-
Notifications
You must be signed in to change notification settings - Fork 120
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
15 changed files
with
293 additions
and
120 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,7 @@ | ||
| [ [Back to documentation](README.md) ] | ||
|
|
||
| # CMX commands | ||
|
|
||
| ## Command Line | ||
|
|
||
| ## Python API |
This file was deleted.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1 @@ | ||
| TBD |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1 @@ | ||
| TBD |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,77 +1,14 @@ | ||
| [ [Back to index](README.md) ] | ||
| [ [Back to documentation](README.md) ] | ||
|
|
||
| Introduction to the MLCommons Collective Mind (CM) workflow automation framework and its new version, Common Metadata eXchange (CMX). | ||
| # CK/CM/CMX motivation | ||
|
|
||
| ## Introduction | ||
| To learn more about the concepts and motivation behind this project, please explore the following articles and presentations: | ||
|
|
||
| During the past 10 years, the community has considerably improved | ||
| the reproducibility of experimental results from research projects and published papers | ||
| by introducing the [artifact evaluation process](https://cTuning.org/ae) | ||
| with a [unified artifact appendix and reproducibility checklists](https://github.com/mlcommons/ck/blob/master/docs/artifact-evaluation/checklist.md), | ||
| Jupyter notebooks, containers, and Git repositories. | ||
| * HPCA'25 article "MLPerf Power: Benchmarking the Energy Efficiency of Machine Learning Systems from Microwatts to Megawatts for Sustainable AI": [ [Arxiv](https://arxiv.org/abs/2410.12032) ], [ [tutorial to reproduce results using CM/CMX](https://github.com/aryatschand/MLPerf-Power-HPCA-2025/blob/main/measurement_tutorial.md) ] | ||
| * "Enabling more efficient and cost-effective AI/ML systems with Collective Mind, virtualized MLOps, MLPerf, Collective Knowledge Playground and reproducible optimization tournaments": [ [ArXiv](https://arxiv.org/abs/2406.16791) ] | ||
| * ACM REP'23 keynote about the MLCommons CM automation framework: [ [slides](https://doi.org/10.5281/zenodo.8105339) ] | ||
| * ACM TechTalk'21 about Collective Knowledge project: [ [YouTube](https://www.youtube.com/watch?v=7zpeIVwICa4) ] [ [slides](https://learning.acm.org/binaries/content/assets/leaning-center/webinar-slides/2021/grigorifursin_techtalk_slides.pdf) ] | ||
| * Journal of Royal Society'20: [ [paper](https://royalsocietypublishing.org/doi/10.1098/rsta.2020.0211) ] | ||
|
|
||
| On the other hand, [our experience reproducing more than 150 papers](https://www.youtube.com/watch?v=7zpeIVwICa4) | ||
| revealed that it still takes weeks and months of painful and | ||
| repetitive interactions between researchers and evaluators to reproduce experimental results. | ||
| You are welcome to contact the [author](https://cKnowledge.org/gfursin) to discuss long-term plans and potential collaboration. | ||
|
|
||
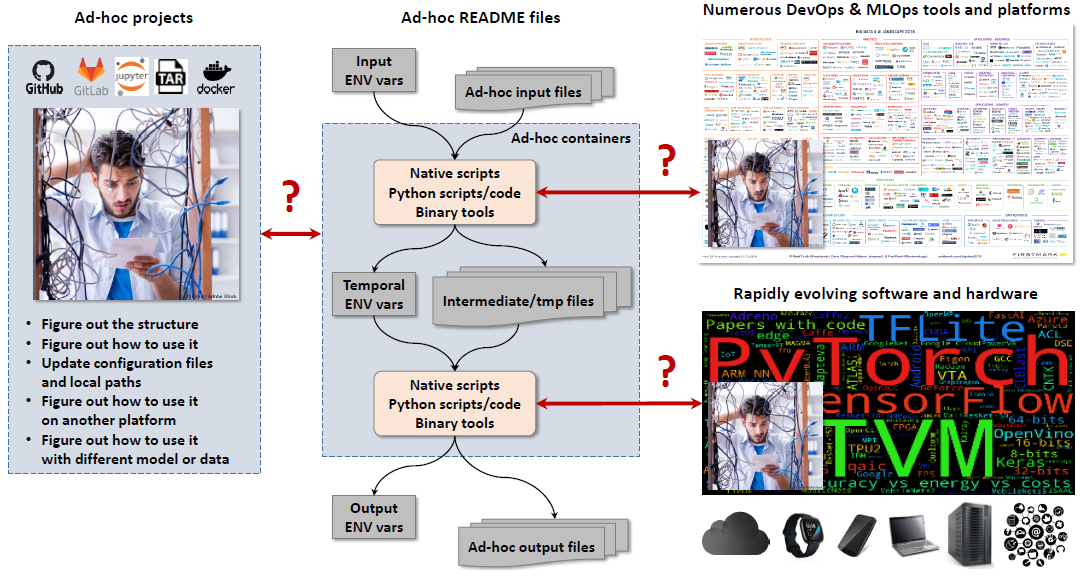
| This effort includes decrypting numerous README files, examining ad-hoc artifacts | ||
| and containers, and figuring out how to reproduce computational results. | ||
| Furthermore, snapshot containers pose a challenge to optimize algorithms' performance, | ||
| accuracy, power consumption and operational costs across diverse | ||
| and rapidly evolving software, hardware, and data used in the real world. | ||
|
|
||
|  | ||
|
|
||
| This practical experience and the feedback from the community motivated | ||
| us to establish the [MLCommons Task Force on Automation and Reproducibility](taskforce.md) | ||
| and develop a light-weight, technology agnostic, and English-like | ||
| workflow automation language called Collective Mind (MLCommons CM). | ||
|
|
||
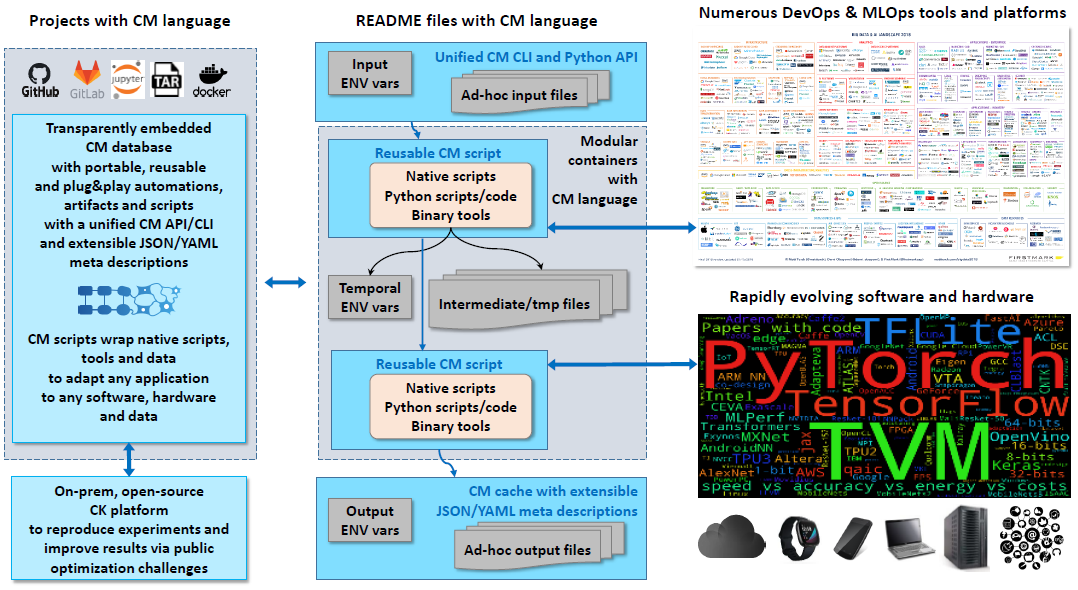
| This language provides a common, non-intrusive and human-readable interface to any software project | ||
| transforming it into a collection of [reusable automation recipes (CM scripts)]( https://github.com/mlcommons/ck/tree/master/cm-mlops/script ). | ||
| Following [FAIR principles](https://www.go-fair.org/fair-principles), CM automation actions and scripts | ||
| are simple wrappers around existing user scripts and artifacts to make them | ||
| * findable via human-readable tags, aliases and unique IDs; | ||
| * accessible via a unified CM CLI and Python API with JSON/YAML meta descriptions; | ||
| * interoperable and portable across any software, hardware, models and data; | ||
| * reusable across all projects. | ||
|
|
||
| CM is written in simple Python and uses JSON and/or YAML meta descriptions with a unified CLI | ||
| to minimize the learning curve and help researchers and practitioners describe, share, and reproduce experimental results | ||
| in a unified, portable, and automated way across any rapidly evolving software, hardware, and data | ||
| while solving the "dependency hell" and automatically generating unified README files and modular containers. | ||
|
|
||
|  | ||
|
|
||
| Our ultimate goal is to use CM language to facilitate reproducible research for AI, ML and systems projects, | ||
| minimize manual and repetitive benchmarking and optimization efforts, | ||
| and reduce time and costs when transferring technology to production | ||
| across continuously changing software, hardware, models, and data. | ||
|
|
||
|
|
||
| ## Some projects supported by CM | ||
|
|
||
| * [A unified way to run MLPerf inference benchmarks with different models, software and hardware](mlperf/inference). See [current coverage](https://github.com/mlcommons/ck/issues/1052). | ||
| * [A unitied way to run MLPerf training benchmarks](tutorials/reproduce-mlperf-training.md) *(prototyping phase)* | ||
| * [A unified way to run MLPerf tiny benchmarks](tutorials/reproduce-mlperf-tiny.md) *(prototyping phase)* | ||
| * A unified CM to run automotive benchmarks *(prototyping phase)* | ||
| * [An open-source platform to aggregate, visualize and compare MLPerf results](https://access.cknowledge.org/playground/?action=experiments) | ||
| * [Leaderboard for community contributions](https://access.cknowledge.org/playground/?action=contributors) | ||
| * [Artifact Evaluation and reproducibility initiatives](https://cTuning.org/ae) at ACM/IEEE/NeurIPS conferences: | ||
| * [A unified way to run experiments and reproduce results from ACM/IEEE MICRO'23 and ASPLOS papers](https://github.com/ctuning/cm4research) | ||
| * [Student Cluster Competition at SuperComputing'23](https://github.com/mlcommons/ck/blob/master/docs/tutorials/scc23-mlperf-inference-bert.md) | ||
| * [CM automation to reproduce IPOL paper](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/reproduce-ipol-paper-2022-439/README-extra.md) | ||
| * [Auto-generated READMEs to reproduce official MLPerf BERT inference benchmark v3.0 submission with a model from the Hugging Face Zoo](https://github.com/mlcommons/submissions_inference_3.0/tree/main/open/cTuning/code/huggingface-bert/README.md) | ||
| * [Auto-generated Docker containers to run and reproduce MLPerf inference benchmark](../cm-mlops/script/app-mlperf-inference/dockerfiles/retinanet) | ||
|
|
||
| ## Presentations | ||
|
|
||
| * [CK vision (ACM Tech Talk at YouTube)](https://www.youtube.com/watch?v=7zpeIVwICa4) | ||
| * [CK concepts (Philosophical Transactions of the Royal Society)](https://doi.org/10.1098/rsta.2020.0211) | ||
| * [CM workflow automation introduction (slides from ACM REP'23 keynote)](https://doi.org/10.5281/zenodo.8105339) | ||
| * [MLPerf inference submitter orientation (slides)](https://doi.org/10.5281/zenodo.8144274) | ||
|
|
||
| ## Common Metadata eXchange automation framework (CMX) | ||
|
|
||
| Since 2025, we have been developing a new backward-compatible version of CM with simpler | ||
| and more intuitive interfaces for automation recipes in MLOps, DevOps, and MLPerf. |
Oops, something went wrong.