Remote UDF execution #14053
Comments
|
Happy to see this proposal, thanks for working on it. I'm interested and have a few questions that I couldn't readily understand from the above. Some of these might just be a level of detail that has yet to have been mapped out so don't hesitate to call that out.
We ran into some of the above decision points while working on remote UDFs for Amazon Athena's use of Presto so I'm happy to share any learnings I can that might be useful. |
|
|
Thanks for the quick reply Regarding #1, if I am understanding you correctly ... have you considered something other than THRIFT? Like Apache Arrow? Arrow seems to be gaining popularity as an interchange format. For #2, I was wondering if it might be useful for Presto's coordinator to change the rate at which it schedules work if a query is constrained by UDF throughput. Tying up resources to just buffer going into a bottleneck is something I've been contemplating with UDFs in general but even more so with remote UDFs. |
|
We have talks internally at Facebook in potentially converge different query engines to use the same format, which could potentially be an extended version of Arrow. If that happens, we might potentially add support for Arrow. Currently there's no use case for us. That's said, this is open source. We'd very much appreciate it if you want to contribute a Arrow implementation! Regarding smarter scheduling, slow UDF is not dramatically different from a slow local expression (regex or json), so if we are looking into improving scheduling, I wouldn't restrict us to remote UDF throughput. We (Facebook) are forming a resource management effort to look into these problems overall. Maybe other folks have thought about this more than I do. cc @tdcmeehan |
|
Thanks for the info. |
|
This remote function looks very useful for customer's exsited udf! I wonder what's the milestone about this issue? |
|
@gravitys169 Thanks for your interests. I'm actively working on this. The presto engine change should be ready in a couple of months. We want to eventually open source a remote udf server implementation as well but there's no concrete timeline about that yet. We want to first launch this in production in Facebook and see what kind of scaling problems we would see and how to manage it better. However, you will be able to implement a simple thrift service and hook it up to Presto to run small scale workloads in a few months. |
|
thanks for your answer! I wonder is the UDF server a separate JVM process from presto server? and How does it support the exsited hive udf, by adding the hvie udf to the UDF server's classpath? |
Currently our plan is that UDF server is a separate set of machines running separate JVMs from Presto server. You could potentially have the UDF server running on the same machines as presto server (colocated) as well if you have beefy machines with extra resources. We want to have separate JVMs because these UDFs could potentially use a lot of resource, calling external services, doing other expensive / unreliable operations and we do not want this to affect Presto servers' performance. Currently in my naive implementation of the remote UDF server, i used reflection to get all Hive UDFs and registered them. When getting a request, there will be a piece of function metadata, which will be used to lookup the hive function, gather the input / return types so we know how to parse the data and convert to Hive format, and invoke the Hive function. Hope this helps. |
|
@rongrong ,thanks for you sharing! It seems your implementation's idea is close to the Flink's way(am I right?). |
|
@gravitys169 I'm not familiar with Flink. If you can point me to the code I can take a look. I'm not sure that I understand your "two levels of invoking hive function" |
|
If you use reflection to invoke hive function in presto you may need these two function concepts. And the Remote UDF Server is different from presto, so maybe don't need them. |
|
@gravitys169 Currently, in the thrift remote UDF server, we plan to use ThriftFunctionId. Function name and input types would give you enough information to invoke the Hive function, and return type is used to serialize results. |
|
@rongrong I'm curious how do we handle expressions like TRY(remote_func(a, b, c)) as I think these cannot be split into 2 projections without changing the semantics. For example, if remote_func(a, b, c) throws, we expect TRY(remote_func(a, b, c)) to not throw, but return false. However, if we split this expression into two projections, then first projection will throw and query will fail: Project: y := try(x) The same challenge exists for other special forms (AND, OR and COALESCE) which may exit early before evaluating all arguments and therefore "mask" errors which would occur if all arguments were evaluated. |
My memories are vague. The try issue is a known issue but I don't remember whether we handled it or not. I tried to look at the code but didn't find anything so I'm assuming we didn't handle it yet. One way to handle it is to identify this in planning and add a flag to the remote function to mask exceptions. For the operators that has order of execution you can also change the plan to push them into different stages but I don't think surfacing the error is wrong in that case. People might find it annoying but I think it's not against the spec. |
The Challenge
Over the years, users have been asking for a more flexible way of running complex business logic in the form of user defined functions (UDF). However, due to system constraints of Presto (lack of isolation, high requirement of performance, etc), it is unsafe to allow arbitrary UDFs running within the same JVM. As a result, we only allow users to write Presto builtin Java functions and they are reviewed by people who are familiar with Presto as function plugins. This caused several problems:
Propose Remote UDF Execution
With #9613, we can semantically support non-builtin functions (functions that are not tied to Presto's release and deployment cycles). This enabled us to explore the possibility of supporting a wide range of other functions. We are already adding support for SQL expression functions. SQL expression function is a safe choice to be executed within the engine because they could be compiled to byte code the same way as normal expressions. However, this cannot be assumed for functions implemented in other languages. For the wider range of arbitrary functions implemented in arbitrary languages, we'd like to propose to consider them as remote functions, and execute them on separate UDF servers.
Architecture
Planning
Expressions can appear in projections, filters, joins, lambda functions, etc. We will focus on supporting remote functions in projections and filters for now. Currently Presto would compile these expressions into byte code and execute them directly in
ScanFilterAndProjectOperatororFilterAndProjectOperator. To allow functions to run remotely, one option is to generate the byte code to invoke functions remotely. However, this means that the function invocation would be triggered once for each row. This could be really expensive when each function invocation need to do an RPC call. So we propose another approach, which is to break up the expression into local and remote parts. Consider the following query:where
local_foois a traditional local function andremote_foois a function that can only be run on a remote UDF server. We now need to break it down to local projection:and remote project
Now we can compile the local projection to byte code and execute as usual and introduce a new operator to handle the remote projections. Since operators work on a page at a time, we can send the whole page to remote UDF server for batch processing.
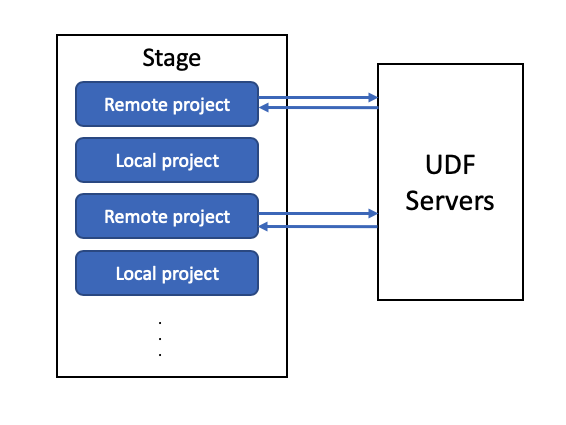
The above proposal would solve the case for expressions in projection. What about filter? If a filter expression contains remote function, we can always convert that into a projection with subquery. For example, we can rewrite
to
Execution
Once we separate remote projections as a separate operator during query planning, we can execute these with a new
RemoteProjectOperator. We propose to use Thrift as the protocol to invoke these remote functions. The reason for choosing Thrift at the moment is because Presto has already support Thrift connectors, thus all data serde with Thrift are already available to use.SPI changes
We propose to make the following changes in function related SPI to support remote functions.
RoutineCharacteristics.Language
We propose to augment function's
RoutineCharacteristics.Languageto describe more kind of functions. These can be programing language, or specific platforms. For example,PYTHONcould be used to describe functions implemented in the Python programing language, whileHIVEcan be used for HiveUDFs implemented in Java.FunctionImplementationType
There's also the concept of
FunctionImplementationType, which currently hasBUILTINANDSQL. We propose to extend this withTHRIFTand mapping all languages that could not be run within the engine to this type.ThriftScalarFunctionImplementation
Corresponding to Thrift functions, we also propose to introduce
ThriftScalarFunctionImplementationas a new type ofScalarFunctionImplementation. Since the engine will not execute this function directly, theThriftScalarFunctionImplementationwill only need to wrap theSqlFunctionHandlewhich the remote UDF server tier can use to resolve a particular version of the function to execution.FunctionNamespaceManager
As all other functions, remote functions will be managed by a
FunctionNamespaceManager. Thus the function namespace manager needs to provide information connecting / routing to the remote thrift service that could run the function. Ideally the sameFunctionNamespaceManager(or metadata the configured thisFunctionNamespaceManager) should be used on the remote UDF server to resolve the actual implementation and execute the function.The text was updated successfully, but these errors were encountered: