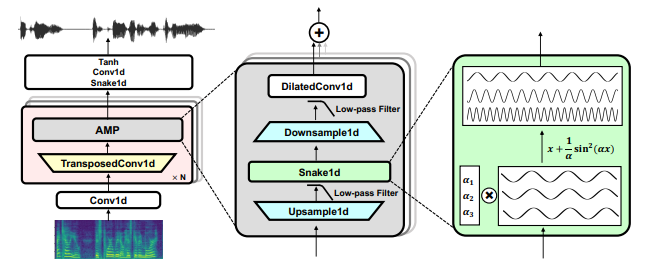
In this repository, I try to implement BigVGAN (specifically BigVGAN-base model) [Paper] [Demo].
2023-02-18: The official implementation of BigVGAN is released [Link] 😊
-
Leaky Relu --> x + (1/a)*sin^2(ax)
-
MRF --> AMP block
- Up --> Low-pass filter --> Snake1D --> Down --> Low-pass filter
-
MSD --> MRD (Univnet discriminator) UnivNet unofficial github
-
max_fre 8000 --> 12,000 for universal vocoder (sr: 24,000)
- We use the sampling rate of 22,050 and linear spectrogram for input speech.
-
Pytorch >=3.9 and torchaudio >= 0.9
-
Download datasets
- Download the VCTK dataset
mkdir dataset
cd dataset
wget https://datashare.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip -d VCTK-Corpus
cd ..# VCTK
python preprocess.py
python train_bigvgan_vocoder.py -c configs/vctk_bigvgan.json -m bigvgan- Original Snake1D paper states that it is important to initialize a proper value for alpha. For BigVGAN, I just wonder which value and initialization method BigVGAN used. I just set it to 1. The official source code of Snake1D is as below:
# official snake function (https://github.com/AdenosHermes/NeurIPS_2020_Snake/blob/main/Snake_Atmospheric_Temperature.ipynb)
class Snake(nn.Module):#learnable a
def __init__(self):
super(Snake, self).__init__()
self.a = nn.Parameter()
self.first = True
def forward(self, x):
if self.first:
self.first = False
a = torch.zeros_like(x[0]).normal_(mean=0,std=50).abs()
self.a = nn.Parameter(a)
return (x + (torch.sin(self.a * x) ** 2) / self.a)
- I will change the alpha parameter with initialization soon
- I tested some values for initialization. std=0.5 is better than others (1, 5, and 50). However, because I just trained the model for 50,000 steps, I'm not sure it is optimal value for neural vocoder.
Thanks to @PiotrDabkowski, I have noticed that alpha is not trained.
I fix it by changing list to torch.nn.ParameterList
Please see this issue (#10)
After some discussion, I only change the rolloff value (0.25 --> 0.5) and use torchaudio without modification.
After Transposed convolution for upsampling, aliasing may occur so it may be reduced by a low-pass filter.
At first, I misunderstand the frequency information of input feature in AMP block should be maintained after up/down sampling so I tried to modify resampling code to maintain the frequency information under original frequency. But this feature is also upsampled by transposed convolution and aliasing may occuer in this process.
Hence, I only change the rolloff value (0.25 --> 0.5) for anti-aliasing which I mis-implemented.
Thanks to @Yeongtae, I found that there are something wrong in the cutoff function of low-pass filter.
There are two problems in this function.
- The reference sampling rate of Cutoff is an lower frequency value between origial sampling rate and resampled sampling rate
- I used wrong rolloff value of 0.25 --> I will change it soon (0.25 --> 0.5)

- (Left) 22,050
- (Middle) Upsampling (44,100) -->Low-pass filter (rolloff=0.25, torchaudio)
- (Right) Upsampling (44,100) -->Low-pass filter (rolloff=0.25, torchaudio) --> Downsampling (22,050) --> Low-pass filter (rolloff=0.25, torchaudio)

- (Left) 22,050
- (Middle) Upsampling (44,100) -->Low-pass filter (rolloff=0.5, torchaudio)
- (Right) Upsampling (44,100) -->Low-pass filter (rolloff=0.5, torchaudio) --> Downsampling (22,050) --> Low-pass filter (rolloff=0.5, torchaudio)

- (Left) 22,050
- (Middle) Upsampling (44,100) -->Low-pass filter (rolloff=0.5, modified torchaudio)
- (Right) Upsampling (44,100) -->Low-pass filter (rolloff=0.5, modified torchaudio) --> Downsampling (22,050) --> Low-pass filter (rolloff=0.5, modified torchaudio)

- (Left) Upsampling (44,100) -->Low-pass filter (rolloff=0.99, modified torchaudio)
- (Middle)Upsampling (44,100) -->Low-pass filter (rolloff=0.5, modified torchaudio)
- (Right) Upsampling (44,100) -->Low-pass filter (rolloff=0.25, modified torchaudio)
I will update the source code of modified resampling tommorrow. Please do not use this repository for a while...
- Build Monotonic Alignment Search first (https://github.com/jaywalnut310/vits)
# Monotonic alignment search
Build MAS (https://github.com/jaywalnut310/vits)
python train_vits_with_bigvgan.py -c configs/vctk_bigvgan_vits.json -m vits_with_bigvgan- Current ver has some redundant parts in some modules (e.g., data_utils have some TTS module. Ignore it plz)
- pytorch extension ver with scipy??? StarGAN3
- torchaudio ver (0.9 >=) can use Kaiser window and rolloff (cutoff frequency)
torchaudio.transforms is much faster than torchaudio.functional when resampling multiple waveforms using the same paramters.
# beta
m = 2
n = 6
f_h = 0.6/m
A = 2.285*((m*n)/2 - 1)*math.pi*4*f_h+7.95
beta = 0.1102*(A-8.7)
4.663800127934911- (2022-06-14) Roll-off (https://pytorch.org/audio/main/_modules/torchaudio/functional/functional.html)
# In torchaudio.functional (https://pytorch.org/audio/main/_modules/torchaudio/functional/functional.html)
base_freq = min(orig_freq, new_freq)
# This will perform antialiasing filtering by removing the highest frequencies.
# At first I thought I only needed this when downsampling, but when upsampling
# you will get edge artifacts without this, as the edge is equivalent to zero padding,
# which will add high freq artifacts.
base_freq *= rolloff
width = math.ceil(lowpass_filter_width * orig_freq / base_freq)
idx = torch.arange(-width, width + orig_freq, device=device, dtype=idx_dtype)
for i in range(new_freq):
t = (-i / new_freq + idx / orig_freq) * base_freq
t = t.clamp_(-lowpass_filter_width, lowpass_filter_width)
.
.
.
Hence, I think that using rolloff=0.25 may restrict the bandwith under nyquist freq (fs/2).
Somebody... check it again Please 😢- (2022-06-12) I need to review this module. I used torchaudio to implement up/downsampling with low-pass filter. I used the rolloff value of 0.25 in the T.resample but I'm not sure this value is equal to sr/(2*m) where m is 2.
torchaudio > 0.9 is needed to use the rolloff parameter for anti-aliasing in T.resample
There are some issues of STFT function in pytorch of 3.9 (When using mixed precision, waveform need to be changed to float before stft )
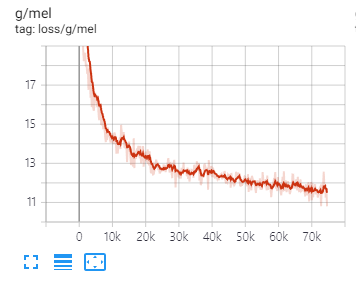
I train the BigVGAN-base model with batch size of 64 (using two A100 GPU) and an initial learning rate of 2 × 10−4
(In original paper, BigVGAN (large model) uses batch size of 32 and an initial learning rate of 1 × 10−4 to avoid an early training collapse)
For the BigVGAN-base model, I have not yet experienced an early training collapse with batch size of 64 and an initial learning rate of 2 × 10−4
The original paper may not use the AMP during training but this implementation includes AMP. Hence, the results may be different in original setting.
For training with AMP, I change the dtype of representation to float for torchaudio resampling (Need to be changed for precise transformation).