Programmatic and Manual pathways for table and column descriptions #147
Comments
On table levelFor the User model in databuilder, I noticed it already takes an optional kwargs parameter: https://github.com/lyft/amundsendatabuilder/blame/1.4.10/databuilder/models/user.py#L62 so you can give keynames that can double as field description(s) in the UI and values I'd imagine something similar could be added to the Table model in https://github.com/lyft/amundsendatabuilder/blob/1.4.10/databuilder/models/table_metadata.py Note: I haven't tried out the kwargs mechanism though - but the PR amundsen-io/amundsendatabuilder#95 gives some hints in the unit test On column levelI wonder to what extents The metadata model in Architecture.md: https://github.com/lyft/amundsen/blob/master/docs/architecture.md#metadata If Stats doesn't suit the needs then Column could of course also get a kwargs parameter. |
|
thanks for the detailed thoughts @jornh! If I understand you correctly, we should be able to use the kwargs of the TableMetadata model (looks like there is already one there with the comment: I will take a look at this tomorrow hopefully and see how it works and get back to this issue with my research. |
|
Ok @jornh I looked into it a bit today and I was able to get table kwarg properties into neo4j as extra properties of a given node. However, nothing showed up in the table ui. Looking through the frontend code, unless I am missing something, I don't see how these extra properties get wired up to the frontend code even for User (I know next to nothing about frontend though so me missing something could be quite likely). If it is true that the frontend currently does not display the extra kwarg properties, would this story then be frontend only changes, plus possibly additions to sample_data_loader to show how it can take any key value pairs? UPDATE: now that I have taken a look at column_stats, I definitely think this takes care of what we need on column level. I wonder if having a table_stats analogous to table_column_stats would be a better approach even over the kwargs? Thanks for your help and sorry for any dumb questions! |
|
@feng-tao @markgrover @jinhyukchang we could really use your insights on this one. idk if it would be best to bring this up at the next community meeting, or, best to solicit this on slack, or, just submit a PR. Overall, I think this could be adopted without too much disruption. What it would take:
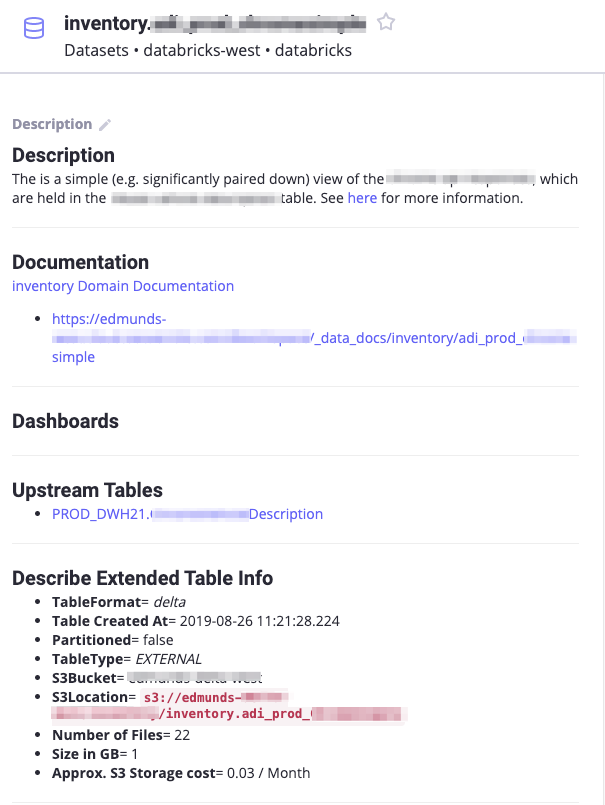
To reiterate, why do we want to do this? Consider these images:
First, you will notice, that all of this markdown data is quite useful, but, it was not created by user entry in amundsen. Instead if was machine generated upstream. Some of this information, such as description, documentation, dashboards we would want editable. Other parts, such as "Describe Extended Table Info" should not be editable, since it is metadata (similar to column info). Please lmk what you think. We'd really like to do this work, and we think others in the community could benefit, but, we don't want to do the work in such a way as to be unsatisfactory (e.g. if you feel like it is unwanted\unneeded). |

Will scroll past GitHub repo folders (specially more handy on small screens like phones/tablets)
|
@javamonkey79 not sure if everyone sees the discussion in the issue, would you mind posting above into the slack channel so that everyone could take a look? Thanks. |
|
hi @feng-tao yes, I'll solicit feedback there |
|
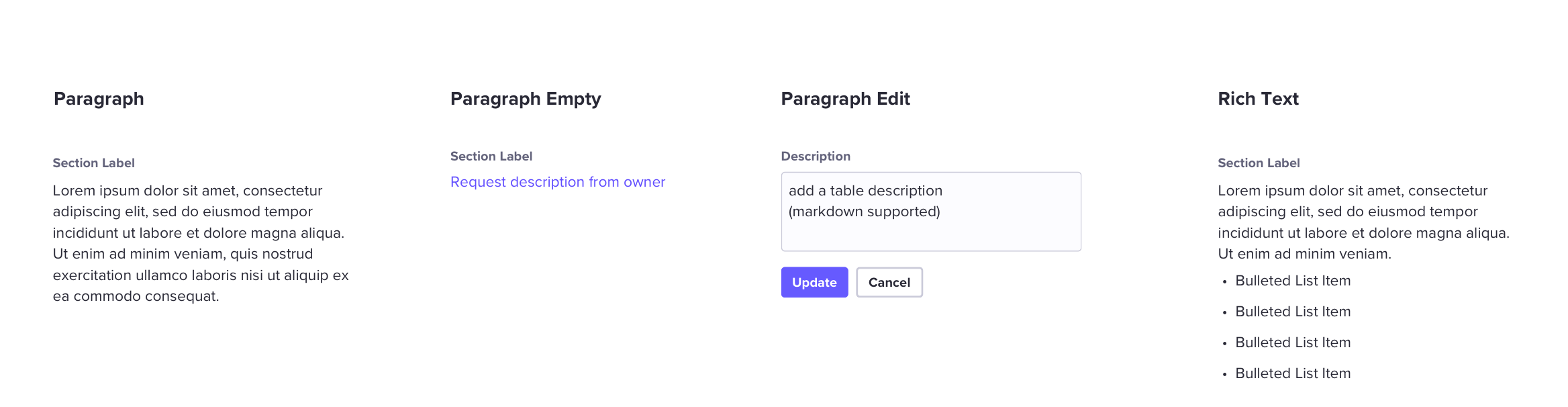
There was some discussion in slack about this today. The general consensus is that, instead of just 2 description sections, we should allow for N description sections and whether or not the section will be editable or not would be set as a property of that section. This solution would be quite versatile, and should fit everyones needs. However, it comes with a bit of cost, namely complexity. Here is one example, of how this might look (courtesy of Matt Spiel): And here are some possible concerns Tamika has raised as far as implementation:
Further discussion should happen here. |

|
@ttannis I've been thinking about this some more, and based on the backing neo4j structure, it would appear to be possible to assign multiple description nodes for each table. The only issue with this approach, is that we would need some ordering id assigned to each description. Further, we would also likely want to set a new flag on each description node "editable" which could then be propagated to the front end. wdyt? @feng-tao is there another more suitable approach? |
|
That sounds good on my end. The descriptions would be rendered according to the ordering id -- with what we currently know as My current thoughts are:
|
What needs to be talked about? I think it would need to be updated per the new logic, but, that's about it. Did I miss something?
We'd just need to update the logic that populates elasticsearch to look at all description nodes, instead of the one. Or, is there more to it? |
|
Thanks @javamonkey79 for this, and @ttannis for all your help. Would love to see this problem to be fixed, let me know if there's something that I can help with. |
|
Just writing here that I am going to take a stab at this to at least get some more clarity on what could be done. I imagine that my thoughts below are not going to be the final solution because I am sure I am missing important details. Given this, here are my thoughts on more specific implementation details: I am going to start first with the data loader changes to populate more description objects in neo4j. I am going to make it backwards compatible. At first, I thought it would be simpler to only support just one is_editable text box, but thinking through it more, I am only saying this because I don't know enough about frontend. I could see how it would be great to have different boxes that are editable to help guide users to curate specific things. We could even lock down security on different boxes based on roles. Only users who are owners can edit table_description box, but all users can edit another box for example. Two options here:
I actually think approach 2 is better, because that way we can more easily decouple the different "sources" of programmatic descriptions and re-use the existing description parameter. Will then construct the neo4j nodes accordingly using the "source" as part of the description node id. After above is done, I will modify Metadata Service to have a new method to fetch all of the programmatic description nodes and concat them together based on order as a first attempt. It is possible that it would be better to return all separately for more frontend flexibility. Then the frontend would need to be modified to make these requests and display them. As a first pass for frontend, I will just concatenate all of the programmatic descriptions and display them in a single box. |
|
A couple of other thoughts that came up since working on it on Friday. I think we should get rid of description_order as part of data loader as that seems like we are coupling presentation logic to the data. Instead, I think the frontend should be configurable to display the different descriptions based on the "description_source" (where is this description metadata coming from? i.e. s3_scraper, extended table details etc.) |
|
Hey @javamonkey79 @ttannis, as promised I made some headway on this and was able to get a very early stages prototype together here:
This contrived example shows 2 different sources of metadata (s3 status and quality report) that now populate dedicated boxes in the left pane. The data is being populated from rows like this: I have not tested out columns yet. Notice that tags can also come from these client specific metadata sources. A big thing that needs to be still decided is a name for this new concept. I think "programmatic descriptions" is not a good name. Other possible names that have been suggested are:
Please loop in anybody else that should be part of this conversation. cc @markgrover |

|
@samshuster do you have any branches that you can share with this, it's alright if things aren't clean or perfect. |
|
sure thing @ttannis I will get up some WIP branches for all of the modules that had to be touched... basically all of them! I imagine that there will be some major rework that is asked by you guys, so no worries there. NOTE: I didn't bother with search at this point, I figure that can be a separate story down the line to index these new datapoints. But happy to try and do it if you feel differently. |
|
ok @ttannis you can check out the above WIP MRs. Let me know if you have any questions! |
|
It seems it first started with un-editable description, but now it became generic metadata. I understand the value of being flexible, but on the other side, I am afraid we are opening the door such that most of new metadata could just go through this approach, not being captured as a new use case model. (And also, we would need control on which metadata should be indexed in search service or not which adds more complexity). In other words, if I understand it correctly, most of current metadata (and future metadata) can be represented by this flexible model, and I wonder if that is better path as it would easily make new metadata model hide in each companies private repo in databuilder configuration. I think there's trade-off between being flexible on new metadata introduction vs we may see less contribution on new metadata model. May be I am too worried. WDYT? |
|
hey @jinhyukchang I guess this is an aged old question flexibility vs explicit. You raised some great points! Here are some of my thoughts for why I believe there will always be a use case for having a flexible option like this approach, but I could be wrong.
|
|
Fair points, @samshuster ! Let's not make it too powerful :) |
|
If there are no major concerns with the approach (happy to make changes if there are!) I am going to revisit where I left off on this a few days ago and focus on:
|
|
hey @ttannis @jinhyukchang checking in here again with a couple more updates.
With those above 2 changes, I think this is almost ready to go! I should have some complete MRs by tomorrow for you guys to take a look at.
Given this, I moved databuilder MR out of WIP but anticipate that there will still be some major changes left: https://github.com/lyft/amundsendatabuilder/pull/187/files Thanks for your feedback and help! |
|
Thanks @samshuster ! On the editable properties, I prefer to remove it as it won't be an active code. Let me know what you think. |
|
sounds good @jinhyukchang that makes sense, i will remove the is_editable property from the data model and will tag you tomorrow when they are all ready to be reviewed |
|
ok @jinhyukchang @ttannis https://github.com/lyft/amundsendatabuilder/pull/187/files this change is ready for you guys to review. NOTE: the other MR's are also ready for you to review too! but the builds won't pass until amundsen-common is pushed |
|
ok @jinhyukchang amundsen-common and metadata are ready for review (sorry to keep tagging you!) below will build once above is merged in |
|
hey @ttannis just checking in to see when we can start revisiting this MR |
Last Thursday one of our designers took a look at this concept and is currently working on some suggestions. They will either respond directly on your PR, or I'll relay the information once it's ready. |
|
hey @ttannis @feng-tao would you guys be open to having my plain design get pushed through as a starting point? It would only show up on amundsen if people ingest programmatic data on the backend, so it would be low risk. We could consider it "beta". That could give you guys more time to rework the design. Just an idea, understood if that isn't going to work! |
|
i believe this issue can be closed now. Thanks everybody! |
|
👏👏👏 thanks for pulling through on this feature Sam. I’m sure it will benefit a lot of other orgs using Amundsen. |
|
I agree, nice work on a Herculean effort @samshuster 💪 💯 💥 |
|
Indeed, awesome stuff! Thanks Sam!
…On Thu, Mar 19, 2020 at 9:40 AM Shaun Elliott ***@***.***> wrote:
I agree, nice work on a Herculean effort @samshuster
<https://github.com/samshuster> 💪 💯 💥
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#147 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AANBLC6FIJFZA3B7DHRYZA3RIJDIFANCNFSM4JEIACXQ>
.
--
Mark Grover
Product Manager
<https://www.lyft.com/>
|
Thanks Sam, I'll be closing this issue after creating and publishing the new release for frontend, and updating the quick starts. |
* 🎉 Initial commit. * ♻️ Refactoring code. * 👌 Updating code due to code review changes. * 👌 Updating code due to code review changes. (tests)
Will scroll past GitHub repo folders (specially more handy on small screens like phones/tablets)
* 🎉 Initial commit. * ♻️ Refactoring code. * 👌 Updating code due to code review changes. * 👌 Updating code due to code review changes. (tests)
Will scroll past GitHub repo folders (specially more handy on small screens like phones/tablets)
* 🎉 Initial commit. * ♻️ Refactoring code. * 👌 Updating code due to code review changes. * 👌 Updating code due to code review changes. (tests)
* 🎉 Initial commit. * ♻️ Refactoring code. * 👌 Updating code due to code review changes. * 👌 Updating code due to code review changes. (tests)
Will scroll past GitHub repo folders (specially more handy on small screens like phones/tablets)
* 🎉 Initial commit. * ♻️ Refactoring code. * 👌 Updating code due to code review changes. * 👌 Updating code due to code review changes. (tests)
Overview
As a data engineer, there are quite a few properties that we can extract programmatically that are currently not supported by amundsen as first class properties in the UI. For some of these properties that are likely widely useful, I can understand creating issues to ingest them so that they appear in the panel on the right. However, some of these properties are very company specific and wouldn't be needed by other companies. Therefore, I think that it would be useful to allow users to ingest structured data without needing to make changes to amundsen infrastructure.
What do we do now? And why it won't work in long run?
Currently, we get around this by programmatically updating the table description with prepared markdown, however in the long run we also want users to be able to edit table and column descriptions through amundsen which will put us in a bind. We no longer would able to update programmatically without a lot of added complexity concerning reconciliation and merging of changes.
Proposal
My proposal is that there are two types of descriptions for tables and columns
One would be programmatic and cannot be modified manually.
The other would be the current description.
By default, the programmatic description would not appear on the page unless it is populated.
Note about column level
This is true on the column level as well, where we may want to include company specific attributes, but I can understand why column level programmatic descriptions maybe too much to ask for in terms of cluttering the UI.
The text was updated successfully, but these errors were encountered: