Max bytes read limit #8670
Max bytes read limit #8670
Conversation
29eb2ae to
4780298
Compare
pkg/validation/limits.go
Outdated
| QuerySplitDuration model.Duration `yaml:"split_queries_by_interval" json:"split_queries_by_interval"` | ||
| MinShardingLookback model.Duration `yaml:"min_sharding_lookback" json:"min_sharding_lookback"` | ||
| MaxQueryBytesRead flagext.ByteSize `yaml:"max_query_bytes_read" json:"max_query_bytes_read"` | ||
| MaxSubqueryBytesRead flagext.ByteSize `yaml:"max_subquery_bytes_read" json:"max_subquery_bytes_read"` |
There was a problem hiding this comment.
We had this open question in the epic:
Where should we enforce the querier level limit?
I decided to implement this check on the frontend rather than on the querier since that way the query and subqueries limits enforcement are close to each other on the same component.
| // skipRequestType returns whether we should cache the r request type. | ||
| // This is needed when we have middlewares that send different requests types down | ||
| // in the pipeline that do not support caching. | ||
| func (s *resultsCache) skipRequestType(r Request) bool { |
There was a problem hiding this comment.
This is needed to avoid caching the IndexStats request sent down the middleware pipeline by the querySizeLimiter. The same applies to sharding and splitting as these panic if the quest type is an IndexStats request.
I feel this type-checking solution is a bit too hacky. I think it would be nice if we could set a flag in the context to skip caching. Same for splitting and sharding. In the querySizeLimiter.Do function we would clone the input request context and enable these new flags so the stats request is not cached, split, or sharded.
I don't think implementing that would be too complicated. Moreover, we could set those context flags by looking at the HTTP request headers, which can be handy for debugging and testing. Wdyt?
There was a problem hiding this comment.
Rather than threading this logic through our middleware chain, what if we had a separate skip middleware chain for pre-querying these IndexStats requests? Look at how NewQueryShardMiddleware embeds two different middleware chains depending on whether we should use sharding or not. This would allow us to handle this without subsequent middlewares needing to be aware of this.
Another idea for later: what if we cached IndexStats requests in a results cache? What if we cached other types of index queries in results caches?
There was a problem hiding this comment.
Look at how NewQueryShardMiddleware embeds two different middleware chains depending on whether we should use sharding or not. This would allow us to handle this without subsequent middlewares needing to be aware of this.
IIUC, the pattern used in NewQueryShardMiddleware is useful only for bypassing that middleware itself, not the middlewares above or below the shard middleware itself in the pipeline.
In other words, when sharding is disabled, the request will skip the sharding-related middleware (shardingware) configured in NewQueryShardMiddleware but it will still go throughout the rest of middlewares configured in NewMetricTripperware after the sharding middleware (for example, it will go throughout the NewRetryMiddleware). The same applies to the IndexStats req done at dynamicShardResolver.Shard it skips the sharding mechanism, but not whatever is configured after sharding.
pkg/querier/queryrange/limits.go
Outdated
| } | ||
|
|
||
| // Get Stats for this query | ||
| var indexStatsReq definitions.Request = &logproto.IndexStatsRequest{} |
There was a problem hiding this comment.
IIUC, it's expected that the stats can report more bytes than what is actually read. What's the maximum difference we have seen or are aware of? I'm concerned about a query that would run just ok being refused because the stats misreported that the query would load too much data.
If we know that the stats values can be up to X% bigger than the true values, maybe we can add that X% as a threshold to the limit set by the user?
There was a problem hiding this comment.
We can also just target the bytes returned by the index, which seems more straightforward
There was a problem hiding this comment.
We can also just target the bytes returned by the index, which seems more straightforward.
That's what the IndexStatsRequest returns, doesn't it? If so, my comment above still applies: IIRC the IndexStatsResponse can return way more bytes than what is actually in the chunks.
There was a problem hiding this comment.
The index will return the bytes in the chunks, but we may not need to query them all (in the case of reaching the limit first). There is some duplication due to replication_factor (which still needs to be deduped at query time) and some chunks being recorded in multiple indices (which are time-sharded by day). I don't think this really matters though. We'll just set the expected limit based on what the index returns rather than the amount of data that ends up being queried, which is harder to measure/not known before we run the query (in the case of limited queries).
For instance, if the IndexStats returns 100GB but we regularly query 70GB of underlying data, that's fine. We'll just set the query.max-bytes=100GB. Basically, base our idea of what the limit should be on the IndexStats response, not the amount of data we ended up querying.
There was a problem hiding this comment.
This is heading in a great direction.
Elaborating on some of my comments, there are two new limits we need to enforce:
- max bytes for the entire query. We can query the index once prior to issuing smaller query pieces to the queriers.
- max bytes scheduled onto an individual querier. This is post-split+shard.
Right now, we submit IndexStats requests after splitby-time. This is means we query the entire query time range once. Now that we'll want to error when the entire query would process too much data, we'll also need to query the index for the entire range up front. We can look at optimizing this later, but for now I think it's an OK choice. However, let's try to avoid doing it three times by grouping together the post-split index queries that are used in query planning (shard_resolver.go) and limits enforcement.
pkg/querier/queryrange/limits.go
Outdated
| } | ||
|
|
||
| // Get Stats for this query | ||
| var indexStatsReq definitions.Request = &logproto.IndexStatsRequest{} |
There was a problem hiding this comment.
We can also just target the bytes returned by the index, which seems more straightforward
pkg/logql/syntax/parser.go
Outdated
| @@ -134,6 +134,29 @@ func ParseMatchers(input string) ([]*labels.Matcher, error) { | |||
| return matcherExpr.Mts, nil | |||
| } | |||
|
|
|||
| // ExtractMatchersFromQuery extracts the matchers from a query. | |||
| // compared to ParseMatchers, it will not fail if the query contains anything else. | |||
| func ExtractMatchersFromQuery(input string) ([]*labels.Matcher, error) { | |||
There was a problem hiding this comment.
There's a function syntax.MatcherGroups which is is what you'll want as it gives [(matchers, time_range)] pairs within a query. This is used in queryrange/shard_resolver.go.
There was a problem hiding this comment.
Good call! I didn't think about the queries that may contain multiple matchers. E.g from (TestMatcherGroups).
count_over_time({job="foo"}[5m]) / count_over_time({job="bar"}[5m] offset 10m)
IIUC, similarly to in shard_resolver.go, we need to create a IndexStats request for each matcher. Then we need to sum the bytes for each IndexStats response. That's the amount of data a query would read.
There was a problem hiding this comment.
I implemented this in 2a1df3e. Looks like it works fine. If this is what you meant, I do have some new questions 😅:
- Shall we set the concurrency to get index stats from a config as done in shardResolverForConf?
- I can see some places where the
ForEachis set to nonconfigurable values. - For simplicity, I think it should be ok to leave the concurrency as
len(matcherGroups)or to a fixed not-so-high value (e.g. 10). But happy to change my mind.
- I can see some places where the
- As in dynamicShardResolver.Shards, for log selector queries, should we also subtract the
max_look_back_periodfrom the query start time? I think I don't quite understand why is that needed on sharding.
There was a problem hiding this comment.
max_look_back_period is generally most important in limited instant queries (which are rarely used). If I submit {job="foo"} with start=end, It would always return zero results. Prometheus has a concept of "look back amount of time for instant queries" since metric data is sampled at some configurable scrape_interval (commonly 15s, 30s, or 1m). We sort of copy that idea and say, "find me logs from the past when start=end".
There was a problem hiding this comment.
Just came across this myself. I don't think we need an extra method.
pkg/querier/queryrange/limits.go
Outdated
| @@ -45,13 +50,16 @@ type Limits interface { | |||
| // TSDBMaxQueryParallelism returns the limit to the number of split queries the | |||
| // frontend will process in parallel for TSDB queries. | |||
| TSDBMaxQueryParallelism(string) int | |||
| MaxQueryBytesRead(u string) int | |||
| MaxSubqueryBytesRead(u string) int | |||
There was a problem hiding this comment.
I'd rename this to MaxQuerierBytesRead as the term subquery is overloaded in prometheus (and we may add this concept eventually in loki)
pkg/querier/queryrange/limits.go
Outdated
| limitErrTmpl = "maximum of series (%d) reached for a single query" | ||
| limitErrTmpl = "maximum of series (%d) reached for a single query" | ||
| limErrQueryTooManyBytesTmpl = "the query would read too many bytes (query: %s, limit: %s)" | ||
| limErrSubqueryTooManyBytesTmpl = "after splitting and sharding, at least one sub-query would read too many bytes (query: %s, limit: %s)" |
There was a problem hiding this comment.
| limErrSubqueryTooManyBytesTmpl = "after splitting and sharding, at least one sub-query would read too many bytes (query: %s, limit: %s)" | |
| limErrSubqueryTooManyBytesTmpl = "query too large to execute on a single querier, either because parallelization is not enabled or the query is unshardable: (query: %s, limit: %s)" |
pkg/querier/queryrange/limits.go
Outdated
|
|
||
| // NewQuerySizeLimiterMiddleware creates a new Middleware that enforces query size limits. | ||
| // The errorTemplate should format two strings: the bytes that would be read and the bytes limit. | ||
| func NewQuerySizeLimiterMiddleware(maxQueryBytesRead func(string) int, errorTemplate string) queryrangebase.Middleware { |
There was a problem hiding this comment.
Each request will send a request to the index-gws to sample the index. Here's a few things we'll want to take into account
- Skip non-TSDB schemas since they don't have support for this.
All TSDB requests already query the index-gw for the same data to use in query planning (guessing correct shard factors). Look at howThinking about this more, we'll need to query the index for the entire query time-range first to figure out if the query is too large. This will effectively double the index load forshard_resolver.goimplements this, but we'll want to make sure we only pre-query the index once per request.IndexStatsrequests traffic, but I think that's OK for now (we can optimize that part later if/when it becomes an issue). We will want to split these first-pass IndexStats requests in a maximum of 24h chunks since our indices are sharded by 24h periods. Take a look atNewSeriesTripperwarefor an idea of how this works. Note: adding this limit may expose new bottlenecks in our idx-gws+tsdb that we need to address.
There was a problem hiding this comment.
Skip non-TSDB schemas since they don't have support for this.
Implemented in 1674e67.
We will want to split these first-pass IndexStats requests in a maximum of 24h chunks since our indices are sharded by 24h periods. Take a look at NewSeriesTripperware for an idea of how this works. Note: adding this limit may expose new bottlenecks in our idx-gws+tsdb that we need to address.
By "first-pass IndexStats requests" here: Do you mean the IndexStat requests to get the stats for all the matcher groups in the whole query (before splitting and sharding)?
I'm not sure I understand the 24h part, do we have any docs so I can better understand this 24h sharding at the index level?
pkg/validation/limits.go
Outdated
| QuerySplitDuration model.Duration `yaml:"split_queries_by_interval" json:"split_queries_by_interval"` | ||
| MinShardingLookback model.Duration `yaml:"min_sharding_lookback" json:"min_sharding_lookback"` | ||
| MaxQueryBytesRead flagext.ByteSize `yaml:"max_query_bytes_read" json:"max_query_bytes_read"` | ||
| MaxSubqueryBytesRead flagext.ByteSize `yaml:"max_subquery_bytes_read" json:"max_subquery_bytes_read"` |
There was a problem hiding this comment.
| MaxSubqueryBytesRead flagext.ByteSize `yaml:"max_subquery_bytes_read" json:"max_subquery_bytes_read"` | |
| MaxQuerierBytesRead flagext.ByteSize `yaml:"max_querier_bytes_read" json:"max_querier_bytes_read"` |
nit: naming as specified earlier
pkg/validation/limits.go
Outdated
| @@ -223,6 +225,11 @@ func (l *Limits) RegisterFlags(f *flag.FlagSet) { | |||
| _ = l.MinShardingLookback.Set("0s") | |||
| f.Var(&l.MinShardingLookback, "frontend.min-sharding-lookback", "Limit queries that can be sharded. Queries within the time range of now and now minus this sharding lookback are not sharded. The default value of 0s disables the lookback, causing sharding of all queries at all times.") | |||
|
|
|||
| _ = l.MaxQueryBytesRead.Set("0B") | |||
There was a problem hiding this comment.
| _ = l.MaxQueryBytesRead.Set("0B") |
nit: 0B is the default when unset
pkg/validation/limits.go
Outdated
| @@ -223,6 +225,11 @@ func (l *Limits) RegisterFlags(f *flag.FlagSet) { | |||
| _ = l.MinShardingLookback.Set("0s") | |||
| f.Var(&l.MinShardingLookback, "frontend.min-sharding-lookback", "Limit queries that can be sharded. Queries within the time range of now and now minus this sharding lookback are not sharded. The default value of 0s disables the lookback, causing sharding of all queries at all times.") | |||
|
|
|||
| _ = l.MaxQueryBytesRead.Set("0B") | |||
| f.Var(&l.MaxQueryBytesRead, "frontend.max-query-bytes-read", "TODO: Max number of bytes a query would fetch") | |||
| _ = l.MaxSubqueryBytesRead.Set("0B") | |||
There was a problem hiding this comment.
| _ = l.MaxSubqueryBytesRead.Set("0B") |
nit: 0B is the default zero value when unset
There was a problem hiding this comment.
Things we'll still need to address:
Rather than threading this logic through our middleware chain, what if we had a separate
skipmiddleware chain for pre-querying theseIndexStatsrequests? Look at howNewQueryShardMiddlewareembeds two different middleware chains depending on whether we should use sharding or not. This would allow us to handle this without subsequent middlewares needing to be aware of this.Another idea for later: what if we cached
IndexStatsrequests in a results cache? What if we cached other types of index queries in results caches?
- Let's avoid tripling the load on the index-gateway
Right now, we submit IndexStats requests after splitby-time. This is means we query the entire query time range once. Now that we'll want to error when the entire query would process too much data, we'll also need to query the index for the entire range up front. We can look at optimizing this later, but for now I think it's an OK choice. However, let's try to avoid doing it three times by grouping together the post-split index queries that are used in query planning (shard_resolver.go) and limits enforcement.
This is important because in this PR, each query through the query frontend requests IndexStats three times.
- First to satisfy
max-total-bytes-per-query - Second during shard-planning to determine the ideal shard factor per query
- Third at the end (post-split) to satisfy
max-querier-bytes-per-query
This PR effectively triples all IndexStats work. We should think about ways to reduce this. Additionally, we should add a middleware to parallelize the first call above so it doesn't send a huge request to a single index-gw (i.e. {app=~".+"} for 30d). I mentioned that here:
We will want to split these first-pass IndexStats requests in a maximum of 24h chunks since our indices are sharded by 24h periods. Take a look at NewSeriesTripperware for an idea of how this works. Note: adding this limit may expose new bottlenecks in our idx-gws+tsdb that we need to address.
pkg/querier/queryrange/limits.go
Outdated
| if matcherGroups[i].Interval == 0 { | ||
| // TODO: IIUC, this is needed for instant queries. | ||
| // Should we use the MaxLookBackPeriod as done in shardResolverForConf? | ||
| adjustedFrom = adjustedFrom.Add(-100) |
There was a problem hiding this comment.
Yes, MaxLookBackPeriod is what we want here (and I think it's a good idea to extract this to a utility somewhere we can reuse)
There was a problem hiding this comment.
Done with aaf90e5
|
|
||
| resp, err := q.next.Do(ctx, indexStatsReq) | ||
| // TODO: This is pretty similar to ShardingConfigs.ValidRange, we should probably extract the functionality to a new function | ||
| func (q *querySizeLimiter) getSchemaCfg(r queryrangebase.Request) (config.PeriodConfig, error) { |
There was a problem hiding this comment.
I think you can reuse ShardingConfigs here. We can actually extend that functionality in the case there are multiple period configs in the query and they all are tsdb (and have the IndexStats support).
There was a problem hiding this comment.
Done with c9c8610.
We can actually extend that functionality in the case there are multiple period configs in the query and they all are tsdb
I don't know what you mean by this. If two consecutive PeriodConfig are TSDB, combine them into a new PeriodConfig with a From and Interval adjusted to cover both original periods?
There was a problem hiding this comment.
Let's leave it for a followup PR but yes. The idea is we can shard requests across two different TSDB schemas
pkg/querier/queryrange/limits.go
Outdated
| } | ||
|
|
||
| // Get Stats for this query | ||
| var indexStatsReq definitions.Request = &logproto.IndexStatsRequest{} |
There was a problem hiding this comment.
The index will return the bytes in the chunks, but we may not need to query them all (in the case of reaching the limit first). There is some duplication due to replication_factor (which still needs to be deduped at query time) and some chunks being recorded in multiple indices (which are time-sharded by day). I don't think this really matters though. We'll just set the expected limit based on what the index returns rather than the amount of data that ends up being queried, which is harder to measure/not known before we run the query (in the case of limited queries).
For instance, if the IndexStats returns 100GB but we regularly query 70GB of underlying data, that's fine. We'll just set the query.max-bytes=100GB. Basically, base our idea of what the limit should be on the IndexStats response, not the amount of data we ended up querying.
pkg/logql/syntax/parser.go
Outdated
| @@ -134,6 +134,29 @@ func ParseMatchers(input string) ([]*labels.Matcher, error) { | |||
| return matcherExpr.Mts, nil | |||
| } | |||
|
|
|||
| // ExtractMatchersFromQuery extracts the matchers from a query. | |||
| // compared to ParseMatchers, it will not fail if the query contains anything else. | |||
| func ExtractMatchersFromQuery(input string) ([]*labels.Matcher, error) { | |||
There was a problem hiding this comment.
max_look_back_period is generally most important in limited instant queries (which are rarely used). If I submit {job="foo"} with start=end, It would always return zero results. Prometheus has a concept of "look back amount of time for instant queries" since metric data is sampled at some configurable scrape_interval (commonly 15s, 30s, or 1m). We sort of copy that idea and say, "find me logs from the past when start=end".
Done with 648589e and 75b1d54.
Done at a024f95.
Working on this one now. |
|
@dannykopping raises some good points about messaging. After talking with @salvacorts , we're going to address the following in separate PRs since this is already so large:
|
|
great, 👍 |
**What this PR does / why we need it**: In #8670 we introduced a new limit `max_querier_bytes_read`. When the limit was surpassed the following error message is printed: ``` query too large to execute on a single querier, either because parallelization is not enabled, the query is unshardable, or a shard query is too big to execute: (query: %s, limit: %s). Consider adding more specific stream selectors or reduce the time range of the query ``` As pointed out in [this comment][1], a user would have a hard time figuring out whether the cause was `parallelization is not enabled`, `the query is unshardable` or `a shard query is too big to execute`. This PR improves the error messaging for the `max_querier_bytes_read` limit to raise a different error for each of the causes above. **Which issue(s) this PR fixes**: Followup for #8670 **Special notes for your reviewer**: **Checklist** - [x] Reviewed the [`CONTRIBUTING.md`](https://github.com/grafana/loki/blob/main/CONTRIBUTING.md) guide (**required**) - [x] Documentation added - [x] Tests updated - [ ] `CHANGELOG.md` updated - [ ] Changes that require user attention or interaction to upgrade are documented in `docs/sources/upgrading/_index.md` [1]: #8670 (comment) --------- Co-authored-by: Danny Kopping <[email protected]>
**What this PR does / why we need it**: At #8670, we applied a time split of 24h intervals to all index stats requests to enforce the `max_query_bytes_read` and `max_querier_bytes_read` limits. When the limit is surpassed, the following message get's displayed:  As can be seen, the reported bytes read by the query are not the same as those reported by Grafana in the lower right corner of the query editor. This is because: 1. The index stats request for enforcing the limit is split in subqueries of 24h. The other index stats rquest is not time split. 2. When enforcing the limit, we are not displaying the bytes in powers of 2, but powers of 10 ([see here][2]). I.e. 1KB is 1000B vs 1KiB is 1024B. This PR adds the same logic to all index stats requests so we also time split by 24 intervals all requests that hit the Index Stats API endpoint. We also use powers of 2 instead of 10 on the message when enforcing `max_query_bytes_read` and `max_querier_bytes_read`. 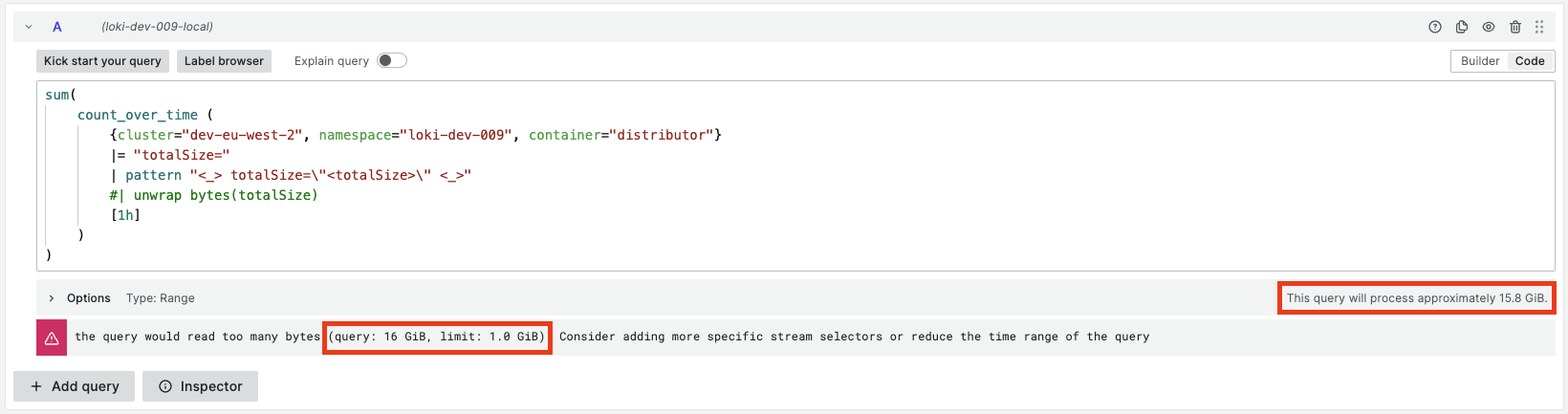 Note that the library we use under the hoot to print the bytes rounds up and down to the nearest integer ([see][3]); that's why we see 16GiB compared to the 15.5GB in the Grafana query editor. **Which issue(s) this PR fixes**: Fixes #8910 **Special notes for your reviewer**: - I refactored the`newQuerySizeLimiter` function and the rest of the _Tripperwares_ in `rountrip.go` to reuse the new IndexStatsTripperware. So we configure the split-by-time middleware only once. **Checklist** - [x] Reviewed the [`CONTRIBUTING.md`](https://github.com/grafana/loki/blob/main/CONTRIBUTING.md) guide (**required**) - [x] Documentation added - [x] Tests updated - [x] `CHANGELOG.md` updated - [ ] Changes that require user attention or interaction to upgrade are documented in `docs/sources/upgrading/_index.md` [1]: https://grafana.com/docs/loki/latest/api/#index-stats [2]: https://github.com/grafana/loki/blob/main/pkg/querier/queryrange/limits.go#L367-L368 [3]: https://github.com/dustin/go-humanize/blob/master/bytes.go#L75-L78
{kind=link}
{kind=link}
**What this PR does / why we need it**: At #8670, we applied a time split of 24h intervals to all index stats requests to enforce the `max_query_bytes_read` and `max_querier_bytes_read` limits. When the limit is surpassed, the following message get's displayed:  As can be seen, the reported bytes read by the query are not the same as those reported by Grafana in the lower right corner of the query editor. This is because: 1. The index stats request for enforcing the limit is split in subqueries of 24h. The other index stats rquest is not time split. 2. When enforcing the limit, we are not displaying the bytes in powers of 2, but powers of 10 ([see here][2]). I.e. 1KB is 1000B vs 1KiB is 1024B. This PR adds the same logic to all index stats requests so we also time split by 24 intervals all requests that hit the Index Stats API endpoint. We also use powers of 2 instead of 10 on the message when enforcing `max_query_bytes_read` and `max_querier_bytes_read`.  Note that the library we use under the hoot to print the bytes rounds up and down to the nearest integer ([see][3]); that's why we see 16GiB compared to the 15.5GB in the Grafana query editor. **Which issue(s) this PR fixes**: Fixes #8910 **Special notes for your reviewer**: - I refactored the`newQuerySizeLimiter` function and the rest of the _Tripperwares_ in `rountrip.go` to reuse the new IndexStatsTripperware. So we configure the split-by-time middleware only once. **Checklist** - [x] Reviewed the [`CONTRIBUTING.md`](https://github.com/grafana/loki/blob/main/CONTRIBUTING.md) guide (**required**) - [x] Documentation added - [x] Tests updated - [x] `CHANGELOG.md` updated - [ ] Changes that require user attention or interaction to upgrade are documented in `docs/sources/upgrading/_index.md` [1]: https://grafana.com/docs/loki/latest/api/#index-stats [2]: https://github.com/grafana/loki/blob/main/pkg/querier/queryrange/limits.go#L367-L368 [3]: https://github.com/dustin/go-humanize/blob/master/bytes.go#L75-L78 (cherry picked from commit ee69f2b)
|
Wrt #8670 (comment) and #8670 (comment), I just created this PR to pass down the engine opts to the middlewares creating a new downstream engine. |
**What this PR does / why we need it**:
The following middlewares in the query frontend uses a downstream
engine:
- `NewQuerySizeLimiterMiddleware` and `NewQuerierSizeLimiterMiddleware`
- `NewQueryShardMiddleware`
- `NewSplitByRangeMiddleware`
These were all creating the downstream engine as follows:
```go
logql.NewDownstreamEngine(logql.EngineOpts{LogExecutingQuery: false}, DownstreamHandler{next: next, limits: limits}, limits, logger),
```
As can be seen, the [engine options configured in Loki][1] were not
being used at all. In the case of `NewQuerySizeLimiterMiddleware`,
`NewQuerierSizeLimiterMiddleware` and `NewQueryShardMiddleware`, the
downstream engine was created to get the `MaxLookBackPeriod`. When
creating a new Downstream Engine as above, the `MaxLookBackPeriod`
[would always be the default][2] (30 seconds).
This PR fixes this by passing down the engine config to these
middlewares, so this config is used to create the new downstream
engines.
**Which issue(s) this PR fixes**:
Adresses some pending tasks from
#8670 (comment).
**Special notes for your reviewer**:
**Checklist**
- [x] Reviewed the
[`CONTRIBUTING.md`](https://github.com/grafana/loki/blob/main/CONTRIBUTING.md)
guide (**required**)
- [ ] Documentation added
- [x] Tests updated
- [x] `CHANGELOG.md` updated
- [ ] Changes that require user attention or interaction to upgrade are
documented in `docs/sources/upgrading/_index.md`
[1]:
https://github.com/grafana/loki/blob/1bcf683513b5e11fb1dcc5625761b9760cfbd958/pkg/querier/querier.go#L52
[2]:
https://github.com/grafana/loki/blob/edc6b0bff76714ff584c20d7ff0235461a4f4a88/pkg/logql/engine.go#L136-L140
|
@salvacorts When will this be released ? I installed 2.8.3 but doesn't look it's there. |
|
I am seeing instances of this setting (max_query_bytes_read) blocking a query, but then the log volume query still gets ran. That query seems to then read more bytes then I have configured to block. Is this expected behavor? |
|
The log volume query just queries the index and approximates the amount of data to be processed. |
|
No, I am talking about the log volume query that is ran to generate the graph above the log lines. |
|
Ah right, apologies. Which version of Grafana are you running? |
|
v10.1.1 |
|
Inside Grafana, please open devtools and execute this in the console, and report back the result please: |
|
false |
|
Interesting, ok. |
|
Loki v2.9.1 Here is an example of a query that is blocked, but the log volume query is still ran. |
|
OK thanks. These logs are from your |
|
I run loki in Monolithic mode. |
What this PR does / why we need it:
This PR implements two new per-tenant limits that are enforced on log and metric queries (both range and instant) when TSDB is used:
max_query_bytes_read: Refuse queries that would read more than the configured bytes here. Overall limit regardless of splitting/sharding. The goal is to refuse queries that would take too long. The default value of 0 disables this limit.max_querier_bytes_read: Refuse queries in which any of their subqueries after splitting and sharding would read more than the configured bytes here. The goal is to avoid a querier from running a query that would load too much data in memory and can potentially get OOMed. The default value of 0 disables this limit.These new limits can be configured per tenant and per query (see #8727).
The bytes a query would read are estimated through TSDB's index stats. Even though they are not exact, they are good enough to have a rough estimation of whether a query is too big to run or not. For more details on this refer to this discussion in the PR: #8670 (comment).
Both limits are implemented in the frontend. Even though we considered implementing
max_querier_bytes_readin the querier, this way, the limits for pre and post splitting/sharding queries are enforced close to each other on the same component. Moreover, this way we can reduce the number of index stats requests issued to the index gateways by reusing the stats gathered while sharding the query.With regard to how index stats requests are issued:
{app=~".+"} for 30d.max_querier_bytes_read, we re-use the stats requests issued by the sharding ware. Specifically, we look at the bytesPerShard to enforce this limit.Note that once we merge this PR and enable these limits, the load of index stats requests will increase substantially and we may discover bottlenecks in our index gateways and TSDB. After speaking with @owen-d, we think it should be fine as, if needed, we can scale up our index gateways and support caching index stats requests.
Here's a demo of this working:

Which issue(s) this PR fixes:
This PR addresses https://github.com/grafana/loki-private/issues/698
Special notes for your reviewer:
Checklist
CONTRIBUTING.mdguide (required)CHANGELOG.mdupdateddocs/sources/upgrading/_index.md