{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The following outlines some simple steps to take a single table of data and split it into a set of relationship tables within a database or schema.
Note: This is strictly for demonstration and is not perfect.

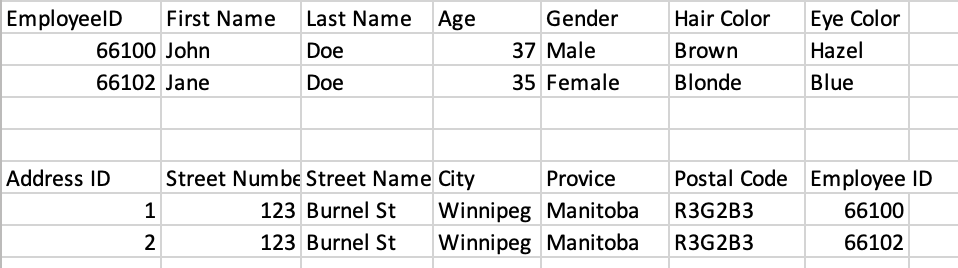
In the image provided above we have a set of employee records that have not been structured for efficiency. In this simply dataset it's easy to locate specific information for an employee. However, as this data increases the following issues will be found:
- Lots of duplicate fields (cells) which wastes space in your simple database
- Searching for employees by specific criteria (e.g. By age) becomes more complex
- Risk of user input issues araise from duplication of fields
- Filtering the dataset (e.g. getting a list of employee names only) becomes more time consuming with larger datasets
Using this dataset we can break it down into sections (tables) removing duplication and making it easier and faster to search.
What is a Primary Key and a Foreign Key you ask? In simple terms these are fields that allow our tables to be related to each other and allow us to join two (or more) tables together when we search our database after we have deconstructed our table above into individual tables. To better understand this concept we need to dig into database tables a bit further.
In a database you often create many tables each holding specific details. Often these details are based on real-world objects. We then create relationships between this tables (e.g. An employee has 1 home address). In our example, one table could be an Employee table which contains information about our employees and another table could be an Address table which stores house address information for our employees. If we use the concept of an Employee record and an Address record we need to some how relate these records together to know which address belongs to which employee. For example, where does an employee with an employee ID of 1 live? This is where primary and foreign keys come to the rescue.
A Primary key is a field within a table (or record) that must be unique and not missing (or null in database terms). This field (or fields; can be more than one) makes each record (or row) within the table unique. Going back to our Employee table we'd have an employee ID which is often unique across employees. In otherwords a single employee will have an employee ID and that employee ID will never be shared with any other employee.
A Foreign key is a field within a table (or record) that may be unique (e.g. in a one-to-one relationship) but doesn't have to be however for the foreign key value to exist (in a record/row) it must have a corresponding Primary key record listed in another table (or within its own table). If the primary key record doesn't exist the relationship is incomplete and often indicates bad data and should not be allowed. This foreign key allows us to connect our table back to another table by it's primary key (most times it's the primary key but it can be another field that is unique in the table as well). So for our example say we have a table called Address and in that table we stored a list of addresses for our employees. If we don't have a foreign key in our Address table with a corresponding primary key in the Employee table how do we know what Employee record an address belongs to? Whenever we create an employee record with an employee id (i.e. Primary key) we also create a record in our address table with a foreign key that matches our employee ID from the Employee table. Now when we search an address we can also ask our employee table who lives at the address we found.
Although the above example is not completely truthful (e.g. more than 1 employee can live at the same address if the business allows it) it is an example of a one-to-one relationship: a single employee lives at a single address and an address can only belong to a single employee. Pay special attention to the wording of that last sentence as it provided the clue that it's a one-to-one relationship.
The diagram below shows a snippet of our database tables constructed using an employee and address table:
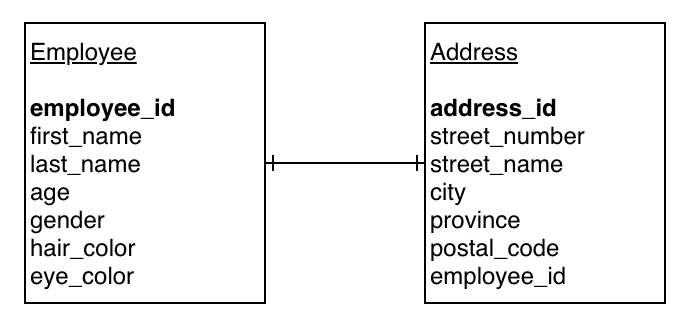
The single-dash through the line on each side stands for 1 (i.e. 1-to-1).
When creating tables from a dataset we need to consider the different types of relationships between these tables. For this discussion we will talk about one-to-one relationships and one-to-many relationships. There is a third relationship called a many-to-many relationship which is a bit more complex and will have its own section.
In our example above we create a one-to-one relationship by saying a single employee has at most one address and one address has at most one employee. This is often referred to as a business constraint and in this case the business is essentially stating that they will never have two employees with the same address. When this type of relationship is created often the primary key and foreign key exist and are both marked as unique non-null keys to enforce the one-to-one relationship. If we try to insert a second record with a foreign key that already exists in our application/database we will be deny the transaction as this breaks the relationship rules.
What if our business rules change and now we can have more than one employee with the same home address (e.g. A husband and a wife now work for our business)? We now need to create a new relationship called a one-to-many relationship. In this new relationship which table has the many records and which table as the single record? This is often up for debate depending on the table however in our case the decision is simple. To figure out which table has the many side (or has more than one record in it) ask yourself which table should I create a record in such that I don't duplicate my data? For example, assuming we think our Address table should be the many side what would that look like? In the table below we created two address records referencing the two employees who live at the same address. Do we have duplicate data in either table now? Yes we do. The Address table is storing the same address information twice and the only field that is unique is the address id. In this case, our assumption is incorrect. If we were to read this relationship from left-to-right we are saying one employee is associated with one address (based on primary/foreign keys) and so this is still a one-to-one relationship. Instead of adding the employee_id to the address table we will add the address_id to the employee record instead. In the image below (second figure) we can now see that the only thing duplicated is the address_id in the employee table and this is exactly what we want. In this case we have created a many-to-one relationship (which is the same thing as a one-to-many just read in reverse order). If we read this from right-to-left now we can say an address can have one or more employees associated with it (i.e. one-to-many relationship)
incorrect one-to-many relationship

correct one-to-many relationship
Before you begin reading about this topic it's important that you understand one-to-one and one-to-many relationships and know how to implement them. Once you understand these topics proceed with this topic.
Now what exactly is a many-to-many relationship? To understand this topic let's take a look at our dataset at the top of this article. In our dataset we have the concept of 3-types of phone numbers: home, mobile and work. This means that a single employee can have 1, 2 or 3 phone numbers (i.e. one-to-many). However upon closer inspection we can see that the same home phone number exists for the first two employees which suggests a phone number can also have 1 or more employees associated with it as well. Based on these two relationships we know that we have a many-to-many relationship (i.e. two one-to-many relationships in both directions).
Now if we use the same rules as above in the one-to-many relationships to build a relationship will we create lots of duplicate records? If you answered yes you are correct. In fact there is no way to relate the two tables in both directions without creating new foreign key columns in each table that reference the other table. In the example below I show exactly what I mean by showing duplicate records in both tables. Wait... what's wrong with this dataset now? Well, first off if we look at the data we can see the duplication in both tables is out of control and we only have two employees and 5 phone numbers (imagine what happens with 100s of employees). Now if you are paying attention you will also notice another big problem that will actually prevent us from implementing this solution within our database. The employee id cannot be duplicated becuase it's a primary key which means it must be unique.. what now?
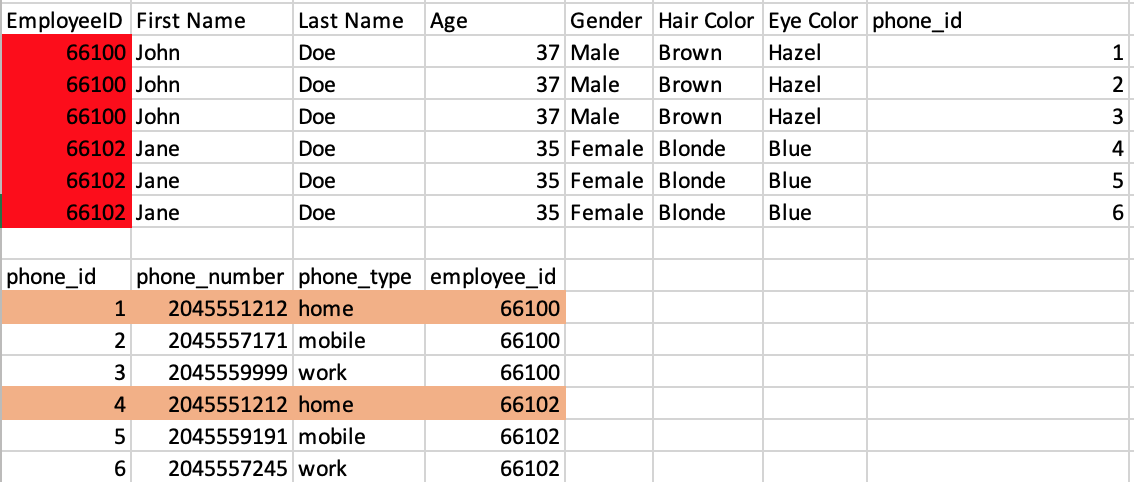
A common (but wrong) solution to this problem is to store a comma-seperated list of employee IDs (or Phone IDs) in the phone number table. In theory this works (and creates a one-to-many relationship partially) however this doesn't make searching any easier. In fact this makes it harder because there is no methods in SQL that split the column into rows and search using that split data. If you pull this into an application it also means you have to pull all the data in and then extract only the data you want after you split the comma-seperated values. Rule of thumb is let the tools do the work for you when you can.
I know what you are asking. What is the solution to this problem then? Actually the answer is really simple. If you have a many-to-many relationship such as this you need to create a third table called a bridging table. This table serves one purpose (usually) and that is to create a one-to-one mapping between the two tables (Employee and Phone). This bridging table will have a primary key consisting of the primary keys from both the other tables (i.e. an employee id plus a phone id together create a unique primary key for the bridging table). One thing to note is that you don't necessarily have to mark these fields as a primary key however if you are using referential integrirty in your database you often will. This simply means your database will ensure the primary keys exist in the other tables before creating a new record the bridging table.
In the example below I created a third table called EmployeePhoneNumber (often the convention is to name it after the two tables it maps) and removed the reference fields from the Employee and Phone number table (the foreign key column). Now whenever we create a new employee and a new address (or using an existing address) we will now also create a mapping entry using the two primary keys from the Employee table and the Phone number table. We only ever need to store the phone number once and using the bridge table we can map this phone number to one or more employees. For example, for employee with id 66100 we'd have an entry in the mapping table for 66100 (employee_id) and 1 (phone_id). For employee with id 66101 we'd have one entry of 66101 (employee_id) and 1 (phone_id) to reference the same home phone number. Using these tables we can now join the two tables when required by using the mapping entries in the bridge table. Best of all we have no duplicate data!
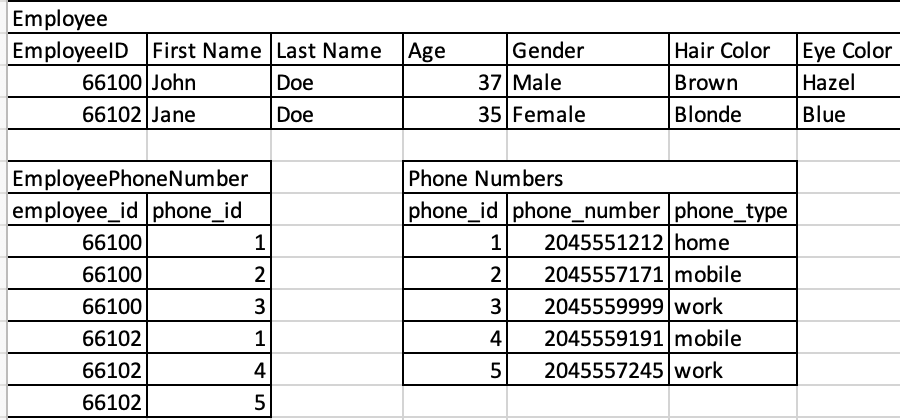
Mapping the Employee table to the Phone number table using a bridge table
Now that we understand relationships we should be able to take our original dataset and break down the data into individual tables. Additionally, we can also create our ERD (Entity Relationship Diagram) that shows our relationships. Often our primary key and foriegn keys are bold within the diagram and we use lines with forks (many) and | (one) to symbolize relationships. To demonstrate this below is the diagram created for this simply dataset using our business constraints:
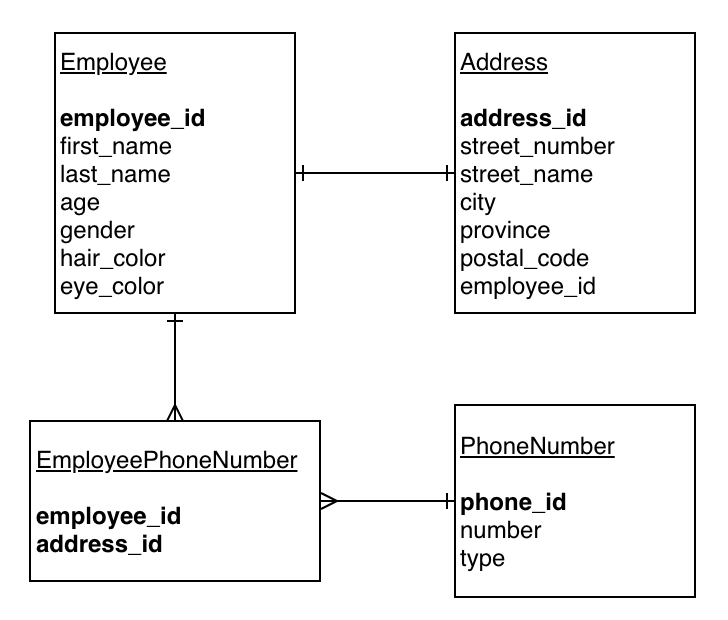
In the example above we show a one-to-many relationship between Employee and Address and we show an many-to-many relationship between the Employee and PhoneNumber table. One thing to notice is the bridging table is still stated as a many-to-many relationship.
Now if we look at this data can you see any other relationships? Is there still duplicate data in our existing tables?
The answer is yes there is duplicate data and additional relationships. For example, we could extract the city and provice into lookup tables and create a one-to-many (maybe even a many-to-many) relationship to remove duplication. We could even extract the postal codes into a seperate table creating a one-to-many relationship (postal codes belong to a group of addresses). The question you have to ask yourself is how far do you want to take the design. Sometimes it's simplier (e.g. maybe a business rule complicates things) to not extract the data into seperate tables or more efficient and if that's the case it's perfectly acceptable to leave the design as-is. The decision really comes down to effort and benefit. In our simple example it wouldn't take much time to add a few more relationships but in a complicated solution there may be 10s or 100s of tables to design.
With this information you should be able to take it as far as you need with some confidence. Also there is no "right answer" to database design and every admin will have their own thoughts on what is required. Key things to try are to reduce data duplication and make searching more efficient by seperating data by type (e.g don't retrieve phone numbers when all you want is a list of employee names).
Good luck!