Support Vector Machines, in short SVM, are defined as supervised machine learning models for both classification as well as regression problems. SVM falls under the category of classification algorithms that allows a computer to take a set of data and classify it into two groups. What's unique about SVM is its benefit of maximizing the margin (or space) between the two groups to allow for new observation that the computer has not seen before to be better classified. This learning model can solve both linear and non-linear problems and work well for many practical problems!
Support Vectors are closest data points about which the classifier would distinguish among classes. These vectors determine the orientation of the line suitable for maximized separation as shown below:
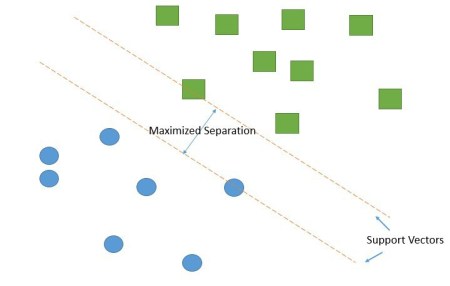
SVM gets its name from these support vectors that are ultimately supporting the model vectors by providing sufficient information to the computer as all other points have no effect on the model or predictions.
Kernel Trick enables SVM to be interpreted in higher dimensional spaces. It is even very effective on data sets where the number of dimensions is greater than the number of samples. SVM can classify both the linear and non-linear data!
For humans the above image seems pretty intuitive. We just draw a line to separate the different labeled classes from each other. But how does SVM solve this problem?

Well, the SVM want to find so-called maximum-margin hyperplane which iterates anything from n-dimensional space into higher ones so as to classify them properly. This is what we call Kernel Trick! In case of a non-linear data set SVM cannot simply draw a linear hyperplane. Therefore Support Vector Machines use the Kernel Trick.
Kernel Trick equips SVM with the ability to build a classification model for non-linear data sets

Well, SVM is capable of doing both classification and regression. The benefit is that you can capture much more complex relationships between your data points without having to perform difficult transformations on your own. The downside is that the training time is much longer as it's much more computationally intensive.
Further advantages of Support Vector Machines are the memory efficiency, speed and general accuracy in comparison to other classification methods like k-nearest neighbor or deep neural networks in some particular cases!