan.com/)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/json-parser-with-javascript.md](https://github.com/xitu/gold-miner/blob/master/TODO1/json-parser-with-javascript.md)
+> * 译者:[Gavin-Gong](https://github.com/Gavin-Gong)
+> * 校对者:[vitoxli](https://github.com/vitoxli),[Chorer](https://github.com/Chorer)
+
+# 使用 JavaScript 编写 JSON 解析器
+
+这周的 Cassidoo 的每周简讯有这么一个面试题:
+> 写一个函数,这个函数接收一个正确的 JSON 字符串并将其转化为一个对象(或字典,映射等,这取决于你选择的语言)。示例输入:
+
+```text
+fakeParseJSON('{ "data": { "fish": "cake", "array": [1,2,3], "children": [ { "something": "else" }, { "candy": "cane" }, { "sponge": "bob" } ] } } ')
+```
+
+一度我忍不住想这样写:
+
+```js
+const fakeParseJSON = JSON.parse;
+```
+
+但是,我记起我写过一些关于 AST 的文章:
+
+* [使用 Babel 创建自定义 JavaScript 语法](/creating-custom-javascript-syntax-with-babel)
+* [一步一步教你写一个自定义 babel 转化器](/step-by-step-guide-for-writing-a-babel-transformation)
+* [使用 JavaScript 操作 AST](/manipulating-ast-with-javascript)
+
+其中包括编译器管道的概述,以及如何操作 AST,但是我还没有详细介绍如何实现解析器。
+
+这是因为在一篇文章中实现 JavaScript 编译器对我来说是一项艰巨的任务。
+
+好了,不用担心。JSON 也是一种语言。它有自己的语法,你可以查阅它的 [规范](https://www.json.org/json-en.html)。编写 JSON 解析器所需的知识和技术可以助你编写 JS 解析器。
+
+那么,让我们开始编写一个 JSON 解析器吧!
+
+## 理解语法
+
+如果你有查看 [规范页面](https://www.json.org/json-en.html),你会发现两个图:
+
+* 左边的 [语法图 (或者铁路图)](https://en.wikipedia.org/wiki/Syntax_diagram),
+
+ Image source: [https://www.json.org/img/object.png](https://www.json.org/img/object.png)
+
+* 右边的 [The McKeeman Form](https://www.crockford.com/mckeeman.html),[巴科斯-诺尔范式(BNF)](https://en.wikipedia.org/wiki/Backus%E2%80%93Naur_form) 的一种变体
+
+```text
+json
+ element
+
+value
+ object
+ array
+ string
+ number
+ "true"
+ "false"
+ "null"
+
+object
+ '{' ws '}'
+ '{' members '}'
+```
+
+两个图是等价的。
+
+一个基于视觉,一个基于文本。基于文本语法的语法 —— 巴科斯-诺尔范式,通常被提供给另一个解析这种语法并为其生成解析器的解析器,终于说到解析器了!🤯
+
+在本文中,我们将重点关注铁路图,因为它是可视化的,而且似乎对我更友好。
+
+让我们看看第一张铁路图:
+
+ Image source: [https://www.json.org/img/object.png](https://www.json.org/img/object.png)
+
+我们可以看出这是 **『object』** 在 JSON 中的语法。
+
+我们从左边开始,沿着箭头走,一直走到右边为止。
+
+圈圈里面是字符,例如 `{`、`,`、`:`、`}`,矩形里面是其它语法的占位符,例如 `whitespace`、`string` 和 `value`。因此要解析『whitespace』,我们需要查阅 **『whitepsace』** 语法。
+
+因此,对于一个对象而言,从左边开始,第一个字符必须是一个左花括号 `{`。然后我们有两种情况:
+
+* `whitespace` → `}` → 结束,或者
+* `whitespace` → `string` → `whitespace` → `:` → `value` → `}` → 结束
+
+当然当你抵达『value』的时候,你可以选择继续下去:
+
+* → `}` → 结束,或者
+* → `,` → `whitespace` → … → `value`
+
+你可以继续循环,直到你决定去:
+
+* → `}` → 结束。
+
+那么,我想我们现在已经熟悉了铁路图,让我们继续到下一节。
+
+## 实现解析器
+
+让我们从以下结构开始:
+
+```js
+function fakeParseJSON(str) {
+ let i = 0;
+ // TODO
+}
+```
+
+我们初始化 `i` 将其作为当前字符的索引值,只要 `i` 值到达 `str` 的长度,我们就会结束函数。
+
+让我们实现 **『object』** 语法:
+
+```js
+function fakeParseJSON(str) {
+ let i = 0;
+ function parseObject() {
+ if (str[i] === '{') {
+ i++;
+ skipWhitespace();
+
+ // 如果不是 '}',
+ // 我们接收 string -> whitespace -> ':' -> value -> ... 这样的路径字符串
+ while (str[i] !== '}') {
+ const key = parseString();
+ skipWhitespace();
+ eatColon();
+ const value = parseValue();
+ }
+ }
+ }
+}
+```
+
+我们可以调用 `parseObject` 来解析类似『string』和『whitespace』之类的语法,只要我们实现这些功能,一切都会工作🤞。
+
+我忘了加上一个逗号 `,`。`,`只出现在我们开始第二次 `whitespace` → `string` → `whitespace` → `:` → … 循环之前。
+
+在此基础上,我们增加了以下几行:
+
+```js
+function fakeParseJSON(str) {
+ let i = 0;
+ function parseObject() {
+ if (str[i] === '{') {
+ i++;
+ skipWhitespace();
+
+ let initial = true;
+ // 如果不是 '}',
+ // 我们接收 string -> whitespace -> ':' -> value -> ... 这样的路径字符串
+ while (str[i] !== '}') {
+ if (!initial) {
+ eatComma();
+ skipWhitespace();
+ }
+ const key = parseString();
+ skipWhitespace();
+ eatColon();
+ const value = parseValue();
+ initial = false; }
+ // 移动到下一个 '}' 字符
+ i++;
+ }
+ }
+}
+```
+
+一些命名约定:
+
+* 当我们根据语法解析代码并使用返回值时,命名为 `parseSomething`
+* 当我们期望字符在那里,但是我们没有使用字符时,命名为 `eatSomething`
+* 当字符不存在,我们也可以接受。命名为 `skipSomething`
+
+让我们实现 `eatComma` 和 `eatColon`:
+
+```js
+function fakeParseJSON(str) {
+ // ...
+ function eatComma() {
+ if (str[i] !== ',') {
+ throw new Error('Expected ",".');
+ }
+ i++;
+ }
+
+ function eatColon() {
+ if (str[i] !== ':') {
+ throw new Error('Expected ":".');
+ }
+ i++;
+ }
+}
+```
+
+目前为止我们成功实现一个 `parseObject` 语法,但是这个解析函数返回什么值呢?
+
+不错,我们需要返回一个 JavaScript 对象:
+
+```js
+function fakeParseJSON(str) {
+ let i = 0;
+ function parseObject() {
+ if (str[i] === '{') {
+ i++;
+ skipWhitespace();
+
+ const result = {};
+ let initial = true;
+ // 如果不是 '}',
+ // 我们接收 string -> whitespace -> ':' -> value -> ... 这样的路径字符串
+ while (str[i] !== '}') {
+ if (!initial) {
+ eatComma();
+ skipWhitespace();
+ }
+ const key = parseString();
+ skipWhitespace();
+ eatColon();
+ const value = parseValue();
+ result[key] = value; initial = false;
+ }
+ // 移动到下一个 '}' 字符
+ i++;
+
+ return result; }
+ }
+}
+```
+
+既然你已经看到我实现了『object』语法,现在是时候让你尝试一下『array』语法了:
+
+ Image source: [https://www.json.org/img/array.png](https://www.json.org/img/array.png)
+
+```js
+function fakeParseJSON(str) {
+ // ...
+ function parseArray() {
+ if (str[i] === '[') {
+ i++;
+ skipWhitespace();
+
+ const result = [];
+ let initial = true;
+ while (str[i] !== ']') {
+ if (!initial) {
+ eatComma();
+ }
+ const value = parseValue();
+ result.push(value);
+ initial = false;
+ }
+ // 移动到下一个 '}' 字符
+ i++;
+ return result;
+ }
+ }
+}
+```
+
+现在,我们来看一个更有趣的语法,『value』:
+
+ Image source: [https://www.json.org/img/value.png](https://www.json.org/img/value.png)
+
+一个值以 『whitespace』 开始,然后是以下任何一种:『string』、『number』、『object』、『array』、『true』、『false』或者『null』,然后以一个『whitespace』结束:
+
+```js
+function fakeParseJSON(str) {
+ // ...
+ function parseValue() {
+ skipWhitespace();
+ const value =
+ parseString() ??
+ parseNumber() ??
+ parseObject() ??
+ parseArray() ??
+ parseKeyword('true', true) ??
+ parseKeyword('false', false) ??
+ parseKeyword('null', null);
+ skipWhitespace();
+ return value;
+ }
+}
+```
+
+`??` 称之为 [空值合并运算符](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Nullish_coalescing_operator),它类似我们用来设置默认值 `foo || default` 中的 `||`,只要`foo`是假值,`||` 就会返回 `default`,
+而空值合并运算符只会在 `foo` 为 `null` 或 `undefined` 时返回 `default`。
+
+`parseKeyword` 将检查当前 `str.slice(i)` 是否与关键字字符串匹配,如果匹配,将返回关键字值:
+
+```js
+function fakeParseJSON(str) {
+ // ...
+ function parseKeyword(name, value) {
+ if (str.slice(i, i + name.length) === name) {
+ i += name.length;
+ return value;
+ }
+ }
+}
+```
+
+这就是 `parseValue`!
+
+我们还有 3 个以上的语法要实现,但我为了控制文章篇幅,在下面的 [CodeSandbox](https://codesandbox.io/s/json-parser-k4c3w?from-embed) 中实现这些语法。
+
+在我们完成所有的语法实现之后,现在让我们返回 `parseValue` 返回的 json 值:
+
+```js
+function fakeParseJSON(str) {
+ let i = 0;
+ return parseValue();
+
+ // ...
+}
+```
+
+就是这样!
+
+好吧,别急,我的朋友,我们刚刚完成了理想情况,那非理想情况呢?
+
+## 处理意外输入
+
+作为一个优秀的开发人员,我们也需要优雅地处理非理想情况。对于解析器,这意味着使用适当的错误消息大声警告开发人员。
+
+让我们来处理两个最常见的错误情况:
+
+* Unexpected token
+* Unexpected end of string
+
+### Unexpected token
+
+### Unexpected end of string
+
+在所有的 while 循环中,例如 `parseObject` 中的 while 循环:
+
+```js
+function fakeParseJSON(str) {
+ // ...
+ function parseObject() {
+ // ...
+ while(str[i] !== '}') {
+```
+
+我们需要确保访问的字符不会超过字符串的长度。这发生在字符串意外结束时,而我们仍然在等待一个结束字符 —— `}`。比如说下面的例子:
+
+```js
+function fakeParseJSON(str) {
+ // ...
+ function parseObject() {
+ // ...
+ while (i < str.length && str[i] !== '}') { // ...
+ }
+ checkUnexpectedEndOfInput();
+ // 移动到下一个 '}' 字符
+ i++;
+
+ return result;
+ }
+}
+```
+
+## 加倍努力
+
+你还记得当你还是一个初级开发者时,每次遇到含糊不清的语法报错时,你都完全不知道哪里出错了吗?
+现在你更有经验了,是时候停止这种恶性循环,停止吐槽了。
+
+```js
+Unexpected token "a"
+```
+
+然后让用户盯着屏幕发呆。
+
+有很多比吐槽更好的处理错误消息的方法,下面是一些你可以考虑添加到你的解析器的要点:
+
+### 错误代码和标准错误消息
+
+标准关键字对用户谷歌寻求帮助很有用。
+
+```js
+// 不要这样显示
+Unexpected token "a"
+Unexpected end of input
+
+// 而要这样显示
+JSON_ERROR_001 Unexpected token "a"
+JSON_ERROR_002 Unexpected end of input
+```
+
+### 更好地查看哪里出了问题
+
+像 Babel 这样的解析器,会向你显示一个代码框架,它是一个带有下划线、箭头或突出显示错误的代码片段
+
+```js
+// 不要这样显示
+Unexpected token "a" at position 5
+
+// 而要这样显示
+{ "b"a
+ ^
+JSON_ERROR_001 Unexpected token "a"
+```
+
+一个如何输出代码片段的例子:
+
+```js
+function fakeParseJSON(str) {
+ // ...
+ function printCodeSnippet() {
+ const from = Math.max(0, i - 10);
+ const trimmed = from > 0;
+ const padding = (trimmed ? 3 : 0) + (i - from);
+ const snippet = [
+ (trimmed ? '...' : '') + str.slice(from, i + 1),
+ ' '.repeat(padding) + '^',
+ ' '.repeat(padding) + message,
+ ].join('\n');
+ console.log(snippet);
+ }
+}
+```
+
+### 错误恢复建议
+
+如果可能的话,解释出了什么问题,并给出解决问题的建议
+
+```js
+// 不要这样显示
+Unexpected token "a" at position 5
+
+// 而要这样显示
+{ "b"a
+ ^
+JSON_ERROR_001 Unexpected token "a".
+Expecting a ":" over here, eg:
+{ "b": "bar" }
+ ^
+You can learn more about valid JSON string in http://goo.gl/xxxxx
+```
+
+如果可能,根据解析器目前收集的上下文提供建议
+
+```js
+fakeParseJSON('"Lorem ipsum');
+
+// 这样显示
+Expecting a `"` over here, eg:
+"Foo Bar"
+ ^
+
+// 这样显示
+Expecting a `"` over here, eg:
+"Lorem ipsum"
+ ^
+```
+
+基于上下文的建议会让人感觉更有关联性和可操作性。
+记住所有的建议,用以下几点检查已经更新的 [CodeSandbox](https://codesandbox.io/s/json-parser-with-error-handling-hjwxk?from-embed)
+
+* 有意义的错误消息
+* 带有错误指向失败点的代码段
+* 为错误恢复提供建议
+
+## 总结
+
+要实现解析器,你需要从语法开始。
+你可以用铁路图或巴科斯-诺尔范式来使语法正式化。设计语法是最困难的一步。
+一旦你解决了语法问题,就可以开始基于语法实现解析器。
+错误处理很重要,更重要的是要有有意义的错误消息,以便用户知道如何修复它。
+现在,你已经了解了如何实现简单的解析器,现在应该关注更复杂的解析器了:
+
+* [Babel parser](https://github.com/babel/babel/tree/master/packages/babel-parser)
+* [Svelte parser](https://github.com/sveltejs/svelte/tree/master/src/compiler/parse)
+
+最后,请关注 [@cassidoo](https://twitter.com/cassidoo),她的每周简讯棒极了!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/kafka-vs-rabbitmq-why-use-kafka.md b/TODO1/kafka-vs-rabbitmq-why-use-kafka.md
new file mode 100644
index 00000000000..3c6e4d264ac
--- /dev/null
+++ b/TODO1/kafka-vs-rabbitmq-why-use-kafka.md
@@ -0,0 +1,118 @@
+> * 原文地址:[Kafka vs. RabbitMQ: Why Use Kafka?](https://medium.com/better-programming/kafka-vs-rabbitmq-why-use-kafka-8401b2863b8b)
+> * 原文作者:[SeattleDataGuy](https://medium.com/@SeattleDataGuy)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/kafka-vs-rabbitmq-why-use-kafka.md](https://github.com/xitu/gold-miner/blob/master/TODO1/kafka-vs-rabbitmq-why-use-kafka.md)
+> * 译者:
+> * 校对者:
+
+# Kafka vs. RabbitMQ: Why Use Kafka?
+
+> Are all data streaming services made equal?
+
+ on [Unsplash](https://unsplash.com/s/photos/data?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/5754/1*DJvGajoZpUGKsSSEFyzwwQ.jpeg)
+
+A vital part of the successful completion of any project is the selection of the right tools for performing essential basic functions. For developers, the availability of several messaging services to pick from always poses a challenge.
+
+One crucial question unanswered is the use of [Apache Kafka](https://kafka.apache.org/) or [RabbitMQ](https://www.rabbitmq.com/) services. Both platforms feature several functionalities and use cases that can help users make an informed decision.
+
+Apache Kafka and RabbitMQ are two top platforms in the area of messaging services. Although both platforms handle messaging differently, the difference lies in their selected architecture, design, and approach to delivery.
+
+## But What Are Apache Kafka and RabbitMQ?
+
+Apache Kafka and RabbitMQ are open-source platforms that are utilized for streaming data as well as come equipped with [pub/sub](https://www.rabbitmq.com/tutorials/tutorial-three-ruby.html) (which we will describe later) systems that are commercial — supported and used by several enterprises.
+
+#### What is Apache Kafka?
+
+Apache Kafka, in simple terms, is a message bus optimized for high-access data replays and streams. The robust message broker allows applications to continually process and re-process stream data.
+
+The open-source platform uses an uncomplicated and easy routing approach that engages a routing key in sending messages to a topic. Launched in 2011, the Kafka tool was created for streaming setups.
+
+#### What is RabbitMQ?
+
+RabbitMQ is an all-round messaging broker with support protocols like Advanced Message Queuing Protocol (AMQP), MQ Telemetry Transport (MQTT), and Simple (or Streaming) Text-Oriented Messaging Protocol (STOMP).
+
+RabbitMQ can handle use cases seeking high efficiency, like processing online payments. RabbitMQ can also serve as a message broker amongst microservices.
+
+Launched in 2007, RabbitMQ started as a primary element in messaging and SOA systems. Nowadays, its expanded roles also include streaming use cases.
+
+So, if you are considering whether to use Apache Kafka or RabbitMQ, read on to learn about the difference in architectures, approaches, and their performance pros and cons.
+
+## Architecture Differences
+
+#### Apache Kafka architecture
+
+The Apache Kafka architecture uses a high volume of publish-subscribe messages and a streams platform that is quick and scalable. The robust message store, like logs, makes use of server clusters that hold several records in topics (categories).
+
+[All Kafka messages feature a key, value, and timestamp](http://kth.diva-portal.org/smash/get/diva2:813137/FULLTEXT01.pdf). The smart consumer or dumb broker model do not attempt tracking on consumer messages and only retain unread messages. Apache Kafka holds all messages for a defined time frame.
+
+#### RabbitMQ architecture
+
+The RabbitMQ architecture makes use of an all-round message broker which entails variations in point-to-point, request/reply, and pub/sub communication designs.
+
+The use of a dumb consumer and smart broker method allows for reliable message delivery to consumers with similar speed to that of a broker monitoring the state of consumers.
+
+With the use of synchronous or asynchronous communication methods, the platform provides adequate support for several plugins including .NET, client libraries, Java, Node.js, Ruby, and more.
+
+It also makes available distributed deployment scenarios alongside a multi-node cluster to cluster federation with zero reliance on external services.
+
+With [RabbitMQ](http://kth.diva-portal.org/smash/get/diva2:813137/FULLTEXT01.pdf), publishers can transmit messages to exchanges, and retrieve messages from queues by consumers. The decoupling producers from lines through exchanges guarantee that producers are not troubled with hardcoded routing choices.
+
+## Publish/Subscribe (Pub/Sub)
+
+Publish/subscribe is amongst the main messaging patterns for asynchronous messaging, a messaging scheme where message production is decoupled from its processing by a consumer.
+
+#### Apache Kafka
+
+In Apache Kafka, the platform is created for high volume publish-subscribe messages and streams, which are intended to be durable, quick, and scalable. In essence, Kafka makes available a sustainable message store and a server cluster.
+
+#### RabbitMQ
+
+In RabbitMQ, the design entails an all-round message broker, using several variations of point-to-point, request/reply, and pub-sub communication style patterns.
+
+## Push/Pull Model
+
+#### Apache Kafka: Pull-based method
+
+Kafka makes use of a pull model where consumers make message requests in batches from a specified offset. Apache Kafka also allows for long-pooling, which stops tight loops when no message goes through the offset.
+
+The pull model remains logical for Apache Kafka due to its partitions. Its platform makes available message order within a barrier without contending consumers.
+
+This approach lets users leverage message batching for efficient message delivery and better throughput.
+
+#### RabbitMQ: Push-based method
+
+RabbitMQ pushes messages to the consumer, which includes a prefetch limit configuration essential to preventing the consumer from becoming overwhelmed by multiple messages.
+
+They can also be useful for low latency messaging. The purpose of the push method is the quick distribution of individual messages individually, alongside a guarantee that all of it is parallelized evenly and messages are processed in an ordered queue, usually as they arrive.
+
+## Use Cases
+
+#### Apache Kafka
+
+Apache Kafka provides an additional broker itself, for which it is best known and it is a popular element of the platform. The additional broker has been premeditated and marketed in the direction of stream processing setups.
+
+Also, the addition of Kafka Streams serves as an alternative to streaming platforms like Apache Flink, Apache Spark, Google Cloud Data Flow, and Spring Cloud Data Flow.
+
+The exceptional [use cases](https://kafka.apache.org/uses) documentation provides a detailed use case for Apache Kafka including its commit logs, event sourcing, log aggregation, metrics, web activity tracking, and more tasks.
+
+#### RabbitMQ
+
+RabbitMQ delivers an all-round messaging solution with widespread usage amongst web servers’ timely response to requests in place of enforced response to performing resource-heavy measures while users await the result.
+
+RabbitMQ is also excellent for distributing messages to multiple receivers as it offers a lot of [features for reliable delivery](http://www.rabbitmq.com/confirms.html), federation, management tools, routing, security, and [other functions](http://www.rabbitmq.com/features.html).
+
+With assistance from additional software, RabbitMQ can also effectively address several substantial uses cases. A combination with Apache Cassandra can provide access to stream history, or with the [LevelDB](https://github.com/google/leveldb) plugin for access to an “infinite” queue.
+
+## Conclusion
+
+Both [Apache Kafka and RabbitMQ](https://www.theseattledataguy.com/kafka-vs-rabbitmq-why-use-kafka/) platforms offer a variety of critical services intended to suit a lot of demands.
+
+RabbitMQ is sufficient for simple use cases that entail low data traffic. Also, with RabbitMQ, other additional benefits include flexible routing prospects and priority queue options.
+
+On the other hand, if the proposed use case features the need for massive data and high traffic, then Apache Kafka is worth considering.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/learn-to-cache-your-nodejs-application-with-redis-in-6-minutes.md b/TODO1/learn-to-cache-your-nodejs-application-with-redis-in-6-minutes.md
new file mode 100644
index 00000000000..d8d6475ba3f
--- /dev/null
+++ b/TODO1/learn-to-cache-your-nodejs-application-with-redis-in-6-minutes.md
@@ -0,0 +1,447 @@
+> * 原文地址:[Learn to Cache your NodeJS Application with Redis in 6 Minutes!](https://itnext.io/learn-to-cache-your-nodejs-application-with-redis-in-6-minutes-745a574a9739)
+> * 原文作者:[Abdullah Amin](https://medium.com/@abdamin)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/learn-to-cache-your-nodejs-application-with-redis-in-6-minutes.md](https://github.com/xitu/gold-miner/blob/master/TODO1/learn-to-cache-your-nodejs-application-with-redis-in-6-minutes.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[lsvih](https://github.com/lsvih),[GPH](https://github.com/PingHGao)
+
+# 用 6 分钟学习如何用 Redis 缓存您的 NodeJS 应用!
+
+
+
+缓存您的 web 应用非常重要,并且在应用扩展时缓存可以提高系统性能。Redis 可以是一个 **搜索引擎**,可以用最小的延迟来响应频繁查询的请求;可以是一个**短链接生成器**,可以更快地重定向到经常访问的 URL;可以是一个**社交网络**,可以更快地得到红人的用户资料。还可以是一个非常简单的从第三方 web API 请求数据的 web 服务器,它在项目扩展和缓存数据的情况下,表现是相当出色的!
+
+## 什么是 Redis?为什么要用 Redis?
+
+**Redis** 是一个高性能的开源 **NoSQL** 数据库,主要是被用作各种类型的应用的缓存解决方案。它将所有数据存储在 RAM 中,并提供高度优化的数据读写。Redis 还支持许多不同的数据类型和基于很多不同编程语言的客户端。您可以在[这里](https://redis.io/topics/introduction)找到更多关于 **Redis** 的信息。
+
+## 概述
+
+今天,我们将在 **NodeJS** web 应用上实现基本的缓存机制,我们的 web 应用将会从 **[Star Wars API](https://swapi.co)** 请求**星球大战的星际飞船信息**。我们将学习如何将频繁请求的星际飞船数据存储到我们的缓存中。之后我们 web 服务器的请求将首先搜索缓存,如果缓存不包含我们请求的数据,再向 [**Star Wars API**](https://swapi.co) 发送请求。这将使我们向第三方 API 发送更少的请求,从而总体上加快了我们应用的速度。为确保我们的缓存是最新的,缓存的数据将被设置生存时间(TTL),数据在一定时间后过期。听起来是不是很有意思?让我们开始吧!
+
+## 安装 Redis
+
+如果您已经在本地机器上安装了 Redis,或者正在使用 Redis 云托管解决方案,就可以跳过这一步。
+
+#### 在 Mac 上安装
+
+在 Mac 上 可以使用 **Homebrew** 来安装 Redis。如果您的 Mac 上没有安装 Homebrew,您可以在终端上运行以下命令来安装它。
+
+```bash
+/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
+```
+
+现在,您可以通过在终端上运行以下命令来安装 Redis。
+
+```bash
+brew install redis
+```
+
+#### 在 Ubuntu 上安装
+
+您可以使用这个[简易指南](https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-redis-on-ubuntu-18-04)在您的 Ubuntu 机器上安装 Redis。
+
+#### 在 Windows 上安装
+
+您可以使用这个[简易指南](https://redislabs.com/blog/redis-on-windows-8-1-and-previous-versions/)在您的 Windows 机器上安装 Redis。
+
+## 启动 Redis 服务端 和 Redis CLI 客户端
+
+在您的终端上,您可以运行以下命令在本地启动您的 Redis 服务端。
+
+```bash
+redis-server
+```
+
+
+
+要使用 Redis CLI 客户端,您可以新建一个终端窗口或者终端选项卡后,运行以下命令。
+
+```bash
+redis-cli
+```
+
+
+
+就像在您的机器上安装的任何其他数据库解决方案一样,您可以使用 Redis 的 CLI 与它进行交互。关于 [Redis CLI](https://redis.io/topics/rediscli) 我推荐看它的官方指南。但是,在这里我们只关注于将 Redis 用于我们的 NodeJS web 应用的缓存解决方案,并只通过我们的 web 服务器与它进行交互。
+
+## NodeJS 项目安装
+
+在一个单独的文件夹中,运行 **npm init** 来构建您的 NodeJS 项目。
+
+
+
+#### 项目依赖
+
+我们将在 NodeJS 应用中使用一系列的依赖项。在您的项目目录下的终端中运行以下命令。
+
+```bash
+npm i express redis axios
+```
+
+**Express** 将帮助我们设置服务器。我们将使用 **redis** 包来将我们的应用与在我们机器上本地运行的 Redis 服务端相连,我们还将使用 **axios** 向 [**Star Wars API**](https://swapi.co) 请求数据。
+
+#### 开发依赖
+
+我们还将使用 **nodemon** 作为我们的 **开发依赖** 从而能够在项目代码更改保存后立即运行到我们的服务器而不必重新启动它(译者注:也就是热更新)。在我们的项目目录的终端中运行以下命令。
+
+```bash
+npm i -D nodemon
+```
+
+#### 在 package.json 中设置启动脚本
+
+用以下脚本替换 **package.json** 中的现有脚本,以便我们可以使用 **nodemon** 运行服务器。
+
+```
+"start": "nodemon index"
+```
+
+```JSON
+{
+ "name": "redis-node-tutorial",
+ "version": "1.0.0",
+ "description": "A step by step guide to setup caching with Redis on a NodeJS Web Application",
+ "main": "index.js",
+ "scripts": {
+ "start": "nodemon index"
+ },
+ "repository": {
+ "type": "git",
+ "url": "git+https://github.com/abdamin/redis-node-tutorial.git"
+ },
+ "author": "Abdullah Amin",
+ "license": "ISC",
+ "bugs": {
+ "url": "https://github.com/abdamin/redis-node-tutorial/issues"
+ },
+ "homepage": "https://github.com/abdamin/redis-node-tutorial#readme",
+ "dependencies": {
+ "axios": "^0.19.0",
+ "express": "^4.17.1",
+ "redis": "^2.8.0"
+ },
+ "devDependencies": {
+ "nodemon": "^1.19.4"
+ }
+}
+
+```
+
+#### 设置我们的初始服务器的入口文件:index.js
+
+在我们的项目目录的终端中运行以下命令来创建 **index.js** 文件。
+
+```bash
+touch index.js
+```
+
+下面是 **index.js** 文件添加了一些代码后的样子。
+
+```JavaScript
+//设置依赖
+const express = require("express");
+const redis = require("redis");
+const axios = require("axios");
+const bodyParser = require("body-parser");
+
+//设置端口常量
+const port_redis = process.env.PORT || 6379;
+const port = process.env.PORT || 5000;
+
+//配置 Redis 客户端使用 6379 端口
+const redis_client = redis.createClient(port_redis);
+
+//配置 express 服务器
+const app = express();
+
+//Body 解析中间件
+app.use(bodyParser.urlencoded({ extended: false }));
+app.use(bodyParser.json());
+
+//监听 5000 端口
+app.listen(port, () => console.log(`Server running on Port ${port}`));
+```
+
+如果您以前使用过 **NodeJS** 和 **ExpressJS**,那么这应该难不倒您。首先,我们设置之前使用 npm 安装的依赖项。接着,我们设置端口常量并创建我们的 Redis 客户端。最后,我们在**6379 端口** 上配置我们的 Redis 客户端,在 **5000 端口**上配置我们的 Express 服务器。我们还在服务器上设置了 **Body-Parser**,来解析 JSON 数据。您可以在终端中运行以下命令来使用 **package.json** 中的启动脚本运行 web 服务器。
+
+```bash
+npm start
+```
+
+**注意**,如前所述,我们的 Redis 服务端应该运行在另一个终端上,以便成功地将我们的NodeJS 应用连接到 Redis。
+
+您现在应该能够在终端上看到以下输出,它表明您的 web 服务器正在 **5000 端口** 上运行。
+
+
+
+## 发送请求到 Star Wars API
+
+现在我们已经完成了我们的项目设置,让我们编写一些代码来发送一个 **GET** 请求到 **Star Wars API** 来获得星际飞船的数据。
+
+注意,我们将向 **[https://swapi.co/api/starships/](https://swapi.co/api/starships/${id}):id** 发送一个 GET 请求来获取与 URL 中的标识符 **id** 相对应的星际飞船的数据。
+
+下面是后端代码的样子。
+
+```js
+// 请求路由: GET /starships/:id
+
+// @desc 返回特定 id 星际飞船的飞船数据
+app.get("/starships/:id", async (req, res) => {
+ try {
+ const { id } = req.params;
+ const starShipInfo = await axios.get(
+ `https://swapi.co/api/starships/${id}`
+ );
+ //从响应中获取数据
+ const starShipInfoData = starShipInfo.data;
+ return res.json(starShipInfoData);
+ }
+ catch (error) {
+ console.log(error);
+ return res.status(500).json(error);
+ }
+});
+```
+
+我们将使用一个带有 try 和 catch 块的传统**异步**回调函数和 **axios** 向 **Star Wars API** 发出 GET 请求。如果成功,我们的请求路由将返回与 URL 中 id 对应的星际飞船数据。否则,我们的请求将返回一个错误。这很简单吧。
+
+```JavaScript
+//设置依赖
+const express = require("express");
+const redis = require("redis");
+const axios = require("axios");
+const bodyParser = require("body-parser");
+
+//设置端口常量
+const port_redis = process.env.PORT || 6379;
+const port = process.env.PORT || 5000;
+
+//配置 Redis 客户端使用 6379 端口
+const redis_client = redis.createClient(port_redis);
+
+//配置 express 服务器
+const app = express();
+
+//Body 解析中间件
+app.use(bodyParser.urlencoded({ extended: false }));
+app.use(bodyParser.json());
+
+// 请求路由: GET /starships/:id
+// @desc 返回特定 id 星际飞船的飞船数据
+app.get("/starships/:id", async (req, res) => {
+ try {
+ const { id } = req.params;
+ const starShipInfo = await axios.get(
+ `https://swapi.co/api/starships/${id}`
+ );
+
+ //从响应中获取数据
+ const starShipInfoData = starShipInfo.data;
+
+ return res.json(starShipInfoData);
+ } catch (error) {
+ console.log(error);
+ return res.status(500).json(error);
+ }
+});
+
+app.listen(port, () => console.log(`Server running on Port ${port}`));
+```
+
+让我们尝试通过运行我们的代码来搜索 **id=9** 的星际飞船。
+
+
+
+哇!请求成功了。但是您注意到完成请求所花费的时间了吗? 您可以在浏览器的 Chrome 开发工具下检查网络选项卡来查看花费的时间。
+
+**769 ms。** 太慢了!这就是 **Redis** 的用武之地了。
+
+## 为服务实现 Redis 缓存
+
+#### 添加到缓存
+
+由于Redis 将数据以键值对的形式进行储存,我们需要确保无论何时向 Star Wars API 发出请求并成功接收到响应,我们就马上将星际飞船的 id 与其数据一起存储在缓存中。
+
+为此,我们将添加以下代码到接收到的来自 Star Wars API 的响应的那段代码后。
+
+```js
+//向 Redis 增加数据
+
+redis_client.setex(id, 3600, JSON.stringify(starShipInfoData));
+```
+
+上面代码的意思是我们将 **key=id**、**expiration=3600s**、**value=JSON 字符串格式化后的星际飞船数据**添加到缓存中。现在我们的 **index.js** 是这个样子。
+
+```JavaScript
+//设置依赖
+const express = require("express");
+const redis = require("redis");
+const axios = require("axios");
+const bodyParser = require("body-parser");
+
+//设置端口常量
+const port_redis = process.env.PORT || 6379;
+const port = process.env.PORT || 5000;
+
+//配置 Redis 客户端使用 6379 端口
+const redis_client = redis.createClient(port_redis);
+
+//配置 express 服务器
+const app = express();
+
+//Body 解析中间件
+app.use(bodyParser.urlencoded({ extended: false }));
+app.use(bodyParser.json());
+
+// 请求路由: GET /starships/:id
+// @desc 返回特定 id 星际飞船的飞船数据
+app.get("/starships/:id", async (req, res) => {
+ try {
+ const { id } = req.params;
+ const starShipInfo = await axios.get(
+ `https://swapi.co/api/starships/${id}`
+ );
+
+ //从响应中获取数据
+ const starShipInfoData = starShipInfo.data;
+
+ //向 Redis 增加数据
+ redis_client.setex(id, 3600, JSON.stringify(starShipInfoData));
+
+ return res.json(starShipInfoData);
+ } catch (error) {
+ console.log(error);
+ return res.status(500).json(error);
+ }
+});
+
+app.listen(port, () => console.log(`Server running on Port ${port}`));
+```
+
+现在如果我们打开浏览器,对星际飞船发送 GET 请求,它的数据就会被添加到我们的 Redis 缓存中。
+
+
+
+如前所述,您可以使用以下命令从终端访问 Redis CLI 客户端。
+
+```bash
+redis-cli
+```
+
+
+
+运行命令 **get 9** 表明,**id=9**的星际飞船数据确实添加到了我们的缓存中!
+
+#### 从缓存中检查并检索数据
+
+现在,只有在缓存中不存在所需的数据时,我们才需要向 **Star Wars API** 发送 GET 请求。我们将使用 **Express 中间件**来实现这个函数,它在执行向 **Star Wars API** 的请求之前会检查缓存。它将作为**第二个参数**传递到我们之前写好的请求函数中。
+
+中间件函数如下所示。
+
+```js
+//用于检查缓存的中间件函数
+checkCache = (req, res, next) => {
+ const { id } = req.params;
+ //得到 key = id 的数据
+ redis_client.get(id, (err, data) => {
+ if (err) {
+ console.log(err);
+ res.status(500).send(err);
+ }
+ //如果没有找到对应的数据
+ if (data != null) {
+ res.send(data);
+ }
+ else {
+ //继续下一个中间件函数
+ next();
+ }
+ });
+};
+```
+
+添加 checkCache 中间件函数后的 index.js:
+
+```JavaScript
+//设置依赖
+const express = require("express");
+const redis = require("redis");
+const axios = require("axios");
+const bodyParser = require("body-parser");
+
+//设置端口常量
+const port_redis = process.env.PORT || 6379;
+const port = process.env.PORT || 5000;
+
+//配置 Redis 客户端使用 6379 端口
+const redis_client = redis.createClient(port_redis);
+
+//配置 express 服务器
+const app = express();
+
+//Body 解析中间件
+app.use(bodyParser.urlencoded({ extended: false }));
+app.use(bodyParser.json());
+
+//用于检查缓存的中间件函数
+checkCache = (req, res, next) => {
+ const { id } = req.params;
+
+ redis_client.get(id, (err, data) => {
+ if (err) {
+ console.log(err);
+ res.status(500).send(err);
+ }
+ //如果没有找到对应的数据
+ if (data != null) {
+ res.send(data);
+ } else {
+ //继续下一个中间件函数
+ next();
+ }
+ });
+};
+
+// 请求路由: GET /starships/:id
+// @desc 返回特定 id 星际飞船的飞船数据
+app.get("/starships/:id", checkCache, async (req, res) => {
+ try {
+ const { id } = req.params;
+ const starShipInfo = await axios.get(
+ `https://swapi.co/api/starships/${id}`
+ );
+
+ //从响应中获取数据
+ const starShipInfoData = starShipInfo.data;
+
+ //向 Redis 增加数据
+ redis_client.setex(id, 3600, JSON.stringify(starShipInfoData));
+
+ return res.json(starShipInfoData);
+ } catch (error) {
+ console.log(error);
+ return res.status(500).json(error);
+ }
+});
+
+app.listen(port, () => console.log(`Server running on Port ${port}`));
+```
+
+让我们再次发送一个 GET 请求向我们 **id=9** 的星际飞船。
+
+
+
+**115 ms。**性能几乎提升了 **7 倍**!
+
+## 总结
+
+值得注意的是,我们在本教程中只是讲了些皮毛而已,Redis 还有很多更多的功能!我强烈建议您查看它的[官方文档](https://redis.io/documentation)。[**这个链接**](https://github.com/abdamin/redis-node-tutorial)是我们应用的完整代码的 Github 仓库地址。
+
+如果您有任何问题,请尽管留言。另外,如果这篇文章对您有帮助,您请可以帮忙转发分享。我会定期发布与 web 开发相关的文章。您可以在[**此处输入您的电子邮件**](https://abdullahsumsum.com/subscribe)以获取有关 web 开发相关的文章和教程的最新信息。您还可以在 [**abdullahsumsum.com**](http://abdullahsumsum.com/) 上找到有关我的更多信息。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/learning-parser-combinators-with-rust-1.md b/TODO1/learning-parser-combinators-with-rust-1.md
index 7bbbfc99b3f..e6e108bca3f 100644
--- a/TODO1/learning-parser-combinators-with-rust-1.md
+++ b/TODO1/learning-parser-combinators-with-rust-1.md
@@ -108,7 +108,7 @@ fn the_letter_a(input: &str) -> Result<(&str, ()), &str> {
更糟糕的是,一个 `char` 类型甚至可能不是我们想象的 `Unicode` 中的字符。这很可能就是 `Unicode` 中的 “[字母集合](http://www.unicode.org/glossary/#grapheme_cluster)”,它可以由几个 `char` 类型的字符组成,这些字符实际上表示 “[标量值](http://www.unicode.org/glossary/#unicode_scalar_value)”,它比 "字母集合" 差不多还低 2 个层次。但是,这样想未免有些激进了,就我们的目的而言,我们甚至不太可能看到 ASCII 字符集以外的字符,所以暂且忽略这个问题。
-我们对 `Some('a')` 进行模式匹配,它就是我们正在寻找的特定结果,如果匹配成功,我们将返回成功 `Ok((&input['a'.len_utf8]()..], ()))`。也就是说,我们从字符串 slice 中移出的解析的项('a'),并返回剩余的字符,以及解析后的值,也就是 `()` 类型。考虑到 Unicode 字符集问题,在对字符串 range 处理前,我们用标准库中的方法查询一下字符 `'a'` 在 UTF-8 中的长度 —— 长度是1,这样不会遇到之前认为的 Unicode 字符问题。
+我们对 `Some('a')` 进行模式匹配,它就是我们正在寻找的特定结果,如果匹配成功,我们将返回成功 `Ok((&input['a'.len_utf8()..], ()))`。也就是说,我们从字符串 slice 中移出的解析的项('a'),并返回剩余的字符,以及解析后的值,也就是 `()` 类型。考虑到 Unicode 字符集问题,在对字符串 range 处理前,我们用标准库中的方法查询一下字符 `'a'` 在 UTF-8 中的长度 —— 长度是1,这样不会遇到之前认为的 Unicode 字符问题。
如果我们得到其他类型的结果 `Some(char)`,或者 `None`,我们将返回一个异常。正如之前提到的,我们刚刚的异常类型就是解析失败时的字符串 slice,也就是我们我们传递的输入。它不是以 `a` 开头,所以返回异常给我们。这不是一个很严重的错误,但至少比“一些地方出了严重错误”要好一些。
diff --git a/TODO1/levels-of-seniority.md b/TODO1/levels-of-seniority.md
new file mode 100644
index 00000000000..05025978969
--- /dev/null
+++ b/TODO1/levels-of-seniority.md
@@ -0,0 +1,94 @@
+> * 原文地址:[Levels of Seniority](https://roadmap.sh/guides/levels-of-seniority)
+> * 原文作者:[Kamran Ahmed](https://twitter.com/kamranahmedse)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/levels-of-seniority.md](https://github.com/xitu/gold-miner/blob/master/TODO1/levels-of-seniority.md)
+> * 译者:[👊Badd](https://juejin.im/user/5b0f6d4b6fb9a009e405dda1)
+> * 校对者:[Imsiaocong](https://github.com/Imsiaocong), [PingHGao](https://github.com/PingHGao)
+
+# 论资历的级别
+
+> 作为初级、中级或高级开发人员如何脱颖而出?
+
+一直以来,我都在重做[路径图](https://roadmap.sh) —— 根据资历级别划分技能组,使它们更容易遵循,以免吓跑新入行的开发者。因为这些路径图只是关于技术知识的,所以我想有必要把它们回顾一遍,并且写一篇文章来表达我对不同资历职位的思考。
+
+我已经见过太多组织在给开发者评定资历时过于注重工作年数。我见过顶着“初级”头衔的开发者干着高级开发者的活儿,也见过有的“领头”开发者其实连“高级”头衔都不配。开发者的资历不应该只凭他们的年龄、工作年数或掌握的技术知识来定。还有其他因素要考虑 —— 对工作的认知、与同事的相处以及解决问题的方式。下面,我们就针对每个资历等级,详细讨论这三个关键因素。
+
+### 不同的资历头衔
+
+不同的组织可能会设置不同的资历头衔,但主要可以归为三类:
+
+* 初级开发者
+* 中级开发者
+* 高级开发者
+
+### 初级开发者
+
+初级开发者通常是应届毕业生,他们的行业经验为零或者极少。他们不但编程能力薄弱,而且会在其他一些方面暴露新手的短板:
+
+* 他们的口头禅是“能用就行”,从不关心解决方案是如何实现的。在他们眼里,能用的软件和优秀的软件没什么不同。
+* 他们通常需要非常具体和结构化的方向才能实现目标。他们眼界不够开阔,需要监督和持续的引导,才能成长为高效率的团队成员。
+* 大多数初级开发者都觉得自己做到初级就够了,当他们遇到难题,他们会甩给高级开发者,甚至不愿意浅尝一下。
+* 他们不了解公司的业务层面,没有管理、销售、市场等岗位的思维意识,也不明白如果能了解这些业务层面的东西,能避免多少次返工、无用的努力以及终端用户的流失。
+* 总是过度工程化,常常导致程序的健壮性差、Bug 多。
+* 面对问题时,他们往往只会尝试解决眼前的问题,也就是治标不治本。
+* 你会注意到,他们经常遇到“[别人的问题](https://en.wikipedia.org/wiki/Somebody_else%27s_problem”。
+* 由于[达克效应](https://en.wikipedia.org/wiki/Dunning%E2%80%93Kruger_effect),他们不知道自己的认知盲区在哪里、有多大。
+* 他们欠缺积极性,害怕面对不熟悉的代码库。
+* 他们不参与团队讨论。
+
+没必要觉得在团队里扮演初级开发者的角色是一件坏事,既然你刚入行,大家也不期望你全知全能,然而,你有责任去学习、积累经验、摘掉菜鸟的帽子并提升你自己。下面是一些建议,能帮助初级开发者在资历的阶梯上不断攀登:
+
+* 只要功夫深,铁杵磨成针。当你在 Stack Overflow 或者 GitHub 中也找不到答案时,不要放弃。跟带你的前辈说“我遇到难题了,已经试过了 X 方案、Y 方案和 Z 方案。你能给我一些指点吗?”,总好过说“这太难了,我搞不定”。
+* 大量阅读代码,不要局限于你所做的项目的代码,还有引用/框架的源码、开源代码。向你的开发伙伴 —— 也可以在 Reddit 上 —— 取取经,找找你所选择的语言/工具的开源范例。
+* 做一些个人项目,并和其他人分享,为开源做贡献。向他人求助 —— 社区能带给你的帮助会让你大吃一惊。我至今还记得大概六年前我在 GitHub 上第一次开源我自己的项目,那是一个小小的 PHP 脚本(一个库),能够从 Google 的地理 API 请求数据 —— 代码写得一团糟,没有经过任何测试,毫无代码美化,完全没有代码嗅探,而且没使用任何脚手架,因为那时候我对这些统统不了解。不知是何契机,一位好心人发现了这个项目,并且一路 Fork、重构、“现代化”、增加代码美化和嗅探、增加脚手架、发起 Pull Request。这个 Pull Request 教会了我太多,单靠我自己绝对不会学得这么快,因为我还在上学,在一家做服务的小公司兼职,做一些小网站,完全单打独斗,不知对错。GitHub 上的这个 Pull Request 帮我打开了开源的大门,我所有的一切都要归功于它。
+* 不要养成[“都是别人的事,与我无关”](https://en.wikipedia.org/wiki/Somebody_else%27s_problem)这样的毛病。
+* 解决问题时,要试着抓住问题的根本,而非只解决表面。记住,不能重现的问题就是没有解决的问题。仅当你理解了问题出现的原因,以及不再出现的原因,你才算解决了它。
+* 要尊重你接手的代码。要宽容看待代码的结构或设计理念。要明白代码的丑陋和奇怪往往都自有其原因。学会和遗留代码和平相处,并与其共同成长,这是一个重要技能。不要觉得别人都很蠢。相反,要弄清楚这些聪明的、善意的、有经验的人是如何做出现在这个愚蠢的决定的。用“机会心态”而不是抱怨的心态来接手遗留代码。
+* 有所不知很正常。你不必因为自己不知道而羞愧。世界上不存在愚蠢的问题,尽可能多地提问题可以让你更有效率地工作。
+* 不要让你的职称限制你,要坚持不懈地自我提升。
+* 做好功课,预测接下来会发生什么。要积极参与团队讨论,即使你说错了,那你也有所斩获。
+* 了解你的工作所在的的领域。从终端用户的角度全面地理解产品。不要想当然,有疑问时就发问、一探究竟。
+* 学会有效沟通 —— 软技能很重要。学会如何写出漂亮的 Email、如何汇报工作、如何三思而后问。
+* 近距离接触高级开发者,看看他们是如何工作的,找一个做你的导师。没人喜欢万事通。放低自我,以谦逊的态度向有经验的人学习。
+* 不要迷信“专家”的建议,要有自己的判断。
+* 如果让你评估某些工作,在你掌握了能做出合理评估的所有细节前,不要妄下言论。如果实在迫不得已,那就以双倍甚至更高的预备量去考虑,这取决于你对完成任务的必要工作知道多少。
+* 花些时间去学习如何使用调试工具。当遇到全新的、没有文档或者文档不全的代码库,或者调试疑难杂症时,调试工具是十分得力的助手。
+* 尽量不要说“在我电脑上是好的呀” —— 是是是,我听过一万遍了。
+* 试着把任何不足感或冒名顶替综合征(Imposter Syndrome)转化为能量,推动自己前进,增加自己的技能和知识。
+
+### 中级开发者
+
+比初级开发者高一级的是中级开发者。他们的技术水平比初级开发者高,能够在最少的监督下保持工作。要想跃进高级开发者的龙门,他们还得解决一部分问题。
+
+中级开发者比初级开发者更能胜任工作,他们开始审视他们之前所写的代码中的瑕疵,他们的知识量增长了,但却陷入了下一个陷阱,也就是想要用对的方式实现,结果搞砸,比如抽象过于草率、过度使用或非必要使用设计模式 —— 他们可能能够比初级开发者更快地给出解决方案,但那个解决方案可能会在后续过程中把你绊倒。在无人监管时,他们可能会为了“正确实现”而使项目延期。他们不知道应该何时去做权衡,也不知道什么时候该教条,什么时候该务实。他们很容易对自己的解决方案产生依赖,变得目光短浅,无法接受反馈。
+
+中级开发人员非常普遍,大多数组织错误地将他们标记为“高级开发人员”。然而,他们需要更进一步的引导,才能成为高级开发者。下一部分描述了高级开发者的职责,以及如何成为高级开发者。
+
+### 高级开发者
+
+比中级开发者高一级的是高级开发者。他们能够独立完成任务,无需监督,也不会产生任何问题。他们更加成熟,在以往交付的或优或劣的软件中积累了经验,并从中学习 —— 他们知道如何务实。以下是高级开发人员通常会做的事情:
+
+* 根据他们过去的经验、所犯的错误、过度设计或设计不足的软件所面临的问题,他们能够预见问题,能够决定代码库或体系结构的方向。
+* 他们没有“发光玩具(Shiny-Toy)”综合征。他们在执行中非常务实。他们可以在需要的时候做出权衡,而且他们知道为什么。他们知道在什么地方应该教条,在什么地方应该务实。
+* 他们对开发领域有很深的了解,在大多数情况下知道什么是最适合这个工作的工具(即使他们不熟悉这个工具)。他们有学习新工具/语言/模式等以解决问题的天赋。
+* 他们有团队意识。他们将指导他人视为自己责任的一部分。从与初级开发人员进行结对编程,到从事编写文档或测试或其他任何需要完成的脏活儿累活儿。
+* 他们对所在的领域有深刻的理解 —— 他们了解公司的业务方面,了解管理/销售/市场营销等岗位的思维模式,并在发展过程中受益于他们对业务领域的理解。
+* 他们从不空洞地抱怨,他们根据经验证据做出判断,并能为解决问题提出建议。
+* 他们的思考量比代码量多得多 —— 他们知道他们的工作是针对问题提出解决方案,而不仅仅是敲代码。
+* 他们有能力处理庞大的、模糊的问题,能够定义、分解它们并各个击破。高级开发人员能够搞定一些庞大的、抽象的东西。他们会给出一些备选方案,与团队讨论并实施它们。
+* 他们尊重接手的代码。在对体系结构或代码库中的设计决策进行判别时,他们非常宽容。他们用“机会心态”而不是抱怨的心态来接手遗留代码。
+* 他们知道如何在不伤害他人的情况下提供反馈。
+
+### 总结
+
+所有的团队都是由不同资历的角色组成的。满足现状是一件坏事,你应该努力把自己提高到更高的等级。本文是基于我对行业的理念和观察,很多公司越来越依赖工作年数来评定资深程度,但这是一个蹩脚的刻度尺 —— 你的资历并不是随年龄增长的,你是通过不断解决不同类型的问题才积累的资历,不管你在行业里摸爬滚打了几年。我曾看到没有行业经验的应届毕业生迅速提升并完成高级工程师的工作,我也曾看到“高级”开发人员仅仅因为他们的年龄和“多年的经验”而被贴上“资深”的标签。
+
+要想在事业上有所进步,你需要具备的最重要的品质是不甘于平庸、心态开放、谦虚、从错误中吸取教训、解决有挑战性的问题、拥有机会心态而不是抱怨心态。
+
+话说到这里,这篇文章就该结束了。你对开发者的资历有什么看法?欢迎提出改进意见。下次再见!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/making-logs-colorful-in-nodejs.md b/TODO1/making-logs-colorful-in-nodejs.md
new file mode 100644
index 00000000000..baa6a14d6c2
--- /dev/null
+++ b/TODO1/making-logs-colorful-in-nodejs.md
@@ -0,0 +1,105 @@
+> * 原文地址:[Making Logs Colorful in NodeJS](https://medium.com/front-end-weekly/making-logs-colorful-in-nodejs-b26b6cf9f0bf)
+> * 原文作者:[Prateek Singh](https://medium.com/@prateeksingh_31398)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/making-logs-colorful-in-nodejs.md](https://github.com/xitu/gold-miner/blob/master/TODO1/making-logs-colorful-in-nodejs.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[Long Xiong](https://github.com/xionglong58),[Zavier Tang](https://github.com/ZavierTang)
+
+# 给 NodeJS 的 Logs 点颜色看看!
+
+](https://cdn-images-1.medium.com/max/2000/1*fVkQKafnrC3U6YL7yynPag.jpeg)
+
+在任何应用中,日志都是一个非常重要的部分。我们借助它来调试代码,还可以将它通过 [Splunk](https://en.wikipedia.org/wiki/Splunk) 等框架的分析处理,了解应用中的重要统计数据。从我们敲出 “Hello Word!” 的那一天起,日志就成为了我们的好朋友,帮助了我们很多。所以说,日志基本上是所有后端代码架构中必不可少的部分之一。市面上有许多可用的日志库,比如 [Winston](https://github.com/winstonjs/winston)、[Loggly](https://www.loggly.com/docs/api-overview/)、[Bunyan](https://github.com/trentm/node-bunyan) 等等。但是,在调试我们的 API 或者需要检查某个变量的值时,我们需要的只是用 JavaScript 的 **console.log()** 来输出调试。我们先来看一些您可能会觉得很熟悉的日志代码。
+
+```javascript
+console.log("MY CRUSH NAME");
+console.log("AAAAAAA");
+console.log("--------------------");
+console.log("Step 1");
+console.log("Inside If");
+```
+
+为什么我们要放这样做?是因为懒吗?不,这样输出日志,是因为需要将我们期待的输出与控制台上打印的其他日志区分开。
+
+
+
+目前我们仅仅在当前的控制台增加了 console.log(“Got the packets”) 这一行。您能在这堆日志(图 1)中找到 “Got the packets” 吗?我知道找到这条日志是很困难的。那么该怎么做呢?如何才能使我们的开发更加顺手,日志看起来更加优雅。
+
+## 有颜色的 Log
+
+如果我告诉您,这些日志可以同时用各种各样的颜色打印出来。这样开发就会更加顺手了,对吧?让我们看看下一张图片,并再次找一找 “**Got the packets**” 这条 log。
+
+
+
+“**Got the packets**“ 现在是明显的红色。很棒吧?我们可以将不同的 log 用不同的颜色表示。我打赌这个技能会改变您的日志风格,让日志变得更简单。我们来再看一个例子。
+
+
+
+新添加的 log 也是明显的。现在让我们来看看如何实现这个功能。我们可以使用 **Chalk** 包来实现这一点。
+
+## 安装
+
+```bash
+npm install chalk
+```
+
+## 使用
+
+```javascript
+const chalk = require('chalk');
+console.log(chalk.blue('Hello world!'));//打印蓝色字符串
+```
+
+您也可以自己定制主题并使用,就像下面这样。
+
+```javascript
+const chalk = require('chalk');
+
+const error = chalk.bold.red;
+
+const warning = chalk.keyword('orange');
+
+console.log(error('Error!'));
+console.log(warning('Warning!'));
+```
+
+基本上它就像 chalk[修改符][颜色] 这样,我们可以在代码中打印彩色日志 😊。“**Chalk**” 包给我们提供了很多修改符和颜色来打印。
+
+## 修饰符
+
+* `reset` —— 重置当前颜色链。
+* `bold` —— 加粗文本。
+* `dim` —— 使亮度降低。
+* `italic` —— 将文字设为斜体。**(未被广泛支持)**
+* `underline` —— 使文字加下划线。**(未被广泛支持)**
+* `inverse` —— 反色背景和前景色。
+* `hidden` —— 打印文本,但使其不可见。
+* `strikethrough` —— 在文本的中间画一条水平线。**(未被广泛支持)**
+* `visible` —— 仅当 Chalk 的颜色级别 > 0 时才打印文本。它对于输出一个整洁好看的日志很有帮助。
+
+## 颜色
+
+* `black`
+* `red`
+* `green`
+* `yellow`
+* `blue`
+* `magenta`
+* `cyan`
+* `white`
+* `blackBright`(即:`gray`、`grey`)
+* `redBright`
+* `greenBright`
+* `yellowBright`
+* `blueBright`
+* `magentaBright`
+* `cyanBright`
+* `whiteBright`
+
+感谢您的阅读。后续,我将向您更新一些不太为人所知的 JavaScript 小技巧,帮助您的开发更加顺手。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/making-svg-icon-component-in-vue.md b/TODO1/making-svg-icon-component-in-vue.md
new file mode 100644
index 00000000000..1349fe7eb17
--- /dev/null
+++ b/TODO1/making-svg-icon-component-in-vue.md
@@ -0,0 +1,186 @@
+> * 原文地址:[Making SVG Icon Component in Vue](https://medium.com/js-dojo/making-svg-icon-component-in-vue-cb7fac70e758)
+> * 原文作者:[Achhunna Mali](https://medium.com/@achhunna)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/making-svg-icon-component-in-vue.md](https://github.com/xitu/gold-miner/blob/master/TODO1/making-svg-icon-component-in-vue.md)
+> * 译者:[zoomdong](https://github.com/fireairforce)
+> * 校对者:[Xu Jianxiang](https://github.com/Alfxjx)
+
+# 在 Vue 中编写 SVG 图标组件
+
+#### 一种类似图标字体的酷方法来使用 SVG
+
+ 在 [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral) 拍摄的照片](https://cdn-images-1.medium.com/max/12000/0*bac2YeLYkqgbsZuH)
+
+在考虑了将矢量图标从图标字体迁移到内联 SVG 的[原因](https://www.keycdn.com/blog/icon-fonts-vs-svgs)之后,我在 Vue.js 中找到了一个用 SVG 替换图标字体的解决方案,同时仍能保持使用图标字体的灵活性和易用性——能够使用 CSS 轻松改变图标的大小、颜色以及其它属性。
+
+一种流行的方法是使用 `v-html` 指令和 npm 模块 `html-loader` 来将 SVG 导入到我们的 Vue 模板中,并在 Vue 的生命周期函数 `mounted()` 中修改渲染的 `<svg>` 元素。CSS 样式可以直接应用到 `<svg>` 元素或者是其父元素上,并且这些能够组成一个可复用的组件。
+
+## 创建 Svg-icon 组件
+
+让我们创建 `Svg-icon.vue` 组件文件,并在里面接收三个 prop 变量。
+
+1. `icon` 是一个字符串类型的 prop 变量用来传递 `.svg` 文件名的导入
+2. `hasFill` 是一个布尔类型的 prop 变量来告诉组件 `fill` 属性是否用于更改 `<svg>` 元素的颜色,默认值为 false 即不使用 `fill` 属性
+3. `growByHeight` 是一个布尔类型的 prop 变量来决定 `height` 或 `width` 是否相对于 `font-size` 进行缩放,默认值为 true 即使用 `height`
+
+```Vue
+<script>
+function recursivelyRemoveFill(el) {
+ if (!el) {
+ return;
+ }
+ el.removeAttribute('fill');
+ [].forEach.call(el.children, child => {
+ recursivelyRemoveFill(child);
+ });
+}
+export default {
+ name: 'svg-icon',
+ props: {
+ icon: {
+ type: String,
+ default: null
+ },
+ hasFill: {
+ type: Boolean,
+ default: false
+ },
+ growByHeight: {
+ type: Boolean,
+ default: true
+ },
+ },
+ mounted() {
+ if (this.$el.firstElementChild.nodeName === 'svg') {
+ const svgElement = this.$el.firstElementChild;
+ const widthToHeight = (svgElement.clientWidth / svgElement.clientHeight).toFixed(2);
+ if (this.hasFill) {
+ // recursively remove all fill attribute of element and its nested children
+ recursivelyRemoveFill(svgElement);
+ }
+ // set width and height relative to font size
+ // if growByHeight is true, height set to 1em else width set to 1em and remaining is calculated based on widthToHeight ratio
+ if (this.growByHeight) {
+ svgElement.setAttribute('height', '1em');
+ svgElement.setAttribute('width', `${widthToHeight}em`);
+ } else {
+ svgElement.setAttribute('width', '1em');
+ svgElement.setAttribute('height', `${1 / widthToHeight}em`);
+ }
+ svgElement.classList.add('svg-class');
+ }
+ }
+}
+</script>
+
+<template>
+ <div v-html="require(`html-loader!../assets/svg/${icon}.svg`)" class="svg-container"></div>
+</template>
+
+<style lang="scss" scoped>
+.svg-container {
+ display: inline-flex;
+}
+.svg-class {
+ vertical-align: middle;
+}
+</style>
+```
+
+我们将 `.svg` 图标文件通过 `require()` 传递给 `html-loader` 方法,该方法会将文件字符串化,并且通过 `v-html` 指令将其渲染为 `<svg>` 元素。
+
+所有对 `<svg>` 元素修改的地方都在 `mounted()` 生命周期方法里面。
+
+* 将由 `growByHeight` 定义的 `<svg>` 元素的 `height` 或 `width` 属性设置为 `1em`(`font-size` 的一倍)并对另一个元素使用 `widthToHeight`。由于并非所有的 SVG 都是正方形的,因此我们从渲染的元素计算 `withToHeight` 比率,以便 SVG 在父元素的 `font-size` 属性大小改变的时候按比例缩放到其原始尺寸。
+* 为了设置 `<svg>` 元素的 `fill` 属性,我们需要覆盖掉 SVG 文件内部附带的 `fill` 属性。当 `hasFill` 值为 true 的时候,我们从 `<svg>` 元素及其子元素中递归地删除 fill 属性。然后使用 CSS 选择器将 fill 值添加到其父元素或 `<svg>` 元素就可以了。
+* 还可以向元素中添加例如 `class` 等其它 DOM 属性,这些属性可用于设置组件中的范围样式
+
+---
+
+## 创建微笑图标
+
+让我们使用 [Font Awesome](https://fontawesome.com/icons/smile?style=solid) 和我们的 `Svg-icon` 组件中的图标字体创建一个微笑图标。
+
+](https://cdn-images-1.medium.com/max/2276/1*TegYEwSxB4dJEFql2T1k9A.png)
+
+#### 使用图标字体
+
+```Vue
+<template>
+ <i class="fas fa-smile smile-icon"></i>
+</template>
+
+<style lang="scss" scoped>
+.smile-icon {
+ font-size: 24px;
+ color: #aaa;
+
+ &:hover {
+ color: #666;
+ }
+}
+</style>
+```
+
+`.smile-icon` 类的 CSS 选择器以及伪类选择器 `:hover` 来设置图标的 `font-size` 和 `color` 属性。
+
+#### 使用 Svg-icon 组件
+
+```Vue
+<script>
+import SvgIcon from './components/Svg-icon';
+
+export default {
+ name: 'my-component',
+ components: {
+ 'svg-icon': SvgIcon,
+ },
+}
+</script>
+
+<template>
+ <div class="smile-icon">
+ <svg-icon icon="smile-solid" :hasFill="true"></svg-icon>
+ </div>
+</template>
+
+<style lang="scss" scoped>
+.smile-icon {
+ font-size: 24px;
+ fill: #aaa;
+
+ &:hover {
+ fill: #666;
+ }
+}
+</style>
+```
+
+上面的实现和图标字体方法相同,除了 `.smile-icon` 类在父元素中,在 `Svg-icon` 组件中,`color` 属性被替换为 `fill`。我们还必须确保 `smile-solid.svg` 文件位于 `Svg-icon` 组件的 `require()` 方法指定的路径(`./assets/svg/`)中。
+
+#### 渲染成 HTML
+
+这是由 `v-html` 的输出渲染的 HTML。注意:会删除掉所有的 `fill` 属性,并将 `height` 和 `width` 属性添加到 `<svg>` 中。
+
+```html
+<div class="smile-icon">
+ <svg height="1em" width="1em" aria-hidden="true" focusable="false" data-prefix="fas" data-icon="smile" class="svg-inline--fa fa-smile fa-w-16" role="img" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 496 512">
+ <path d="M248 8C111 8 0 119 0 256s111 248 248 248 248-111 248-248S385 8 248 8zm80 168c17.7 0 32 14.3 32 32s-14.3 32-32 32-32-14.3-32-32 14.3-32 32-32zm-160 0c17.7 0 32 14.3 32 32s-14.3 32-32 32-32-14.3-32-32 14.3-32 32-32zm194.8 170.2C334.3 380.4 292.5 400 248 400s-86.3-19.6-114.8-53.8c-13.6-16.3 11-36.7 24.6-20.5 22.4 26.9 55.2 42.2 90.2 42.2s67.8-15.4 90.2-42.2c13.4-16.2 38.1 4.2 24.6 20.5z">
+ </path>
+ </svg>
+</div>
+```
+
+---
+
+## 过渡到 SVG
+
+](https://cdn-images-1.medium.com/max/2000/1*gbV6Hisa64jh0tb5ughaig.gif)
+
+由于 SVG 被认为是未来的发展方向,因此最好是在保留图标字体的易用性的基础上,逐步放弃使用图标字体。`Svg-icon` 组件是一个例子,告诉了我们如何使用可用的库来抽离出 `<svg>` 元素中的混乱部分,同时模仿使用图标字体的好处!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/master-the-javascript-interview-what-is-a-pure-function.md b/TODO1/master-the-javascript-interview-what-is-a-pure-function.md
new file mode 100644
index 00000000000..664f3fa5c4b
--- /dev/null
+++ b/TODO1/master-the-javascript-interview-what-is-a-pure-function.md
@@ -0,0 +1,300 @@
+> * 原文地址:[Master the JavaScript Interview: What is a Pure Function?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-pure-function-d1c076bec976)
+> * 原文作者:[Eric Elliott](https://medium.com/@_ericelliott)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/master-the-javascript-interview-what-is-a-pure-function.md](https://github.com/xitu/gold-miner/blob/master/TODO1/master-the-javascript-interview-what-is-a-pure-function.md)
+> * 译者:[niayyy-S](https://github.com/niayyy-S)
+> * 校对者:[chaingangway](https://github.com/chaingangway)、[IAMSHENSH](https://github.com/IAMSHENSH)
+
+# 掌握 JavaScript 面试:什么是纯函数?
+
+
+
+纯函数对于实现各种目的是必不可少的,包括函数式编程,可靠地并发和 React + Redux 构造的应用程序。但是纯函数是什么意思?
+
+我们将通过来自 [《跟 Eric Elliott 学习 JavaScript》](http://ericelliottjs.com/product/lifetime-access-pass/) 的免费课程来回答的这个问题:
+
+在我们解决什么是纯函数这个问题之前,仔细研究一下什么是函数可能更好。也许存在一种不一样的看待函数的方式,会让函数式编程更易于理解。
+
+#### 什么是函数?
+
+**函数**是一个过程:它需要一些叫做**参数**的输入,然后产生一些叫做**返回值**的输出。函数可以用于以下目的:
+
+* **映射:**基于输入值产生一些的输出。函数把输入值**映射到**输出值。
+* **过程化:**可以调用一个函数去执行一系列步骤。该一系列步骤称为过程,而这种方式的编程称为**面向过程编程**。
+* **I/O:**一些函数存在与系统其他部分进行通信,例如屏幕,存储,系统日志或网络。
+
+#### 映射
+
+纯函数都是关于映射的。函数将输入参数映射到返回值,这意味着对于每组输入,都存在对应的输出。函数将获取输入并返回相应的输出。
+
+**`Math.max()`** 以一组数字作为参数并返回最大数字:
+
+```js
+Math.max(2, 8, 5); // 8
+```
+
+在此示例中,2,8 和 5 是**参数**。它们是传递给函数的值。
+
+**`Math.max()`** 是一个可以接受任意数量的参数并返回最大参数值的函数。在这个案例中,我们传入的最大数是 8,对应了返回的数字。
+
+函数在计算和数学中非常重要。它们帮助我们用合适的方式处理数据。好的程序员会给函数起描述性的名称,以便当我们查看代码时,我们可以通过函数名了解函数的作用。
+
+数学也有函数,它们的工作方式与 JavaScript 中的函数非常相似。您可能见过代数函数。他们看起来像这样:
+
+**f**(**x**) = 2**x**
+
+这意味着我们要声明了一个名为 f 的函数,它接受一个叫 x 的参数并将 x 乘以 2。
+
+要使用这个函数,我们只需为 x 提供一个值:
+
+**f**(2)
+
+在代数中,这意味着与下面的写法完全相同:
+
+4
+
+因此,在任何看到 **f**(2) 的地方都可以替换 4。
+
+现在让我们用 JavaScript 来描述这个函数:
+
+```js
+const double = x => x * 2;
+```
+
+你可以使用 **`console.log()`** 检查函数输出:
+
+```js
+console.log( double(5) ); // 10
+```
+
+还记得我说过的在数学函数中,你可以替换 **`f(2)`** 为 **`4`** 吗?在这种情况下,JavaScript 引擎用 **`10`** 替换 **`double(5)`**。
+
+因此, **`console.log( double(5) );`** 与 **`console.log(10);`** 相同
+
+这是真实存在的,因为 **`double()`** 是一个纯函数,但是如果 **`double()`** 有副作用,例如将值保存到磁盘或打印到控制台,用 10 替换 **`double(5)`** 会改变函数的含义。
+
+如果想要引用透明,则需要使用纯函数。
+
+#### 纯函数
+
+**纯函数**是一个函数,其中:
+
+* 给定相同的输入,将始终返回相同的输出。
+* 无副作用。
+
+> 如果你合理调用一个函数,而没有使用它的返回值,则毫无疑问不是纯函数。对于纯函数来说,相当于未进行调用。
+
+我建议你偏向于使用纯函数。意思是,如果使用纯函数实现程序需求是可行的,应该优先选择使用。纯函数接受一些输入,并根据输入返回一些输出。它们是程序中最简单的可重用代码块。也许计算机科学中最重要的设计原理是 KISS(保持简单明了)。我更喜欢保持傻瓜式的简单。纯函数是傻瓜式简单的最佳方式。
+
+纯函数具有许多有益的特性,并构成了**函数式编程**的基础。纯函数完全独立于外部状态,因此,它们不受所有与共享可变状态有关问题的影响。它们的独立特性也使其成为跨多个 CPU 以及整个分布式计算集群进行并行处理的极佳选择,这使其对许多类型的科学和资源密集型计算任务至关重要。
+
+纯函数也是非常独立的 —— 在代码中可以轻松移动,重构以及重组,使程序更灵活并能够适应将来的更改。
+
+#### 共享状态问题
+
+几年前,我正在开发一个应用程序,该程序允许用户搜索音乐艺术家的数据库并将该艺术家的音乐播放列表加载到 web 播放器中。大约在 Google Instant 上线的那个时候,当输入搜索查询时,它会显示即时搜索结果。AJAX 驱动的自动完成功能风靡一时。
+
+唯一的问题是,用户输入的速度通常快于 API 的自动完成搜索并返回响应的速度,从而导致一些奇怪的错误。这将触发竞争条件(race condition),在此情况下,较新的结果可能会被过期的所取代。
+
+为什么会这样呢?因为每个 AJAX 成功处理程序都有权直接更新显示给用户的建议列表。最慢的 AJAX 请求总是可以通过盲目替换获得用户的注意,即使这些替换的结果可能是较新的。
+
+为了解决这个问题,我创建了一个建议管理器 —— 一个单一数据源去管理查询建议的状态。它知道当前有一个待处理的 AJAX 请求,并且当用户输入新内容时,这个待处理的 AJAX 请求将在发出新请求之前被取消,因此一次只有一个响应处理程序将能够触发 UI 状态更新。
+
+任何种类的异步操作或并发都可能导致类似的竞争条件。如果输出取决于不可控事件的顺序(例如网络,设备延迟,用户输入,随机性等),则会发生竞争条件。实际上,如果你正在使用共享状态,并且该状态依赖于一系列不确定性因素,总而言之,输出都是无法预测的,这意味着无法正确测试或完全理解。正如 Martin Odersky(Scala 语言的创建者)所说:
+
+> **不确定性 = 并行处理 + 可变状态**
+
+程序的确定性通常是计算中的理想属性。可能你认为还好,因为 JS 在单线程中运行,因此不受并行处理问题的影响,但是正如 AJAX 示例所示,单线程JS引擎并不意味着没有并发。相反,JavaScript 中有许多并发来源。API I/O,事件侦听,Web Worker,iframe 和超时都可以将不确定性引入程序中。将其与共享状态结合起来,就可以得出解决 bug 的方法。
+
+纯函数可以帮助你避免这些 bug。
+
+#### 给定相同的输入,始终返回相同的输出
+
+使用上面的 **`double()`** 函数,你可以用结果替换函数调用,程序仍然具有相同的含义 —— **`double(5)`** 始终与程序中的 **`10`** 具有相同含义,而不管上下文如何,无论调用它多少次或何时调用。
+
+但是你不能对所有函数都这么认为。某些函数依赖于你传入的参数以外的信息来产生结果。
+
+考虑以下示例:
+
+```js
+Math.random(); // => 0.4011148700956255
+Math.random(); // => 0.8533405303023756
+Math.random(); // => 0.3550692005082965
+```
+
+尽管我们没有传递任何参数到任何函数调用的,他们都产生了不同的输出,这意味着 **`Math.random()`** 是**不是纯函数**。
+
+**`Math.random()`** 每次运行时,都会产生一个介于 0 和 1 之间的新随机数,因此很明显,你不能只用 0.4011148700956255 替换它而不改变程序的含义。
+
+那将每次都会产生相同的结果。当我们要求计算机产生一个随机数时,通常意味着我们想要一个与上次不同的结果。每一面都印着相同数字的一对骰子有什么意义呢?
+
+有时我们必须询问计算机当前时间。我们不会详细地了解时间函数的工作原理。只需复制以下代码:
+
+```js
+const time = () => new Date().toLocaleTimeString();
+
+time(); // => "5:15:45 PM"
+```
+
+如果用当前时间取代 **`time()`** 函数的调用会发生什么?
+
+它总是输出相同的时间:这个函数调用被替换的时间。换句话说,它只能每天产生一次正确的输出,并且仅当你在替换函数的确切时刻运行程序时才可以。
+
+很明显,**`time()`** 不像 **`double()`** 函数。
+
+**如果函数在给定相同的输入的情况下始终产生相同的输出,则该函数是纯函数**。你可能还记得代数课上的这个规则:相同的输入值将始终映射到相同的输出值。但是,许多输入值可能会映射到相同的输出值。例如,以下函数是**纯函数**:
+
+```js
+const highpass = (cutoff, value) => value >= cutoff;
+```
+
+相同的输入值将始终映射到相同的输出值:
+
+```js
+highpass(5, 5); // => true
+highpass(5, 5); // => true
+highpass(5, 5); // => true
+```
+
+许多输入值可能映射到相同的输出值:
+
+```js
+highpass(5, 123); // true
+highpass(5, 6); // true
+highpass(5, 18); // true
+
+highpass(5, 1); // false
+highpass(5, 3); // false
+highpass(5, 4); // false
+```
+
+纯函数一定不能依赖任何外部可变状态,因为它不再是确定性的或引用透明的。
+
+## 纯函数不会产生副作用
+
+纯函数不会产生任何副作用,意味着它无法更改任何外部状态。
+
+## 不变性
+
+JavaScript 的对象参数是引用的,这意味着如果函数更改对象或数组参数上的属性,则将使该函数外部可访问的状态发生变化。纯函数不得改变外部状态。
+
+考虑一下这种改变的,**不纯的** **`addToCart()`** 函数:
+
+```JavaScript
+// 不纯的 addToCart 函数改变了现有的 cart 对象
+const addToCart = (cart, item, quantity) => {
+ cart.items.push({
+ item,
+ quantity
+ });
+ return cart;
+};
+
+
+test('addToCart()', assert => {
+ const msg = 'addToCart() should add a new item to the cart.';
+ const originalCart = {
+ items: []
+ };
+ const cart = addToCart(
+ originalCart,
+ {
+ name: "Digital SLR Camera",
+ price: '1495'
+ },
+ 1
+ );
+
+ const expected = 1; // cart 中的商品数
+ const actual = cart.items.length;
+
+ assert.equal(actual, expected, msg);
+
+ assert.deepEqual(originalCart, cart, 'mutates original cart.');
+ assert.end();
+});
+
+```
+
+这个函数通过传递 cart 对象,添加商品和商品数量到 cart 对象上来调用的。然后,该函数返回相同的 cart 对象,并添加了商品。
+
+这样做的问题是,我们刚刚改变了一些共享状态。其他函数可能依赖于 cart 对象状态 —— 被该函数调用之前的状态,而现在我们已经更改了这个共享状态,如果我们改变函数调用的顺序,我们不得不担心将会对程序逻辑上产生怎样的影响。重构代码可能会导致 bug 出现,从而可能破坏订单并导致客户不满意。
+
+现在考虑这个版本:
+
+```JavaScript
+// 纯 addToCart() 函数返回一个新的 cart 对象
+// 这不会改变原始对象
+const addToCart = (cart, item, quantity) => {
+ const newCart = lodash.cloneDeep(cart);
+
+ newCart.items.push({
+ item,
+ quantity
+ });
+ return newCart;
+
+};
+
+
+test('addToCart()', assert => {
+ const msg = 'addToCart() should add a new item to the cart.';
+ const originalCart = {
+ items: []
+ };
+
+ // npm 上的 deep-freeze
+ // 如果原始对象被改变,则抛出一个错误
+ deepFreeze(originalCart);
+
+ const cart = addToCart(
+ originalCart,
+ {
+ name: "Digital SLR Camera",
+ price: '1495'
+ },
+ 1
+ );
+
+
+ const expected = 1; // cart 中的商品数
+ const actual = cart.items.length;
+
+ assert.equal(actual, expected, msg);
+
+ assert.notDeepEqual(originalCart, cart,
+ 'should not mutate original cart.');
+ assert.end();
+});
+
+```
+
+在此示例中,我们在对象中嵌套了一个数组,这是我要进行深克隆的原因。这比你通常要处理的状态更为复杂。对于大多数事情,你可以将其分解为较小的块。
+
+例如,Redux 让你可以组成 reducers,而不是在每个 reducers 中的解决整个应用程序状态。结果是,你不必每次更新整个应用程序状态的一小部分时就创建一个深克隆。相反,你可以使用非破坏性数组方法,或 **`Object.assign()`** 更新应用状态的一小部分。
+
+轮到你了。[Fork 这个 codepen 代码](http://codepen.io/ericelliott/pen/MyojLq?editors=0010),并将非纯函数转换为纯函数。使单元测试通过而不更改测试。
+
+#### 探索这个系列
+
+* [什么是闭包?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-closure-b2f0d2152b36#.ecfskj935)
+* [类和原型继承有什么区别?](https://medium.com/javascript-scene/master-the-javascript-interview-what-s-the-difference-between-class-prototypal-inheritance-e4cd0a7562e9#.h96dymht1)
+* [什么是纯函数?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-pure-function-d1c076bec976#.4256pjcfq)
+* [函数由什么构成?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-function-composition-20dfb109a1a0#.i84zm53fb)
+* [什么是函数式编程?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-functional-programming-7f218c68b3a0#.jddz30xy3)
+* [什么是 Promise ?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-promise-27fc71e77261#.aa7ubggsy)
+* [软技能](https://medium.com/javascript-scene/master-the-javascript-interview-soft-skills-a8a5fb02c466)
+
+> 该帖子已包含在《Composing Software》书中。**[ 买这本书](https://leanpub.com/composingsoftware) | [索引](https://medium.com/javascript-scene/composing-software-the-book-f31c77fc3ddc) | [<上一页](https://medium.com/javascript-scene/why-learn-functional-programming-in-javascript-composing-software-ea13afc7a257) | [下一页>](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-functional-programming-7f218c68b3a0)**
+
+---
+
+**埃里克·埃利奥特(Eric Elliott)** 是一名分布式系统专家,并且是[《Composing Software》](https://leanpub.com/composingsoftware)和[《Programming JavaScript Applications》](https://ericelliottjs.com/product/programming-javascript-applications-ebook/)这两本书的作者。作为 [DevAnywhere.io](https://devanywhere.io/) 的联合创始人,他教开发人员远程工作和实现工作 / 生活平衡所需的技能。他建立并为加密项目的开发团队提供咨询,并为 **Adobe 公司、Zumba Fitness、《华尔街日报》、ESPN、BBC** 和包括 **Usher、Frank Ocean、Metallica** 在内的顶级唱片艺术家的软件体验做出了贡献。
+
+**他与世界上最美丽的女人一起享受着远程办公的生活方式。**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/master-the-javascript-interview-what-is-functional-programming.md b/TODO1/master-the-javascript-interview-what-is-functional-programming.md
new file mode 100644
index 00000000000..3432dd47480
--- /dev/null
+++ b/TODO1/master-the-javascript-interview-what-is-functional-programming.md
@@ -0,0 +1,344 @@
+> * 原文地址:[Master the JavaScript Interview: What is Functional Programming?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-functional-programming-7f218c68b3a0)
+> * 原文作者:[Eric Elliott](https://medium.com/@_ericelliott)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/master-the-javascript-interview-what-is-functional-programming.md](https://github.com/xitu/gold-miner/blob/master/TODO1/master-the-javascript-interview-what-is-functional-programming.md)
+> * 译者:
+> * 校对者:
+
+# Master the JavaScript Interview: What is Functional Programming?
+
+
+
+> “Master the JavaScript Interview” is a series of posts designed to prepare candidates for common questions they are likely to encounter when applying for a mid to senior-level JavaScript position. These are questions I frequently use in real interviews.
+
+Functional programming has become a really hot topic in the JavaScript world. Just a few years ago, few JavaScript programmers even knew what functional programming is, but every large application codebase I’ve seen in the past 3 years makes heavy use of functional programming ideas.
+
+**Functional programming** (often abbreviated FP) is the process of building software by composing **pure functions**, avoiding **shared state,** **mutable data,** and **side-effects**. Functional programming is **declarative** rather than **imperative**, and application state flows through pure functions. Contrast with object oriented programming, where application state is usually shared and colocated with methods in objects.
+
+Functional programming is a **programming paradigm**, meaning that it is a way of thinking about software construction based on some fundamental, defining principles (listed above). Other examples of programming paradigms include object oriented programming and procedural programming.
+
+Functional code tends to be more concise, more predictable, and easier to test than imperative or object oriented code — but if you’re unfamiliar with it and the common patterns associated with it, functional code can also seem a lot more dense, and the related literature can be impenetrable to newcomers.
+
+If you start googling functional programming terms, you’re going to quickly hit a brick wall of academic lingo that can be very intimidating for beginners. To say it has a learning curve is a serious understatement. But if you’ve been programming in JavaScript for a while, chances are good that you’ve used a lot of functional programming concepts & utilities in your real software.
+
+> Don’t let all the new words scare you away. It’s a lot easier than it sounds.
+
+The hardest part is wrapping your head around all the unfamiliar vocabulary. There are a lot of ideas in the innocent looking definition above which all need to be understood before you can begin to grasp the meaning of functional programming:
+
+* Pure functions
+* Function composition
+* Avoid shared state
+* Avoid mutating state
+* Avoid side effects
+
+In other words, if you want to know what functional programming means in practice, you have to start with an understanding of those core concepts.
+
+A **pure function** is a function which:
+
+* Given the same inputs, always returns the same output, and
+* Has no side-effects
+
+Pure functions have lots of properties that are important in functional programming, including **referential transparency** (you can replace a function call with its resulting value without changing the meaning of the program). Read [“What is a Pure Function?”](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-pure-function-d1c076bec976) for more details.
+
+**Function composition** is the process of combining two or more functions in order to produce a new function or perform some computation. For example, the composition `f . g` (the dot means “composed with”) is equivalent to `f(g(x))` in JavaScript. Understanding function composition is an important step towards understanding how software is constructed using the functional programming. Read [“What is Function Composition?”](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-function-composition-20dfb109a1a0) for more.
+
+## Shared State
+
+**Shared state** is any variable, object, or memory space that exists in a shared scope, or as the property of an object being passed between scopes. A shared scope can include global scope or closure scopes. Often, in object oriented programming, objects are shared between scopes by adding properties to other objects.
+
+For example, a computer game might have a master game object, with characters and game items stored as properties owned by that object. Functional programming avoids shared state — instead relying on immutable data structures and pure calculations to derive new data from existing data. For more details on how functional software might handle application state, see [“10 Tips for Better Redux Architecture”](https://medium.com/javascript-scene/10-tips-for-better-redux-architecture-69250425af44).
+
+The problem with shared state is that in order to understand the effects of a function, you have to know the entire history of every shared variable that the function uses or affects.
+
+Imagine you have a user object which needs saving. Your `saveUser()` function makes a request to an API on the server. While that’s happening, the user changes their profile picture with `updateAvatar()` and triggers another `saveUser()` request. On save, the server sends back a canonical user object that should replace whatever is in memory in order to sync up with changes that happen on the server or in response to other API calls.
+
+Unfortunately, the second response gets received before the first response, so when the first (now outdated) response gets returned, the new profile pic gets wiped out in memory and replaced with the old one. This is an example of a race condition — a very common bug associated with shared state.
+
+Another common problem associated with shared state is that changing the order in which functions are called can cause a cascade of failures because functions which act on shared state are timing dependent:
+
+```JavaScript
+// With shared state, the order in which function calls are made
+// changes the result of the function calls.
+const x = {
+ val: 2
+};
+
+const x1 = () => x.val += 1;
+
+const x2 = () => x.val *= 2;
+
+x1();
+x2();
+
+console.log(x.val); // 6
+
+// This example is exactly equivalent to the above, except...
+const y = {
+ val: 2
+};
+
+const y1 = () => y.val += 1;
+
+const y2 = () => y.val *= 2;
+
+// ...the order of the function calls is reversed...
+y2();
+y1();
+
+// ... which changes the resulting value:
+console.log(y.val); // 5
+```
+
+When you avoid shared state, the timing and order of function calls don’t change the result of calling the function. With pure functions, given the same input, you’ll always get the same output. This makes function calls completely independent of other function calls, which can radically simplify changes and refactoring. A change in one function, or the timing of a function call won’t ripple out and break other parts of the program.
+
+```JavaScript
+const x = {
+ val: 2
+};
+
+const x1 = x => Object.assign({}, x, { val: x.val + 1});
+
+const x2 = x => Object.assign({}, x, { val: x.val * 2});
+
+console.log(x1(x2(x)).val); // 5
+
+
+const y = {
+ val: 2
+};
+
+// Since there are no dependencies on outside variables,
+// we don't need different functions to operate on different
+// variables.
+
+// this space intentionally left blank
+
+
+// Because the functions don't mutate, you can call these
+// functions as many times as you want, in any order,
+// without changing the result of other function calls.
+x2(y);
+x1(y);
+
+console.log(x1(x2(y)).val); // 5
+```
+
+In the example above, we use `Object.assign()` and pass in an empty object as the first parameter to copy the properties of `x` instead of mutating it in place. In this case, it would have been equivalent to simply create a new object from scratch, without `Object.assign()`, but this is a common pattern in JavaScript to create copies of existing state instead of using mutations, which we demonstrated in the first example.
+
+If you look closely at the `console.log()` statements in this example, you should notice something I’ve mentioned already: function composition. Recall from earlier, function composition looks like this: `f(g(x))`. In this case, we replace `f()` and `g()` with `x1()` and `x2()` for the composition: `x1 . x2`.
+
+Of course, if you change the order of the composition, the output will change. Order of operations still matters. `f(g(x))` is not always equal to `g(f(x))`, but what doesn’t matter anymore is what happens to variables outside the function — and that’s a big deal. With impure functions, it’s impossible to fully understand what a function does unless you know the entire history of every variable that the function uses or affects.
+
+Remove function call timing dependency, and you eliminate an entire class of potential bugs.
+
+## Immutability
+
+An **immutable** object is an object that can’t be modified after it’s created. Conversely, a **mutable** object is any object which can be modified after it’s created.
+
+Immutability is a central concept of functional programming because without it, the data flow in your program is lossy. State history is abandoned, and strange bugs can creep into your software. For more on the significance of immutability, see [“The Dao of Immutability.”](https://medium.com/javascript-scene/the-dao-of-immutability-9f91a70c88cd)
+
+In JavaScript, it’s important not to confuse `const`, with immutability. `const` creates a variable name binding which can’t be reassigned after creation. `const` does not create immutable objects. You can’t change the object that the binding refers to, but you can still change the properties of the object, which means that bindings created with `const` are mutable, not immutable.
+
+Immutable objects can’t be changed at all. You can make a value truly immutable by deep freezing the object. JavaScript has a method that freezes an object one-level deep:
+
+```JavaScript
+const a = Object.freeze({
+ foo: 'Hello',
+ bar: 'world',
+ baz: '!'
+});
+
+a.foo = 'Goodbye';
+// Error: Cannot assign to read only property 'foo' of object Object
+
+```
+
+But frozen objects are only superficially immutable. For example, the following object is mutable:
+
+```JavaScript
+const a = Object.freeze({
+ foo: { greeting: 'Hello' },
+ bar: 'world',
+ baz: '!'
+});
+
+a.foo.greeting = 'Goodbye';
+
+console.log(`${ a.foo.greeting }, ${ a.bar }${a.baz}`);
+```
+
+As you can see, the top level primitive properties of a frozen object can’t change, but any property which is also an object (including arrays, etc…) can still be mutated — so even frozen objects are not immutable unless you walk the whole object tree and freeze every object property.
+
+In many functional programming languages, there are special immutable data structures called **trie data structures** (pronounced “tree”) which are effectively deep frozen — meaning that no property can change, regardless of the level of the property in the object hierarchy.
+
+Tries use **structural sharing** to share reference memory locations for all the parts of the object which are unchanged after an object has been copied by an operator, which uses less memory, and enables significant performance improvements for some kinds of operations.
+
+For example, you can use identity comparisons at the root of an object tree for comparisons. If the identity is the same, you don’t have to walk the whole tree checking for differences.
+
+There are several libraries in JavaScript which take advantage of tries, including [Immutable.js](https://github.com/facebook/immutable-js) and [Mori](https://github.com/swannodette/mori).
+
+I have experimented with both, and tend to use Immutable.js in large projects that require significant amounts of immutable state. For more on that, see [“10 Tips for Better Redux Architecture”](https://medium.com/javascript-scene/10-tips-for-better-redux-architecture-69250425af44).
+
+## Side Effects
+
+A side effect is any application state change that is observable outside the called function other than its return value. Side effects include:
+
+* Modifying any external variable or object property (e.g., a global variable, or a variable in the parent function scope chain)
+* Logging to the console
+* Writing to the screen
+* Writing to a file
+* Writing to the network
+* Triggering any external process
+* Calling any other functions with side-effects
+
+Side effects are mostly avoided in functional programming, which makes the effects of a program much easier to understand, and much easier to test.
+
+Haskell and other functional languages frequently isolate and encapsulate side effects from pure functions using [**monads**](https://en.wikipedia.org/wiki/Monad_(functional_programming)). The topic of monads is deep enough to write a book on, so we’ll save that for later.
+
+What you do need to know right now is that side-effect actions need to be isolated from the rest of your software. If you keep your side effects separate from the rest of your program logic, your software will be much easier to extend, refactor, debug, test, and maintain.
+
+This is the reason that most front-end frameworks encourage users to manage state and component rendering in separate, loosely coupled modules.
+
+## Reusability Through Higher Order Functions
+
+Functional programming tends to reuse a common set of functional utilities to process data. Object oriented programming tends to colocate methods and data in objects. Those colocated methods can only operate on the type of data they were designed to operate on, and often only the data contained in that specific object instance.
+
+In functional programming, any type of data is fair game. The same `map()` utility can map over objects, strings, numbers, or any other data type because it takes a function as an argument which appropriately handles the given data type. FP pulls off its generic utility trickery using **higher order functions**.
+
+JavaScript has **first class functions**, which allows us to treat functions as data — assign them to variables, pass them to other functions, return them from functions, etc…
+
+A **higher order function** is any function which takes a function as an argument, returns a function, or both. Higher order functions are often used to:
+
+* Abstract or isolate actions, effects, or async flow control using callback functions, promises, monads, etc…
+* Create utilities which can act on a wide variety of data types
+* Partially apply a function to its arguments or create a curried function for the purpose of reuse or function composition
+* Take a list of functions and return some composition of those input functions
+
+#### Containers, Functors, Lists, and Streams
+
+A functor is something that can be mapped over. In other words, it’s a container which has an interface which can be used to apply a function to the values inside it. When you see the word functor, you should think “mappable”.
+
+Earlier we learned that the same `map()` utility can act on a variety of data types. It does that by lifting the mapping operation to work with a functor API. The important flow control operations used by `map()` take advantage of that interface. In the case of `Array.prototype.map()`, the container is an array, but other data structures can be functors, too — as long as they supply the mapping API.
+
+Let’s look at how `Array.prototype.map()` allows you to abstract the data type from the mapping utility to make `map()` usable with any data type. We’ll create a simple `double()` mapping that simply multiplies any passed in values by 2:
+
+```JavaScript
+const double = n => n * 2;
+const doubleMap = numbers => numbers.map(double);
+console.log(doubleMap([2, 3, 4])); // [ 4, 6, 8 ]
+```
+
+What if we want to operate on targets in a game to double the number of points they award? All we have to do is make a subtle change to the `double()` function that we pass into `map()`, and everything still works:
+
+```JavaScript
+const double = n => n.points * 2;
+
+const doubleMap = numbers => numbers.map(double);
+
+console.log(doubleMap([
+ { name: 'ball', points: 2 },
+ { name: 'coin', points: 3 },
+ { name: 'candy', points: 4}
+])); // [ 4, 6, 8 ]
+```
+
+The concept of using abstractions like functors & higher order functions in order to use generic utility functions to manipulate any number of different data types is important in functional programming. You’ll see a similar concept applied in [all sorts of different ways](https://github.com/fantasyland/fantasy-land).
+
+> # “A list expressed over time is a stream.”
+
+All you need to understand for now is that arrays and functors are not the only way this concept of containers and values in containers applies. For example, an array is just a list of things. A list expressed over time is a stream — so you can apply the same kinds of utilities to process streams of incoming events — something that you’ll see a lot when you start building real software with FP.
+
+## Declarative vs Imperative
+
+Functional programming is a declarative paradigm, meaning that the program logic is expressed without explicitly describing the flow control.
+
+**Imperative** programs spend lines of code describing the specific steps used to achieve the desired results — the **flow control: How** to do things.
+
+**Declarative** programs abstract the flow control process, and instead spend lines of code describing the **data flow: What** to do. The **how** gets abstracted away.
+
+For example, this **imperative** mapping takes an array of numbers and returns a new array with each number multiplied by 2:
+
+```JavaScript
+const doubleMap = numbers => {
+ const doubled = [];
+ for (let i = 0; i < numbers.length; i++) {
+ doubled.push(numbers[i] * 2);
+ }
+ return doubled;
+};
+
+console.log(doubleMap([2, 3, 4])); // [4, 6, 8]
+```
+
+This **declarative** mapping does the same thing, but abstracts the flow control away using the functional `Array.prototype.map()` utility, which allows you to more clearly express the flow of data:
+
+```JavaScript
+const doubleMap = numbers => numbers.map(n => n * 2);
+
+console.log(doubleMap([2, 3, 4])); // [4, 6, 8]
+```
+
+**Imperative** code frequently utilizes statements. A **statement** is a piece of code which performs some action. Examples of commonly used statements include `for`, `if`, `switch`, `throw`, etc…
+
+**Declarative** code relies more on expressions. An **expression** is a piece of code which evaluates to some value. Expressions are usually some combination of function calls, values, and operators which are evaluated to produce the resulting value.
+
+These are all examples of expressions:
+
+```
+2 * 2
+doubleMap([2, 3, 4])
+Math.max(4, 3, 2)
+```
+
+Usually in code, you’ll see expressions being assigned to an identifier, returned from functions, or passed into a function. Before being assigned, returned, or passed, the expression is first evaluated, and the resulting value is used.
+
+## Conclusion
+
+Functional programming favors:
+
+* Pure functions instead of shared state & side effects
+* Immutability over mutable data
+* Function composition over imperative flow control
+* Lots of generic, reusable utilities that use higher order functions to act on many data types instead of methods that only operate on their colocated data
+* Declarative rather than imperative code (what to do, rather than how to do it)
+* Expressions over statements
+* Containers & higher order functions over ad-hoc polymorphism
+
+## Homework
+
+Learn & practice this core group of functional array extras:
+
+* `.map()`
+* `.filter()`
+* `.reduce()`
+
+Use map to transform the following array of values into an array of item names:
+
+Use filter to select the items where points are greater than or equal to 3:
+
+Use reduce to sum the points:
+
+#### Explore the Series
+
+* [What is a Closure?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-closure-b2f0d2152b36#.ecfskj935)
+* [What is the Difference Between Class and Prototypal Inheritance?](https://medium.com/javascript-scene/master-the-javascript-interview-what-s-the-difference-between-class-prototypal-inheritance-e4cd0a7562e9#.h96dymht1)
+* [What is a Pure Function?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-pure-function-d1c076bec976#.4256pjcfq)
+* [What is Function Composition?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-function-composition-20dfb109a1a0#.i84zm53fb)
+* [What is Functional Programming?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-functional-programming-7f218c68b3a0#.jddz30xy3)
+* [What is a Promise?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-promise-27fc71e77261#.aa7ubggsy)
+* [Soft Skills](https://medium.com/javascript-scene/master-the-javascript-interview-soft-skills-a8a5fb02c466)
+
+> This post was included in the book “Composing Software”.**[
+Buy the Book](https://leanpub.com/composingsoftware) | [Index](https://medium.com/javascript-scene/composing-software-the-book-f31c77fc3ddc) | [\< Previous](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-pure-function-d1c076bec976) | [Next >](https://medium.com/javascript-scene/a-functional-programmers-introduction-to-javascript-composing-software-d670d14ede30)**
+
+---
+
+****Eric Elliott** is the author of the books, [“Composing Software”](https://leanpub.com/composingsoftware) and [“Programming JavaScript Applications”](http://pjabook.com). As co-founder of [EricElliottJS.com](https://ericelliottjs.com) and [DevAnywhere.io](https://devanywhere.io), he teaches developers essential software development skills. He builds and advises development teams for crypto projects, and has contributed to software experiences for **Adobe Systems, Zumba Fitness,** **The Wall StreetJournal,** **ESPN,** **BBC,** and top recording artists including **Usher, Frank Ocean, Metallica,** and many more.**
+
+**He enjoys a remote lifestyle with the most beautiful woman in the world.**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/mathematical-programming-a-key-habit-to-built-up-for-advancing-in-data-science.md b/TODO1/mathematical-programming-a-key-habit-to-built-up-for-advancing-in-data-science.md
index 2fab34eb64b..d1434035656 100644
--- a/TODO1/mathematical-programming-a-key-habit-to-built-up-for-advancing-in-data-science.md
+++ b/TODO1/mathematical-programming-a-key-habit-to-built-up-for-advancing-in-data-science.md
@@ -1,108 +1,107 @@
-> * 原文地址:[Mathematical programming — a key habit to build up for advancing in data science](https://towardsdatascience.com/mathematical-programming-a-key-habit-to-built-up-for-advancing-in-data-science-c6d5c29533be)
+> * 原文地址:[数学编程 —— 为个人在数据科学领域所有进步而培养的一个关键习惯](https://towardsdatascience.com/mathematical-programming-a-key-habit-to-built-up-for-advancing-in-data-science-c6d5c29533be)
> * 原文作者:[Tirthajyoti Sarkar](https://medium.com/@tirthajyoti)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/mathematical-programming-a-key-habit-to-built-up-for-advancing-in-data-science.md](https://github.com/xitu/gold-miner/blob/master/TODO1/mathematical-programming-a-key-habit-to-built-up-for-advancing-in-data-science.md)
-> * 译者:
-> * 校对者:
+> * 译者:[Weirdochr](https://github.com/Weirdochr)
+> * 校对者:[TokenJan](https://github.com/TokenJan)、[mymmon](https://github.com/mymmon)
-# Mathematical programming — a key habit to build up for advancing in data science
+# 数学编程 —— 为个人在数据科学领域有所进步而培养的一个关键习惯
-> We show how, by simulating the random throw of a dart, you can compute the value of pi approximately. This is a small step towards building the habit of mathematical programming, which should be a key skill in the repertoire of a budding data scientist.
+> 我们通过模拟随机向飞镖靶投掷飞镖,向大家展示了如何近似计算圆周率的值。这是朝建立数学编程习惯迈出的一小步,数学编程应是初露头角的数据科学家所有傍身之技中的一项关键技能。

-## Note
+## 备注
-This [story has also been featured](https://www.kdnuggets.com/2019/05/mathematical-programming-key-habit-advancing-data-science.html) as one of the most viewed (Gold badge) on KDnuggets platform.
+该 [事迹](https://www.kdnuggets.com/2019/05/mathematical-programming-key-habit-advancing-data-science.html) 被认作是 KDnuggets 平台上最受关注的“金徽章(Gold badge)”之一。

-## Introduction
+## 简介
-The essence of **mathematical programming** is that you build a habit of coding up mathematical concepts, especially the ones involving a series of computational tasks in a systematic manner.
+**数学编程**的本质在于养成将数学概念编码的习惯,尤其是编码那些以系统性方式涉及的一系列计算任务。
-**This kind of programming habit is extremely useful for a career in analytics and data science**, where one is expected to encounter and make sense of a wide variety of numerical patterns every day. The ability of mathematical programming helps in rapid prototyping of quick numerical analyses, which are often the first steps in building a data model.
+**这种编程习惯对分析和数据科学的职业生涯大有裨益**,从事该类职业的人日常会遇到并需要弄懂各种各样的数值模式。数学编程的能力有助于其快速建立模型以便快速进行数值分析,这通常是建立数据模型的第一步。
-## A few examples
+## 一些范例
-So, what do I mean by mathematical programming? Isn’t a bunch of mathematical functions already built-in and optimized in various Python libraries like [NumPy](https://towardsdatascience.com/lets-talk-about-numpy-for-datascience-beginners-b8088722309f) and [SciPy](https://scipy-lectures.org/intro/language/python_language.html)?
+那么,我所说的数学编程究竟是什么?一堆数学函数不是已经内嵌在了许多像 [NumPy](https://towardsdatascience.com/lets-talk-about-numpy-for-datascience-beginners-b8088722309f) 和 [SciPy](https://scipy-lectures.org/intro/language/python_language.html) 这样的 Python 库中并进行过优化了吗?
-Yes, but that should not stop you from coding up various numerical computation tasks from scratch and getting into the habit of mathematical programming.
+千真万确,但这不应该阻止你从头开始编写各种数值计算任务,并养成数学编程的习惯。
-Here are a few random examples,
+以下是几个随机示例:
-* Compute pi by a [Monte Carlo experiment](https://www.palisade.com/risk/monte_carlo_simulation.asp) —simulating randomly throwing darts at a board
-* Build a function or class incorporating all the methods for handling complex numbers (Python already has such a module, but can you mimic it?)
-* Compute the [average return of an investment portfolio](https://www.quantinsti.com/blog/portfolio-optimization-maximum-return-risk-ratio-python) given the variance of each stock over by simulating a number of economic scenarios
-* [Simulate and plot a random walk event](https://www.geeksforgeeks.org/random-walk-implementation-python/)
-* Simulate [collision of two balls and compute their trajectories](https://github.com/yoyoberenguer/2DElasticCollision) subject to random starting points and directions
+* 通过 [蒙特卡洛实验](https://www.palisade.com/risk/monte_carlo_simulation.asp) 计算圆周率 — 该实验模拟了随机向飞镖靶投掷飞镖
+* 构建一个包含处理复数所有方法的函数或类(Python 已有这样一个模块,但你能模仿出来一个吗?)
+* 通过模拟多种经济场景,考虑每只股票的差异,计算 [一组投资组合的平均回报率](https://www.quantinsti.com/blog/portfolio-optimization-maximum-return-risk-ratio-python)
+* [模拟并绘制随机漫步事件](https://www.geeksforgeeks.org/random-walk-implementation-python/)
+* 模拟 [两球碰撞,并根据随机的起点和方向计算它们的轨迹](https://github.com/yoyoberenguer/2DElasticCollision)
-As you can see, the examples can be made extremely interesting and close to real-life scenarios. This technique, therefore, also leads to the ability of writing code for discrete or stochastic simulations.
+如你所见,我们可以举出很多有趣并且接近真实生活场景的例子。因此,这项技能也能培养为离散或随机模拟编写代码的能力。
-> When you are browsing through some mathematical properties or ideas on the internet, do you feel the urge to quickly test the concept using a simple piece of code in your favorite programming language?
+> 你在网上浏览一些数学性质或概念时,有没产生过一种冲动,用你最喜欢的编程语言和一段简单的代码快速测试这个概念?
-If yes, then congratulations! You have the ingrained habit of mathematical programming and it will take you far in your pursuit of a satisfactory data science career.
+如果你的回答是“是”,那么恭喜你!你有本身就具备深厚的数学编程习惯,它将带领着你在你理想的数据科学事业中走得更远。
-## Why is mathematical programming a key skill for data science?
+## 为什么数学编程是数据科学的关键技能?
-The practice of data science needs an extremely friendly relationship with numbers and numerical analyses. However, this does not mean memorization of complicated formula and equations.
+数据科学实践需要在数字和数值分析之间建立起良好的关联。然而,这并不意味着仅是记住复杂的公式和方程式。
-A faculty of discovering patterns in numbers and an ability to quickly testing ideas by writing simple code go far for a budding data scientist.
+对于一个初露头角的数据科学家来说,发现数字模式的能力和通过编写简单代码快速测试想法的能力大有裨益。

-This is akin to an electronics engineer being fairly hands-on with laboratory-equipments and automation scripting to run those pieces of equipment to capture hidden patterns in the electrical signals.
+类似于电子工程师直接操作实验室设备和自动化脚本来运行这些设备以捕捉电信号中隐藏的模式。
-Or, think of a young biologist who is proficient in creating cross-section samples of cells on a slide and quickly run automated tests under a microscope to gather data for testing her ideas.
+你也可以想象一位年轻的生物学家,她擅长在载玻片上制作细胞横截面样本,并在显微镜下快速执行自动化测试,以收集数据来测试她的想法。

-> The point is that while the whole enterprise of data science may comprise of many disparate components — data wrangling, text processing, file handling, database processing, machine learning and statistical modeling, visualization, presentation, etc. — a quick experimentation with ideas often do not require much more than solid mathematical programming ability.
+> 关键在于,尽管整个数据科学大厦可能由许多不同的部分组成,如:数据整理、文本处理、文件处理、数据库处理、机器学习和统计建模、可视化、演示等,快速试验想法通常只需要扎实的数学编程能力。
-It is difficult to exactly pin-point all the necessary elements that are required to develop the skill of mathematical programming, but some of the common ones are,
+我们很难列举出培养数学编程技能的所有必备要素,但可以给出一些常见要素:
-* A habit of modularized programming,
-* A clear idea about various **randomization techniques**
-* Ability to read and understand the fundamental topics of **linear algebra, calculus, and discrete mathematics**,
-* Familiarity with basic **descriptive and inferential statistics**,
-* Rudimentary ideas about **discrete and continuous optimization methods** (such as linear programming)
-* Basic proficiency with the core **numerical libraries and functions** in the language of choice, in which the data scientists wants to test her ideas
+* 模块化编程的习惯
+* 关于各种**随机化技术**的清晰想法
+* 能够阅读和理解**线性代数、微积分和离散数学**的基本课题
+* 熟悉基础的**描述性和推断性统计**
+* 具备**离散和连续优化方法**(如:线性规划)的基础概念
+* 基本熟练掌握一门偏好的语言的核心**数字库和函数**,并用这门语言测试自己的想法
-You can refer to this article which discusses what to learn in essential hands-on mathematics for data science.
-[**Essential Math for Data Science**
-**The key topics to master to become a better data scientist**towardsdatascience.com](https://towardsdatascience.com/essential-math-for-data-science-why-and-how-e88271367fbd)
+以下文章讨论了在数据科学基础动手数学实践中应该学些什么,仅供参考:[**数据科学中的基础数学**
+**为成为更优秀的数据科学家而掌握的关键主题** towardsdatascience.com](https://towardsdatascience.com/essential-math-for-data-science-why-and-how-e88271367fbd)
-In this article, we will illustrate the mathematical programming by discussing a very simple example, computing the approximate value of pi using a [Monte Carlo method](https://www.palisade.com/risk/monte_carlo_simulation.asp) of throwing random darts at a board.
+本文通过一个非常简单的例子来说明数学编程,即用 [蒙特卡洛方法](https://www.palisade.com/risk/monte_carlo_simulation.asp) 随机向飞镖靶投掷飞镖,来计算圆周率的近似值。
-## Computing pi by throwing (a lot of) darts
+## 投掷(大量)飞镖计算圆周率
-This is a fun method to compute the value of pi by simulating the random process of throwing darts at a board. It does not use any sophisticated mathematical analysis or formula but tries to compute the approximate value of pi from the emulation of a purely physical (but [**stochastic**](https://en.wikipedia.org/wiki/Stochastic_process)) process.
+这个方法很有意思,它通过模拟向飞镖靶随机投掷飞镖的过程来计算圆周率的值。该方法没有使用任何复杂的数学分析方法或计算公式,而是试图通过模拟纯粹的物理(但 [**随机**](https://en.wikipedia.org/wiki/Stochastic_process))过程,来计算圆周率的近似值。
-> This technique falls under the banner of **Monte Carlo method**, whose basic concept is to emulate a random process, which, when repeated a large number of times, gives rise to the approximation of some mathematical quantity of interest.
+> 我们将这种方法命名为**蒙特卡洛方法**,其基本概念是模拟随机过程,当重复多次后,就能得到一些让人感兴趣的数学数量近似值。
-Imagine a square dartboard.
+请想象此刻在你面前有一个方形镖靶。
-Then, the dartboard with a circle drawn inside it touching all its sides.
+镖靶内画了一个圆,该圆内切于镖靶四边。
-And then, you throw darts at it. **Randomly**. That means some fall inside the circle, some outside. But assume that no dart falls outside the board.
+接着,向镖靶投掷飞镖。记住是**随机**投掷。这意味着,飞镖可能在圆内,也可能在圆外。但此处假设没有飞镖落在镖靶外。

-At the end of your dart throwing session, you count the fraction of darts that fell inside the circle of the total number of darts thrown. Multiply that number by 4.
+飞镖投掷训练结束后,计算飞镖落在圆圈内的次数占投掷总数的比列。再把该数字乘以 4。
-The resulting number should be pi. Or, a close approximation if you had thrown a lot of darts.
+计算结果应该是圆周率的值。投掷次数越多,计算结果越接近圆周率。
-#### What’s the idea?
+#### 关于该实验的原理
-The idea is extremely simple. If you throw a large number of darts, then the **probability of a dart falling inside the circle is just the ratio of the area of the circle to that of the area of the square board**. With the help of basic mathematics, you can show that this ratio turns out to be pi/4. So, to get pi, you just multiply that number by 4.
+这个想法非常简单。如果你投掷了大量飞镖,那么**飞镖落入圆内的概率就是圆与方形镖靶面积之比**。借助基础数学,你就能计算出这个比率是 π/4。因此,要得到圆周率,只需把该数字乘以 4。
-The key here is to simulate the throwing of a lot of darts so as to **make the fraction (of the darts that fall inside the circle) equal to the probability, an assertion valid only in the limit of a large number of trials** of this random event. This comes from the law of large number or the frequentist definition of probability.
+该实验的关键在于,模拟投掷大量飞镖,以便**让(落入圆圈内的飞镖)这一分数等于概率,该结果仅在大量随机实验条件下成立**。这是大数定律或者说是频率派概率的结果。
-#### Python code
+#### Python 代码
-A [Jupyter notebook illustrating the Python code is given here in my Github repo](https://github.com/tirthajyoti/Stats-Maths-with-Python/blob/master/Computing_pi_throwing_dart.ipynb). Please feel free to copy or fork. The steps are simple.
+我在自己的 [Github 仓库的 Jupyter notebook](https://github.com/tirthajyoti/Stats-Maths-with-Python/blob/master/Computing_pi_throwing_dart.ipynb) 里给出了这一段 Python 代码。请随意复制或 fork。步骤很简单。
-First, create a function to simulate the random throw of a dart.
+首先,创建一个函数来模拟随机投掷飞镖。
```Python
def throw_dart():
@@ -121,7 +120,7 @@ def throw_dart():
return (position_x,position_y)
```
-Then, write a function to determine if a dart, given its landing coordinates, falls inside the circle,
+然后编写一个函数,给定飞镖的着陆坐标,确定飞镖是否落在圆圈内,
```Python
def is_within_circle(x,y):
@@ -139,7 +138,7 @@ def is_within_circle(x,y):
return False
```
-Finally, write a function to simulate a large number of dart throwing and calculate the value of pi from the cumulative result.
+最后,编写一个函数来模拟大量投掷飞镖,并根据累积结果计算圆周率的值。
```Python
def compute_pi_throwing_dart(n_throws):
@@ -158,15 +157,15 @@ def compute_pi_throwing_dart(n_throws):
return result
```
-But the programming must not stop there. We must test how good the approximation is and how it changes with the number of random throws. **As with any Monte Carlo experiment, we expect the approximation to get better with a higher number of experiments**.
+本段代码结束了,但是编程不能就此止步。我们必须测试近似值能在多大程度上接近,以及它如何随着随机投掷次数的增多而变化。**与所有蒙特卡洛实验一样,随着实验次数增加,近似值会越来越接近**。
-> This is the core of data science and analytics. It is not enough to write a function which prints the expected output and stop there. The essential programming may be done but the scientific experiment does not stop there without further exploration and testing of the hypothesis.
+> 这就是数据科学和分析的核心。仅仅编写一个打印预期输出并在那里停止的函数是不够的。基础的编程可以结束,但如果没有进一步的探索和假设检验,科学实验就不能就此停止。


-We can see that a large number of random throws can be repeated a few times to calculate an average and get a better approximation.
+我们可以看到,重复几次大量随机投掷实验来计算平均值能得到更精确的近似值。
```Python
n = 5000000
@@ -180,50 +179,48 @@ pi_computed = round(sum/20,4)
print("Average value from 20 experiments:",pi_computed)
```
-## Simple code, rich ideas
+## 代码看似简单,内核却极为丰富
-The theory and code behind this technique seem extremely simple. However, behind the facade of this simple exercise, some pretty interesting ideas are hidden.
+这项实验背后的理论和代码看似极其简单。然而,在这个简单练习的外表之下,隐藏着一些非常有趣的想法。
-**Functional programming approach**: The description of the technique can be coded using a monolith code block. However, we show how the tasks should be partitioned into simple functions mimicking real human actions —
+**函数式编程方法**:用整块代码对实验进行编码,描述整个实验。在这个过程中,我们展示了如何将多个任务划分为简单的函数,来模拟真实人类的行为 ——
-* throwing a dart,
-* examining the landing coordinate of the dart and determining whether it landed inside the circle,
-* repeating this process an arbitrary number of times
+* 扔飞镖,
+* 检查飞镖的着陆坐标并确定它是否落在圆圈内,
+* 重复该过程任意次数
-To write high-quality code for large programs, it is instructive to use this kind of [**modularized programming**](https://www.geeksforgeeks.org/modular-approach-in-programming/) style.
+为大型程序编写高质量代码时,使用这种 [**模块化编程**](https://www.geeksforgeeks.org/modular-approach-in-programming/) 方法是非常具有指导意义的。
-**Emergent behavior**: Nowhere in this code, any formula involving pi or properties of a circle was used. Somehow, the value of pi emerges from the collective action of throwing a bunch of darts randomly at a board and calculating a fraction. This is an example of [**emergent behavior**](http://wiki.c2.com/?EmergentBehavior) in which **a mathematical pattern emerges from a set of a large number of repeated experiments of a similar kind through their mutual interaction.**
+**突现行为**:这段代码没有使用任何涉及圆周率或圆的性质的公式。圆周率的值是从随机向飞镖靶扔一堆飞镖并计算分数的过程中得到的。这是 [**突现行为**](http://wiki.c2.com/?EmergentBehavior) 的一个示例,即**通过相互作用,大量类似的重复实验形成一种数学模式。**
-**Frequentist definition of probability**: There are two broad categories of the definition of probability and two fiercely rival camps — [frequentists and Bayesians](https://stats.stackexchange.com/questions/31867/bayesian-vs-frequentist-interpretations-of-probability). It is easy to think as a frequentist and define probability as a frequency (as a fraction of the total number of random trials) of an event. In this coding exercise, we could see how this particular notion of probability emerges from repeating random trials a large number of times.
+**频率派概率定义**:对概率的定义有两大类,这两类分属于截然对立的阵营 — [频率派和贝叶斯派](https://stats.stackexchange.com/questions/31867/bayesian-vs-frequentist-interpretations-of-probability)。人们很容易以频率派的思维方式思考,把概率定义为一个事件的频率(随机试验总数的一部分)。在这次编程练习中,我们可以看到,概率这个特殊概念是如何从多次重复随机试验中显现出来的。
-**[Stochastic simulation](https://www.andata.at/en/stochastic-simulation.htmlhttps://www.andata.at/en/stochastic-simulation.html):** The core function of throwing dart uses a random generator at its heart. Now, a computer-generated random number is not truly random, but for all practical purpose, it can be assumed to be one. In this programming exercise, we used a uniform random generator function from the `random` module of Python. Use of this kind of randomization method is at the heart of stochastic simulation, which is a powerful method used in the practice of data science.
+**[随机模拟](https://www.andata.at/en/stochastic-simulation.htmlhttps://www.andata.at/en/stochastic-simulation.html)**:掷飞镖实验使用的核心函数是一个随机数发生器。实际上,计算机生成的随机数并非真正随机,但出于实际操作可行性考虑,我们可以假定它生成的都是随机数。在这次编程练习中,我们使用了 Python `随机` 模块中的统一随机生成器函数。使用这种随机化方法是随机模拟的核心,这是数据科学实践中一种有效的方法。
-**Testing the assertion by repeated simulations and visualization**: Often, in data science, we deal with stochastic processes and probabilistic models, which must be tested based on a large number of simulations/experiments. Therefore, it is imperative to think in those asymptotic terms and test the validity of the data model or the scientific assertion in a statistically sound manner.
+**通过重复模拟和可视化测试断言**:通常,在数据科学中,我们必须通过大量模拟/实验,来测试随机过程和概率模型。因此,必须用这些渐进项来思考,并以统计上合理的方式来测试数据模型或科学断言的有效性。

-## Summary (and a challenge for the reader)
+## 总结(以及对读者的挑战)
-We demonstrate what it means to develop a habit of mathematical programming. Essentially, it is thinking in terms of programming to test out the mathematical properties or data patterns that you are developing in your mind. This simple habit can aid in the development of good practices for an upcoming data scientist.
+我们展现了培养数学编程习惯的意义。本质上,它是从编程的角度来测试你头脑中正在开发的数学方法或数据模式。这个简单的习惯可以帮助未来的数据科学家开发优质的实践。
-An example was demonstrated using simple geometric identities, concepts of stochastic simulation, and frequentist definition of probability.
+我们使用简单的几何恒等式、随机模拟的概念和频率派概率定义演示了一个例子。
-If you are looking for more challenge,
+如果你还想接受更多挑战,
-> # can you compute pi by simulating a [random walk event](https://en.wikipedia.org/wiki/Random_walk)?
+> 你能通过模拟 [随机漫步事件](https://en.wikipedia.org/wiki/Random_walk) 来计算圆周率吗?
---
-If you want to fork the code for this fun exercise, [**please fork this repo**](https://github.com/tirthajyoti/Stats-Maths-with-Python).
+点击此处 fork 这个简单练习的代码 [**请 fork 这个 repo**](https://github.com/tirthajyoti/Stats-Maths-with-Python)。
---
-If you have any questions or ideas to share, please contact the author at [**tirthajyoti[AT]gmail.com**](mailto:tirthajyoti@gmail.com). Also, you can check the author’s **[GitHub ](https://github.com/tirthajyoti?tab=repositories)repositories** for other fun code snippets in Python, R, or MATLAB and machine learning resources. If you are, like me, passionate about machine learning/data science, please feel free to [add me on LinkedIn](https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/) or [follow me on Twitter.](https://twitter.com/tirthajyotiS)
-[**Tirthajyoti Sarkar - Sr. Principal Engineer - Semiconductor, AI, Machine Learning - ON…**
-**Georgia Institute of Technology Master of Science - MS, Analytics This MS program imparts theoretical and practical…**www.linkedin.com](https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/)
+若你有任何问题或想法想要分享,请联系作者 [**tirthajyoti[AT]gmail.com**](mailto:tirthajyoti@gmail.com)。另外,你也可以查看作者的 **[GitHub ](https://github.com/tirthajyoti?tab=repositories)仓库** 获取 Python、R 或 MATLAB 中其他有趣的代码片段和机器学习资源。如果你像我一样,对机器学习/数据科学充满热情,请 [添加我的领英](https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/) 或者 [关注我的推特账号](https://twitter.com/tirthajyotiS)。
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
---
-> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/more-reasons-why-developers-should-blog.md b/TODO1/more-reasons-why-developers-should-blog.md
new file mode 100644
index 00000000000..214e7b5bbb2
--- /dev/null
+++ b/TODO1/more-reasons-why-developers-should-blog.md
@@ -0,0 +1,94 @@
+> * 原文地址:[More Reasons Why Developers Should Blog](https://levelup.gitconnected.com/more-reasons-why-developers-should-blog-ba947be9e869)
+> * 原文作者:[John Au-Yeung](https://medium.com/@hohanga)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/more-reasons-why-developers-should-blog.md](https://github.com/xitu/gold-miner/blob/master/TODO1/more-reasons-why-developers-should-blog.md)
+> * 译者:
+> * 校对者:
+
+# More Reasons Why Developers Should Blog
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/12000/0*HJLkHYtt8SbRtrra)
+
+Blogging is a way to share what we learn with others.
+
+In this article, we’ll look at why developers should keep a blog.
+
+## Become a Better Writer
+
+By writing on our blogs repeatedly, we’ll become better writers. The more we write and adapt to better writing habits, we can become better writers.
+
+Better writers are better communications and that’ll bring us more and better opportunities in the long run.
+
+## Explaining Things to Others is the Best Way to Learn
+
+There’s no question that explaining things to others is the best way to learn.
+
+We get to do research on our topics that we’re writing about and we have to be able to produce our own examples for any technical topic we’re writing about to explain our points.
+
+Also, we’ve to able to explain the different aspects of the technologies ourselves.
+
+If we learn enough to explain to others without looking through online resources, then we know that we’re proficient at what we’ve learned.
+
+Blogging will let us internalize our knowledge by writing about it and practicing by producing examples as we explain the technologies in our blog.
+
+## Create a Discussion and Learn New Things from That
+
+We can create a discussion based on our blog and engage with our audience.
+
+If our blog has an audience then we’ll get a discussion going in no time.
+
+And from the discussion, we learn new things from that. This is a win-win situation. We know that our blog has engagement from the audience, which is good.
+
+Also, we can learn new things from the discussions that we’re raising by posting our blog posts.
+
+## Present Our Own View On a Topic
+
+Even the topic we’re writing about already had lots of people writing on it, we can still write about it since people will appreciate new views on our existing topic.
+
+As long as we aren’t copying someone else’s work directly, it’s fine to write on a topic that many people have written about before.
+
+We all have our own style and we can present new angles on the same topic that people have written about before by presenting our own view on it.
+
+Therefore, we should write our own pieces on a topic despite many people writing about them already.
+
+## Read More and More for Writing a Blog
+
+For most blog posts that we write, we have to do research so that we can write about them.
+
+There’s just no way that we hold enough information and insights on our heads to write stuff to put into our blogs.
+
+Therefore, we have to do lots of lots of research if we’re going to maintain a developer blog.
+
+This makes blogging a great way to learn about whatever we’re writing about and absorb the knowledge by explaining and writing examples.
+
+## Educate Others
+
+Educating others is a good reason to maintain our own developer blog. With it, we can help each other learn by providing our own views and insights to help us learn, which in turn helps other people learn.
+
+There aren’t enough resources on developer topics, so getting readers is pretty much guaranteed if we keep maintaining and promoting our blog.
+
+People will look at our stuff and learn them even though they might not be commenting on our blogs or be engaging with us.
+
+They’ll find our stuff when they’re looking for help and some people will stumble on our blog and they get the help they need.
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/12000/0*4SGrplnJ1EYYeSt4)
+
+## Enjoyment
+
+Blogging is a great hobby. It’s something that we can do for enjoyment. It’s a lost cost hobby as we can blog on sites like Medium or WordPress or web can pay a few bucks a month to blog in our own blog.
+
+Both are great ways to spend time since we’ve to do lots of research and wire about stuff that we want to write about.
+
+## Conclusion
+
+We can use blogging as a hobby. It’s a great hobby since it’s cheap or free to set up a blog.
+
+Also, we’ll help people they don’t comment on us. If we keep our blog for long enough, someone will stumble onto our blog eventually.
+
+Finally, we become better writers by practicing our writing skills by blogging and presenting our work in front of the audience worldwide.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/my-personal-git-tricks-cheatsheet.md b/TODO1/my-personal-git-tricks-cheatsheet.md
index 0fd1f60c0a9..bc7820415d7 100644
--- a/TODO1/my-personal-git-tricks-cheatsheet.md
+++ b/TODO1/my-personal-git-tricks-cheatsheet.md
@@ -2,127 +2,127 @@
> * 原文作者:[Antonin Januska](https://dev.to/antjanus)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/my-personal-git-tricks-cheatsheet.md](https://github.com/xitu/gold-miner/blob/master/TODO1/my-personal-git-tricks-cheatsheet.md)
-> * 译者:
-> * 校对者:
+> * 译者:[Pingren](https://github.com/Pingren)
+> * 校对者:[zh1an](https://github.com/zh1an),[Badd](https://github.com/Baddyo),[shixi-li](https://github.com/shixi-li)
-# My Personal Git Tricks Cheatsheet
+# 我个人的 Git 技巧备忘录
-Besides the "basic" commands of Git, everyone has their own little Git tricks they use. I wanted to quickly write a list of my own which I tend to alias in my `.gitconfig`. Scroll to the bottom to see some fun `git` related commands that run outside of git! :)
+除了 “基础的” 命令之外,每个人都有他们常用的 Git 技巧。我想列出我愿意在 `.gitconfig` 保存别名(alias)的命令。在文章末尾,你可以看到一些在 git 之外与 `git` 相关的有意思的命令!:)
-## Quick amend
+## 快速纠正
-I often forget to commit a file, or leave a `console.log` in. I absolutely hate doing commits like `removed console.log`. So instead, I add the file as if I was going to make a commit and run:
+我经常忘记提交(commit)某文件,或者遗留了 `console.log` 在文件里。我十分讨厌如 `删除 console.log` 的提交。因此,我将添加文件至暂存区,就好像我要提交一样,接着运行命令:
-```
+```bash
git commit --amend --reuse-message HEAD
```
-Which will add the file to the last commit and reuse the old commit message. I alias this one as `git amend` for quickfixes
+这个命令会将文件加入上次提交,并且重新使用旧的提交信息。我将它的别名设置为 `git amend`,用于快速修正错误。
-**NOTE** Based on feedback below, it's also possible to do `git commit --amend --no-edit` for the same effect.
+**注意** 基于底下评论区的回复,也可以使用命令 `git commit --amend --no-edit` 达到一样的效果。
-## Rebase on top of origin/master
+## 在 origin/master 分支的顶部变基
-Older branches often fall behind pretty far, so far that I have to get up to speed to eliminate build errors, ci errors, or just resolve conflicts. My favorite is to do the following:
+旧的分支通常情况下会落后相当久远,久到我不得不准备好消除编译错误、ci 错误,或者解决冲突。此时我最喜欢使用以下命令:
-```
+```bash
git fetch origin # fetch latest origin
git rebase origin/master
```
-This way, I'm stacking my current branch commits on top of the latest version of master!
+通过这种方式,我将当前分支的提交都叠加在最新版本的 master 分支之上。
-## Last commit
+## 上次的提交
-Sometimes, the `git log` gets overwhelming. Due to my frequent use of the aforementioned `amend` command, i tend to want to view just the last commit in my git log:
+有时,`git log` 命令的结果冗长。由于我频繁使用的前文中提过的 `amend` 命令,我倾向于查看最后一条提交记录:
-```
+```bash
git log -1
```
-## checkout older version of a file (like a lock file!)
+## 签出到旧版文件 (比如一个锁文件!)
-Occasionally, I screw up a file unrelated to my branch. Mostly, that happens with lock files (mix.lock, package-lock.json, etc.). Rather than reverting a commit which probably contained a bunch of other stuff, I just "reset" the file back to an older version
+有时,我把某个与我的分支不相关文件搞坏了。这通常发生在锁文件上(`mix.lock`、`package-lock.json` 等等)。我只是将这个文件“重置”回旧版本而不是还原一个可能包含许多其他内容的提交:
-```
-git checkout hash-goes-here mix.lock
+```bash
+git checkout hash值 mix.lock
```
-And then I can commit the fix!
+接着我就可以提交修复!
## cherry-pick
-An underrated command that I occasionally use. When a branch gets stale, it's sometimes easier to just get the stuff you really need from it rather than try to get the entire branch up to speed. A good example, for me, have been branches that involve UI/backend code that is no longer necessary. In that case, I might want to cherry pick only certain commits from the branch
+我偶尔会使用这个被低估的命令。当一个分支变得老旧,有时候从中只获取真正需要的东西,比让整个分支跟上进度简单。举个例子,这个分支有关于 UI 或后端的冗余代码。在这种情况下,我可能只想从分支中挑选出特定的提交:
-```
-git cherry-pick hash-goes-here
+```bash
+git cherry-pick hash值
```
-This will magically bring that commit over to the branch you're on. You can also do a list!
+这将会把提交带到你所处的分支。你也可以使用列表!
-```
-git cherry-pick first-hash second-hash third-hash
+```bash
+git cherry-pick 第一个hash值 第二个hash值 第三个hash值
```
-You can also do a range
+你也可以使用区间:
-```
-git cherry-pick first-hash..last-hash
+```bash
+git cherry-pick 开始的hash值..结束的hash值
```
-### The reflog
+### 参考日志
-This is such a power-user feature that I **rarely** use it. I mean, once a year! But it's good to know about it. Sometimes, I lose commits. I delete a branch or reset or amend a commit I didn't mean to mess up.
+这是一个高级功能,以至于我几乎不用它。我的意思是,大概一年用一次。但是了解一下它还是挺好的。有时,我丢失了提交:我不小心删除了分支、重置或修改了一个提交。
-In those situations, it's good to know `reflog` exists. It's not a log of individual commits for the branch you're on, it's a log of all of your commits -- even ones that were on dead branches. However, the log gets emptied from time to time (pruned) so that only relevant information stays.
+在这些情况下,知道 `reflog` 的存在就挺好的。它不是你当前所处的分支的提交日志,它是你所有提交(包括了在失效分支之上)的日志。然而,这个日志将会随着时间推移被清空(pruned),因此只有有关的信息会保留。
-```
+```bash
git reflog
```
-The command returns a log and what's useful is cherry-picking or rebasing on top of a commit. Very powerful when you pipe into `grep`.
+这个命令将返回一个日志,你可以在某个提交之上使用挑选或者变基。使用 pipe 管道命令连接 `grep` 之后非常强大。
-## Bash command aliases
+## Bash 命令别名
-Aside from git commands, I like to also use some fun bash aliases to help my workflow
+除了 git 命令,我也喜欢使用一些有趣的 bash 别名来帮助我的工作流。
-### Current branch
+### 当前分支
-To get the name of the current branch, I have this alias:
+为了获取当前分支的名字,我有这个别名:
-```
+```bash
alias git-branch="git branch | sed -n -e 's/^\* \(.*\)/\1/p'"
```
-When I run `git-branch` or run `$(git-branch)` in another command, I'll get the name of the current branch I'm on.
+当我运行 `git-branch` 或者在其它命令中运行 `$(git-branch)`,我将得到我目前所在的分支的名字。
-**NOTE** Based on feedback in the comments, I switched this over to `git symbolic-ref --short HEAD` which works just as well but you can actually read it.
+**注意** 基于评论区的回复,我将它切换为 `git symbolic-ref --short HEAD`,可以达到一样的效果并且命令更具有可读性。
-### Track upstream branch
+### 跟踪上游分支
-While I'm sure this is doable in the `.gitconfig`, I've yet to figure out how. When I run the first push on a new branch, I always get asked to setup the branch for upstream tracking. Here's my alias for that:
+虽然我确定配置 `.gitconfig` 可以解决问题,我暂时还没弄清楚如何做(译者注:使用命令 `git config --global push.default current`,参见[官方文档](https://git-scm.com/docs/git-config/#Documentation/git-config.txt-pushdefault))。当我在新的分支上首次运行推送命令时,我总是被要求先设置上游分支的跟踪状态。这种情况下我使用别名:
-```
+```bash
alias git-up="git branch | sed -n -e 's/^\* \(.*\)/\1/p' | xargs git push -u origin "
```
-Now when I run `git-up`, I push my current branch and setup upstream tracking!
+现在当我运行 `git-up`,我可以推送当前的分支并设置好上游分支的跟踪状态!
-## Feedback
+## 回复
-Based on some of the very helpful feedback in the comments, I made some adjustments to what I'm using.
+基于评论中一些有用的反馈,我对我所使用的别名做了一些修改。
-### Current branch
+### 当前分支
-It looks like there are a bunch of new ways to get the current branch name. If you scroll up, you'll see that I've used a crazy `sed` parsing command to get the branch name.
+似乎有许多新方式来获取当前的分支名称。如果你往上看,你将看到我使用了一个疯狂的 `sed` 命令来获取分支名称。
-Here's my new alternative:
+以下是我使用的新办法:
-```
+```bash
alias git-branch="git symbolic-ref --short HEAD"
```
-And it seems to work exactly as you'd expect!
+它的运行与期望完全一样!
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/nestjs-basic-auth-and-sessions.md b/TODO1/nestjs-basic-auth-and-sessions.md
new file mode 100644
index 00000000000..a20d32731ce
--- /dev/null
+++ b/TODO1/nestjs-basic-auth-and-sessions.md
@@ -0,0 +1,934 @@
+> * 原文地址:[NestJS Basic Auth and Sessions](https://blog.exceptionfound.com/2018/06/07/nestjs-basic-auth-and-sessions/)
+> * 原文作者:[Just Another Typescript Blog](https://blog.exceptionfound.com/)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/nestjs-basic-auth-and-sessions.md](https://github.com/xitu/gold-miner/blob/master/TODO1/nestjs-basic-auth-and-sessions.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[samyu2000](https://github.com/samyu2000)
+
+# NestJS 实现基本用户认证和会话
+
+> **代码免责声明**
+>
+> 本网站所有代码均为免费软件:您可以根据自由软件基金会发布的 GNU 通用公共许可证的条款,重新发布或者修改它。其中许可证的版本为 3 或者(由您选择的)任何更新版本。
+>
+> 我希望文章里的所有代码能够对您有所帮助,但**不作任何担保**。也不保证代码的性能以及它适用于某种功能。有关更多细节,请参阅 GNU 通用公共许可证。
+
+本文研究NestJS 和认证策略,并记录了我使用Node知识在NestJS 中实现认证策略的过程。**但是,这不意味着您在实际项目中要像我这么做**。
+
+在本文中,我们将探讨如何在 [NestJS](https://docs.nestjs.com/)中使用 [passport.js](https://github.com/jaredhanson/passport) 来轻松地实现基本的身份验证和会话管理。
+
+首先,从 github 克隆这个预设置好的入门项目,其中 **package.json** 文件中包含了本项目所需的所有库,然后执行 **npm install**。
+
+* [https://github.com/artonio/nestjs-session-tutorial](https://github.com/artonio/nestjs-session-tutorial)
+* [https://github.com/artonio/nestjs-session-tutorial-finished](https://github.com/artonio/nestjs-session-tutorial-finished) —— 项目的完整源码。
+
+本项目将使用以下方法和库。
+
+* [Swagger](https://swagger.io/) —— 它能为您的应用生成对应的 REST API 接口的最终文档。同时还是一个快速测试 API 的好工具。您可以在 NestJS 网站浏览到有关 Swagger 的[文档](https://docs.nestjs.com/recipes/swagger),以便在我们的项目中使用 Swagger。
+* [Exception Filters](https://docs.nestjs.com/exception-filters) —— 它是 NestJS 内置的异常处理模块,负责处理整个应用中抛出的所有异常。当应用程序捕获到未处理的异常时,用户得到的响应是友好得体的。这意味着我们在应用中的任何地方抛出的异常,都会被全局异常处理程序捕获并且返回预定义的 JSON 响应。
+* [TypeORM](http://typeorm.io/#/) —— 它是一个健壮性极好、成熟的ORM框架,虽然是不久前面世的。它使用 TypeScript 编写。同时支持 [ActiveRecord 和 DataMapper](http://typeorm.io/#/active-record-data-mapper) 模式,还支持缓存等许多其他功能。它的文档也十分优秀。TypeORM 支持大多数 SQL 和 NoSQL 数据库。对于本项目,我们将使用 sqlite 数据库。并使用 ActiveRecord 模式。[TypeORM TypeDocs(类似 javadocs)](http://typeorm-doc.exceptionfound.com/)
+* [Custom Decorator](https://docs.nestjs.com/custom-decorators) —— 我们将创建一个自定义的路由装饰器来在 session 中访问用户对象。
+* Basic Auth —— 使用 Basic Auth Header 的用户身份验证。
+* [Sessions](https://github.com/expressjs/session) —— 一旦用户通过身份验证,就会创建一个 session 和一个 cookie,这样在每个需要用户信息的请求中,我们都能够从 session 对象中访问登录的用户。
+
+#### 数据库 schema
+
+
+
+**我们将要创建的。** 本项目的 schema 很简单。我们有很多 user 和 project,但一个 user 只能够匹配到自己对应的 project。我们希望能够使用与数据库中的记录匹配的用户凭证进行登录,一旦登录,我们将使用 cookie 为用户检索项目。
+
+**功能设计。** 创建 user;为登录的 user 创建一个 project;获取所有 user;获取所有已登录 user 的 project。本项目没有更新或删除的功能。
+
+#### 项目结构
+
+
+
+**common 目录:** 自定义异常和异常过滤器。
+
+**project 目录:** project 服务、project 控制器、 project 数据库实体、project 模块。
+
+**user 目录:** user 服务、user 控制器、user 数据库实体、user 模块。
+
+**auth 目录:** AppAuthGuard、Cookie 序列化器/反序列化器、Http 策略、Session Guard、Auth 服务、Auth 模块。
+
+#### 创建 user 模块
+
+**前提:必须全局安装 @nest/cli**
+
+###### 创建 user 模块
+
+```
+nest g mo user
+```
+
+这将会创建一个 user 目录和一个 user 模块。
+
+###### 创建 user 控制器
+
+```
+nest g co user
+```
+
+这将 user 的控制器放入 user 目录并更新 user 模块。
+
+###### 创建 user 服务
+
+```
+nest g s user
+```
+
+这将创建一个 user 服务并更新 user 模块。但是我的 user 服务最终被放置在根项目文件夹下而不是 user 文件夹中,我不是很清楚这是个 **bug 还是 Nestjs的框架特性**?如果您也碰上了这种情况,请手动将其移动到 user 文件夹中,并更新 user 模块中 user 服务的引用路径。
+
+###### 创建 user 实体
+
+```typescript
+import {BaseEntity, Column, Entity, OneToMany, PrimaryGeneratedColumn} from 'typeorm';
+import * as crypto from 'crypto';
+import {ProjectEntity} from '../project/project.entity';
+import {CreateUserDto} from './models/CreateUserDto';
+import {AppErrorTypeEnum} from '../common/error/AppErrorTypeEnum';
+import {AppError} from '../common/error/AppError';
+
+@Entity({name: 'users'})
+export class UserEntity extends BaseEntity {
+ @PrimaryGeneratedColumn()
+ id: number;
+
+ @Column({
+ length: 30
+ })
+ public firstName: string;
+
+ @Column({
+ length: 50
+ })
+ public lastName: string;
+
+ @Column({
+ length: 50
+ })
+ public username: string;
+
+ @Column({
+ length: 250,
+ select: false,
+ name: 'password'
+ })
+ public password_hash: string;
+
+ set password(password: string) {
+ const passHash = crypto.createHmac('sha256', password).digest('hex');
+ this.password_hash = passHash;
+ }
+
+ @OneToMany(type => ProjectEntity, project => project.user)
+ projects: ProjectEntity[];
+
+ public static async findAll(): Promise<UserEntity[]> {
+ const users: UserEntity[] = await UserEntity.find();
+ if (users.length > 0) {
+ return Promise.resolve(users);
+ } else {
+ throw new AppError(AppErrorTypeEnum.NO_USERS_IN_DB);
+ }
+
+ }
+
+ public static async createUser(user: CreateUserDto): Promise<UserEntity> {
+ let u: UserEntity;
+ u = await UserEntity.findOne({username: user.username});
+ if (u) {
+ throw new AppError(AppErrorTypeEnum.USER_EXISTS);
+ } else {
+ u = new UserEntity();
+ Object.assign(u, user);
+ return await UserEntity.save(u);
+ }
+ }
+}
+```
+
+这里有一些关于 UserEntity 的注意事项。当设置 password 属性时,我们将使用 TypeScript 的 **setter** ,并哈希加密我们的密码。在这个文件中,我们使用到了 AppError 和 AppErrorTypeEnum。不要担心,我们稍后会创建它们。我们还将在 password_hash 变量上设置以下属性:
+
+* **select: false ——** 当查询某个用户时,不要返回此列信息。
+* **name: ‘password’ ——** 将实际列名设置为 “password”,如果未设置此选项,TypeORM 则会将变量名自动生成为列名。
+
+#### 创建 project 模块
+
+创建 project 模块的方式与创建 **user 模块**的方式相同。也需要创建一个project 服务和一个 project 控制器。
+
+###### 创建 project 实体
+
+```typescript
+import {BaseEntity, Column, Entity, ManyToOne, PrimaryGeneratedColumn} from 'typeorm';
+import {UserEntity} from '../user/user.entity';
+
+@Entity({name: 'projects'})
+export class ProjectEntity extends BaseEntity{
+ @PrimaryGeneratedColumn()
+ id: number;
+
+ @Column()
+ name: string;
+
+ @Column()
+ description: string;
+
+ @ManyToOne(type => UserEntity)
+ user: UserEntity;
+}
+```
+
+现在我们需要告诉 TypeORM 这些实体的信息,并且还需要设置配置选项,以便让 TypeORM 连接到 sqlite 数据库。
+
+在 AppModule 中添加以下代码:
+
+```typescript
+import { Module } from '@nestjs/common';
+import { AppController } from './app.controller';
+import { AppService } from './app.service';
+import {TypeOrmModule} from '@nestjs/typeorm';
+import { UserModule } from './user/user.module';
+import { ProjectModule } from './project/project.module';
+import {UserEntity} from './user/user.entity';
+import {ProjectEntity} from './project/project.entity';
+
+@Module({
+ imports: [
+ TypeOrmModule.forRoot({
+ type: 'sqlite',
+ database: `${process.cwd()}/tutorial.sqlite`,
+ entities: [UserEntity, ProjectEntity],
+ synchronize: true,
+ // logging: 'all'
+ }),
+ UserModule,
+ ProjectModule,
+ ],
+ controllers: [AppController],
+ providers: [ AppService ],
+})
+export class AppModule {}
+```
+
+**logging** 是日志相关,我们对它加了注释符号,但您可以在 [http://typeorm.io/#/logging](http://typeorm.io/#/logging) 了解更多信息。
+
+**user 模块**现在应该是这样的:
+
+```typescript
+import { Module } from '@nestjs/common';
+import { UserController } from './user.controller';
+import { UserService } from './user.service';
+import {TypeOrmModule} from '@nestjs/typeorm';
+import {UserEntity} from './user.entity';
+
+@Module({
+ imports: [TypeOrmModule.forFeature([UserEntity])],
+ controllers: [UserController],
+ providers: [UserService]
+})
+export class UserModule {}
+```
+
+**project 模块**现在应该是这样的:
+
+```typescript
+import { Module } from '@nestjs/common';
+import { ProjectController } from './project.controller';
+import { ProjectService } from './project.service';
+import {TypeOrmModule} from '@nestjs/typeorm';
+import {ProjectEntity} from './project.entity';
+
+@Module({
+ imports: [TypeOrmModule.forFeature([ProjectEntity])],
+ controllers: [ProjectController],
+ providers: [ProjectService]
+})
+export class ProjectModule {}
+```
+
+###### 设置全局异常处理
+
+在 **src/** 目录下创建 common 目录,在 common 目录下,我们将创建两个目录:error 和 filters。(可参考文章开头的项目结构截图)
+
+#### Error 目录
+
+如下所示,创建 **AppErrorTypeEnum.ts** 文件。
+
+```typescript
+export const enum AppErrorTypeEnum {
+ USER_NOT_FOUND,
+ USER_EXISTS,
+ NOT_IN_SESSION,
+ NO_USERS_IN_DB
+}
+```
+
+我们将创建一个枚举类型变量,它不是对象,而是生成一个简单的 var->number 的关系映射,如果不是必须需要查找枚举的表示形式为字符串,选择创建 enum const 的话,性能会更高。
+
+如下所示,创建 **IErrorMessage.ts** 文件。
+
+```typescript
+import {AppErrorTypeEnum} from './AppErrorTypeEnum';
+import {HttpStatus} from '@nestjs/common';
+
+export interface IErrorMessage {
+ type: AppErrorTypeEnum;
+ httpStatus: HttpStatus;
+ errorMessage: string;
+ userMessage: string;
+}
+```
+
+这将是返回给用户的 JSON 结构。
+
+最终,如下所示,创建 **AppError.ts** 文件。
+
+```typescript
+import {AppErrorTypeEnum} from './AppErrorTypeEnum';
+import {IErrorMessage} from './IErrorMessage';
+import {HttpStatus} from '@nestjs/common';
+
+export class AppError extends Error {
+
+ public errorCode: AppErrorTypeEnum;
+ public httpStatus: number;
+ public errorMessage: string;
+ public userMessage: string;
+
+ constructor(errorCode: AppErrorTypeEnum) {
+ super();
+ const errorMessageConfig: IErrorMessage = this.getError(errorCode);
+ if (!errorMessageConfig) throw new Error('Unable to find message code error.');
+
+ Error.captureStackTrace(this, this.constructor);
+ this.name = this.constructor.name;
+ this.httpStatus = errorMessageConfig.httpStatus;
+ this.errorCode = errorCode;
+ this.errorMessage = errorMessageConfig.errorMessage;
+ this.userMessage = errorMessageConfig.userMessage;
+ }
+
+ private getError(errorCode: AppErrorTypeEnum): IErrorMessage {
+
+ let res: IErrorMessage;
+
+ switch (errorCode) {
+ case AppErrorTypeEnum.USER_NOT_FOUND:
+ res = {
+ type: AppErrorTypeEnum.USER_NOT_FOUND,
+ httpStatus: HttpStatus.NOT_FOUND,
+ errorMessage: 'User not found',
+ userMessage: 'Unable to find the user with the provided information.'
+ };
+ break;
+ case AppErrorTypeEnum.USER_EXISTS:
+ res = {
+ type: AppErrorTypeEnum.USER_EXISTS,
+ httpStatus: HttpStatus.UNPROCESSABLE_ENTITY,
+ errorMessage: 'User exisists',
+ userMessage: 'Username exists'
+ };
+ break;
+ case AppErrorTypeEnum.NOT_IN_SESSION:
+ res = {
+ type: AppErrorTypeEnum.NOT_IN_SESSION,
+ httpStatus: HttpStatus.UNAUTHORIZED,
+ errorMessage: 'No Session',
+ userMessage: 'Session Expired'
+ };
+ break;
+ case AppErrorTypeEnum.NO_USERS_IN_DB:
+ res = {
+ type: AppErrorTypeEnum.NO_USERS_IN_DB,
+ httpStatus: HttpStatus.NOT_FOUND,
+ errorMessage: 'No Users exits in the database',
+ userMessage: 'No Users. Create some.'
+ };
+ break;
+ }
+ return res;
+ }
+
+}
+```
+
+这段代码表示,我们在代码中的任何地方抛出错误时,全局异常处理程序将捕获它并返回一个结构与 IErrorMessage 一致的对象。
+
+#### filters 目录
+
+如下所示,创建 **DispatchError.ts** 文件。
+
+```typescript
+import {ArgumentsHost, Catch, ExceptionFilter, HttpStatus, UnauthorizedException} from '@nestjs/common';
+import {AppError} from '../error/AppError';
+
+@Catch()
+export class DispatchError implements ExceptionFilter {
+ catch(exception: any, host: ArgumentsHost): any {
+ const ctx = host.switchToHttp();
+ const res = ctx.getResponse();
+
+ if (exception instanceof AppError) {
+ return res.status(exception.httpStatus).json({
+ errorCode: exception.errorCode,
+ errorMsg: exception.errorMessage,
+ usrMsg: exception.userMessage,
+ httpCode: exception.httpStatus
+ });
+ } else if (exception instanceof UnauthorizedException) {
+ console.log(exception.message);
+ console.error(exception.stack);
+ return res.status(HttpStatus.UNAUTHORIZED).json(exception.message);
+ } else if (exception.status === 403) {
+ return res.status(HttpStatus.FORBIDDEN).json(exception.message);
+ }
+
+ else {
+ console.error(exception.message);
+ console.error(exception.stack);
+ return res.status(HttpStatus.INTERNAL_SERVER_ERROR).send();
+ }
+ }
+
+}
+```
+
+您可以用任何您认为合适的方式实现这个类,上面这段代码只是一个小例子。
+
+现在我们要做的就是让应用程序使用此过滤器,这很简单。在我们的 **main.ts** 中添加以下内容:
+
+```typescript
+app.useGlobalFilters(new DispatchError());
+```
+
+现在,您的 **main.ts** 文件内容大致如下:
+
+```typescript
+import { NestFactory } from '@nestjs/core';
+import { AppModule } from './app.module';
+import {DocumentBuilder, SwaggerModule} from '@nestjs/swagger';
+import {DispatchError} from './common/filters/DispatchError';
+
+async function bootstrap() {
+ const app = await NestFactory.create(AppModule);
+ app.useGlobalFilters(new DispatchError());
+ const options = new DocumentBuilder()
+ .setTitle('User Session Tutorial')
+ .setDescription('Basic Auth and session management')
+ .setVersion('1.0')
+ .addTag('nestjs')
+ .build();
+ const document = SwaggerModule.createDocument(app, options);
+ SwaggerModule.setup('api', app, document);
+ await app.listen(3000);
+}
+bootstrap();
+```
+
+#### 创建和获取 user
+
+好的,现在我们准备添加一些逻辑来创建和获取 user。让我们遵循 Spring Boot 中服务的风格。我们的 user 服务将在 IUserService 中实现。在 user 文件夹,创建 **IUserService.ts** 文件。同时,我们还需要定义一个 model,这个 model 将在创建 user 的请求中使用到。创建 **user/models/CreateUserDto.ts** 文件。
+
+```typescript
+import {ApiModelProperty} from '@nestjs/swagger';
+
+export class CreateUserDto {
+ @ApiModelProperty()
+ readonly firstName: string;
+
+ @ApiModelProperty()
+ readonly lastName: string;
+
+ @ApiModelProperty()
+ readonly username: string;
+
+ @ApiModelProperty()
+ readonly password: string;
+}
+```
+
+这个类的主要功能是告诉 Swagger 它应该发送什么样的数据结构。
+
+这里是我们的 **IUserService.ts**。
+
+```typescript
+import {CreateUserDto} from './models/CreateUserDto';
+import {UserEntity} from './user.entity';
+import {ProjectEntity} from '../project/project.entity';
+
+export interface IUserService {
+ findAll(): Promise<UserEntity[]>;
+ createUser(user: CreateUserDto): Promise<UserEntity>;
+ getProjectsForUser(user: UserEntity): Promise<ProjectEntity[]>;
+}
+```
+
+这里是我们的 **user.service.ts**。
+
+```typescript
+import { Injectable } from '@nestjs/common';
+import {UserEntity} from './user.entity';
+import {IUserService} from './IUserService';
+import {CreateUserDto} from './models/CreateUserDto';
+import {ProjectEntity} from '../project/project.entity';
+
+@Injectable()
+export class UserService implements IUserService{
+ public async findAll(): Promise<UserEntity[]> {
+ return await UserEntity.findAll();
+ }
+
+ public async createUser(user: CreateUserDto): Promise<UserEntity> {
+ return await UserEntity.createUser(user);
+ }
+
+ public async getProjectsForUser(user: UserEntity): Promise<ProjectEntity[]> {
+ return undefined;
+ }
+}
+```
+
+最后是 **user.controller.ts**。
+
+```typescript
+import {Body, Controller, Get, HttpStatus, Post, Req, Res, Session} from '@nestjs/common';
+import {UserService} from './user.service';
+import {ApiBearerAuth, ApiOperation, ApiResponse} from '@nestjs/swagger';
+import {UserEntity} from './user.entity';
+import {CreateUserDto} from './models/CreateUserDto';
+import {Request, Response} from 'express';
+
+@Controller('user')
+export class UserController {
+ constructor(private readonly usersService: UserService) {}
+
+ @Get('')
+ @ApiOperation({title: 'Get List of All Users'})
+ @ApiResponse({ status: 200, description: 'User Found.'})
+ @ApiResponse({ status: 404, description: 'No Users found.'})
+ public async getAllUsers(@Req() req: Request, @Res() res, @Session() session) {
+ const users: UserEntity[] = await this.usersService.findAll();
+ return res
+ .status(HttpStatus.OK)
+ .send(users);
+
+ }
+
+ @Post('')
+ @ApiOperation({title: 'Create User'})
+ public async create(@Body() createUser: CreateUserDto, @Res() res) {
+ await this.usersService.createUser(createUser);
+ return res.status(HttpStatus.CREATED).send();
+ }
+}
+```
+
+控制器的优雅之处在于它只是将成功结果返回给用户,我们不需要处理任何错误异常,因为它们是由全局异常处理程序处理的。
+
+现在,通过运行 **npm run start** 或者 **npm run start:dev** 来启动服务器(**npm run start:dev** 会监视您的代码更改,并在每次保存时重新启动服务器)。服务器启动后,访问[http://localhost:3000/api/#/](http://localhost:3000/api/#/)。
+
+如果一切顺利,您应该会看到 Swagger 的界面和一些 API 接口。阅读 **sqlite 的教程** 并选择您认为合适的 sqlite 工具(Firefox 浏览器有 sqlite 的扩展插件)确认数据的 schema 是否正确。当数据库中没有用户时,尝试获取所有 user,它应该会返回状态码 404 和一个包含 userMessage、errorMessage 等 (我们在 **AppError.ts** 中定义的信息)的 JSON。现在,创建一个 user 再执行获取所有 user。如果一切正常,那么我们继续创建一个**登录**的 API 接口。如果有问题,请在评论区留下问题。
+
+#### 实现认证
+
+在 **user.controller.ts** 文件后追加如下代码。
+
+```typescript
+@Post('login')
+@ApiOperation({title: 'Authenticate'})
+@ApiBearerAuth()
+public async login(@Req() req: Request, @Res() res: Response, @Session() session) {
+ return res.status(HttpStatus.OK).send();
+}
+```
+
+**@ApiBearerAuth()** 注解是为了让 Swagger 知道,通过此请求,我们希望在 Header 中发送 Basic Auth。不过,我们还必须添加一些代码到 **main.ts** 中。
+
+```typescript
+const options = new DocumentBuilder()
+ .setTitle('User Session Tutorial')
+ .setDescription('Basic Auth and session management')
+ .setVersion('1.0')
+ .addTag('nestjs')
+ .addBearerAuth('Authorization', 'header')
+ .build();
+```
+
+现在,如果重新启动服务器,我们可以在 API 接口旁边看到一个小锁图标。但这个接口现在什么都没有,所以让我们给它添加一些逻辑。在我写这篇教程的时候,我认为文档中关于如何正确实现这种功能的内容不够完善,我跟着 [NestJS 官方文档](https://docs.nestjs.com/techniques/authentication) 来实现,但遇到了以下[问题](https://github.com/nestjs/passport/issues/7)。不过,我发现 [@nestjs/passport](https://github.com/nestjs/passport) 这个库,我可以将其与以下内容一起使用:
+
+在设计认证的逻辑之前,我们需要将以下内容添加到 **main.ts** 中。
+
+```typescript
+* import * as passport from 'passport';
+ import * as session from 'express-session'
+ app.use(session({
+ secret: 'secret-key',
+ name: 'sess-tutorial',
+ resave: false,
+ saveUninitialized: false
+ }))
+ app.use(passport.initialize());
+ app.use(passport.session());
+```
+
+#### 创建 auth 模块
+
+执行 **nest g mo auth** 和 **nest g s auth**,这将创建带有 auth 模块的 **auth** 目录。和之前一样,如果 auth.service 在 auth 目录外生成了,把它移进去就好。NestJS 官方文档说这里需要使用 **@UseGuards(AuthGuard(‘bearer’))** 但是由于刚刚我提到的那个问题,我自己实现了 AuthGuard,亲测可以登录用户。接着,我们还需要实现我们的“通行证策略”。创建 **src/auth/AppAuthGuard.ts** 文件。
+
+```typescript
+import {CanActivate, ExecutionContext, UnauthorizedException} from '@nestjs/common';
+import * as passport from 'passport';
+
+export class AppAuthGuard implements CanActivate {
+ async canActivate(context: ExecutionContext): Promise<boolean> {
+ const options = { ...defaultOptions };
+ const httpContext = context.switchToHttp();
+ const [request, response] = [
+ httpContext.getRequest(),
+ httpContext.getResponse()
+ ];
+ const passportFn = createPassportContext(request, response);
+
+ const user = await passportFn(
+ 'bearer',
+ options
+ );
+ if (user) {
+ request.login(user, (res) => {});
+ }
+
+ return true;
+ }
+
+}
+
+const createPassportContext = (request, response) => (type, options) =>
+ new Promise((resolve, reject) =>
+ passport.authenticate(type, options, (err, user, info) => {
+ try {
+ return resolve(options.callback(err, user, info));
+ } catch (err) {
+ reject(err);
+ }
+ })(request, response, resolve)
+ );
+
+const defaultOptions = {
+ session: true,
+ property: 'user',
+ callback: (err, user, info) => {
+ if (err || !user) {
+ throw err || new UnauthorizedException();
+ }
+ return user;
+ }
+};
+```
+
+创建 **src/auth/http.strategy.ts** 文件。
+
+```typescript
+import {Injectable} from '@nestjs/common';
+import {PassportStrategy} from '@nestjs/passport';
+import { Strategy } from 'passport-http-bearer';
+
+@Injectable()
+export class HttpStrategy extends PassportStrategy(Strategy) {
+ async validate(token: any, done: Function) {
+ done(null, {user: 'test'});
+ }
+}
+```
+
+* **token** —— 我们将在请求的中 Header 中接收到一个令牌,一般称它为 ”token“,其格式如下:**“Bearer base64encode(‘somestring’)”.**
+* **done(null, {user: test})** —— 将对象存储在 session 的第二个参数中。现在我们先暂时存储一个假对象,稍后我们将用从数据库检索出的用户对象替换。
+
+更新 **AuthModule.ts** 文件。
+
+```typescript
+import { Module } from '@nestjs/common';
+import { AuthService } from './auth.service';
+import {HttpStrategy} from './http.strategy';
+import {AppAuthGuard} from './AppAuthGuard';
+
+@Module({
+ providers: [AuthService, HttpStrategy, AppAuthGuard]
+})
+export class AuthModule {}
+```
+
+现在运行我们的服务器。
+
+测试我们项目的最好方法是进入浏览器中的 Swagger API,单击锁图标并输入 “**Bearer test**”,然后单击 “Authorize”。打开 **Chrome 开发者工具** 切换到 **Application** 选项卡,在左侧面板上点击,`Cookies->http://localhost:3000`。现在点击 **POST /login** 接口的 “Execute”,来发出请求。我们期望会看到一个名为“**sess-tutorial**” 的 cookie。但是目前我们什么也没看到。哪里出了问题?如果再我们仔细看一下[passport 的文档](https://github.com/jaredhanson/passport),会发现我们还需要在 passport 在对象上增加以下内容。
+
+```typescript
+passport.serializeUser(function(user, done) {
+ done(null, user.id);
+});
+
+passport.deserializeUser(function(id, done) {
+ User.findById(id, function (err, user) {
+ done(err, user);
+ });
+});
+```
+
+ 文档说,**@nestjs/passport** 中有一个名为**PassportSerializer** 的抽象类。为什么必须是一个抽象类呢?我们先试一试再说,先将抽象类实现为具体类,并加上 **@Injectable()** 注解,然后供我们的 **auth.module.ts.** 使用。
+
+如下所示,创建 **src/auth/cookie-serializer.ts** 文件。
+
+```typescript
+import {PassportSerializer} from '@nestjs/passport/dist/passport.serializer';
+import {Injectable} from '@nestjs/common';
+
+@Injectable()
+export class CookieSerializer extends PassportSerializer {
+ serializeUser(user: any, done: Function): any {
+ done(null, user);
+ }
+
+ deserializeUser(payload: any, done: Function): any {
+ done(null, payload);
+ }
+
+}
+```
+
+**AuthModule**
+
+```typescript
+import { Module } from '@nestjs/common';
+import { AuthService } from './auth.service';
+import {HttpStrategy} from './http.strategy';
+import {AppAuthGuard} from './AppAuthGuard';
+import {CookieSerializer} from './cookie-serializer';
+
+@Module({
+ providers: [AuthService, HttpStrategy, AppAuthGuard, CookieSerializer]
+})
+export class AuthModule {}
+```
+
+现在,运行我们的服务器并使用 Basic Auth Header 请求 **POST /login** 接口,现在我们应该可以在 Chrome 开发者工具中看到一个 cookie 了。刚刚我们遇到了一点小问题,但是通过阅读开发文档和 `@nestjs/passport` 的文档我们很快地找到了答案。
+
+现在需要添加逻辑来根据数据库中的记录对用户进行身份验证,并且保证只有在用户登录后才能进行路由请求。
+
+将下面的函数添加到 **UserEntity.ts** 中。
+
+```typescript
+public static async authenticateUser(user: {username: string, password: string}): Promise<UserEntity> {
+ let u: UserEntity;
+ u = await UserEntity.findOne({
+ select: ['id', 'username', 'password_hash'],
+ where: { username: user.username}
+ });
+ const passHash = crypto.createHmac('sha256', user.password).digest('hex');
+ if (u.password_hash === passHash) {
+ delete u.password_hash;
+ return u;
+ }
+ }
+```
+
+以及更新 **AuthService.ts**。
+
+```typescript
+import { Injectable } from '@nestjs/common';
+import {UserEntity} from '../user/user.entity';
+
+@Injectable()
+export class AuthService {
+ async validateUser(user: {username: string, password: string}): Promise<any> {
+ return await UserEntity.authenticateUser(user);
+ }
+}
+```
+
+接着修改一下我们的 **http.strategy.ts**。
+
+```typescript
+import {Injectable, UnauthorizedException} from '@nestjs/common';
+import {PassportStrategy} from '@nestjs/passport';
+import { Strategy } from 'passport-http-bearer';
+import {AuthService} from './auth.service';
+
+@Injectable()
+export class HttpStrategy extends PassportStrategy(Strategy) {
+
+ constructor(private readonly authService: AuthService) {
+ super();
+ }
+
+ async validate(token: any, done: Function) {
+ let authObject: {username: string, password: string} = null;
+ const decoded = Buffer.from(token, 'base64').toString();
+ try {
+ authObject = JSON.parse(decoded);
+ const user = await this.authService.validateUser(authObject);
+ if (!user) {
+ return done(new UnauthorizedException(), false);
+ }
+ done(null, user);
+ } catch (e) {
+ return done(new UnauthorizedException(), false);
+ }
+ }
+}
+```
+
+现在打开免费[ base64 加密网站](https://www.base64encode.org/),加密的下面的 JSON 字段,并将在 Swagger 中发送。
+
+```json
+{
+ "username" : "johnny",
+ "password": "1234"
+}
+```
+
+现在回到 Swagger 中,在刚刚点击右侧的 **Authorize** 弹出的输入框中输入 **“Bearer ew0KICAidXNlcm5hbWUiIDogImpvaG5ueSIsDQogICJwYXNzd29yZCI6ICIxMjM0Ig0KfQ==”**。Bearer 后面的字符串是上面刚刚加密过的 JSON 字符串,它将在 **UserEntity.ts** 的 **authenticateUser** 函数中被解码和匹配。现在执行 **POST /login**,您应该看到 Chrome 开发者工具 中出现了一个 cookie(如果您的用户在数据库中为用户名 “jonny”,密码为 “1234”的话)。
+
+让我们创建一个路由,它将用于为当前登录的用户创建一个项目,但在此之前,我们需要一个“会话保护程序”,它将保护我们的路由,如果 session 中没有用户,它会抛出一个 AppError。
+
+###### 保护路由免遭未经授权的访问
+
+创建 **src/auth/SessionGuard.ts** 文件。
+
+```typescript
+import {CanActivate, ExecutionContext} from '@nestjs/common';
+import {AppError} from '../common/error/AppError';
+import {AppErrorTypeEnum} from '../common/error/AppErrorTypeEnum';
+
+export class SessionGuard implements CanActivate {
+ canActivate(context: ExecutionContext): boolean | Promise<boolean> {
+ const httpContext = context.switchToHttp();
+ const request = httpContext.getRequest();
+
+ try {
+ if (request.session.passport.user)
+ return true;
+ } catch (e) {
+ throw new AppError(AppErrorTypeEnum.NOT_IN_SESSION);
+ }
+
+ }
+}
+```
+
+我们还可以用一种更方便的方法来从 session 中检索 user 对象。使用 **req.session.passport.user** 这样的方式可以,但是不够优雅。现在,创建 **src/user/user.decorator.ts** 文件。
+
+```typescript
+import {createParamDecorator} from '@nestjs/common';
+
+export const SessionUser = createParamDecorator((data, req) => {
+ return req.session.passport.user;
+})
+```
+
+接着,我们向 **ProjectEntity** 类中添加一个函数来为给定的用户创建 project。
+
+```typescript
+public static async createProjects(projects: CreateProjectDto[], user: UserEntity): Promise<ProjectEntity[]> {
+ const u: UserEntity = await UserEntity.findOne(user.id);
+ if (!u) throw new AppError(AppErrorTypeEnum.USER_NOT_FOUND);
+ const projectEntities: ProjectEntity[] = [];
+ projects.forEach((p: CreateProjectDto) => {
+ const pr: ProjectEntity = new ProjectEntity();
+ pr.name = p.name;
+ pr.description = p.description;
+ projectEntities.push(pr);
+ });
+ u.projects = projectEntities;
+ const result: ProjectEntity[] = await ProjectEntity.save(projectEntities);
+ await UserEntity.save([u]);
+ return Promise.all(result);
+ }
+```
+
+在 **ProjectService** 类中,添加将下内容。
+
+```typescript
+public async createProject(projects: CreateProjectDto[], user: UserEntity): Promise<ProjectEntity[]> {
+ return ProjectEntity.createProjects(projects, user);
+}
+```
+
+再更新 **ProjectController**。
+
+```typescript
+import {Body, Controller, HttpStatus, Post, Res, UseGuards} from '@nestjs/common';
+import {SessionGuard} from '../auth/SessionGuard';
+import {SessionUser} from '../user/user.decorator';
+import {UserEntity} from '../user/user.entity';
+import {ApiOperation, ApiUseTags} from '@nestjs/swagger';
+import {CreateProjectDto} from './models/CreateProjectDto';
+import {ProjectService} from './project.service';
+import {ProjectEntity} from './project.entity';
+
+@ApiUseTags('project')
+@Controller('project')
+export class ProjectController {
+
+ constructor(private readonly projectService: ProjectService) {}
+
+ @Post('')
+ @UseGuards(SessionGuard)
+ @ApiOperation({title: 'Create a project for the logged in user'})
+ public async createProject(@Body() createProjects: CreateProjectDto[], @Res() res, @SessionUser() user: UserEntity) {
+ const projects: ProjectEntity[] = await this.projectService.createProject(createProjects, user);
+ return res.status(HttpStatus.OK).send(projects);
+ }
+
+}
+```
+
+* **@UseGuards(SessionGuard)** —— 如果 user 不在 session 中,则响应的 AppError 中会返回预定义的 JSON。
+* **@SessionUser()** —— 我们的自定义装饰器可以使我们轻松地从 session 中获取到 **UserEntity** 对象。(其实我们没有必要存储整个 **UserEntity** 对象,我们可以通过修改 CookieSerializer 类来保存用户的 id)。
+
+在 Swagger 中,尝试在不进行用户身份验证和用户登陆通过的情况下分别创建 project,看看有什么区别。在创建 project 时您发送的必须是一个包含项目的数组。(请注意,在服务器重启后,seesion 将会丢失)。您也可以通过使用 Chrome 开发者工具来删除一个 cookie。
+
+现在,我们添加获取 project 的用户功能。
+
+###### 为已认证的 user 获取 project
+
+在 **ProjectEntity** 中添加如下代码:
+
+```typescript
+public static async getProjects(user: UserEntity): Promise<ProjectEntity[]> {
+ const u: UserEntity = await UserEntity.findOne(user.id, { relations: ['projects']});
+ if (!u) throw new AppError(AppErrorTypeEnum.USER_NOT_FOUND);
+ return Promise.all(u.projects);
+ }
+```
+
+在 **ProjectService** 中添加如下代码:
+
+```typescript
+public async getProjectsForUser(user: UserEntity): Promise<ProjectEntity[]> {
+ return ProjectEntity.getProjects(user);
+ }
+```
+
+在 **ProjectController** 中添加如下代码:
+
+```typescript
+@Get('')
+@UseGuards(SessionGuard)
+@ApiOperation({title: 'Get Projects for User'})
+public async getProjects(@Res() res, @SessionUser() user: UserEntity) {
+ const projects: ProjectEntity[] = await this.projectService.getProjectsForUser(user);
+ return res.status(HttpStatus.OK).send(projects);
+}
+```
+
+以上就是全部内容。
+
+您可以在 [https://github.com/artonio/nestjs-session-tutorial-finished](https://github.com/artonio/nestjs-session-tutorial-finished) 查看完成的源码。
+
+译者注:原作者的文章写于 2018 年,NestJS 的版本是 5.0.0,现在 NestJS 已经更新到 v6 了,所以是不兼容的。但是 NestJS 的官方有 v5 迁移到 v6 的[迁移指南](https://docs.nestjs.cn/6/migrationguide),有需要可以参考。同理,文章中提到的其他库也需要注意版本。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/offline-graphql-queries-with-redux-offline-and-apollo.md b/TODO1/offline-graphql-queries-with-redux-offline-and-apollo.md
index 6c271281207..77bc0a62b10 100644
--- a/TODO1/offline-graphql-queries-with-redux-offline-and-apollo.md
+++ b/TODO1/offline-graphql-queries-with-redux-offline-and-apollo.md
@@ -2,48 +2,48 @@
> * 原文作者:[Pete Corey](http://www.petecorey.com/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/offline-graphql-queries-with-redux-offline-and-apollo.md](https://github.com/xitu/gold-miner/blob/master/TODO1/offline-graphql-queries-with-redux-offline-and-apollo.md)
-> * 译者:
-> * 校对者:
+> * 译者:[vitoxli](https://github.com/vitoxli)
+> * 校对者:[Baddyo](https://github.com/Baddyo)
-# Offline GraphQL Queries with Redux Offline and Apollo
+# 使用 Redux Offline 和 Apollo 进行离线 GraphQL 查询
-Ironically, in our ever more connected world, demands for offline capabilities of web applications are growing. Our users (and clients) expect to use rich internet applications while online, offline, and in areas of questionable connectivity.
+具有讽刺意味的是,在我们日益连接的世界中,对 web 应用程序离线功能的需求正在不断增长。我们的用户(和客户端)希望在联机、脱机和在连接不稳定的区域使用富互联网应用。
-This can be… difficult.
+这其实是一件很困难的事情。
-Let’s dive into how we can build a reasonably powerful offline solution using [React](https://facebook.github.io/react/) and a [GraphQL data layer](http://graphql.org/) powered by [Apollo Client](http://www.apollodata.com/). We’ll split this article into two parts. This week, we’ll discuss offline querying. Next week, we’ll tackle mutations.
+让我们深入探讨如何通过 [React](https://facebook.github.io/react/) 和 [Apollo Client](http://www.apollodata.com/) 提供的 [GraphQL data layer](http://graphql.org/) 构建一个功能强大的脱机解决方案。这篇文章将会分为两部分,本周我们将会讨论脱机查询。下周我们将会讨论脱机修改。
-## Redux Persist and Redux Offline
+## Redux Persist 和 Redux Offline
-Under the hood, [Apollo Client](https://github.com/apollographql/apollo-client) is powered by [Redux](http://redux.js.org/). This means that the entire Redux ecosystem of tools and libraries are available for us to use in our Apollo application.
+在底层,[Apollo Client](https://github.com/apollographql/apollo-client) 由 [Redux](http://redux.js.org/) 提供支持。这意味着我们可以在 Apollo 应用程序中使用整个 Redux 生态系统中的工具和库。
-In the world of Redux offline support, there are two major players: Redux Persist, and Redux Offline.
+在 Redux 离线支持的世界中,有两个主要参与者:Redux Persist 和 Redux Offline。
-[Redux Persist](https://github.com/rt2zz/redux-persist) is a fantastic, but bare bones, tool designed to store and retrieve (or “rehydrate”) a redux store to and from `localStorage` (or any other [supported storage engine](https://github.com/rt2zz/redux-persist#storage-engines)).
+[Redux Persist](https://github.com/rt2zz/redux-persist) 是一个非常棒但很简单的工具。它被设计用来从 `localStorage` (或者从这些[支持的存储引擎](https://github.com/rt2zz/redux-persist#storage-engines))中存储和检索(或者说“rehydrate”) redux store。
-[Redux Offline](https://github.com/jevakallio/redux-offline) expands on Redux Persist and adds additional layers of functionality and utility. Redux Offline automatically detects network disconnections and reconnections, lets you queue up actions and operations while offline, and automatically retries those actions once reconnected.
+[Redux Offline](https://github.com/jevakallio/redux-offline) 扩展自 Redux Persist 并添加功能和实用层。Redux Offline 自动检测网络的断开和重新连接,允许您在脱机时将操作排入队列,并在重新连接后自动重试这些操作。
-Redux Offline is the batteries-included option for offline support. 🔋
+Redux Offline 是离线支持的标配选项。🔋
-## Offline Queries
+## 离线查询
-Out of the box, Apollo Client works fairly well in partially connected network situations. Once a query is made by the client, the results of that query are saved to the Apollo store.
+开箱即用地,Apollo Client 在部分连接的网络情况下工作得相当好。客户一旦进行查询,该查询的结果就会保存到 Apollo store。
-If that same query is made again [with any `fetchPolicy` other than `network-only`](http://dev.apollodata.com/react/api-queries.html#graphql-config-options-fetchPolicy), the results of that query will be immediately pulled from the client’s store and returned to the querying component. This means that even if our client is disconnected from the server, repeated queries will still be resolved with the most recent results available.
+如果[使用 `network only` 以外的任何 `fetchPolicy`](http://dev.apollodata.com/react/api-queries.html#graphql-config-options-fetchPolicy) 再次执行同一查询,则该查询的结果将立即从客户端的 store 中提取出来并返回到查询组件。这意味着,即使我们的客户端与服务器断开连接,重复的查询仍将返回最新的可用结果。
[](https://github.com/jevakallio/redux-offline)
-Unfortunately, as soon as a user closes our application, their store is lost. How can we persist the client’s Apollo store through application restarts?
+不幸的是,一旦用户关闭我们的应用,他们的 store 就会丢失。那如何在应用重启的情况下来持久化客户机的 Apollo store 呢?
-Redux Offline to the rescue!
+Redux Offline 正是解决问题的良药!
-The Apollo store actually exists within our application’s Redux store (under the `apollo` key). By persisting the entire Redux store to `localStorage`, and rehydrating it every time the application is loaded, we can carry over the results of past queries through application restarts, [even while disconnected from the internet](https://github.com/jevakallio/redux-offline#progressive-web-apps)!
+Apollo store 实际上存在于我们的应用的 Redux store(在 `apollo` key 中)中。通过将整个 Redux store 持久化到 `localStorage` 中,并在每次加载应用程序时重新获取。通过这种方法,[即便在断开网络连接时](https://github.com/jevakallio/redux-offline#progressive-web-apps),我们也可以通过应用程序重新启动来传递过去查询的结果!
-Using Redux Offline with an Apollo Client application doesn’t come without its kinks. Let’s explore how to get these two libraries to work together.
+在 Apollo Client 应用程序中使用 Redux Offline 并非不存在问题。让我们看看如何让这两个库协同工作。
-### Manually Building a Store
+### 手动构建一个 Store
-Normally, setting up an Apollo client is fairly simple:
+通常情况下,建立一个 Apollo client 十分简单:
```javascript
export const client = new ApolloClient({
@@ -51,7 +51,7 @@ export const client = new ApolloClient({
});
```
-The `ApolloClient` constructor would create our Apollo store (and indirectly, our Redux store) automatically for us. We’d simply drop this new `client` into our `ApolloProvider` component:
+`ApolloClient` 的构造函数将自动为我们创建 Apollo store(并间接创建我们的 Redux store)。我们只需将这个新的 `client` 放入我们的 `ApolloProvider` 组件中:
```javascript
ReactDOM.render(
@@ -62,7 +62,7 @@ ReactDOM.render(
);
```
-When using Redux Offline, we’ll need to manually construct our Redux store to pass in our Redux Offline middleware. To start, let’s just recreate what Apollo does for us:
+当使用 Redux Offline 时,我们需要手动构造 Redux store,以传入 Redux Offline 的中间件。首先,让我们来重现 Apollo 为我们所做的一切:
```javascript
export const store = createStore(
@@ -72,9 +72,9 @@ export const store = createStore(
);
```
-Our new `store` uses the reducer and middleware provided by our Apollo `client`, and initializes with an initial store value of `undefined`.
+新的 `store` 使用了 Apollo `client` 为我们提供的 reducer 和 middleware,并使用了一个值为 `undefined` 的初始 store 来进行初始化。
-We can now pass this `store` into our `ApolloProvider`:
+我们现在可以把这个 `store` 传入我们的 `ApolloProvider` 中:
```javascript
<ApolloProvider client={client} store={store}>
@@ -82,11 +82,11 @@ We can now pass this `store` into our `ApolloProvider`:
</ApolloProvider>
```
-Perfect. Now that we have control over the creation of our Redux store, we can wire in offline support with Redux Offline.
+完美。既然我们已经手动创建了 Redux store,我们就可以使用 Redux Offline 来开发支持离线的应用。
-### Basic Query Persistence
+### 基础查询持久化
-Adding Redux Offline into the mix, in its simplest form, consists of adding a new piece of middleware to our store:
+以最简单的形式引入 Redux Offline,包括为我们的 store 添加一个中间件:
```javascript
import { offline } from 'redux-offline';
@@ -103,39 +103,39 @@ export const store = createStore(
);
```
-Out of the box, this `offline` middleware will automatically start persisting our Redux store into `localStorage`.
+这个 `offline` 中间件将会自动地把我们的 Redux store 持久化到 `localStorage` 中。
-Don’t believe me?
+不相信我吗?
-Fire up your console and pull up this `localStorage` entry:
+启动你的控制台并查看此 `localStorage`:
```javascript
localStorage.getItem("reduxPersist:apollo");
```
-You should be given a massive JSON blob that represents the entire current state of your Apollo application.
+你将会看到一个巨大的 JSON blob,它代表着你 Apollo 应用程序的整个当前状态。
[redux_persist_apollo.webm](https://s3-us-west-1.amazonaws.com/www.east5th.co/static/redux_persist_apollo.webm)
-Awesome!
+太棒啦!
-Redux Offline is now automatically saving snapshots of our Redux store to `localStorage`. Any time you reload your application, this state will be automatically pulled out of `localStorage` and rehydrated into your Redux store.
+Redux Offline 现在将自动地把 Redux store 的快照保存到 `localStorage` 中。任何时候重新加载应用程序,此状态都将自动从 `localStorage` 中提取并 rehydrate 到你的 Redux store 中。
-Any queries that have resolutions living in this store will return that data, even if the application is currently disconnected from the server.
+即使当前应用程序已与服务器断开连接,任何在 store 中使用此方案的查询都将返回该数据。
-### Rehydration Race Conditions
+### Rehydration 竞争的情况
-Unfortunately, store rehydration isn’t instant. If our application tries to make queries while Redux Offline is rehydrating our store, Strange Things™ can happen.
+不幸地是,store 的 rehydration 不是即刻完成的。如果我们的应用程序试图在 Redux Offline 取得 store 时进行查询,奇怪的事情就会发生啦。
-If we turn on `autoRehydrate` logging within Redux Offline (which is an ordeal in and of itself), we’d see similar errors when we first load our application:
+如果我们打开了 Redux Offline 的 `autoRehydrate` 日志记录(这本身就是一种折磨),我们会在首次加载应用程序时会看到类似的错误:
> 21 actions were fired before rehydration completed. This can be a symptom of a race condition where the rehydrate action may overwrite the previously affected state. Consider running these actions after rehydration: …
-The creator of Redux Persist acknowledges this and has written [a recipe for delaying the rendering of your application](https://github.com/rt2zz/redux-persist/blob/master/docs/recipes.md#delay-render-until-rehydration-complete) until rehydration has taken place. Unfortunately, his solution relies on manually calling `persistStore`, which Redux Offline does for us behind the scenes.
+Redux Persist 的作者承认了这一点,并已经编写了[一种延迟应用程序的渲染直到完成 rehydration 的方法](https://github.com/rt2zz/redux-persist/blob/master/docs/recipes.md#delay-render-until-rehydration-complete)。不幸的是,他的解决方案依赖于手动调用 `persistStore`,而 Redux Offline 已经默默为我们做了这项工作。
-Let’s come up with another solution.
+让我们看看其它的解决方法。
-We’ll start by creating a new Redux action called `REHYDRATE_STORE`, and a corresponding reducer that sets a `rehydrated` flag in our Redux store to `true`:
+我们将会创建一个新的 Redux action,并将其命名为 `REHYDRATE_STORE`,同时我们创建一个对应的 reducer,并在我们的 Redux store 中设置一个值为 `true` 的 `rehydrated` 标志位:
```javascript
export const REHYDRATE_STORE = 'REHYDRATE_STORE';
@@ -152,7 +152,7 @@ export default (state = false, action) => {
};
```
-Now let’s add our new reducer to our store and tell Redux Offline to trigger our action when it finishes rehydrating the store:
+现在让我们把这个新的 reducer 添加到我们的 store 中,并且告诉 Redux Offline 在获取到 store 的时候触发我们的 action:
```javascript
export const store = createStore(
@@ -176,11 +176,11 @@ export const store = createStore(
);
```
-Perfect. When Redux Offline finishes hydrating our store, it’ll trigger the `persistCallback` function, which dispatches our `REHYDRATE_STORE` action, and eventually updates the `rehydrate` field in our store.
+完美。当 Redux Offline 恢复完我们的 store 后,会触发 `persistCallback` 回调函数,这个函数会 dispatch 我们的 `REHYDRATE_STORE` action,并最终更新我们 store 中的 `rehydrate`。
-Adding `rehydrate` to our Redux Offline `blacklist` ensures that that piece of our store will never be stored to, or rehydrated from `localStorage`.
+将 `rehydrate` 添加到 Redux Offline 的`黑名单`可以确保我们的 store 永远不会存储到 `localStorage` 或从 `localStorage` 取得我们的 store。
-Now that our store is accurately reflecting whether or not rehydration has happened, let’s write a component that listens for changes to our new `rehydrate` field and only renders its children if `rehydrate` is `true`:
+既然我们的 store 能准确地反映是否发生了 rehydration 操作,那么让我们编写一个组件来监听 `rehydrate` 字段,并且只在 `rehydrate` 为 `true` 时对它的 children 进行渲染。
```javascript
class Rehydrated extends Component {
@@ -200,7 +200,7 @@ export default connect(state => {
})(Rehydrate);
```
-Finally, we can wrap our `<App />` component in our new `<Rehydrate>` component to prevent our application from rendering until rehydration has taken place:
+最后,我们可以用新的 `<Rehydrate>` 组件把 `<App/>` 组件包裹起来,以防止应用程序在 rehydration 之前进行渲染:
```javascript
<ApolloProvider client={client} store={store}>
@@ -210,19 +210,19 @@ Finally, we can wrap our `<App />` component in our new `<Rehydrate>` component
</ApolloProvider>
```
-Whew.
+哇哦。
-Now our application will happily wait until Redux Offline has completely rehydrated our store from `localStorage` before continuing on to render and make any subsequent GraphQL queries or mutations.
+现在,我们的应用程序可以愉快地等待 Redux Offline 从 `localStorage` 中完全取得我们的 store,然后继续渲染并进行任何后续的 GraphQL 查询或修改了。
-## Quirks and Notes
+## 注意事项
-There are a few quirks and things to take note of when using Redux Offline with Apollo client.
+在配合 Apollo client 使用 Redux Offline 时,需要注意以下这些事项。
-First, it’s important to note that the examples in this article are using version `1.9.0-0` of the `apollo-client` package. Fixes were introduced to Apollo Client in [version 1.9](https://github.com/apollographql/apollo-client/blob/df42883c3245ba206ddd72a9cffd9a1522eee51c/CHANGELOG.md#v190-0) that resolved some [strange behaviors when combined with Redux Offline](https://github.com/apollographql/apollo-client/issues/424#issuecomment-316634765).
+首先,需要注意的是本文的示例使用的是 `1.9.0-0` 版本的 `apollo-client` 包。Apollo Client 在 [1.9 版本](https://github.com/apollographql/apollo-client/blob/df42883c3245ba206ddd72a9cffd9a1522eee51c/CHANGELOG.md#v190-0)中引入了修复程序,来解决[与 Redux Offline 同时使用时的一些怪异表现](https://github.com/apollographql/apollo-client/issues/424#issuecomment-316634765)。
-Another oddity related to this setup is that Redux Offline doesn’t seem to play nicely with the [Apollo Client Devtools](http://dev.apollodata.com/core/devtools.html#Apollo-Client-Devtools). Trying to use Redux Offline with the Devtools installed can sometimes lead to unexpected, and seemingly unrelated errors.
+与此文相关的另一个需要关注的点是,[Apollo Clinent Devtools](http://dev.apollodata.com/core/devtools.html#Apollo-Client-Devtools) 对 Redux Offline 的支持不太友好。在安装了 Devtools 的情况下使用 Redux Offline 有时会导致意外的错误。
-These errors can be easily avoided by not connecting to the Devtools when creating your Apollo `client` instance:
+在创建 Apollo `client` 实例时,不连接 Devtools 即可很容易避免这些错误:
```javascript
export const client = new ApolloClient({
@@ -231,13 +231,13 @@ export const client = new ApolloClient({
});
```
-## Stay Tuned
+## 敬请期待
-Redux Offline should give you basic support for query resolution for your Apollo-powered React application, even if your application is re-loaded while disconnected from your server.
+Redux Offline 应该为您的 Apollo 支持的 React 应用程序的查询解析提供基本支持,即使您的应用程序是在与服务器断开连接时重新加载的。
-Next week we’ll dive into handling offline mutations with Redux Offline.
+下周我们会进一步探讨如何使用 Redux Offline 处理脱机修改的问题。
-Stay tuned!
+敬请期待!
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/password-hashing-pbkdf2-scrypt-bcrypt-and-argon2.md b/TODO1/password-hashing-pbkdf2-scrypt-bcrypt-and-argon2.md
new file mode 100644
index 00000000000..2f3f711df9e
--- /dev/null
+++ b/TODO1/password-hashing-pbkdf2-scrypt-bcrypt-and-argon2.md
@@ -0,0 +1,103 @@
+> * 原文地址:[Password Hashing: PBKDF2, Scrypt, Bcrypt and ARGON2](https://medium.com/@mpreziuso/password-hashing-pbkdf2-scrypt-bcrypt-and-argon2-e25aaf41598e)
+> * 原文作者:[Michele Preziuso](https://medium.com/@mpreziuso)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/password-hashing-pbkdf2-scrypt-bcrypt-and-argon2.md](https://github.com/xitu/gold-miner/blob/master/TODO1/password-hashing-pbkdf2-scrypt-bcrypt-and-argon2.md)
+> * 译者:[司徒公子](https://github.com/todaycoder001)
+> * 校对者:[xionglong58](https://github.com/xionglong58)、[GJXAIOU](https://github.com/GJXAIOU)
+
+# 密码哈希的方法:PBKDF2,Scrypt,Bcrypt 和 ARGON2
+
+关于如何安全的存储密码以及使用何种算法总是有很多的争论:MD5、SHA1,SHA256、PBKDF2,Bcrypt、Scrypt、Argon2、明文??
+
+因此,我试图分析并总结了最新的合理选择:Scrypt、Bcrypt 和 Argon2 是符合条件的,MD5、SHA1、SHA256 就不太适合存储密码!😉
+
+
+
+#### 总结
+
+在 2015 年,我就已经发布了‘[密码哈希:PBKDF2、Scrypt、Bcrypt](https://medium.com/@mpreziuso/password-hashing-pbkdf2-scrypt-bcrypt-1ef4bb9c19b3)’文章,来作为对朋友问题的延伸回答。
+
+概括的说:
+
+> 攻击者通常拥有与我们不同的、更专业(强大)的硬件
+>
+> 攻击者之所以使用专业的硬件,是因为它能根据某些算法进行定制,定制化的硬件允许某些算法能比非专业硬件(CPU)上运行的更快,而且 —— 总体而言 —— 某些算法还可以并行化;
+>
+> 我们依赖慢哈希方法来对密码进行哈希,从而实现你采用的 CPU/GPU 处理器与攻击者的 GPU/FPGA/ASIC 处理器在计算能力上处于同一水准。
+
+**以上这些都是正确的**,然而,数字加密货币的竞争又上升到另一个层面:数十亿美元的市值,
+基于软件/硬件,以最快的速度来实现一种数字加密货币的底层算法,这相比于其他矿工来说也是一种优势,因此,也是最赚钱的一个。
+
+在比特币使用 SHA256 来作为其底层加密方法的时候(因此,可以在已经优化的硬件上对其进行极大的优化,使其对矿工来说成为一种‘不公平’的数字货币),但其他加密货币的创建者试图通过依赖内存的方法来使新的数字加密货币能被更加公平的开采:[莱特币](https://litecoin.org/)([Scrypt](https://en.wikipedia.org/wiki/Scrypt)) 是早期的示例,[Zcash](https://z.cash/)([Equihash](https://en.wikipedia.org/wiki/Equihash))是最近的示例。
+
+这意味着用于密码哈希的慢方法正在被用来保护数百万甚至数十亿美元市值的数字加密货币,这使得慢哈希方法的最快实现是有意义的,而且通常这也是[公开可用的](https://github.com/tpruvot/ccminer)。
+
+#### 那么今天什么是安全的呢?
+
+原理还是一样的:我们需要一个加密社区审核过的慢函数并且依然未被破解。
+
+**PBKDF2** 已经存在很长时间了,像[之前文章](https://medium.com/@mpreziuso/password-hashing-pbkdf2-scrypt-bcrypt-1ef4bb9c19b3)讨论的一样,它有点过时了:轻松的在多核系统(GPU)上实现并行,这对于定制系统(FPGA/ASIC)来说微不足道。所以我拒绝了它。
+
+虽然在 1999 年 **BCrypt** 就产生了,并且在对抗 GPU/ASIC 方面要优于 PBKDF2,但是我还是不建议你在新系统中使用它,因为它在离线破解的威胁模型分析中表现并不突出。
+尽管有一些数字加密货币依赖于它(即:NUD),但它并没有因此获得较大的普及,因此,FPGA/ASIC 社区也并没有足够的兴趣来构建它的硬件实现。
+话虽如此,[Solar Designer](https://twitter.com/solardiz)(OpenWall)、Malvoni 和 Knezovic(萨格勒布大学)在 2014 年撰写了一篇论文,这篇文章描述了一种混合使用 ARM/FPGA 的单片系统来攻击该算法。
+
+**SCrypt** 在如今是一个更好的选择:比 BCrypt设计得更好(尤其是关于内存方面)并且已经在该领域工作了 10 年。另一方面,它也被用于许多加密货币,并且我们有一些硬件(包括 FPGA 和 ASIC)能实现它。
+尽管它们专门用于采矿,也可以将其重新用于破解。
+
+## Argon2
+
+写完[我的第一篇文章](https://medium.com/@mpreziuso/password-hashing-pbkdf2-scrypt-bcrypt-1ef4bb9c19b3)后不久,Argon2 在 2015 年 7 月赢得了密码哈希竞赛。
+
+#### 密码哈希竞赛
+
+该竞赛于 2012 年秋季启动,2013 年第一季度,竞赛委员会发布了征集参赛作品的通知,截止日期为 2014 年 3 月底。作为比赛的一部分,小组成员对提交的参赛作品进行了全面审核,并发布了一份初步的简短报告,其中描述了他们的选择标准和理由。
+
+#### 介绍
+
+Argon2 有两个主要的版本:**Argon2i** 是对抗侧信道攻击的最安全选择,而 **Argon2d** 是抵抗 GPU 破解攻击的最安全选择。
+
+源代码可以在 [Github](https://github.com/p-h-c/phc-winner-argon2) 上获得,使用兼容 C89 的 C 语言编写,并在知识共享许可协议下获取许可,并且可以在大多数 ARM、x86 和 x64 架构的硬件上编译。
+
+#### 基于 AES 实现
+
+Argon2 基于 [AES](https://en.wikipedia.org/wiki/Advanced_Encryption_Standard) 实现,现代的 x64 和 ARM 处理器已经在指令集扩展中实现了它,从而大大缩小了普通系统和攻击者系统之间的性能差距,
+
+#### 参数调整
+
+两个版本的算法都可以实现参数化:
+
+* **时间**开销,它定义了执行的时间
+* **内存**开销,它定义了内存的使用情况
+* **并行**程度,它定义了线程的数量
+
+这意味着你可以分别调整这些参数,并根据你的用例、威胁模型和硬件规范来量身定制安全约束。
+
+#### 权衡攻击
+
+除此之外,Argon2 尤其能抵挡**排名权衡攻击**,这使得在现场可编程逻辑门阵列上进行低成本攻击变得更加困难:虽然,最近的现场可编程逻辑门阵列已经嵌入 RAM 区块,但是,内存带宽仍然是一个限制,并且为了减少内存带宽要求,攻击者必须为了 Argon2 使用更多的计算资源。
+
+[规范](https://github.com/P-H-C/phc-winner-argon2/blob/master/argon2-specs.pdf)(见第 5 章)和同一作者的另外[一篇文章](https://orbilu.uni.lu/bitstream/10993/20043/1/Tradeoff%20Cryptanalysis.pdf)中讨论了这些攻击手段和相似的攻击手段,并将其与 scrypt 进行比较。
+
+#### Argon2id
+
+以下是来自 [Argon2 互联网工程任务组草案](https://datatracker.ietf.org/doc/draft-irtf-cfrg-argon2/)的引用/释义。
+
+> **Argon2d** 使用依赖数据的内存访问,这使得它很适合用于加密数字货币和工作量证明的应用程序,而不会受到侧信道定时攻击的威胁。**Argon2i** 使用与数据无关的内存访问,这是密码哈希的首选方法。**Argon2id** 在内存第一次迭代的前半部分充当 Argon2i,其余部分则充当 Argon2d。因此,基于时间 —— 空间的平衡,它既提供了侧信道攻击保护也节约了暴力开销。Argon2i 对内存进行了更多的传递,以防止权衡攻击的发生。
+
+
+
+如果你担心侧信道攻击(例如:[恶意数据缓存加载/幽灵漏洞](https://meltdownattack.com/),它允许通过基于缓存的侧信道读取同一硬件上其他正在运行的进程的私有内存数据),你应该使用 Argon2i,否则使用 Argon2d。
+如果你不确定或你对混合方法感到满意,你可以使用 Argon2id 来获得两个方面的优势。
+
+## 结论
+
+在 2019 年,我建议你以后**不要使用** PBKDF2 或 BCrypt,并强烈建议将 Argon2(最好是 Argon2id)用于最新系统。
+
+Scrypt 是当 Argon2 不可用时的不二选择,但要记住,它在侧侧信道泄露方面也存在相同的问题。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/performant-javascript-best-practices.md b/TODO1/performant-javascript-best-practices.md
new file mode 100644
index 00000000000..bcd8b33e01a
--- /dev/null
+++ b/TODO1/performant-javascript-best-practices.md
@@ -0,0 +1,113 @@
+> * 原文地址:[Performant JavaScript Best Practices](https://levelup.gitconnected.com/performant-javascript-best-practices-c5a49a357e46)
+> * 原文作者:[John Au-Yeung](https://medium.com/@hohanga)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/performant-javascript-best-practices.md](https://github.com/xitu/gold-miner/blob/master/TODO1/performant-javascript-best-practices.md)
+> * 译者:
+> * 校对者:
+
+# Performant JavaScript Best Practices
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/5760/0*UyQ42ciE79LF-bK4)
+
+Like any program, JavaScript programs can get slow fast if we aren’t careful with writing our code.
+
+In this article, we’ll look at some best practices for writing fast JavaScript programs.
+
+## Reduce DOM Manipulation With Host Object and User’s Browser
+
+DOM manipulation is slow. The more we do, the slower it’ll be. Since DOM manipulation is synchronous, each action is done one at a time, holding the rest of our program.
+
+Therefore, we should minimize the number of DOM manipulation actions that we're doing.
+
+The DOM can be blocked by loading CSS and JavaScript. However, images aren’t blocking render so that they don’t hold up our page from finishing loading.
+
+However, we still want to minimize the size of our images.
+
+Render blocking JavaScript code can be detected with Google PageSpeed Insights, which tells us how many pieces of render-blocking JavaScript code we have.
+
+Any inline CSS would block the rendering of the whole page. They are the styles that are scattered within our page with `style` attributes.
+
+We should move them all to their own style sheets, inside the `style` tag, and below the body element.
+
+CSS should be concatenated and minified to reduce the number of the stylesheet to load and their size.
+
+We can also mark `link` tags as non-render blocking by using media queries. For instance, we can write the following to do that:
+
+```html
+<link href="portrait.css" rel="stylesheet" media="orientation:portrait">
+```
+
+so that it only loads when the page is displayed in portrait orientation.
+
+We should move style manipulation outside of our JavaScript and put styles inside our CSS by putting styles within their own class in a stylesheet file.
+
+For instance, we can write the following code to add a class in our CSS file:
+
+```css
+.highlight {
+ background-color: red;
+}
+```
+
+and then we can add a class with the `classList` object as follows:
+
+```js
+const p = document.querySelector('p');
+p.classList.add('highlight');
+```
+
+We set the p element DOM object to its own constant so we can cache it and reuse it anywhere and then we call `classList.add` to add the `hightlight` class to it.
+
+We can also remove it if we no longer want it. This way, we don’t have to do a lot of unnecessary DOM manipulation operations in our JavaScript code.
+
+If we have scripts that no other script depends on, we can load then asynchronously so that they don’t block the loading of other scripts.
+
+We just put `async` in our script tag so that we can load our script asynchronously as follows:
+
+```html
+<script async src="script.js"></script>
+```
+
+Now `script.js` will load in the background instead of in the foreground.
+
+We can also defer the loading of scripts by using the `defer` directive. However, it guarantees that the script in the order they were specified on the page.
+
+This is a better choice if we want our scripts to load one after another without blocking the loading of other things.
+
+Minifying scripts is also a must-do task before putting our code into production. To do that, we use module bundlers like Webpack and Parcel, which so create a project and then build them for us automatically.
+
+Also, command-line tools for frameworks like Vue and Angular also do code minification automatically.
+
+## Minimize the Number of Dependencies Our App Uses
+
+We should minimize the number of scripts and libraries that we use. Unused dependencies should also be removed.
+
+For instance, if we’re using Lodash methods for array manipulation, then we can replace them with native JavaScript array methods, which are just as good.
+
+Once we remove our dependency, we should remove them from `package.json` and the run `npm prune` to remove the dependency from our system.
+
+ on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/6154/0*9Qx9V9XpyjsjvSME)
+
+## Poor Event Handling
+
+Event handling code is always slow if they’re complex. We can improve performance by reducing the depth of our call stack.
+
+That means we call as few functions as possible. Put everything in CSS style sheets if possible if we’re manipulating styles in our event handlers.
+
+And do everything to reduce calling functions like using the `**` operator instead of calling `Math.pow` .
+
+## Conclusion
+
+We should reduce the number of dependencies and loading them in an async manner if possible.
+
+Also, we should reduce the CSS in our code and move them to their own stylesheets.
+
+We can also add media queries so that stylesheets don’t load everywhere.
+
+Finally, we should reduce the number of functions that are called in our code.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/polymorphic-react-components.md b/TODO1/polymorphic-react-components.md
new file mode 100644
index 00000000000..560e20eb2c1
--- /dev/null
+++ b/TODO1/polymorphic-react-components.md
@@ -0,0 +1,390 @@
+> * 原文地址:[Writing Type-Safe Polymorphic React Components (Without Crashing TypeScript)](https://blog.andrewbran.ch/polymorphic-react-components/)
+> * 原文作者:[Andrew Branch](https://blog.andrewbran.ch/about)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/polymorphic-react-components.md](https://github.com/xitu/gold-miner/blob/master/TODO1/polymorphic-react-components.md)
+> * 译者:
+> * 校对者:
+
+# Writing Type-Safe Polymorphic React Components (Without Crashing TypeScript)
+
+When designing a React component for reusability, you often need to be able to pass different DOM attributes to the component’s container in different situations. Let’s say you’re building a `<Button />`. At first, you just need to allow a custom `className` to be merged in, but later, you need to support a wide range of attributes and event handlers that aren’t related to the component itself, but rather the context in which it’s used—say, `aria-describedby` when composed with a Tooltip component, or `tabIndex` and `onKeyDown` when contained in a component that manages focus with arrow keys.
+
+It’s impossible for Button to predict and to handle every special context where it might be used, so there’s a reasonable argument for allowing arbitrary extra props to be passed to Button, and letting it pass extra ones it doesn’t understand through.
+
+```tsx
+interface ButtonProps extends React.ButtonHTMLAttributes<HTMLButtonElement> {
+ color?: ColorName;
+ icon?: IconName;
+}
+
+function Button({ color, icon, className, children, ...props }: ButtonProps) {
+ return (
+ <button
+ {...props}
+ className={getClassName(color, className)}
+ >
+ <FlexContainer>
+ {icon && <Icon name={icon} />}
+ <div>{children}</div>
+ </FlexContainer>
+ </button>
+ );
+}
+```
+
+Awesome: we can now pass extra props to the underlying `<button>` element, and it’s perfectly type-checked too. Since the props type extends `React.ButtonHTMLAttributes`, we can pass only props that are actually valid to end up on a `<button>`:
+
+```tsx
+<Button onKeyDown={({ currentTarget }) => { /* do something */ }} />
+<Button foo="bar" /> // Correctly errors 👍
+```
+
+## When passthrough isn’t enough
+Half an hour after you send Button v1 to the product engineering team, they come back to you with a question: how do we use Button as a react-router Link? How about as an HTMLAnchorElement, a link to an external site? The component you sent them _only_ renders as an HTMLButtonElement.
+
+If we weren’t concerned about type safety, we could write this pretty easily in plain JavaScript:
+
+```tsx
+function Button({
+ color,
+ icon,
+ className,
+ children,
+ tagName: TagName,
+ ...props
+}) {
+ return (
+ <TagName
+ {...props}
+ className={getClassName(color, className)}
+ >
+ <FlexContainer>
+ {icon && <Icon name={icon} />}
+ <div>{children}</div>
+ </FlexContainer>
+ </TagName>
+ );
+}
+
+Button.defaultProps = { tagName: 'button' };
+```
+
+This makes it trivial for a consumer to use whatever tag or component they like as the container:
+
+```tsx
+<Button tagName="a" href="https://github.com">GitHub</Button>
+<Button tagName={Link} to="/about">About</Button>
+```
+
+But, how do we type this correctly? Button’s props can no longer unconditionally extend `React.ButtonHTMLAttributes`, because the extra props might not be passed to a `<button>`.
+
+> Fair warning: I’m going to go down a serious rabbit hole to explain several reasons why this doesn’t work well. If you’d rather just take my word for it, feel free to [jump ahead](#an-alternative-approach) to a better solution.
+
+
+
+Let’s start with a slightly simpler case where we only need to allow `tagName` to be `'a'` or `'button'`. (I’ll also remove props and elements that aren’t relevant to the point for brevity.) This would be a reasonable attempt:
+
+```tsx
+interface ButtonProps {
+ tagName: 'a' | 'button';
+}
+
+function Button<P extends ButtonProps>({ tagName: TagName, ...props }: P & JSX.IntrinsicElements[P['tagName']]) {
+ return <TagName {...props} />;
+}
+
+<Button tagName="a" href="/" />
+```
+
+> N.B. To make sense of this, a basic knowledge of [JSX.IntrinsicElements](https://github.com/DefinitelyTyped/DefinitelyTyped/blob/0bb210867d16170c4a08d9ce5d132817651a0f80/types/react/index.d.ts#L2829) is required. Here’s a [great deep dive on JSX in TypeScript](https://dev.to/ferdaber/typescript-and-jsx-part-iii---typing-the-props-for-a-component-1pg2) by one of the maintainers of the React type definitions.
+
+The two immediate observations that arise are
+
+1. It doesn’t compile—it tells us, in so many words, that the type of `props.ref` is not correct for the type of `TagName`.
+2. Despite that, it _does_ kind of produce the results we want when `tagName` is inferred as a string literal type. We even get completions from `AnchorHTMLAttributes`:
+
+
+
+However, a little more experimentation reveals that we’ve also effectively disabled excess property checking:
+
+```tsx
+<button href="/" fakeProp={1} /> // correct errors 👍
+<Button tagName="button" href="/" fakeProp={1} /> // no errors 👎
+```
+
+Every prop you put on Button will be inferred as a property of the type parameter `P`, which in turn becomes part of the props that are allowed. In other words, the set of allowed props always includes all the props you pass. The moment you add a prop, it becomes part of the very definition of what Button’s props should be. (In fact, you can witness this by hovering `Button` in the example above.) This is decidedly the opposite of how you intend to define React components.
+
+### What’s the problem with `ref`?
+
+If you’re not yet convinced to abandon this approach, or if you’re just curious why the above snippet doesn’t compile cleanly, let’s go deeper down the rabbit hole. And before you implement a clever workaround with `Omit<typeof props, 'ref'>`, spoiler alert: `ref` isn’t the only problem; it’s just the _first_ problem. The rest of the problems are _every event handler prop_.[^1]
+
+So what do `ref` and `onCopy` have in common? They both have the general form `(param: T) => void` where `T` mentions the instance type of the DOM element rendered: `HTMLButtonElement` for buttons and `HTMLAnchorElement` for anchors, for example. If you want to call a _union_ of call signatures, you have to pass the _intersection_ of their parameter types to ensure that regardless of which function gets called at runtime, it receives a subtype of what it expects for its parameter.[^2] Easier shown than said:
+
+```ts
+function addOneToA(obj: { a: number }) {
+ obj.a++;
+}
+
+function addOneToB(obj: { b: number }) {
+ obj.b++;
+}
+
+// Let’s say we have a function that could be either
+// of the ones declared above
+declare var fn: typeof addOneToA | typeof addOneToB;
+
+// The function might access a property 'a' or 'b'
+// of whatever we pass, so intuitively, the object
+// needs to define both those properties.
+fn({ a: 0 });
+fn({ b: 0 });
+fn({ a: 0, b: 0 });
+```
+
+In this example, it should be easy to recognize that we have to pass `fn` an object with the type `{ a: number, b: number }`, which is the _intersection_ of `{ a: number }` and `{ b: number }`. The same thing is happening with `ref` and all the event handlers:
+
+```ts
+type Props1 = JSX.IntrinsicElements['a' | 'button'];
+
+// Simplifies to...
+type Props2 =
+ | JSX.IntrinsicElements['a']
+ | JSX.IntrinsicElements['button'];
+
+// Which means ref is...
+type Ref =
+ | JSX.IntrinsicElements['a']['ref']
+ | JSX.IntrinsicElements['button']['ref'];
+
+// Which is a union of functions!
+declare var ref: Ref;
+// (Let’s ignore string refs)
+if (typeof ref === 'function') {
+ // So it wants `HTMLButtonElement & HTMLAnchorElement`
+ ref(new HTMLButtonElement());
+ ref(new HTMLAnchorElement());
+}
+```
+
+So now we can see why, rather than requiring the _union_ of the parameter types, `HTMLAnchorElement | HTMLButtonElement`, `ref` requires the _intersection_: `HTMLAnchorElement & HTMLButtonElement`—a theoretically possible type, but not one that will occur in the wild of the DOM. And we know intuitively that if we have a React element that’s either an anchor or a button, the value passed to `ref` will be either be an `HTMLAnchorElement` or an `HTMLButtonElement`, so the function we provide for `ref` _should_ accept an `HTMLAnchorElement | HTMLButtonElement`. Ergo, back to our original component, we can see that `JSX.IntrinsicElements[P['tagName']]` legitimately allows unsafe types for callbacks when `P['tagName']` is a union, and that’s what the compiler is complaining about. The manifest example of an unsafe operation that could occur by ignoring this type error:
+
+```tsx
+<Button
+ tagName={'button' as 'a' | 'button'}
+ ref={(x: HTMLAnchorElement) => x.href.toLowerCase()}
+/>
+```
+
+### Writing a better type for `props`
+
+I think what makes this problem unintuitive is that you always expect `tagName` to instantiate as exactly one string literal type, not a union. And in that case, `JSX.IntrinsicElements[P['tagName']]` is sound. Nevertheless, inside the component function, `TagName` looks like a union, so the props need to be typed as an intersection. As it turns out, it this [is possible](https://stackoverflow.com/questions/50374908/transform-union-type-to-intersection-type), but it’s a bit of a hack. So much so, I’m not going even going to put `UnionToIntersection` down in writing here. Don’t try this at home:
+
+```tsx
+interface ButtonProps {
+ tagName: 'a' | 'button';
+}
+
+function Button<P extends ButtonProps>({
+ tagName: TagName,
+ ...props
+}: P & UnionToIntersection<JSX.IntrinsicElements[P['tagName']]>) {
+ return <TagName {...props} />;
+}
+
+<Button tagName="button" type="foo" /> // Correct error! 🎉
+```
+
+How about when `tagName` is a union?
+
+```tsx
+<Button
+ tagName={'button' as 'a' | 'button'}
+ ref={(x: HTMLAnchorElement) => x.href.toLowerCase()} // 🎉
+/>
+```
+
+Let’s not celebrate prematurely, though: we haven’t solved our effective lack of excess property checking, which is an unacceptable tradeoff.
+
+### Getting excess property checking back
+
+As we discovered earlier, the problem with excess property checking is that all of our props become part of the type parameter `P`. We need a type parameter in order to infer `tagName` as a string literal unit type instead of a large union, but maybe the rest of our props don’t need to be generic at all:
+
+```tsx
+interface ButtonProps<T extends 'a' | 'button'> {
+ tagName: T;
+}
+
+function Button<T extends 'a' | 'button'>({
+ tagName: TagName,
+ ...props
+}: ButtonProps<T> & UnionToIntersection<JSX.IntrinsicElements[T]>) {
+ return <TagName {...props} />;
+}
+```
+
+Uh-oh. What is this new and unusual error?
+
+It comes from the combination of the generic `TagName` and React’s definition for [JSX.LibraryManagedAttributes](https://github.com/DefinitelyTyped/DefinitelyTyped/blob/e4a0d4f532b177fc800e8ade7f1b39e9879d4b3c/types/react/index.d.ts#L2817-L2821) as a [distributive conditional type](https://www.typescriptlang.org/docs/handbook/release-notes/typescript-2-8.html#distributive-conditional-types). TypeScript currently doesn’t allow _anything_ to be assigned to conditional type whose “checked type” (the bit before the `?`) is generic:
+
+```ts
+type AlwaysNumber<T> = T extends unknown ? number : number;
+
+function fn<T>() {
+ let x: AlwaysNumber<T> = 3;
+}
+```
+
+Clearly, the declared type of `x` will always be `number`, and yet `3` isn’t assignable to it. What you’re seeing is a conservative simplification guarding against cases where distributivity might change the resulting type:
+
+```ts
+// These types appear the same, since all `T` extend `unknown`...
+type Keys<T> = keyof T;
+type KeysConditional<T> = T extends unknown ? keyof T : never;
+
+// They’re the same here...
+type X1 = Keys<{ x: any, y: any }>;
+type X2 = KeysConditional<{ x: any, y: any }>;
+
+// But not here!
+type Y1 = Keys<{ x: any } | { y: any }>;
+type Y2 = KeysConditional<{ x: any } | { y: any }>;
+```
+
+Because of the distributivity demonstrated here, it’s often unsafe to assume anything about a generic conditional type before it’s instantiated.
+
+### Distributivity schmistributivity, I’m gonna make it work
+
+Ok, fine. Let’s say you work out a way around that assignability error, and you’re ready to replace `'a' | 'button'` with all `keyof JSX.IntrinsicElements`.
+
+```tsx
+interface ButtonProps<T extends keyof JSX.IntrinsicElements> {
+ tagName: T;
+}
+
+function Button<T extends keyof JSX.IntrinsicElements>({
+ tagName: TagName,
+ ...props
+}: ButtonProps<T> & UnionToIntersection<JSX.IntrinsicElements[T]>) {
+ // @ts-ignore YOLO
+ return <TagName {...props} />;
+}
+
+<Button tagName="a" href="/" />
+```
+
+…and, congratulations, you’ve crashed TypeScript 3.4! The constraint type `keyof JSX.IntrinsicElements` is a union type of 173 keys, and the type checker will instantiate generics with their constraints to ensure all possible instantiations are safe. So that means `ButtonProps<T>` is a union of 173 object types, and, suffice it to say that `UnionToIntersection<...>` is one conditional type wrapped in another, one of which distributes into another union of 173 types upon which type inference is invoked. Long story short, you’ve just invented a button that cannot be reasoned about within Node’s default heap size. And we never even got around to supporting `<Button tagName={Link} />`!
+
+TypeScript 3.5 _does_ handle this without crashing by deferring a lot of the work that was happening to simplify conditional types, but do you _really_ want to write components that are just waiting for the right moment to explode?
+
+> If you followed me this far down the rabbit hole, I’m duly impressed. I spent weeks getting here, and it only took you ten minutes!
+
+
+
+## An alternative approach
+
+As we go back to the drawing board, let’s refresh on what we’re actually trying to accomplish. Our Button component should:
+
+* be able to accept arbitrary props like `onKeyDown` and `aria-describedby`
+* be able to render as a `button`, an `a` with an `href` prop, or a `Link` with a `to` prop
+* ensure that the root element has all the props it requires, and none that it doesn’t support
+* not crash TypeScript or bring your favorite code editor to a screeching halt
+
+It turns out that we can accomplish all of these with a render prop. I propose naming it `renderContainer` and giving it a sensible default:
+
+```tsx
+interface ButtonInjectedProps {
+ className: string;
+ children: JSX.Element;
+}
+
+interface ButtonProps {
+ color?: ColorName;
+ icon?: IconName;
+ className?: string;
+ renderContainer: (props: ButtonInjectedProps) => JSX.Element;
+ children?: React.ReactChildren;
+}
+
+function Button({ color, icon, children, className, renderContainer }: ButtonProps) {
+ return renderContainer({
+ className: getClassName(color, className),
+ children: (
+ <FlexContainer>
+ {icon && <Icon name={icon} />}
+ <div>{children}</div>
+ </FlexContainer>
+ ),
+ });
+}
+
+const defaultProps: Pick<ButtonProps, 'renderContainer'> = {
+ renderContainer: props => <button {...props} />
+};
+Button.defaultProps = defaultProps;
+```
+
+Let’s try it out:
+
+```tsx
+// Easy defaults
+<Button />
+
+// Renders a Link, enforces `to` prop set
+<Button
+ renderContainer={props => <Link {...props} to="/" />}
+/>
+
+// Renders an anchor, accepts `href` prop
+<Button
+ renderContainer={props => <a {...props} href="/" />}
+/>
+
+// Renders a button with `aria-describedby`
+<Button
+ renderContainer={props =>
+ <button {...props} aria-describedby="tooltip-1" />}
+/>
+```
+
+We completely defused the type bomb by getting rid of the 173-constituent union `keyof JSX.IntrinsicElements` while simultaneously allowing even more flexibility, _and_ it’s perfectly type-safe. Mission accomplished. 🎉
+
+## The overwritten prop caveat
+There’s a small cost to an API design like this. It’s fairly easy to make a mistake like this:
+
+```tsx
+<Button
+ color={ColorName.Blue}
+ renderContainer={props =>
+ <button {...props} className="my-custom-button" />}
+/>
+```
+
+Oops. `{...props}` already included a `className`, which was needed to make the Button look nice and be blue, and here we’ve completely overwritten that class with `my-custom-button`.
+
+On one hand, this provides the ultimate degree of customizability—the consumer has total control over what does and doesn’t go onto the container, allowing for fine-grained customizations that weren’t possible before. But on the other hand, you probably wanted to merge those classes 99% of the time, and it might not be obvious why it appears visually broken in this case.
+
+Depending on the complexity of the component, who your consumers are, and how solid your documentation is, this may or may not be a serious problem. When I started using patterns like this in my own work, I wrote a [small utility](https://github.com/andrewbranch/merge-props) to help with the ergonomics of merging injected and additional props:
+
+```tsx
+<Button
+ color={ColorName.Blue}
+ renderContainer={props =>
+ <button {...mergeProps(props, {
+ className: 'my-custom-button',
+ onKeyDown: () => console.log('keydown'),
+ })} />}
+/>
+```
+
+This ensures the class names are merged correctly, and if `ButtonInjectedProps` ever expands its definition to inject its own `onKeyDown`, both the injected one and the console-logging one provided here will be run.
+
+- [^1]:
+ You can discover this, if you want, by going into the React typings and commenting out [the `ref` property](https://github.com/DefinitelyTyped/DefinitelyTyped/blob/86303f134e12cf701a3f3f5e24867c3559351ea2/types/react/index.d.ts#L97). The compiler error will remain, substituting `onCopy` where it previously said `ref`.
+- [^2]:
+ I attempt to explain this relationship intuitively, but it arises from the fact that parameters are _contravariant_ positions within function signatures. There are several [good](https://www.typescriptlang.org/docs/handbook/release-notes/typescript-2-6.html) [explanations](https://www.stephanboyer.com/post/132/what-are-covariance-and-contravariance) of this topic.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/rel-noopener.md b/TODO1/rel-noopener.md
new file mode 100644
index 00000000000..8f5efff85ad
--- /dev/null
+++ b/TODO1/rel-noopener.md
@@ -0,0 +1,71 @@
+> * 原文地址:[About `rel=noopener`](https://mathiasbynens.github.io/rel-noopener/)
+> * 原文作者:[mathias](https://twitter.com/mathias)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/rel-noopener.md](https://github.com/xitu/gold-miner/blob/master/TODO1/rel-noopener.md)
+> * 译者:
+> * 校对者:
+
+# About `rel=noopener`
+
+## What problems does it solve?
+
+You’re currently viewing `index.html`.
+
+Imagine the following is user-generated content on your website:
+
+[**Click me!!1 (same-origin)**](malicious.html)
+
+Clicking the above link opens `malicious.html` in a new tab (using `target=_blank`). By itself, that’s not very exciting.
+
+However, the `malicious.html` document in this new tab has a `window.opener` which points to the `window` of the HTML document you’re viewing right now, i.e. `index.html`.
+
+This means that once the user clicks the link, `malicious.html` has full control over this document’s `window` object!
+
+Note that this also works when `index.html` and `malicious.html` are on different origins — `window.opener.location` is accessible across origins! (Things like `window.opener.document` are not accessible cross-origin, though; and [CORS](https://fetch.spec.whatwg.org/#http-cors-protocol) does not apply here.) Here’s an example with a cross-origin link:
+
+[**Click me!!1 (cross-origin)**](https://mathiasbynens.be/demo/opener)
+
+In this proof of concept, `malicious.html` replaces the tab containing `index.html` with `index.html#hax`, which displays a hidden message. This is a relatively harmless example, but instead it could’ve redirected to a phishing page, designed to look like the real `index.html`, asking for login credentials. The user likely wouldn’t notice this, because the focus is on the malicious page in the new window while the redirect happens in the background. This attack could be made even more subtle by adding a delay before redirecting to the phishing page in the background (see [**tab nabbing**](http://www.azarask.in/blog/post/a-new-type-of-phishing-attack/)).
+
+TL;DR If `window.opener` is set, a page can trigger a navigation in the opener regardless of security origin.
+
+## Recommendations
+
+To prevent pages from abusing `window.opener`, use [`rel=noopener`](https://html.spec.whatwg.org/multipage/semantics.html#link-type-noopener). This ensures `window.opener` is `null` in [Chrome 49 & Opera 36](https://dev.opera.com/blog/opera-36/#a-relnoopener "What’s new in Chromium 49 and Opera 36"), Firefox 52, Desktop Safari 10.1+, and iOS Safari 10.3+.
+
+[**Click me!!1 (now with `rel=noopener`)**](malicious.html)
+
+For older browsers, you could use [`rel=noreferrer`](https://html.spec.whatwg.org/multipage/semantics.html#link-type-noreferrer) which also disables the `Referer` HTTP header, or the following JavaScript work-around which potentially triggers the popup blocker:
+
+```
+var otherWindow = window.open();
+otherWindow.opener = null;
+otherWindow.location = url;
+```
+
+[**Click me!!1 (now with `rel=noreferrer`-based workaround)**](malicious.html) [**Click me!!1 (now with `window.open()`-based workaround)**](malicious.html)
+
+Note that [the JavaScript-based work-around fails in Safari](https://github.com/danielstjules/blankshield#solutions). For Safari support, inject a hidden `iframe` that opens the new tab, and then immediately remove the `iframe`.
+
+Don’t use `target=_blank` (or any other `target` that opens a new navigation context), **especially for links in user-generated content**, unless you have [a good reason to](https://css-tricks.com/use-target_blank/).
+
+## Notes
+
+In [Safari Technology Preview 68](https://webkit.org/blog/8475/release-notes-for-safari-technology-preview-68/), `target="_blank"` on anchors implies `rel="noopener"`. To explicitly opt-in to having `window.opener` be present, use `rel="opener"`. An attempt is being made to [standardize this](https://github.com/whatwg/html/issues/4078).
+
+## Bug tickets to follow
+
+* [Gecko/Firefox bug #1222516](https://bugzilla.mozilla.org/show_bug.cgi?id=1222516) fixed
+* [WebKit/Safari bug #155166](https://bugs.webkit.org/show_bug.cgi?id=155166) fixed
+* [Microsoft Edge feature request](https://wpdev.uservoice.com/forums/257854-microsoft-edge-developer/suggestions/12942405-implement-rel-noopener)
+* [Chromium/Chrome/Opera bug #168988](https://bugs.chromium.org/p/chromium/issues/detail?id=168988) fixed
+
+---
+
+Questions? Feedback? Tweet [@mathias](https://twitter.com/mathias). if (location.search) { // https://news.ycombinator.com/item?id=11553740 location = document.querySelector('link\[rel="canonical"\]').href; }
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/separation-of-data-and-ui-in-your-web-app.md b/TODO1/separation-of-data-and-ui-in-your-web-app.md
new file mode 100644
index 00000000000..65e2a23b3fb
--- /dev/null
+++ b/TODO1/separation-of-data-and-ui-in-your-web-app.md
@@ -0,0 +1,94 @@
+> * 原文地址:[Separation of Data and Ui in your Web App](https://medium.com/front-end-weekly/separation-of-data-and-ui-in-your-web-app-2c3f1cc3fbda)
+> * 原文作者:[Georgy Glezer](https://medium.com/@georgyglezer)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/separation-of-data-and-ui-in-your-web-app.md](https://github.com/xitu/gold-miner/blob/master/TODO1/separation-of-data-and-ui-in-your-web-app.md)
+> * 译者:[fireairforce](https://github.com/fireairforce)
+> * 校对者:[Roc](https://github.com/QinRoc)
+
+# Web 应用程序中的数据和 UI 分离
+
+大家好,我是 Georgy,是 **[Bringg](http://bringg.com/)** 的一个全栈开发人员,这是我写的第一篇文章。 😅
+
+今天我想重点介绍一下在构建 web 应用程序时数据和 UI 分离的概念,它是怎样帮助你构建更清晰、更易于维护和更出色的 web 应用程序,以及我如何用 4 个不同的 UI/框架库呈现相同内容的一个小例子。😄
+
+通常在任意的 web 应用程序中,都有两个主要部分:
+
+* 数据
+* UI
+
+因此,你可以选择一个框架/UI 库,比如 React、Angular、Vue 等等,然后决定使用什么状态管理器,或者在没有状态管理器的情况下如何管理你的数据。
+
+你开始写你的第一个功能,以一个用户列表为例,你有一个复选框来选择用户,然后你需要决定在哪里保存你当前选择的用户。
+
+> 你是将它们保存在 React 组件的 state 里?或者把它们放在你的 redux store 里?亦或者是把它们放在你的 Angular 服务或 controller 里?
+> 被选择的用户是否与你的数据有关?或者只是纯粹的视图指示器?
+
+好的,我将和你分享编写功能的思路或想法,通过上面的例子,让你能更清晰地分离数据和 UI。
+
+用户是我们应用程序中的数据,我们可以添加用户、修改用户数据、删除用户、从我们拥有的用户中获取诸如谁在线和用户总数之类的信息。
+
+当我们显示一个用户列表时,我们只是以一种对用户更可见的方式来展示我们的数据,就像一个供用户查看的列表一样。我们允许他选择用户和取消选择用户,这只是视图的当前状态,页面上被选择的用户和数据没有任何关系,应该分离开。
+
+通过这种分离,我们将 JavaScript 应用程序开发为纯 JavaScript 应用程序,然后选择我们想要表示数据的方式。这可以让我们获得最大的灵活性,比如在不同的地方使用不同的 UI 库,这组组件我想用 react 来表示,其它一些组件我想用 web 组件来表示,现在通过这种分离,我可以很容易实现这个想法。
+
+> # 下面是我为展示这个概念而制作的一个示例:
+
+我选择 [MobX](https://github.com/mobxjs/mobx) 来管理我的应用程序中的状态,并帮助我进行跨不同框架/UI 库的渲染。它具有出色的反应系统,可让你自动响应所需的事件。
+
+我这里的 model 是 **Template**,它只有一个名称和 setter(MobX action), 我在项目中保存了一个所有模板的列表,我用一个 `TemplateList` 来保存它,这是我全部的**数据**了。
+
+
+
+
+
+我的程序已经可以作为 JavaScript 应用程序运行了,我可以添加模板并更新它的文本,但我仍然没有它的 UI,让我们添加 React 来作为第一个 UI。
+
+对于 React,我使用了 **[mobx-react](https://github.com/mobxjs/mobx-react)**,它是一个连接 MobX 的库,并使用其功能在 react 中渲染。
+
+
+
+然后我选择另一个库,Vue JS。我保持几乎相同的 Html 和 CSS 类,只是用 Vue 来进行渲染。
+
+我使用 MobX `autorun`(https://mobx.js.org/refguide/autorun.html) 并在每次添加或删除新模板时重新渲染视图。
+
+
+
+现在,我们有了另一个 UI,它使用不同的库来渲染,但是基于相同的数据存储,而不需额外改变一行应用程序数据管理代码。
+
+
+
+因此现在屏幕有了更多的空间,我们还需要选择 2 个其它的库,这次我们选择 AngularJS。
+
+AngularJS 的渲染有点烦人,因为它的 `ng-model` 把模型搞乱了,所以我不得不把模板的文本保存在一个对象中,然后在新模板上重新渲染。
+
+
+
+
+
+最后一个库,我决定选择 [Preact](https://preactjs.com),它和 React 很相似,在这里,我还是用 `autorun` 来更新 UI。
+
+
+
+在这里,我还必须在每次更改时更新模板本身(类似于 mobx-react 所做的)。
+
+
+
+现在我们有 4 个不同的 UI/框架库,在同一个屏幕上显示相同的数据。
+
+
+
+我真的很喜欢这种分离,它使代码更加清晰,因为它只需要管理 UI 状态,甚至只需要表示数据,它使得代码更易于维护和扩展。
+
+希望你喜欢这个概念,如果有人有任何问题或想要讨论,或给我任何改进的意见,欢迎通过 [Facebook](https://www.facebook.com/gglezer) 或邮件 stolenng@gmail.com 与我交流。
+
+以下是仓库和网站的链接:
+
+[**stolenng/mobx-cross-data-example**](https://github.com/stolenng/mobx-cross-data-example)
+
+[http://mobx-cross-data.georgy-glezer.com/](http://mobx-cross-data.georgy-glezer.com/)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/should-you-learn-vim-as-a-developer-in-2020.md b/TODO1/should-you-learn-vim-as-a-developer-in-2020.md
new file mode 100644
index 00000000000..a3dc8b0ae64
--- /dev/null
+++ b/TODO1/should-you-learn-vim-as-a-developer-in-2020.md
@@ -0,0 +1,58 @@
+> * 原文地址:[Should You Learn VIM as a Developer in 2020?](https://medium.com/better-programming/should-you-learn-vim-as-a-developer-in-2020-75fde02c5443)
+> * 原文作者:[Joey Colon](https://medium.com/@joey_colon)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/should-you-learn-vim-as-a-developer-in-2020.md](https://github.com/xitu/gold-miner/blob/master/TODO1/should-you-learn-vim-as-a-developer-in-2020.md)
+> * 译者:[chaingangway](https://github.com/chaingangway)
+> * 校对者:[IAMSHENSH](https://github.com/IAMSHENSH)、[QinRoc](https://github.com/QinRoc)、[Amberlin1970](https://github.com/Amberlin1970)
+
+# 作为 2020 年的开发者,你应该学习 VIM 吗?
+
+on [Unsplash](http://unsplash.com)](https://cdn-images-1.medium.com/max/2000/1*6RF4SWv3nDsFlX1vDzc8Nw.jpeg)
+
+## 开场白
+
+关于使用什么文本编辑器,哪一种 shell 和哪一类操作系统一直是开发者热衷于讨论的话题。我们知道,肯定有人很热衷于 VIM。遗憾的是,这篇文章不打算赞美 VIM,而是来讨论我为什么决定学习 VIM,它能为我解决什么问题,不能为我解决什么问题,以及最重要的:你应不应该学习 VIM?
+
+下文中我会对我的编程背景做一个简要介绍。大概在 2018 年末,我决定把编程作为职业后,就开始认真对待编程。在这之前,我经常为我玩的各种游戏创建(相当糟糕的)脚本,同时也把运行一些网站或游戏服务器作为副业。自从把编程作为事业之后,我涉猎了几种语言,其中在 JavaScript 的生态中我做了很多事情。介绍结束,我们来开始正文吧!
+
+
+
+## VIM 没有为我解决的问题
+
+VIM 没有让我变成更优秀的软件工程师。我要重申一遍:学习 VIM 不会让你变成更优秀的软件工程师。核心意思是,软件工程与你开发所使用的 shell、编辑器或者操作系统无关。我相信肯定有很多人会有这样的观点:为了让你变成一个“优秀”的软件工程师,你需要使用 X 或者 Y。
+
+作为这个行业的新人,我发现这种普遍的“要么不做,要么破产”的心态是畏缩者和精英主义者所有的。我们都是在为复杂问题创造解决方案。而用于解决方案的工具,不会让你成为更好的或者更差的开发者。
+
+## 我为什么决定学习 VIM
+
+#### 建立习惯
+
+既然我是一个相对比较萌新的程序员,我在很多领域有提升的空间,工作流绝对是其中之一。在学习 VIM 之前,我是一个连快捷键都不会设置的人。我非常依赖于鼠标。在 VIM 给我洗脑时,“让手专注于键盘”这个观点吸引了我,因为我打字一直很快。我的潜意识里告诉我,学习 VIM 不会造成任何负面影响。
+
+#### 无限潜能
+
+在纠结应不应该学 VIM 时,我看了一个关于它的科技讨论,唯一能获得的要点是,人们用 VIM 很多年了,现在还能在这个工具上进行改进。
+
+这个观点提示了我很多事情。首先,学会 VIM 需要投资巨多的时间,但更重要的是,你总是在想办法提高你的技能。作为一个萌新的开发者,我想同步我的努力。这是我之前观点的重申,当我把不同的工具(本例中的 VIM )整合进我的开发工作流中,我就有一石二鸟的能力了。
+
+#### 在 Linux 服务器上,我再也不需要 nano
+
+这句话有点传闻的味道,说这句话的人,在 Linux 远程环境下,远程运营了很多年的网站和服务器,他肯定不知道 VIM 确实很烦人。如果要为正在运行的服务修改配置文件,我得安装 nano,因为我对 VIM 的认知是用 `:q!` 来操作。
+
+## 我的工作环境
+
+日常工作中,我在 VSCode 上设置了 VIM 的插件。我曾经尝试安装过像 coc.nvim 这样的插件,以便直接用终端进行开发,但是这些都不是我的菜。我一直很喜欢在 VSCode 上写代码的体验。使用 VSCode 上的 VIM 插件提供了与运行 VIM 同样的体验,除此之外,我还能获得 VSCode 生态圈提供的好处。对于我来说,使用这个设置两全其美。
+
+## 总结
+
+你应该学习 VIM 吗?如果你没有任何使用快捷键的习惯,我觉得你至少需要试一下。我过去没有设置“舒服”的热键或者工作流的情况,让学习 VIM 对我充满了吸引力。学完 VIM 之后,我可以说我获得了只有自己才能构建的新的基础知识。
+
+浏览 VIM 的教程(Vimtutor)大概花了我两周的时间,然后我才适应 VSCode 上的 VIM 插件。之后,又花了我另外一周的开发时间,通过肌肉记忆建立用快捷键浏览代码的习惯。这种方式现在看来,我是在用两种方式写代码。学会 VIM 让我的时间更有价值。
+
+但是,我想重申,程序员最终还是为难题创造解决方案的。你想用哪一种快捷键方案、编辑器或者其他的东西,完全基于你的偏好。你编辑文件的速度往往不是你开发工作的瓶颈。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/stop-using-everywhere.md b/TODO1/stop-using-everywhere.md
new file mode 100644
index 00000000000..6a5573f871e
--- /dev/null
+++ b/TODO1/stop-using-everywhere.md
@@ -0,0 +1,255 @@
+> * 原文地址:[Stop Using === Everywhere](https://medium.com/better-programming/stop-using-everywhere-fd025342132d)
+> * 原文作者:[Seifeldin Mahjoub](https://medium.com/@seif.sayed)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/stop-using-everywhere.md](https://github.com/xitu/gold-miner/blob/master/TODO1/stop-using-everywhere.md)
+> * 译者:[Zavier](https://github.com/zaviertang)
+> * 校对者:[Chorer](https://github.com/Chorer)、[Long Xiong](https://github.com/xionglong58)
+
+# 停止在任何地方使用 `===`
+
+#### 这是一个不同寻常的观点,让我们来探讨一下吧!
+
+ on [Unsplash](https://unsplash.com/s/photos/stop?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/8480/1*ofXvrzbMMofNyhgXuY7dYw.jpeg)
+
+大多数的开发者总是更青睐于使用 `===` 来代替 `==`,这是为什么呢?
+
+我在网上看到的大多数教程都是认为:JavaScript 的强制转换机制太复杂而不能正确地预知结果,所以建议使用 `===`。
+
+网上不少教程提出的信息和观点都是错误的。除此之外,许多 lint 规则和知名网站也固执地偏好于使用 `===`。
+
+这些都导致很多程序员不把它当作语法的一部分去深入理解它,而只是把它当作一个语法缺陷。
+
+这里我会举两个使用 `==` 的例子,来支持我的观点。
+
+---
+
+## 1. 空值判断
+
+```JavaScript
+if (x == null)
+
+vs
+
+if (x === undefined || x === null)
+```
+
+---
+
+## 2. 读取用户输入
+
+```JavaScript
+let userInput = document.getElementById('amount');
+let amount = 999;
+if (amount == userInput)
+vs
+if (amout === Number(userInput))
+```
+
+在这篇文章中,我们将会通过一些常见的例子,来深入分析它们的区别、理解强制转换机制,最终形成一个指导方案来帮助我们决定是使用 `===` 还是 `==`。
+
+---
+
+## 介绍
+
+在 JavaScript 中,有两种操作符可以帮助我们进行相等判断。
+
+1. `=== ` —— 严格相等操作符(三等号)。
+2. `==` —— 标准相等操作符(双等号)。
+
+我一直在使用 `===`,因为我被告知,它比 `==` 更好、更优越。我根本不需要去考虑原因,作为一个懒惰的人,我觉得很方便。
+
+直到我看了[《你不知道的 JS》](https://github.com/getify/You-Dont-Know-JS)的作者 [Kyle](https://medium.com/@getify)(Twitter:[@getfiy](https://twitter.com/getify))在 [Frontend Masters](https://medium.com/@FrontendMasters) 上写的文章“Deep JavaScript Foundations”。
+
+作为一名专业的程序员,我没有深入思考我每天工作中使用的这些操作符,这一事实激励着我去传播相关意识以及鼓励人们更多地去深入理解并关注我们自己编写的代码。
+
+---
+
+## 阅读文档
+
+知道答案在哪里也许是重要的。它不在 Mozilla 的网站上,不在 W3schools 网站上,也不在那些声称 `=== ` 比 `==` 更好的文章中,当然它也不在这篇文章中。
+
+它在 **JavaScript 规范** 中,那里有关于 JavaScript 如何工作的文档。[**ECMAScript®2020语言规范**](https://tc39.es/ecma262/#sec-abstract-equalcomparison)
+
+---
+
+## 纠正认知
+
+#### 1. == 只做值的判断 (宽松的)
+
+如果我们看一下文档,从定义上就可以清楚地看到,`==` 做的第一件事实际上是类型检查。
+
+
+
+#### 2. === 同时检查类型和值 (严格的)
+
+在这里,我们同样可以看到,`===` 先检查类型,如果类型不同,则根本不检查值是否相同。
+
+
+
+所以,双等号 `==` 和三重等号 `===` 的区别在于我们是否允许强制转换。
+
+---
+
+## JavaScript 强制类型转换
+
+强制类型转换是任何编程语言的基础之一。对于动态类型语言(如 JavaScript),这更为重要,因为如果类型发生了变化,编译器并不会报错。
+
+理解强制转换意味着我们能够去解释 JavaScript 代码的运行原理,因此,为我们提供了更多的可扩展性和更少的错误。
+
+#### 显式转换
+
+类型转换可以在调用下面其中一种方法时显式地发生,从而强制改变变量的类型:
+
+`Boolean()`, `Number()`, `BigInt()`, `String()`, `Object()`
+
+例如:
+
+```JavaScript
+let x = 'foo';
+
+typeof x // string
+
+x = Boolean('foo')
+
+typeof x // boolean
+```
+
+#### 隐式转换
+
+在 JavaScript 中,变量是弱类型的,所以这意味着它们可以自动转换(隐式转换)。比如我们在当前上下文中使用算术运算 `+ / - *` 时,或者是使用 `==` 时。
+
+```JavaScript
+2 / '3' // '3' coerced to 3
+new Date() + 1 // coerced to a string of date that ends with 1
+if(x) // x is coerced to boolean
+1 == true // true coerced to number 1
+1 == 'true' // 'true' coreced to NaN
+`this ${variable} will be coreced to string`
+```
+
+隐式转换是一把双刃剑,合理使用可以增加代码的可读性,减少冗长。如果使用不当或被误解,人们经常会咆哮并指责这是 JavaScript 语法缺陷。
+
+---
+
+## 相等判断算法
+
+#### 标准相等操作符 ==
+
+1. 如果 X 和 Y 类型相同 —— 执行 `===`;
+2. 如果 X 和 Y 一个是 `null` 一个是 `undefined` —— 返回`true`;
+3. 如果一个是 number 类型,则把另一个也强制转换为 number 类型;
+4. 如果一个是对象,则强制转换为原始类型;
+5. 其它情况,返回 `false`。
+
+#### 严格相等操作符 ===
+
+1. 类型不同 —— 返回`false`;
+2. 类型相同 —— 比较值是否相同(都为 `NaN` 时返回 `false`);
+3. `-0 === +0` —— 返回`true`。
+
+---
+
+## 常见例子
+
+#### 1. 类型相同 (大多数情况)
+
+如果类型相同,则 `===` 与 `==` **完全相同**。因此,您应该使用语义性更强的那个。
+
+```JavaScript
+1 == 1 // true ...... 1 === 1 // true
+
+'foo' == 'foo' // true ...... 'foo' === 'foo' //true
+```
+
+“我更喜欢使用 `===`,以防类型不同。”
+
+这不是一个逻辑上的错误,它就像我们会按两次保存按钮,不断地刷新网页。但是,为了以防万一,我们并不会在代码中重复调用同一个方法,不是吗?
+
+#### 2. 类型不同 (常见的)
+
+首先,我想提醒大家,不同的类型**并不意味着未知的**类型。
+
+不知道变量的类型说明您的代码中有一个比使用 `===` 还是 `==` 更严重的问题。
+
+了解变量的类型会对代码有更深入的理解,这将帮助您减少错误和开发更可靠的程序。
+
+在我们有几种可能类型的情况下,通过理解强制转换机制,我们可以选择是否进行强制转换,进而决定使用 `===` 还是 `==`。
+
+假设可能是 `number` 或者 `string` 类型。
+
+请记住,这个算法更愿意比较 `number` 类型,因此它将尝试使用 [`toNumber()`](https://tc39.es/ecma262/#sec-tonumber) 方法。
+
+```JavaScript
+let foo = 2;
+let bar = 32; // number 或者 string
+
+foo == bar // 如果 bar 是 string 类型,它将会被强制转换为 number 类型。
+
+foo === Number(bar) // 原理类似
+
+foo === bar // 如果 bar 是 string 类型,则总是返回 false
+```
+
+#### 3. null 和 undefined
+
+当使用 `==` 时,`null` 和 `undefined` 是相等的。
+
+```JavaScript
+let foo = null
+let bar = undefined;
+
+foo == bar // true
+
+foo === bar // false
+```
+
+#### 4. 非原始类型 [Objects, Arrays]
+
+不应该使用 `==` 或 `===` 来比较对象和数组等非原始类型。
+
+---
+
+## 指导方案
+
+1. 能使用 `==` 时尽量使用 `==`;
+2. 知道变量类型时,或者您需要转换变量类型时,使用 `==`;
+3. 知道变量类型总比不知道好;
+4. 不知道变量类型时不要使用 `==`;
+5. 知道变量的类型时,`==` 和 `===` 就是一样的;
+6. 当类型不相同时,使用 `===` 是无意义的;
+7. 而当类型相同时,使用 `===` 是没必要的;
+
+---
+
+## 避免使用 `==` 的情况
+
+在没有真正理解 JavaScript 中 `falsy` 值之前,某些情况下应避免使用 `==`。
+
+```JavaScript
+== 后面是 0 或者 "" 或者 " "
+
+== 后面是非原始类型
+
+== true 或者 == false
+```
+
+---
+
+## 总结
+
+根据我的经验,到目前为止,我编码时总是会知道要处理的变量的类型,如果不知道,我就使用 `typeof` 来判断。
+
+以下是给看到文末的读者最后的 4 点建议:
+
+1. 如果您无法知道变量的类型,那么使用 `===` 是唯一合理的选择;
+2. 不知道变量的类型可能意味着您不够理解代码,也许您需要重构;
+3. 了解变量的类型有助于编写出更好的程序;
+4. 如果变量的类型已知,则最好使用 `==`,否则只能使用 `===`。
+
+感谢您的阅读,我希望这篇文章能够帮助您加深对 JavaScript 的理解。我建议您可以去看看**你不知道的 JS** 系列,因为它对 JavaScript 这门语言有很深度的分析。[**You-Dont-Know-JS**](https://github.com/getify/You-Dont-Know-JS)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/swiftui-3d-scroll-effect.md b/TODO1/swiftui-3d-scroll-effect.md
new file mode 100644
index 00000000000..59364454984
--- /dev/null
+++ b/TODO1/swiftui-3d-scroll-effect.md
@@ -0,0 +1,162 @@
+> * 原文地址:[SwiftUI 3D Scroll Effect](https://levelup.gitconnected.com/swiftui-3d-scroll-effect-fa5310665738)
+> * 原文作者:[Jean-Marc Boullianne](https://medium.com/@jboullianne)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/swiftui-3d-scroll-effect.md](https://github.com/xitu/gold-miner/blob/master/TODO1/swiftui-3d-scroll-effect.md)
+> * 译者:
+> * 校对者:
+
+# SwiftUI 3D Scroll Effect
+
+
+
+Here’s a look at the kind of 3D scroll effect we’ll be making today. At the end of this tutorial, you’ll be able to add this 3D effect to any custom SwiftUI view in your app. Let’s get started!
+
+## Getting Started
+
+Start by creating a new SwiftUI View. For example purposes, I’ll be showing a list of rectangles in different colors, so I named my view `ColorList`.
+
+```swift
+import SwiftUI
+
+struct ColorList: View {
+ var body: some View {
+ Text("Hello, World!")
+ }
+}
+
+struct ColorList_Previews: PreviewProvider {
+ static var previews: some View {
+ ColorList()
+ }
+}
+```
+
+## Color Data
+
+At the top of your view struct, add a variable for keeping track of colors.
+
+```swift
+var colors: [Colors]
+```
+
+## Making the List
+
+Inside your `body` variable, get rid of the placeholder `Text`. Add in a `HStack` wrapping in a `ScrollView` like this.
+
+```swift
+var body: some View {
+ ScrollView(.horizontal, showsIndicators: false) {
+ HStack(alignment: .center, spacing: 50) {
+
+ }
+ }
+}
+```
+
+## Show the Rectangles
+
+Inside your `HStack` we need to show a `Rectangle` for each color stored in `colors`. For this we'll use a `ForEach`. I've gone ahead and modified the frame for the rectangle to something more relatable to a traditional UI Card.
+
+```swift
+var body: some View {
+ ScrollView(.horizontal, showsIndicators: false) {
+ HStack(alignment: .center, spacing: 20) {
+ ForEach(colors, id: \.self) { color in
+ Rectangle()
+ .foregroundColor(color)
+ .frame(width: 200, height: 300, alignment: .center)
+ }
+ }
+ }
+}
+```
+
+And if you go ahead and provide the preview struct with a list of colors like this:
+
+```swift
+struct ColorList_Previews: PreviewProvider {
+ static var previews: some View {
+ ColorList(colors: [.blue, .green, .orange, .red, .gray, .pink, .yellow])
+ }
+}
+```
+
+You should see this!
+
+
+
+## Adding the 3D Effect
+
+Start by wrapping your `Rectangle` in a `GeometryReader`. This will allow us to grab a reference to the frame of the `Rectangle` as it moves across the screen.
+
+```swift
+var body: some View {
+ ScrollView(.horizontal, showsIndicators: false) {
+ HStack(alignment: .center, spacing: 230) {
+ ForEach(colors, id: \.self) { color in
+ GeometryReader { geometry in
+ Rectangle()
+ .foregroundColor(color)
+ .frame(width: 200, height: 300, alignment: .center)
+ }
+ }
+ }
+ }
+}
+```
+
+You will need to change the `HStack` spacing you defined above, due to the way `GeometryReader` works.
+
+Then add this line to your `Rectangle`
+
+```swift
+.rotation3DEffect(Angle(degrees: (Double(geometry.frame(in: .global).minX) - 210) / -20), axis: (x: 0, y: 1.0, z: 0))
+```
+
+The `Angle` you're passing into the function is changing as the `Rectangle` moves across the screen. Take a particular look at the `.frame(in:)` function. It allows you to grab the `CGRect` of the `Rectangle` and uses its `minX` coordinate for angle calculations.
+
+The `axis` parameter is a Tuple that details which axis to modify using the angle you just passed in. In this case it's the Y-axis.
+
+> The documentation for the rotation3DEffect() can be found [here](https://developer.apple.com/documentation/swiftui/scrollview/3287538-rotation3deffect) on Apple’s Official Website.
+
+If you go ahead and run the example you should see your `Rectangles` rotating as they move across the screen!
+
+> I’ve also modified the corner radius of the rectangle as well as added a drop shadow to make it look a little better.
+
+
+
+## Final Product
+
+```swift
+struct ColorList: View {
+
+ var colors:[Color]
+
+ var body: some View {
+ ScrollView(.horizontal, showsIndicators: false) {
+ HStack(alignment: .center, spacing: 230) {
+ ForEach(colors, id: \.self) { color in
+ GeometryReader { geometry in
+ Rectangle()
+ .foregroundColor(color)
+ .frame(width: 200, height: 300, alignment: .center)
+ .cornerRadius(16)
+ .shadow(color: Color.black.opacity(0.2), radius: 20, x: 0, y: 0)
+ .rotation3DEffect(Angle(degrees: (Double(geometry.frame(in: .global).minX) - 210) / -20), axis: (x: 0, y: 1.0, z: 0))
+ }
+ }
+ }.padding(.horizontal, 210)
+ }
+ }
+}
+```
+
+## That’s all Folks!
+
+If you enjoyed this post, please consider subscribing to my website using this [link](https://trailingclosure.com/signup/), and if you aren’t reading this on [TrailingClosure.com](https://trailingclosure.com/), please come check us out sometime!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/syslog-the-complete-system-administrator-guide.md b/TODO1/syslog-the-complete-system-administrator-guide.md
index fbb3b97303a..523a39e4bec 100644
--- a/TODO1/syslog-the-complete-system-administrator-guide.md
+++ b/TODO1/syslog-the-complete-system-administrator-guide.md
@@ -2,259 +2,259 @@
> * 原文作者:[Schkn](https://devconnected.com/author/schkn/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/syslog-the-complete-system-administrator-guide.md](https://github.com/xitu/gold-miner/blob/master/TODO1/syslog-the-complete-system-administrator-guide.md)
-> * 译者:
-> * 校对者:
+> * 译者:[githubmnume](https://github.com/githubmnume)
+> * 校对者:[todaycoder001](https://github.com/todaycoder001), [shixi-li](https://github.com/shixi-li), [portandbridge](https://github.com/portandbridge)
-# Syslog : The Complete System Administrator Guide
+# Syslog:系统管理员完整指南
-[](https://devconnected.com/wp-content/uploads/2019/08/syslog-featured-1.png)
+
-If you are a **system administrator**, or just a regular Linux user, there is a very high chance that you worked with **Syslog**, at least one time.
+如果你是**系统管理员**,或者只是一个普通的 Linux 用户,那么你很有可能至少使用过一次 **Syslog**。
-On your Linux system, pretty much everything related to system logging is linked to the **Syslog protocol**.
+在你的 Linux 系统上,几乎所有与系统日志相关的东西都与 **Syslog 协议**有关。
-Designed in the early 80’s by Eric Allman (from Berkeley University), the syslog protocol is a specification that defines a **standard for message logging on any system**.
+协议由埃里克·奥尔曼(伯克利大学)在 80 年代早期设计,它是一个规范,定义了**任何系统上消息记录的标准**。
-Yes.. any system.
+是的……任何系统。
-Syslog is not tied to Linux operating systems, it can also be used on Windows instances, or ony operating system that implements the syslog protocol.
+Syslog 并不依赖 Linux 操作系统,它也可以在 Windows 操作系统上使用,或者在任何实现 syslog 协议的操作系统上使用。
-If you want to know more about syslog and about Linux logging in general, this is probably the tutorial that you should read.
+如果你想更多地了解 syslog 和通常的 Linux 日志记录,这可能是你应该阅读的教程。
-**Here is everything that you need to know about Syslog.**
+**以下是你需要了解的关于 syslog 的所有信息。**
-## I – What is the purpose of Syslog?
+## I – Syslog 的目的是什么?

-**Syslog is used as a standard to produce, forward and collect logs produced on a Linux instance. Syslog defines severity levels as well as facility levels helping users having a greater understanding of logs produced on their computers. Logs can later on be analyzed and visualized on servers referred as Syslog servers.**
+**Syslog 是生成、转发和收集在 Linux 实例上生成日志的标准。Syslog 定义了严重性级别和设施级别,有助于用户更好地理解其计算机上生成的日志。日志稍后可以在部署 Syslog 协议的服务器上分析和展示。**
-Here are a few more reasons why the syslog protocol was designed in the first place:
+以下是 syslog 协议最初设计的几个原因:
-* **Defining an architecture**: this will be explained in details later on, but if syslog is a protocol, it will probably be part of a complete network architecture, with multiple clients and servers. As a consequence, we need to define roles, in short : are you going to receive, produce or relay data?
-* **Message format**: syslog defines the way messages are formatted. This obviously needs to be standardized as logs are often parsed and stored into different storage engines. As a consequence, we need to define what a syslog client would be able to produce, and what a syslog server would be able to receive;
-* **Specifying reliability**: syslog needs to define how it handles messages that can not be delivered. As part of the TCP/IP stack, syslog will obviously be opiniated on the underlying network protocol (TCP or UDP) to choose from;
-* **Dealing with authentication or message authenticity:** syslog needs a reliable way to ensure that clients and servers are talking in a secure way and that messages received are not altered.
+* **定义体系结构**:稍后将详细解释这一点,但是如果 syslog 是一个协议,它可能是具有多个客户端和服务器的完整网络体系结构的一部分。因此,我们需要定义角色,简而言之:你是接收、生成还是转发数据?
+* **消息格式**:syslog 定义了消息的格式化方式。这显然需要标准化,因为日志经常被解析并存储到不同的存储引擎中。因此,我们需要定义 syslog 客户端能够产生什么,syslog 服务器能够接收什么;
+* **指定可靠性**:syslog 需要定义它如何处理无法传递的消息。作为 TCP/IP 堆栈的一部分,syslog 显然会在底层网络协议(TCP 或 UDP)上被选择;
+* **处理身份验证或消息真实性**:syslog 需要一种可靠的方法来确保客户端和服务器以安全的方式进行交互,并且接收到的消息不会被更改。
-Now that we know why Syslog is specified in the first place, **let’s see how a Syslog architecture works.**
+现在我们知道最初为什么制定 Syslog,**让我们看看 Syslog 架构是如何工作的。**
-## II – What is Syslog architecture?
+## II – 什么是 Syslog 架构?
-When designing a logging architecture, like a centralized logging server, it is very likely that multiple instances will work together.
+当设计一个日志架构时,比如一个集中式日志服务器,很可能多个实例会一起工作。
-Some will generate log messages, and they will be called “**devices**” or “**syslog clients**“.
+有些实例将生成日志消息,它们将被称为“**设备**”或 “**syslog 客户端**”。
-Some will simply forward the messages received, they will be called “**relays**“.
+有些只是转发收到的消息,它们将被称为“**中继**”。
-Finally, there is some instances where you are going to receive and store log data, those are called “**collectors**” or “syslog servers”.
+最后,在某些情况下,你将接收和存储日志数据,这些被称为“**收集器**”或 “**syslog 服务器**”。
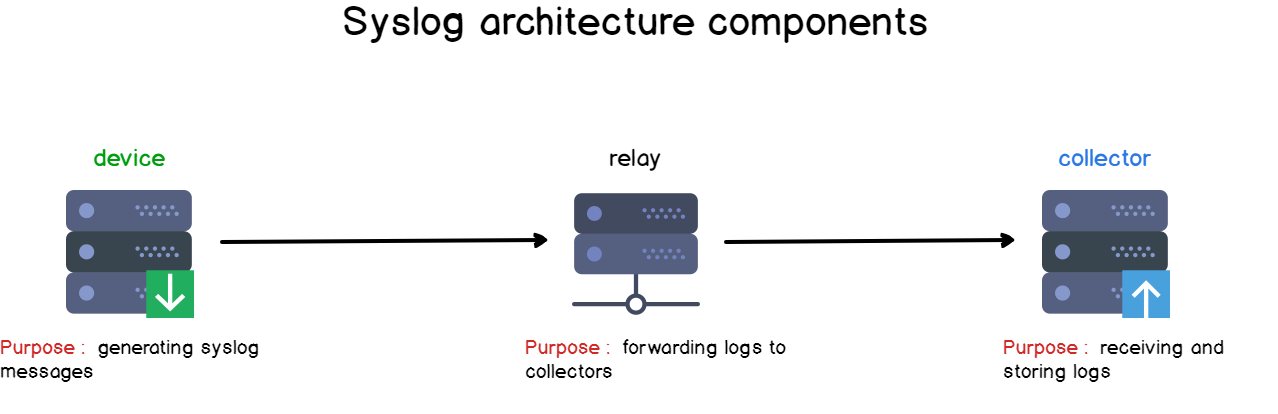
-Knowing those concepts, we can already state that a standalone Linux machine acts as a “**syslog client-server**” on its own : it **produces** log data, it is **collected** by rsyslog and stored right into the filesystem.
+了解这些概念后,我们可以说独立的 Linux 计算机本身就充当了 “**syslog 客户端 - 服务器**”:它**生成**日志数据,由 rsyslog **收集**并存储到文件系统中。
-Here’s a set of architecture examples around this principle.
+这里有一组围绕这一原则的架构示例。
-In the first design, you have one device and one collector. This is the most simple form of logging architecture out there.
+在第一种设计中,你有一个设备和一个收集器。这是最简单的日志架构形式。
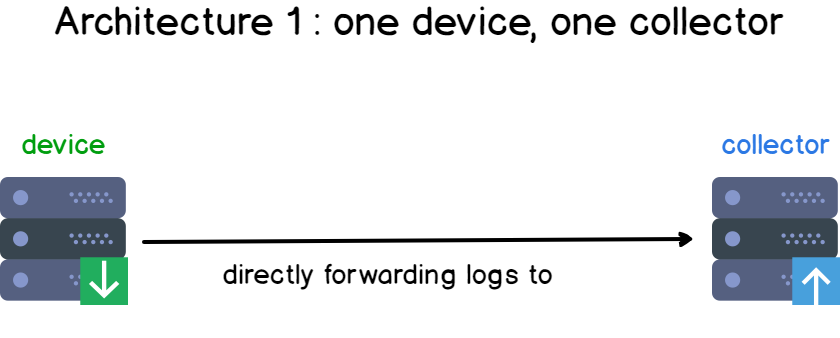
-Add a few **more clients** in your infrastructure, and you have the basis of a **centralized logging architecture.**
+在你的基础架构中添加一些**更多的客户端**,你就拥有了**集中式日志架构**的基础。
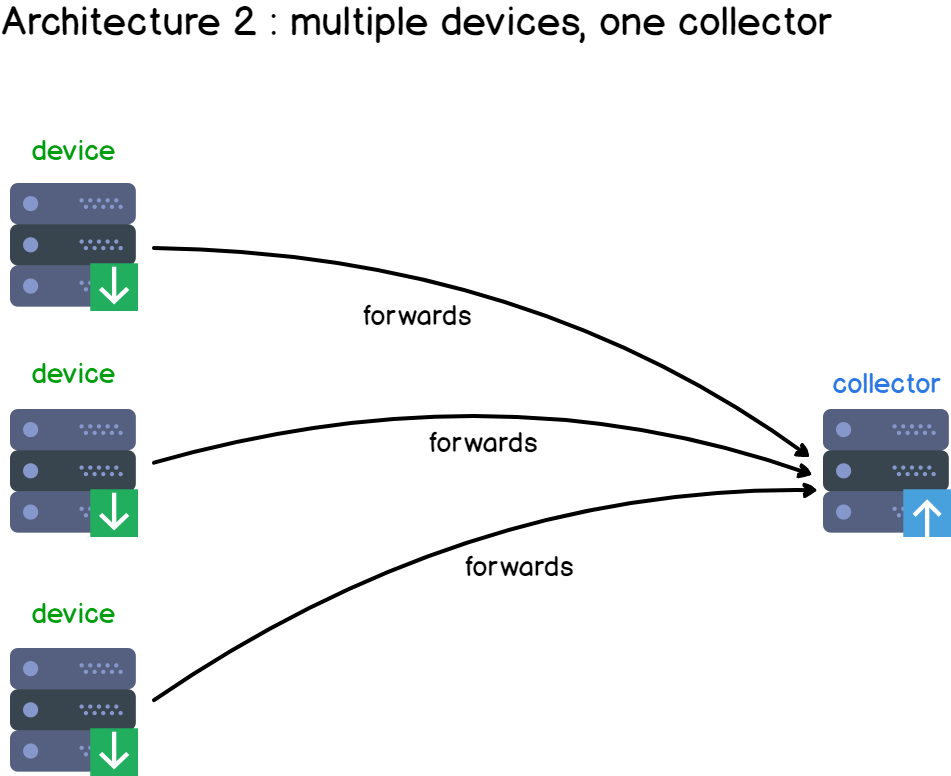
-Multiple clients are producing data and are sending it to a centralized syslog server, responsible for aggregating and storing client data.
+多个客户端正在生成数据,并将其发送到负责聚合和存储客户端数据的集中式 syslog 服务器。
-If we were to complexify our architecture, we can add a “**relay**“.
+如果我们要复杂化我们的架构,我们可以添加一个“**中继**”。
-Examples of relays could be **Logstash** instances for example, but they also could be **rsyslog rules** on the client side.
+例如,中继可以是 **Logstash** 实例,但在客户端也可以是 **rsyslog 规则**。
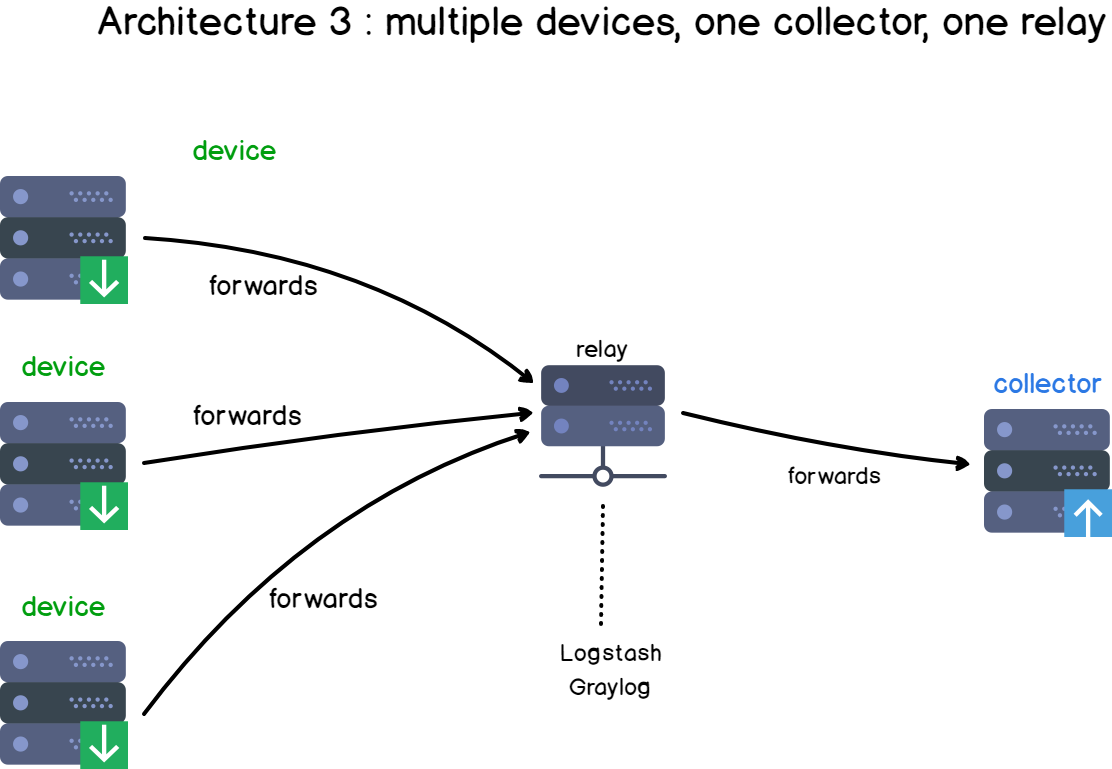
-Those relays act most of the time as “content-based routers” ([if you are not familiar with content-based routers, here is a link to understand it](https://www.enterpriseintegrationpatterns.com/patterns/messaging/ContentBasedRouter.html)).
+这些中继大多充当“基于内容的路由器”([如果你不熟悉基于内容的路由器,这里有一个链接便于你理解它](https://www.enterpriseintegrationpatterns.com/patterns/messaging/ContentBasedRouter.html))。
+这意味着基于日志内容,数据将被重定向到不同的位置。如果你对数据不感兴趣,也可以将其完全丢弃。
-It means that based on the log content, data will be redirected to different places. Data can also be completely discarded if you are not interested in it.
+现在我们已经有了详细的 Syslog 组件,让我们看看 Syslog 消息是什么样子的。
-Now that we have detailed Syslog components, let’s see what a Syslog message looks like.
+## III – Syslog 消息格式是什么?
-## III – What is Syslog message format?
+Syslog 格式分为三个部分:
-The syslog format is divided into three parts:
-
-* **PRI part**: that details the message priority levels (from a debug message to an emergency) as well as the facility levels (mail, auth, kernel);
-* **HEADER part:** composed of two fields which are the TIMESTAMP and the HOSTNAME, the hostname being the machine name that sends the log;
-* **MSG part:** this part contains the actual information about the event that happened. It is also divided into a TAG and a CONTENT field.
+* **PRI 部分**: 详细说明消息优先级(从调试消息到紧急事件)以及设施级别(邮件、授权、内核);
+* **HEADER 部分**: 由时间戳和主机名两个字段组成,主机名是发送日志的计算机名;
+* **MSG 部分**: 该部分包含发生事件的实际信息。它也分为 TAG 和 CONTENT 字段。

-Before detailing the different parts of the syslog format, let’s have a quick look at syslog severity levels as well as syslog facility levels.
+在详细描述 syslog 格式的不同部分之前,让我们快速了解 syslog 的严重性级别以及系统日志设施级别。
-### a – What are Syslog facility levels?
+### a – 什么是 Syslog 设施级别?
-In short, **a facility level** is used to determine the program or part of the system that produced the logs.
+简单来说,**设施级别**用于确定生成日志的程序或系统的一部分。
-By default, some parts of your system are given facility levels such as the kernel using the **kern facility**, or your **mailing system using the mail facility.**
+默认情况下,系统的某些部分会被赋予功能级别,例如使用 **kern 功能的内核**,或者**使用邮件功能的邮件系统。**
-If a third-party wants to issue a log, it would probably a reserved set of facility levels from 16 to 23 called “**local use” facility levels.**
+如果第三方想要记录日志,它可能会保留一组从 16 到 23 的设施级别,称为**“本地使用”设施级别**。
-Alternatively, they can use the “**user-level**” facility, meaning that they would issue logs related to the user that issued the commands.
+或者,他们可以使用“**用户级别**”工具,这意味着他们可以记录与执行命令的用户相关的日志。
-In short, if my Apache server is run by the “apache” user, then the logs would be stored under a file called “apache.log” (<user>.log)
+简而言之,如果我的 Apache 服务器由 “apache” 用户运行,那么日志将存储在一个名为 “apache.log” 的文件中(<user>.log)
-**Here are the Syslog facility levels described in a table:**
+**下表描述了 Syslog 设施级别:**
| **Numerical Code** | **Keyword** | **Facility name** |
| ------------------ | ---------------- | ----------------------- |
-| 0 | kern | Kernel messages |
-| 1 | user | User-level messages |
-| 2 | mail | Mail system |
+| 0 | kern | Kernel messages |
+| 1 | user | User-level messages |
+| 2 | mail | Mail system |
| 3 | daemon | System Daemons |
-| 4 | auth | Security messages |
+| 4 | auth | Security messages |
| 5 | syslog | Syslogd messages |
-| 6 | lpr | Line printer subsystem |
-| 7 | news | Network news subsystem |
-| 8 | uucp | UUCP subsystem |
-| 9 | cron | Clock daemon |
-| 10 | authpriv | Security messages |
-| 11 | ftp FTP | daemon |
-| 12 | ntp NTP | subsystem |
-| 13 | security | Security log audit |
-| 14 | console | Console log alerts |
+| 6 | lpr | Line printer subsystem |
+| 7 | news | Network news subsystem |
+| 8 | uucp | UUCP subsystem |
+| 9 | cron | Clock daemon |
+| 10 | authpriv | Security messages |
+| 11 | ftp FTP | daemon |
+| 12 | ntp NTP | subsystem |
+| 13 | security | Security log audit |
+| 14 | console | Console log alerts |
| 15 | solaris-cron | Scheduling logs |
-| 16-23 | local0 to local7 | Locally used facilities |
+| 16-23 | local0 to local7 | Locally used facilities |
-Do those levels sound familiar to you?
+这些级别你是不是很眼熟?
-Yes! On a Linux system, by default, files are separated by facility name, meaning that you would have a file for auth (auth.log), a file for the kernel (kern.log) and so on.
+是的!在 Linux 系统中,默认情况下,文件由设施名称分隔,这意味着你将有一个用于身份验证的文件(auth.log),一个用于内核的文件(kern.log)等等。
-Here’s a screenshot example of [my Debian 10 instance](https://devconnected.com/how-to-install-and-configure-debian-10-buster-with-gnome/).
+这是[我的 Debian 10 实例的截屏示例](https://devconnected.com/how-to-install-and-configure-debian-10-buster-with-gnome/).
-
+
-Now that we have seen syslog facility levels, let’s describe what syslog severity levels are.
+现在我们已经看到了 syslog 设施级别,让我们来描述什么是 syslog 严重性级别。
-### b – What are Syslog severity levels?
+### b – Syslog 严重性级别是什么?
-**Syslog severity levels** are used to how severe a log event is and they range from debug, informational messages to emergency levels.
+**Syslog 严重级别**用于事件的严重程度,范围从调试、信息消息到紧急级别。
-Similarly to Syslog facility levels, severity levels are divided into numerical categories ranging from 0 to 7, 0 being the **most critical emergency level**.
+与 Syslog 设施级别相似,严重性级别分为 0 到 7 的数字类别,0 是**最紧急的紧急级别**。
-**Here are the syslog severity levels described in a table:**
+**下表中描述的是 syslog 严重性级别:**
| **Value** | **Severity** | **Keyword** |
| --------- | ------------- | ------------|
-| 0 | Emergency | `emerg` |
-| 1 | Alert | `alert` |
-| 2 | Critical | `crit` |
-| 3 | Error | `err` |
-| 4 | Warning | `warning` |
-| 5 | Notice | `notice` |
-| 6 | Informational | `info` |
-| 7 | Debug | `debug` |
+| 0 | Emergency | `emerg` |
+| 1 | Alert | `alert` |
+| 2 | Critical | `crit` |
+| 3 | Error | `err` |
+| 4 | Warning | `warning` |
+| 5 | Notice | `notice` |
+| 6 | Informational | `info` |
+| 7 | Debug | `debug` |
-Even if logs are stored by facility name by default, you could totally decide to have them stored by severity levels instead.
+即使默认情况下日志是按设施名称存储的,你也可以完全按事件的严重性级别来存储它们。
-If you are using rsyslog as a default syslog server, you can check **[rsyslog properties](https://www.rsyslog.com/doc/master/configuration/properties.html)** to configure how logs are separated.
+如果你使用 rsyslog 作为默认系统日志服务器,你可以检查 **[rsyslog 属性](https://www.rsyslog.com/doc/master/configuration/properties.html)** 配置日志的分隔方式。
-Now that you know a bit more about facilities and severities, let’s go back to our **syslog message format.**
+现在你对设施和严重性有了更多的了解,让我们回到 **syslog 消息格式。**
-### c – What is the PRI part?
+### c – PRI 部分是什么?
-The PRI chunk is the first part that you will get to read on a syslog formatted message.
+PRI 块是 syslog 格式消息的第一部分。
-The PRI stores the “**Priority Value**” between angle brackets.
+PRI 在尖括号之间存储“**优先级值**”。
-> Remember the facilities and severities you just learned?
+> 还记得你刚刚学到的设施和严重程度吗?
-If you take the message facility number, multiply it by eight, and add the severity level, you get the “Priority Value” of your syslog message.
+如果你使用消息设施号,将其乘以 8,并加上严重性级别,你将获得 syslog 消息的“优先级值”。
-Remember this if you want to **decode** your syslog message in the future.
+如果你希望将来**解码**你的 syslog 消息,请记住这一点。

-### d – What is the HEADER part?
+### d – HEADER 部分是什么?
-As stated before, the HEADER part is made of two crucial information : the **TIMESTAMP** part and the **HOSTNAME** part (that can sometimes be resolved to an IP address)
+如前所述,HEADER 部分由两个关键信息组成: **TIMESTAMP** 部分和 **HOSTNAME** 部分(有时可以解析为一个 IP 地址)
-This HEADER part directly follows the PRI part, right after the right angle bracket.
+该 HEADER 部分直接连着 PRI 部分,正好在右尖括号之后。
-It is noteworthy to say that the **TIMESTAMP** part is formatted on the “**Mmm dd hh:mm:ss**” format, “Mmm” being the first three letters of a month of the year.
+值得注意的是 **TIMESTAMP** 部分的格式是 “**Mmm dd hh:mm:ss**” 格式,“Mmm” 是一年中一个月的前三个字母。
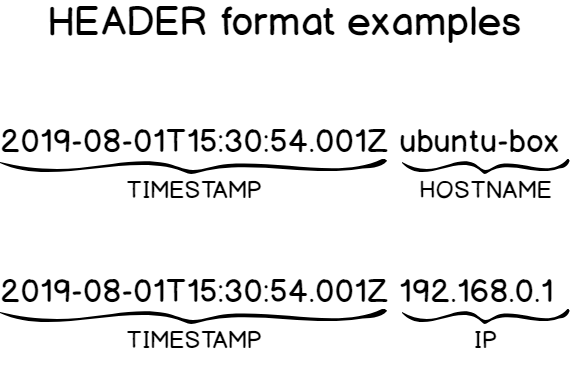
-When it comes to the **HOSTNAME**, it is often the one given when you type the hostname command. If not found, it will be assigned either the IPv4 or the IPv6 of the host.
+谈到 **HOSTNAME** ,它通常是在你键入 HOSTNAME 命令时给出的。如果找不到,将为其分配主机的 IPv4 或 IPv6。

-## IV – How does Syslog message delivery work?
+## IV – Syslog 消息传递是如何工作的?
+
+发布 Syslog 消息时,你需要确保使用可靠和安全的方式来传递日志数据。
-When issuing a syslog message, you want to make sure that you use reliable and secure ways to deliver log data.
+Syslog 在这方面当然也自有一套想法,下面是这些问题的一些解答。
-Syslog is of course opiniated on the subject, and here are a few answers to those questions.
+### a – syslog 转发是什么?
-### a – What is syslog forwarding?
+**Syslog 转发包括将客户端日志发送到远程服务器,以便对其进行集中记录,从而使日志分析和可视化更加容易。**
-**Syslog forwarding consists in sending clients logs to a remote server in order for them to be centralized, making log analysis and visualization easier.**
+大多数情况下,系统管理员不是监控一台机器,而是需要现场和远程监控几十台机器。
-Most of the time, system administrators are not monitoring one single machine, but they have to monitor dozens of machine, on-site and off-site.
+因此,使用不同的通信协议(如 UDP 或 TCP)将日志发送到称为集中式日志服务器的远程机器是一种非常常见的做法。
-As a consequence, it is a very common practice to send logs to a distant machine, called a centralized logging server, using different communication protocols such as UDP or TCP.
+### b – Syslog 使用 TCP 还是 UDP ?
-### b – Is Syslog using TCP or UDP?
+根据[ RFC 3164规范](https://tools.ietf.org/html/rfc3164#section-6.4)的规定,syslog 客户端使用 UDP 向系统日志服务器发送消息。
-As specified on [the RFC 3164 specification](https://tools.ietf.org/html/rfc3164#section-6.4), syslog clients use UDP to deliver messages to syslog servers.
+此外,Syslog 使用端口 514 进行 UDP 通信。
-Moreover, Syslog uses the port 514 for UDP communication.
+但是,在最近的 syslog 实现中,例如 rsyslog 或 syslog-ng,你可以使用 TCP (Transmission Control Protocol) 作为安全的通信通道。
-However, on recent syslog implementations such as rsyslog or syslog-ng, you have the possibility to use TCP (Transmission Control Protocol) as a secure communication channel.
+例如,rsyslog 使用端口 10514 进行 TCP 通信来确保传输链路中没有数据包丢失。
-For example, rsyslog uses the port 10514 for TCP communication, ensuring that no packets are lost along the way.
+此外,你可以基于 TCP 使用 TLS/SSL 协议来加密系统日志数据包,确保不会出现中间人攻击来监视你的日志。
-Furthermore, you can use the TLS/SSL protocol on top of TCP to encrypt your Syslog packets, making sure that no man-in-the-middle attacks can be performed to spy on your logs.
+如果你对 rsyslog 感兴趣,这里有一个关于[如何以安全可靠的方式设置一个完整的集中式日志服务器的教程。](http://devconnected.com/the-definitive-guide-to-centralized-logging-with-syslog-on-Linux/)
-If you are curious about rsyslog, here’s a tutorial on [how to setup a complete centralized logging server in a secure and reliable way.](https://devconnected.com/the-definitive-guide-to-centralized-logging-with-syslog-on-linux/)
+## V – 当前的 Syslog 实现有哪些?
-## V – What are current Syslog implementations?
+Syslog 是一个规范,但不是 Linux 系统中的实际实现。
-Syslog is a specification, but not the actual implementation in Linux systems.
+以下是 Linux 上当前 Syslog 实现的列表:
-Here is a list of current Syslog implementations on Linux:
+* **Syslog daemon**:发布于 1980 年,syslog 守护程序可能是第一个实现,并且只支持有限的一组功能(如 UDP 传输)。它通常被称为 Linux 上的 sysklogd 守护程序;
-* **Syslog daemon**: published in 1980, the syslog daemon is probably the first implementation ever done and only supports a limited set of features (such as UDP transmission). It is most commonly known as the sysklogd daemon on Linux;
+* **Syslog-ng**:syslog-ng 于 1998 年发布,它扩展了原始 syslog daemon 的功能集,包括 TCP 转发(从而增强了可靠性)、TLS 加密和基于内容的过滤器。你还可以将日志存储到本地数据库中以供进一步分析。
-* **Syslog-ng**: published in 1998, syslog-ng extends the set of capabilities of the original syslog daemon including TCP forwarding (thus enhancing reliability), TLS encryption and content-based filters. You can also store logs to local databases for further analysis.
+
-
+* **Rsyslog**:rsyslog 于 2004 年由 Rainer Gerhards 发布,是大多数实际 Linux 发行版( Ubuntu、RHEL、Debian 等)上的默认 syslog 实现)。它提供了与 syslog-ng 相同的转发功能,但是它允许开发人员从更多的来源(例如 Kafka、文件或者 Docker)中选择数据
-* **Rsyslog**: released in 2004 by Rainer Gerhards, rsyslog comes as a default syslog implementation on most of the actual Linux distributions (Ubuntu, RHEL, Debian etc..). It provides the same set of features as syslog-ng for forwarding but it allows developers to pick data from more sources (Kafka, a file, or Docker for example)
+
-
+## VI – 什么是日志最佳实践?
-## VI – What are the log best practices?
+在操作系统日志或构建完整的日志架构时,你需要了解一些最佳实践:
-When manipulating Syslog or when building a complete logging architecture, there are a few best practices that you need to know:
+* **除非你愿意丢失数据,否则请使用可靠的通信协议。** 在 UDP(一种不可靠的协议)和 TCP(一种可靠的协议)之间进行选择真的很重要。提前做出这个选择;
+* **使用 NTP 协议配置你的主机:** 当你想要使用实时日志调试时,最好让主机同步,否则很难准确调试事件;
+* **保护好你的日志:** 使用 TLS/SSL 协议肯定会对你的实例产生一些性能影响,但是如果你要转发身份验证或内核日志,最好对它们进行加密,以确保没有人能够访问关键信息;
+* **你应该避免过度记录:** 定义好的日志策略对你的公司至关重要。例如,你必须决定你是否有兴趣存储(并且基本上消耗带宽)信息日志或调试日志。例如,你可能只对错误日志感兴趣;
+* **定期备份日志数据:** 如果你关注保留敏感日志,或者如果你定期接受审计,你可能在有关的外部驱动器或正确配置的数据库上备份日志;
+* **设置日志保留策略:** 如果日志太旧,你可能会有兴趣丢弃它们,也称为“轮换”它们。该操作是通过 Linux 系统上的 logrotate 实用程序完成的。
-* **Use reliable communication protocols unless you are willing to lose data**. Choosing between UDP (a non-reliable protocol) and TCP (a reliable protocol) really matters. Make this choice ahead of time;
-* **Configure your hosts using the NTP protocol:** when you want to work with real time log debugging, it is best for you to have hosts that are synchronized, otherwise you would have a hard time debugging events with a good precision;
-* **Secure your logs:** using the TLS/SSL protocol surely has some performance impacts on your instance, but if you are to forward authentication or kernel logs, it is best to encrypt them to make sure that no one is having access to critical information;
-* **You should avoid over-logging**: defining a good log policy is crucial for your company. You have to decide if you are interested in storing (and essentially consuming bandwidth) for informational or debug logs for example. You may be interested in having only error logs for example;
-* **Backup log data regularly:** if you are interested in keeping sensitive logs, or if you are audited on a regular basis, you may be interested in backing up your log on an external drive or on a properly configured database;
-* **Set up log retention policies:** if logs are too old, you may be interested in dropping them, also known as “rotating” them. This operation is done via the logrotate utility on Linux systems.
+## VII – 结论
-## VII – Conclusion
+对于愿意深入了解服务器中的日志功能如何运作的**系统管理员**或 **Linux 工程师**来说,syslog 协议绝对是经典之作。
-The Syslog protocol is definitely a classic for **system administrators** or **Linux engineers** willing to have a deeper understanding on how logging works on a server.
+然而,有理论的时候,也有实践的时候。
-However, there is a time for theory, and there is a time for practice.
+> 那么你应该做什么?你有多种选择。
-> So where should you go from there? You have multiple options.
+你可以从在你的实例上设置**syslog 服务器**开始,例如 Kiwi Syslog 服务器,并开始从中收集数据。
-You can start by setting up a **syslog server** on your instance, like a Kiwi Syslog server for example, and starting gathering data from it.
+或者,如果你有更大的基础架构,你可能应该首先建立 **[集中式日志体系结构](https://devconnected.com/the-definitive-guide-to-centralized-logging-with-syslog-on-linux/)**, 然后[使用非常现代的工具如 Kibana 可视化工具对其进行监控](https://devconnected.com/monitoring-linux-logs-with-kibana-and-rsyslog/)。
-Or, if you have a bigger infrastructure, you should probably start by setting up a **[centralized logging architecture](https://devconnected.com/the-definitive-guide-to-centralized-logging-with-syslog-on-linux/)**, and later on [monitor it using very modern tools such as Kibana for visualization](https://devconnected.com/monitoring-linux-logs-with-kibana-and-rsyslog/).
+我希望你今天学到了一些东西。
-I hope that you learned something today.
+活在当下,一如既往地享受乐趣。
-Until then, have fun, as always.
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/the-7-programming-languages-frameworks-to-learn-in-2020.md b/TODO1/the-7-programming-languages-frameworks-to-learn-in-2020.md
new file mode 100644
index 00000000000..46bb07ce3a4
--- /dev/null
+++ b/TODO1/the-7-programming-languages-frameworks-to-learn-in-2020.md
@@ -0,0 +1,161 @@
+> * 原文地址:[The 7 Programming Languages & Frameworks to Learn in 2020](https://medium.com/swlh/the-7-programming-languages-frameworks-to-learn-in-2020-6f9ac923ec5d)
+> * 原文作者:[Kent Sia](https://medium.com/@kentscg)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/the-7-programming-languages-frameworks-to-learn-in-2020.md](https://github.com/xitu/gold-miner/blob/master/TODO1/the-7-programming-languages-frameworks-to-learn-in-2020.md)
+> * 译者:[司徒公子](http://github.com/todaycoder001)
+> * 校对者:[GJXAIOU](https://github.com/GJXAIOU)、[niayyy](https://github.com/niayyy-S)
+
+# 2020 年要学习的 7 种编程语言和框架
+
+> 推荐给充满激情的程序员
+
+
+
+为你的应用程序选择合适的编程语言或框架不仅会影响开发速度和开发周期,而且还会影响你未来职业发展的广度。
+
+在这里,我将分享 2020 年你最应该学习了解的 —— 7 种编程语言,并且在未来几年与你息息相关。如果你还在为前端或后端选择哪一门编程语言而苦苦挣扎或热情于此,那么这篇文章非常适合你。
+
+## 1. Java/Kotlin —— Spring 框架
+
+
+
+很多人可能会问为什么是 **Java**?Java 依然存在?还在流行?答案是**肯定的**。选择学习任何一门编程语言都不仅仅是基于流行程度或者它诞生的时间。无论你喜不喜欢,Java 仍然是一门企业标准的编程语言,并且得到了广泛的运用。工作机会也是我们选择学习编程语言时要考虑的因素之一。
+
+**Kotlin** 是一门具有类型推断的跨平台、静态类型和通用的编程语言。Kotlin 旨在与 Java 完全互操作,并且它标准库的 JVM 版本依赖于 Java 类库,但是类型推断允许它的语法更简洁。Kotlin 由推出 IntelliJ IDEA 的 JetBrains 公司在 2010 年创立,并从 2012 年开始开放源码。
+
+**Spring** 框架是最流行的 Java 开源框架之一。它面向开发人员,并且提供了一个全面、灵活的框架。Spring 5.0 之后的版本为 Kotlin 提供了专门的支持,人们总是将 Kotlin 与 Java 进行比较。对于 Spring 框架来说,既然两种语言都有它的优点和缺点,为什么不把两者结合起来呢?
+
+借助 Internet 上的扩展、资源和文档。使得开发人员可以更轻松的找到并添加与之不同类型的第三方应用程序集成所需的依赖项。
+
+Spring 框架最受欢迎的产品:
+
+* **Spring Boot** 旨在以最少的前期配置实现尽快的运行
+* **Spring Cloud** 旨在简化分布式和微服务风格的架构
+* **Spring Cloud Data Flow** 是用于创建可组合数据微服务的统一服务
+
+你应该考虑使用,当:
+
+* 构建企业级应用程序
+* 使用流行的云服务提供商实现微服务架构
+* 使用代码控件构建大型项目
+* 寻找易于扩展且具有弹性的框架
+
+## 2. Golang
+
+
+
+**Go**,也称为 **Golang**,是 Google 创建的一种开源的编程语言,它可以轻松构建简单、可靠和高效的软件。语法干净,新手易于理解。
+
+Go 的美妙之处在于它对并发性的一流支持。Go 不仅支持**多线程**,它本身也是多线程的。
+
+如果你在寻找轻量级、快速执行和快速开发的产品,Go 是最佳选择之一。与 Spring jar 文件相比,Go 的二进制文件要小的多(10 倍)。
+
+你应该考虑使用,当:
+
+* 构建小型轻量级的应用程序
+* 构建基于微服务的容器平台
+* 快速开发,易于构建,学习曲线更平缓
+* 构建异步和多线程服务
+
+## 3. Python —— Django 框架
+
+**Django** 框架被认为是构建 web 应用程序的最佳 Python 框架之一,并且它是免费和开源的。Django 提供稳定性、包、和最好的文档,并且有良好的社区支持。
+
+Django 广泛用于构建 CRM、CMS、预定引擎和各种 web 应用程序,它支持以**最少的编码**快速开发后端 API。
+
+除其他事项外,Django 非常适合用于数据分析解决方案、复杂的计算和机器学习。它是目前开发人员首选的框架之一。
+
+你应该考虑使用,当:
+
+* 构建大规模 web 应用程序
+* API 驱动的应用程序
+* 不在意整体架构
+* 数据分析解决方案和机器学习
+
+## 4. Node.js —— Express
+
+JavaScript 可能是过去几年最强大和增长最快的编程语言之一。那时候,JavaScript 只用于构建 web 应用程序,但是,现在如果你精通 JavaScript,就可以开发构建 web 应用程序、后端数据库集成、桌面应用程序,甚至是移动应用程序。
+
+如今,JavaScript 几乎无处不在。由于 JavaScript 的占比很高,并且没有竞争,因此,我们无法预见它不久的将来会走向何方。
+
+**Express** 以快速、无约束、极简的 Node.js web框架而闻名。它基于 JavaScript 构建,学习曲线相对较平缓。如今,大多数开发人员都选择 Express 是因为它的灵活性、简单性和可扩展性。更不用说,Express 是 MEAN(软件捆绑包)技术栈的一部分,该技术栈是基于 JavaScript 技术开发 web 应用程序的完整全栈技术的集合。
+
+你应该考虑使用,当:
+
+* 构建小型 web 应用程序,例如门户网站、看板等
+* 构建桌面应用程序
+* 最小可行产品构建(MVP)
+* 学习曲线更平缓
+* 你只有一个小团队和较短的开发周期
+* 尽量减少雇用后端开发团队的成本
+* 你不想打扰或等待现有的后端团队 😆
+
+## 5. Angular —— Web 框架
+
+
+
+多年来,我一直关注 Angular,那时 AngularJS 曾经是最好的框架之一。**Angular** 是一个基于 TypeScript 的开源 web 应用框架,由谷歌构建。Angular 是谷歌的同一个 Angular 团队对 AngularJS 的完全重写。它功能强大,并且有很好的社区支持。
+
+Angular 支持 web、手机和桌面的各种平台。学习 Angular 最主要的原因之一是因为其庞大的生态系统且蓬勃发展。Angular 团队已经向社区交付了大量的工具和库。我参加了 2019 年的 Angular 大会,非常高兴能与世界各地的所有伟大开发者会面,分享使用 Angular 的经验。
+
+新版本的 Angular(9.0)将会成为关于 JavaScript 框架接的下一个大事件。它有更小的包大小、更快速的构建和更好用的调试工具等。
+
+你应该考虑使用,当:
+
+* 构建大规模的 web 应用程序
+* 为社区中所有的工具和库寻找一个大型的生态系统
+* 不介意陡峭的学习曲线
+* 你喜欢写 Typescript 而不是 JavaScript 🙄
+* 有**谷歌**的支持
+
+## 6. Vue.js —— 渐进式 JavaScript 框架
+
+
+
+**Vue** 是一个非常受欢迎的 JavaScript 框架,在过去几年里发展迅猛,Vue 是尤雨溪创建的,当时他在谷歌的 AngularJS 团队工作。
+
+为什么 Vue 会这么受欢迎?Vue 是一个构建接口的渐进式 JavaScript 框架,它从一开始就被设计成为可以逐步采用的。Vue 最主要的优势之一是,它从竞争对手(Angular 和 React)那里吸取了许多优质成分,并向其中加入了自己的特色。
+
+我个人非常喜欢 Vue,因为它简单、灵活,最重要的是它是纯 JavaScript 编写的。然而,Vue 仍然很新,社区仍然很小,而且大多数开发人员都不会说英语。
+
+你应该考虑使用,当:
+
+* 构建中型规模的 web 应用程序
+* 寻找快速开发和较短交付周期(纯 JavaScript)
+* 学习曲线平稳
+* 你可以看懂中文 😉
+* 你非常喜欢 JavaScript(这就是我!)
+
+## 7. lonic 框架
+
+
+
+2014年,我开始使用 AngularJS 和 Apache Cordova 对 Ionic 进行开发。它是一个用于混合移动应用程序的开源 SDK。开发人员可以使用 JavaScript 框架构建移动应用程序。Ionic 包括移动组件、排版、移动主题和交互范例来构建移动应用程序。
+
+在最新版本的 Ionic 中,它允许用户选择任何用户界面框架,例如 Angular,React 或 Vue.js。Ionic 正在推广一个全平台(IOS/Android/Electron/PWA)的代码库。Ionic 也提供了实时更新的工具,并且使用 Appflow 来实现 DevOps 生命周期的持续集成、持续交付。
+
+你应该考虑使用,当:
+
+* 你想构建小型/中型移动应用
+* 快速开发和平稳的学习曲线
+* 你不想学习原生编程
+* 节省构建 Android 和 IOS 移动应用程序的时间和成本
+* 你喜欢使用 JavaScript 框架来构建移动应用程序
+
+## 结论
+
+总之,学习任何编程语言都没有对错之分。还有其他好的一些编程语言可以学习,比如 iOS 的 Swift,谷歌的 Dart、数据科学的 R,Python 的 Flask 等等。从长远来看,为正确的应用场景选择最佳的编程语言非常重要。
+
+以上的排名列表都是基于受欢迎程度、学习曲线、特性以及我的拙见选出来的。我相信,在 2020 年,只学习一门编程语言并成为这方面的专家已经不可能了。如今,每个人都在讨论全栈编程。
+
+> 真正的程序员是活到老,学到老。
+
+我希望你们喜欢这篇文章,如果你觉得这篇文章对你有用,请把它分享给你的朋友,并与我分享你的评论。感谢!
+
+开心写代码! 😊
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/the-algorithm-is-not-the-product.md b/TODO1/the-algorithm-is-not-the-product.md
new file mode 100644
index 00000000000..1bcd0803942
--- /dev/null
+++ b/TODO1/the-algorithm-is-not-the-product.md
@@ -0,0 +1,70 @@
+> * 原文地址:[The Algorithm Is Not The Product](https://towardsdatascience.com/the-algorithm-is-not-the-product-2e0b3740bdfa)
+> * 原文作者:[Ori Cohen](https://medium.com/@cohenori)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/the-algorithm-is-not-the-product.md](https://github.com/xitu/gold-miner/blob/master/TODO1/the-algorithm-is-not-the-product.md)
+> * 译者:[fireairforce](https://github.com/fireairforce)
+> * 校对者:[Shuyun6](https://github.com/Shuyun6), [司徒公子](https://github.com/todaycoder001)
+
+# 算法不是产品
+
+## 为什么我认为数据科学家应该更多地学习怎样制作好的产品
+
+.](https://cdn-images-1.medium.com/max/2000/0*9aCTQ8j7DiGTAZjj.jpg)
+
+我在行业内学到的第一个教训就是,即使我们构建了极其复杂的算法来解决特定的问题,这些工具还是要被一些客户来使用。 因此无论是内部的算法还是外部的用户体验,客户需要的不仅仅是一段精心构造、打包和部署的代码。
+
+换而言之,产品不仅仅是个算法,它是一个能让你的用户从中获得巨大价值的完整体系。构建一个以算法为核心的产品并不是件容易事情,它需要产品经理、开发人员、研究人员、数据工程师、DevOps、ui/ux 等团队之间的合作。
+
+构建一个产品依赖于研究方法,你反复假设(基于先验或后验知识)、衡量、推断见解和调整产品,直到它适合产品市场。这是一场与未知世界的无休止的战斗,除了过程,你可能一无所获。当然,过程越好,你就越有可能得到一个好产品。
+
+**但是,往往我们倾向于忘记。**
+
+以下是应重点强调的几点,即在这种情况下,除了考虑数据科学方面之外,我们还需要重视产品的情况。
+
+## 面试
+
+在面试一个新的数据科学家(DS)的时候,我们通常会询问过去的研究、算法、方法,并提出一个看不见的、需要候选人亲自动手解决的研究问题。
+
+作为招聘经理,我们真的应该考虑从 DS 的角度问一些与产品相关的问题,我们应该看看应聘者的研究作业,问一些相关问题,比如求职者为什么要做出与产品相关的数据或算法决策。例如,询问与产品问题相关的特性工作选择。例如“为什么他们会选择将特征 X 包含在 Y 中”或“为什么他们选择用一种特定的方式去处理特征 Z”之类的决策。
+
+## 初始模型
+
+对于许多组织来说,第一个应该投入生产的模型是最简单的算法,通常被描述为“基于规则”的模型或“80-20”模型。在进入研究阶段之前,放入这样一个基本模型的动机,通常是为了让开发人员、DevOps 和其他团队为新模型创建一个支持性的基础架构,然后 DS 将工作在一个“真实的”模型上,以取代临时的替代者。
+
+从 DS 候选人那里听到这个想法,或者让当前的 DS 们来执行它是非常重要的。它显示了对一个组织需要提前做好准备的深刻理解。它允许 PM 们并行地促进和推进相关的任务,允许我们更加敏捷,并鼓励非产品人员理解产品。
+
+## 模型决策
+
+有一些考虑应该由候选人提出,或者由你自己的数据科学家进行实践。训练一个 **balance = true** 的算法,以使不平衡的数据集正则化,这是一个数据科学家应该做出的产品决策。他应该问产品经理,这些类对于手头的问题是否同样重要,还是我们希望在更大的类中变现得更好?
+
+这类问题使我们在面试过程中应该问应聘者的一些重要问题,在问完他是否能描述他所知道的关于平衡类的所有方法(过采样、欠采样、损失正则化、合成数据等)之后,我们也应该在面试过程中立即询问候选人。
+我也简单讲一下[这里](https://towardsdatascience.com/data-science-recruitment-why-you-may-be-doing-it-wrong-b8e9c7b6dae5)。
+
+## 和 PM 合作
+
+在我们数据科学(DS)领域,我们与产品经理(PM)紧密合作,共同实现我们梦寐以求的目标。我们与不同的团队都有许多摩擦点,但最重要的还是与 PM 的摩擦点,如下图所示。
+
+
+
+考虑一个需要达到或者优化的业务产品(BP)KPI 和一个需要找到适当的 DS-KPI 的数据科学家,DS-KPI 最大限度地为 BP-KPI 服务。这是我们面临的最大挑战之一,但经常被所有利益相关者忽视。上图显示了一个允许迭代研究的工作流,以便优化这两种 KPI 类型,允许与业务、产品和数据科学进行协作。
+你可以阅读更多关于[我管理这个摩擦点的方法](https://towardsdatascience.com/why-business-product-should-always-define-kpis-goals-for-data-science-450404392990)。
+
+## 不要迷恋你的算法
+
+我们在完善算法算法方面进行了乏味的工作,以确保算法能正确地进行优化,但是,很多时候,系统中的某个人改变了主意或没有适当的研究市场,并且你为服务于某个功能而构建的算法不需要或没有按预期执行。一个常见的错误是推动、尝试修复或重新利用算法。但是,根据新产品的要求,最好采用一种新算法从头开始做起。这将使你从以前的约束中解脱出来,并且对组织内的团队具有良好的战略意义。
+
+---
+
+我希望这些想法能让专业的数据科学家们在开始一个新项目或为一个产品添加新功能时对产品管理进行更多的探索,变得更加灵活,并有望帮助企业经理、产品经理、数据科学家和研究人员之间的复杂关系。
+
+我要感谢我的同事,[Natanel Davidovits](https://towardsdatascience.com/@ndor123) 和 [Sefi Keller](https://medium.com/@sefikeller) 校验这篇文章。
+
+---
+
+Dr. Ori Cohen 拥有计算机科学博士学位,主要研究机器学习。他是 New Relic TLV、AIOps 领域的实践机器和深度学习研究的首席数据科学研究员。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/the-dao-of-immutability.md b/TODO1/the-dao-of-immutability.md
new file mode 100644
index 00000000000..3d4cbe2abcf
--- /dev/null
+++ b/TODO1/the-dao-of-immutability.md
@@ -0,0 +1,111 @@
+> * 原文地址:[The Dao of Immutability](https://medium.com/javascript-scene/the-dao-of-immutability-9f91a70c88cd)
+> * 原文作者:[Eric Elliott](https://medium.com/@_ericelliott)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/the-dao-of-immutability.md](https://github.com/xitu/gold-miner/blob/master/TODO1/the-dao-of-immutability.md)
+> * 译者:[niayyy](https://github.com/niayyy-S)
+> * 校对者:[S_Shi-Hua](https://github.com/IAMSHENSH)、[Roc](https://github.com/QinRoc)
+
+# 不变性之道
+
+> 函数式程序设计方法
+
+## 前言
+
+我徘徊在一个旧图书馆档案室,发现了一条通往计算机教室的黑暗隧道。在那里,我发现了一个似乎被遗落在地上的卷轴。
+
+卷轴被装在满是灰尘的铁筒中,上面贴着这样的标签:“**Lambda(匿名函数)教堂**的档案。”
+
+它被包裹在一张纸里,上面写道:
+
+---
+
+**一位高级程序员和他的徒弟陷入图灵沉思中,思考着 Lambda(匿名函数)。徒弟看着师傅,问道:“师傅,你告诉我要简单化,但是程序是复杂的。框架可以通过消除困难的选择来简化创建的工作。那么类库和框架哪个更好呢?”**
+
+**高级程序员看着他的徒弟反问道:“难道你没读过智者 Carmack 的学说吗?”,并引用道…**
+
+> “有时,优雅的实现仅仅是一个函数。不是一个方法。不是一个类库。也不是一个框架。仅仅是函数”
+
+**徒弟又开始说到:“但是,师傅,” —— 但是师傅打断了他的话,问道:**
+
+**“‘not functional(无功能)’这个词不就是 ‘dysfunctional(功能障碍)’吗?”**
+
+**然后徒弟明白了。**
+
+---
+
+在这张纸的背面是一个索引,似乎引用了计算机行业的许多书籍。我偷偷看了一眼这些书籍的名称,但是里面充满着我不能理解的词汇,因此我略过它们,继续阅读卷轴。我注意到索引旁边的空白页面被写满了简短的评论,我将在这忠实地抄录这些评论以及卷轴里面的文字:
+
+---
+
+> **不变性:** 唯一的不变就是改变。变异隐藏变化。而被隐藏的变化会带来混乱。因此,智者拥抱历史。
+
+如果你有一美元,而我又给你了一美元,前一刻你仅有一美元,现在你拥有了两美元,这一事实并没有改变。事态的变异会尝试抹除历史记录,但是历史记录无法真正被删除。如果不保存过去,它将表现为程序中的 bug,再次困扰你。
+
+> **分离:** 逻辑就是思考,效果就是行动。因此,智者三思而后行。
+
+如果你尝试同时执行效果和逻辑,你可能创建导致逻辑错误的副作用。尽可能保存函数功能的单一。一次只做一件事并做好。
+
+> **组合:** 自然界中万物和谐相处。没有水,树木无法生长。没有空气,鸟儿不能飞翔。因此,智者把原料混合在一起,让汤尝起来更美味。
+
+规划组合的方式。设计函数时确保最终编写的函数的输出结果可以作为许多其他函数的输入参数。让函数标识尽可能的简单。
+
+> **节约:** 时间是宝贵的,而努力需要时间。因此,智者尽可能地重用他们的工具。愚蠢的人会为每个新的东西创造特殊的工具。
+
+特定类型的函数不能用于其它类型的数据。明智的程序员通过 lift 函数来处理多种数据类型,或者把数据包装为函数所需要的格式。列表和列表项构成了很好的通用抽象。
+
+> **流动:** 流水不腐,户枢不蠹。智者之所以成功,是因为他们让事务顺其流动。
+
+**[编者注:卷轴上唯一的插画在这节经文的上方,画面上有一排看起来不同的鸭子在顺流而下。我没有复制插画,因为我不相信我可以做到这一点。奇怪的是,他的标题是:]**
+
+---
+
+> 列表像是一条随着时间推移而变化的水流。
+
+---
+
+**[相应的说明如下:]**
+
+共享对象和数据配件(data fixtures)可能导致函数相互干扰。竞争相同资源的多个线程会互相阻碍。只有当数据通过纯函数自由流动时,才能对程序进行推演并预测结果。
+
+**[编者注:卷轴以最后一节经文结尾,没有注释:]**
+
+> **智慧:** 明智的程序员在走上这条路之前,会先了解透彻这条路的走法。因此,明智的程序员是有价值的,而不明智的程序员会迷失在[丛林](https://medium.com/javascript-scene/the-two-pillars-of-javascript-ee6f3281e7f3)中。
+
+> **注意:** 这是“组合软件”系列[**(丛书)**](https://leanpub.com/composingsoftware)中的从头学习 JavaScript ES6+ 中的函数式编程和组合软件技术。后续还有更多文章!敬请关注。
+
+本系列目录:
+
+* [简介](https://medium.com/javascript-scene/composing-software-an-introduction-27b72500d6ea)
+* [不变性之道](https://medium.com/javascript-scene/the-dao-of-immutability-9f91a70c88cd)
+* [跌宕起伏的函数式编程](https://medium.com/javascript-scene/the-rise-and-fall-and-rise-of-functional-programming-composable-software-c2d91b424c8c)
+* [为什么用 JavaScript 学习函数式编程?](https://medium.com/javascript-scene/why-learn-functional-programming-in-javascript-composing-software-ea13afc7a257)
+* [纯函数](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-pure-function-d1c076bec976)
+* [什么是函数式编程?](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-functional-programming-7f218c68b3a0)
+* [函数式程序员的 JavaScript 简介](https://medium.com/javascript-scene/a-functional-programmers-introduction-to-javascript-composing-software-d670d14ede30)
+* [高阶函数](https://medium.com/javascript-scene/higher-order-functions-composing-software-5365cf2cbe99)
+* [柯里化与函数组合](https://medium.com/javascript-scene/curry-and-function-composition-2c208d774983)
+* [抽象与组合](https://medium.com/javascript-scene/abstraction-composition-cb2849d5bdd6)
+* [Functor 与 Category](https://medium.com/javascript-scene/functors-categories-61e031bac53f)
+* [JavaScript 让 Monad 更简单](https://medium.com/javascript-scene/javascript-monads-made-simple-7856be57bfe8)
+* [被遗忘的面向对象编程史](https://medium.com/javascript-scene/the-forgotten-history-of-oop-88d71b9b2d9f)
+* [对象组合中的宝藏](https://medium.com/javascript-scene/the-hidden-treasures-of-object-composition-60cd89480381)
+* [ES6+ 中的 JavaScript 工厂函数](https://medium.com/javascript-scene/javascript-factory-functions-with-es6-4d224591a8b1)
+* [函数式 Mixin](https://medium.com/javascript-scene/functional-mixins-composing-software-ffb66d5e731c)
+* [为什么类中使用组合很难](https://medium.com/javascript-scene/why-composition-is-harder-with-classes-c3e627dcd0aa)
+* [可自定义数据类型](https://medium.com/javascript-scene/composable-datatypes-with-functions-aec72db3b093)
+* [Lenses:可组合函数式编程的 Getter 和 Setter](https://medium.com/javascript-scene/lenses-b85976cb0534)
+* [Transducers:JavaScript 中高效的数据处理 Pipeline](https://medium.com/javascript-scene/transducers-efficient-data-processing-pipelines-in-javascript-7985330fe73d)
+* [JavaScript 样式元素](https://medium.com/javascript-scene/elements-of-javascript-style-caa8821cb99f)
+* [模拟是一种代码异味](https://medium.com/javascript-scene/mocking-is-a-code-smell-944a70c90a6a)
+
+---
+
+**埃里克·埃利奥特(Eric Elliott)** 是一名分布式系统专家,并且是[《Composing Software》](https://leanpub.com/composingsoftware)和[《Programming JavaScript Applications》](https://ericelliottjs.com/product/programming-javascript-applications-ebook/)这两本书的作者。作为 [DevAnywhere.io](https://devanywhere.io/) 的联合创始人,他教开发人员远程工作和实现工作 / 生活平衡所需的技能。他为加密项目组建开发团队并提供咨询,并为 **Adobe 公司、Zumba Fitness、《华尔街日报》、ESPN、BBC** 和包括 **Usher、Frank Ocean、Metallica** 在内的顶级唱片艺术家的软件体验做出了贡献。
+
+**他与世界上最美丽的女人一起享受着远程办公的生活方式。**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/the-importance-of-why-docs.md b/TODO1/the-importance-of-why-docs.md
new file mode 100644
index 00000000000..bb37f23ac08
--- /dev/null
+++ b/TODO1/the-importance-of-why-docs.md
@@ -0,0 +1,111 @@
+> * 原文地址:[The Importance of “Why” Docs](https://medium.com/better-programming/the-importance-of-why-docs-c8ffba0ea520)
+> * 原文作者:[Bytebase](https://medium.com/@bytebase)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/the-importance-of-why-docs.md](https://github.com/xitu/gold-miner/blob/master/TODO1/the-importance-of-why-docs.md)
+> * 译者:
+> * 校对者:
+
+# The Importance of “Why” Docs
+
+> Giving future engineers context on why decisions were made
+
+ on [Unsplash](https://unsplash.com/s/photos/why?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/10368/1*2KhDOt8Dgcq17b-8rlMsig.jpeg)
+
+Many of us have, at one time or another, blindly followed a pattern we noticed, thinking that must be the way to do it. We do so without questioning if that pattern is the best fit for our particular situation or if that pattern was ever a good idea to begin with.
+
+In doing this, we rob ourselves of the opportunity to learn and deepen our understanding, to be intentional with our work, and, ultimately, to get better at our craft. Even more, we set yet another precedent for colleagues to do the same, instead of encouraging them to dig deeper.
+
+## The Girl and the Fish
+
+
+
+I recently learned about the fable of a young girl watching her mother cook fish:
+
+> A little girl was watching her mother prepare a fish for dinner. Her mother cut the head and tail off the fish and then placed it into a baking pan.
+>
+> The little girl asked her mother why she cut the head and tail off the fish.
+>
+> Her mother thought for a while and then said, “I’ve always done it that way. That’s how grandma always did it.”
+>
+> Not satisfied with the answer, the little girl went to visit her grandma to find out why she cut the head and tail off the fish before baking it. Grandma thought for a while and replied, “I don’t know. My mother always did it that way.”
+>
+> So the little girl and the grandma went to visit great-grandma to find ask if she knew the answer. Great-grandma thought for a while and said, “Because my baking pan was too small to fit in the whole fish!”
+
+**— [via Ptex Group](https://ptexgroup.com/learned-story-fish/)**
+
+The girl’s mother took off the head and tail of the fish because she was unaware of the great grandmother’s constraint of a small pan. She didn’t ask “why” when she adopted the recipe, and the great grandmother didn’t realize she should tell her. As a result, the girl’s mother was still able to cook fish, but she was cooking suboptimally. She was cooking uninformed.
+
+By asking “why,” the little girl can change the recipe with confidence because she knows the original constraint of a small pan no longer holds.
+
+---
+
+## Asking “Why” in Docs
+
+Like the little girl, we want to break the cycle of doing without understanding. We can break this cycle by asking “why,” and by documenting why as we build.
+
+Code tells you **how** a software system works. Docs tell you **why** a system works this way.
+
+> Code tells what, docs tell you why.” — **Steve Konves at [Hacker Noon](https://hackernoon.com/write-good-documentation-6caffb9082b4)**
+
+Writing down “why” as we build will:
+
+* Reduce the number of outages caused by changing code without understanding it
+* Reduce the time spent hunting down why software was written a certain way
+* Build a culture of craft and critical thinking in our teams
+* Empower our teams to build better
+
+#### When to write “why”
+
+As you code, throughout the day, ask yourself:
+
+> Are there certain constraints that are impacting my work?
+>
+> Is there anything I’m doing that requires explanation to understand fully?
+
+These constraints can be related to:
+
+* Tight deadlines
+* Lacking resources on a project
+* Known bugs we’d like to mitigate
+* User-traffic patterns
+
+Some building that requires explanation can be:
+
+* Why we decided to duplicate code instead of reuse code
+* Why we’re committing code in this order
+* Why we have this unusual-looking edge case handling
+
+Write those constraints and explanations down.
+
+#### Example constraints
+
+* This feature needs to be released immediately, so we’re accepting poorer code quality
+* We need to support backward compatibility of our iOS app to v1.1, so we have to pass this extra field
+* We’re expecting a 100x burst load tomorrow, so we’re increasing our base instance size
+* Team size is three engineers, so we only want to support one programming stack
+* Our project requirements aren’t clear enough, so we’re holding off on updating this feature for now
+
+#### Example explanations
+
+* We’re duplicating our blog model because we want to move to a backward-incompatible model
+* We’re avoiding our usual API for this because that API has been known to cause performance issues in use cases like ours
+* The special account balance value of -$200 indicates this is an employee account
+
+## How to Make “Why” Easy to Find
+
+Part 2 of this post will cover how you can use Git to capture the “why” related to your code as part of your daily routine.
+
+We’ll also go over how Bytebase makes sharing and finding the “why” behind your team’s work easy.
+
+## References
+
+[**Write Good Documentation**](https://hackernoon.com/write-good-documentation-6caffb9082b4)
+
+* [“Etsy’s experiment with immutable documentation”](https://codeascraft.com/2018/10/10/etsys-experiment-with-immutable-documentation/) via Code as Craft
+* [“What I Learned from the Story of the Fish”](https://ptexgroup.com/learned-story-fish/) via Ptex Group
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/the-ripple-effect-expanding-our-icon-design-system.md b/TODO1/the-ripple-effect-expanding-our-icon-design-system.md
new file mode 100644
index 00000000000..a5af0b03270
--- /dev/null
+++ b/TODO1/the-ripple-effect-expanding-our-icon-design-system.md
@@ -0,0 +1,68 @@
+> * 原文地址:[The Icon Kaleidoscope](https://medium.com/microsoft-design/the-ripple-effect-expanding-our-icon-design-system-74b4d916b7a4)
+> * 原文作者:[Jon Friedman](https://medium.com/@designjon)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/the-ripple-effect-expanding-our-icon-design-system.md](https://github.com/xitu/gold-miner/blob/master/TODO1/the-ripple-effect-expanding-our-icon-design-system.md)
+> * 译者:[👊Badd](https://juejin.im/user/5b0f6d4b6fb9a009e405dda1)
+> * 校对者:[PingHGao](https://github.com/PingHGao), [zh1an](https://github.com/zh1an)
+
+# 图标万花筒
+
+#### 用全新的颜色、材质和润饰来重新设计超过 100 种图标
+
+
+
+空白和重新设计都没有后续的好。
+
+去年,我们推出了 [Office 新版图标](https://medium.com/microsoft-design/redesigning-the-office-app-icons-to-embrace-a-new-world-of-work-91d72608ee8f?source=friends_link&sk=499905fb0d5a65d594aab35201debf40),向客户表明我们已经开发了产品来支持不断变化的工作环境。在这个世界里,尽管这个世界比以往任何时候都[更具有移动性](https://medium.com/microsoft-design/microsoft365mobile-3b5b7782152c?source=friends_link&sk=6f3168beb86bf945f6c512fc38c03aad),但社交联系和协作对成功都至关重要。借助新的信息流,这个世界将具有巨大的创造力和发展潜力。
+
+在 Microsoft 的整个产品体系中,我们一直致力于帮助促进和加强此类交互和体验。将图标设计工作从 10 种扩展到上百种,以反映这种新世界的工作既艰巨又令人兴奋。
+
+
+
+但是,公司的设计团队作为一个整体聚集在一起,共同制定设计准则,以鼓励个性化的同时创造出更强凝聚力的整体。从巨鳄企业到小本经营,再到芸芸用户,产品团队确保了每个图标都能切切实实地传达出产品的真谛和更博大的 Microsoft 品牌文化。
+
+我们共享知识,共同迭代,共渡难关,也共同分享成功的喜悦。我们比较了不同应用场景下的图标,对不同场景做了不同的改变。更重要的是,我们互相鼓舞激励。这真正是 Microsoft 万众一心的努力成果,我们迫不及待想要听到你们的反馈。
+
+
+
+
+
+#### 扩大设计系统的覆盖范围
+
+从诸如计算器这样的工具,到能让行家里手瞬间触及世界各个角落的混合现实 App,用户需求的多样性一直呈指数级增长。我们需要让我们的现代图标系统紧随时代潮流。
+
+随着最新一轮图标焕新浪潮的到来,我们面临两大创造性的挑战。我们需要在创新和变革的同时,保持住用户的亲切感。我们还需要建立一套灵活、开放的设计系统,使其能够适应一系列不同的应用场景,同时仍旧忠于 Microsoft 的理念。
+
+
+
+我们的 [Fluent 设计系统](https://medium.com/microsoft-design/evolving-the-microsoft-fluent-design-system-9b37fb890c82?source=friends_link&sk=056e4f7cdd2085c3ec9a872846b84787)能够帮助我们应对这两个挑战。Fluent 强调的是建立亲切感 —— 针对用户的现有认知进行设计,而非要求他们养成新的使用习惯或者学习新的概念。Fluent 还意味着使一个多样化但具有关联性的系统成为可能。为了承载范围如此宽广的应用场景和体验,我们将初始库中的图标颜色、材质和润饰的进行了扩充。
+
+
+
+
+
+用户会花大量时间使用 Microsoft Edge 和 Office 来完成工作,所以一想到要在这些明星产品上试验新的设计风格,各个团队就兴奋不已。我们深知这些使用体验对用户有多么重要,因此,这些图标既要浑然一体,又要卓尔不群。基于大量的测试和用户反馈,我们采用了层次丰富的渐变色,拓宽了色彩范围,用丝带质感实现了活力十足的动态效果。
+
+用户也开始借助混合现实,用全新的方式实现目标。将现实世界与数字世界在图标中交融,使我们能够突破传统思路的局限,尝试新的颜色、润饰和材质。我们需要考虑如何实现三维立体感,因此我们选择了能够反映光线、深度和更多触感的全新设计材质。
+
+不论用户使用手机、PC 还是 VR 头戴设备来完成工作,我们想要在每一个场景里都能触及用户。最新的设计指南帮助我们统一了公司内部乃至每一个产品家族的图标构造。
+
+#### 携手设计我们的未来
+
+从始至终,我们都和社区同舟共济,在这条重新设计图标的路上当然也没有例外。我们为每一个图标都做了无数次的调查。从婉约到豪放,我们研究了大量不同风格的设计指导方案,收集了全世界用户的意见。我们明白了什么样的设计能引起用户的共鸣(有深度、有层次、色彩丰富、富有动感),什么样的不能(扁平化设计、简约用色),是这些经验教训引导着我们去斟酌。
+
+
+
+随着我们持续不断地提升技术、推出能够展现 Microsoft 未来风貌的图标集,我们的设计系统也会不断进化,从而适应我们未曾想到过的全新场景。建立一个既能涵盖从文字到抽象概念的全部范围,又能够平衡产品特征和 Microsoft 整体风格的系统,这是一个巨大的挑战 —— 但只有百炼才能成钢。
+
+路漫漫其修远兮,但团队目前的成就已让我们颇感自豪,我们迫不及待想要得到你们的反馈。请在评论区留下你们的真知灼见!
+
+---
+
+**如果想要跟踪 Microsoft Design的最新动向,请在 [Instagram](https://www.instagram.com/microsoft_design/)、[Twitter](http://www.twitter.com/microsoftdesign) 和 [Facebook](http://www.facebook.com/microsoftdesign) 关注我们,或者加入 [Windows 预览体验计划](https://insider.windows.com/)。如果你有意加入 Microsoft 团队,请点击 [aka.ms/DesignCareers](http://aka.ms/designcareers)。**
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/top-7-modern-programming-language-to-learn-now.md b/TODO1/top-7-modern-programming-language-to-learn-now.md
new file mode 100644
index 00000000000..e54a928ff07
--- /dev/null
+++ b/TODO1/top-7-modern-programming-language-to-learn-now.md
@@ -0,0 +1,402 @@
+> * 原文地址:[Top 7 Modern programming languages to learn now](https://towardsdatascience.com/top-7-modern-programming-language-to-learn-now-156863bd1eec)
+> * 原文作者:[Md Kamaruzzaman](https://medium.com/@md.kamaruzzaman)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/top-7-modern-programming-language-to-learn-now.md](https://github.com/xitu/gold-miner/blob/master/TODO1/top-7-modern-programming-language-to-learn-now.md)
+> * 译者:[lihaobhsfer](https://github.com/lihaobhsfer)
+> * 校对者:[impactCn](https://github.com/impactCn)、[司徒公子](https://github.com/todaycoder001)
+
+# 现在就该学习的 7 门现代编程语言
+
+> 来看看 Rust、Go、Kotlin、TypeScript、Swift、Dart、Julia 能如何促进你的职业生涯发展,提升你的软件开发技能
+
+ 作者 [h heyerlein](https://unsplash.com/@heyerlein?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/6000/1*sY77VQEyI1Dbm_RnO0bxIA.jpeg)
+
+如果我们把人类现代文明比做一辆车,那么软件开发行业就像汽车的发动机,编程语言就像发动机的燃料。**你该学习哪门编程语言呢**?
+
+学习一门新的编程语言需要投入大量**时间、精力和脑力**。但是,就如我在另一篇文章中所写,学习一门新的编程语言能够提升你的编程技能,加速你的职业发展
+[**2020 年学一门新的编程语言的五大理由**](https://medium.com/@md.kamaruzzaman/5-reasons-to-learn-a-new-programming-language-in-2020-bfc9a4b9a763)
+
+
+一般来讲,我们需要选择一门对你职业发展有益的编程语言。与此同时,我们也需要选择受欢迎程度正在上升的语言。这意味着你应该选择较成熟的、广受好评的语言来学习。
+
+我很尊敬主流编程语言。但在这篇文章中我将推荐给你**一系列能够提高生产力、助你升职加薪、成为更优秀的开发者的现代编程语言**。同时,我会涉及到**许多领域:系统编程、app 开发、web 开发、科学计算**。
+
+
+
+**现代编程语言**这一术语定义比较模糊。许多人认为如 Python、JavaScript 这样的语言是现代编程语言,认为 Java 是比较老的语言。而实际上,他们问世的时间都在 1995 年前后。
+
+多数主流编程语言都是在上个世纪开发的,主要在**七十年代(例如 C 语言)、八十年代(如 C++)和九十年代(如 Java、Python 和 JavaScript)**。这些语言的设计方式,不能很好利用现代软件开发的生态系统:**多核 CPU、GPU、高速网络、移动设备、容器和云端**。尽管它们中的很多语言都有**诸如并发一类的改进特性**,并在不断适应新时代,但是他们也需要向下兼容,因此无法抛弃老旧过时的特性。
+
+在这一方面,Python 在 Python 2 和 Python 3 之间就划分得很清楚,做得很好(或者很差,这取决于上下文)。这些语言**通常提供 10 种方式来做同样的事情,这对开发者很不友好**根据 StackOverflow 上的一个调查,主流的比较老的编程语言在 **最令人望而生畏的编程语言** 中都位居前列:
+
+](https://cdn-images-1.medium.com/max/2000/1*ohNTSynK0hp_v73Y_aEl2A.jpeg)
+
+我认为老编程语言和新的编程语言的界限可以定在 **2007 年 6 月 29 日**,第一代 iPhone 的发布日。在那之后,整个科技产业前景都改变了。我将主要讨论 **2007 年以后的编程语言**。
+
+
+
+首先,**现代编程语言开发出来是为了最大化利用现代计算机硬件(多核 CPU、GPU、TPU)、移动设备、大数据、高速互联网、容器和云端的优势**。并且,多数现代编程语言对开发者更加友好,提供了大量如下特性:
+
+* 代码简洁(模板代码更少)
+* 原生支持并发
+* 空指针安全
+* 类型推断
+* 特性更精简
+* 较低的认知负荷
+* 融合所有编程范式的最佳特性
+
+其次,本榜单中的许多编程语言是**颠覆性的,将永远改变软件行业**。他们中有些已经是主流编程语言,而另一些则有望取得突破。至少作为第二编程语言来学习这些语言是明智的。
+
+在之前发表的文章《关于 2020 年软件开发趋势的 20 项预测》中,我预测了 2020 年会有很多现代编程语言取得突破:[**关于 2020 年软件开发趋势的 20 项预测**](https://towardsdatascience.com/20-predictions-about-software-development-trends-in-2020-afb8b110d9a0)
+
+---
+
+## Rust
+
+](https://cdn-images-1.medium.com/max/2406/1*fr1Gjc_bt6gB06fUlfQNPQ.jpeg)
+
+系统编程语言领域被非常接近硬件层的 C 和 C++ 霸占。它们让你全权控制程序和硬件,但缺少内存安全。就算它们支持并发,用 C 或者 C++ 写并发程序也因没有并发安全而非常困难。其他编程语言是如 Java、Python 和 Haskell 这样的解释型语言。它们安全,但是需要的运行时间很长、或者依赖虚拟机。过长的运行时间使得像 Java 这样的语言不适合系统编程。
+
+**不乏想要结合 C 或 C++ 的强大功能和 Java、Haskell 的安全性的尝试**。Rust 或许是首个成功做到这一点的生产级编程语言。
+
+**Graydon Hoare** 起初仅仅将 Rust 作为业余项目开发。他受到用于科研的编程语言 **Cyclone** 的启发。Rust 是开源的,Mozilla 与许多其他公司和社区一起领导 Rust 语言的开发。Rust 在 2015 年首次亮相,并迅速受到社区的关注。在之前一篇文章中,我更加深入地探讨了 Rust 并指出为何在大数据领域它比 C++ 和 Java 更好:
+[**回归硬件:2019 年用于开发大数据框架最好的 3 门编程语言**](https://towardsdatascience.com/back-to-the-metal-top-3-programming-language-to-develop-big-data-frameworks-in-2019-69a44a36a842)
+
+
+**关键特性**:
+
+* 通过**所有权与借出**的概念提供内存安全、线程安全
+* **编译时确保内存安全和线程安全**,比如,如果一段程序成功编译,那它就是既内存安全又没有数据竞争。这是 Rust 最吸引人的特性。
+* 它也像 ML、Haskell 一样有很强的表达性。有了不可变的数据结构和函数式编程特性,Rust 提供函数并发和数据并发。
+* Rust 相当快。根据 [**Benchmark Game**](https://benchmarksgame-team.pages.debian.net/benchmarksgame/fastest/rust-gpp.html),一些常见场景下 Rust 性能比 C++ 更好
+* 由于不需要运行时环境,Rust 提供对现代硬件(TPU、GPU、多核 CPU)的完全控制
+* Rust 支持 **LLVM**。因此 Rust 和 **WebAssembly** 有上乘的互操作性,让网页应用的代码高速运行。
+
+**受欢迎程度:**
+
+自 2015 年问世以来,Rust 就被广大开发者接受,并在 StackOverflow 开发者调查中**连续四年**(2016-2019)被选为最受喜爱的语言:
+
+](https://cdn-images-1.medium.com/max/2000/1*JQSUr9o0igYb22h_RnYTlA.jpeg)
+
+根据 Github Octoverse,Rust 是增长第二快的编程语言,仅次于 Dart:
+
+](https://cdn-images-1.medium.com/max/2000/1*gwjGGcibFfZhUZSJKqpT-A.jpeg)
+
+并且,Rust 在编程语言排名网站 PyPl 排在第 18 名,并呈上升趋势。
+
+](https://cdn-images-1.medium.com/max/2000/1*evWgcSuw1qfOb9wpr3ckqQ.jpeg)
+
+看看它提供的特性,难怪像**微软、亚马逊、谷歌**那些科技公司巨头都发布声明,会将 Rust 作为长期系统编程语言进行投资。
+
+谷歌趋势显示,过去五年里,Rust 获得的关注持续增长:
+
+
+
+**主要使用场景:**
+
+* 系统编程
+* 无服务器计算
+* 商业应用
+
+**主要竞争语言:**
+
+* C
+* C++
+* Go
+* Swift
+
+## Go
+
+
+
+谷歌是最大的互联网公司之一。在本世纪初,谷歌面临着两个规模化问题:**开发规模和应用规模**。开发规模的意思是他们不能够再简单地通过增加开发人员来添加更多新特性。应用规模的意思是他们无法简单地开发一个能够扩大到“谷歌级”计算机集群的规模的应用。2007 年前后,谷歌提出了一个新的“**务实的**”编程语言,以解决这两个规模化的问题。在 **Rob Pike** (UTF-8) 和 **Ken Thompson** (UNIX 系统),他们拥有全世界两个最具天赋的软件工程师来开发一门新语言。
+
+2012年,谷歌发布了 **Go** 语言的第一个官方版本。Go 是一个系统编程语言,但是和 Rust 不同。它有运行时环境和垃圾回收(几 Mb 大)。但是不像 Java 和 Python,这个运行时环境是打包在生成的代码里的。最后,Go 生成一个可以在机器上无需依赖或者运行时环境的原生二进制代码。
+
+**关键特性:**
+
+* Go 有顶级的并发支持。它不通过线程和锁提供“**共享内存**”并发,因为这更难编写。相反,它提供**基于 CSP 的消息传递并发**(根据 **Tony Hoare** 的论文)。Go 使用 “**Goroutine**”(轻量的安全线程)和“**频道**”来实现消息传递。
+* Go 的杀手锏特性是它非常简洁。它是最简单的系统编程语言。一个新手软件开发者可以像用 Python 一样在几天内写出高效率的代码。几个最大的云原生项目(**Kubernetes、Docker**)就是用 Go 写的。
+* Go 也有内置的垃圾回收机制,开发者无需像在使用 C 或 C++ 时一样担心内存管理。
+* 谷歌在 Go 上投入巨大。因此,Go 拥有庞大的工具支持。对于新手 Go 开发者而言,有一个庞大的工具生态。
+* 通常,开发者花百分之二十的时间写新代码,而百分之八十的时间是在维护已有代码。Go 的简单性、使它在维护方面非常出色。现在,Go 在商业应用中被广泛使用。
+
+**受欢迎程度:**
+
+从 Go 首次问世以来,软件开发社区就对它敞开怀抱。在 2009 年(在它发布不久后)和 2018 年,根据 [**TIOBE 指数**](https://www.tiobe.com/tiobe-index/),Go 都进入了**编程语言名人堂**名单。Go 的成功为如 Rust 一样的新一代编程语言铺路,也不足为奇。
+
+Go 已经是一个主流编程语言。最近,Go 团队对外宣布了他们在 **Go 2** 上的进展,这使得这门语言更加坚挺。
+
+在几乎所有编程语言对比网站上,Go 都排名靠前并且超过了很多语言。在 2019 年 12 月的 **TIOBE 指数** 排名中 Go 排在第 15 位:
+
+
+
+根据 StackOverflow 调查,Go 是最受欢迎的十大编程语言之一:
+
+](https://cdn-images-1.medium.com/max/2000/1*AlZjgpQhANe7uJ_pJMQmdQ.jpeg)
+
+根据GitHub Octoverse,Go 也是发展最快的十大编程语言之一:
+
+](https://cdn-images-1.medium.com/max/2000/1*avYTdU-SuMxL3qMufe9Xag.jpeg)
+
+谷歌趋势也显示,Go 在过去五年中受关注程度在上升:
+
+
+
+**主要应用场景:**
+
+* 系统编程
+* 无服务器计算
+* 商业应用
+* 云原生开发
+
+**主要竞争语言:**
+
+* C
+* C++
+* Rust
+* Python
+* Java
+
+## Kotlin
+
+
+
+Java 企业级软件开发无可争议的霸主。近期,Java 受到了不少批评:代码量大,需要写很多模板代码,容易一不留神就发现程序过于复杂。然而,没有谁对 **Java 虚拟机**(JVM)评头论足。JVM 是软件工程界的一项佳作,是经历了行业战场和时间双重历练的运行时环境。在一篇文章中,我详细讨论了 JVM 的优势:
+[**统治数据密集型(大数据 + 高速数据流)框架的编程语言**](https://towardsdatascience.com/programming-language-that-rules-the-data-intensive-big-data-fast-data-frameworks-6cd7d5f754b0)
+
+
+近几年来,像 **Scala** 运行在 JVM 环境中的语言,试着解决 Java 的短板,想要成为更好的 Java,却以失败告终。不过最后,从 Kotlin 之中可以看出,似乎对一个更好的 Java 的寻找可以告一段落了。Jet Brains(开发 IntelliJ 这款热门 IDE 的公司)开发了 Kotlin,它运行在 JVM 上,并提供很多现代特性。最好的一点是,不像 Scala,**Kotlin** 比 Java 精简很多,并且能够在 JVM 平台上提供像 Go 和 Python 一样的开发效率。
+
+谷歌宣布将 Kotlin 作为开发**安卓**系统的首选语言,提升了 Kotlin 在社区中的接纳程度。并且,热门 Java **企业级框架 Spring** 也从 2017 年开始在 Spring 生态中支持 Kotlin。我配合响应式 Spring 使用过 Kotlin,体验相当不错。
+
+**主要特性:**
+
+* Kotlin 的独特卖点是它的语言设计。因其代码简洁,我一直视 Kotlin 为 JVM 上的 Go 或 Python。因此,Kotlin 生产力很强。
+* 与其他很多现代语言一样,Kotlin 提供空指针安全,类型推断等特性。
+* 由于 Kotlin 也在 JVM 上运行,你可以使用已有的 Java 库的庞大生态。
+* Kotlin 是开发安卓应用的首选编程语言,并已经超过 Java 成为最广泛使用的安卓开发语言。
+* Kotlin 由 JetBrains 和开源社区支持,因此,Kotlin 拥有出色的工具支持。
+* 有两个有趣的项目: **Kotlin Native**(可将 Kotlin 编译为原生代码)和 **Kotlin.js**(将 Kotlin 转为 JavaScript)。如果它们成功,Kotlin 便可以在 JVM 外使用。
+* Kotlin 也提供简单的方式来编写 **DSL**(Domain Specific Language,领域专用语言,与通用编程语言相对)
+
+**受欢迎程度:**
+
+从 2015 年首次发布以来,Kotlin 的火热程度直线上升。在 StackOverflow 上,Kotlin 在 2019 年人们最爱的编程语言中位列第四:
+
+](https://cdn-images-1.medium.com/max/2000/1*PmUb6Ozt9Cngh0IA9DCpAg.jpeg)
+
+Kotlin 也是上升最快的编程语言之一,在其中同样位列第四:
+
+
+
+PyPl 上,Kotlin 在最火编程语言中排名 12 位,且有**很高的上升趋势**:
+
+](https://cdn-images-1.medium.com/max/2000/1*YKOiuBgCDHSKU4TQBbYbXw.jpeg)
+
+由于谷歌宣布了将 Kotlin 作为安卓应用开发首选语言,Kotlin 在谷歌趋势中有积极上涨。
+
+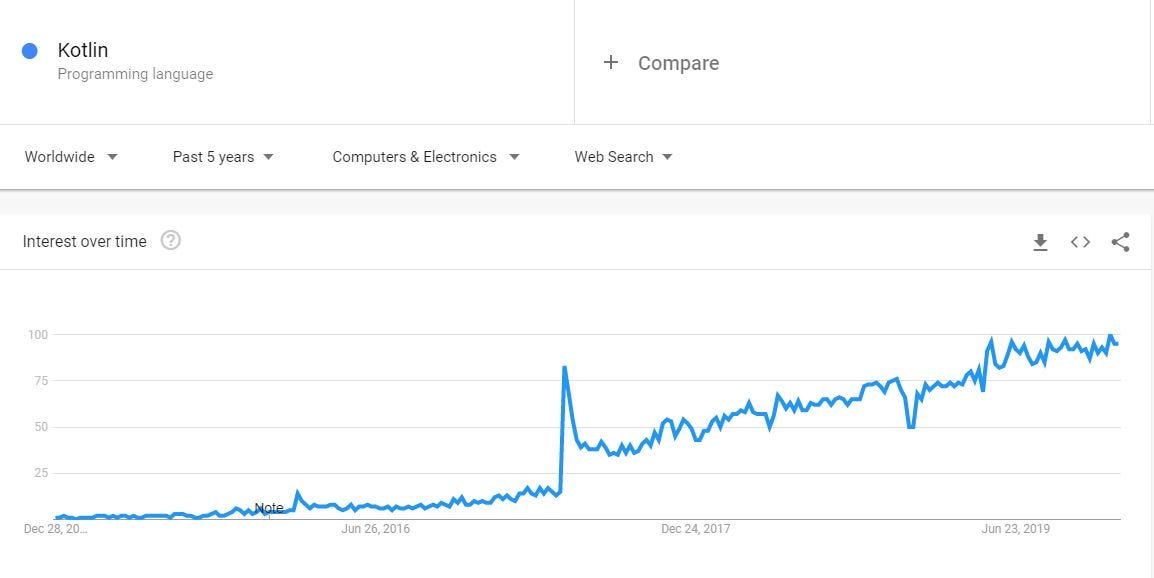
+
+**主要应用场景:**
+
+* 企业级应用
+* 安卓应用开发
+
+**主要竞争语言:**
+
+* Java
+* Scala
+* Python
+* Go
+
+## TypeScript
+
+
+
+JavaScript 是一门优秀的语言,但 2015 以前的 JavaScript 有不少缺点。连著名软件工程师 **Douglas Crockford** 都写了一本书《**JavaScript 语言精粹**》并指出 JavaScript 有**糟糕之处**。不支持模块化,加上“回调地狱”,开发者尤其不愿意维护那些大型的 JavaScript 项目。
+
+谷歌甚至开发了一个将 Java 代码转为 JavaScript 的平台(**GWT**)。很多公司或个人尝试开发更好的 JavaScript,如**Coffee Script、Flow、ClojureScript**,但是来自微软的 **TypeScript** 夺得头魁。微软的一个工程师团队,在著名的 **Anders Hejlsberg**(Delphi、Turbo Pascal、C# 的发明者)的带领下,开发了 TypeScript,作为一种静态类型、模块化的 JavaScript 超集。
+
+TypeScript 会在编译时转为 JavaScript。在 2014 年首次发布后,它很快获得了社区的关注。谷歌当时也在计划开发一个提供静态类型检查的 JavaScript 的超集。谷歌被 TypeScript 惊艳,从而由策划开发一门新语言转为与微软合作来改进 TypeScript。
+
+谷歌将 TypeScript 作为它 SPA 框架 **Angular2** 的主要编程语言。同样,热门 SPA 框架 **React** 也提供 TypeScript 支持。另一热门 JavaScript 框架 Vue.js 也宣布在新的 **Vue.js 3** 中使用 TypeScript 开发。
+
+](https://cdn-images-1.medium.com/max/2278/1*8Kaj35gc8dr3FmdlnmN6_A.jpeg)
+
+并且,Node.js 的创造者 **Ryan Dahl** 决定使用 TypeScript 来开发一款安全的 **Node.js** 替代品,**Deno**。
+
+**关键特性:**
+
+* 像本名单中的 Go 和 Kotlin,TypeScript 的重要特性就是语言设计。它清晰而简洁的代码,使之成为**最优雅的编程语言之一**。至于开发者生产力,它与 Kotlin、Go、Python并驾齐驱。TypeScript 是最具生产力的 JavaScript 超集。
+* TypeScript 是强类型的 JavaScript 超集。它非常适合大型项目,不负“可规模化的 JavaScript” 的美誉。
+* 单页应用程序框架“三巨头”(**Angular、React、Vue.js**)都提供优秀的 TypeScript 支持。在 Angular 中,TypeScript 是建议使用的语言。在其他两个框架中,TypeScript 也逐渐流行起来。
+* 科技公司的两个巨头:**微软和谷歌**正在合作,与活跃的开源社区一起开发 TypeScript。因此,TypeScript 的工具支持在最优行列之中。
+* 由于 TypeScript 是 JavaScript 的超集,JavaScript 能在哪运行,它就能在哪运行 —— 也就是任何地方。TypeScript 可以运行在**浏览器、服务器、移动设备、物联网设备和云端**。
+
+**受欢迎程度:**
+
+开发者因 TypeScript 优雅的语言设计而热爱它。在 StackOverflow 开发者调查中,它与 Python 在最受喜爱的编程语言榜单上并列第二:
+
+](https://cdn-images-1.medium.com/max/2000/1*t6wkuoA1IdPg9ncsg4bLBQ.jpeg)
+
+TypeScript 是上升最快的语言之一,在 GitHub Octoverse 上位列第五:
+
+](https://cdn-images-1.medium.com/max/2000/1*JTRjZ8ZBee5T-cfcH64Jtg.jpeg)
+
+TypeScript 在 GitHub 贡献上位列前十(第七名):
+
+](https://cdn-images-1.medium.com/max/2046/1*Ad7zxTCZGSzt4ioC0ylf5A.jpeg)
+
+TypeScript 每年都吸引更多的眼球,在谷歌趋势上就有所体现:
+
+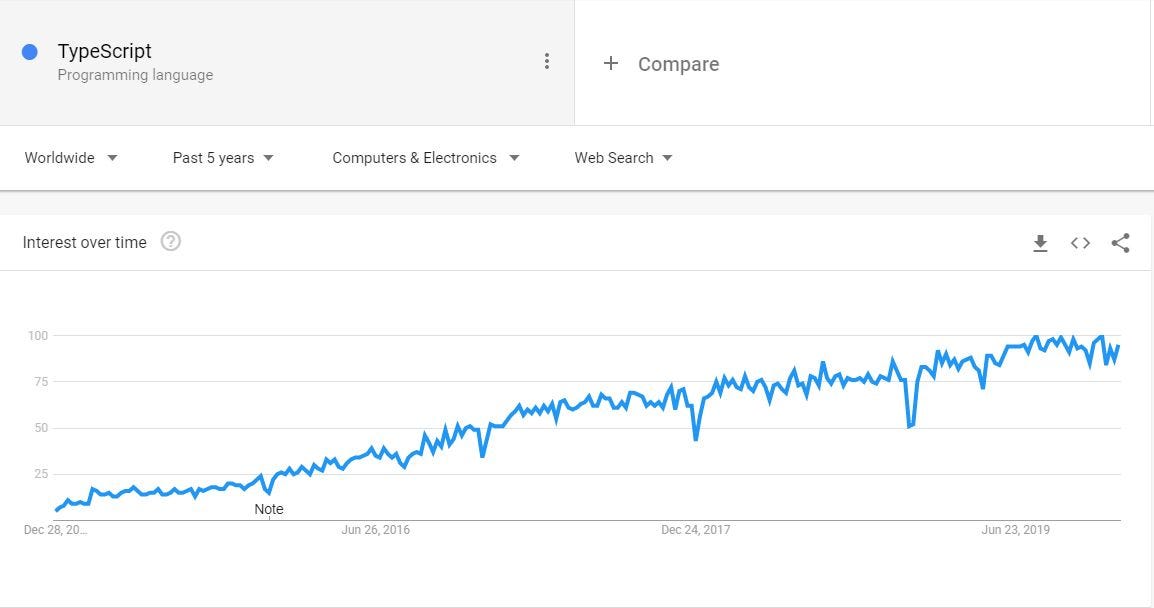
+
+**主要应用场景:**
+
+* Web 用户界面开发
+* 服务端开发
+
+**主要竞争语言:**
+
+* JavaScript
+* Dart
+
+## Swift
+
+
+
+**史蒂夫·乔布斯**拒绝在 iOS 平台上支持 **Java**(和 JVM),并曾引用过一句著名的话:Java 再也不是一个主流编程语言。我们现在知道他对 Java 的评价是错的,然而 iOS 还是没有支持 Java。相反,苹果选择用 **Objective-C** 作为 iOS 平台的首选语言。Objective-C 想要精通很难。并且,它的开发者高生产力的支持也不够好,达不到现代编程语言的要求。
+
+在苹果,**Chris Lattner** 等人开发了 **Swift**,作为一个多范式、通用编译编程语言,作为 Objective-C 的备选项。Swift 的首个稳定版本发布于 2014 年。Swift 也支持 **LLVM** 编译器工具链(同样由**Chris Lattner**)开发。Swift 可以很好地与 Objective-C 代码共存,并且已经成功确立了 iOS 平台应用首选开发语言的地位。
+
+**主要特性:**
+
+* Swift 的一个杀手锏就是它的语言设计。通过更简洁的语法,它比 Objective-C 更高效。
+* Swift 也支持现代编程语言的特性,如空值安全。并且,它提供语法糖来避免缩进过多的问题。
+* 作为一门编译语言,Swift 和 C++ 一样快。
+* Swift 支持 LLVM 编译器工具链。因此,我们可以将 Swift 用于服务端编程,甚至是浏览器编程(借助 WebAssembly)。
+* Swift 支持**自动引用计数(ARC)**,由此控制了内存管理不当的问题。
+
+**受欢迎程度:**
+
+像其他很多现代编程语言一样,开发者也喜爱 Swift 编程语言。根据 StackOverflow 调查,Swift 在最受喜爱编程语言中排名第六位:
+
+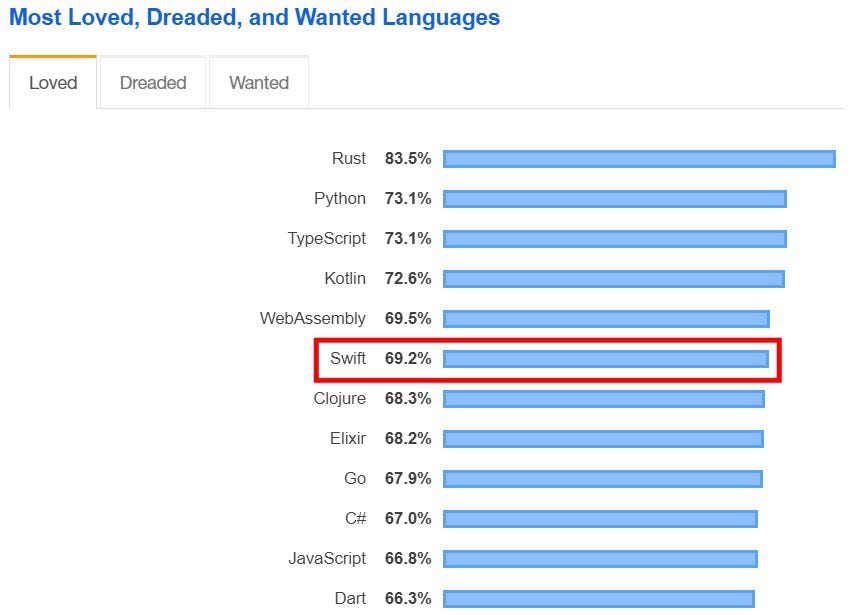
+
+在 TIOBE 编程语言排名中,Swift 在 2019 年排在第十。考虑到这门语言多么年轻(只有 5 年),这已经很优秀了:
+
+
+
+谷歌趋势也显示了 Swift 迅猛的上升趋势,不过近些日子有些下降:
+
+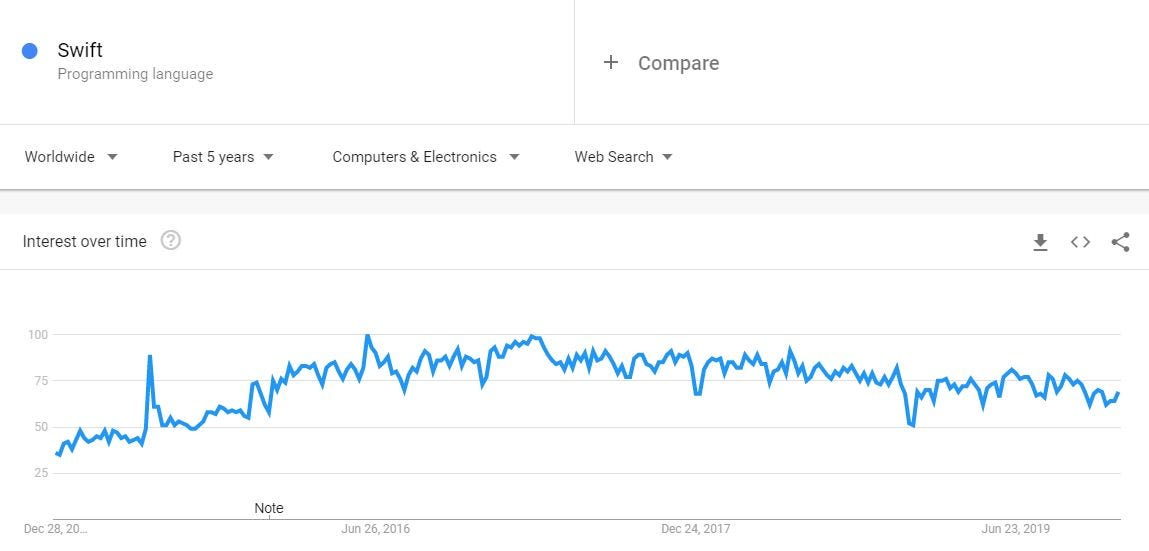
+
+**主要使用场景:**
+
+* iOS 应用开发
+* 系统编程
+* 客户端开发(通过 WebAssembly)
+
+**主要竞争语言:**
+
+* Objective-C
+* Rust
+* Go
+
+## Dart
+
+
+
+**Dart** 是本榜单中谷歌开发的第二个语言。谷歌是 Web 和 Android 领域的关键参与者,因此它在这些领域开发了自己的编程语言不足为奇。由著名丹麦软件工程师 **Lars Bak**(带领了 Chrome 浏览器的 V8 JavaScript 引擎)带领,谷歌在 2013 年发布了 Dart。
+
+Dart 是一门通用编程语言,支持强类型和面向对象编程。Dart 也可以被转为 JavaScript,并在 JavaScript 的运行环境中运行 —— 几乎任何地方(网页、移动端、服务器)。
+
+**主要特性**
+
+* 像谷歌的另外一门语言 Go,Dart 也非常专注于开发者生产效率。Dart 因其简洁精炼的语法而具有很强的生产力,并受到开发者的喜爱。
+* Dart 也提供强类型和面向对象编程,Dart 也是本榜单中可以戴上“**可规模化的 JavaScript**” 标签的第二个语言。
+* Dart 是为数不多支持 **JIT 编译**(在运行时进行编译)和 **AOT 编译**(在创建时编译)的语言。因此 Dart 可以针对 JavaScript 运行时环境(V8 引擎),也可以(通过 AOT 编译)编译成高速的原生代码。
+* **跨平台原生应用开发平台 Flutter** 选择了 Dart 作为其开发语言,来开发 iOS 和安卓应用。从那以后,Dart 就变得越来越流行。
+* 像 Go 一样,Dart 也有完善的工具支持,以及 Flutter 的庞大生态。随着 **Flutter** 越来越火,Dart 很快会被更多人接受。
+
+**受欢迎程度**
+
+根据 GitHub Octoverse, Dart 是 **2019 年增长最快的编程语言,其受欢迎程度在过去一年中涨了五倍**:
+
+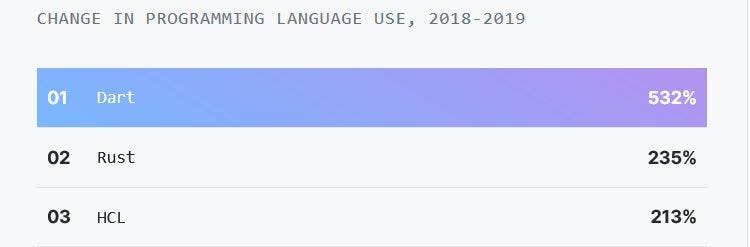
+
+根据 TIOBE 指数,Dart 排在第 23 位,并在短短四年中超过了其他很多已有的现代编程语言:
+
+
+
+它也是最受喜爱的编程语言之一,在 StackOverflow 开发者调查中排名第 12 位:
+
+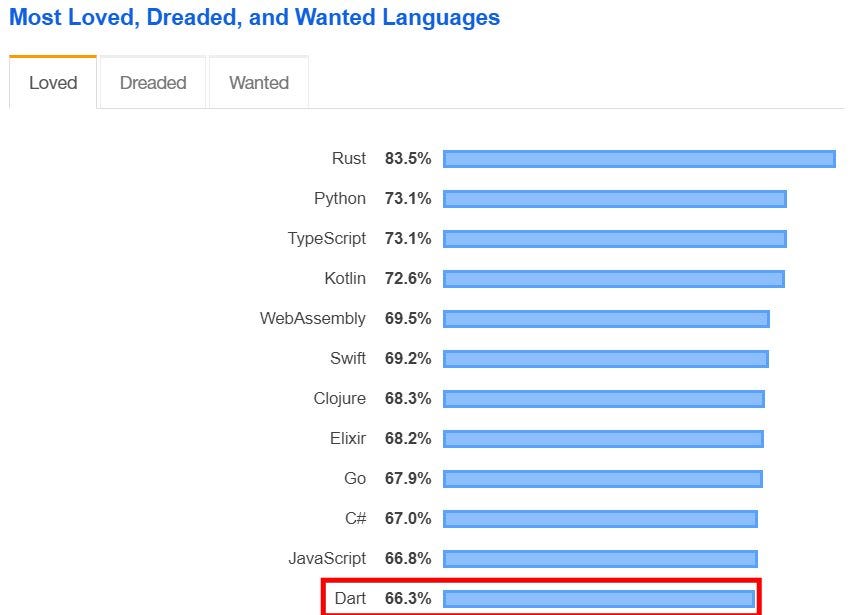
+
+根据谷歌趋势,和 Flutter 一起,Dart 在近两年也获得了很多的关注:
+
+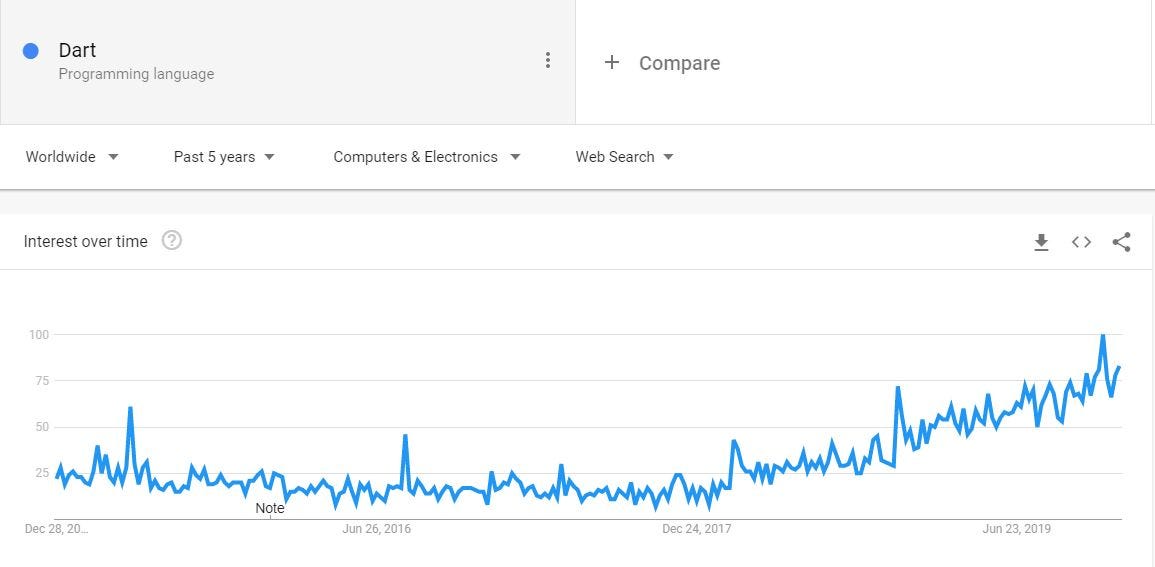
+
+**主要使用场景:**
+
+* 应用开发
+* 用户界面开发
+
+**主要竞争语言:**
+
+* JavaScript
+* TypeScript
+
+## Julia
+
+
+
+本榜单中多数编程语言都由大公司开发,Julia 除外。在**技术型计算**中,通常使用 **Python、Matlab** 这样的动态语言。这些语言提供易用的语法,但是不适于大型的技术运算。人们通常使用 C 或 C++ 的库来进行 CPU 密集型任务,由此导致了**双语言问题**,因为他们需要**胶水代码**来绑定两个语言。由于代码需要在两种语言之间翻译,就会有性能损失。
+
+为了解决这一问题,一群 MIT 的研究人员计划从头开发一门新的语言,能够利用现代硬件,并且结合其他语言的优点。他们在 MIT 创新实验室,在下图中的宣言的指导下工作:
+
+](https://cdn-images-1.medium.com/max/2756/1*sqvWUec74Co1DpySnbQihg.jpeg)(图片译文:……我们想要一门开源、拥有自由协议的语言。我们想要它有 C 一样的速度,和 Ruby 一样的动态性。我们想要它具有[同像性](https://zh.wikipedia.org/wiki/%E5%90%8C%E5%83%8F%E6%80%A7),像 Lisp 一样有真正的宏,但是也像 Matlab 一样有显而易见的、熟悉的数学标记。我们想要它和 Python 一样可以用于通用编程,和 R 一样对统计学友好,有像 Perl 一样自然的字符串处理,在线性代数上像 Matlab 一样强大,像 shell 脚本一样长于将程序粘合在一起。(我们想要)一个极易学习、却又能让那些硬核黑客开心的语言。我们让它可以交互,还想让它是编译语言。)
+
+Julia 是**动态的高级编程语言**,提供顶尖的**并发、并行及分布式计算**支持。Julia 的首个稳定版本在 **2018** 年发布,并很快受到了社区和产业界的关注。Julia 可以用于科学计算、人工智能以及很多其他领域,并可以解决**双语言**问题。
+
+**特性:**
+
+* 和 Rust 一样,Julia 的关键特性是其语言设计。它尝试在不损失性能的同时,将已有的高性能的、可用于科学计算的语言的优秀特性结合在一起。到现在为止,它做得很好。
+* Julia 是动态编程语言,可选类型支持。因此,Julia 是一个易于学习、高生产效率的编程语言。
+* 它的核心使用了**多调度**编程范式。
+* 它内置支持**并发、并行、分布式计算**。
+* 它对于读写密集型任务也提供**异步读写**。
+* 它**相当快**,并且可以用于需要百万级线程的科学计算。
+
+**受欢迎程度:**
+
+Julia 主要和 Python 在多个领域竞争。由于 Python 是当下最流行的编程语言,Julia 需要几年时间才会成为主流。
+
+Julia 相对更年轻(只有一年),但是仍能在 TIOBE 上排名第 43 位:
+
+
+
+谷歌趋势也显示了近年来稳定的关注。
+
+
+
+考虑到它的特性集,以及诸如**NSF(美国科学基金会)、DARPA(美国国防部高级研究计划局)、NASA(美国航天局)、英特尔**这些背后支持 Julia 的组织和公司,Julia 取得突破也只是时间问题,而不是能否的问题。
+
+**主要使用场景:**
+
+* 科学计算
+* 高性能计算
+* 数据科学
+* 可视化
+
+**主要竞争语言:**
+
+* Python
+* Matlab
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/understanding-recursion.md b/TODO1/understanding-recursion.md
new file mode 100644
index 00000000000..6aba15eca79
--- /dev/null
+++ b/TODO1/understanding-recursion.md
@@ -0,0 +1,519 @@
+> * 原文地址:[Understanding Recursion, Tail Call and Trampoline Optimizations](https://marmelab.com/blog/2018/02/12/understanding-recursion.html)
+> * 原文作者:[Thiery Michel](https://twitter.com/hyriel_mecrith)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/understanding-recursion.md](https://github.com/xitu/gold-miner/blob/master/TODO1/understanding-recursion.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[PingHGao](https://github.com/PingHGao),[Chorer](https://github.com/Chorer)
+
+# 理解递归、尾调用优化和蹦床函数优化
+
+想要理解递归,您必须先理解递归。开个玩笑罢了,[递归](https://en.wikipedia.org/wiki/Recursion)是一种编程技巧,它可以让函数在不使用 `for` 或 `while` 的情况下,使用一个调用自身的函数来实现循环。
+
+## 例子 1:整数总和
+
+例如,假设我们想要求从 1 到 i 的整数的和,目标是得到以下结果:
+
+```js
+sumIntegers(1); // 1
+sumIntegers(3); // 1 + 2 + 3 = 6
+sumIntegers(5); // 1 + 2 + 3 + 4 + 5 = 15
+```
+
+这是不用递归来实现的代码:
+
+```js
+// 循环
+const sumIntegers = i => {
+ let sum = 0; // 初始化
+ do { // 重复
+ sum += i; // 操作
+ i --; // 下一步
+ } while(i > 0); // 循环停止的条件
+
+ return sum;
+}
+```
+
+用递归来实现的代码如下:
+
+```js
+// 循环
+const sumIntegers = (i, sum = 0) => { // 初始化
+ if (i === 0) { //
+ return sum; // 结果
+ }
+
+ return sumIntegers( // 重复
+ i - 1, // 下一步
+ sum + i // 操作
+ );
+}
+
+// 甚至实现得更简单
+const sumIntegers = i => {
+ if (i === 0) {
+ return i;
+ }
+ return i + sumIntegers(i - 1);
+}
+```
+
+这就是递归的基础。
+
+注意,递归版本中是没有**中间变量**的。它不使用 `for` 或者 `do...while`。由此可见,它是**声明式**的。
+
+我还可以告诉您的是,事实上递归版本比循环版本**慢** —— 至少在 JavaScript 中是这样。但是递归解决的不是性能问题,而是可表达性的问题。
+
+
+
+## [](#example-2-sum-of-array-elements)例子 2:数组元素之和
+
+让我们尝试一个稍微复杂一点的例子,一个将数组中的所有数字相加的函数。
+
+```js
+sumArrayItems([]); // 0
+sumArrayItems([1, 1, 1]); // 1 + 1 + 1 = 3
+sumArrayItems([3, 6, 1]); // 3 + 6 + 1 = 10
+
+// 循环
+const sumArrayItems = list => {
+ let result = 0;
+ for (var i = 0; i++; i <= list.length) {
+ result += list[i];
+ }
+ return result;
+}
+```
+
+正如您所看到的,循环版本是命令性的:您需要确切地告诉程序要**做什么**才能得到所有数字的和。下面是递归的版本:
+
+```js
+// 递归
+const sumArrayItems = list => {
+ switch(list.length) {
+ case 0:
+ return 0; // 空数组的和为 0
+ case 1:
+ return list[0]; // 一个元素的数组之和,就是这个唯一的元素。#显而易见
+ default:
+ return list[0] + sumArrayItems(list.slice(1)); // 否则,数组的和就是数组的第一个元素 + 其余元素的和。
+ }
+}
+```
+
+递归版本中,我们并没有告诉程序要**做什么**,而是引入了简单的规则来**定义**数组中所有数字的和是多少。这可比循环版本有意思多了。
+
+如果您是函数式编程的爱好者,您可能更喜欢 `Array.reduce()` 版本:
+
+```text
+// reduce 版本
+const sumArrayItems = list => list.reduce((sum, item) => sum + item, 0);
+```
+
+这种写法更短,而且更直观。但这是另一篇文章的主题了。
+
+
+
+## [](#example-3-quick-sort)例子 3:快速排序
+
+现在,我们来看另一个例子。这次的更复杂一点:[快速排序](https://zh.wikipedia.org/wiki/Quicksort)。快速排序是对数组排序最快的算法之一。
+
+快速排序的排序过程:获取数组的第一个元素,然后将其余的元素分成比第一个元素小的数组和比第一个元素大的数组。然后,再将获取的第一个元素放置在这两个数组之间,并且对每一个分隔的数组重复这个操作。
+
+要用递归实现它,我们只需要遵循这个定义:
+
+```js
+const quickSort = array => {
+ if (array.length <= 1) {
+ return array; // 一个或更少元素的数组是已经排好序的
+ }
+ const [first, ...rest] = array;
+
+ // 然后把所有比第一个元素大和比第一个元素小的元素分开
+ const smaller = [], bigger = [];
+ for (var i = 0; i < rest.length; i++) {
+ const value = rest[i];
+ if (value < first) { // 小的
+ smaller.push(value);
+ } else { // 大的
+ bigger.push(value);
+ }
+ }
+
+ // 排序后的数组为
+ return [
+ ...quickSort(smaller), // 所有小于等于第一个的元素的排序数组
+ first, // 第一个元素
+ ...quickSort(bigger), // 所有大于第一个的元素的排序数组
+ ];
+};
+```
+
+简单,优雅和声明式,通过阅读代码,我们可以读懂快速排序的定义。
+
+现在想象一下用循环来实现它。我先让您想一想,您可以在本文的最后找到答案。
+
+
+
+## [](#example-4-get-leaves-of-a-tree)例子 4:取得一棵树的叶节点
+
+当我们需要处理**递归数据结构**(如树)时,递归真的很有用。树是具有某些值和`孩子`属性的对象;孩子们又包含着其他的树或叶子(叶子指的是没有孩子的对象)。例如:
+
+```js
+const tree = {
+ name: 'root',
+ children: [
+ {
+ name: 'subtree1',
+ children: [
+ { name: 'child1' },
+ { name: 'child2' },
+ ],
+ },
+ { name: 'child3' },
+ {
+ name: 'subtree2',
+ children: [
+ {
+ name: 'child1',
+ children: [
+ { name: 'child4' },
+ { name: 'child5' },
+ ],
+ },
+ { name: 'child6' }
+ ]
+ }
+ ]
+};
+```
+
+假设我需要一个函数,该函数接受一棵树,返回一个叶子(没有孩子节点的对象)数组。预期结果是:
+
+```js
+getLeaves(tree);
+/*[
+ { name: 'child1' },
+ { name: 'child2' },
+ { name: 'child3' },
+ { name: 'child4' },
+ { name: 'child5' },
+ { name: 'child6' },
+]*/
+```
+
+我们先用老方法试试,不用递归。
+
+```js
+// 对于没有嵌套的树来说,这是小菜一碟
+const getChildren = tree => tree.children;
+
+// 对于一层的递归来说,它会变成:
+const getChildren = tree => {
+ const { children } = tree;
+ let result = [];
+
+ for (var i = 0; i++; i < children.length - 1) {
+ const child = children[i];
+ if (child.children) {
+ for (var j = 0; j++; j < child.children.length - 1) {
+ const grandChild = child.children[j];
+ result.push(grandChild);
+ }
+ } else {
+ result.push(child);
+ }
+ }
+
+ return result;
+}
+
+// 对于两层:
+const getChildren = tree => {
+ const { children } = tree;
+ let result = [];
+
+ for (var i = 0; i++; i < children.length - 1) {
+ const child = children[i];
+ if (child.children) {
+ for (var j = 0; j++; j < child.children.length - 1) {
+ const grandChild = child.children[j];
+ if (grandChild.children) {
+ for (var k = 0; k++; j < grandChild.children.length - 1) {
+ const grandGrandChild = grandChild.children[j];
+ result.push(grandGrandChild);
+ }
+ } else {
+ result.push(grandChild);
+ }
+ }
+ } else {
+ result.push(child);
+ }
+ }
+
+ return result;
+}
+```
+
+呃,这已经很令人头疼了,而且这只是两层递归。您想想看如果递归到第三层、第四层、第十层会有多糟糕。
+
+ 而且这仅仅是求一些叶子;如果您想要将树转换为一个数组并返回,又该怎么办?更麻烦的是,如果您想使用这个循环版本,您必须确定您想要支持的最大深度。
+
+现在看看递归版本:
+
+```js
+const getLeaves = tree => {
+ if (!tree.children) { // 如果一棵树没有孩子,它的叶子就是树本身。
+ return tree;
+ }
+
+ return tree.children // 否则它的叶子就是所有子节点的叶子。
+ .map(getLeaves) // 在这一步,我们可以嵌套数组 ([child1, [grandChild1, grandChild2], ...])
+ .reduce((acc, item) => acc.concat(item), []); // 所以我们用 concat 来连接铺平数组 [1,2,3].concat(4) => [1,2,3,4] 以及 [1,2,3].concat([4]) => [1,2,3,4]
+}
+```
+
+仅此而已,而且它适用于任何层级的递归。
+
+## [](#drawbacks-of-recursion-in-javascript)JavaScript 中递归的缺点
+
+遗憾的是,递归函数有一个很大的缺点:该死的越界错误。
+
+```text
+Uncaught RangeError: Maximum call stack size exceeded
+```
+
+与许多语言一样,JavaScript 会跟踪**堆栈**中的所有函数调用。这个堆栈大小有一个最大值,一旦超过这个最大值,就会导致 `RangeError`。在循环嵌套调用中,一旦根函数完成,堆栈就会被清除。但是在使用递归时,在所有其他的调用都被解析之前,第一个函数的调用不会结束。所以如果我们调用太多,就会得到这个错误。
+
+
+
+为了解决堆栈大小问题,您可以尝试确保计算不会接近堆栈大小限制。这个限制取决于平台,这个值似乎都在 10,000 左右。所以,我们仍然可以在 JavaScript 中使用递归,只是需要小心谨慎。
+
+如果您不能限制递归的大小,这里有两个解决方案:尾调用优化和蹦床函数优化。
+
+## [](#tail-call-optimization)尾调用优化
+
+所有严重依赖递归的语言都会使用这种优化,比如 Haskell。JavaScript 的尾调用优化的支持是在 Node.js v6 中实现的。
+
+[尾调用](https://en.wikipedia.org/wiki/Tail_call) 是指一个函数的最后一条语句是对另一个函数的调用。优化是在于让尾部调用函数替换堆栈中的父函数。这样的话,递归函数就不会增加堆栈。注意,要使其工作,递归调用必须是递归函数的**最后一条语句**。所以 `return loop(..);` 是一次有效的尾调用优化,但是 `return loop() + v;` 不是。
+
+让我们把求和的例子用尾调用优化一下:
+
+```js
+const sum = (array, result = 0) => {
+ if (!array.length) {
+ return result;
+ }
+ const [first, ...rest] = array;
+
+ return sum(rest, first + result);
+}
+```
+
+这使运行时引擎可以避免调用堆栈错误。但是不幸的是,它在 Node.js 中已经不再有效,因为[在 Node 8 中已经删除了对尾调用优化的支持](https://stackoverflow.com/questions/42788139/es6-tail-recursion-optimisation-stack-overflow/42788286#42788286)。也许将来它会支持,但到目前为止,是不存在的。
+
+## [](#trampoline-optimization)蹦床函数优化
+
+另一种解决方法叫做[蹦床函数](http://funkyjavascript.com/recursion-and-trampolines/)。其思想是使用延迟计算稍后执行递归调用,每次执行一个递归。我们来看一个例子:
+
+```js
+const sum = (array) => {
+ const loop = (array, result = 0) =>
+ () => { // 代码不是立即执行的,而是返回一个稍后执行的函数:它是惰性的
+ if (!array.length) {
+ return result;
+ }
+ const [first, ...rest] = array;
+ return loop(rest, first + result);
+ };
+
+ // 当我们执行这个循环时,我们得到的只是一个执行第一步的函数,所以没有递归。
+ let recursion = loop(array);
+
+ // 只要我们得到另一个函数,递归过程中就还有其他步骤
+ while (typeof recursion === 'function') {
+ recursion = recursion(); // 我们执行现在这一步,然后重新得到下一个
+ }
+
+ // 一旦执行完毕,返回最后一个递归的结果
+ return recursion;
+}
+```
+
+这是可行的,但是这种方法也有一个很大的缺点:它很**慢**。在每次递归时,都会创建一个新函数,在大型递归时,就会产生大量的函数。这就很令人心烦。的确,我们不会得到一个错误,但这会减慢(甚至冻结)函数运行。
+
+
+
+## [](#from-recursion-to-iteration)从递归到迭代
+
+如果最终出现性能或者最大调用堆栈大小超出的问题,您仍然可以将递归版本转换为迭代版本。但不幸的是,正如您将看到的,迭代版本通常更复杂。
+
+让我们以 `getLeaves` 的实现为例,并将递归逻辑转换为迭代。我知道结果,我以前试过,很糟糕。现在我们再试一次,但这次是递归的。
+
+```js
+// 递归版本
+const getLeaves = tree => {
+ if (!tree.children) { // 如果一棵树没有孩子,它的叶子就是树本身。
+ return tree;
+ }
+
+ return tree.children // 否则它的叶子就是所有子节点的叶子。
+ .map(getLeaves) // 在这一步,我们可以嵌套数组 ([child1, [grandChild1, grandChild2], ...])
+ .reduce((acc, item) => acc.concat(item), []); // 所以我们用 concat 来连接铺平数组 [1,2,3].concat(4) => [1,2,3,4] 以及 [1,2,3].concat([4]) => [1,2,3,4]
+}
+```
+
+首先,我们需要重构递归函数以获取累加器参数,该参数将用于构造结果。它写起来甚至会更短:
+
+```js
+const getLeaves = (tree, result = []) => {
+ if (!tree.children) {
+ return [...result, tree];
+ }
+
+ return tree.children
+ .reduce((acc, subTree) => getLeaves(subTree, acc), result);
+}
+```
+
+然后,这里技巧就是将递归调用展开到剩余计算的堆栈中。**在递归外部**初始化结果累加器,并将进入递归函数的参数推入堆栈。最后,将堆叠的运算解堆叠,得到最后的结果:
+
+```js
+const getLeaves = tree => {
+ const stack = [tree]; // 将初始树添加到堆栈中
+ const result = []; // 初始化结果累加器
+
+ while (stack.length) { // 只要堆栈中有一个项
+ const currentTree = stack.pop(); // 得到堆栈中的第一项
+ if (!currentTree.children) { // 如果一棵树没有孩子,它的叶子就是树本身。
+ result.unshift(currentTree); // 所以把它加到结果里
+ continue;
+ }
+ stack.push(...currentTree.children);// 否则,将所有子元素添加到堆栈中,以便在下一次迭代中处理
+ }
+
+ return result;
+}
+```
+
+这好像有点难,所以让我们用 quickSort 再次做一次。这是递归版本:
+
+```js
+const quickSort = array => {
+ if (array.length <= 1) {
+ return array; // 一个或更少元素的数组是已经排好序的
+ }
+ const [first, ...rest] = array;
+
+ // 然后把所有比第一个元素大和比第一个元素小的元素分开
+ const smaller = [], bigger = [];
+ for (var i = 0; i < rest.length; i++) {
+ const value = rest[i];
+ if (value < first) { // 小的
+ smaller.push(value);
+ } else { // 大的
+ bigger.push(value);
+ }
+ }
+
+ // 排序后的数组为
+ return [
+ ...quickSort(smaller), // 所有小于等于第一个的元素的排序数组
+ first, // 第一个元素
+ ...quickSort(bigger), // 所有大于第一个的元素的排序数组
+ ];
+};
+```
+
+
+
+```js
+const quickSort = (array, result = []) => {
+ if (array.length <= 1) {
+ return result.concat(array); // 一个或更少元素的数组是已经排好序的
+ }
+ const [first, ...rest] = array;
+
+ // 然后把所有比第一个元素大和比第一个元素小的元素分开
+ const smaller = [], bigger = [];
+ for (var i = 0; i < rest.length; i++) {
+ const value = rest[i];
+ if (value < first) { // 小的
+ smaller.push(value);
+ } else { // 大的
+ bigger.push(value);
+ }
+ }
+
+ // 排序后的数组为
+ return [
+ ...quickSort(smaller, result), // 所有小于等于第一个的元素的排序数组
+ first, // 第一个元素
+ ...quickSort(bigger, result), // 所有大于第一个的元素的排序数组
+ ];
+};
+```
+
+然后使用堆栈来存储数组进行排序,在每个循环中应用前面的递归逻辑将其解堆栈。
+
+```js
+const quickSort = (array) => {
+ const stack = [array]; // 我们创建一个数组堆栈进行排序
+ const sorted = [];
+
+ //我们遍历堆栈直到它被清空
+ while (stack.length) {
+ const currentArray = stack.pop(); // 我们取堆栈中的最后一个数组
+
+ if (currentArray.length == 1) { // 如果只有一个元素,那么我们把它加到排序中
+ sorted.push(currentArray[0]);
+ continue;
+ }
+ const [first, ...rest] = currentArray; // 否则我们取数组中的第一个元素
+
+ //然后把所有比第一个元素大和比第一个元素小的元素分开
+ const smaller = [], bigger = [];
+ for (var i = 0; i < rest.length; i++) {
+ const value = rest[i];
+ if (value < first) { // 小的
+ smaller.push(value);
+ } else { // 大的
+ bigger.push(value);
+ }
+ }
+
+ if (bigger.length) {
+ stack.push(bigger); // 我们先向堆栈中添加更大的元素来排序
+ }
+ stack.push([first]); // 我们在堆栈中添加 first 元素,当它被解堆时,更大的元素就已经被排序了
+ if (smaller.length) {
+ stack.push(smaller); // 最后,我们将更小的元素添加到堆栈中来排序
+ }
+ }
+
+ return sorted;
+}
+```
+
+瞧!我们就这样有了快速排序的迭代版本。但是记住,这只是一个优化,
+
+> 不成熟的优化是万恶之源 —— 唐纳德·高德纳
+
+因此,仅在您需要时再这样做。
+
+
+
+## [](#conclusion)结论
+
+我喜欢递归。它比迭代版本更具声明式,并且通常情况下代码也更短。递归可以轻松地实现复杂的逻辑。尽管存在堆栈溢出问题,但在不滥用的前提下,在 JavaScript 中使用它是没问题的。并且如果有需要,可以将递归函数重构为迭代版本。
+
+所以尽管它有缺点,我还是向您强烈安利它!
+
+如果您喜欢这种模式,可以看看 Scala 或 Haskell 等函数式编程语言。它们也喜欢递归!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/understanding-service-workers-and-caching-strategies.md b/TODO1/understanding-service-workers-and-caching-strategies.md
new file mode 100644
index 00000000000..6849c7a439f
--- /dev/null
+++ b/TODO1/understanding-service-workers-and-caching-strategies.md
@@ -0,0 +1,145 @@
+> * 原文地址:[Understanding Service Workers and Caching Strategies](https://blog.bitsrc.io/understanding-service-workers-and-caching-strategies-a6c1e1cbde03)
+> * 原文作者:[Aayush Jaiswal](https://medium.com/@aayush1408)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/understanding-service-workers-and-caching-strategies.md](https://github.com/xitu/gold-miner/blob/master/TODO1/understanding-service-workers-and-caching-strategies.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[noname](https://github.com/Eternaldeath)
+
+# 理解 Service Worker 和缓存策略
+
+> 看了本指南,包您能学会 Service Worker 并知道何时使用哪种缓存策略。
+
+ 在 [Unsplash](https://unsplash.com/search/photos/workflow?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 上发布的照片](https://cdn-images-1.medium.com/max/10368/1*vMvkVSydVwjeXBOAXDjC5w.jpeg)
+
+如果您钻研 Javascript 或从事开发工作已经有一段时间了,那您一定听说过 Service Worker。它到底是什么?简单来说,**它是浏览器在后台运行一个脚本,与 web 页面或 DOM 没有任何关系,并具有开箱即用的特性。** 这些功能包括代理网络请求、推送通知以及后台同步。Service Worker 能保证用户拥有良好的离线体验。
+
+您可以将 Service Worker 看作是一个位于客户端和服务器之间的人,对服务器的所有请求都将通过 Service Worker。本质上来说,它就是个**中间人**。由于所有请求都通过 Service Worker,所以它能够动态拦截这些请求。
+
+
+
+不同的 Service Worker 运行在不同的线程上,它们是没有权限直接访问 DOM 元素的,就像一个个与 DOM 和 Web 页面没有交互的 Javascript。虽然不能直接访问 DOM,但是它们可以通过 **postMessage** 间接访问 DOM。如果您打算构建一个渐进式 Web 应用,那么您应该熟练掌握 Service Worker 和缓存策略。
+
+> **注意:** Service worker 不是 Web Worker。Web Worker 是在不同线程上运行运行负载密集型计算的脚本,它不会阻塞主事件循环,也不会阻塞 UI 的渲染。
+
+---
+
+小安利:使用 **[Bit](https://github.com/teambit/bit)** 在项目之间复用和同步组件。作为一个团队来构建与共享组件,可以使组件更快地构建多个应用。
+[**团队共享可重用的代码组件 · Bit**
+在 Bit ,开发人员可以共享组件并共同构建出优秀软件。快来 bit.dev 上发现共享的组件。](https://bit.dev/)
+
+
+
+---
+
+## 注册 Service Worker
+
+要在网站中使用 Service Worker,我们必须首先在一个 Javascript 文件中注册一个 Service Worker。
+
+
+
+在上面的代码中,我们首先检查 Service Worker API是否存在。如果存在,我们将通过上面刚刚写的 Javascript 文件的路径使用 register 方法来注册 Service Worker。因此,一旦页面被加载,您的 Service Worker 就会被注册。
+
+## Service Worker 的生命周期
+
+
+
+#### 安装(Install)
+
+在 Service Worker 注册好时,将触发 **install** 事件。我们可以在 **sw.js** 文件中监听此事件。在深入了解代码前,先让我们了解一下在这个 **install** 事件中应该做些什么。
+
+* 我们想在此事件中设置缓存。
+* 将所有静态资源添加到缓存中。
+
+**event.waitUntil()** 方法接收一个 Promise ,使用它来知道安装需要多长时间,以及安装是否成功。如果任何一个文件在缓存过程中失败,那么 Service Worker 的安装也会失败。因此,确保一个短的缓存文件地址列表是很重要的,因为即使一个文件缓存的失败,也会�中断 Service Worker 的安装。
+
+
+
+#### 激活(Activate)
+
+一旦一个新的 Service Worker 安装好,并且在不使用以前的版本的 Service Worker 的情况下,就会激活一个新的 Service Worker,同时我们还会得到一个 **activate** 事件。在这个激活事件里,我们可以移除或删除现有的旧缓存。下面给出的代码段摘自[离线指南 中的 Service Worker 部分](https://juejin.im/post/5c0788a65188250808259ae4)。
+
+
+
+#### 空闲(Idle)
+
+这个阶段没什么好说的,在 Activate 阶段之后,Service Worker 将处于空闲,不执行任何操作,直到另一个事件被触发。
+
+#### 获取(Fetch)
+
+每当发出 fetch 请求时,就会触发一个 **fetch** 事件。我们在这个事件里实现缓存策略。正如我之前提到的,Service Worker 就像一个中间人,所有请求都经过 Service Worker。在这里,我们可以决定是将请求走到网络还是从缓存中获取。下面是一个例子,Service Worker 拦截请求,如果缓存没有返回有效的响应,则将请求发送到网络。
+
+
+
+上面的代码是缓存策略的一个例子。您应该已经掌握了 Service Worker 的原理了。现在,我们将深入研究一些缓存策略。
+
+## 缓存策略
+
+在上面的 **fetch** 事件中,我们讨论了一种叫**缓存优先,若无缓存则回退到网络**的缓存策略。需要注意是,所有的缓存策略都将在 **fetch** 事件中实现。让我们来看看这些缓存策略。
+
+#### 仅缓存(Cache only)
+
+最简单的。就像它名字所说的,它意味着所有请求都将进入缓存。
+
+**何时使用:当您只想访问静态资源的时候使用它。**
+
+
+
+#### 仅网络(Network only)
+
+客户端发出请求,Service Worker 拦截该请求并将请求发送到网络。
+
+**何时使用:当不是请求静态资源时,比如 ping 检测、非 GET 的请求。**
+
+
+
+> **注意:**如果我们不使用 **responseWith** 方法,请求也会正常发出。
+
+#### 缓存优先,若无缓存则回退到网络请求(Cache,falling back to network)
+
+这是之前在 fetch 事件中讨论的内容,如果请求缓存不成功,Service Worker 则会将请求网络。
+
+**何时使用:当您在构建离线优先的应用时**
+
+
+
+#### 网络优先,若获取失败则回退到缓存获取(Network falling back to cache)
+
+首先,Service Worker 将向网络发出一个请求,如果请求成功,那么就将资源存入缓存。
+
+**何时使用:当您在构建一些需要频繁改变的内容时,比如实时发布的页面或者游戏排行榜。当您最新数据优先时,此策略便是首选。**
+
+
+
+#### 常规回退(Generic fallback)
+
+当两个请求都失败时(一个请求失败于缓存,另一个失败于网络),您将显示一个通用的回退,以便您的用户不会感受到白屏或某些奇怪的错误。
+
+
+
+我们已经学习完了在开发一个渐进式 Web 应用最常用和最基本的缓存策略。还有更多详细内容,可以查看由 Jake Archibald 编写的 [离线指南](https://developers.google.com/web/fundamentals/instant-and-offline/offline-cookbook?hl=zh-cn)。
+
+## 总结
+
+在这篇文章中,我们了解了一些与 Service Worker 和缓存策略相关的很有意思的内容。希望您能喜欢这篇文章,如果您很喜欢我的文章,欢迎您为我点个赞 💖并关注我以了解更多内容。感谢您的阅读🙏,欢迎随时评论和询问。
+
+---
+
+## 了解更多
+- [**5 个 加速 React 开发的工具**
+5 个工具来加速您的 React 应用开发,专注于组件。](https://blog.bitsrc.io/5-tools-for-faster-development-in-react-676f134050f2)
+- [**11 个 2019 年流行的 JavaScript 动画库**
+一些最好的 JS 和 CSS 动画库。](https://blog.bitsrc.io/11-javascript-animation-libraries-for-2018-9d7ac93a2c59)
+- [**如何构建一个 React 渐进式 Web 应用(PWA)**
+包括透彻、全面的指南与现成的代码例子。](https://blog.bitsrc.io/how-to-build-a-react-progressive-web-application-pwa-b5b897df2f0a)
+
+## 译者注:
+
+本文是一篇入门小总结,强烈建议读者阅读文中提到的由 Jake Archibald 编写的 [离线指南](https://developers.google.com/web/fundamentals/instant-and-offline/offline-cookbook?hl=zh-cn)。阅读需翻墙,但在掘金已有译文:
+- [[译]前端离线指南(上)](https://juejin.im/post/5c0788a65188250808259ae4)
+- [[译]前端离线指南(下)](https://juejin.im/post/5c078e146fb9a049db72e9c3#heading-7)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/use-web-workers-for-your-event-listeners.md b/TODO1/use-web-workers-for-your-event-listeners.md
new file mode 100644
index 00000000000..f9e8f1331fe
--- /dev/null
+++ b/TODO1/use-web-workers-for-your-event-listeners.md
@@ -0,0 +1,102 @@
+> * 原文地址:[For the Sake of Your Event Listeners, Use Web Workers](https://macarthur.me/posts/use-web-workers-for-your-event-listeners)
+> * 原文作者:[Alex MacArthur](https://macarthur.me/)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/use-web-workers-for-your-event-listeners.md](https://github.com/xitu/gold-miner/blob/master/TODO1/use-web-workers-for-your-event-listeners.md)
+> * 译者:[vitoxli](https://github.com/vitoxli)
+> * 校对者:[Alfxjx](https://github.com/Alfxjx)、[febrainqu](https://github.com/febrainqu)、[jilanlan](https://github.com/jilanlan)
+
+# 使用 Web Workers 优化事件监听器
+
+我最近一直在捣鼓 [Web Worker API](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Using_web_workers),结果,我真的后悔没有尽早去研究这个功能强大的工具。现代 Web 应用程序对浏览器主线程的要求越来越高,进而影响程序的性能和提供流畅用户体验的能力。而 Web Worker 正是应对这种挑战的一种方法。
+
+## 点击后发生了什么
+
+Web Workers 有很多优点,但当涉及到程序中多个 DOM 事件监听器(表单提交、窗口大小调整、点击按钮等)的时候,我真的被震撼到了。这些监听器都必须存在于浏览器的主线程上,当主线程因长时间运行的进程而阻塞时,监听器的响应能力会受到影响,在事件循环可以正常运行之前,整个应用程序都会被阻塞。
+
+诚然,监听器之所以困扰我多时,是因为我一开就误解了 Workers 要解决的问题。最开始,我一直以为它主要是关于代码的执行**速度**。“如果我可以在不同的线程上并行执行更多操作,那么我的代码执行速度将大大提升!”但是!在通常情况下,一件事开始执行前需要另一件事发生为前提,例如当你希望一系列计算完成之后才能更新 DOM。所以我幼稚地想:“如果我仍然要等待事件完成后才进行别的操作,把一些任务移到单独的线程中执行的意义没有那么大”。
+
+这是我想到的代码:
+
+```javascript
+const calculateResultsButton = document.getElementById('calculateResultsButton');
+const openMenuButton = document.getElementById('#openMenuButton');
+const resultBox = document.getElementById('resultBox');
+
+calculateResultsButton.addEventListener('click', (e) => {
+ // "在它执行完前,我不能更新 DOM,
+ // 所以我为什么要把它放到 Worker 里呢?"
+ const result = performLongRunningCalculation();
+ resultBox.innerText = result;
+});
+
+openMenuButton.addEventListener('click', (e) => {
+ // Do stuff to open menu.
+});
+```
+
+在这里,我在执行某种可能大计算量的操作后更新了 box 中的文本。并行执行这些操作没有什么意义(DOM 的更新取决于计算的结果),所以,**理所当然**,我希望所有操作都是同步的。但最开始我不了解的是,**如果线程被阻塞,**其它**所有的监听器都无法被触发**。这意味着,操作变得不可靠了。
+
+## 举例说明不靠谱的场景
+
+在下面的示例中,点击“Freeze”按钮将会在增加计数,但在这之前会执行3秒的同步暂停(来模拟长时间运行的计算),而点击“Increment”按钮将立即增加计数。在第一个按钮暂停期间,整个线程处于静止状态,在事件循环可以再次执行前,不会触发其它任何主线程的活动。
+
+为了证明这一点,请单击第一个按钮,然后立即单击第二个按钮。
+
+请在 <a href='https://codepen.io'>CodePen</a> 中查看 Alex MacArthur (<a href='https://codepen.io/alexmacarthur'>@alexmacarthur</a>)的 <a href='https://codepen.io/alexmacarthur/pen/XWWKyGe'>Event Blocking - No Worker</a>。
+
+页面卡住是因为较长的同步暂停阻塞了线程。但造成的影响不止于此。再次执行此操作,但是这次,单击“Freeze”后立即尝试调整蓝色边框的大小。由于布局更改和重绘也在主线程中进行,因此在计时完成前,将再次被阻塞。
+
+## 它们监听的远比你想象得多
+
+任何普通的用户都不愿意经历这种体验,而我们不过是处理了几个事件监听器。不过,在现实世界中,我们要做的还很多。通过使用 Chrome 的`getEventListeners`方法,我使用以下脚本汇总了页面上每个 DOM 元素的事件监听器。将这段代码放到控制台中,它会返回监听器的总数。
+
+```javascript
+Array
+ .from([document, ...document.querySelectorAll('*')])
+ .reduce((accumulator, node) => {
+ let listeners = getEventListeners(node);
+ for (let property in listeners) {
+ accumulator = accumulator + listeners[property].length
+ }
+ return accumulator;
+ }, 0);
+```
+
+我在下列程序中任意的页面运行以上代码,得到的可用的监听器数如下。
+
+| Application | Number of Listeners |
+| --------------- | ------------------- |
+| Dropbox | 602 |
+| Google Messages | 581 |
+| Reddit | 692 |
+| YouTube | 6,054 (!!!) |
+
+注意这些特殊的数字。绑定到 DOM 中监听器的数量很多,而且即使应用程序中只有一个长时间运行的进程出错了,**所有**的监听器都将无响应。这很有可能就降低你程序的用户体验。
+
+## 更靠谱一些的同样的示例(多亏了 Web Workers!)
+
+考虑到以上种种情况,让我们升级上述示例。同样地方法,但是这次,我们把长时间运行的操作移至单独的线程中。再次执行相同的点击,你会发现点击“Freeze”仍然会延迟 3 秒钟更新点击次数,但是**不会阻止页面上其他任何事件监听器**。 相反,其它按钮仍可单击,并且 box 的大小仍然可以调整,这正是我们想要的。
+
+请在 <a href='https://codepen.io'>CodePen</a> 中查看 Alex MacArthur (<a href='https://codepen.io/alexmacarthur'>@alexmacarthur</a>)的 <a href='https://codepen.io/alexmacarthur/pen/qBEORdO'>Event Blocking - Worker</a>。
+
+如果你深入研究该代码,你会注意到,虽然 Web Worker API 可能更符合人机工程学,但实际上并没有想象中那么可怕(恐惧更多是由于直接将众多代码示例放在一起)。为了变得不那么吓人,有一些好的工具可以简化其实现。以下是一些我觉得不错的内容:
+
+* [workerize](https://github.com/developit/workerize) — 在 Web Worker 中运行模块
+* [greenlet](https://github.com/developit/greenlet) — 在 worker 中运行任意一端异步代码
+* [comlink](https://github.com/GoogleChromeLabs/comlink) — 基于 Web Worker API 的抽象封装
+
+## 开始线程编程吧(可以更有意义)
+
+如果你的应用程序是典型的,则可能已经绑定了很多监听器。而且它可能还会执行很多不需要在主线程上进行的计算。因此,可以考虑使用 Web Workers 进行监听并提高用户体验。
+
+需要明确的是,将**所有**非 UI 工作放到工作线程中可能不是一个好方法。可能只是给你的程序增加了很多重构和复杂性,而收效甚微。或许,可以考虑先确定有哪些明显的计算密集的进程,然后分别给这些进程分配一个小型 Web Worker。随着时间的推移,再逐步深入研究并考虑在更大地范围内使用 UI/Worker 架构。
+
+无论如何,深入研究它吧。其强大的浏览器支持以及现代应用程序对性能的需求不断增长,我们没有理由不去研究这类工具。
+
+愉快地开始线程编程吧!
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/webassembly-why-and-how-to-use-it.md b/TODO1/webassembly-why-and-how-to-use-it.md
new file mode 100644
index 00000000000..c49156cda90
--- /dev/null
+++ b/TODO1/webassembly-why-and-how-to-use-it.md
@@ -0,0 +1,115 @@
+> * 原文地址:[WebAssembly: Easy explanation with code example](https://medium.com/front-end-weekly/webassembly-why-and-how-to-use-it-2a4f95c8148f)
+> * 原文作者:[Vaibhav Kumar](https://medium.com/@vaibhav_kumar)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/webassembly-why-and-how-to-use-it.md](https://github.com/xitu/gold-miner/blob/master/TODO1/webassembly-why-and-how-to-use-it.md)
+> * 译者:[fireairforce](https://github.com/fireairforce)
+> * 校对者:[钱俊颖](https://github.com/Baddyo)
+
+# WebAssembly: 带有代码示例的简单介绍
+
+
+
+## 为什么要用 WebAssembly?
+
+#### 背景:Web 和 JavaScript
+
+毫无疑问,web 具有高度移植性并且与机器无关,这使其能成为一个真正通用的平台。
+
+> Web 是唯一真正的通用平台。☝️
+
+JavaScript(JS)是 Web 开发的默认语言。它有许多原生的 Web API 例如(DOM、Fetch、Web-sockets、Storage 等等),并且随着浏览器功能越来越强大,我们正在使用 JavaScript(或者其它能转译成 JS 的语言)来编写更复杂的客户端程序。
+
+但是在浏览器上运行一些大型的应用程序时,JavaScript 存在一些限制。
+
+#### JavaScript 的限制
+
+* 不利于 CPU 密集型任务
+* JS 基于文本而非二进制,因此需要下载更多的字节,启动时间也更长
+* JS 解释和 JIT 优化会消耗 CPU 和电池寿命
+
+
+
+* 需要用 JS 重写已经存在的非 JS 库、模块和应用程序
+
+Web 开发社区正在尝试克服这些限制,并通过引入 Web 开发新成员 **WebAssembly** 来向其它编程语言开放 Web。
+
+> 在 2019 年 12 月 5 日,WebAssembly 和 [HTML](https://en.wikipedia.org/wiki/HTML)、[CSS](https://en.wikipedia.org/wiki/CSS)、[JavaScript](https://en.wikipedia.org/wiki/JavaScript) 一样,成为了第四个 Web 语言标准,能在浏览器上运行。
+
+## Web Assembly (WASM)
+
+> WebAssembly 是一种能在现代 Web 浏览器中运行的二进制代码,它使得我们能用多种语言编写代码并以接近本地运行的速度在 Web 上运行。
+
+#### WASM 的功能
+
+* WASM 是一种不能由开发者编写的底层语言,而是由其它语言例如 C/C++、Rust、AssemblyScript 编译而来
+* WASM 是二进制格式,因此只用下载更少的字节(开发者也有等效的文本格式,称为 [**WAT**](https://developer.mozilla.org/en-US/docs/WebAssembly/Understanding_the_text_format))
+* 与 JS 不同,WASM 二进制文件无需任何优化就可以解码和编译成机器代码,因为在生成 WASM 二进制文件时就已经对其进行了优化
+
+
+
+## 什么时候使用 WebAssembly。
+
+* CPU 密集型任务,例如游戏或其它图形应用中的数学、图像和视频处理等
+* 在 Web 上运行旧的 C/C++ 库和应用程序,提供了可移植性,并且避免了将 C/C++ 代码用 JS 重写的需求
+* 消除将原生应用程序和各种编译目标作为单个 WASM 编译的需求,可以使其通过 Web 浏览器在不同的处理器上运行
+
+> WASM 在这里并不是要取代 JS,而是要与之一起工作。**JavaScript 本身已经具有不错的原生 Web API 集合,WASM 在这里可以协助完成繁重的工作。**
+
+> **注意:**
+现代 JavaScript 引擎非常快速并且可以高度优化我们的 JS 代码,因此 WASM 软件包的大小和执行时间对于简单任务可能不是很有利。
+在本文中,我不做任何基准测试,但请参考本文底部的参考资料,可以获取基准测试链接。
+
+## 怎么使用 WASM(加深学习 🤿)
+
+
+
+让我们参照上述步骤在 **C** 中创建一个程序,用来计算数字的阶乘并将其作为 WASM 在 JS 中使用。
+
+
+
+我们可以使用 [Emscripten](https://emscripten.org/) 将上面 C 函数编译成 WASM:
+
+```
+emcc factorial.c -s WASM=1 -o factorial.html
+```
+
+它会生成 `**factorial.wasm**` 二进制文件以及 **html-js** 粘合代码。[这里](https://emscripten.org/docs/tools_reference/emcc.html#emcc-o-target)引用了输出目标的列表。
+
+有效的可读文本格式 [**WAT**](https://developer.mozilla.org/en-US/docs/WebAssembly/Understanding_the_text_format) 如下所示。
+
+
+
+可以通过多种方式将 WASM 的二进制数据发送到 Web 客户端,我们可以使用 javascript 的 `**WebAssembly**` API 编译二进制数据来创建 **WASM 模块**然后实例化这个**模块**来访问导出的功能。
+
+加载 WASM 代码最有效、最优化的方法是使用 **WebAssembly.instantiateStreaming()** 这个直接从流式基础源编译和实例化 WebAssembly 模块的函数。
+
+以下是使用 `**instantiateStreaming**` 来调用之前生成的 **`factorial.wasm`** 文件的示例代码,该文件可以由我们的服务器提供,也可以被我们的 Web 客户端按需调用。然后,我们可以使用以下 JS 代码实例化接收到的 WASM 模块,并可以访问导出的 **`factorial` function**。
+
+
+
+> 想快速理解所说明的步骤而无需进行繁琐的设置,可以使用 [WASM fiddle](https://wasdk.github.io/WasmFiddle)。
+
+## 浏览器支持
+
+所有的现代浏览器(Chrome、Firefox、Safari、Edge)都支持 WebAssembly。[点击此处以查看最新的支持统计信息](https://caniuse.com/#search=wasm)。
+
+> IE 不支持 WASM。如果需要在 IE 中使用 C/C++ 代码,我们可以使用 Emscripten 将其编译为 [**asm.js**](http://asmjs.org/)(JS 的一个子集)。
+
+## 未来
+
+正在实现对**线程管理**和**垃圾收集**的支持。这会让 WebAssembly 更适合作为 **Java**、**C#**、**Go** 之类的语言的编译目标。
+
+## 参考资料
+
+* [https://webassembly.org/](https://webassembly.org/)
+* [WASM Explorer](https://mbebenita.github.io/WasmExplorer/)
+* [Online WASM IDE](https://webassembly.studio/)
+* [WASM Fiddle](https://wasdk.github.io/WasmFiddle/)
+* [Google code-labs tutorial](https://codelabs.developers.google.com/codelabs/web-assembly-intro/index.html)
+* [Benchmarking reference](https://medium.com/@torch2424/webassembly-is-fast-a-real-world-benchmark-of-webassembly-vs-es6-d85a23f8e193)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/what-on-earth-is-the-shadow-dom-and-why-it-matters.md b/TODO1/what-on-earth-is-the-shadow-dom-and-why-it-matters.md
new file mode 100644
index 00000000000..8a2780ce8bf
--- /dev/null
+++ b/TODO1/what-on-earth-is-the-shadow-dom-and-why-it-matters.md
@@ -0,0 +1,195 @@
+> * 原文地址:[What on Earth is the Shadow DOM and Why Does it Matter?](https://medium.com/better-programming/what-on-earth-is-the-shadow-dom-and-why-it-matters-eff0884bd33d)
+> * 原文作者:[Aphinya Dechalert](https://medium.com/@PurpleGreenLemon)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/what-on-earth-is-the-shadow-dom-and-why-it-matters.md](https://github.com/xitu/gold-miner/blob/master/TODO1/what-on-earth-is-the-shadow-dom-and-why-it-matters.md)
+> * 译者:
+> * 校对者:
+
+# What on Earth is the Shadow DOM and Why Does it Matter?
+
+ on [Unsplash](https://unsplash.com/s/photos/shadow?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/6538/1*wDb9Aw5YXEM_O8DqrsG0vQ.jpeg)
+
+> Isn’t one DOM enough?
+
+We’ve all heard of the DOM at some point. It’s a topic that is quickly brushed over, and there’s not enough discussion of it. The name **shadow DOM** sounds somewhat sinister — but trust me, it’s not.
+
+The concept of DOMs is one of the foundations of the web and interfaces, and it’s deeply intertwined with JavaScript.
+
+Many know what a DOM is. For starters, it stands for Document Object Model. But what does that mean? Why is it important? And how is understanding how it works relevant to your next coding project?
+
+---
+
+Read on to find out.
+
+## What Exactly Is a DOM?
+
+There’s a misconception that HTML elements and DOM are one and the same. However, they are separate and different in terms of functionality and how they are created.
+
+HTML is a markup language. Its sole purpose is to dress up content for rendering. It uses tags to define elements and uses words that are human-readable. It is a standardized markup language with a set of predefined tags.
+
+Markup languages are different from typical programming syntaxes because they don’t do anything other than create demarcations for content.
+
+The DOM, however, is a constructed tree of objects that are created by the browser or rendering interface. In essence, it acts sort of like an API for things to hook into the markup structure.
+
+So what does this tree look like?
+
+Let’s take a quick look at the HTML below:
+
+```HTML
+<!doctype html>
+ <html>
+ <head>
+ <title>DottedSquirrel.com</title>
+ </head>
+ <body>
+ <h1>Welcome to the site!</h1>
+ <p>How, now, brown, cow</p>
+ </body>
+ </html>
+```
+
+This will result in the following DOM tree.
+
+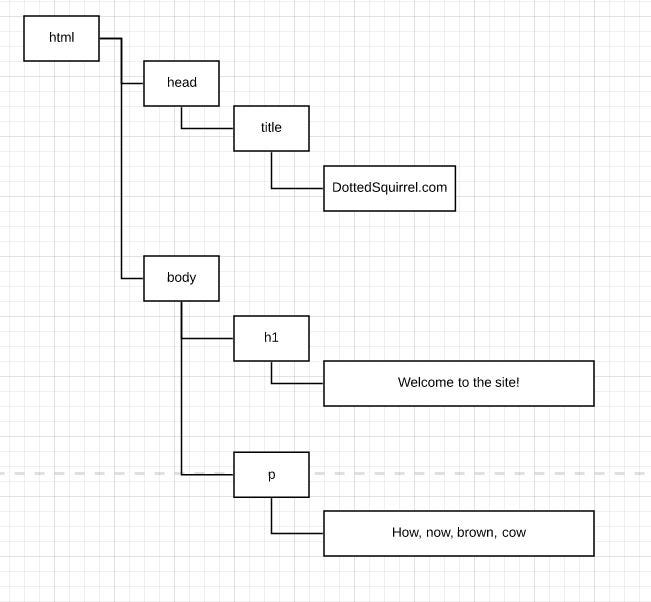
+
+Since all elements and any styling in an HTML document exist on the global scope, it also means that the DOM is one big globally scoped object.
+
+`document` in JavaScript refers to the global space of a document. The `querySelector()` method lets you find and access a particular element type, regardless of how deeply nested it sits in the DOM tree, provided that you have the pathway to it correct.
+
+For example:
+
+```js
+document.querySelector(".heading");
+```
+
+This will select the first element in the document with `class="heading"`.
+
+Suppose you do something like the following:
+
+```js
+document.querySelector("p");
+```
+
+This will target the first `\<p>` element that exists in a document.
+
+To be more specific, you can also do something like this:
+
+```js
+document.querySelector("h1.heading");
+```
+
+This will target the first instance of `\<h1 class="heading">`.
+
+Using `.innerHTML = ""` will give you the ability to modify whatever sits in between the tags. For example, you can do something like this:
+
+```js
+document.querySelector("h1").innerHTML = "Moooo!"
+```
+
+This will change the content inside the first `\<h1>` tags to `Moooo!`.
+
+---
+
+Now that we have the basics of DOMs sorted, let’s talk about when a DOM starts to exist within a DOM.
+
+## DOM Within DOMs (aka Shadow DOMs)
+
+There are times when a straight single-object DOM will suffice for all the requirements of your web app or web page. Sometimes, though, you need third-party scripts to display things without it messing with your pre-existing elements.
+
+This is where shadow DOMs come into play.
+
+Shadow DOMs are DOMs that sit in isolation, have their own set of scopes, and aren’t part of the original DOM.
+
+Shadow DOMs are essentially self-contained web components, making it possible to build modular interfaces without them clashing with one another.
+
+Browsers automatically attach shadow DOMs to some elements, such as `\<input>` , `\<textarea>` and, `\<video>`.
+
+But sometimes you need to manually create the shadow DOM to extract the parts you need. To do this, you need to first create a shadow host, followed by a shadow root.
+
+#### Setting up the shadow host
+
+To split out a shadow DOM, you need to figure out which set of wrappers you want to extract.
+
+For example, you want the `host` class to be the set of wrappers that defines the boundaries of your shadow DOM.
+
+```HTML
+<!doctype html>
+ <html>
+ <head>
+ <title>DottedSquirrel.com</title>
+ </head>
+ <body>
+ <h1>Welcome to the site!</h1>
+ <p>How, now, brown, cow</p>
+ <span class="host">
+ ...
+ <span class="host">
+ </body>
+ </html>
+```
+
+Under normal circumstances, `span` isn’t automatically converted into a shadow DOM by the browser. To do this via JavaScript, you need to use `querySelector()` and `attachShadow()` methods.
+
+```js
+const shadowHost = document.querySelector(".host");
+const shadow = shadowHost.attachShadow({mode: 'open'});
+```
+
+`shadow` is set up to be the shadow root of our shadow DOM. The elements then become a child of an extracted and separate DOM with `.host` as the root class element.
+
+While you can still see the HTML in your inspector, the `host` portion of the code is no longer visible to the root code.
+
+To access this new shadow DOM, you just need to use a reference to the shadow root, i.e., `shadow` in the example above.
+
+For example, you want to add some content. You can do so with something like this:
+
+```js
+const paragraph = document.createElement("p");
+paragraph.text = shadow.querySelector("p");
+paragraph.innerHTML = "helloooo!";
+```
+
+This will create a new `p` element with the text `helloooo!` inside your shadow root.
+
+#### Parts of a shadow DOM
+
+A shadow DOM consists of four parts: the shadow host, the shadow tree, the shadow boundary, and the shadow root.
+
+The shadow host is the regular DOM node that the shadow DOM is attached to. In the examples previously, this is through the class `host`.
+
+The shadow tree looks and acts like a normal DOM tree, except its scope is limited to the edges of the shadow host.
+
+The shadow boundary is the place where the shadow DOM starts and ends.
+
+And finally, the shadow root is the root node of the shadow tree. This is different from the shadow host (i.e., `host` class, based on the examples above).
+
+Let’s look at this code again:
+
+```js
+const shadowHost = document.querySelector(".host");
+const shadow = shadowHost.attachShadow({mode: 'open'});
+```
+
+The `shadowHost` constant is our shadow host, while `shadow` is actually the shadow root. The difference between these two is that `shadow` returns a `DocumentFragment` while the `shadowHost` returns a `document` element.
+
+---
+
+Think of the host as a placeholder for the location of your actual shadow DOM.
+
+## Why Do Shadow DOMs Matter?
+
+Now comes the big question — why do shadow DOMs matter?
+
+Shadow DOM is a browser technology that’s used to scope variables and CSS in web components.
+
+For starters, a DOM is an object, and you can’t possibly do all you need to do with a single object without it stepping over boundaries you want to certainly keep separate.
+
+This means that shadow DOMs allow for encapsulation, that is, the ability to keep markup structure, style, and behavior separated and hidden from other code so they don’t clash.
+
+And those are the basics of shadow DOMs.
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/whats-going-on-in-that-front-end-head.md b/TODO1/whats-going-on-in-that-front-end-head.md
new file mode 100644
index 00000000000..bda23e108c3
--- /dev/null
+++ b/TODO1/whats-going-on-in-that-front-end-head.md
@@ -0,0 +1,148 @@
+> * 原文地址:[What’s going on in that front end head?](https://medium.com/front-end-weekly/whats-going-on-in-that-front-end-head-dd443f3fb7d5)
+> * 原文作者:[Andreea Macoveiciuc](https://medium.com/@andreea.macoveiciuc)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/whats-going-on-in-that-front-end-head.md](https://github.com/xitu/gold-miner/blob/master/TODO1/whats-going-on-in-that-front-end-head.md)
+> * 译者:[Jessica](https://github.com/cyz980908)
+> * 校对者:[Long Xiong](https://github.com/xionglong58)
+
+# 前端代中的 head 标签里都有些什么?
+
+> 即使负责 SEO 和市场营销的同事没有要求,在我们前端代码中也应该有的必备标签。
+
+ on [Unsplash](https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 的照片](https://cdn-images-1.medium.com/max/8064/1*lgPqPdewofN-QeUyeocZ8w.jpeg)
+
+当我在准备团队内分享的 SEO 研讨会时,我仔细列出了一些我认为我们应该在 \<head> 中使用的标签。但令我惊讶的是,现实代码中有许多标签并未出现,可能是因为这些标签不是必须项。
+
+因此,如果您是一个想要与负责市场营销和 SEO 的同时成为好基友的前端人员,或者是一个想要寻找一些能够快速提高平台搜索性能的产品负责人,请确保您的代码中没有漏掉下面的标签和属性。
+
+## 文档的语言 —— lang 标签
+
+```html
+<html lang=”en”>…</html>
+```
+
+Google 会忽略 lang 标签,但 Bing 和屏幕阅读器不会,所以,对于可访问性和排名来说,它是一个重要的标签。准确来说,Google 并不是忽略它,而是它是用于识别文档语言并提供翻译服务的。但这对 SEO 来说并不重要。
+
+通常,lang 标签都包含在 \<head> 中,但是也可以用于其他标签,如 \<blockquote> 或 \<p>。当这些元素的语言(实际内容中的语言)发生了变化,就可以使用 lang 标签。
+
+例如:
+
+```html
+<blockquote lang="fr" cite="URL">Some french quote here</blockquote>
+```
+
+## hreflang 标签
+
+前面我们提到 Google 在检索到不同语言的文档时会忽略 lang 标签,那么 Google 又是使用什么的呢?答案就是 hreflang 标签!
+
+```html
+<link rel="alternate" href="https://masterPageURL" hreflang="en-us" />
+<link rel="alternate" href="https://DEVersionURL-" hreflang="de-de" />
+```
+
+这些标签里面发生了什么?
+
+第一个行告诉 Google,该页面上使用的语言是英语,更准确地说,是针对我们的美国用户的。
+
+第二行告诉 Google,如果有来自德国的用户在浏览,应该加载有 **hreflang=”de-de”** 的标签中 href 属性对应的页面。
+
+如上图所示,hreflang 标签可以在 <head> 中使用,它还可以在 sitemap 中使用。如果您有多种语言的内容,并且希望降低异国用户获取到不相匹配的语言内容的风险,那么此标签非常有用。
+
+但是,注意 lang 和 hreflang 标签都是**参考信息**,而不是指令。这意味着搜索引擎仍然可以显示页面的错误版本。
+
+## canonical 标签
+
+canonical 标签可能是所有标签中最烦人和最令人困惑的,下面是最通俗易懂的解释,这样您就能一劳永逸地理解它们的作用。
+
+canonical 标签长这样:
+
+```html
+<link rel="canonical" href="https://masterPageURL" />
+```
+
+它有什么用?它告诉搜索引擎在 href 属性中添加的 URL 是主版页,或者是一组重复页面中和主题最相关的。
+
+例如,在一个商城网站中,动态 URL 非常常见。在动态 URL 中,通过添加诸如 ?category= 或会话 ID 之类的参数来表示页面中的需要传递的值。
+
+当这种情况发生时,您需要告诉 Google 哪些参数是应该被主版页索引的。您可以通过添加 canonical 标签并将其指向主版页的 URL 来实现。
+
+请注意,**所有重复的页面**都需要包含此标签并指向主页面。
+
+## Robots meta 标签
+
+它和 robots.txt 文件不同。它是一个像下面这样的标签:
+
+```html
+<meta name="robots" content="noindex, nofollow" />
+```
+
+它有什么用?这个标签告诉搜索引擎机器人如何爬取一个页面,建立索引或不建立索引,继续爬取或不继续爬取。
+
+与 lang 标签 和 robots.txt 文件不同,robots meta 标签是一个**指令**,因此它为搜索引擎机器人提供严格的指令。
+
+可能的值如下:
+
+* noindex:告诉搜索引擎不索引该页面。
+* index:告诉搜索引擎索引该页面。这是默认值,因此如果希望页面被索引,可以跳过不设置它。
+* nofollow:告诉爬虫不要继续爬取该页面中的任何链接,也不要传递任何链接权重。
+* follow:告诉爬虫继续爬取页面上的链接并传递链接权重(“juice”)。即使页面不能被索引到,也不影响。
+
+## 社交 meta 标签:OG
+
+OG 是 Open Graph Protocol 的缩写,它是一种允许您控制在社交媒体上分享页面时显示什么数据的技术。下面是标签的样子:
+
+```html
+<meta property="og:title" content="The title" />
+<meta property="og:type" content="website" />
+<meta property="og:url" content="http://page.com" />
+<meta property="og:image" content="img.jpg" />
+```
+
+以上四个标签是必须的,但是您可以添加更多其他标签,您可以在[这里](https://ogp.me/)查看列表。
+
+如果缺少这些,您可能迟早会听到一些抱怨,因为每当同事分享一个页面时,如果 og:image 标签没被指定,将随机选择图像。
+
+## Meta title & meta description 标签
+
+老实说,我认为这些是在 \<head> 中必须存在的。但为了以防万一,您可以点击右键并检查。
+
+这两个 meta 标签非常重要,因为它们告诉搜索引擎和社交平台该页面是关于什么的,并且它们会在搜索结果页面中显示出来。此外,title 将显示在浏览器选项卡中以及在添加书签时的书签中。
+
+下面是标签的样子:
+
+```html
+<title>This is the page title<title />
+<meta name="description" content="This is the meta description, meaning the text that's displayed in SERP snippets." />
+```
+
+现在,您可能想起了一个来自 Google 的老答案,这个答案可以追溯到 2009 年,它说 meta description 标签对 SEO 没有帮助。尽管如此,它们与 meta title 和页面 URL 一起依然是最能说服用户点击页面的元素。所以不管对 SEO 有没有帮助,它们都是非常重要的。
+
+## 用于响应式设计的 meta 标签
+
+这个标签的官方名称是 viewport,它看起来是这样的:
+
+```html
+<meta name="viewport" content="width=device-width, initial-scale=1" />
+```
+
+将其添加到文档的 /<head> 中,可以使页面是响应式的,并且使页面在移动设备和平板电脑上展示正常。您可能也听说过,Google 会首先扫描和索引移动版本的网站,目的是使网页在移动端更友好。
+
+虽然它在技术上来说并没有把您的网站变成一个移动版本,但是如果搜索引擎没有找到移动优先的设计,它会参考这个标签。因此,当 m.site.com 缺失时,Google 将扫描 web 版本,理想情况下它应该能找到 viewport 标签。不支持移动和响应的页面排名较低。
+
+## 用于展示网站图标的标签
+
+您的同事会因为它高兴的,因为它使浏览器能够在选项卡中显示一个漂亮的图标或徽标,旁边是站点的名称。添加 favicon 的标签是这样的:
+
+```html
+<link rel="icon" href="favicon-img.ico" type="image/x-icon" />
+```
+
+图片最好以 .ico 的格式保存,在这方面它比 .png 和 .gif 支持得更好。
+
+(我觉得这里可以不翻译了,没读懂作者的意思。看看校对的意见,我再改)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/whats-new-in-php-7-4-top-10-features-that-you-need-to-know.md b/TODO1/whats-new-in-php-7-4-top-10-features-that-you-need-to-know.md
index b921e297927..37d0dea9c09 100644
--- a/TODO1/whats-new-in-php-7-4-top-10-features-that-you-need-to-know.md
+++ b/TODO1/whats-new-in-php-7-4-top-10-features-that-you-need-to-know.md
@@ -2,36 +2,36 @@
> * 原文作者:[Daniel Dan](https://medium.com/@daniel.dan)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/whats-new-in-php-7-4-top-10-features-that-you-need-to-know.md](https://github.com/xitu/gold-miner/blob/master/TODO1/whats-new-in-php-7-4-top-10-features-that-you-need-to-know.md)
-> * 译者:
-> * 校对者:
+> * 译者:[司徒公子](https://github.com/todaycoder001)
+> * 校对者:[江五渣](http://jalan.space)、[suhanyujie](https://github.com/suhanyujie)
-# What’s new in PHP 7.4? Top 10 features that you need to know
+# PHP 7.4 有什么新功能?你必须掌握的 10 大特性
-> In just 7 days, we’ll see the release of PHP 7.4. With new updates, reduced memory usage, and a significant performance increase will be achieved. Take a look at the 10 main features of PHP 7.4 in this article!
+> 在短短 7 天之内,我们看到了 PHP 7.4 的发布。更新包括:减少内存的使用、性能显著提升。看下本文中 PHP 7.4 的 10 大主要特性。
-
+
-Why are some programming languages so popular while others are seldom used for project development and sometimes even fall into oblivion? There are plenty of reasons for that. The simplicity of syntax, functionality, development network, and community support affect the demand level for each technology.
+为什么有些编程语言如此的流行,而其他编程语言却很少用于项目开发,有时甚至被遗忘。有很多原因,语法的简洁性、函数化程度、开发生态以及社区支持对于每项技术需求层级的影响。
-As the world of IT is constantly developing, coding technologies have to keep pace with the changing environment by providing new features, updates, and enhancements. This is one of the most important elements of language success.
+随着全世界 IT 的不断发展,编码技术必须要通过提供、更新或者增强新特性来应对不断变化的环境。这也是一门编程语言成功最重要的因素之一。
-In our company, I enjoy PHP due to the frequent improvements being performed each year and believe that it will be popular for many years to come. Since the release of PHP 5 in 2004, its performance has doubled and perhaps, even tripled. This is one of the reasons why we use PHP in our [software development company](https://y-sbm.com/).
+在我们公司,由于每年都频繁地改进并优化性能,因此,我很喜欢 PHP,并且我相信在未来几年也会广受欢迎。自从 2004 年 PHP 5 发布以来,它的性能已经翻倍或许甚至翻了三倍,这就是为什么我们[软件开发公司](https://y-sbm.com/)会使用 PHP 语言来开发的原因之一。
-It’s no wonder that for the second year in a row, PHP is among the top 10 most popular programming languages according to [StackOverflow Developer Survey 2019](https://insights.stackoverflow.com/survey/2019#technology). This year, it took the 8th place which is one rank higher than [in the previous year](https://insights.stackoverflow.com/survey/2019#technology).
+毫无疑问,根据 [2019 StackOverflow 开发者调查结果](https://insights.stackoverflow.com/survey/2019#technology),PHP 连续第二年成为十大最受欢迎的编程语言之一。今年,它排在第八位,比[去年排名](https://insights.stackoverflow.com/survey/2018#technology)高出一位。
-In just **7 days**, on Thursday, November 28th, we’ll see the new release of PHP — PHP 7.4, which will become one of the most feature-packed versions ever. In this article, I will list and cover the updated features overview of PHP 7.4. Let’s get started!
+在 7 天之后,也就是 11 月 28 日星期四,我们会看到 PHP 新版本的发布 —— PHP 7.4,它将成为有史以来功能最丰富的版本之一。这篇文章,我将列出并介绍 PHP 7.4 的更新特性概述。让我们开始吧!
-## What’s new in PHP 7.4? PHP features list
+## PHP 7.4 的新功能是什么?PHP 特性列表
-#### 1. Arrow functions’ support
+#### 1. 箭头函数的支持
-Since anonymous functions, or closures, are mainly applied in JS, they seem to be verbose in PHP. Their implementation and maintenance procedures are also more complex.
+由于匿名函数或闭包主要应用于 JS 中,因此,他们在 PHP 中似乎很啰嗦,他们的实现和程序的维护也会更复杂一些。
-The introduction of arrow functions’ support will enable PHP developers to dramatically clean up their code and make the syntax more concise. As a result, you will get a higher level of code readability and simplicity. Take a look at the example below.
+引入对箭头函数的支持使得 PHP 开发者大大简化他们的代码并且使语法更加简洁。这样,你代码的可读性和简洁性会大大提高。看下面的例子。
-So, if you previously had to write this piece of code:
+因此,如果是以前的话,你必须按以下代码块写:
-```
+``` php
function cube($n){
return ($n * $n * $n);
@@ -45,9 +45,9 @@ $b = array_map('cube', $a);
print_r($b);
```
-With PHP 7.4, you will be able to rewrite it in the following way:
+在 PHP 7.4 发布后,你就可以按如下的方法写:
-```
+``` php
$a = [1, 2, 3, 4, 5];
$b = array_map(fn($n) => $n * $n * $n, $a);
@@ -55,37 +55,37 @@ $b = array_map(fn($n) => $n * $n * $n, $a);
print_r($b);
```
-Thanks to the ability to create neat, shorter code, the web development process will go faster, allowing you to save time.
+由于拥有了创建整齐、更短代码的能力。web 开发过程将会更快,也节省了你的时间。
-#### 2. Typed properties’ support
+#### 2. 类型化属性的支持
-The introduction of typed properties in the next release will likely be considered one of the most important updated PHP features. While previously there was no possibility to use declaration methods for class variables and properties (including static properties), now programmers can easily code it without creating specific getter and setter methods.
+在下一个版本引入类型化属性可能被视为 PHP 最重要的特性更新之一。虽然之前不可能将声明方法用于类变量和属性(包括静态属性),但现在程序员能很轻松地进行编码,而无需创建特定的 getter 和 setter 方法。
-Due to declaration types (excluding void and callable), you can use nullable types, int, float, array, string, object, iterable, self, bool, and parent.
+由于声明类型(不包括 void 和 callable),你可以使用可为空(Nullable)类型,即 int、float、array、string、object、iterable、self、bool 和 parent。
-If a web developer tries to assign an irrelevant value from the type, for instance, declaring $name as string, he or she will get a TypeError message.
+如果一位 web 开发者尝试从类型中分配一个不相关的值,例如,声明 name 变量为字符串类型,他或她就会接收到 TypeError 的报错。
-Like arrow functions, typed properties also let PHP engineers make their code shorter and cleaner
+像箭头函数一样,类型化属性也能让 PHP 工程师写出更简短和清晰的代码。
-#### 3. Preloading
+#### 3. 预加载
-The main purpose of this cool new feature is to increase PHP 7.4 performance. Simply put, preloading is the process of loading files, frameworks, and libraries in [OPcache](https://www.php.net/manual/en/book.opcache.php) and is definitely a great addition to the new release. For example, if you use a framework, its files had to be downloaded and recompiled for each request.
+这个很酷新特性的主要目的是提升 PHP 7.4 的性能。简而言之,预加载是在 [OPcache](https://www.php.net/manual/en/book.opcache.php) 中加载文件、框架和库的过程,绝对是新版本的最佳补充。例如,如果你使用框架,则必须为每个请求下载并重新编译其文件。
-When configuring OPcache, for the first time these code files participate in the request processing and then they are checked for changes each time. Preloading enables the server to load the specified code files into shared memory. It’s important to note that they will be constantly available for all subsequent requests without additional checks for file changes.
+在配置 OPcache 的时候,这些代码文件首次参与请求处理,然后每次都检查它们的更改。预加载使服务器可以将指定的代码文件加载到共享内存中。请务必注意,它们将始终可用于后续所有的请求,而无需检查其他文件的改变。
-It is also noteworthy to mention that during preloading, PHP also eliminates needless includes and resolves class dependencies and links with traits, interfaces, and more.
+还值得一提的是,在预加载期间,PHP 还消除了不必要的包含,并解决了类依赖以及具有 Traits 和 Interfaces 等的链接。
-#### 4. Covariant returns & contravariant parameters
+#### 4. 协变量返回和协变量参数
-At the moment, PHP has mostly invariant parameter types and invariant return types which presents some constraints. With the introduction of covariant (types are ordered from more specific to more generic) returns and contravariant (types are ordered from more generic to more specific) parameters, PHP developers will be able to change the parameter’s type to one of its supertypes. The returned type, in turn, can be easily replaced by its subtype.
+目前,PHP 中大多数是不变的参数类型和不变的返回类型,这带来了一些约束。随着协变量(类型从更具体到更通用)返回和协变量(类型从更通用到更具体)参数的引入,PHP 开发者们将能够将参数类型更改为超类型之一。
-#### 5. Weak References
+#### 5. 弱引用
-In PHP 7.4, the WeakReference class allows web developers to save a link to an object that does not prevent its destruction. Don’t confuse it with the WeakRef class of the Weakref extension. Due to this feature, they can more easily implement cache-like structures.
+在 PHP 7.4 中,弱引用类(WeakReference class)允许 web 开发者们将链接保存到不阻止其销毁的对象中。请勿将弱引用类和弱引用扩展混淆。由于这些特性,它们更容易实现类似缓存的结构。
-See the example of using this class:
+请参考使用此类的示例:
-```
+``` php
<?php
$obj = new stdClass;
@@ -101,45 +101,39 @@ var_dump($weakref->get());
?>
```
-Also, note that you can’t serialize Weak References.
+另外,请注意,你无法序列化弱引用。
-#### 6. Coalescing assign operator
+#### 6. 合并分配运算符
-A coalesce operator is another new feature available in PHP 7.4. It’s very helpful when you need to apply a ternary operator together with isset(). This will enable you to return the first operand if it exists and is not NULL. If not, it will just return the second operand.
+合并运算符是 PHP 7.4 提供的另一个新功能。当你需要将三元运算符和 isset 方法一起使用时非常有用。如果它存在且不为空,那么就会返回第一个操作数,否则就会返回第二个操作数。
-Here is an example:
+这就是个例子:
-```
+``` php
<?php
-// Fetches the value of $_GET['user'] and returns 'nobody'
-
-// if it does not exist.
+// 获取 $_GET['user'] 的值,如果它不存在则返回 nobody
$username = $_GET['user'] ?? 'nobody';
-// This is equivalent to:
+// 这等价于:
$username = isset($_GET['user']) ? $_GET['user'] : 'nobody';
-// Coalescing can be chained: this will return the first
-
-// defined value out of $_GET['user'], $_POST['user'], and
-
-// 'nobody'.
+// 链式合并:将返回 $_GET['user']、$_POST['user'] 以及 noboody 中第一个不为 NULL 的值
$username = $_GET['user'] ?? $_POST['user'] ?? 'nobody';
?>
```
-#### 7. A spread operator in array expression
+#### 7. 数组表达式中的展开运算符
-PHP 7.4 will give engineers the ability to use spread operators in arrays that are faster compared to array_merge. There are two key reasons for that. First, a spread operator is considered to be a language structure and array_merge is a function. The second reason is that now your compile-time can be optimized for constant arrays. As a consequence, you will have increased PHP 7.4 performance.
+与 array_merge 相比,在 PHP 7.4 中,工程师们能在数组中使用展开运算符。有两个主要原因,首先,展开运算符被认为是一种语言结构,而 array_merge 是一个函数,其次是针对常量数组“编译时”的优化。因此 PHP 7.4 的性能将会提升。
-Take a look at the example of argument unpacking in array expression:
+看一下数组表达式中的参数解压缩示例:
-```
+``` php
$parts = ['apple', 'pear'];
$fruits = ['banana', 'orange', ...$parts, 'watermelon'];
@@ -147,25 +141,25 @@ $fruits = ['banana', 'orange', ...$parts, 'watermelon'];
var_dump($fruits);
```
-Also, it will be possible to expand the same array multiple times. Furthermore, since normal elements can be added before or after the spread operator, PHP developers will be able to use its syntax in the array.
+同样,它也有可能展开同一数组多次。此外,由于可以在扩展运算符的前后添加普通元素,因此 PHP 开发人员将能够在数组中使用其语法。
-#### 8. A new custom object serialization mechanism
+#### 8. 新的自定义对象序列化机制
-In the new version of PHP, two new methods become available: __serialize and __unserialize. Combining the versatility of the Serializable interface with the approach of implementing __sleep / __ wakeup methods, this serialization mechanism will allow PHP developers to avoid customization issues associated with the existing methods. Find out [more information about this PHP feature](https://wiki.php.net/rfc/custom_object_serialization).
+在 PHP 新的版本中,有两种新的可用方法 __serialize 和 __unserialize。将 Serializable 接口的多功能性与实现 __sleep 和 __wakeup 方法结合起来,这种序列化机制使得 PHP 开发者可以避免与已存在的方法产生一些自定义的问题。发现[有关 PHP 特性的更多信息](https://wiki.php.net/rfc/custom_object_serialization)。
-#### 9. Reflection for references
+#### 9. 为引用提供的反射
-Libraries, such as symfony/var-dumper, heavily rely on ReflectionAPI to accurately display variables. Previously, there was no proper support for reference reflection, which forced these libraries to rely on hacks to detect references. PHP 7.4 adds the ReflectionReference class which solves this problem.
+类似于 symfony/var-dumper 之类的库,严重依赖 Reflection API 来准确罗列变量。原来,对于引用反射没有很好的支持,这迫使这些库只能依靠 hack 的方式来检测引用。在 PHP 7.4 中添加了 ReflectionReference 类来解决此问题。
-#### 10. Support for throwing exceptions from __toString()
+#### 10. 支持从 __toString() 方法抛出异常
-Previously there was no ability to throw exceptions from the __toString method. The reason for that is the conversion of objects to strings is performed in many functions of the standard library, and not all of them are ready to “process” exceptions correctly. As part of this RFC, a comprehensive audit of string conversions in the codebase was carried out and this restriction was removed.
+之前无法从 __toString 方法中抛出异常。原因是标准库中的许多函数都执行从对象到字符串的转化,它们当中并非所有的都准备好正确的“处理”异常。作为该 RFC 的一部分,对代码库中的字符串转换进行了全面的审核,并取消了此限制。
-## Final thoughts
+## 最后的思考
-In just a week, PHP 7.4 will be released. There are plenty of new PHP features that reduce memory usage and greatly increase PHP 7.4 performance. You will gain the ability to avoid some previous limitations of this programming language, write cleaner code, and create web solutions faster.
+在短短的一周之内,PHP 7.4 将发布。有许多新的 PHP 特性会减少内存的使用并且大大提升 PHP 7.4 的性能。你将能够避免此编程语言之前的某些限制,编写更加简洁的代码,并更快地创建 web 解决方案。
-The Beta 3 version is already available for downloading and testing on dev servers. However, I wouldn’t recommend using it on your production servers and live projects. If you have questions about PHP 7.4/PHP development or just enjoyed the article, feel free to leave your comments below.
+Beta 3 版本已经可以下载并用于测试服务器的测试了。然而,我并不建议你在生产环境或者正在开发的项目中使用它。如果你对于 PHP 7.4 或者 PHP 开发还有疑惑,或者仅仅只是喜欢这篇文章,欢迎在下方留下你的评论。
> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
diff --git a/TODO1/when-workers.md b/TODO1/when-workers.md
new file mode 100644
index 00000000000..342ebddd7c6
--- /dev/null
+++ b/TODO1/when-workers.md
@@ -0,0 +1,196 @@
+> * 原文地址:[When should you be using Web Workers?](https://dassur.ma/things/when-workers/)
+> * 原文作者:[Surma](https://dassur.ma/)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/when-workers.md](https://github.com/xitu/gold-miner/blob/master/TODO1/when-workers.md)
+> * 译者:[weibinzhu](https://github.com/weibinzhu)
+> * 校对者:[ahabhgk](https://github.com/ahabhgk),[febrainqu](https://github.com/febrainqu)
+
+# 在什么时候需要使用 Web Workers?
+
+你应该在什么时候都使用 Web Workers。与此同时在我们当前的框架世界中,这几乎不可能。
+
+我这么说吸引到你的注意吗?很好。当然对于任何一个主题,都会有其精妙之处,我会将他们都展示出来。但我会有自己的观点,并且它们很重要。系紧你的安全带,我们马上出发。
+
+## 性能差异正在扩大
+
+> **注意:** 我讨厌“新兴市场”这个词,但是为了让这篇博客尽可能地通俗易懂,我会在这里使用它。
+
+手机正变得越来越快。我想不会有人不同意。更强大的 GPU,更快并且更多的 CPU,更多的 RAM。手机正经历与 2000 年代早期桌面计算机经历过的一样的快速发展时期。
+
+
+
+从 [Geekbench](https://browser.geekbench.com/ios-benchmarks) 获得的基准测试分数(单核)。
+
+然而,这仅仅是真实情况的其中一个部分。**低阶的手机还留在 2014 年。**用于制作 5 年前的芯片的流程已经变得非常便宜,以至于手机能够以大约 20 美元的价格卖出,同时便宜的手机能吸引更广的人群。全世界大约有 50% 的人能接触到网络,同时也意味着还有大约 50% 的人没有。然而,这些还没上网的人也**正在**去上网的路上并且主要是在新兴市场,那里的人买不起[有钱的西方网络(Wealthy Western Web)](https://www.smashingmagazine.com/2017/03/world-wide-web-not-wealthy-western-web-part-1/)的旗舰手机。
+
+在 Google I/O 2019 大会期间,[Elizabeth Sweeny](https://twitter.com/egsweeny) 与 [Barb Palser](https://twitter.com/barb_palser) 在一个合作伙伴会议上拿出了 Nokia 2 并鼓励合作伙伴去使用它一个星期,去**真正**感受一下这个世界上很多人日常是在用什么级别的设备。Nokia 2 是很有意思的,因为它看起来有一种高端手机的感觉但是在外表下面它更像是一台有着现代浏览器和操作系统的 5 年前的智能手机 —— 你能感受到这份不协调。
+
+让事情变得更加极端的是,功能手机正在回归。记得哪些没有触摸屏,相反有着数字键和十字键的手机吗?是的,它们正在回归并且现在它们运行着一个浏览器。这些手机有着更弱的硬件,也许有些奇怪,却有着更好的性能。部分原因是它们只需要控制更少的像素。或者换另一种说法,对比 Nodia 2,它们有更高的 CPU 性能 - 像素比。
+
+
+
+Nokia 8110,或者说“香蕉手机”
+
+虽然我们每个周期都能拿到更快的旗舰手机,但是大部分人负担不起这些手机。更便宜的手机还留在过去并有着高度波动的性能指标。在接下来的几年里,这些低端手机更有可能被大量的人民用来上网。**最快的手机与最慢的手机之间的差距正在变大,中位数在减少。**
+
+
+
+手机性能的中位数在降低,所有上网用户中使用低端手机的比例则在上升。**这不是一个真实的数据,只是为了直观展现。**我是根据西方世界和新兴市场的人口增长数据以及对谁会拥有高端手机的猜测推断出来的。
+
+## JavaScript 是阻塞的
+
+也许有必要解释清楚:长时间运行的 JavaScript 的缺点就是它是阻塞的。当 JavaScript 在运行时,不能去做任何其他事情。**除了运行一个网页应用的 JavaScript 以外,主线程还有别的指责。**它也需要渲染页面,及时将所有像素展示在屏幕上,并且监听诸如点击或者滑动这样的用户交互。在 JavaScript 运行的时候这些都不能发生。
+
+浏览器已经对此做了一些缓解措施,例如在特定情况下会把滚动逻辑放到不同的线程。不过整体而言,如果你阻塞了主线程,那么你的用户将会有**很差**的体验。他们会愤怒地点击你的按钮,被卡顿的动画与滚动所折磨。
+
+## 人类的感知
+
+多少的阻塞才算过多的阻塞?[RAIL](https://developers.google.com/web/fundamentals/performance/rail) 通过给不同的任务提供基于人类感知的时间预算来尝试回答这个问题。比如说,为了让人眼感到动画流畅,在下一帧被渲染之前你要有大约 16 毫秒的间隔。**这些数字是固定的**,因为人类心理学不会因为你所拿着的设备而改变。
+
+看一下日趋扩大的性能差距。你可以构建你的 app,做你的尽职调查以及性能分析,解决所有的瓶颈并达成所有目标。**但是除非你是在最低端的手机上开发,不然是无法预测一段代码在如今最低端手机上要运行多久,更不要说未来的最低端手机。**
+
+这就是由不一样的水平带给 web 的负担。你无法预测你的 app 将会运行在什么级别的设备上。你可以说“Sura,这些性能低下的手机与我/我的生意无关!”,但对我来讲,这如同“那些依赖屏幕阅读器的人与我/我的生意无关!”一样的恶心。**这是一个包容性的问题。我建议你 仔细想想,是否正在通过不支持低端手机来排除掉某些人群。**我们应该努力使每一个人都能获取到这个世界的信息,而不管喜不喜欢,你的 app 正是其中的一部分。
+
+话虽如此,由于涉及到很多术语和背景知识,本博客无法给所有人提供指导。上面的那些段落也一样。我不会假装无障碍访问或者给低端手机编程是一件容易的事,但我相信作为一个工具社区和框架作者还是有很多事情可以去做,去以正确的方式帮助人们,让他们的成果默认就更具无障碍性并且性能更好,默认就更加包容。
+
+## 解决它
+
+好了,尝试从沙子开始建造城堡。尝试去制作那些能在各种各样的,你都无法预测一段在代码在上面需要运行多久的设备上都能保持符合 RAIL 模型性能评估的时间预算的 app。
+
+### 共同合作
+
+一个解决阻塞的方式是“分割你的 JavaScript”或者说是“让渡给浏览器”。意思是通过在代码添加一些固定时间间隔的**断点**来给浏览器一个暂停运行你的 JavaScript 的机会然后去渲染下一帧或者处理一个输入事件。一旦浏览器完成这些工作,它就会回去执行你的代码。这种在 web 应用上让渡给浏览器的方式就是安排一个宏任务,而这可以通过多种方式实现。
+
+> **必要的阅读:** 如果你对宏任务或者宏任务与微任务的区别,我推荐你去阅读 [Jake Archibald](https://twitter.com/jaffathecake) 的[谈谈事件循环](https://www.youtube.com/watch?v=cCOL7MC4Pl0)。
+
+在 PROXY,我们使用一个 `MessageChannel` 并且使用 `postMessage()` 去安排一个宏任务。为了在添加断点之后代码仍能保持可读性,我强烈推荐使用 `async/await`。在 [PROXX](https://proxx.app) 上,用户在主界面与游戏交互的同时,我们在后台生成精灵。
+
+```js
+const { port1, port2 } = new MessageChannel();
+port2.start();
+
+export function task() {
+ return new Promise(resolve => {
+ const uid = Math.random();
+ port2.addEventListener("message", function f(ev) {
+ if (ev.data !== uid) {
+ return;
+ }
+ port2.removeEventListener("message", f);
+ resolve();
+ });
+ port1.postMessage(uid);
+ });
+}
+
+export async function generateTextures() {
+ // ...
+ for (let frame = 0; frame < numSprites; frame++) {
+ drawTexture(frame, ctx);
+ await task(); // 断点
+ }
+ // ...
+}
+```
+
+但是**分割依旧受到日趋扩大的性能差距的影响:**一段代码运行到下一个断点的时间是取决于设备的。在一台低端手机上耗时小于 16 毫秒,但在另一台低端手机上也许就会耗费更多时间。
+
+## 移出主线程
+
+我之前说过,主线程除了执行网页应用的 JavaScript 以外,还有别的一些职责。而这就是为什么我们要不惜代价避免长的,阻塞的 JavaScript 在主线程。但假如说我们把大部分的 JavaScript 移动到一条**专门**用来运行我们的 JavaScript,除此之外不做别的事情的线程中呢。一条没有其他职责的线程。在这样的情况下,我们不需要担心我们的代码受到日趋扩大的性能差距的影响,因为主线程不会收到影响,依然能处理用户输入并保持帧率稳定。
+
+### Web Workers 是什么?
+
+**[Web Workers](https://developer.mozilla.org/en-US/docs/Web/API/Worker),也被叫做 “Dedicated Workers”,是 JavaScript 在线程方面的尝试。**JavaScript 引擎在设计时就假设只有一条线程,因此时没有并发访问的 JavaScript 对象内存,而这符合所有同步机制的需求。如果一条具有共享内存模型的普通线程被添加到 JavaScript,那么少说也是一场灾难。相反,我们有了 [Web Workers](https://developer.mozilla.org/en-US/docs/Web/API/Worker),它基本上就是一个运行在另一条独立线程上的完整的 JavaScript 作用域,没有任何的共享内存或者共享值。为了使这些完全分离并且孤立的 JavaScript 作用域能共同工作,你可以使用 [`postMessage()`](https://developer.mozilla.org/en-US/docs/Web/API/Worker/postMessage),它使你能够在**另一个** JavaScript 作用域内触发一个 `message` 事件并带有一个你提供的值的拷贝(使用[结构化克隆算法](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Structured_clone_algorithm) 来拷贝)。
+
+到目前为止,除了一些通常涉及长时间运行的计算密集任务的“银弹”用例以外 workers 基本没得到采用。我想这应该被改变。**我们应该开始使用 workers。经常使用。**
+
+### 所有酷小孩都在这么做
+
+这不是一个新的想法,实际上还挺老的。**大部分原生平台都把主线程称为 UI 线程,因为它应该只会被用来处理 UI 工作**,并且它们给你提供了工具去实现。安卓从很早的版本开始就有一个叫 [`AsyncTask`](https://developer.android.com/reference/android/os/AsyncTask) 的东西,并从那开始添加了更多更方便的 API(最近的是 [Coroutines](https://kotlinlang.org/docs/reference/coroutines/basics.html) 它可以很容易地被派发在不同线程)。如果你选用了[“严格模式”](https://developer.android.com/reference/android/os/StrictMode),那么在 UI 线程上使用某些 API —— 例如文件操作 —— 会导致你的应用奔溃,以此来提醒你在 UI 线程上做了一些与 UI 无关的操作。
+
+从一开始 iOS 就有一个叫 [Grand Central Dispatch](https://developer.apple.com/documentation/dispatch) (“GCD”)的东西,用来在不同的系统提供的线程池上派发任务,其中包括 UI 线程。通过这方式他们强制了两个模式:你总是要将你的逻辑分割成若干任务,然后才能被放到队列中,允许 UI 线程在需要的时候将其放入对应的线程,但同时也允许你通过简单地将任务放到不同的队列来在不同的线程执行非 UI 相关的工作。锦上添花的是还可以给任务指定优先级,这样帮助我们确保时间敏感的工作能尽快被完成,并且不会牺牲系统整体的响应。
+
+我的观点是这些原生平台从一开始就已经支持使用非 UI 线程。我觉得可以公正地说,经过这么多时间,他们已经证明来这是一个好主意。将在 UI 线程的工作量降到最低有助于让你的 app 保持响应灵敏。为什么不把这样的模式用在 web 上呢?
+
+## 开发体验是一个障碍
+
+我们只能通过 Web Worker 这么一个简陋的工具在 web 上使用线程。当你开始使用 Workers 以及他们提供的 API 时,`message` 事件处理器就是其中的核心。这感觉并不好。此外,Workers **像**线程,但又跟线程不完全一样。你无法让多个线程访问同一个变量(例如一个静态对象),所有的东西都要通过消息传递,这些消息能携带很多但不是全部 JavaScript 值。例如你不能发送一个 `Event` 或者没有数据损失的对象实例。我想,对于开发者来说这是最大的阻碍。
+
+### Comlink
+
+因为这样的原因,我编写了 [Comlink](https://github.com/GoogleChromeLabs/comlink) 它不仅帮你隐藏掉 `postMessage()`,甚至能让你忘记正在使用 Workers。**感觉**就像是你能够访问到来自别的线程的共享变量:
+
+```js
+// main.js
+import * as Comlink from "https://unpkg.com/comlink?module";
+
+const worker = new Worker("worker.js");
+// 这个 `state` 变量其实是在别的 worker 中!
+const state = await Comlink.wrap(worker);
+await state.inc();
+console.log(await state.currentCount);
+```
+
+```js
+// worker.js
+import * as Comlink from "https://unpkg.com/comlink?module";
+
+const state = {
+ currentCount: 0,
+
+ inc() {
+ this.currentCount++;
+ }
+}
+
+Comlink.expose(state);
+```
+
+> **说明:**我用了顶层 await 以及模块 worker(modules-in-workers)来让例子变短。请到 [Comlink 的代码仓库](https://github.com/GoogleChromeLabs/comlink)查看真实的例子以及更多细节。
+
+在这问题上 Comlink 不是唯一的解决方案,只是我最熟悉它(很正常,考虑到是我写的 🙄)。如果你对其他方法感兴趣,看一下 [Andrea Giammarchi](https://twitter.com/webreflection) 的 [workway](https://github.com/WebReflection/workway) 或者 [Jason Miller](https://twitter.com/_developit) 的 [workerize](https://github.com/developit/workerize)。
+
+我不在意你用哪个库,只要你最终转换到“离开主线程”架构。我们在 [PROXX](https://proxx.app) 和 [Squoosh](https://squoosh.app) 上成功使用了 Comlink,因为它很小(gzip 后 1.2KiB)并且让我们不需要在开发上改动太多就能使用很多来自其他有“真正”线程的语言的常用模式。
+
+### 参与者
+
+最近我和 [Paul Lewis](https://twitter.com/aerotwist) 一起评估过其他的方法。除了说隐藏你正在使用 Worker 的事实以及 `postMessage`,我们还从 70 年代和使用过的[参与者模式](https://dassur.ma/things/actormodel/)中得到灵感,这种架构模式将消息传递当作基本的积木。经过那次思想实验,我们编写了一个[支撑参与者模式的库](https://github.com/PolymerLabs/actor-helpers),一个[入门套件](https://github.com/PolymerLabs/actor-boilerplate),并在 2018 Chrome 开发者峰会上做了[一次演讲](https://www.youtube.com/watch?v=Vg60lf92EkM),介绍了这个架构以及它的应用。
+
+## “基准测试”
+
+你也许会想:**是不是值得去使用“离开主线程”架构?**让我们来做一个投入/产出分析:有了 [Comlink](https://github.com/GoogleChromeLabs/comlink) 这样的库,切换到“离开主线程”架构的代价应该会比以前有显著的降低,非常接近于零。那么好处呢?
+
+[Dion Almaer](https://twitter.com/dalmaer) 叫过我去给 [PROXX](https://proxx.app) 写一个完全运行在主线程上的版本,这也许能解答那个问题。因此[我就这么做了](https://github.com/GoogleChromeLabs/proxx/pull/437)。在 Pixel 3 或者 MacBook 上仅仅有一点可感知的差别。但是在 Nokia 2 上则有了明显不同。**如果把所有东西都运行在主线程上,在最差的情形下应用卡住了高达 6.6 秒。**并且还有很多正在流通的设备的性能比 Nokia 2 还要低!而运行使用了“离开主线程”架构的 PROXX 版本,执行一个 `tap` 事件处理函数仅仅耗时 48 毫秒,因为所做的仅仅是通过调用 `postMessage()` 发了一条消息到 Worker 中。这代表着,特别是考虑到日趋扩大的性能差距,**“离开主线程”架构能够提高处理意想不到的大且长的任务的韧性**。
+
+
+
+PROXX 的事件处理器是非常简洁的并且只会被用来给指定的 worker 发送消息。总而言之这个任务耗时 48 毫秒。
+
+
+
+在一个所有东西都运行在主线程的 PROXX 版本,执行一个事件处理器需要耗时超过 6 秒。
+
+有一个需要注意的是,任务并没有消失。即使使用了“离开主线程”架构,代码仍需要运行大约 6 秒的事件(在 PROXX 这实际上会更加长)。然而由于这些工作是在另一个线程上进行的,UI 线程仍然能保持响应。我们的 worker 也会把中间结果传回主线程。**通过保持事件处理器的简洁,我们保证了 UI 线程能保持响应并能更新视觉状态。**
+
+## 框架的窘困
+
+现在说一下我一个脱口而出的意见:**我们现有的框架让“离开主线程”架构变得困难并减少了它的回归。** UI 框架应该去做 UI 的工作,也因此有权去运行在 UI 线程。然而实际上,它们所做的工作是 UI 工作以及其他一些相关但是非 UI 的工作。
+
+让我们拿 VDOM diff 做例子:虚拟 DOM 的目的将开发者的代码与真实 DOM 的更新解耦。虚拟 DOM 仅仅是一个模拟真实 DOM 的数据结构,这样它的改变就不会引起高消耗的副作用。只有当框架认为时机合适的时候,虚拟 DOM 的改变才会引起真实 DOM 的更新。这通常被称为“冲洗(flushing)”。直到冲洗之前的所有工作是绝对不需要运行在 UI 线程的。然而实际上它正在耗费你宝贵的 UI 线程资源。鉴于低端手机无法应付 diff 的工作量,在 [PROXX](https://proxx.app) 我们[去除了 VDOM diff](https://github.com/GoogleChromeLabs/proxx/blob/94b08d0b410493e2867ff870dee1441690a00700/src/services/preact-canvas/components/board/index.tsx#L116-L118) 并实现了我们自己的 DOM 操作。
+
+VDOM diff 仅仅是其中一个框架引导的开发体验的例子,或者一个简单的克服用户设备性能的例子。一个面向全球发布的框架,除非它明确表明自己只针对哪些[富有的西方网络](https://www.smashingmagazine.com/2017/03/world-wide-web-not-wealthy-western-web-part-1/),**否则他是有责任去帮助开发者开发支持不同级别手机的应用。**
+
+## 结论
+
+Web Worker 帮助你的应用运行在更广泛的设备上。像 [Comlink](https://github.com/GoogleChromeLabs/comlink) 这样的库协助你在无需放弃便利以及开发速度的情况下使用 worker。我想**我们应该思考的是,为什么除了 web 以外的所有平台都在尽可能的少占用 UI 线程的资源**。我们应该改变自己的老办法,并帮助促成下一代框架改变。
+
+---
+
+特别感谢 [Jose Alcérreca](https://twitter.com/ppvi) 和 [Moritz Lang](https://twitter.com/slashmodev),他们帮我了解原生平台是如何解决类似问题的。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/why-is-object-immutability-important.md b/TODO1/why-is-object-immutability-important.md
new file mode 100644
index 00000000000..0b3502d2ae3
--- /dev/null
+++ b/TODO1/why-is-object-immutability-important.md
@@ -0,0 +1,234 @@
+> * 原文地址:[Why is object immutability important?](https://levelup.gitconnected.com/why-is-object-immutability-important-d6882929e804)
+> * 原文作者:[Alex Pickering](https://medium.com/@pickeringacw)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/why-is-object-immutability-important.md](https://github.com/xitu/gold-miner/blob/master/TODO1/why-is-object-immutability-important.md)
+> * 译者:[IAMSHENSH](https://github.com/IAMSHENSH)
+> * 校对者:[zhanght9527](https://github.com/zhanght9527)
+
+# 为什么对象不变性很重要?
+
+## 为什么要对象不变性?
+
+为了探索不变性的重要性,我们应该先了解可变性的概念。我们需要知道可变性是什么,有什么意义,以及会造成什么影响。
+
+在这篇文章中,我们将会使用 JavaScript 介绍可变性概念。不过其中原理是跟编程语言无关的。
+
+
+
+## 可变……是什么?
+
+可变性呀!从本质上来说,可变性描述的是对象被声明后,是否还能被修改。就这么简单。
+
+设想一下,声明一个变量并为其赋值。在后面的代码中,我们遇到需要在那里立刻修改此变量的值的情况。如果我们能立刻修改此变量的值,更改其状态,则认为这个对象是**可变的**。
+
+```js
+// 原始数组
+const foo = [ 1, 2, 3, 4, 5 ]
+
+// 改变原始数组
+foo.push(6) // [ 1, 2, 3, 4, 5, 6 ]
+
+// 原始对象
+const bar = { becky: 'lemme' }
+
+// 改变原始对象
+bar.becky = true
+```
+
+说起数组,修改它的值和改变它值的状态实在是太容易了。而为了防止这种情况发生,我们保持一个不可变的状态,需要从原始数组上派生出新数组,并将新的内容插入其中。
+
+对象也是一样的,需要从现有对象上派生出新对象,并将所需的改变添加到其中。
+
+不过……
+
+JavaScript 有基本类型的概念,即**字符串**和**数字**。基础类型被认为是不可变的。这里要理解的棘手地方是:字符串本身是不可变的,但被赋值的变量是可变的。意思是,如果我们创建了一个变量,并对其赋值字符串,接着如果对其重新赋值新的字符串,从技术上来说没有改变原始的字符串,而只是改变了变量赋值。这是一个重要的区别。
+
+```js
+// 实例化和声明变量
+let foo = 'something'
+
+// 利用现有的基础类型实例化和声明变量
+let bar = foo
+
+// 对原始变量重新赋值
+foo = 'else'
+
+// 在控制台上输出结果
+console.log(foo, bar)
+> 'else', 'something'
+```
+
+基础类型被不可变地创建了 —— 意思是当 `bar` 被实例化时,虽然被赋值成 `foo`,但是这个值在内存中是另外储存的。所有的基础类型都是这种情况!目的是,新的赋值不会作为指针泄露到任何其它变量中去!
+
+## 试试不变性
+
+可变性的反面是不变性。不变性在这里的意思是,一旦变量被声明并且状态被设置,就不能被再次修改。而基于原始的新对象,任何改变都**需要**被重新创建。
+
+让我们看看如何不可变地插入一项内容到数组中。
+
+```js
+const foo = [ 1, 2, 3, 4, 5 ]
+
+// 不可改变的,不修改原始的数组(ES6 扩展运算)
+const bar = [ ...foo, 6 ]
+const arr = [ 6, ...foo ]
+```
+
+我们现在从原始数组上创建 `bar` 和 `arr`,分别在结尾处和开头处添加想要的修改。我们在新数组中使用[扩展运算语法](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Spread_syntax)来展开现有数组项。
+
+如果我们有一个更复杂的数组,例如对象数组,如何修改其中每一个对象,而维持不可变的原则呢?非常简单!我们可以使用 `.map`,这是一个原生的数组方法。
+
+```js
+const foo = [{ a: 'b', c: 'd' }]
+
+// 不可改变的,不修改原始数组
+const bar = foo.map(item => ({
+ ...item,
+ a: 'something else'
+}))
+```
+
+那对象呢?我们如何在独立对象上更新属性,而不修改原始对象?我们可以简单地使用扩展运算语法再来一次。
+
+```js
+const foo = { becky: 'lemme' }
+
+// 不可改变的,不修改原始对象
+const bar = { ...foo, smash: false }
+```
+
+原始对象 `foo` 还是保持原样,而同时也发现 —— 我们已经创建了具有我们预期变化的新对象。太棒了!
+
+不过,让我们暂时假设一下,在无法使用 ES6 标准的情况下,如何实现不可变性呢?
+
+```js
+const foo = { becky: 'lemme' }
+
+// 不可改变的,不修改原始对象
+const bar = Object.assign({}, foo, { smash: false })
+```
+
+在上面的例子里,我们使用了为新对象赋值的古老方法。
+
+请注意 —— 在嵌套对象的顶层使用扩展运算符不能保证嵌套在其中对象的不变性。我们可以看看下面的示例。
+
+```js
+const personA = {
+ address: {
+ city: 'Cape Town'
+ }
+}
+
+const personB = {
+ ...personA
+}
+
+const personC = {
+ address: {
+ ...personA.address,
+ }
+}
+
+personA.address.city = 'Durban' // 这会同时修改 personA 与 personB。
+
+console.log(personB.address.city) // 'Durban'
+console.log(personC.address.city) // 'Cape Town'
+```
+
+为了确保嵌套对象保持不变,如上面示例所示,每一个嵌套对象都需要被扩展或者被赋值。
+
+
+
+## 你是在回答怎么做,但到底是为什么呢?
+
+在大多数应用中,数据的完整性和一致性通常是最重要的。我们不愿意数据被莫名修改,因此被错误地存到数据库中,或者被错误地返回给使用者。我们期望有最佳的可预测性,以确保所使用的数据与预期保持一致。当涉及到异步和多线程应用程序时,这至关重要。
+
+为了更好地理解以上内容,让我们看看下面的图。让我们假设 `foo` 依稀包含着我们系统中一个用户的重要数据。如果我们有 Promise A 和 Promise B,他们都同时运行在 Promise 中。这两个以及所有接收 `foo` 作为参数的 Promise,如果其中的一个 Promise 修改 `foo`,那么 `foo` 的新状态就会泄露到另一个 Promise 中去。
+
+
+
+如果 Promise 依赖于 `foo` 的原始状态,则在执行的过程中可能会产生副作用。
+
+如果两个 Promise 都有修改 `foo` 对象的话,上图的结果可能会有不同的情况,结果取决于哪个 Promise 先执行。这被称为资源竞争 (race-condition)。当对象被传入时,被传入的只是一个指针,指向所传递的基础对象,而不是新的对象。
+
+```js
+// 初始化对象
+const obj = {
+ a: 'b',
+ c: 'd'
+}
+
+// 在模拟的 1 秒计算后,控制台输出被传入的 `item`
+const foo = item => setTimeout(() => console.log(item), 1000)
+
+// 修改被传入的 `item`
+const bar = item => item.a = 'something'
+
+// 使用 Promise 对象同时运行这两个方法,并提供 `obj` 作为这两个方法输入参数。
+Promise.all([ foo(obj), bar(obj) ])
+
+// 预期结果
+> { a: "b", c: "d" }
+
+// 实际结果
+> { a: "something", c: "d" }
+```
+
+在调试代码甚至尝试实现新功能时,这可能会引起不少麻烦。所以我建议保持不变性原则!
+
+## 所以我应该创建新的对象吗?
+
+简而言之,是的。无论怎样,您**不**应该直接地将旧变量简单地设置为新变量。这是会产生副作用的,并且可能不完全符合我们的预期。
+
+```js
+const foo = { a: 'b', c: 'd' }
+
+// 这将创建一个指针,或者是浅拷贝
+const bar = foo
+
+// 这创建一个深拷贝
+const bar = { ...foo }
+```
+
+在 JavaScript 中,这两者是有根本区别的,特别是涉及到如何将变量存储在内存中时。
+
+更多技术层面的解释是:当创建 `foo` 对象时,其被储存在所谓的[堆](https://medium.com/javascript-in-plain-english/understanding-javascript-heap-stack-event-loops-and-callback-queue-6fdec3cfe32e)中,并在[栈](https://medium.com/javascript-in-plain-english/understanding-javascript-heap-stack-event-loops-and-callback-queue-6fdec3cfe32e)中创建指向这块内存的指针。和上面示例中第一个声明一样,当我们创建一个浅拷贝,一个新的指针会被放在[栈](https://medium.com/javascript-in-plain-english/understanding-javascript-heap-stack-event-loops-and-callback-queue-6fdec3cfe32e)中,但其指向[堆](https://medium.com/javascript-in-plain-english/understanding-javascript-heap-stack-event-loops-and-callback-queue-6fdec3cfe32e)中相同的内存块。
+
+
+
+这意味着,如果 `foo` 被修改,那么 `bar` 也会被改变。**这是意料之外的后果**!
+
+## 那性能怎么样呢?
+
+好吧,在性能方面,您可能会认为与对现有对象简单地修改相比,这会是一个更繁琐的过程。是的,您是正确的。但这并不像您认为的那样糟糕。
+
+JavaScript 使用结构共享的概念,这意味着从您的第一个对象派生出修改后的对象,其实不会产生太多的开销。考虑到这一点以及不变性带来的好处,这开始看起来是个不错的选择。下面列举一些好处……
+
+* 线程安全(对于多线程语言)
+* 易于测试与使用
+* 最小故障性(Failure atomicity)
+* 解耦合
+
+最终,如果正确使用,不变性肯定会提升应用程序与开发的总体性能,即使是在某些计算任务更重的功能上。
+
+
+
+## 我们还要用吗?
+
+总之,是否要使用不变性的概念取决于您。我个人的观点呢,至少从表面上看,我认为不变性解决了很多问题,甚至是一些潜在的问题,这值得我们称赞。所以我也尝试确保我的对象始终保持不可变。
+
+如果您想了解更多的信息,或者想开始在您的代码库中实现不变性,以下是一些资源参考,它们也许会引起您的兴趣。
+
+[Immutable.js](https://immutable-js.github.io/immutable-js/)
+[不变性的益处](https://hackernoon.com/5-benefits-of-immutable-objects-worth-considering-for-your-next-project-f98e7e85b6ac)
+
+[MDN — 数组](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array)
+[MDN — 对象](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object)
+
+感谢您的阅读,希望您能喜欢并学到一些东西。如果您有任何反馈,批评或建议,请随时在下面的评论部分中写下来。
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/TODO1/why-svelte-wont-kill-react.md b/TODO1/why-svelte-wont-kill-react.md
new file mode 100644
index 00000000000..cc996501e94
--- /dev/null
+++ b/TODO1/why-svelte-wont-kill-react.md
@@ -0,0 +1,344 @@
+> * 原文地址:[Why Svelte won’t kill React](https://medium.com/javascript-in-plain-english/why-svelte-wont-kill-react-3cfdd940586a)
+> * 原文作者:[Kit Isaev](https://medium.com/@nikis05)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO1/why-svelte-wont-kill-react.md](https://github.com/xitu/gold-miner/blob/master/TODO1/why-svelte-wont-kill-react.md)
+> * 译者:[👊Badd](https://juejin.im/user/5b0f6d4b6fb9a009e405dda1)
+> * 校对者:[PingHGao](https://github.com/PingHGao), [shixi-li](https://github.com/shixi-li)
+
+# 为何 Svelte 杀不死 React
+
+#### 是仅现状造成的吗?还是说只因为 React 更强大?
+
+当我刚刚开始读 Svelte 的文档时,我发现这东西太振奋人心了,我简直想要在 Medium 上写封表扬信给它。而当我读完来自官方博客和社区的一些文章后,我就冷静下来了,因为我注意到了一些在 JavaScript 世界中很常见的言辞 —— 这种言辞让我**非常**苦恼。
+
+> 嘿,是否还记得那个 30 年来人类绞尽脑汁想要解决的问题?我刚刚发现了一个通用的解决方案!为什么它还没征服全世界?这多么显而易见啊。Facebook 的营销团队正在密谋对付我们。
+
+在我看来,你可以说你的工具与现有的工具相比是革命性的。而且人很难对自己的作品保持完全公正的态度,这我能理解。举个正面的例子 —— 与其他解决方案比起来,我觉得 Vue 实在是[干得漂亮](https://vuejs.org/v2/guide/comparison.html)。没错,确实存在一些我不敢苟同的质疑声音,但这些声音都在传达一个建设性的信息:
+
+> 我们的解决方案是怎样怎样的,还有别的一些现有的解决方案。而且我们坚信我们的方案更优秀,原因是什么什么。一些常见的反对论点是什么什么。
+
+Svelte 的官方博客却正好相反,它通过只显露片面的事实来愚弄读者,甚至有时会宣扬一些关于 Web 技术和其他库(我会着重提到 React,只因我对它的理解更深一些)的不实言论。因此在本文中,我会对 Svelte 调侃一二,平衡一下官方吹斜的天平。话虽如此,我仍认为 Svelte 中还是有闪光点的,我会在文末告诉你原因 😊
+
+](https://cdn-images-1.medium.com/max/2000/1*w4uLFcsyeLWeVetzq0VgqQ.jpeg)
+
+## 何为 Svelte?
+
+Svelte 是一个构建用户界面的工具。主流的框架 —— 如 React 和 Vue —— 都是利用虚拟 DOM 根据组件输出进行高效的 DOM 更新,而 Svelte 没有走这条路线,它使用静态分析,在运行时创建 DOM 更新代码<sup>[1](#footnote1)</sup>。 一个 Svelte 组件长这样:
+
+**App.svelte**
+
+```html
+<script>
+ import Thing from './Thing.svelte';
+
+let things = [
+ { id: 1, color: '#0d0887' },
+ { id: 2, color: '#6a00a8' },
+ { id: 3, color: '#b12a90' },
+ { id: 4, color: '#e16462' },
+ { id: 5, color: '#fca636' }
+ ];
+
+function handleClick() {
+ things = things.slice(1);
+ }
+</script>
+
+<button on:click={handleClick}>
+ Remove first thing
+</button>
+
+{#each things as thing}
+ <Thing color={thing.color}/>
+{/each}
+```
+
+**Thing.svelte**
+
+```html
+<script>
+ export let color;
+</script>
+
+<p>
+ <span style="background-color: {color}">current</span>
+</p>
+
+<style>
+ span {
+ display: inline-block;
+ padding: 0.2em 0.5em;
+ margin: 0 0.2em 0.2em 0;
+ width: 4em;
+ text-align: center;
+ border-radius: 0.2em;
+ color: white;
+ }
+</style>
+```
+
+而对应的 React 组件是这样的:
+
+```jsx
+import React, {useState} from 'react'
+import styled from 'styled-components';
+
+const things = [
+ { id: 1, color: '#0d0887' },
+ { id: 2, color: '#6a00a8' },
+ { id: 3, color: '#b12a90' },
+ { id: 4, color: '#e16462' },
+ { id: 5, color: '#fca636' }
+ ];
+
+const Block = styled.span`
+ display: inline-block;
+ padding: 0.2em 0.5em;
+ margin: 0 0.2em 0.2em 0;
+ width: 4em;
+ text-align: center;
+ border-radius: 0.2em;
+ color: white;
+ background-color: ${props => props.backgroundColor}
+`;
+
+const Thing = ({color}) => {
+ return (
+ <p>
+ <Block backgroundColor={color} />
+ </p>
+ );
+}
+
+export const App = () => {
+ const [things, setThings] = useState(things);
+ const removeFirstThing = () => setThings(things.slice(1))
+ return (
+ <>
+ <button onClick={removeFirstThing} />
+ {things.map(thing =>
+ <Thing key={thing.key} color={thing.color} />
+ }
+ </>
+ );
+}
+```
+
+#### Svelte 不是一个框架 —— 它是一种语言
+
+Svelte 简单地用 `<script>` 和 `<style>` 创建 Vue 风格的“单文件组件”。该语言中增加了一些结构,用以解决 UI 开发中最大的问题之一 —— 状态管理。
+
+我在[上一篇文章](https://medium.com/swlh/what-is-the-best-state-container-library-for-react-b6989a45f236)提到了几个在 React 里用 JavaScript 解决此问题的方法。Svelte 借助其作为编译器之便利,使得响应性成为该语言的特性 <sup>[2](#footnote2)</sup>。Svelte 引入了两种新型的语言结构来达到这个目的。
+
+* 在语句前加 `$:` 能够[让该语句具有响应性](https://svelte.dev/tutorial/reactive-declarations)的运算符,即每当该语句读取的变量有更新时,它都会被重新执行。一个语句可以是一次赋值(即“依赖变量”或“派生变量”)、一个代码块或者一个调用(即“作用”)。这有点类似 MobX 的方式,只不过是集成到语言中了。
+* `$` 一个能[创建指向仓库(存储状态的容器)的订阅](https://svelte.dev/tutorial/auto-subscriptions)的运算符,当组件解除挂载时,该订阅即被自动取消。
+
+Svelte 的响应性概念使我们能够使用常规的 JavaScript 变量存储状态 —— 不再需要状态容器了。但这样做真的提升了开发体验(DX)吗?
+
+](https://cdn-images-1.medium.com/max/2000/1*c0shUq7fn3MHYBr39JJvQQ.jpeg)
+
+## Svelte 的响应性
+
+> React 最初的承诺是,你可以在每次状态改变时重新渲染整个应用,而无需担心性能问题。而实际上,我认为那不准确。如果确实如此,那像 `shouldComponentUpdate`(一种告诉 React 何时可以安全跳过一个组件的方法)这种优化就没有存在的必要了 —— Rich Harris,Svelte 的维护者<sup>[3](#footnote3)</sup>
+>
+> 真正的问题在于,程序员花费了大量的时间在错误的地点和时间去担心效率;**在编程中,过早优化是万恶(或者至少大部分)之源**。—— Donald Knuth,美国计算机科学家<sup>[4](#footnote4)</sup>
+
+首先,我们得搞清楚一点。就算你的代码中没有任何 `shouldComponentUpdate` 这类优化标识,React 也**不会**在每个状态改变时就重新渲染整个应用。这很容易验证 —— 你只需在应用的根组件调用一次 `console.log`。
+
+
+
+在此例中,除非 `isAuthorized` 发生改变,否则 `App` 不会被重新渲染。任何子组件的改变都不会导致 `App` 重新渲染。仅当组件自己的状态改变,或者被 React Context 触发,或者父组件重新渲染时,它才会被重新渲染。
+
+最后一种情况导致了所谓的**无用渲染** —— 预先知道父组件重新渲染不会导致子组件 DOM 层级发生任何改变时的渲染。这种无用渲染发生在子组件的 prop 不可变,或者这种改变不会影响可视界面的情况中。你可以通过定义 `shouldComponentUpdate`(或者使用 `React.memo` 作为一个更现代化的功能备选方案)来避免无用渲染。
+
+#### 仅在特殊情况下优化,不要默认开启优化
+
+在绝大多数情况下,无用渲染并没有什么坏处。它们耗费的资源小到了肉眼不可见的程度。事实上,对每个组件的 prop 进行浅层(我甚至都不用说深层)的前后比较,比简单粗暴地重新渲染整个子树占用的资源还多。这就是为什么 React 回退到把 `shouldComponentUpdate: () => true` 作为默认设置。此外,React 团队甚至在调试工具中移除了“highlight updates”特性,因为此前人们习惯毫无根据的优化任何一个无用渲染<sup>[5](#footnote5)</sup>。
+
+这是一个非常危险的做法,因为每次优化都意味着要做假设。当你压缩一张图片时,你就会假设有些负载可以在不影响质量的前提下被削减,当你向后端增加缓存数据时,你就会假设 API 可能会返回相同的结果。恰当的假设能让你节省资源。而不恰当的假设就会给应用带来 Bug。这就是应该合理做优化的原因。
+
+Svelte 选择了相反的处理方式。除非你用 `$:` 运算符做出了明确指定,否则组件代码不会在更新时重新运行。我可不想花上几十个小时来查找我哪个地方忘了加 `$:` 运算符,并试图搞清楚为何我的应用跑不起来 —— 只为了用户能享受那快了 20 毫秒的重渲染。如果偶然遇到一个体积庞大的组件,我确实会优化它,但那是极其少见的情况了。在这一点上死扣开发体验是没有意义的。
+
+#### Svelte 的优化不够优
+
+顺便说,如果我们要在技术上较真,其实 Svelte 检查某个更新是否必需的结果也不总是最优的。假设一个组件的计算开销非常大,它接受一个这样的 prop:`Array<{id: string, otherProps}>`。假设我已知 id 都是唯一的,数组中的元素是不可变的,我可以通过下列代码得出某个更新是否必要:
+
+```js
+const shouldUpdate = (prevArr, nextArr) => {
+ if (prevArr.length !== nextArr.length) return true;
+ return nextArr.some((item, index) => item.id !== prevArr[index].id)
+}
+```
+
+在 Svelte 中,无法指定自定义的反应比较器(Reaction comparator),只能像这样比较数组:
+
+```js
+export function safe_not_equal(a, b) {
+ return a != a ? b == b : a !== b
+ || ((a && typeof a === 'object') || typeof a === 'function');
+}
+```
+
+我可以使用一些第三方内存工具给 Svelte 的比较器**打个补丁**,这我能接受,但我在意的是 —— 世上没有仙丹神药,优化得“过了头”就会造成束手束脚的限制。
+
+#### 意义不明的状态更新
+
+在 React 中,当你想要更新状态,你必须调用 `setState`。而在 Svelte 中,要更新状态,你得这样:
+
+> …… 被更新的变量的名字必须位于赋值运算的左侧。
+
+Svelte 很神奇地给内部运行时用于出发反应的空函数添加一个调用。这可能会让人抓狂。
+
+```js
+const foo = obj.foo;
+foo.bar = 'baz';
+obj = obj; // 如果你不这样做,更新就不会发生
+```
+
+同样,用 `push` 或或其他变种方法更新一个数组,都不会自动触发组件更新。因此你必须用数组或对象扩展:
+
+```js
+arr = [...arr, newItem];
+obj = {...obj, updatedValue: newValue};
+```
+
+这跟在 React 中基本一致,除了在 React 里你要调用函数并把被更新的状态传给函数,而在 Svelte 中你会有种正在处理常规的可变变量的错觉。这种体验会从某种程度上降低 Svelte 的优势,降低你发出“哇哦你看太酷了,Svelte 是一个编译器”这种惊叹的冲动。
+
+## 虚拟 DOM
+
+> 虚拟 DOM 很有价值,因为它使你能在构建应用时不用考虑状态转变,并且性能**一般都足够强劲** —— Rich Harris,Svelte 的维护者<sup>[6](#footnote6)</sup>
+
+Svelte 博客中几乎每篇文章都声称,虚拟 DOM[是一个不必要的开销](https://svelte.dev/blog/virtual-dom-is-pure-overhead),而且开销相当大,可以轻易地用预先生成的 DOM 更新器替换它并且无副作用。但这句话对吗?不全对。
+
+](https://cdn-images-1.medium.com/max/2000/1*jomQ-J1bF6mx8eziWMnMww.jpeg)
+
+#### 虚拟 DOM 会增加开销吗?
+
+是的,肯定会。虚拟 DOM 不是个特性,把它放进应用中,并不能妙手回春地让潜在的“真实”DOM 和浏览器跑得更快。它只是一种将易写、易读、易调试的声明式代码转为高效、易于执行的命令式 DOM 操作。
+
+但开销就一定是不好的吗?我觉得不是 —— 否则 Svelte 的维护者就得用 Rust 或 C 来写他们的编译器了,因为 JavaScript 的垃圾收集器就是最大的开销。我猜在决定编译器的技术栈时,他们做了一个权衡 —— 开销有多高与社区得到的好处有多大之间的取舍。在这种情况下,开销相对不高 —— 设备上并没有一直在运行的编译器,你只是时不时地运行它而已,涉及到的计算不多,几秒钟的时间不会给用户体验造成很大影响。另一方面,因为 Svelte 基于 JavaScript,并把 JavaScript 作为执行环境,用 TypeScript/JavaScript 开发的工具为开发体验提供了相对可观的好处:每个对此工具感兴趣的人 —— 因此想贡献代码或需要学习编译器源代码 —— 可能都是了解 JavaScript 的人。
+
+因此,对于开销总是需要权衡的。使用虚拟 DOM 所花费的开销是否值得?
+
+#### 虚拟 DOM 的开销
+
+下载、解析并渲染一个 React 应用需要多长时间?
+
+Rich Harris 本人对第一个问题给出了如是答案:
+
+> 我们向用户装载的代码太多了。与许多其他前端开发者一样,我曾一直拒绝承认此事实,觉得给一个页面加载 100kb 的 JavaScript 也无不妥 —— [少用一个 .jpg 就行了](https://twitter.com/miketaylr/status/227056824275333120)!<sup>[7](#footnote7)</sup>
+
+但接下来他说:
+
+> 100kb 的 .js 和 100kb 的 .jpg 不可等而视之。不仅仅是网络时间开销会使应用的启动性能变差,消耗在解析和评估脚本上的时间也会导致此效果,并且在这段时间内浏览器是完全无响应的。<sup>[7](#footnote7)</sup>
+
+听起来好怕怕呀,让我们用 Google Chrome 浏览器的 Audit 工具测量一下。很幸运,借助 [realworld.io](https://realworld.io),我们能测出结果:
+
+[React-redux](https://react-redux.realworld.io/):
+
+
+
+[Svelte](https://realworld.svelte.dev/):
+
+
+
+区别就是 0.15 秒 —— 毛毛雨啦。
+
+那基准测试呢?Svelte 博客提到的[基准测试](https://github.com/krausest/js-framework-benchmark)表明,滑动 1000 行,React 需要 430.7 毫秒,而 Svelte 可以在 51.8 毫秒内做到。
+
+但是这个度量标准并不可信,因为这种特殊操作是 React 做出[协调假设](https://reactjs.org/docs/reconciliation.html)导致的弱点 —— 这种场景在现实世界中很少见,同样的基准测试表明,React 和 Svelte 在几乎其他所有的案例中的差异都可以忽略不计。
+
+
+
+现在,我们终于意识到,那些基准测试应该信一半扔一半。我们有窗口和虚拟化可以利用,一次渲染 1000 行真是个馊主意。说真的,你真这样干过吗?
+
+](https://cdn-images-1.medium.com/max/2000/1*qvW2rqknyPnztVy4KTUfzA.png)
+
+但 Svelte 的维护者声称虚拟 DOM 完全没必要 —— 那何必浪费**任何**资源呢?什么都不做最节约资源。
+
+#### 虚拟 DOM 的杀手锏
+
+虚拟 DOM 有一个杀手锏,是 Svelte 无论如何都打不败的。那就是把组件层级作为对象来处理的能力。
+
+React 代码:
+
+```jsx
+const UnorderedList = ({children}) => (
+ <ul>
+ {
+ children.map((child, i) => <li key={i}>{child}</li>
+ }
+ </ul>
+)
+
+const App = () => (
+ <UnorderedList>
+ <a href="http://example.com">Example</a>
+ <span>Example</span>
+ Text
+ </UnorderedList>
+);
+```
+
+这个任务对 React 来说小菜一碟,但对 Svelte 来说难于登天。因为模板不是图灵完备(Turing-complete)的,如果是,那它们就得需要虚拟 DOM。看起来似乎问题不大,但对我来说,已经是一个足够正当的理由去给应用额外增加 0.15 秒到 0.25 秒的响应时间了。这正是我们需要虚拟 DOM 之处 —— 我们可能不需要用它来进行响应式的状态更新、条件渲染或者列表渲染,但只要我们有了它,我们就能把组件层级作为完全动态的、可控的对象来处理。没有这个功能,你不可能写出一个真正的声明式应用。
+
+## 暂时性的限制(未来会修复)
+
+还有其他几个不使用 Svelte 的原因,它们可能会被修复。这需要社区成员大量的辛勤付出,但只要成本大于收益,修复就不会发生。
+
+#### 不支持 TypeScript
+
+由于 Svelte 使用了模板,所以很难实现对 TypeScript 的完全支持,比如如 React 一般实现让我们觉得十分便利的支持 prop 检查的 TypeScript 支持。想解决这个问题,要么在 Microsoft TypeScript 实现中做大幅更改(这不太可能,因为 Svelte 的影响力远不如 React),要么新建一个 fork 然后坚持不懈地维护。代码生成也是个可选方案,但对元素层级中的每个细微的改变都运行一次代码生成器,是个可怕的开发体验。
+
+#### 不成熟
+
+> 考虑互用性。想要用 npm 安装炫酷的日历工具并用在自己的应用中?在以前,只有你用的是(一个确定版本的)该工具适配的框架才行 —— 如果 `cool-calendar-widget` 是用 React 开发的,而你在用 Angular,那么好吧,算你倒霉。但如果该工具的作者用了 Svelte 开发,那么你可以随意用哪种框架开发要使用该工具的应用。—— Rich Harris,Svelte 的维护者<sup>[7](#footnote7)</sup>
+
+支持 React 的工具已经是应有尽有了 —— 十几个 GraphQL 客户端、超过 30 个表单状态管理工具、上百个日期组件。
+
+
+
+
+
+如果是在 2013 年,那 Svelte 这个功能可以算是杀手锏了,但如今已经不值一提了。
+
+## 前途光明?
+
+虽然上面说了一些局限,但我觉得 Svelte 实际上提出一了个前途无量的概念。没错,如果不牺牲灵活性和代码可重用性,就无法通过模板完整地表达现代应用程序。但**绝大多数**的应用做的都只是条件渲染和列表渲染罢了。然后,我再说一遍,如果我只是在组件中使用 `onChange={e => setState(e.target.value)}` 并渲染一打 `<div>`,那我们为何还要去支持键盘事件、鼠标滚轮事件和内容可编辑功能呢?
+
+实话实说,我并不相信 Svelte 能以当前这种形式打败 React、横扫世界。但如果有一个框架,它没有任何特定的限制,却能 100% 甩脱所有无用的部分,那就太酷了。要是能生成一些在运行时可用的有关其正确执行的构建时提示,那就更棒了。
+
+## 说说可读性
+
+我们已经知道了,Svelte 的主打特性不是性能(这方面的益处微不足道),也没那么神奇(有些警告信息在 JavaScript 里非常少见,理解起来非常吃力,而且缺少调试工具的支持简直雪上加霜),更不具备互用性(放在 2014 年可能还算个角色,但如今我们的 React-NG-Vue 三大框架下已经应有尽有了)。那可读性方面如何呢?
+
+> 差距如此明显,实在不多见 —— 在我的经验里,一个 React 组件要比对应的 Svelte 组件大 40% —— Rich Harris,Svelte 的维护者<sup>[8](#footnote8)</sup>。
+
+](https://cdn-images-1.medium.com/max/2000/1*H3YESgYacAyOpH31TVVNSQ.jpeg)
+
+每段代码你只会写一次,但会读许多次。我知道这是个人喜好的问题,也知道这是个有争议的话题,但我觉得 JSX 和常规 JavaScript 流运算符要比其他任何形式的 `{#blocks}` 和指令都要通俗易懂。在 Vue 大红大紫前,我就是它的忠实粉丝了。后来我时不时会被一些限制和意义不明的模板绊倒,于是开始全面使用 JSX —— 而因为 JSX 和 Vue 不是一个风格,我后来就转向了 React。我不想再重蹈覆辙。
+
+---
+
+**感谢阅读! 😍**
+
+衷心希望你们喜欢本文。如果你有什么高见,想要交流或者研讨 —— 我全心全意地欢迎你在评论区留言!
+
+---
+
+引用:
+
+<a name="footnote1">1</a>:[https://svelte.dev/](https://svelte.dev/)
+<a name="footnote2">2</a>:[https://github.com/sveltejs/rfcs/blob/master/text/0001-reactive-assignments.md](https://github.com/sveltejs/rfcs/blob/master/text/0001-reactive-assignments.md)
+<a name="footnote3">3</a>:[https://svelte.dev/blog/virtual-dom-is-pure-overhead](https://svelte.dev/blog/virtual-dom-is-pure-overhead)
+<a name="footnote4">4</a>:[https://en.wikiquote.org/wiki/Donald_Knuth](https://en.wikiquote.org/wiki/Donald_Knuth)
+<a name="footnote5">5</a>:[https://www.reddit.com/r/reactjs/comments/cqx554/introducing_the_new_react_devtools/ex1r9nb/](https://www.reddit.com/r/reactjs/comments/cqx554/introducing_the_new_react_devtools/ex1r9nb/)
+<a name="footnote6">6</a>:[https://svelte.dev/blog/virtual-dom-is-pure-overhead](https://svelte.dev/blog/virtual-dom-is-pure-overhead)
+<a name="footnote7">7</a>:[https://svelte.dev/blog/frameworks-without-the-framework](https://svelte.dev/blog/frameworks-without-the-framework)
+<a name="footnote8">8</a>: [https://svelte.dev/blog/write-less-code](https://svelte.dev/blog/write-less-code)
+
+> 如果发现译文存在错误或其他需要改进的地方,欢迎到 [掘金翻译计划](https://github.com/xitu/gold-miner) 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 **本文永久链接** 即为本文在 GitHub 上的 MarkDown 链接。
+
+---
+
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
diff --git a/integrals.md b/integrals.md
index bea7fb59593..7e8e0ce2b6d 100644
--- a/integrals.md
+++ b/integrals.md
@@ -114,7 +114,7 @@
|[编写高性能的 Swift 代码](http://gold.xitu.io/entry/56b60c97816dfa005ae0c0d4)|翻译|15|
|[第一次翻译计划文章已兑换Octocat小]()|减去积分|15|
-## 译者:[l9m](https://github.com/L9m) 历史贡献积分:99 当前积分:64 二零一九:1.5
+## 译者:[l9m](https://github.com/L9m) 历史贡献积分:99 当前积分:64
|文章|类型|积分|
|------|-------|-------|
@@ -270,7 +270,7 @@
|[使用 webP 减少图片的大小](http://gold.xitu.io/entry/57383657c4c97100601212d5)|翻译|4|
|[Vector For All (slight return)](http://gold.xitu.io/entry/5756697ea341310063dd532c)|校对|1|
-## 译者:[cdpath](https://github.com/cdpath) 历史贡献积分:134 当前积分:89 二零一九:8
+## 译者:[cdpath](https://github.com/cdpath) 历史贡献积分:134 当前积分:89
|文章|类型|积分|
|------|-------|-------|
@@ -555,7 +555,7 @@
|文章|类型|积分|
|------|-------|-------|
|[选择使用正确的 Markdown Parser](https://github.com/xitu/gold-miner/blob/master/TODO/choosing-right-markdown-parser.md)|校对|1|
-|[如何更高效地使用 OkHttp](https://github.com/brucezz/gold-miner/blob/73e487049f7c3ccc69ff6156142e6fa14060f4a1/TODO/effective-okhttp.md)|翻译|第一次翻译计划遗留文章|
+|[如何更高效地使用 OkHttp](https://github.com/brucezz/gold-miner/blob/73e487049f7c3ccc69ff6156142e6fa14060f4a1/TODO/effective-okhttp.md)|翻译|0|
## 译者:[aleen42](https://github.com/aleen42) 历史贡献积分:35 当前积分:13
@@ -806,7 +806,7 @@
|[在网站 Logo 上右击时提示下载网站的 Logo 素材下载](https://github.com/rainyear/gold-miner/blob/fabff8780118b24c61c57b13577cf971757c84d5/TODO/right-click-logo-show-logo-download-options.md)|校对|1|
|[给产品经理的简易优先级法则](http://gold.xitu.io/entry/572ad1cc1532bc0065d5e36b)|翻译|7|
-## 译者:[loneyiserror](https://github.com/LoneyIsError) 历史贡献积分:48.5 当前积分:48.5 二零一九:22.5
+## 译者:[loneyiserror](https://github.com/LoneyIsError) 历史贡献积分:48.5 当前积分:48.5
|文章|类型|积分|
|------|-------|-------|
@@ -893,7 +893,7 @@
|[承载了巨大访问量的热门游戏 Pokémon GO 的后端架构是什么?](https://github.com/xitu/gold-miner/blob/master/TODO/bringing-Pokemon-GO-to-life-on-Google-Cloud.md)|校对|1|
|[构建应用状态时,你应该避免不必要的复杂性](http://gold.xitu.io/entry/58044c2a0e3dd900571475fa/)|校对|2|
|[开发 Electron app 必知的 4 个 tips](http://gold.xitu.io/entry/58025536bf22ec0064d5f3d9)|校对|1|
-|[如何测试 Android �Service 里的 �Singleton (1) ?](http://gold.xitu.io/entry/57fb306da341310060135cbb/)|校对|1|
+|[如何测试 Android Service 里的 Singleton (1) ?](http://gold.xitu.io/entry/57fb306da341310060135cbb/)|校对|1|
|[开发移动应用,你应该注意这些小细节](http://gold.xitu.io/entry/57d2d60667f3560057d0cd85/)|校对|1|
|[人们为什么会打开你的营销电子邮件?](http://gold.xitu.io/entry/57d170f82e958a00544ebf7c/)|翻译|5|
|[用 Swift 枚举完美实现 3D touch 快捷操作](http://gold.xitu.io/entry/57c6b223efa631005ad6e7d1)|翻译|6|
@@ -1533,7 +1533,7 @@
|[iOS 开发中的 Flux 架构模式](http://gold.xitu.io/entry/57972cdcc4c97100542c2ed4)|校对|2|
|[使用 Zopfli 优化 PNG 图片](http://gold.xitu.io/entry/578e3a34c4c971005e059ee9)|校对|1|
-## 译者:[siegeout](https://github.com/siegeout) 历史贡献积分:55 当前积分:5 二零一九:1
+## 译者:[siegeout](https://github.com/siegeout) 历史贡献积分:55 当前积分:5
|文章|类型|积分|
|------|-------|-------|
@@ -1579,8 +1579,8 @@
|[iOS 10 中的 NSPersistentContainer](http://gold.xitu.io/entry/580444efa34131005fe77197/)|校对|1|
|[Pury — 一个新的 Android App 性能分析工具](http://gold.xitu.io/entry/57fe4b92a22b9d005b1a8a2a/)|校对|1|
|[减少认知过载可以为用户带来更佳体验](http://gold.xitu.io/entry/58007345816dfa0056e8ff5c)|校对|2|
-|[如何测试 Android �Service 里的 �Singleton (2) ?](http://gold.xitu.io/entry/57fcb8f68ac2470058c9f621/)|校对|1|
-|[如何测试 Android �Service 里的 �Singleton (1) ?](http://gold.xitu.io/entry/57fb306da341310060135cbb/)|校对|1|
+|[如何测试 Android Service 里的 Singleton (2) ?](http://gold.xitu.io/entry/57fcb8f68ac2470058c9f621/)|校对|1|
+|[如何测试 Android Service 里的 Singleton (1) ?](http://gold.xitu.io/entry/57fb306da341310060135cbb/)|校对|1|
|[好的设计准则是如何塑造更强大的产品形态的](http://gold.xitu.io/entry/57db572ed203090069d2e201)|校对|1|
|[用心设计的艺术](http://gold.xitu.io/entry/57d6bd1bd20309006a08e25e/)|校对|1|
|[3 分钟掌握 CSS Flexbox](http://gold.xitu.io/entry/57ce68bf2e958a00543a7df9/)|翻译|4|
@@ -1620,7 +1620,7 @@
|------|-------|-------|
|[ES6 中 的 var、let 和 const 应该如何选择?](http://gold.xitu.io/entry/57962ef22e958a00651f7387)|校对|1|
-## 译者:[rottenpen](https://github.com/rottenpen) 历史贡献积分:47.5 当前积分:47.5 二零一九:1
+## 译者:[rottenpen](https://github.com/rottenpen) 历史贡献积分:47.5 当前积分:47.5
|文章|类型|积分|
|------|-------|-------|
@@ -1731,7 +1731,7 @@
|[用 Swift 开发我的第一个 iOS 应用前,我想要知道这些内容](http://gold.xitu.io/entry/57c66667c4c9710061a57b3f/)|校对|2|
|[你的设计应该「所见即所得」](http://gold.xitu.io/entry/57c5978f128fe1005fdf4858/)|校对|1|
-## 译者:[steinliber](https://github.com/steinliber) 历史贡献积分:132 当前积分:27 二零一九:16
+## 译者:[steinliber](https://github.com/steinliber) 历史贡献积分:132 当前积分:27
|文章|类型|积分|
|------|-------|-------|
@@ -1851,7 +1851,7 @@
|------|-------|-------|
|[快速构建原型最好用的 10 个 ReactJS UI 框架](http://gold.xitu.io/entry/57ea0bc2a3413100624e62ff/)|校对|1|
-## 译者:[danny1451](https://github.com/Danny1451) 历史贡献积分:64.5 当前积分:0.5 二零一九:1.5
+## 译者:[danny1451](https://github.com/Danny1451) 历史贡献积分:64.5 当前积分:0.5
|文章|类型|积分|
|------|-------|-------|
@@ -2027,10 +2027,11 @@
|[iOS 10 今日控件向后兼容的几个技巧](http://gold.xitu.io/entry/580eec1b8ac247005b620267/)|校对|1|
|[11月份兑换大章鱼猫一只]()|减去积分|30|
-## 译者:[jacksonke](https://github.com/jacksonke) 历史贡献积分:17 当前积分:17
+## 译者:[jacksonke](https://github.com/jacksonke) 历史贡献积分:19 当前积分:19
|文章|类型|积分|
|------|-------|-------|
+|[在你的 Instant 体验中使用 showInstallPrompt 的 5 个技巧](https://juejin.im/post/5dac5bc86fb9a04e1b57fa33)|校对|2|
|[使用 Gradle 做构建检查](https://juejin.im/entry/5937f0a48fd9c513c627114a/detail)|翻译|5|
|[Android 中的 Effective Java(速查表)](https://gold.xitu.io/entry/5858efc1128fe10069b28de4/)|校对|1|
|[彻底理解引用在 Android 和 Java 中的工作原理](https://gold.xitu.io/entry/58476f2c128fe10058bae7ca/)|翻译|4|
@@ -2078,7 +2079,7 @@
|[理解 iOS 应用程序的代码签名 (CODE SIGN) 机制](http://gold.xitu.io/entry/5826ef85570c3500586b241d/)|校对|1|
|[Swift 3 语言中的全模块优化](http://gold.xitu.io/entry/5818b6f52f301e005cf0ef8e/)|校对|1|
-## 译者:[romeo0906](https://github.com/Romeo0906) 历史贡献积分:149 当前积分:54 二零一九:7
+## 译者:[romeo0906](https://github.com/Romeo0906) 历史贡献积分:149 当前积分:54
|文章|类型|积分|
|------|-------|-------|
@@ -2158,7 +2159,7 @@
|[成为一个编译器之「使用 JavaScript 来制作编译器」](http://gold.xitu.io/entry/582343555bbb500059056d4b/)|校对|1|
|[给 iOS App 开发者的 39 个开源的 Swift UI 库](http://gold.xitu.io/entry/58209322570c350060b73588)|校对|1|
-## 译者:[phxnirvana](https://github.com/phxnirvana) 历史贡献积分:98 当前积分:15 二零一九:13
+## 译者:[phxnirvana](https://github.com/phxnirvana) 历史贡献积分:98 当前积分:15
|文章|类型|积分|
|------|-------|-------|
@@ -2215,7 +2216,7 @@
|[我在手撕 SVG 条形图时踩过的定位坑](http://gold.xitu.io/entry/58306b428ac2470061b60ede/)|校对|1|
|[构建 Android APP 一定要绕过的 30 个坑](http://gold.xitu.io/entry/58217b84570c350060bc40f8/)|校对|1|
-## 译者:[aceleewinnie](https://github.com/AceLeeWinnie) 历史贡献积分:107 当前积分:61 二零一九:5
+## 译者:[aceleewinnie](https://github.com/AceLeeWinnie) 历史贡献积分:107 当前积分:61
|文章|类型|积分|
|------|-------|-------|
@@ -2411,11 +2412,11 @@
|[防守式编程的艺术](https://gold.xitu.io/entry/58980dbc1b69e6005997f069)|翻译|4|
|[容器时代的分布式日志架构](https://gold.xitu.io/entry/5870f966a22b9d00588bafce)|校对|1|
-## 译者:[frankxiong](https://github.com/FrankXiong) 历史贡献积分:21 当前积分:21 二零一九:4
+## 译者:[frankxiong](https://github.com/FrankXiong) 历史贡献积分:21 当前积分:21
|文章|类型|积分|
|------|-------|-------|
-|[图解 Map、Reduce 和 Filter 数组方法](https://juejin.im/post/5caf030d6fb9a068736d2d7c)|翻译|3+1|
+|[图解 Map、Reduce 和 Filter 数组方法](https://juejin.im/post/5caf030d6fb9a068736d2d7c)|翻译|4|
|[Node.js 子进程:你应该知道的一切](https://juejin.im/entry/595dc35b51882568d00a97ab)|翻译|9|
|[让 Node.js 核心库更大](https://gold.xitu.io/entry/5897289b0ce463005603a5d5/detail)|校对|1|
|[2017 年要去学的 3 个 CSS 新属性](https://gold.xitu.io/entry/5896c8ee570c3500623eeaeb/detail)|翻译|4|
@@ -2492,7 +2493,7 @@
|文章|类型|积分|
|------|-------|-------|
|2018 年 9 月兑套头衫 M 号 1 个|减去积分|20|
-|[[字幕翻译] Graham Dumpleton — Secrets of a WSGI master. — PyCon 2018](https://github.com/xitu/gold-miner/blob/master/TODO1/secrets-of-a-wsgi-master-pycon-2018.md) |翻译|9|
+|[[字幕翻译] Graham Dumpleton — Secrets of a WSGI master. — PyCon 2018](https://github.com/xitu/gold-miner/blob/master/TODO1/secrets-of-a-wsgi-master-pycon-2018.md)|翻译|9|
|[用 Python 做一个 H5 游戏机器人](https://juejin.im/post/5aa9e7645188257bf550c745)|校对|1.5|
|[2018 年要学习的优秀 JavaScript 库与知识](https://juejin.im/post/5a4e23f0f265da3e377bce4f)|校对|2|
|[如何在 JavaScript 中使用 Generator?](https://juejin.im/post/5a44968df265da4335630fb9)|校对|1|
@@ -2578,7 +2579,7 @@
|[Workcation App – 第三部分. 带有动画的标记(Animated Markers) 与 RecyclerView 的互动](https://juejin.im/post/5934bb10ac502e0068aa7598)|校对|1|
|[Workcation App – 第二部分 . Animating Markers 和 MapOverlayLayout](https://juejin.im/post/5934ba6aa22b9d0058ed37c5)|校对|1|
|[Workcation App – 第一部分 . 自定义 Fragment 转场动画](https://juejin.im/post/5934b96c570c35005b548218)|校对|1|
-|[大战 RxJava2 和 Java8 Stream \[ Android RxJava2 \] (这到底是什么) 第四部分](https://juejin.im/post/58f44a705c497d006c95436b)|校对|2|
+|[大战 RxJava2 和 Java8 Stream [ Android RxJava2 ] (这到底是什么) 第四部分](https://juejin.im/post/58f44a705c497d006c95436b)|校对|2|
|[观察者模式 – 响应式编程 [Android RxJava2](这到底是什么):第一部分](https://gold.xitu.io/entry/58ada9738fd9c5006704f5a1)|校对|2|
## 译者:[showd0wn](https://github.com/showd0wn) 历史贡献积分:1 当前积分:1
@@ -2733,7 +2734,7 @@
|[在 Xcode 项目中使用 swift package fetch](https://juejin.im/entry/58c7a4cb1b69e6006bec354c/)|校对|1|
|[Swift + 关键字](https://gold.xitu.io/entry/58bf76aaa22b9d0058896bff/)|校对|1|
-## 译者:[xilihuasi](https://github.com/xilihuasi) 历史贡献积分:71 当前积分:71 二零一九:37
+## 译者:[xilihuasi](https://github.com/xilihuasi) 历史贡献积分:71 当前积分:71
|文章|类型|积分|
|------|-------|-------|
@@ -2841,7 +2842,7 @@
|[如何在 ChromeOS 下用 Go 搭建 Web 服务](https://juejin.im/post/58d9e1711b69e6006bc38b1a)|翻译|8|
|[Pull request review 的十大错误](https://juejin.im/post/58ce3b3e61ff4b006c988f63)|校对|1|
-## 译者:[sunui](https://github.com/sunui) 历史贡献积分:141.5 当前积分:31.5 二零一九:32.5
+## 译者:[sunui](https://github.com/sunui) 历史贡献积分:141.5 当前积分:31.5
|文章|类型|积分|
|------|-------|-------|
@@ -2938,7 +2939,7 @@
|[当设计模式遇上 Kotlin](https://juejin.im/post/594b2ac00ce4630057425bd5)|翻译|4|
|[一个人的 Android 开发](https://juejin.im/entry/58dca515b123db00603887fd)|翻译|5|
|[当发布安卓开源库时我希望知道的东西](https://juejin.im/post/58d247b00ce4630057e92e9c)|校对|2|
-|[大战 RxJava2 和 Java8 Stream \[ Android RxJava2 \] (这到底是什么) 第四部分](https://juejin.im/post/58f44a705c497d006c95436b)|翻译|8|
+|[大战 RxJava2 和 Java8 Stream [ Android RxJava2 ] (这到底是什么) 第四部分](https://juejin.im/post/58f44a705c497d006c95436b)|翻译|8|
## 译者:[gaozp](https://github.com/gaozp) 历史贡献积分:6 当前积分:6
@@ -2966,10 +2967,13 @@
|[你正在阅读的用户体验文章是不是在向你进行推销?](https://juejin.im/post/58d4c501a22b9d00645544d9)|校对|2|
|[震惊,还可以用这种姿势学习编程](https://juejin.im/post/58d3ebd4128fe1006cb43722)|翻译|3|
-## 译者:[lsvih](https://github.com/lsvih) 历史贡献积分:385 当前积分:319 二零一九:90
+## 译者:[lsvih](https://github.com/lsvih) 历史贡献积分:393.5 当前积分:327.5 二零二零:8.5
|文章|类型|积分|
|------|-------|-------|
+|[用 6 分钟学习如何用 Redis 缓存您的 NodeJS 应用!](https://juejin.im/post/5e4df6d7518825496452ac98)|校对|2.5|
+|[图像修复:人类和 AI 的对决](https://juejin.im/post/5e43b2edf265da576543a0bb)|校对|3|
+|[使用 Python 进行边缘检测](https://juejin.im/post/5e3d4b53e51d4526c26fadd4)|翻译|3|
|[使用 Typescript 使无效状态不可恢复](https://juejin.im/post/5d628841518825332d3fec3d)|校对|1|
|[人工智能何以留存](https://juejin.im/post/5d4c1155e51d4562061159d1)|校对|2|
|[XGBoost 算法万岁!](https://juejin.im/post/5d484040e51d4561f95ee9de)|翻译|4|
@@ -2978,8 +2982,8 @@
|[使用 What-If 工具来研究机器学习模型](https://juejin.im/post/5d143abff265da1bb80c4005)|校对|3|
|[JavaScript 线性代数:使用 ThreeJS 制作线性变换动画](https://juejin.im/post/5d05dba86fb9a07ece67ce76)|翻译|3|
|[线性代数:矩阵基本运算](https://juejin.im/post/5d107b00f265da1b67211a21)|翻译|3|
-|[JavaScript 线性代数:线性变换与矩阵](https://juejin.im/post/5cfdc1fb518825361d02aa41)|翻译|2+1|
-|[JavaScript 线性代数:向量](https://juejin.im/post/5cf61bf8e51d45775653674e)|翻译|3+1|
+|[JavaScript 线性代数:线性变换与矩阵](https://juejin.im/post/5cfdc1fb518825361d02aa41)|翻译|3|
+|[JavaScript 线性代数:向量](https://juejin.im/post/5cf61bf8e51d45775653674e)|翻译|4|
|[使用谷歌 FACETS 可视化机器学习数据集](https://juejin.im/post/5d0226986fb9a07ecb0ba33a)|校对|2.5|
|[在 Keras 下使用自编码器分类极端稀有事件](https://juejin.im/post/5cff17296fb9a07ec63b0a7f)|校对|2.5|
|[用 React 制作线性代数教程示例:网格与箭头](https://juejin.im/post/5cefbc37f265da1bd260d129)|翻译|3|
@@ -3079,7 +3083,7 @@
|------|-------|-------|
|[如何在 ChromeOS 下用 Go 搭建 Web 服务](https://juejin.im/post/58d9e1711b69e6006bc38b1a)|校对|2|
-## 译者:[1992chenlu](https://github.com/1992chenlu) 历史贡献积分:20.5 当前积分:20.5 二零一九:1.5
+## 译者:[1992chenlu](https://github.com/1992chenlu) 历史贡献积分:20.5 当前积分:20.5
|文章|类型|积分|
|------|-------|-------|
@@ -3164,7 +3168,7 @@
|[同中有异的 Webpack 与 Rollup](https://juejin.im/post/58edb865570c350057f199a7)|校对|1|
|[webpack 拾翠:充分利用 CommonsChunkPlugin()](https://juejin.im/post/58ec4e3f5c497d0062c470bf)|校对|1|
-## 译者:[yoyoyohamapi](https://github.com/yoyoyohamapi) 历史贡献积分:92.5 当前积分:12.5 二零一九:3.5
+## 译者:[yoyoyohamapi](https://github.com/yoyoyohamapi) 历史贡献积分:92.5 当前积分:12.5
|文章|类型|积分|
|------|-------|-------|
@@ -3239,7 +3243,7 @@
|------|-------|-------|
|[从形式到功能,设计思维的改变](https://juejin.im/post/58fedca744d9040069f720e4)|校对|1|
-## 译者:[mnikn](https://github.com/mnikn) 历史贡献积分:52.5 当前积分:2.5 二零一九:2.5
+## 译者:[mnikn](https://github.com/mnikn) 历史贡献积分:52.5 当前积分:2.5
|文章|类型|积分|
|------|-------|-------|
@@ -3346,7 +3350,7 @@
|------|-------|-------|
|[开发者(也就是我)与Rx Observable 类的对话 [ Android RxJava2 ] ( 这到底是什么?) 第五部分](https://juejin.im/post/590ab4f7128fe10058f35119)|校对|1|
-## 译者:[leviding](https://github.com/leviding) 历史贡献积分:196 当前积分:151 二零一九:11
+## 译者:[leviding](https://github.com/leviding) 历史贡献积分:196 当前积分:151
|文章|类型|积分|
|------|-------|-------|
@@ -3399,7 +3403,7 @@
|文章|类型|积分|
|------|-------|-------|
-|[大战 RxJava2 和 Java8 Stream \[ Android RxJava2 \] (这到底是什么) 第四部分](https://juejin.im/post/58f44a705c497d006c95436b)|校对|2|
+|[大战 RxJava2 和 Java8 Stream [ Android RxJava2 ] (这到底是什么) 第四部分](https://juejin.im/post/58f44a705c497d006c95436b)|校对|2|
## 译者:[ymz1124](https://github.com/ymz1124) 历史贡献积分:4 当前积分:4
@@ -3484,7 +3488,7 @@
|[消息同步 —— 在 Airbnb 我们是怎样扩展移动消息的](https://juejin.im/post/593a7647128fe1006acafaf9)|校对|1|
|[对元素持有弱引用的 Swift 数组](https://juejin.im/post/5927a34c0ce46300575a81e1)|校对|1|
-## 译者:[feximin](https://github.com/Feximin) 历史贡献积分:49.5 当前积分:49.5 二零一九:17.5
+## 译者:[feximin](https://github.com/Feximin) 历史贡献积分:49.5 当前积分:49.5
|文章|类型|积分|
|------|-------|-------|
@@ -3522,7 +3526,7 @@
|[设计作品集网站的真正角色是什么?](https://juejin.im/post/598959b65188253d2968eaab)|翻译|4|
|[如何理智地构建复杂用户界面](https://juejin.im/post/5937a61f2f301e006b2879a9)|校对|1|
-## 译者:[whatbeg](https://github.com/whatbeg) 历史贡献积分:43 当前积分:23 二零一九:15.5
+## 译者:[whatbeg](https://github.com/whatbeg) 历史贡献积分:43 当前积分:23
|文章|类型|积分|
|------|-------|-------|
@@ -3643,10 +3647,11 @@
|------|-------|-------|
|[如何在无损的情况下让图片变的更小](https://juejin.im/post/5959fbe0f265da6c2518d740)|校对|2|
-## 译者:[swants](https://github.com/swants) 历史贡献积分:96.5 当前积分:31.5 二零一九:28
+## 译者:[swants](https://github.com/swants) 历史贡献积分:98 当前积分:33
|文章|类型|积分|
|------|-------|-------|
+|[开源难题:如何保持长久](https://juejin.im/post/5db27be36fb9a02040687055)|校对|1.5|
|[Xcode 和 LLDB 高级调试教程:第 3 部分](https://juejin.im/post/5d383c7d5188257dab043145)|校对|2|
|[iOS 中的 File Provider 拓展](https://juejin.im/post/5cff5b0af265da1b8b2b54c7)|校对|3|
|[理解 WebView](https://juejin.im/post/5ce76ee4f265da1b8d15f700)|校对|2.5|
@@ -3886,7 +3891,7 @@
|[REST API 已死,GraphQL 长存](https://juejin.im/post/5991667b518825485d28dfb1)|校对|2|
|[机器之魂:聊天机器人是怎么工作的](https://juejin.im/post/599155d86fb9a03c467c151d)|校对|1|
-## 译者:[undead25](https://github.com/undead25) 历史贡献积分:47.5 当前积分:47.5 二零一九:3
+## 译者:[undead25](https://github.com/undead25) 历史贡献积分:47.5 当前积分:47.5
|文章|类型|积分|
|------|-------|-------|
@@ -4091,7 +4096,7 @@
|[在 HTTP/2 的世界里管理 CSS 和 JS](https://juejin.im/post/59bb463d51882519777c5a85)|校对|0.5|
|[Coursera 的 GraphQL 之路](https://juejin.im/post/59b8d1d36fb9a00a3f24c439)|校对|1|
-## 译者:[Usey95](https://github.com/Usey95) 历史贡献积分:59 当前积分:59 二零一九:23
+## 译者:[Usey95](https://github.com/Usey95) 历史贡献积分:59 当前积分:59
|文章|类型|积分|
|------|-------|-------|
@@ -4143,7 +4148,7 @@
|------|-------|-------|
|[Web 设计准则](https://juejin.im/post/59c9c6f66fb9a00a4d53eec7)|校对|1|
-## 译者:[HydeSong](https://github.com/HydeSong) 历史贡献积分:37 当前积分:37 二零一九:19.5
+## 译者:[HydeSong](https://github.com/HydeSong) 历史贡献积分:37 当前积分:37
|文章|类型|积分|
|------|-------|-------|
@@ -4188,7 +4193,7 @@
|------|-------|-------|
|[你不知道的 Node](https://juejin.im/post/59cf06caf265da0665640008)|校对|1|
-## 译者:[skychenbo](https://github.com/skychenbo) 历史贡献积分:35 当前积分:5 二零一九:5
+## 译者:[skychenbo](https://github.com/skychenbo) 历史贡献积分:35 当前积分:5
|文章|类型|积分|
|------|-------|-------|
@@ -4351,7 +4356,7 @@
|[Python 3.7 的新特性](https://juejin.im/post/5a127e60f265da430f31b45b)|翻译|4|
|[如何为通知设计更好的用户体验](https://juejin.im/post/59f9b14f518825295f5d411f)|校对|3|
-## 译者:[ppp-man](https://github.com/ppp-man) 历史贡献积分:30.5 当前积分:30.5 二零一九:6
+## 译者:[ppp-man](https://github.com/ppp-man) 历史贡献积分:30.5 当前积分:30.5
|文章|类型|积分|
|------|-------|-------|
@@ -4385,7 +4390,7 @@
|------|-------|-------|
|[RNN 循环神经网络系列 4: 注意力机制](https://juejin.im/post/59f72f61f265da432002871c)|校对|2|
-## 译者:[Raoul1996](https://github.com/Raoul1996) 历史贡献积分:112 当前积分:29 二零一九:14.5
+## 译者:[Raoul1996](https://github.com/Raoul1996) 历史贡献积分:112 当前积分:29
|文章|类型|积分|
|------|-------|-------|
@@ -4514,7 +4519,7 @@
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译|1|
|[Vue Report 2017](https://juejin.im/post/5a138fae5188254d28732899)|翻译|2|
-## 译者:[JohnJiangLA](https://github.com/JohnJiangLA) 历史贡献积分:139 当前积分:9 二零一九:19.5
+## 译者:[JohnJiangLA](https://github.com/JohnJiangLA) 历史贡献积分:139 当前积分:9
|文章|类型|积分|
|------|-------|-------|
@@ -4686,7 +4691,6 @@
|------|-------|-------|
|[TensorFlow 官方文档翻译校对](https://github.com/xitu/tensorflow-docs)|翻译|2|
-
## 译者:[elijahxyc](https://github.com/elijahxyc) 历史贡献积分:3.5 当前积分:3.5
|文章|类型|积分|
@@ -4825,7 +4829,7 @@
|文章|类型|积分|
|------|-------|-------|
-|[翻译开源库 JS 分类 100 个]()|翻译|10|
+|[翻译开源库 JS 分类 100 个]()|翻译开源库|10|
## 译者:[kangkai124](https://github.com/kangkai124) 历史贡献积分:15.5 当前积分:10.5
@@ -4882,7 +4886,7 @@
|------|-------|-------|
|[从 Gzip 压缩 SVG 说起 — 论如何减小资源文件的大小](https://juejin.im/post/5a30a7fdf265da4309452517)|校对|1|
-## 译者:[noahziheng](https://github.com/noahziheng) 历史贡献积分:46 当前积分:28 二零一九:2
+## 译者:[noahziheng](https://github.com/noahziheng) 历史贡献积分:46 当前积分:28
|文章|类型|积分|
|------|-------|-------|
@@ -5005,7 +5009,7 @@
|------|-------|-------|
|[使用 CSS Grid:以兼容不支持栅格化布局的浏览器](https://juejin.im/post/5a3f494d6fb9a0450a678f8d)|校对|2|
-## 译者:[proYang](https://github.com/proYang) 历史贡献积分:4 当前积分:4 二零一九:1
+## 译者:[proYang](https://github.com/proYang) 历史贡献积分:4 当前积分:4
|文章|类型|积分|
|------|-------|-------|
@@ -5024,7 +5028,7 @@
|[做好准备:新的 V8 即将到来,Node.js 的性能正在改变。](https://juejin.im/post/5aaf755851882555627d16e5)|校对|3|
|[论原子 CSS 的日益普及](https://juejin.im/post/5a4387af6fb9a045186b04d1)|校对|1.5|
-## 译者:[lcx-seima](https://github.com/lcx-seima) 历史贡献积分:40 当前积分:40 二零一九:2.5
+## 译者:[lcx-seima](https://github.com/lcx-seima) 历史贡献积分:40 当前积分:40
|文章|类型|积分|
|------|-------|-------|
@@ -5136,7 +5140,7 @@
|[JavaScript 自动化爬虫入门指北(Chrome + Puppeteer + Node JS)](https://juejin.im/post/5a4e1038f265da3e591e1247)|翻译|7|
|[智对订阅难点:教你如何应对工作中 10 种常见订阅问题](https://juejin.im/post/5a406644f265da430d583cb7)|翻译|5|
-## 译者:[Wangalan30](https://github.com/Wangalan30) 历史贡献积分:34.5 当前积分:34.5 二零一九:11
+## 译者:[Wangalan30](https://github.com/Wangalan30) 历史贡献积分:34.5 当前积分:34.5
|文章|类型|积分|
|------|-------|-------|
@@ -5179,7 +5183,7 @@
|------|-------|-------|
|[为 APP 设计通知提醒](https://juejin.im/post/5ba31ee3e51d450e4115500b)|校对|3.5|
|2018 年 9 月兑 Google DIY 纸板音箱 1 个|减去积分|45|
-|[React Native:回顾 Udacity 移动工程团队的使用历程](https://juejin.im/post/5b421b606fb9a04fd15ff802)|翻译|礼物|
+|[React Native:回顾 Udacity 移动工程团队的使用历程](https://juejin.im/post/5b421b606fb9a04fd15ff802)|翻译送礼|0|
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译校对|5|
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译|15|
|[2018 年 2 月兑 树莓派套餐 1 个]()|减去积分|45|
@@ -5338,10 +5342,11 @@
|[我未曾见过的 JS 特性](https://juejin.im/post/5a723216f265da3e2e62d0a5)|校对|1|
|[通过后台数据预获取技术实现性能提升](https://juejin.im/post/5a71a9c3f265da3e2f01459b)|校对|2|
-## 译者:[foxxnuaa](https://github.com/foxxnuaa) 历史贡献积分:28.5 当前积分:28.5
+## 译者:[foxxnuaa](https://github.com/foxxnuaa) 历史贡献积分:30 当前积分:30
|文章|类型|积分|
|------|-------|-------|
+|[使用因果分析优化 Go HTTP/2 服务器](https://juejin.im/post/5dc3e5faf265da4d144e86c2)|校对|1.5|
|[Tab Bar 就是新的汉堡菜单](https://juejin.im/post/5b61684fe51d451986517e31)|校对|1.5|
|[React Native 中使用转场动画!](https://juejin.im/post/5b69467e5188251b3c3b4e4e)|校对|0.5|
|[重写 loadView() 方法使 Swift 视图代码更加简洁](https://juejin.im/post/5b68fe5b6fb9a04fd16039c0)|校对|1|
@@ -5363,7 +5368,7 @@
|[这些 CSS 命名规范将省下你大把调试时间](https://juejin.im/post/5a6c5881518825733201daf7)|校对|2|
|[Facebook 开源了物体检测研究项目 Detectron](https://juejin.im/post/5a6c2ba56fb9a01cb64f0591)|校对|0.5|
-## 译者:[xingqiwu55555](https://github.com/xingqiwu55555) 历史贡献积分:17 当前积分:17 二零一九:17
+## 译者:[xingqiwu55555](https://github.com/xingqiwu55555) 历史贡献积分:17 当前积分:17
|文章|类型|积分|
|------|-------|-------|
@@ -5506,7 +5511,7 @@
|[json — JavaScript 对象表示法](https://juejin.im/post/5a9432ae5188257a5c6092b0)|翻译|2.5|
|[教你使用 CSS 计数器](https://juejin.im/post/5a811c6251882528b63ff8d7)|校对|0.5|
-## 译者:[weberpan](https://github.com/weberpan) 历史贡献积分:41 当前积分:41 二零一九:2
+## 译者:[weberpan](https://github.com/weberpan) 历史贡献积分:41 当前积分:41
|文章|类型|积分|
|------|-------|-------|
@@ -5564,7 +5569,7 @@
|[使用 MVI 开发响应式 APP - 第三部分 - 状态减少(state reducer)](https://juejin.im/post/5a955c50f265da4e853d856a)|翻译|4|
|[二十年后比特币会变成什么样?- 第二部分](https://juejin.im/post/5a955721f265da4e826377b6)|翻译|6|
-## 译者:[Starriers](https://github.com/Starriers) 历史贡献积分:488 当前积分:212 二零一九:55
+## 译者:[Starriers](https://github.com/Starriers) 历史贡献积分:488 当前积分:212
|文章|类型|积分|
|------|-------|-------|
@@ -5675,7 +5680,7 @@
|[json — JavaScript 对象表示法](https://juejin.im/post/5a9432ae5188257a5c6092b0)|校对|1|
|[嵌套三元表达式棒极了(软件编写)(第十四部分)](https://juejin.im/post/5a7d6769f265da4e7e10ad82)|校对|1|
-## 译者:[zhmhhu](https://github.com/zhmhhu) 历史贡献积分:125 当前积分:25 二零一九:19.5
+## 译者:[zhmhhu](https://github.com/zhmhhu) 历史贡献积分:125 当前积分:25
|文章|类型|积分|
|------|-------|-------|
@@ -5789,6 +5794,7 @@
|[测试 React & Redux 应用真实引导](https://juejin.im/post/5a9cc812518825556f54e3b6)|校对|1.5|
## 译者:[razertory](https://github.com/razertory) 历史贡献积分:18 当前积分:3
+
|文章|类型|积分|
|------|-------|-------|
|2018 年 12 月兑掘金水杯 2 个和 GitHub 贴纸 1 包|减去积分|15|
@@ -5822,7 +5828,7 @@
|[如何修改域名来提高国际增长率](https://juejin.im/post/5aaf0542f265da239530c653)|校对|1|
|[开始设计动画的九个步骤](https://juejin.im/post/5aa1f965f265da23994e1e1f)|校对|1|
-## 译者:[talisk](https://github.com/talisk) 历史贡献积分:48 当前积分:25 二零一九:13
+## 译者:[talisk](https://github.com/talisk) 历史贡献积分:48 当前积分:25
|文章|类型|积分|
|------|-------|-------|
@@ -5928,10 +5934,21 @@
|[让 Apache Cassandra 尾部延迟减小 10 倍(已开源)](https://juejin.im/post/5ac31083f265da239a5fff0c)|翻译|4|
|[让我们来简化 UserDefaults 的使用](https://juejin.im/post/5abde324f265da23826e1723)|校对|0.5|
-## 译者:[EmilyQiRabbit](https://github.com/EmilyQiRabbit) 历史贡献积分:214 当前积分:194 二零一九:132
+## 译者:[EmilyQiRabbit](https://github.com/EmilyQiRabbit) 历史贡献积分:258.5 当前积分:238.5 二零二零:2
|文章|类型|积分|
|------|-------|-------|
+|2020 年 2 月推荐文章 1 篇|奖励|1|
+|2020 年 1 月推荐文章 1 篇|奖励|1|
+|2019 年 10 至 12 月推荐文章 5 篇|奖励|5|
+|[深入解析 Flutter Provider 包](https://juejin.im/post/5e01a677518825124c50e99d)|翻译|6.5|
+|[类型及其在参数中的应用:能优化代码的的 Dart 特性](https://juejin.im/post/5dea0a4551882512252db2d7)|翻译|3|
+|[设计离线优先的网络应用](https://juejin.im/post/5dd608eef265da47f12cb018)|翻译|4.5|
+|[JavaScript 的发布者/订阅者(Publisher/Subscriber)模式](https://juejin.im/post/5dbff49ff265da4d3761dd27)|翻译|3|
+|[关于现代应用样式的探讨](https://juejin.im/post/5db93b67f265da4d417648a1)|翻译|13|
+|[设置 git 别名](https://juejin.im/post/5dafc502f265da5b783f1ae1)|翻译|3|
+|[趣味学习 CSS 布局 —— 第二部分:网格布局](https://juejin.im/post/5dafc45a51882555a8431266)|翻译|2.5|
+|[使用 `import()` 执行 JavaScript 代码](https://juejin.im/post/5dafc573e51d4524bb096393)|翻译|2|
|[Python 的打包现状(写于 2019 年)](https://juejin.im/post/5d72104851882572ed0004d2)|翻译|14|
|[Docker 的学习和应用](https://juejin.im/post/5d650a36f265da03c34c0bb4)|翻译|3|
|[如何使用 Keras 训练目标检测模型](https://juejin.im/post/5d4bb1db6fb9a06add4e18b6)|翻译|13|
@@ -6030,7 +6047,6 @@
|[React 的内联函数和性能](https://juejin.im/post/5ac20b5ff265da23945fa6bd)|校对|1.5|
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译校对|5|
-
## 译者:[mrcangye](https://github.com/mrcangye) 历史贡献积分:6.5 当前积分:6.5
|文章|类型|积分|
@@ -6050,7 +6066,7 @@
|[使用 Swift 实现原型动画](https://juejin.im/post/5ae28a9b6fb9a07aaa10fa1e)|校对|2|
|[不使用 fastlane 实现持续交付的 5 种选项](https://juejin.im/post/5acf47cb6fb9a028c523944c)|翻译|5|
-## 译者:[luochen1992](https://github.com/luochen1992) 历史贡献积分:58.5 当前积分:13.5 二零一九:1.5
+## 译者:[luochen1992](https://github.com/luochen1992) 历史贡献积分:58.5 当前积分:13.5
|文章|类型|积分|
|------|-------|-------|
@@ -6107,7 +6123,7 @@
|[关于 SPA 你需要掌握的 4 层](https://juejin.im/post/5ac9ae935188255caf067974)|校对|1.5|
|[设计师与工程师协作的 5 项准则](https://juejin.im/post/5ac9e56af265da23945fc201)|校对|1|
-## 译者:[wznonstop](https://github.com/wznonstop) 历史贡献积分:34.5 当前积分:34.5 二零一九:25.5
+## 译者:[wznonstop](https://github.com/wznonstop) 历史贡献积分:34.5 当前积分:34.5
|文章|类型|积分|
|------|-------|-------|
@@ -6123,7 +6139,7 @@
|[React & Redux 顶级开发伴侣](https://juejin.im/post/5acae8dc6fb9a028c06b1c4c)|校对|1|
|[拖放库中 React 性能的优化](https://juejin.im/post/5ac31b096fb9a028bc2dedfc)|校对|3|
-## 译者:[Hopsken](https://github.com/Hopsken) 历史贡献积分:57 当前积分:4 二零一九:9
+## 译者:[Hopsken](https://github.com/Hopsken) 历史贡献积分:57 当前积分:4
|文章|类型|积分|
|------|-------|-------|
@@ -6190,7 +6206,7 @@
|[用户体验中的稀缺性:成为常态的心理偏见](https://juejin.im/post/5aef0943518825672a02d2ca)|校对|1.5|
|[The JavaScript Tutorial 翻译](https://github.com/xitu/javascript-tutorial-en)|翻译校对|2|
-## 译者:[sisibeloved](https://github.com/sisibeloved) 历史贡献积分:85 当前积分:85 二零一九:17
+## 译者:[sisibeloved](https://github.com/sisibeloved) 历史贡献积分:85 当前积分:85
|文章|类型|积分|
|------|-------|-------|
@@ -6200,7 +6216,7 @@
|[TensorFlow 中的 RNN 串流](https://juejin.im/post/5bcb2975f265da0a8d36c7d8)|翻译|4|
|[Sklearn 中的朴素贝叶斯分类器](https://juejin.im/post/5b8510be51882542d23a1d66)|翻译|4|
|[如何在数据科学中写出生产层面的代码?](https://juejin.im/post/5b7adb7751882542d63b2805)|翻译|7|
-|[Web 应用架构基础课](https://juejin.im/post/5b69a8eef265da0f926baa56)|校对||2|
+|[Web 应用架构基础课](https://juejin.im/post/5b69a8eef265da0f926baa56)|校对|2|
|[在 UNIX 中,一切皆文件](https://juejin.im/post/5b652d346fb9a04fc03129e6)|校对|2.5|
|[介绍 Google Play 上新的优质 Android 应用与游戏](https://juejin.im/post/5ae978d151882567370633ca)|翻译|2|
|[给人类的机器学习指南🤖👶](https://juejin.im/post/5b136f12f265da6e5415114b)|翻译|7.5|
@@ -6213,7 +6229,7 @@
|[用 Java 代码实现区块链](https://juejin.im/post/5ae57d9e6fb9a07ab83dcc03)|校对|4|
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译校对|6|
-## 译者:[mingxing47](https://github.com/mingxing47) 历史贡献积分:30.5 当前积分:30.5 二零一九:3
+## 译者:[mingxing47](https://github.com/mingxing47) 历史贡献积分:30.5 当前积分:30.5
|文章|类型|积分|
|------|-------|-------|
@@ -6228,7 +6244,7 @@
|[利用 Keras 深度学习库进行词性标注教程](https://juejin.im/post/5ae4613a5188256727742d7d)|校对|1|
|[GAN 的 Keras 实现:构建图像去模糊应用](https://juejin.im/post/5ad6e358f265da237b229bb2)|校对|1|
-## 译者:[radialine](https://github.com/radialine) 历史贡献积分:12 当前积分:12 二零一九:6
+## 译者:[radialine](https://github.com/radialine) 历史贡献积分:12 当前积分:12
|文章|类型|积分|
|------|-------|-------|
@@ -6290,7 +6306,7 @@
|[在 Google I/O 2018 观看 Flutter 的正确姿势](https://juejin.im/post/5aebd7166fb9a07ab4587b3f)|翻译|1.5|
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译校对|7|
-## 译者:[kezhenxu94](https://github.com/kezhenxu94) 历史贡献积分:50 当前积分:50 二零一九:5
+## 译者:[kezhenxu94](https://github.com/kezhenxu94) 历史贡献积分:50 当前积分:50
|文章|类型|积分|
|------|-------|-------|
@@ -6341,7 +6357,7 @@
|------|-------|-------|
|[使用 python 和 keras 实现卷积神经网络](https://juejin.im/post/5aefb0f351882567336aa3c7)|校对|1|
-## 译者:[shery](https://github.com/shery) 历史贡献积分:41 当前积分:11 二零一九:2
+## 译者:[shery](https://github.com/shery) 历史贡献积分:41 当前积分:11
|文章|类型|积分|
|------|-------|-------|
@@ -6385,10 +6401,11 @@
|[Awesome Flutter 校对](https://github.com/xitu/awesome-flutter)|校对|1|
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译校对|1|
-## 译者:[lihanxiang](https://github.com/lihanxiang) 历史贡献积分:63.5 当前积分:25.5 二零一九:4.5
+## 译者:[lihanxiang](https://github.com/lihanxiang) 历史贡献积分:68 当前积分:30
|文章|类型|积分|
|------|-------|-------|
+|[开源难题:如何保持长久](https://juejin.im/post/5db27be36fb9a02040687055)|翻译|4.5|
|[用 Apache Shiro 来强化一个 Spring Boot 应用](https://juejin.im/post/5c9f60c7e51d451cf929305d)|翻译|3.5|
|2019 年 2 月兑 GitHub 贴纸 1 包,掘金水杯 1 个|减去积分|10|
|[如何写一篇软件工程必杀简历](https://juejin.im/post/5c6ca8b9f265da2dc13c7a10)|校对|1|
@@ -6448,10 +6465,10 @@
|文章|类型|积分|
|------|-------|-------|
-|[怎样更好地使用 Vue:我在新工作中遇到的一些问题清单](https://juejin.im/post/5b0a36366fb9a07a9c04aca2)|校对1|
+|[怎样更好地使用 Vue:我在新工作中遇到的一些问题清单](https://juejin.im/post/5b0a36366fb9a07a9c04aca2)|校对|1|
|[可微可塑性:一种学会学习的新方法](https://juejin.im/post/5b055308f265da0ba063879d)|校对|1.5|
-## 译者:[zhongdeming428](https://github.com/zhongdeming428) 历史贡献积分:24 当前积分:9 二零一九:1
+## 译者:[zhongdeming428](https://github.com/zhongdeming428) 历史贡献积分:24 当前积分:9
|文章|类型|积分|
|------|-------|-------|
@@ -6533,7 +6550,7 @@
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译校对|4|
|[怎样(以及为什么要)保持你的 Git 提交记录的整洁](https://juejin.im/post/5b29060ee51d4558cd2adac0)|校对|1.5|
-## 译者:[xujunjiejack](https://github.com/xujunjiejack) 历史贡献积分:16 当前积分:16 二零一九:3
+## 译者:[xujunjiejack](https://github.com/xujunjiejack) 历史贡献积分:16 当前积分:16
|文章|类型|积分|
|------|-------|-------|
@@ -6583,7 +6600,7 @@
|[Kubernetes 分布式应用部署和人脸识别 app 实例](https://juejin.im/post/5b2db0576fb9a00e50313904)|校对|0.5|
|[[字幕翻译] James Bennett — 理解 Python 字节码 — PyCon 2018](https://github.com/xitu/gold-miner/issues/3990)|校对|0.5|
-## 译者:[kasheemlew](https://github.com/kasheemlew) 历史贡献积分:63.5 当前积分:3.5 二零一九:49
+## 译者:[kasheemlew](https://github.com/kasheemlew) 历史贡献积分:63.5 当前积分:3.5
|文章|类型|积分|
|------|-------|-------|
@@ -6627,7 +6644,7 @@
|[自然语言处理真是有趣](https://juejin.im/post/5b6d08e2f265da0f9c67cf0b)|校对|3|
|[支撑现代存储系统的算法](https://juejin.im/post/5b10f80b5188257d92206851)|校对|1.5|
-## 译者:[7Ethan](https://github.com/7Ethan) 历史贡献积分:62.5 当前积分:7.5 二零一九:0
+## 译者:[7Ethan](https://github.com/7Ethan) 历史贡献积分:62.5 当前积分:7.5
|文章|类型|积分|
|------|-------|-------|
@@ -6744,15 +6761,16 @@
|[苹果公司如何修复 3D Touch](https://juejin.im/post/5b35e5886fb9a00e3642724f)|校对|0.5|
|[怎样使用简单的三角函数来创建更好的加载动画](https://juejin.im/post/5b33055f518825748871c590)|校对|1|
-## 译者:[JackEggie](https://github.com/JackEggie) 历史贡献积分:56 当前积分:56 二零一九:53
+## 译者:[JackEggie](https://github.com/JackEggie) 历史贡献积分:59.5 当前积分:59.5
|文章|类型|积分|
|------|-------|-------|
+|[使用因果分析优化 Go HTTP/2 服务器](https://juejin.im/post/5dc3e5faf265da4d144e86c2)|翻译|3.5|
|[为什么你要学习 Go?](https://juejin.im/post/5d6ce211f265da03cd0a99be)|校对|2|
|[数据分片是如何在分布式 SQL 数据库中起作用的](https://juejin.im/post/5d42867a6fb9a06ac76d915d)|校对|2.5|
|[Go 语言概览](https://juejin.im/post/5d386166e51d454fd8057c6a)|翻译|6.5|
|[线性代数:矩阵基本运算](https://juejin.im/post/5d107b00f265da1b67211a21)|校对|1|
-|[我们从招聘技术经理的过程中学到了什么](https://juejin.im/post/5cdcf463f265da0392580820)|翻译|4+1.5|
+|[我们从招聘技术经理的过程中学到了什么](https://juejin.im/post/5cdcf463f265da0392580820)|翻译|5.5|
|[化 Markdown 为 HTML:用 Node.js 和 Express 搭建接口](https://juejin.im/post/5cdcc216e51d453a543f9e68)|校对|2|
|[使用 WFST 进行语音识别](https://juejin.im/post/5cd7f7c56fb9a03218556ea4)|校对|1.5|
|[Spring 的分布式事务实现 — 使用和不使用 XA — 第一部分](https://juejin.im/post/5cce4659f265da038a1487c9)|翻译|7|
@@ -6798,7 +6816,7 @@
|[The JavaScript Tutorial 翻译](https://github.com/xitu/javascript-tutorial-en)|翻译校对|3.5|
|[修订 The JavaScript Tutorial](https://github.com/xitu/javascript-tutorial-zh/pull/151)|修订|1|
-## 译者:[ssshooter](https://github.com/ssshooter) 历史贡献积分:59 当前积分:59 二零一九:5
+## 译者:[ssshooter](https://github.com/ssshooter) 历史贡献积分:59 当前积分:59
|文章|类型|积分|
|------|-------|-------|
@@ -6850,7 +6868,7 @@
|[使用 Python 进行自动化特征工程](https://juejin.im/post/5b6ea0e4e51d4519044adff0)|校对|2.5|
|[从 Cron 到 Airflow 的迁移中我们学到了什么](https://juejin.im/post/5b4c3575f265da0f7334bbc9)|校对|2|
|[Airflow: 一个工作流程管理平台](https://juejin.im/post/5b5bd2b6f265da0f60131d0c)|翻译|4|
-|[Web 应用架构基础课](https://juejin.im/post/5b69a8eef265da0f926baa56)|校对||2.5|
+|[Web 应用架构基础课](https://juejin.im/post/5b69a8eef265da0f926baa56)|校对|2.5|
|[Robinhood 为什么使用 Airflow](https://juejin.im/post/5b4808f751882519ec07eaba)|校对|1.5|
|[我们是如何高效实现一致性哈希的](https://juejin.im/post/5b5488a96fb9a04fad3a181a)|翻译|8|
|[在 UNIX 中,一切皆文件](https://juejin.im/post/5b652d346fb9a04fc03129e6)|校对|2|
@@ -6875,7 +6893,7 @@
|[The JavaScript Tutorial 翻译](https://github.com/xitu/javascript-tutorial-en)|翻译校对|3|
|[The JavaScript Tutorial 翻译](https://github.com/xitu/javascript-tutorial-en)|翻译校对|1|
-## 译者:[Moonliujk](https://github.com/Moonliujk) 历史贡献积分:90.5 当前积分:35.5 二零一九:25.5
+## 译者:[Moonliujk](https://github.com/Moonliujk) 历史贡献积分:90.5 当前积分:35.5
|文章|类型|积分|
|------|-------|-------|
@@ -6914,7 +6932,7 @@
|[让我们一起解决“this”难题 — 第二部分](https://juejin.im/post/5b6915cce51d4519962f0ca7)|校对|2|
|[The JavaScript Tutorial 翻译](https://github.com/xitu/javascript-tutorial-en)|翻译校对|2.5|
-## 译者:[xutaogit](https://github.com/xutaogit) 历史贡献积分:62 当前积分:55 二零一九:16
+## 译者:[xutaogit](https://github.com/xutaogit) 历史贡献积分:62 当前积分:55
|文章|类型|积分|
|------|-------|-------|
@@ -6965,7 +6983,7 @@
|[在 Sketch 中使用一个设计体系创作: 第二部分 [教程]](https://juejin.im/post/5b5d2a456fb9a04fc80b8f4b)|翻译|2.5|
|[在 Sketch 中使用一个设计体系创作:第一部分 [教程]](https://juejin.im/post/5b591a655188257bca290b24)|校对|0.5|
-## 译者:[Park-ma](https://github.com/Park-ma) 历史贡献积分:54 当前积分:9 二零一九:10.5
+## 译者:[Park-ma](https://github.com/Park-ma) 历史贡献积分:54 当前积分:9
|文章|类型|积分|
|------|-------|-------|
@@ -7006,7 +7024,7 @@
|[正则表达式要跑 5 天,所以我做了个工具将其缩短至 15 分钟。](https://juejin.im/post/5b6d426f6fb9a04fd1604341)|校对|0.5|
|[Tab Bar 就是新的汉堡菜单](https://juejin.im/post/5b61684fe51d451986517e31)|校对|1.5|
-## 译者:[StellaBauhinia](https://github.com/StellaBauhinia) 历史贡献积分:16 当前积分:16 二零一九:1
+## 译者:[StellaBauhinia](https://github.com/StellaBauhinia) 历史贡献积分:16 当前积分:16
|文章|类型|积分|
|------|-------|-------|
@@ -7074,20 +7092,23 @@
|[ECMAScript 修饰器微指南](https://juejin.im/post/5b543d8af265da0f4a4e711f)|校对|2|
|[让我们一起解决“this”难题 — 第二部分](https://juejin.im/post/5b6915cce51d4519962f0ca7)|校对|1|
-## 译者:[Gavin-Gong](https://github.com/Gavin-Gong) 历史贡献积分:17 当前积分:17
+## 译者:[Gavin-Gong](https://github.com/Gavin-Gong) 历史贡献积分:26 当前积分:26
|文章|类型|积分|
|------|-------|-------|
+|[使用 JavaScript 编写 JSON 解析器](https://juejin.im/post/5e098728f265da33cd03c6c7)|翻译|8|
+|2019 年 12 月推荐文章 1 篇|奖励|1|
|[理解编译器 — 从人类的角度(版本 2)](https://juejin.im/post/5c10b2f6e51d452ad958631f)|校对|3|
|推荐优秀英文文章一篇|奖励|1|
|[如何使用纯函数式 JavaScript 处理脏副作用](https://juejin.im/post/5b82bdb351882542e241ed32)|翻译|8.5|
|[关于 React Motion 的简要介绍](https://juejin.im/post/5b48061551882519790c77f3)|校对|1.5|
|[设计 React 组件 API](https://juejin.im/post/5b545f0b6fb9a04fc93748ba)|翻译|3|
-## 译者:[Eternaldeath](https://github.com/Eternaldeath) 历史贡献积分:8 当前积分:8 二零一九:4
+## 译者:[Eternaldeath](https://github.com/Eternaldeath) 历史贡献积分:10 当前积分:10 二零二零:2
|文章|类型|积分|
|------|-------|-------|
+|[理解 Service Worker 和缓存策略](https://juejin.im/post/5e60e0ce5188254919497644)|校对|2|
|[使用 React 和 ImmutableJS 构建一个拖放布局构建器](https://juejin.im/post/5cccfa56f265da034c7038f3)|校对|1.5|
|[使用 Recompose 来构建高阶组件](https://juejin.im/post/5c484a43e51d452ec621b6a9)|校对|1|
|[新愿景: 未来的程序应用平台](https://juejin.im/post/5c2cce475188256a272ac4d6)|校对|1.5|
@@ -7095,7 +7116,7 @@
|[一行 JavaScript 代码竟然让 FT.com 网站慢了十倍](https://juejin.im/post/5b7bb6dfe51d4538bf55aa5f)|校对|1|
|[使用 Web Beacon API 记录活动](https://juejin.im/post/5b694b5de51d4519700fa56a)|校对|1|
-## 译者:[YueYongDev](https://github.com/YueYongDev) 历史贡献积分:67 当前积分:32 二零一九:38
+## 译者:[YueYongDev](https://github.com/YueYongDev) 历史贡献积分:67 当前积分:32
|文章|类型|积分|
|------|-------|-------|
@@ -7123,7 +7144,7 @@
|------|-------|-------|
|[Slidable:一个 Flutter 的故事](https://juejin.im/post/5b5e84b86fb9a04fa91bfeb6)|校对|1.5|
-## 译者:[CoolRice](https://github.com/CoolRice) 历史贡献积分:122 当前积分:52 二零一九:30
+## 译者:[CoolRice](https://github.com/CoolRice) 历史贡献积分:122 当前积分:52
|文章|类型|积分|
|------|-------|-------|
@@ -7185,7 +7206,7 @@
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译校对|8|
|[用 Scikit-Learn 实现 SVM 和 Kernel SVM](https://juejin.im/post/5b7fd39af265da43831fa136)|校对|2|
-## 译者:[TrWestdoor](https://github.com/TrWestdoor) 历史贡献积分:43 当前积分:33 二零一九:20
+## 译者:[TrWestdoor](https://github.com/TrWestdoor) 历史贡献积分:43 当前积分:33
|文章|类型|积分|
|------|-------|-------|
@@ -7268,7 +7289,7 @@
|------|-------|-------|
|[The JavaScript Tutorial 翻译](https://github.com/xitu/javascript-tutorial-en)|翻译校对|5|
-## 译者:[CoderMing](https://github.com/CoderMing) 历史贡献积分:49 当前积分:14 二零一九:4
+## 译者:[CoderMing](https://github.com/CoderMing) 历史贡献积分:49 当前积分:14
|文章|类型|积分|
|------|-------|-------|
@@ -7342,7 +7363,7 @@
|[理解 JavaScript 中的执行上下文和执行栈](https://juejin.im/post/5ba32171f265da0ab719a6d7)|校对|2.5|
|[以申请大学流程来解释 JavaScript 的 filter](https://juejin.im/post/5b9f09685188255c5e66d60c)|校对|1.5|
-## 译者:[jianboy](https://github.com/jianboy) 历史贡献积分:46 当前积分:21 二零一九:4
+## 译者:[jianboy](https://github.com/jianboy) 历史贡献积分:46 当前积分:21
|文章|类型|积分|
|------|-------|-------|
@@ -7381,7 +7402,7 @@
|------|-------|-------|
|[为 APP 设计通知提醒](https://juejin.im/post/5ba31ee3e51d450e4115500b)|校对|1.5|
-## 译者:[zx-Zhu](https://github.com/zx-Zhu) 历史贡献积分:25.5 当前积分:10.5 二零一九:0
+## 译者:[zx-Zhu](https://github.com/zx-Zhu) 历史贡献积分:25.5 当前积分:10.5
|文章|类型|积分|
|------|-------|-------|
@@ -7416,7 +7437,7 @@
|[当你创建 Flexbox 布局时,都发生了什么](https://juejin.im/post/5bb9740de51d450e782647ed)|校对|3|
|[现代浏览器内部揭秘(第二部分)](https://juejin.im/post/5bc293cf6fb9a05ce95c8468)|校对|3|
-## 译者:[GpingFeng](https://github.com/GpingFeng) 历史贡献积分:17 当前积分:12 二零一九:1
+## 译者:[GpingFeng](https://github.com/GpingFeng) 历史贡献积分:17 当前积分:12
|文章|类型|积分|
|------|-------|-------|
@@ -7430,10 +7451,11 @@
|[The JavaScript Tutorial 翻译](https://github.com/xitu/javascript-tutorial-en)|翻译校对|7|
|[我在阅读 MDN 时发现的 3 个 Input 元素属性](https://juejin.im/post/5bbc6f035188255c5d56b160)|校对|1|
-## 译者:[haiyang-tju](https://github.com/haiyang-tju) 历史贡献积分:83 当前积分:83 二零一九:21.5
+## 译者:[haiyang-tju](https://github.com/haiyang-tju) 历史贡献积分:90 当前积分:90
|文章|类型|积分|
|------|-------|-------|
+|[如何用 Keras 从头搭建一维生成对抗网络](https://juejin.im/post/5dcf5aba6fb9a0203161f376)|校对|7|
|[从 Instagram 上的故事和反馈机器学习中收获的一些经验](https://juejin.im/post/5c683dfce51d45164c7599fb)|校对|2|
|[提取图像中的文字、人脸或者条形码 — 形状检测 API](https://juejin.im/post/5c64026fe51d457f963d249c)|校对|1.5|
|[降维技术中常用的几种降维方法](https://juejin.im/post/5c4513a06fb9a049dc028d0c)|翻译|8|
@@ -7464,7 +7486,7 @@
|------|-------|-------|
|推荐优秀英文文章|奖励|1|
-## 译者:[Augustwuli](https://github.com/Augustwuli) 历史贡献积分:33 当前积分:33 二零一九:4.5
+## 译者:[Augustwuli](https://github.com/Augustwuli) 历史贡献积分:33 当前积分:33
|文章|类型|积分|
|------|-------|-------|
@@ -7482,7 +7504,7 @@
|[以面试官的角度来看 React 工作面试](https://juejin.im/post/5bca74cfe51d450e9163351b)|校对|1.5|
|[你需要知道的所有 Flexbox 排列方式](https://juejin.im/post/5bc728f2f265da0aef4e3f6d)|校对|3.5|
-## 译者:[Ivocin](https://github.com/Ivocin) 历史贡献积分:77.5 当前积分:77.5 二零一九:37
+## 译者:[Ivocin](https://github.com/Ivocin) 历史贡献积分:77.5 当前积分:77.5
|文章|类型|积分|
|------|-------|-------|
@@ -7565,7 +7587,7 @@
|------|-------|-------|
|[深入理解 React 高阶组件](https://juejin.im/entry/5bdd226cf265da616f6f6cce)|校对|4|
-## 译者:[iWeslie](https://github.com/iWeslie) 历史贡献积分:135.5 当前积分:83.5 二零一九:91.5
+## 译者:[iWeslie](https://github.com/iWeslie) 历史贡献积分:135.5 当前积分:83.5
|文章|类型|积分|
|------|-------|-------|
@@ -7601,7 +7623,7 @@
|推荐优秀英文文章两篇|奖励|2|
|[从现有的代码库创建 Swift 包管理器](https://juejin.im/post/5bec2b735188253b6e5c132a)|翻译|4|
-## 译者:[Mcskiller](https://github.com/Mcskiller) 历史贡献积分:50 当前积分:50 二零一九:34.5
+## 译者:[Mcskiller](https://github.com/Mcskiller) 历史贡献积分:50 当前积分:50
|文章|类型|积分|
|------|-------|-------|
@@ -7613,7 +7635,7 @@
|[通过一些例子深入了解 JavaScript 的 Async 和 Await](https://juejin.im/post/5cec8a475188255816489878)|校对|1.5|
|[2019 前端工具调研](https://juejin.im/post/5cb800fce51d456e4514f550)|校对|0.5|
|[Vue.js 逐渐集成 第三方 JavaScript](https://juejin.im/post/5c8e5a776fb9a070d013ef71)|校对|3|
-|[如何心平气和的阅读代码](https://juejin.im/post/5c9c521b5188252d876e5dcb)|翻译|4+1|
+|[如何心平气和的阅读代码](https://juejin.im/post/5c9c521b5188252d876e5dcb)|翻译|5|
|[如何学习 CSS](https://juejin.im/post/5c74daaaf265da2d9d1cb774)|翻译|7|
|[5 个可以立刻在你的 Ionic App 中用上的动画包](https://juejin.im/post/5c517544f265da613b702848)|校对|0.5|
|[2019 CSS 新属性“连字符”初探](https://juejin.im/post/5c612cfee51d4501515c8edf)|校对|1|
@@ -7634,7 +7656,7 @@
|------|-------|-------|
|修订文章 https://github.com/xitu/gold-miner/pull/4753|奖励|2|
-## 译者:[nanjingboy](https://github.com/nanjingboy) 历史贡献积分:75 当前积分:55 二零一九:30.5
+## 译者:[nanjingboy](https://github.com/nanjingboy) 历史贡献积分:75 当前积分:55
|文章|类型|积分|
|------|-------|-------|
@@ -7663,10 +7685,11 @@
|------|-------|-------|
|[使用递归神经网络(LSTMs)对时序数据进行预测](https://juejin.im/post/5bf8a70cf265da61776ba1dc)|校对|2|
-## 译者:[weibinzhu](https://github.com/weibinzhu) 历史贡献积分:19 当前积分:9 二零一九年:7
+## 译者:[weibinzhu](https://github.com/weibinzhu) 历史贡献积分:22 当前积分:12 二零二零:3
|文章|类型|积分|
|------|-------|-------|
+|[在什么时候你需要使用 Web Workers?](https://juejin.im/post/5e290aaee51d451c8836284f)|翻译|3|
|[2019 前端性能优化年度总结 — 第六部分](https://juejin.im/post/5c6167f6f265da2ddf7866ec)|校对|2.5|
|[2019 前端性能优化年度总结 — 第四部分](https://juejin.im/post/5c56345951882524b77b9f20)|校对|3.5|
|[渐进增强的含义及意义](https://juejin.im/post/5c2f42556fb9a049f57148ca)|校对|1|
@@ -7685,7 +7708,7 @@
|[在远程工作中领悟到的 10 件事](https://juejin.im/post/5bf7a79f51882511a8528cf0)|校对|2|
|[如何让高效的代码评审成为一种文化](https://juejin.im/post/5bfc9ff9e51d454b6c371f5d)|校对|3|
-## 译者:[KarthusLorin](https://github.com/KarthusLorin) 历史贡献积分:20.5 当前积分:15.5 二零一九:14
+## 译者:[KarthusLorin](https://github.com/KarthusLorin) 历史贡献积分:20.5 当前积分:15.5
|文章|类型|积分|
|------|-------|-------|
@@ -7711,7 +7734,7 @@
|------|-------|-------|
|[使用 Swift 的 iOS 设计模式(第一部分)](https://juejin.im/post/5c05d4ee5188250ab14e62d6)|校对|3.5|
-## 译者:[DevMcryYu](https://github.com/DevMcryYu) 历史贡献积分:54 当前积分:54 二零一九:34
+## 译者:[DevMcryYu](https://github.com/DevMcryYu) 历史贡献积分:54 当前积分:54
|文章|类型|积分|
|------|-------|-------|
@@ -7736,7 +7759,7 @@
|[三人研发小组的高效研发尝试](https://juejin.im/post/5c19d1846fb9a049f06a33fc)|校对|2|
|[你不知道的 console 命令](https://juejin.im/post/5bf64218e51d45194266acb7)|翻译|6|
-## 译者:[RicardoCao-Biker ](https://github.com/RicardoCao-Biker ) 历史贡献积分:7 当前积分:2 二零一九:3.5
+## 译者:[RicardoCao-Biker ](https://github.com/RicardoCao-Biker ) 历史贡献积分:7 当前积分:2
|文章|类型|积分|
|------|-------|-------|
@@ -7752,14 +7775,14 @@
|------|-------|-------|
|[React 是如何区分 Class 和 Function 的?](https://juejin.im/post/5c088c4ce51d451d8b7bd8de)|翻译|6|
-## 译者:[Xcco](https://github.com/Xcco) 历史贡献积分:6 当前积分:6 二零一九:3
+## 译者:[Xcco](https://github.com/Xcco) 历史贡献积分:6 当前积分:6
|文章|类型|积分|
|------|-------|-------|
|[避免那些可恶的 "cannot read property of undefined" 错误](https://juejin.im/post/5c810170e51d450a453fb48e)|翻译|3|
|[写给 React 开发者的自定义元素指南](https://juejin.im/post/5c0873a8e51d451de96890dc)|校对|3|
-## 译者:[newraina](https://github.com/newraina) 历史贡献积分:13 当前积分:13 二零一九:1
+## 译者:[newraina](https://github.com/newraina) 历史贡献积分:13 当前积分:13
|文章|类型|积分|
|------|-------|-------|
@@ -7767,14 +7790,14 @@
|[用 Shadow DOM v1 和 Custom Elements v1 实现一个原生 Web Component](https://juejin.im/post/5c1a401b6fb9a049c042fa07)|翻译|9|
|[以太坊入门:互联网政府](https://juejin.im/post/5c03c68851882551236eaa82)|翻译|3|
-## 译者:[slyrx](https://github.com/slyrx) 历史贡献积分:24 当前积分:24 二零一九:6
+## 译者:[slyrx](https://github.com/slyrx) 历史贡献积分:24 当前积分:24
|文章|类型|积分|
|------|-------|-------|
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译校对|6|
|[TensorFlow 官方文档翻译](https://github.com/xitu/tensorflow-docs)|翻译校对|18|
-## 译者:[ElizurHz](https://github.com/ElizurHz) 历史贡献积分:27 当前积分:27 二零一九:17
+## 译者:[ElizurHz](https://github.com/ElizurHz) 历史贡献积分:27 当前积分:27
|文章|类型|积分|
|------|-------|-------|
@@ -7788,7 +7811,7 @@
|[创建并发布一个小而美的 npm 包](https://juejin.im/post/5c26c1b65188252dcb312ad6)|校对|1.5|
|[用 React 和 Node.js 实现受保护的路由和权限验证](https://juejin.im/post/5c1cdaaa6fb9a049aa6f0f8b)|翻译|4|
-## 译者:[wuzhengyan2015](https://github.com/wuzhengyan2015) 历史贡献积分:12 当前积分:12 二零一九:5.5
+## 译者:[wuzhengyan2015](https://github.com/wuzhengyan2015) 历史贡献积分:12 当前积分:12
|文章|类型|积分|
|------|-------|-------|
@@ -7810,7 +7833,7 @@
|------|-------|-------|
|[使用自定义文件模板加快你的应用开发速度](https://juejin.im/post/5c204bcdf265da611b585bcd)|校对|1.5|
-## 译者:[Qiuk17](https://github.com/Qiuk17) 历史贡献积分:27 当前积分:27 二零一九:20
+## 译者:[Qiuk17](https://github.com/Qiuk17) 历史贡献积分:27 当前积分:27
|文章|类型|积分|
|------|-------|-------|
@@ -7826,7 +7849,7 @@
|[了解 Android 的矢量图片格式:`VectorDrawable`](https://juejin.im/post/5c1a21ff5188252eb759600e)|校对|2.5|
|[当 Kotlin 中的监听器包含多个方法时,如何让它 “巧夺天工”?](https://juejin.im/post/5c1e43646fb9a04a102f45ab)|校对|1.5|
-## 译者:[gs666](https://github.com/gs666) 历史贡献积分:42 当前积分:32 二零一九:29.5
+## 译者:[gs666](https://github.com/gs666) 历史贡献积分:42 当前积分:32
|文章|类型|积分|
|------|-------|-------|
@@ -7848,11 +7871,11 @@
|[Android 内核控制流完整性](https://juejin.im/post/5c1740dcf265da614a3a66c1)|校对|1.5|
|[了解 Android 的矢量图片格式:`VectorDrawable`](https://juejin.im/post/5c1a21ff5188252eb759600e)|校对|1.5|
-## 译者:[snpmyn](https://github.com/snpmyn) 历史贡献积分:9.5 当前积分:9.5 二零一九:8
+## 译者:[snpmyn](https://github.com/snpmyn) 历史贡献积分:9.5 当前积分:9.5
|文章|类型|积分|
|------|-------|-------|
-|[格子拼贴 — 关于模块化的故事](https://juejin.im/post/5c31e7aee51d4543805e6a96)|翻译+校对|6.5+1.5|
+|[格子拼贴 — 关于模块化的故事](https://juejin.im/post/5c31e7aee51d4543805e6a96)|翻译+校对|8|
|[如何使用 Dask Dataframes 在 Python 中运行并行数据分析](https://juejin.im/post/5c1feeaf5188257f9242b65c)|校对|1.5|
## 译者:[ZyGan1999](https://github.com/ZyGan1999) 历史贡献积分:1.5 当前积分:1.5
@@ -7861,7 +7884,7 @@
|------|-------|-------|
|[以太坊入门指南](https://juejin.im/post/5c1080fbe51d452b307969a3)|校对|1.5|
-## 译者:[xiaxiayang](https://github.com/xiaxiayang) 历史贡献积分:19 当前积分:6 二零一九:18
+## 译者:[xiaxiayang](https://github.com/xiaxiayang) 历史贡献积分:19 当前积分:6
|文章|类型|积分|
|------|-------|-------|
@@ -7870,12 +7893,12 @@
|[Android 生命周期备忘录 — 第三部分:Fragments](https://juejin.im/post/5ca3517a6fb9a05e462b967a)|校对|1|
|2019 年 3 月兑掘金桌垫 1 个|减去积分|13|
|[绘制路径:Android 中矢量图渲染](https://juejin.im/post/5c75e73051882562ea724cd4)|翻译|4|
-||[Android 上一次编写,到处测试](https://juejin.im/post/5c32cbc9f265da611d66d14e)|校对|1.5|
+|[Android 上一次编写,到处测试](https://juejin.im/post/5c32cbc9f265da611d66d14e)|校对|1.5|
|[轻松发布私有 APP](https://juejin.im/post/5c42d0fde51d4511dc72d8d1)|校对|1.5|
|[充分利用多摄像头 API](https://juejin.im/post/5c3da4f76fb9a04a0c2eb3fc)|翻译|7|
|[2019 年你应该要知道的 11 个 React UI 组件库](https://juejin.im/post/5c260f13e51d45473a5c07a4)|校对|1|
-## 译者:[SinanJS](https://github.com/SinanJS) 历史贡献积分:3.5 当前积分:3.5 二零一九:2
+## 译者:[SinanJS](https://github.com/SinanJS) 历史贡献积分:3.5 当前积分:3.5
|文章|类型|积分|
|------|-------|-------|
@@ -7889,7 +7912,7 @@
|------|-------|-------|
|[无容器下的云计算](https://juejin.im/post/5c24800a518825673b02dcfe)|校对|2.5|
-## 译者:[SHERlocked93](https://github.com/SHERlocked93) 历史贡献积分:32 当前积分:32 二零一九:32
+## 译者:[SHERlocked93](https://github.com/SHERlocked93) 历史贡献积分:32 当前积分:32
|文章|类型|积分|
|------|-------|-------|
@@ -7905,20 +7928,20 @@
|[讨论 JS ⚡:文档](https://juejin.im/post/5c4039bbe51d4551733494a6)|校对|2|
|推荐五篇英文文章|奖励积分|3|
-## 译者:[chausson](https://github.com/chausson) 历史贡献积分:2 当前积分:2 二零一九:2
+## 译者:[chausson](https://github.com/chausson) 历史贡献积分:2 当前积分:2
|文章|类型|积分|
|------|-------|-------|
|[状态恢复入门教程](https://juejin.im/post/5c330d0ce51d45518e147fd2)|校对|2|
-## 译者:[kuangbao9](https://github.com/kuangbao9) 历史贡献积分:3.5 当前积分:3.5 二零一九:3.5
+## 译者:[kuangbao9](https://github.com/kuangbao9) 历史贡献积分:3.5 当前积分:3.5
|文章|类型|积分|
|------|-------|-------|
|[提高营销效率的工程(第一部分)](https://juejin.im/post/5c403b5ce51d452c8e6d3dc4)|校对|1.5|
|[提高营销效率的工程(二)— 广告制作和管理的规模化](https://juejin.im/post/5c441193518825258604ecd0)|校对|2|
-## 译者:[Jingyuan0000](https://github.com/Jingyuan0000) 历史贡献积分:6 当前积分:6 二零一九:6
+## 译者:[Jingyuan0000](https://github.com/Jingyuan0000) 历史贡献积分:6 当前积分:6
|文章|类型|积分|
|------|-------|-------|
@@ -7926,7 +7949,7 @@
|[2019 前端性能优化年度总结 — 第三部分](https://juejin.im/post/5c5ccbefe51d457f95354a46)|校对|2.5|
|[提高营销效率的工程(二)— 广告制作和管理的规模化](https://juejin.im/post/5c441193518825258604ecd0)|校对|2|
-## 译者:[PrinceChou](https://github.com/PrinceChou) 历史贡献积分:4.5 当前积分:4.5 二零一九:4.5
+## 译者:[PrinceChou](https://github.com/PrinceChou) 历史贡献积分:4.5 当前积分:4.5
|文章|类型|积分|
|------|-------|-------|
@@ -7934,49 +7957,50 @@
|[轻松发布私有 APP](https://juejin.im/post/5c42d0fde51d4511dc72d8d1)|校对|1|
|[充分利用多摄像头 API](https://juejin.im/post/5c3da4f76fb9a04a0c2eb3fc)|校对|1.5|
-## 译者:[hongruqi](https://github.com/hongruqi) 历史贡献积分:14.5 当前积分:14.5 二零一九:14.5
+## 译者:[hongruqi](https://github.com/hongruqi) 历史贡献积分:14.5 当前积分:14.5
|文章|类型|积分|
|------|-------|-------|
|[Flutter 从 0 到 1 第二部分](https://juejin.im/post/5c6ca802f265da2dce1f3af6)|翻译|8.5|
|[Flutter 从 0 到 1](https://juejin.im/post/5c331b436fb9a049db734b85)|翻译|6|
-## 译者:[lianghx-319](https://github.com/lianghx-319) 历史贡献积分:1.5 当前积分:1.5 二零一九:1.5
+## 译者:[lianghx-319](https://github.com/lianghx-319) 历史贡献积分:1.5 当前积分:1.5
|文章|类型|积分|
|------|-------|-------|
|[我们采用 GraphQL 技术的经验:营销技术活动](https://juejin.im/post/5c4522566fb9a049d2365cd6)|校对|1.5|
-## 译者:[H246802](https://github.com/H246802) 历史贡献积分:4 当前积分:4 二零一九:4
+## 译者:[H246802](https://github.com/H246802) 历史贡献积分:4 当前积分:4
|文章|类型|积分|
|------|-------|-------|
|[理解异步 JavaScript](https://juejin.im/post/5c304097e51d45520c3b14cd)|翻译|4|
-## 译者:[Yangfan2016](https://github.com/Yangfan2016) 历史贡献积分:3.5 当前积分:3.5 二零一九:3.5
+## 译者:[Yangfan2016](https://github.com/Yangfan2016) 历史贡献积分:3.5 当前积分:3.5
|文章|类型|积分|
|------|-------|-------|
|[Transducers: JavaScript 中高效的数据处理 pipeline](https://juejin.im/post/5c337b50f265da61746501bf)|校对|2|
|[理解异步 JavaScript](https://juejin.im/post/5c304097e51d45520c3b14cd)|校对|1.5|
-## 译者:[HumesFork](https://github.com/HumesFork) 历史贡献积分:13.5 当前积分:13.5 二零一九:13.5
+## 译者:[HumesFork](https://github.com/HumesFork) 历史贡献积分:13.5 当前积分:13.5
|文章|类型|积分|
|------|-------|-------|
|[一文带你看完 2018 年浏览器之争的最新进展](https://juejin.im/post/5c45a392f265da61483be57c)|翻译|12|
|[渐进增强的含义及意义](https://juejin.im/post/5c2f42556fb9a049f57148ca)|校对|1.5|
-## 译者:[sfmDev](https://github.com/sfmDev) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[sfmDev](https://github.com/sfmDev) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[审校文章 https://github.com/xitu/gold-miner/issues/5118](https://github.com/xitu/gold-miner/issues/5118)|奖励|1|
-## 译者:[Fengziyin1234](https://github.com/Fengziyin1234) 历史贡献积分:114 当前积分:114 二零一九:114
+## 译者:[Fengziyin1234](https://github.com/Fengziyin1234) 历史贡献积分:117 当前积分:117
|文章|类型|积分|
|------|-------|-------|
+|[写给大家的代数效应入门](https://juejin.im/post/5dafe28b5188252e734f5376)|校对|3|
|[属于 JavaScript 开发者的 Crypto 简介](https://juejin.im/post/5ce0c39a51882525f07ef0fa)|校对|2|
|[Web 使用 CSS Shapes 的艺术设计](https://juejin.im/post/5cdba21051882568841f0f47)|校对|2|
|[Elixir、Phoenix、Absinthe、GraphQL、React 和 Apollo:一次近乎疯狂的深度实践 —— 第二部分](https://juejin.im/post/5ce4dae36fb9a07ed524755d)|翻译|9|
@@ -8028,10 +8052,11 @@
|[Flutter 从 0 到 1 第二部分](https://juejin.im/post/5c6ca802f265da2dce1f3af6)|校对|3|
|推荐英文文章一篇|奖励|1|
-## 译者:[Jerry-FD](https://github.com/Jerry-FD) 历史贡献积分:19 当前积分:19 二零一九:19
+## 译者:[Jerry-FD](https://github.com/Jerry-FD) 历史贡献积分:27 当前积分:27
|文章|类型|积分|
|------|-------|-------|
+|[开发模式的工作原理是什么?](https://juejin.im/post/5d5e6964f265da0391351c59)|翻译|8|
|2019 年 9 月 推荐[前端文章](https://github.com/xitu/gold-miner/issues/6371)|奖励|1|
|推荐[前端文章](https://github.com/xitu/gold-miner/issues/6307)|奖励|1|
|[Google 的 Pagespeed 的工作原理:提升你的分数和搜索引擎排名](https://juejin.im/post/5d36903ce51d4510803ce491)|翻译|4|
@@ -8041,7 +8066,7 @@
|[X 为啥不是 hook?](https://juejin.im/post/5c6ca856f265da2dce1f3af9)|翻译|3|
|推荐英文文章一篇|奖励|1|
-## 译者:[EdmondWang](https://github.com/EdmondWang) 历史贡献积分:10.5 当前积分:10.5 二零一九:10.5
+## 译者:[EdmondWang](https://github.com/EdmondWang) 历史贡献积分:10.5 当前积分:10.5
|文章|类型|积分|
|------|-------|-------|
@@ -8052,7 +8077,7 @@
|[用这些 iOS 技巧让你的 APP 性能更佳](https://juejin.im/post/5c6a0b6ef265da2de660f83f)|校对|3|
|推荐英文文章一篇|奖励|1|
-## 译者:[WangLeto](https://github.com/WangLeto) 历史贡献积分:21 当前积分:21 二零一九:21
+## 译者:[WangLeto](https://github.com/WangLeto) 历史贡献积分:21 当前积分:21
|文章|类型|积分|
|------|-------|-------|
@@ -8065,10 +8090,12 @@
|[💅 styled-components 背后的魔力](https://juejin.im/post/5c6d3a32e51d451804732248)|翻译|3|
|推荐英文文章一篇|奖励|1|
-## 译者:[shixi-li](https://github.com/shixi-li) 历史贡献积分:64.5 当前积分:64.5 二零一九:64.5
+## 译者:[shixi-li](https://github.com/shixi-li) 历史贡献积分:69 当前积分:69 二零二零:2.5
|文章|类型|积分|
|------|-------|-------|
+|[为何 Svelte 杀不死 React](https://juejin.im/post/5e12aa81e51d4541162c9a3a)|校对|2.5|
+|[我个人的 Git 技巧备忘录](https://juejin.im/post/5e006ad4e51d45582248e63f)|校对|2|
|[思考实践:用 Go 实现 Flutter](https://juejin.im/post/5d215b8df265da1b7b31ac8f)|翻译|3.5|
|[Git:透过命令学概念 —— 第二部分](https://juejin.im/post/5d2da05ae51d45106b15ffca)|校对|2|
|[使用 SVG 和 Vue.Js 构建动态树图](https://juejin.im/post/5d2806fb518825121c0058d8)|校对|1.5|
@@ -8096,7 +8123,7 @@
|[我与 Flutter 的一年](https://juejin.im/post/5c5aeb8a6fb9a04a027acddf)|校对|2|
|[2019 区块链平台与技术展望](https://juejin.im/post/5c613e6e6fb9a049e4132ba5)|校对|3|
-## 译者:[jerryOnlyZRJ](https://github.com/jerryOnlyZRJ) 历史贡献积分:55 当前积分:55 二零一九:55
+## 译者:[jerryOnlyZRJ](https://github.com/jerryOnlyZRJ) 历史贡献积分:55 当前积分:55
|文章|类型|积分|
|------|-------|-------|
@@ -8118,7 +8145,7 @@
|[为什么你的应用需要对各种尺寸屏幕做适配优化?](https://juejin.im/post/5c662023518825767633ab86)|校对|2.5|
|[提取图像中的文字、人脸或者条形码 — 形状检测 API](https://juejin.im/post/5c64026fe51d457f963d249c)|翻译|4|
-## 译者:[Mirosalva](https://github.com/Mirosalva) 历史贡献积分:71 当前积分:71 二零一九:71
+## 译者:[Mirosalva](https://github.com/Mirosalva) 历史贡献积分:71 当前积分:71
|文章|类型|积分|
|------|-------|-------|
@@ -8145,7 +8172,7 @@
|[为什么你的应用需要对各种尺寸屏幕做适配优化?](https://juejin.im/post/5c662023518825767633ab86)|翻译|3|
|[我与 Flutter 的一年](https://juejin.im/post/5c5aeb8a6fb9a04a027acddf)|校对|3|
-## 译者:[TUARAN](https://github.com/TUARAN) 历史贡献积分:30 当前积分:30 二零一九:30
+## 译者:[TUARAN](https://github.com/TUARAN) 历史贡献积分:30 当前积分:30
|文章|类型|积分|
|------|-------|-------|
@@ -8163,7 +8190,7 @@
|[资助 ESLint 的未来](https://juejin.im/post/5c6cc48551882562654ac2c0)|校对|1|
|[为什么你的应用需要对各种尺寸屏幕做适配优化?](https://juejin.im/post/5c662023518825767633ab86)|校对|1|
-## 译者:[ScDadaguo](https://github.com/ScDadaguo) 历史贡献积分:5 当前积分:5 二零一九:5
+## 译者:[ScDadaguo](https://github.com/ScDadaguo) 历史贡献积分:5 当前积分:5
|文章|类型|积分|
|------|-------|-------|
@@ -8171,20 +8198,20 @@
|[使用智能 CSS 基于用户滚动位置应用样式](https://juejin.im/post/5c67817fe51d45082e13300c)|校对|0.5|
|[Android Dev Summit 2018 应用(instant app 的总结 + 开源)](https://juejin.im/post/5c6798486fb9a049e660c839)|校对|1.5|
-## 译者:[MeandNi](https://github.com/MeandNi) 历史贡献积分:6 当前积分:6 二零一九:6
+## 译者:[MeandNi](https://github.com/MeandNi) 历史贡献积分:6 当前积分:6
|文章|类型|积分|
|------|-------|-------|
|[React Native 与 iOS 和 Android 通信](https://juejin.im/post/5c6ca781f265da2da8356c81)|翻译|4|
|[13 个你应该选择/考虑使用 Flutter 的理由](https://juejin.im/post/5c4fcd54e51d45527201db80)|校对|2|
-## 译者:[CasualJi](https://github.com/CasualJi) 历史贡献积分:4.5 当前积分:4.5 二零一九:4.5
+## 译者:[CasualJi](https://github.com/CasualJi) 历史贡献积分:4.5 当前积分:4.5
|文章|类型|积分|
|------|-------|-------|
|[我作为软件工程师与一名数据科学家合作的经历](https://juejin.im/post/5c550038f265da2d8532b2f9)|翻译|4.5|
-## 译者:[HearFishle](https://github.com/HearFishle) 历史贡献积分:48.5 当前积分:48.5 二零一九:48.5
+## 译者:[HearFishle](https://github.com/HearFishle) 历史贡献积分:48.5 当前积分:48.5
|文章|类型|积分|
|------|-------|-------|
@@ -8204,7 +8231,7 @@
|[Widget - State - Context - InheritedWidget](https://juejin.im/post/5c768ad2f265da2dce1f535c)|校对|3|
|[Swift:通过示例避免内存泄漏](https://juejin.im/post/5c6a0abaf265da2dc675a9b2)|校对|1|
-## 译者:[kirinzer](https://github.com/kirinzer) 历史贡献积分:22 当前积分:22 二零一九:22
+## 译者:[kirinzer](https://github.com/kirinzer) 历史贡献积分:22 当前积分:22
|文章|类型|积分|
|------|-------|-------|
@@ -8215,7 +8242,7 @@
|[在 iOS 上使用 Carthage 建立依赖](https://juejin.im/post/5c4f04ef51882525eb3663be)|校对|1.5|
|[iOS 设计模式进阶](https://juejin.im/post/5c51b959f265da6115112e3e)|校对|5|
-## 译者:[kikooo](https://github.com/kikooo) 历史贡献积分:6 当前积分:6 二零一九:6
+## 译者:[kikooo](https://github.com/kikooo) 历史贡献积分:6 当前积分:6
|文章|类型|积分|
|------|-------|-------|
@@ -8223,16 +8250,17 @@
|[2019 前端性能优化年度总结 — 第三部分](https://juejin.im/post/5c5ccbefe51d457f95354a46)|校对|3|
|[谷歌迈出了消除 URL 的第一步](https://juejin.im/post/5c643cb7e51d450dfc6eec1e)|校对|1|
-## 译者:[oshinoOugi](https://github.com/oshinoOugi) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[oshinoOugi](https://github.com/oshinoOugi) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[谷歌迈出了消除 URL 的第一步](https://juejin.im/post/5c643cb7e51d450dfc6eec1e)|校对|1|
-## 译者:[iceytea](https://github.com/iceytea) 历史贡献积分:43 当前积分:43 二零一九:43
+## 译者:[iceytea](https://github.com/iceytea) 历史贡献积分:44.5 当前积分:44.5
|文章|类型|积分|
|------|-------|-------|
+|[设计的变革 —— 从用户体验到个人体验](https://juejin.im/post/5e00d1b4f265da33b636145a)|校对|1.5|
|[4 个 CSS 调色滤镜](https://juejin.im/post/5d039c36f265da1b60290096)|翻译|3|
|[Go 语言工具概述](https://juejin.im/post/5ce4dc17518825240245be5b)|翻译|10.5|
|[使用 VS Code 调试 Node.js 的超简单方法](https://juejin.im/post/5cce9b976fb9a0322415aba4)|翻译|5|
@@ -8244,31 +8272,31 @@
|[如何利用 Webpack4 为你的 React.js 开发提速](https://juejin.im/post/5c669f14e51d457f093b1767)|校对|1.5|
|[设计一个页面原则上应该指的是编写 HTML 和 CSS](https://juejin.im/post/5c6425d6e51d454ba22ba414)|校对|1.5|
-## 译者:[SeanZhouSiyuan](https://github.com/SeanZhouSiyuan) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[SeanZhouSiyuan](https://github.com/SeanZhouSiyuan) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[使用 Recompose 来构建高阶组件](https://juejin.im/post/5c484a43e51d452ec621b6a9)|校对|1|
-## 译者:[salomezhang](https://github.com/salomezhang) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[salomezhang](https://github.com/salomezhang) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[使用 Proxy 来观测 Javascript 中的类](https://juejin.im/post/5c484b76e51d45522b4f5f7d)|校对|1|
-## 译者:[cyuamber](https://github.com/cyuamber) 历史贡献积分:1.5 当前积分:1.5 二零一九:1.5
+## 译者:[cyuamber](https://github.com/cyuamber) 历史贡献积分:1.5 当前积分:1.5
|文章|类型|积分|
|------|-------|-------|
|[使用 Proxy 来观测 Javascript 中的类](https://juejin.im/post/5c484b76e51d45522b4f5f7d)|校对|1.5|
-## 译者:[connie610](https://github.com/connie610) 历史贡献积分:3 当前积分:3 二零一九:3
+## 译者:[connie610](https://github.com/connie610) 历史贡献积分:3 当前积分:3
|文章|类型|积分|
|------|-------|-------|
|[一文带你看完 2018 年浏览器之争的最新进展](https://juejin.im/post/5c45a392f265da61483be57c)|校对|3|
-## 译者:[Honwhy](https://github.com/Honwhy) 历史贡献积分:9 当前积分:9 二零一九:9
+## 译者:[Honwhy](https://github.com/Honwhy) 历史贡献积分:9 当前积分:9
|文章|类型|积分|
|------|-------|-------|
@@ -8276,13 +8304,13 @@
|推荐英文文章一篇|奖励|1|
|推荐英文文章七篇|奖励|7|
-## 译者:[iliYF](https://github.com/iliYF) 历史贡献积分:2 当前积分:2 二零一九:2
+## 译者:[iliYF](https://github.com/iliYF) 历史贡献积分:2 当前积分:2
|文章|类型|积分|
|------|-------|-------|
|推荐英文文章一系列|奖励|2|
-## 译者:[Bruce-pac](https://github.com/Bruce-pac) 历史贡献积分:9 当前积分:9 二零一九:9
+## 译者:[Bruce-pac](https://github.com/Bruce-pac) 历史贡献积分:9 当前积分:9
|文章|类型|积分|
|------|-------|-------|
@@ -8290,7 +8318,7 @@
|[在 swift 中使用 errors 作为控制流](https://juejin.im/post/5c90c0d9f265da612d6335cb)|校对|1.5|
|[Swift 5 强制独占性原则](https://juejin.im/post/5c778b5e6fb9a049c64487e0)|校对|1.5|
-## 译者:[Daltan](https://github.com/Daltan) 历史贡献积分:11 当前积分:11 二零一九:11
+## 译者:[Daltan](https://github.com/Daltan) 历史贡献积分:11 当前积分:11
|文章|类型|积分|
|------|-------|-------|
@@ -8298,10 +8326,12 @@
|[如何在远程服务器上运行 Jupyter Notebooks](https://juejin.im/post/5cb5e0a9f265da036c577f24)|翻译|4|
|[数据科学领域十大必知机器学习算法](https://juejin.im/post/5c73bbfff265da2da771d42a)|校对|2|
-## 译者:[xionglong58](https://github.com/xionglong58) 历史贡献积分:101 当前积分:21 二零一九:101
+## 译者:[xionglong58](https://github.com/xionglong58) 历史贡献积分:106.5 当前积分:26.5 二零二零:3
|文章|类型|积分|
|------|-------|-------|
+|[停止在任何地方使用 ===](https://juejin.im/post/5e5fb5e951882549522ac8a2)|校对|3|
+|[设计离线优先的网络应用](https://juejin.im/post/5dd608eef265da47f12cb018)|校对|2.5|
|2019 年 7 月兑 GitHub Octoplush 毛绒玩偶 2 个|减去积分|80|
|[多网站项目的 CSS 架构](https://juejin.im/post/5d3a58df5188251ce02ff228)|校对|1|
|[理解 React 中的高阶组件](https://juejin.im/post/5d1037966fb9a07ee4636de3)|校对|1|
@@ -8345,13 +8375,14 @@
|[我是怎么最终玩转了 Vue 的作用域插槽](https://juejin.im/post/5c8856e6e51d456b30397f31)|校对|1.5|
|[如何用 Python 从零开始构建你自己的神经网络](https://juejin.im/post/5c7a478c518825787e6a0f67)|校对|1|
-## 译者:[LeoooY](https://github.com/LeoooY) 历史贡献积分:2.5 当前积分:2.5 二零一九:2.5
+## 译者:[LeoooY](https://github.com/LeoooY) 历史贡献积分:2.5 当前积分:2.5
|文章|类型|积分|
+|------|-------|-------|
|[Golang 数据结构:树](https://juejin.im/post/5c8e023351882545eb718c9d)|校对|1|
|[Hooks 对 Vue 而言意味着什么](https://juejin.im/post/5c7784d5f265da2de713629c)|校对|1.5|
-## 译者:[Reaper622](https://github.com/Reaper622) 历史贡献积分:19.5 当前积分:19.5 二零一九:19.5
+## 译者:[Reaper622](https://github.com/Reaper622) 历史贡献积分:19.5 当前积分:19.5
|文章|类型|积分|
|------|-------|-------|
@@ -8366,7 +8397,7 @@
|[选择 Grid 还是 Flex?](https://juejin.im/post/5c7ce781e51d4514913c5bc4)|翻译|5|
|[如何学习 CSS](https://juejin.im/post/5c74daaaf265da2d9d1cb774)|校对|2|
-## 译者:[hanxiansen](https://github.com/hanxiansen) 历史贡献积分:13.5 当前积分:13.5 二零一九:13.5
+## 译者:[hanxiansen](https://github.com/hanxiansen) 历史贡献积分:13.5 当前积分:13.5
|文章|类型|积分|
|------|-------|-------|
@@ -8380,17 +8411,20 @@
|[避免那些可恶的 "cannot read property of undefined" 错误](https://juejin.im/post/5c810170e51d450a453fb48e)|校对|1|
|[模块化系统中的 event.stopPropagation ()](https://juejin.im/post/5c74a8bef265da2d881b331f)|校对|1.5|
-## 译者:[nettee](https://github.com/nettee) 历史贡献积分:31 当前积分:31 二零一九:31
+## 译者:[nettee](https://github.com/nettee) 历史贡献积分:45.5 当前积分:45.5 二零二零:5
|文章|类型|积分|
|------|-------|-------|
+|[如何为求职准备你的 GitHub](https://juejin.im/post/5e1310a8f265da5d7275de8e)|翻译|5|
+|2019 年 11 月推荐文章 1 篇|奖励|1|
+|[动态规划算法的实际应用:接缝裁剪](https://juejin.im/post/5de8b483f265da33d039c618)|翻译|8.5|
|[超快速的分析器(一):优化扫描器](https://juejin.im/post/5ce8cbd9e51d4556bb4cd2f9)|翻译|7|
|[分布式系统如何从故障中恢复?— 重试、超时和退避](https://juejin.im/post/5ccf98ace51d456e6d133541)|翻译|8|
|[教程 — 用 C 写一个 Shell](https://juejin.im/post/5c73dd7d6fb9a049aa6fb9aa)|翻译|5.5|
|[谷歌搜索操作符大全(包含 42 个高级操作符)](https://juejin.im/post/5c73744ef265da2dc675c029)|校对|2.5|
|[用 Rust 写一个微服务](https://juejin.im/post/5c7a3777f265da2dd773fc38)|翻译|8|
-## 译者:[LucaslEliane](https://github.com/LucaslEliane) 历史贡献积分:44 当前积分:44 二零一九:44
+## 译者:[LucaslEliane](https://github.com/LucaslEliane) 历史贡献积分:44 当前积分:44
|文章|类型|积分|
|------|-------|-------|
@@ -8404,34 +8438,34 @@
|[TSLint in 2019](https://juejin.im/post/5c7c0451e51d4569951518fe)|翻译|3|
|[在 GO 语言中创建你自己 OAuth2 服务:客户端凭据授权流程](https://juejin.im/post/5c77639a5188251fd46eea45)|校对|1.5|
-## 译者:[oliyg](https://github.com/oliyg) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[oliyg](https://github.com/oliyg) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|推荐英文文章一篇|奖励|1|
-## 译者:[brilliantGuo](https://github.com/brilliantGuo) 历史贡献积分:4 当前积分:4 二零一九:4
+## 译者:[brilliantGuo](https://github.com/brilliantGuo) 历史贡献积分:4 当前积分:4
|文章|类型|积分|
|------|-------|-------|
|[TypeScript 和 Babel:美丽的结合](https://juejin.im/post/5c8f4dcb5188252db02e404c)|校对|2|
|[我是怎么最终玩转了 Vue 的作用域插槽](https://juejin.im/post/5c8856e6e51d456b30397f31)|校对|2|
-## 译者:[huimingwu](https://github.com/huimingwu) 历史贡献积分:7 当前积分:7 二零一九:7
+## 译者:[huimingwu](https://github.com/huimingwu) 历史贡献积分:7 当前积分:7
|文章|类型|积分|
|------|-------|-------|
|[浏览器中 CSS 支持指南](https://juejin.im/post/5c87a9006fb9a049e4138c7e)|翻译|6|
|[Javascript - Generator-Yield/Next 和 Async-Await](https://juejin.im/post/5c7ca6d95188256ec63f289c)|校对|1|
-## 译者:[zsky](https://github.com/zsky) 历史贡献积分:5.5 当前积分:5.5 二零一九:5.5
+## 译者:[zsky](https://github.com/zsky) 历史贡献积分:5.5 当前积分:5.5
|文章|类型|积分|
|------|-------|-------|
|[TypeScript 和 Babel:美丽的结合](https://juejin.im/post/5c8f4dcb5188252db02e404c)|翻译|4.5|
|[Javascript - Generator-Yield/Next 和 Async-Await](https://juejin.im/post/5c7ca6d95188256ec63f289c)|校对|1|
-## 译者:[QiaoN](https://github.com/QiaoN) 历史贡献积分:31.5 当前积分:31.5 二零一九:31.5
+## 译者:[QiaoN](https://github.com/QiaoN) 历史贡献积分:31.5 当前积分:31.5
|文章|类型|积分|
|------|-------|-------|
@@ -8443,7 +8477,7 @@
|[四个理由让你使用灰度色调进行设计](https://juejin.im/post/5c961b1fe51d456a6743109e)|校对|1.5|
|[浏览器中 CSS 支持指南](https://juejin.im/post/5c87a9006fb9a049e4138c7e)|校对|2.5|
-## 译者:[Endone](https://github.com/Endone) 历史贡献积分:26 当前积分:26 二零一九:26
+## 译者:[Endone](https://github.com/Endone) 历史贡献积分:26 当前积分:26
|文章|类型|积分|
|------|-------|-------|
@@ -8465,10 +8499,11 @@
|[Node.js 基础知识: 没有依赖关系的 Web 服务器](https://juejin.im/post/5c88a6855188257b0b126564)|校对|1|
|[Golang 数据结构:树](https://juejin.im/post/5c8e023351882545eb718c9d)|校对|3|
-## 译者:[portandbridge](https://github.com/portandbridge) 历史贡献积分:83.5 当前积分:83.5 二零一九:83.5
+## 译者:[portandbridge](https://github.com/portandbridge) 历史贡献积分:84.5 当前积分:84.5
|文章|类型|积分|
|------|-------|-------|
+|[设置 git 别名](https://juejin.im/post/5dafc502f265da5b783f1ae1)|校对|1|
|[如何杀死一个进程和它的所有子进程](https://juejin.im/post/5d68a1a951882525830c7093)|校对|1|
|[我用 Javascript 实现 tic tac toe 游戏](https://juejin.im/post/5d627dc36fb9a06af05cbfdc)|校对|2.5|
|[作为初级开发人员,我没有学过的 7 个绝对真理](https://juejin.im/post/5d3d25dce51d457756536881)|校对|4|
@@ -8501,29 +8536,30 @@
|[使用网格布局实现响应式图片](https://juejin.im/post/5ca0ad80f265da30920059ae)|校对|2|
|[[审校] 线框图变得不那么重要了 — 好事啊!](https://github.com/xitu/gold-miner/pull/5463)|奖励|3|
-## 译者:[shengyang998](https://github.com/shengyang998) 历史贡献积分:2 当前积分:2 二零一九:2
+## 译者:[shengyang998](https://github.com/shengyang998) 历史贡献积分:2 当前积分:2
|文章|类型|积分|
|------|-------|-------|
|[[审校] Swift 5 强制独占性原则](https://github.com/xitu/gold-miner/pull/5491)|奖励|2|
-## 译者:[TBLGSn](https://github.com/TBLGSn) 历史贡献积分:3 当前积分:3 二零一九:3
+## 译者:[TBLGSn](https://github.com/TBLGSn) 历史贡献积分:3 当前积分:3
|文章|类型|积分|
|------|-------|-------|
|[什么时候需要进行数据的标准化? 为什么?](https://juejin.im/post/5d41a46bf265da03d727f85d)|校对|2|
|推荐英文文章一篇|奖励|1|
-## 译者:[letica](https://github.com/letica) 历史贡献积分:3.5 当前积分:3.5 二零一九:3.5
+## 译者:[letica](https://github.com/letica) 历史贡献积分:3.5 当前积分:3.5
|文章|类型|积分|
|------|-------|-------|
|[2019 版 web 浏览器现状](https://juejin.im/post/5c89e69a51882536fe67b5b4)|校对|3.5|
-## 译者:[Xuyuey](https://github.com/Xuyuey) 历史贡献积分:89 当前积分:89 二零一九:89
+## 译者:[Xuyuey](https://github.com/Xuyuey) 历史贡献积分:98 当前积分:98
|文章|类型|积分|
|------|-------|-------|
+|[TypeScript 3.7 Beta 版发布](https://juejin.im/post/5db2537d6fb9a0208b11f94f)|翻译|9|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|4|
|[JavaScript 简明代码 — 最佳实践](https://juejin.im/post/5d07abcc6fb9a07eda031858)|校对|1|
|[如何用 React Hooks 打造一个不到 100 行代码的异步表单校验库](https://juejin.im/post/5cf4e2c2f265da1b80202f83)|校对|2|
@@ -8544,12 +8580,12 @@
|[构建世界上最快的会议网站](https://juejin.im/post/5cbdafce6fb9a031fe3bc5db)|翻译|6|
|[使用 Shadow DOM 封装样式和结构](https://juejin.im/post/5cb3f5b95188251add7f11bc)|翻译|5|
|[React 中的调度](https://juejin.im/post/5ca347306fb9a05e4c0e69e5)|翻译|7|
-|[从没有人告诉过我的 CSS 小知识](https://juejin.im/post/5ca2fa5551882543db10d489)|翻译|3+1|
-|[Web Components 的高级工具](https://juejin.im/post/5caef9f25188251b2b20b20b)|翻译|3+1|
+|[从没有人告诉过我的 CSS 小知识](https://juejin.im/post/5ca2fa5551882543db10d489)|翻译|4|
+|[Web Components 的高级工具](https://juejin.im/post/5caef9f25188251b2b20b20b)|翻译|4|
|[JavaScript 中为什么会有 Symbols 类型?](https://juejin.im/post/5c9b11e8518825529a0c78c9)|校对|2.5|
|[浏览器帧原理剖析](https://juejin.im/post/5c9c66075188251dab07413d)|校对|1.5|
-## 译者:[xiantang](https://github.com/xiantang) 历史贡献积分:8 当前积分:8 二零一九:8
+## 译者:[xiantang](https://github.com/xiantang) 历史贡献积分:8 当前积分:8
|文章|类型|积分|
|------|-------|-------|
@@ -8557,43 +8593,43 @@
|[Spring 的分布式事务实现 — 使用和不使用XA — 第二部分](https://juejin.im/post/5cae93ddf265da03a85aaac3)|翻译|6|
|[线框图变得不那么重要了 — 好事啊!](https://juejin.im/post/5c9269edf265da6116245ee9)|校对|1|
-## 译者:[BYChoo](https://github.com/BYChoo) 历史贡献积分:0.5 当前积分:0.5 二零一九:0.5
+## 译者:[BYChoo](https://github.com/BYChoo) 历史贡献积分:0.5 当前积分:0.5
|文章|类型|积分|
|------|-------|-------|
|[如何使用 Phaser 3 和 TypeScript 在浏览器中构建一个简单的游戏](https://juejin.im/post/5c91b77ee51d4574b27c9219)|校对|0.5|
-## 译者:[SevenOutman](https://github.com/SevenOutman) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[SevenOutman](https://github.com/SevenOutman) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[Vue.js 逐渐集成 第三方 JavaScript](https://juejin.im/post/5c8e5a776fb9a070d013ef71)|校对|1|
-## 译者:[thaiwu0107](https://github.com/thaiwu0107) 历史贡献积分:2 当前积分:2 二零一九:2
+## 译者:[thaiwu0107](https://github.com/thaiwu0107) 历史贡献积分:2 当前积分:2
|文章|类型|积分|
|------|-------|-------|
|推荐英文文章两篇|奖励|2|
-## 译者:[ish-kafel](https://github.com/ish-kafel) 历史贡献积分:3 当前积分:3 二零一九:3
+## 译者:[ish-kafel](https://github.com/ish-kafel) 历史贡献积分:3 当前积分:3
|文章|类型|积分|
|------|-------|-------|
|翻译现代 JavaScript 教程|翻译|3|
-## 译者:[kaigregliu](https://github.com/kaigregliu) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[kaigregliu](https://github.com/kaigregliu) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|校对现代 JavaScript 教程|校对|1|
-## 译者:[jxderic](https://github.com/jxderic) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[jxderic](https://github.com/jxderic) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[使用网格布局实现响应式图片](https://juejin.im/post/5ca0ad80f265da30920059ae)|校对|1|
-## 译者:[yzw7489757](https://github.com/yzw7489757) 历史贡献积分:13.5 当前积分:13.5 二零一九:13.5
+## 译者:[yzw7489757](https://github.com/yzw7489757) 历史贡献积分:13.5 当前积分:13.5
|文章|类型|积分|
|------|-------|-------|
@@ -8604,13 +8640,13 @@
|[从 0 创建自定义元素](https://juejin.im/post/5cb2b5465188257abd66c354)|翻译|3|
|[写给大家看的 Cache-Control 指令配置](https://juejin.im/post/5c9d92506fb9a070f5067b3d)|校对|2|
-## 译者:[Graywd](https://github.com/Graywd) 历史贡献积分:2.5 当前积分:2.5 二零一九:2.5
+## 译者:[Graywd](https://github.com/Graywd) 历史贡献积分:2.5 当前积分:2.5
|文章|类型|积分|
|------|-------|-------|
|[多线程简介](https://juejin.im/post/5ca351da6fb9a05e6a08745b)|校对|2.5|
-## 译者:[TloveYing](https://github.com/TloveYing) 历史贡献积分:4 当前积分:4 二零一九:4
+## 译者:[TloveYing](https://github.com/TloveYing) 历史贡献积分:4 当前积分:4
|文章|类型|积分|
|------|-------|-------|
@@ -8618,10 +8654,11 @@
|[用 Rust 打造你的第一个命令行工具](https://juejin.im/post/5cb33b94e51d456e63760453)|校对|1.5|
|[如何在远程服务器上运行 Jupyter Notebooks](https://juejin.im/post/5cb5e0a9f265da036c577f24)|校对|1.5|
-## 译者:[ccJia](https://github.com/ccJia) 历史贡献积分:37 当前积分:37 二零一九:37
+## 译者:[ccJia](https://github.com/ccJia) 历史贡献积分:38 当前积分:38 二零二零:1
|文章|类型|积分|
|------|-------|-------|
+|2020 年 2 月推荐文章 1 篇|奖励|1|
|[在 Python 中过度使用列表解析器和生成表达式](https://juejin.im/post/5d281b0ff265da1b8b2b8ae0)|翻译|5|
|[在 Keras 下使用自编码器分类极端稀有事件](https://juejin.im/post/5cff17296fb9a07ec63b0a7f)|翻译|5|
|[在数据可视化中,我们曾经“画”下的那些错误](https://juejin.im/post/5cd39e1de51d453a3a0acb7b)|翻译|7|
@@ -8629,7 +8666,7 @@
|[在深度学习训练过程中如何设置数据增强?](https://juejin.im/post/5cc87ec8f265da03b446202b)|翻译|8|
|[哪一个深度学习框架增长最迅猛?TensorFlow 还是 PyTorch?](https://juejin.im/post/5caefef45188251b070f7d70)|翻译|5|
-## 译者:[renyuhuiharrison](https://github.com/renyuhuiharrison) 历史贡献积分:11 当前积分:11 二零一九:11
+## 译者:[renyuhuiharrison](https://github.com/renyuhuiharrison) 历史贡献积分:11 当前积分:11
|文章|类型|积分|
|------|-------|-------|
@@ -8638,7 +8675,7 @@
|[制定良好的路线图:产品负责人的六个实施步骤](https://juejin.im/post/5cb299436fb9a068744e70a7)|校对|3|
|[你不能成为成功程序员的 10 个迹象](https://juejin.im/post/5ca2f5ce51882565cb5b962c)|校对|4|
-## 译者:[ezioyuan](https://github.com/ezioyuan) 历史贡献积分:13 当前积分:13 二零一九:13
+## 译者:[ezioyuan](https://github.com/ezioyuan) 历史贡献积分:13 当前积分:13
|文章|类型|积分|
|------|-------|-------|
@@ -8651,13 +8688,13 @@
|[创意运用 Console API!](https://juejin.im/post/5cc1517e5188252e7a0247dd)|校对|1.5|
|[我们为什么看好加密收藏品(NFT)的前景](https://juejin.im/post/5cb87819518825329e7ea61e)|校对|1|
-## 译者:[ZYuMing](https://github.com/ZYuMing) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[ZYuMing](https://github.com/ZYuMing) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[使用 closest() 函数获取正确的 DOM 元素](https://juejin.im/post/5cc811796fb9a0321c45e5e0)|校对|1|
-## 译者:[xujiujiu](https://github.com/xujiujiu) 历史贡献积分:14 当前积分:14 二零一九:14
+## 译者:[xujiujiu](https://github.com/xujiujiu) 历史贡献积分:14 当前积分:14
|文章|类型|积分|
|------|-------|-------|
@@ -8667,16 +8704,18 @@
|[我多希望在我学习 React.js 之前就已经知晓这些小窍门](https://juejin.im/post/5cc53af6f265da038e54b2e6)|校对|1|
|[你认为“figure”怎么用?](https://juejin.im/post/5cc5ad456fb9a032233532df)|校对|2|
-## 译者:[Tammy-Liu](https://github.com/Tammy-Liu) 历史贡献积分:2 当前积分:2 二零一九:2
+## 译者:[Tammy-Liu](https://github.com/Tammy-Liu) 历史贡献积分:2 当前积分:2
|文章|类型|积分|
|------|-------|-------|
|[创意运用 Console API!](https://juejin.im/post/5cc1517e5188252e7a0247dd)|校对|2|
-## 译者:[Charlo-O](https://github.com/Charlo-O) 历史贡献积分:41 当前积分:41 二零一九:41
+## 译者:[Charlo-O](https://github.com/Charlo-O) 历史贡献积分:46.5 当前积分:46.5
|文章|类型|积分|
|------|-------|-------|
+|2019 年 11 月推荐文章 2 篇|奖励|2|
+|[设计的变革 —— 从用户体验到个人体验](https://juejin.im/post/5e00d1b4f265da33b636145a)|翻译|3.5|
|[当每个产品设计都是一种意见](https://juejin.im/post/5d5a77676fb9a06b1417e4b3)|翻译|5|
|[元设计师的崛起](https://juejin.im/post/5d4919e5f265da03a1484008)|校对|2|
|[敏捷也许是个问题](https://juejin.im/post/5d2dfb4ae51d45775f516b1e)|翻译|5|
@@ -8685,11 +8724,11 @@
|[微设计系统 — 打破藩篱](https://juejin.im/post/5d0335395188255ee806a5da)|翻译|7|
|[关于 Flutter 页面路由过渡动画,你所需要知道的一切](https://juejin.im/post/5ceb6179f265da1bc23f55d0)|校对|0.5|
|[声音设计与无声设计](https://juejin.im/post/5ce354bee51d4510727c7fd1)|校对|0.5|
-|[项目世界 — 在数字设计中实现上帝模式](https://juejin.im/post/5ce63193518825332978ef65)|翻译|10+3|
+|[项目世界 — 在数字设计中实现上帝模式](https://juejin.im/post/5ce63193518825332978ef65)|翻译|13|
|[在数据可视化中,我们曾经“画”下的那些错误](https://juejin.im/post/5cd39e1de51d453a3a0acb7b)|校对|1.5|
|[伟大设计与好设计之间区别是什么?这里告诉你真相](https://juejin.im/post/5cc15d1c5188252d6a6b1886)|校对|1.5|
-## 译者:[qiuyuezhong](https://github.com/qiuyuezhong) 历史贡献积分:17 当前积分:17 二零一九:17
+## 译者:[qiuyuezhong](https://github.com/qiuyuezhong) 历史贡献积分:17 当前积分:17
|文章|类型|积分|
|------|-------|-------|
@@ -8699,14 +8738,14 @@
|[减少 Python 中循环的使用](https://juejin.im/post/5cc8e012e51d453b6d4d13fd)|翻译|2.5|
|[通过 Play Cloud 的 ART 优化配置提升应用性能](https://juejin.im/post/5cc297f36fb9a0323d6e0be2)|校对|1.5|
-## 译者:[MollyAredtana](https://github.com/MollyAredtana) 历史贡献积分:2.5 当前积分:2.5 二零一九:2.5
+## 译者:[MollyAredtana](https://github.com/MollyAredtana) 历史贡献积分:2.5 当前积分:2.5
|文章|类型|积分|
|------|-------|-------|
|[减少 Python 中循环的使用](https://juejin.im/post/5cc8e012e51d453b6d4d13fd)|校对|1|
|[用 Flutter 打造一个圆形滑块(Slider)](https://juejin.im/post/5cbec995f265da03576ec5a1)|校对|1.5|
-## 译者:[JasonLinkinBright](https://github.com/JasonLinkinBright) 历史贡献积分:8 当前积分:8 二零一九:8
+## 译者:[JasonLinkinBright](https://github.com/JasonLinkinBright) 历史贡献积分:8 当前积分:8
|文章|类型|积分|
|------|-------|-------|
@@ -8715,13 +8754,13 @@
|[依赖注入在多模块工程中的应用](https://juejin.im/post/5cc15dae5188252dcf5d4c68)|校对|1.5|
|[用 Flutter 打造一个圆形滑块(Slider)](https://juejin.im/post/5cbec995f265da03576ec5a1)|校对|1.5|
-## 译者:[yinguangyao](https://github.com/yinguangyao) 历史贡献积分:1.5 当前积分:1.5 二零一九:1.5
+## 译者:[yinguangyao](https://github.com/yinguangyao) 历史贡献积分:1.5 当前积分:1.5
|文章|类型|积分|
|------|-------|-------|
|[如何避免我作为初级开发者时所犯下的 7 个错误](https://juejin.im/post/5cbea729e51d456e8240dcfa)|校对|1.5|
-## 译者:[Minghao23](https://github.com/Minghao23) 历史贡献积分:19.5 当前积分:19.5 二零一九:19.5
+## 译者:[Minghao23](https://github.com/Minghao23) 历史贡献积分:19.5 当前积分:19.5
|文章|类型|积分|
|------|-------|-------|
@@ -8732,13 +8771,16 @@
|[Keras 速查表:使用 Python 构建神经网络](https://juejin.im/post/5cd40d24f265da038412a8be)|翻译|3|
|[在深度学习训练过程中如何设置数据增强?](https://juejin.im/post/5cc87ec8f265da03b446202b)|校对|2|
-## 译者:[fireairforce](https://github.com/fireairforce) 历史贡献积分:65 当前积分:34 二零一九:65
+## 译者:[fireairforce](https://github.com/fireairforce) 历史贡献积分:76 当前积分:45 二零二零:11
|文章|类型|积分|
|------|-------|-------|
+|[在 Vue 中编写 SVG 图标组件](https://juejin.im/post/5e4fc62de51d4527110a85dd)|翻译|4|
+|[WebAssembly:带有代码示例的简单介绍](https://juejin.im/post/5e49394de51d452717262197)|翻译|5|
+|[算法不是产品](https://juejin.im/post/5e398e806fb9a07cb52bb462)|翻译|2|
|[可维护的 ETL: 使管道更容易支持和扩展的技巧](https://juejin.im/post/5d08e178518825166f36bf89)|翻译|9|
|[Python 实现排序算法](https://juejin.im/post/5d1323b6e51d45108b2caeaf)|翻译|6|
-|[13 种用于 DOM 操作的 JavaScript 方法](https://juejin.im/post/5cf65369f265da1bc94edad8)|翻译|2+1|
+|[13 种用于 DOM 操作的 JavaScript 方法](https://juejin.im/post/5cf65369f265da1bc94edad8)|翻译|3|
|2019 年 06 月兑掘金 T 恤 1 件,掘金笔记本 1 个,掘金桌垫 1 个|减去积分|31|
|[Node.js 日志记录指南](https://juejin.im/post/5cf213e4e51d4577407b1cda)|翻译|6.5|
|[什么是 `this`?JavaScript 对象的内部工作原理](https://juejin.im/post/5cedfdbd5188252fbc37f920)|翻译|3|
@@ -8758,10 +8800,19 @@
|[自动补全规则](https://juejin.im/post/5cd556ef6fb9a03218556cb7)|翻译|3|
|[使用 PyTorch 在 MNIST 数据集上进行逻辑回归](https://juejin.im/post/5cc66d946fb9a032286173a7)|校对|1|
-## 译者:[Chorer](https://github.com/Chorer) 历史贡献积分:16 当前积分:6 二零一九:16
+## 译者:[Chorer](https://github.com/Chorer) 历史贡献积分:45.5 当前积分:35.5 二零二零:16
|文章|类型|积分|
|------|-------|-------|
+|[关于 icon 设计的 7 大准则](https://juejin.im/post/5e5dbd3e6fb9a07cd323dd2b)|校对|3|
+|[停止在任何地方使用 ===](https://juejin.im/post/5e5fb5e951882549522ac8a2)|校对|3|
+|[您可能不知道的原生 JavaScript 方法](https://juejin.im/post/5e4bc03cf265da572446685a)|校对|2.5|
+|[5 个简单步骤为您的网站创建 Sitemap](https://juejin.im/post/5e22fc43f265da3e254c7555)|校对|3|
+|[JavaScript 简史](https://juejin.im/post/5e158fe6e51d4541082c8143)|校对|1.5|
+|[如何为求职准备你的 GitHub](https://juejin.im/post/5e1310a8f265da5d7275de8e)|校对|3|
+|[使用 JavaScript 编写 JSON 解析器](https://juejin.im/post/5e098728f265da33cd03c6c7)|校对|3.5|
+|[理解递归、尾调用优化和蹦床函数优化](https://juejin.im/post/5e003a67e51d45583f44d396)|校对|7|
+|[什么将会替代 JavaScript 呢?](https://juejin.im/post/5daa897c6fb9a04e3902f4e6)|校对|3|
|[响应式设计的基本原则](https://juejin.im/post/5d2ed18af265da1ba56b5374)|校对|1|
|[前端 vs 后端:哪一个适合你?](https://juejin.im/post/5d36b5e3f265da1bd3059a21)|校对|1|
|2019 年 7 月兑掘金 T 恤黑色 1 个|减去积分|10|
@@ -8773,10 +8824,31 @@
|[ES6:理解参数默认值的实现细节](https://juejin.im/post/5cd0eab95188251b984d8abe)|翻译|3.5|
|推荐英文文章一篇|奖励|1|
-## 译者:[cyz980908](https://github.com/cyz980908) 历史贡献积分:33 当前积分:33 二零一九:33
-
-|文章|类型|积分|
-|------|-------|-------|
+## 译者:[cyz980908](https://github.com/cyz980908) 历史贡献积分:139.5 当前积分:139.5 二零二零:71.5
+
+|文章|类型|积分|
+|------|-------|-------|
+|20 年 3 月推荐文章 1 篇|奖励|1|
+|[关于 icon 设计的 7 大准则](https://juejin.im/post/5e5dbd3e6fb9a07cd323dd2b)|翻译|7.5|
+|[理解 Service Worker 和缓存策略](https://juejin.im/post/5e60e0ce5188254919497644)|翻译|4|
+|[SQL 将死于 No-SQL 之手?](https://juejin.im/post/5e5517bff265da576b566551)|校对|1.5|
+|[用 6 分钟学习如何用 Redis 缓存您的 NodeJS 应用!](https://juejin.im/post/5e4df6d7518825496452ac98)|翻译|8|
+|[WebRTC 联手 Node.js:打造实时视频聊天应用](https://juejin.im/post/5e0ae59d5188253a5b3ccf74)|校对|3.5|
+|[您可能不知道的原生 JavaScript 方法](https://juejin.im/post/5e4bc03cf265da572446685a)|翻译|4|
+|[如何选择合适的数据库](https://juejin.im/post/5e3c10e6518825494f7de8ff)|翻译|5|
+|[使用 Nuxt (Vue.js)、Strapi 和 Apollo 构建博客](https://juejin.im/post/5e2a59ba6fb9a030026e8375)|校对|4|
+|[如何写出优雅且有意义的 README.md](https://juejin.im/post/5e3a7363e51d452701795512)|翻译|5|
+|[5 个简单步骤为您的网站创建 Sitemap](https://juejin.im/post/5e22fc43f265da3e254c7555)|翻译|5|
+|[如何用 Nest.js、MongoDB 和 Vue.js 搭建一个博客](https://juejin.im/post/5e1820a951882526334a1d1f)|翻译|14|
+|2020 年 2 月推荐文章 4 篇|奖励|4|
+|2020 年 1 月推荐文章 4 篇|奖励|4|
+|2020 年 1 月推荐文章 1 篇|奖励|1|
+|2019 年 11 月 12 月推荐文章 2 篇|奖励|2|
+|[理解递归、尾调用优化和蹦床函数优化](https://juejin.im/post/5e003a67e51d45583f44d396)|翻译|14|
+|[将 GraphQL 概念可视化](https://juejin.im/post/5de480d7f265da05ce3b7368)|翻译|5|
+|[Node.js 新特性将颠覆 AI、物联网等更多惊人领域](https://juejin.im/post/5dbb8d70f265da4d12067a3e)|校对|3|
+|[如何设计一款讨人喜欢的暗色主题](https://juejin.im/post/5dad4ef1f265da5bb86ad294)|翻译|5|
+|[什么将会替代 JavaScript 呢?](https://juejin.im/post/5daa897c6fb9a04e3902f4e6)|翻译|6|
|[CSS 小妙招:CSS 变量 —— 如何轻松创建一个🌞白色/🌑暗色主题](https://juejin.im/post/5da6c370e51d4524a0060385)|翻译|3|
|[如何编写全栈 JavaScript 应用](https://juejin.im/post/5d8ae3a56fb9a04e2902fbf6)|翻译|8|
|[HTTP Security Headers 完整指南](https://juejin.im/post/5d648e766fb9a06b122f4ab4)|翻译|4|
@@ -8787,10 +8859,27 @@
|[在数据可视化中,我们曾经“画”下的那些错误](https://juejin.im/post/5cd39e1de51d453a3a0acb7b)|校对|1.5|
|[使用 VS Code 调试 Node.js 的超简单方法](https://juejin.im/post/5cce9b976fb9a0322415aba4)|校对|1.5|
-## 译者:[Baddyo](https://github.com/Baddyo) 历史贡献积分:147 当前积分:147 二零一九:147
-
-|文章|类型|积分|
-|------|-------|-------|
+## 译者:[Baddyo](https://github.com/Baddyo) 历史贡献积分:203.5 当前积分:203.5 二零二零:29.5
+
+|文章|类型|积分|
+|------|-------|-------|
+|[WebRTC 联手 Node.js:打造实时视频聊天应用](https://juejin.im/post/5e0ae59d5188253a5b3ccf74)|翻译|11|
+|[图标万花筒](https://juejin.im/post/5e0ac4756fb9a048526aa26b)|翻译|2|
+|[您可能不知道的原生 JavaScript 方法](https://juejin.im/post/5e4bc03cf265da572446685a)|校对|2|
+|[WebAssembly:带有代码示例的简单介绍](https://juejin.im/post/5e49394de51d452717262197)|校对|2.5|
+|[论资历的级别](https://juejin.im/post/5e1549736fb9a0483c632bf8)|翻译|5|
+|[为何 Svelte 杀不死 React](https://juejin.im/post/5e12aa81e51d4541162c9a3a)|翻译|7|
+|[我个人的 Git 技巧备忘录](https://juejin.im/post/5e006ad4e51d45582248e63f)|校对|2|
+|[为什么自己动手写代码能让你成为更好的开发者](https://juejin.im/post/5de88ed16fb9a016470c151a)|校对|2|
+|[设计的变革 —— 从用户体验到个人体验](https://juejin.im/post/5e00d1b4f265da33b636145a)|校对|1.5|
+|[使用 Redux Offline 和 Apollo 进行离线 GraphQL 查询](https://juejin.im/post/5e00a06f6fb9a0161a0c3d78)|校对|1.5|
+|[深入解析 Flutter Provider 包](https://juejin.im/post/5e01a677518825124c50e99d)|校对|2|
+|[如何确定团队工作的优先级](https://juejin.im/post/5de4fc675188252edd0e2828)|校对|2|
+|[将 GraphQL 概念可视化](https://juejin.im/post/5de480d7f265da05ce3b7368)|校对|2|
+|[让字母“i”的点动起来的秘密](https://juejin.im/post/5dd7fe84e51d4523564243d5)|校对|1|
+|[Node.js 新特性将颠覆 AI、物联网等更多惊人领域](https://juejin.im/post/5dbb8d70f265da4d12067a3e)|翻译|8|
+|[现代脚本加载](https://juejin.im/post/5dafdcd45188256b030ad8cf)|校对|1|
+|[写给大家的代数效应入门](https://juejin.im/post/5dafe28b5188252e734f5376)|校对|4|
|[冲冠一怒为代码:论程序员与负能量](https://juejin.im/post/5d67540df265da039d32e0cc)|翻译|12|
|[小提示:伪元素是子元素,吧。](https://juejin.im/post/5d6271895188253a5635002e)|翻译|2|
|[愿未来没有 Webpack](https://juejin.im/post/5d4bcdb7e51d453b386a62c6)|翻译|5|
@@ -8828,30 +8917,31 @@
|推荐英文文章一篇|奖励|1|
|[Javascript Array.push 要比 Array.concat 快 945 倍!🤯🤔](https://juejin.im/post/5cd67fb9f265da037129bb64)|校对|1|
-## 译者:[hzdaqo](https://github.com/hzdaqo) 历史贡献积分:4.5 当前积分:4.5 二零一九:4.5
+## 译者:[hzdaqo](https://github.com/hzdaqo) 历史贡献积分:4.5 当前积分:4.5
|文章|类型|积分|
|------|-------|-------|
|[帮你高效使用 VS Code 的秘诀](https://juejin.im/post/5cd8fcedf265da03761eaa45)|校对|3|
|[Javascript Array.push 要比 Array.concat 快 945 倍!🤯🤔](https://juejin.im/post/5cd67fb9f265da037129bb64)|校对|1.5|
-## 译者:[alictopo](https://github.com/alictopo) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[alictopo](https://github.com/alictopo) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[使用 Python Flask 框架发布机器学习 API](https://juejin.im/post/5cd7f862e51d453aa44ad6f3)|校对|1|
-## 译者:[CLOXnu](https://github.com/CLOXnu) 历史贡献积分:4 当前积分:4 二零一九:4
+## 译者:[CLOXnu](https://github.com/CLOXnu) 历史贡献积分:4 当前积分:4
|文章|类型|积分|
|------|-------|-------|
-|[声音设计与无声设计](https://juejin.im/post/5ce354bee51d4510727c7fd1)|翻译|2+0.5|
+|[声音设计与无声设计](https://juejin.im/post/5ce354bee51d4510727c7fd1)|翻译|2.5|
|[Swift 里的强制 @inline 注解](https://juejin.im/post/5cd67d64518825686244635a)|校对|1.5|
-## 译者:[suhanyujie](https://github.com/suhanyujie) 历史贡献积分:58 当前积分:58 二零一九:58
+## 译者:[suhanyujie](https://github.com/suhanyujie) 历史贡献积分:60 当前积分:60
|文章|类型|积分|
|------|-------|-------|
+|[PHP 7.4 有什么新功能?你必须掌握的 10 大特性](https://juejin.im/post/5dfa04316fb9a0160770a501)|校对|2|
|[通过 Rust 学习解析器组合器 — 第四部分](https://juejin.im/post/5d629f75e51d456210163bc0)|校对|2|
|[思考实践:用 Go 实现 Flutter](https://juejin.im/post/5d215b8df265da1b7b31ac8f)|翻译|11|
|[使用 Gomobile 和 Gopherjs 的动态二维码数据传输](https://juejin.im/post/5d2bfccef265da1bb77699e8)|校对|3.5|
@@ -8870,7 +8960,7 @@
|[超快速的分析器(一):优化扫描器](https://juejin.im/post/5ce8cbd9e51d4556bb4cd2f9)|校对|2|
|推荐英文文章一篇|奖励|1|
-## 译者:[wuyanan](https://github.com/wuyanan) 历史贡献积分:5.5 当前积分:5.5 二零一九:5.5
+## 译者:[wuyanan](https://github.com/wuyanan) 历史贡献积分:5.5 当前积分:5.5
|文章|类型|积分|
|------|-------|-------|
@@ -8879,14 +8969,15 @@
|[用 React 的钩子函数和调试工具提升应用性能](https://juejin.im/post/5ce974d76fb9a07f0420250e)|校对|1|
|[理解 WebView](https://juejin.im/post/5ce76ee4f265da1b8d15f700)|校对|2|
-## 译者:[jilanlan](https://github.com/jilanlan) 历史贡献积分:5 当前积分:5 二零一九:5
+## 译者:[jilanlan](https://github.com/jilanlan) 历史贡献积分:6 当前积分:6 二零二零:1
|文章|类型|积分|
|------|-------|-------|
+|[使用 Web Workers 优化事件监听器](https://juejin.im/post/5e241bb9f265da3e46090215)|校对|1|
|[理解 Vue.js 中的 Mixins](https://juejin.im/post/5cdeac5851882525f52cf662)|校对|1|
|[为什么 HTML 中复选框样式难写 — 本文给你答案](https://juejin.im/post/5ce65dd36fb9a07ef06f6cd2)|翻译|4|
-## 译者:[twang1727](https://github.com/twang1727) 历史贡献积分:20 当前积分:20 二零一九:20
+## 译者:[twang1727](https://github.com/twang1727) 历史贡献积分:20 当前积分:20
|文章|类型|积分|
|------|-------|-------|
@@ -8898,10 +8989,12 @@
|[Android中的简易协程:viewModelScope](https://juejin.im/post/5cf35ec76fb9a07ed657bbcd)|翻译|3|
|[C++ 和 Android 本地 Activity 初探](https://juejin.im/post/5ce62d4851882532e9631b63)|翻译|2|
-## 译者:[ZavierTang](https://github.com/ZavierTang) 历史贡献积分:25 当前积分:25 二零一九:25
+## 译者:[ZavierTang](https://github.com/ZavierTang) 历史贡献积分:33 当前积分:33 二零二零:7
|文章|类型|积分|
|------|-------|-------|
+|[停止在任何地方使用 ===](https://juejin.im/post/5e5fb5e951882549522ac8a2)|翻译|7|
+|[如何将 SVG 图标用做 React 组件?](https://juejin.im/post/5df22bf7f265da33ea009225)|校对|1|
|[如何用 JavaScript 编写扫雷游戏](https://juejin.im/post/5d6276cd6fb9a06ade111bb4)|翻译|7|
|[前端 vs 后端:哪一个适合你?](https://juejin.im/post/5d36b5e3f265da1bd3059a21)|校对|1|
|[Git:透过命令学概念 —— 第一部分](https://juejin.im/post/5d0b3c7ce51d4577531381e3)|校对|2.5|
@@ -8911,7 +9004,7 @@
|[ECMAScript 类 - 定义私有属性](https://juejin.im/post/5d006e406fb9a07ed22465de)|翻译|4|
|[用 React 制作线性代数教程示例:网格与箭头](https://juejin.im/post/5cefbc37f265da1bd260d129)|校对|1|
-## 译者:[linxiaowu66](https://github.com/linxiaowu66) 历史贡献积分:12 当前积分:12 二零一九:12
+## 译者:[linxiaowu66](https://github.com/linxiaowu66) 历史贡献积分:12 当前积分:12
|文章|类型|积分|
|------|-------|-------|
@@ -8919,7 +9012,7 @@
|[WebSockets 与长轮询的较量](https://juejin.im/post/5d0b1381e51d455a694f9544)|校对|1.5|
|[如何在 Google Play 应用商店中发布 PWA](https://juejin.im/post/5cefe63a6fb9a07ef3764dbe)|校对|2|
-## 译者:[lgh757079506](https://github.com/lgh757079506) 历史贡献积分:20 当前积分:20 二零一九:20
+## 译者:[lgh757079506](https://github.com/lgh757079506) 历史贡献积分:20 当前积分:20
|文章|类型|积分|
|------|-------|-------|
@@ -8936,14 +9029,14 @@
|[ECMAScript 类 - 定义私有属性](https://juejin.im/post/5d006e406fb9a07ed22465de)|校对|1.5|
|[在项目中集成第三方动画库 —— 第二部分](https://juejin.im/post/5ce973a75188257ac625162b)|校对|1.5|
-## 译者:[Lobster-King](https://github.com/Lobster-King) 历史贡献积分:3 当前积分:3 二零一九:3
+## 译者:[Lobster-King](https://github.com/Lobster-King) 历史贡献积分:3 当前积分:3
|文章|类型|积分|
|------|-------|-------|
|[用于 iOS 的 ML Kit 教程:识别图像中的文字](https://juejin.im/post/5cfe23af6fb9a07ee742d401)|校对|2|
|[Swift 5 中的枚举冻结](https://juejin.im/post/5cea9597e51d45775f5169f2)|校对|1|
-## 译者:[fakeinc](https://github.com/fakeinc) 历史贡献积分:6.5 当前积分:6.5 二零一九:6.5
+## 译者:[fakeinc](https://github.com/fakeinc) 历史贡献积分:6.5 当前积分:6.5
|文章|类型|积分|
|------|-------|-------|
@@ -8951,13 +9044,13 @@
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|2|
|[The JavaScript Tutorial 翻译](https://github.com/javascript-tutorial/zh.javascript.info)|翻译|3|
-## 译者:[owlikesj](https://github.com/owlikesj) 历史贡献积分:3 当前积分:3 二零一九:3
+## 译者:[owlikesj](https://github.com/owlikesj) 历史贡献积分:3 当前积分:3
|文章|类型|积分|
|------|-------|-------|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|3|
-## 译者:[lycheeEng](https://github.com/lycheeEng) 历史贡献积分:53 当前积分:1 二零一九:53
+## 译者:[lycheeEng](https://github.com/lycheeEng) 历史贡献积分:53 当前积分:1
|文章|类型|积分|
|------|-------|-------|
@@ -8965,7 +9058,7 @@
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|40|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|13|
-## 译者:[smilemuffie](https://github.com/smilemuffie) 历史贡献积分:10 当前积分:10 二零一九:10
+## 译者:[smilemuffie](https://github.com/smilemuffie) 历史贡献积分:10 当前积分:10
|文章|类型|积分|
|------|-------|-------|
@@ -8978,16 +9071,21 @@
|[Flutter 布局备忘录](https://juejin.im/post/5cfe0d136fb9a07efc497d7d)|校对|1.5|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|1.5|
-## 译者:[lihaobhsfer](https://github.com/lihaobhsfer) 历史贡献积分:16 当前积分:16 二零一九:16
+## 译者:[lihaobhsfer](https://github.com/lihaobhsfer) 历史贡献积分:40.5 当前积分:40.5 二零二零:19
|文章|类型|积分|
|------|-------|-------|
+|[现在就该学习的 7 门现代编程语言](https://juejin.im/post/5e1e00fee51d4577794c04f8)|翻译|12|
+|[如何用 Nest.js、MongoDB 和 Vue.js 搭建一个博客](https://juejin.im/post/5e1820a951882526334a1d1f)|校对|6|
+|2020 年 1 月推荐文章 1 篇|奖励|1|
+|2019 年 11 月推荐文章 1 篇|奖励|1|
+|[我们为何抛弃 Redux 拥抱 MobX](https://juejin.im/post/5e068fa551882512657bc16c)|翻译|4.5|
|[微前端:未来前端开发的新趋势 — 第二部分](https://juejin.im/post/5d1a91c7e51d45775f516ab9)|翻译|6.5|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|1.5|
|[10 分钟爆改终端](https://juejin.im/post/5d053fc56fb9a07ee85c283d)|翻译|5|
|[将第三方动画库集成到项目中 —— 第 1 部分](https://juejin.im/post/5d037b655188252af2012702)|校对|3|
-## 译者:[csming1995](https://github.com/csming1995) 历史贡献积分:6 当前积分:6 二零一九:6
+## 译者:[csming1995](https://github.com/csming1995) 历史贡献积分:6 当前积分:6
|文章|类型|积分|
|------|-------|-------|
@@ -8996,10 +9094,16 @@
|[改善 Android Studio 的构建速度](https://juejin.im/post/5d1388b1f265da1b6d403560)|校对|1.5|
|[揭秘变量提升](https://juejin.im/post/5d026b71518825710d2b1f63)|校对|1.5|
-## 译者:[JalanJiang](https://github.com/JalanJiang) 历史贡献积分:70.5 当前积分:70.5 二零一九:70.5
+## 译者:[JalanJiang](https://github.com/JalanJiang) 历史贡献积分:84.5 当前积分:84.5 二零二零:2.5
|文章|类型|积分|
|------|-------|-------|
+|[SQL 将死于 No-SQL 之手?](https://juejin.im/post/5e5517bff265da576b566551)|翻译|2.5|
+|[如何提升你的数据结构、算法以及解决问题的能力](https://juejin.im/post/5d80fdcbf265da03e83ba163)|校对|2|
+|[PHP 7.4 有什么新功能?你必须掌握的 10 大特性](https://juejin.im/post/5dfa04316fb9a0160770a501)|校对|2|
+|[动态规划算法的实际应用:接缝裁剪](https://juejin.im/post/5de8b483f265da33d039c618)|校对|3.5|
+|[将 GraphQL 概念可视化](https://juejin.im/post/5de480d7f265da05ce3b7368)|校对|2|
+|[什么将会替代 JavaScript 呢?](https://juejin.im/post/5daa897c6fb9a04e3902f4e6)|校对|2|
|[冲冠一怒为代码:论程序员与负能量](https://juejin.im/post/5d67540df265da039d32e0cc)|校对|1|
|[如何杀死一个进程和它的所有子进程](https://juejin.im/post/5d68a1a951882525830c7093)|翻译|2|
|[深入理解 Python 类型提示](https://juejin.im/post/5d64905fe51d4561fd6cb50f)|校对|1|
@@ -9023,16 +9127,18 @@
|[类(Class)与数据结构(Data Structures)](https://juejin.im/post/5d12efe7e51d455c8838e193)|校对|2|
|[揭秘变量提升](https://juejin.im/post/5d026b71518825710d2b1f63)|校对|2|
-## 译者:[xiaonizi1994](https://github.com/xiaonizi1994) 历史贡献积分:1.5 当前积分:1.5 二零一九:1.5
+## 译者:[xiaonizi1994](https://github.com/xiaonizi1994) 历史贡献积分:1.5 当前积分:1.5
|文章|类型|积分|
|------|-------|-------|
|[如何用 React Hooks 打造一个不到 100 行代码的异步表单校验库](https://juejin.im/post/5cf4e2c2f265da1b80202f83)|校对|1.5|
-## 译者:[Stevens1995](https://github.com/Stevens1995) 历史贡献积分:17 当前积分:17 二零一九:17
+## 译者:[Stevens1995](https://github.com/Stevens1995) 历史贡献积分:20 当前积分:20
|文章|类型|积分|
|------|-------|-------|
+|[我们为何抛弃 Redux 拥抱 MobX](https://juejin.im/post/5e068fa551882512657bc16c)|校对|2|
+|[趣味学习 CSS 布局 —— 第一部分:弹性布局](https://juejin.im/post/5dafaca351882575446cd16e)|校对|1|
|[如何用 JavaScript 编写扫雷游戏](https://juejin.im/post/5d6276cd6fb9a06ade111bb4)|校对|3|
|[Web 组件的问题](https://juejin.im/post/5d42aec96fb9a06ae94d1146)|翻译|5|
|[使用 Cypress 进行 React 应用的端到端测试](https://juejin.im/post/5d3702dcf265da1b961345d1)|翻译|3.5|
@@ -9041,10 +9147,14 @@
|[微前端:未来前端开发的新趋势 — 第一部分](https://juejin.im/post/5d0e367b6fb9a07ebf4b781a)|校对|1|
|[JavaScript 线性代数:使用 ThreeJS 制作线性变换动画](https://juejin.im/post/5d05dba86fb9a07ece67ce76)|校对|1|
-## 译者:[TiaossuP](https://github.com/TiaossuP) 历史贡献积分:23 当前积分:23 二零一九:23
+## 译者:[TiaossuP](https://github.com/TiaossuP) 历史贡献积分:40 当前积分:40
|文章|类型|积分|
|------|-------|-------|
+|[如何将 SVG 图标用做 React 组件?](https://juejin.im/post/5df22bf7f265da33ea009225)|翻译|3|
+|[TypeScript 3.7 Beta 版发布](https://juejin.im/post/5db2537d6fb9a0208b11f94f)|校对|3.5|
+|[写给大家的代数效应入门](https://juejin.im/post/5dafe28b5188252e734f5376)|翻译|7.5|
+|[如何使用 Mountebank 和 Node.js 来 Mock 服务](https://juejin.im/post/5dad5a6951882509674032cd)|校对|3|
|[postMessage 很慢吗?](https://juejin.im/post/5d423cc4f265da03bf0f2159)|校对|4|
|[CSS 开发必知必会的 16 个调试工具技巧](https://juejin.im/post/5d39d27cf265da1bc14b6f47)|校对|1.5|
|[从 Reddit 讨论中看到的 GraphQL 现状](https://juejin.im/post/5d380909e51d4510624f98a0)|翻译|5.5|
@@ -9053,17 +9163,18 @@
|[在 npm 上启用现在 JavaScript](https://juejin.im/post/5d15d64be51d4510a5033603)|校对|2|
|[理解 React 中的高阶组件](https://juejin.im/post/5d1037966fb9a07ee4636de3)|校对|1|
-## 译者:[Jenniferyingni](https://github.com/Jenniferyingni) 历史贡献积分:1 当前积分:11 二零一九:11
+## 译者:[Jenniferyingni](https://github.com/Jenniferyingni) 历史贡献积分:11 当前积分:11
|文章|类型|积分|
|------|-------|-------|
|[Web 流式文字排版的现状](https://juejin.im/post/5d267d9de51d45773d4686ab)|翻译|7|
|[微前端:未来前端开发的新趋势 — 第一部分](https://juejin.im/post/5d0e367b6fb9a07ebf4b781a)|翻译|4|
-## 译者:[MarchYuanx](https://github.com/MarchYuanx) 历史贡献积分:33.5 当前积分:33.5 二零一九:33.5
+## 译者:[MarchYuanx](https://github.com/MarchYuanx) 历史贡献积分:35.5 当前积分:35.5
|文章|类型|积分|
|------|-------|-------|
+|[趣味学习 CSS 布局 —— 第一部分:弹性布局](https://juejin.im/post/5dafaca351882575446cd16e)|翻译|2|
|[React 16 生命周期函数:如何以及何时使用它们](https://juejin.im/post/5d6dfefef265da0391353196)|翻译|6|
|[Docker 的学习和应用](https://juejin.im/post/5d650a36f265da03c34c0bb4)|校对|1.5|
|[愿未来没有 Webpack](https://juejin.im/post/5d4bcdb7e51d453b386a62c6)|校对|2|
@@ -9077,10 +9188,11 @@
|[设计师如何成长为 Leader?](https://juejin.im/post/5d172fca6fb9a07eda032c6f)|校对|2|
|[在 npm 上启用现在 JavaScript](https://juejin.im/post/5d15d64be51d4510a5033603)|校对|1.5|
-## 译者:[mymmon](https://github.com/mymmon) 历史贡献积分:15 当前积分:15 二零一九:15
+## 译者:[mymmon](https://github.com/mymmon) 历史贡献积分:18 当前积分:18 二零二零:3
|文章|类型|积分|
|------|-------|-------|
+|[数学编程 —— 一个为推进数据科学发展而培养的关键习惯](https://zhuanlan.zhihu.com/p/100212596)|校对|3|
|[数据科学家需要掌握的十种统计技术](https://juejin.im/post/5d42340d6fb9a06ae61a95f5)|校对|4.5|
|[设计任何图表的六项原则](https://juejin.im/post/5d27fca7f265da1b5e731f92)|校对|2|
|[利用 84 种认知偏见设计更好的产品 —— 第一部分](https://juejin.im/post/5d2acf995188254c1915bd12)|校对|1.5|
@@ -9088,19 +9200,19 @@
|[Web 流式文字排版的现状](https://juejin.im/post/5d267d9de51d45773d4686ab)|校对|4|
|[npm 的经济风云 —— 上半部分](https://juejin.im/post/5d146225e51d4556db694a4b)|校对|2|
-## 译者:[krircc](https://github.com/krircc) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[krircc](https://github.com/krircc) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|推荐英文文章一篇|奖励|1|
-## 译者:[Yixian15](https://github.com/Yixian15) 历史贡献积分:3 当前积分:3 二零一九:3
+## 译者:[Yixian15](https://github.com/Yixian15) 历史贡献积分:3 当前积分:3
|文章|类型|积分|
|------|-------|-------|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|3|
-## 译者:[solerji](https://github.com/solerji) 历史贡献积分:15 当前积分:15 二零一九:15
+## 译者:[solerji](https://github.com/solerji) 历史贡献积分:15 当前积分:15
|文章|类型|积分|
|------|-------|-------|
@@ -9111,44 +9223,45 @@
|[微前端:未来前端开发的新趋势 — 第四部分](https://juejin.im/post/5d23394ae51d45778f076db0)|校对|1.5|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|2|
-## 译者:[Amabel](https://github.com/Amabel) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[Amabel](https://github.com/Amabel) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|1|
-## 译者:[lycheeEng](https://github.com/lycheeEng) 历史贡献积分:13 当前积分:13 二零一九:13
+## 译者:[lycheeEng](https://github.com/lycheeEng) 历史贡献积分:13 当前积分:13
|文章|类型|积分|
|------|-------|-------|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|13|
-## 译者:[MartinsYong](https://github.com/MartinsYong) 历史贡献积分:20 当前积分:20 二零一九:20
+## 译者:[MartinsYong](https://github.com/MartinsYong) 历史贡献积分:20 当前积分:20
|文章|类型|积分|
|------|-------|-------|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|20|
-## 译者:[scarqin](https://github.com/scarqin) 历史贡献积分:3 当前积分:3 二零一九:3
+## 译者:[scarqin](https://github.com/scarqin) 历史贡献积分:5.5 当前积分:5.5
|文章|类型|积分|
|------|-------|-------|
+|[如何计划你的一天 —— 这里有一份攻略请查收](https://juejin.im/post/5db16664f265da4d4c201997)|校对|2.5|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|3|
-## 译者:[savokiss](https://github.com/savokiss) 历史贡献积分:5 当前积分:5 二零一九:5
+## 译者:[savokiss](https://github.com/savokiss) 历史贡献积分:5 当前积分:5
|文章|类型|积分|
|------|-------|-------|
|[The JavaScript Tutorial 教程](https://github.com/javascript-tutorial/zh.javascript.info)|翻译校对|5|
-## 译者:[JasonWu1111](https://github.com/JasonWu1111) 历史贡献积分:4.5 当前积分:4.5 二零一九:4.5
+## 译者:[JasonWu1111](https://github.com/JasonWu1111) 历史贡献积分:4.5 当前积分:4.5
|文章|类型|积分|
|------|-------|-------|
|[Kotlin Clean 架构](https://juejin.im/post/5d33e13be51d4555fd20a41b)|翻译|3|
|[Xcode 和 LLDB 高级调试教程:第 2 部分](https://juejin.im/post/5d2321eee51d454f71439d64)|校对|1.5|
-## 译者:[shinichi4849](https://github.com/shinichi4849) 历史贡献积分:8.5 当前积分:8.5 二零一九:8.5
+## 译者:[shinichi4849](https://github.com/shinichi4849) 历史贡献积分:8.5 当前积分:8.5
|文章|类型|积分|
|------|-------|-------|
@@ -9157,7 +9270,7 @@
|[设计任何图表的六项原则](https://juejin.im/post/5d27fca7f265da1b5e731f92)|校对|1|
|[利用 84 种认知偏见设计更好的产品 —— 第一部分](https://juejin.im/post/5d2acf995188254c1915bd12)|校对|2.5|
-## 译者:[40m41h42t](https://github.com/40m41h42t) 历史贡献积分:5.5 当前积分:5.5 二零一九:5.5
+## 译者:[40m41h42t](https://github.com/40m41h42t) 历史贡献积分:5.5 当前积分:5.5
|文章|类型|积分|
|------|-------|-------|
@@ -9165,21 +9278,22 @@
|[喷泉码和动态二维码](https://juejin.im/post/5d391ae1f265da1bb0040352)|校对|1.5|
|[Go 语言概览](https://juejin.im/post/5d386166e51d454fd8057c6a)|校对|2|
-## 译者:[JaneLdq](https://github.com/JaneLdq) 历史贡献积分:4 当前积分:4 二零一九:4
+## 译者:[JaneLdq](https://github.com/JaneLdq) 历史贡献积分:4 当前积分:4
|文章|类型|积分|
|------|-------|-------|
|[数据分片是如何在分布式 SQL 数据库中起作用的](https://juejin.im/post/5d42867a6fb9a06ac76d915d)|校对|2.5|
|[使用 Node.js 读取超大的文件(第一部分)](https://juejin.im/post/5d3c27ccf265da1b8d1665ba)|校对|1.5|
-## 译者:[yangxy81118](https://github.com/yangxy81118) 历史贡献积分:2.5 当前积分:2.5 二零一九:2.5
+## 译者:[yangxy81118](https://github.com/yangxy81118) 历史贡献积分:4 当前积分:4
|文章|类型|积分|
|------|-------|-------|
+|[开源难题:如何保持长久](https://juejin.im/post/5db27be36fb9a02040687055)|校对|1.5|
|[Kotlin Clean 架构](https://juejin.im/post/5d33e13be51d4555fd20a41b)|校对|1|
|[从 Reddit 讨论中看到的 GraphQL 现状](https://juejin.im/post/5d380909e51d4510624f98a0)|校对|1.5|
-## 译者:[Ultrasteve](https://github.com/Ultrasteve) 历史贡献积分:36.5 当前积分:36.5 二零一九:36.5
+## 译者:[Ultrasteve](https://github.com/Ultrasteve) 历史贡献积分:36.5 当前积分:36.5
|文章|类型|积分|
|------|-------|-------|
@@ -9195,49 +9309,69 @@
|[作为初级开发人员,我没有学过的 7 个绝对真理](https://juejin.im/post/5d3d25dce51d457756536881)|校对|2|
|[喷泉码和动态二维码](https://juejin.im/post/5d391ae1f265da1bb0040352)|校对|1.5|
-## 译者:[Pingren](https://github.com/Pingren) 历史贡献积分:22.5 当前积分:22.5 二零一九:22.5
+## 译者:[Pingren](https://github.com/Pingren) 历史贡献积分:45 当前积分:45 二零二零:5
|文章|类型|积分|
|------|-------|-------|
+|[JavaScript 简史](https://juejin.im/post/5e158fe6e51d4541082c8143)|翻译|3|
+|2020 年 1 月推荐文章 2 篇|奖励|2|
+|2019 年 9 月推荐文章 1 篇|奖励|1|
+|[我个人的 Git 技巧备忘录](https://juejin.im/post/5e006ad4e51d45582248e63f)|翻译|4.5|
+|[如何使用 Mountebank 和 Node.js 来 Mock 服务](https://juejin.im/post/5dad5a6951882509674032cd)|翻译|12|
|[可靠地运维一个大型分布式系统:我的学习实践](https://juejin.im/post/5d567cd4e51d4561e224a324)|翻译|12|
|[响应式设计的基本原则](https://juejin.im/post/5d2ed18af265da1ba56b5374)|翻译|4|
|[Web 端的 SwiftUI:SwiftWebUI](https://juejin.im/post/5d35e0ac5188257dc103e364)|校对|2.5|
|[仅使用 HTML 和 CSS 创建多级嵌套弹出式导航菜单](https://juejin.im/post/5d3c2852f265da1bac405fae)|校对|4|
-## 译者:[redagavin](https://github.com/redagavin) 历史贡献积分:1.5 当前积分:1.5 二零一九:1.5
+## 译者:[redagavin](https://github.com/redagavin) 历史贡献积分:3.5 当前积分:3.5 二零二零:2
|文章|类型|积分|
|------|-------|-------|
+|[5 个简单步骤为您的网站创建 Sitemap](https://juejin.im/post/5e22fc43f265da3e254c7555)|校对|2|
|[敏捷也许是个问题](https://juejin.im/post/5d2dfb4ae51d45775f516b1e)|校对|1.5|
-## 译者:[LanceZhu](https://github.com/LanceZhu) 历史贡献积分:2 当前积分:2 二零一九:2
+## 译者:[LanceZhu](https://github.com/LanceZhu) 历史贡献积分:3 当前积分:3 二零二零:1
|文章|类型|积分|
|------|-------|-------|
+|2020 年 2 月推荐文章 1 篇|奖励|1|
|[npm 的经济风云 —— 下半部分](https://juejin.im/post/5d2d9e7af265da1b8b2b91ca)|校对|2|
-## 译者:[imononoke](https://github.com/imononoke) 历史贡献积分:1.5 当前积分:1.5 二零一九:1.5
+## 译者:[imononoke](https://github.com/imononoke) 历史贡献积分:6 当前积分:6
|文章|类型|积分|
|------|-------|-------|
+|[设置 git 别名](https://juejin.im/post/5dafc502f265da5b783f1ae1)|校对|1.5|
+|[如何使用 Mountebank 和 Node.js 来 Mock 服务](https://juejin.im/post/5dad5a6951882509674032cd)|校对|3|
|[通过阅读源码提高您的 JavaScript 水平](https://juejin.im/post/5d3c56c26fb9a07efd475414)|校对|1.5|
-## 译者:[Fxymine4ever](https://github.com/Fxymine4ever) 历史贡献积分:0 当前积分:0 二零一九:0
+## 译者:[Fxymine4ever](https://github.com/Fxymine4ever) 历史贡献积分:0 当前积分:0
|文章|类型|积分|
|------|-------|-------|
-|积分待更新|||
-## [GoToBoy](https://github.com/GoToBoy) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[GoToBoy](https://github.com/GoToBoy) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|推荐前端文章[A Future Without Webpack](https://github.com/xitu/gold-miner/issues/6246)|奖励|1|
-## 译者:[todaycoder001](https://github.com/todaycoder001) 历史贡献积分:13 当前积分:13 二零一九:13
+## 译者:[todaycoder001](https://github.com/todaycoder001) 历史贡献积分:63 当前积分:63 二零二零:21
|文章|类型|积分|
|------|-------|-------|
+|20 年 3 月推荐文章 2 篇|奖励|2|
+|[2020 年要学习的 7 种编程语言和框架](https://juejin.im/post/5e663cec518825496e786051)|翻译|7.5|
+|[SQL 将死于 No-SQL 之手?](https://juejin.im/post/5e5517bff265da576b566551)|校对|1.5|
+|[算法不是产品](https://juejin.im/post/5e398e806fb9a07cb52bb462)|校对|1.5|
+|[C++ 中清晰明了的状态机代码](https://juejin.im/post/5e0ad822e51d45414f5c7fc1)|校对|2.5|
+|[现在就该学习的 7 门现代编程语言](https://juejin.im/post/5e1e00fee51d4577794c04f8)|校对|6|
+|2019 年 9 至 12 月推荐文章 5 篇|奖励|5|
+|[如何提升你的数据结构、算法以及解决问题的能力](https://juejin.im/post/5d80fdcbf265da03e83ba163)|翻译|4|
+|[PHP 7.4 有什么新功能?你必须掌握的 10 大特性](https://juejin.im/post/5dfa04316fb9a0160770a501)|翻译|4.5|
+|[如何确定团队工作的优先级](https://juejin.im/post/5de4fc675188252edd0e2828)|翻译|4|
+|[如何用 Keras 从头搭建一维生成对抗网络](https://juejin.im/post/5dcf5aba6fb9a0203161f376)|校对|7|
+|[如何计划你的一天 —— 这里有一份攻略请查收](https://juejin.im/post/5db16664f265da4d4c201997)|翻译|4.5|
|[为什么你要学习 Go?](https://juejin.im/post/5d6ce211f265da03cd0a99be)|翻译|7|
|[通过 Rust 学习解析器组合器 — 第四部分](https://juejin.im/post/5d629f75e51d456210163bc0)|校对|2|
|2019 年 9 月推荐[后端文章](https://github.com/xitu/gold-miner/issues/6367)|奖励|1|
@@ -9245,39 +9379,41 @@
|推荐[后端文章](https://github.com/xitu/gold-miner/issues/6331)|奖励|1|
|推荐[后端文章](https://github.com/xitu/gold-miner/issues/6367)|奖励|1|
-## 译者:[hu7may](https://github.com/hu7may) 历史贡献积分:10 当前积分:10 二零一九:10
+## 译者:[hu7may](https://github.com/hu7may) 历史贡献积分:10 当前积分:10
|文章|类型|积分|
|------|-------|-------|
|[深入理解 Python 类型提示](https://juejin.im/post/5d64905fe51d4561fd6cb50f)|翻译|7|
|[数据科学家需要掌握的十种统计技术](https://juejin.im/post/5d42340d6fb9a06ae61a95f5)|校对|3|
-
-## 译者:[Fxy4ever](https://github.com/Fxy4ever) 历史贡献积分:3 当前积分:3 二零一九:3
+## 译者:[Fxy4ever](https://github.com/Fxy4ever) 历史贡献积分:7.5 当前积分:7.5
|文章|类型|积分|
|------|-------|-------|
+|[在你的 Instant 体验中使用 showInstallPrompt 的 5 个技巧](https://juejin.im/post/5dac5bc86fb9a04e1b57fa33)|翻译|4.5|
|[Android 应用程序的订阅 101 系列视频](https://juejin.im/post/5d490c9ae51d4561e224a2cb)|翻译|3|
-## 译者:[IT-rosalyn](https://github.com/IT-rosalyn) 历史贡献积分:6 当前积分:6 二零一九:6
+## 译者:[IT-rosalyn](https://github.com/IT-rosalyn) 历史贡献积分:6 当前积分:6
|文章|类型|积分|
|------|-------|-------|
|[Python 的打包现状(写于 2019 年)](https://juejin.im/post/5d72104851882572ed0004d2)|校对|3|
|[利用 84 种认知偏见设计更好的产品 —— 第三部分](https://juejin.im/post/5d568c9ce51d453bc64801cd)|校对|3|
-
-## 译者:[LeonJankos](https://github.com/LeonJankos) 历史贡献积分:3 当前积分:3 二零一九:3
+## 译者:[LeonJankos](https://github.com/LeonJankos) 历史贡献积分:3 当前积分:3
|文章|类型|积分|
|------|-------|-------|
|[当每个产品设计都是一种意见](https://juejin.im/post/5d5a77676fb9a06b1417e4b3)|校对|3|
-
-## 译者:[TokenJan](https://github.com/TokenJan) 历史贡献积分:13 当前积分:13 二零一九:13
+## 译者:[TokenJan](https://github.com/TokenJan) 历史贡献积分:37.5 当前积分:37.5 二零二零:3
|文章|类型|积分|
|------|-------|-------|
+|[数学编程 —— 一个为推进数据科学发展而培养的关键习惯](https://zhuanlan.zhihu.com/p/100212596)|校对|3|
+|[开发模式的工作原理是什么?](https://juejin.im/post/5d5e6964f265da0391351c59)|校对|3|
+|[动态规划算法的实际应用:接缝裁剪](https://juejin.im/post/5de8b483f265da33d039c618)|校对|3.5|
+|[如何用 Keras 从头搭建一维生成对抗网络](https://juejin.im/post/5dcf5aba6fb9a0203161f376)|翻译|15|
|[为什么你要学习 Go?](https://juejin.im/post/5d6ce211f265da03cd0a99be)|校对|2|
|[冲冠一怒为代码:论程序员与负能量](https://juejin.im/post/5d67540df265da039d32e0cc)|校对|2|
|[Python 的打包现状(写于 2019 年)](https://juejin.im/post/5d72104851882572ed0004d2)|校对|3|
@@ -9286,39 +9422,243 @@
|[HTTP Security Headers 完整指南](https://juejin.im/post/5d648e766fb9a06b122f4ab4)|校对|1.5|
|[我用 Javascript 实现 tic tac toe 游戏](https://juejin.im/post/5d627dc36fb9a06af05cbfdc)|校对|2|
-
-## 译者:[githubmnume](https://github.com/githubmnume) 历史贡献积分:5 当前积分:5 二零一九:5
+## 译者:[githubmnume](https://github.com/githubmnume) 历史贡献积分:5 当前积分:5
|文章|类型|积分|
|------|-------|-------|
|[如何用 JavaScript 编写扫雷游戏](https://juejin.im/post/5d6276cd6fb9a06ade111bb4)|校对|3|
|[重建桌面端的 Slack 而不是重写](https://juejin.im/post/5d624db86fb9a06b2650a262)|校对|2|
-
-## 译者:[hanxiaosss](https://github.com/hanxiaosss) 历史贡献积分:2.5 当前积分:2.5 二零一九:2.5
+## 译者:[hanxiaosss](https://github.com/hanxiaosss) 历史贡献积分:5.5 当前积分:5.5
|文章|类型|积分|
|------|-------|-------|
+|[开发模式的工作原理是什么?](https://juejin.im/post/5d5e6964f265da0391351c59)|校对|3|
|[React 16 生命周期函数:如何以及何时使用它们](https://juejin.im/post/5d6dfefef265da0391353196)|校对|1|
|[HTTP Security Headers 完整指南](https://juejin.im/post/5d648e766fb9a06b122f4ab4)|校对|1.5|
-
-## 译者:[Zelda256](https://github.com/Zelda256) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[Zelda256](https://github.com/Zelda256) 历史贡献积分:1 当前积分:1
|文章|类型|积分|
|------|-------|-------|
|[React 16 生命周期函数:如何以及何时使用它们](https://juejin.im/post/5d6dfefef265da0391353196)|校对|1|
-
-## 译者:[sin7777](https://github.com/sin7777) 历史贡献积分:2 当前积分:2 二零一九:2
+## 译者:[sin7777](https://github.com/sin7777) 历史贡献积分:3 当前积分:3
|文章|类型|积分|
|------|-------|-------|
+|[现代脚本加载](https://juejin.im/post/5dafdcd45188256b030ad8cf)|校对|1|
|[如何编写全栈 JavaScript 应用](https://juejin.im/post/5d8ae3a56fb9a04e2902fbf6)|校对|2|
+## 译者:[sleepingxixi](https://github.com/sleepingxixi) 历史贡献积分:3 当前积分:3
+
+|文章|类型|积分|
+|------|-------|-------|
+|[趣味学习 CSS 布局 —— 第二部分:网格布局](https://juejin.im/post/5dafc45a51882555a8431266)|校对|1|
+|[趣味学习 CSS 布局 —— 第一部分:弹性布局](https://juejin.im/post/5dafaca351882575446cd16e)|校对|1|
+|[CSS 小妙招:CSS 变量 —— 如何轻松创建一个🌞白色/🌑暗色主题](https://juejin.im/post/5da6c370e51d4524a0060385)|校对|1|
+
+## 译者:[ArcherGrey](https://github.com/ArcherGrey) 历史贡献积分:6 当前积分:6
+
+|文章|类型|积分|
+|------|-------|-------|
+|[类型及其在参数中的应用:能优化代码的的 Dart 特性](https://juejin.im/post/5dea0a4551882512252db2d7)|校对|1|
+|[TypeScript 3.7 Beta 版发布](https://juejin.im/post/5db2537d6fb9a0208b11f94f)|校对|3|
+|[如何设计一款讨人喜欢的暗色主题](https://juejin.im/post/5dad4ef1f265da5bb86ad294)|校对|2|
+
+## 译者:[HytonightYX](https://github.com/HytonightYX) 历史贡献积分:3.5 当前积分:3.5
+
+|文章|类型|积分|
+|------|-------|-------|
+|2019 年 11 月推荐文章 1 篇|奖励|1|
+|[如何设计一款讨人喜欢的暗色主题](https://juejin.im/post/5dad4ef1f265da5bb86ad294)|校对|2.5|
+
+## 译者:[w2ly](https://github.com/w2ly) 历史贡献积分:5.5 当前积分:5.5
+
+|文章|类型|积分|
+|------|-------|-------|
+|[现代脚本加载](https://juejin.im/post/5dafdcd45188256b030ad8cf)|翻译|5.5|
+
+## 译者:[quzhen12](https://github.com/quzhen12) 历史贡献积分:4.5 当前积分:4.5
+
+|文章|类型|积分|
+|------|-------|-------|
+|[为什么自己动手写代码能让你成为更好的开发者](https://juejin.im/post/5de88ed16fb9a016470c151a)|翻译|3.5|
+|[使用 `import()` 执行 JavaScript 代码](https://juejin.im/post/5dafc573e51d4524bb096393)|校对|1|
+
+## 译者:[weisiwu](https://github.com/weisiwu) 历史贡献积分:4 当前积分:4
+
+|文章|类型|积分|
+|------|-------|-------|
+|[JavaScript 的发布者/订阅者(Publisher/Subscriber)模式](https://juejin.im/post/5dbff49ff265da4d3761dd27)|校对|1.5|
+|[设置 git 别名](https://juejin.im/post/5dafc502f265da5b783f1ae1)|校对|1.5|
+|[使用 `import()` 执行 JavaScript 代码](https://juejin.im/post/5dafc573e51d4524bb096393)|校对|1|
+
+## 译者:[Alfxjx](https://github.com/Alfxjx) 历史贡献积分:11 当前积分:11 二零二零:3
+
+|文章|类型|积分|
+|------|-------|-------|
+|[在 Vue 中编写 SVG 图标组件](https://juejin.im/post/5e4fc62de51d4527110a85dd)|校对|2|
+|[使用 Web Workers 优化事件监听器](https://juejin.im/post/5e241bb9f265da3e46090215)|校对|1|
+|[设计离线优先的网络应用](https://juejin.im/post/5dd608eef265da47f12cb018)|校对|2.5|
+|[JavaScript 的发布者/订阅者(Publisher/Subscriber)模式](https://juejin.im/post/5dbff49ff265da4d3761dd27)|校对|1.5|
+|[Node.js 新特性将颠覆 AI、物联网等更多惊人领域](https://juejin.im/post/5dbb8d70f265da4d12067a3e)|校对|3|
+|[趣味学习 CSS 布局 —— 第二部分:网格布局](https://juejin.im/post/5dafc45a51882555a8431266)|校对|1|
+
+## 译者:[sunbufu](https://github.com/sunbufu) 历史贡献积分:4 当前积分:4
+
+|文章|类型|积分|
+|------|-------|-------|
+|[如何确定团队工作的优先级](https://juejin.im/post/5de4fc675188252edd0e2828)|校对|1.5|
+|[如何计划你的一天 —— 这里有一份攻略请查收](https://juejin.im/post/5db16664f265da4d4c201997)|校对|2.5|
+
+## 译者:[chechebecomestrong](https://github.com/chechebecomestrong) 历史贡献积分:2 当前积分:2
+
+|文章|类型|积分|
+|------|-------|-------|
+|[关于现代应用样式的探讨](https://juejin.im/post/5db93b67f265da4d417648a1)|校对|2|
+
+## 译者:[vitoxli](https://github.com/vitoxli) 历史贡献积分:31.5 当前积分:31.5 二零二零:18
+
+|文章|类型|积分|
+|------|-------|-------|
+|[使用 Nuxt (Vue.js)、Strapi 和 Apollo 构建博客](https://juejin.im/post/5e2a59ba6fb9a030026e8375)|翻译|7|
+|[如何写出优雅且有意义的 README.md](https://juejin.im/post/5e3a7363e51d452701795512)|校对|2|
+|[使用 Web Workers 优化事件监听器](https://juejin.im/post/5e241bb9f265da3e46090215)|翻译|2|
+|[如何用 Nest.js、MongoDB 和 Vue.js 搭建一个博客](https://juejin.im/post/5e1820a951882526334a1d1f)|校对|6|
+|2020 年 1 月推荐后端文章 1 篇|奖励|1|
+|[使用 JavaScript 编写 JSON 解析器](https://juejin.im/post/5e098728f265da33cd03c6c7)|校对|3.5|
+|2019 年 11 月 12 月推荐文章 2 篇|奖励|2|
+|[使用 Redux Offline 和 Apollo 进行离线 GraphQL 查询](https://juejin.im/post/5e00a06f6fb9a0161a0c3d78)|翻译|4|
+|[如何将 SVG 图标用做 React 组件?](https://juejin.im/post/5df22bf7f265da33ea009225)|校对|1.5|
+|[让字母“i”的点动起来的秘密](https://juejin.im/post/5dd7fe84e51d4523564243d5)|翻译|2.5|
+
+## 译者:[lzfcc](https://github.com/lzfcc) 历史贡献积分:1 当前积分:1
+
+|文章|类型|积分|
+|------|-------|-------|
+|[让字母“i”的点动起来的秘密](https://juejin.im/post/5dd7fe84e51d4523564243d5)|校对|1|
+
+## 译者:[jiapengwen](https://github.com/jiapengwen) 历史贡献积分:1.5 当前积分:1.5
+
+|文章|类型|积分|
+|------|-------|-------|
+|[为什么自己动手写代码能让你成为更好的开发者](https://juejin.im/post/5de88ed16fb9a016470c151a)|校对|1.5|
+
+## 译者:[PingHGao](https://github.com/PingHGao) 历史贡献积分:25 当前积分:25 二零二零:20
+
+|文章|类型|积分|
+|------|-------|-------|
+|[一份数据科学 A/B 测试的简单指南](https://juejin.im/post/5e61b88cf265da57602c5b95)|校对|2.5|
+|[用 6 分钟学习如何用 Redis 缓存您的 NodeJS 应用!](https://juejin.im/post/5e4df6d7518825496452ac98)|校对|2.5|
+|[图标万花筒](https://juejin.im/post/5e0ac4756fb9a048526aa26b)|校对|1|
+|[使用 Python 进行边缘检测](https://juejin.im/post/5e3d4b53e51d4526c26fadd4)|校对|1.5|
+|[C++ 中清晰明了的状态机代码](https://juejin.im/post/5e0ad822e51d45414f5c7fc1)|校对|2.5|
+|[JavaScript 简史](https://juejin.im/post/5e158fe6e51d4541082c8143)|校对|1.5|
+|[论资历的级别](https://juejin.im/post/5e1549736fb9a0483c632bf8)|校对|2|
+|[如何为求职准备你的 GitHub](https://juejin.im/post/5e1310a8f265da5d7275de8e)|校对|3|
+|[为何 Svelte 杀不死 React](https://juejin.im/post/5e12aa81e51d4541162c9a3a)|校对|3.5|
+|[理解递归、尾调用优化和蹦床函数优化](https://juejin.im/post/5e003a67e51d45583f44d396)|校对|5|
+
+## 译者:[zh1an](https://github.com/zh1an) 历史贡献积分:11 当前积分:11 二零二零:8
+
+|文章|类型|积分|
+|------|-------|-------|
+|[图标万花筒](https://juejin.im/post/5e0ac4756fb9a048526aa26b)|校对|1|
+|[再见,整洁的代码](https://juejin.im/post/5e2411e0f265da3e4244e683)|翻译|3|
+|[C++ 中清晰明了的状态机代码](https://juejin.im/post/5e0ad822e51d45414f5c7fc1)|翻译|4|
+|2019 年 11 月推荐文章 1 篇|奖励|1|
+|[我个人的 Git 技巧备忘录](https://juejin.im/post/5e006ad4e51d45582248e63f)|校对|2|
+
+## 译者:[xurui1995](https://github.com/xurui1995) 历史贡献积分:1.5 当前积分:1.5
+
+|文章|类型|积分|
+|------|-------|-------|
+|[如何提升你的数据结构、算法以及解决问题的能力](https://juejin.im/post/5d80fdcbf265da03e83ba163)|校对|1.5|
+
+## 译者:[zyfsuzy](https://github.com/zyfsuzy) 历史贡献积分:1 当前积分:1
+
+|文章|类型|积分|
+|------|-------|-------|
+|2019 年 12 月推荐文章 1 篇|奖励|1|
+
+## 译者:[Imsiaocong](https://github.com/Imsiaocong) 历史贡献积分:2 当前积分:2 二零二零:2
+
+|文章|类型|积分|
+|------|-------|-------|
+|[论资历的级别](https://juejin.im/post/5e1549736fb9a0483c632bf8)|校对|2|
+
+## 译者:[impactCn](https://github.com/impactCn) 历史贡献积分:4 当前积分:4 二零二零:4
+
+|文章|类型|积分|
+|------|-------|-------|
+|[现在就该学习的 7 门现代编程语言](https://juejin.im/post/5e1e00fee51d4577794c04f8)|校对|4|
+
+## 译者:[febrainqu](https://github.com/febrainqu) 历史贡献积分:4 当前积分:4 二零二零:4
+
+|文章|类型|积分|
+|------|-------|-------|
+|[在什么时候你需要使用 Web Workers?](https://juejin.im/post/5e290aaee51d451c8836284f)|校对|1.5|
+|[使用 Web Workers 优化事件监听器](https://juejin.im/post/5e241bb9f265da3e46090215)|校对|1|
+|[再见,整洁的代码](https://juejin.im/post/5e2411e0f265da3e4244e683)|校对|1.5|
+
+## 译者:[ahabhgk](https://github.com/ahabhgk) 历史贡献积分:3 当前积分:3 二零二零:3
+
+|文章|类型|积分|
+|------|-------|-------|
+|[在什么时候你需要使用 Web Workers?](https://juejin.im/post/5e290aaee51d451c8836284f)|校对|1.5|
+|[再见,整洁的代码](https://juejin.im/post/5e2411e0f265da3e4244e683)|校对|1.5|
+
+## 译者:[Starry316](https://github.com/Starry316) 历史贡献积分:10 当前积分:10 二零二零:10
+
+|文章|类型|积分|
+|------|-------|-------|
+|[图像修复:人类和 AI 的对决](https://juejin.im/post/5e43b2edf265da576543a0bb)|翻译|6|
+|[如何选择合适的数据库](https://juejin.im/post/5e3c10e6518825494f7de8ff)|校对|2|
+|[如何写出优雅且有意义的 README.md](https://juejin.im/post/5e3a7363e51d452701795512)|校对|2|
+
+## 译者:[Shuyun6](https://github.com/Shuyun6) 历史贡献积分:1 当前积分:1 二零二零:1
+
+|文章|类型|积分|
+|------|-------|-------|
+|[算法不是产品](https://juejin.im/post/5e398e806fb9a07cb52bb462)|校对|1|
+
+## 译者:[RubyJy](https://github.com/RubyJy) 历史贡献积分:6 当前积分:6 二零二零:6
+
+|文章|类型|积分|
+|------|-------|-------|
+|[WebRTC 联手 Node.js:打造实时视频聊天应用](https://juejin.im/post/5e0ae59d5188253a5b3ccf74)|校对|4|
+|[如何选择合适的数据库](https://juejin.im/post/5e3c10e6518825494f7de8ff)|校对|2|
+
+## 译者:[Amberlin1970](https://github.com/Amberlin1970) 历史贡献积分:9.5 当前积分:9.5 二零二零:9.5
+
+|文章|类型|积分|
+|------|-------|-------|
+|[一份数据科学 A/B 测试的简单指南](https://juejin.im/post/5e61b88cf265da57602c5b95)|翻译|5|
+|[图像修复:人类和 AI 的对决](https://juejin.im/post/5e43b2edf265da576543a0bb)|校对|3|
+|[使用 Python 进行边缘检测](https://juejin.im/post/5e3d4b53e51d4526c26fadd4)|校对|1.5|
+
+## 译者:[Weirdochr](https://github.com/Weirdochr) 历史贡献积分:7 当前积分:7 二零二零:7
+
+|文章|类型|积分|
+|------|-------|-------|
+|[数学编程 —— 一个为推进数据科学发展而培养的关键习惯](https://zhuanlan.zhihu.com/p/100212596)|翻译|7|
+
+## 译者:[niayyy-S](https://github.com/niayyy-S) 历史贡献积分:6 当前积分:6 二零二零:6
+
+|文章|类型|积分|
+|------|-------|-------|
+|[2020 年要学习的 7 种编程语言和框架](https://juejin.im/post/5e663cec518825496e786051)|校对|3|
+|[关于 icon 设计的 7 大准则](https://juejin.im/post/5e5dbd3e6fb9a07cd323dd2b)|校对|3|
+
+## 译者:[Jiangzhiqi4551](https://github.com/Jiangzhiqi4551) 历史贡献积分:2.5 当前积分:2.5 二零二零:2.5
+
+|文章|类型|积分|
+|------|-------|-------|
+|[一份数据科学 A/B 测试的简单指南](https://juejin.im/post/5e61b88cf265da57602c5b95)|校对|2.5|
-## 译者:[sleepingxixi](https://github.com/sleepingxixi) 历史贡献积分:1 当前积分:1 二零一九:1
+## 译者:[GJXAIOU](https://github.com/GJXAIOU) 历史贡献积分:3 当前积分:3 二零二零:3
|文章|类型|积分|
|------|-------|-------|
-|[CSS 小妙招:CSS 变量 —— 如何轻松创建一个🌞白色/🌑暗色主题](https://juejin.im/post/5da6c370e51d4524a0060385)|校对|1|
\ No newline at end of file
+|[2020 年要学习的 7 种编程语言和框架](https://juejin.im/post/5e663cec518825496e786051)|校对|3|