Hash Table
Let's learn how to implement a hash table in C!
The basic concept of a hash table is to store key-value relationships in an array of slots. A hashing function is used to turn the key into a slot index.
Because the core of the data structure is an array, all of the hash table operations are O(1) time.
The simplest place to start is a humble array of void* pointers.
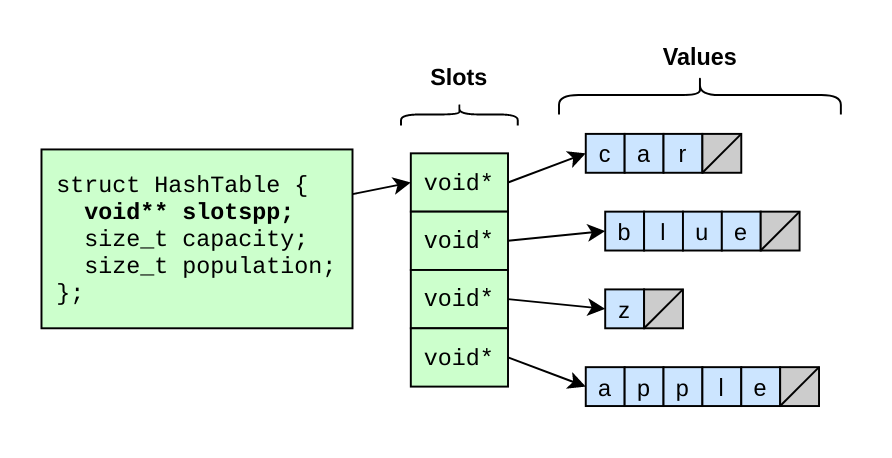
As we will see, this is not a good hash table, but it makes for a good conceptual starting place.
Our initial hash table structure has:
- a pointer to an array of pointers to values
- the length of that array
- how many slots in the array are occupied
struct _HashTable {
void** slotspp;
size_t capacity;
size_t population;
};
typedef struct _HashTable HashTable;A couple of functions to create and destory a HashTable.
HashTable* HashTableMake(size_t capacity) {
HashTable* htp = dmalloc(sizeof(HashTable));
htp->capacity = capacity;
htp->slotspp = dmalloc(sizeof(void*) * capacity);
return htp;
}void HashTableFree(HashTable* htp) {
free(htp->slotspp);
free(htp);
}For now, we aren't interested in being pedantic with error handling. If malloc fails, just bail.
void* dmalloc(size_t size) {
void* p = malloc(size);
if (p == NULL) {
perror("Error: malloc failed: ");
exit(1);
}
memset(p, 0, size);
return p;
}
#define malloc(x) dont_use_malloc_use_dmallocHere we see the core of the hash table concept: values are accessed using a key's hash value, which is modded by the size of the array.
void* HashTableGet(HashTable* htp, size_t keyHash) {
size_t slotIndex = keyHash % htp->capacity;
return htp->slotspp[slotIndex];
}Setting a value is essentially the same, with some additional population bookkeeping.
void HashTableSet(HashTable* htp, size_t keyHash, void* valuep) {
size_t slotIndex = keyHash % htp->capacity;
if (htp->slotspp[slotIndex] == NULL && valuep != NULL) {
htp->population++;
} else if (htp->slotspp[slotIndex] != NULL && valuep == NULL) {
htp->population--;
}
htp->slotspp[slotIndex] = valuep;
}A hashing function reduces a piece of data (a key) to an integer.
We'll start with the simplest possible hashing function: just sum all of the bytes into an integer. Let's name this function after its performance: terrible!
size_t terribleHash(void* datap, size_t length) {
size_t sum = 0;
for (size_t i=0; i < length; i++) {
uint8_t* byte = datap + i;
sum += *byte;
continue;
}
return sum;
}Let's write a few tests to ensure setting and getting values works correctly.
void testSet() {
printf("%s... ", __FUNCTION__);
size_t capacity = 3;
HashTable* htp = HashTableMake(capacity);
char* keyp = "hello";
char* valuep = "world";
size_t keyHash = terribleHash(keyp, strlen(keyp)+1);
HashTableSet(htp, keyHash, valuep);
assert(htp->population == 1);
printf("OK\n");
}void testGet() {
printf("%s... ", __FUNCTION__);
size_t capacity = 3;
HashTable* htp = HashTableMake(capacity);
char* keyp = "hello";
char* valuep = "world";
size_t keyHash = terribleHash(keyp, strlen(keyp)+1);
HashTableSet(htp, keyHash, valuep);
char* gotp = HashTableGet(htp, keyHash);
assert(strcmp(valuep, gotp) == 0);
printf("OK\n");
}Our next test illustrates the most obvious limitation of this design: if two keys hash to the same slot, we have no way to mitigate this "slot collision".
The easiest way to trigger this problem is by creating a hash table with capacity 1, then attempting to store two values. Storing the second value causes the first value to be lost.
void testSlotCollision() {
printf("%s... ", __FUNCTION__);
size_t capacity = 1;
HashTable* htp = HashTableMake(capacity);
char* key1p = "hello";
char* value1p = "world";
size_t key1Hash = terribleHash(key1p, strlen(key1p)+1);
HashTableSet(htp, key1Hash, value1p);
assert(htp->population == 1);
char* key2p = "foo";
char* value2p = "bar";
size_t key2Hash = terribleHash(key2p, strlen(key2p)+1);
HashTableSet(htp, key2Hash, value2p);
assert(htp->population == 2);
char* got1p = HashTableGet(htp, key1Hash);
assert(strcmp(value1p, got1p) == 0);
char* got2p = HashTableGet(htp, key2Hash);
assert(strcmp(value2p, got2p) == 0);
printf("OK\n");
}tests: tests.c:64: testSlotCollision: Assertion `htp->population == 2' failed.
One technique to resolve the problem of "slot collisions" is the concept of chaining, which is a fancy way of saying "use linked lists".
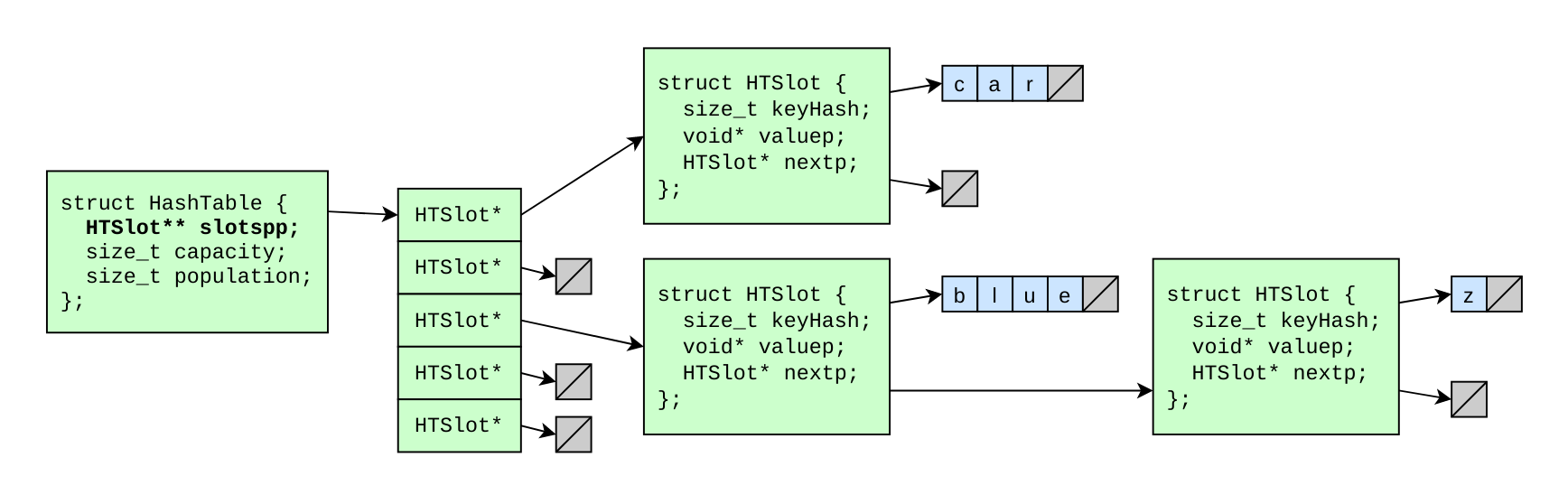
We'll call our linked list node an HTSlot. It will contain:
- a key's hash
- a pointer to a value
- a pointer to the next
HTSlot
struct _HTSlot {
size_t keyHash;
void* valuep;
struct _HTSlot* nextp;
};
typedef struct _HTSlot HTSlot;Our HashTable needs to be updated.
struct _HashTable {
- void** slotspp;
+ HTSlot** slotspp;
size_t capacity;
size_t population;
};HashTableFree needs to walk and free each HTSlot list.
void HashTableFree(HashTable* htp) {
+ for (size_t i=0; i < htp->capacity; i++) {
+ HTSlot* slotp = htp->slotspp[i];
+ while (slotp != NULL) {
+ HTSlot* tmp = slotp;
+ free(slotp);
+ slotp = tmp->nextp;
+ continue;
+ }
+ }
free(htp->slotspp);
free(htp);
}HashTableGet needs to walk each slot list and look for an exact key hash match.
void* HashTableGet(HashTable* htp, size_t keyHash) {
size_t slotIndex = keyHash % htp->capacity;
- return htp->slotspp[slotIndex];
+ HTSlot* cursorp = htp->slotspp[slotIndex];
+ while (cursorp != NULL) {
+ if (cursorp->keyHash == keyHash) {
+ return cursorp->valuep;
+ } else {
+ cursorp = cursorp->nextp;
+ continue;
+ }
+ }
+ return NULL;
}HashTableSet walks the slot list, looking for a match to update.
If it doesn't find one, it appends a new slot onto the list.
void HashTableSet(HashTable* htp, size_t keyHash, void* valuep) {
size_t slotIndex = keyHash % htp->capacity;
HTSlot* cursorp = htp->slotspp[slotIndex];
while (cursorp != NULL) {
if (cursorp->keyHash == keyHash) {
cursorp->valuep = valuep;
if (cursorp->valuep == NULL && valuep != NULL) {
htp->population++;
} else if (cursorp->valuep != NULL && valuep == NULL) {
htp->population--;
}
return;
} else {
cursorp = cursorp->nextp;
continue;
}
}
// no existing match? append a new slot to the list.
if (valuep != NULL) {
HTSlot* newSlotp = _HTSlotMake();
newSlotp->keyHash = keyHash;
newSlotp->valuep = valuep;
if (htp->slotspp[slotIndex] == NULL) {
htp->slotspp[slotIndex] = newSlotp;
} else {
HTSlot* lastp = htp->slotspp[slotIndex];
while (lastp->nextp != NULL) {
lastp = lastp->nextp;
continue;
}
lastp->nextp = newSlotp;
}
htp->population++;
}
}With these changes, our slot collision test passes!
./tests
testMake... OK
testFree... OK
testSet... OK
testGet... OK
testSlotCollision... OK
However, there is still a problem with this hash table: it doesn't handle the case where two different keys happen to produce the same hash.
We can demonstrate this with a test.
This is an easy task for us, as terribleHash is so simplistic
that intentionally creating a hash collision is as easy as rearranging the letters in a key.
void testHashCollision() {
printf("%s... ", __FUNCTION__);
size_t capacity = 1;
HashTable* htp = HashTableMake(capacity);
char* key1p = "ab";
char* value1p = "cd";
size_t key1Hash = terribleHash(key1p, strlen(key1p)+1);
HashTableSet(htp, key1Hash, value1p);
assert(htp->population == 1);
char* key2p = "ba";
char* value2p = "dc";
size_t key2Hash = terribleHash(key2p, strlen(key2p)+1);
HashTableSet(htp, key2Hash, value2p);
assert(htp->population == 2);
char* got1p = HashTableGet(htp, key1Hash);
assert(strcmp(value1p, got1p) == 0);
char* got2p = HashTableGet(htp, key2Hash);
assert(strcmp(value2p, got2p) == 0);
printf("OK\n");
}tests: tests.c:90: testHashCollision: Assertion `htp->population == 2' failed.
In order to handle hash collisions, we can do a byte-for-byte comparison of the keys. To do this, each slot needs to store a reference to the key as well as its length.

struct _HTSlot {
+ void* keyp;
+ size_t keyLength;
size_t keyHash;
void* valuep;
struct _HTSlot* nextp;
};
typedef struct _HTSlot HTSlot;HashTableGet and HashTableSet are both updated to perform a full byte-for-byte comparison of the keys.
-void* HashTableGet(HashTable* htp, size_t keyHash) {
+void* HashTableGet(HashTable* htp, void* keyp, size_t keyLength,
+ size_t keyHash
+) {
size_t slotIndex = keyHash % htp->capacity;
HTSlot* cursorp = htp->slotspp[slotIndex];
while (cursorp != NULL) {
- if (cursorp->keyHash == keyHash) {
+ if (cursorp->keyHash == keyHash
+ && cursorp->keyLength == keyLength
+ && memcmp(cursorp->keyp, keyp, keyLength) == 0
+ ) {
return cursorp->valuep;
} else {
cursorp = cursorp->nextp;
continue;
}
}
return NULL;
}Additionally, HashTableSet is updated to store the key pointer and key length.
-void HashTableSet(HashTable* htp, size_t keyHash, void* valuep) {
+void HashTableSet(HashTable* htp, void* keyp, size_t keyLength,
+ size_t keyHash, void* valuep
+) {
+ size_t slotIndex = keyHash % htp->capacity;
+ HTSlot* cursorp = htp->slotspp[slotIndex];
+ while (cursorp != NULL) {
+ if (cursorp->keyHash == keyHash
+ && cursorp->keyLength == keyLength
+ && memcmp(cursorp->keyp, keyp, keyLength) == 0
+ ) {
cursorp->valuep = valuep;
if (cursorp->valuep == NULL && valuep != NULL) {
htp->population++;
} else if (cursorp->valuep != NULL && valuep == NULL) {
htp->population--;
}
return;
} else {
cursorp = cursorp->nextp;
continue;
}
}
// no existing match? append a new slot to the list.
if (valuep != NULL) {
HTSlot* newSlotp = _HTSlotMake();
+ newSlotp->keyp = keyp;
+ newSlotp->keyLength = keyLength;
newSlotp->keyHash = keyHash;
newSlotp->valuep = valuep;
if (htp->slotspp[slotIndex] == NULL) {
htp->slotspp[slotIndex] = newSlotp;
} else {
HTSlot* lastp = htp->slotspp[slotIndex];
while (lastp->nextp != NULL) {
lastp = lastp->nextp;
continue;
}
lastp->nextp = newSlotp;
}
htp->population++;
}
}Our hash table now handles hash collisions!
./tests
testMake... OK
testFree... OK
testSet... OK
testGet... OK
testSlotCollision... OK
testHashCollision... OK
However, this is a bit of a performance hit, as every operation performs a full memcmp of the keys.
In a future part, we will look at adding a slightly unsafe set of functions which address this performance hit.
Let's learn how to implement a hash table in C! (See also part 1, part 2, and part 3).
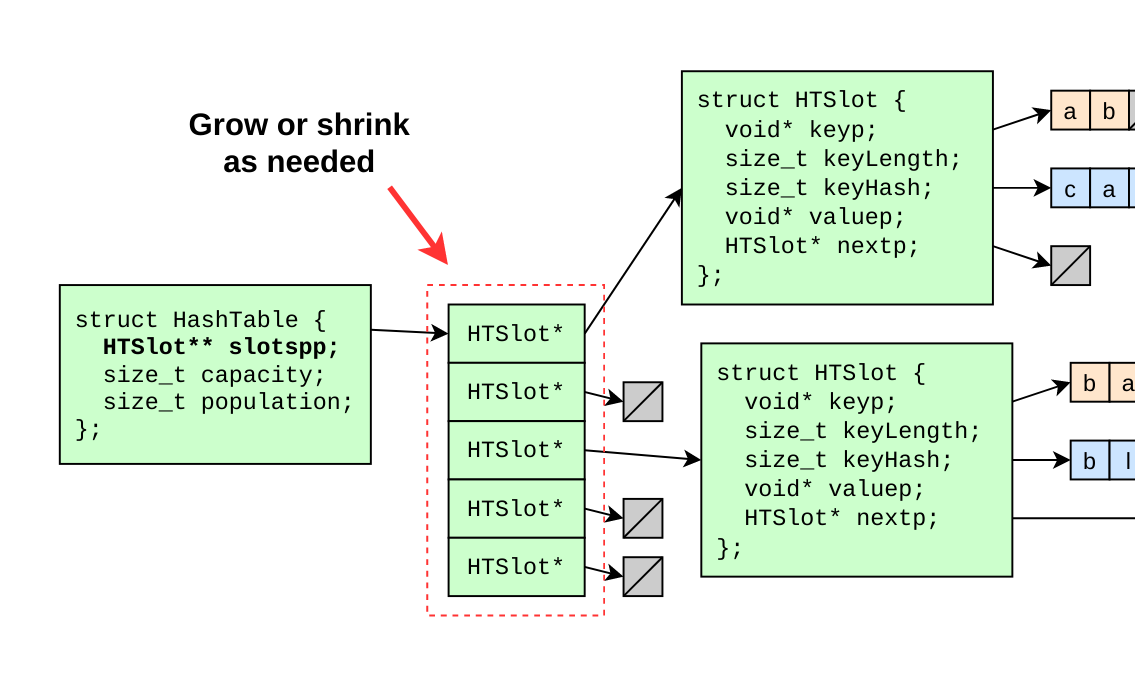
Each time the population changes, we check if the array size should be adjusted.
void HashTableSet(HashTable* htp, void* keyp, size_t keyLength,
size_t keyHash, void* valuep
) {
+ size_t origPop = htp->population;
size_t slotIndex = keyHash % htp->capacity;
HTSlot* cursorp = htp->slotspp[slotIndex];
while (cursorp != NULL) {
if (cursorp->keyHash == keyHash
&& cursorp->keyLength == keyLength
&& memcmp(cursorp->keyp, keyp, keyLength) == 0
) {
if (cursorp->valuep == NULL && valuep != NULL) {
htp->population++;
} else if (cursorp->valuep != NULL && valuep == NULL) {
htp->population--;
}
cursorp->valuep = valuep;
- return;
+ goto adjust;
} else {
cursorp = cursorp->nextp;
continue;
}
}
// no existing match? append a new slot to the list.
if (valuep != NULL) {
HTSlot* newSlotp = _HTSlotMake();
newSlotp->keyp = keyp;
newSlotp->keyLength = keyLength;
newSlotp->keyHash = keyHash;
newSlotp->valuep = valuep;
if (htp->slotspp[slotIndex] == NULL) {
htp->slotspp[slotIndex] = newSlotp;
} else {
HTSlot* lastp = htp->slotspp[slotIndex];
while (lastp->nextp != NULL) {
lastp = lastp->nextp;
continue;
}
lastp->nextp = newSlotp;
}
htp->population++;
}
+
+adjust:
+ if (origPop != htp->population) {
+ _adjustCapacityIfNeeded(htp);
+ }
+}To grow or shrink the array, a new array is allocated and all of the existing slots are migrated to their new positions in the new array, determined by modding the key hash by the new array size.
static void _adjustCapacityIfNeeded(HashTable* htp) {
size_t newCapacity;
if (_shouldShrink(htp)) {
newCapacity = htp->capacity / 2;
} else if (_shouldGrow(htp)) {
newCapacity = htp->capacity * 2;
} else {
return;
}
if (newCapacity < htp->minCapacity) {
return;
}
HTSlot** slots2pp = dmalloc(sizeof(void*) * newCapacity);
for (size_t i=0; i < htp->capacity; i++) {
HTSlot* cursorp = htp->slotspp[i];
while (cursorp != NULL) {
HTSlot* tmp = cursorp;
cursorp = cursorp->nextp;
if (tmp->valuep != NULL) {
tmp->nextp = NULL;
size_t slotIndex = tmp->keyHash % newCapacity;
if (slots2pp[slotIndex] == NULL) {
slots2pp[slotIndex] = tmp;
} else {
HTSlot* lastp = slots2pp[slotIndex];
while (lastp->nextp != NULL) {
lastp = lastp->nextp;
continue;
}
lastp->nextp = tmp;
}
}
continue;
}
}
free(htp->slotspp);
htp->slotspp = slots2pp;
htp->capacity = newCapacity;
}static bool _shouldShrink(HashTable* htp) {
return htp->capacity >= (htp->population * 2);
}static bool _shouldGrow(HashTable* htp) {
return htp->population >= (htp->capacity * 2);
}We also store the capacity with which the hash table was initially created, and treat that as a minimum capacity which the hash table will not shrink below.
struct _HashTable {
HTSlot** slotspp;
size_t capacity;
size_t population;
+ size_t minCapacity;
};
typedef struct _HashTable HashTable; HashTable* HashTableMake(size_t capacity) {
HashTable* htp = dmalloc(sizeof(HashTable));
htp->capacity = capacity;
+ htp->minCapacity = capacity;
htp->slotspp = dmalloc(sizeof(void*) * capacity);
return htp;
}We add a couple of tests around resizing.
void testGrow() {
printf("%s... ", __FUNCTION__);
size_t capacity = 1;
HashTable* htp = HashTableMake(capacity);
assert(htp->population == 0);
assert(htp->capacity == capacity);
char* key1p = "hello";
size_t key1Length = strlen(key1p) + 1;
size_t key1Hash = terribleHash(key1p, key1Length);
char* value1p = "world";
HashTableSet(htp, key1p, key1Length, key1Hash, value1p);
assert(htp->population == 1);
assert(htp->capacity == capacity);
char* key2p = "foo";
size_t key2Length = strlen(key2p) + 1;
size_t key2Hash = terribleHash(key2p, key2Length);
char* value2p = "bar";
HashTableSet(htp, key2p, key2Length, key2Hash, value2p);
assert(htp->population == 2);
assert(htp->capacity == capacity*2);
printf("OK\n");
}void testShrink() {
printf("%s... ", __FUNCTION__);
size_t capacity = 1;
HashTable* htp = HashTableMake(capacity);
assert(htp->population == 0);
assert(htp->capacity == capacity);
char* key1p = "hello";
size_t key1Length = strlen(key1p) + 1;
size_t key1Hash = terribleHash(key1p, key1Length);
char* value1p = "world";
HashTableSet(htp, key1p, key1Length, key1Hash, value1p);
assert(htp->population == 1);
assert(htp->capacity == capacity);
char* key2p = "foo";
size_t key2Length = strlen(key2p) + 1;
size_t key2Hash = terribleHash(key2p, key2Length);
char* value2p = "bar";
HashTableSet(htp, key2p, key2Length, key2Hash, value2p);
assert(htp->population == 2);
assert(htp->capacity == capacity*2);
HashTableSet(htp, key2p, key2Length, key2Hash, NULL);
assert(htp->population == 1);
assert(htp->capacity == capacity);
printf("OK\n");
}./tests
testMake... OK
testFree... OK
testSet... OK
testGet... OK
testSlotCollision... OK
testHashCollision... OK
testGrow... OK
testShrink... OK
Let's learn how to implement a hash table in C! (See also part 1, 2, 3 and 4).
Let's take a look at the importance of the hash function by comparing "terrible hash" to DJB2 and SDBM
size_t djb2Hash(void* datap, size_t length) {
size_t hash = 5381;
uint8_t* cursorp = datap;
for (size_t i=0; i < length; cursorp++, i++) {
hash = ((hash << 5) + hash) ^ (*cursorp);
}
return hash;
}size_t sdbmHash(void* datap, size_t length) {
size_t hash = 0;
uint8_t* cursorp = datap;
for (size_t i=0; i < length; cursorp++, i++) {
hash = (*cursorp) + (hash << 6) + (hash << 16) - hash;
}
return hash;
}To analyze the performance of these hash functions,
we'll add all of the words (about 100,000) in /usr/share/dict/words as keys in a hash table,
then look at a histogram of slot list lengths.
We'll use a function pointer so that we can easily pass in different hashing functions.
HashTable* hashTheDictionary(size_t (*hashFuncp)(void*, size_t)) {
// open the dictionary file
int fd = open("/usr/share/dict/words", O_RDONLY);
assert(fd != -1);
// get the size of the file
struct stat statbuf;
int err = fstat(fd, &statbuf);
assert(err == 0);
off_t fsize = statbuf.st_size;
// read the file into memory.
char* fbuff = (char*)malloc(fsize);
assert(fbuff != NULL);
ssize_t bytesRead = read(fd, fbuff, fsize);
assert(bytesRead == fsize);
HashTable* htp = HashTableMake(1);
char* valuep = "common value";
char* cursorp = fbuff;
char* endp = fbuff + fsize;
char* keyp = cursorp;
while (cursorp != endp) {
if (*cursorp == '\n') {
*cursorp = '\0';
size_t keyLength = cursorp - keyp;
if (keyLength > 0) {
size_t keyHash = hashFuncp(keyp, keyLength);
HashTableSet(htp, keyp, keyLength, keyHash, valuep);
}
cursorp++;
keyp = cursorp;
continue;
} else {
cursorp++;
continue;
}
}
return htp;
}void analyzeHashTable(HashTable* htp) {
#define LENGTHS_LEN (1000)
size_t score = 0;
size_t lengths[LENGTHS_LEN] = {0};
for (size_t i=0; i < htp->capacity; i++) {
HTSlot* slotp = htp->slotspp[i];
size_t chainLength = 0;
while (slotp != NULL) {
if (slotp->valuep != NULL) {
chainLength++;
}
slotp = slotp->nextp;
continue;
}
lengths[chainLength]++;
score += (chainLength * chainLength);
continue;
}
printf("Chain lengths histogram:\n");
printf("length occurrences\n");
printf("------ -----------\n");
for (size_t i=0; i < LENGTHS_LEN; i++) {
if (lengths[i] == 0) {
continue;
}
if (i < 10) {
printf(" ");
} else if (i < 100) {
printf(" ");
} else if (i < 1000) {
printf(" ");
} else if (i < 10000) {
printf(" ");
} else if (i < 100000) {
printf(" ");
}
printf("%zu %zu\n", i, lengths[i]);
}
printf("population: %zu, slots: %zu, empty slots: %zu, score: %zu\n",
htp->population, htp->capacity, lengths[0], score
);
}int main(int argc, char** argv) {
HashTable* htp;
printf("\ndjb2 hash\n");
htp = hashTheDictionary(djb2Hash);
analyzeHashTable(htp);
printf("\nsdbm hash\n");
htp = hashTheDictionary(sdbmHash);
analyzeHashTable(htp);
printf("\nterrible hash\n");
htp = hashTheDictionary(terribleHash);
analyzeHashTable(htp);
return 0;
}What we are looking for is a "short tail". The ideal hash function would give us an even distribution of hash values. That is, if we had N slots and N keys, all of our slot lists would be length 1.
Practically, some slots will be empty and others will be length > 1.
First, let's take a look at "terrible hash":
terrible hash
Chain lengths histogram:
length occurrences
------ -----------
0 63741
1 206
2 95
3 67
4 55
5 35
6 36
7 28
8 28
9 32
10 20
11 20
12 13
13 22
14 14
15 12
(...many rows elided...)
82 8
83 10
84 12
85 7
86 11
87 6
88 8
89 2
90 6
91 5
(...many rows elided...)
266 1
267 1
268 2
269 2
272 2
274 1
279 1
283 1
288 2
298 1
population: 102401, slots: 65536, empty slots: 63741, score: 13240151
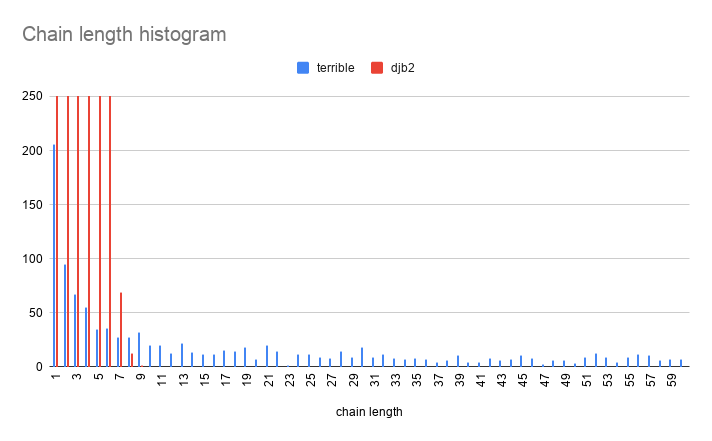
Oof! This is truly terrible! 97% of the slots are unused, and one of the slots has a chain which is 298 elements long!!!
This hash produces a long tail, which is the opposite of what we want!
Now let's compare that to DJB2 and SDBM.
DJB2 hash
Chain lengths histogram:
length occurrences
------ -----------
0 13809
1 21547
2 16591
3 8633
4 3484
5 1096
6 292
7 69
8 13
9 2
population: 102401, slots: 65536, empty slots: 13809, score: 263639
SDBM hash
Chain lengths histogram:
length occurrences
------ -----------
0 13778
1 21522
2 16539
3 8841
4 3447
5 1056
6 275
7 66
8 11
10 1
population: 102401, slots: 65536, empty slots: 13778, score: 262737
Visually:
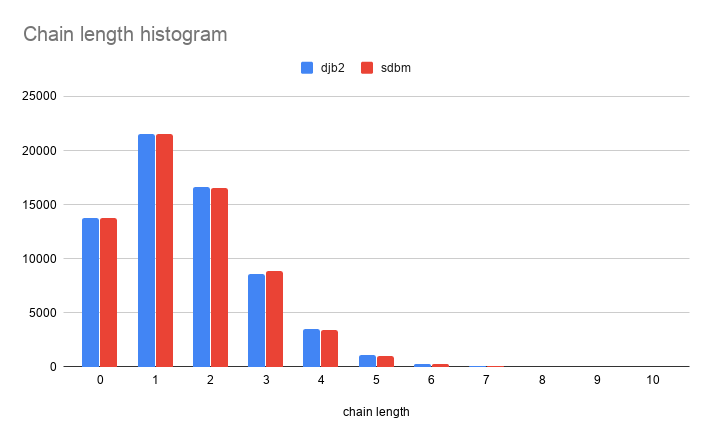
DBJ2 and SDBM are remarkably similar in distribution!
Now let's compare DJB2 to "terrible hash" :)
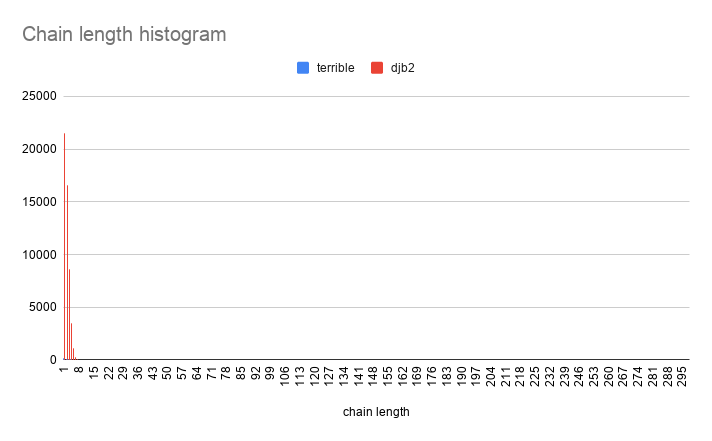
The difference in performance is so severe that they can't really be compared on the same graph! Let's zoom in: