-
Notifications
You must be signed in to change notification settings - Fork 9
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
2 changed files
with
32 additions
and
28 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,62 +1,66 @@ | ||
| Hipster | ||
| Forgetsy | ||
| ======= | ||
|
|
||
| __Note__: This is a draft readme. Implementation is on-going. I will remove this notice when the interface described below is fully operational. | ||
|
|
||
| Hipster is a trending library designed to track temporal trends in non-stationary categorical distributions. It uses [forget-table](https://github.com/bitly/forgettable/) style data structures which decay observations over time. Using two such sets decaying over different time periods, it picks up on temporal trends, forgetting historical data responsibly. | ||
| Forgetsy is a trending library designed to track temporal trends in non-stationary categorical distributions. It uses [forget-table](https://github.com/bitly/forgettable/) style data structures which decay observations over time. Using two such sets decaying over different lifetimes, it picks up on time differentials, whilst forgetting historical data responsibly. | ||
|
|
||
| Trends are encapsulated by a construct named _Delta_. A _Delta_ consists of two sets of counters, each of which implements exponential decay of the form: | ||
|
|
||
| 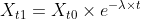 | ||
|
|
||
| Where the inverse of the _decay rate_ (lambda) is the mean lifetime of an observation in the set, expressed in time units. By normalising such a set by a set with a slower decay rate, we obtain a temporal trending score for each category in a distribution. | ||
| Where the inverse of the _decay rate_ (lambda) is the mean lifetime of an observation in the set. By normalising such a set by a set with a slower decay rate, we obtain a trending score for each category in a distribution. | ||
|
|
||
| Hipster avoids the need for sliding time windows and explicit rolling counts, as observations naturally decay away over time. It's designed for heavy writes and sparse reads, as it implements decay at read time. | ||
| Forgetsy avoids the need for manually sliding time windows or explicitly maintaining rolling counts, as observations naturally decay away over time. It's designed for heavy writes and sparse reads, as it implements decay at read time. | ||
|
|
||
| Each set is implemented as a redis `sorted set`, and keys are scrubbed when a count is decayed to near zero, providing storage efficiency. | ||
|
|
||
| Hipster handles distributions with upto around 10^5 active categories, receiving dozens of writes per second, without much fuss. Its scalability is highly dependent on your redis deployment. | ||
| Forgetsy handles distributions with upto around 10^6 active categories, receiving hundreds of writes per second, without much fuss. Its scalability is highly dependent on your redis deployment. | ||
|
|
||
| It requires redis to be running on localhost at the default port (6379). | ||
|
|
||
| Usage | ||
| ----- | ||
|
|
||
| Take, for example, a social network in which users can follow each other. You want to track trending users. You construct a one week delta, to capture trends in your follows data over one week periods: | ||
|
|
||
| follows_delta = Hipster::Delta.new('user_follows', t: 1.week) | ||
|
|
||
| ```ruby | ||
| follows_delta = Forgetsy::Delta.new('user_follows', t: 1.week) | ||
| ``` | ||
| The delta consists of two sets of counters indexed by category identifiers. In this example, the identifiers will be user ids. One set decays over the mean lifetime specified by _t_, and another set decays over double the lifetime. | ||
|
|
||
| You can now add observations to the delta, in the form of follow events. Each time a user follows another, you increment the followed user id. You can also do this retrospectively: | ||
|
|
||
| follows_delta = Hipster::Delta.fetch('user_follows') | ||
| follows_delta.incr('UserFoo', date: 2.weeks.ago) | ||
| follows_delta.incr('UserBar', date: 2.weeks.ago) | ||
| follows_delta.incr('UserBar', date: 1.week.ago) | ||
| follows_delta.incr('UserFoo', date: 1.day.ago) | ||
| follows_delta.incr('UserFoo') | ||
|
|
||
| ```ruby | ||
| follows_delta = Forgetsy::Delta.fetch('user_follows') | ||
| follows_delta.incr('UserFoo', date: 2.weeks.ago) | ||
| follows_delta.incr('UserBar', date: 10.days.ago) | ||
| follows_delta.incr('UserBar', date: 1.week.ago) | ||
| follows_delta.incr('UserFoo', date: 1.day.ago) | ||
| follows_delta.incr('UserFoo') | ||
| ``` | ||
| Providing an explicit date is useful if you are processing data asynchronously. You can also use `incr_by` to increment a counter in batches. | ||
|
|
||
| You can now consult your follows delta to find your top trending users: | ||
|
|
||
| a = follows_delta.fetch() | ||
| puts a | ||
|
|
||
| ```ruby | ||
| puts follows_delta.fetch() | ||
| ``` | ||
| Will print: | ||
|
|
||
| { 'UserFoo' => 0.789, 'UserBar' => 0.367 } | ||
|
|
||
| ```ruby | ||
| { 'UserFoo' => 0.789, 'UserBar' => 0.367 } | ||
| ``` | ||
| Each user is given a dimensionless score in the range [0..1] corresponding to the normalised follows delta over the time period. | ||
|
|
||
| Optionally fetch the top _n_ users, or an individual user's trending score: | ||
|
|
||
| follows_delta.fetch(n: 20) | ||
| follows_delta.fetch(bin: 'UserFoo') | ||
|
|
||
| ```ruby | ||
| follows_delta.fetch(n: 20) | ||
| follows_delta.fetch(bin: 'UserFoo') | ||
| ``` | ||
| Contributing | ||
| ------------ | ||
|
|
||
| Just fork the repo and submit a pull request. | ||
|
|
||
| Copyright & License | ||
| ------------------- | ||
| MIT license. See [LICENSE](LICENSE) for details. | ||
|
|
||
| (c) 2013 [Art.sy Inc.](http://artsy.github.com) |