forked from elecrabbit/front-end-interview
-
Notifications
You must be signed in to change notification settings - Fork 4
/
Copy pathmemory.md
191 lines (118 loc) · 10.3 KB
/
memory.md
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
# JavaScript内存管理
点击关注本[公众号](#公众号)获取文档最新更新,并可以领取配套于本指南的 **《前端面试手册》** 以及**最标准的简历模板**.
## 前言
像C语言这样的底层语言一般都有底层的内存管理接口,比如 malloc()和free()。另一方面,JavaScript创建变量(对象,字符串等)时分配内存,并且在不再使用它们时“自动”释放。 后一个过程称为垃圾回收。这个“自动”是混乱的根源,并让JavaScript(和其他高级语言)开发者感觉他们可以不关心内存管理,这是错误的。
> 本文主要参考了深入浅出nodejs中的内存章节
## 内存模型
平时我们使用的基本类型数据或者复杂类型数据都是如何存放的呢?
基本类型普遍被存放在『栈』中,而复杂类型是被存放在堆内存的。
> 如果你不了解执行栈和内存堆的概念,请先阅读[JavaScript执行机制](#mechanism.md)
当你读完上述文章后,你会问,既然复杂类型被存放在内存堆中,执行栈的函数是如何使用内存堆的复杂类型?
实际上,执行栈的函数上下文会保存一个内存堆对应复杂类型对象的内存地址,通过引用来使用复杂类型对象。
一个例子:
```js
function add() {
const a = 1
const b = {
num: 2
}
const sum = a + b.num
}
```
示意图如下(我们暂时不考虑函数本身的内存)
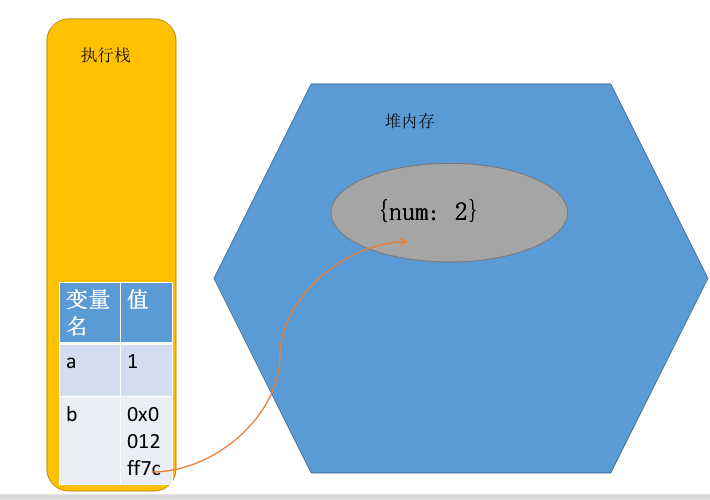
还有一个问题是否所有的基本类型都储存在栈中呢?
并不是,当一个基本类型被闭包引用之后,就可以长期存在于内存中,这个时候即使他是基本类型,也是会被存放在堆中的。
## 生命周期
不管什么程序语言,内存生命周期基本是一致的:
1. 分配你所需要的内存
2. 使用分配到的内存(读、写)
3. 不需要时将其释放\归还

所有语言第二部分都是明确的。第一和第三部分在底层语言中是明确的,但在像JavaScript这些高级语言中,大部分都是隐含的。
## 内存回收
V8的垃圾回收策略基于分代回收机制,该机制又基于**世代假说**,该假说有两个特点:
* 大部分新生对象倾向于早死
* 不死的对象,会活得更久
基于这个理论,现代垃圾回收算法根据对象的存活时间将内存进行了分代,并对不同分代的内存采用不同的高效算法进行垃圾回收
### V8的内存分代
在V8中,将内存分为了新生代(new space)和老生代(old space)。它们特点如下:
* 新生代:对象的存活时间较短。新生对象或只经过一次垃圾回收的对象。
* 老生代:对象存活时间较长。经历过一次或多次垃圾回收的对象。
### Stop The World (全停顿)
在介绍垃圾回收算法之前,我们先了解一下「全停顿」。
为避免应用逻辑与垃圾回收器看到的情况不一致,垃圾回收算法在执行时,需要停止应用逻辑。垃圾回收算法在执行前,需要将应用逻辑暂停,执行完垃圾回收后再执行应用逻辑,这种行为称为 「全停顿」(Stop The World)。例如,如果一次GC需要50ms,应用逻辑就会暂停50ms。
### Scavenge 算法
Scavenge 算法的缺点是,它的算法机制决定了只能利用一半的内存空间。但是新生代中的对象生存周期短、存活对象少,进行对象复制的成本不是很高,因而非常适合这种场景。
新生代中的对象主要通过 Scavenge 算法进行垃圾回收。Scavenge 的具体实现,主要采用了Cheney算法。

Cheney算法采用复制的方式进行垃圾回收。它将堆内存一分为二,每一部分空间称为 semispace。这两个空间,只有一个空间处于使用中,另一个则处于闲置。使用中的 semispace 称为 「From 空间」,闲置的 semispace 称为 「To 空间」。
过程如下:
* 从 From 空间分配对象,若 semispace 被分配满,则执行 Scavenge 算法进行垃圾回收。
* 检查 From 空间的存活对象,若对象存活,则检查对象是否符合晋升条件,若符合条件则晋升到老生代,否则将对象从 From 空间复制到 To 空间。
* 若对象不存活,则释放不存活对象的空间。
* 完成复制后,将 From 空间与 To 空间进行角色翻转(flip)。
### 对象晋升
1. 对象是否经历过Scavenge回收。对象从 From 空间复制 To 空间时,会检查对象的内存地址来判断对象是否已经经过一次Scavenge回收。若经历过,则将对象从 From 空间复制到老生代中;若没有经历,则复制到 To 空间。
2. To 空间的内存使用占比是否超过限制。当对象从From 空间复制到 To 空间时,若 To 空间使用超过 25%,则对象直接晋升到老生代中。设置为25%的比例的原因是,当完成 Scavenge 回收后,To 空间将翻转成From 空间,继续进行对象内存的分配。若占比过大,将影响后续内存分配。
对象晋升到老生代后,将接受新的垃圾回收算法处理。下图为Scavenge算法中,对象晋升流程图。

### Mark-Sweep & Mark-Compact
老生代中的对象有两个特点,第一是存活对象多,第二个存活时间长。若在老生代中使用 Scavenge 算法进行垃圾回收,将会导致复制存活对象的效率不高,且还会浪费一半的空间。因而,V8在老生代采用Mark-Sweep 和 Mark-Compact 算法进行垃圾回收。
Mark-Sweep,是标记清除的意思。它主要分为标记和清除两个阶段。
* 标记阶段,它将遍历堆中所有对象,并对存活的对象进行标记;
* 清除阶段,对未标记对象的空间进行回收。
与 Scavenge 算法不同,Mark-Sweep 不会对内存一分为二,因此不会浪费空间。但是,经历过一次 Mark-Sweep 之后,内存的空间将会变得不连续,这样会对后续内存分配造成问题。比如,当需要分配一个比较大的对象时,没有任何一个碎片内支持分配,这将提前触发一次垃圾回收,尽管这次垃圾回收是没有必要的。

为了解决内存碎片的问题,提高对内存的利用,引入了 Mark-Compact (标记整理)算法。Mark-Compact 是在 Mark-Sweep 算法上进行了改进,标记阶段与Mark-Sweep相同,但是对未标记的对象处理方式不同。与Mark-Sweep是对未标记的对象立即进行回收,Mark-Compact则是将存活的对象移动到一边,然后再清理端边界外的内存。

由于Mark-Compact需要移动对象,所以执行速度上,比Mark-Sweep要慢。所以,V8主要使用Mark-Sweep算法,然后在当空间内存分配不足时,采用Mark-Compact算法。
### Incremental Marking(增量标记)
在新生代中,由于存活对象少,垃圾回收效率高,全停顿时间短,造成的影响小。但是老生代中,存活对象多,垃圾回收时间长,全停顿造成的影响大。为了减少全停顿的时间,V8对标记进行了优化,将一次停顿进行的标记过程,分成了很多小步。每执行完一小步就让应用逻辑执行一会儿,这样交替多次后完成标记。如下图所示:

长时间的GC,会导致应用暂停和无响应,将会导致糟糕的用户体验。从2011年起,v8就将「全暂停」标记换成了增量标记。改进后的标记方式,最大停顿时间减少到原来的1/6。
### lazy sweeping(延迟清理)
* 发生在增量标记之后
* 堆确切地知道有多少空间能被释放
* 延迟清理是被允许的,因此页面的清理可以根据需要进行清理
* 当延迟清理完成后,增量标记将重新开始
## 内存泄露
### 引起内存泄漏的几个禁忌
* 滥用全局变量:直接用全局变量赋值,在函数中滥用this指向全局对象
* 不销毁定时器和回调
* DOM引用不规范,很多时候, 我们对 Dom 的操作, 会把 Dom 的引用保存在一个数组或者 Map 中,往往无法对其进行内存回收,ES6中引入 WeakSet 和 WeakMap 两个新的概念, 来解决引用造成的内存回收问题. WeakSet 和 WeakMap 对于值的引用可以忽略不计, 他们对于值的引用是弱引用,内存回收机制, 不会考虑这种引用. 当其他引用被消除后, 引用就会从内存中被释放.
* 滥用闭包:
```js
// 滥用闭包引起内存泄漏
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing) // 对于 'originalThing'的引用
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log("message");
}
};
};
setInterval(replaceThing, 1000);
```
### 查看内存泄漏
* 打开开发者工具,选择 Timeline 面板
* 在顶部的Capture字段里面勾选 Memory
* 点击左上角的录制按钮。
* 在页面上进行各种操作,模拟用户的使用情况。
* 一段时间后,点击对话框的 stop 按钮,面板上就会显示这段时间的内存占用情况。
---
参考:
[深入浅出Node.js](https://book.douban.com/subject/25768396/)
[MDN内存管理](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Memory_Management)
---
## 公众号
想要实时关注笔者最新的文章和最新的文档更新请关注公众号**程序员面试官**,后续的文章会优先在公众号更新.
**简历模板:** 关注公众号回复「模板」获取
**《前端面试手册》:** 配套于本指南的突击手册,关注公众号回复「fed」获取
