Faster pointwise fusion graph pass #19269
Conversation
|
Hey @ptrendx , Thanks for submitting the PR
CI supported jobs: [website, sanity, windows-cpu, edge, unix-gpu, windows-gpu, centos-gpu, miscellaneous, unix-cpu, centos-cpu, clang] Note: |
|
Seems cpplint that we use does not like structured binding from C++17. |
|
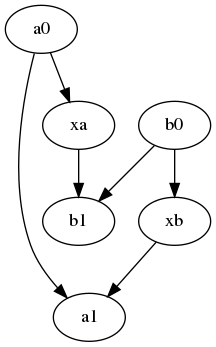
Ok, issue #19264 came at a perfect time - it actually exposed a corner case that breaks both the original and the new algorithm. The minimal example looks like this: I am working on a solution that will fix that. |
|
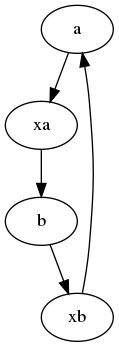
I fixed the problem with the cycle - every time when I add a new node to a subset, I check whether it's exclusion set is fully included in the future fusion node exclusion set. If so, I update all descendants of the fusion node (with the assumption that typically fusion subsets are not very big and their nodes are quite close together in the indexed graph, so the cost of that is not very high). Still, the check is quite expensive compared to the rest of the algorithm and now the cost of the graph pass for XLNet is ~10-11 ms (still a huge improvement compared to the previous algorithm). |
|
Thanks for the optimization @ptrendx . A couple of questions based on the PR description:
|
|
@ptrendx In regards to this edge case #19269 (comment), considering a0 -> xa -> b0 -> b1 -> xb -> a1 as the topological graph, before reaching node xb, we should have already combined b0 and b1 into subset b and updated exclusion set of b to contain a0. If that's the case, a0 should automatically be included in the exclusion set for xb. Why then do we need to "update all descendants of the fusion node"? |
|
Hi @mseth10, I think all of your 3 questions are quite connected. I agree that the nomenclature here is slightly confusing. I use "subsets" because in this algorithm there are actually 2 parts:
|
|
@mxnet-bot run ci [unix-cpu, unix-gpu] |
|
Jenkins CI successfully triggered : [unix-cpu, unix-gpu] |
|
Unix-gpu failed due to test_countsketch (issue #10988) @mxnet-bot run ci [unix-gpu, unix-cpu] |
|
Jenkins CI successfully triggered : [unix-cpu, unix-gpu] |
|
@mseth10 any more comments on the PR? |
| node_id)); | ||
| new_nodes[i]->control_deps.insert(new_nodes[i]->control_deps.begin() + dep_num, | ||
| std::move(helper_node)); | ||
| } else if (their_subgraph_id != subgraph_id && |
There was a problem hiding this comment.
can subgraph_id be -1 here? or should we add that check here?
There was a problem hiding this comment.
It can. The role of FusedOpHelper is to get information (for shape/type inference) from inside the FusedOp to the outside world.
There was a problem hiding this comment.
So if your dependency is going to be fused, then you need to have this helper instead.
There was a problem hiding this comment.
Makes sense. In general, what are the control flow dependencies of a node? Is it just the dependency of backward op node on its corresponding forward op node?
There was a problem hiding this comment.
Yeah, that is the dependency we are changing as it is used for infershape/infertype. Going forward I would like to get rid of this and never do the inferattr on the fused graph (instead do it on the original graph and map the results to the fused one), but it is outside the scope of this PR.
|
@mxnet-bot run ci [all] |
|
Jenkins CI successfully triggered : [windows-gpu, unix-gpu, sanity, edge, windows-cpu, miscellaneous, centos-cpu, clang, website, unix-cpu, centos-gpu] |
|
@ChaiBapchya FYI - there seem to be some connection issues in CI - first sanity test failed because of connection reset, then centos-cpu test failed with @mxnet-bot run ci [centos-cpu] |
|
Undefined action detected. |
|
@mxnet-bot run ci [centos-cpu] |
|
Jenkins CI successfully triggered : [centos-cpu] |
* Faster pointwise fusion graph pass * Fix lint * Fix lint 2 * Fixes * Fixing slice parameter handling in fusion * Fixing the slice fix * Fix the cycle bug * Added test * Fix lint * Fix merging of subgraphs * Fixes from review
* Faster pointwise fusion graph pass * Fix lint * Fix lint 2 * Fixes * Fixing slice parameter handling in fusion * Fixing the slice fix * Fix the cycle bug * Added test * Fix lint * Fix merging of subgraphs * Fixes from review
* Faster pointwise fusion graph pass (#19269) * Faster pointwise fusion graph pass * Fix lint * Fix lint 2 * Fixes * Fixing slice parameter handling in fusion * Fixing the slice fix * Fix the cycle bug * Added test * Fix lint * Fix merging of subgraphs * Fixes from review * Use std::tie instead of C++17 structured binding * More fixes for lack of c++17 * Fix
…che#19413) * Faster pointwise fusion graph pass (apache#19269) * Faster pointwise fusion graph pass * Fix lint * Fix lint 2 * Fixes * Fixing slice parameter handling in fusion * Fixing the slice fix * Fix the cycle bug * Added test * Fix lint * Fix merging of subgraphs * Fixes from review * Use std::tie instead of C++17 structured binding * More fixes for lack of c++17 * Fix
Description
This PR greatly increases the speed of pointwise fusion graph pass. As a test case I used XLNet from Gluon-NLP which did expose slowness in this graph pass before: #17105 - the total time of fwd+bwd fusion after the fix from that issue was ~8s, after this PR the time is ~11 ms, with 3 ms of that taken by IndexedGraph construction from the original graph (so the actual fusion graph pass takes ~8ms for that case - about 1000x improvement).
The motivation of this PR is getting the pointwise fusion graph pass to be lightweight enough to possibly be run every time the shapes change in the graph, enabling the fusion to be shape-aware. This is important as in 2.0 NumPy semantics make multiple operations (like add, sub etc.) broadcast by default, even if in the end they are simple elementwise operations. This PR does not fully get us there (I would much like it being <5ms for the network like XLNet to be sure it is lightweight enough to not be bottleneck for all usecases), although there are some parts that would not be needed anymore if we could make this pass after infershape is already done (e.g. we would not need to insert
FusedOpHelper/FusedOpOutHelper, which currently takes a little over 1ms). That said, it is a big step in that direction.The main problem that the fusion graph pass needs to solve is not allowing the cycles to be formed: nodes which both consume the output of and provide the input to a single subgraph. The original pointwise fusion graph pass' algorithm to avoid cycles was to first construct a mapping, which nodes are excluded to be in the same subgraph with a given node. The construction of the mapping was simple but inefficient (and then improved in #17114, but still pretty slow):
This was
O(n^3)algorithm (improved in #17114 to beO(n^2)on average) and required a separateBidirectionalGraphdatastructure that enabled DFS in both directions.The new algorithm for pointwise fusion graph pass is designed based on 2 observations:
In the new algorithm the graph is traversed in the topological order (and so we are sure that all the inputs of the current node were already processed) and each node has its own exclusion set of subgraphs that it can't be a part of. The exclusion set of node is constructed as the union of the exclusion sets of its inputs + all the subsets that its inputs are part of if the node itself is ineligible to be in a subgraph. Because subsets can merge (e.g. when you have operation
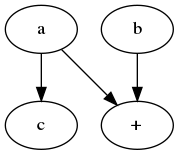
a + bwhereais part of subgraph s1 andbis part of subgraph s2, then s1 and s2 need to be merged into a single subgraph containing everything from s1, s2 and the+operator), the mapping is maintained to know which other subsets the current subset is merged with.There are number of additional optimizations:
The second part of the PR is the overhaul of the actual subgraph substitution - previously it was done 1 subgraph at a time, with multiple
DFSVisitcalls per subgraph. UnfortunatelyDFSVisitis costly and most of that work was wasted (as the DFS over the entire graph was needed for the substitution of a few nodes. In the new approach a new graph is created based on the subgraph assignment generated in the previous part, which requires only a single pass over the graph to apply all subgraphs.@samskalicky @Caenorst @mk-61
Checklist
Essentials
Comments