diff --git a/docs-website/sidebars.js b/docs-website/sidebars.js
index 801e0fbd07d365..be12aa3a827f2f 100644
--- a/docs-website/sidebars.js
+++ b/docs-website/sidebars.js
@@ -30,17 +30,16 @@ module.exports = {
],
},
{
- Integrations: [
+ type: "category",
+ label: "Integrations",
+ link: { type: "doc", id: "metadata-ingestion/README" },
+ items: [
// The purpose of this section is to provide a deeper understanding of how ingestion works.
// Readers should be able to find details for ingesting from all systems, apply transformers, understand sinks,
// and understand key concepts of the Ingestion Framework (Sources, Sinks, Transformers, and Recipes)
- {
- type: "doc",
- label: "Introduction",
- id: "metadata-ingestion/README",
- },
{
"Quickstart Guides": [
+ "metadata-ingestion/cli-ingestion",
{
BigQuery: [
"docs/quick-ingestion-guides/bigquery/overview",
@@ -85,15 +84,18 @@ module.exports = {
},
],
},
+ "metadata-ingestion/recipe_overview",
{
- Sources: [
+ type: "category",
+ label: "Sources",
+ link: { type: "doc", id: "metadata-ingestion/source_overview" },
+ items: [
// collapse these; add push-based at top
{
type: "doc",
id: "docs/lineage/airflow",
label: "Airflow",
},
-
//"docker/airflow/local_airflow",
"metadata-integration/java/spark-lineage/README",
"metadata-ingestion/integration_docs/great-expectations",
@@ -106,7 +108,10 @@ module.exports = {
],
},
{
- Sinks: [
+ type: "category",
+ label: "Sinks",
+ link: { type: "doc", id: "metadata-ingestion/sink_overview" },
+ items: [
{
type: "autogenerated",
dirName: "metadata-ingestion/sink_docs",
@@ -114,10 +119,13 @@ module.exports = {
],
},
{
- Transformers: [
- "metadata-ingestion/docs/transformer/intro",
- "metadata-ingestion/docs/transformer/dataset_transformer",
- ],
+ type: "category",
+ label: "Transformers",
+ link: {
+ type: "doc",
+ id: "metadata-ingestion/docs/transformer/intro",
+ },
+ items: ["metadata-ingestion/docs/transformer/dataset_transformer"],
},
{
"Advanced Guides": [
diff --git a/docs/cli.md b/docs/cli.md
index 7dfac1e9b2bffc..8845ed5a6dac78 100644
--- a/docs/cli.md
+++ b/docs/cli.md
@@ -99,6 +99,36 @@ Command Options:
--strict-warnings If enabled, ingestion runs with warnings will yield a non-zero error code
--test-source-connection When set, ingestion will only test the source connection details from the recipe
```
+#### ingest --dry-run
+
+The `--dry-run` option of the `ingest` command performs all of the ingestion steps, except writing to the sink. This is useful to validate that the
+ingestion recipe is producing the desired metadata events before ingesting them into datahub.
+
+```shell
+# Dry run
+datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml --dry-run
+# Short-form
+datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml -n
+```
+
+#### ingest --preview
+
+The `--preview` option of the `ingest` command performs all of the ingestion steps, but limits the processing to only the first 10 workunits produced by the source.
+This option helps with quick end-to-end smoke testing of the ingestion recipe.
+
+```shell
+# Preview
+datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml --preview
+# Preview with dry-run
+datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml -n --preview
+```
+
+By default `--preview` creates 10 workunits. But if you wish to try producing more workunits you can use another option `--preview-workunits`
+
+```shell
+# Preview 20 workunits without sending anything to sink
+datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml -n --preview --preview-workunits=20
+```
#### ingest deploy
@@ -115,6 +145,37 @@ To update an existing recipe please use the `--urn` parameter to specify the id
**Note:** Updating a recipe will result in a replacement of the existing options with what was specified in the cli command.
I.e: Not specifying a schedule in the cli update command will remove the schedule from the recipe to be updated.
+#### ingest --no-default-report
+By default, the cli sends an ingestion report to DataHub, which allows you to see the result of all cli-based ingestion in the UI. This can be turned off with the `--no-default-report` flag.
+
+```shell
+# Running ingestion with reporting to DataHub turned off
+datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yaml --no-default-report
+```
+
+The reports include the recipe that was used for ingestion. This can be turned off by adding an additional section to the ingestion recipe.
+
+```yaml
+source:
+ # source configs
+
+sink:
+ # sink configs
+
+# Add configuration for the datahub reporter
+reporting:
+ - type: datahub
+ config:
+ report_recipe: false
+
+# Optional log to put failed JSONs into a file
+# Helpful in case you are trying to debug some issue with specific ingestion failing
+failure_log:
+ enabled: false
+ log_config:
+ filename: ./path/to/failure.json
+```
+
### init
The init command is used to tell `datahub` about where your DataHub instance is located. The CLI will point to localhost DataHub by default.
diff --git a/metadata-ingestion/README.md b/metadata-ingestion/README.md
index a0fef614528cbe..54478fddbe2d04 100644
--- a/metadata-ingestion/README.md
+++ b/metadata-ingestion/README.md
@@ -1,228 +1,41 @@
# Introduction to Metadata Ingestion
-
- Find Integration Source
-
-
-## Integration Options
-
-DataHub supports both **push-based** and **pull-based** metadata integration.
-
-Push-based integrations allow you to emit metadata directly from your data systems when metadata changes, while pull-based integrations allow you to "crawl" or "ingest" metadata from the data systems by connecting to them and extracting metadata in a batch or incremental-batch manner. Supporting both mechanisms means that you can integrate with all your systems in the most flexible way possible.
-
-Examples of push-based integrations include [Airflow](../docs/lineage/airflow.md), [Spark](../metadata-integration/java/spark-lineage/README.md), [Great Expectations](./integration_docs/great-expectations.md) and [Protobuf Schemas](../metadata-integration/java/datahub-protobuf/README.md). This allows you to get low-latency metadata integration from the "active" agents in your data ecosystem. Examples of pull-based integrations include BigQuery, Snowflake, Looker, Tableau and many others.
-
-This document describes the pull-based metadata ingestion system that is built into DataHub for easy integration with a wide variety of sources in your data stack.
-
-## Getting Started
-
-### Prerequisites
-
-Before running any metadata ingestion job, you should make sure that DataHub backend services are all running. You can either run ingestion via the [UI](../docs/ui-ingestion.md) or via the [CLI](../docs/cli.md). You can reference the CLI usage guide given there as you go through this page.
-
-## Core Concepts
-
-### Sources
-
-Please see our [Integrations page](https://datahubproject.io/integrations) to browse our ingestion sources and filter on their features.
-
-Data systems that we are extracting metadata from are referred to as **Sources**. The `Sources` tab on the left in the sidebar shows you all the sources that are available for you to ingest metadata from. For example, we have sources for [BigQuery](https://datahubproject.io/docs/generated/ingestion/sources/bigquery), [Looker](https://datahubproject.io/docs/generated/ingestion/sources/looker), [Tableau](https://datahubproject.io/docs/generated/ingestion/sources/tableau) and many others.
-
-#### Metadata Ingestion Source Status
-
-We apply a Support Status to each Metadata Source to help you understand the integration reliability at a glance.
-
-: Certified Sources are well-tested & widely-adopted by the DataHub Community. We expect the integration to be stable with few user-facing issues.
-
-: Incubating Sources are ready for DataHub Community adoption but have not been tested for a wide variety of edge-cases. We eagerly solicit feedback from the Community to streghten the connector; minor version changes may arise in future releases.
-
-: Testing Sources are available for experiementation by DataHub Community members, but may change without notice.
-
-### Sinks
-
-Sinks are destinations for metadata. When configuring ingestion for DataHub, you're likely to be sending the metadata to DataHub over either the [REST (datahub-sink)](./sink_docs/datahub.md#datahub-rest) or the [Kafka (datahub-kafka)](./sink_docs/datahub.md#datahub-kafka) sink. In some cases, the [File](./sink_docs/file.md) sink is also helpful to store a persistent offline copy of the metadata during debugging.
-
-The default sink that most of the ingestion systems and guides assume is the `datahub-rest` sink, but you should be able to adapt all of them for the other sinks as well!
-
-### Recipes
-
-A recipe is the main configuration file that puts it all together. It tells our ingestion scripts where to pull data from (source) and where to put it (sink).
-
-:::tip
-Name your recipe with **.dhub.yaml** extension like _myrecipe.dhub.yaml_ to use vscode or intellij as a recipe editor with autocomplete
-and syntax validation.
-
-Make sure yaml plugin is installed for your editor:
-
-- For vscode install [Redhat's yaml plugin](https://marketplace.visualstudio.com/items?itemName=redhat.vscode-yaml)
-- For intellij install [official yaml plugin](https://plugins.jetbrains.com/plugin/13126-yaml)
-
+:::tip Find Integration Source
+Please see our **[Integrations page](https://datahubproject.io/integrations)** to browse our ingestion sources and filter on their features.
:::
-Since `acryl-datahub` version `>=0.8.33.2`, the default sink is assumed to be a DataHub REST endpoint:
-
-- Hosted at "http://localhost:8080" or the environment variable `${DATAHUB_GMS_URL}` if present
-- With an empty auth token or the environment variable `${DATAHUB_GMS_TOKEN}` if present.
-
-Here's a simple recipe that pulls metadata from MSSQL (source) and puts it into the default sink (datahub rest).
-
-```yaml
-# The simplest recipe that pulls metadata from MSSQL and puts it into DataHub
-# using the Rest API.
-source:
- type: mssql
- config:
- username: sa
- password: ${MSSQL_PASSWORD}
- database: DemoData
-# sink section omitted as we want to use the default datahub-rest sink
-```
-
-Running this recipe is as simple as:
+## Integration Methods
-```shell
-datahub ingest -c recipe.dhub.yaml
-```
+DataHub offers three methods for data ingestion:
-or if you want to override the default endpoints, you can provide the environment variables as part of the command like below:
+- [UI Ingestion](../docs/ui-ingestion.md) : Easily configure and execute a metadata ingestion pipeline through the UI.
+- [CLI Ingestion guide](cli-ingestion.md) : Configure the ingestion pipeline using YAML and execute by it through CLI.
+- SDK-based ingestion : Use [Python Emitter](./as-a-library.md) or [Java emitter](../metadata-integration/java/as-a-library.md) to programmatically control the ingestion pipelines.
-```shell
-DATAHUB_GMS_URL="https://my-datahub-server:8080" DATAHUB_GMS_TOKEN="my-datahub-token" datahub ingest -c recipe.dhub.yaml
-```
+## Types of Integration
-A number of recipes are included in the [examples/recipes](./examples/recipes) directory. For full info and context on each source and sink, see the pages described in the [table of plugins](../docs/cli.md#installing-plugins).
+Integration can be divided into two concepts based on the method:
-> Note that one recipe file can only have 1 source and 1 sink. If you want multiple sources then you will need multiple recipe files.
+### Push-based Integration
-### Handling sensitive information in recipes
+Push-based integrations allow you to emit metadata directly from your data systems when metadata changes.
+Examples of push-based integrations include [Airflow](../docs/lineage/airflow.md), [Spark](../metadata-integration/java/spark-lineage/README.md), [Great Expectations](./integration_docs/great-expectations.md) and [Protobuf Schemas](../metadata-integration/java/datahub-protobuf/README.md). This allows you to get low-latency metadata integration from the "active" agents in your data ecosystem.
-We automatically expand environment variables in the config (e.g. `${MSSQL_PASSWORD}`),
-similar to variable substitution in GNU bash or in docker-compose files. For details, see
-https://docs.docker.com/compose/compose-file/compose-file-v2/#variable-substitution. This environment variable substitution should be used to mask sensitive information in recipe files. As long as you can get env variables securely to the ingestion process there would not be any need to store sensitive information in recipes.
+### Pull-based Integration
-### Basic Usage of CLI for ingestion
+Pull-based integrations allow you to "crawl" or "ingest" metadata from the data systems by connecting to them and extracting metadata in a batch or incremental-batch manner.
+Examples of pull-based integrations include BigQuery, Snowflake, Looker, Tableau and many others.
-```shell
-pip install 'acryl-datahub[datahub-rest]' # install the required plugin
-datahub ingest -c ./examples/recipes/mssql_to_datahub.dhub.yml
-```
-
-The `--dry-run` option of the `ingest` command performs all of the ingestion steps, except writing to the sink. This is useful to validate that the
-ingestion recipe is producing the desired metadata events before ingesting them into datahub.
-
-```shell
-# Dry run
-datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml --dry-run
-# Short-form
-datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml -n
-```
-
-The `--preview` option of the `ingest` command performs all of the ingestion steps, but limits the processing to only the first 10 workunits produced by the source.
-This option helps with quick end-to-end smoke testing of the ingestion recipe.
-
-```shell
-# Preview
-datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml --preview
-# Preview with dry-run
-datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml -n --preview
-```
-
-By default `--preview` creates 10 workunits. But if you wish to try producing more workunits you can use another option `--preview-workunits`
-
-```shell
-# Preview 20 workunits without sending anything to sink
-datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yml -n --preview --preview-workunits=20
-```
-
-#### Reporting
-
-By default, the cli sends an ingestion report to DataHub, which allows you to see the result of all cli-based ingestion in the UI. This can be turned off with the `--no-default-report` flag.
-
-```shell
-# Running ingestion with reporting to DataHub turned off
-datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yaml --no-default-report
-```
-
-The reports include the recipe that was used for ingestion. This can be turned off by adding an additional section to the ingestion recipe.
-
-```yaml
-source:
- # source configs
-
-sink:
- # sink configs
-
-# Add configuration for the datahub reporter
-reporting:
- - type: datahub
- config:
- report_recipe: false
-
-# Optional log to put failed JSONs into a file
-# Helpful in case you are trying to debug some issue with specific ingestion failing
-failure_log:
- enabled: false
- log_config:
- filename: ./path/to/failure.json
-```
-
-#### Deploying and scheduling ingestion to the UI
-
-The `deploy` subcommand of the `ingest` command tree allows users to upload their recipes and schedule them in the server.
-
-```shell
-datahub ingest deploy -n -c recipe.yaml
-```
-
-By default, no schedule is done unless explicitly configured with the `--schedule` parameter. Schedule timezones are UTC by default and can be overriden with `--time-zone` flag.
-```shell
-datahub ingest deploy -n test --schedule "0 * * * *" --time-zone "Europe/London" -c recipe.yaml
-```
-
-## Transformations
-
-If you'd like to modify data before it reaches the ingestion sinks – for instance, adding additional owners or tags – you can use a transformer to write your own module and integrate it with DataHub. Transformers require extending the recipe with a new section to describe the transformers that you want to run.
-
-For example, a pipeline that ingests metadata from MSSQL and applies a default "important" tag to all datasets is described below:
-
-```yaml
-# A recipe to ingest metadata from MSSQL and apply default tags to all tables
-source:
- type: mssql
- config:
- username: sa
- password: ${MSSQL_PASSWORD}
- database: DemoData
-
-transformers: # an array of transformers applied sequentially
- - type: simple_add_dataset_tags
- config:
- tag_urns:
- - "urn:li:tag:Important"
-# default sink, no config needed
-```
-
-Check out the [transformers guide](./docs/transformer/intro.md) to learn more about how you can create really flexible pipelines for processing metadata using Transformers!
-
-## Using as a library (SDK)
-
-In some cases, you might want to construct Metadata events directly and use programmatic ways to emit that metadata to DataHub. In this case, take a look at the [Python emitter](./as-a-library.md) and the [Java emitter](../metadata-integration/java/as-a-library.md) libraries which can be called from your own code.
-
-### Programmatic Pipeline
-
-In some cases, you might want to configure and run a pipeline entirely from within your custom Python script. Here is an example of how to do it.
-
-- [programmatic_pipeline.py](./examples/library/programatic_pipeline.py) - a basic mysql to REST programmatic pipeline.
-
-## Developing
+## Core Concepts
-See the guides on [developing](./developing.md), [adding a source](./adding-source.md) and [using transformers](./docs/transformer/intro.md).
+The following are the core concepts related to ingestion:
-## Compatibility
+- [Sources](source_overview.md): Data systems from which extract metadata. (e.g. BigQuery, MySQL)
+- [Sinks](sink_overview.md): Destination for metadata (e.g. File, DataHub)
+- [Recipe](recipe_overview.md): The main configuration for ingestion in the form or .yaml file
-DataHub server uses a 3 digit versioning scheme, while the CLI uses a 4 digit scheme. For example, if you're using DataHub server version 0.10.0, you should use CLI version 0.10.0.x, where x is a patch version.
-We do this because we do CLI releases at a much higher frequency than server releases, usually every few days vs twice a month.
+For more advanced guides, please refer to the following:
-For ingestion sources, any breaking changes will be highlighted in the [release notes](../docs/how/updating-datahub.md). When fields are deprecated or otherwise changed, we will try to maintain backwards compatibility for two server releases, which is about 4-6 weeks. The CLI will also print warnings whenever deprecated options are used.
+- [Developing on Metadata Ingestion](./developing.md)
+- [Adding a Metadata Ingestion Source](./adding-source.md)
+- [Using Transformers](./docs/transformer/intro.md)
diff --git a/metadata-ingestion/cli-ingestion.md b/metadata-ingestion/cli-ingestion.md
new file mode 100644
index 00000000000000..cbdde2cd301678
--- /dev/null
+++ b/metadata-ingestion/cli-ingestion.md
@@ -0,0 +1,59 @@
+# CLI Ingestion
+
+## Installing the CLI
+
+Make sure you have installed DataHub CLI before following this guide.
+```shell
+# Requires Python 3.7+
+python3 -m pip install --upgrade pip wheel setuptools
+python3 -m pip install --upgrade acryl-datahub
+# validate that the install was successful
+datahub version
+# If you see "command not found", try running this instead: python3 -m datahub version
+```
+Check out the [CLI Installation Guide](../docs/cli.md#installation) for more installation options and troubleshooting tips.
+
+After that, install the required plugin for the ingestion.
+
+```shell
+pip install 'acryl-datahub[datahub-rest]' # install the required plugin
+```
+Check out the [alternative installation options](../docs/cli.md#alternate-installation-options) for more reference.
+
+## Configuring a Recipe
+Create a recipe.yml file that defines the source and sink for metadata, as shown below.
+```yaml
+# my_reipe.yml
+source:
+ type:
+ config:
+ option_1:
+ ...
+
+sink:
+ type:
+ config:
+ ...
+```
+
+For more information and examples on configuring recipes, please refer to [Recipes](recipe_overview.md).
+
+## Ingesting Metadata
+You can run ingestion using `datahub ingest` like below.
+
+```shell
+datahub ingest -c
+```
+
+## Reference
+
+Please refer the following pages for advanced guids on CLI ingestion.
+- [Reference for `datahub ingest` command](../docs/cli.md#ingest)
+- [UI Ingestion Guide](../docs/ui-ingestion.md)
+
+:::Tip Compatibility
+DataHub server uses a 3 digit versioning scheme, while the CLI uses a 4 digit scheme. For example, if you're using DataHub server version 0.10.0, you should use CLI version 0.10.0.x, where x is a patch version.
+We do this because we do CLI releases at a much higher frequency than server releases, usually every few days vs twice a month.
+
+For ingestion sources, any breaking changes will be highlighted in the [release notes](../docs/how/updating-datahub.md). When fields are deprecated or otherwise changed, we will try to maintain backwards compatibility for two server releases, which is about 4-6 weeks. The CLI will also print warnings whenever deprecated options are used.
+:::
\ No newline at end of file
diff --git a/metadata-ingestion/recipe_overview.md b/metadata-ingestion/recipe_overview.md
new file mode 100644
index 00000000000000..a748edbf3bb449
--- /dev/null
+++ b/metadata-ingestion/recipe_overview.md
@@ -0,0 +1,124 @@
+import Tabs from '@theme/Tabs';
+import TabItem from '@theme/TabItem';
+
+# Recipes
+
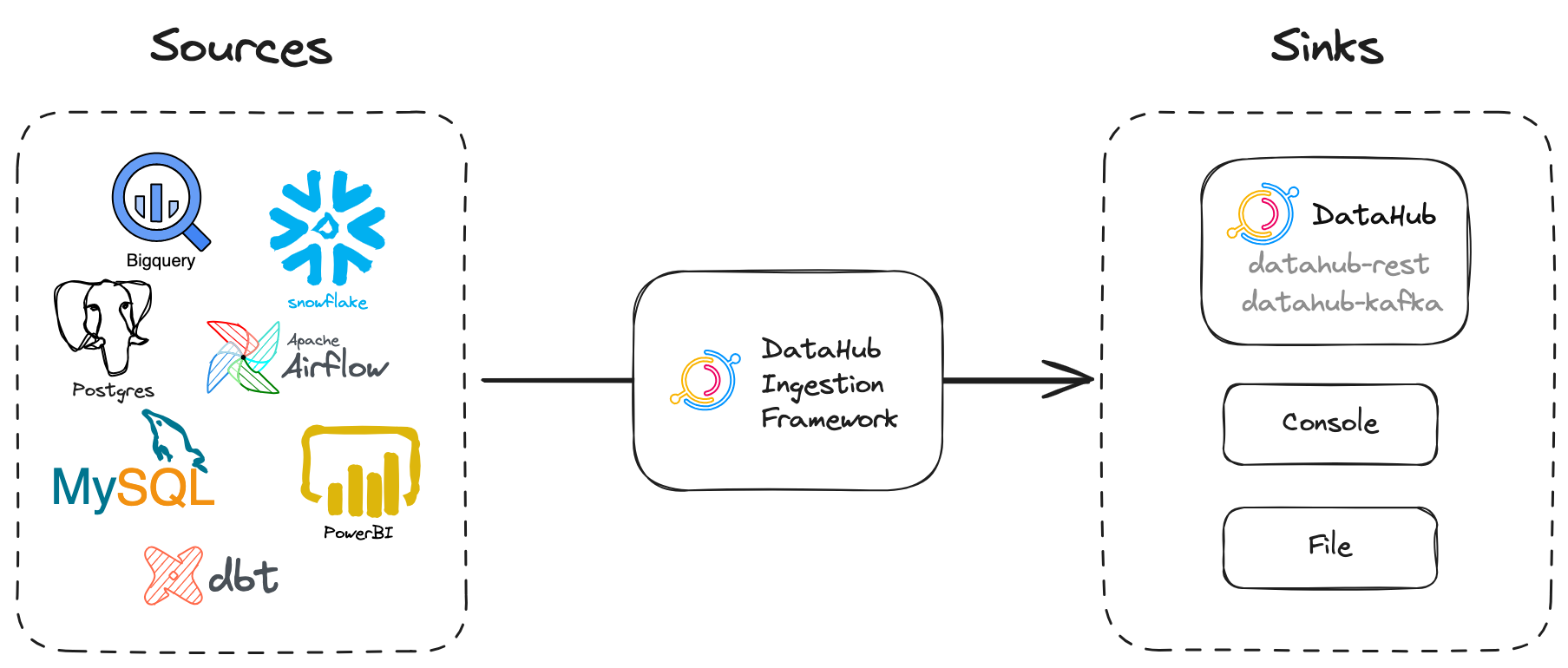
+A recipe is the main configuration file for metadata ingestion. It tells our ingestion scripts where to pull data from (source) and where to put it (sink).
+
+
+  +
+
+
+
+## Configuring Recipe
+
+The basic form of the recipe file consists of:
+
+- `source`, which contains the configuration of the data source. (See [Sources](source_overview.md))
+- `sink`, which defines the destination of the metadata (See [Sinks](sink_overview.md))
+
+Here's a simple recipe that pulls metadata from MSSQL (source) and puts it into the default sink (datahub rest).
+
+```yaml
+# The simplest recipe that pulls metadata from MSSQL and puts it into DataHub
+# using the Rest API.
+source:
+ type: mssql
+ config:
+ username: sa
+ password: ${MSSQL_PASSWORD}
+ database: DemoData
+# sink section omitted as we want to use the default datahub-rest sink
+sink:
+ type: "datahub-rest"
+ config:
+ server: "http://localhost:8080"
+```
+
+A number of recipes are included in the [examples/recipes](./examples/recipes) directory. For full info and context on each source and sink, see the pages described in the [table of plugins](../docs/cli.md#installing-plugins).
+
+:::note One Source/Sink for One Recipe!
+Note that one recipe file can only have 1 source and 1 sink. If you want multiple sources then you will need multiple recipe files.
+:::
+
+## Running a Recipe
+
+DataHub supports running recipes via the CLI or UI.
+
+
+
+
+Install CLI and the plugin for the ingestion.
+```shell
+python3 -m pip install --upgrade acryl-datahub
+pip install 'acryl-datahub[datahub-rest]'
+```
+Running this recipe is as simple as:
+
+```shell
+datahub ingest -c recipe.dhub.yaml
+```
+For a detailed guide on running recipes via CLI, please refer to [CLI Ingestion Guide](cli-ingestion.md).
+
+
+
+
+
+You can configure and run the recipe in **Ingestion** tab in DataHub.
+
+
+  +
+
+
+* Make sure you have the **Manage Metadata Ingestion & Manage Secret** privileges.
+* Navigate to **Ingestion** tab in DataHub.
+* Create an ingestion source & configure the recipe via UI.
+* Hit **Execute**.
+
+For a detailed guide on running recipes via UI, please refer to [UI Ingestion Guide](../docs/ui-ingestion.md).
+
+
+
+
+
+## Advanced Configuration
+
+### Handling Sensitive Information in Recipes
+
+We automatically expand environment variables in the config (e.g. `${MSSQL_PASSWORD}`),
+similar to variable substitution in GNU bash or in docker-compose files.
+For details, see [variable-substitution](https://docs.docker.com/compose/compose-file/compose-file-v2/#variable-substitution).
+This environment variable substitution should be used to mask sensitive information in recipe files. As long as you can get env variables securely to the ingestion process there would not be any need to store sensitive information in recipes.
+
+### Transformations
+
+If you'd like to modify data before it reaches the ingestion sinks – for instance, adding additional owners or tags – you can use a transformer to write your own module and integrate it with DataHub. Transformers require extending the recipe with a new section to describe the transformers that you want to run.
+
+For example, a pipeline that ingests metadata from MSSQL and applies a default "important" tag to all datasets is described below:
+
+```yaml
+# A recipe to ingest metadata from MSSQL and apply default tags to all tables
+source:
+ type: mssql
+ config:
+ username: sa
+ password: ${MSSQL_PASSWORD}
+ database: DemoData
+
+transformers: # an array of transformers applied sequentially
+ - type: simple_add_dataset_tags
+ config:
+ tag_urns:
+ - "urn:li:tag:Important"
+# default sink, no config needed
+```
+
+Check out the [transformers guide](./docs/transformer/intro.md) to learn more about how you can create really flexible pipelines for processing metadata using Transformers!
+
+### Autocomplete and Syntax Validation
+
+Name your recipe with **.dhub.yaml** extension like `myrecipe.dhub.yaml_` to use vscode or intellij as a recipe editor with autocomplete
+and syntax validation. Make sure yaml plugin is installed for your editor:
+
+- For vscode install [Redhat's yaml plugin](https://marketplace.visualstudio.com/items?itemName=redhat.vscode-yaml)
+- For intellij install [official yaml plugin](https://plugins.jetbrains.com/plugin/13126-yaml)
diff --git a/metadata-ingestion/sink_overview.md b/metadata-ingestion/sink_overview.md
new file mode 100644
index 00000000000000..c71ba1f97932cf
--- /dev/null
+++ b/metadata-ingestion/sink_overview.md
@@ -0,0 +1,33 @@
+# Sinks
+
+Sinks are **destinations for metadata**.
+
+
+
+
+
+In general, the sink will be defined in the [recipe](./recipe_overview.md) after the [source](./source-docs-template.md) like below.
+
+```yaml
+source: ...
+
+sink:
+ type:
+ config: ...
+```
+
+## Types of Sinks
+
+When configuring ingestion for DataHub, you're likely to be sending the metadata to DataHub over either one of the following.
+
+- [REST (datahub-rest)](sink_docs/datahub.md#datahub-rest)
+- [Kafka (datahub-kafka)](sink_docs/datahub.md#datahub-kafka)
+
+For debugging purposes or troubleshooting, the following sinks can be useful:
+
+- [File](sink_docs/file.md)
+- [Console](sink_docs/console.md)
+
+## Default Sink
+
+Since `acryl-datahub` version `>=0.8.33.2`, the default sink is assumed to be a `datahub-rest` endpoint.
diff --git a/metadata-ingestion/source_overview.md b/metadata-ingestion/source_overview.md
new file mode 100644
index 00000000000000..9647fbdde0a0f8
--- /dev/null
+++ b/metadata-ingestion/source_overview.md
@@ -0,0 +1,37 @@
+# Sources
+
+
+Sources are **the data systems that we are extracting metadata from.**
+
+
+
+
+
+In general, the source will be defined at the top of the [recipe](./recipe_overview.md) like below.
+
+
+```yaml
+#my_recipe.yml
+source:
+ type:
+ config:
+ option_1:
+ ...
+```
+
+## Types of Source
+The `Sources` tab on the left in the sidebar shows you all the sources that are available for you to ingest metadata from. For example, we have sources for [BigQuery](https://datahubproject.io/docs/generated/ingestion/sources/bigquery), [Looker](https://datahubproject.io/docs/generated/ingestion/sources/looker), [Tableau](https://datahubproject.io/docs/generated/ingestion/sources/tableau) and many others.
+
+:::tip Find an Integration Source
+See the full **[list of integrations](https://datahubproject.io/integrations)** and filter on their features.
+:::
+
+## Metadata Ingestion Source Status
+
+We apply a Support Status to each Metadata Source to help you understand the integration reliability at a glance.
+
+: Certified Sources are well-tested & widely-adopted by the DataHub Community. We expect the integration to be stable with few user-facing issues.
+
+: Incubating Sources are ready for DataHub Community adoption but have not been tested for a wide variety of edge-cases. We eagerly solicit feedback from the Community to streghten the connector; minor version changes may arise in future releases.
+
+: Testing Sources are available for experiementation by DataHub Community members, but may change without notice.