Add sparse marlin AQT layout #621
Conversation
🔗 Helpful Links🧪 See artifacts and rendered test results at hud.pytorch.org/pr/pytorch/ao/621
Note: Links to docs will display an error until the docs builds have been completed. ✅ No FailuresAs of commit 333a88f with merge base a246d87 ( This comment was automatically generated by Dr. CI and updates every 15 minutes. |

|
Hi @Diogo-V! Thank you for your pull request and welcome to our community. Action RequiredIn order to merge any pull request (code, docs, etc.), we require contributors to sign our Contributor License Agreement, and we don't seem to have one on file for you. ProcessIn order for us to review and merge your suggested changes, please sign at https://code.facebook.com/cla. If you are contributing on behalf of someone else (eg your employer), the individual CLA may not be sufficient and your employer may need to sign the corporate CLA. Once the CLA is signed, our tooling will perform checks and validations. Afterwards, the pull request will be tagged with If you have received this in error or have any questions, please contact us at [email protected]. Thanks! |
| @@ -0,0 +1,49 @@ | |||
| /* | |||
There was a problem hiding this comment.
Make sure to also create a test here https://github.com/pytorch/ao/tree/main/test for the cuda kernel and a test for an end to end flow https://github.com/pytorch/ao/tree/main/test/sparsity
|
so you should have perms to trigger CI, keep in mind that CI wont run if you have merge conflicts like now |
There was a problem hiding this comment.
Looks like this is coming along nicely @Diogo-V ! Left a couple comments
BTW, once you get the subclass hooked up we should try this on SAM:
https://github.com/pytorch/ao/blob/main/torchao/_models/sam/eval_combo.py#L286
I'm putting together a collection of ViT sparsification results for our PTC poster and would love to add your result and give you a shout out.
Also, feel free to @ me, I may not be the most responsive otherwise.
test/sparsity/test_marlin.py
Outdated
|
|
||
| class TestQuantSparseMarlin(TestCase): | ||
|
|
||
| @pytest.mark.skipif(not TORCH_VERSION_AFTER_2_3, reason="pytorch 2.3+ feature") |
There was a problem hiding this comment.
You don't need a skip here AFAIK, we can add it back if CI fails though
| self.layout_type = layout_type | ||
| self.initial_shape = initial_shape | ||
|
|
||
| @classmethod |
There was a problem hiding this comment.
FYI Jerry merged in some helper functions for utils, so you can do this a little nicer like this:
torchao/sparsity/marlin.py
Outdated
| return (cols_maj * m * interleave + dst_rows * interleave + cols_min).view(-1) | ||
|
|
||
|
|
||
| def _mask_creator(tensor): |
There was a problem hiding this comment.
I think we should move these to a general sparsity/utils.py.
torchao/sparsity/marlin.py
Outdated
| # This function converts dense matrix into sparse semi-structured | ||
| # representation, producing "compressed" matrix, in the layout used by | ||
| # CUTLASS backend, and corresponding metadata matrix. | ||
| def _sparse_semi_structured_from_dense_cutlass(dense): |
There was a problem hiding this comment.
I believe that this are the same functions that are available here: https://github.com/pytorch/pytorch/blob/main/torch/sparse/_semi_structured_conversions.py
So we don't have to copy them over.
There was a problem hiding this comment.
It seems some of them have small differences:
- https://www.diffchecker.com/ZWzCCGen/
- https://www.diffchecker.com/rIyyxGDx/
- https://www.diffchecker.com/kUzQSdpR/
Do you want me to leave it as is or should I change anything?
There was a problem hiding this comment.
cc @alexsamardzic I'm assuming they may have changed some stuff for int4 support. n00b question here, would it make sense to upstream some of the changes that they made?
@Diogo-V let's leave it for now, we can revisit once Alex responds.
There was a problem hiding this comment.
Yes - it would be good to have this upstream, but it would be good then also to have corresponding tests in test/test_sparse_semi_structured.py extended accordingly.
There was a problem hiding this comment.
Would you have bandwidth to update that? Otherwise I can take a stab after I'm done with pytorch/pytorch#132928
There was a problem hiding this comment.
I'll make a note; if taking on this, I'd also fully extend CUTLASS variant of SparseSemiStructuredTensor for int4 support. Am at the moment working on stuff related to mixed data types MM, so can't promise exactly if/when I'll have cycles for this - sorry about that.
|
@jcaip - Thank you for the comments! I am going to continue working on this today and will take care of them. Once we merge this, I’d be happy to add it to SAM and run the benchmarks! Also, feel free to let me know if there is anything that I can help out on for the PTC poster. I managed to finish mine earlier this week and so I have a bit more time 🙂 |
Awesome! I am going to resolve them and try it out once I am at the computer |
fecb1f8 to
7f9c65a
Compare
wip_test_llama2.py
Outdated
| from transformers import AutoTokenizer, LlamaForCausalLM | ||
|
|
||
| device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu") | ||
| name = "meta-llama/Llama-2-7b-hf" |
There was a problem hiding this comment.
You can use "nm-testing/SparseLlama-3-8B-pruned_50.2of4" as a checkpoint
|
|
||
| # Marlin Sparse op dispatch registration | ||
| @MarlinSparseAQTLayout.implements(aten.detach.default) | ||
| def block_sparse_detach(func, types, args, kwargs): |
There was a problem hiding this comment.
nit: I think @jerryzh168 has been using def _( for all of these, you should do the same.
|
Hi, I did a bit more work on this PR this last few days and, if possible, I would like to ask for another preliminary review on it. It is not yet finished because I am still having a bug somewhere that is causing llama2 to output some weird text (I am using llama2 to validate everything E2E). Will be working on it the next couple of days: 
I added a file in root of the project called The main difference from last time is that instead of using the code from the original repo I went with the code that they have in the nm-vllm repo. Three reasons for it: the code was easier to follow, had better APIs and their kernel implementation also supports fp8 making it fairly straightforward to add support for it in the future if we want to. There are two parts of the code of which I am not confident if it is correct. To make it easier for you to look for them, I added a comment above the code section with the text
Let me know if you find something that needs refactoring! Aside from that, I have a question:
tagging for visibility: @msaroufim @jcaip |
|
Thanks for the update @Diogo-V! I 'll take a more thorough pass through later tonight |
7f9c65a to
e5390a6
Compare
|
Hi @jcaip, just saw that you did a commit getting |
|
@Diogo-V Thanks for your help, and good job landing the op! I took a look at your code and I do think there might be an issue in the way we hook up the marlin gemm op. I noticed for that changing the batch dimension (32, 16, 14096) for the input breaks the test, which shouldn't be the case. The compile test is also failing for me. I don't know exactly what's where the problem is, but the general gist is that we have Could you open a PR with just the marlin op (without the affine quantized tensor implementation) for now? You can git squash all your commits and then remove the AQT files with: https://stackoverflow.com/questions/12481639/remove-file-from-latest-commit. We can merge that in first, since I'll be on PTO next week. cc @jerryzh168 @msaroufim I think the compile debugging will be a bit more involved, so don't want you to get blocked on that. Will update if I find the bug. |
|
Yeah totally! Will open the PR in a bit I am not super acquainted with the compile process (have been learning it the past few weeks). Do you have any resources that would be good for me to take a look at so that I can help out more and get across this issues in future PRs? This weekend, I will take another stab at this and try to get the tests to pass. I would also be happy to pass this work off to someone else if you feel like it would be too tight of a schedule for the poster. |
|
Hey @Diogo-V
https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html is a good tutorial. I would actually recommend not debugging with compile, until you first fix the batch size=32 eager test case, since it'll be a lot easier to be able to debug in eager.
Thanks, that would be awesome! It would definitely help to have another person debug this. Let me try to explain a bit more about what I think is going on here: On CUDA, tensors are represented as just blobs of data, and we keep track of the strides / offsets / dimensions of the tensor separately in metadata. This is nice because we can do something like a transpose without needing to modify our existing blog of data, we just change how we access it via the strides / offsets. The Marlin kernel also takes in these m.k.n values, likely to make the kernel implementation easier. I think somewhere along the line we are flubbing a transpose somewhere, where we are switching up our mkn dimensions (because transpose), but still passing in the contiguous data of the non-transposed tensor. I think this mismatch is the cause of our error. This is especially confusing because for 2:4 spares support, the tensor cores only support the first element being sparse really, which we can deal with by using transpose properties to move the second element sparse. But note how we are now returning a transposed matrix, which means it is not contiguous, hence why it is in column major format. I think this row/column major format mismatch, or something related is the cause of our compile / batch_size=n bug. To make sure, we can check that both the marlin output and the reference output share the same strides in our unit test: Just a tip, feel free to do whatever you feel is best: I would gradually work up from your test_marlin_24 test here, by writing a nn.Linear layer that outputs the same values as your reference mm implementation. Basically my thinking is that we go from mm unit test -> nn.Linear unit test -> e2e test. Let me know if you have any questions, I'll try to answer them the best I can. As far as deadlines - just FYI: 9/6 is the deadline for our torchAO announcement, with the 9/16 is the deadline for making updates to our PTC poster. |
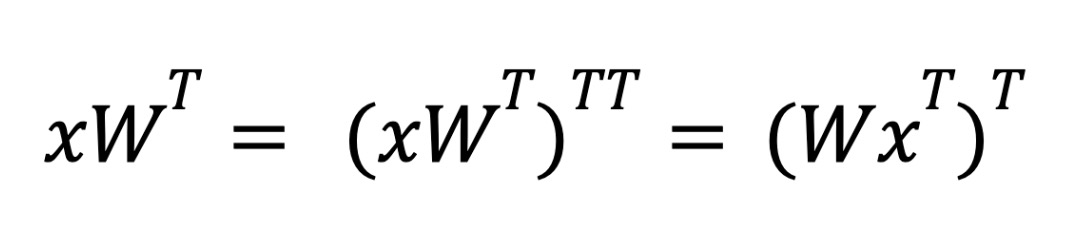
Thank you very much! I will start off by tackling the batch size issue before moving onto the compile test as you suggested.
Yep, I agree with you on this. Thanks for sharing your insights about the current problem! I think I have a better idea of how to debug this after reading your explanation 🙂
I think that suggestion is pretty good. I will follow that flow to debug this issue.
Thanks for sharing the deadlines. I was getting a bit concerned because I know that this is a time sensitive task and I don't want to risk missing an important date. I will try to surface updates and blocks as often as I can. |
| int_data, scale, zero_point = self.get_plain() | ||
| layout_type = self.get_layout_type() | ||
| return f"{self.__class__.__name__}(int_data={int_data}, scale={scale}, zero_point={zero_point}, layout_type={layout_type})" | ||
| # This is a hack, torch.compile tries to trace the __repr__ function which then calls `dequantize` function, causing an error. |
There was a problem hiding this comment.
can these changes be reverted now with dynamo.disable decorator?
There was a problem hiding this comment.
yeah, will take care of that. let me just take care of finding this bug first
9bcc422 to
694e2d1
Compare
e78d93f to
552603d
Compare
fix: namespace of common modules chore: remove not needed test file fix: op name being registered chore: can compile the cuda kernel fix: segmentation fault chore: wip - paste test code just to check if everything passes feat: wip - adding layout. unpack not working fix: circular import feat: wip - can almost revert feat: can unpack. just needs cleanup chore: improve layout code chore: wip - mm needs work feat: wip - something seems wrong fix: e2e test feat: wip - add group param fix: unpack weights feat: marlin is implemented and correct chore: rebase chore: remove old import feat: use int4 instead of dequantizing chore: remove unused fn feat: add checks and validation feat: add new kernel and refactor code (#1) * feat: wip - adding new kernel * feat: wip - continue working on the unpack * feat: wip - working on unpacking * feat: remove old op * feat: more code changes * chore: remove old code * feat: more code * chore: more code changes * chore: more code changes * feat: add more documentation * fix: dataclass * feat: add more docs * feat: remove assert chore: block 8 bits chore: update comment feat: refactor dispatch chore: add validation on group size chore: wip - working on fixing unpack feat: add small readme with sources feat: add checks feat: tests pass & can execute llama2
* wip * feat: wip
552603d to
ea70c74
Compare
|
I tried runnning this with SAM but was running into a CUDA graph error, however with the 24_sparse_hf_example, I'm seeing: 🚀 🚀 🚀 cc @Diogo-V I'll write this up and update the README @jerryzh168 for BE day tomorrow. It would be best if we could hook up into @HDCharles LLaMa benchmarks for consistency. |
only test this in nightly sounds good if that's the issue |
yeah looks good to me, this is trying to test the e2e API so it's slightly different from test_marlin.py I think |
| @@ -1219,6 +1413,47 @@ def _linear_fp_act_fp8_weight_impl( | |||
| ).reshape(out_shape) | |||
|
|
|||
|
|
|||
| def _linear_fp_act_int4_weight_sparse_marlin_check(input_tensor, weight_tensor, bias): | |||
There was a problem hiding this comment.
cc @jcaip now we support registering layout type and these things in a separate file, maybe we can create a folder for all sparse layouts and move these
There was a problem hiding this comment.
Yeah, that sounds like a good idea.
|
@jerryzh168 - Should be good to go now :) |
|
Perfect, let me add my benchmarking updates to this branch so it's easier for Andrew to cherry-pick the whole thing. BTW I'm seeing 226 tok/s for LLama3 - a 25% increase from 180 tok/s for our tiny gemm int4 kernel. |
|
@jcaip - Yeah, I also noticed that sometimes the model's outputs were not super great. My simple sanity check was comparing against a Let me know if there is anything else that I might be of help to get this across today and feel free to ping me on discord (Diogo-V on #cuda-mode) if you run into any issues! |
|
Yes, for context, I am seeing the same text generation output on the hf example with the neuralmagic 2:4 sparse model, when I run But I'm very pleased with the speedup you've achieved (+25%), thats a great result :) |
|
I wouldn't mind taking a look at adding support for GPTQ with Sparse Marlin if you feel like it would be a good thing to work on afterwards. I would have some time for it after the 21st of September. |
* feat: starting layout implementation fix: namespace of common modules chore: remove not needed test file fix: op name being registered chore: can compile the cuda kernel fix: segmentation fault chore: wip - paste test code just to check if everything passes feat: wip - adding layout. unpack not working fix: circular import feat: wip - can almost revert feat: can unpack. just needs cleanup chore: improve layout code chore: wip - mm needs work feat: wip - something seems wrong fix: e2e test feat: wip - add group param fix: unpack weights feat: marlin is implemented and correct chore: rebase chore: remove old import feat: use int4 instead of dequantizing chore: remove unused fn feat: add checks and validation feat: add new kernel and refactor code (#1) * feat: wip - adding new kernel * feat: wip - continue working on the unpack * feat: wip - working on unpacking * feat: remove old op * feat: more code changes * chore: remove old code * feat: more code * chore: more code changes * chore: more code changes * feat: add more documentation * fix: dataclass * feat: add more docs * feat: remove assert chore: block 8 bits chore: update comment feat: refactor dispatch chore: add validation on group size chore: wip - working on fixing unpack feat: add small readme with sources feat: add checks feat: tests pass & can execute llama2 * compile kind of working * fix: batching and layout outputs correct results * fix: torch.compile * wip * feat: wip * chore: cleanup * chore: review * chore: review v2 * update benchmarks + README --------- Co-authored-by: Jesse Cai <[email protected]>
* feat: starting layout implementation fix: namespace of common modules chore: remove not needed test file fix: op name being registered chore: can compile the cuda kernel fix: segmentation fault chore: wip - paste test code just to check if everything passes feat: wip - adding layout. unpack not working fix: circular import feat: wip - can almost revert feat: can unpack. just needs cleanup chore: improve layout code chore: wip - mm needs work feat: wip - something seems wrong fix: e2e test feat: wip - add group param fix: unpack weights feat: marlin is implemented and correct chore: rebase chore: remove old import feat: use int4 instead of dequantizing chore: remove unused fn feat: add checks and validation feat: add new kernel and refactor code (#1) * feat: wip - adding new kernel * feat: wip - continue working on the unpack * feat: wip - working on unpacking * feat: remove old op * feat: more code changes * chore: remove old code * feat: more code * chore: more code changes * chore: more code changes * feat: add more documentation * fix: dataclass * feat: add more docs * feat: remove assert chore: block 8 bits chore: update comment feat: refactor dispatch chore: add validation on group size chore: wip - working on fixing unpack feat: add small readme with sources feat: add checks feat: tests pass & can execute llama2 * compile kind of working * fix: batching and layout outputs correct results * fix: torch.compile * wip * feat: wip * chore: cleanup * chore: review * chore: review v2 * update benchmarks + README --------- Co-authored-by: Jesse Cai <[email protected]>
* feat: starting layout implementation fix: namespace of common modules chore: remove not needed test file fix: op name being registered chore: can compile the cuda kernel fix: segmentation fault chore: wip - paste test code just to check if everything passes feat: wip - adding layout. unpack not working fix: circular import feat: wip - can almost revert feat: can unpack. just needs cleanup chore: improve layout code chore: wip - mm needs work feat: wip - something seems wrong fix: e2e test feat: wip - add group param fix: unpack weights feat: marlin is implemented and correct chore: rebase chore: remove old import feat: use int4 instead of dequantizing chore: remove unused fn feat: add checks and validation feat: add new kernel and refactor code (#1) * feat: wip - adding new kernel * feat: wip - continue working on the unpack * feat: wip - working on unpacking * feat: remove old op * feat: more code changes * chore: remove old code * feat: more code * chore: more code changes * chore: more code changes * feat: add more documentation * fix: dataclass * feat: add more docs * feat: remove assert chore: block 8 bits chore: update comment feat: refactor dispatch chore: add validation on group size chore: wip - working on fixing unpack feat: add small readme with sources feat: add checks feat: tests pass & can execute llama2 * compile kind of working * fix: batching and layout outputs correct results * fix: torch.compile * wip * feat: wip * chore: cleanup * chore: review * chore: review v2 * update benchmarks + README --------- Co-authored-by: Jesse Cai <[email protected]>
Summary
Introduces a Layout for AQT class called Sparse Marlin 2:4.
E2E Results
Tests
test/sparsity/test_marlin.py
Considerations for reviewers
torch.compileI had to covert the section of here and here from numpy to torch. If I used torch.uint32, it would throw an error ofrshift_cpu not supported for uint32. Usingtorch.int64seems to not cause any problemsNotes
Feel free to let me know if there is anything that needs to be refactored!