merge upstream changes #15
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
```
+ export USE_LIBUV=1
+ USE_LIBUV=1
+ TRAINER_DIR=/home/gnadathur/local/torchtrain
+ NGPU=4
+ LOG_RANK=0,1
+ CONFIG_FILE=./train_configs/debug_model.toml
+ torchrun --nproc_per_node=4 --rdzv_endpoint=localhost:5972 --local-ranks-filter 0,1 --role rank --tee 3 train.py --job.config_file ./train_configs/debug_model.toml
W0304 17:01:26.766000 140549371597824 torch/distributed/run.py:717]
W0304 17:01:26.766000 140549371597824 torch/distributed/run.py:717] *****************************************
W0304 17:01:26.766000 140549371597824 torch/distributed/run.py:717] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
W0304 17:01:26.766000 140549371597824 torch/distributed/run.py:717] *****************************************
[rank0]:2024-03-04 17:01:28,834 - torchtrain.parallelisms - INFO - Building 1-D device mesh with ('dp',), [4]
[rank1]:2024-03-04 17:01:28,857 - torchtrain.parallelisms - INFO - Building 1-D device mesh with ('dp',), [4]
[rank0]:2024-03-04 17:01:29,712 - root - INFO - Starting job: debug training
[rank0]:2024-03-04 17:01:29,712 - root - INFO - Building llama
[rank0]:2024-03-04 17:01:29,719 - root - INFO - Reloaded SentencePiece model from ./torchtrain/datasets/tokenizer/tokenizer.model
[rank0]:2024-03-04 17:01:29,719 - root - INFO - #words: 32000 - BOS ID: 1 - EOS ID: 2
[rank1]:2024-03-04 17:01:31,187 - root - INFO - Reloaded SentencePiece model from ./torchtrain/datasets/tokenizer/tokenizer.model
[rank1]:2024-03-04 17:01:31,188 - root - INFO - #words: 32000 - BOS ID: 1 - EOS ID: 2
[rank0]:2024-03-04 17:01:31,346 - root - INFO - Model fully initialized via reset_params
[rank0]:2024-03-04 17:01:31,346 - root - INFO - Model built with: ModelArgs(dim=256, n_layers=2, n_heads=16, n_kv_heads=None, vocab_size=32000, multiple_of=256, ffn_dim_multiplier=None, norm_eps=1e-05, max_batch_size=32, max_seq_len=32768, depth_init=True)
[rank0]:2024-03-04 17:01:31,347 - root - INFO - �[34mModel llama debugmodel �[31msize: 18,089,216 total parameters�[39m
[rank0]:2024-03-04 17:01:31,347 - root - INFO - GPU memory usage: NVIDIA H100 (0): 95.0396 GiB capacity, 0.0 GiB in-use, 0.0% in-use
[rank0]:2024-03-04 17:01:32,502 - root - INFO - Applied FSDP to the model...
[rank0]:2024-03-04 17:01:32,503 - root - INFO - Gradient scaling not enabled.
[rank0]:2024-03-04 17:01:32,504 - root - INFO - Metrics logging active. Tensorboard logs will be saved at ./outputs/tb/20240304-1701.
[rank0]:2024-03-04 17:01:32,901 - root - INFO - Profiling active. Traces will be saved at ./outputs/profiling/traces
[rank0]:2024-03-04 17:01:34,806 - root - INFO - �[36mstep: 1 �[32mloss: 10.8424 �[39miter: �[34m 1.8688�[39m data: �[34m0.0316 �[39mlr: �[33m0.00026667�[39m
[rank0]:2024-03-04 17:01:34,891 - root - INFO - �[36mstep: 2 �[32mloss: 10.7581 �[39miter: �[34m 0.0476�[39m data: �[34m0.0357 �[39mlr: �[33m0.00053333�[39m
[rank0]:2024-03-04 17:01:34,970 - root - INFO - �[36mstep: 3 �[32mloss: 10.6239 �[39miter: �[34m 0.045�[39m data: �[34m0.0333 �[39mlr: �[33m0.0008�[39m
[rank0]:2024-03-04 17:01:35,048 - root - INFO - �[36mstep: 4 �[32mloss: 10.4163 �[39miter: �[34m 0.0455�[39m data: �[34m0.0323 �[39mlr: �[33m0.0007�[39m
[rank0]:2024-03-04 17:01:35,127 - root - INFO - �[36mstep: 5 �[32mloss: 10.1529 �[39miter: �[34m 0.0459�[39m data: �[34m0.032 �[39mlr: �[33m0.0006�[39m
[rank0]:2024-03-04 17:01:35,206 - root - INFO - �[36mstep: 6 �[32mloss: 9.8899 �[39miter: �[34m 0.0468�[39m data: �[34m0.0311 �[39mlr: �[33m0.0005�[39m
[rank0]:2024-03-04 17:01:35,284 - root - INFO - �[36mstep: 7 �[32mloss: 9.7204 �[39miter: �[34m 0.0461�[39m data: �[34m0.0312 �[39mlr: �[33m0.0004�[39m
[rank0]:2024-03-04 17:01:35,425 - root - INFO - �[36mstep: 8 �[32mloss: 9.3757 �[39miter: �[34m 0.0457�[39m data: �[34m0.0319 �[39mlr: �[33m0.0003�[39m
[rank0]:STAGE:2024-03-04 17:01:35 3850444:3850444 ActivityProfilerController.cpp:314] Completed Stage: Warm Up
[rank0]:2024-03-04 17:01:35,537 - root - INFO - �[36mstep: 9 �[32mloss: 9.1883 �[39miter: �[34m 0.0762�[39m data: �[34m0.0318 �[39mlr: �[33m0.0002�[39m
[rank0]:[rank0]:[W CPUAllocator.cpp:249] Memory block of unknown size was allocated before the profiling started, profiler results will not include the deallocation event
[rank1]:STAGE:2024-03-04 17:01:35 3850445:3850445 ActivityProfilerController.cpp:314] Completed Stage: Warm Up
[rank1]:[rank1]:[W CPUAllocator.cpp:249] Memory block of unknown size was allocated before the profiling started, profiler results will not include the deallocation event
[rank0]:STAGE:2024-03-04 17:01:35 3850444:3850444 ActivityProfilerController.cpp:320] Completed Stage: Collection
[rank0]:STAGE:2024-03-04 17:01:35 3850444:3850444 ActivityProfilerController.cpp:324] Completed Stage: Post Processing
[rank1]:STAGE:2024-03-04 17:01:35 3850445:3850445 ActivityProfilerController.cpp:320] Completed Stage: Collection
[rank1]:STAGE:2024-03-04 17:01:35 3850445:3850445 ActivityProfilerController.cpp:324] Completed Stage: Post Processing
[rank0]:2024-03-04 17:01:35,958 - root - INFO - exporting profile traces to ./outputs/profiling/traces/iteration_10
[rank0]:2024-03-04 17:01:35,971 - root - INFO - �[36mstep: 10 �[32mloss: 9.1212 �[39miter: �[34m 0.0808�[39m data: �[34m0.0319 �[39mlr: �[33m0.0001�[39m
[rank0]:2024-03-04 17:01:35,972 - root - INFO - Average iter time: 0.0553 seconds
[rank0]:2024-03-04 17:01:35,972 - root - INFO - Average data load time: 0.0317 seconds
[rank0]:2024-03-04 17:01:35,972 - root - INFO - Current Memory: NVIDIA H100 (0): Reserved: 9.6465%, Alloc 2.1969%, Active: 2.2%
[rank0]:Peak Memory: Reserved 9.65%, Alloc 8.43%, Active: 8.44%
[rank0]:num retries: 0, num ooms: 0
[rank0]:NCCL version 2.19.3+cuda12.0
```
Co-authored-by: gnadathur <[email protected]>
This PR enables meta_init functionality to avoid OOM'ing on cpu for
larger models.
The core functionality is in meta_init.py, and a few changes in
parallelization and train.py.
Key items:
1 - this is largely the same as the earlier PR I had for meta_init, but
I did a new one b/c faster than reworking it with all the interim
changes.
2 - to address feedback in previous PR:
a - why do we need meta_init.py, can't we just do:
~~~
with torch.device("meta"):
model = Model.from_args(...)
~~~
Unfortunately this does not work b/c the rope embeddings are treated
differently (buffer) and thus the simple lambda call from param_init_fn
in FSDP (lambda module: module.to_device('cuda') ) will not invoke or
move the rope embeddings and the model will fail on first forward.
This issue relates to the nn.embeddings not being moved, and that the
device is referenced in the forward pass for the current rope class.
Have opened pytorch#110 to track
this and investigate while not holding up meta init that is working from
landing.
b - per earlier feedback - meta init is now 'not optional' but simply
the default. This should ensure all models leverage it and ensure we
aren't missing things for future meta_init aspects.
3 - misc change - I switched the model_params to just do the normal all
params count instead of 'unique params' b/c it does not mesh with what
people perceive model size as.
Testing:
tested both debugmodel and 26B model with and without meta init to
confirm same loss curves.
Note for future reference - if you get a bad init (meta init failure)
you will simply not train (loss is same every iter).
If you fail to call reset params after FSDP, then you will train (b/c we
default to torch.randn_like) but your starting loss will be 5x+ higher
(telling you that you have not properly init'ed the model).
Co-authored-by: gnadathur <[email protected]>
ghstack-source-id: 5133a8d97ad209b569e0fc528e58daafdd31d80d Pull Request resolved: pytorch#114
ghstack-source-id: a0c8b4454f75ad1cd9824ac89a1df0182f6a7d8c Pull Request resolved: pytorch#112
…data' at 40 iters issue) (pytorch#88) This PR add's minipile (1M, 6GB) dataset as an option for pretraining with torchtrain. It resolves the issue where we run out of data after 40 iterations with the default alpaca dataset. Per @tianyu-l's excellent suggestion, have refactored to have a single hf_datasets.py file that supports both minipile and alpaca since it turned out no need for any different tokenizer, etc. Also cleaned up the datasets package so that create_tokenizer is exposed directly, and thus all public apis can be used directly from torchtrain.datasets. Lastly - added warning if/when a dataset is being re-looped so users don't get burned by overfitting: <img width="1294" alt="Screenshot 2024-03-06 at 5 11 09 AM" src="https://github.com/pytorch/torchtrain/assets/46302957/82480b6f-c677-4794-80c5-5c10b037732a"> Adds a color highlight to showcase what dataloader was built: <img width="1360" alt="Screenshot 2024-03-05 at 9 19 10 PM" src="https://github.com/pytorch/torchtrain/assets/46302957/4717ec6a-14bb-4283-a3ae-fa40c27deee0"> and <img width="1360" alt="Screenshot 2024-03-05 at 9 22 01 PM" src="https://github.com/pytorch/torchtrain/assets/46302957/dbf32d51-2dd4-4526-8855-9b33b627559e"> Usage: just add "minipile" or "alpaca" as the dataset in the training config toml file. <img width="439" alt="Screenshot 2024-02-25 at 12 35 26 PM" src="https://github.com/pytorch/torchtrain/assets/46302957/1afbaed1-07f8-4e37-b8cc-80190db7fb27"> Testing: verified training loss is improving and ran for 100 iters to verify no issue with out of data any longer with minipile. reran with alpaca and saw the expected out of data at 40 iters without infinite loop option, runs to 100 with infinite. Notes: I did not make this a default dataset since for debugmodel, mostly running 10 iters is fine and there's 6GB to pull down. <img width="869" alt="Screenshot 2024-02-25 at 12 30 29 PM" src="https://github.com/pytorch/torchtrain/assets/46302957/1070a80a-ad20-4f0f-a860-e13caa3120a0">
ghstack-source-id: 3c930054d3b04faf3866048740a2ef887d066dd6 Pull Request resolved: pytorch#117
ghstack-source-id: 733bf85716cda3a5b9af780eba79c9b5dd66abad Pull Request resolved: pytorch#121
ghstack-source-id: d7cd26d84aa2442ac45223992e1766397e52c8d8 Pull Request resolved: pytorch#122
according to suggestions in pytorch#118 (comment) ghstack-source-id: 357f0872cd1c9bad2c4c256d47adbd3f716a7651 Pull Request resolved: pytorch#123
…t job configs (pytorch#124) This PR: 1 - adds the english language portion of c4 dataset, which has 177M entries. (https://huggingface.co/datasets/allenai/c4) Due to the size, streaming is enabled as the default. This is the allen-ai/c4, as apparently the original c4 is being deprecated and HF advises to use allen-ai now. For comparison per @tianyu-l request - 40 iterations avg time: alpaca cached loading: Average data load time: 0.0279 seconds c4 streaming loading: Average data load time: 0.0290 seconds There is a longer initial delay during the 'preparing c4' vs alpaca (i.e. 45 seconds vs 10 seconds), but after that speed is similar. Dataset sample (not displayed in training, just an excerpt I pulled to double check the data flow): <img width="1233" alt="Screenshot 2024-03-08 at 5 31 06 PM" src="https://github.com/pytorch/torchtrain/assets/46302957/94915f80-da70-48d1-8c43-43f874fef121"> 2 - I also updated the multi-node slurm file to account for the new job config. Test: verified no looping with 100 iterations, sampled data streamed to verify.
…ytorch#130) This PR adds the openwebtext 1M dataset. This is a homogenous dataset, so we are able to train successfully while not having any shuffle in our dataset loader. 1 - adds the dateset to hf_datasets 2 - makes the default dataset for 13b and 70b as openwebtext since that is the preferred choice for larger scale training. Testing - ran 5K iters (9 nodes) to verify no spiking issues: <img width="787" alt="Screenshot 2024-03-12 at 9 50 57 AM" src="https://github.com/pytorch/torchtrain/assets/46302957/420fa1fc-50f8-47bc-9b07-02c8fa132e7c">
…pytorch#131) This fix would temporarily unblock loading. So we won't run into the issue of: ``` [rank0]:[rank0]: train_state.losses.append(train_state.current_loss) [rank0]:[rank0]: AttributeError: 'float' object has no attribute 'append' ``` However, current_loss and losses are still not correct, since by current setup, losses and current_losses would be different across different ranks. Also, we don't know the size of losses because this is based on the # of steps. So loading still work but the value of current_loss and losses are not being loaded correctly. I will follow up with further fixes.
ghstack-source-id: de61ec093b43a2ccbf1156c76ba81ecd698a6a8a Pull Request resolved: pytorch#132
simplify things given we already have SequenceParallel style landed in main
ghstack-source-id: c13ebb8de8e8e9203624b5dd710a046d17311b0f Pull Request resolved: pytorch#137
ghstack-source-id: ca6eb8f42bf3c2a59d8e6389e7fe94ed85103099 Pull Request resolved: pytorch#136
…ing AC on or off. (pytorch#125) This PR: 1 - adds selective layer checkpointing - this lets the user select every x layer to checkpoint: i.e. 2 = every other layer is checkpointed. spec for config was updated by Wanchao - so we now have this layout for AC which is hopefully self-explanatory (covers None, full, Selective Op or Selective Layer and layer filtering policy: <img width="941" alt="Screenshot 2024-03-13 at 6 09 52 PM" src="https://github.com/pytorch/torchtrain/assets/46302957/4b992286-1fbd-4a14-957a-4325f81a9ab4"> Thus, it lets user toggle between traditional 'all layers' to more and more fine grained checkpointing. Note that I implemented this for IBM last summer and in their llama testing, every 2nd layer was the best bang/buck so I have made that the default. 2 - the config file has been updated to make a new [activation_checkpointing] section and make it easier to modify vs being dumped into the training section. Testing and results: I tested all the AC options to ensure all options are working, and that we fail if both types are set to true in config: <img width="608" alt="Screenshot 2024-03-09 at 3 43 52 PM" src="https://github.com/pytorch/torchtrain/assets/46302957/e3c20fbf-73e2-492d-9fb9-f32e772e239e">
ghstack-source-id: 581c9115e89d3de57e558175b527c12c06a6808c Pull Request resolved: pytorch#134
…#103) Timeout ------- It's convenient whether during iterative debugging or long running training to find out asap about a failure. The default timeout is way too long and leads to wasted cluster time or developer frustration. Timeout can be adjusted via cmdline or in .toml if it needs to be larger for a particular model. Another useful pattern can be to set a large timeout for initialization and then tighten it after iteration 1. We can add this later if desired. Ideally we could pass the timeout to the device mesh ctor, but it's not ready yet. Also, we can change timeouts of the existing PGs after creating them, but that's more LOC and not necessary unless we want to change the timeouts at runtime. Dumps ----- Dumping on timeout should be a safe default for everyone. It has the side-effect of requiring a dump path which defaults to ~/pgnccl_dump but can be overridden via DUMP_PATH env. The raw content of the dump is a pickle that is intended to be consumed through scripts/tools which are under development, so it may not be easy to know how to use these for now. As the tooling matures, we should provide reference docs and probably print out pointers in the logs when we perform the dump. Test plan: tested locally by adding a rank0 sleep for 10sec inside the training loop, validating all 8 ranks dumped a trace.
ghstack-source-id: 2f79d081c7724dbc34f357913671e8aefdf437b1 Pull Request resolved: pytorch#147
Allow a tighter timeout during training than during init. Init includes the first train step, as well as any loading and setup. It can be slower and less predictable due to various factors including lazy initialization or jit compilation. After the first train step, we expect more predictable runtime and benefit from a tighter timeout to give quick feedback on a hang. Tested by pasting this code in 2 places ``` if dp_mesh.get_local_rank() == 0 and train_state.step == 1: import time time.sleep(10) ``` (a) before calling set_pg_timeout, which did not cause a timeout (b) after calling set_pg_timeout, which timed out
(second attempt, didn't land correctly) ghstack-source-id: 3dfec3ed134105cc5a951f8db160c8c2a9b3349b Pull Request resolved: pytorch#154
This PR adds control over Python garbage collection to help avoid stragglers during large scale training. updates - this feature is now exposed as a controllable option gc_schedule, with a default of 50. 0 = not enabled. int = schedules gc at every int iters during training loop. <img width="1078" alt="Screenshot 2024-03-15 at 12 39 26 PM" src="https://github.com/pytorch/torchtrain/assets/46302957/1ee387c5-f0a6-4366-936c-a1e281dad88f"> Effectively we disable the gc, run one collection to ensure a good starting point, and then at the start of each gc_schedule iter, we call gc to free up things. By enforcing a fixed schedule for collection, it helps all ranks stay more in synch. Point of reference - on 512 GPU FSDP, adding this (gc_schedule=1) gave a perf boost of ~1.5% per iter just by virtue of better synch. (this was originally developed during dist compiler to resolve stragglers, I believe @fegin came up with this solution).
ghstack-source-id: 995efd6f460f3fe83ecf8d72c2178554f325485b Pull Request resolved: pytorch#151
disable buffer reuse for compile to have close numerics to eager mode, as suggested by @Chillee This is probably only a temp change until buff reuse fix in inductor
This PR supports explicit cmd overrides, to allow infra layers to override certain options (the most important one is dump_folder)
add float8 link in README so we can redirect people from dev-discuss post to torchtitan repo README looks like this after rendering <img width="518" alt="Screenshot 2024-08-06 at 5 42 10 PM" src="https://github.com/user-attachments/assets/50af99d7-93be-459a-89d7-8c08b8fb95d4"> float8.md looks like this <img width="563" alt="Screenshot 2024-08-06 at 5 04 17 PM" src="https://github.com/user-attachments/assets/06d30aad-4133-4cec-9037-cfcf155b45c4"> I tried the command locally and traces are looking good <img width="726" alt="Screenshot 2024-08-06 at 5 00 00 PM" src="https://github.com/user-attachments/assets/bdfa3d7e-efe1-4009-92a1-0f5c310013fb">
ghstack-source-id: 2927f0a8082171da3e9f59a5d04f8325cbdf3653 Pull Request resolved: pytorch#508
ghstack-source-id: 003bfbfbcf1511ddbd18e15d031b39f597d8e7db Pull Request resolved: pytorch#510
… entries ghstack-source-id: 319f4961b092778703101b98937803073132afa1 Pull Request resolved: pytorch#512
Explain the rationale and challenges behind certain changes we made to llama model to support 3D parallelism. --------- Co-authored-by: tianyu-l <[email protected]>
ghstack-source-id: 1965d3122885fed3c28e2e058c55581187e7816c Pull Request resolved: pytorch#513
…ch#516) Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at bottom): * pytorch#473 * pytorch#517 * __->__ pytorch#516 Allows PP to be used without a seed checkpoint by calling `init_weight` on each model part. This is the solution in step 1 of pytorch#514 proposed by @wconstab
Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at bottom): * pytorch#473 * __->__ pytorch#517 * pytorch#516 Ran `pre-commit run --all-files`
…ng DTensor strided sharding (pytorch#507) Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at bottom): * __->__ pytorch#507 **Summary** 1. check if users are using new nightly-build pytorch that includes DTensor strided sharding (pytorch/pytorch#130760) when 2D/3D is used. Print warning if not. 2. remove temporary re-enablement added in pytorch#460 . **Test** Command: `python test_runner.py outputs --test pp_dp_tp --ngpu 8` GPUs: A100 Output: - without strided sharding: ``` [rank7]:2024-08-06 03:21:26,706 - root - INFO - step: 2 loss: 8.1652 memory: 0.51GiB(0.64%) wps: 8,250 mfu: 0.25% [rank7]:2024-08-06 03:21:27,013 - root - INFO - step: 3 loss: 8.0951 memory: 0.51GiB(0.64%) wps: 13,358 mfu: 0.41% [rank7]:2024-08-06 03:21:27,309 - root - INFO - step: 4 loss: 7.9748 memory: 0.51GiB(0.64%) wps: 13,865 mfu: 0.42% [rank7]:2024-08-06 03:21:27,582 - root - INFO - step: 5 loss: 7.8025 memory: 0.51GiB(0.64%) wps: 15,057 mfu: 0.46% [rank7]:2024-08-06 03:21:28,076 - root - INFO - step: 6 loss: 7.5612 memory: 0.51GiB(0.64%) wps: 8,300 mfu: 0.25% [rank7]:2024-08-06 03:21:28,608 - root - INFO - step: 7 loss: 7.3649 memory: 0.51GiB(0.64%) wps: 7,705 mfu: 0.23% [rank7]:2024-08-06 03:21:28,927 - root - INFO - step: 8 loss: 7.2946 memory: 0.51GiB(0.64%) wps: 12,832 mfu: 0.39% [rank7]:2024-08-06 03:21:29,251 - root - INFO - step: 9 loss: 7.1311 memory: 0.51GiB(0.64%) wps: 12,669 mfu: 0.38% [rank7]:2024-08-06 03:21:29,627 - root - INFO - step: 10 loss: 7.0540 memory: 0.51GiB(0.64%) wps: 10,918 mfu: 0.33% >>>>>>>>>>>>>>>>>Checkpoint save & load<<<<<<<<<<<<<<<<<<< [rank7]:2024-08-06 03:21:59,723 - root - INFO - step: 11 loss: 7.0822 memory: 0.51GiB(0.64%) wps: 1,139 mfu: 0.03% [rank7]:2024-08-06 03:22:00,054 - root - INFO - step: 12 loss: 7.0508 memory: 0.51GiB(0.64%) wps: 12,366 mfu: 0.38% [rank7]:2024-08-06 03:22:00,340 - root - INFO - step: 13 loss: 6.9182 memory: 0.51GiB(0.64%) wps: 14,370 mfu: 0.44% [rank7]:2024-08-06 03:22:00,624 - root - INFO - step: 14 loss: 6.8948 memory: 0.51GiB(0.64%) wps: 14,442 mfu: 0.44% [rank7]:2024-08-06 03:22:00,907 - root - INFO - step: 15 loss: 6.8358 memory: 0.51GiB(0.64%) wps: 14,514 mfu: 0.44% [rank7]:2024-08-06 03:22:01,574 - root - INFO - step: 16 loss: 6.7653 memory: 0.51GiB(0.64%) wps: 6,144 mfu: 0.19% [rank7]:2024-08-06 03:22:02,209 - root - INFO - step: 17 loss: 6.7340 memory: 0.51GiB(0.64%) wps: 6,453 mfu: 0.20% [rank7]:2024-08-06 03:22:02,532 - root - INFO - step: 18 loss: 6.6874 memory: 0.51GiB(0.64%) wps: 12,695 mfu: 0.39% [rank7]:2024-08-06 03:22:02,863 - root - INFO - step: 19 loss: 6.6566 memory: 0.51GiB(0.64%) wps: 12,406 mfu: 0.38% [rank7]:2024-08-06 03:22:03,257 - root - INFO - step: 20 loss: 6.6629 memory: 0.51GiB(0.64%) wps: 10,392 mfu: 0.32% ``` - with strided sharding ``` [rank7]:2024-08-06 03:26:18,288 - root - INFO - step: 1 loss: 8.2069 memory: 0.50GiB(0.63%) wps: 915 mfu: 0.03% [rank7]:2024-08-06 03:26:19,084 - root - INFO - step: 2 loss: 8.1913 memory: 0.51GiB(0.64%) wps: 5,144 mfu: 0.16% [rank7]:2024-08-06 03:26:19,365 - root - INFO - step: 3 loss: 8.1148 memory: 0.51GiB(0.64%) wps: 14,593 mfu: 0.44% [rank7]:2024-08-06 03:26:19,698 - root - INFO - step: 4 loss: 7.9982 memory: 0.51GiB(0.64%) wps: 12,328 mfu: 0.37% [rank7]:2024-08-06 03:26:20,011 - root - INFO - step: 5 loss: 7.8382 memory: 0.51GiB(0.64%) wps: 13,100 mfu: 0.40% [rank7]:2024-08-06 03:26:20,498 - root - INFO - step: 6 loss: 7.6293 memory: 0.51GiB(0.64%) wps: 8,423 mfu: 0.26% [rank7]:2024-08-06 03:26:21,126 - root - INFO - step: 7 loss: 7.4454 memory: 0.51GiB(0.64%) wps: 6,530 mfu: 0.20% [rank7]:2024-08-06 03:26:21,472 - root - INFO - step: 8 loss: 7.3337 memory: 0.51GiB(0.64%) wps: 11,843 mfu: 0.36% [rank7]:2024-08-06 03:26:21,849 - root - INFO - step: 9 loss: 7.1960 memory: 0.51GiB(0.64%) wps: 10,892 mfu: 0.33% [rank7]:2024-08-06 03:26:22,229 - root - INFO - step: 10 loss: 7.1208 memory: 0.51GiB(0.64%) wps: 10,798 mfu: 0.33% >>>>>>>>>>>>>>>>>Checkpoint save & load<<<<<<<<<<<<<<<<<<< [rank7]:2024-08-06 03:26:50,306 - root - INFO - step: 11 loss: 7.1222 memory: 0.51GiB(0.64%) wps: 866 mfu: 0.03% [rank7]:2024-08-06 03:26:50,632 - root - INFO - step: 12 loss: 7.1189 memory: 0.51GiB(0.64%) wps: 12,589 mfu: 0.38% [rank7]:2024-08-06 03:26:50,917 - root - INFO - step: 13 loss: 6.9646 memory: 0.51GiB(0.64%) wps: 14,417 mfu: 0.44% [rank7]:2024-08-06 03:26:51,217 - root - INFO - step: 14 loss: 6.9626 memory: 0.51GiB(0.64%) wps: 13,680 mfu: 0.42% [rank7]:2024-08-06 03:26:51,514 - root - INFO - step: 15 loss: 6.8694 memory: 0.51GiB(0.64%) wps: 13,799 mfu: 0.42% [rank7]:2024-08-06 03:26:52,207 - root - INFO - step: 16 loss: 6.7994 memory: 0.51GiB(0.64%) wps: 5,910 mfu: 0.18% [rank7]:2024-08-06 03:26:53,053 - root - INFO - step: 17 loss: 6.7634 memory: 0.51GiB(0.64%) wps: 4,847 mfu: 0.15% [rank7]:2024-08-06 03:26:53,370 - root - INFO - step: 18 loss: 6.7233 memory: 0.51GiB(0.64%) wps: 12,915 mfu: 0.39% [rank7]:2024-08-06 03:26:53,686 - root - INFO - step: 19 loss: 6.7054 memory: 0.51GiB(0.64%) wps: 12,995 mfu: 0.39% [rank7]:2024-08-06 03:26:54,059 - root - INFO - step: 20 loss: 6.7130 memory: 0.51GiB(0.64%) wps: 10,991 mfu: 0.33% ```
`torch.nn.Module.to_empty` takes keyword only arg of "device" according to https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.to_empty
ghstack-source-id: 7e1c7071f8126072ab0e25194b75f280bf4277ec Pull Request resolved: pytorch#523
Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at bottom): * pytorch#473 * __->__ pytorch#522
ghstack-source-id: c8f611742ffbb4859988b97e706b9e0d1b4ad6f1 Pull Request resolved: pytorch#521
ghstack-source-id: 9894aa1bc6d6026f59d6a4cc28b573dbb87d20d0 Pull Request resolved: pytorch#526
ghstack-source-id: 28a28926bec3c1a6671a18b403deab0fc096d218 Pull Request resolved: pytorch#538
ghstack-source-id: ceb4fa54121be241633daf06a0ca2eb407667274 Pull Request resolved: pytorch#535
closes: pytorch#548 > Nvidia Ada Lovelace GPUs (e.g., RTX 4090, L20, L40) with SM89 version are also support FP8 MMA, and hence, it is recommended to relax the CUDA architecture limitations to enable FP8 training on a broader range of devices. > > and the [CUDA 12.0 announcement](https://developer.nvidia.com/blog/cuda-toolkit-12-0-released-for-general-availability/) says that it supports Lovelace architecture: > '*CUDA 12.0 exposes programmable functionality for many features of the NVIDIA Hopper and NVIDIA Ada Lovelace architectures: ...32x Ultra xMMA (including FP8 and FP16)*' > > - https://developer.nvidia.com/blog/cuda-toolkit-12-0-released-for-general-availability/ > - https://nvidia.github.io/TensorRT-LLM/reference/support-matrix.html > - https://github.com/NVIDIA/cutlass/blob/c4e3e122e266644c61b4af33d0cc09f4c391a64b/include/cutlass/arch/mma_sm89.h#L57 > > 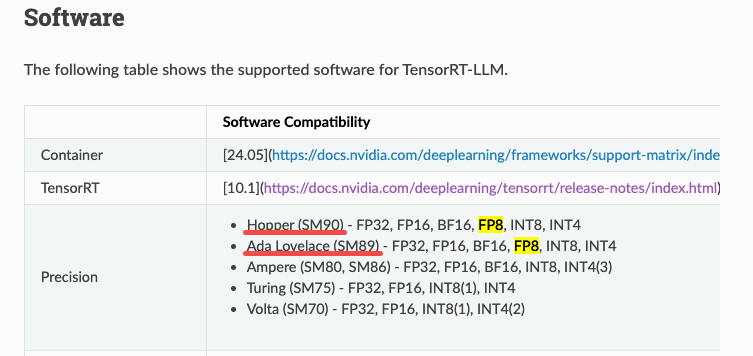 After relaxing the CUDA architecture limitations for FP8, my environment with **4 x L40 GPUs (SM89)** can still successfully train llama under float8 precision.  --------- Co-authored-by: Andrew Gu <[email protected]>
ghstack-source-id: ab6a7cec6ba4f4690f5834d22bc16d8d9f2bdba8 Pull Request resolved: pytorch#555
In this PR, we mostly measured the performance and loss curves for 405B model with some optimizations techniques we recently developed. We also want to log the actual peak TFLOPs used for MFU calculation for cross-validation. Also we should get device information from system rather from device name because it does not contain "NVL" or "SXM". <img width="496" alt="image" src="https://github.com/user-attachments/assets/ba822de5-cf23-4ecd-b29c-70f9aac38290">
As title. We have updated the peak FLOPs for H100 so we need to use the correct number here
The lspci command is part of the `pciutils` package, which provides tools for listing and querying PCI devices. But somehow `pciutils` is not installed in CI machines. This PR is to first unblock CI failure and then we can see if we want to make `pciutils` a requirement for Titan.
Somehow, when rebasing, the legacy float8 enabling flag stays in the 405B toml. Let's remove it. And this does not affect the perf number we obtained because the old flag is just a no-op after rebase.
ghstack-source-id: 3ece57ae6d8dbf7ff66e3c41f1804ddb08078ba4 Pull Request resolved: pytorch#525
Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at bottom): * pytorch#564 * __->__ pytorch#563 Add test to test runner for 3d + compile composability
ghstack-source-id: fbbf3fdd2d52334b76e45bac8b22a69de71baa5f Pull Request resolved: pytorch#565
ghstack-source-id: c2337c6f976b41288498b7f3aa9b6f3d54d49ad9 Pull Request resolved: pytorch#567
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
It seems SimpleFSDP + TP works with PP out-of-box, but whole-model compile doesn't. So torch.compile on SimpleFSDP won't take effect with PP. Need to figure out what's the best way to do it.