Implementation of Naive bayes algorithm on 20_newsgroup dataset to classify text files consising of emails into 20 different categories.
The implementation involves:
Splitting the data into training and testing and making a dataframe where the path of files and their corresponding class( category ) is stored.
All the files in the training data are traversed and some of the top frequency words, except the stop Words are selected as features.
A dataframe is then made where for every file in training data the frequency of the words selected as features are stored and their corresponding class values. Similarly a dataframe for testing data is also formed.
For the fit function , a 2-level dictionary called as 'counts' is formed in which the key values are the classes( categories ). Within these , another dictionary is formed whose key values are the features selected.
Now all the files in the dataframe belonging to a particular category are selected and the sum of frequencies of the corresponding features were stored in the dictionary 'counts' under that particular category.
A total count of frequencies is also stored for each class.
For making predictions, each tuple from testing data(where each tuple denotes a file in testing data) is passed to the predict single fuction which calculates its probability for each class using naive bayes and predicts the class with maximum probability.
Naive Bayes is a classification technique based on Bayes’ Theorem with an assumption of independence among predictors. A Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature
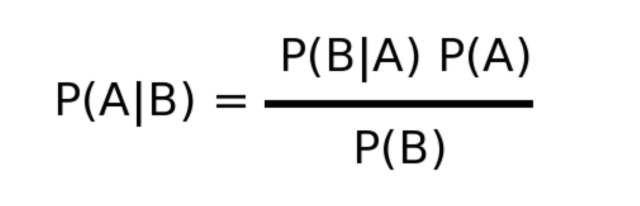
Here , P(A)= probability of class/category.
P(B)=Probability of testing document
P(B|A)= Probability of the document given that it belongs to the particular class. For calculating P(document | category), for every feature (top frequency words selected as features) , we find the probability of that word occurring in the document given that the document belongs to a particular category.All the log probabilities are then added .
Laplace correction is also considered and the Class with maximum probability is predicted.