Releases: FEX-Emu/FEX
FEX-2501
da06957Read the blog post at FEX-Emu's Site!
Welcome back to another new FEX-Emu release in the new year! While everyone was out celebrating the holidays, we still managed to get some work done.
So let's get in to what we did this last month!
Official WINE WoW64 and Arm64ec package support
This month we have updated our Ubuntu ppa repository to now support a fex-emu-wine package. This package provides wow64 and arm64ec emulator DLL files
that can be applied directly to an AArch64 build of WINE, thus allowing you to do x86 and x86-64 emulation inside of WINE directly and removing a ton
of CPU overhead in the emulation! This is relatively fresh so there will be some teething issues around getting it setup, like the current upstream
WINE may not integrate directly in to these builds yet. Check out our wiki for more
information about getting this hooked up.
Partial support for inline self-modifying code and trap flag
As we work towards supporting more edge-case behaviour of anti-tamper and anti-debugger software. We have spent some time this month implementing support for inline self-modifying code and the trap flag.
In particular Denuvo uses inline self-modifying code which is relatively annoying to support, but we can use the fact that it tends to generate
invalid instructions to determine that a block of code is invalid early, thus letting it work. There's some more work towards making this more robust
but this gets a decent number of games running.
The trap flag on the other hand is interesting because this is an anti-debugger tactic that some badly behaving launchers use. This is because of how
debuggers treat the trap flag versus how it works when a debugger isn't running, this lets the application detect the debugger and throw an error.
FEX didn't quite handle this correctly which was causing these launchers to throw their hands up and stop running.
A note is that some of this work is only wired up on the WINE side rather than the FEX-Emu Linux emulation side, so mileage may vary!
JIT bug fixes and performance improvements
As usual, a lot of fixes landed for our JIT, ranging from incorrect backpatching of unaligned atomics, to incorrect instruction handling, to improving
performance of a couple of instructions. Let's break down what we fixed this month.
Fixed backpatching of unaligned atomics with small immediates
ARM's FEAT_LRCPC2 extension added TSO instructions for small immediate offsets in the range of -256 to 255. These still have the regular atomic
limitation of ARM where the address needs to be naturally aligned (or within 16 byte granule!) of the access type. FEX needs to emulate unaligned
memory accesses from x86 by backpatching these instructions to be a DMB plus load or store. We were incorrectly patching these instructions with the
small offsets. This will improve stability of emulation on hardware that supports the new FEAT_LRCPC2 instructions
Fix float to integer overflow behaviour
This is a very important change for how FEX handles when converting a float value to an integer and an overflow occurs. While we knew of the problem,
we didn't realize how wide reaching the problem was causing problems. In particular this fixes The Talos Principle's audio cuting out, Animal Well's
music having chirping artifacts, SOMA not allowing interactions with things in the world, Satisfactory's server crashing, and Metaphor Refantazio
infinite looping before getting in-game!
There are sure to be a bunch of other little fixes that this also fixes because it's a pervasive problem that games rely upon!
Fix ModRM decoding of 3DNow! instructions
While 3DNow! isn't used in any recent games, to the point that AMD has removed the instruction set from Zen CPU cores, older games still use this
extension if possible. Turns out we had a gap in our testing infrastructure for when a 3DNow! instruction used the SIB encoding form of the
instruction. This would result in crashes and misinterpreting of instructions. This will fix some older 32-bit games using 3DNow! and of course we
added new unittests to our testing infrastructure to make sure it keeps working.
Fixes H0F3A table decoding
This fix doesn't affect any known applications, but because of how x86 compilers aggressively pad instruction sizes, this could crop up anywhere
without us noticing. When the H0F3A instruction table gets decoded, FEX was incorrectly applying the REX_W prefix to instructions that would ignore
the prefix. Out of all the instructions in the table, only three actually care about the prefix while the others always ignore it. If this padding
occured then FEX would think it is an unknown instruction and crash. This has now been resolved which should keep us from ever hitting the issue.
Generate 80-bit SVE loadstores when necessary
For all the users that have SVE supporting hardware (There aren't a lot of you!), we have added a new optimization that converts two loads or stores
in to a single 80-bit masked loadstore instruction. While this isn't going to be a huge improvement because this only occurs with x87 code, it's
another little optimization in the list of things that SVE improves for x86 emulation.
Increase minimum kernel requirement from 5.0 to 5.15
We're moving in to the future with some changes that require increasing our minimum kernel version. Because we were allowing such an old version of
the Linux kernel, we were hitting some heartburn in some codepaths. In order to make this easier, we are moving up the minimum kernel requirement to
an LTS release of the kernel released back in 2021 already! We don't expect this to cause too many problems, since this is an kernel supported by
Ubuntu for 22.04
Drop official support for ArchLinux
Due to a clarification from the ArchLinux team this last month, they are no longer allowing packages in the AUR that don't support x86-64. Due to this
change and that FEX only supports running on an AArch64 host, they have removed our official packages from AUR. There's nothing that we can do about
this besides dropping support for ArchLinux.
Raw Changes
FEX Release FEX-2501
-
ArchHelpers
-
Arm64
-
Fixes LDAPUR and STLUR backpatching (1e827ec)
-
ConstProp
-
fix 32-bit masking behaviour (c902b88)
-
Context
-
Constify GPRs passed to ReconstructCompactedEFLAGS (a86c922)
-
External
-
Update bundled libfmt (7e257cc)
-
FEXCore
-
Emulate EFLAGS.TF (e88c92d)
-
Override x87 precision control when necessary (8111b7c)
-
Don't
WaitForEmptyJobQueueif CodeObjectCacheService isn't used (5a4691f) -
FEXLoader
-
Increase minimum kernel requirement from 5.0 to 5.15 (6bc7a83)
-
Enable early logs output to stderr (e32c538)
-
Frontend
-
Fix ModRM handling with 3DNow! (15a1a0f)
-
GdbServer
-
Fixes encoding of hex (735a4f9)
-
Support 32-bit context definitions (072cf4c)
-
Implement support for
$vKill(46fb858) -
IR
-
Change convention from number of elements to elementsize (a6c67ca)
-
Passes
-
Adds missing comment that clang-format keeps complaining about locally (b03b02d)
-
InstCountCI
-
Adds more LRCPC2 tests that are missed (cd6722f)
-
Implement support for TSO and LRCPC and add hot block that could be optimized (9fb69ed)
-
InstructionCountCI
-
add some hot blocks from Factorio (e44d1f1)
-
Linux
-
Fixes typo in removing RESOLVE_IN_ROOT flag (e55b5d0)
-
FaultSafeUserMemAccess
-
Break out fault safe handler (57178ab)
-
LinuxEmulation
-
Don't use clone3 for fork (71187d3)
-
LinuxSyscalls
-
Log unhandled clone3 fork flags (c3261b4)
-
Ensure CSIGNAL is merged back in to flags for clone2 (c7fb95a)
-
Fixes exit syscall (bdae4f6)
-
OpcodeDispatcher
-
Fixes FEX's H0F3A table handling of REX.W (90b1ac4)
-
Minor division improvement (04e785e)
-
ThreadManager
-
Add some sanity asserts (d8ef702)
-
Threads
-
Fix memory leak in ...
FEX-2412
20caf69Read the blog post at FEX-Emu's Site!
Welcome back to another FEX release! With the last month's release being cancelled there is a few more changes than average.
Fix Steam's webhelper process again
On November 5th, Valve's Steam client updated their embedded version of
Chromium. This uncovered new bugs in FEX-Emu and caused Steam to constantly restart its UI. Luckily Asahi Lina diagnosed
the issues and resolved the problems that were occuring! Now Steam is more stable than it has ever been!
Fix WINE path execution problems
Asahi Lina had encountered a bug when running WINE under Fedora which wasn't seen before. Turns out FEX-Emu was incorrectly concating some filepaths
together when child processes were getting executed inside WINE. This usually worked but due to the combination of a newer version of WINE and how
Fedora set up its paths caused this to break under FEX. With this issue resolved, WINE is working again. There are likely some more bugs due to
the nature of how FEX sets up its path handling, but those will likely get solved in time.
Emulate PAUSE instruction using WFE instead of YIELD
This is mostly just a passing curiousity since it doesn't really matter. FEX has long emulated the x86 instruction PAUSE by using a theoretically
functionally equivalent ARM64 instruction called YIELD. It came to our attention over the last couple months that Apple Silicon and ARM Cortex
implement the YIELD instruction as a nop, so it effectively does nothing. This kind of makes sense since it is typically useful for SMT systems, and
no relevant ARM cores support SMT.
On x86 CPUs this matters more since they do support SMT, but PAUSE depending on CPU will also have the CPU core sleep for some number of nanoseconds
that is implementation dependent. To be more similar to how PAUSE operates, we have instead switched over to using the WFE instruction which provides
similar guarantees on most ARM64 hardware. The trade-off here is that Qualcomm's new Oryon CPU treats WFE as a nop instead. A reasonable trade-off and
just an interesting quirk of their hardware.
Adds support for compat input prctl
A major problem that constantly comes back to bite FEX is emulating 32-bit syscalls with complete accuracy. Due to the Linux Kernel hiding information
about a syscall returning opaque data structures, FEX jumps through a lot of hoops to make sure everything works while running as a 64-bit ARM
process.
The ioctl syscall is one of these annoying syscalls that completely change how they behave depending on the device that is being communicated with,
requiring FEX to track file descriptors and wrap all ioctl syscalls with checks see which ioctl it is, to which device. This is fraught with problems
since we can't always know 100% if we are actually communicating with a device that we think it is.
This leads us to this new bug that we encountered. When a 32-bit process is communicating with a gamepad, it uses a combination of the joydev and
udev subsystems inside of the Linux kernel. Any 32-bit game was having issues where gamepads where the controls were "sticky".
While FEX is catching the ioctl communications and translating the data as necessary, there was a more nefarious problem happening. Turns out the
Linux kernel in some instances will check to see if a syscall is coming from either a "compat" process, or is inside of a "compat" syscall. A
compatibility process is just a process in which the Linux kernel knows it is a 32-bit process, while the kernel is 64-bit. In x86 land this is easy
since you just check if it is x86 or x86-64. When running under FEX, the process is /never/ a compatibility process, because it is always 64-bit.
Turns out that the read and write syscalls, depending on what type of device it is communicating with, will return different data if it is compat or
not! This isn't just specific to gamepads, there are various subsystems in Linux that check if they are in a compat process and modify the data. This
is a huge problem since we would introduce a ton of overhead tracking every read, write, seek, etc syscall and try to compare it against something
that needs modified data or not. slp decided to tackle this for the Asahi Linux distro by adding a new prctl to changing the
data to the "compat" versions if enabled, even in a 64-bit process. This is a bandage to a significant problem as it only covers gamepad devices
today. We will continue tracking these issues in to more subsystems as we find them over on our 32Bit Syscall
Woes wiki page.
Support CPU index through TPIDRRO
This is a fun little feature to make FEX's life easier. When FEX is emulating the CPUID and RDTSCP instructions, we need to know the physical CPU
index because the instructions will give that information to the program. The RDTSCP instruction gives the index directly, while the CPUID instruction
uses it for per-cpu data lookup and also some indexing data.
The fun thing is that Windows is the only operating system that supports this today. So FEX only gets to enjoy this in a little toy sandbox for when
it is running under Windows. The linux implementation on the other hand does a syscall to getcpu for each one of these instructions getting
emulated, which adds a bunch of overhead. This is due to Linux not supporting using TPIDRRO in this fashion, instead the register is set to zero.
This has an additional knock-on effect that if WINE wants to run Arm64 native Windows applications, this is going to break any algorithm that relies
on that Windows feature. Ideally the Linux kernel implements this feature for both WINE compatibility, and FEX performance improvements some day!
FEXCore cleanups and restructuring
While not user facing at all, there has been some restructuring of how FEXCore, the CPU emulation backend of FEX-Emu, exposes its CPU emulation.
Historically FEX-Emu has had a problem where we leak OS information across the boundary, making the interface to the CPU backend more convoluted than
it needed to be. Over the last couple of months we have been removing large amounts of the Linux specific code from FEXCore and moving it in to the
frontend.
While this doesn't affect the user, it makes our programmer's lives easier since they don't need to dance around OS abstractions quite as much. It
also makes it easier for upcoming debugger improvements that FEX-Emu is sorely lacking today.
Fixed some JIT bugs
We uncovered some implementation bugs in our AVX emulation this last month. There were four instructions that had some incorrect behaviour. While
fixed, we don't know of any actual bugs in games that happened because of these edge case failures. It's a good testament towards having unittesting
infrastructure that can catch behaviours like this, and knowing that even with thousands of hand-written assembly tests, some edge cases still aren't
tested.
There were also a couple of other misc optimizations and bug fixes but we've gone on for quite a while now.
Raw Changes
FEX Release FEX-2412
-
AVX128
-
Fixes some AVX bugs (c4306f2)
-
CMake
-
Generate test list even when testing is disabled (ee592ba)
-
FEXCore
-
Removes ExitHandler and RunUntilExit (41c8731)
-
Removes GetGPRSize and convert all uses to GetGPROpSize (9febdde)
-
Removes stale function definition (c7098d0)
-
Removes CoreShuttingDown from ContextImpl (65a162b)
-
Removes remaining RunningEvents from InternalThreadState (baddfe0)
-
Moves InternalThreadState ExecutionThread to the frontend (95d5b14)
-
Move InternalThreadState StartRunning to frontend (e89f48f)
-
Removes ExitReason from InternalThreadState (f59fc0f)
-
Moves ThreadWaiting to the frontend (56fadec)
-
Constify CTX ptr in InternalThreadState (649a494)
-
Moves StatusCode to the frontend (aa2180d)
-
Moves DeferredSignalFrames to the frontend (fad2214)
-
Moves SignalThread/SignalEvent to Frontend (b440e17)
-
Removes EarlyExit running event (56c6b0d)
-
Moves TLS initialization for Alloc::OSAllocator (0596a96)
-
Adds support for CPU Index through TPIDRRO (992d6e8)
-
Change yield implementation to use wfe (ff51435)
-
adds support for compat input prctl (6a07ea7)
-
FEXLoader
-
Align stack base (09b...
FEX Release FEX-2410
cac3767Read the blog post at FEX-Emu's Site!
A bit of a slower month for this release as our developers prepare for the X.Org Developer's Conference 2024 and
the GStreamer Conference 2024!
We're going to keep this release short and sweet as GStreamer conference has already started and XDC is kicking off in two days.
ARM64EC changes
This month we had some ARM64EC changes to fix some AVX bugs around state saving and restoring when running under Wine. In addition some changes to dynamically determine Windows syscall numbers under WINE rather than hardcoding it.
Additionally some fixes around the how the call checker works, which fixes issues when applications hook function calls early using the Win32 APIs.
For any user that wants to tinker with these, you can find instructions for how to build & install on our wiki.
JIT optimizations
We had some optimizations land in the JIT this month which speeds up the time it takes the JIT to emit code. In some microbenchmarks this has shown up
to 9% less CPU time spent JIT'ing code. This is very important for reducing stutters when encountering new code inside of applications.
JIT fixes
We fixed multiple bugs in the JIT emulation this month, one of which was fixing the x87 FPREM instruction. This instruction is interesting because x87
actually offers another variant called FPREM1, which FEX did emulate correctly. Once we found the bug in the implementation, it actually managed to
fix a major issue where Steam's login was super flaky and had to attempt it about a dozen times before it worked. This also happened to fix
Touhou Luna Nights which rendered its 2D tiles incorrectly before this change.
We also fixed an issue where Halls of Torment was copying data from a thread-local object using vector instructions and FEX had mistakenly broken
vector memory accesses to TLS objects. Fixing this solves this game problem, and probably many other games that happens to inline a memcpy accelerated
using vector operations!
We also happened to fix a bug with the SSE MAXSS instruction where in the face of NaNs we were returning the incorrect result. Only affected some edge
case behaviour, but nice to see little bug fixes like this.
An aside
Make sure to check out the XDC livestreams over the next few days! You definitely won't want to miss it!
See the 2410 Release Notes or the detailed change log in Github.
Raw Changes
FEX Release FEX-2410
-
AOTIR
-
Move debugdata structure to internal header (304b5de)
-
ARM64EC
-
Dynamically determine syscall numbers under wine. (967c04e)
-
AVX register save/restore support under wine (e9d34c7)
-
Patch the call checker before calling any syscall exports (2672e06)
-
Switch to exception-based native syscall dispatch (07f117b)
-
Arm64
-
Fix warning (ebae1bf)
-
CMake
-
Disable vixl compiling if not enabled (f99900b)
-
Compile with system libraries for xxhash, Catch2, and fmt, if available (a4acd64)
-
CPUBackend
-
Remove unused functions (5f79761)
-
CPUID
-
Update to something a little more modern (5bd0afa)
-
Config
-
Be a bit smarter in ReloadMetaLayer (b5c9eb3)
-
Fixes stack usage in EnvLoader (4f8d7cb)
-
ConstProp
-
speed it up (36e4f9a)
-
FEXConfig
-
Add the ability to watch and configure global rootfs (f49d82d)
-
FEXCore
-
Remove BlockSamplingData (9310ac5)
-
Convert Base tables over to constexpr (20fb0da)
-
Remove Context header include when unneeded (4cb4c0e)
-
Delete ThreadsState struct (219a477)
-
Move
CustomIRResultto internal header (29f0e9b) -
Move
JITSymbolBufferto internal header (b75efc4) -
Context
-
Removes unused features (05be944)
-
FEXLoader
-
Drop the binfmt_misc
Iflag (e190d02) -
FEXRootFSFetcher
-
Fallback to TTY if zenity isn't installed (bebd740)
-
XXHash
-
Fix double fd close (360ea53)
-
FEXServer
-
PipeScanner
-
Stop writing null to incoming pipes (0a35029)
-
JIT
-
always use 64-bit moves for SRA (cd4c224)
-
Linux
-
Optimize CreateNewThread and HandleNewClone stack usage (d547f2b)
-
LinuxEmulation
-
Update syscalls for v6.11 (aaa8eef)
-
Update DRM for v6.11 (c036868)
-
LinuxSyscalls
-
Update max reported kernel version to 6.11 (9716fc7)
-
With poll syscall, ensure fds is writable only if nfds is not zero (f77841d)
-
OpcodeDispatcher
-
Fixes segment prefixing on vector element loadstores (2726f35)
-
Constexpr-ify all the tables possible (9d6865f)
-
Do not forbid INT 2E syscalls on 64-bit Windows (bbef4d7)
-
SignalDelegator
-
Let the frontend inform AVX support (9100235)
-
Thunks
-
Move to the frontend (f640dcc)
-
Vulkan
-
Updates thunks to v1.3.296 (1670c89)
-
Tools
-
Delete imgui FEXConfig (c0b8a0d)
-
VDSO
-
Implements v6.11 vdso getrandom (e902ad5)
-
VDSOEmulation
-
Stop using dlopen for VDSO (5745b41)
-
Windows
-
Switch supported MinGW CRT to UCRT (c2f2c58)
-
Don't assume the log file was successfully opened (f20e626)
-
Misc
-
speed up the JIT (e82d2c7)
-
Fixes fprem (b89f5b8)
-
x87 small cleanups; NFC (5e9c211)
-
Build host tools without jemalloc (49de1fa)
-
Fix FScale'ing zero that should return zero (4d62e75)
-
Stop installing binfmt_misc on x86 (b6d3df0)
-
Fix (v)maxss on non-AFP platforms (9e4de3b)
-
Support for emulated overcommit on Windows (4a2b4be)
-
Bunch of little things reported by coverity (b4c797c)
-
Global flag optimizations (1c59bfe)
-
gitignore
-
ignore build symlink (90dbd47)
-
unittests
-
Be more strict with -- separator (3c205eb)
-
Fixes incorrect argument (c8f3fe3)
FEX-2409
d5db894Read the blog post at FEX-Emu's Site!
FEX-2409 is now released... with a big performance boost.
Inline Graph
I'm tired, carry me.
Little differences between x86 and Arm can cause big performance penalties for
emulators. None more so than flags.
What are those?
Flags are bits representing the processor state. For example, if an operation
results in zero, the "zero flag" is set. Both x86 and Arm have flags, so for
emulating x86 on Arm, we map x86 flags to Arm flags to reduce emulation
overhead. That is possible because x86 and Arm have similar flags. By contrast,
architectures like RISC-V lack flags, slowing down x86-on-RISC-V emulators.
Many arithmetic operations set flags. Programs can then conditionally jump
("branch") according to the flags. On x86, the flags are thus the building blocks
of if statements and loops. To check if two variables are equal, x86 code
subtracts them and checks the zero flag. To check if one variable is less than
another, x86 code subtracts and checks the negative flag. This pattern --
subtracting, setting flags, and discarding the actual result -- is so common
that it has a special instruction: CMP ("CoMPare").
If the story ended here, emulation would be easy. Unfortunately, we need to
talk about the carry flag.
After an addition, the carry flag indicates if the result overflowed.
Programs can then check the carry flag to detect overflows. The flag can also
be input to another addition to implement 128-bit additions.
Subtractions are similar. In hardware, subtractions are additions with an
operand negated. Because they are additions in hardware, subtractions set the
carry flag. Precisely how is the carry flag defined for subtraction? There are
two competing conventions.
The first sets the flag when there is a borrow, by mathematical analogy with
addition. x86 uses this "borrow flag" convention, as it seems more natural.
The second option sets the flag when there is not a borrow. Isn't that
backwards? It turns out that adding a (two's complement) negated operand
overflows exactly when the subtraction does not borrow. This "true carry"
convention matches actual hardware behaviour, while the "borrow" x86 convention
requires extra gates to invert carry. Arm uses the "true carry" convention to
save a few gates.
Which convention should FEX use?
We could store the x86 carry flag in the Arm carry flag. Unfortunately, that
requires an extra instruction after each subtraction to invert carry to get the
borrow flag.
The counter-intuitive alternative is storing the opposite of the x86 flag.
That requires an extra invert after every addition, but it eliminates the
invert after subtraction.
Either we pay after additions or after subtractions. Which should we pick?
While addition is common, using the flags from an addition is not. Flags are
typically used with comparisons, which are subtractions. Therefore, the
inverted convention usually wins. This month, Alyssa adjusted FEX to invert
carries, speeding up typical workloads by a few percent.
After tackling the carry flag, Alyssa optimized FEX's translations of address
modes, push/pop, AVX load/stores, and more. Overall, benchmarks are upwards of
10% faster since the last release.
A Qt change
What about more user-visible changes? If you use the FEXConfig tool to
configure the emulator, you're in for a treat. While it works, this ImGui-based
tool isn't exactly known for its convenience. In
between his work optimizing the [redacted] out of FEX's [redacted], Tony
rewrote FEXConfig as a simple Qt application, improving aesthetics, usability,
and accessibility all in one go. Here's a preview:
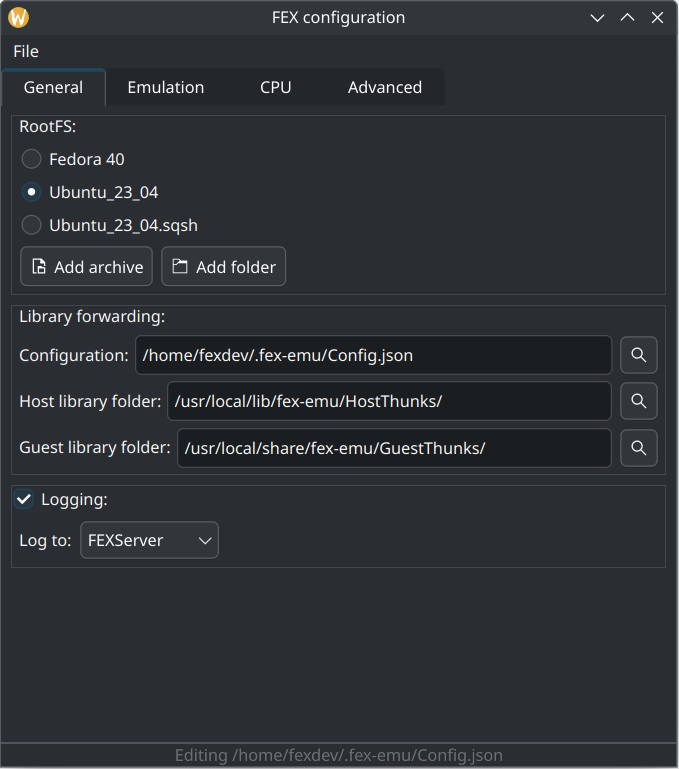
Besides look and feel, we've polished first-time setup for logging,
library forwarding, and RootFS images. We've also made tweaking various
emulation settings a bit nicer. Users of our Ubuntu PPA can simply
update to unlock these improvements without any further action.
But with so much optimization, who needs speedhacks anymore?
Raw Changes
FEX Release FEX-2409
-
ARM64EC
-
Always use the CPU area context for BeginSimulation (cc589ba)
-
Fix ContextFlag member tests (47b3637)
-
AVX128
-
Fixes 256-bit float compares (2478abb)
-
Fixes incorrect size usage in AVX128_Vector_CVT_Int_To_Float (a4db585)
-
Arm64
-
Implement support for strict in-process split-locks (74e95df)
-
Ensure 256-bit operations always assert without 256-bit SVE (90f7cc9)
-
Fixes SIGBUS handler for FEAT_LRCPC (2357253)
-
Allow directly correlating an ARM register back to an x86 register (92c951c)
-
Handle backpatching in a thread-safe manner (226f5e2)
-
CMake
-
Adds an AArch64 cross-compile toolchain file (06497fd)
-
Don't install binfmts for MinGW builds (f009a00)
-
CPUID
-
add missing Apple core part numbers (8296bfc)
-
ConstProp
-
stop pooling inline constants (5013b8a)
-
DeadStoreElimination
-
handle PF/AF invalidate (03832b2)
-
External
-
Update robin-map from 1.2.1 to 1.3.0 (96055cb)
-
Update fmt from 10.1.1 to 11.0.2 (f1d7879)
-
FEX
-
Moves sigreturn symbols to frontend (4baeffe)
-
FEXCore
-
Dynamically scale TSC (46a2a06)
-
Splits up atomic enablement checks (689b461)
-
Stop installing static library (4abac0c)
-
Disable vixl linking if vixl disasm or simulator is disabled (5e706df)
-
FEXInterpreter
-
Support portable installs (9336e35)
-
FEXLoader
-
don't install FEXUpdateAOTIRCache (1e1bcc4)
-
FEXQConfig
-
Add strict split-lock option (8fe1e95)
-
FEXQonfig
-
Fix minor saving/loading quirks (e234e11)
-
Minor followup changes (c74df6a)
-
FEXRootFSFetcher
-
Allow UI override through options (5b65f30)
-
Frontend
-
short-circuit code generation on invalid instructions with multiblock (92ddc00)
-
HostFeatures
-
Moves MIDR querying to the frontend (fbf62f1)
-
Removes vixl usage (1caa31c)
-
fix clang reformat constantly with missing comment (86e5e1a)
-
IR
-
fix scalar FMA tied sources (a66fac6)
-
InstCountCI
-
include x86 instruction count (50a9cea)
-
InstructionCountCI
-
explicitly enable flagm for multiinst (33558e6)
-
LinuxEmulation
-
Implement support for seccomp (b368223)
-
Moves guest signal frame generation to its own file (d9544e7)
-
LinuxSyscalls
-
Adds missing header (4f40416)
-
Implements less invasive assertion only EFAULT handlers (ce88f5f)
-
Some minor cleanups (27cd399)
-
OpcodeDispatcher
-
Convert more template handlers to Bind handlers (2829ad5)
-
Allow x86 code to read CNTVCT on ARM64EC (e6aa268)
-
fix tso checks (2a170cf)
-
Remove old bad assumption in INC/DEC (c634c53)
-
SignalDelegator
-
Refactor how thre...
FEX-2408
fb60a8aRead the blog post at FEX-Emu's Site!
In the beginning, there were integers.
And robots wanted precise math, and so the x87 floating
point unit was created.
And robots wanted faster math, and so SSE was created to
replace x87, and it was good.
Speeding up x87
Although x87 is slow and deprecated, it hasn't disappeared. 64-bit games will
use SSE or even AVX for floating point math, but older 32-bit binaries --
compiled decades ago -- are filled with x87.
FEX aims to support your entire game catalogue. Last release, we added AVX to
support the newest games. This release, we've circled back to the oldest. Old
games ought to run well on new hardware, but if they use x87, performance can
nosedive. Why? Two x87 quirks: 80-bit precision and the stack.
Floating point numbers are typically 32-bits or 64-bits. 32-bit is
faster, while 64-bit enhances precision for numerical computing. Our
target Arm hardware supports both 32-bit and 64-bit, but
x87 adds an unfortunate third mode: 80-bit. Ostensibly, the extra bits of
precision in intermediate calculations minimizes the accumulated error of
the final result.
Is that necessary? Careful code can mitigate rounding error without the massive
80-bit hammer, thanks to techniques like the Kahan summation
algorithm. New
code doesn't miss the 80-bit hardware.
Sadly, the FEX team can't afford a time machine. They're not cheap anymore.
We'll see what happens with Moore's Law eighteen months ago. So we can't teach
game developers in 2005 how to make do with 64-bit floats. All we can do is
slowly emulate 80-bit floats in software, or substitute 64-bit and the game
won't notice.
The second problem with x87 is more obscure. In a typical instruction set, each
instruction specifies which registers it accesses. By contrast, x87 arranges
registers in a stack. Instead of a destination register, x87 instructions
push to the stack. Instead of source registers, sources are indexed relative
to the top of the stack. Unlike 80-bit floats, stack machines are alive and
well for virtual machines. Like 80-bit floats, they complicate
emulation.
Arm instructions specify their registers directly, but we don't know which
registers an x87 instruction will use without knowing the stack top.
Previously, FEX worked around this mismatch by keeping the emulated x87 stack
in memory instead of registers. Arm can indirectly index memory, so this
works. However, it's slow. Because Arm is a RISC architecture, this approach
requires multiple load/store instructions for every x87 arithmetic operation.
We can do better.
Instead of single instructions, we can translate entire x87 code blocks. That
gives us the full context of each instruction. In "good" conditions, that lets
us statically determine the stack layout, so we can translate stack access to
real Arm floating point registers. The stack loads and stores disappear the
our generated code.
There's another trick we can play. Sometimes games will copy 80-bit floats
without performing any calculations. Translating these copies naïvely is slow
due to 80-bit emulation overhead. However, we can analyze multiple
instructions together to detect 80-bit copies and translate to efficient Arm
code.
These optimizations combine to a surprisingly large speed-up. To illustrate: a
hot block in Psychonauts swizzles a 4x4 matrix. That's light on arithmetic but
heavy on x87 overhead. These optimization reduce the translated code from 2340
to 165 instructions. That's a 93% improvement!
Big thanks to Paulo for taming x87, available in
this month's FEX release.

[redacted]
...
"I'm working on a branch that's 10% faster than upstream. Should I mention that
in the blog?""No, we don't want to ruin the surprise for next month's release."
...
Raw Changes
FEX Release FEX-2408
-
AOTIR
-
Change std::unique_ptr to fextl::unique_ptr (5fe405e)
-
ARM64EC
-
Install a custom call checker to bypass NTDLL function patches (2c3e6cb)
-
Set appropriate AFP and SVE256 state on JIT entry/exit (85d1b57)
-
Introduce FEX-side CRT and Windows API replacements (7b1d954)
-
Handle direct syscall instructions (24ea4b7)
-
Improvements to exception flag handling (cadb0a2)
-
Support the JIT API as is used by Windows (7ffd3e5)
-
AVX128
-
Optimize blends (4882f10)
-
Optimize all cases of vpermq (69ed39d)
-
Implement support for scalar FMA with AFP (9201ac5)
-
Improve VPERMILPS/PD and VPSHUFD (f8c4c54)
-
Fixes vmovq loading too much data (b9a6cae)
-
Extends 32-bit indexes path for 128-bit operations (7ccb252)
-
Optimize the vpgatherdd/vgatherdps cases that would fall back to ASIMD (22b2669)
-
Optimize QPS/QD variant of gather loads! (3627de4)
-
Extend 32-bit address indices when possible (aad7656)
-
Prescale addresses in gathers if possible (47d077f)
-
AllocatorHooks
-
Correct memory API usage on Windows (f98c010)
-
Allocate from the top down on windows (9d0b6ce)
-
ArgumentLoader
-
Removes static fextl::vector usage (f81fc4e)
-
Arm64
-
Implements support for DAZ using AFP.FIZ (f8c6baa)
-
Implement support for SVE bitperm (b282620)
-
Remove one move if possible in FMA operations (3bea08d)
-
Fixes long signed divide (3d65b70)
-
Arm64Emitter
-
Reload STATE before SRA fill on ARM64EC (a742441)
-
CMake
-
Add option to build PDB debug info instead of DWARF (49b8dae)
-
CPUID
-
Adds a few missing CPU names for new CPU cores (c4ae761)
-
CodeEmitter
-
Removes vestigial vixl usage (2da819c)
-
Config
-
Little assume non-null check (f40bc13)
-
Converts two LUT maps over linear scan arrays (c5fe872)
-
Removes a static vector initializer (e0c783d)
-
Search more locations for the config directory on Windows (1f59f0e)
-
EmulatedFiles
-
Adds a few leaf CPUID flags (d385e49)
-
Fix bad formatting (d1249ec)
-
F80
-
Drop dependency on state stored in TLS (c3c2b61)
-
FEX
-
Moves HostFeatures querying to the frontend (434bffa)
-
FEXCore
-
Pass HostFeatures in to CreateNewContext directly (0ecfc65)
-
Drop deferred signal handling on Windows (1007f87)
-
Add a generic spill/fill-all syscall ABI and use for Windows (10ee963)
-
Removes ThreadManager (403fd62)
-
Refactor ExitHandler slightly (380ba0a)
-
Removes CPUBackendFeatures (1fe497d)
-
FixedSizePooledAllocation
-
Fix a race when unclaiming disowned buffers (228009c)
-
HostFeatures
-
Removes feature flags always supported by FEX (633f624a697f...
FEX-2407
d3399a2Read the blog post at FEX-Emu's Site!
I hope you're ready to game, because your Arm system just got support for AVX.
And AVX2. And FMA3. And F16C. And BMI1. And BMI2. And VAES. And VPCLMULQDQ.
Yeah, we've been busy.
We did a little team-building exercise this month: "bring up AVX on 128-bit
hardware in a week". Now our team is built, and AVX games run on FEX:




AVX on 128-bit Arm
Computers traditionally perform one operation at a time. The hardware decodes
an instruction, evaluates the operation on a single pair of numbers, and
repeats for the next instruction. In mathematical terms, the instructions
operate on scalars.
That design leaves performance on the table.
Many programs repeat one operation many times with different data. Modern
instruction sets exploit that repetition. A single "vector" instruction can
operate on multiple pieces of data at once. Programs will perform the same
amount of arithmetic overall, but there are fewer instructions to decode and
the arithmetic is more predictable. That enables more efficient hardware.
A "scalar" instruction adds a pair of numbers; a "vector" instruction adds
multiple pairs. How many pairs? That is, what length is the vector?
That's a design trade-off. Increasing the vector length decreases the number of
instructions we need to execute while increasing the hardware cost.
Supporting large vectors efficiently requires a large register file and many
arithmetic logic units. Besides, there are diminishing returns past a certain
vector length.
There is no-one-size-fits-all vector length. Different instruction sets make
different choices. In x86, the SSE instruction set uses 128-bit vectors, while
AVX and AVX-512 instructions support 256-bit and 512-bit respectively. For Arm,
the traditional ASIMD (NEON) instructions use 128-bit vectors. Depending on the
specific Arm hardware implementation, the flexible new SVE instructions can use
either 128-bit or 256-bit.
For performance, we try to translate each x86 instruction to an equivalent arm64
instruction. There's no perfect 1:1 correspondence, but we can get close. For
vector instructions, we translate 128-bit SSE instructions into equivalent
128-bit ASIMD instructions.
In theory, we can do the same for AVX, mapping 256-bit AVX instructions to
256-bit SVE instructions. Mai implemented that last year, speculating that their
work would enable AVX on future 256-bit SVE hardware.
...
That hardware never came. Some recent hardware supports SVE but only 128-bit.
Others don't have that, supporting only ASIMD. We had a shiny AVX-256
implementation with no 256-bit hardware to use it with.
Our position remains that efficient AVX emulation requires 256-bit SVE. Unfortunately,
many games today have a hard requirement on AVX. We want to let you play
those games on your Arm devices, so we need to plug our noses and implement
256-bit AVX on 128-bit hardware.
The idea is simple; the implementation is not. To translate a 256-bit
instruction, we decompose it into two 128-bit instructions operating on each
half of the 256-bit vector. In effect, we partially "undo" the vectorization.
This plan has a gaping hole: the register file. Arm has more general purpose
registers than x86, so we statically assign each x86 register to an Arm
register. If we didn't, accessing certain x86 registers would require slow
memory accesses. All efficient x86-on-Arm emulators therefore statically map
registers.
This scheme unfortunately fails with AVX emulation. Our Arm hardware has 128-bit
vectors, but we're emulating 256-bit AVX vectors. We would need twice as many Arm
vector registers as x86 vector registers, and we don't have enough.
Still, running AVX games suboptimally is better than not running at all. Yes,
we're out of registers -- we'll just have to keep some in memory. The assembly
isn't pretty, but it works well enough.
Building on Mai's SVE-256 implementation of AVX, Ryan whipped together a
version supporting both SVE-128 and ASIMD. That means it should work on
all arm64 devices, all the way back to ARMv8.0.
F16C, FMA, and more
AVX isn't the only x86 extension new games require. After beating AVX, x86 has a
post-AVX questline for emulator developers, with extensions like F16C.
Fortunately, nothing could scare Ryan and Mai after AVX, and they tackled the
new extensions without a hitch.
Speeding up translation
Dynamically assigning AVX registers means we can't translate instructions
directly and expect good results. While we don't need a full optimizing
compiler, we do need enough intelligence for basic inter-instruction
optimizations. FEX has had some optimizations since day one, but the priority
has always been on bringing up new games. There's been even less focus on the
translation time -- not how fast the generated arm64 code executes but how
fast we can generate the arm64 code. Translation overhead contributes to slow
loading screens and in-game stutter, so while it flies under the issue radar,
it does matter. So, Alyssa optimized the
FEX optimizer this month by merging compiler passes. That both simplifies the
code and speeds up translation. Since the start of June, we've reduced
translation time 10%... and more optimization is coming.
Happy gaming :-)



Raw Changes
FEX Release FEX-2407
-
ARM64
-
Adds new FMA vector instructions (00cf8d5)
-
AVX128
-
Fixes vmovlhps (e2d4010)
-
Minor optimization to 256-bit vpshufb (5821054)
-
Fixes scalar FMA accidentally using vector wide (4626145)
-
Minor optimization to vmov{l,h}{ps,pd} (cf24d3c)
-
Some quick bugfixes (739ac0f)
-
Enable all the things (e519bf5)
-
Fixes wide shifts (a031a49)
-
F16C support (4d821b8)
-
Implement support for gathers (6226c7f)
-
FMA3 (7d939a3)
-
fix VPCLMULQDQl (5da205d)
-
More instructions Part 4 (77aaa9a)
-
Fix vmovntdqa failing to zero upper 128-bits (7ff9622)
-
Fixes SSE4.2 string compare instructions (dce1b24)
-
More instructions Part 3 (8c751d7)
-
More instructions (ddb9f6d)
-
More various instructions (be8ff9c)
-
Some pun pickles, moves and conversions (7bbbd95)
-
Move moves! (f489135)
-
Arm64
-
Minor VBSL optimization with SVE128 (2e6b08c)
-
Remove contiguous masked element optimization (dc44eb4)
-
Implement support for emulated masked vector loadstores (3d26e23)
-
Arm64Emitter
-
drop out of date comment (825d2c9)
-
BMI2
-
Ensure rorx immediate masks by operation size correctly. (54a1f7d)
-
CMake
-
Add a clang version check (5d67223)
-
CPUID
-
Oops, forgot to enable AVX2 (58e949e)
-
Update labeling on some reserved bits (2da1e90)
-
CodeEmitter
-
Fixes vector {ldr,str}{b,h} with reg-reg source (2e84f21)
-
CoreState
-
Move
InlineJITBlockHeaderto ...
FEX-2406
aa0f2c3Read the blog post at FEX-Emu's Site!
A little late this month but we have a new FEX release has finally landed. This month we have some good optimization and fixes so let's get right in to it.
A bunch of JIT optimizations
This last month is finally the culmination of preparation work over the past few months of cleanups in the FEX JIT. The new register allocator has
landed in FEX which is significantly better than our previous RA. Our prior implementation was meant to be a temporary solution when FEX initially
started as a project and as with most temporary code, it became permanent. It was excessively slow, best case it ran in quadratic time, worst case it
could take INFINITE time which resulted in significant stutters or hangs. This new implementation by Alyssa now runs in two passes in linear time,
significantly improving performance and also removing a ton of bad design decisions from the first implementation.
In addition to the new RA, we also have a bunch of little optimizations spread around that improves performance all over the place. One of the bigger
performance improvements for people with new hardware is enabling the AFP extension and RPRES if supported. Apple supports these in their latest SoC
and the newer Cortex also supports them. This improves scalar SSE performance by quite a bit. We won't dive in to these too much but the various
optimizations can improve performance from 2% to 12% in testing. We're marching ever closer to running applications at near native speeds now.
Add support for 32-bit OpenGL thunking
This is a big feature! 32-bit thunking has been a long time coming and has crossed some significant hurdles towards actually working! One of the
biggest CPU time sinks with games is the amount of time we need to spend in the video driver when running a game. "Thunking" allows us to remove that
overhead and jump directly in to the AArch64 libGL directly and remove a bunch of emulation overhead. We have done a bunch of testing with this but we
expect there will still be some bugs that need to be worked out. As for fun performance improvements, we have seen one game go from 150FPS up to
270FPS, so it's worth trying in some cases.
As a note though, this is only 32-bit OpenGL thunking. 32-bit Vulkan drivers still need to go down the emulation path, so things like DXVK in older
32-bit games won't get these performance improvements.
Default TSO emulation options changed
Over the course of the past couple months we have been testing the new TSO memory model emulation toggles and during this time we have determined the
cost of accurately emulating Vector and Memory copy memory atomics to be too high for most hardware. The good news is that from all the testing we
have done, this doesn't actually cause any problems in any known games. So from this release onward we are by default disabling TSO emulation on these
operations. We may come back and visit this once hardware ships that has FEAT_LRCPC3 which adds new instructions for Vector TSO loadstores.
Users with an older configuration can go in to FEXConfig to toggle these options off and enjoy the free speed benefits of not doing accurate emulation
today! As a note, Apple Silicon's TSO hardware emulation bit doesn't suffer the same performance degradation so once Asahi Linux supports this for
users then they get accurate emulation and speed!

Unaligned Half-barrier TSO Enabled is still recommended to keep enabled as that can cause significant bugs
Fix fstatat/statx with NOFOLLOW And JIT bugs
During a livestream one of our users encountered a bug in FEX-Emu that was breaking Darwinia.
After diving in to the game to figure out what it was doing, it actually turned out to be three separate bugs that broke the game. The first bug fix
with fstatat and statx syscalls were around edge case behaviour with the NOFOLLOW flag. The game was attempting to find the directory that the
executable was living in and being smart in a way that broke FEX.
The other bugs were behaviour in our optimization passes where we broke x86 SIB addressing in a couple ways. We have since added unittests for
these two bugs but if you would like to read more you can check out ConstProp fixes for Darwinia
With these bugs fixed the game now runs correctly under FEX-Emu without issue!
More ARM64EC improvements
This was some cleanup work for helping more easily integrating with what upstream WINE is doing for ARM64EC support. While still not entirely usable
for end-users yet, it is steadily improving and can run real games if the environment is setup correctly. A lot of good work here and we're hoping
for more testing going forward.
NVIDIA Orin CPU errata!
Over the past month or two we had noticed that the NVIDIA Orin platform with its Cortex-A78AE CPU cores were running games markedly worse than our
Snapdragon 8cx Gen 3 platform with Cortex-A78C cores. While these CPU cores are not identical between platforms, they are both based on the Cortex-A78
CPU core design so they should be relatively close. The NVIDIA Orin runs its cores at a 2.2Ghz clock frequency, while the Snapdragon runs its cores at
2.4Ghz. Nearly a 9% clock speed difference wasn't accounting for the performance delta we were seeing!
The game we were testing was the PC port of Sonic Adventure 2: Battle; On Orin the board could only achieve 18FPS, while on Snapdragon we were easily
hitting 60FPS with headroom to go higher if VSync was disabled. We were stunned by this absolute performance difference and couldn't nail down the
difference being due to different drivers.
Turns out we only needed to look at the Cortex-A78AE Software Developer Errata Notice to find out why.
1951502
Atomic instructions with acquire semantics might not be ordered with respect to older stores with release semanticsUnder certain conditions, atomic instructions with acquire semantics might not be ordered with respect to older instructions with release semantics. The older instruction could either be a store or store atomic.
This erratum can be avoided by inserting a DMB ST before acquire atomic instructions without release semantics. This can be implemented through execution of the following code at EL3 as soon as possible after boot:
This then goes on to talking about some code that programs the CPU so that it injects these DMB ST instructions before atomic acquires automatically!
This is why this platform has been so weird for performance testing for years! This massive hardware errata basically deletes any advantage that the
FEAT_LRCPC extension gives FEX and goes back to emulating atomics using half-barriers similar to how FEX already does it around unaligned
atomics!
We are now looking to move off of this NVIDIA Orin platform as quickly as possible, it was already old and now that we have identified a significant
problem around atomic performance it is higher priority. Luckily over the last few months we have great new hardware announcements. The Snapdragon X
Elite devices are shipping soon, NVIDIA has announced a new Jetson AGX Thor platform, The NVIDIA Grace server platform is starting to become available, and
Apple has some new M4 devices that will be interesting! Ideally we will get a new platform that we can plug a Radeon GPU in since it is a huge boon to
our testing performance, but depending we may not have that luxury. We'll see as we move on to new and better platforms!
Video game showcase
Instead of a video showcase from FEX this month, go checkout Asahi Lina's Youtube Page. She recently did a
couple of live streams fixing issues with the Asahi Linux MicroVM solution for running FEX-Emu on on Apple Silicon! She showcases a bunch of games
while covering some of the more technical problems involved with getting FEX-Emu running on that platform.
Be warned, these are very long streams.


Raw Changes
FEX Release FEX-2406
-
AOTIR
-
Refactor interfaces to clarify ownership flow (3bac767)
-
CMake
-
Remove obsolete Catch2 setting (170204d)
-
CPUID
-
Adds Qualcomm Oryon product name (f7bfecd)
-
Config
-
Change default TSO options (6954ebe)
-
ConstProp
-
remove x86 jit leftover (58614ff)
-
Constprop
-
clean up (14bfe60)
-
FEXCore
-
Fixes the difference between CPL-0 and undefined instructions (efe7c54)
-
Get rid of DeferredSignalFaultAddress and use the InterruptFaultPage (f27f187)
-
ARM64EC x64 entry/exit support (2cae2f2)
-
docs
-
Adds programmer documentation about memory model emulation (a515b70)
-
FEXLoader
...
FEX-2405
7c79e5dRead the blog post at FEX-Emu's Site!
One month older and we have a new release for FEX. This month is a little bit slower for user facing features but behind the scenes we had a large amount of refactoring to facilitate future improvements.
Support OpenGL and Vulkan thunking with forwarding X11
A thorn in FEX's side has been forwarding X11 calls when thunking OpenGL and Vulkan. This has caused us pain since X11's API is a fairly leaky
abstraction that leaks data symbols which FEX's thunking can't accurately thunk. We have now instead redirect the X11 Display object directly in
OpenGL and Vulkan. This not only reduces the amount of code we need to thunk, but also is required for us to eventually thunk 32-bit libraries.
This may change behaviour in some games when thunks are enabled, so it will be useful to do some testing and regression testing.
Enable Enhanced REP MOVS when memcpy TSO is disabled
Alongside last month's optimization when optimizing memcpy instructions, we now enable this CPUID bit when memcpy TSO emulation is disabled. This
means that glibc will take advantage of the optimization when it is doing memcpy and memset operations. This is a minor performance improvement
depending on the application.
Implement support for SMSW instruction
This instruction isn't too notable since all it does on recent x86 CPUs is return the same data no matter what, but legacy CPUs it was useful for
checking if x87 was supported. As this is considered a system level instruction, FEX didn't implement it originally but we finally found a game that
uses it. The original Far Cry game from 2004 uses this instruction for some reason. Now that we have implemented the instruction the game at least
gets to the menus but seems to still stall out when going in-game. Kind of neat!

Fix disabling TSO emulation on some stack accesses
When emulating the x86 memory model, we can get away with not emulating it when a thread accesses its stack. This works since we know that stack
accesses are usually not shared between threads. While we usually disabled the TSO emulation in these cases, we had accidentally missed some cases.
This will mean that there is some performance improvements for "free."
Fix ADC and SBC instructions
Back in FEX-2403 we had landed some optimizations for these instructions. Turns out that we had inadvertently introduced some broken behaviour as an
edge case. Most games didn't hit these edge cases so they were fine but it completely broke rendering in the Steam release of Final Fantasy 7.
With that fixed, we now get correct rendering again!

Option to disable half-barrier TSO emulation on unaligned atomics
On x86 most atomic instructions don't care about alignment, with a feature that Intel calls "Split-locks" to even support unaligned atomics that cross
a cacheline. On ARM we don't have this luxury, where all atomic instructions need to be naturally aligned to their size. Newer ARM CPUs added a
feature that allows unaligned atomics inside of a 16-byte region, but if the data crosses the edge then FEX needs to handle this instruction in a
different way. We backpatch the instruction stream with a "half-barrier" access which still emulates the x86 memory model but is exceedingly heavy.
Now we have an option to convert these "half-barrier" implementations in to non-atomic access. While this doesn't match true x86 behaviour, this can
accelerate some games that heavily abuse unaligned atomic memory accesses. So if a game is running slow, this is an option to try out!

Refactor code using clang-format
As alluded to at the start, the FEX codebase has now been completely refactored using clang-format to ensure a more consistent coding experience. We
provide a helper script and CI enforcement to ensure this stays in place. This took quite a bit of work to ensure the feature was up to everyone's
standards. Major thanks to everyone that worked on this!
Eliminate cross-block liveness for instructions
This is preparation work for future JIT improvements and speedups. Cross-block liveness makes our register allocator more complex and by removing this
from our JIT we can start working on improving the register allocator. Look forward to register allocator improvements in the coming months.
Support arm64ec function calls
This changes how some of FEX's JIT infrastructure works in order to support the ARM64ec windows ABI. This will get used in conjunction with Wine's
ARM64ec support. While still a work in progress, this is starting to become interesting as WINE continues to implement more features to handle this
case.
Video game showcase
YouTube Link

Raw Changes
FEX Release FEX-2405
-
Allocator
-
Fixes compiling on Fedora 40 (7b88b0f)
-
AllocatorHooks
-
Mark JIT code memory as EC code on ARM64EC (bb24e14)
-
AppConfig
-
Disable libGL forwarding for steamwebhelper (02ebb6e)
-
Arm64
-
Adds another TSO hack to disable half-barrier TSO (1069cab)
-
CI
-
Drop use of obsolete ENABLE_X86_HOST_DEBUG setting (c126b20)
-
CPUID
-
Removes FEX version string from CPU model name (faa494c)
-
Fix inverted RDTSCP check (9781b95)
-
Enable enhanced rep movs in more situations (68e543c)
-
DebugData
-
Remove header (1616b4e)
-
FEXCore
-
Support x64 -> arm64ec calls (1a8b61b)
-
FHU
-
Switch over win32 file operations to std::filesystem (ae5e388)
-
IR
-
Remove VectorZero (a0f2cae)
-
JIT
-
fix neon vec4 faddv (fe70ec7)
-
fix ShiftFlags shuffles (376936c)
-
Adds support for spilling/Filling GPRPair (eedb120)
-
LookupCache
-
Track ARM64EC page state in the code cache (f0dad86)
-
OpcodeDispatcher
-
Implement support for SMSW (20bd864)
-
Fixes disabling TSO access on RSP SIB stores (1ba678f)
-
Add helper for making segment offset addresses (66cbb66)
-
RCLSE
-
disable store-after-store optimization (5cb11ae)
-
X87
-
Simplify constant loading for FLD family (271700e)
-
Misc
-
Library Forwarding: Support libGL/libvulkan without forwarding libX11 (b33e0e3)
-
clang-format: allow overriding clang-format (3fda47e)
-
Fix 8/16-bit ADC/SBC (9c6f749)
-
Library Forwarding: Fix issues with libGL's fake X11 dependency (81a4206)
-
Factor out SetWriteCursorBefore (a0bf6a4)
-
WOW64 backend code invalidation fixes (81c219c)
-
Clang Format file and script (53bed6d)
-
CI workflow to check clang-format usage on pull requests (f9097c0)
-
Add second reformat to git blame ignore file (55c054b)
-
Reformat until fixed-point (07e58f8)
-
Create .git-blame-ignore-revs with whole-tree reformat sha (7e97db8)
-
Remove trace of clang-tidy experiment from CMakeLists.txt (7614ac9)
-
Whole-tree reformat (1d806ac)
-
Move const to the left in preparation for reformatting (028c220)
-
Enable jemalloc for ARM64EC (a9b7ad8)
-
Validate that we have no crossblock liveness (e91e1d5)
-
Elimina...
FEX-2404
e8127b9Read the blog post at FEX-Emu's Site!
After last month having an absolute ton of improvements, this month of changes is going to look positively tiny in comparison. We have some good new
options for tinkering with FEX's behaviour and more performance improvements. Let's get in to it!
Implement more memory model emulation toggles
The biggest performance hit with FEX's x86 emulation has always been emulating the memory model of x86. ARM has added various extensions over the years to make this emulation faster but it still isn't enough.
- FEAT_LSE - Adds a bunch of atomic memory instructions
- Original ARMv8.0 doesn't support this. Massive impact on performance.
- FEAT_LSE2 - Adds unaligned atomics (within a 16-byte granule) to improve performance of x86 atomics.
- Doesn't quite cover the full 64-byte cacheline of unaligned atomics that x86 supports
- FEAT_LRCPC - Adds new load instructions which match the x86 memory model
- FEAT_LRCPC2 - Adds even more loadstore instructions which match x86 instructions
- FEAT_LRCPC3 - Adds even more, including vector loadstore instructions
- No hardware today supports this extension
Even with this set of extensions, emulating x86's memory model can have near a 10x performance hit. This performance impact is most felt in games because they use vector instructions very heavily, which is because of the lack of the FEAT_LRCPC3 extension.
With this in mind, we are introducing some sub-options around emulating x86's TSO memory model to try and lessen the impact when we can get away with it. These new options can be found in the FEXConfig Hacks tag.
These two new options are only available for toggling when TSO emulation is enabled. If your CPU supports FEAT_LRCPC and FEAT_LRCPC2 then a recommended configuration is to keep the TSO Enabled option enabled, but disable the Vector and Memcpy options.
While this will incur a performance hit compared to disabling TSO emulation, it is significantly more stable to keep TSO emulation on.
If you still need more performance, then it may be beneficial to turn off TSO emulation entirely. It's unstable though! It's incorrect emulation to gain speed!
Vector TSO enabled
This option enables emulating the memory model around vector loadstore instructions. This has a HUGE performance impact even on latest generation hardware.
Memcpy TSO enabled
This option enables emulating the memory model around x86's REP MOVS and REP STOS instructions. These are used for doing memory copying and memory setting respectively.
The impact of this option depends heavily on the application. This is because most memcpy and memset functions actually use vectors to modify the memory.
JIT core improvements
Once again this month there has been a focus on JIT optimizations. Although this time it might be hard to see what is improving. Overall in benchmarks
there has been roughly a 3% performance improvement. With a mixture of improvements this month being foundational work to lower JIT compile time
overhead in the coming months. As usual there is too much to dive in to each change individually so we'll just have a list.
- Optimize LOOP/N/E
- Negate more inline constants
- Optimize PF calculation using integers rather than vectors
- Optimize CLC
- Optimize cmpxchg
- A bunch of instructions cleaned up and rewritten to remove small amounts of overhead
- Improves 32-bit address mode accesses
- Implements support for prefetch and rdpid instructions
Optimize memcpy and memset IR operations when TSO emulation is disabled
Speaking of the previous optimization. We have now optimized the implementation of the memcpy and memset instructions to be significantly faster. Sometimes a compiler will inline these instructions which was causing upwards of 5% CPU time doing memory copies.
With this optimization in place we have benchmarked and improvement from 2-3GB/s up to 88GB/s! That'll teach that code to be slow.
Fix memory leaks in thread creation
A memory leak that has occured where FEX would leak some thread stacks when they shutdown. This has now been resolved which lowers memory usage for
long running applications that shutdown threads. In particular this makes Steam consume less RAM.
We have more memory leaks to solve as we move forward but they are significantly less severe than this.
A ton of small cleanups in the code
This month has had a lot of code cleanup in FEX but these aren't user facing so it isn't very interesting. Let it be known although that something
like half the commits this month were cleaning up various bits of code or restructuring which isn't getting a focus.
Raw Changes
FEX Release FEX-2404
-
Allocator
-
Cleanup StealMemoryRegions implementation (8a3d08e)
-
ConstProp
-
drop dead code (202a60b)
-
ELFParser
-
Stop using a VLA (32ec4a3)
-
Externals
-
Update Catch2 to v3.5.3 (b892da7)
-
FEXCore
-
Fixes priority of FEX_APP_CONFIG (7786c23)
-
Move nearly all IR definitions to internal (e2a0953)
-
Moves CodeLoader to frontend (3bed305)
-
Moves CPUBackend definition internal (f6639c3)
-
Remove DebugStore map (2ad170b)
-
Adds more TSO control levers (24fd28e)
-
Removes vestigial mman SMC checking (542f454)
-
Fallback to the memcpy slow path for overlaps within 32 bytes (167896d)
-
Add non-atomic Memcpy and Memset IR fast paths (7dcacfe)
-
FEXLoader
-
Add a way to sleep a process on startup (624bc3f)
-
Add some debug-only tracking for FEX owned FDs (79454ed)
-
InstcountCI
-
Adds a block that is causing panic spilling (150af80)
-
IoctlEmulation
-
Add missing nouveau ioctl (6d94d79)
-
JIT
-
Optimize pmovmaskb with a named vector constant (ab8ee64)
-
Linux
-
Expose support for v6.8 (e33a76a)
-
Threads
-
Fixes a stack memory leak for pthreads (3d31291)
-
OpcodeDispatcher
-
clean up shifts (c43af8e)
-
drop ZeroMultipleFlags (b632f72)
-
eliminate xblock liveness for rcl/rcr (cd9ffd2)
-
eliminate branch in cmpxchg pair (aa26b62)
-
Fixes 32-bit mode LOOP RCX register usage (7698347)
-
optimize LOOP/N/E (8852d94)
-
Implement support for the various prefetch instructions (2a9fcc6)
-
Implement rdpid (ba3029b)
-
RA
-
drop dead block interference code (f2d001e)
-
Removes VLA usage (67baff8)
-
Adds RIP when a block panic spills (a8b59c1)
-
RCLSE
-
Optimize store-after-store (ca6b2e4)
-
Telemetry
-
Allow redirecting directory that data is written to (970d5d5)
-
Adds tracker for non-canonical memory access crash (7f90ca5)
-
Rename old file instead of copying (002ca36)
-
Misc
-
Negate more to inline constants (aa8d04c)
-
Minor cleanups around flags (37f2b41)
-
Use scalar integer code to calculate PF (bd0b5ec)
-
Eliminate xblock liveness with rep cmp/lod/scas (e8abc88)
-
rewrite ROL/ROR (29c6281)
-
Fix reference to out of bounds address in offsetof (4214d9b)
-
optimize clc (b1ddd8cd3b53f0866f04668240...
FEX-2403
ee56a2cRead the blog post at FEX-Emu's Site!
Welcome back to another new tagged version of FEX-Emu! This month we have quite a few important bug fixes and optimizations, so let's get right in to
it!
Steam fix
As of Steam's February 27th update there was a fairly major change to how Steam starts its embedded Chromium instance.
With this most recent change it now is run inside of the Steam Linux Runtime environment. In turn Steam has disabled the sandbox feature of the
Chromium instance because it is incompatible. FEX was already disabling this sandbox and forcibly passing in the argument to disable it.
Chromium really didn't like the argument being passed in twice and it was causing it to crash early. We have now removed our application profile and
let Steam configure the arguments as required.
As a side effect of Steam updating their version of Chromium, some users have noted that they are experiencing problems with GPU acceleration on
Raspberry Pi systems. This is seemingly a video driver problem and unrelated to this crash that was fixed. It is currently unknown if we can fix this
problem, as it is working find on Tegra and Snapdragon systems.
Rootfs images updated
FEX's rootfs images have been updated to include the latest versions of Mesa, gfxreconstruct, and Renderdoc. The major change here is having Mesa
updated to 24.0 as the other two packages are mostly for developers.
Fix a potential hang on forking with memory allocations
We have fixed a known hang that occurs when a process is forking while another thread is allocating memory. This tended to occur as a hang when
running Proton applications. While this fixes one hang, we still have another one that sporatically happens that we haven't tracked down. While the
occurence is relatively rare, it's good to watch the process trees if the program is stuck waiting on a futex.
A bunch of CPU optimizations
As per usual, this last month has added a bunch of CPU optimizations! We have noted up to a 14% performance improvement in one benchmark and an
average of around 4% in Geekbench. We need to commend our developers for
hammering out these optimizations, even a small optimization can have big impacts on games that abuse a particular feature.
- Use FlagM SETF8/16 for INC/DEC
- Optimize LOCK DEC
- Optimize ADC/SBC
- Fuse add+cmn in to adds
- Misc other optimizations
- Optimize less than 32-bit add and sub
Small timestamp counter scaling
Recently we have found out that some games rely on an x86 CPU's RDTSC instruction operating at Ghz frequencies. While this is not a good idea to make
assumptions, it is relatively common that x86 CPUs have a really high frequency cycle counter frequency. Most laptop CPUs operating in the 1-2Ghz
range while desktop CPUs can go up to 3Ghz in our testing.
Unreal Engine 5 has a new work graph system that spin-loops CPUs for a fixed number of cycles, expecting to not spin for very long. While this is
relatively okay at 1Ghz, since it is only a few nanoseconds, When an ARM CPU's cycle counter gets added to the mix it starts encountering problems.
The primary problem here is that all 64-bit Snapdragon processors ship with a fixed rate 19.2Mhz cycle counter. This continues all the way to their
latest flagship the Snapdragon 8 Gen 3. Additionally other ARM devices we have tested like the Nvidia Jetson ARM boards and Apple M1 also ship a
similarly low cycle counter. So while Unreal engine will only spin-loop for a measily 1597 cycles, on an ARM board this takes ~51,000 nanoseconds but
on an x86 PC it only takes 591 nanoseconds! This was causing games to burn CPU time unnecessarily and run slower than they should!
To compensate for these slow cycle counters on most ARM devices, we are now scaling the value we return to the applications by multiplying the value
by 128 times! This makes snapdragon cycle counters behave more similarly to a 2457 Mhz cycle counter, but with a 128 cycle granularity. This improves
the FPS in Tekken 8 and will also improve performance in all other Unreal Engine 5 games. There may be other games affected as well!
As a side-note, a 1Ghz cycle counter is now mandated by ARMv8.6 and ARMv9.1 spec! So this problem will soon go away as new SoCs get on to the market.
Introduce ARM64EC static register allocation mapping
As part of the ongoing effort to support WINE's Arm64EC code, we have changed the order in which our registers get allocated to more closely match
what the Arm64EC ABI
wants for register layout. Matching what Arm64EC wants for the regster layout means that when the JIT jumps out to some code, we shuffle less data
around which gives a performance improvement. The Linux side of code doesn't need this, so this only happens when building as a WINE module.
32-bit thunking improvements
This last month has had an exciting milestone for 32-bit thunking! We have landed support for thunking Wayland on 32-bit. Which this means with our
previously implemented Vulkan thunking, we can now run some games using Wayland plus Vulkan and Zink thrown in to the mix! In particular we have been
able to test that Super Meat Boy works in this configuration! We still have more work to do before X11 and GLX works with 32-bit thunking so stay
tuned to the future!
Memory leak fix
FEX had an issue with long running processes leaking memory. This showed up in applications that would start hundreds of threads and tear them down
over and over. Steam is one of these long running processes that would starve the system of memory if left open over night. This is because the
program spins up helper threads fairly aggressively and then shuts them down.
We have fixed one major memory leak but we still have a few more to go before its nailed down!
Syscall passthrough optimization
One important thing to be wary of when running games is syscall overhead. Every time an ioctl or other syscall is made, FEX can incur significant
overhead compared to running the application natively. Additionally if we are passing syscalls through to glibc helpers then this can add more
overhead and sometimes introduce bad behaviour.
This month we spent some time looking at how syscalls are handled when we know that we can pass the data directly to the kernel. This allows us to
more quickly add new system calls when the kernel adds them, and ensures they are as fast as possible. With this optimization in-place FEX now
directly emits small syscall handlers per syscall and jumps directly to the kernel if possible. This lowers CPU overhead for the most common syscalls,
thus removing emulation overhead. While FEX's syscalls were already fairly low overhead, this just improves the situation further!
Raw Changes
FEX Release FEX-2403
-
ASM
-
Arm64
-
Stop moving source in atomic swap (98572b9)
-
Arm64Emitter
-
Introduce ARM64EC SRA mappings (6ec628f)
-
CMake
-
Define _M_ARM_64EC when building for ARM64EC (3e5694b)
-
FEXCore
-
Expose AbsoluteLoopTopAddress to the frontend (d4be2dc)
-
Add a frontend pointer to InternalThreadState (5769ffb)
-
FEXLoader
-
Allocate the second 4GB of virtual memory when executing 32-bit (0b34035)
-
FileFormatCheck
-
Fixes FD leak (0505b30)
-
InstCountCI
-
enable preserve_all (2f9449c)
-
add FMOD block (cc9c80d)
-
add The Witcher 3 block (60e8da0)
-
InstcountCI
-
Add a monster of a game block (f41674b)
-
Adds a vector addition loop from bytemark (44d1502)
-
Adds addressing limitations to instcountci (cf06799)
-
Linux
-
Converts passthrough syscalls to direct passthrough handlers (b74de53)
-
More safe stack cleanup for clone (9687ac5)
-
Make sure to destroy thread object when thread shuts down (a7c7fe4)
-
OpcodeDispatcher
-
Don't use AddShift with no shift (d24446e)
-
RedundantFlagCalculationElimination
-
fix missing NEG case (32a4abb)
-
Syscalls
-
Fix SourcecodeMap generation for GDB JIT integration (7e2f20c)
-
Misc
-
Removes steamwebhelper config (d66a83a)
-
Use SETF8/16 for 8/16-bit INC/D...