https://<account-name>.documents.azure.com:443/ (SQL)
- Global Distribution: ⚡ and 99.999% availability for multi-region databases.
- Data Models: Supports Key-Value, Document, Column-family, and Graph formats.
- Scalability: Scales throughput and storage elastically as needed.
- Consistency: Choose trade-off between data accuracy and performance.
- SLAs: Covers latency, throughput, consistency, and availability.
- IoT: Handles massive real-time data and traffic spikes.
- Retail: Offers low-latency data access worldwide.
- Gaming: Scales for millions of players with synchronized game states.
- Analytics: Balances performance and consistency for real-time analysis.
- Personalization: query user activity data to drive real-time, personalized experiences
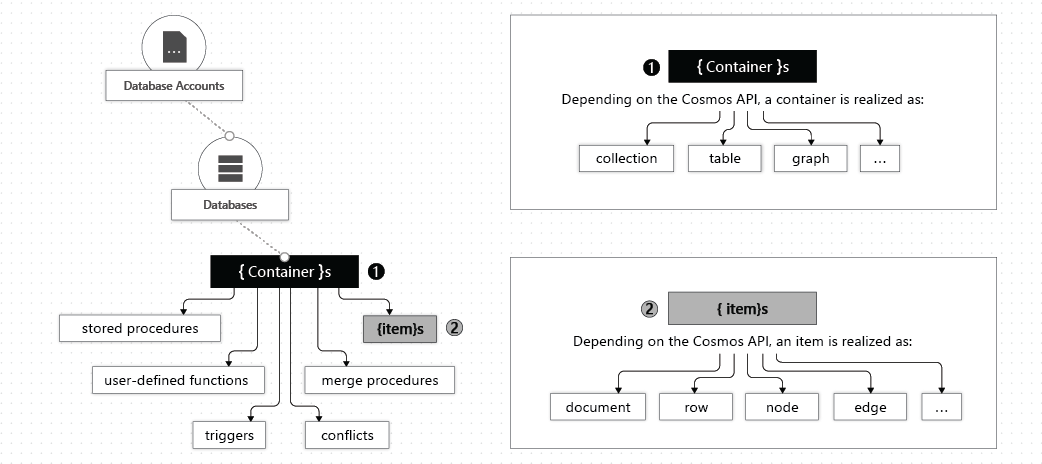
- Cosmos DB Account: Manages databases like storage accounts manage containers. Free tier availability is limited to one per subscription.
- Databases: Serves as a namespace, managing containers, users, permissions, and consistency levels.
- Containers: Data is stored on one or more servers, called partitions. Partition keys are used for efficient data distribution. Containers are schema-agnostic.
- Items: Smallest read/write data units. Schema-agnostic and API-dependent, they can represent documents, rows, nodes, or edges. Automatically indexed in containers without explicit management.
Note: Partition keys always start with / (ex: /partitionkey). Min length for all names is 3 chars, alphanumeric.
Auto-deletes items after a set time (seconds) from last modification. Configurable at container or item level; item settings take precedence. Deletion consumes spare RUs; low RUs cause deletion delays but expired data is not shown in queries. No container-level TTL or a value of -1 prevents auto-expiration unless item-specific TTL exists. Use DefaultTimeToLive in ContainerProperties to set TTL in C#.
# Create a Cosmos DB account
az cosmosdb create --name $account --kind GlobalDocumentDB ...
# Create a database
az cosmosdb sql database create --account-name $account --name $database
# Create a container
az cosmosdb sql container create --account-name $account --database-name $database --name $container --partition-key-path "/mypartitionkey"
# Create an item
az cosmosdb sql container item create --account-name $account --database-name $database --container-name $container --value "{\"id\": \"1\", \"mypartitionkey\": \"mypartitionvalue\", \"description\": \"mydescription\"}"var cosmosClient = new CosmosClient("<connection-string>"); // credentials or/and options
// Create a database
Database database = await cosmosClient.CreateDatabaseIfNotExistsAsync("<database>");
// NOTE: You can use DatabaseResponse instead of Database if you need information like status codes or headers.
// database = await database.ReadAsync(); // Re-fetch data
// Create a container
Container container = await database.CreateContainerIfNotExistsAsync(id: "<container>", partitionKeyPath: "/mypartitionkey", throughput: number);
ItemResponse<dynamic> response = await container.ReadItemAsync<dynamic>(id, new PartitionKey(partitionKey));
// Create an item (note that mypartitionkey doesn't contain leading slash (/))
dynamic testItem = new { id = "1", mypartitionkey = "mypartitionvalue", description = "mydescription" };
await container.CreateItemAsync(testItem, new PartitionKey(testItem.mypartitionkey));
// NOTE: This example is for another container
QueryDefinition query = new QueryDefinition(
"select * from sales s where s.AccountNumber = @AccountInput ")
.WithParameter("@AccountInput", "Account1");
string query = $@"
SELECT VALUE products
FROM models
JOIN products in models.Products
WHERE products.id = '{id}'
";
FeedIterator<SalesOrder> rs = container.GetItemQueryIterator<SalesOrder>(
query,
// Optional:
// requestOptions: new QueryRequestOptions()
// {
// PartitionKey = new PartitionKey("Account1"),
// MaxItemCount = 1
// }
);
while (rs.HasMoreResults)
{
Model next = await iterator.ReadNextAsync();
matches.AddRange(next);
}Azure Cosmos DB provides a balanced approach to consistency, availability, and latency. Its globally linearizable consistency (serving requests concurrently) levels remain unaffected by regional settings, operation origins, number of associated regions, or whether your account has one or multiple write regions. 'Read consistency' specifically denotes a singular read operation, scoped within a particular partition-key range or logical partition, initiated by either a remote client or a stored procedure.
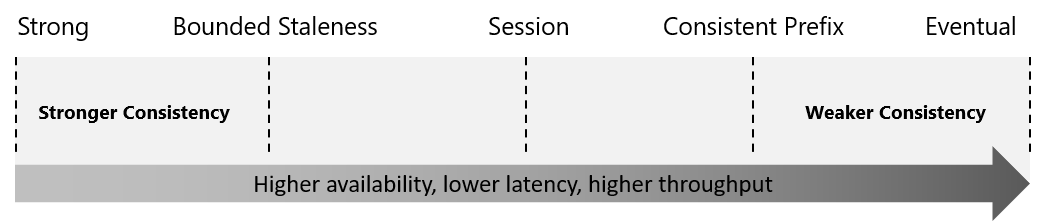
- Strong - Every reader sees the latest data right away, but it may be slower (higher latency) and less available. ⭐: serious stuff like bank transactions where accuracy is vital. Clients will never receive a partial write.
- Bounded staleness - Readers may see slightly old data, but there's a limit on how old (determined by number of operations K or the time interval T for staleness - in single-region accounts, the minimum values are 10 write operations or 5 seconds, while in multi-region accounts, they are 100,000 write operations or 300 seconds). Good for things like game leaderboards where a small delay is okay.
- Session (⏺️, can be configured) - Within a single user's session, the data is always up-to-date. Great for scenarios like a personal shopping cart on a website.
- Consistent prefix - Readers might be a bit behind, but they always see things in order. Update operations made as a batch within a transaction are always visible together. Good for situations where sequence matters, like following a chain of events.
- Eventual - Readers might see things out of order (non-consistent) or slightly old, but it eventually catches up. ⭐: when speed and availability are more important than immediate consistency, like a social media like counter. Lowest latency and highest availability.
# Get the default consistency level
az cosmosdb show --name $database--query defaultConsistencyLevel ...
# Set the default consistency level
az cosmosdb update --name $database--default-consistency-level "BoundedStaleness" ...ConsistencyLevel defaultConsistencyLevel = cosmosClient.ConsistencyLevel;
cosmosClient.ConsistencyLevel = ConsistencyLevel.BoundedStaleness;Improves⚡. Enables independent scaling of storage and throughput.
- Partition Key: A property in data used to distribute data across partitions. Critical for performance and scalability. Type: string only.
- Logical Partitions: Sets of items with the same partition key. Enables efficient queries and transactions. Max storage: 20 GB; Max throughput: 10,000 RU/s.
- Physical Partitions: Internal resources hosting logical partitions. Cosmos DB auto-splits and merges these for workload balance. Max throughput: 10,000 RU/s.
- Partition Sets: Groups of physical partitions. Split into subsets for ⚡.
Use a key that appears often in your queries' WHERE clause and has many unique (distinct) values to avoid 'hot' partitions (overused, or uneven partition sizes) that could become a performance bottleneck. For instance, in multi-tenant apps, using the tenant ID as the key improves read/write speeds and data isolation. Validate your choice through Azure SDKs and monitor metrics like data size, throughput, and cost for any needed adjustments.
When no property has many distinct values:
- Concatenate multiple properties of an item
- Use a partition key with a random suffix
- Use a partition key with pre-calculated suffixes
RUs measure the cost of operations like read, write, and query. The cost varies based on factors like item size and query complexity. If an operation costs more RUs than you have, it's rate-limited until more RUs are available. Typically, reading a 1-KB document costs 1 RU.
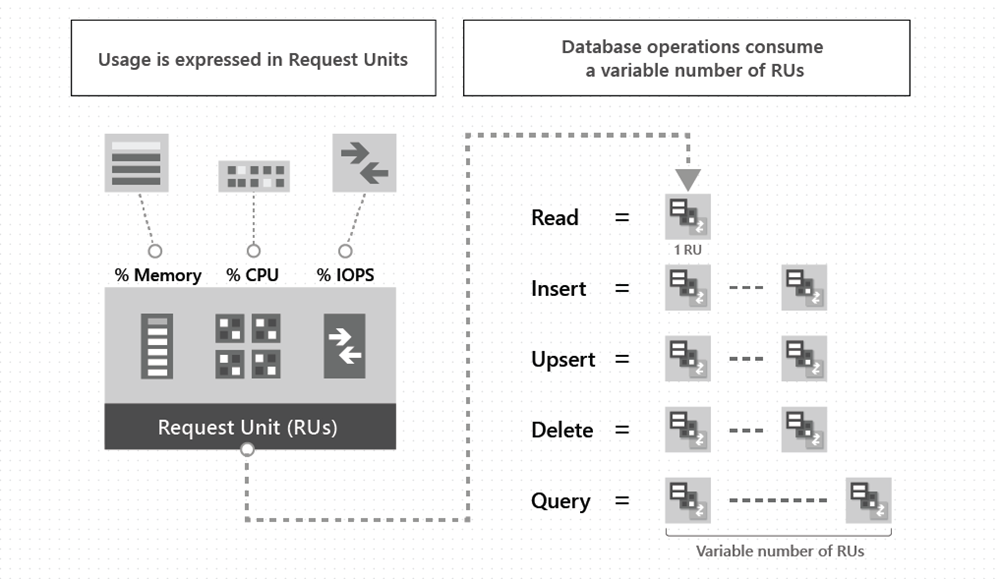
🧊. You set the number of Request Units (RUs) per second your application needs in multiples of 100. Minimum value: 400.
-
Container-level throughput (Dedicated): Reserves a set amount of processing power (consistent ⚡) for one container (guaranteed by SLA). ⭐: 🏋🏿 workloads, large data volumes.
-
Database-level throughput (Shared): Multiple containers in the same database share processing power. Does not effect containers with dedicated throughput. 🏷️. ⭐: small to large workloads with light/variable traffic, multitenant applications.
-
Serverless mode: No need to set throughput in Azure Cosmos DB. You're billed for the RUs used by database operations at the end of the billing cycle.
-
Autoscale Throughput: Dynamically adjusts provisioned RUs based on current usage, applicable to both single containers and databases. It scales between 10% and 100% of a set maximum (100 to 1000 RU/s), optimizing for unpredictable traffic while maintaining high performance and scale SLAs.
az cosmosdb sql container create --throughput-type autoscale --max-throughput 4000
await this.cosmosDatabase.CreateContainerAsync(new ContainerProperties(id, partitionKeyPath), ThroughputProperties.CreateAutoscaleThroughput(1000));
All API models return JSON formatted objects, regardless of the API used.
- API for NoSQL - A JSON-based, document-centric API that provides SQL querying capabilities. ⭐: web, mobile, and gaming applications, and anything that requires handling complex hierarchical data with a schemaless design.
- API for MongoDB - stores data in a document structure, via BSON format.
- API for PostgreSQL - Stores data either on a single node, or distributed in a multi-node configuration.
- API for Apache Cassandra - Supports a column-oriented schema, aligns with Apache Cassandra's distributed, scalable NoSQL philosophy, and is wire protocol compatible with it.
- API for Table - A key-value based API that offers compatibility with Azure Table Storage, overcoming its limitations. ⭐: applications that need a simple schemaless key-value store. Only supports OLTP scenarios.
- API for Apache Gremlin - Graph-based API for highly interconnected datasets. ⭐: handling dynamic, complexly related data that exceeds the capabilities of relational databases.
Using these APIs, you can emulate various database technologies, modeling real-world data via documents, key-value, graph, and column-family models, minus the management and scaling overheads.
Azure Cosmos DB allows transactional execution of JavaScript in the form of stored procedures, triggers, and user-defined functions (UDFs). Each needs to be registered prior to calling. They are created and managed in Azure Portal.
// Gist
var context = getContext(); // root for container and response
var container = context.getCollection(); // for modifying container (collection)
// container.createDocument(container.getSelfLink(), documentToCreate, callback);
// container.queryDocuments(container.getSelfLink(), filterQueryString, updateMetadataCallback);
// container.replaceDocument(metadataItem._self, metadataItem, callback);
var response = context.getResponse(); // getting and setting current item
// response.getBody();
// request.setBody(itemToCreate);-
Stored Procedures: JavaScript functions registered to a collection (container), enabling CRUD and query tasks on its documents. They run within a time limit and support transactions via "continuation tokens". Functions like
collection.createDocument()return aBooleanindicating operation success.var helloWorldStoredProc = { id: "helloWorld", serverScript: function () { // context provides access to all operations that can be performed in Azure Cosmos DB // and access to the request and response objects var context = getContext(); var response = context.getResponse(); response.setBody("Hello, World"); }, };
var createDocumentStoredProc = { id: "createMyDocument", // This stored procedure creates a new item in the Azure Cosmos container body: function createMyDocument(documentToCreate) { var context = getContext(); var container = context.getCollection(); // Async 'createDocument' operation, depends on JavaScript callbacks // returns true if creation was successful var accepted = container.createDocument( container.getSelfLink(), documentToCreate, // Callback function with error and created document parameters function (err, documentCreated) { // Handle or throw error inside the callback if (err) throw new Error("Error" + err.message); // Return the id of the newly created document context.getResponse().setBody(documentCreated.id); } ); // If the document creation was not accepted, return if (!accepted) return; }, };
// Parameter is always string! function sample(arr) { if (typeof arr === "string") arr = JSON.parse(arr); arr.forEach(function (a) { // do something here console.log(a); }); }
-
Triggers: Pretriggers and post-triggers operate before and after a database item modification, respectively. They aren't automatically executed, and must be registered and specified for each operation where execution is required.
- Pre-triggers: Can't have any input parameters. Validates properties of an item that is being created, modifies properties (ex: add a timestamp of an item to be created).
- Post-triggers: Runs as part of the same transaction for the underlying item itself. Modifies properties (ex: update metadata of newly created item).
// Pretrigger function validateToDoItemTimestamp() { var context = getContext(); var request = context.getRequest(); // item to be created in the current operation var itemToCreate = request.getBody(); // validate properties if (!("timestamp" in itemToCreate)) { var ts = new Date(); itemToCreate["timestamp"] = ts.getTime(); } // update the item that will be created request.setBody(itemToCreate); } // Posttrigger function updateMetadata() { var context = getContext(); var container = context.getCollection(); var response = context.getResponse(); // item that was created var createdItem = response.getBody(); // query for metadata document var filterQuery = 'SELECT * FROM root r WHERE r.id = "_metadata"'; var accept = container.queryDocuments( container.getSelfLink(), filterQuery, updateMetadataCallback ); if (!accept) throw "Unable to update metadata, abort"; function updateMetadataCallback(err, items, responseOptions) { if (err) throw new Error("Error" + err.message); if (items.length != 1) throw "Unable to find metadata document"; var metadataItem = items[0]; // update metadata metadataItem.createdItems += 1; metadataItem.createdNames += " " + createdItem.id; var accept = container.replaceDocument( metadataItem._self, metadataItem, function (err, itemReplaced) { if (err) throw "Unable to update metadata, abort"; } ); if (!accept) throw "Unable to update metadata, abort"; return; } }
-
User-defined functions (UDFs): These are functions used within a query, such as a function to calculate income tax based on different brackets.
function tax(income) { if (income == undefined) throw "no input"; if (income < 1000) return income * 0.1; else if (income < 10000) return income * 0.2; else return income * 0.4; }
Cosmos DB operations must complete within a limited time frame.
Registering pre/post trigger uses TriggerProperties class with specific TriggerType. Calling them is a matter of using ItemRequestOptions with proper property and new List<string> { "<name-of-registered-trigger>" } }.
var container = await client.GetContainer("db", "container");
// Register Stored Procedure
container.Scripts.CreateStoredProcedureAsync(new StoredProcedureProperties { Id = "spCreateToDoItems", Body = File.ReadAllText("sp.js") });
// Call Stored Procedure
dynamic[] items = { new { category = "Personal", name = "Groceries" } };
container.Scripts.ExecuteStoredProcedureAsync<string>("spCreateToDoItem", new PartitionKey("Personal"), new[] { items });
// Register Pretrigger
container.Scripts.CreateTriggerAsync(new TriggerProperties { Id = "preTrigger", Body = File.ReadAllText("preTrigger.js"), TriggerOperation = TriggerOperation.Create, TriggerType = TriggerType.Pre });
// Call Pretrigger
dynamic newItem = new { category = "Personal", name = "Groceries" };
container.CreateItemAsync(newItem, null, new ItemRequestOptions { PreTriggers = new List<string> { "preTrigger" } });
// Register Post-trigger
container.Scripts.CreateTriggerAsync(new TriggerProperties { Id = "postTrigger", Body = File.ReadAllText("postTrigger.js"), TriggerOperation = TriggerOperation.Create, TriggerType = TriggerType.Post });
// Call Post-trigger
container.CreateItemAsync(newItem, null, new ItemRequestOptions { PostTriggers = new List<string> { "postTrigger" } });
// Register UDF
container.Scripts.CreateUserDefinedFunctionAsync(new UserDefinedFunctionProperties { Id = "Tax", Body = File.ReadAllText("Tax.js") });
// Call UDF
var iterator = container.GetItemQueryIterator<dynamic>("SELECT * FROM Incomes t WHERE udf.Tax(t.income) > 20000");Enabled by default, tracking container changes chronologically (order is guaranteed only per partition key) but not deletions. For deletions, use a "deleted" attribute and set TTL. Azure Functions uses the change feed processor.
Azure Functions utilizes the change feed processor internally.
Not compatible with Table and PostgreSQL databases.
Interaction Models:
- Push Model: Automatically sends updates to the client. ⭐.
- Pull Model: Requires manual client requests for updates. Useful for specialized tasks like data migration or controlling processing speed.
Host instance lifecycle: Reads change feed, sleeps if no changes, sends changes to delegate for processing, and updates lease store with latest processed time.
- Monitored container: has the data from which the change feed is generated. Inserts and updates are reflected in the change feed.
- Lease container: acts as a state storage and coordinate the processing of change feed across multiple workers. It can be in the same or different account as the monitored container.
- Delegate componet can be used to implement custom logic to process the changes that the change feed reads.
- Compute Instance: Hosts change feed processor to listen for changes. Can be a VM, Kubernetes pod, Azure App Service instance, or a physical machine.
private static async Task<ChangeFeedProcessor> StartChangeFeedProcessorAsync(CosmosClient cosmosClient)
{
Container monitoredContainer = cosmosClient.GetContainer("databaseName", "monitoredContainerName");
Container leaseContainer = cosmosClient.GetContainer("databaseName", "leaseContainerName");
ChangeFeedProcessor changeFeedProcessor = monitoredContainer
.GetChangeFeedProcessorBuilder<ToDoItem>(processorName: "changeFeedSample", onChangesDelegate: DelagateHandleChangesAsync)
.WithInstanceName("consoleHost") // Compute Instance
.WithLeaseContainer(leaseContainer)
.Build();
Console.WriteLine("Starting Change Feed Processor...");
await changeFeedProcessor.StartAsync();
Console.WriteLine("Change Feed Processor started.");
return changeFeedProcessor;
}
//////////////////
// The delegate //
//////////////////
static async Task HandleChangesAsync(
ChangeFeedProcessorContext context,
IReadOnlyCollection<ToDoItem> changes,
CancellationToken cancellationToken)
{
Console.WriteLine($"Started handling changes for lease {context.LeaseToken}...");
Console.WriteLine($"Change Feed request consumed {context.Headers.RequestCharge} RU.");
// SessionToken if needed to enforce Session consistency on another client instance
Console.WriteLine($"SessionToken ${context.Headers.Session}");
foreach (ToDoItem item in changes)
{
Console.WriteLine($"Detected operation for item with id {item.id}.");
await Task.Delay(10);
}
}- Data in Azure Cosmos DB is stored as JSON documents. This means you can query nested properties and arrays directly.
- Queries in Azure Cosmos DB are case sensitive.
- Azure Cosmos DB automatically indexes all properties in your data (configurable:
containerProperties.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath{ Path = "/nonQueriedProperty/*" });to exclude property you never query on). This makes queries fast, but it can also increase the cost of writes. - Azure Cosmos DB supports ACID transactions within a single partition.
- Azure Cosmos DB uses optimistic concurrency control to prevent conflicts when multiple clients are trying to update the same data. This is done using
ETagsand HTTP headers.
SELECT
c.name,
c.age,
{
"phoneNumber": p.number,
"phoneType": p.type
} AS phoneInfo
FROM c
JOIN p IN c.phones
JOIN (SELECT VALUE t FROM t IN p.tags WHERE t.name IN ("winter", "fall"))
WHERE c.age > 21 AND ARRAY_CONTAINS(c.tags, 'student') AND STARTSWITH(p.number, '123')
ORDER BY c.age DESC
OFFSET 10 LIMIT 20
- Column names require specifiers, e.g.
c.name, notname. FROMclause is just an alias (no need to specify container name).- You can only join within a single container. You can't join data across different containers.
- Aggregation functions are not supported.
Queries that have an ORDER BY clause with two or more properties require a composite index:
{
"compositeIndexes": [
[
{ "path": "/name", "order": "ascending" },
{ "path": "/age", "order": "descending" }
]
]
}The VALUE keyword is used to flatten the result of a SELECT statement (not individual fields within that statement)
SELECT VALUE {
"name": p.name,
"sku": p.sku,
"vendor": p.manufacturer.name
}
FROM products p
WHERE p.sku = "teapo-surfboard-72109"This is similar to aliasing SELECT p.name AS name
SELECT c.id, udf.GetMaxNutritionValue(c.nutrients) AS MaxNutritionValue FROM cSELECT VALUE COUNT(1) FROM models-
Gateway mode (⏺️): For environments that have a limited number of socket connections, or corporate network with strict firewall restrictions. It uses HTTPS port and a single DNS endpoint.
-
Direct mode: Connectivity through TCP protocol, using TLS for initial authentication and encryption. ⚡
- Latest SDK version
- Application must be in the same Azure region as the Cosmos DB account
- Use single instance of
CosmosClient Directmode for ⚡- Leverage
PartitionKeyfor efficient point reads and writes - Retry logic for handling transient errors
- Read 🏋🏿:
Stream APIandFeedIterator - Write 🏋🏿: Enable bulk support, set
EnableContentResponseOnWriteto false, exclude unused paths from indexing and keep the size of your documents minimal
- Multi-region Writes - Perform writes in all configured regions. This enhances write latency and availability.
- Automatic Failover - If an Azure region goes down, Cosmos DB can automatically failover to another region.
- Manual Failover - For testing purposes, you can trigger a manual failover to see how your application behaves during regional failures.
- No downtime when adding or removing regions
🧊, conflict resolution policy can only be specified at container creation time.
- Automatic: Uses a Last Writer Wins (LWW) policy based on a system or user-defined property.
- Custom: Uses a user-defined stored procedure to handle conflicts.
- Authentication: Utilizes Entra and generates an access key upon account creation for request authentication.
- Authorization: Role-based with built-in resources for granular control over containers and documents.
- Encryption: 🔑 (⏺️) or 🗝️ for at-rest data; TLS for in-transit data.
Regular automatic secure (🔑) backups without affecting performance. Restores are limited to accounts in the same subscription with equal or higher RU/s and partitions.
- Continuous: 7 or 30-day retention. Can't switch to periodic.
- Periodic: ⏺️. Custom intervals (min 1 hour), max retention: 1 month. Support team handles restores.
- Metrics: Built-in tracking for aspects like storage, latency, and availability.
- Azure Monitor: Enables custom dashboards, alerts, and metric visualization.
- Diagnostic Logs: Offers operation traces, which can be analyzed further in various Azure services.
- Query Stats: Provides execution metrics to help optimize and troubleshoot queries.