We present HEXA-MoE, an efficient and heterogeneous-aware MoE computing framework. We re-formulate MoE computing with expert-specific operators rather than general matrix multiplication (GeMM), enabling the computation to be implemented in an in-place manner and freeing it from the inefficient dispatch & combine operations.
Instead of implementing MoE computing with general matrix multiplication or grouped matrix multiplication, we propose to conduct MoE computing in an in-place manner using 3 expert-specific operators:

To implement these operators, we also construct an auxiliary re-index vector, where tokens routed to the same expert are gathered together. The illustration of the vector and the operators are also provided as below, taking top-1 routing, 4 global experts and 10 tokens as an example.
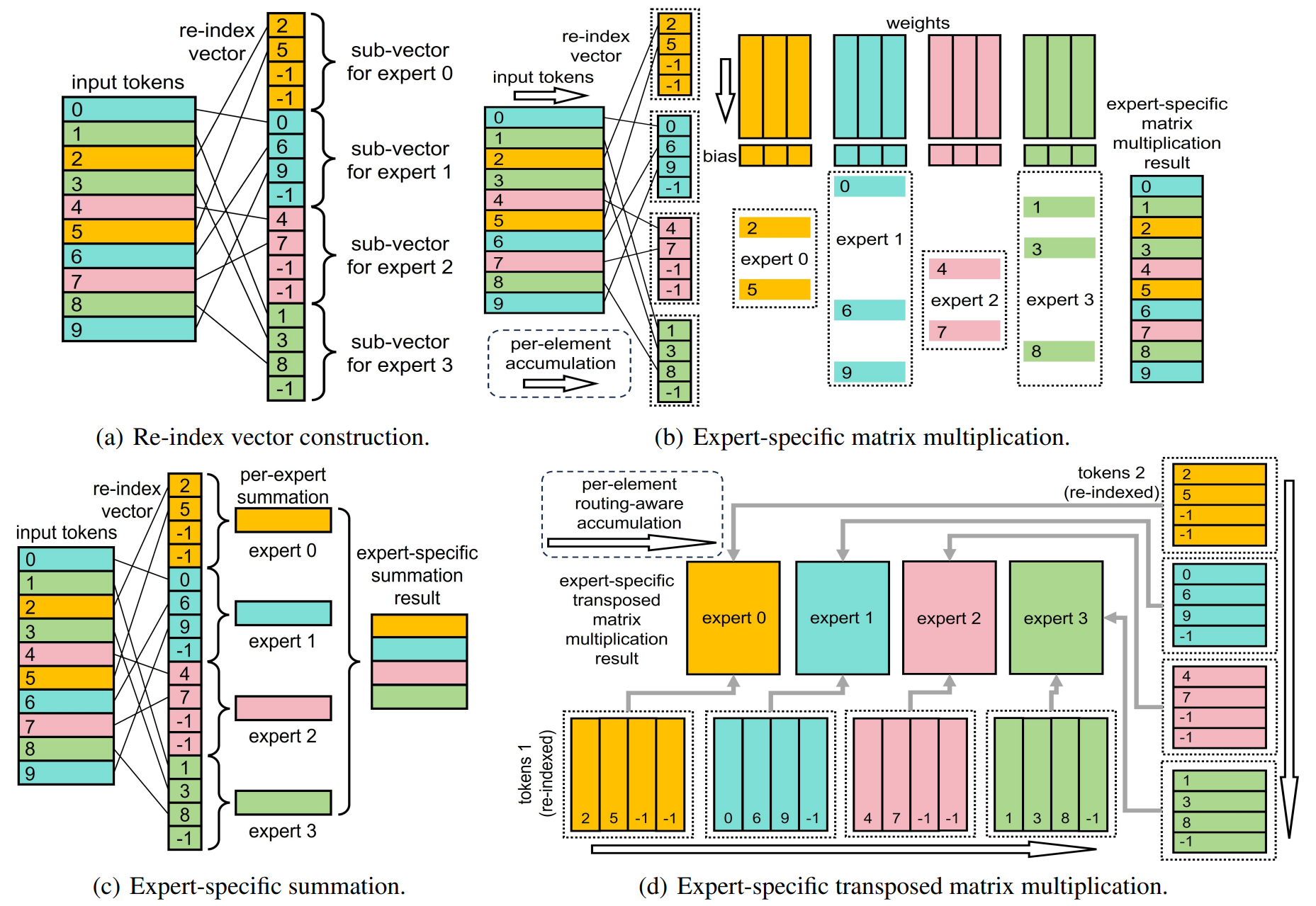
For input tokens
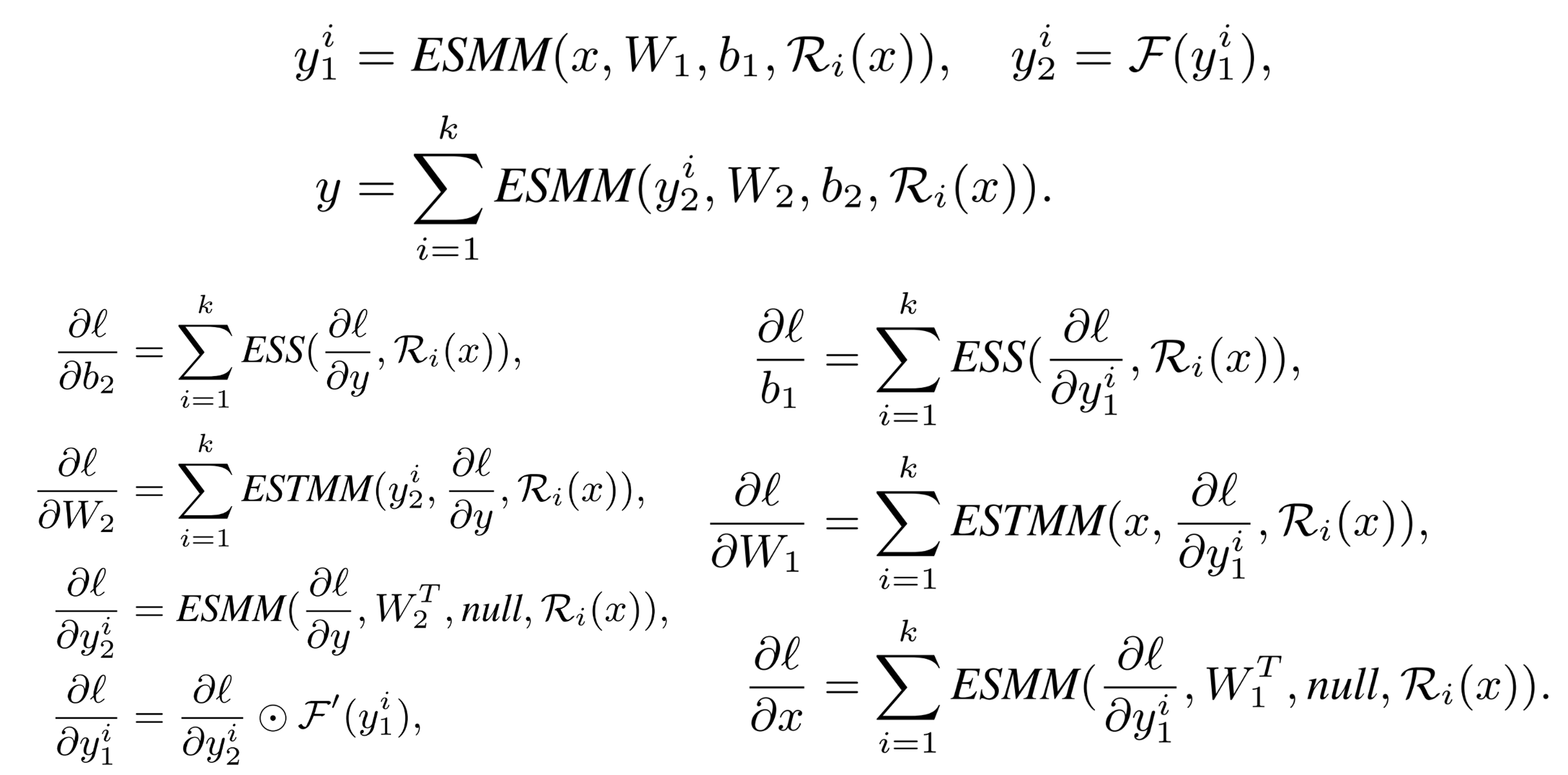
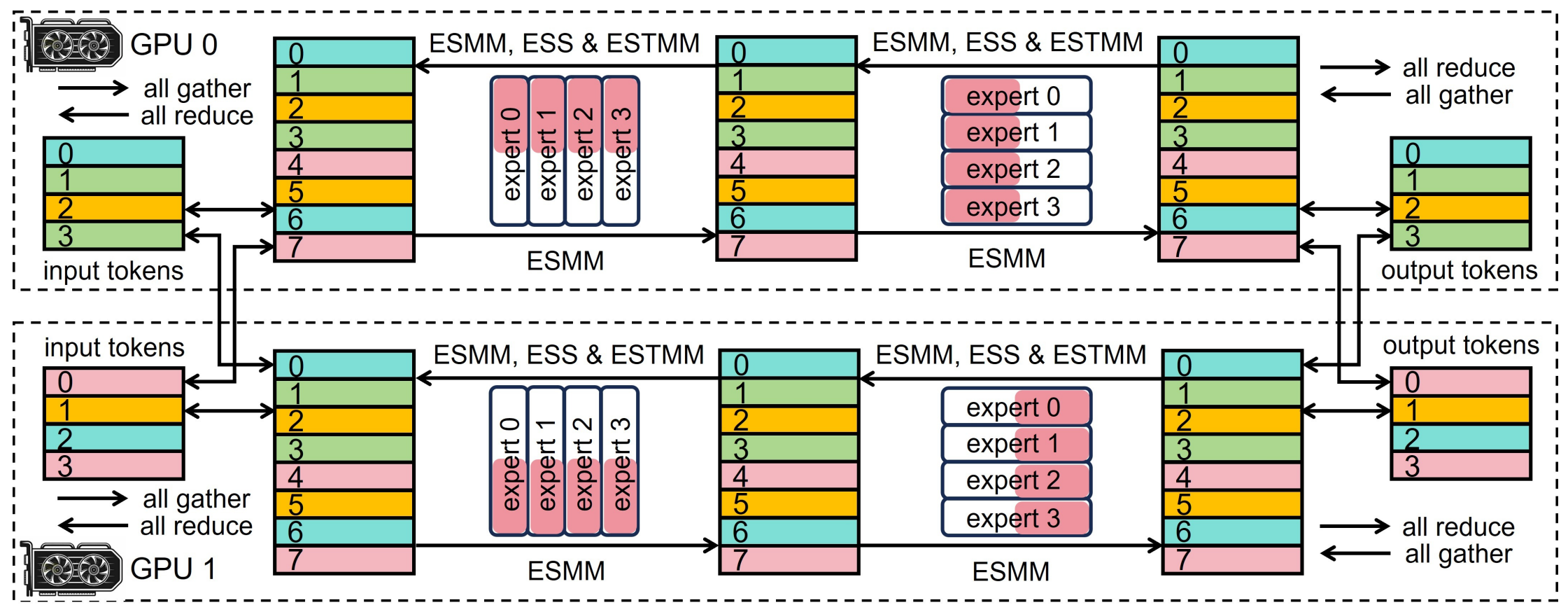
The sheer size of MoE layer makes it necessary to distribute it among different devices. Currently expert parallelism is the most common approach. Our HEXA-MoE takes pure tensor parallelism for this layer, since the proposed expert-specific operators can perform MoE computing in an in-place manner.

Data-centric MoE computing was first introduced in Janus, employed for heavy workloads. In this case, each device gathers model parameters rather than local data batches from other devices, which can reduce communication overhead and also be overlapped with other operations such as attention. However, it suffers from heavy memory consumption. To achieve both low memory consumption and reduced overall latency, we propose to introduce a pipeline-shared cache region on each device to dynamically cache the all-gathered MoE parameters for each layer.
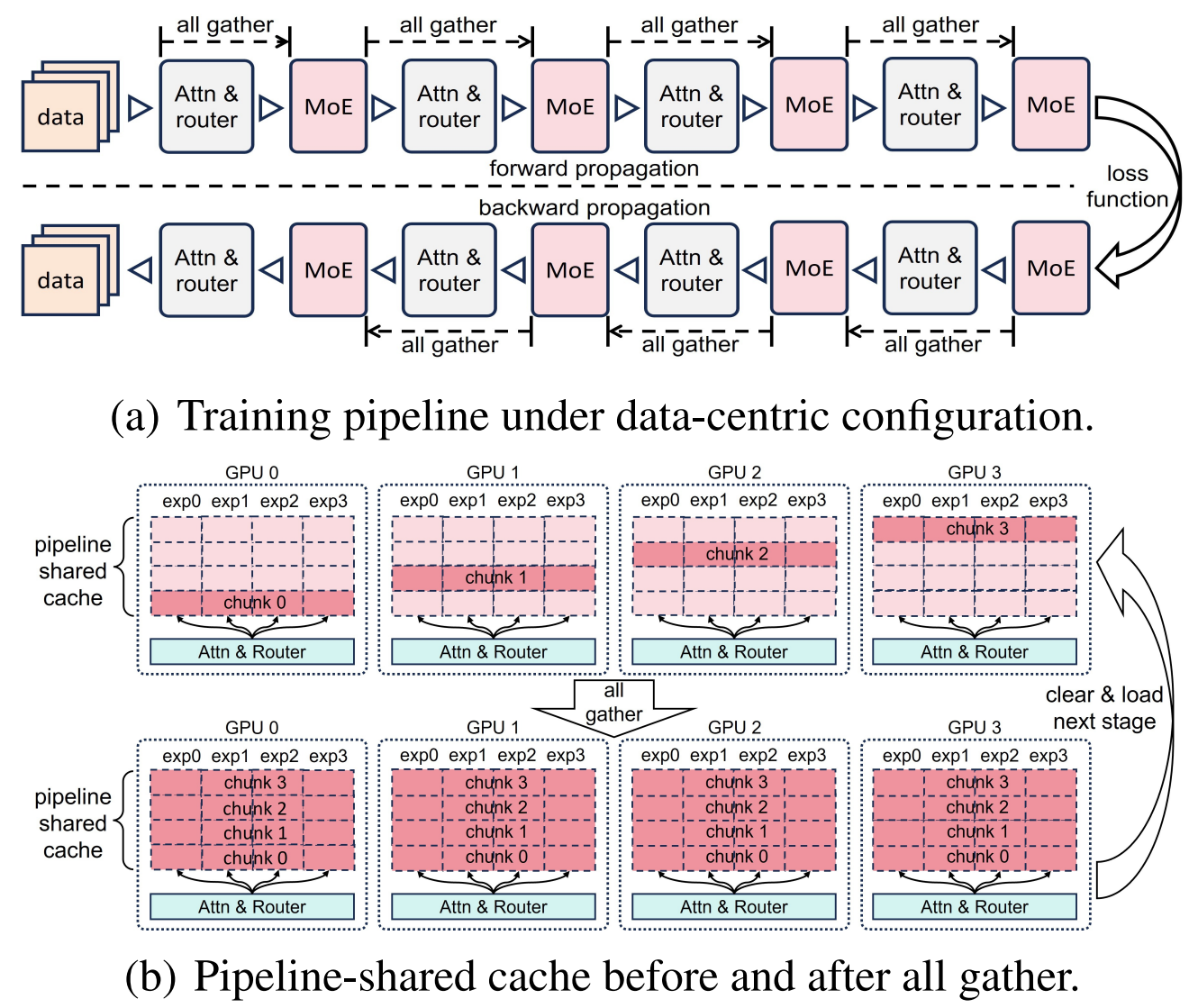
Apart from data-centric, we also provide model-centric MoE computing implemented with tensor parallelism. Each device all gathers the local data batches from other devices, and computes the local output using local MoE parameters. The local outputs are finally all reduced in forward propagation. For backward, the all gather and all reduce communication are interchanged.
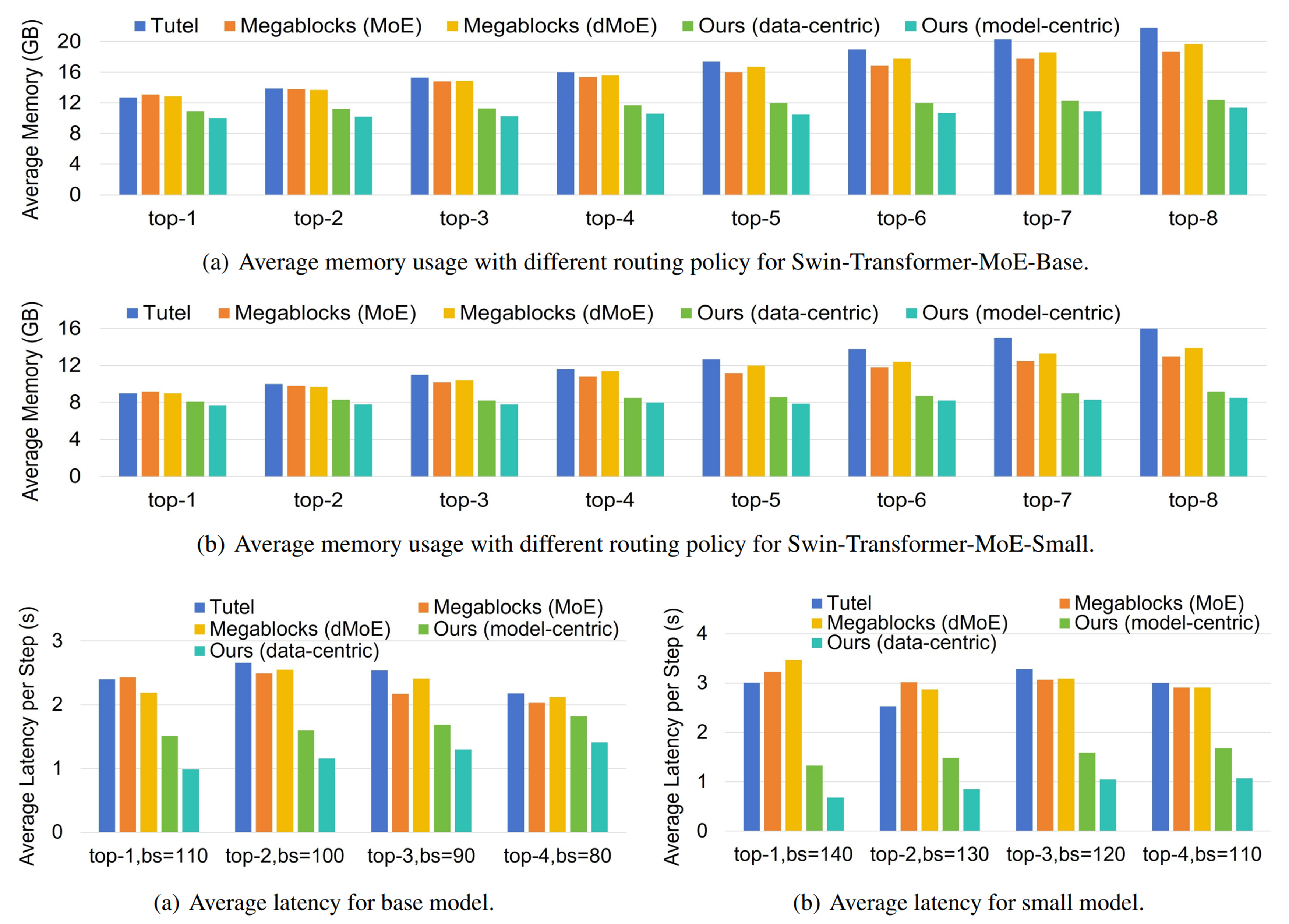
We take the training for Swin-MoE as an example for all the experiments. Details for the homogeneous and heterogeneous devices are provided below.

Experiments on homogeneous devices show that our method can reduce 10%-48% memory consumption while achieve 0.5-4.3× speed up.
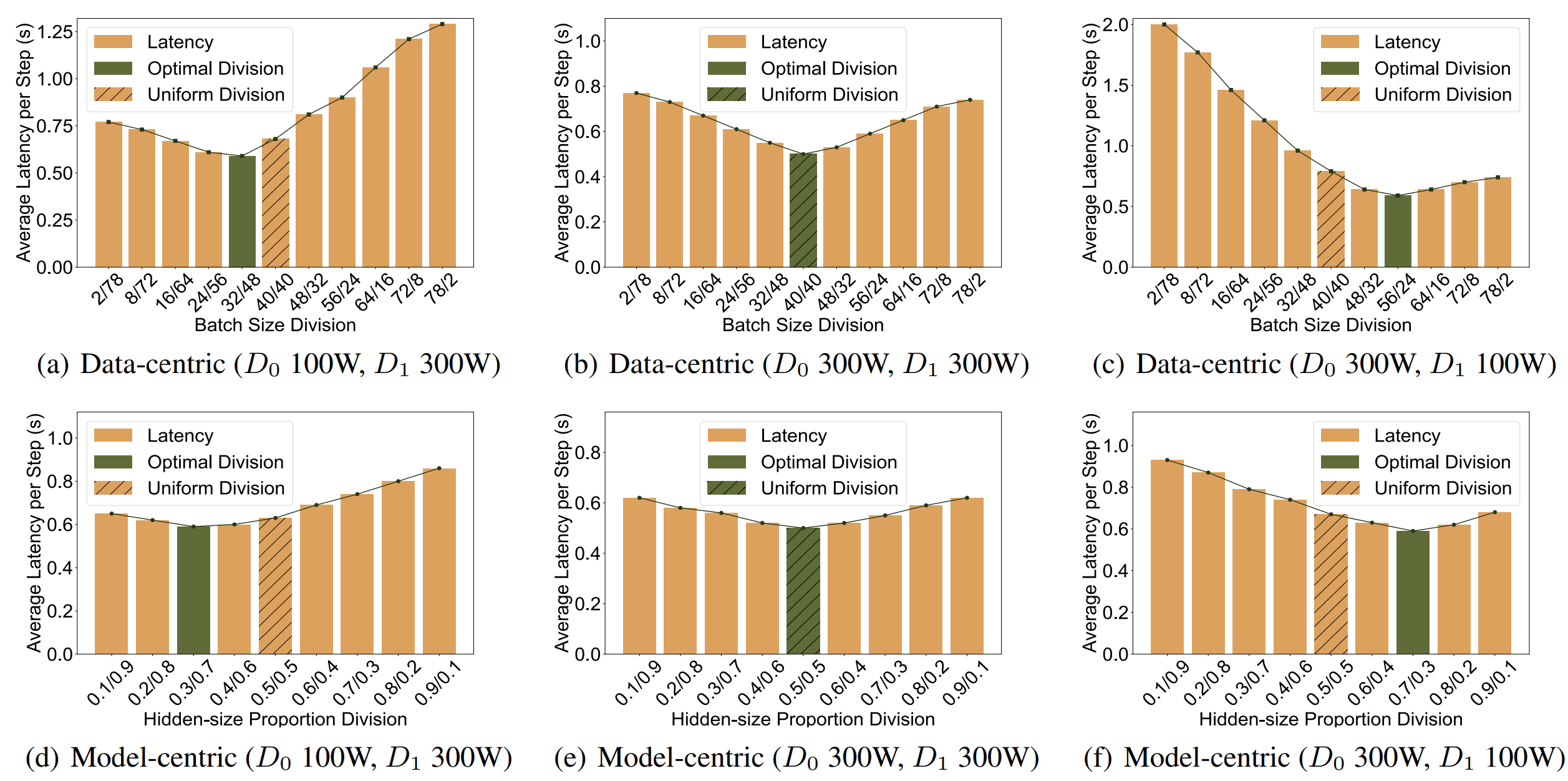
We adjust power limits for the 2 devices, and record the average latency under different parallel configurations. The optimal configuration can reach lower latency compared to the baseline.
We provide HEXA-MoE implementations using both Triton and CUDA. The programming interface for both are the same:
import torch.nn.functional as F
from hexa_moe import moe as hmoe
# In the class for model definition
_gate_type = {'type': 'top', 'k': 1, 'gate_noise': 1.0, 'fp32_gate': True}
self.cascaded_moe = hmoe.MoE_Cascaded(
gate_type=_gate_type,
model_dim_list=[128,128,128,128],
moe_idx_list=[2,3],
mlp_ratio=4,
mlp_proportion=None, # Or a list with length world_size and sum 1
num_global_experts=8,
total_depth=4,
data_centric=True,
mlp_fc1_bias=True,
mlp_fc2_bias=True,
activation_fn=lambda x: F.gelu(x)
)
# In forward(self, xxx) function in the class
for depth_idx in range(self.total_depth):
x, cur_l_aux = self.cascaded_moe(depth_idx, x)
We define all the FFN/MoE layers for an MoE model in a single class to facilitate the pipeline-shared cache.