Debugging
pywb is a state of the art recording and replay tool for web archives that are stored as WARC data. SUL have acquired WARC data from multiple services such as the California Digital Library and Archive-It, and also by using "crawling" tools such as httrack, wget, Heritrix, Webrecorder and ArchiveWeb.page. Given that these services and tools can perform collection in slightly different ways it is not uncommon to encounter inconsistencies in replay when viewing the archived content in pywb. Since the source of these problems can often be difficult to diagnose this document provides a guide to what causes some of these errors, and also provides some tips on how to investigate them.
A replay problem for a page in pywb usually stems from two possible causes:
- Access controls
- Problems with the crawled data (WARC).
- Problems in pywb's replay mechanism.
While it might not be obvious if pywb isn't playing back a URL at all it might be because it was told not to. This can be the case when a URL has been intentionally restricted using pywb's Access Control settings. Stanford use this occasionally to block particular material, and the replay page does not say that the content has been blocked. The current production access list can be found in was-pywb-prod.stanford.edu:/web-archiving-stacks/data/access.aclj. It can be useful to view this file to see if a URL, or its prefix, is included there. Note, a block of example.com will also include a block of example.com/1234. If you do find a block do not remove it or change it without talking to the Web Archives Service Product Owner.
Ordinarily the source of a replay problem is 2. The crawling mechanism that was used to create the WARC data can sometimes fail to collect resources that are needed for rendering the page. This could be missing CSS, image or JavaScript files that were blocked by a robots.txt file. It's also possible that certain resources were not archived because of the scoping rules used during crawling.
In addition, some crawling tools like Archive-It's Brozzler, ArchiveWeb.page or browsertrix-cloud use browser based collection which executes JavaScript, which in turn can fetch additional resources. Other tools may not execute JavaScript, which can lead to partially captured pages, especially for sites that are more like web applications, such as social media platforms, Google Docs, etc.
Once you have determined that resources are missing from an archive you can us Archive-It to patch the crawl, or you can perform a new crawl using an updated crawl configuration in order to get a more complete snapshot of the resources needed to render the page. You will need to add that crawl SWAP.
While it is less common, pywb can also sometimes fail to find the correct archived resource when looking up a URL. This can happen for a variety of reasons, such as revisit records and redirects not working properly, or fuzzy matching rules not picking up the correct WARC records. These problems are much trickier to track down and correct, and are discussed below in the Internals section.
This guide is not meant to replace existing documentation from [Archive-It] on how to debug and patch fault crawls that are created with Archive-It. If you know which collection and crawl that the faulty page render is from, and it originated with Archive-It, it is a good idea to try to use Archive-It's QA Tool to see if the source of the problem can be identified and remediated.
While you can debug content in swap.stanford.edu directly, sometimes it is helpful to load the WARC data into a dev instance of pywb to see if the cause of problems can be determined in isolation. You can do this by following the instructions in the was-pywb repository to bring up pywb in a local Docker environment.
When trying to determine a problem with playback, especially when the WARC data came from Archive-It or another source, it can be helpful to archive the page with express.archiveweb.page or the ArchiveWeb.page Chrome extension. Once you have created the archive you can download the WACZ file, which is a ZIP file that you can unzip, and extract the WARC data from the archives subdirectory. Adding these files to your local pywb can let you see if a browser based crawl helps capture resources that are missing from the other crawl.
Both Chrome and Firefox have Developer Tools console, which allow you to view diagnostic information about what is happening to render the page. When viewing the faulty page in swap.stanford.edu, you can open DeveloperTools, and look at the Network tab to see if there are any 404 Not Found errors. These missing resources can provide evidence of why the page is not rendering correctly, and can provide information about how to adjust the crawl's configuration, or select a new tool.
In this example it's clear that some images were not captured as part of the crawl:
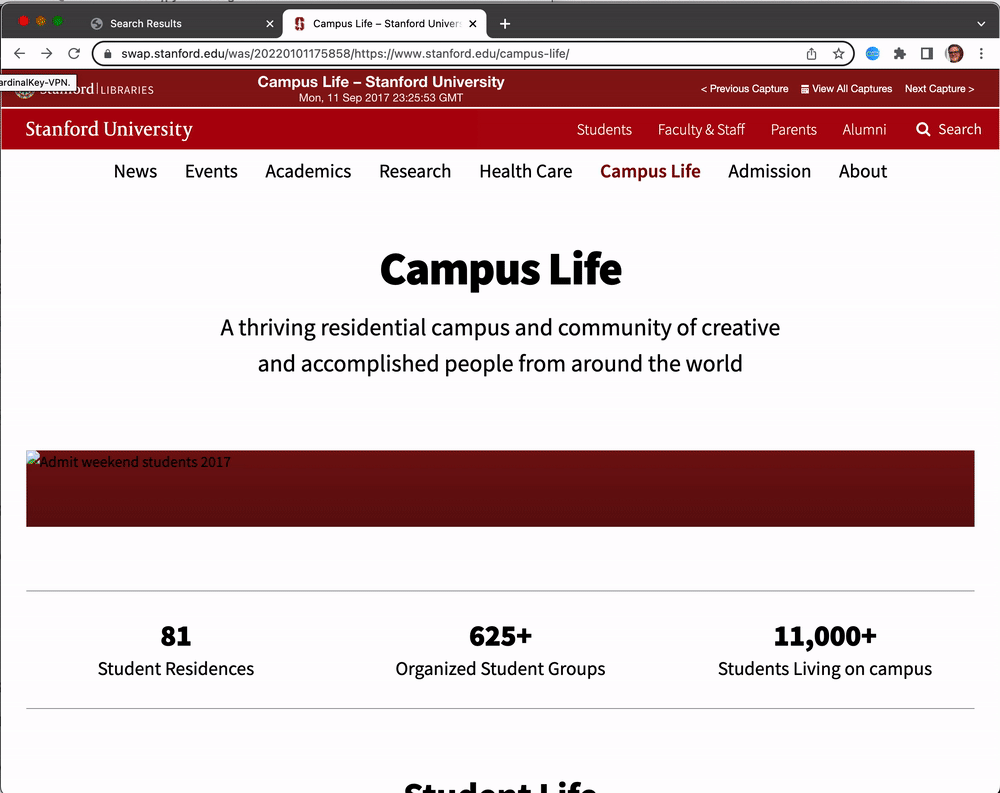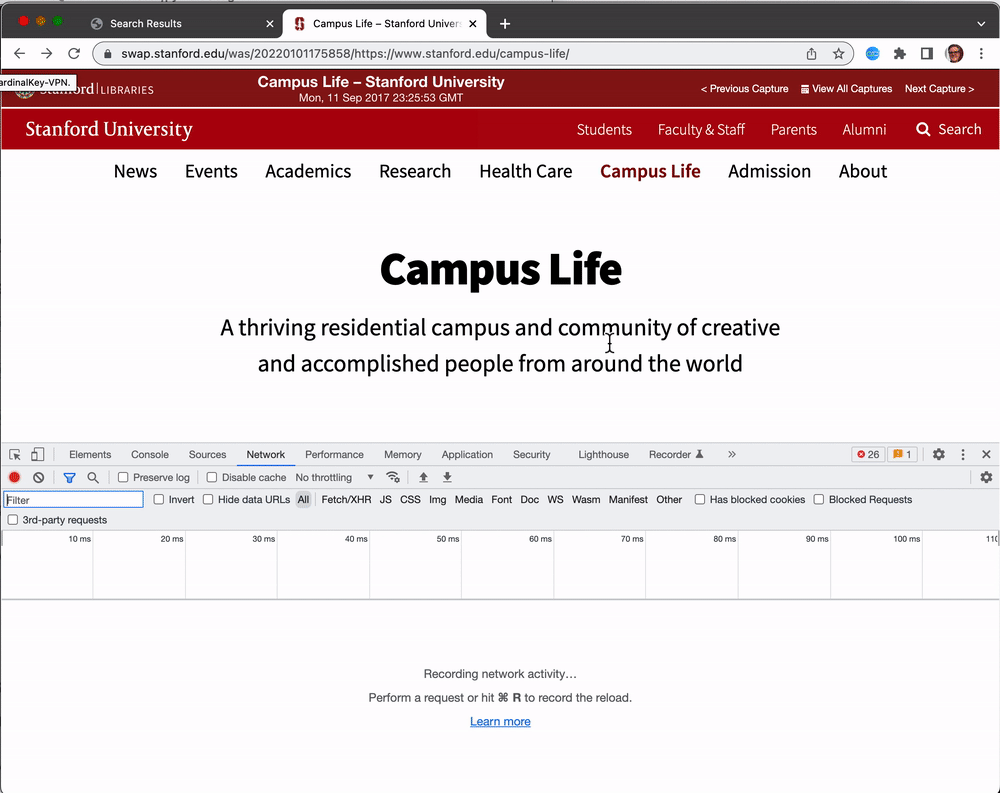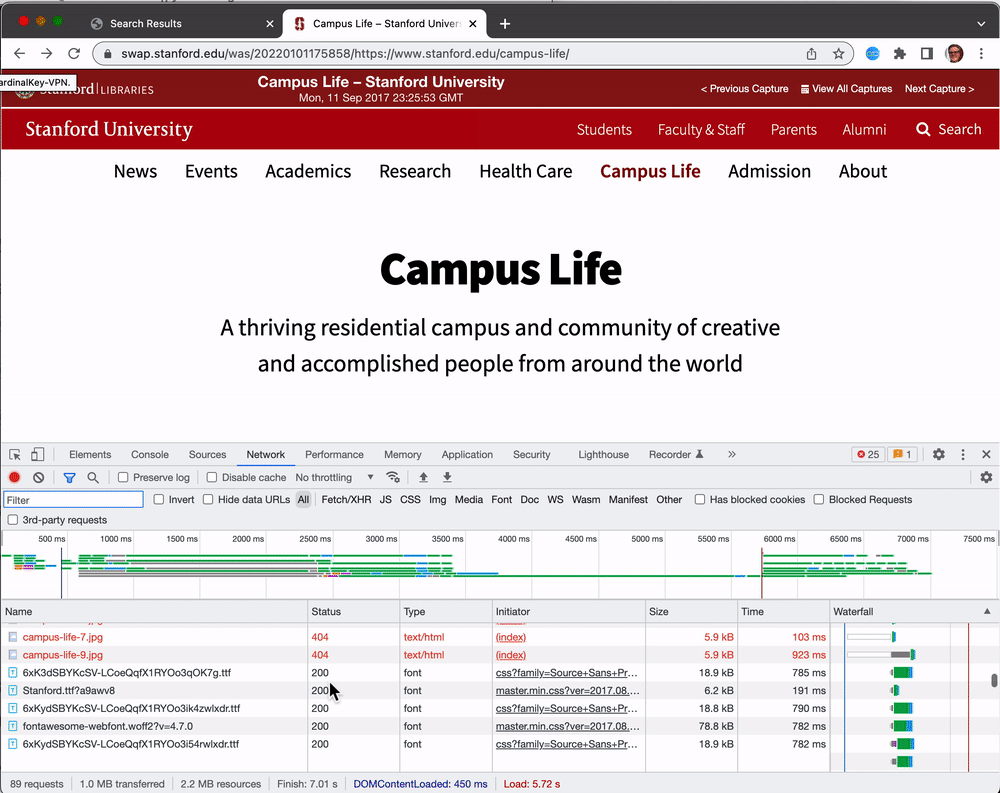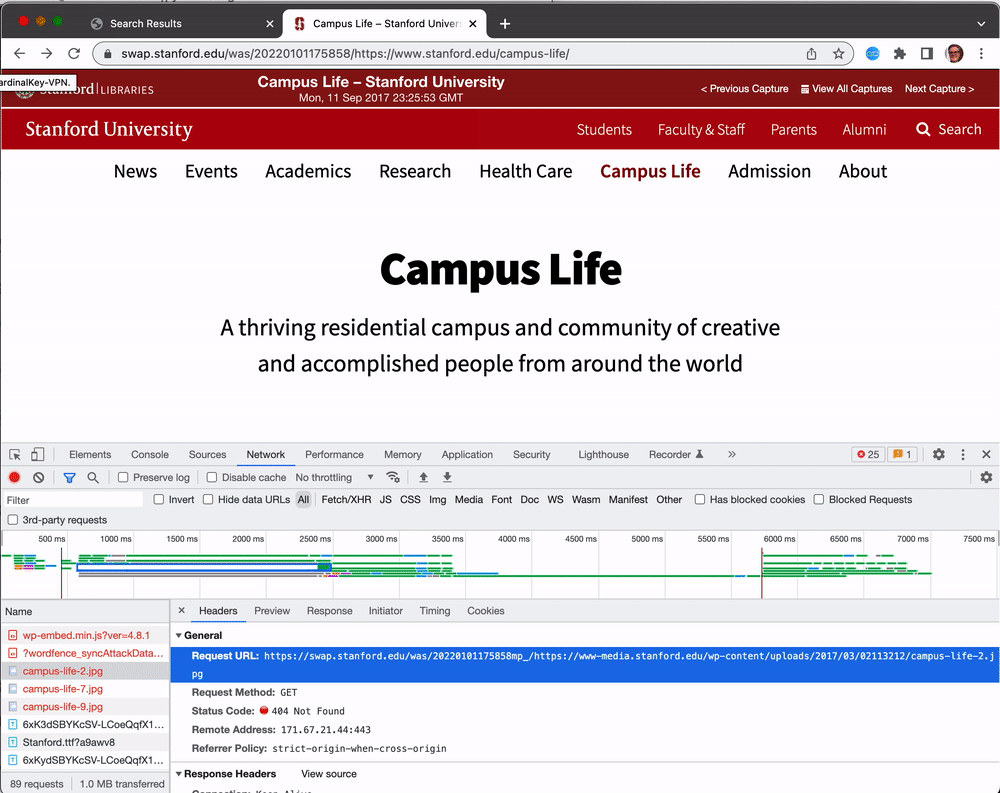
Here the URL https://swap.stanford.edu/was/20220101175858mp_/https://www-media.stanford.edu/wp-content/uploads/2017/03/02113212/campus-life-2.jpg was not being loaded from pywb. Notice how the original URL is embedded in the pywb URL? https://www-media.stanford.edu/wp-content/uploads/2017/03/02113212/campus-life-2.jpg. This can provide a clue as to how the crawl could be improved to collect the missing resource, and in some cases (see the CDX section below) it can be used to look to see if the resource is available in the archive. In this case the scoping rules that were used for the crawl were not allowing resources from www-media.stanford.edu to be collected.
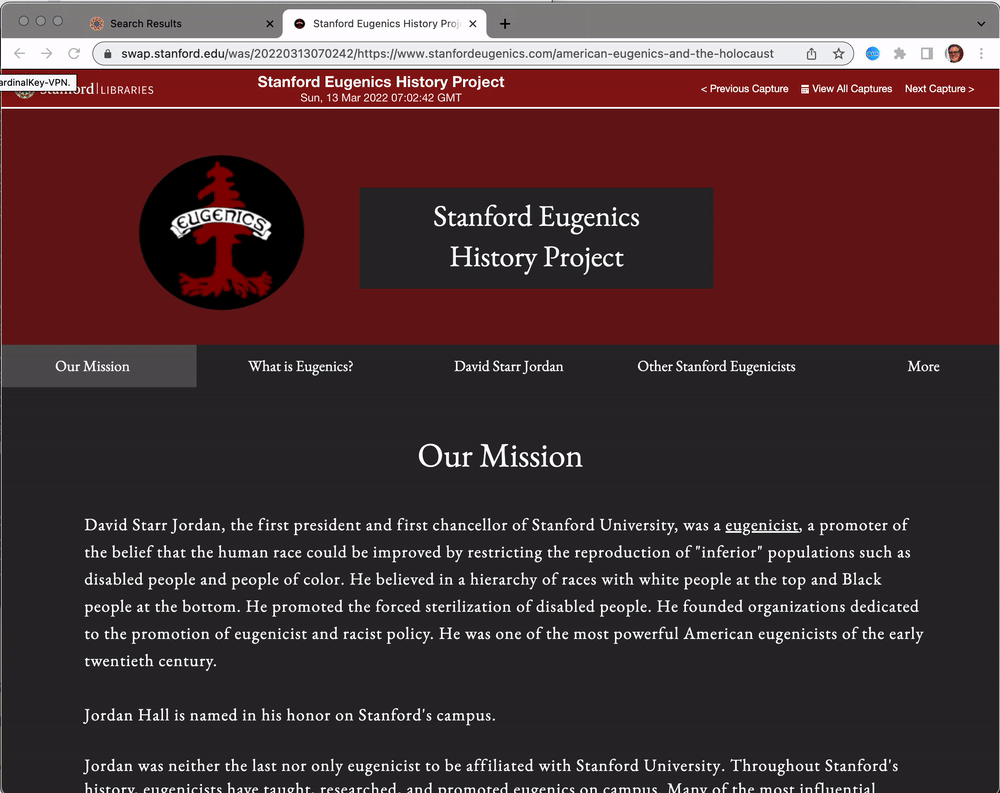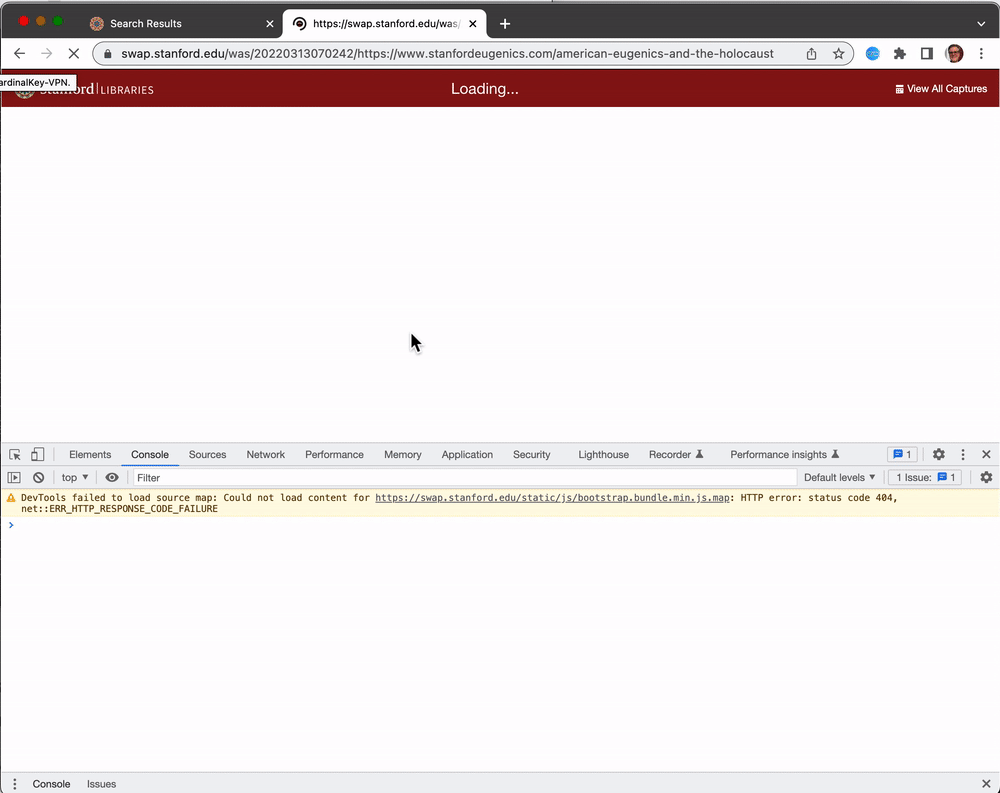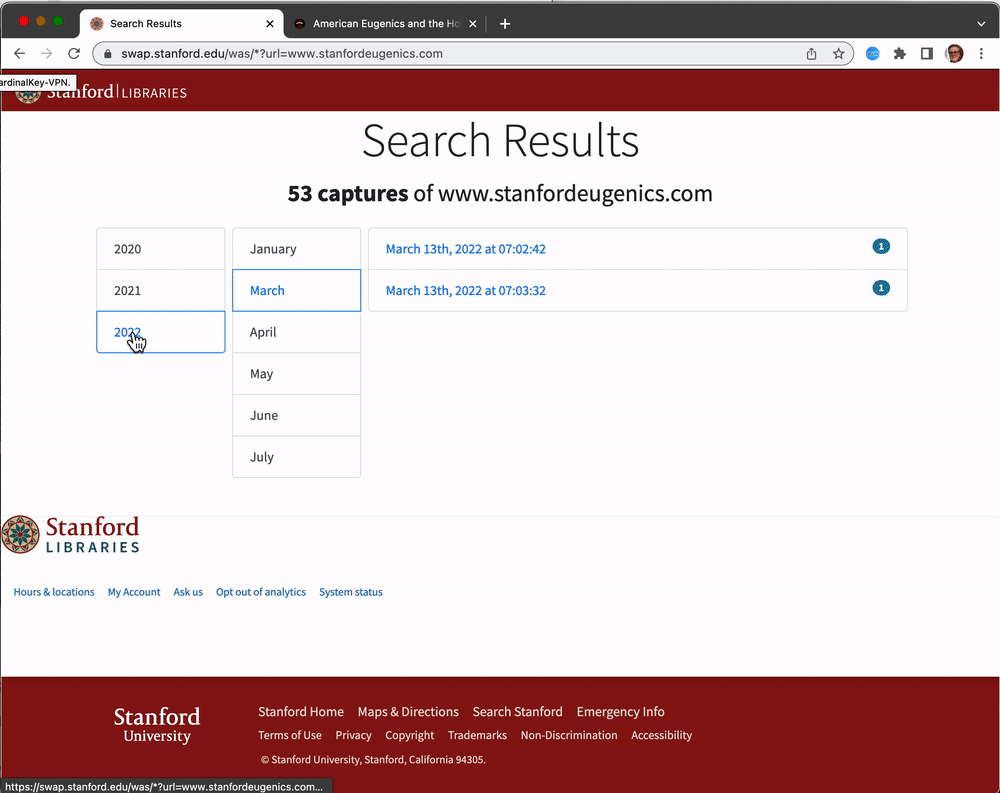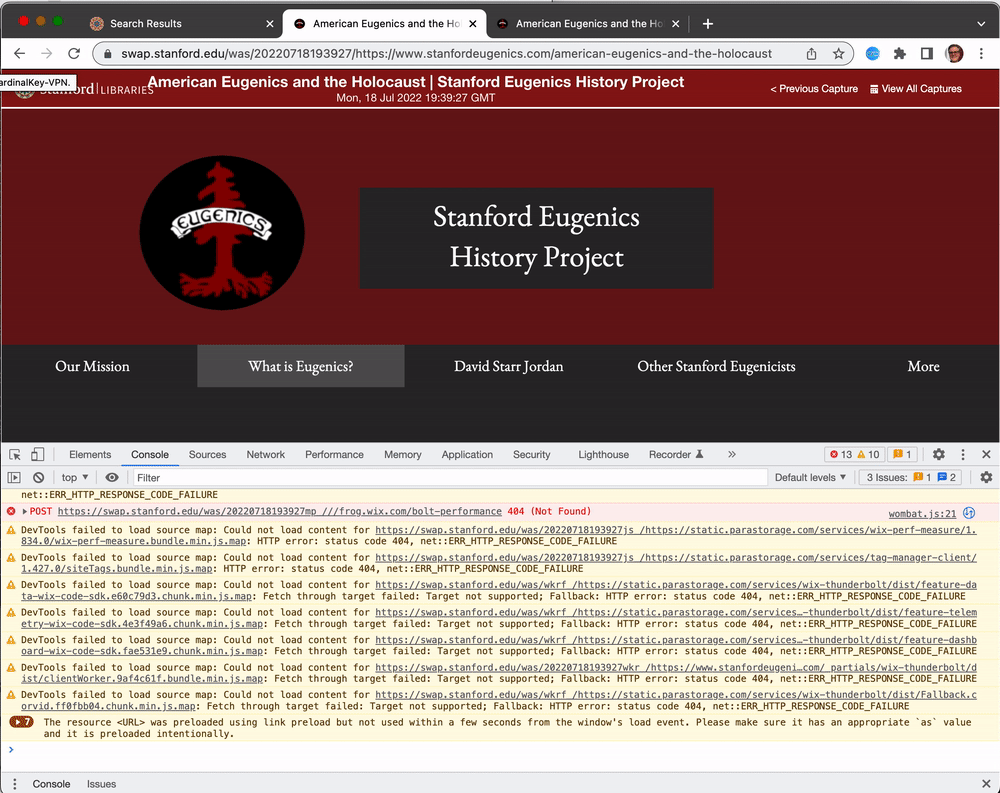
In addition to using the Network view, it can also be useful to look at the Console view, since it will print errors that are encountered, especially ones related to JavaScript execution. If JavaScript execution results in failures to load resources, the program can terminate with an error, which can prevent other parts of the page from loading.
In this example the page menus were not working properly (they couldn't be selected) because the JavaScript was attempting to use resources that were not available in the web archive.
If there are many resources on a given page, and it is proving difficult to analyze them visually in DevTools it may be helpful to download the activity as a HAR file, and programatically inspect the activity. This can be especially useful in situations where you would like to compare the success and failure of resources fetched in pywb with the live site, or in another replay tool like ReplayWeb.page.
A HAR file, or HTTP Archive can be created in Chrome for a given page by right clicking on the table of network traffic and selecting Save as HAR with Content (Firefox has similar functionality). The HAR file is a JSON object that contains a list of entries each of which includes the HTTP request and response information. For example here is the entry for fetching a page from Instagram:
{
"_initiator": {
"type": "other"
},
"_priority": "VeryHigh",
"_resourceType": "document",
"cache": {},
"connection": "370",
"pageref": "page_1",
"request": {
"method": "GET",
"url": "http://swap.stanford.edu/was/20210909173940626/https://www.instagram.com/clubcardinal/",
"httpVersion": "HTTP/1.1",
"headers": [
{
"name": "Accept",
"value": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
},
{
"name": "Accept-Encoding",
"value": "gzip, deflate, br"
},
{
"name": "Accept-Language",
"value": "en-US,en;q=0.9"
},
{
"name": "Cache-Control",
"value": "max-age=0"
},
{
"name": "Connection",
"value": "keep-alive"
},
{
"name": "Host",
"value": "swap.stanford.edu"
},
{
"name": "Sec-Fetch-Dest",
"value": "document"
},
{
"name": "Sec-Fetch-Mode",
"value": "navigate"
},
{
"name": "Sec-Fetch-Site",
"value": "none"
},
{
"name": "Sec-Fetch-User",
"value": "?1"
},
{
"name": "Upgrade-Insecure-Requests",
"value": "1"
},
{
"name": "User-Agent",
"value": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
},
{
"name": "sec-ch-ua",
"value": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\""
},
{
"name": "sec-ch-ua-mobile",
"value": "?0"
},
{
"name": "sec-ch-ua-platform",
"value": "\"macOS\""
}
],
"queryString": [],
"cookies": [],
"headersSize": 749,
"bodySize": 0
},
"response": {
"status": 200,
"statusText": "OK",
"httpVersion": "HTTP/1.1",
"headers": [
{
"name": "Content-Length",
"value": "1518"
},
{
"name": "Content-Type",
"value": "text/html"
},
{
"name": "Date",
"value": "Fri, 15 Jul 2022 01:06:40 GMT"
},
{
"name": "Link",
"value": "<https://www.instagram.com/clubcardinal/>; rel=\"original\", <http://swap.stanford.edu/was/https://www.instagram.com/clubcardinal/>; rel=\"timegate\", <http://swap.stanford.edu/was/timemap/link/https://www.instagram.com/clubcardinal/>; rel=\"timemap\"; type=\"application/link-format\", <http://swap.stanford.edu/was/20210909173940626mp_/https://www.instagram.com/clubcardinal/>; rel=\"memento\"; datetime=\"Thu, 09 Sep 2021 17:39:40 GMT\""
},
{
"name": "Memento-Datetime",
"value": "Thu, 09 Sep 2021 17:39:40 GMT"
}
],
"cookies": [],
"content": {
"size": 1518,
"mimeType": "text/html",
"compression": 0,
"text": "<!DOCTYPE html>\n<html>\n<head>\n<style>\nhtml, body\n{\n height: 100%;\n margin: 0px;\n padding: 0px;\n border: 0px;\n overflow: hidden;\n}\n\n</style>\n<script src='http://swap.stanford.edu/static/wb_frame.js'> </script>\n\n\n<script>\nwindow.banner_info = {\n is_gmt: true,\n\n liveMsg: decodeURIComponent(\"Live on\"),\n\n calendarAlt: decodeURIComponent(\"Calendar icon\"),\n calendarLabel: decodeURIComponent(\"View All Captures\"),\n choiceLabel: decodeURIComponent(\"Language:\"),\n loadingLabel: decodeURIComponent(\"Loading...\"),\n logoAlt: decodeURIComponent(\"Logo\"),\n\n locale: \"en\",\n curr_locale: \"\",\n locales: [],\n locale_prefixes: {},\n prefix: \"http://swap.stanford.edu/was/\",\n staticPrefix: \"http://swap.stanford.edu/static\"\n};\n</script>\n\n<!-- default banner, create through js -->\n<script src='http://swap.stanford.edu/static/default_banner.js'> </script>\n<link rel='stylesheet' href='http://swap.stanford.edu/static/default_banner.css'/>\n\n\n\n</head>\n<body style=\"margin: 0px; padding: 0px;\">\n\n<div id=\"wb_iframe_div\">\n<iframe id=\"replay_iframe\" frameborder=\"0\" seamless=\"seamless\" scrolling=\"yes\" class=\"wb_iframe\" allow=\"autoplay; fullscreen\"></iframe>\n</div>\n<script>\n var cframe = new ContentFrame({\"url\": \"https://www.instagram.com/clubcardinal/\" + window.location.hash,\n \"prefix\": \"http://swap.stanford.edu/was/\",\n \"request_ts\": \"20210909173940626\",\n \"iframe\": \"#replay_iframe\"});\n\n</script>\n</body>\n</html>\n"
},
"redirectURL": "",
"headersSize": 581,
"bodySize": 1518,
"_transferSize": 2099,
"_error": null
},
}Being able to look through the entries for HTTP errors, and also compare the requested URLs and their responses to a HAR file created from the live site can help in noticing potential problems during replay. You may need to extract the archived URL from the URL that is used to access it from the archive.
When trying to determine what snapshots are available for a given URL pywb's CDXJ API can be quite useful. pywb uses the CDXJ API internally when replaying a page in order to determine when a particular snapshot was captured, and where to find it. But you can also use the API to find specific date ranges of captures, to limit to particular media types, and also to find snapshots that match a particular URL pattern.
The CDXJ API is useful in debugging when you are trying to understand why a particular URL was not captured, or where a particular capture is stored. For example you can query the CDXJ API for any snapshots of the URL https://apod.nasa.gov/apod/astropix.html using curl:
$ curl https://swap.stanford.edu/was/cdx\?output=json&url=https://apod.nasa.gov/apod/astropix.html
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20101107223428", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:UJ6U6LTQSU4AWXTCW3PCGOIRAEJQ6KPX", "length": "2529", "offset": "27234007", "filename": "rf785yk7955/tf/035/xd/8616/ARCHIVEIT-969-QUARTERLY-VGGPKT-20101107223145-00030-crawling01.us.archive.org-6680.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20110207224259", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:NVZS7DHBKNS7DXPZ7TB4NQVSI7LJ4AHD", "length": "2531", "offset": "27295630", "filename": "rf785yk7955/gy/651/yq/2370/ARCHIVEIT-969-QUARTERLY-CRBTVP-20110207224029-00017-crawling114.us.archive.org-6682.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20110507231023", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:WYX6JQV7NVIOEXVNUJQIYCY43XTQT7CH", "length": "2072", "offset": "52251477", "filename": "rf785yk7955/ms/340/zr/6917/ARCHIVEIT-969-QUARTERLY-OPUIUI-20110507230638-00018-crawling202.us.archive.org-6682.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20110807235931", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:RVXVLDD74SW5RN5DEO4Q4X7EEKOU6DUJ", "length": "2370", "offset": "14032504", "filename": "rf785yk7955/jy/578/yv/3977/ARCHIVEIT-969-QUARTERLY-IBBILQ-20110807235753-00020-crawling203.us.archive.org-6683.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20111108001123", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:RUAQK6XFNF4LEXFMLHFLBQF2ZHRLBWPX", "length": "2320", "offset": "2357422", "filename": "rf785yk7955/wb/649/kf/9908/ARCHIVEIT-969-QUARTERLY-EYGKQU-20111108001109-00023-crawling115.us.archive.org-6682.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20120208004549", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:DRQDM23SMGR6E55GP2Y666V6RMFOGYXI", "length": "2397", "offset": "42921932", "filename": "rf785yk7955/dr/084/zz/3857/ARCHIVEIT-969-QUARTERLY-NNRQQY-20120208004113-00019-crawling207.us.archive.org-6680.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20120508025635", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:C5FBXRSFZH7F4MFNWJ4M5M2MWOHZZ7IJ", "length": "2178", "offset": "48090740", "filename": "rf785yk7955/cn/491/qd/0514/ARCHIVEIT-969-QUARTERLY-KROGGZ-20120508024906-00026-crawling109.us.archive.org-6680.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20120808001402", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:GYNUHHAOSYNEI7LGBZ5IQWFMHROVJHJC", "length": "2035", "offset": "87853343", "filename": "rf785yk7955/mb/134/zk/9741/ARCHIVEIT-969-QUARTERLY-LJPBKE-20120807235948-00016-crawling201.us.archive.org-6680.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20121108011249", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:DVJ5VID3RNX3CTYIHRDX6ZGA462CUHMY", "length": "2743", "offset": "72144363", "filename": "rf785yk7955/kt/606/mk/5650/ARCHIVEIT-969-QUARTERLY-VBHCZS-20121108011019-00138-wbgrp-crawl054.us.archive.org-6681.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
{"urlkey": "gov,nasa,apod)/apod/astropix.html", "timestamp": "20130208012039", "url": "http://apod.nasa.gov/apod/astropix.html", "mime": "text/html", "status": "200", "digest": "sha1:MZ7LZQKSVDQNE547ZFE37CWFYOLL6P6X", "length": "2442", "offset": "37937619", "filename": "rf785yk7955/zm/800/qx/9530/ARCHIVEIT-969-QUARTERLY-XMLFOM-20130208011956-00181-wbgrp-crawl057.us.archive.org-6682.warc.gz", "source": "was:level3.cdxj", "source-coll": "was", "access": "allow"}
Note that the results have a complete JSON object on each line, which contains:
- the archived URL
- a timestamp when the URL was archived
- the media type
- the HTTP status of the response
- a hash of the response content
- the content-length in bytes
- the source pywb collection
- the CDXJ index file that the entry was found in
- the path to the WARC file that the response can be found in
- the offset into the WARC file where the specific response can be found
In addition to searching for an exact URL it can sometimes be helpful to use the matchType parameter to search for any URL matching a prefix. This is helpful in situations where you think a URL may have been captured, but perhaps with additional characters appended on the end (e.g. tracking parameters). Similarly host can be used to collect records for an entire site in order to do some analysis of what is available. But this can return a lot of data. More about how the WARC file and offest are useful in the next section.
When you need to access information from the CDX index without using a URL as a key it can be useful to bypass the API service and search the index files directly using a tool like grep. The index files can be found in was-pywb.stanford.edu:/web-archiving-stacks/data/indexes/cdxj/. Each "level" in the filename corresponds to a daily, weekly, monthly and yearly view. New content is added to level0.cdxj and is merged into the next level via a cron job. The full index level3.cdxj is hundreds of gigabytes in size, and can take considerable time to scan. So it can sometimes be useful to filter the complete indexes using some broad pattern into a smaller file for subsequent analysis.
As mentioned in the section above it is useful to examine the actual WARC records that pywb is using to generate a response. Each CDXJ entry includes the path to the WARC file where the corresponding WARC record can be found, as well as the byte offset into that file where the exact record can be found.
For example to locate the corresponding record for this index entry you would seek 72144363 bytes into the rf785yk7955/kt/606/mk/5650/ARCHIVEIT-969-QUARTERLY-VBHCZS-20121108011019-00138-wbgrp-crawl054.us.archive.org-6681.warc.gz WARC file, and read 2743 bytes:
{
"urlkey": "gov,nasa,apod)/apod/astropix.html",
"timestamp": "20121108011249",
"url": "http://apod.nasa.gov/apod/astropix.html",
"mime": "text/html",
"status": "200",
"digest": "sha1:DVJ5VID3RNX3CTYIHRDX6ZGA462CUHMY",
"length": "2743",
"offset": "72144363",
"filename": "rf785yk7955/kt/606/mk/5650/ARCHIVEIT-969-QUARTERLY-VBHCZS-20121108011019-00138-wbgrp-crawl054.us.archive.org-6681.warc.gz",
"source": "was:level3.cdxj",
"source-coll": "was",
"access": "allow"
}While you could do this manually it's a bit tedious because the WARC files are usually gzip compressed, and the byte offset is relative to the compressed data. To make it easier you can use the warcio command line utility that is installed when you install pywb. To do that you would ssh to the was-pywb environment and then use the path (combined with the root /web-archiving-stacks/data/collections and offset to view the WARC record:
$ warcio extract /web-archiving-stacks/data/collections/rf785yk7955/kt/606/mk/5650/ARCHIVEIT-969-QUARTERLY-VBHCZS-20121108011019-00138-wbgrp-crawl054.us.archive.org-6681.warc.gz 72144363
WARC/1.0
WARC-Type: response
WARC-Target-URI: http://apod.nasa.gov/apod/astropix.html
WARC-Date: 2012-11-08T01:12:49Z
WARC-Payload-Digest: sha1:DVJ5VID3RNX3CTYIHRDX6ZGA462CUHMY
WARC-IP-Address: 129.164.179.22
WARC-Record-ID: <urn:uuid:b17f5a61-33a8-40b9-b4a0-30333c551f0a>
Content-Type: application/http; msgtype=response
Content-Length: 5763
HTTP/1.1 200 OK
Date: Thu, 08 Nov 2012 01:12:49 GMT
Server: WebServer/1.0
Accept-Ranges: bytes
Content-Length: 5576
Connection: close
Content-Type: text/html; charset=ISO-8859-1
<html>
<head>
<title>Astronomy Picture of the Day
</title>
<!-- gsfc meta tags -->
<meta name="orgcode" content="661">
<meta name="rno" content="phillip.a.newman">
<meta name="content-owner" content="Jerry.T.Bonnell.1">
<meta name="webmaster" content="Stephen.F.Fantasia.1">
...
Viewing the WARC record can be useful when trying to trace pywb's behavior, since the WARC record headers can influence how pywb chooses to play back the content. This is especially relevant for revisit records where instead of repeating the same content, a content hash for the content is supplied which can be used to look for the relevant response that is included in another record
While they are rare if you encounter an error in pywb when replaying content you may notice that the error you see displayed in your browser is brief, and lacks sufficient detail. To help provide more context you will want to enable debugging either by starting pywb using the --debug option, or by adding debug: true to the pywb configuration file. This will cause a full stack trace to be written to /var/log/apache2/wayback_error_ssl.log when encountering exceptions.
When you are attempting to track down why a particular WARC record is being displayed it can be helpful to trace the logic pywb is using when looking up a URL in the CDX index. While there aren't currently any diagnostic information for this available in the logs, you can instrument parts of the pywb.warcserver.index.cdxops to be able to trace the logic for what is being returned. Two functions of particular note are cdx_sort_closest() which performs the binary search to find the closest entries for a particular URL and timestamp. Also pywb.warcserver.index.fuzzymatcher can be be useful to look at to determine why a particular resource is being returned instead of another. This can be particularly important as pywb has rules for ignoring platform specific, time sensitive, URL parameters that are used.