written by 문다빈
코틀린 리액티브 프로그래밍 저서를 읽고 작성하는 글입니다.
- 연산자는 피연산자에 대해 특정 작업을 수행하고 최종 결과를 반환하는 특수한 문자 혹은 문자열이다
- 리액티브에서도 정의는 동일함
- 연산자는 하나 이상의 Observable/Flowable을 피연산자로 사용해 변환하고 결과 Observable/Flowable을 반환함
- 연산자는 선행하는 Observable/Flowable에 대해 컨슈머처럼 작동함
- 배출되는 아이템을 기다리다가 변환한 다음 다운스트림 컨슈머에게 전달함
- map 연산자 → 업스트림 생산자를 대기하다가 배출된 아이템에 대한 일부 작업을 수행한 다음 수정된 항목을 다운스트림으로 배출함
- 연산자는 비즈니스 로직과 동작을 표현할 수 있도록 도와준다
- 애플리케이션에서 비즈니스 로직과 동작을 구현하려면 블로킹 코드를 작성하거나 명령형 프로그래밍과 리액티브 프로그래밍을 혼합하는 대신 연산자를 사용해야 한다
- 알고리즘과 프로세스를 순수하게 반응형으로 유지하면 낮은 메모리 사용, 유연한 동시성 및 일회성(disposability)들을 쉽게 얻을 수 있음
- 이런 장점은 리액티브 프로그래밍과 명령형 프로그래밍을 섞어서 사용할 경우 효과가 줄어들거나 사라지게 된다
- 필터링(filtering/suppressing) 연산자
- 변환(Transforming) 연산자
- 리듀스(Reducing) 연산자
- 집합(Collection) 연산자
- 오류 처리 연산자
- 유틸리티 연산자
- 프로듀서로부터 원하는 배출만 받고 나머지는 폐기하고자 하는 경우 → 적절한 배출을 결정하거나 대량으로 제거하기 위한 로직이 존재할 것 → 필터링(filtering/suppressing) 연산자
- 필터링 연산자 목록
- debounce
- distinct와 distinctUntilChanged
- elementAt
- Filter
- first와 last
- ignoreElements
- skip, skipLast, skipUntil, skipWhile
- take, takeLast, takeUntil, takeWhile
- 배출량이 급격히 증가하는 상황에서 충분히 시간이 지난 뒤에 마지막 항목을 가져오기를 원하는 상황 자주 발생
- 애플리케이션 UI/UX를 개발할 때 종종 그런 상황에 처하게 됨
- ex. 텍스트 입력을 생성하고 사용자가 무언가를 입력할 때 연산을 수행하려고 하지만 모든 키 눌림에 대해서 연산을 원하지 않는 경우
- 사용자가 실제로 원하는 키워드와 일치하는 쿼리를 얻을 수 있을 때까지 입력을 중단하기를 잠시 기다렸다가 다운스트림 연산자에게 전달함
- 디바운스(debounce) 연산자는 정확히 이런 목적을 위한 연산자
fun main(args: Array<String>) {
createObservable()//(1)
.debounce(200, TimeUnit.MILLISECONDS)//(2)
.subscribe {
println(it)//(3)
}
}
inline fun createObservable():Observable<String> = Observable.create<String> {
it.onNext("R")//(4)
runBlocking { delay(100) }//(5)
it.onNext("Re")
it.onNext("Reac")
runBlocking { delay(130) }
it.onNext("Reactiv")
runBlocking { delay(140) }
it.onNext("Reactive")
runBlocking { delay(250) }//(6)
it.onNext("Reactive P")
runBlocking { delay(130) }
it.onNext("Reactive Pro")
runBlocking { delay(100) }
it.onNext("Reactive Progra")
runBlocking { delay(100) }
it.onNext("Reactive Programming")
runBlocking { delay(300) }
it.onNext("Reactive Programming in")
runBlocking { delay(100) }
it.onNext("Reactive Programming in Ko")
runBlocking { delay(150) }
it.onNext("Reactive Programming in Kotlin")
runBlocking { delay(250) }
it.onComplete()
}- 위 예제는 Observable 작성을 다른 함수(createObservable())로 위임해서 사용자가 더 잘 이해할 수 있도록 메인 함수를 깨끗하게 유지
- createObservable() 함수에서는 간격을 두고 차례대로 문자열을 내보내 최종적으로 원하는 문자열에 도달하는 사용자 UI 동작을시뮬레이션
- 이상적인 사용자 행동을 흉내내 각 단어가 완성된 후에 더 큰 간격으로 대기
- debounce() 연산자는 200과 TimeUnit.MILLISECONDS를 매개변수로 사용해 각 배출 이후 200밀리초 동안 대기하고 있다가 각 간격에서 아무런 배출이 발생하지 않았을 때만 아이템을 배출하는 다운스트림을 생성함
- 옵저버블이 적어도 200밀리초 이상이 걸린 배출에 대해서만 옵저버가 배출을 받게 됨
- 업스트림에서 중복 배출을 필터링할 수 있도록 도와주는 연산자
fun main(args: Array<String>) {
listOf(1,2,2,3,4,5,5,5,6,7,8,9,3,10)//(1)
.toObservable()//(2)
.distinct()//(3)
.subscribe { println("Received $it") }//(4)
}- 많은 중복 값을 포함하는 Int의 목록을 생성 → toObservable() 메서드로 해당 리스트에서 옵저버블 인스턴스 생성
- distinct 연산자로 모든 중복 아이템을 걸러냄
- distinct 연산자는 뒤이어 발생하는 모든 배출을 기억하고 미래에 동일한 아이템을 걸러낸다
- distinctUntilChange 연산자는 모든 중복된 배출을 폐기하는 대신 연속적인 중복 배출만 폐기하고 나머지는 그대로 유지함
fun main(args: Array<String>) {
listOf(1,2,2,3,4,5,5,5,6,7,8,9,3,10)//(1)
.toObservable()//(2)
.distinctUntilChanged()//(3)
.subscribe { println("Received $it") }//(4)
}- 여기서 숫자 3은 두 번 인쇄됨
- distinct 연산자는 onComplete를 받을 때까지 각 아이템을 기억하고 있지만 distinctUntilChanged 연산자는 새로운 아이템을 받기 전까지의 아이템만을 기억
- 명령형 프로그래밍에는 모든 배열이나 목록의 n번째 요소에 액세스할 수 있는 기능이 있다
- elementAt 연산자는 프로듀서로부터 n번째 요소를 받아서 단독 배출로 내보낸다
fun main(args: Array<String>) {
val observable = listOf(10,1,2,5,8,6,9)
.toObservable()
observable.elementAt(5)//(1)
.subscribe { println("Received $it") }
observable.elementAt(50)//(2)
.subscribe { println("Received $it") }
}- Observable에 존재하지 않는 인덱스의 원소를 요청할 경우 아무것도 배출되지 않음
- 해당 연산자는 Maybe 모나드의 도움으로 이 동작을 수행
- filter 연산자를 통해 사용자 정의 로직으로 배출을 필터링할 수 있음
fun main(args: Array<String>) {
Observable.range(1,20)//(1)
.filter{//(2)
it%2==0
}
.subscribe {
println("Received $it")
}
}- Observable.range() 연산자의 도움으로 옵저버블 인스턴스를 생성
- filter 연산자를 사용해 배출에서 홀수를 필터링
- 이 연산자는 첫 번째 또는 마지막 배출만 유지하고 나머지는 폐기한다
fun main(args: Array<String>) {
val observable = Observable.range(1,10)
observable.first(2)//(1)
.subscribeBy { item -> println("Received $item") }
observable.last(2)//(2)
.subscribeBy { item -> println("Received $item") }
Observable.empty<Int>().first(2)//(3)
.subscribeBy { item -> println("Received $item") }
}- defaultValue 매개 변수가 2로 설정된 first 연산자를 사용
- 첫 번째 요소에 액세스할 수 없는 경우 defaultValue 매개변수를 배출한다
- 프로듀서의 onComplete에만 관심이 있을 경우 ignoreElements 연산자를 사용할 수 있다
fun main(args: Array<String>) {
val observable = Observable.range(1,10)
observable
.ignoreElements()
.subscribe { println("Completed") }//(1)
}- ignoreElements 연산자는 onComplete 이벤트만 존재하는 Completable 모나드를 반환한다
- 변환 연산자는 프로듀서가 배출한 아이템을 변형하도록 도와줌
- map
- flatMap, concatMap,flatMapIterable
- switchMap
- switchIfEmpty
- scan
- groupBy
- startWith
- defaultIfEmpty
- sorted
- buffer
- window
- cast
- delay
- repeat
- map 연산자는 배출된 각 아이템에 주어진 작업(람다)을 수행하고 이를 다운스트림으로 내보낸다
- Observable 또는 Flowable에 대해 map 연산자는 제공된 Function<T, R> 람다를 적용해 타입 T로 배출된 아이템을 타입 R의 배출로 변환
fun main(args: Array<String>) {
val list = listOf<MyItemInherit>(
MyItemInherit(1),
MyItemInherit(2),
MyItemInherit(3),
MyItemInherit(4),
MyItemInherit(5),
MyItemInherit(6),
MyItemInherit(7),
MyItemInherit(8),
MyItemInherit(9),
MyItemInherit(10)
)//(1)
list.toObservable()//(2)
.map { it as MyItem }//(3)
.subscribe {
println(it)
}
println("cast")
list.toObservable()
.cast(MyItem::class.java)//(4)
.subscribe {
println(it)
}
}
open class MyItem(val id:Int) {//(5)
override fun toString(): String {
return "[MyItem $id]"
}
}
class MyItemInherit(id:Int):MyItem(id) {//(6)
override fun toString(): String {
return "[MyItemInherit $id]"
}
}- 해당 코드에선 map 연산자를 사용해 캐스팅을 시도한 다음 cast 연산자를 사용해 동일한 작업을 수행한다
- 리스트를 옵저버블로 생성하고 map 연산자에 배출을 MyItemInherit으로 캐스팅하는 람다를 전달
- 코드의 단순함 측면에서 cast 연산자 쪽이 훨씬 깨끗하고 단순해 보임
- map 연산자는 각 배출을 가져와서 변환하지만 flatMap 연산자는 새로운 프로듀서를 만들고 원천 프로듀서에 전달한 함수를 각 배출에 적용한다
- 타입 형태의 옵저버블을 반환하는 게 특징이다
- 단일 배출에서 여러 아이템을 가져와야하는 경우 용이
- onComplete 알림을 보내기 전에 모든 항목을 배출함
- 모든 옵저버블이 함께 결합된 후 다운스트림으로 가입해서 그럼
- flatMap 연산자는 내부적으로 merge 연산자를 사용해 여러 옵저버블을 결합한다
- concatMap은 merge 연산자 대신 concat 연산자를 사용해 두 개의 Observable/Flowables를 결합하는 동일한 연산을 수행
- 연산자를 필터링하거나 복잡한 요구 사항을 다루는 동안 빈 프로듀서가 나타날 수 있다
fun main(args: Array<String>) {
Observable.range(0,10)//(1)
.filter{it>15}//(2)
.subscribe({
println("Received $it")
})
}- Observable을 0에서 10 사이의 수로 생성
- 배출을 15 이상으로 필터링 → 결과적으로 예제는 빈 옵저버블을 반환
fun main(args: Array<String>) {
Observable.range(0,10)//(1)
.filter{it>15}//(2)
.defaultIfEmpty(15)//(3)
.subscribe({
println("Received $it")
})
}- 필터링 후 비어 있는 옵저버블에 15를 더한다
- switchIfEmpty 연산자는 defaultIfEmpty 연산자와 유사
- defaultIfEmpty 연산자의 경우 빈 프로듀서에 배출을 추가하지만 switchIfEmpty 연산자는 원천 프로듀서가 비어 있을 경우 대체 프로듀서로부터 배출한다
- 아이템을 전달하는 defaultIfEmpty 연산자와 달리 switchIfEmpty 연산자는 대체 프로듀서를 전달해야 한다
- 원천 프로듀서가 비어 있으면 대체 프로듀서로부터 배출을 시작한다
fun main(args: Array<String>) {
Observable.range(0,10)//(1)
.filter{it>15}//(2)
.switchIfEmpty(Observable.range(11,10))//(3)
.subscribe({
println("Received $it")
})
}- defaultIfEmpty 대신 대체 Observable과 함께 switchIfEmpty 사용
- 다음 출력은 배출이 switchIfEmpty 연산자로 전달된 대체 Observable에서 취해짐
- 프로듀서의 기존 아이템의 맨 위에 다른 아이템을 추가함
fun main(args: Array<String>) {
Observable.range(0,10)//(1)
.startWith(-1)//(2)
.subscribe({
println("Received $it")
})
listOf("C","C++","Java","Kotlin","Scala","Groovy")//(3)
.toObservable()
.startWith("Programming Languages")//(4)
.subscribe({
println("Received $it")
})
}- startWith 연산자는 기존 배출 리스트에 접두사를 추가함
- 배출을 정렬하고 싶은 경우 sorted 연산자를 사용
- 정렬 연산자는 원천 프로듀서로부터 모든 배출을 내부적으로 수집한 후 정렬해서 다시 배출함
fun main(args: Array<String>) {
println("default with integer")
listOf(2,6,7,1,3,4,5,8,10,9)
.toObservable()
.sorted()//(1)
.subscribe { println("Received $it") }
println("default with String")
listOf("alpha","gamma","beta","theta")
.toObservable()
.sorted()//(2)
.subscribe { println("Received $it") }
println("custom sortFunction with integer")
listOf(2,6,7,1,3,4,5,8,10,9)
.toObservable()
.sorted { item1, item2 -> if(item1>item2) -1 else 1 }//(3)
.subscribe { println("Received $it") }
println("custom sortFunction with custom class-object")
listOf(MyItem1(2),MyItem1(6),
MyItem1(7),MyItem1(1),MyItem1(3),
MyItem1(4),MyItem1(5),MyItem1(8),
MyItem1(10),MyItem1(9))
.toObservable()
.sorted { item1, item2 -> if(item1.item<item2.item) -1 else 1 }//(4)
.subscribe { println("Received $it") }
}
data class MyItem1(val item:Int)- sorted 연산자는 배출을 정렬하는 데 사용함
- 정렬하기 위해선 비교가 필요한데 sorted 연산자는 Comparable 인스턴스를 사용해 배출된 아이템을 비교하고 각각 정렬함
- 이 연산자에는 두 개의 오버로드가 있음
- 오버로드 한 개에는 매개 변수가 없는데 프로듀서 유형이 Comparable을 구현하고 compareTo 함수를 호출한다고 가정
- compareTo 호출이 실패하면 오류가 발생한다
- 나머지 오버로드는 비교를 위한 메서드(람다)을 입력받는다
- 기본 sorted 연산자를 사용
- 즉, 배출된 아이템 인스턴스에서 compareTo 함수를 호출하고 데이터 유형이 Comparable을 구현하지 않았다면 오류가 발생
- 위 코드의 경우 옵저버블 형식의 MyItem1을 사용했는데 Comparable을 구현하지 않으므로 sortFunction 람다를 인자로 전달
- sorted 연산자는 모든 배출을 수집한 다음 정렬된 순서로 배출하기 전에 정렬을 수행
- 따라서 이 연산자를 사용하면 성능에 심각한 영향을 줄 수 있다
- 또한 규모가 큰 프로듀서와 함께 사용하면 OutOfMemory(OOM) 오류가 발생할 수 있다
- 따라서 sorted 연산자를 신중하게 사용해야함
- 스캔(scan) 연산자는 롤링 애그리게이터(Aggregator)다
- 이전 배출에서 증분의 누적 아이템을 배출함
fun main(args: Array<String>) {
Observable.range(1,10)
.scan { previousAccumulation, newEmission -> previousAccumulation+newEmission }//(1)
.subscribe { println("Received $it") }
listOf("String 1","String 2", "String 3", "String 4")
.toObservable()
.scan{ previousAccumulation, newEmission -> previousAccumulation+" "+newEmission }//(2)
.subscribe { println("Received $it") }
Observable.range(1,5)
.scan { previousAccumulation, newEmission -> previousAccumulation*10+newEmission }//(3)
.subscribe { println("Received $it") }
}- 스캔 연산자는 인자를 가지는 람다가 필요하다
- 첫 번째 매개 변수는 모든 이전 배출량을 집계한 결과이다
- 두 번째 매개 변수는 현재 배출이다
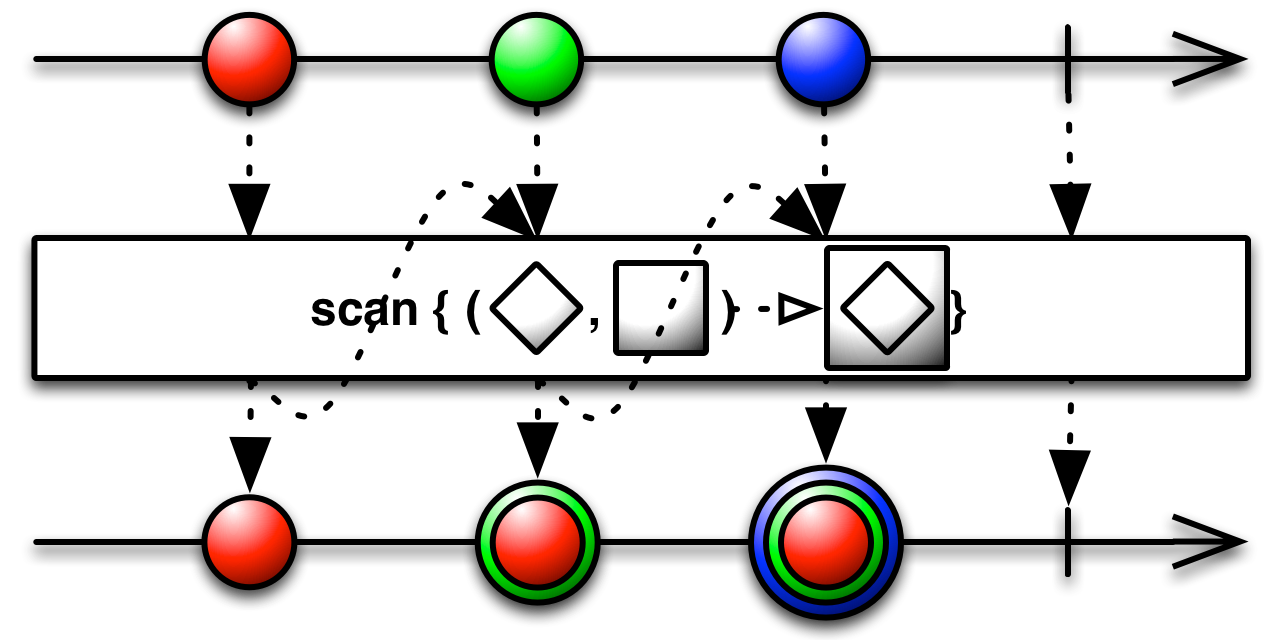
- 스캔 연산자는 제공된 누적 함수를 기반으로 현재 배출 아이템과 모든 이전 배출 아이템을 모은다
- 동일한 데이터 타입을 반환하는 한 합계뿐만 아니라 거의 모든 작업에 대해 스캔 연산자를 사용할 수 있다는 것을 주의해야함
- 스캔 연산자는 rdeuce 연산자와 유사하다
- 그렇지만 스캔 운영자는 롤링 애그리게이터(roll aggregator)로 수신되는 모든 배출을 누적으로 변환함
- reduce 연산자는 onComplete 알림을 받았을 때 모든 배출을 누적해 한 번만 배출한다
- 애플리케이션을 개발하는 동안 배출을 축적하고 통합해야 하는 상황에 직면할 수 있음
- 이런 요구사항에 따르는 거의 모든 연산자는 일반적으로 유한한 데이터 집합만 통합할 수 있으므로 onComplete()를 호출하는 유한한 프로듀서(옵저버블/플로어블)에서만 작동한다
- count
- reduce
- all
- any
- contains
-
count 연산자는 프로듀서를 구독하고 배출량을 계산하며 프로듀서의 배출량을 담고 있는 Single 객체를 배출한다
fun main(args: Array<String>) { listOf(1,5,9,7,6,4,3,2,4,6,9).toObservable() .count() .subscribeBy { println("count $it") } }
-
카운트 연산자는 프로듀서 배출을 계산하고 onComplete 알림을 받으면 배출량을 내보낸다
- reduce는 완벽한 누적 연산자다
- 프로듀서의 모든 배출을 누적해서 onComplete 알림을 받으면 그것들을 내보낸다
fun main(args: Array<String>) {
Observable.range(1,10)
.reduce { previousAccumulation, newEmission -> previousAccumulation+newEmission }
.subscribeBy { println("accumulation $it") }
Observable.range(1,5)
.reduce { previousAccumulation, newEmission -> previousAccumulation*10+newEmission }
.subscribeBy { println("accumulation $it") }
}- scan 연산자와 비슷하게 작동하지만, 스캔은 배출이 발생할 때마다 누적했다가 배출하는 반면 reduce는 모든 배출을 누적하다가 onComplete 알림을 수신했을 때 배출함
- all과 any 연산자는 프로듀서가 배출을 검증할 수 있도록 도움
- RxKotlin은 예외적인 경우를 모두 고려해 컬렉션 연산자를 제공함
- 모든 배출을 대기하고 있다가 컬렉션 객체로 축적해서 반환함
- 컬렉션 연산자는 기본적으로 축소 연산자의 하위 집합이다
- toList와 toSortedList
- toMap
- toMultiMap
- collect
- onError 이벤트의 문제점은 오류가 다운스트림인 컨슈머 체인에 배출되고 구독이 즉시 종료된다는 점이다
- onError 핸들러에서 예외를 처리하더라도 Subscription은 더 이상 배출을 받지 못한다
- 이는 언제나 바람직한 동작이 아닐 수도 있다
- 오류가 발생하지 않은 척하면서 계속 진행할 수는 없지만 최소한 대체 원천 프로듀서를 통해 다시 가입하거나 전환할 수 있는 방법이 있어야한다
- 오류처리 연산자를 사용하면 동일한 결과를 얻을 수 있다
- onErrorResumeNext()
- onErrorReturn()
- onExceptionResumeNext()
- retry()
- etryWhen()
- 유틸리티 연산자는 배출물에 대한 특정 행동, 각 항목의 타임 스탬프 저장, 캐싱 등과 같은 다양한 유틸리티 작업을 수행하는 데 도움을 준다
- doOnNext, doOnComplete, doOnError
- doOnSubscribe, doOnDispose, doOnSuccess
- serialize
- cache