
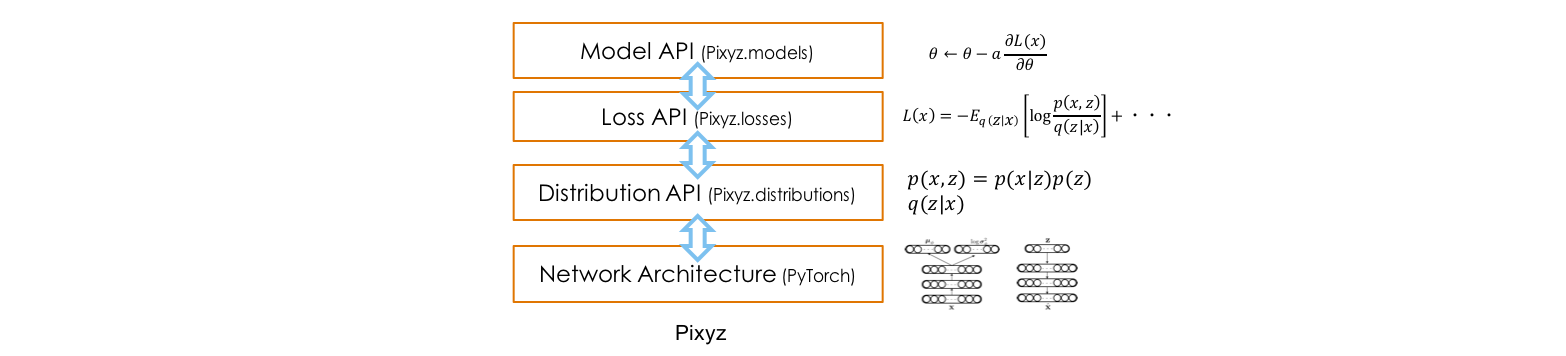
Pixyz is a high-level deep generative models framework, based on PyTorch. It is developed with a focus on enabling easy implementation of various deep generative models.
Recently, many papers about deep generative models have been published. However, its reproduction becomes a hard task, for both specialists and practitioners, because such recent models become more complex and there are no unified tools that bridge mathematical formulation of them and implementation. The vision of our library is to enable both specialists and practitioners to implement such complex deep generative models by just as if writing the formulas provided in these papers.
Our library supports following typical deep generative models.
- Explicit models (likelihood-based)
- variational autoencoders (variational inference)
- flow-based models
- Implicit models
- generative adversarial networks
Using Pixyz, you can implement these different models in the same framework and in combination with each other.
The overview of Pixyz is as follows. Each API will be discussed below.
Note: since this library is under development, there are possibilities to have many bugs.
$ git clone https://github.com/masa-su/pixyz.git
$ pip install -e pixyz
So now, let's create a deep generative model with Pixyz!
Here, we consider to implement a variational auto-encoder (VAE) which is one of the most well-known deep generative models. VAE is composed of a inference model q(z|x) and a generative model p(x,z)=p(x|z)p(z), which are defined by DNNs, and this objective function is as follows.
(1)
First, we need to define two distributions (q(z|x), p(x|z)) with DNNs. In Pixyz, you can do this by implementing DNN architectures just as you do in PyTorch. The main difference is that we should write a class which inherits the pixyz.distributions.* class (Distribution API), not the torch.nn.Module class.
For example, p(x|z) (Bernoulli) and q(z|x) (normal) can be defined as follows.
from pixyz.distributions import Bernoulli, Normal
# inference model (encoder) q(z|x)
class Inference(Normal):
def __init__(self):
super(Inference, self).__init__(cond_var=["x"], var=["z"], name="q") # var: variables of this distribution, cond_var: coditional variables.
self.fc1 = nn.Linear(784, 512)
self.fc2 = nn.Linear(512, 512)
self.fc31 = nn.Linear(512, 64)
self.fc32 = nn.Linear(512, 64)
def forward(self, x): # the name of this argument should be same as cond_var.
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
return {"loc": self.fc31(h), "scale": F.softplus(self.fc32(h))} # return paramaters of the normal distribution
# generative model (decoder) p(x|z)
class Generator(Bernoulli):
def __init__(self):
super(Generator, self).__init__(cond_var=["z"], var=["x"], name="p")
self.fc1 = nn.Linear(64, 512)
self.fc2 = nn.Linear(512, 512)
self.fc3 = nn.Linear(512, 128)
def forward(self, z): # the name of this argument should be same as cond_var.
h = F.relu(self.fc1(z))
h = F.relu(self.fc2(h))
return {"probs": F.sigmoid(self.fc3(h))} # return a paramater of the Bernoulli distributionOnce defined, we can create these instances from them.
p = Generator()
q = Inference()If you want to use distributions which don't need to be defined with DNNs, you just create new instance from pixyz.distributions.*. In VAE, p(z) is usually defined as the standard normal distribution.
loc = torch.tensor(0.)
scale = torch.tensor(1.)
prior = Normal(loc=loc, scale=scale, var=["z"], dim=64, name="p_prior")If you want to see what kind of distribution and architecture each instance defines, just print them!
print(p)
# Distribution:
# p(x|z) (Bernoulli)
# Network architecture:
# Generator(
# (fc1): Linear(in_features=64, out_features=512, bias=True)
# (fc2): Linear(in_features=512, out_features=512, bias=True)
# (fc3): Linear(in_features=512, out_features=784, bias=True)
# )Conveniently, each instance (distribution) can perform sampling and estimate (log-)likelihood over given samples regardless of the form of the internal DNN architecture. It will be explained later (see section 2.3).
Moreover, in VAE, we should define the joint distribution p(x,z)=p(x|z)p(z) as the generative model. In Distribution API, you can directly calculate the product of different distributions! See some examples for details.
p_joint = p * prior
print(p_joint)
# Distribution:
# p(x,z) = p(x|z)p_prior(z)
# Network architecture:
# p_prior(z) (Normal): Normal()
# p(x|z) (Bernoulli): Generator(
# (fc1): Linear(in_features=64, out_features=512, bias=True)
# (fc2): Linear(in_features=512, out_features=512, bias=True)
# (fc3): Linear(in_features=512, out_features=784, bias=True)
# )This distribution can also perform sampling and likelihood estimation in the same way. Thanks to this API, we can easily implement even more complicated probabilistic models.
After defining distributions, we should set the objective fuction of the model and train (optimize) it. In Pixyz, there are three ways to do this.
- Model API
- Loss API
- Use Distribution API only
We can choose either of these three ways, but upper one is for beginners and lower is for developers/researchers.
The simplest way to create trainable models is to use Model API (pixyz.models.*). Our goal in this tutorial is to implement the VAE, so we choose pixyz.models.VI (which is for variational inference) and set distributions defined above and the optimizer.
from pixyz.models import VI
model = VI(p_joint, q, optimizer=optim.Adam, optimizer_params={"lr":1e-3})Mission complete! To train this model, simply run the train method with data as input.
loss = model.train({"x": x_tensor}) # x_tensor is the input data (torch.Tensor)In addition to VI, we prepared various models for Model API such as GAN, VAE (negative reconstruction error + KL), ML etc.
In the simple case, it is enough to just use the Model API. But how about this case?
(2)
This is the (negative) loss function of semi-supervised VAE [Kingma+ 2015] (note that this loss function is slightly different from what is described in the original paper). It seems that it is too complicated to implement in Model API.
Loss API enables us to implement such complicated models as if just writing mathmatic formulas. If we have already defined distributions which appear in Eq.(2) by Distribution API, we can easily convert Eq.(2) to the code style with pixyz.losses.* as follows.
from pixyz.losses import ELBO, NLL
# The defined distributions are p_joint_u, q_u, p_joint, q, f.
# p_joint: p(x,z|y) = p(x|z,y)prior(z)
# p_joint_u: p(x_u,z|y_u) = p(x_u|z,y_u)prior(z)
# q: p(z,y|x) = q(z|x,y)p(y|x)
# q_u: p(z,y_u|x_u) = q(z|x_u,y_u)p(y_u|x_u)
# f: p(y|x)
elbo_u = ELBO(p_joint_u, q_u)
elbo = ELBO(p_joint, q)
nll = NLL(f)
loss_cls = -(elbo - (0.1 * nll)).sum() - elbo_u.sum() We can check what format this loss is just by printing!
print(loss_cls)
# -(sum(E_q(z|x,y)[log p(x,z|y)/q(z|x,y)] - log p(y|x) * 0.1)) - sum(E_p(z,y_u|x_u)[log p(x_u,z|y_u)/p(z,y_u|x_u)])When you want to estimate a value of the loss function given data, use the estimate method.
loss_tensor = loss_cls.estimate({"x": x_tensor, "y": y_tensor, "x_u": x_u_tensor})
print(loss_tensor)
# tensor(1.00000e+05 * 1.2587, device='cuda:0')Since the type of this value is just torch.Tensor, you can train it just like a normal way in PyTorch,
optimizer = optim.Adam(list(q.parameters())+list(p.parameters())+list(f.parameters()), lr=1e-3)
optimizer.zero_grad()
loss_tensor.backward()
optimizer.step()Alternatively, you can set it as the loss function of the pixyz.Model class to train (using pixyz.models.Model).
from pixyz.models import Model
model = Model(loss_cls, distributions=[p, q, f], optimizer=optim.Adam, optimizer_params={"lr":1e-3})
model.train({"x":x, "y":y, "x_u":x_u})Distribution API itself can perform sampling. The type of arguments and return values in the sample method is dictionary format.
# p: p(x|z)
# prior: p(z)
samples_dict = prior.sample()
print(samples_dict)
# {'z': tensor([[-0.5472, -0.7301,...]], device='cuda:0')}
print(p.sample(samples_dict))
# {'x': tensor([[ 0., 0.,...]], device='cuda:0', 'z': tensor([[-0.5472, -0.7301,...]], device='cuda:0')}
p_joint = p * p_prior # p(x,z)
print(p_joint.sample())
# {'x': tensor([[ 0., 1.,...]], device='cuda:0', 'z': tensor([[1.2795, 0.7561,...]], device='cuda:0')}Moreover, estimating log-likelihood is also possible (using the log_likelihood method).
# p: p(x|z)
# data: {"x": x_tensor, "z": z_tensor}
loglike = p.log_likelihood(data)
print(loglike)
# tensor([[-540.9977, -541.6169, -542.1608,...]], device='cuda:0')By using these functions in Distribution API, ELBO (Eq.(1)) under given data (x_tensor) can also be calculated as follows.
# p: p(x|z)
# q: q(z|x)
# prior: p(z)
samples_dict = q.sample({"x": x_tensor}) # z~q(z|x)
p_joint = p * prior # p(x, z)
elbo = p_joint.log_likelihood(samples_dict) -q.log_likelihood(samples_dict) # log p(x,z)-log q(z|x)For more detailed usage, please check our sample codes and the pixyzoo repository.
If you encounter some problems in using Pixyz, please let us know.
This library is based on results obtained from a project commissioned by the New Energy and Industrial Technology Development Organization (NEDO).