+++
- Sandro Koll
+++
- Pascal Rimann
+++
+++
- Kurze Vorstellung
- Erfahrungen?
- Docker
- Kubernetes
- Erwartungen?
+++
- Setup
- Container
- Monolithen vs. Microservices
- Container-Orchestrierung
- Prinzipien hinter Kubernetes
sudo usermod -aG docker ${USER}
git clone https://github.com/x-cellent/k8s-workshop.git
cd k8s-workshop
make
mkdir -p ~/bin
mv bin/w6p ~/bin/
echo "export PATH=$PATH:~/bin" >> ~/.bashrc
source ~/.bashrc
w6p+++
Usage:
w6p [flags]
w6p [command]
Available Commands:
cluster Runs the workshop cluster or exercises
exercise Runs the given exercise
help Help about any command
install Installs tools on local machine
slides Shows or exports workshop slides
Flags:
-h, --help help for w6p+++
Go CLI executable ausschließlich für diesen Workshop
- w6p install TOOL
- lokale Installation von gebräuchlichen k8s Tools
- w6p exercise CONTEXT -n NUMBER
- Startet Aufgaben aus dem jeweiligen Kontext (docker oder k8s)
- w6p cluster
- Startet/stoppt Single-Node Kubernetes Cluster in Container
+++
- w6p slides
- Startet Webserver Container, der die Workshop Slides hosted
- erreichbar unter localhost:8080
Software wird schon seit Jahrzehnten in Archive oder Single-Binaries verpackt
- Einfache Auslieferung
- Einfache Verteilung
+++
- Installation notwendig
- Dependency Hell
- No cross platform functionality
+++
- Verpacken der Software mitsamt aller Dependencies (Image)
- Nichts darüber hinaus (Betriebssytem notwendig?)
- Container-Runtime für alle Plattformen
+++
- Linux
- Idee: Container teilen sich Kernel
- LXC: basierend auf Kernel-Funktionalitäten
- namespaces
- cgroups
- Docker erweitert LXC um
- ...CLI zum Starten und Verwalten von Containern
- Image Registry
- Networking
- docker-compose
- Geringere Größe
- Erhöhte Sicherheit
- Funktional auf allen Systemen
- Immutable
- Damit Baukastenprinzip möglich (DRY)
+++
- Geringere Größe
- Geringerer Ressourcenverbrauch
- Viel schnellere Startup-Zeiten
- Auch geeignet für Entwicklung und Test
+++
- Geringere Sicherheit
- Keine echte Trennung
- z.B. kein Block-Storage möglich
Container und VMs schließen sich aber nicht gegenseitig aus
- Image
- Layer
- Dockerfile
- Container
- Image Registry
+++
- Referenz
- Image-Rezept mit u.a. folgenden Zutaten:
- FROM
- COPY/ADD
- RUN
- USER
- WORKDIR
- ARG/ENV
- ENTRYPOINT
- CMD
+++
# Basis-Image
FROM alpine:3.15
# Installiert busybox-extras ins Basis-Image
RUN apk add --no-cache busybox-extras
# ...und committed den FS-Diff als neuen Layer
# Installiert auf dem obigen Layer mysql-client
RUN apk add --no-cache mysql-client
# ...und commited das FS-Diff als neuen Layer
# Default command
ENTRYPOINT ["mysql"]
# Default arg(s)
CMD ["--help"]+++
- docker build
- Baut ein Image von Dockerfile
- docker images / docker image ls
- Listet alle (lokalen) Images
- docker tag
- Erstellt Image "Kopie" unter anderem Namen
- docker rmi / docker image rm
- Löscht ein Image
- docker login/logout
- docker push/pull
+++
- docker run
- Startet ein Image -> Container
- docker ps [-q]
- Listet alle (laufenden) Container
- docker rm
- Löscht einen Container
- docker logs
- Zeigt Container Logs
- docker exec
- Führt Befehl in laufendem Container aus
+++
- docker [image] inspect
- Zeigt Metadaten von Container/Images
- docker cp
- Kopiert eine Datei aus Container ins Host-FS und umgekehrt
- docker save/load
- Erzeugt Tarball aus Image und umgekehrt
- docker network
- Netzwerk Management
+++
docker build -t [REPOSITORY_HOST/]IMAGENAME:IMAGETAG \
[-f path/to/Dockerfile] path/to/context-dir- Kontext-Verzeichnis wird zum Docker Daemon hochgeladen
- lokal oder remote (via DOCKER_HOST)
- Nur darin enthaltene Dateien können im Dockerfile verwendet werden (COPY/ADD)
- Nach Möglichkeit keine ungenutzten Dateien hochladen
+++
w6p exercise docker -n 1Lösung nach 5 min
+++
docker run [--name NAME] [-i] [-t] [-d|--rm] [--net host|NETWORK] [-v HOST_PATH:CONTAINER_PATH] \
[-p HOST_PORT:CONTAINER_PORT] [-u UID:GID] IMAGE [arg(s)]- Mehr Optionen möglich
- Referenz
+++
docker exec [-i] [-t] CONTAINER COMMANDVia Bash in den Container "springen":
docker exec -it CONTAINER /bin/bash+++
...vom Host in den Container:
docker cp HOST_FILE CONTAINER_NAME:CONTAINER_FILEz.B.:
docker cp ~/local-index.html my-server:/static/index.html+++
...vom Container in das Host-FS:
docker cp CONTAINER_NAME:CONTAINER_FILE HOST_FILEz.B.:
docker cp my-server:/static/index.html ~/local-index.html+++
w6p exercise docker -n2Lösung nach 20 min
docker inspect IMAGE|CONTAINER- Image Metadaten
- ID
- Architecture
- Layers
- Env
- ...
+++
- Container Metadaten
- ID
- Image ID
- NetworkSettings
- Mounts
- State
- ...
+++
w6p exercise docker -n3Lösung nach 15 min
- hadolint
- Erhältlich als Docker Image:
docker run ... hadolint/hadolint hadolint path/to/Dockerfile+++
w6p exercise docker -n4Lösung nach 5 min
# Build as usual in the first stage
FROM golang:1.17 AS builder # named stage
WORKDIR /work
# Copy source code into image
COPY app.go .
# Compile source(s)
RUN go build -o bin/my-app
# Further builder images possible, e.g.
# FROM nginx AS webserver
# ...
# Final stage: all prior images will be discarded after build
FROM scratch
# ...but here we can copy files from builder image(s)
COPY --from=builder /work/bin/my-app /
ENTRYPOINT ["/my-app"]+++
- Kompakte Imagegröße
- Erhöhte Sicherheit
+++
w6p exercise docker -n5Lösung nach 15 min
- Docker-Hub
- öffentlich
- private Registries möglich
- Image registry
- absicherbar
- praktisch in jeder Firma eingesetzt
+++
w6p exercise docker -n6Lösung nach 15 min
- Orchestrierung
- Ausfallsicherheit
=> Kubernetes - bietet beides - ...und noch viel mehr
+++
- Für Multi-Container Docker Anwendungen
- docker-compose.yaml
- Definition der Container
- docker-compose up/down
- Start/Stop aller Anwendungen in einem Rutsch
- Rudimentäre Funktionalitäten
- Geeignet für sehr kleine (Dev-/Test-)Umgebungen
- Mittel der Wahl ist aber Kubernetes
+++

liegt daran, dass sich alle systeme ein host os teilen können
dazu zählen kernel Aufgaben
deployments schneller da nicht alle prozesse beendet und neugestartet werden müssen
+++
- Orchestrierung von Containern
Vorteile: Bessere Ressourcennutzung
Bessere Bereitsstellung von Containern -> zero downtime rollouts
+++
- Warum nicht Docker Swarm?
- Mehr Flexibilität
- Eingebautes Monitoring und Logging
- Bereitstellung von Storage
- Größere User-Base
es hat ja eine leichtere installation und kommt aus dem gleichen haus wie docker
bei kubernetes hat man eine größere flexibilität, sodass man anwendungen bereitstellen kann, wie man möchtet
kubernetes hat ein eingebautes monitoring und logging, docker swarm nicht
speicher kann man bei kubernetes so hinzufügen, dass es als einzeiler genutzt werden kann
+++
- kein Container
- beinhaltet mindestens einen Container
- kann init container beinhalten
- kann sidecar container beinhalten
- kleinste Einheit in Kubernetes
aber ein pod ist grundsätzlich eine gruppe (gruppe von walen vergleich)
teilen sich speicher und Netzwerkressourcen
befinden sich auf dem selber server
erhält einen oder mehrere container > abhängig voneinader
init container kann script vor start ausführen
sidecar container kann daten im pod aktualisieren
dazu morgen mehr
+++
- Auf (Worker-)Nodes
+++
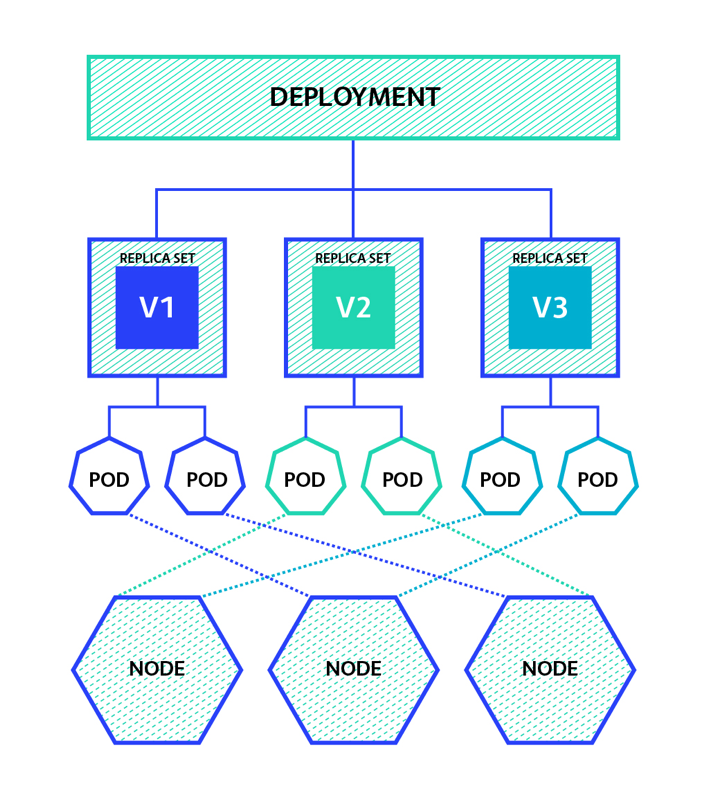
- ReplicaSet
- Deployment
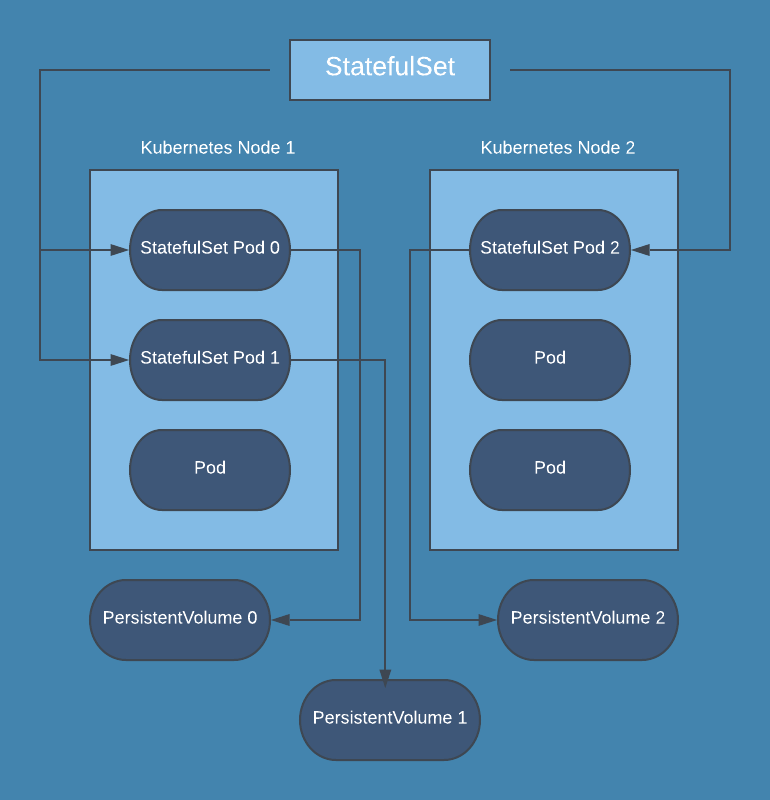
- StatefulSet
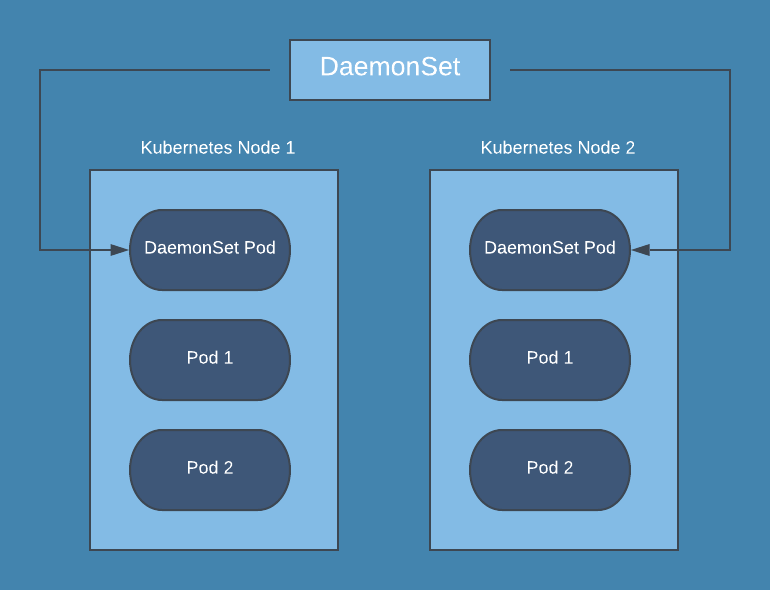
- DaemonSet
- Job
- CronJob
Selten setzt man ihn einzeln ein
Normalerweise nutzt man ein übergeortnetes Ordnungselement:
ReplicaSet: Stellt eine genaue Anzahl an Pods sicher, wird äußerst selten explizit verwenden. Statt dessen:
Deployment: Kombiniert ReplicaSets mit Versionierung für stateless Pods und bietet die Möglichkeit zum staged rollout
StatefulSet: Wie Deployment, nur für für stateful Pods, d.h. Pods, die zur Laufzeit CRUD Operationen auf persistenten Daten ausführen
DaemonSet: Garantiert, dass auf allen Nodes genau ein Pod läuft
Job: Ein Pod, der nur einmal gestartet wird, um eine bestimmte Aufgabe zu erledigen
CronJob: Für wiederkehrende Tasks zu bestimmten Zeitpunkten, z.B. um regelmäßige Backups zu erstellen
- Hab ihr noch Fragen an uns?
- Architektur von Kubernetes
- Basis Objekte von Kubernetes
+++
- Rewind
- Architektur von Kubernetes
- Einrichtung eurer Umgebung
- kubectl
- k9s
- Basisobjekte Kubernetes
+++
- Container Runtime Engine
- docker CLi
- Bau von Images
- Start von Images (Container)
- Image Registry (Verteilung von Images, vgl. AppStore)
- ...
+++
- Schreibe ein Dockerfile (Rezept)
- Instruktionen (Zutaten)
- FROM, COPY, RUN, ENTRYPOINT, ...
- jede Instruktion = neuer Layer (vgl. mit Binärdatei)
- Instruktionen (Zutaten)
- docker build [-t TAG] CONTEXT
- Image = N übereinander gelegte RO Layer (overlay FS)
+++
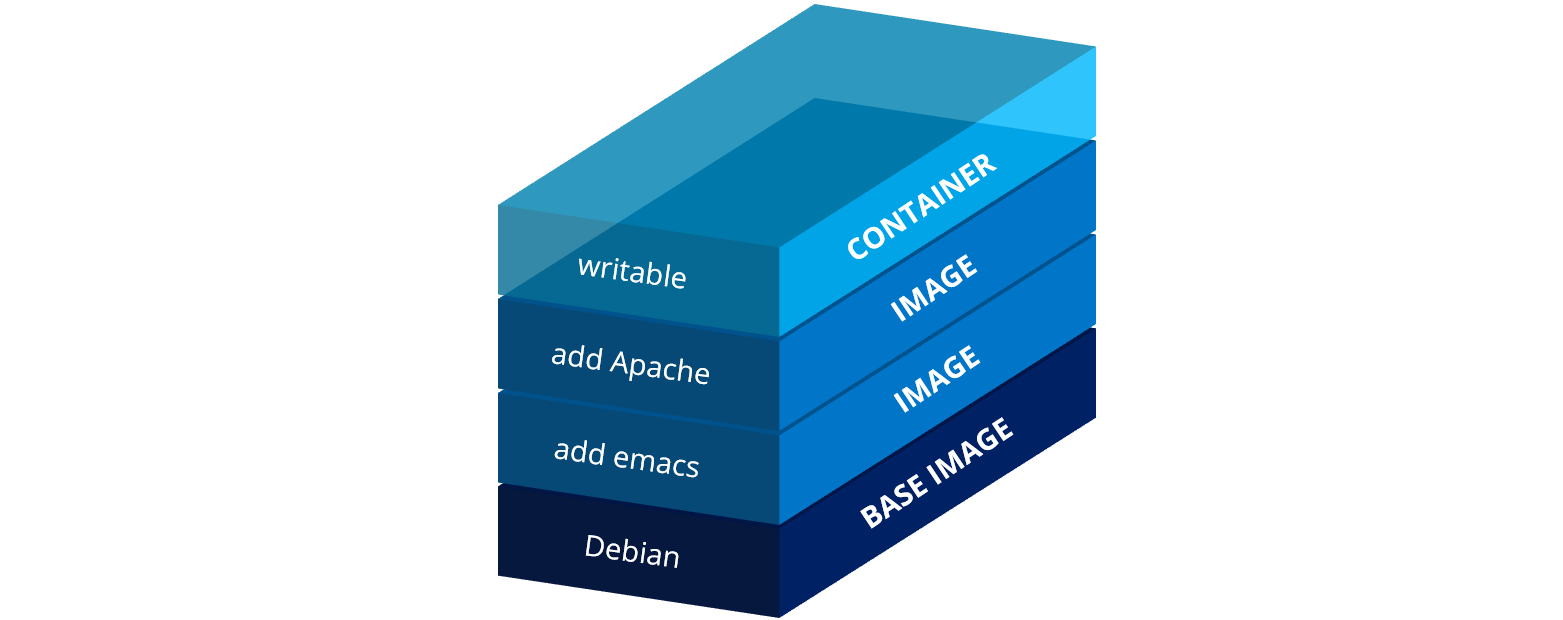
- docker run [OPTS] IMAGE [COMMAND] [ARGS]
- Container = N Image RO Layers plus ein leerer RW Layer on top
- RW Layer kann zur Laufzeit modifiziert werden
- Delete File/Dir
- Löscht, wenn im RW Layer vorhanden
- Versteckt, wenn in einem darunter liegenden RO Layer
- Stirbt PID 1, stirbt der Container
- docker rm CONTAINER => RW Layer wird gelöscht
+++
- Container Orchestrierungstool
- Verwaltet Pods
- besteht aus 1 bis N Containern
- eigene IP, eigenes Netzwerk
- Started, stoppt und überwacht Pods
- Verteilung auf Worker-Nodes
- Garantiert Pods Ressourcen (CPU/Memory)
- Self-Healing
- Dynamische Skalierung
- ...
- Verwaltet Pods
+++
- Pod
- kleinste deploybare Einheit
- beinhaltet 1 bis N Container
- eigener Netzbereich und IP
- ReplicaSet
- Stellt sicher, dass zu jeder Zeit genau N Pods laufen
- Matching über Labels
+++
- Deployment
- Managed ein ReplicaSet
- Bietet Versionierung und zero downtime Rollouts
- DeamonSet
- Spec wie Deployment nur ohne Replica Count
- Managed damit kein ReplicaSet
- Stattdessen je ein Replica pro Node
+++
- Service
- Loadbalancer für Pods
- Auch hier Matching via Labels
- Typen
- None (headless)
- ClusterIP (Default)
- NodePort
- Loadbalancer
Note: Service - headless (erstellt für jeden Pod einen DNS entry innerhalb des Clusters (coredns), kein externer Zugriff möglich)
Service - ClusterIP (routet über die clusterinternen Pod IPs, kein externer Zugiff möglich)
Service - NodePort (öffnet auf jedem Node denselben Port, über den von außen der Service erreicht werden kann)
Service - Loadbalancer (exosed den Service ins Internet, bedarf eines Loadbalancers der den Traffic an der Service weiterleitet)
+++
- StatefulSet
- Spec ähnlich zu Deployment
- Geordnetes Starten (einer nach dem anderen)
- Geordnetes Stoppen in umgekehrter Reihenfolge
- ConfigMap
- Plain-Text Key-Value Store
- Kann in Pods, Deployments, STSs und DSs gemounted werden
- Secret
- base64 encoded Data Store
- Kann in Pods, Deployments, STSs und DSs gemounted werden
+++
- kubectl
- CLI zur Interaktion mit k8s Clustern
- krew
- kubectl Plugin Manager
- k9s
- Terminal UI zur Interaktion mit k8s Clustern
- kind (Kubernetes in Docker)
- Single-Node k8s Cluster in Docker Container
+++
- helm
- Paket-Manager für Kubernetes
- vgl. mit apt für Ubuntu oder apk für Alpine
- Lens
- Graphical UI zur Interaktion mit k8s Clustern
- Nicht Teil des Workshops
+++
- Liste von verfügbaren Plugins
- Installation
- kubectl krew install NAME [NAME...]
+++
Go CLI executable ausschließlich für diesen Workshop
- w6p install TOOL
- lokale Installation von gebräuchlichen k8s Tools
- w6p exercise CONTEXT -n NUMBER
- Startet Aufgaben aus dem jeweiligen Kontext (docker oder k8s)
- w6p cluster
- Startet/stoppt Single-Node Kubernetes Cluster in Container
- Ursprünglich 2014 entwickelt von Google
- Abgegeben 2015 an die Cloud Native Compute Fondation (CNCF)
aktuelle version 1.23.5
+++
- Cloud Native Computing Foundation
- 2015 Gegründet
- äber 500 Hersteller und Betreiber
untergeordnet der Linux Fondation
Größte Unternehmen sind Amazon, Google, Apple, Microsoft
x-cellent ist auch teil der CNCF
+++

+++
- Modular und austauschbar
- Control-Plane
- etcd
- API-Server
- Scheduler
- Kube-Controller-Manager
- Nodes
- Kubelet
- Kube-Proxy
- Control-Plane
- Open-Source
zusammengefasst werden einige diese unter dem Namen "ControlPlane" welche nur auf dem Master server laufen
Kernkomponenten sind ...
bei Nodes zählen alle, sowohl master als auch worker nodes
Diese Komponenten sind komplett Open Source
gleich kommen einzelheiten zu diesen Komponenten
+++
die Controle Plane Server sind die nodes, welche für die Verwaltung des Clusters zuständig sind, normalerweise keine container auf diesen nodes+++
- entwickelt von CoreOS
- key-value Database
- kann nicht getauscht werden
- speichert stand von cluster
- Consistency notwending
open source tool
quasi hardcoded in kubernetes core
wichtigste K8s komponente
speichert configuration, status, und alle metadaten
wenn man etcd backup in neuen Cluster einspielt, baut es den cluster wie zuvor auf
Consistency, also Wiedersruchsfreiheit ist beim etcd notwendig, anosnsten kann es zu ausfällen des Clusters kommen
+++
- Ansprechpunkt des Users
- Validation der Daten
- bekanntester ist kube-apiserver
- horizontale skalierbarkeit
Validiert, ob rechte vorhanden sind, und anfragen sinn ergeben
updated values in etcd
bekanntester api server tool kube-apiserver
+++
- Verteilt workload
- verantworlich für pods ohne node
nimmt der scheudler die werte und verteilt diese an nodes
Faktoren bei entscheidung welche node
Ressourcenanforderungen
Hard/Software-einschränkungen
bestimmte Flags z.B. niemals auf master/nur auf master
+++
- bringt cluster von "ist" -> "soll"
- Managed Nodes
- mitteilung an scheuduler wenn node down
überwacht nodes, wenn einer down ist, mitteilung an scheuduler, node down bitte pods neu verteilen
+++
die nachfolgende Software ist auf allen nodes, also master und worker installiert+++
- verwaltet pods
- auf jeden node installiert
- verantwortlich für status
startet stoppt updated pods auf node
überwacht pods ob sie gewünschten status haben
+++
- verwaltet Netzwerkanfragen
- routet traffic zu gewünschten pod
- loadbalancer
übernimmt auch loadbalancing funktionen, sollten meherere Pods das gleiche machen (mehere nginx zum beispiel)
+++
- CNI
- Container-Runtime
Network Plugin, also CNI schreibt Network interfaces in die
Container Runtime
dies ist z.B. containerd, cri-o oder die deprecated docker engine
meistens containerd
diese Software ist zuständig um die Container laufen zu lassen
+++
- separierungseinheit in Kubernetes
- Objekte können welche in anderem Namespace nicht sehen
- 4 standart Namespaces
- default
- kube-node-lease
- kube-public
- kube-system
separiert im Cluster verschiedene Anwendungen
Gleiche Anwendung kann im Cluster in verschiedenen Namespaces mit gleichen Namen laufen
default: Objekte welche keinem Anderen Namespace zugeordnet werden
kuube-node-lease: hält objecte welche mit jedem node zusammenhängen
erlaubt dem kubelet hearbeats an die control plane zu schicken
kube-public: wenn anwendungen im kompletten cluster sichtbar sein sollen
kube-system objekte, welche vom Kubernetes system erstellt wurden
+++
- CoreDNS und KubeDNS
- FQDN in cluster
- POD.NAMESPACE.pod.cluster.local
- SERVICE.NAMESPACE.svc.cluster.local
CoreDNS neuer und mittlererweile standart seit kubernetes 1.12
KubeDNS ist mit interner Namensauflösung ca 10% schneller
CoreDNS mit externer Namensauflösung ca 3x besser
CoreDNS Ressourcen schonender
im cluster kann man auch eine FQDN auflösung machen
entweder zum pod mit dem podnamen.namespacenamen.pod.cluster.local
oder die bessere art, zum service mit servicename.namespace.svc.cluster.local
man kann wenn man im gleichen namespace ist alles nach servicename weg lassen
+++
Alle diese Komponenten sind opensource und theoretisch austauschbar, auch wenn einige so sehr in den kubernetes core eingebaut sind, dass diese nur mit sehr hohen aufwand getauscht werden können+++
- Container Health Check
- readyness
- liveness
- Hostsystemausfall
- Update
dies wird erzielt, indem man bei container
readyness checks, also checks die prüfen ob der container gestartet ist
und liveness checks, also checks die fortlaufend prüfen, ob der container noch läuft
definieren kann.
Sollte dies einmal nicht der fall sein, dann versucht das Kubelet den status wieder herzustellen
Bei einem Node ausfall sorgt der scheduler, dass die pods auf einem anderen Node gestartet wird
updates werden bei kubernetes normalerweise so gemacht, dass die replicas nach und nach ausgetauscht werden
dadurch ist die anwendung niemals komplett heruntergefahren und durchgehend erreichbar
+++
- Alle k8s Objekte werden in YAML definiert
- Wird Manifest genannt
- Jedes Objekt hat eigene YAML Spec
- API Server versteht diese Specs
- kubectl apply -f spec.yaml
- Schickt den Inhalt von spec.yaml an k8s API Server
- API Server prüft Inhalt und Berechtigungen (Admission Control)
- Wenn ok -> API Server sorgt für Anlage/Update
- Wenn nicht ok -> Reject
- kubectl apply -f spec.yaml
+++
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gispaces als seperator, wenn es eingerückt drunter steht dann wird es weitergegeben
step für step
+++
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/htmlkennt man schon von docker
name wie --name bei docker run
image: ist wie bei docker das image
ports leitet den port aus dem container in den cluster
volumeMounts: mountet ein volume in ein container
metadata.labels hier werden labels definiert, welche mit selectoren genutzt werden können
in dem fall app aber kann auch alles andere sein
spec: der status in welchem das objekt sein soll, in diesem fall wird ein container definiert
+++
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
namespace: testingapiVersion: nicht wichtig. diverse ressourcen haben andere apiVersionen. Werden im laufe der zeit mehr kennenlernen
kind: in diesem fall statefulset
metadata: name: eindeutiger identifier namespace: Namespace in welches es deployt werden soll
+++
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
replicas: 3 # by default is 1selector: auf welche objekte das object matchen soll
in diesem fall soll es labels matchen, welche den namen app hat
wie unser container von vorhin
replicas, definiert wie viele gleiche pods deployt werden sollen
+++
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gidamit die pods auch daten schreiben können gibt es volume claims
diese definieren, auf welchem filesystem diese daten abgelegt werden sollen
braucht im hintergrund kubernetes object PersistentVolume
metadata name, definiert wieder den namen des volumeclaims
spec: wieder wie dieses object aussehen soll
accessMode: ReadWriteOnce, gibt noch Many, wird aber seltenst genutzt
storageClassName name von persistat volume
ressources. request.storage wie viel speicherplatz reserviert werden soll
w6p exercise k8sCLI Tool für das Management von k8s Clustern
Man kann kubectl über folgende Wege mitteilen, mit welchem Cluster es sich verbinden soll:
- via Command-Line Argument '--kubeconfig path/to/kubeconfig'
- via Umgebungsvariable KUBECONFIG
- via Default Kubeconfig-Datei ~/.kube/config
+++
- Welcher Namespace?
- Alle: '--all-namespaces' oder '-A'
- X: '--namespace X' oder '-n X'
- Was will ich tun?
- Ressource anschauen
- 'get pod', 'get deploy', 'get secret'
- Ressource erstellen
- 'run', 'create deploy', 'create ns'
- Ressource löschen
- 'delete pod', 'delete deploy', 'delete sts'
- Ressource anschauen
+++
- Anlegen einer ConfigMap im NS 'webapp':
kubectl create -n webapp cm db-config \
--from-literal=db-user=dba \
--from-literal=db-password=OH-NO+++
- Erstelle Pod Manifest:
export do='--dry-run=client -o yaml'
kubectl run my-pod --image ubuntu:20.04 $do > pod.yamlDieses Manifest kann jetzt bequem angepasst/vervollständigt werden
+++
- Erstelle Deployment Manifest:
export do='--dry-run=client -o yaml'
kubectl create deploy --image alpine:3.15 my-deploy $do > dp.yaml+++
w6p exercise k8s -n1Lösung nach 20m
Terminal UI zum Management eines k8s Clusters
- Start
k9s [--kubeconfig path/to/kubeconfig] [-n NAMESPACE]- Stop: Ctrl^c
- Hilfe: '?'
- Navigation mit Pfeiltasten
- Tiefer reinspringen mit ENTER
- z.B. von selektiertem Deployment zu allen darüber verwalteten Pods
- Zurück mit ESC
+++
- Ressourcen-Navigation
- ':'
- Gefolgt von der gewünschten Ressource
- Context: 'context' oder 'ctx'
- Namespace: 'namespace' oder 'ns'
- Pod: 'pod' oder 'po'
- Deployment: 'deployment', 'deploy' oder 'dp'
- PodSecurityPolicy: 'psp'
- ...
- TAB sensitiv bei Auto-Vorschlägen
- Mit ENTER bestätigen
+++
- Context-Switch
- ':ctx' ENTER Navigiere-zu-Context ENTER
- Verbindet sich mit dem ausgewählten Cluster
- In der Folge werden nur noch Objekte dieses Clusters angezeigt
- Namespace-Switch
- ':ns' ENTER Navigiere-zu-Namespace ENTER
- In der Folge wird die Sichtbarkeit
- erweitert auf alle Namespaces, wenn NS='all'
- eingeschränkt auf gewählten Namespace, sonst
+++
- Wenn eine Ressource X selektiert ist
- Describe: 'd' (k describe X)
- Zeige YAML: 'y' (k get X -o yaml)
- Delete: 'Ctrl^d' (k delete X)
- Edit: 'e' (k edit X)
- vi oder vim
+++
- Je nachdem welche Resource ausgewählt ist, weitere Optionen möglich
- Für Pods z.B:
- Logs: 'l' (k logs X)
- Shell: 's' (k exec -ti X sh)
- Port Forward: 'Shift^f' (k port-forward X 80)
- Für Deployments z.B:
- Logs: 'l'
- Scale: 's'
- Restart: 'r'
- Für Pods z.B:
+++
w6p exercise k8s -n2Lösung nach 20m
Note: Ende Tag 2
+++
- Recap
- Docker (high-level)
- Kubernetes und API Objekte
+++
- Bündelt Software mitsamt aller Abhängigkeiten
- evtl. auch inklusive OS
- damit über Rechnergrenzen hinweg funktional
- Bau und Starten von Images
- Container Runtime Engine
- Image-Sharing (Docker Registry)
- Client-Server Architektur
- docker CLI bzw. Docker Daemon
+++
- Container Runtime Interface (CRI)
- Wird von Kubernetes unterstützt
- Konkrete Implemetierung damit austauschbar
- Container Runtimes
- containerd (von Docker entwickelt), CRI-O, ...
- Open Container Initiative (OCI) spec
- enthält runtime-spec (runc) und image-spec (basiert stark auf Docker)
+++

Notes: containerd - Linux-Daemon; Pulled Images aus Registry, verwaltet Speicher und Netzwerke, started/stoppt Containern via runc
runc – Low-Level-Container-Runtime; verwendet libcontainer - native Go-basierte Implementierung zum Starten und Stoppen von Containern
+++

docker build -t my-image .+++
+++
docker pull nginxdocker tag my-image my-registry-host/my-image:v1
docker login my-registry-host
docker push|pull my-registry-host/my-image:v1
docker logout my-registry-host+++

+++
+++
- Container Orchestrierungstool
- Verwaltung von Pods
- Reconciliation-Loop / Control-Loop
- Starten, stoppen und Überwachen
- Self-Healing
- Dynamische Skalierung
- u.v.m.
- Zugriffskontrolle (RBAC)
- Validierung
- u.v.m
+++
+++
- Text-Datei
- Beinhaltet URLs und Credentials zu k8s Clustern
- "Login zum Cluster"
- ~/.kube/config (default)
- via KUBECONFIG Umgebungsvariable
- via --kubeconfig flag
+++
+++
- Pod
- kleinste deploybare Einheit
- beinhaltet 1 bis N Container
- eigener Netzbereich und IP
+++
- ReplicaSet
- Stellt sicher, dass zu jeder Zeit genau N Pods laufen
- Matching über Labels
- Deployment
- Managed stateless Pods
- Managed ein ReplicaSet
- Bietet Versionierung und zero downtime Rollouts
+++
+++
- DeamonSet
- Spec fast analog zu Deployment, u.a. ohne Replicas
- Managed damit kein ReplicaSet
- Stattdessen je ein Replica pro Node
+++
+++
- Service
- Loadbalancer für Pods (Layer 3/4)
- Matching via Labels
- Typen
- None (headless)
- ClusterIP (Default)
- NodePort
- Loadbalancer
- ExternalName
Note: Service - headless (erstellt für jeden Pod einen vorbestimmten DNS entry innerhalb des Clusters (coredns), kein externer Zugriff möglich)
Service - ClusterIP (erstellt für jeden Pod einen vorbestimmten DNS entry, kein externer Zugiff möglich)
Service - NodePort (öffnet auf jedem Node denselben Port, über den von außen der Service erreicht werden kann)
Service - Loadbalancer (exposed den Service ins Internet, bedarf eines Loadbalancers der den Traffic an der Service weiterleitet)
Service - ExternalName (erstellt DNS Eintrag, der auf einen externen DNS routet)
+++
- None (headless)
- erstellt für jeden Pod einen DNS Eintrag innerhalb des Clusters (coredns)
- kein externer Zugriff möglich
+++
- ClusterIP
- routet über die clusterinternen Pod IPs
- kein externer Zugiff möglich
+++

+++
- NodePort
- öffnet auf jedem Node einen zufälligen Port zwischen 30000 und 32767
- ist auf allen Nodes immer derselbe
- Traffic wird von dort an den Service weitergeleitet
+++

+++
- Loadbalancer
- macht den Service von außen zugänglich
- bedarf eines Loadbalancers, der den Traffic zum Service routet
- k8s bietet keine Standardimplementierung (Cloud Provider)
- Kosten
+++

+++
- HTTP level router (Level 7)
- Host und Path basiertes Routing
- Auch für verschiedene Hosts (SNI)
- TLS Terminierung möglich
+++

+++
- StatefulSet
- Managed stateful Pods
- Spec ähnlich zu Deployment
- Geordnetes Starten
- Geordnetes Stoppen in umgekehrter Reihenfolge
- Je Pod ein DNS Eintrag der Bauart POD-INDEX.NAMESPACE:
- z.B. redis-0.db, redis-1.db, ...
- Bei Pod Rearrangement wird DNS Eintrag aktualisiert
+++
+++
- ConfigMap
- Plain-Text Key-Value Store
- Kann für Pods, Deployments, STSs und DSs definiert werden
- Secret
- base64 encoded Data Store
- Kann für Pods, Deployments, STSs und DSs definiert werden
+++

+++
- kubectl
- CLI zur Interaktion mit k8s Clustern
- krew
- kubectl Plugin Manager
- k9s
- Terminal UI zur Interaktion mit k8s Clustern
- kind (Kubernetes in Docker)
- Single-Node k8s Cluster in Docker Container
+++
- helm
- Paket-Manager für Kubernetes
- vgl. mit apt für Ubuntu oder apk für Alpine
- Lens
- Graphical UI zur Interaktion mit k8s Clustern
- Nicht Teil des Workshops
+++
- Weitere API Objekttypen
- Admission Controller
- Sicherheit (RBAC)
- Helm
- Cert-Manager + Ingress
- MetalStack / Gardener / FCN
- Logging/Monitoring
+++
- Kleinste deploybare Einheit
- Kann per Manifest werden
+++

+++
- Fehlerhaftes Manifest pod.yaml
- Reparieren und in Namespace der Wahl deployen
+++
apiVersion: v1 #Typo in apiVersion
kind: Pod #Typo
metadata:
labels:
app: frontend
name: web
namespace: ex1 #Optional
spec:
containers: #Einrückung beachten
- name: web #Listenelemente werden mit `-` eingeleitet
image: nginx:latest #Image und Tag mit `:` getrennt
ports:
- containerPort: 80 #hier auch falsch eingerückt
resources:
requests:
cpu: "1.0"
memory: "1G" #Leerzeichen nach Keys beachten
limits:
cpu: "1.0"
memory: "1G" #Text mit führender Zahl in Anführungszeichen+++
- Erstelle Pod Manifest:
export do='--dry-run=client -o yaml'
kubectl run my-pod --image ubuntu:20.04 $do > pod.yamlDieses Manifest kann jetzt bequem angepasst/vervollständigt werden
+++
- Erstelle Deployment Manifest:
export do='--dry-run=client -o yaml'
kubectl create deploy --image alpine:3.15 my-deploy $do > dp.yaml+++
- Erstelle ein Deployment (Objekt) des Pods aus vorangegangener Aufgabe
- Erstelle anschließend ein Service (Objekt) um die Pods zu loadbalancen
+++
- Erstelle deployment.yaml
- kubectl apply -f deployment.yaml -n web
- Erstelle service.yaml
- kubectl apply -f service.yaml -n web
+++
- Zugriff auf Container (Tunnel)
- Debugging
- via kubectl und k9s möglich
+++
- Deployment und Service aus letzter Aufgabe muss im selben Namespace deployed sein
- kubectl create ns web
- kubectl apply -f deployment.yaml -n web
- kubectl apply -f service.yaml -n web
- Anschließend bitte ein Port-Forwarding zu den Pods des Deployments einrichten
- Welche Wege gibt es?
+++
- kubectl -n web port-forward pod/web-6779b45f74-bvc7p :80
- lokaler, zufällig bestimmter Port wird an Pod Port 80 gebunden
- kubectl -n web port-forward svc/web 8081
- lokaler Port 8081 -> von Service bestimmter Service Port 8081
- kubectl -n web port-forward deploy/web 8081:80
- lokaler Port 8081 -> von Deployment bestimmter Service Port 80
- in k9s via
Shift^f
+++
- Jeder Node bekommt ein Replica
- Log-Shipper
- Monitoring Agent
Kann nicht passieren, dass bei einem Node-Ausfall die Pods erst auf einer neuen Node deployed wird.
Oft verwendet für "log collector", da diese die Logs von allen Pods auf allen Nodes braucht.
Ebenso bei "monitoring collectoren", da diese das Monitoring von allen Nodes braucht.
+++
- Deploye ein DaemonSet mit einem nginx Pod in einen Namespace deiner Wahl
- Scale das DaemonSet auf 3 Pods
- ist dies Möglich?
- Warum? Warum nicht?
+++
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: web-ds
labels:
app: web-ds
spec:
selector:
matchLabels:
name: web-ds
template:
metadata:
labels:
name: web-ds
spec:
containers:
- name: web-ds
image: nginx:latest
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi+++
- Scaling ist nicht möglich, da DaemonSets mit den Nodes scalen
+++
- Persistente Pods
- Geordnetes Update/Shutdown
z.B Datenbanken sind klassische Anwendungen, welche man in diesem Zustand haben möchte.
+++
- Einmalige Ausführung eines Commands in einem Pod
- Datenbank Backup
Z.B prüfen ob ein Service im Cluster erreichbar ist, Datenbank-Backups zu erstellen.
+++
- Erstelle einen Job, welcher einmalig die Zahl Pi auf 5000 Stellen genau berechnet.
- gebe Pi aus
+++
- Von Kubernetes Doku das Manifest übernehmen und anpassen
+++
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
labels:
job: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(5000)"]
restartPolicy: Never
backoffLimit: 4+++
- kubectl get logs -n ex7 pi-
+++
- Mischung aus klassischen CronJobs und Jobs
- Regelmäßige Ausführung eines Jobs
- Datenbank Backups
Regelmäßige Außführung von Jobs
Man kann auch einmalig die Jobs eines Cronjobs außführen pratkisch für debugging
+++
- erstelle einen CronJob welcher minütlich das Datum und deinen Namen ausgibt
- dieser Cronjob soll 5 erfolgreiche und 8 fehlgeschlagene Versuche behalten
- teste diesen CronJob ohne eine Minute zu warten
+++
- aus kubernetes Doku Manifest kopieren und anpassen
+++
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
successfulJobsHistoryLimit: 5
failedJobsHistoryLimit: 8
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
cronjob: hello
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Pascal
restartPolicy: OnFailure+++
- Erstellen eines einmaligen runs
kubectl create job -n ex8 --from=cronjob/hello hello-test- Output wieder sichtbar mit
kubectl logs -n ex8 hello-+++
- Speicherung von nicht vertraulichen Daten
- Einbindung in Pods als
- Umgebungsvariable
- command-line argument
- Datei (Volume)
- Kein Reload der Pods bei Änderung
es gibt mehrere Wege diese in die Container einzubinden
Pods reloaden nicht automatisch wenn ConfigMaps geupdated wurden
+++
- dieses Deployment möchte eine ConfigMap einbinden
- diese ConfigMap
- ändere die WorkerConnection und deploye die beiden Ressourcen
+++
- WorkerConnection in Zeile 13 Updaten, anschließend zurst die Configmap deployen:
kubectl apply -f configmap.yaml -n ex9- anschließend das Deployment Objekt deployen
kubectl apply -f deployment.yaml -n ex9- Wichtig! Beides in den gleichen Namespace.
+++
- Speicherung vertraulicher Daten
- Unverschlüsselt in etcd DB
- Bessere Separierung mittels Rollen
- User darf Configmaps sehen aber keine Secrets
Standartmäßig liegen diese Daten aber unverschlüsselt im etcd
Einbindung ähnlich wie bei ConfigMaps
- kapselt Storage in einer API
- sehr viele Volume Typen
- NFS share, iSCSI, Host-Path, emptyDir, ...
- Lightbits, S3 und lokal bei FI-TS
- Vorab oder dynamisch (StorageClass) erstellt
- Kann von Pods via PersistentVolumeClaims (PVC) angefordert werden
- Wird dann bidirektional gebunden
- ReclaimPolicy (Retain/Delete)
+++
- ReadWriteOnce
- Once, nur ein Node darf auf das Volume schreiben
- ReadWriteMany
- Many, mehrere dürfen
- ReadOnlyMany
- mehrere Nodes können das Volume ReadOnly mounten
+++
- Erstelle ein local PV mit 10 GB Capacity
- Erstelle das Verzeichnis auf der Node
- Dieses soll ReadWriteOnce sein
- Dieses muss einen eindeutigen Namen haben
+++
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-pv
labels:
storage: local
spec:
storageClassName: standard
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-workshop-cluster-control-plane+++
- Reserviert Ressourcen eines PV`s
- wird anschließend ins Deployment eingebaut
- Verknüpfung PV und PVC mit Selector labels oder direkt mit Namen
- bei local kein dynamisches (selector) mapping möglich
- Verknüpfung ist eine 1 zu 1 Verknüpfung
- keine 2 PVC an einem PV
+++
- Erstelle ein PVC
- Erstelle ein postgresql statefulset
- Tipp: Configmap und Secret müssen auch erstellt sein um env Variablen in den Container zu übergeben
- Welches das PVC einbindet
- Lasse die Daten, welche in der DB sind anzeigen
+++
- Der PV der letzten Aufgabe muss erstellt sein
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: postgres-pv-claim
labels:
app: postgres
spec:
storageClassName: standard
capacity:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
volumeName: example-pv+++
- Configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-configuration
labels:
app: postgres
data:
POSTGRES_DB: topdb
POSTGRES_USER: user23- Secret
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
type: Opaque
data:
POSTGRES_PASSWORD: sicherespasswort+++
- StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres-statefulset
labels:
app: postgres
spec:
serviceName: "postgres"
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:12
envFrom:
- configMapRef:
name: postgres-configuration
- secretRef:
name: postgres-secret
ports:
- containerPort: 5432
name: postgresdb
volumeMounts:
- name: pv-data
mountPath: /var/lib/postgresql/data
volumes:
- name: pv-data
persistentVolumeClaim:
claimName: postgres-pv-claim+++
- Daten anzeigen lassen
kubectl exec -n postgresql -it postges-statefulset-0 -- /bin/bash
psql -U user23 topdb+++
- Limitiert die Ressourcen (CPU/Memory/Anzahl Pods/...) für Pods auf NS Ebene
- LimitRange einsetzen für Min/Max und default Werte
- Vorsicht bei zu knapper Bemessung
+++
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-rq
namespace: my-namespace
spec:
hard:
requests.cpu: "1"
requests.memory: "1Gi"
limits.cpu: "2"
limits.memory: "2Gi"+++
apiVersion: v1
kind: LimitRange
metadata:
name: mem-cpu-lr
namespace: my-namespace
spec:
limits:
- default:
memory: "512Mi"
defaultRequest:
memory: "256Mi"
type: Container+++
- Passt Ressourcen-Nutzung (CPU/Memory) der Pods automatisch an
- Effiziente Nutzung der Nodes
- Löst das Problem mit den ResourceQuotas/LimitRange
- Noch nicht für Produktion empfohlen
- wegen möglicher eingeschränkter Sichtbarkeit der Arbeitsspeichernutzung
+++
- Automatisches Rescaling von Deployments
- nach CPU Auslastung
- nach Custom Metriken (v2)
+++

+++
kubectl autoscale deployment nginx --cpu-percent=50 --min=1 --max=10apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: nginx
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50+++
- Überwachung und Einschätzung der Pods
- LivenessProbe
- Wann ist ein Pod gestartet und gesund?
- ReadinessProbe
- Wann kann ein Pod Traffic entgegennehmen?
- z.B. wenn Pod von anderen Pods noch abhängt
- StartupProbe
- Deaktiviert liveness und readiness Probes beim Container-Start
- Analog zu LivenessProbe für langsame legacy Applikationen
+++
startupProbe:
httpGet:
path: /health
port: 80
failureThreshold: 30
periodSeconds: 10+++
livenessProbe:
exec:
command:
- cat
- /tmp/health
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /
port: 80Role Based Access Control (RBAC)
- Authentifizierung (Wer bin ich?)
- Analogie Ausreise: Perso
- Autorisierung (Was darf ich?)
- Analogie Ausreise: Visa
- Admission Control
- Stellt Authentifizierung und Autorisierung sicher
- Analogie Ausreise:
- Prüft Perso und Visa
- Zoll: Darf ich mein Gepäck einführen?
+++
- ServiceAccount (SA) / User
- technischer / User Account im Cluster
- (Cluster)Role
- Feingranulare Berechtigungen auf Ressourcen
- get, create, read, watch, ...
- pod, secret, configmap, deployment, ...
- Feingranulare Berechtigungen auf Ressourcen
- (Cluster)RoleBinding
- Mappt (Cluster)Roles auf Accounts (SA/User)
+++
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: pod-reader
namespace: my-ns
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]+++
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: my-ns
subjects:
- kind: User
name: jane
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io- Validate/Mutate API-Requests
- Viele built-in Admission Controller
- LimitRanger, PSP, ImageScanner, RBAC, ...
- Eigene Admission Controller installierbar
- Erweitert den k8s Funktionsumfang
- Wird in der Reconciliation Loop ausgeführt
- CRDs
+++

+++

+++
- Erfordert eigenen Admission Controller
- Damit selbst definierbare Manifeste möglich
- Beispiele
- external-secrets-controller
- cert-manager
- anwendungsspezifische Funktionalitäten
+++

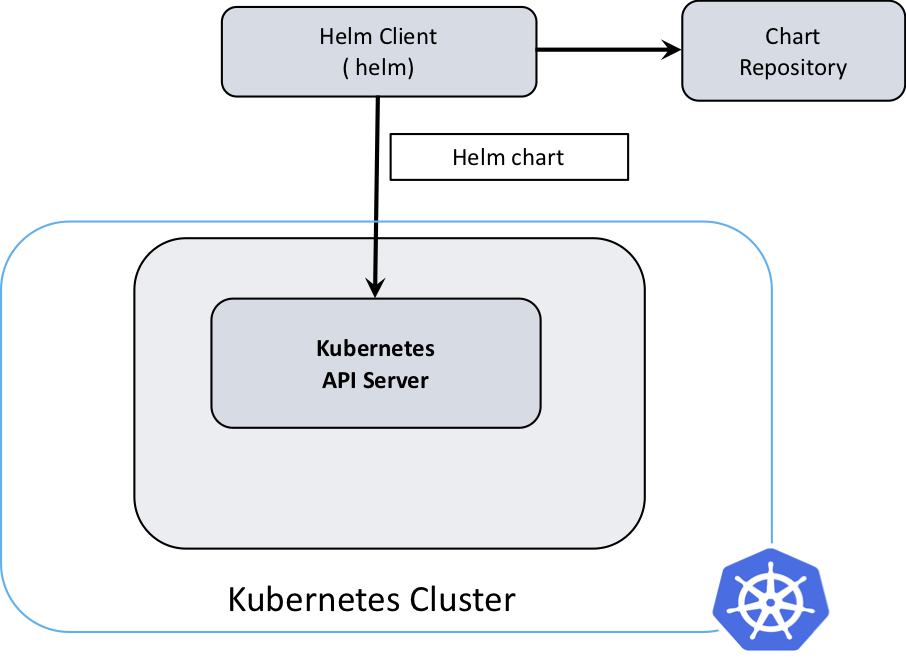
- Package Manager für Kubernetes
- Gegliedert in sogenannten Charts
- Große Softwarehersteller schreiben eigene Helm Charts
- z.B. Gitlab
+++
- Praktisch, um eine Anwendung mit wenigen Änderungen in verschiedenen Umgebungen zu deployen
- test/staging/production
- Helm Charts sind in sogenannten Repos gespeichert
- Chart Ersteller haben meistens eigene Repos
- Nutzung ähnlich wie bei apt in ubuntu
- adden, updaten, installieren
+++
+++
name
├── charts
├── Chart.yaml
├── templates
│ ├── deployment.yaml
│ ├── _helpers.tpl
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── NOTES.txt
│ ├── serviceaccount.yaml
│ ├── service.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yaml+++
- wie so oft im yaml-Format
- das Meiste bis alles templates
- Anpassungen in der values.yaml
+++
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "schulung.fullname" . }}
labels:
{{- include "schulung.labels" . | nindent 4 }}
spec:
{{- if not .Values.autoscaling.enabled }}
replicas: {{ .Values.replicaCount }}
{{- end }}
selector:
matchLabels:
{{- include "schulung.selectorLabels" . | nindent 6 }}
template:
metadata:
{{- with .Values.podAnnotations }}
annotations:
{{- toYaml . | nindent 8 }}
{{- end }}
labels:
{{- include "schulung.selectorLabels" . | nindent 8 }}
spec:
{{- with .Values.imagePullSecrets }}
imagePullSecrets:
{{- toYaml . | nindent 8 }}
{{- end }}
serviceAccountName: {{ include "schulung.serviceAccountName" . }}
securityContext:
{{- toYaml .Values.podSecurityContext | nindent 8 }}
containers:
- name: {{ .Chart.Name }}
securityContext:
{{- toYaml .Values.securityContext | nindent 12 }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
ports:
- name: http
containerPort: 80
protocol: TCP
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
resources:
{{- toYaml .Values.resources | nindent 12 }}
{{- with .Values.nodeSelector }}
nodeSelector:
{{- toYaml . | nindent 8 }}
{{- end }}
{{- with .Values.affinity }}
affinity:
{{- toYaml . | nindent 8 }}
{{- end }}
{{- with .Values.tolerations }}
tolerations:
{{- toYaml . | nindent 8 }}
{{- end }}+++
# Default values for schulung.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
replicaCount: 1
image:
repository: nginx
pullPolicy: IfNotPresent
# Overrides the image tag whose default is the chart appVersion.
tag: ""
imagePullSecrets: []
nameOverride: ""
fullnameOverride: ""
serviceAccount:
create: true
annotations: {}
name: ""
podAnnotations: {}
podSecurityContext: {}
securityContext: {}
service:
type: ClusterIP
port: 80
ingress:
enabled: false
className: ""
annotations: {}
hosts:
- host: chart-example.local
paths:
- path: /
pathType: ImplementationSpecific
tls: []
resources: {}
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources, such as Minikube. If you do want to specify resources, uncomment the following
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
# limits:
# cpu: 100m
# memory: 128Mi
# requests:
# cpu: 100m
# memory: 128Mi
autoscaling:
enabled: false
minReplicas: 1
maxReplicas: 100
targetCPUUtilizationPercentage: 80
# targetMemoryUtilizationPercentage: 80
nodeSelector: {}
tolerations: []
affinity: {}+++
- Beispiel an Container part des Deployment template
+++
containers:
- name: {{ .Chart.Name }}
securityContext:
{{- toYaml .Values.securityContext | nindent 12 }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
ports:
- name: http
containerPort: 80
protocol: TCP
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
resources:
{{- toYaml .Values.resources | nindent 12 }}+++
image:
repository: nginx
pullPolicy: IfNotPresent
# Overrides the image tag whose default is the chart appVersion.
tag: ""
resources: {}
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources, such as Minikube. If you do want to specify resources, uncomment the following
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
# limits:
# cpu: 100m
# memory: 128Mi
# requests:
# cpu: 100m
# memory: 128Mi+++
- helm install
- Installiert ein Helm Chart
- mit "-n namespace" angebbar
- mit "--dry-run --debug" kann man überprüfen ob das deployment klappen sollte
- mit "--version" Versionspinning
- Syntax helm install -n NAMESPACE RELEASE_NAME PFAD_ZUM_HELM_CHART
+++
- helm upgrade
- Upgraden eines Helm Charts auf neue Revision
- "--install" wichtiges Flag. Macht, dass Chart installiert wird wenns nicht da ist
- mit "--version" Versionspinning
- helm create
- Erstellen eines Helm Charts
- Erstellt die grundlegende Ordner-Struktur
+++
- helm uninstall
- Deinstalliert ein Chart und löscht alle Ressourcen
- helm rollback
- Zurückspielen der alten Version des Helm Charts
- helm list
- Zeigt installierte Helm Charts
- entweder mit "-A" für alle Namespaces oder "-n" mit Namespace angabe
- helm lint
- Überprüfung ob das Helm Chart-Template keine Fehler hat
+++
- helm repo
- add
- Hinzufügen eines Repos
- z.B. "helm repo add bitnami"
- update
- Herunterladen, welche Charts im Repo sind
- z.B. in bitnami gibt es ein postgresql-Chart
- add
+++
- erstelle ein Helm Chart für ein nginx deployment mit Service
- deploye dies in einen Namespace deiner Wahl
+++
- Erst das Chart erstellen
helm create NAME
helm create nginx-deployment- dann installieren
helm install -n NAMESPACE RELEASE_NAME PFAD_ZUM_HELM_CHART
helm install -n helm-namespace nginx-deployment ./nginx-deployment+++
- Passe die Replicas mit helm an
- Verifiziere, dass mehr Pods laufen
+++
- Dann die values.yaml anpassen und upgrade
helm upgrade -n NAMESPACE RELEASE_NAME PFAD_ZUM_HELM_CHART
helm upgrade -n helm-namespace nginx-deployment ./nginx-deployment- Mit "kubectl" oder "k9s" anzeigen, dass die angegebenen Pods vorhanden sind
kubectl get pods -n NAMESPACE
kubectl get pods -n helm-namespace+++
- Mache ein Rollback auf eine alte Helm-Version
+++
- Mit "helm rollback" auf alte Revision gehen
helm rollback -n NAMESPACE RELEASE_NAME REVISION
helm rollback -n helm-namespace nginx-deployment 1+++
- Ist ein Packetmanager
- arbeitet mit Templates
- eine zentrale Datei (values.yaml) um komplexe Anwendungen zu deployen
- wird in Repos verwaltet
- HTTP layer 7 router
- Host und Path basiertes Routing (HTTP/HTTPS)
- TCP Routing von Ports != 80/443 über
- Erfordert Installation Ingress Controller
- traefik
- ingress-nginx
+++
- Installiere letsencrypt cert manager via Helm
- Installiere ingress-nginx-controller
- Mache den nginx Server nach außen hin via HTTPS mit Zertifikat zugreifbar via Ingress
- Weil kein LoadBalancer zur Verfügung steht, ändere den ingress-nginx Service in den Typ
NodePort
- Weil kein LoadBalancer zur Verfügung steht, ändere den ingress-nginx Service in den Typ
+++

- von der x-cellent für die FI-TS entwickelte bare-metal cloud
- OpenSource
- Server-Racks in drei Rechenzentren (Nürnberg, Stuttgart, Fellbach)
- ersetzt Nimbus-Cloud
- schon zwei Jahre produktiv im Einsatz
- https://github.com/x-cellent/training-internal/blob/main/metal-stack/metal-stack.md
- metalctl / cloudctl
+++
- Kubernets-as-a-Service (KaaS) von SAP (Open Source)
- Eine Abstraktionsebene höher
- Shoot-Cluster ~ Pod
- beinhaltet die tenant Cluster
- Seed-Cluster ~ Node
- beinhaltet control-planes der tenant Cluster
- gardenlet ~ kubelet
- Shoot-Cluster ~ Pod
+++
- Garden Cluster
- Verwaltet die Seed-Cluster
- Seed-Cluster isoliert lauffähig
- Umgekehrung der Kommunikation
- Unterstützt alle großen CloudProvider, und...
+++

+++

+++
- Bietet cloudctl als zentrales Verwaltungstools von Tenant-Clustern
- Bereitstellung (via Gardener -> MetalStack)
- Netzwerkeinrichtung
- Update
- Kubernetes Version der einzelnen Nodes (auto), Netzwerk, ...
- IP Adressen Reservierung (statisch) für Cluster-LoadBalancer
+++
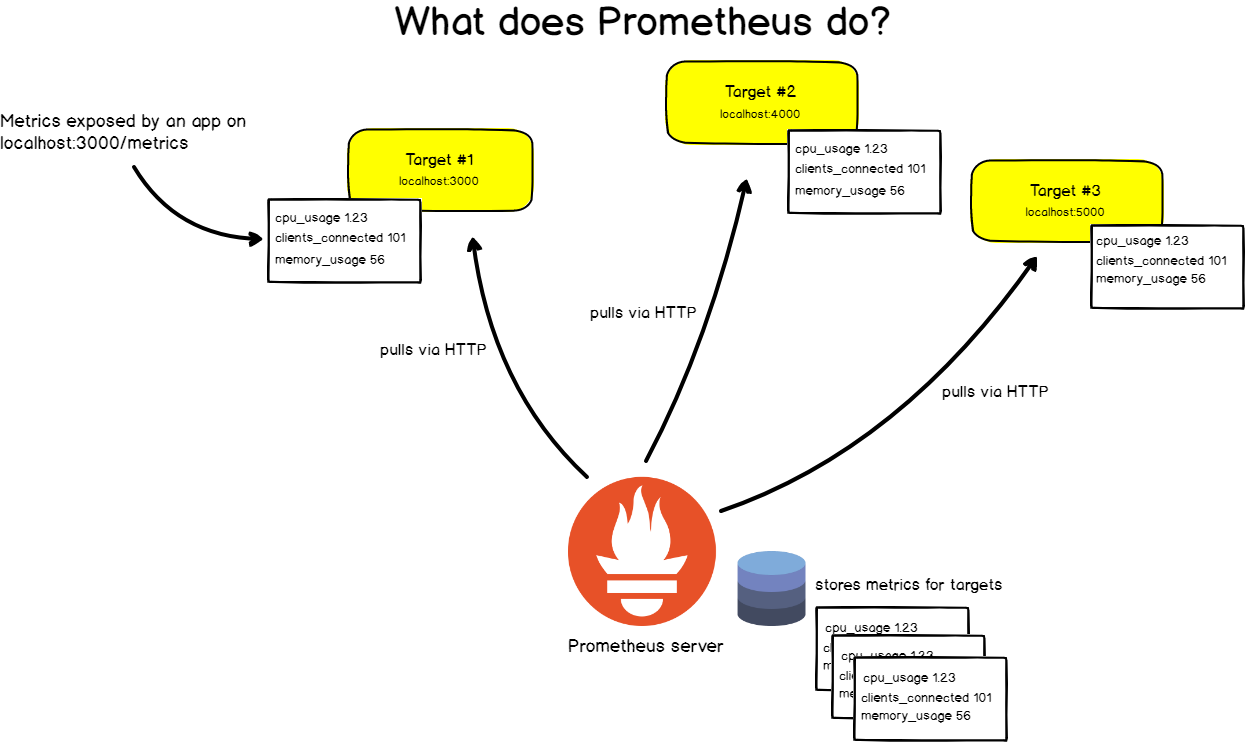
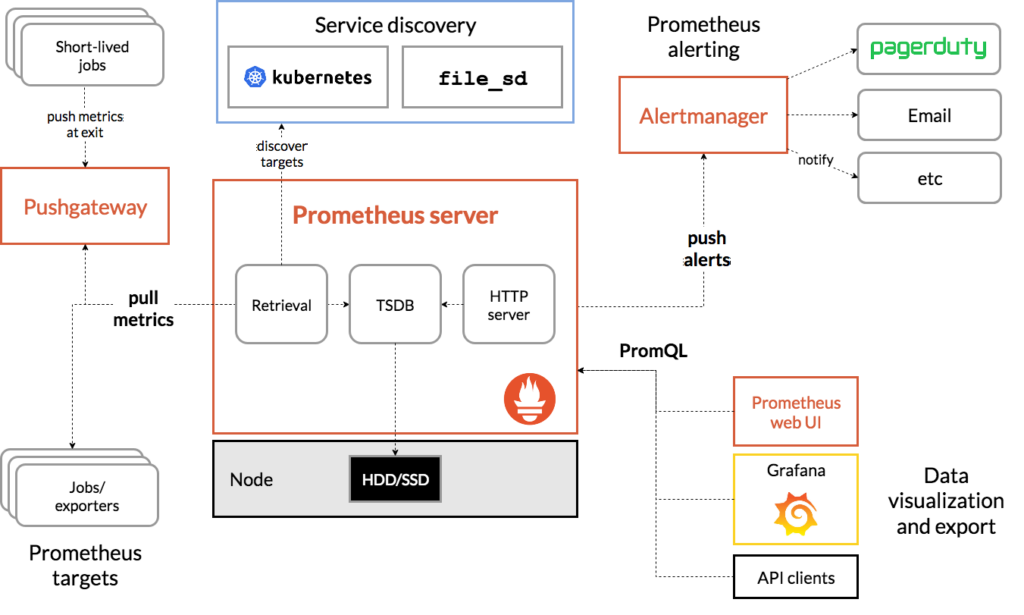
- time series Database
- speichert metric daten einzelner services
- Abrufen der daten mittels PromQL
sum(rate(container_cpu_usage_seconds_total{container!=""}[5m])) by (namespace)
+++
+++
- Alamiert nach erstellten Vorgaben
- Diverse endpoints lassen sich hinzufügen
- div. Instant messanger
- slack
- MS teams
- Telegram
- SMS
- viele weitere
+++
- ließt daten von Datensammelstationen
- Prometheus
- Loki
- MSSQL
- InfluxDB
- viele weitere DataSources
- erstellt Grafiken
- Dashboards auf benutzeroberfläche erstellbar
- Dashboards importierbar
+++
+++
- auch loki-stack genannt
- log aggregation system
- indexiert nicht den Inhalt der Logs
- indexiert Metadaten der Logs
- Integriert sich mit Prometheus und Grafana
- ununterbrochener Wechsel zwischen Logs und Metrics möglich
- promtail um Logs von Nodes einzusammeln
+++

+++
- installiert mit Helm Prometheus, Grafana, loki-stack(loki und promtail)
- in grafana Datasources Prometheus und Loki hinzufügen
- erstellt ein Dashboard welches den Ressourcenverbrauch anzeigt
- erstellt ein Log Dashboard
- Tipp: bei installation mit helm ausgabe nach installation beachten!
+++
- für Prometheus:
- helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
- helm repo update
- helm install -n NAMESPACE prometheus-community prometheus-community/prometheus
- für Grafana:
- helm repo add grafana https://grafana.github.io/helm-charts
- helm repo update
- helm install -n NAMESPACE grafana grafana/grafana
+++
- für Loki-stack (installiert loki und promtail):
- ist auch in grafana helm repo
- helm install -n NAMESPACE loki grafana/loki-stack
+++
- um das grafana Dashboard erreichbar zu machen braucht man ein port-forward
- export POD_NAME=$(kubectl get pods --namespace NAMESPACE -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
- kubectl --namespace NAMESPACE port-forward $POD_NAME 3000
- anschließend grafana auf localhost:3000 erreichbar
- username ist admin, password steht im secret grafana base64 encrypted
+++
- Datasources auf der linken seite bei Configuration
- prometheus braucht in diesem Fall nur die URL: dieses Schema: http://PROMETHEUS-SERVER-SERVICE:PORT
- loki braucht ebenfalls nur URL: diese Schema: http://LOKI-SERVICE:PORT
+++
- Auslastungsdashboard erstellen:
- auf grafischer Oberfläche entweder ein Dashboard mit PromQL erstellen
- oder auf grafischer Oberfläche ein Dashboard importieren
- Log Dashboard erstellen
- auf grafischer Oberfläche mit Loki Query
- oder auf grafischer Oberfläche Importieren
- Hab ihr noch Fragen an uns?