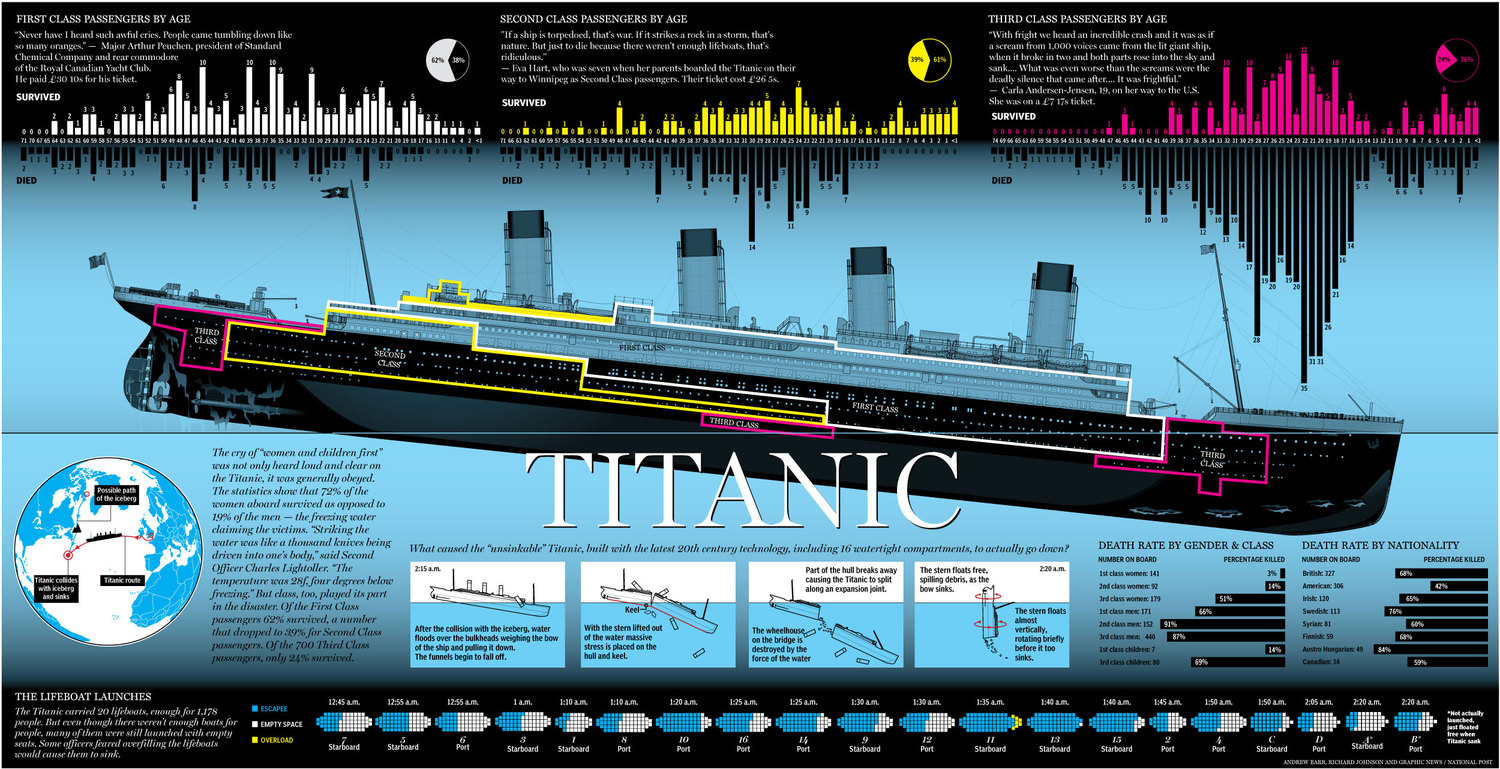
The Titanic Survival Prediction project aims to predict the survival of passengers on the Titanic using machine learning algorithms. This project leverages various features of the Titanic dataset to build a predictive model that can determine the likelihood of a passenger surviving the disaster.
- Overview
- Dataset
- DatasetFeatures
- Installation
- Usage
- Models Used
- Results
- Contributing
- License
- Acknowledgements
The dataset used in this project is the Titanic dataset from Kaggle. It contains information about the passengers on the Titanic, including their demographics, ticket information, and whether they survived the disaster.
- PassengerId: Unique ID for each passenger
- Survived: Survival (0 = No, 1 = Yes)
- Pclass: Ticket class (1 = 1st, 2 = 2nd, 3 = 3rd)
- Name: Name of the passenger
- Sex: Sex
- Age: Age in years
- SibSp: Number of siblings/spouses aboard the Titanic
- Parch: Number of parents/children aboard the Titanic
- Ticket: Ticket number
- Fare: Passenger fare
- Cabin: Cabin number
- Embarked: Port of Embarkation (C = Cherbourg, Q = Queenstown, S = Southampton)
To run this project, you need to have Python installed on your system along with the following libraries:
- Pandas
- NumPy
- Scikit-learn
- Matplotlib
- Seaborn
- Jupyter Notebook
You can install the required libraries using pip:
pip install pandas numpy scikit-learn matplotlib seaborn jupytergit clone https://github.com/JVENKATAPHANISAI/Titanic-survival-prediction-project.git- This command copies the project directly to your local machine.
cd TitanicSurvivalPrediction- This changes your current directory to the project folder.
pip install pandas numpy scikit-learn matplotlib seaborn jupyter- This ensures all necessary Python libraries are installed.
jupyter notebook TitanicClassification.ipynb- This starts the Jupyter Notebook server and opens the notebook in your web browser.
- In your web browser, you will see the Jupyter interface with a list of files. Click on TitanicClassification.ipynb to open it. -Execute each cell in the notebook sequentially to perform the data analysis, train the machine learning models, and generate predictions.
The following machine learning models were used in this project:
- Logistic Regression
- Decision Tree Classifier
- Random Forest Classifier
- Support Vector Machine (SVM)
- K-Nearest Neighbors (KNN)
- The performance of each model was evaluated using accuracy, precision, recall, and F1 score. - The Random Forest Classifier provided the best results with an accuracy of X%.
- Contributions are welcome! Please feel free to submit a Pull Request.
- This project is licensed under the MIT License.
- Kaggle for providing the Titanic dataset
- Scikit-learn documentation
- Matplotlib and Seaborn for data visualization
- Image Source