Multi-regressor inference API to evaluate six metric of a written essay: cohesion, syntax, vocabulary, phraseology, grammar and conventions.
In the context of the FB3 competition,
I used deberta-v3 model in two different ways that I described in detail in my two post :
- Part-1: Use the transformer as feature extractor and train another multi regressor model
- Part-2: Fine tune the transformer by extending the model with a differentiable header
I created two medium posts (Post1 and Post2) to explain in details the two approachs separately
A third post shows in detail all the required steps to deploy the fine-tuned model as a REST-API using FastAPI and Docker.
The /data and the /notebooks directories are optional here: they were used at the exploratory stages.
In the /src directory we will mainly use the following scripts:
predict.py: it contains the needed functions to predict/score essays input with the transformer modelcustom_transformer.py: it includes among other elements the custom transformer class calledFeedBackModelthat will define the fine-tuned model, and the customtorch.utils.data.DatasetcalledEssayIteratorthat will be used to make batch prediction
The main application is located in the /api directory in main.py. it contains also the corresponding test code in test_main.py.
The config.ini file contains all the required config parameters such as paths, model hyper-parameters, target labels names (=the writing skills names), so that we don't have to hardly code each time the config parameters
The Dockerfileand docker-compose.yml[Optional] files are needed to create the docker image of the app to be run in an isolated environment.
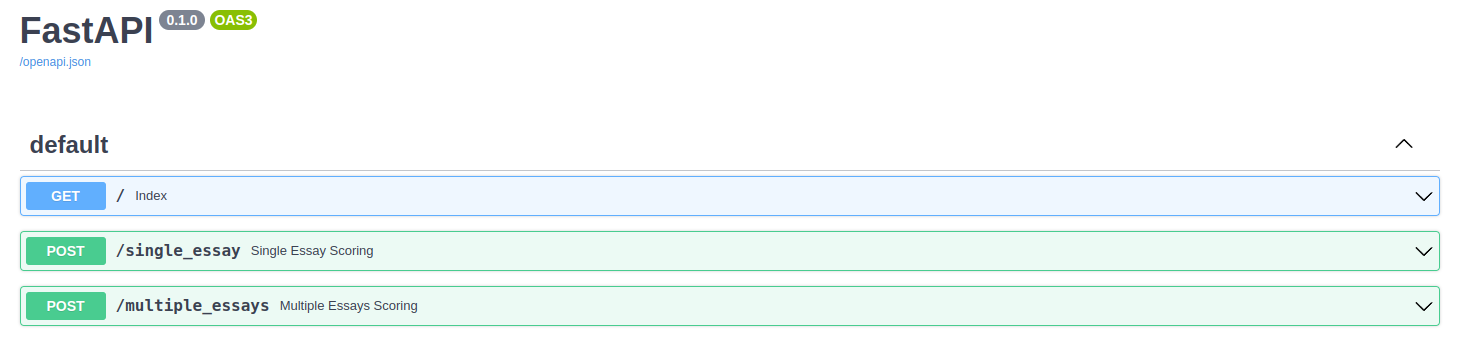
Here's a high-level overview of the API:

It contains the following routes:
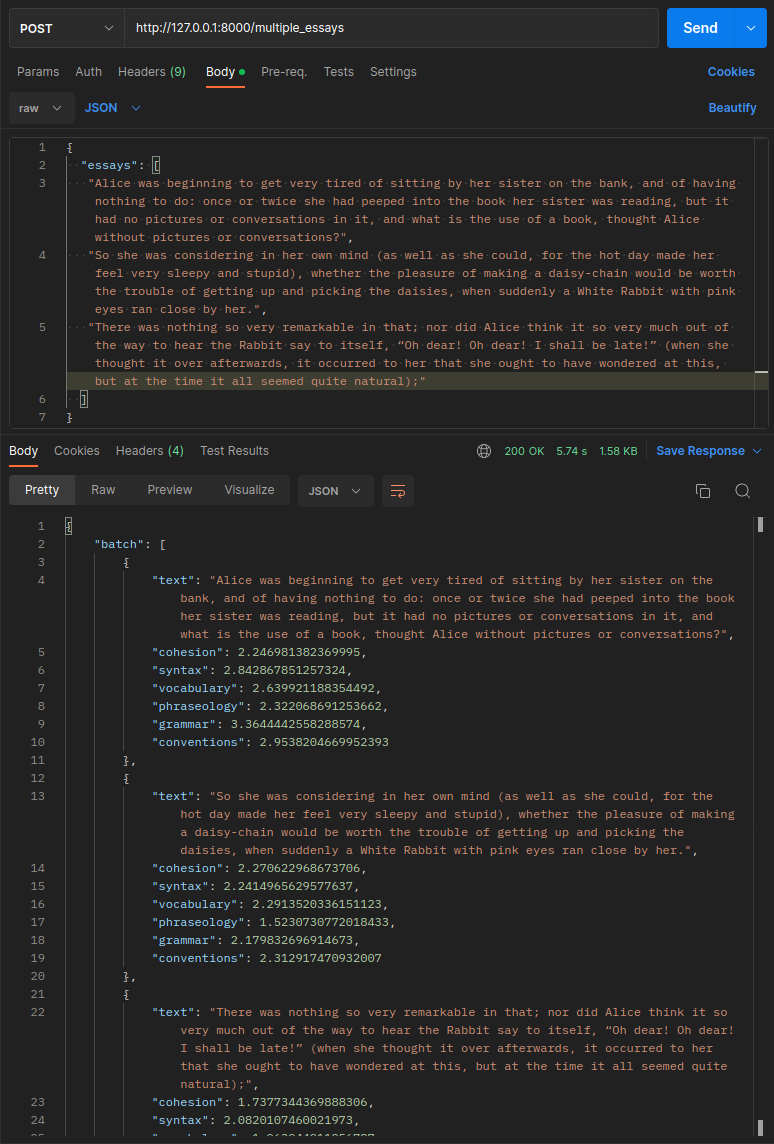
/single_score: POST request that allowing to predict a unique text input: this api can be the best choice for online applications. The/single_essayrelated function usessingle_prediction function, defined insrc/predict.py` file/multiple_essay: POST request that supports batch predictions. The/multiple_essayapi function would use abatch_predictionfunction imported from the `src/predict.py python file
There is two ways to build the related docker image
- build the docker using the
docker buildcmd :
$ docker build -t essayevaluator .
PS do not forget the . at the end of the cmd 2. Export your W&B API token
$ export WANDB_API=YOUR_WANDB_TOKEN
To get your wandb api token follow these steps:
- Sign up for a free account at https://wandb.ai/site and then login to your wandb account.
- Retrieve your api directly from https://wandb.ai/authorize
- Run the built docker image:
$ docker run -e "WANDB_API=$WANDB_API" -p 8000:8000 -t essayevaluator
Even though we do not need to use the docker compase as we have a single service here But in general, if we want to set up a micre-service based infrastructure carriying multiple services, we would want them to run in separate containers. To do so, docker-compose is an excellent solution to handle it.
In this case, just run:
$ export WANDB_API=YOUR_WANDB_TOKEN
$ sudo docker-compose up --build
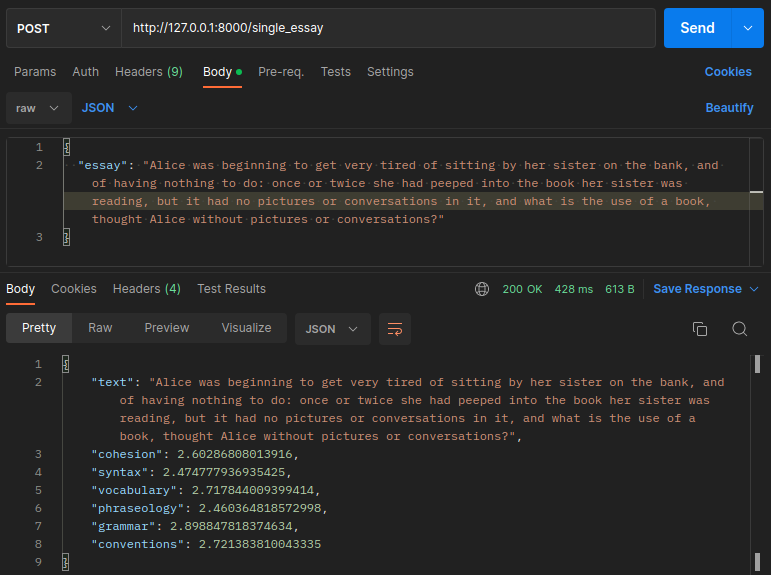
To check the API is doc, you can open http://localhost:8000/docs: it would redirect you to the interactive interface where you can try the API from the browser. You get something like this:
Other ways to try the API request:
- Postman
- Curl cmd
Example:
curl --location --request POST 'http://127.0.0.1:8000/single_essay' \
--header 'Content-Type: application/json' \
--data-raw '{
"essay": "I walked alone through the night to the exit from the Prater. All inhibition had left me, I had been like a man missing, presumed dead, but now I felt my nature flowing out into the whole infinite world in a plenitude I had never known before. I sensed everything as if it lived for me alone, and as if in its own turn it linked me with that flow."\
}'