2bit gradient compression #8662
Conversation
python/mxnet/kvstore.py
Outdated
| @@ -349,6 +349,77 @@ def row_sparse_pull(self, key, out=None, priority=0, row_ids=None): | |||
| check_call(_LIB.MXKVStorePullRowSparse( | |||
| self.handle, mx_uint(len(ckeys)), ckeys, cvals, crow_ids, ctypes.c_int(priority))) | |||
|
|
|||
| def set_gradient_compression(self, compression_params=(('compression', '2bit'),)): | |||
There was a problem hiding this comment.
I don't think there should be a default value at all.
There was a problem hiding this comment.
rename key compression to type
src/kvstore/comm.h
Outdated
| protected: | ||
| Context pinned_ctx_; | ||
|
|
||
| std::shared_ptr<GradientCompression> gc_; | ||
| bool gc_set_ = false; |
There was a problem hiding this comment.
Not necessary. gc_ defaults to nullptr
src/kvstore/gradient_compression.h
Outdated
| namespace mxnet { | ||
| namespace kvstore { | ||
|
|
||
| enum CompressionType { |
There was a problem hiding this comment.
Use scoped enum.
enum class CompressionType{
kNone,
kTwoBit
};
src/kvstore/kvstore_dist_server.h
Outdated
| @@ -41,8 +41,10 @@ namespace kvstore { | |||
|
|
|||
| static const int kRowSparsePushPull = 1; | |||
python/mxnet/kvstore.py
Outdated
| elif compression_params['compression'] not in ['none', '2bit']: | ||
| raise ValueError('Unsupported type of compression') | ||
|
|
||
| if compression_params['compression'] == '2bit': |
There was a problem hiding this comment.
These parsing should be done in backend with dmlc::Parameter
The frontend should pass strings of key value pairs.
include/mxnet/c_api.h
Outdated
| */ | ||
| MXNET_DLL int MXKVStoreSetGradientCompression(KVStoreHandle handle, | ||
| const char *compression, | ||
| const float threshold); |
There was a problem hiding this comment.
API should be
MXKVStoreSetGradientCompression(KVStoreHandle handle, mx_uint num_params, const char **keys, const char **vals)
The values should be parsed in backend with dmlc::Parameter
Signed-off-by: Rahul <[email protected]>
|
@piiswrong Updated to use scoped enums, and DMLC param Wanted to add that tests are all in nightly because this affects either distributed kvstore |
Signed-off-by: Rahul <[email protected]>
| * Used if SetGradientCompression sets the type. | ||
| * Currently there is no support for un-setting gradient compression | ||
| */ | ||
| std::shared_ptr<kvstore::GradientCompression> gradient_compression_; |
There was a problem hiding this comment.
no support for un-setting gradient compression ? What happens if an user tries to unset it?
There was a problem hiding this comment.
if user uses kvstore.set_gradient_compression({'type':'none'} after setting it to 2bit, it throws an error because none can't be a type.
If users sets 2bit again with different threshold, then new threshold will be used from then on, but there might be a period in transition when gradients quantized with old threshold will be dequantized with new threshold, because of delay in sychronization.
Signed-off-by: Rahul <[email protected]>
Signed-off-by: Rahul <[email protected]>
Signed-off-by: Rahul <[email protected]>
frontend was sending command with id=stopServer in old enum Signed-off-by: Rahul <[email protected]>
|
Does this look ready to be merged now? I've updated the results section with more details. I'll hopefully be updating gradient compression with more optimizations before the v1.0 release. But it would be better if we merge this, so next PRs aren't this large. There's no known bug right now. |
* update two bit compression * Update trainer.py * Update test_operator.py * update two bit compression * update two bit compression * update two bit compression * update * update * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * Update comm.h * add original size in comrpessed array * update comm.h * update distributed training * update distributed training * Update ndarray_function.cu * Update kvstore_dist.h * Update kvstore_dist.h * update * update * update * fix bug * fix * add GC test * fix bug in push * fix push and pull * fix * fix * uncompiled * kvstore dist changes. added cpp_package. changed strtof function calls * fix usage of keys in dict * fix push and pull * fix * fix_test * fix_test * fix_test * add print statements * more print statements and move send command to server * set compress handling * kvstore dist changes * working kvstore push and pull. not sure if I commited that. from this commit removing mutable variable changes for residual array gives working push and pull * cleanup test * debug prints * working kvstore dist. includes mutation of inputs and setting threshold array dtype properly * fix operator * kvstore dist changes * fix compress kvstore issues. non compress is broken * fix sparse push issue * fix read lock issue * optimizer is the only issue now? * fix all issues with gc dist * fix read lock issue * pushing sharded data works * works most times. sometimes val instead of 0 has parts of 1 or 1.5... * fix read lock issue * prev commit fixed seg fault issue on pull without push in a server * add waittowrite to fix pull before push problems * refactor quantizing for sharded data * redo break up of data across servers,clearer split * refactor to use param for thresholds. also cleans up code * Added many checks for 0 * cmake changes * formatting issues for easier merge * fix rate * fix compilation errors after merge * fix compile error and ndarray thresholds in dequantize * fix compile error and ndarray thresholds in dequantize * fix compile error * fix compile error, and add comments * update operator comments * comment checks * comment checks * compile error * working on local kvstore compress test * fix module api compressparams, and change quantize tblob to inside engine * 2bit arg wrong kvstore * remove log * fix gpu dequantize and tests * fix seg fault in quantize and test indent * tests print more info order of params corrected * assert almost equal * more debug stuff correct profiler message * intermediate test rewrite * small change in pushing op to engineh * fix concurrency of quantization * wait on kernel * updated tests and removed prints * comment unnecessary stuff * fix test * remove print * Update dist_sync_kvstore.py fix random dist sync test * remove slow kernel launch init * cleanup * undo changes in submodule * submodule reset * remove files * undo changes unrelated to project * undo changes unrelated to project * Comments and cleanup. Remaining are src/kvstore, src/operator and tests * more cleanup and comments * comments for tests * lint changes and comments * speed up operator test by reducing asnumpy() calls * random data for test_kvstore_local * fix variable confusion error in test * fix randomized data test for local kvstore * add nrepeat for test_kvstore * change keys after merge from master introduced same keys * correct test which fails because grad changes * change to bit ops * change to bit ops * use bit array and revert sign changes * correct bits setting to 10 as 2 * remove switch in dequantize * image classification example changes and remove cpp-api * merge all quantize, and new type in dist server * fix ndarray dequantize * debug stuff * fix bug * trying merge dequntize * Frmework and validation tests for operator validation and performance-testing in C++ Normally used for gtest tests. * Remove obsolete file * Fix compile error for non-CUDA build * tweaks in quantize * Allow for no backward pass * Remove unused var * making quantize all compatible as operators * separate mshadow and loop operators * working profiler, dequantize mshadow is slow * fix mshadow dequantize * fix quantize call by kvdist * making quantize all compatible as operators * add profile to measure.py * minor profiler changes * timing print in cpp operator * time quantize * saving data feature added * cleanup test * small updates * cleanup * minor fix * passing additional environment variables through launch.py * update local test * update dmlc with pass-env * fix launch pass env issue * update with pass-env changes * fix operator increment of block, remove unncessary commented code * fix operator increment of block, remove unncessary commented code * fix operator increment of block, remove unncessary commented code * fix operator increment of block, remove unncessary commented code * bring back quantize Signed-off-by: Rahul <[email protected]> * fix test * fix bug with increment of char pointer * fix bug with increment of char pointer * debug module * update test * comment all debug statements * change init to normal for now * remove debug changes * reorg to create gc class, add delayed start to gc, untested: causing segfault * redo header files * remove ps * remove unused header * fix compile issues * remove multiple delete of gc * add expected to local kvstore test * fix operator compile issues * fix operator compile issues * fix operator compile and link issues * remove gc.cpp * add split function * move setting of active gc * move all to gc.cpp, compile works for cpu * WIP gpu compile * compiles and links on both cpu and gpu * move prototypes to header * add split function * undo changes from master * remove cpp perf quantize * undo more changes * add inactive function so that multiple kvstore dist inits have no compression fix tests * undo some formatting changes * make sharding same when inactive and active * remove counts and get_active_type * remove print * add train caltech * increase size of mlp * update to alexa mlp * pass-env changes * add bucketing module compression * attempts for alexnet training * prepare for merge * fix lint issues * fix lint issues * remove caltech * address some comments: shared_ptr, documentation, indentaion, new functions, check_eq * move header * include header corrected * include header corrected * indents, documentation and test update * lint * pylint * rename class, fix local kvstore test, remove confusing active method * fix importing of compute expected in test_kvstore * fix bug in device kvstore * remove active comment in pull * docstring * use dmlc params, enums, Signed-off-by: Rahul <[email protected]> * doc updates Signed-off-by: Rahul <[email protected]> * lint Signed-off-by: Rahul <[email protected]> * typo Signed-off-by: Rahul <[email protected]> * rename field to type Signed-off-by: Rahul <[email protected]> * fix distributed kvstore stopping issue. frontend was sending command with id=stopServer in old enum Signed-off-by: Rahul <[email protected]> * Trigger CI * trigger CI
This reverts commit a499f89.
* update two bit compression * Update trainer.py * Update test_operator.py * update two bit compression * update two bit compression * update two bit compression * update * update * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * update two bit compression * Update comm.h * add original size in comrpessed array * update comm.h * update distributed training * update distributed training * Update ndarray_function.cu * Update kvstore_dist.h * Update kvstore_dist.h * update * update * update * fix bug * fix * add GC test * fix bug in push * fix push and pull * fix * fix * uncompiled * kvstore dist changes. added cpp_package. changed strtof function calls * fix usage of keys in dict * fix push and pull * fix * fix_test * fix_test * fix_test * add print statements * more print statements and move send command to server * set compress handling * kvstore dist changes * working kvstore push and pull. not sure if I commited that. from this commit removing mutable variable changes for residual array gives working push and pull * cleanup test * debug prints * working kvstore dist. includes mutation of inputs and setting threshold array dtype properly * fix operator * kvstore dist changes * fix compress kvstore issues. non compress is broken * fix sparse push issue * fix read lock issue * optimizer is the only issue now? * fix all issues with gc dist * fix read lock issue * pushing sharded data works * works most times. sometimes val instead of 0 has parts of 1 or 1.5... * fix read lock issue * prev commit fixed seg fault issue on pull without push in a server * add waittowrite to fix pull before push problems * refactor quantizing for sharded data * redo break up of data across servers,clearer split * refactor to use param for thresholds. also cleans up code * Added many checks for 0 * cmake changes * formatting issues for easier merge * fix rate * fix compilation errors after merge * fix compile error and ndarray thresholds in dequantize * fix compile error and ndarray thresholds in dequantize * fix compile error * fix compile error, and add comments * update operator comments * comment checks * comment checks * compile error * working on local kvstore compress test * fix module api compressparams, and change quantize tblob to inside engine * 2bit arg wrong kvstore * remove log * fix gpu dequantize and tests * fix seg fault in quantize and test indent * tests print more info order of params corrected * assert almost equal * more debug stuff correct profiler message * intermediate test rewrite * small change in pushing op to engineh * fix concurrency of quantization * wait on kernel * updated tests and removed prints * comment unnecessary stuff * fix test * remove print * Update dist_sync_kvstore.py fix random dist sync test * remove slow kernel launch init * cleanup * undo changes in submodule * submodule reset * remove files * undo changes unrelated to project * undo changes unrelated to project * Comments and cleanup. Remaining are src/kvstore, src/operator and tests * more cleanup and comments * comments for tests * lint changes and comments * speed up operator test by reducing asnumpy() calls * random data for test_kvstore_local * fix variable confusion error in test * fix randomized data test for local kvstore * add nrepeat for test_kvstore * change keys after merge from master introduced same keys * correct test which fails because grad changes * change to bit ops * change to bit ops * use bit array and revert sign changes * correct bits setting to 10 as 2 * remove switch in dequantize * image classification example changes and remove cpp-api * merge all quantize, and new type in dist server * fix ndarray dequantize * debug stuff * fix bug * trying merge dequntize * Frmework and validation tests for operator validation and performance-testing in C++ Normally used for gtest tests. * Remove obsolete file * Fix compile error for non-CUDA build * tweaks in quantize * Allow for no backward pass * Remove unused var * making quantize all compatible as operators * separate mshadow and loop operators * working profiler, dequantize mshadow is slow * fix mshadow dequantize * fix quantize call by kvdist * making quantize all compatible as operators * add profile to measure.py * minor profiler changes * timing print in cpp operator * time quantize * saving data feature added * cleanup test * small updates * cleanup * minor fix * passing additional environment variables through launch.py * update local test * update dmlc with pass-env * fix launch pass env issue * update with pass-env changes * fix operator increment of block, remove unncessary commented code * fix operator increment of block, remove unncessary commented code * fix operator increment of block, remove unncessary commented code * fix operator increment of block, remove unncessary commented code * bring back quantize Signed-off-by: Rahul <[email protected]> * fix test * fix bug with increment of char pointer * fix bug with increment of char pointer * debug module * update test * comment all debug statements * change init to normal for now * remove debug changes * reorg to create gc class, add delayed start to gc, untested: causing segfault * redo header files * remove ps * remove unused header * fix compile issues * remove multiple delete of gc * add expected to local kvstore test * fix operator compile issues * fix operator compile issues * fix operator compile and link issues * remove gc.cpp * add split function * move setting of active gc * move all to gc.cpp, compile works for cpu * WIP gpu compile * compiles and links on both cpu and gpu * move prototypes to header * add split function * undo changes from master * remove cpp perf quantize * undo more changes * add inactive function so that multiple kvstore dist inits have no compression fix tests * undo some formatting changes * make sharding same when inactive and active * remove counts and get_active_type * remove print * add train caltech * increase size of mlp * update to alexa mlp * pass-env changes * add bucketing module compression * attempts for alexnet training * prepare for merge * fix lint issues * fix lint issues * remove caltech * address some comments: shared_ptr, documentation, indentaion, new functions, check_eq * move header * include header corrected * include header corrected * indents, documentation and test update * lint * pylint * rename class, fix local kvstore test, remove confusing active method * fix importing of compute expected in test_kvstore * fix bug in device kvstore * remove active comment in pull * docstring * use dmlc params, enums, Signed-off-by: Rahul <[email protected]> * doc updates Signed-off-by: Rahul <[email protected]> * lint Signed-off-by: Rahul <[email protected]> * typo Signed-off-by: Rahul <[email protected]> * rename field to type Signed-off-by: Rahul <[email protected]> * fix distributed kvstore stopping issue. frontend was sending command with id=stopServer in old enum Signed-off-by: Rahul <[email protected]> * Trigger CI * trigger CI
This reverts commit a499f89.
Description
Implements 2bit gradient compression by quantizing each value in gradient array to 2bits using user specified threshold. Shows about 2x speedup on large models with components like fully connected layers, and LSTM layers.
@eric-haibin-lin @cjolivier01 @anirudh2290 @reminisce
Important files to review
GC : gc-inl.h, gc.cc
KVStore local: comm.h
KVStore dist : kvstore_dist.h, kvstore_dist_server.h
Documentation about gradient compression: kvstore.py
Checklist
Essentials
make lint)Changes
Comments
Problem
When training large scale deep learning models especially with distributed training, communication becomes a bottleneck for networks whose computation is not high compared to the communication.
Approach
We can compress the gradients by considering only those elements that exceed a threshold. Only these elements are encoded and sent. The elements of the gradient that are near zero can safely be delayed by aggregating them in a residual array. When the updated residual with gradient of next iterations exceed the threshold, these values are sent. Effectively these values are updated at a lower frequency.
On the receiver's end we decompress the data and use the decompressed weights.
Specifically in this PR, 2bit quantization has been implemented.
Two bit quantization
Any positive value greater than or equal to the threshold is set to one value (say 11), any negative value whose absolute value is greater or equal to the threshold is set to second value (say 10), and others are set to third value (say 0). We need three values to represent data in this fashion and hence two bits. We understand this leads to one bit going waste, but that's an optimization to be done later. The error in quantization is accumulated as residual and carried over to the next iterations. This is added in the next iteration to the gradient before quantizing.
An example below with thresholds of -2.0 and 2.0.
This format leads to the reduction of gradient size by 1/16th.
Quantization at work
Format of compressed gradient
Eac element, represents upto 16 elements in the original array. For the example above, we get an element whose binary representation is
00 11 00 10 11 00 00 10 0000000000000000Local kvstore
When using local kvstore, gradients compression only happens when using device communication. When gradients are pushed, before summing them up (Reduce), quantization and dequantization happen.
Example: Say we have 4 GPUs, and the gradients are being summed up on GPU0. Each device quantizes gradients, then sends quantized gradient to GPU0, which performs dequantization of this data before merging it with values from other GPUs. Note that here, there is no need to quantize gradients from GPU0 itself, but it is still being done so that there is no bias for the samples which were processed by GPU0.
Dist kvstore
When the set_gradient_compression method for kvstore is called, each worker sets those compress params and one worker sends these params to all servers. From then on, when before each value is pushed to the server, it is quantized. The server dequantizes the data and stores it as an array of the original size. When values are pulled from the server, it returns an array of the original size. The same happens when each server is handling shards of the data.
Usage
The reason I used a dictionary compress_params for the arguments was to ensure uniformity when we extend this to other quantization techniques. This is because each technique might take different type and number of parameters.
KVstore
Module
Gluon Trainer
Results
Summary
Shows about 2x speedup when models are large, have fully connected components, for distributed training. On local training, speedup is about 1.2x when there is no P2P communication.
For smaller models, the overhead of launching OMP threads is costing a bit, to get around it (if training using GPUs), setting OMP_NUM_THREADS=1 results in gradient compression is needed.
Shows speedup when communication is expensive. The above speedup was seen on g2.8x machines which have lower network bandwidth than p2.16x machines. p2.16x didn't see as much speedup.
Network types
On models for imagenet input (input dim: 3,299,299), on g2.8x large, 15 node cluster, used all 4 gpus on each node
LSTM on PennTreeBank with 200dim 2 layers
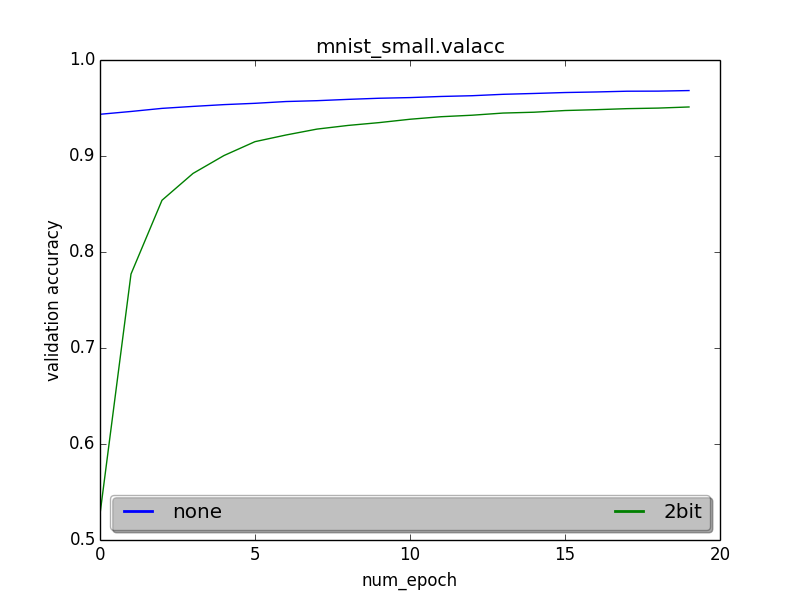
MNIST on MLP
CIFAR with resnet
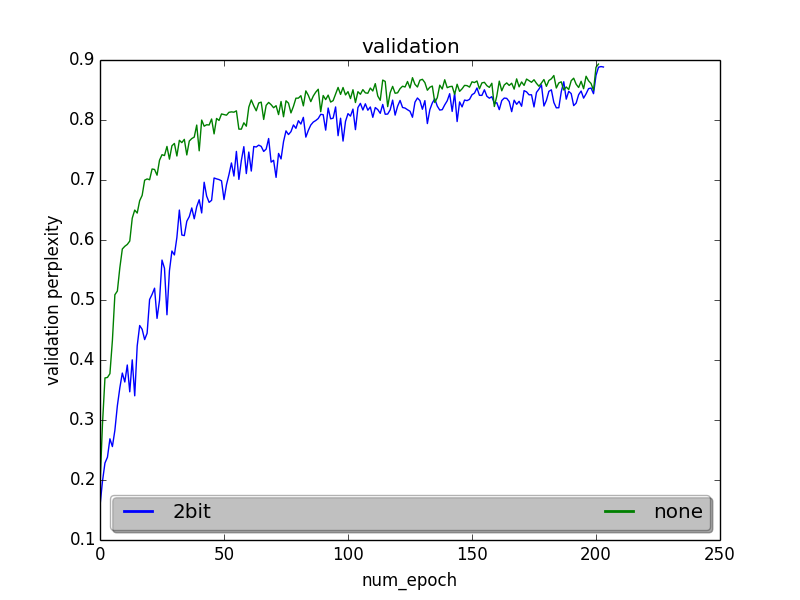
Accuracy starts off slow, but the network converges to similar accuracy.
Accuracies at a few epochs
epoch 101 :
2bit: 0.80645, none: 0.83572, difference: 0.029
epoch153
2bit: 0.841, none: 0.851, difference: 0.0108
CIFAR resnet with pretraining
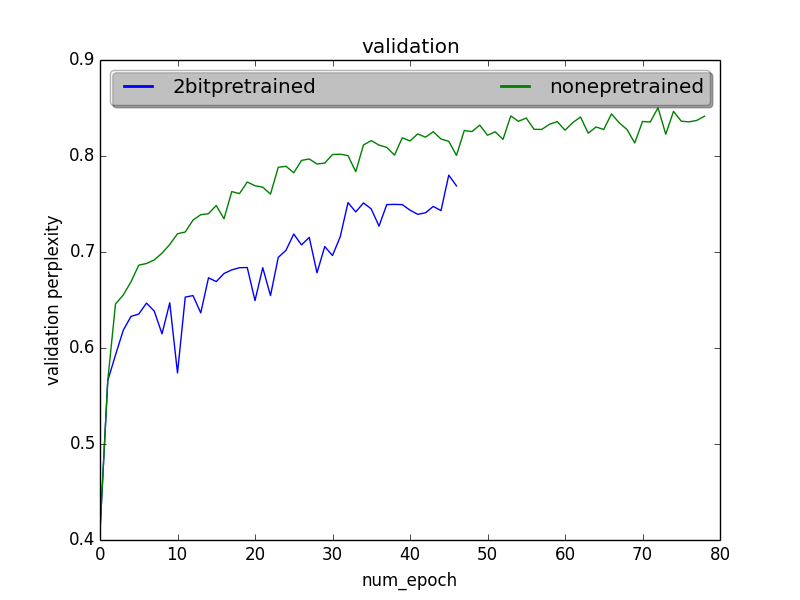
Pre-training without gradient compression for some time(2 epochs), leads to better convergence
We see that in this case, we start off much closer and reaches similar accuracies earlier. In general, the graphs are much closer. Let's look at epoch 33, Earlier, without pretraining, 2bit compression had an accuracy degradation of 0.154 when compared to the case without gradient compression. Now, when both models start with a pretrained network which didn't use gradient compression, it has a degradation of only 0.04.
Reference (although compressed representation is different http://nikkostrom.com/publications/interspeech2015/strom_interspeech2015.pdf )