Title: Morphium Documentation Author: Stephan Bösebeck URL: http://sboesebeck.github.io/morphium/ morphium_version: 3.0 mongodb_version: 3.2 html header: <script src="http://yandex.st/highlightjs/7.3/highlight.min.js"></script> <script>hljs.initHighlightingOnLoad();</script> ...
This documentation is refering to Morphium version [%morphium_version] and mongodb [%mongodb_version]. this documentation follows "MultiMarkdown" and was created using the MultiMarkdownComposer.
HTML Version here: MorphiumDoku If you just want to start right now, read [quick start]!
When we started using MongoDB there was no fully capable POJO Mapper available. The only thing that was close to useable was Morphia (which is now developed by MongoDb. Unfortunately, Morphia had some issues, and lacked some features, we'd like to have, like (besides the usual features fast mapping, reliable query interface and so on):
- Thread safety
- cluster awareness
- declarative caching
- profiling support
- support for partial updates
- reference support incl. lazy loading of references
- adaptable API (need to implement special POJO Mappings, Cache implementation change etc)
- Cache synchronization in cluster
- Validation
- Declarative Index specification
- Aggregation support
At that time there was nothing available providing all those features or what we could use as a basis to create those features (although we tried to implement that on base of Morphia - but the architecture of Morphia was not built for customization).
So, we started creating our own implementation and called it "Morphium" to honor the project "Morphia" which was the best around at that time.
But Morphium is a complete new Project, it was built totally from scratch. Even the POJO-Mapper is our own development (although there were some available at that point), but we had some special needs for Morphium's mapping.
The mapping takes place on a per-type basis. That means, usually (unless configured otherwise) the data of all objects of a certain type, will be stored in a corresponding collection.
In addition to that, the mapping is aware of object hierarchy and would even take annotations and settings into account, that are inherited.
Usually Morphium replaces camel case by underscore-separated strings. So an Object of type MyEntity would be stored in the collection my_entity. This behaviour can be configured as liked, you could even store all Objects in one collection. (see [Polymorphism])
####Motivation#### Morphium 3.0 brings a lot improvements and changes, most of them are not really visible to the user, but unfortunately some of them make V3.x incompatible to V2.x.
The changes were triggered by the recent mongodb java driver update to also 3.0, which brings a whole new API. This API is (unfortunately also) not backward compatible[^not quite true, the driver contains both versions actually, but old API is usually marked _deprecated_]. This made it hard to add the changes in the official driver into morphium. Some of the changes made it also impossible to implement some features in morphium as it was before. So - the current implementation of morphium uses both old and new API - wich will break eventually.
The next step was, to be more independent from the driver, as those changes caused problems almost throughout the whole code of morphium. So, introducing with V3.0 of morphium, the driver is encapsulated deep within morphium.
Unfortunately, even the basic document representation changed[^old version used `BasicDBObject`, new version uses `Document`], which are very similar, but unfortunately represented in a whole new implementation of BSON[^binary json - details can be found here].
Also, we had some problems with dependencies in maven, causing to be several version of the mongodb driver being installed on production - which then caused some weird effects, most of them not really good ones ;-)
This made us reduce all dependency to the mongodb driver to a minimum - actually it is only used in the MorphiumDriver implementation for the official mongodb driver. But that also meant, we needed to get rid of all usages of ObjectID and BasicDBDocument and reduce usages of that into the driver implementation within morphium.
The question was - do we need to introduces some new object type for representing a Map<String,Object>? We thought no, so we changed the whole code in morphium, to internally use only standard Java8 API.
Yes, that is one feature also, since Morphium 3.0 we‘re running on java 8.
As you know the motivation now, these are the changes.
- Driver encapsulated and configurable - you can now implement your own driver for usage with morphium
- no usage of MongoDb classes, replaced by type
MorphiumIdand simpleMap<String,Object>- this might actually break your code! - (soon) MongoDB Dependency in maven will be set to be
provided, so that you can decide, which Version of the driver you want to use (or none...) - Morphium 3.0 includes some own implementation of drivers (mainly for testing purpose):
Driver: This is the Implementation ofMorphiumDriverusing the official Mongodb driver (V3.x)InMemoryDriver: Not connecting to any mongo instance, just storing into memory. Good for testing. Does not support Aggregation!SingleConnectDirectDriver: Just connecting to a master node, no failover. Useful if you do not have a replicasetSingleConnectThreaddedDriver: Same as above, but uses a thread for reading the answers - slightly better performance in multithreaded environments, but only useful if you don't run a replicaSetMetaDriver: A full featured implementation of theMorphiumDriverInterface, can be used as replacement for the mondogdb driver implementation. It uses a pool ofSingleConnectThreaddedDriverto connect to mongodb.
- Many changes in the internals
- in references you can now specify the collection the reference should point to.
- improvements in the internal caches, using the new improved features and performance of Java8[^see also here]
- complete rewrite of the bulk operation handling
- code improvements on many places, including some public interfaces (might break your code!)
Simple example on how to use Morphium:
First you need to create data to be stored in Mongo. This should be some simple class like this one here:
@Entity
public class MyEntity {
@Id
private MorphiumId myId;
private int aField;
private String other;
private long property;
//.... getter & setter here
}
This given entity has a couple of fields which will be stored in Mongo according to their names. Usually the collection name is also derived from the ClassName (as most things in Morphium, that can be changed).
The names are usually translated from camel case (like aField) into lowercase with underscores (like a_field). This is the default behavior, but can be changed according to your needs.
In mongo the corresponding object would be stored in a collection named my_entity and would look like this:
{
_id: ObjectId("53ce59864882233112aa018df"),
a_field: 123,
other: "value"
}
By default, null values are not serialized to mongo. So in this example, there is no field "property".
The next example shows how to store and access data from mongo:
//creating connection
MorphiumConfig cfg=new MorphiumConfig();
cfg.setHosts("localhost:27018", "mongo1","mongo3.home");
//connect to a replicaset
//if you want to connect to a shared environment, you'd add the addresses of
//the mongos-servers here
//you can also specify only one of those nodes,
//Morphium (or better: mongodb driver) will figure out the others
//connect
Morphium morphium=new Morphium(cfg);
//Create an entity
MyEntity ent=new MyEntity();
ent.setAField(123);
ent.setOther("value");
ent.setProperty(122l);
morphium.store(ent);
//the query object is used to access mongo
Query<MyEntity> q=morphium.createQueryFor(MyEntity.class);
q=q.f("a_field").eq(123);
q=q.f("other").eq("value");
q=q.f("property").lt(123).f("property").gt(100);
List<MyEntity> lst=q.asList();
//or use iterator
for (MyEntity e:q.asIterable(100,2)) {
// iterate in windows of 100 objects
// 2 windows lookAhead
}
This gives a short glance of how Morphium works and how it can be used. But Morphium is capable of many more things...
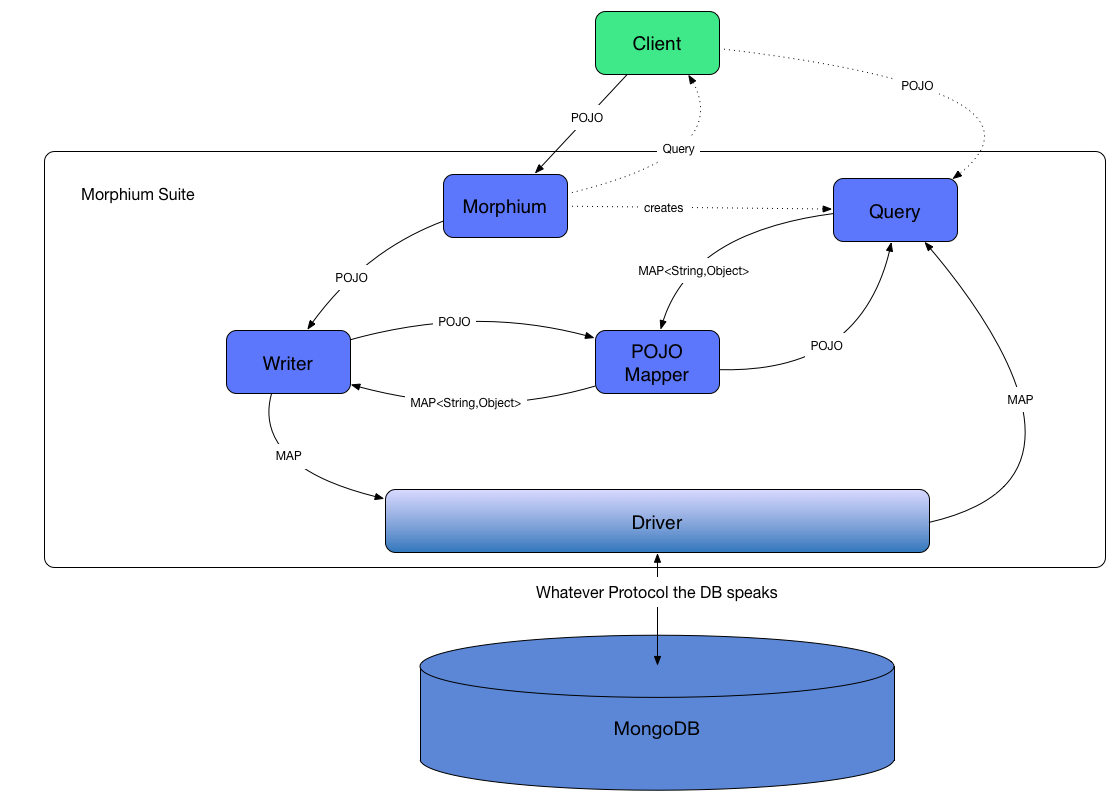
Morphium is built to be very flexible and can be used in almost any environment. So the architecture needs to be flexible and sustainable at the same time. Hence it's possible to use your own implementation for the cache if you want to.

There are four major components of Morphium:
- the Morphium Instance: This is you main entrypoint for interaction with Mongo. Here you create Queries and you write data to mongo. All writes will then be forwarded to the configured Writer implementation, all reads are handled by the Query-Object
- Query-Object: you need a query object to do reads from mongo. This is usually created by using
Morphium.createQueryFor(Class<T> cls). With a Query, you can easily get data from database or have some things changed (update) and alike. - the Cache: For every request that should be sent to mongo, Morphium checks first, whether this collection is to be cached and if there is already a batch being stored for the corresponding request.
- The Writers: there are 3 different types of writers in Morphium: The Default Writer (
MorphiumWriter) - writes directly to database, waiting for the response, the BufferedWriter (BufferedWriter) - does not write directly. All writes are stored in a buffer which is then processed as a bulk. The last type of writer ist the asynchronous writer (AsyncWriter) which is similar to the buffered one, but starts writing immediately - only asynchronous. Morphium decides which writer to use depending on the configuration an the annotations of the given Entities. But you can always use asynchronous calls just by adding aAsyncCallbackimplementation to your request.
Simple rule when using Morphium: You want to read -> Use the Query-Object. You want to write: Use the Morphium Object.
There are some additional features built upon this architecture:
- messaging: Morphium has a own messaging system.
- cache synchronization: Synchronize caches in a clustered environment. Uses messaging
- custom mappers - you can tell Morphium how to map a certain type from and to mongodb. For example there is a "custom" mapper implementation for mapping
BigIntegerinstances to mongodb. - every of those implementations can be changed: it is possible to set the class name for the
BufferedWriterto a custom built one (inMorphiumConfig). Also you could replace the object mapper with your own implementation by implementing theObjectMapperinterface and telling morphium which class to use instead. In short, these things can be changed in morphium / morphiumconfig:- MorphiumCache
- ObjectMapper
- Query
- Field
- QueryFactory
- Driver (> V3.0)
- Object Mapping from and to Strings (using the object mapper)
First lets have a look on how to configure Morphium. As you already saw in the example in the last chapter, the configuration of Morphium ist encapsulated in one Object of type MorphiumConfig. This object has set some reasonable defaults for all settings. So it should be just as described above to use it.
There are a lot of settings and customizations you can do within Morphium. Here we discuss all of them:
- loggingConfigFile: can be set, if you want Morphium to configure your log4j for you. Morphium itself has a dependency to log4j (see Dependencies).
- camelCaseConversion: if set to false, the names of your entities (classes) and fields won't be converted from camelcase to underscore separated strings. Default is
true(convert to camelcase) - maxConnections: Maximum Number of connections to be built to mongo, default is 10
- houseKeepingTimeout: the timeout in ms between cache housekeeping runs. Defaults to 5sec
- globalCacheValidTime: how long are Cache entries valid by default in ms. Defaults to 5sek
- writeCacheTimeout: how long to pause between buffered writes in ms. Defaults to 5sek
- database: Name of the Database to connect to.
- connectionTimeout: Set a value here (in ms) to specify how long to wait for a connection to mongo to be established. Defaults to 0 (⇒ infinite)
- socketTimeout: how long to wait for sockets to be established, defaults to 0 as well
- socketKeepAlive: if
true, use TCP-Keepalive for the connection. Defaults to true - safeMode: Use the safe mode of mongo when set to
true - globalFsync, globalJ: set fsync (file system sync) and j (journal) options. See mongo.org for more information
- checkForNew: This is something interesting related to the creation of ids. Usually Ids in mongo are of type
ObjectId. Anytime you write an object with an_idof that type, the document is either updated or inserted, depending on whether or not the ID is available or not. If it is inserted, the newly created ObjectId is being returned and add to the corresponding object. But if the id is not of type ObjectId, this mechanism will fail, no objectId is being created. This is no problem when it comes to new creation of objects, but with updates you might not be sure, that the object actually is new or not. If this obtion is set totrueMorphium will check upon storing, whether or not the object to be stored is already available in database and would update. Attention: Morphium 3.0 removed the dependency from mogodb.org codebase and hence there is no ObjectId for POJOs anymore. You should replace these with the newMorphiumId. - writeTimeout: this timeout determines how long to wait until a write to mongo has to be finshed. Default is
0⇒ no timeout - maximumRetriesBufferedWriter: When writing buffered, how often should retry to write the data until an exception is thrown. Default is 10
- retryWaitTimeBufferedWriter: Time to wait between retries
- maximumRetriesWriter, maximumRetriesAsyncWriter: same as maximumRetriesBufferedWriter, but for direct storage or asynchronous store operation.
- retryWaitTimeWriter, retryWaitTimeAsyncWriter: similar to retryWaitTimeBufferedWriter, but for the according writing type
- globalW: W sets the number of nodes to have finished the write operation (according to your safe and j / fsync settings)
- maxWaitTime: Sets the maximum time that a thread will block waiting for a connection.
- writeBufferTime: Timeout for buffered writes. Default is 0
- autoReconnect: if set to
trueconnections are re-established, when lost. Default istrue - maxAutoReconnectTime: how long to try to reconnect (in ms). Default is
0⇒ try as long as it takes - blockingThreadsMultiplier: There is a max number of connections to mongo, this factor determines the maximum number of threads that may be waiting for some connection. If this threshold is reached, new threads will get an Exception upon access to mongo.
- mongoLogin,mongoPassword: User Credentials to connect to mongodb. Can be null.
- mongoAdminUser, mongoAdminPwd: Credentials to do admin tasks, like get the replicaset status. If not set, use mongoLogin instead.
- acceptableLatencyDifference: Latency between replicaset members still acceptable for reads.
- autoValuesEnabled: Morphium supports automatic values being set to your POJO. These are configured by annotations (
@LasChange,@CreationTime,@LastAccess, ...). If you want to switch this off globally, you can set it in the config. Very useful for test environments, which should not temper with productional data - readCacheEnabled: Globally disable readcache. This only affects entities with a
@Cacheannotation. By default it's enabled. - asyncWritesEnabled: Globally disable async writes. This only affects entities with a
@AsyncWritesannotation - bufferedWritesEnabled: Globally disable buffered writes. This only affects entities with a
@WriteBufferannotation defaultReadPreference: whether to read from primary, secondary or nearest by default. Can be defined with the@ReadPreferenceannotation for each entity.replicaSetMonitoringTimeout: time interval to update replicaset status.- retriesOnNetworkError: if you happen to have an unreliable network, maybe you want to retry writes / reads upon network error. This settings sets the number of retries for that case.
- sleepBetweenNetworkErrorRetries: set the time to wait between network error retries.
- blockingThreadsMultiplier: Sets the multiplier for number of threads allowed to block waiting for a connection.
In addition to those settings describing the behavior of Morphium, you can also define custom classes to be used internally:
- omClass: here you specify the class, that should be used for mapping POJOs (your entities) to
DBOject. By Default it uses theObjectMapperImpl. Your custom implementation must implement the interfaceObjectMapper. - iteratorClass: set the Iterator implementation to use. By default
MorphiumIteratorImplis being used. Your custom implementation must implement the interfaceMorphiumIterator - aggregatorClass: this is Morphium's representation of the aggregator framework. This can be replaced by a custom implementation if needed. Implements
Aggregatorinterface - queryClass and fieldImplClass: this is used for Queries. If you want to take control over how queries ar built in Morphium and on how fields within queries are represented, you can replace those two with your custom implementation.
- cache: Set your own implementation of the cache. It needs to implement the
MorphiumCacheinterface. Default isMorphiumCacheImpl. You need to specify a fully configured cache object here, not only a class object. - driverClass: Set the driver implementation, you want to use. This is a string, set the class name here. E.g.
morphiumconfig.setDriverClass(MetaDriver.class.getName()
The most straight foreward way of configuring Morphium is, using the object directly. This means you just call the getters and setters according to the given variable names above (like setMaxAutoReconnectTime()).
The minimum configuration is explained above: you only need to specify the database name and the host(s) to connect to. All other settings have sensible defaults, which should work for most cases.
the configuration can be stored and read from a property object.
MorphiumConfig.fromProperties(Properties p); Call this method to set all values according to the given properties. You also can pass the properties to the constructor to have it configured.
To get the properties for the current configuration, just call asProperties() on a configured MorphiumConfig Object.
Here is an example property-file:
maxWaitTime=1000
maximumRetriesBufferedWriter=1
maxConnections=100
retryWaitTimeAsyncWriter=100
maxAutoReconnectTime=5000
blockingThreadsMultiplier=100
housekeepingTimeout=5000
hosts=localhost\:27017, localhost\:27018, localhost\:27019
retryWaitTimeWriter=1000
globalCacheValidTime=50000
loggingConfigFile=file\:/Users/stephan/morphium/target/classes/morphium-log4j-test.xml
writeCacheTimeout=100
connectionTimeout=1000
database=morphium_test
maximumRetriesAsyncWriter=1
maximumRetriesWriter=1
retryWaitTimeBufferedWriter=1000
The minimal property file would define only hosts and database. All other values would be defaulted.
If you want to specify classes in the config (like the Query Implementation), you neeed to specify the full qualified class name, e.g. de.caluga.morphium.customquery.QueryImpl
The standard toString()method of MorphiumConfig creates an Json String representation of the configuration. to set all configuration options from a json string, just call createFromJson.
In some cases it's more convenient to use a singleton Instance to access Morphium. You don't need to implement a thread safe Morphium Singleton yourself, as Morphium does already have one.
The MorphiumSingleton is configured similar to the normal Morphium instance. Just set the config and you're good to go.
MorphiumConfig config=new MorphiumConfig(); //..configure it here
MorphiumSingleton.setConfig(config);
MorphiumSingleton.get().createQueryFor(MyEntity.class).f(...)
Connection to mongo and initializing of Morphium is done at the first call of get.
When talking about POJO Mapping, we're saying we marshall a POJO into a mongodb representation or we unmarshall the mongodb representation into a POJO.
Marshaling and unmarshalling is of utter importance for the functionality. It needs to take care of following things:
- un/marshall every field. Easy if it’s a primitive datatype. Map to corresponding type in Monogo - mostly done by the mongodb java driver (or since 3.0 the
MorphiumDriverimplementation) - when it comes to lists and maps, examine every value. Maps may only have strings as keys (mongoldb limitation), un/marshall values
- when a field contains a reference to another entity, take that into account. either store the
- the POJO transformation needs to be 100% thread safe (Morphium itself is heavily multithreaded)
The ObjectMapper is the core of Morphium. It's used to convert every entity you want to store into a mongoldb document (java representation is a DBObject). Although it's one of the key things in Morphium it's still possible to make use of your own implementation (see chapter [Configuring Morphium]).
This is done by using the Query object. You need to create one for every entity you want to issue a query for. You could create one yourself, but the easiest way of doing so is calling the method .createQueryFor(Class class) in Morphium.
After that querying is very fluent. You add one option at a time, by default all conditions are AND-associated:
Query<MyEntity> q=morphium.createQueryFor(MyEntity.class);
q=q.f("a_field").eq("Value");
q=q.f("counter").lt(10);
q=q.f("name").ne("Stephan").f("zip").eq("1234");
The f method stands for "field" and returns a Morphium internal representation of mongo fields. Threre you can call the operators, in our case it eq for equals, lt for less then and ne not equal. There are a lot more operators you might use, all those are defined in the MongoField interface:
public Query<t> all(List</t>
public Query<T> eq(Object val);
public Query<T> ne(Object val);
public Query<T> size(int val);
public Query<T> lt(Object val);
public Query<T> lte(Object val);
public Query<T> gt(Object val);
public Query<T> gte(Object val);
public Query<T> exists();
public Query<T> notExists();
public Query<T> mod(int base, int val);
public Query<T> matches(Pattern p);
public Query<T> matches(String ptrn);
public Query<T> type(MongoType t);
public Query<T> in(Collection<?> vals);
public Query<T> nin(Collection<?> vals);
/**
* return a sorted list of elements around point x,y
* spherical distance calculation
*
* @param x pos x
* @param y pos y
* @return the query
*/
public Query<T> nearSphere(double x, double y);
/**
* return a sorted list of elements around point x,y
*
* @param x pos x
* @param y pos y
* @return the query
*/
public Query<T> near(double x, double y);
/**
* return a sorted list of elements around point x,y
* spherical distance calculation
*
* @param x pos x
* @param y pos y
* @return the query
*/
public Query<T> nearSphere(double x, double y, double maxDistance);
/**
* return a sorted list of elements around point x,y
*
* @param x pos x
* @param y pos y
* @return the query
*/
public Query<T> near(double x, double y, double maxDistance);
/**
* search for entries with geo coordinates wihtin the given rectancle - x,y upper left, x2,y2 lower right corner
*/
public Query<T> box(double x, double y, double x2, double y2);
public Query<T> polygon(double... p);
public Query<T> center(double x, double y, double r);
/**
* same as center() but uses spherical geometry for distance calc.
*
* @param x - pos x
* @param y - y pos
* @param r - radius
* @return the query
*/
public Query<T> centerSphere(double x, double y, double r);
public Query<T> getQuery();
public void setQuery(Query<T> q);
public ObjectMapper getMapper();
public void setMapper(ObjectMapper mapper);
public String getFieldString();
public void setFieldString(String fld);
Query definitions can be in one line, or as above in several lines. Actually the current query object is changed with every call of f...something combination. The current object is always returned, for making the code more legible and understandable, you should assign the query as shown above. This makes clear: "The object changed"
If you need an "empty" query of the same type, you can call the method q. This method will return an empty query of the same type, using the same mapper etc. But only without conditions or something - just plain empty.
As already mentioned, the query by default creates AND-queries. If you need to create an or query, you can do so using the or method in the query object.
or takes a list of queries as argument, so a query might be built this way:
Query<MyEntity> q=morphium.createQueryFor(MyEntity.class);
q=q.or(q.q().f("counter").le(10),q.q().f("name").eq("Morphium"));
This would create an OR-Query asking for all "MyEntities", that have a counter less than or equal to 10 OR whose name is "Morphium". You can add as much or-queries as you like. OR-Queries can actually be combined with and queries as well:
Query<MyEntity> q=morphium.createQueryFor(MyEntity.class); q=q.f("counter").ge(2); q=q.or(q.q().f("counter").le(10),q.q().f("name").eq("Morphium"));
In that case, the query would be something like: counter is greater than 2 AND (counter is less then or equal to 10 OR name is "Morphium")
Combining and and or-queries is also possible, although the syntax would look a bit unfamiliar:
Query<MyEntity> q=morphium.createQueryFor(MyEntity.class);
q=q.f("counter").lt(100).or(q.q().f("counter").mod(3,0),q.q().f("value").ne("v");
This would create a query returning all entries that do have a counter of less than 100 AND where the modulo to base 3 of the value counter equals 0, and the value of the field value equals "v".
Quite complex, eh?
Well, there is more to it... it is possible, to create a query using a "where"-String... there you can add JavaScript code for your query. This code will be executed at the mongodb node, executing your query:
Query<MyEntity> q=morphium.createQueryFor(MyEntity.class); q=q.where("this.counter > 10");
Attention: you can javascript code in that where clause, but you cannot access the db object there. This was changed when switching to Mongodb 2.6 with V8 Javascript engine
Using the @Cache annotation, you can define cache settings on a per type (= class) basis. This is done totally in background, handled by Morphium 100% transparently. You just add the annotation to your entities and you're good to go. See [Cache] and [Cache Synchronization]
Cache synchronization was already mentioned above. The system of cache synchronization needs a messaging subsystem (see [Messaging] below). You just need to start the cache synchronizer yourself, if you want caches to be synchronized.
CacheSynchronizer cs=new CacheSynchronizer(morphium); cs.start();
If you want to stop your cache synchronizing process, just call cs.setRunning(false); . The synchronizer will stop after a while (depending on your cache synchronization timeout).
By default no cache synchronizer is running.
Morphium is cluster aware in a sense, that it does poll the state of a replicates periodically in order to know what nodes are life and need to be taken into account. (Same does the Java Driver, this information is now moved into the morphium driver implementation, so the double check is not necessary anymore).
Morphium also has support for clusters using it. Like a cluster of tomcats instances. In this case, Morphium is able to synchronize the caches of those cluster nodes.
Morphium supports a simple Messaging system which uses mongoldb as storage. The messaging is more or less transactional (to the extend that mongo gives) and works multithreaded. To use messaging you only need to instantiate a Messaging-Instance. You may add listeners to this instance to process the messages and you may send messages through this instance.
Messaging is 100% multithreaded and thread safe.
All operations regarding lists (list updates, writing lists of objects, deleting lists of objects) will be implemented using the new bulk operation available since mongodb 2.6. This gives significant speed boost and adds reliability.
Actually, all method calls to mongo support a list of documents as argument. This means, you can send a list of updates, a list of documents to be inserted, a list of whatever. The ´BulkOperationContext´ only gathers those requests on the java side together, so that they can be sent in one call, instead of several.
With Morphium 3.0 an own implementation of this bulk operation context was introduced.
You can add a number of Listeners to Morphium in order to be informed about what happens, or to influence the way things are handled.
- MorphiumStorageListeners: will be informed about any write process within morpheme. You can also veto if necessary. Works similar to [Lifecycle] methods, but for all entities.
- CacheListener: Can be added to Morphium cache, will be informed about things to be added to cache, or if something would be updated or cleared. In all cases, a veto is possible.
- ShutdownListener: if the system shuts down, you can be informed using this listener. It's not really Morphium specific.
- ProfilingListener: will be informed about any read or write access to mongo and how long it took. This is useful if you want to track long requests or index misses.
In addition to that, almost all calls to mongo can be done asynchronously - either by defining that in the @Entity annotation or by defining it directly.
That means, an asList() call on a query object can take an AsyncCallback as argument, which then will be called, when the batch is ready. (which also means, the asList call will return null, the batch will be passed on in the callback).
Morphium does have support for Aggregation in mongo. The aggregation Framework was introduced in mongo with V2.6 and is a alternative to MapReduce (which is still used). We implemented support for the new Aggregation framework into mongo. Up until now, there was no request for MapReduce - if you need it, please let me know.
Here is how the aggregation framework is used from mongo (see more info on the aggregation framework at MongoDb
This is the Unit test for Aggregation support in Mongo:
@Test public void aggregatorTest() throws Exception {
createUncachedObjects(1000);
Aggregator<UncachedObject, Aggregate> a = MorphiumSingleton.get().createAggregator(UncachedObject.class, Aggregate.class);
assert (a.getResultType() != null);
//eingangsdaten reduzieren
a = a.project("counter");
//Filtern
a = a.match(MorphiumSingleton.get().createQueryFor(UncachedObject.class).f("counter").gt(100));
//Sortieren - für $first/$last
a = a.sort("counter");
//limit der Daten
a = a.limit(15);
//group by - in dem Fall ALL, könnte auch beliebig sein
a = a.group("all").avg("schnitt", "$counter").sum("summe", "$counter").sum("anz", 1).last("letzter", "$counter").first("erster", "$counter").end();
//ergebnis projezieren
HashMap<String,Object> projection=new HashMap<>();
projection.put("summe",1);
projection.put("anzahl","$anz");
projection.put("schnitt",1);
projection.put("last","$letzter");
projection.put("first","$erster");
a = a.project(projection);
List<DBObject> obj = a.toAggregationList();
for (DBObject o : obj) {
log.info("Object: " + o.toString());
}
List<Aggregate> lst = a.aggregate();
assert (lst.size() == 1) : "Size wrong: " + lst.size();
log.info("Sum : " + lst.get(0).getSumme());
log.info("Avg : " + lst.get(0).getSchnitt());
log.info("Last : " + lst.get(0).getLast());
log.info("First: " + lst.get(0).getFirst());
log.info("count: " + lst.get(0).getAnzahl());
assert (lst.get(0).getAnzahl() == 15) : "did not find 15, instead found: " + lst.get(0).getAnzahl();
}
@Embedded
public static class Aggregate {
private double schnitt;
private long summe;
private int last;
private int first;
private int anzahl;
@Property(fieldName = "_id")
private String theGeneratedId;
public int getAnzahl() {
return anzahl;
}
public void setAnzahl(int anzahl) {
this.anzahl = anzahl;
}
public int getLast() {
return last;
}
public void setLast(int last) {
this.last = last;
}
public int getFirst() {
return first;
}
public void setFirst(int first) {
this.first = first;
}
public double getSchnitt() {
return schnitt;
}
public void setSchnitt(double schnitt) {
this.schnitt = schnitt;
}
public long getSumme() {
return summe;
}
public void setSumme(long summe) {
this.summe = summe;
}
public String getTheGeneratedId() {
return theGeneratedId;
}
public void setTheGeneratedId(String theGeneratedId) {
this.theGeneratedId = theGeneratedId;
}
}
The class Aggregate is used to hold the batch of the aggregation.
If javax.validation can be found in class path, you are able to validate values of your entities using the validation annotations. Those validations will take place before the object would be saved.
Technically it's implemented as a JavaxValidationStorageListener which is a storage listener and vetoes the write operation if validation fails.
an example on how to use validation:
@Id private MorphiumId id;
@Min(3)
@Max(7)
private int theInt;
@NotNull
private Integer anotherInt;
@Future
private Date whenever;
@Pattern(regexp = "m[ueü]nchen")
private String whereever;
@Size(min = 2, max = 5)
private List friends;
@Email
private String email;
Those validation rules will be enforced upon storing the corresponding object:
@Test(expected = ConstraintViolationException.class)
public void testNotNull() {
ValidationTestObject o = getValidObject();
o.setAnotherInt(null);
MorphiumSingleton.get().store(o);
}
Its possible to have different type of entities stored in one collection. Usually this will only make sense if those entities have some things in common. In an object oriented way: they are derived from one single entity.
In order to make this work, you have to tell Morphium that you want to use a certain entity in a polymorph way (property of the annotation @Entity). If so, the full qualified class name will be stored in the mongo document representing the entity. Actually, you can store any type of entity into one list, if each of those types is marked polymorph. Only reading them is a bit hard, as you would iterate over Objects and would have to decide on type yourself.
on the following lines you get a more in depth view of the
Morphium by defaults converts all java CamelCase identifiers in underscore separated strings. So, MyEntity will be stored in an collection called my_entity and the field aStringValue would be stored in as a_string_value.
When specifying a field, you can always use either the transformed name or the name of the corresponding java field. Collection names are always determined by the classname itself.
But in Morphium you can of course change that behaviour. Easiest way is to switch off the transformation of CamelCase globally by setting camelCaseConversionEnabled to false (see above: Configuration). If you switch it off, its off completely - no way to do switch it on for just one collection or so.
If you need to have only several types converted, but not all, you have to have the conversion globally enabled, and only switch it off for certain types. This is done in either the @Entity or @Embedded annotation.
@Entity(convertCamelCase=false) public class MyEntity { private String myField;
This example will create a collection called MyEntity (no conversion) and the field will be called myField in mongo as well (no conversion).
Attention: Please keep in mind that, if you switch off camelCase conversion globally, nothing will be converted!
you can tell Morphium to use the full qualified classname as basis for the collection name, not the simple class name. This would batch in createing a collection de_caluga_morphium_my_entity for a class called de.caluga.morphium.MyEntity. Just set the flag useFQN in the entity annotation to true.
@Entity(useFQN=true) public class MyEntity {
Recommendation is, not to use the full qualified classname unless it's really needed.
In addition to that, you can define custom names of fields and collections using the corresponding annotation (@Entity, @Property).
For entities you may set a custom name by using the collectionName value for the annotation:
@Entity(collectionName="totallyDifferent") public class MyEntity { private String myValue; the collection name will be totallyDifferent in mongo. Keep in mind that camel case conversion for fields will still take place. So in that case, the field name would probably be my_value. (if camel case conversion is enabled in config)
You can also specify the name of a field using the property annotation:
@Property(fieldName="my_wonderful_field") private String something;
Again, this only affects this field (in this case, it will be called my_wondwerful_field in mongo) and this field won't be converted camelcase. This might cause a mix up of cases in your mongodb, so please use this with care.
When accessing fields in Morphium (especially for the query) you may use either the name of the Field in Java (like myEntity) or the converted name depending on the config (camelCased or not, or custom).
In some cases it might be necessary to have the collection name calculated dynamically. This can be acchieved using the NameProvider Interface.
You can define a NameProvider for your entity in the @Entity annotation. You need to specify the type there. By default, the NameProvider for all Entities is DefaultNameProvider. Which acutally looks like this:
public final class DefaultNameProvider implements NameProvider {
@Override
public String getCollectionName(Class<?> type, ObjectMapper om, boolean translateCamelCase, boolean useFQN, String specifiedName, Morphium morphium) {
String name = type.getSimpleName();
if (useFQN) {
name = type.getName().replaceAll("\\.", "_");
}
if (specifiedName != null) {
name = specifiedName;
} else {
if (translateCamelCase) {
name = morphium.getARHelper().convertCamelCase(name);
}
}
return name;
}
}
You can use your own provider to calculate collection names depending on time and date or for example depending on the querying host name (like: create a log collection for each server separately or create a collection storing logs for only one month each).
Attention: Name Provider instances will be cached, so please implement them threadsafe.
Entitys in Morphium ar just "Plain old Java Objects" (POJOs). So you just create your data objects, as usual. You only need to add the annotation @Entity to the class, to tell Morphium "Yes, this can be stored". The only additional thing you need to take care of is the definition of an ID-Field. This can be any field in the POJO identifying the instance. Its best, to use MorphiumId as type of this field, as these can be created automatically and you don't need to care about those as well.
If you specify your ID to be of a different kind (like String), you need to make sure, that the String is set, when the object will be written. Otherwise you might not find the object again. So the shortest Entity would look like this:
@Entity
public class MyEntity {
@Id private MorphiumId id;
//.. add getter and setter here
}
Indexes are very important in mongo, so you should definitely define your indexes as soon as possible during your development. Indexes can be defined on the Entity itself, there are several ways to do so: - @Id always creates an index - you can add an @Index to any field to have that indexed:
@Index private String name;
- you can define combined indexes using the
@Indexannotation at the class itself:
@Index({"counter, name","value,thing,-counter"} public class MyEntity {
This would create two combined indexes: one with counter and name (both ascending) and one with value, thing and descending counter. You could also define single field indexes using this annotations, but it`s easier to read adding the annotation direktly to the field.
- Indexes will be created automatically if you create the collection. If you want the indexes to be created, even if there is already data stores, you need to call
morphium.ensureIndicesFor(MyEntity.class)- You also may create your own indexes, which are not defined in annotations by callingmorphium.ensureIndex(). As parameter you pass on a Map containing field name and order (-1 or 1) or just a prefixed list of strings (like"-counter","name").
Every Index might have a set of options which define the kind of this index. Like buildInBackground or unique. You need to add those as second parameter to the Index-Annotation:
@Entity @Index(value = {"-name, timer", "-name, -timer", "lst:2d", "name:text"}, options = {"unique:1", "", "", ""}) public static class IndexedObject {
here 4 indexes are created. The first two ar more or less standard, wheres the lst index is a geospacial one and the index on name is a text index (only since mongo 2.6). If you need to define options for one of your indexes, you need to define it for all of them (here, only the first index is unique).
We're working on porting Morphium to java8, and there it will be possible to have more than one @Index annotation, making the syntax a bit more ledgeable
Similar as with indexes, you can define you collection to be capped using the @Capped annotation. This annotation takes two arguments: the maximum number of entries and the maximum size. If the collection does not exist, it will be created as capped collection using those two values. You can always ensureCapped your collection, unfortunately then only the size parameter will be honored.
Querying is done via the Query-Object, which is created by Morphium itself (using the Query Factory). The definition of the query is done using the fluent interface:
Query<MyEntity> query=morphium.createQueryFor(MyEntity.class);
query=query.f("id").eq(new MorphiumId());
query=query.f("valueField").eq("the value");
query=query.f("counter").lt(22);
query=query.f("personName").matches("[a-zA-Z]+");
query=query.limit(100).sort("counter");
In this example, I refer to several fields of different types. The Query itself is always of the same basic syntax:
queryObject=queryObject.f(FIELDNAME).OPERATION(Value);
queryObject=queryObject.skip(NUMBER); //skip a number of entreis
queryObject=queryObject.limig(NUMBER); // limit batch
queryObject.sort(FIELD_TO_SORTBY);`
As field name you may either use the name of the field as it is in mongo or the name of the field in java. If you specify an unknown field to Morphium, a RuntimeException will be raised.
For definition of the query, it's also a good practice to define enums for all of your fields. This makes it hard to have mistypes in a query:
public class MyEntity {
private MorphiumId id;
private Double value;
private String personName;
private int counter;
//.... field accessors
public enum Fields { id, value, personName,counter, }
}
There is a plugin for intelliJ creating those enums automatically. Then, when defining the query, you don't have to type in the name of the field, just use the field enum:
query=query.f(MyEntity.Fields.counter).eq(123);
After you defined your query, you probably want to access the data in mongo. Via Morphium,there are several possibilities to do that: - queryObject.get(): returns the first object matching the query, only one. Or null if nothing matched - queryObject.asList(): return a list of all matching objects. Reads all data in RAM. Useful for small amounts of data - Iterator<MyEntity> it=queryObject.asIterator(): creates a MorphiumIterator to iterate through the data, whch does not read all data at once, but only a couple of elements in a row (default 10).
Morphium has support for special Iterators, which steps through the data, a couple of elements at a time. By Default this is the standard behaviour. But the _Morphium_Iterator ist quite capable:
queryObject.asIterable()will step through the results batch by batch. The batch size is determined by the driver settings. This is the most performant, but lacks the ability to "step back" out of the current processed batch.queryObject.asIterable(100)will step through the batch list, 100 at a time using a mongodb cursor iterator.queryObject.asIterable(100,5)will step through the batch list, 100 at a time and keep 5 chunks of 100 elements each as prefetch buffers. Those will be filled in background.queryObject.asIterable(100,1)actually the same as.asIterable(100)but using a query based iterator instead.queryObject.asIterable(100, new PrefetchingIterator())): this is more or less the same as the prefetching above, but using the query based PrefetchingIterator. This is fetching the datachunks using skip and limit functionality of mongodb which showed some decrease in performance, the higher the skip is. It's still there for compatibility reasons.
Internally the default iterator does create queries that are derived from the sort of the query, if there is no sort specified, it will assume you want to sort by _id.
you could put each of those iterators to one of two classes:
- the iterator is using the Mongodb Cursor
- the iterator is using distinct queries for each step / chunk.
these have significant different behaviour.
the query based iterators use the usual query method of morphium. hence all related functionalities work, like caching, life cycle methods etc. It is just like you would create those queries in a row. one by one.
due to the fact that the query is being executed portion by portion, there is no way of having things cached properly. These queries do not use the cache!
Storing is more or less a very simple thing, just call morphium.store(pojo) and you're done. Although there is a bit more to it: - if the object does not have an id (id field is null), there will be a new entry into the corresponding collection. - if the object does have an id set (!= null), an update to db is being issued. - you can call morphium.storeList(lst) where lst is a list of entities. These would be stored in bulkd, if possible. Or it does a bulk update of things in mongo. Even mixed lists (update and inserts) are possible. Morphium will take care of sorting it out - there are additional methods for writing to mongo, like update operations set, unset, push, pull and so on (update a value on one entity or for all elements matching a query), delete objects or objects matching a query, and a like - The writer that acutally writes the data, is chosen depending on the configuration of this entity (see Annotations below)
a lot of things can be configured in Morphium using annotations. Those annotations might be added to either classes, fields or both.
Perhaps the most important Annotation, as it has to be put on every class the instances of which you want to have stored to database. (Your data objects).
By default, the name of the collection for data of this entity is derived by the name of the class itself and then the camel case is converted to underscore strings (unless config is set otherwise).
These are the settings available for entities:
- translateCamelCase: default true. If set, translate the name of the collection and all fields (only those, which do not have a custom name set)
- collectionName: set the collection name. May be any value, camel case won't be converted.
- useFQN: if set to true, the collection name will be built based on the full qualified class name. The Classname itself, if set to false. Default is false
- polymorph: if set to true, all entities of this type stored to mongo will contain the full qualified name of the class. This is necessary, if you have several different entities stored in the same collection. Usually only used for polymorph lists. But you could store any polymorph marked object into that collection Default is false
- nameProvider: specify the class of the name provider, you want to use for this entity. The name provider is being used to determine the name of the collection for this type. By Default it uses the
DefaultNameProvider(which just uses the classname to build the collection name). see above
Marks POJOs for object mapping, but don't need to have an ID set. These objects will be marshaled and unmarshaled, but only as part of another object (Subdocument). This has to be set at class level.
You can switch off camel case conversion for this type and determine, whether data might be used polymorph.
Valid at: Class level
Tells Morphium to create a capped collection for this object (see capped collections above).
Parameters:
| ----|----| | maxSize | maximum size in byte. Is used when converting to a capped collection |
| maxNumber | number of entries for this capped collection |
Special feature for Morphium: this annotation has to be added for at lease one field of type Map<String,Object>. It does make sure, that all data in Mongo, that cannot be mapped to a field of this entity, will be added to the annotated Map properties.
by default this map is read only. But if you want to change those values or add new ones to it, you can set readOnly=false
It's possible to define aliases for field names with this annotation (hence it has to be added to a field).
java @Alias({"stringList","string_list"}) List<String> strLst;
in this case, when reading an object from Mongodb, the name of the field strLst might also be stringList or string_list in mongo. When storing it, it will always be stored as strLst or str_lst according to config.
This feature comes in handy when migrating data.
has to be added to both the class and the field(s) to store the creation time in. This value is set in the moment, the object is being stored to mongo. The data type for creation time might be:
long/Long: store as timestampEate: store as date objectString: store as a string, you may need to specify the format for that
same as creation time, but storing the last access to this type. Attention: will cause all objects read to be updated and written again with a changed timestamp.
Usage: find out, which entries on a translation table are not used for quite some time. Either the translation is not necessary anymore or the corresponding page is not being used.
Same as the two above, except the timestamp of the last change (to mongo) is being stored. The value will be set, just before the object is written to mongo.
Define the read preference level for an entity. This annotation has to be used at class level. Valid types are:
- PRIMARY: only read from primary node
- PRIMARY_PREFERED: if possible, use primary.
- SECONDARY: only read from secondary node
- SECONDARY_PREFERED: if possible, use secondary
- NEAREST: I don't care, take the fastest
Very important annotation to a field of every entity. It marks that field to be the id and identify any object. It will be stored as _id in mongo (and will get an index).
The Id may be of any type, though usage of ObjectId (or MorphiumId in Java) is strongly recommended.
Define indexes. Indexes can be defined for a single field. Combined indexes need to be defined on class level. See above.
If this annotation is present for an entity, this entity would only send changes to mongo when being stored. This is useful for big objects, which only contain small changes.
Attention: in the background your object is being replaced by a Proxy-Object to collect the changes.
Can be added to any field. This not only has documenting character, it also gives the opportunity to change the name of this field by setting the fieldName value. By Default the fieldName is ".", which means "fieldName based".
Mark an entity to be read only. You'll get an exception when trying to store.
If you have a member variable, that is a POJO and not a simple value, you can store it as reference to a different collection, if the POJO is an Entity (and only if!).
This also works for lists and Maps. Attention: when reading Objects from disk, references will be de-referenced, which will batch into one call to mongo each.
Unless you set lazyLoading to true, in that case, the child documents will only be loaded when accessed.
Do not store the field.
Usually, Morphium does not store null values at all. That means, the corresponding document just would not contain the given field(s) at all.
Sometimes that might cause problems, so if you add @UseIfNull to any field, it will be stored into mongo even if it is null.
Sometimes it might be useful to have an entity set to write only (logs). An exception will be raised, if you try to query such a entity.
Sepcify the safety for this entity when it comes to writing to mongo. This can range from "NONE" to "WAIT FOR ALL SLAVES". Here are the available settings:
- timeout: set a timeout in ms for the operation - if set to 0, unlimited (default). If set to negative value, wait relative to replication lag
- level: set the safety level:
IGNORE_ERRORSNone, no checking is doneNORMALNone, network socket errors raisedBASICChecks server for errors as well as network socket errors raisedWAIT_FOR_SLAVEChecks servers (at lease 2) for errors as well as network socket errors raisedMAJORITYWait for at least 50% of the slaves to have written the dataWAIT_FOR_ALL_SLAVES: waits for all slaves to have committed the data. This is depending on how many slaves are available in replica set. Wise timeout settings are important here. See WriteConcern in MongoDB Java-Driver for additional information
If this annotation is present at a given entity, all write access concerning this type would be done asynchronously. That means, the write process will start immediately, but run in background.
You won't be informed about errors or success. If you want to do that, you don't need to set @AsyncWrites, use one of the save method with a Callback for storing your data - those methods are all asynchronous.
Create a write buffer, do not write data directly to mongo, but wait for the buffer to be filled a certain amount:
- size: default 0, max size of write Buffer entries, 0 means unlimited. STRATEGY is meaningless then
- strategy: define what happens when write buffer is full and new things would be written. Can be one of
WRITE_NEW, WRITE_OLD, IGNORE_NEW, DEL_OLD, JUST_WARNWRITE_NEW: write all new incoming entries to the buffer directly to mongo, buffer won't growWRITE_OLD: take one of the oldest entries from the buffer, write it, queue the new entry to buffer. Buffer won't growIGNORE_NEW: do not add new entry to buffer and do not write it. Attention: possible data loss Buffer won't growDEL_OLD: delete an old entry from the buffer, add new one. Buffer won't growJUST_WARN: just issue a warning via log4j, but add the new Object anyway. Buffer will grow, no matter what threshold is set!
Read-Cache Settings for the given entity.
- timeout: How long are entries in cache valid, in ms. Default 60000ms
- clearOnWrite: if set to true (default) the cache will be cleared, when you store or update an instance of this type
- maxEntries: Maximum number of entries in cache for this type. -1 means
infinite - clearStrategy: when reaching the maximum number of entries, how to replace entries in cache.
LRU: remove the least recently used entry from cache, add the newRANDOM: remove a random entry from cache, add the newFIFO: remove the oldest entry from cache, add the new (default)
- syncCache: Set the strategy for syncing cache entries of this type. This is useful when running in a clustered environment to inform all nodes of the cluster to change their caches accordingly. A sync message will be sent to all nodes using the Morphium messaging as soon as an item of this type is written to mongo.
NONE: No cache syncCLEAR_TYPE_CACHE: clear the whole cache for this type on all nodesREMOVE_ENTRY_FROM_TYPE_CACHE: remove an updated entry from the type cache of all nodesUPDATE_ENTRY: update the entry in the cache on all nodes- This may cause heavy load on the messaging system. All sync strategies except
CLEAR_TYPE_CACHEmight batch in dirty reads on some nodes.
Explicitly disable cache for this type. This is important if you have a hierarchy of entities and you want the "super entity" to be cached, but inherited entities from that type not.
This is a marker annotation telling Morphium that in this type, there are some Lifecycle callbacks to be called.
Please keep in mind that all lifecycle annotations (see below) would be ignored, if this annotation is not added to the type.
If @Lifecycle is added to the type, @PostLoad may define the method to be called, after the object was read from mongo.
If @Lifecycle is added to the type, @PreStore may define the method to be called, just before the object is written to mongo. It is possible to throw an Exception here to avoid storage of this object.
If @Lifecycle is added to the type, @PostStore may define the method to be called, after the object was written to mongo.
If @Lifecycle is added to the type, @PreRemove may define the method to be called, just before the object would be removed from mongo. You might throw an exception here to avoid storage.
If @Lifecycle is added to the type, @PostRemove may define the method to be called, after the object was removed from mongo.
If @Lifecycle is added to the type, @PreUpdate may define the method to be called, just before the object would be updated in mongo. Veto is possible by throwing an Exception.
If @Lifecycle is added to the type, @PostUpdate may define the method to be called, after the object was updated in mongo.
Morphium does not have many dependencies:
- log4j
- mongo java driver (usually the latest version available at that time)
- a simple json parser (json-simple)
Here is the excerpt from the pom.xml:
<dependency>
<groupid>cglib</groupid>
<artifactid>cglib</artifactid>
<version>2.2.2</version>
</dependency>
<dependency>
<groupid>log4j</groupid>
<artifactid>log4j</artifactid>
<version>1.2.17</version>
</dependency>
<dependency>
<groupid>org.mongodb</groupid>
<artifactid>mongo-java-driver</artifactid>
<version>2.12.3</version>
</dependency>
<dependency>
<groupid>com.googlecode.json-simple</groupid>
<artifactid>json-simple</artifactid>
<version>1.1</version>
</dependency>
There is one kind of "optional" Dependency: If hibernate validation is available, it's being used. If it cannot be found in class path, it's no problem.
All those Code examples are part of the Morphium source distribution. All of the codes are at least part of a unit test.
for (int i = 1; i <= NO_OBJECTS; i++) {
UncachedObject o = new UncachedObject();
o.setCounter(i);
o.setValue("Uncached " + i % 2);
MorphiumSingleton.get().store(o);
}
Query<uncachedobject> q = MorphiumSingleton.get().createQueryFor(UncachedObject.class);
q = q.f("counter").gt(0).sort("-counter", "value");
List</uncachedobject><uncachedobject> lst = q.asList();
assert (!lst.get(0).getValue().equals(lst.get(1).getValue()));
q = q.q().f("counter").gt(0).sort("value", "-counter");
List<UncachedObject> lst2 = q.asList();
assert (lst2.get(0).getValue().equals(lst2.get(1).getValue()));
log.info("Sorted");
q = MorphiumSingleton.get().createQueryFor(UncachedObject.class);
q = q.f("counter").gt(0).limit(5).sort("-counter");
int st = q.asList().size();
q = MorphiumSingleton.get().createQueryFor(UncachedObject.class);
q = q.f("counter").gt(0).sort("-counter").limit(5);
assert (st == q.asList().size()) : "List length differ?";
And:
Query<complexobject> q = MorphiumSingleton.get().createQueryFor(ComplexObject.class);
q = q.f("embed.testValueLong").eq(null).f("entityEmbeded.binaryData").eq(null);
String queryString = q.toQueryObject().toString();
log.info(queryString);
assert (queryString.contains("embed.test_value_long") && queryString.contains("entityEmbeded.binary_data"));
q = q.f("embed.test_value_long").eq(null).f("entity_embeded.binary_data").eq(null);
queryString = q.toQueryObject().toString();
log.info(queryString);
assert (queryString.contains("embed.test_value_long") && queryString.contains("entityEmbeded.binary_data"));
@Test
public void asyncStoreTest() throws Exception {
asyncCall = false;
super.createCachedObjects(1000);
waitForWrites();
log.info("Uncached object preparation");
super.createUncachedObjects(1000);
waitForWrites();
Query<UncachedObject> uc = MorphiumSingleton.get().createQueryFor(UncachedObject.class);
uc = uc.f("counter").lt(100);
MorphiumSingleton.get().delete(uc, new AsyncOperationCallback<Query<UncachedObject>>() {
@Override
public void onOperationSucceeded(AsyncOperationType type, Query<Query<UncachedObject>> q, long duration, List<Query<UncachedObject>> batch, Query<UncachedObject> entity, Object... param) {
log.info("Objects deleted");
}
@Override
public void onOperationError(AsyncOperationType type, Query<Query<UncachedObject>> q, long duration, String error, Throwable t, Query<UncachedObject> entity, Object... param) {
assert false;
}
});
uc = uc.q();
uc.f("counter").mod(3, 2);
MorphiumSingleton.get().set(uc, "counter", 0, false, true, new AsyncOperationCallback<UncachedObject>() {
@Override
public void onOperationSucceeded(AsyncOperationType type, Query<UncachedObject> q, long duration, List<UncachedObject> batch, UncachedObject entity, Object... param) {
log.info("Objects updated");
asyncCall = true;
}
@Override
public void onOperationError(AsyncOperationType type, Query<UncachedObject> q, long duration, String error, Throwable t, UncachedObject entity, Object... param) {
log.info("Objects update error");
}
});
waitForWrites();
assert MorphiumSingleton.get().createQueryFor(UncachedObject.class).f("counter").eq(0).countAll() > 0;
assert (asyncCall);
}
@Test
public void asyncReadTest() throws Exception {
asyncCall = false;
createUncachedObjects(100);
Query<UncachedObject> q = MorphiumSingleton.get().createQueryFor(UncachedObject.class);
q = q.f("counter").lt(1000);
q.asList(new AsyncOperationCallback<UncachedObject>() {
@Override
public void onOperationSucceeded(AsyncOperationType type, Query<UncachedObject> q, long duration, List<UncachedObject> batch, UncachedObject entity, Object... param) {
log.info("got read answer");
assert (batch != null) : "Error";
assert (batch.size() == 100) : "Error";
asyncCall = true;
}
@Override
public void onOperationError(AsyncOperationType type, Query<UncachedObject> q, long duration, String error, Throwable t, UncachedObject entity, Object... param) {
assert false;
}
});
waitForAsyncOperationToStart(1000000);
int count = 0;
while (q.getNumberOfPendingRequests() > 0) {
count++;
assert (count < 10);
System.out.println("Still waiting...");
Thread.sleep(1000);
}
assert (asyncCall);
}
@Test
public void basicIteratorTest() throws Exception {
createUncachedObjects(1000);
Query<UncachedObject> qu = getUncachedObjectQuery();
long start = System.currentTimeMillis();
MorphiumIterator<UncachedObject> it = qu.asIterable(2);
assert (it.hasNext());
UncachedObject u = it.next();
assert (u.getCounter() == 1);
log.info("Got one: " + u.getCounter() + " / " + u.getValue());
log.info("Current Buffersize: " + it.getCurrentBufferSize());
assert (it.getCurrentBufferSize() == 2);
u = it.next();
assert (u.getCounter() == 2);
u = it.next();
assert (u.getCounter() == 3);
assert (it.getCount() == 1000);
assert (it.getCursor() == 3);
u = it.next();
assert (u.getCounter() == 4);
u = it.next();
assert (u.getCounter() == 5);
while (it.hasNext()) {
u = it.next();
log.info("Object: " + u.getCounter());
}
assert (u.getCounter() == 1000);
log.info("Took " + (System.currentTimeMillis() - start) + " ms");
}
@Test
public void messagingTest() throws Exception {
error = false;
MorphiumSingleton.get().clearCollection(Msg.class);
final Messaging messaging = new Messaging(MorphiumSingleton.get(), 500, true);
messaging.start();
messaging.addMessageListener(new MessageListener() {
@Override
public Msg onMessage(Messaging msg, Msg m) {
log.info("Got Message: " + m.toString());
gotMessage = true;
return null;
}
});
messaging.storeMessage(new Msg("Testmessage", MsgType.MULTI, "A message", "the value - for now", 5000));
Thread.sleep(1000);
assert (!gotMessage) : "Message recieved from self?!?!?!";
log.info("Dig not get own message - cool!");
Msg m = new Msg("meine Message", MsgType.SINGLE, "The Message", "value is a string", 5000);
m.setMsgId(new MorphiumId());
m.setSender("Another sender");
MorphiumSingleton.get().store(m);
Thread.sleep(5000);
assert (gotMessage) : "Message did not come?!?!?";
gotMessage = false;
Thread.sleep(5000);
assert (!gotMessage) : "Got message again?!?!?!";
messaging.setRunning(false);
Thread.sleep(1000);
assert (!messaging.isAlive()) : "Messaging still running?!?";
}
@Test
public void cacheSyncTest() throws Exception {
MorphiumSingleton.get().dropCollection(Msg.class);
createCachedObjects(1000);
Morphium m1 = MorphiumSingleton.get();
MorphiumConfig cfg2 = new MorphiumConfig();
cfg2.setAdr(m1.getConfig().getAdr());
cfg2.setDatabase(m1.getConfig().getDatabase());
Morphium m2 = new Morphium(cfg2);
Messaging msg1 = new Messaging(m1, 200, true);
Messaging msg2 = new Messaging(m2, 200, true);
msg1.start();
msg2.start();
CacheSynchronizer cs1 = new CacheSynchronizer(msg1, m1);
CacheSynchronizer cs2 = new CacheSynchronizer(msg2, m2);
waitForWrites();
//fill caches
for (int i = 0; i < 1000; i++) {
m1.createQueryFor(CachedObject.class).f("counter").lte(i + 10).asList(); //fill cache
m2.createQueryFor(CachedObject.class).f("counter").lte(i + 10).asList(); //fill cache
}
//1 always sends to 2....
CachedObject o = m1.createQueryFor(CachedObject.class).f("counter").eq(155).get();
cs2.addSyncListener(CachedObject.class, new CacheSyncListener() {
@Override
public void preClear(Class cls, Msg m) throws CacheSyncVetoException {
log.info("Should clear cache");
preClear = true;
}
@Override
public void postClear(Class cls, Msg m) {
log.info("did clear cache");
postclear = true;
}
@Override
public void preSendClearMsg(Class cls, Msg m) throws CacheSyncVetoException {
log.info("will send clear message");
preSendClear = true;
}
@Override
public void postSendClearMsg(Class cls, Msg m) {
log.info("just sent clear message");
postSendClear = true;
}
});
msg2.addMessageListener(new MessageListener() {
@Override
public Msg onMessage(Messaging msg, Msg m) {
log.info("Got message " + m.getName());
return null;
}
});
preSendClear = false;
preClear = false;
postclear = false;
postSendClear = false;
o.setValue("changed it");
m1.store(o);
Thread.sleep(1000);
assert (!preSendClear);
assert (!postSendClear);
assert (postclear);
assert (preClear);
Thread.sleep(60000);
long l = m1.createQueryFor(Msg.class).countAll();
assert (l <= 1) : "too many messages? " + l;
// createCachedObjects(50);
// Thread.sleep(90000); //wait for messages to be cleared
// assert(m1.createQueryFor(Msg.class).countAll()==0);
cs1.detach();
cs2.detach();
msg1.setRunning(false);
msg2.setRunning(false);
m2.close();
}
@Test
public void nearTest() throws Exception {
MorphiumSingleton.get().dropCollection(Place.class);
ArrayList<Place> toStore = new ArrayList<Place>();
// MorphiumSingleton.get().ensureIndicesFor(Place.class);
for (int i = 0; i < 1000; i++) {
Place p = new Place();
List<Double> pos = new ArrayList<Double>();
pos.add((Math.random() * 180) - 90);
pos.add((Math.random() * 180) - 90);
p.setName("P" + i);
p.setPosition(pos);
toStore.add(p);
}
MorphiumSingleton.get().storeList(toStore);
Query<Place> q = MorphiumSingleton.get().createQueryFor(Place.class).f("position").near(0, 0, 10);
long cnt = q.countAll();
log.info("Found " + cnt + " places around 0,0 (10)");
List<Place> lst = q.asList();
for (Place p : lst) {
log.info("Position: " + p.getPosition().get(0) + " / " + p.getPosition().get(1));
}
}
@Index("position:2d")
@NoCache
@WriteBuffer(false)
@WriteSafety(level = SafetyLevel.MAJORITY)
@DefaultReadPreference(ReadPreferenceLevel.PRIMARY)
@Entity
public static class Place {
@Id
private MorphiumId id;
public List<Double> position;
public String name;
public MorphiumId getId() {
return id;
}
public void setId(MorphiumId id) {
this.id = id;
}
public List<Double> getPosition() {
return position;
}
public void setPosition(List<Double> position) {
this.position = position;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
today there is a whole bunch of loggin frameworks. Every one is more capable than the other. Most commond probably are java.util.logging and log4j. Morphium used log4j quite some time. But in our high load environment we encountered problems with the logging itself. Also we had problems, that every library did use a different logging framework.
Morphium since V2.2.21 does use its own logger. This can be configured using Environment variables (in linux like export morphium_log_file=/var/log/morphium.log) or java system parameters (like java -Dmorphium.log.level=5).
This logger is built for performance and thread safety. It works find in high load environments. And has the following features:
- it is instanciated with
new- no singleton. Lesser performance / synchronization issues - it has several options for configuration. (see above). You can define global settings like
morphium.log.filebut you can also define settings for a prefix of a fqdn, likemorphium.log.file.de.caluga.morphium. For examplejava -Dmorphium.log.level=2 -Dmorphium.log.level.de.caluga.morphium.messaging=5would switch on debugging only for the messaging package, the default has level 2 (which is ERROR) - it is possible to define 3 Things in the way described above (either global or class / package sepcific): FileName (real path, or STDOUT or STDERR), Log level (0=none, 1=FATAL, 2=ERROR, 3=WARN, 4=INFO, 5=DEBUG) and whether the output should be synced or buffered (synced=false)
- if you want to use log4j or java.util.logging as logging, you can set the log filename to
log4jorjulaccordingly - if you want to use your own logging implementation, just tell morphium the log delegate as filename, e.g.
morphium.log.file=de.caluga.morphium.log.MyLogDelegate - of course, all this configuration can be done in code as well.