From ab19c39e823a5b7378bf1f02e80ab007f233aac1 Mon Sep 17 00:00:00 2001
From: randomJoe211 <69501902+randomJoe211@users.noreply.github.com>
Date: Mon, 13 Mar 2023 15:40:31 +0800
Subject: [PATCH] Rename DB
---
.github/ISSUE_TEMPLATE/BUG_REPORT.md | 2 +-
.github/PULL_REQUEST_TEMPLATE.md | 2 +-
CONTRIBUTING.md | 2 +-
README.md | 4 +-
.../1.introduction/1.what-is-nebula-graph.md | 44 ++++-----
docs-2.0/1.introduction/2.data-model.md | 10 +--
.../1.architecture-overview.md | 14 +--
.../2.meta-service.md | 10 +--
.../3.graph-service.md | 2 +-
.../4.storage-service.md | 58 ++++++------
docs-2.0/1.introduction/3.vid.md | 8 +-
docs-2.0/14.client/1.nebula-client.md | 10 +--
docs-2.0/14.client/3.nebula-cpp-client.md | 10 +--
docs-2.0/14.client/4.nebula-java-client.md | 6 +-
docs-2.0/14.client/5.nebula-python-client.md | 6 +-
docs-2.0/14.client/6.nebula-go-client.md | 6 +-
docs-2.0/15.contribution/how-to-contribute.md | 12 +--
.../2.quick-start/1.quick-start-workflow.md | 20 ++---
.../2.quick-start/2.install-nebula-graph.md | 2 +-
.../3.connect-to-nebula-graph.md | 2 +-
docs-2.0/2.quick-start/4.nebula-graph-crud.md | 16 ++--
.../2.quick-start/5.start-stop-service.md | 2 +-
.../2.quick-start/6.cheatsheet-for-ngql.md | 16 ++--
docs-2.0/20.appendix/0.FAQ.md | 42 ++++-----
docs-2.0/20.appendix/0.vid.md | 2 +-
docs-2.0/20.appendix/5.partition.md | 2 +-
docs-2.0/20.appendix/6.eco-tool-version.md | 66 +++++++-------
docs-2.0/20.appendix/comments.md | 4 +-
docs-2.0/20.appendix/learning-path.md | 52 +++++------
docs-2.0/20.appendix/releasenote.md | 2 +-
docs-2.0/20.appendix/write-tools.md | 2 +-
.../1.nGQL-overview/1.overview.md | 24 ++---
.../1.nGQL-overview/3.graph-patterns.md | 2 +-
.../3.ngql-guide/1.nGQL-overview/comments.md | 4 +-
.../1.nGQL-overview/ngql-style-guide.md | 2 +-
.../10.tag-statements/1.create-tag.md | 4 +-
.../10.tag-statements/2.drop-tag.md | 2 +-
.../10.tag-statements/3.alter-tag.md | 2 +-
.../10.tag-statements/5.describe-tag.md | 2 +-
.../10.tag-statements/6.delete-tag.md | 2 +-
.../improve-query-by-tag-index.md | 2 +-
.../11.edge-type-statements/1.create-edge.md | 4 +-
.../11.edge-type-statements/2.drop-edge.md | 2 +-
.../11.edge-type-statements/3.alter-edge.md | 2 +-
.../5.describe-edge.md | 2 +-
.../12.vertex-statements/1.insert-vertex.md | 6 +-
.../12.vertex-statements/2.update-vertex.md | 2 +-
.../12.vertex-statements/4.delete-vertex.md | 2 +-
.../13.edge-statements/1.insert-edge.md | 4 +-
.../13.edge-statements/2.update-edge.md | 2 +-
.../1.create-native-index.md | 6 +-
.../2.1.show-create-index.md | 2 +-
.../2.show-native-indexes.md | 2 +-
.../4.rebuild-native-index.md | 4 +-
.../6.drop-native-index.md | 2 +-
.../1.search-with-text-based-index.md | 2 +-
.../1.explain-and-profile.md | 2 +-
.../.1.configs-syntax.md | 2 +-
.../2.balance-syntax.md | 8 +-
.../3.ngql-guide/3.data-types/1.numeric.md | 2 +-
.../3.ngql-guide/3.data-types/10.geography.md | 2 +-
.../3.ngql-guide/3.data-types/3.string.md | 4 +-
.../3.data-types/4.date-and-time.md | 4 +-
.../3.property-reference.md | 4 +-
.../3.ngql-guide/5.operators/1.comparison.md | 2 +-
.../3.ngql-guide/5.operators/2.boolean.md | 4 +-
docs-2.0/3.ngql-guide/5.operators/4.pipe.md | 2 +-
docs-2.0/3.ngql-guide/5.operators/6.set.md | 2 +-
docs-2.0/3.ngql-guide/5.operators/7.string.md | 2 +-
docs-2.0/3.ngql-guide/5.operators/8.list.md | 2 +-
.../6.functions-and-expressions/1.math.md | 2 +-
.../6.functions-and-expressions/2.string.md | 2 +-
.../3.date-and-time.md | 2 +-
.../6.functions-and-expressions/4.schema.md | 2 +-
.../6.functions-and-expressions/6.list.md | 2 +-
.../8.predicate.md | 2 +-
.../9.user-defined-functions.md | 2 +-
.../7.general-query-statements/2.match.md | 4 +-
.../7.general-query-statements/3.go.md | 2 +-
.../7.general-query-statements/5.lookup.md | 6 +-
.../6.show/.3.show-configs.md | 6 +-
.../6.show/1.show-charset.md | 2 +-
.../6.show/10.show-roles.md | 6 +-
.../6.show/12.show-spaces.md | 2 +-
.../6.show/2.show-collation.md | 2 +-
.../6.show/6.show-hosts.md | 2 +-
.../6.show/8.show-indexes.md | 2 +-
.../8.clauses-and-options/limit.md | 4 +-
.../8.clauses-and-options/sample.md | 2 +-
.../8.clauses-and-options/ttl-options.md | 2 +-
.../9.space-statements/1.create-space.md | 12 +--
.../9.space-statements/2.use-space.md | 4 +-
.../9.space-statements/3.show-spaces.md | 2 +-
.../1.resource-preparations.md | 56 ++++++------
...bula-graph-by-compiling-the-source-code.md | 40 ++++-----
.../2.install-nebula-graph-by-rpm-or-deb.md | 2 +-
...deploy-nebula-graph-with-docker-compose.md | 64 ++++++-------
.../4.install-nebula-graph-from-tar.md | 18 ++--
.../deploy-nebula-graph-cluster.md | 26 +++---
.../upgrade-nebula-from-200-to-latest.md | 18 ++--
.../upgrade-nebula-graph-to-latest.md | 54 +++++------
.../4.uninstall-nebula-graph.md | 34 +++----
.../1.text-based-index-restrictions.md | 2 +-
.../3.deploy-listener.md | 8 +-
.../connect-to-nebula-graph.md | 2 +-
.../deploy-license.md | 10 +--
.../manage-service.md | 2 +-
.../1.configurations/.1.get-configurations.md | 8 +-
.../1.configurations/1.configurations.md | 22 ++---
.../1.configurations/2.meta-config.md | 16 ++--
.../1.configurations/3.graph-config.md | 18 ++--
.../1.configurations/4.storage-config.md | 20 ++---
.../2.log-management/logs.md | 8 +-
.../1.query-performance-metrics.md | 10 +--
.../2.rocksdb-statistics.md | 2 +-
.../1.authentication/1.authentication.md | 16 ++--
.../1.authentication/2.management-user.md | 10 +--
.../1.authentication/3.role-list.md | 4 +-
.../1.authentication/4.ldap.md | 12 +--
.../2.backup-restore/1.what-is-br.md | 6 +-
.../2.backup-restore/3.br-backup-data.md | 4 +-
.../2.backup-restore/4.br-restore-data.md | 10 +--
docs-2.0/7.data-security/3.manage-snapshot.md | 12 +--
docs-2.0/7.data-security/4.ssl.md | 6 +-
docs-2.0/8.service-tuning/2.graph-modeling.md | 18 ++--
docs-2.0/8.service-tuning/3.system-design.md | 10 +--
docs-2.0/8.service-tuning/4.plan.md | 2 +-
docs-2.0/8.service-tuning/compaction.md | 4 +-
docs-2.0/8.service-tuning/load-balance.md | 12 +--
docs-2.0/8.service-tuning/practice.md | 16 ++--
docs-2.0/8.service-tuning/super-node.md | 8 +-
docs-2.0/README.md | 2 +-
docs-2.0/nebula-algorithm.md | 30 +++----
docs-2.0/nebula-analytics.md | 44 ++++-----
docs-2.0/nebula-bench.md | 8 +-
docs-2.0/nebula-cloud/1.what-is-cloud.md | 18 ++--
.../2.how-to-create-subsciption.md | 6 +-
.../nebula-cloud/3.how-to-set-solution.md | 8 +-
.../nebula-cloud/4.user-role-description.md | 8 +-
.../5.solution/5.0.introduce-solution.md | 2 +-
.../5.solution/5.1.supporting-application.md | 8 +-
.../5.2.connection-configuration-and-use.md | 8 +-
.../5.3.role-and-authority-management.md | 4 +-
.../nebula-cloud/7.terms-and-conditions.md | 6 +-
.../1.what-is-dashboard-ent.md | 10 +--
.../2.deploy-connect-dashboard-ent.md | 2 +-
.../1.create-cluster.md | 6 +-
.../2.import-cluster.md | 18 ++--
.../4.cluster-operator/1.overview.md | 4 +-
.../3.cluster-information.md | 6 +-
.../4.cluster-operator/4.manage.md | 2 +-
.../nebula-dashboard-ent/6.system-settings.md | 2 +-
docs-2.0/nebula-dashboard-ent/8.faq.md | 14 +--
.../nebula-dashboard/1.what-is-dashboard.md | 6 +-
.../nebula-dashboard/2.deploy-dashboard.md | 6 +-
.../nebula-dashboard/3.connect-dashboard.md | 2 +-
.../about-exchange/ex-ug-limitations.md | 6 +-
.../about-exchange/ex-ug-what-is-exchange.md | 24 ++---
docs-2.0/nebula-exchange/ex-ug-FAQ.md | 16 ++--
docs-2.0/nebula-exchange/ex-ug-compile.md | 4 +-
.../ex-ug-para-import-command.md | 2 +-
.../parameter-reference/ex-ug-parameter.md | 24 ++---
.../use-exchange/ex-ug-export-from-nebula.md | 18 ++--
.../ex-ug-import-from-clickhouse.md | 50 +++++------
.../use-exchange/ex-ug-import-from-csv.md | 82 ++++++++---------
.../use-exchange/ex-ug-import-from-hbase.md | 54 +++++------
.../use-exchange/ex-ug-import-from-hive.md | 56 ++++++------
.../use-exchange/ex-ug-import-from-json.md | 88 +++++++++---------
.../use-exchange/ex-ug-import-from-kafka.md | 50 +++++------
.../ex-ug-import-from-maxcompute.md | 52 +++++------
.../use-exchange/ex-ug-import-from-mysql.md | 54 +++++------
.../use-exchange/ex-ug-import-from-neo4j.md | 36 ++++----
.../use-exchange/ex-ug-import-from-orc.md | 88 +++++++++---------
.../use-exchange/ex-ug-import-from-parquet.md | 90 +++++++++----------
.../use-exchange/ex-ug-import-from-pulsar.md | 54 +++++------
.../use-exchange/ex-ug-import-from-sst.md | 82 ++++++++---------
.../about-explorer/ex-ug-what-is-explorer.md | 6 +-
.../deploy-connect/ex-ug-connect.md | 28 +++---
.../deploy-connect/ex-ug-deploy.md | 14 +--
.../deploy-connect/ex-ug-reset-connection.md | 4 +-
docs-2.0/nebula-flink-connector.md | 8 +-
.../nebula-importer/config-with-header.md | 12 +--
.../nebula-importer/config-without-header.md | 14 +--
docs-2.0/nebula-importer/use-importer.md | 48 +++++-----
.../1.introduction-to-nebula-operator.md | 18 ++--
.../2.deploy-nebula-operator.md | 14 +--
.../3.1create-cluster-with-kubectl.md | 22 ++---
.../3.2create-cluster-with-helm.md | 46 +++++-----
.../4.connect-to-nebula-graph-service.md | 54 +++++------
.../nebula-operator/5.operator-failover.md | 6 +-
.../6.get-started-with-operator.md | 8 +-
docs-2.0/nebula-operator/7.operator-faq.md | 6 +-
.../8.1.custom-conf-parameter.md | 8 +-
.../8.2.pv-reclaim.md | 2 +-
.../8.3.balance-data-when-scaling-storage.md | 4 +-
.../9.upgrade-nebula-cluster.md | 24 ++---
docs-2.0/nebula-spark-connector.md | 62 ++++++-------
.../about-studio/st-ug-limitations.md | 12 +--
.../about-studio/st-ug-release-note.md | 4 +-
.../nebula-studio/about-studio/st-ug-terms.md | 4 +-
.../st-ug-what-is-graph-studio.md | 28 +++---
.../deploy-connect/st-ug-connect.md | 30 +++----
.../deploy-connect/st-ug-deploy-by-helm.md | 2 +-
.../deploy-connect/st-ug-deploy.md | 14 +--
.../deploy-connect/st-ug-reset-connection.md | 6 +-
.../manage-schema/st-ug-crud-edge-type.md | 6 +-
.../manage-schema/st-ug-crud-index.md | 6 +-
.../manage-schema/st-ug-crud-space.md | 10 +--
.../manage-schema/st-ug-crud-tag.md | 6 +-
.../quick-start/st-ug-create-schema.md | 6 +-
.../quick-start/st-ug-import-data.md | 6 +-
.../quick-start/st-ug-plan-schema.md | 4 +-
.../st-ug-config-server-errors.md | 22 ++---
.../st-ug-connection-errors.md | 8 +-
.../troubleshooting/st-ug-faq.md | 2 +-
.../use-console/st-ug-open-in-explore.md | 2 +-
.../use-console/st-ug-visualize-subgraph.md | 2 +-
.../reuse/source_connect-to-nebula-graph.md | 28 +++---
...urce_install-nebula-graph-by-rpm-or-deb.md | 18 ++--
docs-2.0/reuse/source_manage-service.md | 32 +++----
mkdocs.yml | 56 ++++++------
third-party-lib-licenses.md | 2 +-
222 files changed, 1558 insertions(+), 1558 deletions(-)
diff --git a/.github/ISSUE_TEMPLATE/BUG_REPORT.md b/.github/ISSUE_TEMPLATE/BUG_REPORT.md
index 47b9079aae8..f1be27bf62f 100644
--- a/.github/ISSUE_TEMPLATE/BUG_REPORT.md
+++ b/.github/ISSUE_TEMPLATE/BUG_REPORT.md
@@ -25,5 +25,5 @@ Please answer the following questions before submitting your issue. Thanks!
- [ ] I searched for existing GitHub issues
-- [ ] I updated Nebula Graph to most recent version
+- [ ] I updated NebulaGraph to most recent version
- [ ] I included all the necessary information above
diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md
index a3c7122b03b..81f0f3171e7 100644
--- a/.github/PULL_REQUEST_TEMPLATE.md
+++ b/.github/PULL_REQUEST_TEMPLATE.md
@@ -1,4 +1,4 @@
-
+
### What is changed, added or deleted? (Required)
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8f8c4a8218d..feb8152296d 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -1,6 +1,6 @@
# Contribute to Documentation
-Contributing to the **Nebula Graph** documentation can be a rewarding experience. We welcome your participation to help make the documentation better!
+Contributing to the **NebulaGraph** documentation can be a rewarding experience. We welcome your participation to help make the documentation better!
## What to Contribute
diff --git a/README.md b/README.md
index 3766eb9384b..3b33ce38d67 100644
--- a/README.md
+++ b/README.md
@@ -1,8 +1,8 @@
-# Nebula Graph documentation
+# NebulaGraph documentation
- [English](https://docs.nebula-graph.io)
- [中文](https://docs.nebula-graph.com.cn/)
## Contributing
-If you have any questions on our documentation, feel free to raise an [Issue](https://github.com/vesoft-inc/nebula-docs/issues) or directly create a [Pull Request](https://github.com/vesoft-inc/nebula-docs/pulls) to help fix or update it. See Nebula Graph [CONTRIBUTING](CONTRIBUTING.md) guide to get started.
+If you have any questions on our documentation, feel free to raise an [Issue](https://github.com/vesoft-inc/nebula-docs/issues) or directly create a [Pull Request](https://github.com/vesoft-inc/nebula-docs/pulls) to help fix or update it. See NebulaGraph [CONTRIBUTING](CONTRIBUTING.md) guide to get started.
diff --git a/docs-2.0/1.introduction/1.what-is-nebula-graph.md b/docs-2.0/1.introduction/1.what-is-nebula-graph.md
index 0da2a1f42c6..721e23f97c4 100644
--- a/docs-2.0/1.introduction/1.what-is-nebula-graph.md
+++ b/docs-2.0/1.introduction/1.what-is-nebula-graph.md
@@ -1,83 +1,83 @@
-# What is Nebula Graph
+# What is NebulaGraph
-Nebula Graph is an open-source, distributed, easily scalable, and native graph database. It is capable of hosting graphs with hundreds of billions of vertices and trillions of edges, and serving queries with millisecond-latency.
+NebulaGraph is an open-source, distributed, easily scalable, and native graph database. It is capable of hosting graphs with hundreds of billions of vertices and trillions of edges, and serving queries with millisecond-latency.
-
+
## What is a graph database
-A graph database, such as Nebula Graph, is a database that specializes in storing vast graph networks and retrieving information from them. It efficiently stores data as vertices (nodes) and edges (relationships) in labeled property graphs. Properties can be attached to both vertices and edges. Each vertex can have one or multiple tags (labels).
+A graph database, such as NebulaGraph, is a database that specializes in storing vast graph networks and retrieving information from them. It efficiently stores data as vertices (nodes) and edges (relationships) in labeled property graphs. Properties can be attached to both vertices and edges. Each vertex can have one or multiple tags (labels).

Graph databases are well suited for storing most kinds of data models abstracted from reality. Things are connected in almost all fields in the world. Modeling systems like relational databases extract the relationships between entities and squeeze them into table columns alone, with their types and properties stored in other columns or even other tables. This makes the data management time-consuming and cost-ineffective.
-Nebula Graph, as a typical native graph database, allows you to store the rich relationships as edges with edge types and properties directly attached to them.
+NebulaGraph, as a typical native graph database, allows you to store the rich relationships as edges with edge types and properties directly attached to them.
-## Benefits of Nebula Graph
+## Benefits of NebulaGraph
### Open-source
-Nebula Graph is open under the Apache 2.0. More and more people such as database developers, data scientists, security experts, and algorithm engineers are participating in the designing and development of Nebula Graph. To join the opening of source code and ideas, surf the [Nebula Graph GitHub page](https://github.com/vesoft-inc/nebula-graph).
+NebulaGraph is open under the Apache 2.0. More and more people such as database developers, data scientists, security experts, and algorithm engineers are participating in the designing and development of NebulaGraph. To join the opening of source code and ideas, surf the [NebulaGraph GitHub page](https://github.com/vesoft-inc/nebula-graph).
### Outstanding performance
-Written in C++ and born for graph, Nebula Graph handles graph queries in milliseconds. Among most databases, Nebula Graph shows superior performance in providing graph data services. The larger the data size, the greater the superiority of Nebula Graph. For more information, see [Nebula Graph benchmarking](https://discuss.nebula-graph.io/t/nebula-graph-1-0-benchmark-report/581).
+Written in C++ and born for graph, NebulaGraph handles graph queries in milliseconds. Among most databases, NebulaGraph shows superior performance in providing graph data services. The larger the data size, the greater the superiority of NebulaGraph. For more information, see [NebulaGraph benchmarking](https://discuss.nebula-graph.io/t/nebula-graph-1-0-benchmark-report/581).
### High scalability
-Nebula Graph is designed in a shared-nothing architecture and supports scaling in and out without interrupting the database service.
+NebulaGraph is designed in a shared-nothing architecture and supports scaling in and out without interrupting the database service.
### Developer friendly
-Nebula Graph supports clients in popular programming languages like Java, Python, C++, and Go, and more are being developed. For more information, see Nebula Graph [clients](../20.appendix/6.eco-tool-version.md).
+NebulaGraph supports clients in popular programming languages like Java, Python, C++, and Go, and more are being developed. For more information, see NebulaGraph [clients](../20.appendix/6.eco-tool-version.md).
### Reliable access control
-Nebula Graph supports strict role-based access control and external authentication servers such as LDAP (Lightweight Directory Access Protocol) servers to enhance data security. For more information, see [Authentication and authorization](../7.data-security/1.authentication/1.authentication.md).
+NebulaGraph supports strict role-based access control and external authentication servers such as LDAP (Lightweight Directory Access Protocol) servers to enhance data security. For more information, see [Authentication and authorization](../7.data-security/1.authentication/1.authentication.md).
### Diversified ecosystem
-More and more native tools of Nebula Graph have been released, such as [Nebula Graph Studio](https://github.com/vesoft-inc/nebula-web-docker), [Nebula Console](https://github.com/vesoft-inc/nebula-console), and [Nebula Exchange](https://github.com/vesoft-inc/nebula-exchange). For more ecosystem tools, see [Ecosystem tools overview](../20.appendix/6.eco-tool-version.md).
+More and more native tools of NebulaGraph have been released, such as [NebulaGraph Studio](https://github.com/vesoft-inc/nebula-web-docker), [Nebula Console](https://github.com/vesoft-inc/nebula-console), and [Nebula Exchange](https://github.com/vesoft-inc/nebula-exchange). For more ecosystem tools, see [Ecosystem tools overview](../20.appendix/6.eco-tool-version.md).
-Besides, Nebula Graph has the ability to be integrated with many cutting-edge technologies, such as Spark, Flink, and HBase, for the purpose of mutual strengthening in a world of increasing challenges and chances. For more information, see [Ecosystem development](../20.appendix/6.eco-tool-version.md).
+Besides, NebulaGraph has the ability to be integrated with many cutting-edge technologies, such as Spark, Flink, and HBase, for the purpose of mutual strengthening in a world of increasing challenges and chances. For more information, see [Ecosystem development](../20.appendix/6.eco-tool-version.md).
### OpenCypher-compatible query language
-The native Nebula Graph Query Language, also known as nGQL, is a declarative, openCypher-compatible textual query language. It is easy to understand and easy to use. For more information, see [nGQL guide](../3.ngql-guide/1.nGQL-overview/1.overview.md).
+The native NebulaGraph Query Language, also known as nGQL, is a declarative, openCypher-compatible textual query language. It is easy to understand and easy to use. For more information, see [nGQL guide](../3.ngql-guide/1.nGQL-overview/1.overview.md).
### Future-oriented hardware with balanced reading and writing
Solid-state drives have extremely high performance and [they are getting cheaper](https://blocksandfiles.com/wp-content/uploads/2021/01/Wikibon-SSD-less-than-HDD-in-2026.jpg).
- Nebula Graph is a product based on SSD. Compared with products based on HDD and large memory, it is more suitable for future hardware trends and easier to achieve balanced reading and writing.
+ NebulaGraph is a product based on SSD. Compared with products based on HDD and large memory, it is more suitable for future hardware trends and easier to achieve balanced reading and writing.
### Easy data modeling and high flexibility
-You can easily model the connected data into Nebula Graph for your business without forcing them into a structure such as a relational table, and properties can be added, updated, and deleted freely. For more information, see [Data modeling](2.data-model.md).
+You can easily model the connected data into NebulaGraph for your business without forcing them into a structure such as a relational table, and properties can be added, updated, and deleted freely. For more information, see [Data modeling](2.data-model.md).
### High popularity
-Nebula Graph is being used by tech leaders such as Tencent, Vivo, Meituan, and JD Digits. For more information, visit the [Nebula Graph official website](https://nebula-graph.io/).
+NebulaGraph is being used by tech leaders such as Tencent, Vivo, Meituan, and JD Digits. For more information, visit the [NebulaGraph official website](https://nebula-graph.io/).
## Use cases
-Nebula Graph can be used to support various graph-based scenarios. To spare the time spent on pushing the kinds of data mentioned in this section into relational databases and on bothering with join queries, use Nebula Graph.
+NebulaGraph can be used to support various graph-based scenarios. To spare the time spent on pushing the kinds of data mentioned in this section into relational databases and on bothering with join queries, use NebulaGraph.
### Fraud detection
-Financial institutions have to traverse countless transactions to piece together potential crimes and understand how combinations of transactions and devices might be related to a single fraud scheme. This kind of scenario can be modeled in graphs, and with the help of Nebula Graph, fraud rings and other sophisticated scams can be easily detected.
+Financial institutions have to traverse countless transactions to piece together potential crimes and understand how combinations of transactions and devices might be related to a single fraud scheme. This kind of scenario can be modeled in graphs, and with the help of NebulaGraph, fraud rings and other sophisticated scams can be easily detected.
### Real-time recommendation
-Nebula Graph offers the ability to instantly process the real-time information produced by a visitor and make accurate recommendations on articles, videos, products, and services.
+NebulaGraph offers the ability to instantly process the real-time information produced by a visitor and make accurate recommendations on articles, videos, products, and services.
### Intelligent question-answer system
-Natural languages can be transformed into knowledge graphs and stored in Nebula Graph. A question organized in a natural language can be resolved by a semantic parser in an intelligent question-answer system and re-organized. Then, possible answers to the question can be retrieved from the knowledge graph and provided to the one who asked the question.
+Natural languages can be transformed into knowledge graphs and stored in NebulaGraph. A question organized in a natural language can be resolved by a semantic parser in an intelligent question-answer system and re-organized. Then, possible answers to the question can be retrieved from the knowledge graph and provided to the one who asked the question.
### Social networking
-Information on people and their relationships are typical graph data. Nebula Graph can easily handle the social networking information of billions of people and trillions of relationships, and provide lightning-fast queries for friend recommendations and job promotions in the case of massive concurrency.
+Information on people and their relationships are typical graph data. NebulaGraph can easily handle the social networking information of billions of people and trillions of relationships, and provide lightning-fast queries for friend recommendations and job promotions in the case of massive concurrency.
## Related links
diff --git a/docs-2.0/1.introduction/2.data-model.md b/docs-2.0/1.introduction/2.data-model.md
index 53116d1d6e3..63dedc0cb6e 100644
--- a/docs-2.0/1.introduction/2.data-model.md
+++ b/docs-2.0/1.introduction/2.data-model.md
@@ -1,10 +1,10 @@
# Data modeling
-A data model is a model that organizes data and specifies how they are related to one another. This topic describes the Nebula Graph data model and provides suggestions for data modeling with Nebula Graph.
+A data model is a model that organizes data and specifies how they are related to one another. This topic describes the Nebula Graph data model and provides suggestions for data modeling with NebulaGraph.
## Data structures
-Nebula Graph data model uses six data structures to store data. They are graph spaces, vertices, edges, tags, edge types and properties.
+NebulaGraph data model uses six data structures to store data. They are graph spaces, vertices, edges, tags, edge types and properties.
- **Graph spaces**: Graph spaces are used to isolate data from different teams or programs. Data stored in different graph spaces are securely isolated. Storage replications, privileges, and partitions can be assigned.
- **Vertices**: Vertices are used to store entities.
@@ -26,7 +26,7 @@ Nebula Graph data model uses six data structures to store data. They are graph s
## Directed property graph
-Nebula Graph stores data in directed property graphs. A directed property graph has a set of vertices connected by directed edges. Both vertices and edges can have properties. A directed property graph is represented as:
+NebulaGraph stores data in directed property graphs. A directed property graph has a set of vertices connected by directed edges. Both vertices and edges can have properties. A directed property graph is represented as:
**G = < V, E, PV, PE >**
@@ -46,10 +46,10 @@ The following table is an example of the structure of the basketball player data
!!! Note
- Nebula Graph supports only directed edges.
+ NebulaGraph supports only directed edges.
!!! compatibility
- Nebula Graph {{ nebula.release }} allows dangling edges. Therefore, when adding or deleting, you need to ensure the corresponding source vertex and destination vertex of an edge exist. For details, see [INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md), [DELETE VERTEX](../3.ngql-guide/12.vertex-statements/4.delete-vertex.md), [INSERT EDGE](../3.ngql-guide/13.edge-statements/1.insert-edge.md), and [DELETE EDGE](../3.ngql-guide/13.edge-statements/4.delete-edge.md).
+ NebulaGraph {{ nebula.release }} allows dangling edges. Therefore, when adding or deleting, you need to ensure the corresponding source vertex and destination vertex of an edge exist. For details, see [INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md), [DELETE VERTEX](../3.ngql-guide/12.vertex-statements/4.delete-vertex.md), [INSERT EDGE](../3.ngql-guide/13.edge-statements/1.insert-edge.md), and [DELETE EDGE](../3.ngql-guide/13.edge-statements/4.delete-edge.md).
The MERGE statement in openCypher is not supported.
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/1.architecture-overview.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/1.architecture-overview.md
index 5410a42fe06..314ed549b69 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/1.architecture-overview.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/1.architecture-overview.md
@@ -1,22 +1,22 @@
# Architecture overview
-Nebula Graph consists of three services: the Graph Service, the Storage Service, and the Meta Service. It applies the separation of storage and computing architecture.
+NebulaGraph consists of three services: the Graph Service, the Storage Service, and the Meta Service. It applies the separation of storage and computing architecture.
-Each service has its executable binaries and processes launched from the binaries. Users can deploy a Nebula Graph cluster on a single machine or multiple machines using these binaries.
+Each service has its executable binaries and processes launched from the binaries. Users can deploy a NebulaGraph cluster on a single machine or multiple machines using these binaries.
-The following figure shows the architecture of a typical Nebula Graph cluster.
+The following figure shows the architecture of a typical NebulaGraph cluster.
-
+
## The Meta Service
-The Meta Service in the Nebula Graph architecture is run by the nebula-metad processes. It is responsible for metadata management, such as schema operations, cluster administration, and user privilege management.
+The Meta Service in the NebulaGraph architecture is run by the nebula-metad processes. It is responsible for metadata management, such as schema operations, cluster administration, and user privilege management.
For details on the Meta Service, see [Meta Service](2.meta-service.md).
## The Graph Service and the Storage Service
-Nebula Graph applies the separation of storage and computing architecture. The Graph Service is responsible for querying. The Storage Service is responsible for storage. They are run by different processes, i.e., nebula-graphd and nebula-storaged. The benefits of the separation of storage and computing architecture are as follows:
+NebulaGraph applies the separation of storage and computing architecture. The Graph Service is responsible for querying. The Storage Service is responsible for storage. They are run by different processes, i.e., nebula-graphd and nebula-storaged. The benefits of the separation of storage and computing architecture are as follows:
* Great scalability
@@ -28,7 +28,7 @@ Nebula Graph applies the separation of storage and computing architecture. The G
* Cost-effective
- The separation of storage and computing architecture provides a higher resource utilization rate, and it enables clients to manage the cost flexibly according to business demands. The cost savings can be more distinct if the [Nebula Graph Cloud](https://www.nebula-cloud.io/ "Nebula Graph Cloud official website") service is used.
+ The separation of storage and computing architecture provides a higher resource utilization rate, and it enables clients to manage the cost flexibly according to business demands. The cost savings can be more distinct if the [NebulaGraph Cloud](https://www.nebula-cloud.io/ "NebulaGraph Cloud official website") service is used.
* Open to more possibilities
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/2.meta-service.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/2.meta-service.md
index 9decb33d7ec..14420bfa29d 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/2.meta-service.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/2.meta-service.md
@@ -15,7 +15,7 @@ The Meta Service is run by nebula-metad processes. Users can deploy nebula-metad
All the nebula-metad processes form a Raft-based cluster, with one process as the leader and the others as the followers.
-The leader is elected by the majorities and only the leader can provide service to the clients or other components of Nebula Graph. The followers will be run in a standby way and each has a data replication of the leader. Once the leader fails, one of the followers will be elected as the new leader.
+The leader is elected by the majorities and only the leader can provide service to the clients or other components of NebulaGraph. The followers will be run in a standby way and each has a data replication of the leader. Once the leader fails, one of the followers will be elected as the new leader.
!!! Note
@@ -27,7 +27,7 @@ The leader is elected by the majorities and only the leader can provide service
The Meta Service stores the information of user accounts and the privileges granted to the accounts. When the clients send queries to the Meta Service through an account, the Meta Service checks the account information and whether the account has the right privileges to execute the queries or not.
-For more information on Nebula Graph access control, see [Authentication and authorization](../../7.data-security/1.authentication/1.authentication.md).
+For more information on NebulaGraph access control, see [Authentication and authorization](../../7.data-security/1.authentication/1.authentication.md).
### Manages partitions
@@ -35,15 +35,15 @@ The Meta Service stores and manages the locations of the storage partitions and
### Manages graph spaces
-Nebula Graph supports multiple graph spaces. Data stored in different graph spaces are securely isolated. The Meta Service stores the metadata of all graph spaces and tracks the changes of them, such as adding or dropping a graph space.
+NebulaGraph supports multiple graph spaces. Data stored in different graph spaces are securely isolated. The Meta Service stores the metadata of all graph spaces and tracks the changes of them, such as adding or dropping a graph space.
### Manages schema information
-Nebula Graph is a strong-typed graph database. Its schema contains tags (i.e., the vertex types), edge types, tag properties, and edge type properties.
+NebulaGraph is a strong-typed graph database. Its schema contains tags (i.e., the vertex types), edge types, tag properties, and edge type properties.
The Meta Service stores the schema information. Besides, it performs the addition, modification, and deletion of the schema, and logs the versions of them.
-For more information on Nebula Graph schema, see [Data model](../2.data-model.md).
+For more information on NebulaGraph schema, see [Data model](../2.data-model.md).
### Manages TTL information
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md
index c1a34bf1174..d0d0df54512 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md
@@ -86,7 +86,7 @@ In the `nebula-graphd.conf` file, when `enable_optimizer` is set to be `true`, P
!!! Note
- Nebula Graph {{ nebula.release }} will not run optimization by default.
+ NebulaGraph {{ nebula.release }} will not run optimization by default.
## Executor
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
index 89cea25c141..fafa4fe9cc7 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
@@ -1,6 +1,6 @@
# Storage Service
-The persistent data of Nebula Graph have two parts. One is the [Meta Service](2.meta-service.md) that stores the meta-related data.
+The persistent data of NebulaGraph have two parts. One is the [Meta Service](2.meta-service.md) that stores the meta-related data.
The other is the Storage Service that stores the data, which is run by the nebula-storaged process. This topic will describe the architecture of Storage Service.
@@ -48,33 +48,33 @@ The following will describe some features of Storage Service based on the above
## KVStore
-Nebula Graph develops and customizes its built-in KVStore for the following reasons.
+NebulaGraph develops and customizes its built-in KVStore for the following reasons.
- It is a high-performance KVStore.
-- It is provided as a (kv) library and can be easily developed for the filtering-pushdown purpose. As a strong-typed database, how to provide Schema during pushdown is the key to efficiency for Nebula Graph.
+- It is provided as a (kv) library and can be easily developed for the filtering-pushdown purpose. As a strong-typed database, how to provide Schema during pushdown is the key to efficiency for NebulaGraph.
- It has strong data consistency.
-Therefore, Nebula Graph develops its own KVStore with RocksDB as the local storage engine. The advantages are as follows.
+Therefore, NebulaGraph develops its own KVStore with RocksDB as the local storage engine. The advantages are as follows.
-- For multiple local hard disks, Nebula Graph can make full use of its concurrent capacities through deploying multiple data directories.
+- For multiple local hard disks, NebulaGraph can make full use of its concurrent capacities through deploying multiple data directories.
- Meta Service manages all the Storage servers. All the partition distribution data and current machine status can be found in the meta service. Accordingly, users can execute a manual load balancing plan in meta service.
!!! Note
- Nebula Graph does not support auto load balancing because auto data transfer will affect online business.
+ NebulaGraph does not support auto load balancing because auto data transfer will affect online business.
-- Nebula Graph provides its own WAL mode so one can customize the WAL. Each partition owns its WAL.
+- NebulaGraph provides its own WAL mode so one can customize the WAL. Each partition owns its WAL.
-- One Nebula Graph KVStore cluster supports multiple graph spaces, and each graph space has its own partition number and replica copies. Different graph spaces are isolated physically from each other in the same cluster.
+- One NebulaGraph KVStore cluster supports multiple graph spaces, and each graph space has its own partition number and replica copies. Different graph spaces are isolated physically from each other in the same cluster.
## Data storage formats
-Nebula Graph stores vertices and edges. Efficient property filtering is critical for a Graph Database. So, Nebula Graph uses keys to store vertices and edges, while uses values to store the related properties.
+NebulaGraph stores vertices and edges. Efficient property filtering is critical for a Graph Database. So, NebulaGraph uses keys to store vertices and edges, while uses values to store the related properties.
-Nebula Graph {{ nebula.base20 }} has changed a lot over its releases. The following will introduce the old and new data storage formats and cover their differences.
+NebulaGraph {{ nebula.base20 }} has changed a lot over its releases. The following will introduce the old and new data storage formats and cover their differences.
- Vertex format
@@ -102,29 +102,29 @@ Nebula Graph {{ nebula.base20 }} has changed a lot over its releases. The follow
!!! compatibility "Legacy version compatibility"
- The differences between Nebula Graph 1.x and 2.0 are as follows:
+ The differences between NebulaGraph 1.x and 2.0 are as follows:
- - In Nebula Graph 1.x, a vertex and an edge have the same `Type` byte, while in Nebula Graph 2.0, the Type byte differs from each other, which separates vertices and edges physically so that all tags of a vertex can be easily queried.
- - Nebula Graph 1.x supports only int IDs, while Nebula Graph 2.0 is compatible with both int IDs and string IDs.
- - Nebula Graph 2.0 removes `Timestamp` in both vertex and edge key formats.
- - Nebula Graph 2.0 adds `PlaceHolder` to edge key format.
- - Nebula Graph 2.0 has changed the formats of indexes for a range query.
+ - In NebulaGraph 1.x, a vertex and an edge have the same `Type` byte, while in NebulaGraph 2.0, the Type byte differs from each other, which separates vertices and edges physically so that all tags of a vertex can be easily queried.
+ - NebulaGraph 1.x supports only int IDs, while NebulaGraph 2.0 is compatible with both int IDs and string IDs.
+ - NebulaGraph 2.0 removes `Timestamp` in both vertex and edge key formats.
+ - NebulaGraph 2.0 adds `PlaceHolder` to edge key format.
+ - NebulaGraph 2.0 has changed the formats of indexes for a range query.
### Property descriptions
-Nebula Graph uses strong-typed Schema.
+NebulaGraph uses strong-typed Schema.
-Nebula Graph will store the properties of vertex and edges in order after encoding them. Since the length of properties is fixed, queries can be made in no time according to offset. Before decoding, Nebula Graph needs to get (and cache) the schema information in the Meta Service. In addition, when encoding properties, Nebula Graph will add the corresponding schema version to support online schema change.
+NebulaGraph will store the properties of vertex and edges in order after encoding them. Since the length of properties is fixed, queries can be made in no time according to offset. Before decoding, NebulaGraph needs to get (and cache) the schema information in the Meta Service. In addition, when encoding properties, NebulaGraph will add the corresponding schema version to support online schema change.
## Data partitioning
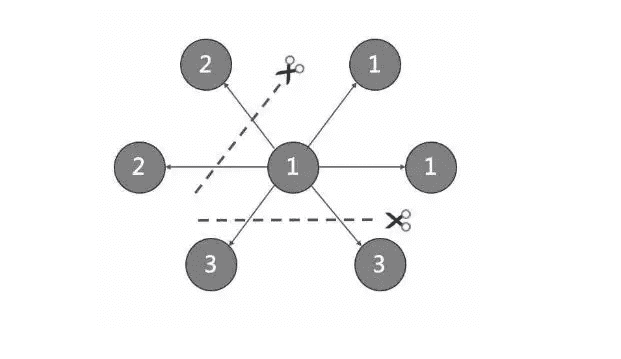
-Since in an ultra-large-scale relational network, vertices can be as many as tens to hundreds of billions, and edges are even more than trillions. Even if only vertices and edges are stored, the storage capacity of both exceeds that of ordinary servers. Therefore, Nebula Graph uses hash to shard the graph elements and store them in different partitions.
+Since in an ultra-large-scale relational network, vertices can be as many as tens to hundreds of billions, and edges are even more than trillions. Even if only vertices and edges are stored, the storage capacity of both exceeds that of ordinary servers. Therefore, NebulaGraph uses hash to shard the graph elements and store them in different partitions.
### Edge and storage amplification
-In Nebula Graph, an edge corresponds to two key-value pairs on the hard disk. When there are lots of edges and each has many properties, storage amplification will be obvious. The storage format of edges is shown in the picture below.
+In NebulaGraph, an edge corresponds to two key-value pairs on the hard disk. When there are lots of edges and each has many properties, storage amplification will be obvious. The storage format of edges is shown in the picture below.
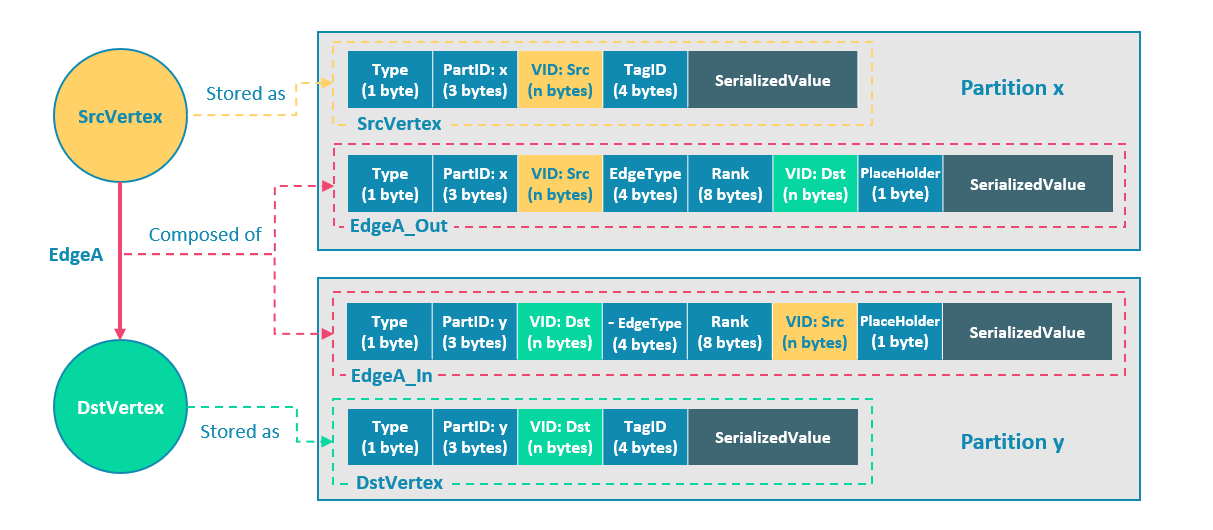
@@ -140,19 +140,19 @@ In this example, ScrVertex connects DstVertex via EdgeA, forming the path of `(S
EdgeA_Out and EdgeA_In are stored in storage layer with opposite directions, constituting EdgeA logically. EdgeA_Out is used for traversal requests starting from SrcVertex, such as `(a)-[]->()`; EdgeA_In is used for traversal requests starting from DstVertex, such as `()-[]->(a)`.
-Like EdgeA_Out and EdgeA_In, Nebula Graph redundantly stores the information of each edge, which doubles the actual capacities needed for edge storage. The key corresponding to the edge occupies a small hard disk space, but the space occupied by Value is proportional to the length and amount of the property value. Therefore, it will occupy a relatively large hard disk space if the property value of the edge is large or there are many edge property values.
+Like EdgeA_Out and EdgeA_In, NebulaGraph redundantly stores the information of each edge, which doubles the actual capacities needed for edge storage. The key corresponding to the edge occupies a small hard disk space, but the space occupied by Value is proportional to the length and amount of the property value. Therefore, it will occupy a relatively large hard disk space if the property value of the edge is large or there are many edge property values.
To ensure the final consistency of the two key-value pairs when operating on edges, enable the [TOSS function](../../5.configurations-and-logs/1.configurations/3.graph-config.md ). After that, the operation will be performed in Partition x first where the out-edge is located, and then in Partition y where the in-edge is located. Finally, the result is returned.
### Partition algorithm
-Nebula Graph uses a **static Hash** strategy to shard data through a modulo operation on vertex ID. All the out-keys, in-keys, and tag data will be placed in the same partition. In this way, query efficiency is increased dramatically.
+NebulaGraph uses a **static Hash** strategy to shard data through a modulo operation on vertex ID. All the out-keys, in-keys, and tag data will be placed in the same partition. In this way, query efficiency is increased dramatically.
!!! Note
The number of partitions needs to be determined when users are creating a graph space since it cannot be changed afterward. Users are supposed to take into consideration the demands of future business when setting it.
-When inserting into Nebula Graph, vertices and edges are distributed across different partitions. And the partitions are located on different machines. The number of partitions is set in the CREATE SPACE statement and cannot be changed afterward.
+When inserting into NebulaGraph, vertices and edges are distributed across different partitions. And the partitions are located on different machines. The number of partitions is set in the CREATE SPACE statement and cannot be changed afterward.
If certain vertices need to be placed on the same partition (i.e., on the same machine), see [Formula/code](https://github.com/vesoft-inc/nebula-common/blob/master/src/common/clients/meta/MetaClient.cpp).
@@ -206,13 +206,13 @@ Failure: Scenario 1: Take a (space) cluster of a single replica as an example. I
Raft and HDFS have different modes of duplication. Raft is based on a quorum vote, so the number of replicas cannot be even.
-Listener: As is a special role in Raft, it cannot vote or keep data consistency. In Nebula Graph, it reads Raft-wal from the Leader and synchronizes it to ElasticSearch cluster.
+Listener: As is a special role in Raft, it cannot vote or keep data consistency. In NebulaGraph, it reads Raft-wal from the Leader and synchronizes it to ElasticSearch cluster.
### Multi Group Raft
-Storage Service supports a distributed cluster architecture, so Nebula Graph implements Multi Group Raft according to Raft protocol. Each Raft group stores all the replicas of each partition. One replica is the leader, while others are followers. In this way, Nebula Graph achieves strong consistency and high availability. The functions of Raft are as follows.
+Storage Service supports a distributed cluster architecture, so NebulaGraph implements Multi Group Raft according to Raft protocol. Each Raft group stores all the replicas of each partition. One replica is the leader, while others are followers. In this way, NebulaGraph achieves strong consistency and high availability. The functions of Raft are as follows.
-Nebula Graph uses Multi Group Raft to improve performance when there are many partitions because Raft-wal cannot be NULL. When there are too many partitions, costs will increase, such as storing information in Raft group, WAL files, or batch operation in low load.
+NebulaGraph uses Multi Group Raft to improve performance when there are many partitions because Raft-wal cannot be NULL. When there are too many partitions, costs will increase, such as storing information in Raft group, WAL files, or batch operation in low load.
There are two key points to implement the Multi Raft Group:
@@ -226,7 +226,7 @@ There are two key points to implement the Multi Raft Group:
### Batch
-For each partition, it is necessary to do a batch to improve throughput when writing the WAL serially. As Nebula Graph uses WAL to implement some special functions, batches need to be grouped, which is a feature of Nebula Graph.
+For each partition, it is necessary to do a batch to improve throughput when writing the WAL serially. As NebulaGraph uses WAL to implement some special functions, batches need to be grouped, which is a feature of NebulaGraph.
For example, lock-free CAS operations will execute after all the previous WALs are committed. So for a batch, if there are several WALs in CAS type, we need to divide this batch into several smaller groups and make sure they are committed serially.
@@ -240,13 +240,13 @@ Raft listener can write the data into Elasticsearch cluster after receiving them
### Transfer Leadership
-Transfer leadership is extremely important for balance. When moving a partition from one machine to another, Nebula Graph first checks if the source is a leader. If so, it should be moved to another peer. After data migration is completed, it is important to [balance leader distribution](../../8.service-tuning/load-balance.md) again.
+Transfer leadership is extremely important for balance. When moving a partition from one machine to another, NebulaGraph first checks if the source is a leader. If so, it should be moved to another peer. After data migration is completed, it is important to [balance leader distribution](../../8.service-tuning/load-balance.md) again.
When a transfer leadership command is committed, the leader will abandon its leadership and the followers will start a leader election.
### Peer changes
-To avoid split-brain, when members in a Raft Group change, an intermediate state is required. In such a state, the quorum of the old group and new group always have an overlap. Thus it prevents the old or new group from making decisions unilaterally. To make it even simpler, in his doctoral thesis Diego Ongaro suggests adding or removing a peer once to ensure the overlap between the quorum of the new group and the old group. Nebula Graph also uses this approach, except that the way to add or remove a member is different. For details, please refer to addPeer/removePeer in the Raft Part class.
+To avoid split-brain, when members in a Raft Group change, an intermediate state is required. In such a state, the quorum of the old group and new group always have an overlap. Thus it prevents the old or new group from making decisions unilaterally. To make it even simpler, in his doctoral thesis Diego Ongaro suggests adding or removing a peer once to ensure the overlap between the quorum of the new group and the old group. NebulaGraph also uses this approach, except that the way to add or remove a member is different. For details, please refer to addPeer/removePeer in the Raft Part class.
## Differences with HDFS
diff --git a/docs-2.0/1.introduction/3.vid.md b/docs-2.0/1.introduction/3.vid.md
index 17387229973..5820954dc14 100644
--- a/docs-2.0/1.introduction/3.vid.md
+++ b/docs-2.0/1.introduction/3.vid.md
@@ -1,6 +1,6 @@
# VID
-In Nebula Graph, a vertex is uniquely identified by its ID, which is called a VID or a Vertex ID.
+In NebulaGraph, a vertex is uniquely identified by its ID, which is called a VID or a Vertex ID.
## Features
@@ -8,7 +8,7 @@ In Nebula Graph, a vertex is uniquely identified by its ID, which is called a VI
- A VID in a graph space is unique. It functions just as a primary key in a relational database. VIDs in different graph spaces are independent.
-- The VID generation method must be set by users, because Nebula Graph does not provide auto increasing ID, or UUID.
+- The VID generation method must be set by users, because NebulaGraph does not provide auto increasing ID, or UUID.
- Vertices with the same VID will be identified as the same one. For example:
@@ -22,7 +22,7 @@ In Nebula Graph, a vertex is uniquely identified by its ID, which is called a VI
## VID Operation
-- Nebula Graph 1.x only supports `INT64` while Nebula Graph 2.x supports `INT64` and `FIXED_STRING()`. In `CREATE SPACE`, VID types can be set via `vid_type`.
+- NebulaGraph 1.x only supports `INT64` while NebulaGraph 2.x supports `INT64` and `FIXED_STRING()`. In `CREATE SPACE`, VID types can be set via `vid_type`.
- `id()` function can be used to specify or locate a VID.
@@ -50,7 +50,7 @@ The data type of VIDs must be defined when you [create the graph space](../3.ngq
## Query `start vid` and global scan
-In most cases, the execution plan of query statements in Nebula Graph (`MATCH`, `GO`, and `LOOKUP`) must query the `start vid` in a certain way.
+In most cases, the execution plan of query statements in NebulaGraph (`MATCH`, `GO`, and `LOOKUP`) must query the `start vid` in a certain way.
There are only two ways to locate `start vid`:
diff --git a/docs-2.0/14.client/1.nebula-client.md b/docs-2.0/14.client/1.nebula-client.md
index 7b7e45b3b44..74167e2f02a 100644
--- a/docs-2.0/14.client/1.nebula-client.md
+++ b/docs-2.0/14.client/1.nebula-client.md
@@ -1,16 +1,16 @@
# Clients overview
-Nebula Graph supports multiple types of clients for users to connect to and manage the Nebula Graph database.
+NebulaGraph supports multiple types of clients for users to connect to and manage the NebulaGraph database.
- [Nebula Console](../2.quick-start/3.connect-to-nebula-graph.md): the native CLI client
-- [Nebula CPP](3.nebula-cpp-client.md): the Nebula Graph client for C++
+- [Nebula CPP](3.nebula-cpp-client.md): the NebulaGraph client for C++
-- [Nebula Java](4.nebula-java-client.md): the Nebula Graph client for Java
+- [Nebula Java](4.nebula-java-client.md): the NebulaGraph client for Java
-- [Nebula Python](5.nebula-python-client.md): the Nebula Graph client for Python
+- [Nebula Python](5.nebula-python-client.md): the NebulaGraph client for Python
-- [Nebula Go](6.nebula-go-client.md): the Nebula Graph client for Golang
+- [Nebula Go](6.nebula-go-client.md): the NebulaGraph client for Golang
!!! note
diff --git a/docs-2.0/14.client/3.nebula-cpp-client.md b/docs-2.0/14.client/3.nebula-cpp-client.md
index c2ae3640ef2..6f92d783d1f 100644
--- a/docs-2.0/14.client/3.nebula-cpp-client.md
+++ b/docs-2.0/14.client/3.nebula-cpp-client.md
@@ -1,6 +1,6 @@
# Nebula CPP
-[Nebula CPP](https://github.com/vesoft-inc/nebula-cpp/tree/{{cpp.branch}}) is a C++ client for connecting to and managing the Nebula Graph database.
+[Nebula CPP](https://github.com/vesoft-inc/nebula-cpp/tree/{{cpp.branch}}) is a C++ client for connecting to and managing the NebulaGraph database.
## Prerequisites
@@ -8,9 +8,9 @@
- You have prepared the [correct resources](../4.deployment-and-installation/1.resource-preparations.md).
-## Compatibility with Nebula Graph
+## Compatibility with NebulaGraph
-|Nebula Graph version|Nebula CPP version|
+|NebulaGraph version|Nebula CPP version|
|:---|:---|
|{{ nebula.release }}|{{cpp.release}}|
|2.0.1|2.0.0|
@@ -90,9 +90,9 @@ Compile the CPP file to an executable file, then you can use it. The following s
$ LIBRARY_PATH=:$LIBRARY_PATH g++ -std=c++11 SessionExample.cpp -I -lnebula_graph_client -o session_example
```
- - `library_folder_path`: The storage path of the Nebula Graph dynamic libraries. The default path is `/usr/local/nebula/lib64`.
+ - `library_folder_path`: The storage path of the NebulaGraph dynamic libraries. The default path is `/usr/local/nebula/lib64`.
- - `include_folder_path`: The storage of the Nebula Graph header files. The default path is `/usr/local/nebula/include`.
+ - `include_folder_path`: The storage of the NebulaGraph header files. The default path is `/usr/local/nebula/include`.
For example:
diff --git a/docs-2.0/14.client/4.nebula-java-client.md b/docs-2.0/14.client/4.nebula-java-client.md
index 6c2e6b0673a..bb136c75ae3 100644
--- a/docs-2.0/14.client/4.nebula-java-client.md
+++ b/docs-2.0/14.client/4.nebula-java-client.md
@@ -1,14 +1,14 @@
# Nebula Java
-[Nebula Java](https://github.com/vesoft-inc/nebula-java/tree/{{java.branch}}) is a Java client for connecting to and managing the Nebula Graph database.
+[Nebula Java](https://github.com/vesoft-inc/nebula-java/tree/{{java.branch}}) is a Java client for connecting to and managing the NebulaGraph database.
## Prerequisites
You have installed Java 8.0 or later versions.
-## Compatibility with Nebula Graph
+## Compatibility with NebulaGraph
-|Nebula Graph version|Nebula Java version|
+|NebulaGraph version|Nebula Java version|
|:---|:---|
|{{ nebula.release }}|{{java.release}}|
|2.0.1|2.0.0|
diff --git a/docs-2.0/14.client/5.nebula-python-client.md b/docs-2.0/14.client/5.nebula-python-client.md
index df1e10f210e..01cc39acb3b 100644
--- a/docs-2.0/14.client/5.nebula-python-client.md
+++ b/docs-2.0/14.client/5.nebula-python-client.md
@@ -1,14 +1,14 @@
# Nebula Python
-[Nebula Python](https://github.com/vesoft-inc/nebula-python) is a Python client for connecting to and managing the Nebula Graph database.
+[Nebula Python](https://github.com/vesoft-inc/nebula-python) is a Python client for connecting to and managing the NebulaGraph database.
## Prerequisites
You have installed Python 3.5 or later versions.
-## Compatibility with Nebula Graph
+## Compatibility with NebulaGraph
-|Nebula Graph version|Nebula Python version|
+|NebulaGraph version|Nebula Python version|
|:---|:---|
|{{ nebula.release }}|{{python.release}}|
|2.0.1|2.0.0|
diff --git a/docs-2.0/14.client/6.nebula-go-client.md b/docs-2.0/14.client/6.nebula-go-client.md
index 804144dfc51..359985d3a24 100644
--- a/docs-2.0/14.client/6.nebula-go-client.md
+++ b/docs-2.0/14.client/6.nebula-go-client.md
@@ -1,14 +1,14 @@
# Nebula Go
-[Nebula Go](https://github.com/vesoft-inc/nebula-go/tree/{{go.branch}}) is a Golang client for connecting to and managing the Nebula Graph database.
+[Nebula Go](https://github.com/vesoft-inc/nebula-go/tree/{{go.branch}}) is a Golang client for connecting to and managing the NebulaGraph database.
## Prerequisites
You have installed Golang 1.13 or later versions.
-## Compatibility with Nebula Graph
+## Compatibility with NebulaGraph
-|Nebula Graph version|Nebula Go version|
+|NebulaGraph version|Nebula Go version|
|:---|:---|
|{{ nebula.release }}|{{go.release}}|
|2.0.1|2.0.0-GA|
diff --git a/docs-2.0/15.contribution/how-to-contribute.md b/docs-2.0/15.contribution/how-to-contribute.md
index 97a04971d33..a463e417d63 100644
--- a/docs-2.0/15.contribution/how-to-contribute.md
+++ b/docs-2.0/15.contribution/how-to-contribute.md
@@ -28,7 +28,7 @@ This method applies to contribute codes, modify multiple documents in batches, o
## Step 1: Fork in the github.com
-The Nebula Graph project has many [repositories](https://github.com/vesoft-inc). Take [the nebula-graph repository](https://github.com/vesoft-inc/nebula) for example:
+The NebulaGraph project has many [repositories](https://github.com/vesoft-inc). Take [the nebula-graph repository](https://github.com/vesoft-inc/nebula) for example:
1. Visit [https://github.com/vesoft-inc/nebula](https://github.com/vesoft-inc/nebula).
@@ -75,7 +75,7 @@ The Nebula Graph project has many [repositories](https://github.com/vesoft-inc).
4. (Optional) Define a pre-commit hook.
- Please link the Nebula Graph pre-commit hook into the `.git` directory.
+ Please link the NebulaGraph pre-commit hook into the `.git` directory.
This hook checks the commits for formatting, building, doc generation, etc.
@@ -123,7 +123,7 @@ The Nebula Graph project has many [repositories](https://github.com/vesoft-inc).
- Code style
- **Nebula Graph** adopts `cpplint` to make sure that the project conforms to Google's coding style guides. The checker will be implemented before the code is committed.
+ **NebulaGraph** adopts `cpplint` to make sure that the project conforms to Google's coding style guides. The checker will be implemented before the code is committed.
- Unit tests requirements
@@ -131,7 +131,7 @@ The Nebula Graph project has many [repositories](https://github.com/vesoft-inc).
- Build your code with unit tests enabled
- For more information, see [Install Nebula Graph by compiling the source code](../4.deployment-and-installation/2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md).
+ For more information, see [Install NebulaGraph by compiling the source code](../4.deployment-and-installation/2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md).
!!! Note
@@ -192,7 +192,7 @@ For detailed methods, see [How to add test cases](https://github.com/vesoft-inc/
### Step 1: Confirm the project donation
-Contact the official Nebula Graph staff via email, WeChat, Slack, etc. to confirm the donation project. The project will be donated to the Nebula Contrib organization.
+Contact the official NebulaGraph staff via email, WeChat, Slack, etc. to confirm the donation project. The project will be donated to the Nebula Contrib organization.
Email address: info@vesoft.com
@@ -202,7 +202,7 @@ Slack: [Join Slack](https://join.slack.com/t/nebulagraph/shared_invite/zt-7ybeju
### Step 2: Get the information of the project recipient
-The Nebula Graph official staff will give the recipient ID of the Nebula Contrib project.
+The NebulaGraph official staff will give the recipient ID of the Nebula Contrib project.
### Step 3: Donate a project
diff --git a/docs-2.0/2.quick-start/1.quick-start-workflow.md b/docs-2.0/2.quick-start/1.quick-start-workflow.md
index 2068f105868..4562a2b29dc 100644
--- a/docs-2.0/2.quick-start/1.quick-start-workflow.md
+++ b/docs-2.0/2.quick-start/1.quick-start-workflow.md
@@ -1,23 +1,23 @@
# Quick start workflow
-The quick start introduces the simplest workflow to use Nebula Graph, including deploying Nebula Graph, connecting to Nebula Graph, and doing basic CRUD.
+The quick start introduces the simplest workflow to use NebulaGraph, including deploying NebulaGraph, connecting to NebulaGraph, and doing basic CRUD.
## Documents
-Users can quickly deploy and use Nebula Graph in the following steps.
+Users can quickly deploy and use NebulaGraph in the following steps.
-1. [Deploy Nebula Graph](2.install-nebula-graph.md)
+1. [Deploy NebulaGraph](2.install-nebula-graph.md)
- Users can use the RPM or DEB file to quickly deploy Nebula Graph. For other ways to deploy Nebula Graph and corresponding preparations, see [deployment and installation](../4.deployment-and-installation/1.resource-preparations.md).
+ Users can use the RPM or DEB file to quickly deploy NebulaGraph. For other ways to deploy NebulaGraph and corresponding preparations, see [deployment and installation](../4.deployment-and-installation/1.resource-preparations.md).
-2. [Start Nebula Graph](5.start-stop-service.md)
+2. [Start NebulaGraph](5.start-stop-service.md)
- Users need to start Nebula Graph after deployment.
+ Users need to start NebulaGraph after deployment.
-3. [Connect to Nebula Graph](3.connect-to-nebula-graph.md)
+3. [Connect to NebulaGraph](3.connect-to-nebula-graph.md)
- Then users can use clients to connect to Nebula Graph. Nebula Graph supports a variety of clients. This topic will describe how to use Nebula Console to connect to Nebula Graph.
+ Then users can use clients to connect to NebulaGraph. NebulaGraph supports a variety of clients. This topic will describe how to use Nebula Console to connect to NebulaGraph.
-4. [CRUD in Nebula Graph](4.nebula-graph-crud.md)
+4. [CRUD in NebulaGraph](4.nebula-graph-crud.md)
- Users can use nGQL (Nebula Graph Query Language) to run CRUD after connecting to Nebula Graph.
+ Users can use nGQL (NebulaGraph Query Language) to run CRUD after connecting to NebulaGraph.
diff --git a/docs-2.0/2.quick-start/2.install-nebula-graph.md b/docs-2.0/2.quick-start/2.install-nebula-graph.md
index 3771365834c..28018072dc2 100644
--- a/docs-2.0/2.quick-start/2.install-nebula-graph.md
+++ b/docs-2.0/2.quick-start/2.install-nebula-graph.md
@@ -1,4 +1,4 @@
-# Step 1: Install Nebula Graph
+# Step 1: Install NebulaGraph
{% include "/source_install-nebula-graph-by-rpm-or-deb.md" %}
diff --git a/docs-2.0/2.quick-start/3.connect-to-nebula-graph.md b/docs-2.0/2.quick-start/3.connect-to-nebula-graph.md
index 9a07a1262a9..11a5ba57da8 100644
--- a/docs-2.0/2.quick-start/3.connect-to-nebula-graph.md
+++ b/docs-2.0/2.quick-start/3.connect-to-nebula-graph.md
@@ -1,4 +1,4 @@
-# Step 3: Connect to Nebula Graph
+# Step 3: Connect to NebulaGraph
{% include "/source_connect-to-nebula-graph.md" %}
diff --git a/docs-2.0/2.quick-start/4.nebula-graph-crud.md b/docs-2.0/2.quick-start/4.nebula-graph-crud.md
index a355f26a21e..6d32e127dce 100644
--- a/docs-2.0/2.quick-start/4.nebula-graph-crud.md
+++ b/docs-2.0/2.quick-start/4.nebula-graph-crud.md
@@ -1,16 +1,16 @@
# Step 4: Use nGQL (CRUD)
-This topic will describe the basic CRUD operations in Nebula Graph.
+This topic will describe the basic CRUD operations in NebulaGraph.
For more information, see [nGQL guide](../3.ngql-guide/1.nGQL-overview/1.overview.md).
-## Graph space and Nebula Graph schema
+## Graph space and NebulaGraph schema
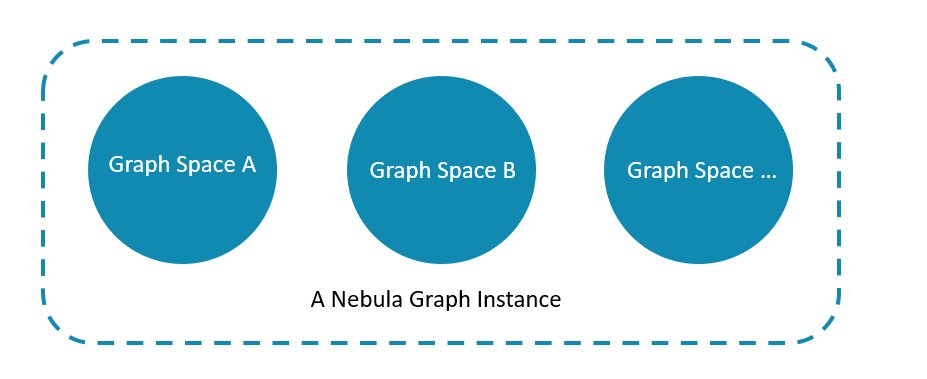
-A Nebula Graph instance consists of one or more graph spaces. Graph spaces are physically isolated from each other. You can use different graph spaces in the same instance to store different datasets.
+A NebulaGraph instance consists of one or more graph spaces. Graph spaces are physically isolated from each other. You can use different graph spaces in the same instance to store different datasets.
-
+
-To insert data into a graph space, define a schema for the graph database. Nebula Graph schema is based on the following components.
+To insert data into a graph space, define a schema for the graph database. NebulaGraph schema is based on the following components.
| Schema component | Description |
| ---------------- | --------------------------------------------------------------------------------------- |
@@ -25,7 +25,7 @@ In this topic, we will use the following dataset to demonstrate basic CRUD opera

-## Check the machine status in the Nebula Graph cluster
+## Check the machine status in the NebulaGraph cluster
!!! Note
@@ -49,7 +49,7 @@ From the **Status** column of the table in the return results, you can see that
!!! caution
- In Nebula Graph, the following `CREATE` or `ALTER` commands are implemented in an async way and take effect in the **next** heartbeat cycle. Otherwise, an error will be returned. To make sure the follow-up operations work as expected, Wait for two heartbeat cycles, i.e., 20 seconds.
+ In NebulaGraph, the following `CREATE` or `ALTER` commands are implemented in an async way and take effect in the **next** heartbeat cycle. Otherwise, an error will be returned. To make sure the follow-up operations work as expected, Wait for two heartbeat cycles, i.e., 20 seconds.
* `CREATE SPACE`
* `CREATE TAG`
@@ -232,7 +232,7 @@ Users can use the `INSERT` statement to insert vertices or edges based on existi
* The [LOOKUP](../3.ngql-guide/7.general-query-statements/5.lookup.md) statement is based on [indexes](#about_indexes). It is used together with the `WHERE` clause to search for the data that meet the specific conditions.
-* The [MATCH](../3ngql-guide/../3.ngql-guide/7.general-query-statements/2.match.md) statement is the most commonly used statement for graph data querying. It can describe all kinds of graph patterns, but it relies on [indexes](#about_indexes) to match data patterns in Nebula Graph. Therefore, its performance still needs optimization.
+* The [MATCH](../3ngql-guide/../3.ngql-guide/7.general-query-statements/2.match.md) statement is the most commonly used statement for graph data querying. It can describe all kinds of graph patterns, but it relies on [indexes](#about_indexes) to match data patterns in NebulaGraph. Therefore, its performance still needs optimization.
### nGQL syntax
diff --git a/docs-2.0/2.quick-start/5.start-stop-service.md b/docs-2.0/2.quick-start/5.start-stop-service.md
index d285815d892..373ed96cf5a 100644
--- a/docs-2.0/2.quick-start/5.start-stop-service.md
+++ b/docs-2.0/2.quick-start/5.start-stop-service.md
@@ -1,4 +1,4 @@
-# Step 2: Manage Nebula Graph Service
+# Step 2: Manage NebulaGraph Service
{% include "/source_manage-service.md" %}
diff --git a/docs-2.0/2.quick-start/6.cheatsheet-for-ngql.md b/docs-2.0/2.quick-start/6.cheatsheet-for-ngql.md
index f9a2ca83c14..a8242b6f27a 100644
--- a/docs-2.0/2.quick-start/6.cheatsheet-for-ngql.md
+++ b/docs-2.0/2.quick-start/6.cheatsheet-for-ngql.md
@@ -333,7 +333,7 @@
| Statement | Syntax | Example | Description |
| ------------------------------------------------------------ | ------------------------------------------------- | ------------------------------------ | -------------------------------------------------------- |
| [SHOW CHARSET](../3.ngql-guide/7.general-query-statements/6.show/1.show-charset.md) | `SHOW CHARSET` | `SHOW CHARSET` | Shows the available character sets. |
- | [SHOW COLLATION](../3.ngql-guide/7.general-query-statements/6.show/2.show-collation.md) | `SHOW COLLATION` | `SHOW COLLATION` | Shows the collations supported by Nebula Graph. |
+ | [SHOW COLLATION](../3.ngql-guide/7.general-query-statements/6.show/2.show-collation.md) | `SHOW COLLATION` | `SHOW COLLATION` | Shows the collations supported by NebulaGraph. |
| [SHOW CREATE SPACE](../3.ngql-guide/7.general-query-statements/6.show/4.show-create-space.md) | `SHOW CREATE SPACE ` | `SHOW CREATE SPACE basketballplayer` | Shows the creating statement of the specified graph space. |
| [SHOW CREATE TAG/EDGE](../3.ngql-guide/7.general-query-statements/6.show/5.show-create-tag-edge.md) | `SHOW CREATE {TAG | EDGE }` | `SHOW CREATE TAG player` | Shows the basic information of the specified tag. |
| [SHOW HOSTS](../3.ngql-guide/7.general-query-statements/6.show/6.show-hosts.md) | `SHOW HOSTS [GRAPH | STORAGE | META]` | `SHOW HOSTS`
`SHOW HOSTS GRAPH` | Shows the host and version information of Graph Service, Storage Service, and Meta Service. |
@@ -342,7 +342,7 @@
| [SHOW PARTS](../3.ngql-guide/7.general-query-statements/6.show/9.show-parts.md) | `SHOW PARTS []` | `SHOW PARTS` | Shows the information of a specified partition or all partitions in a graph space. |
| [SHOW ROLES](../3.ngql-guide/7.general-query-statements/6.show/10.show-roles.md) | `SHOW ROLES IN ` | `SHOW ROLES in basketballplayer` | Shows the roles that are assigned to a user account. |
| [SHOW SNAPSHOTS](../3.ngql-guide/7.general-query-statements/6.show/11.show-snapshots.md) | `SHOW SNAPSHOTS` | `SHOW SNAPSHOTS` | Shows the information of all the snapshots.
- | [SHOW SPACES](../3.ngql-guide/7.general-query-statements/6.show/12.show-spaces.md) | `SHOW SPACES` | `SHOW SPACES` | Shows existing graph spaces in Nebula Graph. |
+ | [SHOW SPACES](../3.ngql-guide/7.general-query-statements/6.show/12.show-spaces.md) | `SHOW SPACES` | `SHOW SPACES` | Shows existing graph spaces in NebulaGraph. |
| [SHOW STATS](../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) | `SHOW STATS` | `SHOW STATS` | Shows the statistics of the graph space collected by the latest `STATS` job. |
| [SHOW TAGS/EDGES](../3.ngql-guide/7.general-query-statements/6.show/15.show-tags-edges.md) | `SHOW TAGS | EDGES` | `SHOW TAGS`、`SHOW EDGES` | Shows all the tags in the current graph space. |
| [SHOW USERS](../3.ngql-guide/7.general-query-statements/6.show/16.show-users.md) | `SHOW USERS` | `SHOW USERS` | Shows the user information. |
@@ -376,7 +376,7 @@
| [CREATE SPACE](../3.ngql-guide/9.space-statements/1.create-space.md) | `CREATE SPACE [IF NOT EXISTS] ( [partition_num = ,] [replica_factor = ,] vid_type = {FIXED_STRING()| INT[64]} ) [COMMENT = '']` | `CREATE SPACE my_space_1 (vid_type=FIXED_STRING(30))` | Creates a graph space with |
| [CREATE SPACE](../3.ngql-guide/9.space-statements/1.create-space.md) | `CREATE SPACE AS ` | `CREATE SPACE my_space_4 as my_space_3` | Clone a graph space. |
| [USE](../3.ngql-guide/9.space-statements/2.use-space.md) | `USE ` | `USE space1` | Specifies a graph space as the current working graph space for subsequent queries. |
-| [SHOW SPACES](../3.ngql-guide/9.space-statements/3.show-spaces.md) | `SHOW SPACES` | `SHOW SPACES` | Lists all the graph spaces in the Nebula Graph examples. |
+| [SHOW SPACES](../3.ngql-guide/9.space-statements/3.show-spaces.md) | `SHOW SPACES` | `SHOW SPACES` | Lists all the graph spaces in the NebulaGraph examples. |
| [DESCRIBE SPACE](../3.ngql-guide/9.space-statements/4.describe-space.md) | `DESC[RIBE] SPACE ` | `DESCRIBE SPACE basketballplayer` | Returns the information about the specified graph space.息。 |
| [DROP SPACE](../3.ngql-guide/9.space-statements/5.drop-space.md) | `DROP SPACE [IF EXISTS] ` | `DROP SPACE basketballplayer` | Deletes everything in the specified graph space. |
@@ -411,7 +411,7 @@
| Statement | Syntax | Example | Description |
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md) | `INSERT VERTEX [IF NOT EXISTS] () [, (), ...] {VALUES | VALUE} VID: ([, ])` | `INSERT VERTEX t2 (name, age) VALUES "13":("n3", 12), "14":("n4", 8)` | Inserts one or more vertices into a graph space in Nebula Graph. |
+| [INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md) | `INSERT VERTEX [IF NOT EXISTS] () [, (), ...] {VALUES | VALUE} VID: ([, ])` | `INSERT VERTEX t2 (name, age) VALUES "13":("n3", 12), "14":("n4", 8)` | Inserts one or more vertices into a graph space in NebulaGraph. |
| [DELETE VERTEX](../3.ngql-guide/12.vertex-statements/4.delete-vertex.md) | `DELETE VERTEX [, ...]` | `DELETE VERTEX "team1"` | Deletes vertices and the related incoming and outgoing edges of the vertices. |
| [UPDATE VERTEX](../3.ngql-guide/12.vertex-statements/2.update-vertex.md) | `UPDATE VERTEX ON SET [WHEN ] [YIELD