Upgrade to RocksDB 5.8.8 and tune settings to reduce space amplification #7348
Conversation
* Switch to level-style compaction * Increase default block size (16K), and use bigger blocks for HDDs (64K) * Increase default file size base (64MB SSDs, 256MB HDDs) * Create a single block cache shared across all column families * Tune compaction settings using RocksDB helper functions, taking into account memory budget spread across all columns * Configure backgrounds jobs based on the number of CPUs * Set some default recommended settings
|
It looks like @andresilva signed our Contributor License Agreement. 👍 Many thanks, Parity Technologies CLA Bot |
|
Wow, such a wonderful work, @andresilva! I would support the idea of migrating old database into the new one. While it's a really reasonable to want a fresh database storage, not having our users to re-sync from scratch will be a huge improvement (warp sync is still not very warpy, by the way, #6372). It hurts to think about our users enabling autoupdates and then us rendering their nodes unusable for days while resyncing! Bonus brownie points if we won't require 2× disk space while migrating, but that's something we can live with, I guess. |
|
@kirushik @andresilva +1 for the migration, I think our migration framework needs a bit of work to support such migration, but it is definitely required. |
|
@kirushik @tomusdrw I agree, I will look into the migrations module. I'm not sure it's worth it to avoid the 2x space overhead but I'll check how feasible it is to implement (I'm also not sure how much space you'd actually save while deleting data from the old database, since compactions are asynchronous). The need for a re-sync actually got me thinking about our auto-update system, e.g. we could take down a network by having all nodes auto-update and start a re-sync right away (the same thing could happen with random bugs / byzantine behavior that is introduced in an auto-update). There should be a way to do a phased roll out |
|
I think 2x space overhead, is a minor goal. We can recommend a block export/import instead of migration for some users. Re auto-update: I suppose it would be cool to expose |
|
@tomusdrw Yes, I think it's possible to add a backward compatibility flag. Alternatively, we should be able to auto-detect if it's a database with old settings. RocksDB stores the used options in a file, so in case we can't open the database we can just fallback to whatever settings were being used. I think we may not need a migration if this works properly, we can just advise users that are having issues to do a |
|
Great! That sound like the best option. |
|
I was wrong, it is indeed possible to open an existing database with these new settings. I had tested this locally with a Unfortunately I can't implement the behavior of reading the RocksDB options from the file (https://github.com/facebook/rocksdb/wiki/RocksDB-Options-File) since that functionality isn't exposed in the C bindings, and so we have no way to use it in our Rust bindings. We don't change any of the settings in So I think we should be safe as it is. Is anyone willing to test this locally and make sure that they don't lose their database? The update should be visible in the database's OPTIONS file: |
|
@andresilva Successfuly run this version on old Kovan database. Still syncing (very slowly, I guess it's performing the compaction), will try mainnet next. Seems that compaction took 15mins for both Kovan and Foundation - no need for migration yay! Kovan logs: Foundation logs: |
|
@tomusdrw Cool! I also tested switching back to the old settings on a new database and it worked properly. In the meantime my archive node has finished syncing, here's the final graph of DB size over time. Took around 48 hours to do the full sync, and it seems there are no more temporary spikes in db size by a factor of 2. |
Just came across this PR now, wow! ❤️ If this does not break too much, we should really backport it to beta and push it asap next year. 👍 |
| opts.set_parsed_options("keep_log_file_num=1")?; | ||
| opts.set_parsed_options("bytes_per_sync=1048576")?; | ||
| opts.set_db_write_buffer_size(config.memory_budget_per_col() / 2); | ||
| opts.increase_parallelism(cmp::max(1, ::num_cpus::get() as i32 / 2)); |
There was a problem hiding this comment.
I'd recommend setting it to num_cpus - 1 if there is more than one CPU. One CPU should be always available for block import job to minimize import latency.
There was a problem hiding this comment.
We set it to num_cpus / 2 currently, so only using half of the cores (which makes sense to me)
|
yipeeh! |

{kind=link}
|
🎉 |
…ion (#7348) * kvdb-rocksdb: update to RocksDB 5.8.8 * kvdb-rocksdb: tune RocksDB options * Switch to level-style compaction * Increase default block size (16K), and use bigger blocks for HDDs (64K) * Increase default file size base (64MB SSDs, 256MB HDDs) * Create a single block cache shared across all column families * Tune compaction settings using RocksDB helper functions, taking into account memory budget spread across all columns * Configure backgrounds jobs based on the number of CPUs * Set some default recommended settings * ethcore: remove unused config blockchain.db_cache_size * parity: increase default value for db_cache_size * kvdb-rocksdb: enable compression on all levels * kvdb-rocksdb: set global db_write_bufer_size * kvdb-rocksdb: reduce db_write_bufer_size to force earlier flushing * kvdb-rocksdb: use master branch for rust-rocksdb dependency
|
using the rocksdb5 Version published some time in december brought back stability even to me- still one of the best "upcatching" node-version- |
This PR is an attempt to fix the space amplification caused by RocksDB. The main changes are:
memory budget spread across all columns
That is based on the recommendations from the RocksDB wiki and guided by benchmarks I ran (importing 2M blocks, restoring a snapshot).
I also started running an archive node which is currently synced at around block 3.5M. This is how the DB size has been over time: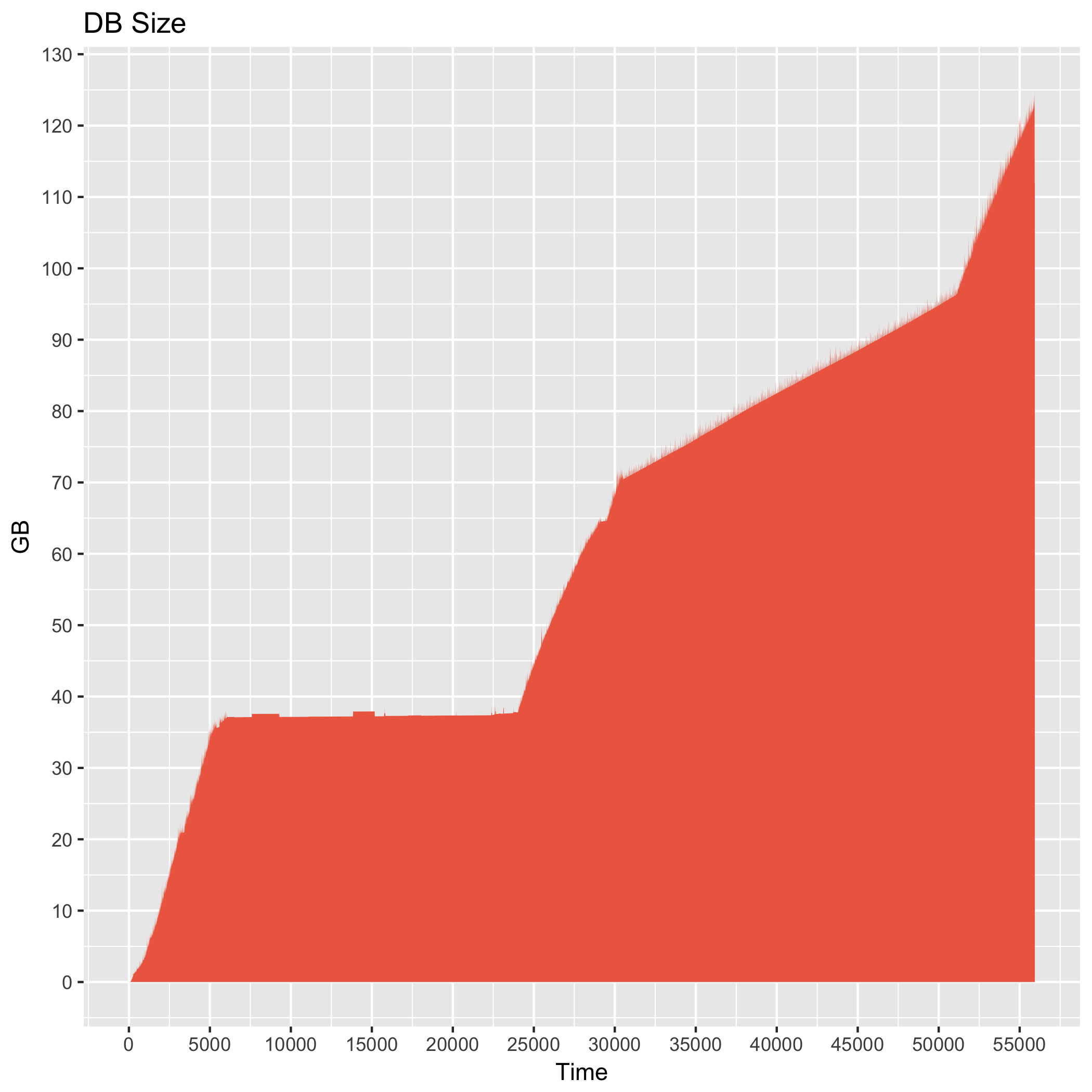
A user on #6280 submitted this graph of db size when syncing: https://i.imgur.com/1IpiTey.png.
The
cache-size-dbis now used as a memory budget for setting up RocksDB settings, instead of referring only to the actual block cache. This better reflects the overall memory usage for RocksDB and allows us to achieve different trade-offs (giving it more memory could reduce IO write amplification and increase performance, at the cost of potentially increasing space amplification). Should we rename this option tomemory-budget-dbor something like that? Also, since this no longer refers to only the size of the block cache I increased its default value to 128MB, memory usage should be below this since, in this case, we would have a global flush limit of 64MB and we would use 42MB for the block cache (one third of the memory budget).These new settings require a re-sync since some options are not compatible with the previous ones (I'm not sure which ones, I haven't tested them individually). Even if all the options were compatible, since we're changing the compaction algorithm it is better to start from scratch to make sure that the LSM has the expected "shape". I'm not familiar with the migration module, but we could probably rebuild the database with the new settings from the existing one. I can look into it if you think this is necessary.
Depends on paritytech/rust-rocksdb#10.
Should fix #6280 but it would be cool to have more people test this on different environments.