Compute perplexity over prompt #270
Conversation
|
Got results for 7B, ctx=1024: |
|
This is indeed very cpu time consuming. I had it running for 25min and only got this far: |
this is likely related to #213 |
|
Very useful work. I think this can be significantly made faster if we have the option for the Lines 733 to 735 in 7392f1c |
|
@glinscott How is it you're seeing Anyway I ran it on the 7B FP16 model before your most recent commits (at commit e94bd9c), with and got
|
Yes, thanks! I was prototyping this last night, just got it working (I think). Current output with: So, it's consistent with the old one, but much more accurate (256x more tokens for 512 size window). |
I did exactly the same 🙈 . but with a slightly different batch size. |
@glinscott can you check your wikitext file is correct? |
There are a couple of possibilities. I get this error tokenizing: So, I assume it truncates the string there? Do other folks not see that? Other possibility is my dataset is wrong, can someone double check? It's 1290590 bytes. |
hmm, so file hash checks out |
|
One thing to note, I don't think the Can someone try adding this debugging printf() in? I get this: |
|
you should check your model files #238 |
I get this: |
|
Same results as @Green-Sky here. @glinscott I suspect you need to rebuild your models; you can check against the md5 hashes listed in #238. I don't see the "failed to tokenize string" message you report, either. I'm guessing you did the conversion before #79. |
|
Sure enough, my model was busted! Ok, I see consistent results now :). Now, at 22 seconds per inference pass, it's ~4 hours to do wikitext-2. So, would be great to see if we can get representative results from a much smaller subset. |
|
I'll do a run with: And log all the perplexities along the way. Once it starts to converge, it's probably a good sign we can cut the dataset off at that point. With the new method, it seems to be converging much faster hopefully. But we will see! |
|
I asked GPT4 for some stats advice, and it recommended:
We will see :). That's [150/649] in our model (256 samples per evaluation). There are some big assumptions about uniform distribution of data in there which probably don't hold for wikitext2, but probably still reasonable. Most recent results do look like they are converging nicely: |
|
I merged in #252 locally and am seeing a much better score: This was done using the same model (7B FP16) and settings I used above (except with the model re-built to use the new tokenizer, of course), and without 91d71fe, so the numbers should be directly comparable to the ones I got above ( I'll re-run both scenarios using the new logic in this branch but I expect very similar results. (Edit: yeah, pretty similar: |
|
@bakkot - wow, that is an incredible delta. Interesting, so the tokens must be subtly off with the existing tokenizer? |
|
Not really subtly, as reported in e.g. #167. Honestly it's impressive that it does as well as it does with the broken tokenizer it's currently using. |
|
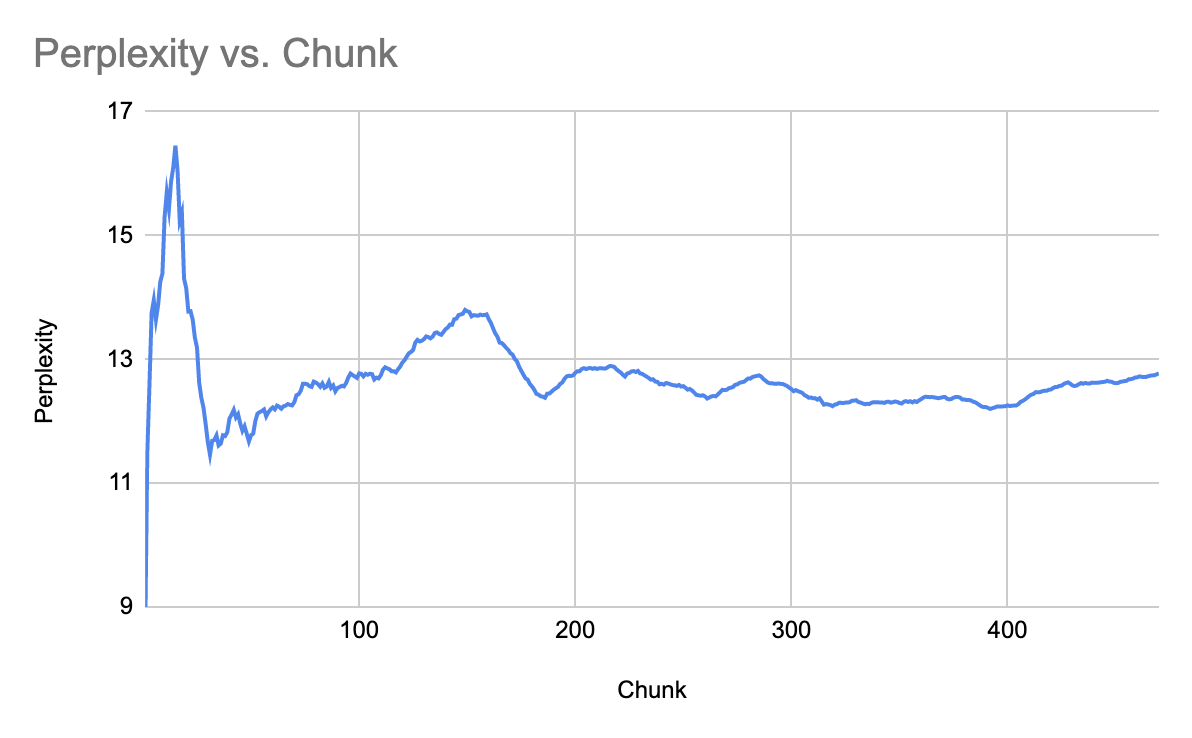
Ok, well, for the 7B model at 4 bit quantization, the perplexity appears to be 12.2-12.9 or so. Doing a little bit of a random walk. Going to stop at 470 since I'm excited to try out #252 :).
|
|
@glinscott Sidebar - the perplexity scores for chunks in wiktext aren't independent, because some articles are easier than others and there's multiple chunks per article. (So e.g. you might have ten chunks in a row from a really difficult article, each of which will raise the perplexity. With independent chunks that sort of consistent change in one direction would happen only very rarely.) That means perplexity isn't going to converge as fast as it should. So you might want to randomize the order in which chunks are processed, as in // Different parts of the prompt are likely to vary in difficulty.
// For example, maybe the first half is easy to predict and the second half is hard.
// That will prevent scores from converging until the whole run finishes.
// So we randomize the order in which we consume each part of the prompt,
// so that the score converges towards the real value as rapidly as possible.
std::mt19937 gen(0x67676d6c); // use a fixed seed so results are reproducible; this seed is `ggml` in hex
std::vector<int> indexes(seq_count);
std::iota(indexes.begin(), indexes.end(), 1);
std::shuffle(indexes.begin(), indexes.end(), gen);
for (int i : indexes) {instead of for (int i = 0; i < seq_count; ++i) {I haven't run this code, nor tested if it actually makes a difference in how fast the scores converge, but I expect it or something like it should work. |
|
Results for 4-bit quantization are looking great so far with #252 merged in as well! |
|
I captured the perplexity for each chunk separately (using 7B FP16, with #252 merged in). From there I looked into how good the measurement would be if you used fewer chunks, assuming you consume the chunks in a random order. Keep in mind there's 655 chunks total. The (empirical) 90% confidence intervals for the difference from the final perplexity (for my specific conditions) after a specific number of chunks are:
Determining whether you can get away with fewer chunks will depend on the size of the effect you're looking at - e.g. the fixed tokenizer is obviously better after only 10 chunks, but confirming the presence of smaller effects (like from improved quantization strategies) will require significantly more. code/data if you want to reproduce my results// this is javascript
let data = [
4.2337, 5.2897, 7.7770, 8.3287, 6.8390, 6.0943, 7.7364, 7.2585, 10.1792, 9.7338, 9.8226, 7.5937, 6.3308, 8.0002, 11.8844, 3.3917, 5.5408, 6.1756, 2.6730, 6.4901, 4.9989, 3.6592, 5.7682, 4.5201, 6.2160, 3.2217, 2.8567, 3.7494, 3.7945, 2.5883, 4.7733, 6.2793, 4.0443, 6.6725, 6.4370, 7.0745, 5.6611, 6.0521, 7.0657, 8.0699, 6.0984, 7.5405, 4.3730, 8.8372, 5.9219, 4.7395, 6.8133, 4.7350, 5.8450, 4.1329, 5.5502, 5.2692, 8.6583, 4.9914, 4.6868, 7.5662, 6.9880, 6.9894, 6.8970, 8.8414, 5.4384, 10.6731, 8.1942, 6.8570, 9.3563, 6.5627, 7.2757, 7.0825, 7.8798, 8.5397, 7.7570, 8.8057, 12.2151, 6.5003, 7.2832, 7.1812, 7.1461, 5.2082, 8.8034, 5.7541, 7.2228, 6.5905, 3.2219, 4.8862, 5.2106, 4.6112, 2.4795, 4.2595, 4.5617, 4.9153, 8.4723, 5.5482, 6.1128, 5.8297, 9.2492, 6.0519, 5.5583, 5.5216, 4.9173, 5.9582, 8.9768, 5.6014, 8.5170, 6.8875, 6.0951, 8.1004, 6.0354, 7.6947, 5.6168, 5.7427, 9.1345, 8.8376, 6.3986, 5.7434, 6.8633, 5.2115, 6.7495, 10.5116, 9.3441, 11.9780, 8.2422, 10.0067, 12.7040, 8.8324, 5.2965, 13.4408, 12.8634, 11.5266, 4.7939, 7.5777, 5.9655, 5.5261, 4.9038, 7.8649, 5.9049, 5.1198, 5.4877, 4.3806, 5.0965, 5.8914, 3.3561, 5.8583, 3.2323, 3.9742, 5.1125, 4.7900, 6.7743, 6.3185, 5.5245, 5.6687, 6.5638, 4.9464, 4.2488, 5.0675, 7.3592, 5.5228, 9.4368, 6.9210, 6.9797, 6.6831, 8.4606, 3.0650, 4.6591, 3.4063, 2.7900, 3.0231, 2.3005, 2.6896, 4.1826, 4.5053, 2.9034, 3.7563, 3.7867, 2.5532, 3.2104, 4.2681, 3.3105, 3.0264, 3.5613, 4.4102, 3.0667, 3.3960, 3.8231, 5.6702, 4.6170, 6.0197, 7.0675, 5.1326, 10.0308, 5.9919, 11.3845, 9.7865, 9.9764, 8.3787, 11.7139, 9.7893, 11.7055, 9.7135, 6.5766, 7.0163, 5.0125, 11.0156, 7.5948, 5.6769, 8.4561, 7.5776, 5.2701, 7.9725, 6.8910, 7.1792, 8.6991, 7.6900, 8.6591, 6.5381, 6.6024, 9.9117, 11.4651, 9.6110, 6.0322, 5.3760, 5.0621, 5.6246, 4.3323, 4.6806, 5.2827, 12.8015, 8.1204, 7.3919, 7.6432, 5.4063, 11.2815, 3.9873, 3.3158, 3.5056, 2.8041, 4.7094, 4.1956, 6.7119, 3.4211, 4.0789, 6.4766, 6.9613, 5.6383, 3.8569, 5.3274, 3.8636, 3.7660, 4.4742, 5.4093, 7.2289, 4.4956, 5.2353, 4.0107, 4.7802, 3.7488, 2.8184, 3.5604, 4.2093, 5.3541, 4.1740, 4.9184, 4.6309, 4.6749, 2.1799, 5.7219, 5.4113, 4.3672, 8.6913, 5.3731, 6.1470, 8.3038, 6.8235, 5.9549, 6.5837, 8.5758, 7.7327, 12.1389, 9.3534, 9.1320, 6.7431, 9.3347, 7.7855, 11.8079, 8.6349, 8.8769, 11.3166, 5.8538, 7.8667, 4.0560, 2.8534, 2.9460, 2.9278, 3.1373, 6.6050, 5.6842, 7.4505, 5.5637, 6.8299, 5.2548, 3.4957, 5.9363, 4.0149, 3.8561, 3.8802, 4.9512, 3.1070, 6.6027, 6.8806, 2.6353, 4.4386, 4.2173, 6.5665, 4.3896, 5.3577, 2.5667, 4.4052, 2.4796, 1.9780, 10.9267, 11.2068, 7.4261, 4.6996, 4.0354, 5.0048, 10.1574, 5.8825, 6.5496, 7.2039, 8.0570, 6.7768, 11.5410, 4.9996, 8.5831, 4.3073, 4.1795, 7.2409, 5.1631, 5.6205, 4.3670, 4.5893, 9.2200, 6.8801, 7.6852, 5.9022, 6.0188, 5.0642, 7.4118, 7.1476, 6.6982, 4.8392, 6.1443, 5.8701, 4.1545, 5.8907, 7.9460, 7.0058, 4.7597, 10.0613, 6.8521, 4.7857, 5.7337, 8.9369, 11.5146, 8.5051, 8.0402, 6.3870, 9.9484, 5.0987, 6.2364, 6.4576, 4.2600, 7.9318, 7.8497, 5.3683, 5.9516, 8.9665, 4.4904, 6.9869, 8.5304, 3.6020, 4.7592, 4.3036, 5.6554, 5.7098, 5.5246, 5.7023, 5.8297, 4.6599, 4.2254, 3.7789, 3.5960, 4.5255, 5.2527, 6.9731, 5.4062, 3.6407, 9.3482, 7.5259, 9.8064, 5.9531, 6.4362, 6.2962, 6.7262, 9.0811, 3.0848, 4.7268, 5.7033, 6.5912, 12.8079, 12.4113, 12.7754, 17.2818, 12.5417, 9.9668, 8.6653, 10.1074, 13.5201, 7.5909, 9.4968, 10.9255, 13.2899, 7.9184, 9.7576, 12.5443, 10.9062, 9.3986, 8.1765, 10.7153, 8.5812, 10.7370, 16.0474, 7.9101, 5.7778, 4.5653, 6.4762, 7.2687, 11.9263, 10.3103, 4.8934, 5.7261, 4.2609, 5.4918, 6.6898, 6.2934, 5.3325, 7.2188, 7.5185, 8.2033, 5.1273, 6.5011, 4.5670, 2.2386, 3.2372, 3.9893, 6.5170, 8.6117, 7.0107, 5.1495, 6.3412, 11.4701, 4.9500, 5.4811, 8.1177, 5.5823, 4.9553, 3.3866, 6.1404, 5.9408, 7.0779, 6.2677, 4.2244, 8.4411, 4.0633, 6.6431, 3.7769, 6.8590, 3.4788, 5.5537, 9.3246, 8.5652, 6.9801, 4.2857, 4.3862, 7.0454, 5.1355, 3.8384, 5.9033, 5.0303, 4.1490, 4.9914, 4.7928, 3.8402, 4.8503, 5.2423, 5.7663, 4.4227, 3.8162, 5.2343, 4.2511, 2.8094, 3.4875, 6.0975, 5.7161, 2.9156, 7.1691, 6.3762, 3.6819, 4.2773, 5.7032, 7.9792, 8.8110, 8.0352, 7.0775, 10.1292, 3.7952, 5.5346, 6.5626, 5.8085, 7.7367, 7.3946, 6.6608, 7.5490, 6.3721, 9.8001, 7.8648, 6.5025, 7.0076, 3.8873, 6.2564, 3.9161, 5.4713, 8.9538, 7.3572, 5.1763, 7.2523, 3.7586, 4.9993, 9.2871, 6.6082, 8.3411, 6.1726, 6.6453, 6.9063, 6.6387, 5.0784, 6.4587, 4.1723, 3.9443, 6.0791, 4.6138, 4.4106, 4.9176, 4.3316, 4.9980, 4.5371, 5.7626, 7.3694, 4.2320, 5.8014, 5.9095, 6.1267, 4.9075, 5.7717, 8.9320, 7.2476, 5.8910, 4.9010, 6.3294, 5.2988, 7.7972, 6.2766, 6.5831, 6.0055, 4.2898, 5.6208, 5.9260, 5.2393, 5.0046, 6.2955, 3.2518, 4.2156, 5.3862, 6.4839, 6.1187, 2.9040, 3.1042, 6.2950, 9.5657, 9.8978, 8.0166, 7.3498, 5.3361, 4.3502, 6.6131, 4.7414, 8.2340, 4.8954, 4.4713, 7.3732, 5.7101, 5.1141, 6.5039, 7.8757, 6.4675, 8.4179, 7.3042, 5.0399, 4.3175, 6.4821, 8.5142, 5.0135, 7.7970, 4.1496, 3.6323, 2.8987, 7.8440, 3.2591, 3.6729, 3.4526, 1.4961, 2.9882, 5.0225, 6.9797, 6.2451, 6.0565, 5.2908, 7.4791, 6.0146, 5.6742, 8.2883, 10.7090, 10.6945, 5.1382, 8.5528, 6.3640, 4.1532, 4.1070, 7.6952, 4.2944, 6.5832, 6.0564, 11.9188, 7.4791, 6.7621, 4.8915, 9.0851, 3.8716, 6.5621, 6.0976, 8.9491, 10.5537, 6.6961, 9.0845, 3.0358, 5.5621,
];
function combinePerp(acc, a, len) {
let avg = Math.log(acc);
let sum = avg * len;
sum += Math.log(a);
avg = sum / (len + 1);
return Math.exp(avg);
}
function chunksToRunningScores(chunks) {
let intermediatePerpScores = [chunks[0]];
for (let i = 1; i < chunks.length; ++i) {
intermediatePerpScores[i] = combinePerp(intermediatePerpScores[i - 1], chunks[i], i);
}
return intermediatePerpScores;
}
function fyShuffle(data) {
let out = [...data];
let i = out.length;
while (--i > 0) {
let idx = Math.floor(Math.random() * (i + 1));
[out[idx], out[i]] = [out[i], out[idx]];
}
return out;
}
let test_N = 20000;
let Ns = data.map(() => []);
for (let i = 0; i < test_N; ++i) {
let randomized = fyShuffle(data);
let running = chunksToRunningScores(randomized);
for (let N = 1; N < data.length; ++N) {
Ns[N].push(Math.abs(5.9565 - running[N]));
}
}
Ns.forEach(x => x.sort((a, b) => a - b));
let idx = Math.floor(.9 * test_N); // 90% CI
for (let N = 1; N < Ns.length; ++N) {
console.log(N, Ns[N][idx].toFixed(4));
} |
|
started a run of 7B q4_0 to verify it still works after the refactor. using my quickfix #385 (comment) brb in ETA 7.22 hours result here: #406 (comment) |
|
I tested my approach now using objective perplexity. Unfortunately, the results are not much improved. I have the first 3 test results here with my Q4_1 improved quantization: $ ./main --perplexity -m models/7B/ggml-model-q4_1.bin -f wikitext-2-raw/wiki.test.raw
[1]4.4862,[2]4.9819,[3]5.8331,The best reference for stock Q4_1 is results from @Green-Sky which were: 4.4880 I suppose it is fair to say that at least it didn't make things much worse, and somewhat improved one of the poorer tests which is #3. The code recalculates the min/max parameters of the quantization using the average of values falling in bins 0 and 15, but rejects the result is root mean square error is not improved by the bounds. Edit: unfortunately, these results are also subject to the batching and threading parameters. They have to be specified or the results will different between otherwise identical runs. It seems I can replicate Green-Sky's results using at least -t 4 and -b 4, or at least the first three are the same, now. So when comparing results across implementations, it is necessary to have the same approximations occurring inside GGML. I produced the above results at default -t 8 and -b 8 on my hardware, so they are not comparable. I think the whole Q4_1 quantization improvements are not so easily proven unless large number of these tests are run, which takes a long time and slows down iterative development. Edit 2: I got comparable results using -t 4 and -b 4 and they are: 4.4791, 4.9720, 5.8831. I reimplemented on top of the old code the simplest algorithm that just averages the 0 and 15 bin values and quantizes with them without checking whether this choice actually improves quantization error. If I can get something that seems improves more than 0.02 or whatever, I may submit a pull request. Given that Q4_1 is only about 0.35 worse than ff16, something like 0.1 may already be worth considering. Edit 3: when introducing a check whether RMS quantization error is reduced before using the optimized parameters, the first three numbers become 4.5279, 4.9482, 5.8555. I have crap hardware for this task, though, barely enough memory to run the perplexity test & iteration time is around 200 seconds, so that is why the results are so few. I ran the "edit 2" test overnight until 199th result in the morning, which looks like it would be good estimate for the final value, and had it say 6.2773 there. ff16 is around 6 at that point. I think this conditional use of optimized parameters improves by about 0.03, so I guess it might be at 6.25 if I had the ability to run it long enough. |
|
Thanks @Green-Sky! I finished a run of 13B q4_0 overnight, and it looks great. A significant improvement vs 7B f16 even. I don't have enough RAM to run 13B f16 to compare though. I'm a bit unsure how batch size is implemented, perhaps it could allow it to work, might be good to test it's impact on perplexity as well.
13B q4_0 raw data4.0769 4.4621 5.3497 5.8519 6.0447 5.9598 6.0964 6.2027 6.4905 6.7087 6.8834 6.9285 6.8792 6.9671 7.1674 6.8171 6.7220 6.7009 6.3737 6.3470 6.2709 6.0945 6.0726 5.9819 5.9864 5.8302 5.6464 5.5507 5.4693 5.3187 5.2764 5.2890 5.2477 5.2937 5.3156 5.3393 5.3268 5.3235 5.3540 5.3967 5.4199 5.4603 5.4172 5.4553 5.4564 5.4264 5.4526 5.4301 5.4358 5.3985 5.4037 5.3947 5.4402 5.4290 5.4082 5.4348 5.4506 5.4722 5.4915 5.5310 5.5271 5.5827 5.6068 5.6159 5.6544 5.6547 5.6711 5.6852 5.7143 5.7453 5.7695 5.8068 5.8600 5.8669 5.8819 5.8954 5.9070 5.8932 5.9203 5.9150 5.9264 5.9268 5.8795 5.8658 5.8596 5.8412 5.7793 5.7415 5.7170 5.7060 5.7288 5.7241 5.7255 5.7242 5.7522 5.7506 5.7491 5.7465 5.7377 5.7326 5.7570 5.7509 5.7653 5.7727 5.7742 5.7895 5.7871 5.8011 5.7991 5.7952 5.8144 5.8324 5.8336 5.8314 5.8345 5.8213 5.8217 5.8448 5.8644 5.8955 5.9109 5.9343 5.9715 5.9905 5.9845 6.0218 6.0560 6.0856 6.0719 6.0811 6.0764 6.0713 6.0595 6.0685 6.0680 6.0586 6.0550 6.0407 6.0320 6.0321 6.0037 6.0004 5.9724 5.9553 5.9468 5.9351 5.9391 5.9411 5.9366 5.9354 5.9413 5.9345 5.9230 5.9158 5.9209 5.9184 5.9353 5.9383 5.9386 5.9416 5.9528 5.9259 5.9151 5.8924 5.8651 5.8405 5.8064 5.7782 5.7637 5.7552 5.7332 5.7192 5.7039 5.6751 5.6530 5.6389 5.6217 5.5997 5.5856 5.5775 5.5591 5.5430 5.5291 5.5277 5.5207 5.5225 5.5287 5.5261 5.5430 5.5440 5.5618 5.5747 5.5907 5.6016 5.6216 5.6340 5.6547 5.6679 5.6691 5.6700 5.6632 5.6784 5.6847 5.6816 5.6916 5.6961 5.6926 5.6981 5.7019 5.7068 5.7163 5.7228 5.7334 5.7373 5.7401 5.7529 5.7699 5.7841 5.7839 5.7797 5.7743 5.7748 5.7673 5.7601 5.7574 5.7782 5.7858 5.7930 5.8005 5.7958 5.8108 5.7986 5.7830 5.7689 5.7474 5.7424 5.7321 5.7347 5.7221 5.7126 5.7162 5.7174 5.7159 5.7066 5.7024 5.6914 5.6811 5.6740 5.6708 5.6744 5.6653 5.6603 5.6504 5.6451 5.6354 5.6186 5.6076 5.6004 5.5993 5.5911 5.5859 5.5802 5.5754 5.5562 5.5564 5.5530 5.5461 5.5535 5.5529 5.5541 5.5607 5.5645 5.5650 5.5658 5.5716 5.5781 5.5903 5.5983 5.6069 5.6104 5.6206 5.6255 5.6384 5.6480 5.6558 5.6684 5.6650 5.6703 5.6639 5.6492 5.6347 5.6206 5.6078 5.6087 5.6088 5.6136 5.6124 5.6148 5.6123 5.6032 5.6036 5.5971 5.5881 5.5801 5.5780 5.5671 5.5702 5.5716 5.5575 5.5539 5.5491 5.5506 5.5444 5.5428 5.5292 5.5256 5.5123 5.4958 5.5068 5.5182 5.5231 5.5192 5.5114 5.5096 5.5193 5.5214 5.5225 5.5263 5.5307 5.5325 5.5430 5.5392 5.5473 5.5419 5.5358 5.5379 5.5365 5.5370 5.5322 5.5289 5.5358 5.5391 5.5429 5.5432 5.5445 5.5429 5.5474 5.5512 5.5534 5.5515 5.5530 5.5534 5.5480 5.5487 5.5537 5.5568 5.5538 5.5625 5.5641 5.5606 5.5606 5.5674 5.5786 5.5840 5.5878 5.5887 5.5977 5.5949 5.5957 5.5973 5.5929 5.5975 5.6023 5.5999 5.5992 5.6055 5.6011 5.6029 5.6071 5.6003 5.5972 5.5926 5.5905 5.5902 5.5886 5.5871 5.5870 5.5838 5.5798 5.5742 5.5684 5.5650 5.5644 5.5677 5.5668 5.5613 5.5680 5.5720 5.5793 5.5779 5.5792 5.5808 5.5837 5.5893 5.5749 5.5707 5.5702 5.5714 5.5829 5.5923 5.6022 5.6166 5.6273 5.6341 5.6403 5.6480 5.6581 5.6610 5.6665 5.6748 5.6845 5.6881 5.6940 5.7036 5.7115 5.7178 5.7222 5.7299 5.7339 5.7405 5.7535 5.7569 5.7556 5.7517 5.7529 5.7557 5.7643 5.7717 5.7686 5.7680 5.7634 5.7616 5.7626 5.7642 5.7637 5.7653 5.7676 5.7711 5.7692 5.7697 5.7668 5.7525 5.7431 5.7383 5.7385 5.7425 5.7439 5.7426 5.7423 5.7503 5.7463 5.7431 5.7430 5.7425 5.7402 5.7327 5.7318 5.7304 5.7318 5.7309 5.7264 5.7279 5.7226 5.7215 5.7150 5.7138 5.7062 5.7040 5.7058 5.7084 5.7092 5.7042 5.6998 5.7011 5.6955 5.6892 5.6885 5.6864 5.6818 5.6790 5.6751 5.6687 5.6657 5.6642 5.6623 5.6585 5.6528 5.6511 5.6474 5.6390 5.6317 5.6308 5.6292 5.6210 5.6215 5.6220 5.6169 5.6127 5.6129 5.6155 5.6203 5.6240 5.6265 5.6324 5.6283 5.6268 5.6266 5.6259 5.6280 5.6290 5.6301 5.6319 5.6323 5.6378 5.6407 5.6408 5.6423 5.6365 5.6374 5.6329 5.6322 5.6372 5.6400 5.6380 5.6406 5.6363 5.6345 5.6397 5.6408 5.6426 5.6426 5.6440 5.6461 5.6477 5.6462 5.6462 5.6430 5.6383 5.6385 5.6364 5.6334 5.6315 5.6278 5.6256 5.6231 5.6222 5.6243 5.6211 5.6213 5.6199 5.6202 5.6175 5.6170 5.6212 5.6223 5.6226 5.6206 5.6214 5.6196 5.6225 5.6238 5.6248 5.6252 5.6222 5.6207 5.6203 5.6186 5.6167 5.6168 5.6110 5.6080 5.6087 5.6092 5.6095 5.6032 5.5976 5.5980 5.6028 5.6078 5.6107 5.6125 5.6115 5.6080 5.6092 5.6076 5.6122 5.6098 5.6068 5.6094 5.6084 5.6076 5.6083 5.6108 5.6120 5.6141 5.6155 5.6139 5.6108 5.6116 5.6160 5.6146 5.6168 5.6136 5.6092 5.6029 5.6053 5.5998 5.5949 5.5901 5.5785 5.5731 5.5709 5.5722 5.5726 5.5733 5.5727 5.5758 5.5761 5.5767 5.5799 5.5849 5.5901 5.5888 5.5918 5.5917 5.5886 5.5851 5.5871 5.5842 5.5848 5.5852 5.5908 5.5929 5.5944 5.5933 5.5969 5.5916 5.5929 5.5933 5.5961 5.6005 5.6009 5.6047 5.5991 5.5985 |

|
@glinscott nice result. Could it be improved further with q4_1 down to 5.21 perplexity like here https://nolanoorg.substack.com/p/int-4-llama-is-not-enough-int-3-and ? |
|
@Andrey36652 any compute resource counts. |
it really depends on how long you can let it compute. |
I think, 12-18 hours per day |
|
I'm running 64B q4_0 and seeing really nice results so far on my M1 Ultra - averaging 3.72 after 11 steps. I'll report when it is done in 15 hours or so. Uses 80GB of RAM. [1]3.0602,[2]3.4535,[3]4.0805,[4]3.8289,[5]3.6680,[6]3.5852,[7]3.7126,[8]3.8242,[9]3.8991,[10]3.9340,[11]3.9331 |
|
@jasontitus i think @gjmulder is running 65B q4_0 right now already, could you do q4_1 instead? |
|
How do I generate a q4_1 quantization? |
|
invoke ./quantize with 3 edit: i am assuming you have the f16 model files. |
Like this? |
|
yea, but for each file individually, or edit the python script and run that edit: editing the python script is more involved actually, since it will also name the file q4_0 |
|
I run this for _0 so just converting |
|
yes, and change filename to q4_1 , so you know :) |
|
@gjmulder can you chime in and tell us which 65B model you are testing right now? |
|
I am moving this to a Discussion. too much chatter in an merged pr :) edit: #406 |
|
Generating the new 65B q4_1 set now. Each file is 5.7GB rather than 4.8GB - I assume that is expected? 15G models/65B/ggml-model-f16.bin.1 |
@jasontitus - nice! to clarify though, the output is already averaged over the steps - so, the perplexity is 3.9331 averaged across the first 11 chunks at this point. |
yes, the quantization stores extra values, but produces better results. |
|
Great work! Evaluating q4_1 on an M1 Ultra might be a bit tough, since we don't have ARM NEON code for q4_1 inference yet (only AVX2 for Skylake-and-beyond Intel processors and compatible) and so it would fall back to the much, much slower scalar code. For those machines that do have AVX2, for Q4_1, I recommend pulling in code from my branch, which should run a little faster (5~10%in my tests). I've also been thinking if we shouldn't introduce a quantization format that matches GPTQ exactly, with a single shared scale and offset for each block. This has potential to be much more performant, as then the data fetched in each AVX2 accumulation step (16 bytes) could be perfectly cache-aligned, memory usage would be almost 1/3 lower, and inference is largely memory-bound anyway. (@ggerganov , what would be a good name for that format? |
|
|
|
I think I understand the GPTQ algorithm a bit better after reading the original paper (but it's not like I have the hardware to run it myself). Otherwise, your post in #397 actually subsumes most ideas I had - I was thinking it might be worth trying to do local gradient descent on the offset/range to minimize the squared error (equivalent to minimizing RMS, since sqrt is monotonic). The paper you linked is quite interesting too - I wonder if some of the simpler techniques mentioned in it/its references (such as picking the nth-percentile value rather than the max to determine the quantization range) are applicable in our case, since most of those tests seem to have been done with int8 but jointly quantizing a lot more values. I was testing the new perplexity measure with my performance fork and was dismayed to see deteriorations on the order of 0.05 for the score on the first batch (no time to run more) (when trying to measure the perplexity on various source files from HEAD). After permuting some more (commuting on \mathbb{R}) operations in the code (and, among others, getting a small improvement relative to baseline with one ordering), I'm pretty sure there are some numerical stability issues we're neglecting there. With my ~n=3 samples (main.cpp, utils.cpp, utils.h), the differences are always directionally the same (that is: variants that are bad on one are bad on all), which means some of them probably systematically result in more big+small additions. |
|
@blackhole89 It is worth running some number of those tests. It doesn't really mean much if the first batch inference is a bit worse or better, only the bigger average is important. While the first result should be composed of the logarithmic average of 256 inferences, it still has a lot of noise there. I am using the 3rd number output, and by that point tests run seems to be acting as expected, e.g. if I know RMS is reduced by a quantization I am trying, by that time the test results appear to get slightly better. This is all a bit preliminary, though. I have only had so much time to play with trying to improve the quantization, and my approach is currently quite boneheaded. I saw this link https://github.com/qwopqwop200/GPTQ-for-LLaMa with tables and they had round-to-nearest, which I take to be similar to Q4_1 judging from the result, though I don't know the details on what batching was used, for example. It had mere 6.28 perplexity result and GPTQ was only 6.26 for 7B model, barely better, with 128 element block size. This doesn't really fit, the other papers that have used round-to-nearest vs. GPTQ show improvement that approach quite close to ff16 baseline. |
|
@alankila I went and performed some tests on that (see this comment). Preliminarily, it seems to me that for quantizations and calculation tweaks to the same model, something like the first 30 batches is enough (though the <10 I did are indeed likely too few to detect improvements/deteriorations at the order of magnitude I see). However, comparing across models is much iffier (and in fact I get the sense that Wikitext itself is too short to really separate out quality differences at the scale we see: the last 5% of blocks produce unpredictable perplexity deviations of almost 0.1, so e.g. the "quality" ordering of two models with perplexity 5.1 and 5.3 resp. could be inverted by adding another 5% more text that's "like Wikitext"). |
"bot-in-a-box" - model d/l and automatic install into a OpenBLAS or CuBLAS Docker image
This adds an option to compute perplexity over the prompt input similar to https://huggingface.co/docs/transformers/perplexity. It does so by chunking up the prompt into non-overlapping chunks of the context window size. It then runs the forward pass and computes the softmax probability of the output logits for the last half of the context window. This is so the model always has some context to predict the next token. Be warned: it is pretty slow, taking about 4 hours or so to complete wikitext2 on a 32 core machine.
Note: when doing prediction over large prompts, the default 10% expansion for the memory buffer is not sufficient - there is definitely a non-linear scaling factor in there somewhere.
Example:
./main --perplexity -m models/7B/ggml-model-q4_0.bin -f wiki.test.rawperplexity: 6.5949 [655/655]Some example runs at context 512:
Context 1024 runs:
Which show that the 16 bit version of the model is the best (lower perplexity is better), the 4 bit quantization introduces a fair amount of error (but not disastrous certainly), and the
--memory_f16flag is almost identical to baseline 4 bit.Comparing to this article: https://nolanoorg.substack.com/p/int-4-llama-is-not-enough-int-3-and, where they compare 4-bit to GPTQ quantization. The results are comparable, which is a good sign!
