Translations #1274
Comments
This comment has been minimized.
This comment has been minimized.
|
Could you clarify this part a little bit?
The part I'm wondering about is whether that could result in changes to the translation messages invalidating existing code due to a shift of parameter order. Quick example: $t.clicked_n_times(n);
// compared to
$t.clicked({times: n});Everything else sounds outstanding and I can't wait to start using it. Thank you for tackling this issue. |
|
Hi, Allow me to jump into the discussion here. I'm planning a new project and a robust i18n is a must-have on it. I have worked in the past with Drupal and Wordpress websites, both using po file format. It seems to be made for this purpose. We may use JSON but it would be nice to see how they handle the pluralization and other translation workflows. But as you said, selecting a locale is an important step that should be done before loading translation. |
|
I have just written something to extract translation functions calls into .po files. Currently, I am integrating it into a rollup plugin. My idea is to use the tooling of gettext for managing the translation lifecycle. I think that we could even use ICU messageformat strings inside .po files. The advantage of .po files is that it is easy to provide a lot of extra context, which is often very important for translators. You can check my repository out at gettext-extractor-svelte. Then there is the package gettext-to-messageformat which converts .po files with gettext format to messageformat. If instead ICU messageformat strings are used in .po files, the conversion is trivial. An option to use json with ICU messageformat instead of .po files should also be easy to implement, but for this, I have to investigate how comments are provided to translators. Then the messageformat project can compile the translated strings into pure functions which can then be injected when building the application and replace the translation function and function calls. The actual translation function could be changed according to the needs of the project. Simple projects would only go with the message string, while other projects could provide unique context and detailed comments for each message string. |
|
Hey, Here is what I use for selecting the initial language I use the accept-language header and then in my src/routes/index.svelte I have I then in src/routes/[lang]/$layout.svelte check if the lang param is supported and if not 404 I than have a static yaml file that holds all translations This works fairly well for static pages which is what I do mostly... I put this together after reading a whole bunch of issues, initially trying svelte-i18n which I then decided was overkill... |
|
I've used svelte-i18n before and one big reason I prefer the
|


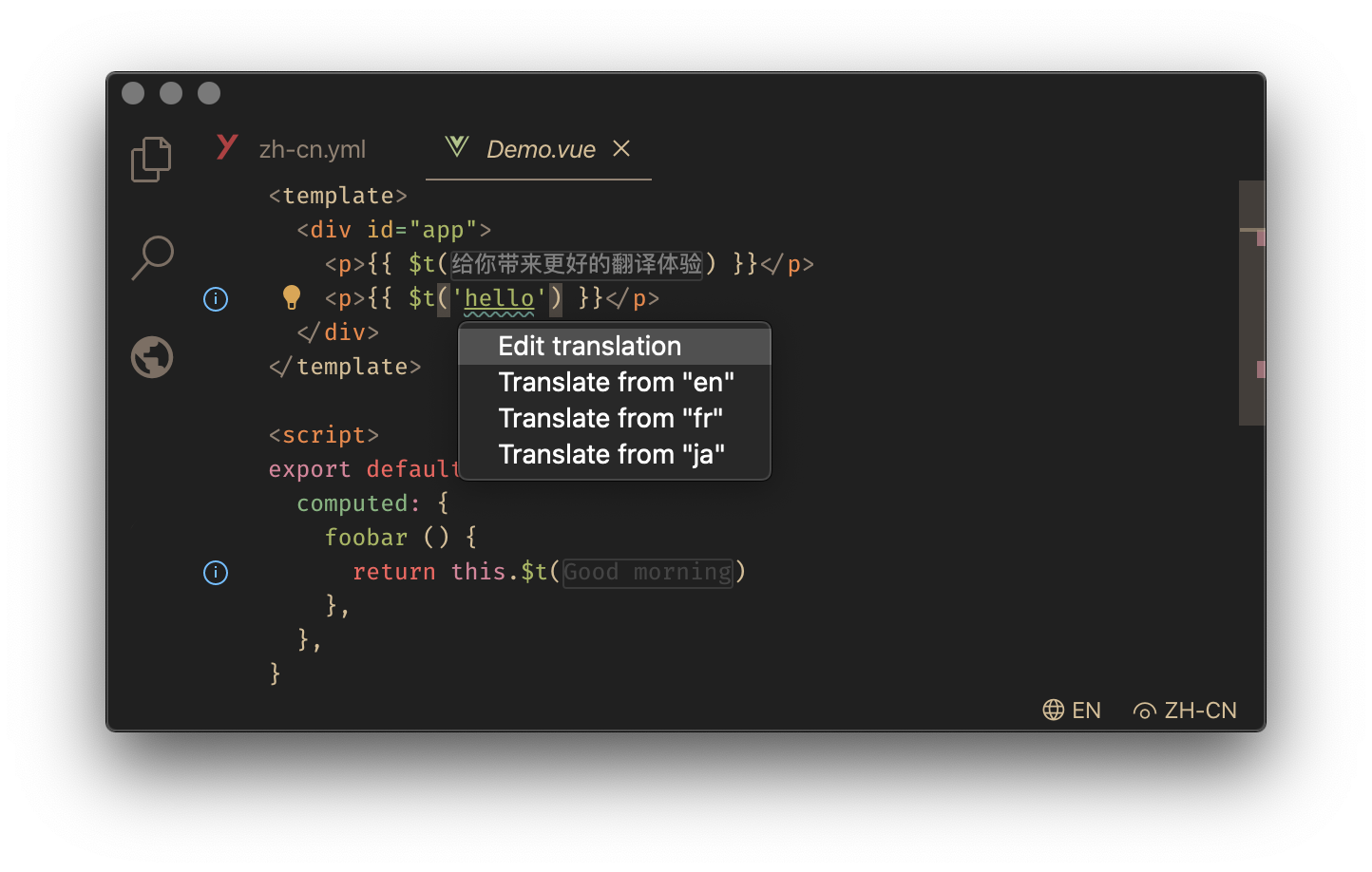
See what is wrong with
|
|
Big THANK YOU to all dealing with the translation topic. |
|
@babakfp i disagree with the point of you have to define keys and default translations {$_('Won {n, plural, =0 {no awards} one {# award} other {# awards}}', { values: { n: 2}})}no need to define a key and define a default translation - same behaviour as gettext |
The plural handling in your example will create a mess where the sentence order is totally different depending on the language: In PO files, the plural is handled with the following syntax The number of plural variant depend on the language, read this for more informations Using a more complex example: we could have the translation function with the following definition: |
|
@tempo22 it's the ICU MessageFormat |
|
@Kapsonfire-DE ICU messageformat can get very similar to gettext: This is also the recommended way for writing messageformat strings. Otherwise, an external translator can get confused. I think that some have the perspective of translating their app/page on their own or in house. But we should not forget, that there are also many use cases where we need professional translations and where we need to provide as much context to the translators as possible. Because of this, I like gettext (.po, .pot, .mo) very much. There are a lot of editors, there is an established workflow and many translators know this system. But messageformat is sometimes more flexible, especially you can use the An other case is when there is already a project which is based on gettext. Then it can make very much sense to use gettext instead of messageformat, because all translations from before can be reused. So it would be nice if there is some flexibility. |
|
More important than the specific syntax is that we understand the typical flow of translations... I can describe how it works at Google for example, which is probably similar to other large tech companies. Translations are a continuous and ongoing process. Commits land constantly and most of them have new strings, then in a periodic process we extract all the untranslated strings and send them off for translation. Google and Amazon I know have "translation consoles" that manage it for you. So say weekly you pull the strings and send them off, then they come back a week or more later, you check that data in and it's available after your next deployment. One thing to note is that, if you're using human translators, you must have a description. The English text alone isn't enough to get a good translation. Not sure how this changes as we move more and more to machine translation. Early on at Google I worked on a GWT project where the translations were declared in code like this: But most stuff at Google uses goog.getMsg(), i.e. What Rich is describing with a key and all versions of the text including the primary English version located elsewhere in a data file, that sounds good for the "glossary of well known terms you want to use across the site" scenario, but the vast majority of strings we use are translated per instance, since their meaning and context varies. Trying to share strings to save on translation costs would just slow down development too much. Maybe smaller projects have different priorities of course though. So I'd push for the English text (or whatever the primary language is) and the description located in the Svelte component itself. That way it works immediately and works even if you lose your translation data, and you don't have the Svelte component author having to hand fill-in a data file for one language while all the other languages come from an automated process. |
|
Thanks @johnnysprinkles — I haven't experienced this sort of translation workflow so that's useful. I'm not wholly convinced that including the primary language in the component alongside a description is ideal though:
So that leaves the question 'how do we associate descriptions with keys'? I think that's actually quite straightforward, we just have a // en.json
{
"brand": {
"name": "SvelteKit",
"tagline": "The fastest way to build Svelte apps",
"description": "SvelteKit is the official Svelte application framework"
},
"greeting": "Welcome!",
"clicked_n_times": "{n, plural,=0 {Click the button} =1 {Clicked once} other {Clicked {n} times}}"
}// description.json
{
"brand": {
"name": "The name of the project",
"tagline": "The tagline that appears below the logo on the home page",
"description": "A description of SvelteKit that appears in search engine results"
},
"greeting": "A message enthusiastically welcoming the user",
"clicked_n_times": "The number of times the user has clicked a button"
}I'm envisaging that we'd have some way to convert between this format and those used by common translation workflows ( declare module '$app/i18n' {
import { Readable } from 'svelte/store';
/**
* A dictionary of translations generated from translations/*.json
*/
export const t: Readable<{
brand: {
/** The name of the project */
name: 'SvelteKit';
/** The tagline that appears below the logo on the home page */
tagline: 'The fastest way to build Svelte apps';
/** A description of SvelteKit that appears in search engine results */
description: 'SvelteKit is the official Svelte application framework'
};
/** A message enthusiastically welcoming the user */
greeting: 'Hello!',
/** The number of times the user has clicked a button */
clicked_n_times: (n: number) => string;
}>;
} |
|
Hi
unrelated stuffIs it possible to know about those tools and features status? like a daily blog or something? Maybe a Discord channel that just the maintainers can send voices, details, pulls, and etc? By the way, I created a fake account to join the Discord server😂 (feels like admitting the crimes to the cops😄). Thanks again for banning me👏, "You are the best" MR. pngwn#8431(if I'm not mistaken)😀 |
|
@babakfp you're describing #1274 (comment), which is what I just responded to, except that you don't suggest a way to provide descriptions. Putting the primary language inline comes with a number of problems, and in terms of implementation/complexity, this...
...couldn't be more wrong, I'm afraid. To reiterate, the expectation isn't that translators would edit JSON files directly. The goal would be to support existing translation workflows. |
Yep, by subscribing to this issue tracker |
|
I mean this is just one perspective on it. We do optimize for frictionless development and happily translate the English string multiple times. We've probably translated 'Name' a thousand times, e.g. Now that I look at it, the context probably isn't necessary, a specific type of "Name" should translate the same way whether it's in a table column header or a text input. But types of names certainly could translate differently, like the name of a person being different that the name of an entity. Sounds like we agree about that and a separate description.json sounds good to me. One nice thing about having the English text and description hashed together as the key is that it's inherently reactive. Those are the two inputs that affect what the translation is, and if either change it needs to be retranslated (generally speaking). I'm realizing now I might have muddled the issue with two totally different examples. In the GWT ui:msg case all the English text and descriptions are inline in the view template, meaning each instance of a string is translated separately. Nice for developer velocity but expensive, good for a big company with deep pockets for translation budget. You technically can share strings by copying the English text and description verbatim into multiple templates, because it'll make the same hash key, but that's not the norm. This whole example is pretty outdated, let's ignore it. What we have with Closure Compiler may be more relevant. It's a constant that starts with MSG_ so we can sniff out which strings you're actually using at build time. I'm thinking about how hard it would be to graft this onto SvelteKit. We'd add a compilation pass either before or after Vite/Rollup. Of course I'd rather use native SvelteKit i18n if that turns out to work for us!
I think it's pretty critical to have this split up per route from day 1, for those who are obsessed with the fastest possible initial page load and hydration. So I guess I'd just say that Rich's proposal sounds good to me if we can make per-route translation string modules and if referencing a key with no primary language translation present fails the build right away. |
|
Of course, the tooling that extracts the untranslated strings could pass along a key it derives however it wants. It could use the developer created name, or it could hash together the primary language/description pair. Maybe it could be a preference which way to go, but if set to the former there would need to be some way to manually invalidate, maybe a third parallel json file full of booleans. Also regarding forcing developers to be copywriters, mostly what I've seen is a simple two stage pipeline where the initial version has the final English text, typically read off a mockup. I could certainly see also offering the option of a three stage pipeline where the initial text is blank or has placeholder text, then the copywriter fills in the English, then it goes off to the translators. Maybe that would be a feature that comes later. |
|
Oh what about this -- two layers. A "stable" layer which is the hand written json you mentioned, and a fallback layer that's english/description hashcode based. So you'd start with your svelte file And add the stable English version: But there's also an "unstable" data file that's keyed by hash: To find Once you get the French version back, you'd normally fill in fr.hashed.json, but you'd also have to option to put it directly in the more stable fr.json if you never want to worry about having to retranslate it. This would cover the case of people who don't use tooling at all, maybe they have a Russian friend and a Japanese friend and just say "hey can you translate this handful of strings for me" and manually plug those into the xx.json files. But for the heavyweight production setups, the incoming translations would only ever go in an xx.hashed.json file. Your file would end up looking like: Later if you change the English to |
|
Hello @Rich-Harris, I am working on a rollup plugin that works on
I want to explain an example workflow with this approach:Translation function calls could be:import { t } from './t/translations';
// If the same message string is used multiple times, than it will be extracted into one msgid
t('Message String');
// add context to prevent messages with the same messagestring to be treated as same, if the same message
// string with the same context is used multiple times, than it will be extracted into one msgid/msgctxt
t('Message String', 'Message Context');
// add comment for the translator
t('Message String', 'Message Context', 'Message Comment');
// unneeded parts can be ommited
t('Message String 2', null, 'Message Comment');
// add messageformat string and supply properties for the string
t(
'Message {FOO}',
'Message Context',
{comment: 'Message Comment', props: {FOO: 'Type of foo'}},
{FOO: getFoo()}
);
// add language for live translations
t('Message String', 'Message Context', 'Message Comment 2', null, getLanguage());The translation function can be defined in a flexible way. If needed the position of all arguments can be changed however it fits the translation function. If Let's say we have defined a translation function as: import MessageFormat from '@messageformat/core';
const mf = new MessageFormat('en');
export function t(
text: string | null,
id?: string | null,
comment?: {props?: Record<string,string>, comment: string, path: string} | string | null,
props?: Record<string, any>
): string {
const msg = mf.compile(text);
return msg(props);
}Than the function calls will be replaced with: 'Message String';
'Message String';
'Message String';
'Message String';
'Message String 2';
((d) => 'Message ' + d.FOO)({FOO: getFoo()});
'Message String';In this case, the translation function would completely disappear. #: src/App.js:3
msgid "Message String"
#. Message Comment
#. Message Comment 2
#: src/App.js:6, src/App.js:8, src/App.js:19
msgctxt "Message Context"
msgid "Message String"
#. Message Comment
#: src/App.js:10
msgid "Message String 2"
#. Message Comment
#. {FOO}: Type of foo
#: src/App.js:12
msgctxt "Message Context"
msgid "Message {FOO}"If somebody does not need A more complicated example // in App.svelte
<script lang="ts">
import { t } from './t/translations';
export let res: number;
</script>
// later
<p>
{t(
'{RES, plural, =0 {No foo} one {One foo} other {Some foo}}',
'Foo Context',
{comment: 'Foo Comment', props: {RES: 'Foo count'}},
{RES: res}
)}
</p>// in Page.svelte
<script lang="ts">
import { t } from './t/translations';
export let d: Date;
export let res: number;
</script>
// later
<p>
{t(
'{ D, date }',
'Date Context',
'Date Comment',
{D: d}
)}
</p>
<p>
{t(
'{RES, plural, =0 {No bar} one {One bar} other {Some bar}}',
'Bar Context',
{comment: 'Bar Comment', props: {RES: 'Bar count'}},
{RES: res}
)}
</p>This would extract the following #. Foo Comment
#. {RES}: Foo count
#: src/App.js:8
msgctxt "Foo Context"
msgid "{RES, plural, =0 {No foo} one {One foo} other {Some foo}}"
#. Date Comment
#: src/Page.js:9
msgctxt "Date Context"
msgid "{ D, date }"
#. Bar Comment
#. {RES}: Bar count
#: src/Page.js:17
msgctxt "Bar Context"
msgid "{RES, plural, =0 {No bar} one {One bar} other {Some bar}}"If we assume that we have translation files for English and German and the translations for german in the file // in App.svelte (engish and german version)
<script lang="ts">
import { t } from './t/t2';
export let res: number;
</script>
// later
<p>
{((d) => t.plural(d.RES, 0, t.en , { "0": "No foo", one: "One foo", other: "Some foo" }))({RES: res})}
</p>// in Page.svelte english version
<script lang="ts">
import { t } from './t/t0';
export let d: Date;
export let res: number;
</script>
// later
<p>
{((d) => t.date(d.D, "en"))({D: d})}
</p>
<p>
{((d) => t.plural(d.RES, 0, t.en , { "0": "No bar", one: "One bar", other: "Some bar" }))({RES: res})}
</p>// in Page.svelte german version
<script lang="ts">
import { t } from './t/t1';
export let d: Date;
export let res: number;
</script>
// later
<p>
{((d) => t.date(d.D, "de"))({D: d})}
</p>
<p>
{(
(d) => t.plural(d.RES, 0, t.de , { "0": "Kein bar", one: "Ein bar", other: "Ein paar bar" })
)({RES: res})}
</p>// ./t/t0.js
import {t as __0} from './t2.js';
import { date } from "@messageformat/runtime/lib/formatters";
export const t = {
...__0,
date
};// ./t/t1.js
import { plural } from "@messageformat/runtime";
import { de } from "@messageformat/runtime/lib/cardinals";
import { date } from "@messageformat/runtime/lib/formatters";
export const t = {
plural,
de,
date
};// ./t/t2.js
import { plural } from "@messageformat/runtime";
import { en } from "@messageformat/runtime/lib/cardinals";
export const t = {
plural,
en
};I have almost finished my plugin up to this point. Some refactoring has to be done and some additional tests written. I think that I will publish the first beta version at the end of this week. I am also thinking to offer a very different approach where all translation strings per file will be in a store. This would give the possibility for 'live' translations. To put pre-compiled translation functions into JSON files, I have first to look into how to serialize them. This would give the possibility to live-load additional translation files on demand. The workflow would be to leave everything in place when developing the application. Maybe there could be some functionality to load already translated strings into the app and/or provide some fake text per language. Then there is the extraction phase where all strings are extracted into The only missing link is now how to get the actual language at build time. For this, I would need svelte kits multi-language routing functionality. |
|
I can say from experience it is nice for the development flow to be able to put your string data right inline. Rich thinks it adds visual noise but I tend to think it orients the code author, and is less cryptic.
Is this talking about both the pre-rendered HTML (as from utils/prerender) and the JS artifacts? |
|
Actually never mind, prerender happens after JS building so of course it would apply the translations there. |
|
We have a list of features, I wonder if something like this would be helpful https://docs.google.com/spreadsheets/d/1yN03V04RI8fBE9ppDkEf2-d9V3f4fHFwekteRNiJskU/edit#gid=0 If @floratmin is suggesting a kind of macro replacement, like |
Just FYI, I encountered a "translation console" recently via the Directus project - they use a system called Crowd-In. Directus is using vue-i18n and .yaml files for translations, but Crowd-In supports many formats. |
|
I think using separate translation keys instead of the primary language string is both more stable and flexible. It allows for namespacing and translation of generated keys, and should make it easier to implement tooling around extraction / missing translations checks etc. I also think providing context for translators should not be done in the template part of a .svelte component as that would be very verbose and detrimental to quickly understanding a components structure. Svelte is in a kind of unique position here as with svelte-preprocess, the compiler, language-tools and sveltekit we have all the tools at hand to build a system that allows to use a wide array of possible input formats, ( eg. an extra |
|
@johnnysprinkles The functions for
|
|
@dominikg I think using the primary language string (and some context if necessary) to be the better option. When a project is fresh and small, creating a hierarchy of keys is easy. But after some refactorings or some new developers on the project, the maintenance of this hierarchy gets quickly more and more hard. If I use only the string it is more like set it and forget it. If I have to differentiate, I simply add some context. See also this comment and the entire discussion on StackOverflow. I think also that retranslating one string is often cheaper than creating and maintaining a system for avoiding retranslation. I see also that providing the context/comments directly in the source code not to be a big problem. Most strings in applications are trivial and don't need a lot of context or comments. And keeping context/comments separated in another part of the file makes the maintenance harder. |
|
Do you put Right to left in consideration or you consider it as a different feature? |
|
@mabujaber Right to left can be almost completely solved with CSS. You have only to set |
|
@samuelstroschein - I take your point; and I accept I'm looking at this from a particular (in my experience typical) workflow: designs are provided with text embedded and devs are expected to work from there. Pre-keyed translations are not available; and sometimes designs aren't stable and subject to change. With the manually keyed solution a dev might have to come up with an id and add it to the source file and land up having to manage that file later. What I'm proposing is that the dev just copy pastes the initial text and (almost) never changes it. A parsing process uses this initial text to generate an id and this is used in the source translation files; which is generated automatically. I totally agree that the ability to change the 'native' language text without requiring dev intervention is really useful; but that can also be achieved simply by having a translation file for the native language (and this could even be rendered into the output during the preprocess step). Also the parsing approach doesn't preclude using 'keys' in the template instead of text. @inta - different syntax is the norm in Angular and IMO it worked fine there. I'd also prefer to avoid |
Con you confirm that the feature request I just opened here opral/monorepo#111 is what you mean?
That seems like a hand-off gap. Theoretical question: If designers create the text in their design files, why is copy & pasting required from developers? A Figma/Sketch/etc. plugin could eliminate the hand-off. |
TBH I'm not aware of these features and nor were the designers I was working with previously 😅 |
|
I'm adding my piece to this big topic. Since a lot has already been said, I'll be as straightforward as possible. String keys VS objectsString keys are most of the time a bad pattern. It's hard to type and you can't have nested values. You just have one big flat namespace. Regular objects are better for autocompletion and complex typing so I would go with that. I've read in this topic than some cool plugins integrate with i18n string keys and show previews. That's super cool, but it can be done as well with regular objects - even so it may not exist yet. Global translation files VS in-component translationI think integrating translation at component-level rather than at global level is an easy way to make sure to not import all translations at once. You import a component => it comes with its own translation. Simple and effective. Also Svelte has an approach of single-component, ie mixing different languages in the same file to create a reusable component. It makes sense to follow this guideline and integrate not only script (JS), template (HTML) and style (CSS), but also a content (ICU / Fluent) part inside the component. The drawback of having an in-component translation is: how to integrate it with translation softwares? It must be easy to parse to allow a svelte preprocessor to only "extract" the translation part of the component. Example of svelte file with an added "content" section: <script>
.. my logic
</script>
.. my template
<style>
.. my style
</style>
<content lang="fluent | yaml | toml | json">
.. my translations
</content>
Also the script should be placed at the bottom of the file because it can get very large when manipulating a lot of languages - and if the user works with a 3rd party translation software, this part can even be edited automatically. Preprocessing contentThe This is quite the easy part. I created a very small library that already does something similar: https://www.npmjs.com/package/@digitak/cox Type safetyWith that architecture, it's easy to check if keys are missing or not. It's the role of the preprocessor. No JSON (or not only JSON)JSON is not a language made for humans. It's great for computers. I would prefer a language like YAML, TOML or Fluent. Concrete example with YAML using ICU strings: <p>
{$content.greetings}
</p>
<p>
{$content.nested.easy}
</p>
<content lang="yaml">
en:
greetings: "Hello world!"
nested:
cool: "That's easy, right?"
fr:
greetings: "Salut le monde !"
nested:
cool: "C'est facile, n'est-ce pas ?"
</content>Using arraysSometimes you need to manipulate arrays of different lengths depending on the language. For example, you want to show some customer reviews in your landing page, but you have only 2 reviews in Polish when you have 5 in english. That would be great to support arrays as well. |
|
This is only marginally related to the topic at hand, but in svelte-intl-precompile (https://svelte-intl-precompile.com/) I've somewhat recently added support for more formats other than JSON, particularly JSON5 (yay comments!) and yaml. I don't use yaml but JSON5 improves regular json ergonomics a lot. I also added support for number skeletons so it allows complex number formatting like |
|
None of this nonsense, please:
Everyone knows Wordpress as an old tool that doesn't do a lot of things right, but here I see a lot of people talking about using JSON files for translations😐🔫. The current way of Wordpress doing translations is via using ...and that's it. You don't need to create any file to keep your translations in, don't need to create a name for each string inside the JSON file, no need for nonsense extra work. You can use tools like PoEdit software, Loco Translate and Automatic Translate Addon For Loco Translate plugins. You can automate translations with Google Translate API (or other APIs). You can use currently added translation to help you speed up the translation process. You can do a lot of other great things that you can find it all in the links above. |



|
The file format doesn't really matter. It's just some implementation detail from the software you are using. The important thing is, that there exist tooling around those file formats. Ideally with strong support for tranlation-specific formats like variables, plural rules and formatting. Not just simle text-fields. Automatic extraction of strings from files can be a great thing but it also needs some context information about where it is beeing used. Similar to the nesting structure of e.g. JSON translations: |
It does matter because software and a lot of other apps are using the same, there is also a big community and resources behind it.
There are already multiple solutions available for kinds of things. The solution that I explained above, it's a mature feature. Such simple issues are a piece of cake. By using JSON, you make the experience hell and miserable both for the developers and translators. There is not even a single benefit in using JSON or similar formats and solutions. Instead of sticking to what you know, try other solutions. No one wants a lazy feature like using JSON files for translations. |
THE file format for translations does not exist. Every programming language, framework, and even SDK uses its own implementations. That said, I do believe there should be one file and syntax format for translations. Mozilla's Fluent project seems to be the most promising one https://projectfluent.org/, and is the one we are building https://github.com/inlang/inlang on top of. |
In the end every file format and message syntax could be transformed to another format. Translators probably don't want to write
I personally also don't like using the JSON file format for storing translations. There exist better solutions that offer more context |
|
For two hours read this discussion, but did not see main benefit of using This approach does even leave possibility of application not being translated and developers time not wasted on making .json files or thinking up unnecessary unique or reusable keys - just text, that needs to be where it needs to be. Edit: As one man band I can do any of the translation workflows. All of my projects have multi-language requirement (living in small country where third of population speaks another language). But in the end 4 out of 5 of applications I write are left untranslated. So you can see possible frustration of making a lot of unnecessary moves on my side to make translation even possible. I do see benefits of keyed translations like PS I fell in love with SVELTE a week ago. Loving every bit of it! Maybe direction of i18n could be better... Keep up the good work! |
|
Don´t force local translation files please. Translation files in every project I have seen have always been a mistake in the long term. The larger the website/application grows, the more rapidly will translations change and it is not desirable re-build the app every time when it happens. You deeply want to fetch that information from a database or external service in the long term. A solution would be to let the user specify a "fetch" function. A default implementation could read some local file, but it would allow the developer to fetch from a database or external SaaS service - if it need too. Best of both worlds. But of course, some "typed" information may get lost with the above solution, but it is worth to lose it 100% if it give the flexibility to fetch translation however the developer wishes. |
|
Just in case, I currently use https://github.com/cibernox/svelte-intl-precompile and it's working very well, for the primary key, I am using an English default value. |
|
@stalkerg thanks for the shout out. I'm following this thread in case there's anything I can do to improve the library. |
|
I'm using Because I think the setup is pretty good and I really like using tagged template literals for translations. Hope my PR will get merged making using TypeScript easier. Here's an example:
<script lang="ts">
import { currentLocale } from "$lib/i18n.js";
</script>
{#key $currentLocale}
<main>
<slot />
</main>
{/key}
<script lang="ts">
import { t } from "ttag";
const text = t`The setup is pretty good.`;
</script>
<h1>{t`Hello world!`}</h1>
<div>{text}</div> |
|
We are exploring building a metaframework agnostic i18n library that would solve this issue. Discussion is ongoing in https://github.com/orgs/inlang/discussions/395 |
|
A small update regarding the metaframework agnostic i18n solution mentioned above: We will soon start with the implementation. The first framework that we will support is |
|
That's how I currently am handling translations in SvelteKit.
import { browser } from '$app/environment'
import { getCookie, setCookie } from 'helper-functions/src/cookies' // simply wrapped calls to document.cookie
import { get, writable } from 'svelte/store'
import translations from './translations'
export const locale = writable(browser ? getCookie('locale') : 'de' || 'de')
export const locales = Object.keys(translations) as unknown as keyof typeof translations
function translation() {
const { subscribe, set } = writable(translations[get(locale)])
return {
subscribe,
changeLanguage: (language: keyof typeof translations) => {
if (!translations[language]) {
console.error(`the language "${language}" does not exist`)
return
}
set(translations[language])
locale.set(language)
if (browser) setCookie('locale', language)
},
locale,
locales,
}
}
export const t = translation()
import type de from './de' // this is a simple exported JS object, which provides keys and acts as default language. It could also be used as a fallback
const en: typeof de = {
title: 'Hello SvelteKit',
}
export default en
<script lang="ts">
import { t } from '$lib/stores/language'
</script>
<h1>{$t.title}}</h1>
import { locale, locales, t } from '$lib/stores/language.js
import { get } from 'svelte/store'
/** @type {import('./$types').LayoutServerLoad} */
export function load({ cookies }) {
const supposedCurrentLocale = (cookies.get('locale') as typeof locales) || 'de'
if (supposedCurrentLocale !== get(locale)) { // better be sure to not set it twice, maybe not needed here
t.changeLanguage(cookies.get(supposedCurrentLocale) as typeof locales)
}
return {}
}
<script lang="ts">
import Page from 'path/to/original/page/+page.svelte'
export let data: any
</script>
<Page {data} />Maybe for the route handling we could implement a file like const aliases = [
'/my/translated/path/1',
'/my/translated/path/2',
]
export aliasesThis file could be used to generate the above mentioned routes automatically. This way the solution I'm currently using would be great for me. best regards |
Is your feature request related to a problem? Please describe.
Translations are largely an unsolved problem. There are good libraries out there, like svelte-i18n and svelte-intl-precompile, but because they are not tightly integrated with an app framework, there are drawbacks in existing solutions:
{$_("awesome", { values: { name: "svelte-i18n" } })}) from the svelte-i18n docsWithout getting too far into the weeds of implementation, what follows is a sketch for what I think the developer experience could and should look like for using translations in SvelteKit. It builds upon the aforementioned prior art (using ICU MessageFormat, precompiling translations etc) while leveraging SvelteKit's unique position as an opinionated app framework. It follows the discussion in #553, but doesn't address issues like picking a locale or handling canonical/alternate URLs, which overlap with translations but can be designed and implemented separately to a large extent.
Describe the solution you'd like
In the
translationsdirectory, we have a series of[language].jsonfiles with ICU MessageFormat strings:Regional dialects inherit from the base language:
These files are human-editable, but could also be manipulated by tooling. For example, the SvelteKit CLI could provide an editor along the lines of this one or this one out of the box.
SvelteKit watches these files, and populates an
ambient.d.tsfile that lives... somewhere (but is picked up by a default SvelteKit installation) with types based on the actual translations that are present (using the default locale, which could be specified insvelte.config.cjs, for the example strings):As well as generating the types, SvelteKit precompiles the strings into a module, similar to svelte-intl-precompile:
This module is using for server-rendering, and is also loaded by the client runtime to populate the
tstore. (Because it's a store, we can change the language without a full-page reload, if necessary. That might be overkill, but if Next can do it then we should too!)A relatively unique thing about this approach is that we get typing and autocompletion:
This extends to parameters (which I think should be positional), for messages that need them:
Because everything is just JSON files, it's trivial to build tooling that can e.g. identify untranslated phrases for a given language. I don't know what common translation workflows look like, but it would presumably be possible to convert between the file format used here and the output of translation software that uses ICU.
Describe alternatives you've considered
How important is this feature to you?
It's time. Though we need to solve the problem of selecting a locale before we can make much of a start on this; will open an issue in due course.
The text was updated successfully, but these errors were encountered: